Тема измерения латентности оперативной памяти на платформах с процессорами семейства Intel Pentium 4 затрагивалась нами неоднократно. Ничего удивительного в этом нет проблема имеет место быть, объективно измерить латентность памяти с этими процессорами весьма затруднительно ввиду значительных ухищрений, реализованных производителем, особенно в последних ядрах процессоров Prescott/Nocona с целью сокрытия этой самой «латентности» т.е. задержек при доступе к оперативной памяти. Под этими ухищрениями мы прежде всего имеем в виду алгоритм аппаратной предвыборки (Hardware Prefetch) данных из памяти как таковой (детали реализации которого неизвестны), а также его важнейшую особенность предвыборку сразу двух строк кэша из памяти в L2-кэш процессора.
Последняя «официальная» методика, изложенная в статье «DDR2 грядущая замена DDR. Теоретические основы и первые результаты низкоуровневого тестирования», насчитывает примерно полгода и успешно применялась нами на протяжении всего этого времени. Ничего не мешает ей существовать и дальше в качестве одной из возможных методик оценки латентности оперативной памяти в реальных условиях. Поэтому изложим основную суть этой методики.
Итак, главная трудность измерения латентности памяти на рассматриваемой платформе обусловлена двумя отмеченными выше обстоятельствами: наличием у процессора механизма Hardware Prefetch и предвыборкой сразу двух соседних 64-байтных строк из памяти в кэш процессора.

Приведенный выше рисунок поясняет суть проблемы. На нем представлена зависимость латентности чтения двух 32-битных элементов из оперативной памяти от расстояния между этими элементами (в байтах). Именно такой тест используется программным пакетом RMMA в качестве внутреннего метода определения эффективной длины строки L2-кэша, которая в нашем случае составляет 128 байт. Предвыборка двух 64-байтных строк видна во всех случаях величины латентности прямого и обратного линейного, псевдослучайного и случайного обхода лишь незначительно возрастают при превышении расстояния между элементами в 64 байта. Дальнейшее возрастание латентностей от 128 байт и выше протекает совершенно неочевидным образом. И здесь виновато другое обстоятельство (первое по списку): наличие алгоритма аппаратной предвыборки.
Достаточно четко и предсказуемо картина выглядит лишь при полностью случайном обходе, таким образом, наиболее корректные значения латентности следовало бы ожидать именно в этом случае, если бы не еще одно «но». На сей раз довольно малый размер буфера трансляции виртуальных адресов памяти в физические адреса (D-TLB). Дело в том, что истинно случайный обход памяти исчерпывает его очень быстро. Ведь загрузка страниц памяти в этом случае также полностью случайна, таким образом, D-TLB может эффективно «кэшировать» количество страниц, не превышающее его собственный размер. Получаем всего 128 (размер буфера) x 4 (размер страницы) = 512 КБ памяти. А в тесте используется сравнительно большой 16-МБ блок… Нетрудно посчитать, что процент промахов D-TLB в этом случае будет составлять (16384 512) / 16384 = 96.88%, что обходится данному семейству процессоров весьма и весьма «дорого». Заметим, что данное ограничение не относится к линейным режимам обхода, где замещение записей в D-TLB идет последовательно и плавно. Отсутствует оно и при псевдослучайном обходе с той целью он и разрабатывался. В этом методе загрузка страниц из памяти идет прямо и последовательно, а обход элементов страницы полностью случаен.
Учитывая изложенную выше теоретическую базу, в нашей первой «официальной» методике было решено использовать следующие параметры для теста латентности оперативной памяти.
Название пресета: Minimal RAM Latency, 16MB Block, L2 Cache Line
Размер блока: 16 МБ
Размер шага: эффективная длина строки L2-кэша (128 байт для Pentium 4)
Режим обхода: псевдослучайный
Использование данного режима позволяет получить примерно следующий результат.
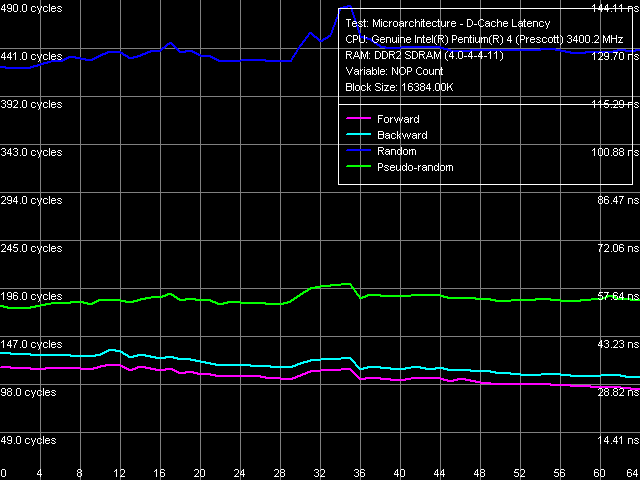
Кривые псевдослучайного и случайного обхода сохраняются на почти постоянном уровне, т.е. эффективность алгоритма Hardware Prefetch не изменяется при увеличении разгрузки Bus Interface Unit (BIU) процессора. В отличие от кривых прямого и обратного линейного обхода памяти, где разгрузка шины явно увеличивает эффективность Hardware Prefetch. На основании анализа этих данных в свое время был сделан вывод о том, что измерение латентности памяти данным образом (используя данные псевдослучайного обхода) можно считать вполне адекватным.
Итак, вроде бы все хорошо что же еще можно придумать, чтобы обмануть весьма хитрый алгоритм предвыборки, и зачем? Начнем с вопроса «что». Обмануть алгоритм Hardware Prefetch, пожалуй, уже никак нельзя, но можно ведь… совсем отключить аппаратную предвыборку! Такая возможность заложена во всех процессорах Pentium 4 и Xeon, но соответствующие настройки в BIOS доступны, как правило, только для последних. С них-то все и началось, мы решили провести небольшое исследование влияют ли они на результаты тестов, и если да, то как оказалось, что очень даже влияют! В связи с чем, в новой версии RMMA 3.45 было решено добавить их в виде отдельной закладки (в последнее время мы очень любим «играться» со специфическими настройками процессоров Pentium 4). Вот как выглядит эта закладка.
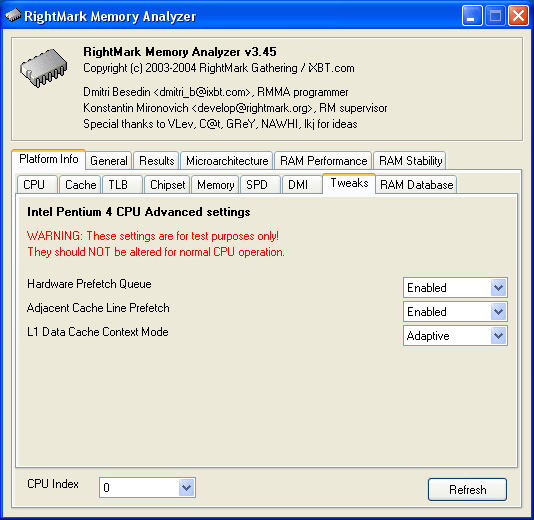
Сразу отметим: данные настройки рассчитаны исключительно для тестовых целей, о чем говорится в самой программе. Для нормального режима работы процессора в частности, и всей системы в целом трогать их не рекомендуется. Опишем вкратце каждую из них.
Hardware Prefetch Queue (Enabled/Disabled) включение/выключение очереди аппаратного префетчера, проще говоря механизма аппаратной предвыборки данных из памяти.
Adjacent Cache Line Prefetch (Enabled/Disabled) включение/выключение режима предвыборки смежной строки. В случае Disabled осуществляется предвыборка только одной (содержащей запрашиваемые данные) 64-байтной строки 128-байтного сектора, в случае Enabled обе строки вне зависимости от наличия/отсутствия необходимых данных.
L1 Data Cache Context Mode (Adaptive/Shared) изменение режима работы L1-кэша данных процессора. Эта настройка практически на результаты теста латентности памяти влиять не должна, тем не менее, она явно относится к тому, с чем имеет дело тестовый пакет RMMA. Данная настройка доступна только для процессоров с технологией Hyper-Threading и задает способ использования L1-кэша данных процессора логическими процессорами. В случае Shared L1-кэш представляется логическим процессором в полном объеме, но содержит данные, принадлежащие обоим процессорам. В режиме Adaptive каждый логический процессор получает свою часть L1-кэша, содержащую данные только этого логического процессора, размер которой варьируется по мере необходимости.
Заметим, что настройки применяются лишь к данному системному процессору, номер которого задается выбором CPU Index. В случае «истинных» многопроцессорных систем (SMP) рекомендуется применять одинаковые настройки для всех физических процессоров. Для систем с технологией Hyper-Threading, напротив, достаточно изменить настройки одного из логических процессоров (любого), составляющих физический процессор.
Итак, отметим главное: отныне у нас есть способ отключить обе особенности механизма аппаратной предвыборки данных: как сам алгоритм, так и предвыборку смежной строки (которая, заметим, может осуществляться независимо от использования Hardware Prefetch).
Последовательность действий для измерения латентности памяти вторым методом будет выглядеть следующим образом.
1. Отключить аппаратную предвыборку в Platform Info -> Tweaks, выставив Hardware Prefetch Queue в положение Disabled.
2. Выбрать тест Microarchitecture -> D-Cache Arrival, пресет Minimal RAM Latency, 16MB Block, L2 Cache Line, или выставить следующие настройки вручную:
Размер блока: 16 МБ
Размер шага: эффективная длина строки L2-кэша (128 байт для Pentium 4)
Режим обхода: псевдослучайный3. Включить аппаратную предвыборку в Platform Info -> Tweaks, выставив Hardware Prefetch Queue в положение Enabled.
Что ж, самое время проверить настройки в действии для начала, запускаем тест Microarchitecture -> D-Cache Arrival, пресет L2 D-Cache Line Size Determination.
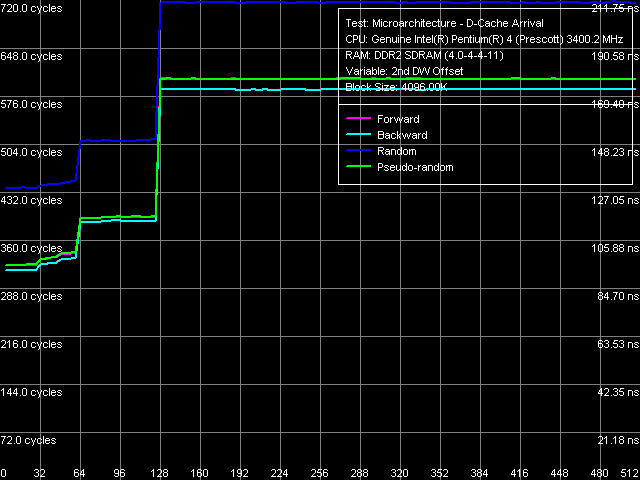
Результатом является «почти идеальная» картина для случая предвыборки смежной строки (его-то, напомним, мы не отключили для наших целей это не требуется). Смотрим далее: тест Microarchitecture -> D-Cache Latency, пресет Minimal RAM Latency, 16MB Block, L2 Cache Line.
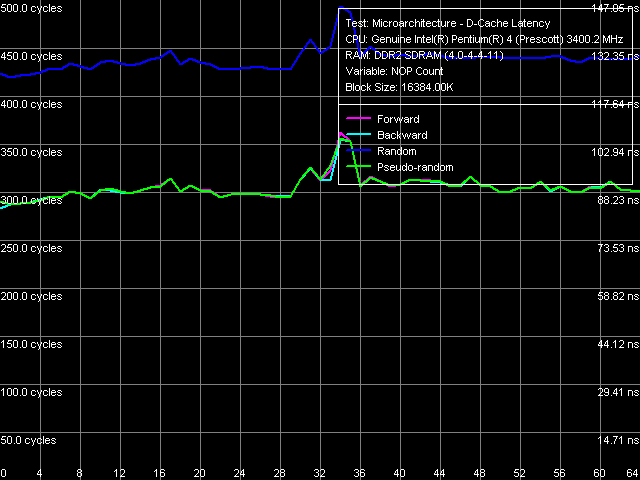
Результат весьма интересный. Кривая случайного обхода осталась почти без изменений как качественных, так и количественных. Следовательно, в случае истинно случайного доступа к памяти Hardware Prefetch действительно практически не работает, даже если он включен. Но… как же быть с псевдослучайным обходом? Качественно соответствующая кривая выглядит так же, как и ранее, но количественно… «поднялась» примерно на 30 нс вверх! Вывод? Hardware Prefetch, когда он включен, работает с некоторой эффективностью и при псевдослучайном обходе! По-видимому, имеет место предвыборка на уровне целых страниц памяти. Избежать которую можно только двумя способами: либо использовать истинно случайный обход (но здесь вспоминаем накладываемые ограничения размера D-TLB), либо отключить предвыборку вообще. Другое дело, а есть ли в этом необходимость?
Вот мы и подходим к другому заданному выше вопросу «зачем». Какие результаты следует считать более «правильными» с аппаратной предвыборкой, или без таковой? Иными словами, нужно ли отключать Hardware Prefetch на время измерения? Ответ на этот вопрос будет предельно прост: все зависит от того, что мы хотим измерить. Если нам требуется оценить реальные задержки при чтении процессором данных из памяти в одной из моделируемых тестом ситуаций прямого, обратного, случайного или псевдослучайного обхода блока памяти (первые две из которых соответствуют кодированию видео или какой-либо другой потоковой обработке данных, а две последних например, поиску в базе данных) то следует остановиться на первом варианте. Именно этот вариант будет отражать действительность, т.е. стандартный режим работы процессора: Hardware Prefetch включен, а считывание данных из памяти осуществляется по 128-байтным секторам, составляющим две строки кэша процессора. Резюмируя, первый метод позволяет нам оценить реальную латентность подсистемы памяти в целом, т.е. включая функциональные блоки процессора, ответственные за обмен данными с оперативной памятью.
Если же нам требуется оценить некую характеристику, ближе соответствующую истинным задержкам при доступе к массиву ячеек памяти, нам больше подойдет вторая методика. Ибо она охватывает более узкую часть подсистемы памяти непосредственно носитель (микросхемы модулей), а также чипсет, таким образом, она позволяет оценить задержки при доступе в память безотносительно возможностей процессорного интерфейса, осуществляющего обмен с памятью (BIU).
Наконец, можно использовать комбинированную методику, сочетающую оба метода: измерение латентности псевдослучайного доступа к 16-МБ блоку со 128-байтовым шагом сначала с Hardware Prefetch, затем без него. И использовать полученный интервал значений в качестве оценки возможных реальных задержек при доступе к подсистеме памяти в различных ситуациях.


