Часть 10: Двухъядерный процессор Intel Core Duo (Yonah)
24 января 2006 г. компания Intel представила новую мобильную платформу под кодовым названием «Napa», являющуюся следующим этапом эволюции мобильной платформы Centrino. Напомним, что эта платформа в своем развитии прошла уже как минимум три этапа (если рассматривать эволюцию платформы по эволюции ее главного компонента процессора): от первого 130-нм процессора Pentium M к первой и, далее, второй ревизии 90-нм процессора Pentium M с ядром Dothan. При этом, как нетрудно видеть, менялся технологический процесс производства процессоров (следовательно, снижалось и их энергопотребление), увеличивался объем L2-кэша. Вместе с тем менялись и применяемые компоненты платформы чипсеты (от i852/i855GM/PM к i915GM/PM) и оперативная память (от DDR-333 к DDR2-400/533), возрастала частота системной шины (от 100 до 133 МГц, или, если выражаться в терминах Quad-Pumped Bus, от 400 до 533 МГц).
Что же изменилось в новой платформе «Napa»? Прежде всего, конечно, сам процессор на смену второго поколения 90-нм процессора Pentium M с ядром Dothan пришли два новых процессора, основанные на 65-нм ядре Yonah, с радикально новым названием Intel Core Solo и Intel Core Duo. Как нетрудно догадаться, эти процессоры отличаются количеством ядер, содержащихся в едином кристалле процессора: Core Solo представляет собой одноядерный, а Core Duo двухъяренный вариант Yonah. Такое подразделение отражается и в наименовании самой платформы: одноядерному Core Solo по-прежнему соответствует наименование «Centrino», а двухъядерному Core Duo соответственно, «двуъхядерный» вариант Centrino «Centrino Duo». Вместе с процессорами, в платформе «Napa» сменился и чипсет отныне используется мобильный вариант чипсета i945 i945GM/PM (с интегрированной графикой и без нее, соответственно) с южным мостом ICH7-M. Третье важное отличие связано собственно с первыми двумя и заключается в дальнейшем увеличением частоты FSB до 166 МГц (667 МГц QP-Bus) правда, не во всех случаях, так, в сегменте начального уровня представлены 133-МГц разновидности новой платформы.
Наше сегодняшнее исследование низкоуровневых характеристик ядра процессора затронет более интересный вариант процессора платформы «Napa» процессор Intel Core Duo, существенная отличительная особенность которого, в рамках нашего исследования, заключается в использовании общего для обоих ядер 2-МБ кэша второго уровня, способного эффективно распределяться между ядрами в зависимости от потребностей каждого из ядер процессоров. Новое процессорное ядро Yonah мы сопоставим по характеристикам с наиболее близким его предшественником второй ревизией ядра Dothan, исследование которого мы проводили ранее.
Данные CPUID
Как обычно, начнем рассмотрение нового процессорного ядра с рассмотрения наиболее существенных значений, выдаваемых инструкцией CPUID процессора с различными входными параметрами.
Таблица 1. Dothan CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 6D8h | Семейство 6, модель 13, степпинг 8 |
| Brand ID | 16h | Процессор Intel(R) Pentium(R) M |
| Дескрипторы кэшей/TLB | B0h B3h 02h F0h 7Dh 30h 04h 2Ch | I-TLB: 4-КБ стр., 4-асс., 128 записей D-TLB: 4-КБ стр., 4-асс., 128 записей I-TLB: 4-МБ стр., полноасс., 2 записи 64-байтная предвыборка L2-кэш: 2 МБ, 8-асс., 64-байтн. строка L1-I кэш: 32 КБ, 8-асс., 64-байтн. строка D-TLB: 4-МБ стр., 4-асс., 8 записей L1-D кэш: 32 КБ, 8-асс., 64-байтн. строка |
| Количество логических процессоров | 00h | Не определено |
| Количество ядер | 00h | Не определено (1 ядро) |
| Basic Features, ECX | 00000180h | Bit 7: Поддержка EIST Bit 8: Поддержка TM2 |
| Extended Features, EDX | 00100000h | Bit 20: Поддержка XD bit |
Таблица 2. Yonah CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 6E8h | Семейство 6, модель 14, степпинг 8 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | B0h B3h 02h F0h 7Dh 30h 04h 2Ch | I-TLB: 4-КБ стр., 4-асс., 128 записей D-TLB: 4-КБ стр., 4-асс., 128 записей I-TLB: 4-МБ стр., полноасс., 2 записи 64-байтная предвыборка L2-кэш: 2 МБ, 8-асс., 64-байтн. строка L1-I кэш: 32 КБ, 8-асс., 64-байтн. строка D-TLB: 4-МБ стр., 4-асс., 8 записей L1-D кэш: 32 КБ, 8-асс., 64-байтн. строка |
| Количество логических процессоров | 02h | 2 логических процессора |
| Количество ядер | 01h | 2 ядра |
| Basic Features, ECX | 0000C1A9h | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 5: Неизвестно Bit 7: Поддержка EIST Bit 8: Поддержка TM2 Bit 14: Поддержка Send Task Priority Messages Bit 15: Неизвестно |
| Extended Features, EDX | 00100000h | Bit 20: Поддержка XD bit |
Существенных отличий по данным CPUID нового ядра Yonah (табл. 2) от предыдущего Dothan (табл. 1) сравнительно немного. Прежде всего, мы видим увеличение номера модели на единицу новый процессор Core Duo с ядром Yonah имеет номер модели 14 (0xE в HEX), тогда как предыдущий носил не самый удачный :) номер 13 (0xD в HEX что, предположительно, соответствовало первой букве наменования «Dothan»). При этом, как ни странно, степпинг ядра по-прежнему остался на отметке «8» (к слову, не изменилась и «официальная расшифровка» степпинга ядра «C0» она едина как для новых Yonah, так и для второго поколения ядер Dothan). Еще более удивительно, что каких-либо изменений не претерпели и дескрипторы кэшей/TLB иными словами, каких-либо признаков отличия обобщенного 2-МБ L2-кэша от «обычного», встречающегося в Dothan, производитель изобретать не стал.
Изменения коснулись количественных характеристик, скажем так, «ядерности» процессора. В CPUID процессора Core Duo прописано число «логических» ядер, равное двум (в Dothan этот параметр был не определен) что, разумеется, немного условно, ибо признавать наличие нескольких логических ядер можно только в том случае, если процессор поддерживает технологию Hyper-Threading чего нет ни у Dothan, ни у Yonah. Вместе с тем, четко обозначено наличие двух физических ядер, что встречается и у последних двухъядерных процессоров Pentium D и Pentium Extreme Edition (ядро Smithfield), включая их 65-нм воплощения (ядро Presler), результаты низкоуровневого исследования которых мы представим в скором времени.
Среди прочих, не менее важных отличий, следует отметить появление поддержки расширений SSE3 (вместе с инструкциями MONITOR/MWAIT), а также двух «неизвестных» технологий (с которыми мы, так или иначе, часто встречаемся в наших исследованиях), на сей раз кодируемых битами 5 и 15 Basic Features, ECX. Логично предположить, что один из этих битов соответствует технологии виртуализации VT, официально реализованной в этом процессоре. К слову, некогда считавшийся «неизвестным» бит 13 Basic Features, ECX, который мы встречали в последних ревизиях процессорных ядер Prescott и Smithfield, ныне известен (т.е. прописан в официальной расшифровке значений CPUID) и соответствует поддержке инструкции CMPXCHG16B, что является одним из незначительных отличий технологии EM64T от технологии AMD64. Тем не менее, рассматриваемый процессор Core Duo не поддерживает ни EM64T как таковую (обозначаемую битом 29 Extended Features, EDX), ни инструкцию CMPXCHG16B, в частности.
На этом можно закончить с рассмотрением параметров CPUID и перейти к результатам низкоуровневого тестирования, проведенного в pre-release версии 3.62 тестового пакета RightMark Memory Analyzer, отличие которого от официального релиза 3.61 заключается исключительно в поддержке «опознавания» компонентов платформы «Napa» процессоров Intel Core Solo / Core Duo и чипсетов i945GM/PM.
Реальная пропускная способность кэша данных/памяти
Кривые зависимости пропускной способности определенной области памяти от размера блока (рис. 1) внешне практически идентичны кривым, полученным ранее на процессоре Pentium M (ядро Dothan ревизии C0).
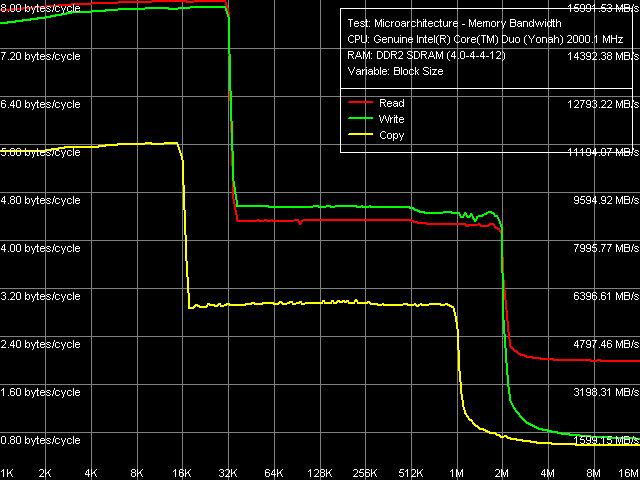
Рис. 1. Средняя реальная ПС кэша данных и оперативной памяти
Действительно, «кажущиеся» объемы L1/L2-кэша данных 32 и 2048 КБ, соответственно, с инклюзивной иерархией их организации (при которой данные, содержащиеся в L1, обязательно содержатся и в L2-кэше). Перегиб в области 2048 КБ, соответствующей «общему» объему L2-кэша, принадлежащего обоим ядрам процессора, наглядно демонстрирует высокую эффективность распределения этого ресурса при условии высокой требовательности одного из ядер к данным, содержащимся в памяти при практически полном бездействии второго ядра.
Таблица 3
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| Pentium M (Dothan) | Core Duo (Yonah) | |
| L1, чтение, MMX L1, чтение, SSE2 L1, запись, MMX L1, запись, SSE2 | 7.99 7.99 7.85 7.89 | 7.99 8.00 7.85 7.89 |
| L2, чтение, MMX L2, чтение, SSE2 L2, запись, MMX L2, запись, SSE2 | 4.36 4.36 3.24 3.24 | 4.34 4.34 4.57 4.57 |
| RAM*, чтение RAM, запись | 2620 МБ/с (60.5%) 830 МБ/с (19.2%) | 3990 МБ/с (74.8%) 1415 МБ/с (26.5%) |
*в скобках указаны значения относительно теоретического предела ПС системной шины
Сопоставление количественных характеристик ПС L1/L2-кэша данных и памяти приведено в таблице 3. Исходя из полной идентичности результатов измерений ПС L1-кэша Dothan и Yonah, разумно предположить, что этот независимый ресурс процессора, имеющийся в наличии у каждого из его ядер, не претерпел изменений при проектировании ядра Yonah. То же самое нельзя сказать об L2-кэше, который, как уже было неоднократно отмечено, отныне является «адаптивно-разделяемым» ресурсом. Что приятно, его скоростные характеристики на чтение практически не изменились, тогда как ПС этого уровня кэша на запись существенно возросла (примерно на 40%). Учитывая возросшую сложность реализации такого решения, данный результат можно считать более чем успешным. Следует также отметить возросшую ПС последнего, наиболее медленного уровня памяти собственно оперативной памяти, как по абсолютным, так и по относительным (в пересчете на ПС системной шины, лимитирующей доступ к памяти на уровне 4.33ГБ/с для Dothan и 5.33 ГБ/с для Yonah). Тем не менее, нельзя однозначно утверждать, связано ли это с увеличением эффективности аппаратной предвыборки данных процессором, или же с увеличением эффективности контроллера памяти в чипсете i945PM по сравнению с i915PM.
Предельная реальная пропускная способность памяти
Как и со всеми процессорами Intel, наилучший результат по максимальной реальной ПСП на чтение получается только в методе Software Prefetch (а также чтения/записи строк кэша), а максимальной реальной ПСП на запись в методе прямого сохранения данных.
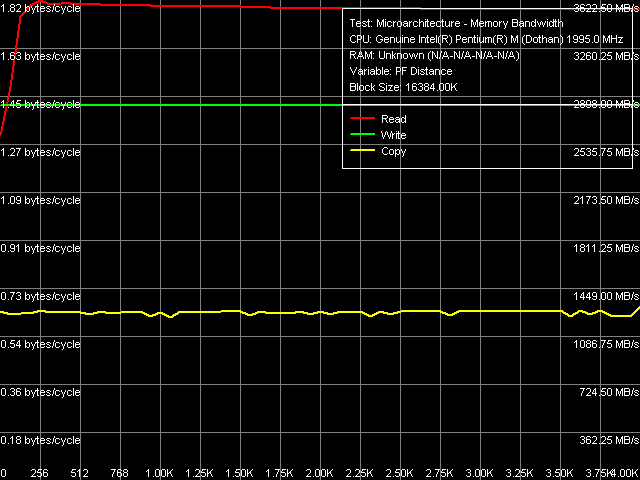
Рис. 2. Максимальная реальная ПСП, Software Prefetch/Non-Temporal Store, ядро Dothan
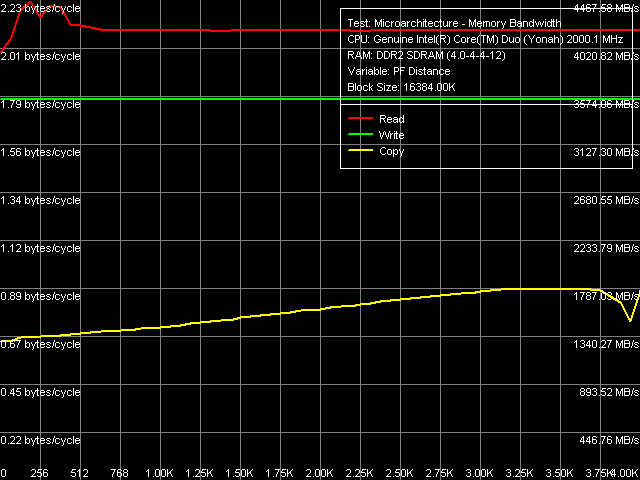
Рис. 3. Максимальная реальная ПСП, Software Prefetch/Non-Temporal Store, ядро Yonah
Прежде чем перейти к оценке количественных характеристик, интересно взглянуть на сам вид кривых, полученных на процессорах Dothan (рис. 2) и Yonah (рис. 3). Прежде всего, заметно отличие в кривой зависимости ПСП на чтение от дистанции программной предвыборки. В случае Dothan предвыборка быстро достигает высокую эффективность уже при 128-байтной дистанции предвыборки, максимум эффективности достигается при 256-байтной дистанции, после чего незначительно снижается, т.е. предвыборка остается эффективной даже при опережающем чтении данных, расположенных на границе той же страницы памяти (4К), в которой находятся непосредственно считываемые в настоящий момент данные. В случае Yonah все обстоит существенно иначе: программная предвыборка также быстро набирает свою эффективность (с максимумами в области 192-байтной дистанции), которая сама по себе оказывается существенно менее выраженной по сравнению с Dothan. Главное же отличие, однако, заключается в ощутимом снижении эффективности программной предвыборки при превышении длины дистанции в 384 байта уже при 512-байтной дистанции предвыборки ее эффективность снижается более чем в 2 раза, после чего остается на постоянном уровне, вплоть до границы страницы памяти.
Тем не менее, заслуживает внимания парадоксальная картина, показываемая кривой зависимости ПС копирования данных (с применением обоих методов оптимизации программной предвыборки на чтение и прямого сохранения данных на запись) от дистанции предвыборки. А именно, в случае Dothan наблюдается практически полная нечувствительность данного показателя к величине дистанции предвыборки (включая «нулевую» длину, что в RMMA означает отключение Software Prefetch), тогда как на Yonah эффективность копирования данных плавно возрастает по мере увеличения дистанции предвыборки примерно до 3.5 3.75КБ, с дальнейшем падением по мере приближения к границе страницы памяти.
Таблица 4
| Операция | Максимальная реальная ПСП, МБ/с* | |
|---|---|---|
| Pentium M (Dothan) | Core Duo (Yonah) | |
| Чтение, Software Prefetch (SWPF) | 3623 (83.6%) | 4468 (83.8%) |
| Запись, Non-Temporal Store (NTS) | 2832 (65.4%) | 3551 (66.6%) |
| Копирование, SWPF + NTS | 2640 (60.9%) | 3567 (66.9%) |
*в скобках указаны значения относительно теоретического предела ПС системной шины
Переходя к количественным оценкам (табл. 4), нетрудно заметить, что они остались практически на том же уровне в случае операций чтения (достигается примерно 84% утилизация ПС системной шины) и записи (максимально достижимая реальная ПСП составляет примерно 67% от ПС системной шины), тогда как для операций копирования, благодаря заметному изменению принципов работы Software Prefetch, предельный реальный показатель возрос от 61 до 67% от ПС системной шины.
Средняя латентность кэша данных/памяти
Общие кривые зависимости латентности кэша данных/оперативной памяти от размера блока (рис. 4) выглядят вполне типично, существенных отличий от кривых, полученных ранее на ядре Dothan, не наблюдается. Важно отметить, что «эффективный» объем L2-кэша, достающегося одному ядру, исполняющему код тестового приложения, и в этом случае составляет полные 2 МБ.
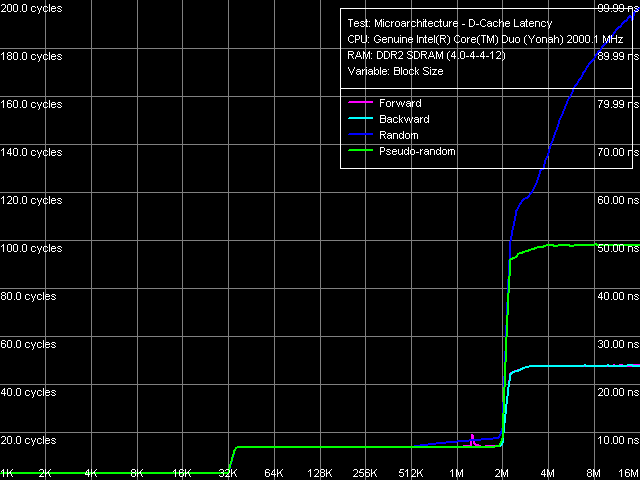
Рис. 4. Латентность кэша данных и памяти, размер шага 64 байта
Из количественных оценок средних величин латентностей L1/L2-кэша и памяти (табл. 5) можно заметить наиболее существенное отличие ядра Yonah от Dothan, заключающееся в возрастании латентности L2-кэша с 10 до 14 тактов. Что ж, введение значительно более сложной схемы управления L2-кэша, заключающейся в эффективном распределении объема данного ресурса между физическими ядрами процессора, не может пройти незаметно и увеличение латентности L2-кэша на 4 такта при сохранении (и даже возрастании) его превосходных скоростных характеристик можно считать весьма малой ценой.
Таблица 5
| Уровень | Латентность | |
|---|---|---|
| Pentium M (Dothan) | Core Duo (Yonah) | |
| L1 кэш | 3 такта (во всех случаях) | 3 такта (во всех случаях) |
| L2 кэш | 10 тактов (во всех случаях) | 14 тактов (во всех случаях) |
| RAM (4-МБ блок) | 27.3 нс (прямой, обратный) 51.0 нс (псевдослучайный) 70.4 нс (случайный) | 24.0 нс (прямой, обратный) 49.1 нс (псевдослучайный) 69.0 нс (случайный) |
Что касается средней латентности оперативной памяти, достигаемой в этом тесте, с эффективно работающей аппаратной предвыборкой, она несколько снизилась (на 3 нс) при строго прямом и обратном обходе цепочки данных, ее снижение при псевдослучайном и случайном обходе выражено менее отчетливо.
Минимальная латентность L2 кэша данных/памяти
Оценку этих величин проведем, как обычно, с помощью разгрузки соответствующей шины данных вставкой «пустых» операций между операциями доступа в L2-кэш или оперативную память.
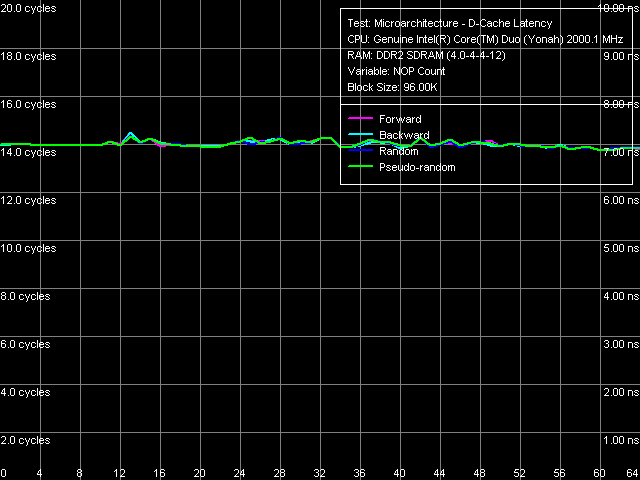
Рис. 5. Минимальная латентность L2-кэша, размер шага 64 байта
Кривая разгрузки шины L1-L2 кэша данных (рис. 5) выглядит привычно для процессоров микроархитектуры P6 такие же кривые наблюдаются на всех Pentium III и Pentium M, в этом отношении Core Duo (Yonah) не является исключением. Латентность L2-кэша остается на постоянном уровне 14 тактов во всех режимах его обхода.
Что касается минимальной латентности оперативной памяти, ее определение мы проведем двумя способами с величиной шага, равной эффективному размеру строки L1-кэша (64 байта) и L2-кэша (128 байт), что позволит оценить степень влияния аппаратной предвыборки (эффективно работающей только в первом случае) на величины латентностей.
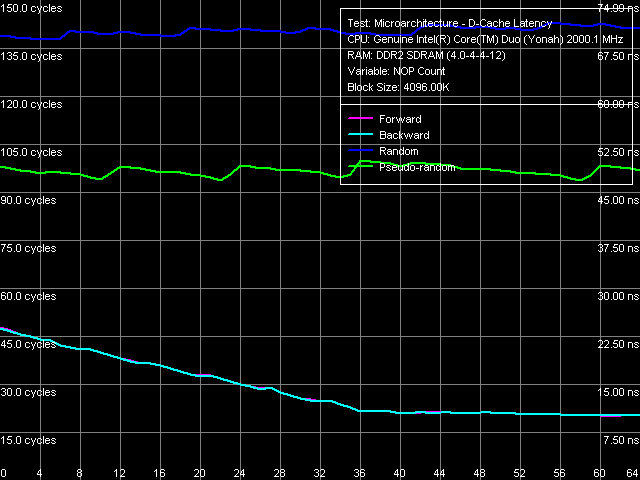
Рис. 6. Минимальная латентность памяти, размер шага 64 байта
В первом случае (рис. 6), ощутимых отличий от Dothan практически не наблюдается (в связи с чем, мы не приводим соответствующие кривые), за исключением того, что максимальная эффективность аппаратной предвыборки достигается несколько раньше, при вставке порядка 36 NOP-ов между соседними обращениями к памяти. Минимальная латентность прямого/обратного обхода достигает 10.1 нс (для сравнения, 9.2 нс на Dothan), псевдослучайного 46.9 нс (против 48.2 нс), случайного 69.0 нс (против 72.5 нс). Таким образом, существенных изменений задержек при доступе в оперативную память с аппаратной предвыборкой на новой платформе не наблюдается.
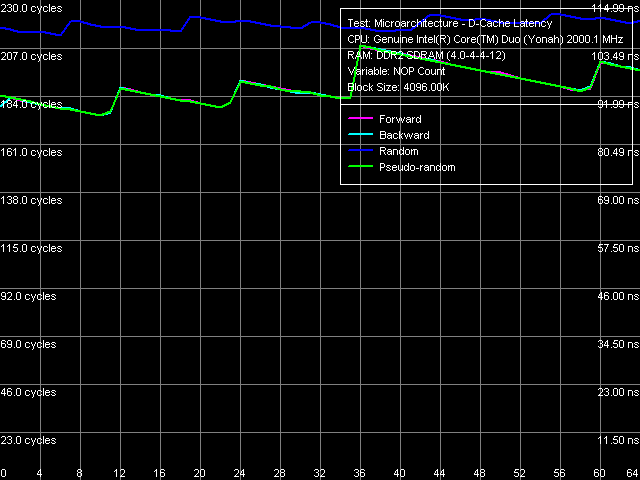
Рис. 7. Минимальная латентность памяти, размер шага 128 байт
Заметных отличий не наблюдается и во втором случае (рис. 7), при практически полном бездействии механизма аппаратной предвыборки (на что указывает идентичность «разгрузочных кривых» прямого, обратного и псевдослучайного обхода памяти). Минимальная величина задержек в этом случае составляет 87.5 нс, против 95.8 нс, полученной ранее на платформе Dothan. Можно сказать, что наблюдаемые в данном случае различия целиком и полностью отражают различия в задержках доступа к подсистеме памяти как таковой, не зависящих от типа процессора.
Ассоциативность кэша данных
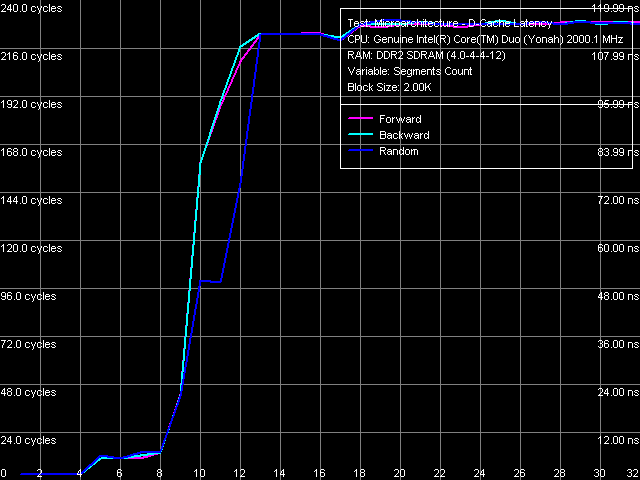
Рис. 8. Ассоциативность L1/L2 кэша данных
Кривые ассоциативности кэша Yonah (рис. 8) выглядят достаточно четко. Ассоциативность первого уровня кэша данных равна четырем (а не восьми, как указано в дескрипторах CPUID), ассоциативность второго уровня восьми (т.е. совпадает с «официальным» значением). Такую же картину ассоциативности мы наблюдали и на Dothan, обобщенный L2-кэш Yonah не вносит в нее каких-либо изменений.
Реальная пропускная способность шины L1-L2
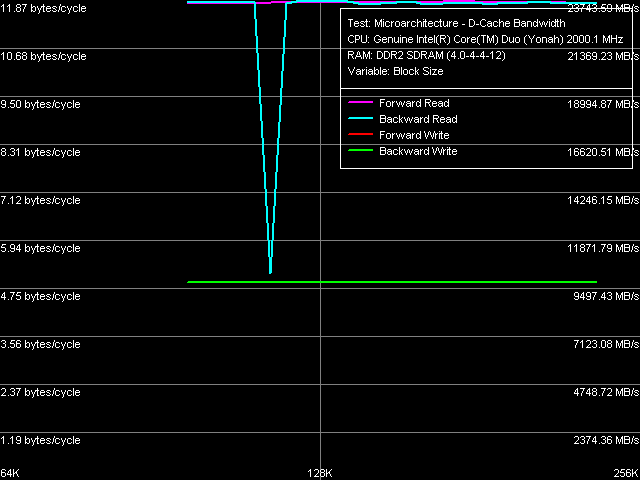
Рис. 9. Реальная пропускная способность шины L1-L2 кэша
Кривые реальной ПС шины L1-L2, полученные методом чтения целых строк L2-кэша (рис. 9), имеют привычный вид (за исключением случайного провала кривой обратного чтения в области ~112 КБ).
Таблица 6
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт | |
|---|---|---|
| Pentium M (Dothan) | Core Duo (Yonah) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 10.86 10.51 3.22 3.22 | 11.86 11.87 4.91 4.91 |
Сравнивая количественные характеристики ПС шины L1-L2 Dothan и Yonah (табл. 6), легко заметить ощутимое их увеличение на последнем. Так, ПС при операциях чтения (как прямого, так и обратного) возросла до 11.87 байт/такт (на 9-13%), при операциях записи до 4.91 байт/такт (на 52.5%). Ощутимое возрастание эффективности L2-кэша на запись мы видели и ранее, в тесте средней пропускной способности этого уровня кэша. Таким образом, мы в очередной раз можем подчеркнуть исключительно удачную реализацию сложного обобщенного L2-кэша, не сказавшуюся отрицательно на его скоростных характеристиках.
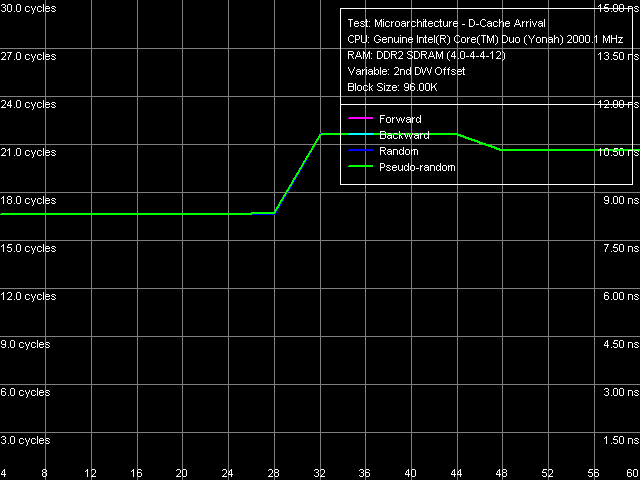
Рис. 10. Тест прибытия данных по шине L1-L2 кэша
Что касается разрядности шины данных L1-L2 кэша, она по-прежнему остается равной 128, что наглядно демонстрируется тестом прибытия данных по указанной шине (рис. 10) запрашиваемая 64-байтная строка кэша «не успевает» прибыть по шине L1-L2 за 3 такта обращения к L1-кэшу, в связи с чем возникают дополнительные задержки при чтении второго элемента данных, отстоящего от первого на 32 байта или выше.
Кэш инструкций, эффективность декодирования
Переходим к наиболее интересной части нашего исследования оценке эффективности декодирования/исполнения различных простейших арифметико-логических операций. Как известно, «переделка» декодера в виде добавления слияния микроопераций, соответствующих SSE-инструкциям и добавления набора инструкций SSE3, является не менее значимым нововведением в ядре Yonah, чем организация общего, адаптивного L2-кэша.
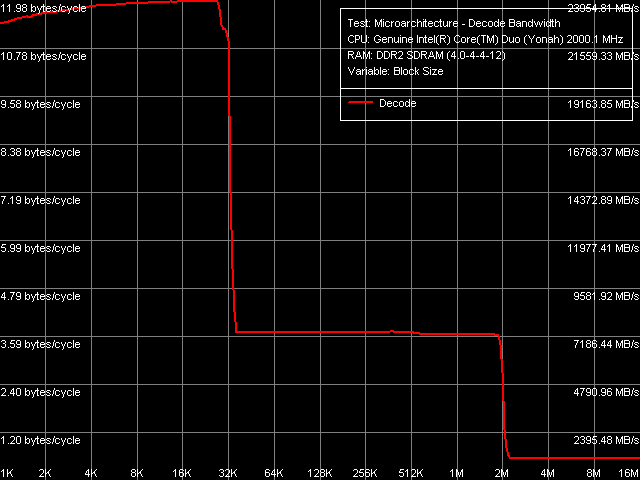
Рис. 11. Эффективность декодирования/исполнения 6-байтных инструкций CMP
Общий вид кривой эффективности декодирования/исполнения крупных 6-байтных инструкций CMP (рис. 11) приведем лишь для наглядности, дабы убедиться, что L2-кэш доступен одному ядру в полном объеме и при исполнении сверхдлинного (до 2 МБ) фрагмента кода из указанной области памяти процессора.
Таблица 7
| Тип инструкций (размер, байт) | Эффективность декодирования, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| Pentium M (Dothan) | Core Duo (Yonah) | |||
| L1-I кэш | L2 кэш | L1-I кэш | L2 кэш | |
| NOP (1) SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) CMP 2 (4) CMP 3-6 (6) Prefixed CMP 1-4 (8) | 1.99 2.02 2.02 3.97 2.01 3.97 7.94 11.92 1.99 | 1.93 1.96 1.96 3.53 1.96 3.53 3.97 4.18 1.77 | 2.00 3.99 3.99 3.99 3.97 3.99 7.99 11.98 2.00 | 1.94 3.19 3.19 3.19 3.19 3.19 3.54 3.71 1.88 |
Более интересны, тем не менее, количественные результаты тестов в сравнении с таковыми на ядре Dothan (табл. 7). В первую очередь, здесь следует обратить внимание на значительное возрастание темпа исполнения последовательности инструкций SUB (sub eax, eax), XOR (xor eax, eax) и смешанной последовательности XOR/ADD (xor eax, eax; add eax, eax). А это значит, что Intel наконец-то победила известную проблему декодера микроархитектуры P6, заключающуюся в неспособности разрешения подобных ложных зависимостей. Так, все процессоры микроархитектуры P6, включая последнюю ревизию ядра Dothan, исполняли указанные инструкции с предельной скоростью 1 инструкция/такт, эффективно используя лишь один из двух доступных блоков ALU процессора. В случае же Yonah справедливость восторжествовала отныне эти инструкции исполняются, как и положено, со скоростью 2 инструкции/такт что максимально приближает декодер Yonah к декодеру процессоров AMD K7/K8, изначально не имеющих данного недостатка. Второе отличие, которое можно заметить, заключается в более эффективном исполнении кода из L1-кэша инструкций, что особенно заметно на сравнительно больших, 6-байтных инструкциях CMP (cmp eax, 00000000h) темп их исполнения возрос от 11.92 байт/такт до почти предельного значения 11.98 байт/такт. С другой стороны, нельзя не отметить и некоторое снижение эффективности исполнения кода из L2-кэша, заметное практически во всех случаях за исключением наиболее «мелких» инструкций NOP. Тем не менее, потребность в непрерывном исполнении участка кода размером свыше 32 КБ выглядит достаточно сомнительной, поэтому данный недостаток вряд ли следует считать чем-то существенным на фоне заметных усовершенствований декодера Yonah.
Что касается «префиксных» инструкций CMP 6-байтных операций сравнения, содержащих перед собой два однобайтовых «бессмысленных» префикса, существенных изменений в Yonah по отношению к ним не наблюдается. Предельная скорость исполнения таких инструкций по-прежнему составляет 4 такта на инструкцию, тем не менее, можно отметить слегка возросшую скорость их исполнения из L2-кэша на фоне некоторого снижения его эффективности в целом.
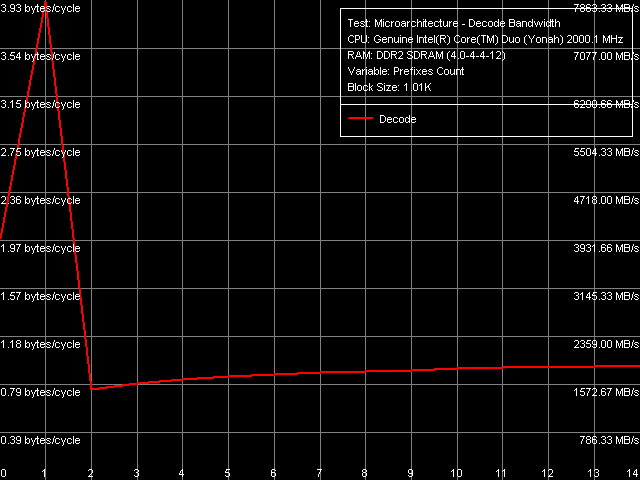
Рис. 12. Эффективность декодирования/исполнения префиксных инструкций NOP
Более подробную картину эффективности декодирования/исполнения инструкций с префиксами дает одноименный тест, в котором исполняются инструкции вида [0x66]nNOP, где n = 0..14. Общая картина этого теста (рис. 12) не изменилась такой вид типичен для всех процессоров микроархитектуры P6, начиная с Pentium III (вполне вероятно, что и Pentium PRO/Pentium II просто мы их не исследовали). Наибольшая эффективность «отсечения» префиксов наблюдается лишь при их количестве, равном единице, после чего (по мере увеличения их количества) происходит резкое уменьшение скорости декодирования/исполнения таких инструкций (особенно если пересчитать полученный результат в количество инструкций, исполняемых за такт процессора).
Ассоциативность кэша инструкций
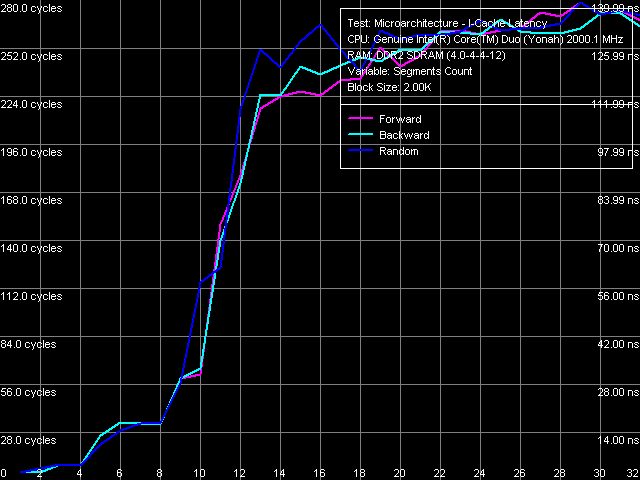
Рис. 13. Ассоциативность кэша инструкций
Тест ассоциативности кэша инструкций (рис. 13), заключающийся в измерении времени исполнения последовательности безусловных переходов, расположенных на различных расстояниях (кратных размеру сегмента кэша) друг относительно друга, наглядно показывает 4-входовую (4-way) ассоциативность L1-кэша инструкций, и 8-входовую (8-way) ассоциативность L2-кэша. Такой же результат мы получили при измерении ассоциативности кэша данных, а также ассоциативности кэша данных и инструкций процессора Pentium M (Dothan).
Буфер переупорядочивания инструкций (I-ROB)
Напомним основной принцип работы относительного нового теста RMMA, позволяющего оценить глубину буфера переупорядочивания инструкций (I-ROB): запускается одна простая, но долго исполняемая инструкция операция зависимой загрузки последующей строки данных из памяти, mov eax, [eax], а сразу вслед за ней серия очень простых, не зависящих от нее операций (nop). Тогда, в идеализированном случае, как только время исполнения такой связки начинает зависеть от количества NOP-ов, можно считать, что глубина ROB исчерпана.
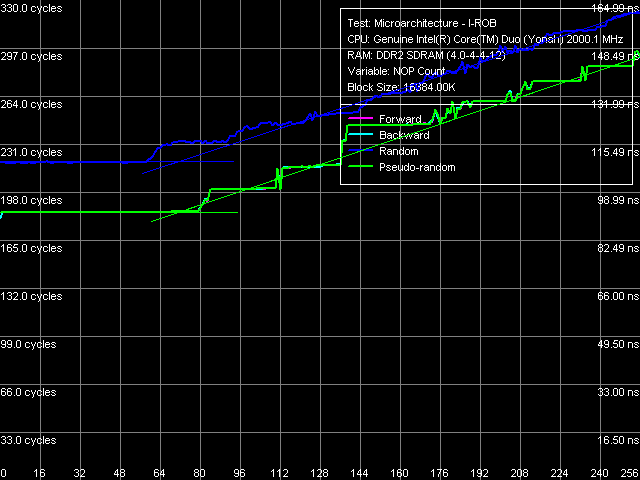
Рис. 14. Глубина буфера переупорядочивания инструкций
Результат исполнения этого теста на Yonah с аппроксимацией полученных кривых прямыми линиями представлен на рис. 14. Отметим, что практически идентичную картину мы получили и при тестировании новой ревизии ядра Dothan, следовательно, можно предположить, что реализация I-ROB в процессорных ядрах Yonah и Dothan идентична. Глубина буфера переупорядочивания инструкций у этих процессоров, которой отвечает количество NOP-ов, соответствующее точке пересечения двух аппроксимационных прямых, составляет величину в 72 инструкции.
Характеристики TLB
Оценим размер и ассоциативность буфера TLB данных.
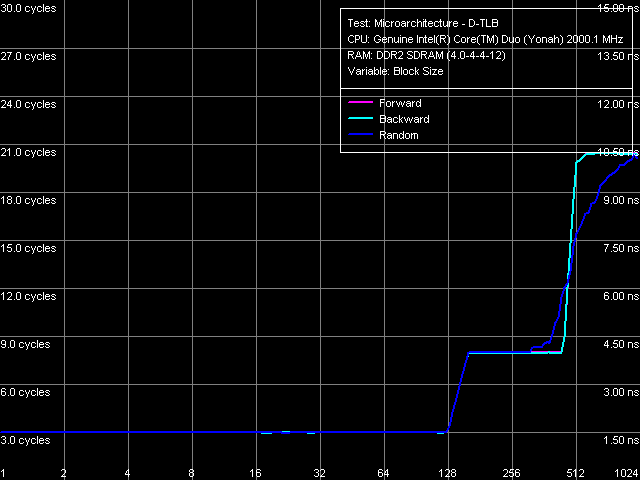
Рис. 15. Размер D-TLB
Картина стандартна (рис. 15): размер D-TLB составляет 128 записей, а его промах обходится процессору в 5 дополнительных «штрафных» тактов. Дальнейшее возрастание латентности в области 512 записей связано с выходом за пределы L1-кэша процессора (512 x 64 байта = 32 КБ).
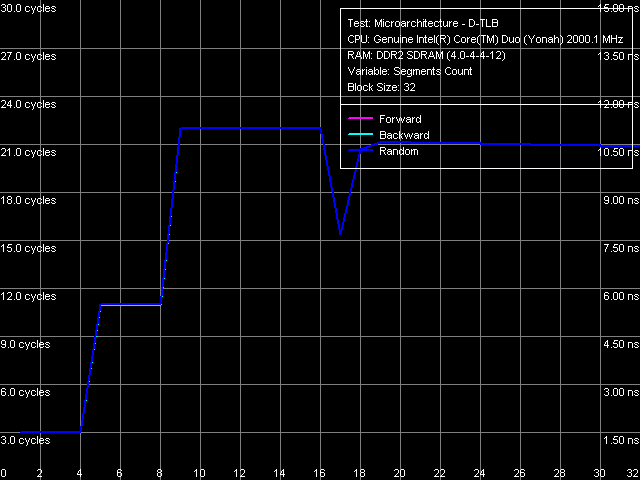
Рис. 16. Ассоциативность D-TLB
Картина ассоциативности D-TLB (рис. 16), характеризующаяся двумя довольно резкими скачками (что гораздо более типично для двухуровневых TLB, каждый уровень которого имеет разную ассоциативность), наблюдалась и ранее на второй ревизии ядра Dothan, более ранние ревизии Pentium M характеризовались стандартными кривыми с единственным перегибом в области 4 сегментов, соответствующим истинной ассоциативности D-TLB процессоров этого семейства.
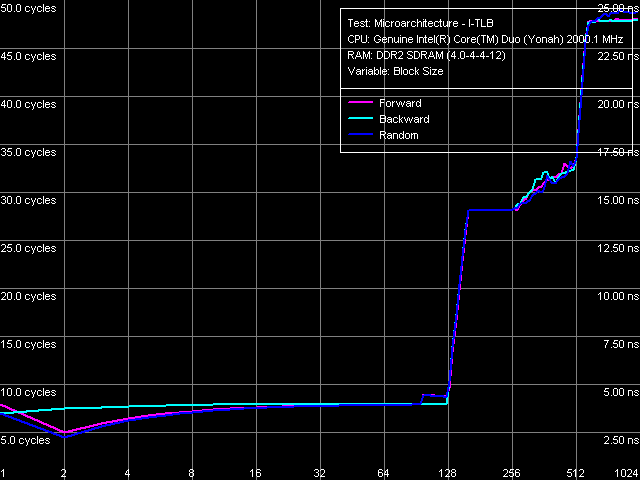
Рис. 17. Размер I-TLB
Результат измерения размера I-TLB (рис. 17): 128 записей, его промах «обходится» процессору примерно в 20 тактов. Такая же картина наблюдалась и на ядре Dothan.
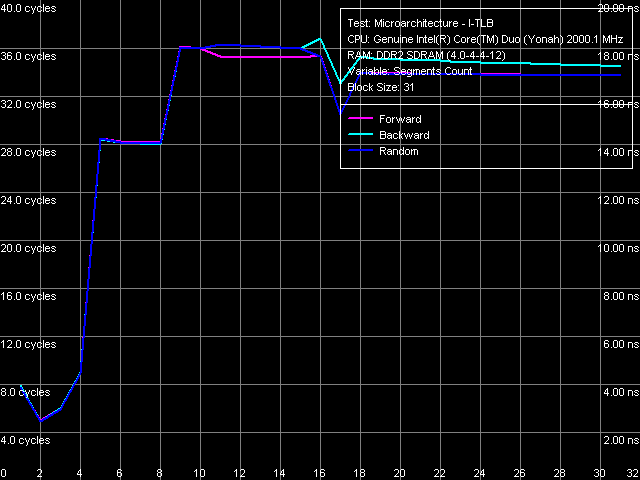
Рис. 18. Ассоциативность I-TLB
Картина ассоциативности I-TLB (рис. 18) вполне четкая и соответствует кривым, полученным ранее, на обоих ревизиях процессорного ядра Dothan ассоциативность I-TLB равна четырем.
Одинаковый вид всех четырех кривых (размера и ассоциативности D-TLB и I-TLB), полученных на процессорах Core Duo (Yonah) и Pentium M (Dothan rev. C0) указывает на одинаковую организацию этих ресурсов у данных процессоров.
Заключение
Изучение основных, избранных низкоуровневых характеристик двухъядерного варианта нового процессорного ядра Yonah, воплощенного в процессорах Intel Core Duo, произвело хорошее впечатление. Прежде всего, следует отметить исключительно удачную реализацию сложной задумки, заключающейся в эффективном распределении общего для ядер L2-кэша между индивидуальными ядрами в зависимости от их потребностей. Успех такой реализации проявляется не только в виде возможности 100% эффективного использования всего объема L2-кэша только одним из ядер (на сегодня, когда превалирующее большинство приложений по-прежнему рассчитаны на одноядерную архитектуру, т.е. являются однопоточными, это весьма актуально), но и в виде хороших скоростных показателей L2-кэша и шины L1-L2 (в ряде случаев даже превышающих соответствующие характеристики последней ревизии ядра Dothan) при относительно малом увеличении задержек доступа в L2-кэш. Второе, не менее важное отличие нового ядра Yonah от предыдущего поколения (Dothan) это значительное улучшение декодера инструкций, позволяющее процессору не только более эффективно исполнять SSE-инструкции (чего мы не можем наблюдать в рамках сегодняшнего исследования), но и устранять ложные зависимости между определенными простейшими арифметико-логическими операциями, реально применяемыми на практике для очистки содержимого регистров. Иными словами, наконец-то устранен ряд недостатков, издревле присущих декодеру микроархитектуры P6, что максимально приблизило его к более совершенному декодеру, уже давно реализованному в процессорах семейств AMD K7 и K8.


