Часть 7: Платформа Intel Sonoma, новая ревизия ядра Dothan процессора Pentium M
19 января 2005 г. состоялся официальный анонс новой мобильной платформы Intel под кодовым названием «Sonoma», но официально она вышла под все той же торговой маркой «Centrino». Ее можно рассматривать в качестве третьего поколения этой платформы (первым поколением Centrino можно считать сочетание 130-нм процессора Pentium M (Banias) с чипсетами 852-й серии, вторым — комбинацию 90-нм процессора Pentium M (Dothan) с чипсетами 855-й серии). Важнейшими составляющими новой платформы являются процессор Pentium M с новой ревизией ядра Dothan (которую мы и рассмотрим ниже) и «мобильный» вариант 915-й серии чипсетов Intel 915GM/PM (в зависимости от используемого типа видеоподсистемы: интегрированной либо внешней).
Конфигурация тестового стенда (Ноутбук Acer TravelMate 8100)
- Процессор: Intel Pentium-M (ядро Dothan, 2000 МГц)
- Чипсет: Intel 915PM
- Память: 2 x 512 МБ DDR-2 533 (PC2-4300)
- Видео: ATI Mobility Radeon X700
Идентификация
Изучать новую платформу мы начнем с ее «опознания», воспользовавшись последней версией нашего универсального инструмента тестового пакета RightMark Memory Analyzer.
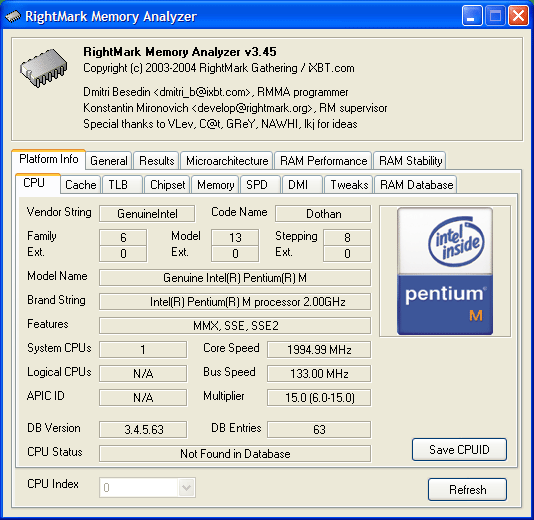
Информация о процессоре. Как и положено, он опознался как Pentium M с ядром Dothan, имеющим сигнатуру (Family/Model/Stepping) 06D8h, что отличает его от нашего предыдущего испытуемого процессора Pentium M (Dothan) с сигнатурой 06D6h. На самом деле, именно это обстоятельство и явилось поводом для настоящих исследований. Итак, мы видим, что процессор функционирует на частоте, близкой к 2 ГГц (учитывая, что система питалась от сети), частота системной шины 133 МГц (533 МГц Quad Pumped), значения множителя могут варьироваться от 6 (800 МГц) до 15 (2000 МГц). Следует однако отметить, что в режиме максимального энергосбережения процессор способен функционировать и при 600 МГц как выяснилось, посредством снижения частоты системной шины до 100 МГц, однако это уже, несомненно, тема отдельного исследования, которое мы постараемся выполнить в скором времени.
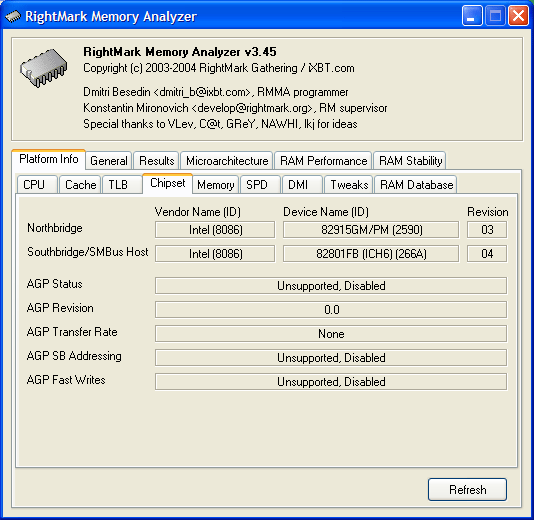
Основная информация о чипсете. Новый i915M получил идентификационный код PCI-устройства вида 8086h:2590h первое число обозначает производителя устройства (Intel), второе модель устройства. Для очистки совести отметим, что здесь мы немного слукавили сначала определили PCI Device ID нового северного моста (которое можно узнать, например, в Device Manager ОС Windows XP), и только потом добавили его определение в модуль SysInfo программы RMMA. Что касается южного моста он остался все тем же ICH6 (код устройства 8086h:266Ah), однако не исключено, что в новой платформе применяется несколько более свежая ревизия последнего (04h).
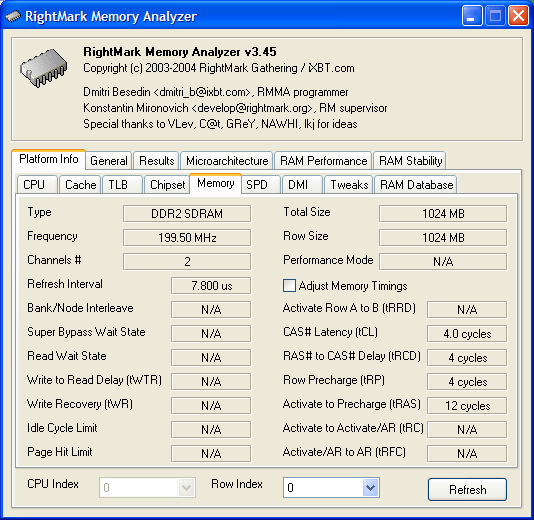
Настройки подсистемы памяти. Применяемый тип памяти — DDR2, частота шины памяти — 200 МГц (DDR2-400), режим доступа — 128-битный (двухканальный). Таким образом, имеем пиковую ПСП 400x128/8 = 6.4 ГБ/с, типичную для современных платформ Pentium 4. Однако для данного случая это выглядит излишне, ибо пиковая ПС системной шины составляет всего 533x64/8 = 4.33 ГБ/с. Кроме того отметим, что тайминги памяти 4-4-4-12 стандартны для DDR2-533, нежели DDR2-400. Смотрим дальше…
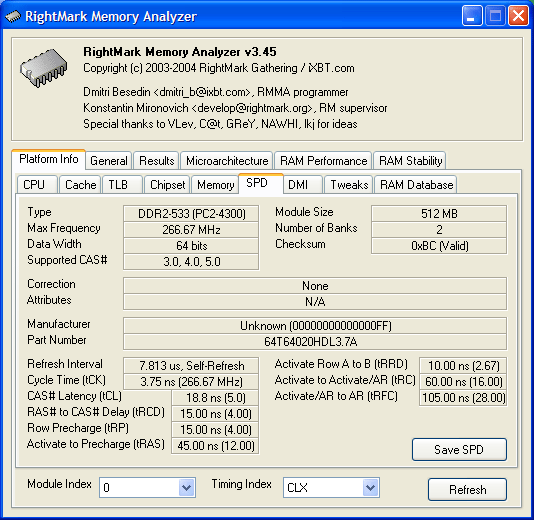
Данные SPD установленных модулей памяти. Это действительно модули DDR2-533 (производитель которых неизвестен). Вот это — уже явное излишество, т.к. вполне сгодились бы модули DDR-333 (или хотя бы DDR2-400, если необходимо использовать DDR2 — а такая потребность, в общем-то, имеется, учитывая меньшее энергопотребление последних). Производителю ноутбука виднее, какие компоненты использовать для сборки системы. Кстати, несколько слов о последнем…
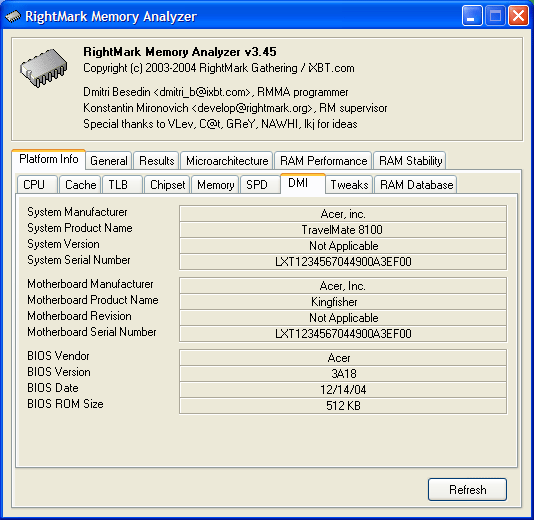
Содержимое области DMI системного BIOS впечатляет своей подробностью! Указаны не только производитель (Acer) и модель ноутбука (TravelMate 8100), но и серийный номер изделия, информация о производителе системной платы, а также версии и дате выпуска BIOS.
На этой радостной ноте закончим с идентификацией, перейдя к рассмотрению главного испытуемого процессора Penitum M с новой ревизией ядра Dothan. Принцип нашего рассмотрения сегодня будет иметь характер сравнения: мы приведем результаты тестов с краткими комментариями, и, если они отличаются от результатов тестирования предыдущей модели, останавливаться подробнее на имеющихся отличиях.
Данные CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 06D8h | Семейство 6, модель 13, степпинг 8 |
| Brand ID | 16h | Процессор Intel(R) Pentium(R) M |
| Дескрипторы кэшей/TLB | B0h B3h 02h 7Dh 30h 04h 2Ch | I-TLB: 4-КБ стр., 4-асс., 128 записей D-TLB: 4-КБ стр., 4-асс., 128 записей I-TLB: 4-МБ стр., полноасс., 2 записи L2-кэш: 2 МБ, 8-асс., 64-байтн. строка L1-I кэш: 32 КБ, 8-асс., 64-байтн. строка D-TLB: 4-МБ стр., 4-асс., 8 записей L1-D кэш: 32 КБ, 8-асс., 64-байтн. строка |
В перечисленных характеристиках есть всего одно отличие, о котором мы уже говорили выше: степпинг ядра сменился с 6 на 8. Идентификатор модели (Brand ID) и характеристики кэшей/TLB остались прежними.
Реальная пропускная способность кэша данных/памяти
Кривые зависимости ПСП от размера блока во всех трех случаях (MMX/SSE/SSE2) имеют примерно одинаковый вид и соответствуют (на качественном уровне) кривым, полученным на предыдущей ревизии Dothan.
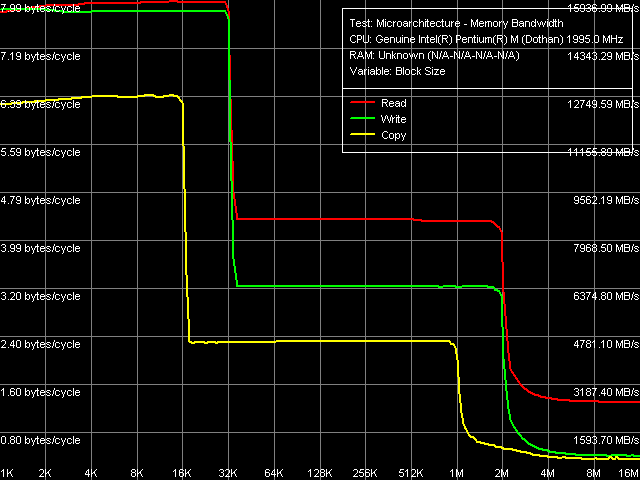
Средняя реальная ПС кэша данных и оперативной памяти
Объем L1/L2 кэшей данных 32 и 2048 КБ, соответственно, тип организации кэша инклюзивный (т.е. данные, содержащиеся в L1, дублируются в L2). Значения ПС L1-кэша на чтение/запись (около 8.0 байт/такт), ПС L2 на чтение (4.36 байт/такт) и ПС L2 на запись (3.24 байта/такт) полностью соответствуют полученным ранее.
Изменилась лишь средняя ПС оперативной памяти, что неудивительно, учитывая разницу между DDR-333 (применяемую в исследованной платформе Centrino) и DDR2-533 (в настоящей платформе). Она составляет 2.6 ГБ/с при операциях чтения и 830 МБ/с при операциях записи (последнее примерно в 2 раза выше в сравнении с предыдущей платформой). Тем не менее, ни то, ни (особенно) другое явно не дотягивают даже до теоретического предела ПС системной шины (4.33 ГБ/с), не говоря уж о максимальной теоретической ПС DDR2-533 (8.53 ГБ/с). В связи с этим, попытаемся оценить предельную ПСП.
Предельная реальная пропускная способность памяти
Как и со всеми остальными процессорами Intel, осмысленный результат по максимальной реальной ПСП на чтение получается только в методе Software Prefetch (а также чтения/записи строк кэша), а максимальной реальной ПСП на запись в методе прямого сохранения данных.
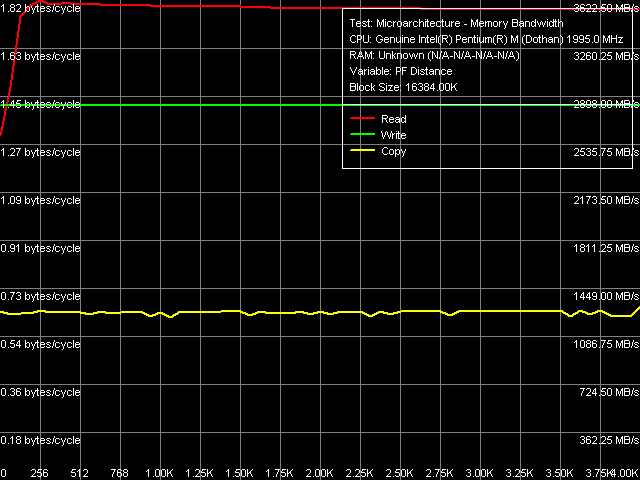
Максимальная реальная ПСП, Software Prefetch/Non-Temporal Store
Максимально достижимая реальная ПСП на чтение — 3.62 ГБ/с, на запись и того меньше — всего 2.83 ГБ/с. Эти параметры вновь весьма далеки от теоретического предела (если считать по предельной ПС системной шины — это 83.6% и 65.3% соответственно). Отметим, что общая картина теста с предвыборкой слегка изменилась — выигрыш от использования Software Prefetch здесь гораздо больше (около 40%), чем в предыдущих исследованиях (примерно 15%).
Средняя латентность кэша данных/памяти
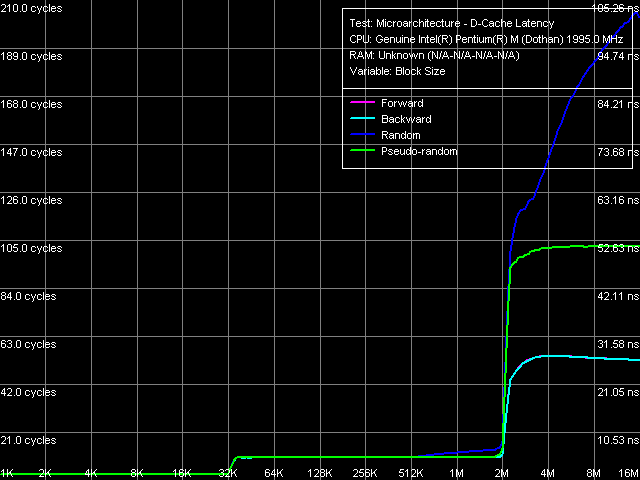
Латентность кэша данных и памяти, размер шага 64 байта
Общая картина латентности (на качественном уровне) остается практически без изменений — стоит отметить лишь немного странное: плавный спад кривых латентности прямого и обратного последовательного доступа при увеличении размера обходимого блока памяти (в области 4 — 16 МБ).
Количественные оценки латентностей приведены в таблице.
| Уровень | Латентность | |
|---|---|---|
| Pentium M (Dothan, степпинг 6) | Pentium M (Dothan, степпинг 8) | |
| L1 кэш | 3 такта (во всех случаях) | 3 такта (во всех случаях) |
| L2 кэш | 10 тактов (во всех случаях) | 10 тактов (во всех случаях) |
| RAM (4-МБ блок) | 35.0 нс (прямой, обратный) 57.4 нс (псевдослучайный) 87.9 нс (случайный) | 27.3 нс (прямой, обратный) 51.0 нс (псевдослучайный) 70.4 нс (случайный) |
Присутствует и значительное снижение латентности доступа к оперативной памяти (исследовался 4-МБ блок), что может являться следствием как улучшения логики Hardware Prefetch процессора, так и использования нового чипсета i915PM вместо i855PM. В то же время, задержки при чтении целочисленных данных из L1/L2 кэша процессора остались равными 3 и 10 тактам соответственно.
Минимальная латентность кэша данных/памяти
Для оценки этой величины воспользуемся, как обычно, методом разгрузки BIU вставкой «пустых» операций между операциями доступа в оперативную память. Кроме того, в отличие от предыдущего тестирования, мы воспользуемся двумя способами измерения с величиной шага, равной эффективному размеру строки L1-кэша (64 байта) и L2-кэша (128 байт), что позволит оценить степень влияния аппаратной предвыборки (эффективно работающей только в первом случае) на результаты теста.
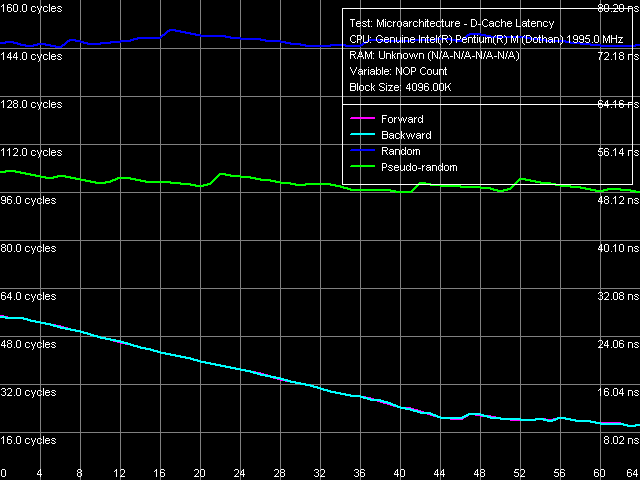
Минимальная латентность памяти, размер шага 64 байта
Первый случай: минимальная латентность прямого/обратного обхода достигает 9.2 нс (12.0 нс для предыдущей модели), псевдослучайного 48.2 нс (против 57.0 нс), случайного 72.5 нс (против 87.8 нс). Таким образом, на новой платформе мы наблюдаем уменьшение задержек при доступе в память с Hardware Prefetch во всех случаях.
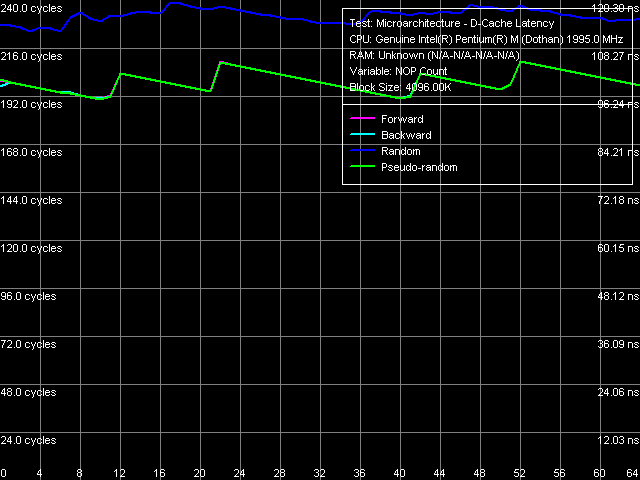
Минимальная латентность памяти, размер шага 128 байт
Оценим теперь более «правильные» результаты (с точки зрения измерения латентности памяти как таковой, а не подсистемы памяти в целом). В случаях прямого, обратного и псевдослучайного обходов получаем одну и ту же (а это значит, что Hardware Prefetch не работает) минимальную величину 95.8 нс большую, чем наихудшее значение (случайный обход) в первом случае. Минимальная латентность случайного доступа еще выше и составляет 112.7 нс как мы неоднократно говорили, это связано с исчерпанием ресурса D-TLB при обходе сравнительно большого блока памяти.
Ассоциативность кэша данных
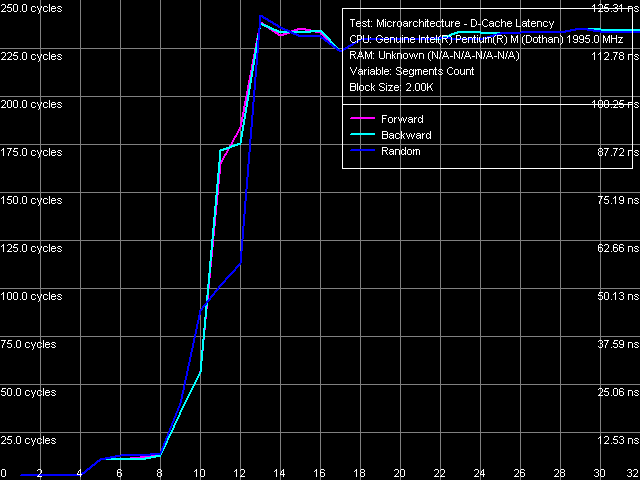
Ассоциативность L1/L2 кэша данных
Общая картина ассоциативности кэша данных очевидна и не нуждается в пояснениях. Ассоциативность первого уровня кэша данных равна четырем (а не восьми, как указано в дескрипторах CPUID), ассоциативность второго уровня восьми (т.е. совпадает с «официальным» значением). Такую же картину мы наблюдали в предыдущей ревизии ядра Dothan.
Реальная пропускная способность шины L1-L2 кэша
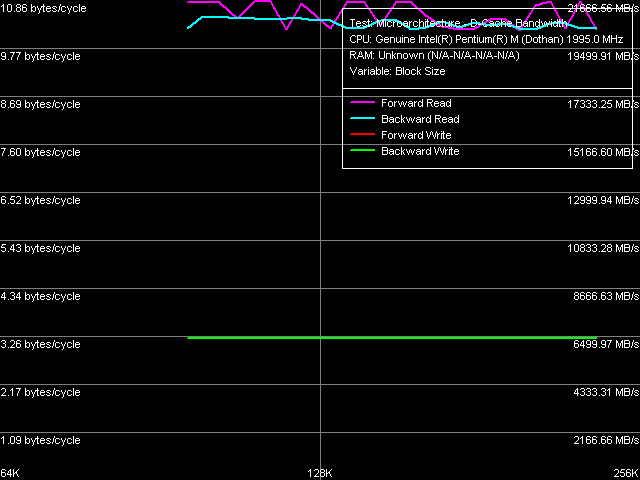
Реальная пропускная способность шины L1-L2 кэша
Реальная ПС шины L1-L2 на чтение попадает в интервал 10.78 10.86 байт/такт (что незначительно выше по сравнению с предыдущей ревизией ядра), ПС этой шины на запись осталась без изменений и составляет 3.24 байта/такт.
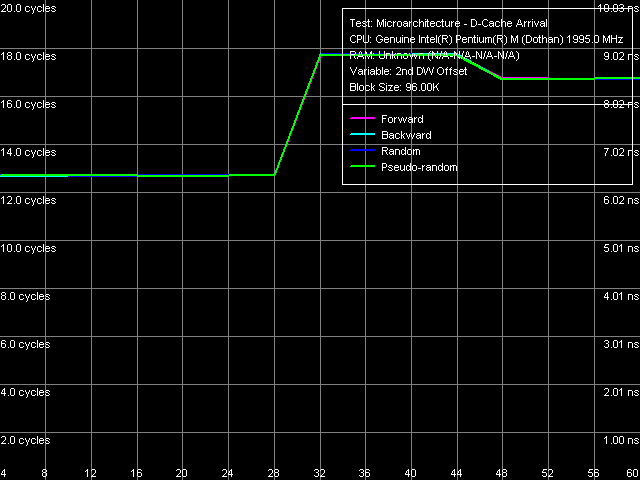
Тест прибытия данных по шине L1-L2 кэша
Полученные данные, а также результаты теста прибытия данных (изображенные выше) указывают на 128-битную организацию шины, которая гордо именуется «Advanced Transfer Cache» (т.е. так же, как в процессорах Pentium 4, с претензией на 256-разрядную организацию). С обоснованием 128-разрядности шины L1-L2 кэша процессоров Pentium M можно ознакомиться в материалах нашего предыдущего исследования. Можно, конечно, предположить, что «внутренняя» ширина шины действительно составляет 256 бит, а данные из L2-кэша передаются в L1-кэш (и наоборот) на каждом втором такте, но это все равно не оправдывает ее названия (повторим: с претензией на высокую пропускную способность), ибо «эффективная» ширина шины все равно остается равной 128 битам, т.е. переслать более чем 128/8 = 16 байт за такт невозможно.
Hardware Prefetch: Дополнительные подробности
В наших предыдущих исследованиях платформ мы никогда не останавливались на результатах теста L2 D-Cache Line Size Determination, считая его чем-то очевидным и не нуждающимся в пояснениях. Тем не менее, этот тест может вскрывать некоторые дополнительные подробности об алгоритме аппаратной предвыборки, реализованной во всех современных процессорах (с целью «сокрытия» задержек при запросе данных из оперативной памяти). Этот тест оказался особенно полезным при относительно недавней разработке и обосновании идеи двух методик измерения латентности подсистемы памяти на платформах с процессорами Pentium 4.
Опишем кратко его идею. Он является разновидностью «теста прибытия данных», который измеряет зависимость общей задержки при чтении двух близкорасположенных элементов от расстояния между этими элементами. В нем выбирается сравнительно большая величина «главного» шага 512 байт, что позволяет варьировать расстояние между элементами в широком пределе, от 4 до 508 байт включительно. При этом, если второй запрашиваемый элемент находится в той же строке кэша, что и первый, общая величина задержки остается более-менее постоянной. Если же второй элемент относительно первого попадает в следующую строку кэша, суммарная задержка резко возрастает, поскольку загрузка двух элементов из двух разных строк из памяти в L2-кэш требует гораздо большего времени, нежели загрузка двух элементов из одной и той же строки. Соответственно, точка перегиба и даст нам значение длины строки кэша. В идеальном случае это выглядит так:
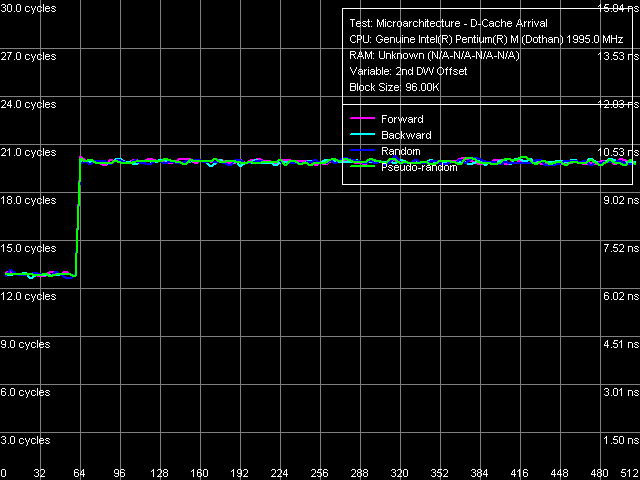
Определение длины строки L1-кэша
Но это лишь идеальный случай (хотя и является результатом реального измерения, но со сравнительно малым размером блока, целиком попадающего в L2-кэш т.е. измерения длины строки L1-кэша). Впрочем, он может вполне наблюдаться реально и при оценки длины строки L2-кэша например, на семействе процессоров AMD K7/K8. В нашем же случае (Pentium M) он выглядит намного запутаннее.
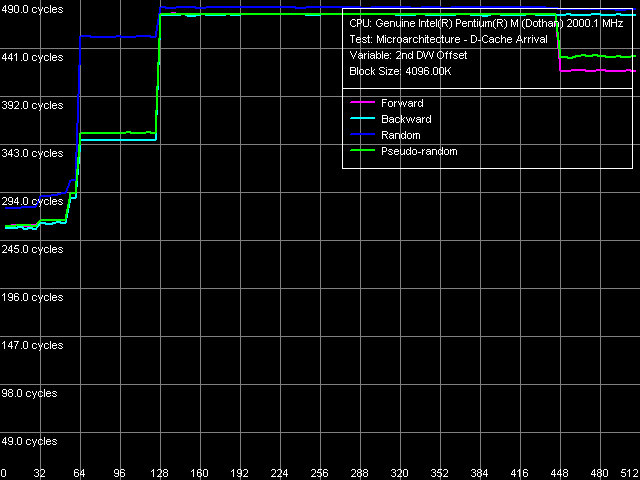
Определение длины строки L2-кэша, Pentium M Dothan (степпинг 6)
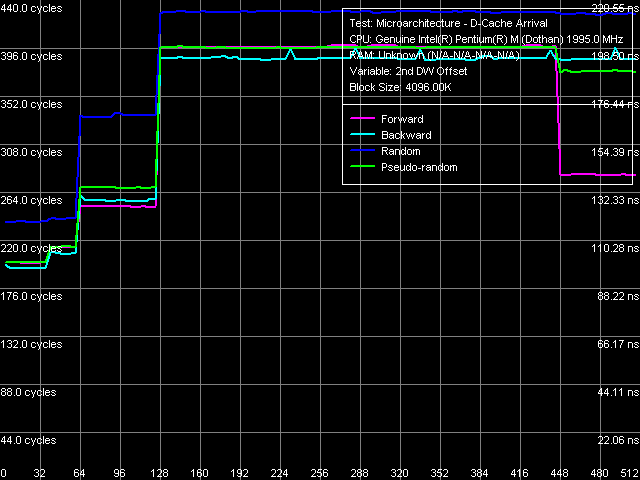
Определение длины строки L2-кэша, Pentium M Dothan (степпинг 8)
Более того, по приведенным рисункам легко заметить, что алгоритм Hardware Prefetch у двух различных ревизиях ядра Dothan отличается! (обратите внимание на кривую прямого последовательного обхода в области 448-512 байт). Найденное различие может вполне являться объяснением некоторых увиденных ранее различий в частности, более низкой латентности подсистемы памяти на новой платформе.
Кэш инструкций, эффективность декодирования
Результаты тестов декодирования/исполнения простейших независимых инструкций в сравнении с предыдущими результатами приведены в таблице.
| Тип инструкций (размер, байт) | Эффективность декодирования, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| Pentium M (Dothan, степпинг 6) | Pentium M (Dothan, степпинг 8) | |||
| L1-I кэш | L2 кэш | L1-I кэш | L2 кэш | |
| NOP (1) SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) CMP 2 (4) CMP 3-6 (6) Prefixed CMP 1-4 (8) | 2.00 2.02 2.02 4.00 2.02 4.00 7.98 11.98 2.00 | 1.94 1.98 1.98 3.55 1.98 3.55 3.99 4.22 1.78 | 1.99 2.02 2.02 3.97 2.01 3.97 7.94 11.92 1.99 | 1.93 1.96 1.96 3.53 1.96 3.53 3.97 4.18 1.77 |
На первый взгляд, полученные значения выглядят вполне одинаково. Однако, учитывая высокую точность измерений и хорошую воспроизводимость результатов тестов, мы вынуждены констатировать, что новая ревизия ядра Dothan ведет себя несколько хуже по отношению к исполнению кода. В абсолютных величинах это особенно заметно при декодировании/исполнении «крупных» инструкций вроде 6-байтных CMP (№3-6). Что наталкивает на мысль о возможном увеличении длины конвейера, хотя бы на одну стадию…
«Латентность кэша инструкций»
Довольно условное понятие, появившееся в последних версиях тестового пакета RMMA, начиная с версии 3.1. Под ним фактически понимается время исполнения определенного количества (в зависимости от размера блока) безусловных переходов, расположенных на заданном расстоянии (величине шага) друг от друга.
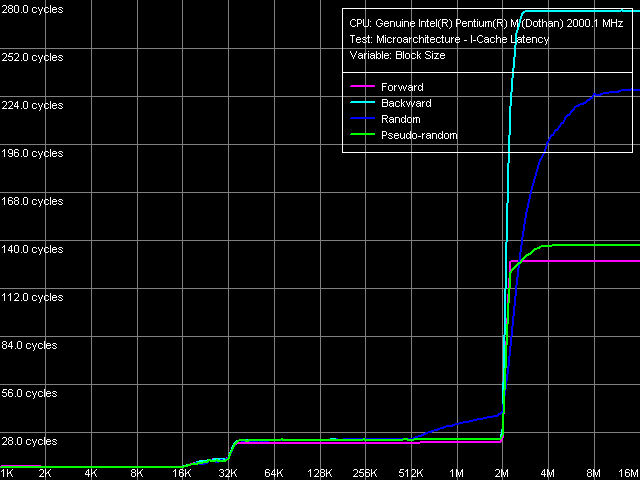
Латентность кэша инструкций, Pentium M Dothan (степпинг 6)
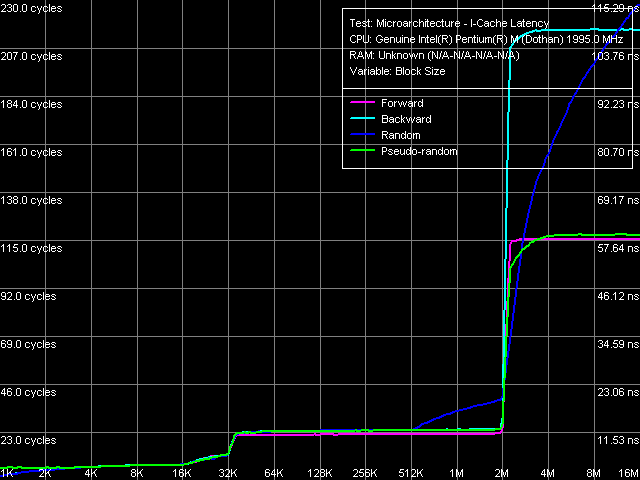
Латентность кэша инструкций, Pentium M Dothan (степпинг 8)
Кривые, полученные на двух разных степпингах ядра Dothan, вскрывают еще одну интересную подробность: помимо уменьшения общей задержки при исполнении кода из оперативной памяти (с 280 до 230 тактов), в новой ревизии изменилось также соотношение между кривыми случайного и обратного последовательного доступа в этой области. Новая ревизия ядра исполняет код, расположенный в обратном порядке эффективнее по сравнению со случайной последовательностью кода, а старая — в точности наоборот. Хотя, конечно, не стоит забывать, что исполнение кода в случайном и, тем более, в строго обратном направлении — весьма экзотическое извращение :). Тем не менее, его изучение позволяет в очередной раз выявить различия в алгоритмах Hardware Prefetch разных ревизий ядра Dothan.
Ассоциативность кэша инструкций
Помимо латентности, вполне можно оценить и ассоциативность L1-кэша инструкций, а также объединенного L2-кэша кода/данных.
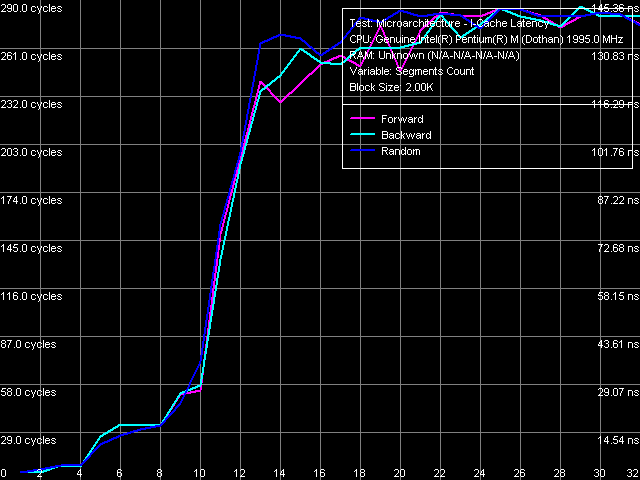
Ассоциативность кэша инструкций
В данном тесте вышли довольно четкие кривые, указывающие на 4-входовую (4-way) ассоциативность L1-кэша инструкций, и 8-входовую (8-way) ассоциативность L2-кэша. Напомним, что именно такой результат мы получили при измерении ассоциативности кэша данных, а также ассоциативности кэша кода и данных ранней модели Dothan.
Характеристики TLB
Для начала, оценим размер и ассоциативность буфера TLB данных.
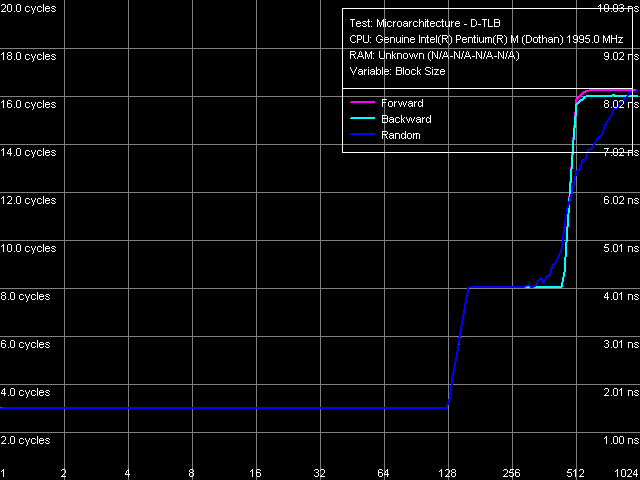
Размер D-TLB
Картина стандартна: размер D-TLB составляет 128 записей, а его промах обходится процессору в 5 «штрафных» тактов. Перегиб в области 512 записей связан с выходом за пределы L1-кэша процессора (512 x 64 байта = 32 КБ).
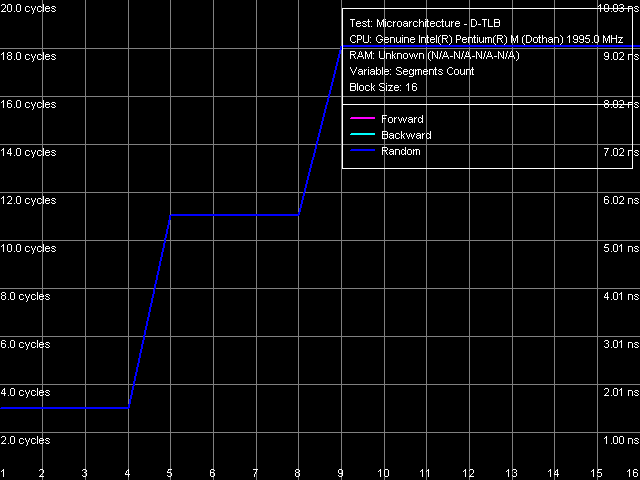
Ассоциативность D-TLB
Гораздо более интересна картина ассоциативности D-TLB, характеризующаяся двумя довольно резкими скачками (что гораздо более типично для двухуровневых TLB, каждый уровень которого имеет разную ассоциативность). Первый скачок соответствует подлинной 4-входовой ассоциативности D-TLB, причина появления второго скачка, соответствующего как бы удвоенной ассоциативности, совершенно непонятна… Особенно если учесть, что таковая отсутствовала у ранней модели Dothan. Таким образом, D-TLB в новой ревизии ядра явно претерпел изменения, однако какие именно, и зачем — понять невозможно.
Перейдем к буферу TLB инструкций.
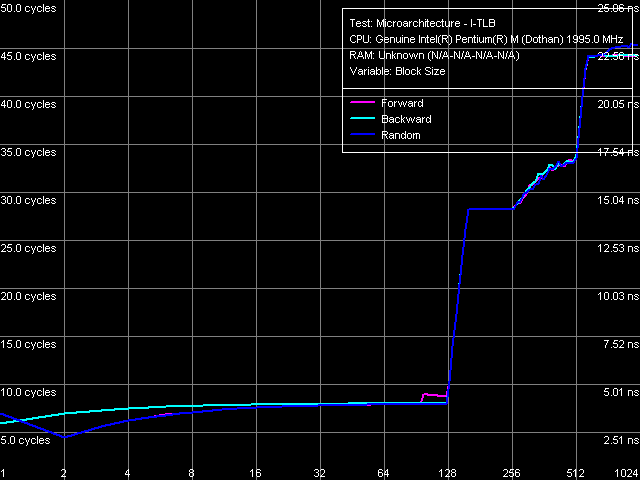
Размер I-TLB
Результат измерения размера I-TLB один-в-один совпадает с полученным ранее. Его размер 128 записей, а его промах «обходится» процессору примерно в 20 тактов.
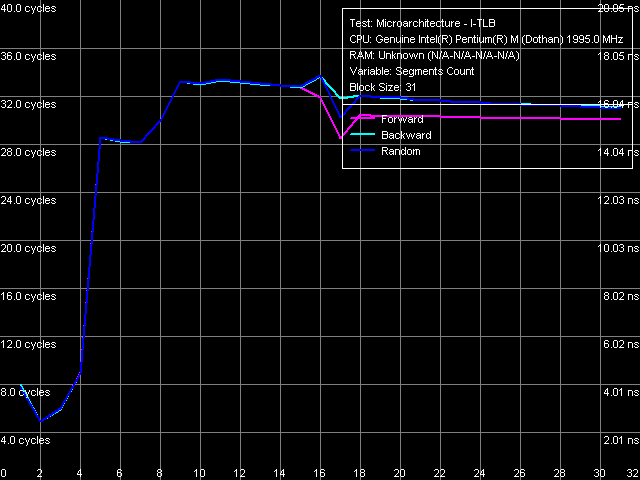
Ассоциативность I-TLB
Картина ассоциативности I-TLB вполне четкая и соответствует полученной на ранней ревизии ядра (ассоциативность I-TLB равна четырем). Таким образом, в отличие от D-TLB, I-TLB в новой ревизии ядра не претерпел изменений.
Заключение
Вот, пожалуй, и все, что можно сказать на данный момент о последней ревизии ядра Dothan процессора Pentium M, ключевого компонента новой платформы Sonoma. Изменения на уровне микроархитектуры ядра однозначно имеются, большинство из них явно пошли на пользу — для примера, достаточно упомянуть хотя бы улучшенный алгоритм аппаратной предвыборки данных из оперативной памяти, ставший несколько ближе к его отличному NetBurst-овскому аналогу, реализованному в ядре Prescott. Тем не менее, работу в этом направлении вполне можно продолжать — достигнув тем самым почти 100% эффективность утилизации шины процессор-память (BIU), которая уже достигнута в упомянутом выше ядре Prescott. А что касается нашего сегодняшнего подопытного и новой платформы в целом — теперь осталось посмотреть, как проявит себя новая платформа в тестах «высокого уровня», т.е. в реальных приложениях.


