Часть 13: Инженерный образец двухъядерного процессора Intel Core 2 (Conroe)
Новая микроархитектура Intel Core еще не получила свое воплощение в виде конечных решений, тем не менее, известна она уже сравнительно давно — начиная с момента ее представления на Intel Developer Forum, проходившего в Сан-Франциско осенью 2005 года. С тех пор появилось немало слухов и было представлено немало фактов о новой микроархитектуре. Последние, можно сказать, окончательно оформились к моменту проведения российского Форума Intel для разработчиков в конце апреля 2006 года в Москве. Напомним основные факты о новой микроархитектуре.
Микроархитектура Intel Core представлена тремя (по сути своей — идентичными) ядрами Conroe (десктопные процессоры), Merom (мобильные процессоры) и Woodcrest (серверные процессоры). Появление готовых решений в виде процессоров Intel Core 2 / Core 2 Extreme ожидается в третьем квартале 2006 г. Ключевые моменты новой микроархитектуры следующие:
- Wide Dynamic Execution — увеличение количества декодеров x86-макроопераций до 4, что на 33% выше по сравнению с предыдущими процессорами Intel Pentium M / Core Duo;
- Advanced Digital Media Boost — удвоенная скорость исполнения 128-битных SIMD-инструкций (1 инструкция за 1 такт в каждом исполнительном устройстве Add/Mul/Load/Store);
- Smart Memory Access — минимизация задержек доступа к памяти за счет безопасного переупорядочивания операций загрузки и сохранения данных (memory disambiguation) и использования аппаратной предвыборки (hardware prefetch) на уровне L2-кэша и оперативной памяти;
- Advanced Smart Cache — эффективно разделяемый объем L2-кэша в зависимости от потребностей каждого ядра, а также удвоенная скорость обмена с L1-кэшем каждого из ядер;
- Intelligent Power Capability — новые и улучшенные технологии энергосбережения (отключение неиспользуемых участков ядра процессора на тонком уровне, использование энергооптимизированных «разделенных» шин).
Не секрет, что новая микроархитектура Intel Core во многом похожа на весьма давнюю короткоконвейерную микроархитектуру P6, успешно продолжавшую свое развитие в процессорах Pentium III, Pentium M (ядра Banias, Dothan) и Core Duo/Core Solo (ядро Yonah). В некоторой степени, «новую» микроархитектуру Core даже можно считать просто дальнейшим развитием микроархитектуры P6, точнее — ее последнего двухъядерного воплощения Yonah, имеющего определенные с ней сходства (вроде разделяемого между ядрами L2-кэша).
Именно поэтому наше сегодняшнее исследование низкоуровневых характеристик процессорного ядра Conroe (представленного инженерным образцом десктопного процессора Intel Core 2) наиболее разумно проводить в сопоставлении с низкоуровневыми характеристиками ядра Yonah, представленного двухъядерным мобильным процессором Intel Core Duo.
Конфигурация тестового стенда
- Процессор: Intel Core 2 Engineering Sample (ядро Conroe, 2.13 ГГц)
- Чипсет: Intel 965, ICH8
- Материнская плата: Intel DG965SS, BIOS MQ96510J.86A.0066.2006.0428.1622
- Память: 2x1 ГБ Corsair XMS2-6400PRO, тайминги 5-5-5-15
Данные CPUID
Как обычно, начнем рассмотрение нового процессорного ядра с рассмотрения наиболее существенных значений, выдаваемых инструкцией CPUID процессора с различными входными параметрами.
Таблица 1. Intel Core Duo (Yonah) CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 06E8h | Семейство 6, модель 14, степпинг 8 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | B0h B3h 02h F0h 7Dh 30h 04h 2Ch | I-TLB: 4-КБ стр., 4-асс., 128 записей D-TLB: 4-КБ стр., 4-асс., 128 записей I-TLB: 4-МБ стр., полноасс., 2 записи 64-байтная предвыборка L2-кэш: 2 МБ, 8-асс., 64-байтн. строка L1-I кэш: 32 КБ, 8-асс., 64-байтн. строка D-TLB: 4-МБ стр., 4-асс., 8 записей L1-D кэш: 32 КБ, 8-асс., 64-байтн. строка |
| Количество логических процессоров | 02h | 2 логических процессора |
| Количество ядер | 01h | 2 ядра |
| Basic Features, ECX | 0000C1A9h | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 5: Неизвестно Bit 7: Поддержка EIST Bit 8: Поддержка TM2 Bit 14: Поддержка Send Task Priority Messages Bit 15: Неизвестно |
| Extended Features, EDX | 00100000h | Bit 20: Поддержка XD bit |
Таблица 2. Intel Core 2 (Conroe) ES CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 06F1h | Семейство 6, модель 15, степпинг 1 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | B1h B0h 05h F0h 57h 56h 49h 30h B4h 2Ch | Неизвестно I-TLB: 4-КБ стр., 4-асс., 128 записей Неизвестно 64-байтная предвыборка Неизвестно Неизвестно L3-кэш: 4 МБ, 16-асс., 64-байтн. строка (?) L1-I кэш: 32 КБ, 8-асс., 64-байтн. строка Неизвестно L1-D кэш: 32 КБ, 8-асс., 64-байтн. строка |
| Количество логических процессоров | 02h | 2 логических процессора |
| Количество ядер | 01h | 2 ядра |
| Basic Features, ECX | 0000E3BDh | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 2: Неизвестно Bit 4: Поддержка CPL Qualified Debug Store Bit 5: Неизвестно Bit 7: Поддержка EIST Bit 8: Поддержка TM2 Bit 9: Неизвестно Bit 13: Поддержка инструкции CMPXCHG16B Bit 14: Поддержка Send Task Priority Messages Bit 15: Неизвестно |
| Extended Features, EDX | 20100000h | Bit 20: Поддержка XD bit Bit 29: Поддержка Intel (R) EM64T |
По представленной в таблице 2 сигнатуре CPUID 06F1h можно сказать, что компания Intel однозначно относит новое процессорное ядро Conroe (а вместе с ним — и микроархитектуру Intel Core) к «6-му поколению» процессоров, т.е. микроархитектуре P6. По сравнению с ядром Yonah изменился лишь номер модели (с 14 на 15). Что касается номера степпинга (1), вряд ли его сейчас стоит считать чем-либо значащим, учитывая, что перед нами — инженерный образец процессора, т.е. ранняя ревизия его ядра.
Среди дескрипторов кэшей/TLB можно встретить достаточно много пока что «неизвестных» значений, относящихся, по-видимому, в основном к буферам трансляции адресов кода и данных (I-TLB/D-TLB). Надо сказать, количество «неизвестных» дескрипторов впечатляет — столь кардинальное изменение характеристик, особенно такого не столь «заметного» ресурса процессора как TLB, можно встретить нечасто. Из «интересных» особенностей этих параметров можно также отметить присутствие дескриптора 49h, отвечающего L3(!)-кэшу объемом 4 МБ с 64-байтной строкой и степенью ассоциативности, равной 16. По всей видимости, данный параметр на самом деле относится к разделяемому L2-кэшу. Так ли это на самом деле — как всегда, покажут соответствующие измерения.
Количество «логических» процессоров (исторический параметр, введенный в связи с появлением технологии Hyper-Threading и реально отражающий количество «системных» процессоров, т.е. процессоров, «видимых» операционной системе) и количество ядер в новом ядре Conroe — 2, как и в любом двухъядерном процессоре без технологии Hyper-Threading, включая рассмотренный ранее процессор Core Duo (ядро Yonah).
Достаточно интересная картина наблюдается по части расширений процессора, представленных регистром ECX Basic Features. Во-первых, в ядре Conroe присутствуют по-прежнему «неизвестные» технологии, кодируемые битами 5 и 15, которые также имеются в процессоре Core Duo, причем одно из этих значений определенно относится к технологии виртуализации Intel Virtualization Technology, ранее известной как VanderPool Technology. Кроме того, в Conroe также присутствует некая «неизвестная» (тем не менее, уже давно реально встречающаяся) технология, кодируемая битом 2 этого регистра — последнюю можно встретить в различных вариантах ядер процессоров с микроархитектурой NetBurst, включая «Prescott/2M», Smithfield и Presler. Наконец, новому ядру Conroe (и пока что только ему) присуща еще одна технология, обозначаемая битом 9 рассматриваемого регистра. Логично предположить, что последняя отражает наличие новых SIMD-расширений SSE4, на самом деле представляющих собой по большей части расширения целочисленных инструкций MMX и «SSE2/MMX». В наборе расширений, представленных регистром ECX Basic Features, нельзя не отметить также присутствие давно известных технологий Thermal Monitor 2 и Enhanced Intel SpeedStep (было бы странно, если бы их не было), а также SSE3 с сопутствующими инструкциями MONITOR/MWAIT и поддержку инструкции CMPXCHG16B. Последняя, как можно догадаться, относится к 64-битному режиму работы процессора, возможность которого заявлена в содержимом регистра EDX Extended Features, наряду с поддержкой технологии XD bit. Таким образом, еще одним из новшеств процессорного ядра Conroe, не упомянутых выше, является введение 64-разрядного режима работы, именуемого Intel Extended Memory 64-bit Technology (EM64T).
Реальная пропускная способность кэша данных/памяти
Перейдем к оценкам реальных низкоуровневых характеристик процессорного ядра, измеренных в последней версии тестового пакета RightMark Memory Analyzer 3.65.
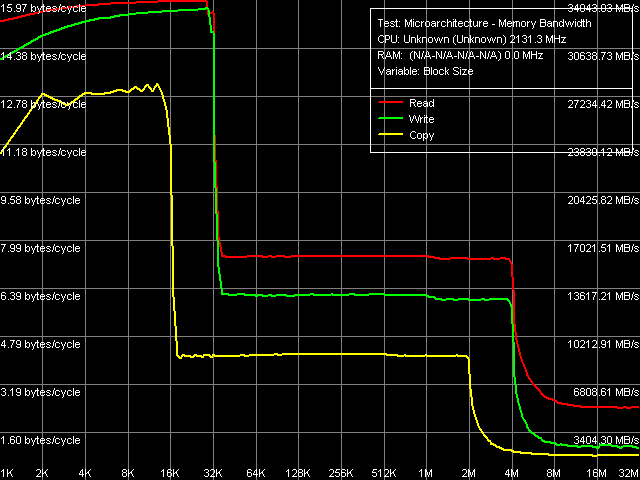
Рис. 1. Средняя реальная ПС кэша данных и оперативной памяти
Общая картина реальной пропускной способности L1/L2-кэша и оперативной памяти (рис. 1) выглядит весьма внушительно. Перед нами — первый процессор, в котором реально можно увидеть эффективный объем L2-кэша, равный 4 МБ, даже при обращении к данным, содержащимся в памяти, лишь со стороны одного ядра. Собственно, подобную картину, но с меньшим общим объемом L2-кэша (2 МБ), мы наблюдали при исследовании процессорного ядра Yonah, т.е. ядра Conroe и Yonah обладают одинаковой способностью высокоэффективного перераспределения всего объема L2-кэша под нужды любого из ядер. В то же время, объем L1-кэша данных не изменился и по-прежнему составляет 32 КБ, о чем говорят также рассмотренные выше дескрипторы кэшей/TLB.
Таблица 3
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) ES | |
| L1, чтение, MMX L1, чтение, SSE2 L1, запись, MMX L1, запись, SSE2 | 7.99 8.00 7.85 7.89 | 7.99 15.97 7.94 15.68 |
| L2, чтение, MMX L2, чтение, SSE2 L2, запись, MMX L2, запись, SSE2 | 4.34 4.34 4.57 4.57 | 5.14 7.47 4.84 6.17 |
| RAM*, чтение (SSE2) RAM, запись (SSE2) | 3990 МБ/с (74.8%) 1415 МБ/с (26.5%) | 5295 МБ/с (62.1%) 2330 МБ/с (27.3%) |
*в скобках указаны значения относительно теоретического предела ПС системной шины
Переходим к количественным оценкам пропускной способности, представленным в таблице 3. Весьма значимые изменения можно наблюдать в области L1-кэша данных. В то время как эффективность его использования при операциях чтения/записи с MMX-регистрами практически не изменилась, она возросла почти в 2 раза при использовании SSE/SSE2-регистров. Понятно, что это — не эффективность L1-кэша данных как такового, а именно эффективность его использования, и ее возрастание связано с «Advanced Digital Media Boost», т.е. исполнением SSE/SSE2-инструкций за 1 такт процессора, что обеспечивает предельную пропускную способность «L1-регистры» в 16 байт/такт, которая практически достигается и в реальности.
Эффективность L2-кэша, в сравнении с Yonah, заметно возросла. Причем на этот раз — как сама эффективность (т.е. пропускная способность шины L1-L2), что можно увидеть по увеличению ПС L2-кэша при использовании MMX-регистров, примерно на 18% при операциях чтения и 6% при операциях записи, так и эффективность его утилизации при использовании «полноскоростного» 128-битного обращения. В этом случае, при использовании SSE/SSE2-инструкций, ПС L2-кэша в сравнении с ядром Yonah возросла примерно на 72% при операциях чтения и 35% при операциях записи данных.
Что касается ПС оперативной памяти, как всегда, говорить об однозначном преимуществе по общей картине достаточно сложно, поскольку на эту величину могут влиять факторы, не относящиеся к процессору. По сравнению с исследованной платформой Yonah, в общем случае удается достичь большие значения ПСП по абсолютному показателю — порядка 5.3 ГБ/с при чтении и 2.3 ГБ/с при записи, однако в относительных величинах (по отношению к теоретической ПС системной шины) исследуемая платформа с инженерным образцом процессора Core 2 пока что проигрывает серийной платформе Core Duo.
Предельная реальная пропускная способность памяти
Попытаемся оценить предельную реальную пропускную способность памяти, иными словами — оценить эффективность реализации программной предвыборки (software prefetch) и прямого сохранения данных (non-temporal store), поскольку именно эти методы дают наилучший результат на платформах Intel.
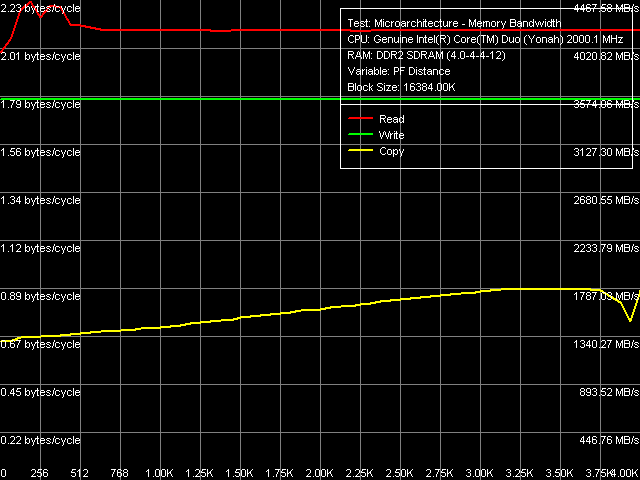
Рис. 2. Максимальная реальная ПСП, Software Prefetch/Non-Temporal Store, ядро Yonah
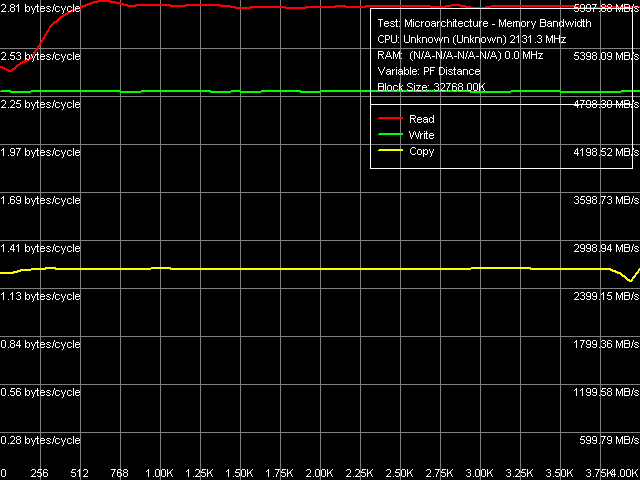
Рис. 3. Максимальная реальная ПСП, Software Prefetch/Non-Temporal Store, ядро Conroe (ES)
Сопоставляя внешний вид кривых зависимости ПСП от дистанции предвыборки на ядрах Yonah (рис. 2) и Conroe (рис. 3) можно заметить некоторые отличия в ее реализации. Так, на ядре Yonah максимум эффективности программной предвыборки при чтении данных наблюдается при ее дистанции в 192 байта и более-менее сохраняется в интервале 192-384 байт, после чего заметно снижается. При копировании данных эффективность предвыборки плавно возрастает при увеличении ее дистанции вплоть до 4096 байт, т.е. до границы страницы запрашиваемых данных. В то же время, на ядре Core наблюдается иная картина: максимум эффективности программной предвыборки при чтении наблюдается при ее дистанции примерно в 640 байт, после чего сохраняется практически на постоянном уровне. А операции копирования вообще оказываются гораздо менее чувствительными к программной предвыборке как таковой.
Таблица 4
| Операция | Максимальная реальная ПСП, МБ/с* | |
|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) ES | |
| Чтение, Software Prefetch | 4470 (83.8%) | 6000 (70.3%) |
| Запись, Non-Temporal Store | 3550 (66.6%) | 4870 (57.1%) |
*в скобках указаны значения относительно теоретического предела ПС системной шины
Взглянем на количественные оценки величин ПСП, реально достижимых на обеих платформах (таблица 4). Как и прежде, на платформе Core 2 величины ПСП оказываются выше по абсолютным показателям, но меньше — по относительным. Эффективность программной предвыборки составляет примерно 12% для Yonah и 13% для Conroe, т.е. оказывается сопоставимой. С чем связана недостижимость больших значений ПСП — пока не ясно. Заметим, что максимум эффективности ПСП не достигается также при записи данных методом прямого сохранения — на платформе Yonah наблюдаются привычная для платформ Intel утилизация 2/3 пропускной способности системной шины, тогда как на Conroe достигается лишь 57% от ее теоретической пропускной способности. Будем надеяться, что ситуация изменится в дальнейшем, с выходом серийных экземпляров процессоров.
Средняя латентность кэша данных/памяти
По общей картине латентности L1/L2-кэша данных и памяти (рис. 4) сразу можно сделать определенные выводы о наличии предвыборки данных на уровне оперативной памяти, а также L2-кэша (латентности при прямом и обратном обходе этих областей заметно ниже, чем при псевдослучайном и случайном обходе). Напомним, что предвыборка данных на уровне L2-кэша впервые наблюдалась в процессорном ядре Presler. Она также официально заявлена и для ядер микроархитектуры Core, что подтверждается результатами данного измерения.
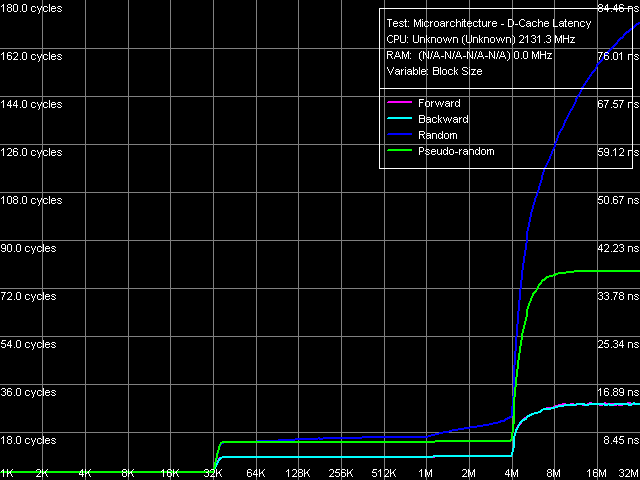
Рис. 4. Латентность кэша данных и памяти, размер шага 64 байта
Кроме того, определенные выводы можно сделать и о буфере D-TLB, заявленные характеристики которого пока что неизвестны. Возрастание латентности случайного доступа в двух областях — 64 КБ и 1 МБ может указывать на двухуровневую организацию последнего (впервые для процессоров Intel!) с размерами уровней в 16 и 256 записей страниц, соответственно. Мы обязательно вернемся к этому вопросу в соответствующем разделе, а пока рассмотрим количественные характеристики, представленные в таблице 5.
Таблица 5
| Уровень | Средняя латентность, тактов | |
|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) ES | |
| L1 кэш | 3.0 (во всех случаях) | 3.0 (во всех случаях) |
| L2 кэш | 14.0 (во всех случаях) | ~8.9 (прямой) ~8.9 (обратный) ~14.5 (псевдослучайный) ~14.5 (случайный) |
| RAM (32-МБ блок), размер шага 64 байта | 24.0 нс (прямой) 24.0 нс (обратный) 49.1 нс (псевдослучайный) 98.0 нс (случайный) | 13.4 нс (прямой) 13.5 нс (обратный) 36.9 нс (псевдослучайный) 80.6 нс (случайный) |
| RAM (32-МБ блок), размер шага 128 байт | 92.2 нс (прямой) 90.0 нс (обратный) 92.2 нс (псевдослучайный) 108.6 нс (случайный) | 32.7 нс (прямой) 31.8 нс (обратный) 68.2 нс (псевдослучайный) 89.3 нс (случайный) |
Что приятно, латентность L1-кэша данных не изменилась — она по-прежнему составляет 3 такта, привычные для процессоров-последователей микроархитектуры P6. Введение предвыборки на уровне L2-кэша существенно усложняет оценку латентности этого уровня. Тогда как в процессорном ядре Yonah она составляет ровно 14 тактов во всех случаях доступа, в ядре Conroe она равняется примерно 8.9 тактам при прямом и обратном последовательном обходе, и примерно 14.5 тактам — при псевдослучайном и случайном, когда аппаратная предвыборка практически бездействует.
Средняя латентность оперативной памяти была измерена в двух режимах — при 64-байтной и 128-байтной величине шага. Первая соответствует реальной длине строки L2-кэша, вторая — «эффективной», с учетом обязательной выборки соседней 64-байтной строки наряду с запрашиваемой.
Легко заметить, не переходя к следующему разделу, что аппаратная предвыборка данных в ядре Conroe работает гораздо более эффективно по сравнению с таковой в ядре Yonah. Это отражается как в виде заметного меньших задержек как при 64-байтном прямом и обратном обходе (их величина — всего 13.5 нс!), так и при 128-байтном прямом и обратном обходе (порядка 32 нс). Иными словами, алгоритм аппаратной предвыборки данных в Conroe эффективно справляется и в случае «черезстрочного» линейного доступа к памяти, тогда как такой вариант доступа в Yonah эффективно отключает аппаратную предвыборку. Приятно также отметить наблюдаемые во всех случаях меньшие величины задержек при доступе в память на новой платформе в целом.
Минимальная латентность L2 кэша данных/памяти
Для начала, оценим минимальную латентность L2-кэша данных. Учитывая аппаратную предвыборку данных уже на этом уровне, следует ожидать, что она окажется меньшей по сравнению со своей средней величиной при разгрузке шины данных L1-L2 вставкой пустых операций между операциями последовательного доступа к данным, содержащимся в L2-кэше.
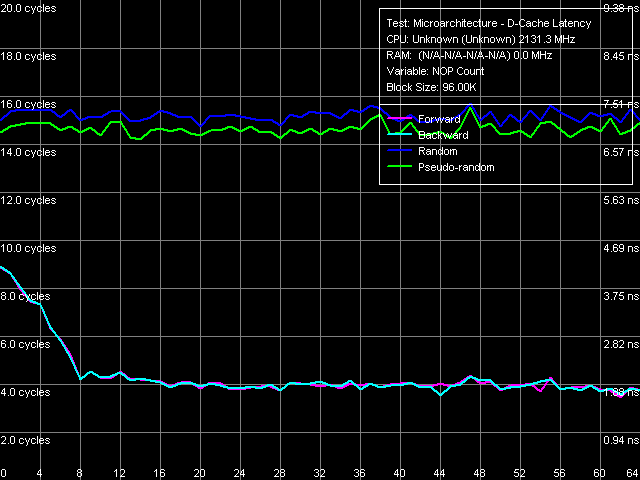
Рис. 5. Минимальная латентность L2-кэша, размер шага 64 байта
Как видно по рис. 5, ожидаемое согласуется с действительным. Уже при вставке 8 пустых операций (NOP) латентность L2-кэша при прямом и обратном вариантах обхода снижается до минимальной отметки в 4(!) такта процессора. Посмотрим, какую латентность мы сможем достичь, применяя аналогичный подход, но уже при доступе к данным. Для начала, сохраним размер шага в 64 байта, отвечающий максимальной эффективности аппаратной предвыборки (рис. 6).
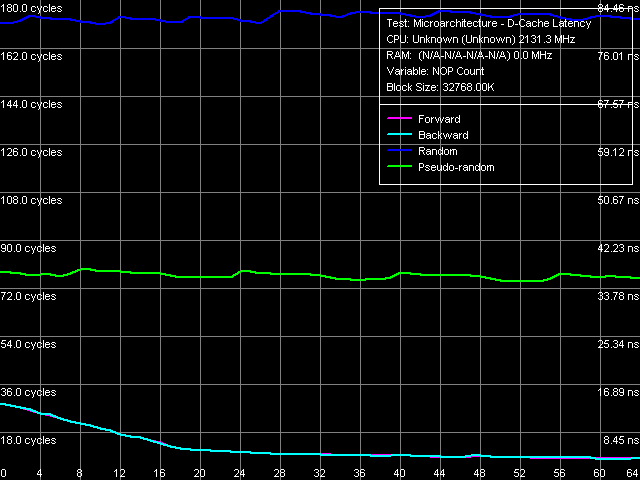
Рис. 6. Минимальная латентность памяти, размер шага 64 байта
Результат впечатляет — при вставке порядка 18 и более пустых операций латентность оперативной памяти при прямом и обратном последовательном обходе плавно снижается до величин порядка… 3.7-3.9 нс(!), т.е. всего 8 тактов процессора! Соответствующий вариант разгрузки шины L2-RAM на процессоре Yonah, как видно из приведенных в таблице 6 данных, приводит к меньшему эффекту — минимально достижимая латентность памяти составляет примерно 10 нс (что, конечно, также весьма неплохо).
Как и следовало ожидать, разгрузка шины L1-L2 (L2-RAM) не оказывает ощутимого эффекта на величины латентности L2-кэша (памяти) при псевдослучайном и случайном обходе.
Таблица 6
| Уровень | Минимальная латентность, тактов | |
|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) ES | |
| L1 кэш | 3.0 (во всех случаях) | 3.0 (во всех случаях) |
| L2 кэш | 14.0 (во всех случаях) | 4.0 (прямой, обратный) ~14.5 (псевдослучайный) ~15.0 (случайный) |
| RAM (32-МБ блок), размер шага 64 байта | 10.1 нс (прямой) 10.1 нс (обратный) 47.0 нс (псевдослучайный) 96.9 нс (случайный) | 3.9 нс (прямой) 3.7 нс (обратный) 35.1 нс (псевдослучайный) 80.4 нс (случайный) |
| RAM (32-МБ блок), размер шага 128 байт | 87.4 нс (прямой) 87.4 нс (обратный) 87.6 нс (псевдослучайный) 107.2 нс (случайный) | < 15.3 нс (прямой) < 15.4 нс (обратный) 65.6 нс (псевдослучайный) 88.5 нс (случайный) |
Оценим теперь эффективность разгрузки шины L2-RAM при 128-байтном обходе памяти (рис. 7). Выше мы видели, что в этом случае аппаратная предвыборка в ядре Conroe обладает меньшей эффективностью, а в ядре Yonah и вовсе бездействует.
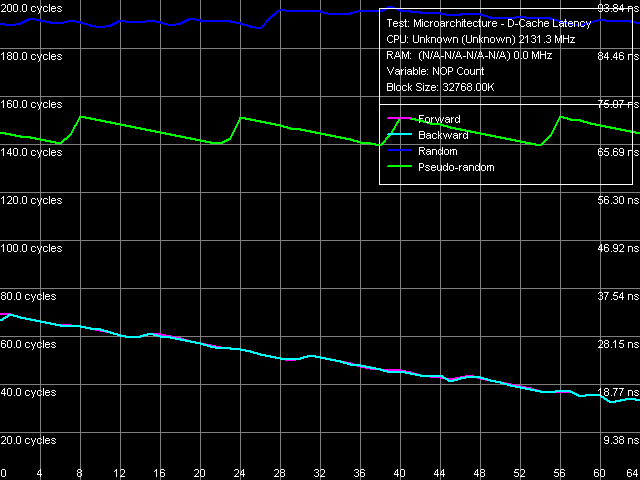
Рис. 7. Минимальная латентность памяти, размер шага 128 байт
Несмотря на сказанное выше, даже в этом случае аппаратной предвыборке данных в Conroe можно значительно помочь, применяя разгрузку соответствующей шины данных. Минимальная латентность памяти в этом случае, однако, не достигается и при вставке 64 пустых операций (значение в этой точке — порядка 15.3 нс), однако логично предположить, что она достигнет тех же минимальных значений (3.9 нс) при дальнейшей разгрузке шины.
Ассоциативность кэша данных
Оценим ассоциативность кэша данных. Из небольшого набора расшифрованных дескрипторов кэшей/TLB следует ожидать, что ассоциативность L1-кэша равна 8, а ассоциативность разделяемого L2-кэша — 16.
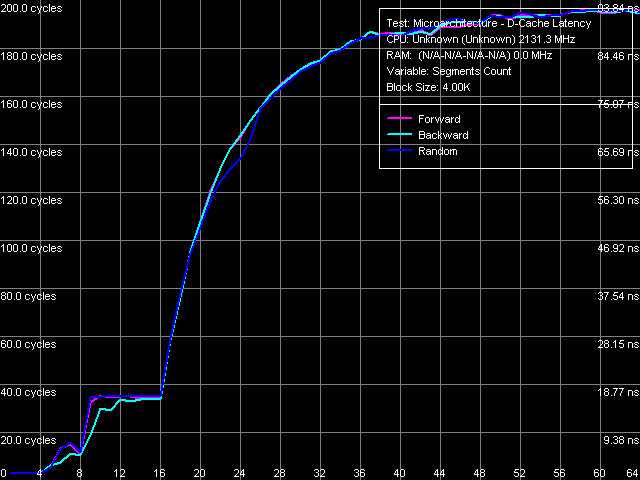
Рис. 8. Ассоциативность L1/L2 кэша данных
По представленным на рис. 8 результатам измерения можно вполне подтвердить заявленные производителем значения. Небольшое увеличение латентности при превышении 4 сегментов может свидетельствовать об исчерпании ассоциативности D-TLB, стабильный же результат исчерпания ассоциативности L1/L2-кэша наблюдается в области 8 и 16 сегментов, соответственно.
Реальная пропускная способность шины L1-L2
По результатам наших первых измерений реальной пропускной способности L2-кэша данных мы видели, что последняя в ядре Conroe эффективно возросла. Проверим, связано ли это с возросшей пропускной способностью шины данных L1-L2 (рис. 9).
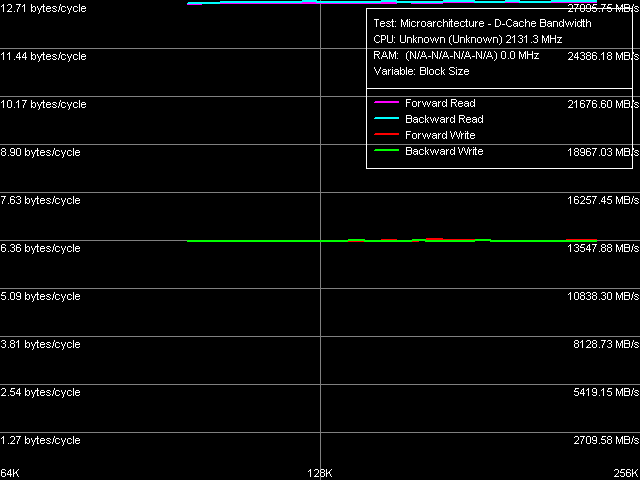
Рис. 9. Реальная пропускная способность шины L1-L2 кэша
На первый взгляд, эффективность этой шины (таблица 6) при операциях чтения по сравнению с Yonah возросла незначительно — всего примерно на 7% (увеличение ее ПС при операциях записи заметно выше — до 30%). Более того, абсолютное значение по-прежнему составляет менее 16 байт/такт, что может указывать на по-прежнему 128-битную эффективную ширину шины L1-L2 кэша данных (т.е. шина L1-L2 представляет собой либо 128-битную шину как таковую, либо 256-битную «полускоростную» шину).
Таблица 6
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт | |
|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) ES | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 11.86 11.87 4.91 4.91 | 12.70 12.71 6.39 6.37 |
Тем не менее, зададимся вопросом, действительно ли эффективная ширина шины L1-L2 кэша данных по-прежнему составляет 128 байт, несмотря на официальные заявления Intel об удвоении ее эффективности (как составной части «Advanced Smart Cache»)? Для этого воспользуемся тестом прибытия данных по шине L1-L2 в условиях достаточной разгрузки последней.
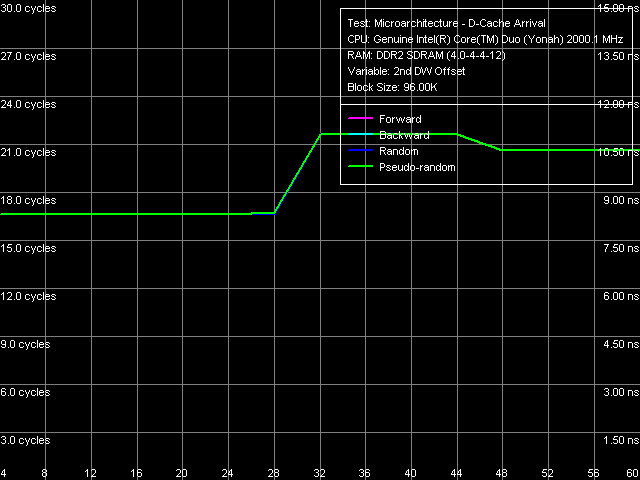
Рис. 10. Тест прибытия данных по шине L1-L2 кэша, ядро Yonah
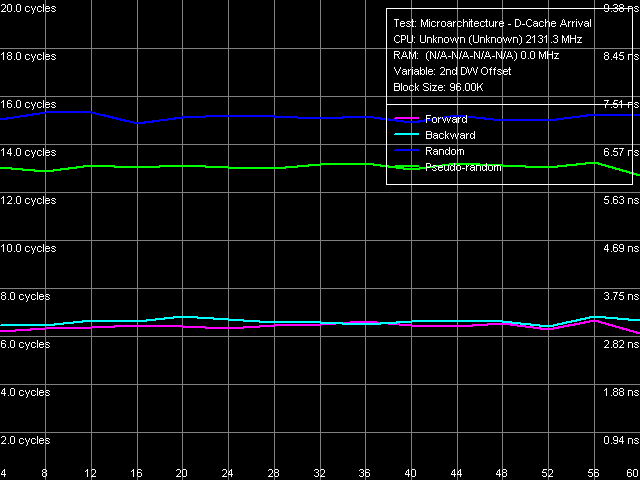
Рис. 11. Тест прибытия данных по шине L1-L2 кэша, ядро Conroe (ES)
По приведенному на рис. 11 результату видно, что процессорное ядро Conroe способно беспрепятственно (без дополнительных задержек) считать любой элемент данных 64-байтной строки L2-кэша, чем резко отличается от всех предыдущих ядер микроархитектуры P6 (для примера — Yonah, рис. 10). Таким образом, эффективная ширина шины L1-L2 в этом ядре действительно возросла вдвое и составляет 256 бит.
Кэш инструкций, эффективность декодирования
Наиболее значимые изменения в микроархитектуре Intel Core касаются декодера и исполнительных устройств процессора. Действительно, введение поддержки 64-битного режима, «расширение» декодера с возможностью обработки до 4 макроопераций/такт, обработка 128-битных SIMD-инструкций за один такт процессора, слияние макроопераций (CMP/TEST+Jcc) и многое, многое другое — все это достаточно сильно отличает устройство указанных функциональных блоков процессоров микроархитектуры Intel Core от устройства этих блоков в предыдущих процессорах, основанных на микроархитектуре P6. Что ж, приступим к их краткому изучению.
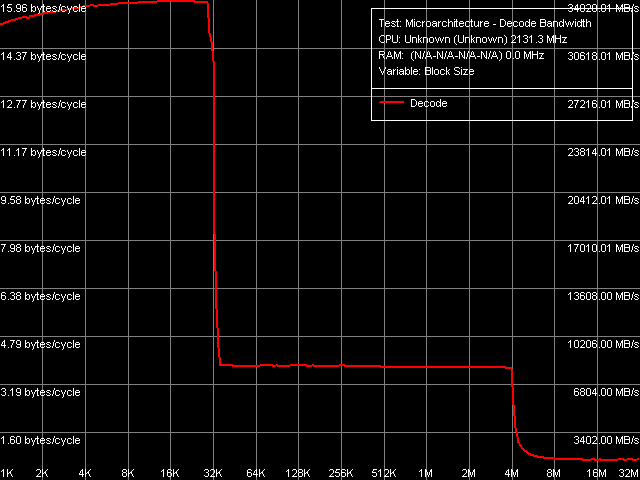
Рис. 12. Эффективность декодирования/исполнения 6-байтных инструкций CMP
На рис. 12 показана кривая эффективности декодирования/исполнения крупных 6-байтных инструкций «CMP 3» (cmp eax, 00000000h), как наиболее показательных в плане абсолютной скорости их обработки. По этому результату уже можно оценить предельную скорость выборки инструкций декодером из L1-кэша инструкций — она составляет 16 байт/такт, что выше по сравнению с результатом, демонстрируемым Yonah (12 байт/такт, см. таблицу 7). Предельная скорость исполнения кода из унифицированного L2-кэша составляет 3.83 байт/такт, что несколько выше по сравнению с Yonah (3.71 байт/такт). Кстати, заметим, что объем L2-кэша и в этом случае (при исполнении сверхдлинного блока кода) целиком предоставляется одному, активному ядру.
Таблица 7
| Тип инструкций (размер, байт) | Эффективность декодирования, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) | |||
| L1-I кэш | L2 кэш | L1-I кэш | L2 кэш | |
| NOP (1) SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) CMP 2 (4) CMP 3-6 (6) Prefixed CMP 1-4 (8) | 2.00 (2.00) 3.99 (2.00) 3.99 (2.00) 3.99 (2.00) 3.97 (1.99) 3.99 (2.00) 7.99 (2.00) 11.98 (2.00) 2.00 (0.25) | 1.94 (1.94) 3.19 (1.60) 3.19 (1.60) 3.19 (1.60) 3.19 (1.60) 3.19 (1.60) 3.54 (0.89) 3.71 (0.62) 1.88 (0.24) | 3.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 11.99 (3.00) 15.96 (2.66) 2.29 (0.29) | 2.90 (2.90) 3.73 (1.87) 3.73 (1.87) 3.73 (1.87) 3.73 (1.87) 3.73 (1.87) 3.83 (0.96) 3.83 (0.64) 2.19 (0.27) |
Обратим внимание на результаты измерений эффективности декодирования/исполнения прочих инструкций. Прежде всего заметим, что «чуда не произошло» — ни одна из простейших независимых ALU-макроопераций, несмотря на «четверной» запуск, не демонстрирует темп исполнения в 4 инструкции/такт. Вместо этого, наблюдается увеличенный по сравнению с Yonah предельный темп исполнения в 3 операции/такт. Причина этого достаточно очевидна. Да, «ширина» декодера была увеличена до 4 макроопераций/такт (в некоторых случаях — и выше, если учесть слияние макроопераций сравнения и условного перехода — CMP/TEST+Jcc). Тем не менее, количество исполнительных ALU-устройств, по сравнению с предыдущими процессорами P6, было увеличено лишь с двух до трех. В результате и наблюдается предельный темп исполнения, соответствующий числу этих блоков.
Заметим, что новое процессорное ядро Conroe с таким же успехом, как и Yonah, способно справляться с «условными зависимостями» в цепочке инструкций SUB (sub eax, eax), XOR (xor eax, eax) и XOR/ADD (xor eax, eax; add eax, eax) — эффективность исполнения таких цепочек не уступает эффективности исполнения цепочек независимых простейших инструкций (NOP, TEST, CMP). В то же время, отсечение бессмысленных префиксов по-прежнему не отличается столь же высокой эффективностью, которую можно наблюдать в процессорах микроархитектуры NetBurst. Тем не менее, определенные подвижки в этом направлении (пусть и далеко не столь значимом) все же имеются. Во-первых, темп исполнения «префиксных CMP» ядром Conroe несколько увеличился (с 2.0 до 2.29 байт/такт) по сравнению с ядром Yonah. Во-вторых, посмотрим на результаты теста декодирования/исполнения «префиксных NOP» — инструкций вида [66h]nNOP, n = 0..14, представленные на рис. 13 и в таблице 8.
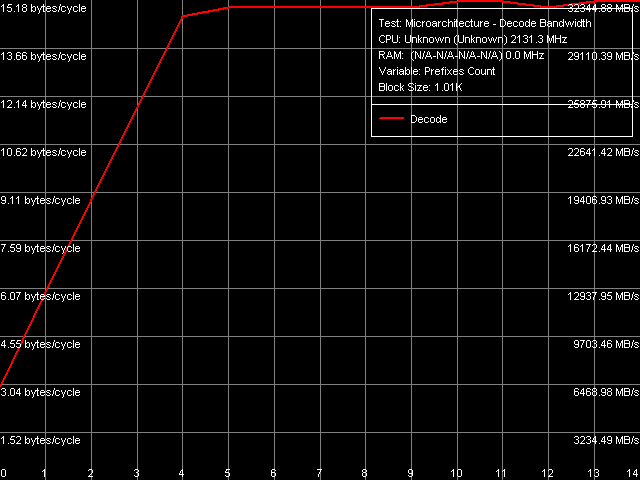
Рис. 13. Эффективность декодирования/исполнения префиксных инструкций NOP
Как видно из представленных данных, эффективность исполнения «префиксных NOP» остается весьма высокой даже при большом количестве префиксов (вплоть до 4). При дальнейшем его увеличении скорость декодирования/исполнения таких инструкций начинает лимитироваться скоростью выборки инструкций из L1-I кэша (в данном случае она несколько не «дотягивает» до предельных 16 байт/такт).
Таблица 8
| Количество префиксов | Эффективность декодирования/исполнения,байт/такт (инструкций/такт) | |
|---|---|---|
| Core Duo (Yonah) | Core 2 (Conroe) ES | |
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1.99 (1.99) 3.93 (1.97) 0.75 (0.25) 0.80 (0.20) 0.83 (0.17) 0.86 (0.14) 0.87 (0.12) 0.89 (0.11) 0.90 (0.10) 0.91 (0.09) 0.92 (0.08) 0.93 (0.08) 0.93 (0.07) 0.94 (0.07) 0.94 (0.06) | 2.99 (2.99) 5.95 (2.98) 8.90 (2.97) 11.82 (2.96) 14.67 (2.93) 14.96 (2.49) 14.96 (2.14) 14.96 (1.87) 14.96 (1.66) 14.96 (1.50) 15.18 (1.38) 15.18 (1.27) 14.96 (1.15) 15.18 (1.08) 15.18 (1.01) |
Ассоциативность кэша инструкций
Оценим ассоциативность кэша инструкций с помощью соответствующего теста, исполняющего время безусловных переходов по цепочке, определенным образом расположенной в выделенном блоке памяти.
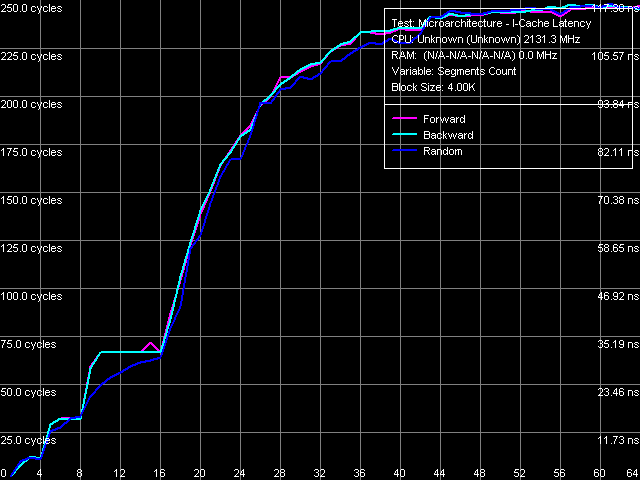
Рис. 14. Ассоциативность кэша инструкций
Картина ассоциативности кэша инструкций (рис. 14) оказывается не менее четкой, чем рассмотренная выше картина ассоциативности кэша данных. Наблюдаемый перегиб в области 4 сегментов, по-видимому, вновь относится к ассоциативности TLB (на сей раз — I-TLB), тогда как перегибы в области 8 и 16 сегментов соответствуют заявленной ассоциативности L1- и L2-кэшей.
Буфер переупорядочивания инструкций (I-ROB)
Напомним принцип работы специального теста RMMA, позволяющего оценить глубину буфера переупорядочивания инструкций (I-ROB): запускается одна простая, но долго исполняемая инструкция — операция зависимой загрузки последующей строки данных из памяти, mov eax, [eax], а сразу вслед за ней — серия очень простых, не зависящих от нее операций (NOP). В идеализированном случае, как только время исполнения такой связки начинает зависеть от количества NOP-ов, можно считать, что размер I-ROB исчерпан.
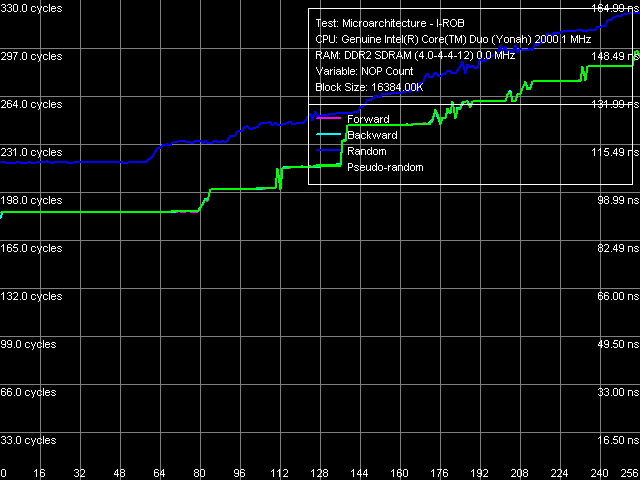
Рис. 15. Глубина буфера переупорядочивания инструкций, ядро Yonah
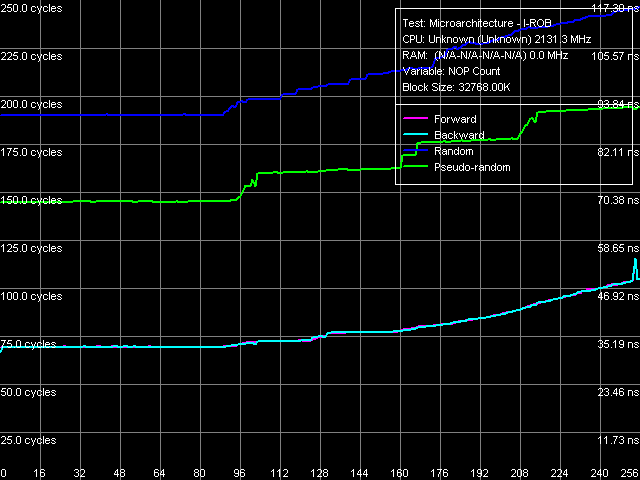
Рис. 16. Глубина буфера переупорядочивания инструкций, ядро Conroe (ES)
Тем не менее, практика показывает, что «идеализированный случай» возникает весьма редко — вместо этого, в реальности получаются характерные «ступенчатые» кривые, «ступенчатость» которых связана с возможностью осуществления доступа к памяти лишь на каждом целом такте шины памяти, на который приходится несколько тактов процессора (в соответствии с коэффициентом умножения тактовой частоты). В связи с этим, точная количественная оценка объема I-ROB по аппроксимационным кривым затруднена и, как правило, оказывается завышенной. Неоднозначны также варианты проведения самой аппроксимации. В связи с этим, в настоящем исследовании (и в дальнейшем) оценку объема I-ROB будем проводить по первому перегибу, т.е. точке возникновения первой «ступеньки» на кривой случайного доступа к памяти.
Указанный перегиб на кривой, полученной при проведении теста на ядре Yonah (рис. 15) наблюдается в области примерно 60 NOP-ов. Легко видеть, что это же перегиб на кривой, снятой на ядре Conroe (рис. 16), наблюдается значительно позже — в области примерно 88 NOP-ов. Таким образом, даже не прибегая к точной количественной оценке объема I-ROB можно заключить, что в ядре Conroe размер этого буфера был увеличен.
Характеристики TLB
Напоследок, оценим размер и ассоциативность буферов трансляции адресов (TLB) данных и инструкций. При исследовании характеристик CPUID ядра Conroe мы уже отмечали, что, сколь бы странным это не выглядело, данные буферы, по-видимому, претерпели некоторые изменения, поскольку большинство дескрипторов, описывающих характеристики этих буферов, не соответствуют каким-либо известным TLB предыдущих процессоров Intel.
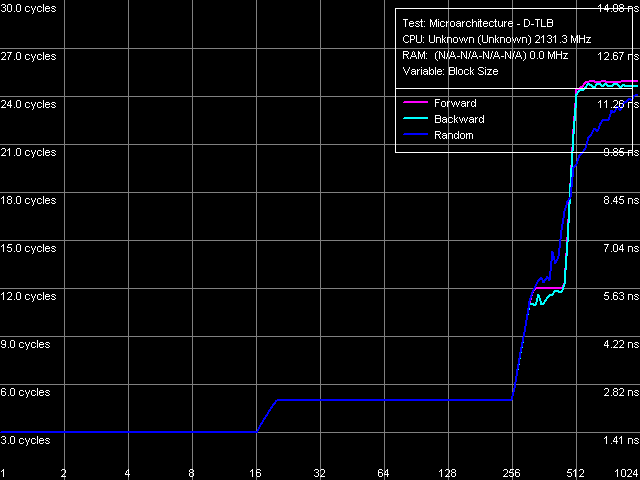
Рис. 17. Размер D-TLB
Результат измерения объема D-TLB представлен на рис. 17. При изучении общей картины латентности L1/L2/RAM мы уже сделали предположение о его двухуровневой структуре (нетипичной для процессоров Intel) с объемами уровней 16 и 256 записей страниц, соответственно. Как ни странно, аналогичная картина получается и в специализированном тесте D-TLB. Промах «малого» D-TLB обходится процессору в 2 такта, а промах второго уровня — в 10 тактов. Тем не менее, не исключено, что полученный результат является артефактом и процессорное ядро Conroe на самом деле имеет лишь одноуровневый D-TLB объемом 256 записей страниц, а первый перегиб на кривой связан с некими особенностями его организации. Так ли это, или нет — это подтвердится лишь при расшифровке пока что неизвестных дескрипторов TLB в данных CPUID процессора.
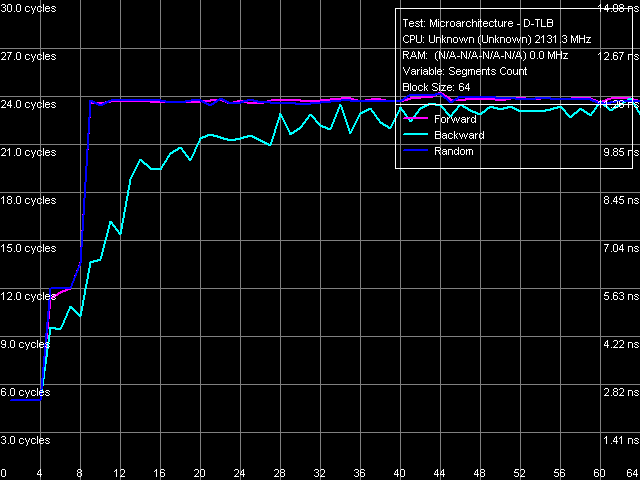
Рис. 18. Ассоциативность D-TLB
Достаточно неоднозначная картина наблюдается и в тесте ассоциативности D-TLB. На рис. 18 представлен его результат с использованием 64 сегментов, что заведомо выше по сравнению с размером первого уровня D-TLB, если таковой имеется, однако заметим, что аналогичный результат получается и при использовании 16 сегментов. Итак, достаточно выраженный перегиб наблюдается в области 4 сегментов, что может соответствовать ассоциативности D-TLB (единой для первого и второго уровней, если их действительно 2). Второй перегиб в области 8 сегментов, по-видимому, не имеет отношения к ассоциативности D-TLB вообще. Можно было бы предположить, что D-TLB имеет двухуровневую организацию с ассоциативностями уровней 4 и 8, соответственно, но в таком случае такая картина должна была бы наблюдаться лишь в тесте с использованием 16, но не 64 сегментов (ибо во втором случае «малый» TLB попросту не участвует). Таким образом, если организация D-TLB действительно двухуровневая, то ассоциативность каждого из уровней может быть равной только 4.
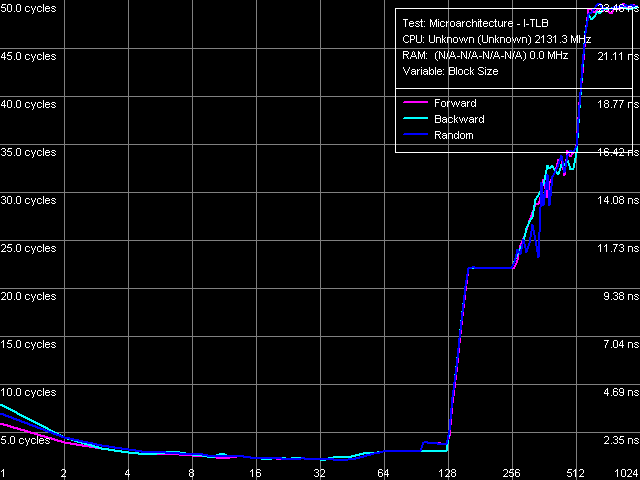
Рис. 19. Размер I-TLB
Перейдем к тестам I-TLB. К счастью, дескриптор последнего известен и соответствует 128-страничному буферу со степенью ассоциативности, равной 4. Его размер в соответствующем тесте (рис. 19) определяется достаточно четко и действительно составляет 128 записей. Промах этого буфера «обходится» процессору примерно в 20 тактов (такое же значение наблюдается у процессоров класса Pentium M).
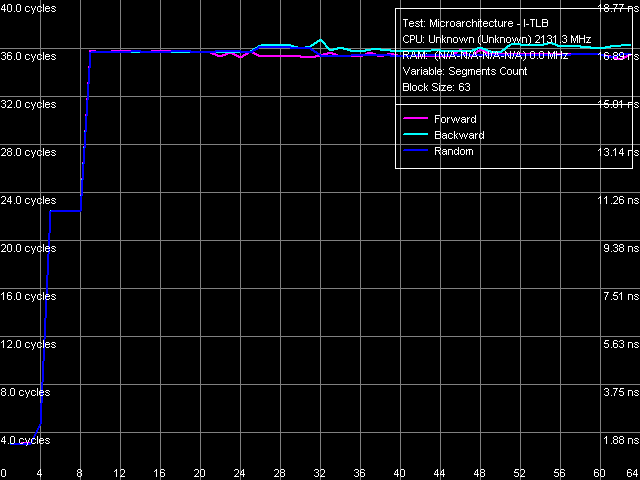
Рис. 20. Ассоциативность I-TLB
Картина ассоциативности I-TLB (рис. 20) весьма похожа на полученную выше для D-TLB. Поскольку ассоциативность I-TLB известна и равна 4, можно заключить, что первый перегиб на кривой, наблюдаемый в области 4 сегментов, действительно соответствует ассоциативности этого буфера, тогда как второй перегиб в области 8 сегментов не имеет к ней прямого отношения.
Заключение
По своим низкоуровневым характеристикам, новое процессорное ядро Conroe, пока что представленное инженерным образцом процессора Intel Core 2, значительно превосходит свой ближайший аналог — ядро Yonah двухъядерного процессора Intel Core Duo. Оно отличается увеличенной эффективностью утилизации L1/L2-кэша данных за счет «полноскоростного» однотактного исполнения 128-битных SIMD-инструкций (включая инструкции загрузки/сохранения данных), увеличенной пропускной способностью шины L1-L2 кэшей данных (теперь это полноценная, полноскоростная 256-битная шина наподобие Advanced Transfer Cache в процессорах микроархитектуры NetBurst), наличием аппаратной предвыборки на уровне L2-кэша и оперативной памяти со значительно улучшенным алгоритмом предвыборки, позволяющим весьма ощутимо скрывать задержки при доступе в эти уровни подсистемы памяти. Значительно лучшими характеристиками обладают декодер и исполнительные устройства процессора. Наряду с разрекламированными «четверной выборкой» и «слиянием макроопераций», а также однотактным исполнением 128-битных SIMD-инструкций и введением поддержки EM64T, здесь следует отметить увеличение количества исполнительных устройств ALU до 3 и значительно большую эффективность декодирования/исполнения префиксных инструкций (заметим, что инструкции с префиксами составляют немалую долю x86-кода — таковыми, например, являются инструкции наборов SSE/SSE2/SSE3).
Первый взгляд на микроархитектуру Intel Core в целом, и процессорное ядро Conroe, в частности, производит весьма неплохое впечатление хорошего, сбалансированного ядра процессора. Как оно проявит в реальных задачах — как всегда, покажут соответствующие тесты.


