NVIDIA GeForce 6800 Ultra (NV40)
Часть 1 — особенности архитектуры и синтетические тесты в D3D RightMark
И вот новая архитектура перед нами:
работа над ошибками прошлого и
одновременно уверенный задел
на будущее. В какой степени?
Сегодня мы исследуем оба аспекта.

СОДЕРЖАНИЕ
- Официальные спецификации
- Архитектура
- 2D и видеопроцессор
- Особенности видеокарты
- Синтетические тесты в D3D RightMark
- Качество трилинейной фильтрации и анизотропии
- Выводы
Данная статья в основном посвящена архитектурным вопросам и синтетическим предельным тестам. Позже, выйдет материал по производительности и качеству в игровых приложениях и затем, после анонса новой архитектуры ATI, мы проведем и опубликуем детальные сравнительные исследования вопросов качества и скорости АА и анизотропной фильтрации в новом поколении ускорителей. Перед прочтением рекомендуем внимательно ознакомиться с базовыми материалами DX Current и DX Next описывающими различные аспекты современных аппаратных ускорителей графики вообще, и архитектурные особенности продукции NVIDIA и ATI в частности.
Официальные спецификации GeForce 6800
- Кодовое имя чипа NV40
- Технология 130 нм FSG (IBM)
- 222 миллиона транзисторов
- FС корпус (flip chip,перевернутый чип, без металлической крышки)
- 256 бит интерфейс памяти
- До 1 гигабайта DDR / GDDR-2/ GDDR-3 памяти
- AGP 3.0 8x шинный интерфейс
- Специальный режим работы APG 16х (в обе стороны), для PCI Express моста HSI
- 16 Пиксельных процессоров, по одному текстурному блоку на каждом с произвольной фильтрацией целочисленных и плавающих текстур (анизотропия степени до 16х включительно).
- 6 Вершинных процессоров, по одному текстурному блоку на каждом, без фильтрации выбираемых значений (дискретная выборка)
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 32 значений глубины и буфера шаблонов за такт (если не производятся операции с цветом)
- Поддержка « двустороннего» буфера шаблонов
- Поддержка специальных оптимизаций прорисовки геометрии для ускорения алгоритмов теней на основе буфера шаблонов (т.н. технология Ultra Shadow II)
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 3.0, включая динамические ветвления в пиксельных и вершинных процессорах, выбор значений текстур из вершинных процессоров и т.д.
- Фильтрация текстур в плавающем формате
- Поддерживается буфер кадра в плавающем формате (включая операции блендинга)
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- 2x RAMDAC 400 МГц
- 2x DVI интерфейса (требуются внешние чипы)
- TV-Out и TV-In интерфейс (требуются отдельные чипы)
- Программируемый потоковый видеопроцессор (для задач компрессии, декомпрессии и постобработки видео)
- 2 D ускоритель с поддержкой всех функций GDI +
Спецификации референсной карты GeForce 6800 Ultra
- Частота ядра 400 МГц
- Эффективная частота памяти 1,1 ГГц (2*550 МГц)
- Тип памяти GDDR-3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 35,2 гигабайта в сек.
- Теоретическая скорость закраски 6,4 гигапикселя в сек.
- Теоретическая скорость выборки текстур 6,4 гигатекселя в сек.
- Два DVI-I разъема
- TV-Out
- Потребляет до 120 Ватт энергии (на карте два разъема дополнительного питания, рекомендуются источники питания суммарной мощностью 480 и более Ватт)
Общая схема чипа
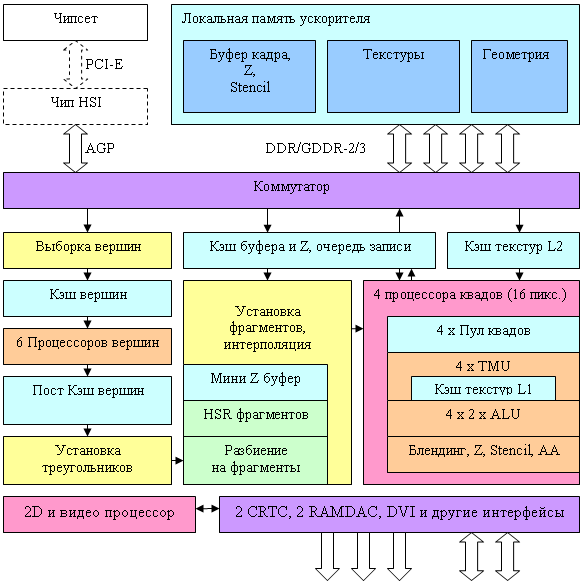
На данном уровне детализации, особые архитектурные отличия от предыдущего поколения не заметны, что, впрочем, не удивительно — схема выверена в течение нескольких поколений и во многом оптимальна. Хочется отметить наличие шести вершинных процессоров, и четырех независимых пиксельных процессоров, каждый из которых работает с одним квадом (фрагментом 2х2 пикселя). Отметим также наличие двух уровней кэширования данных текстур (общий кэш и персональный кэш для каждой группы из 4 TMU в пиксельном процессоре) и, как следствие, новое соотношение 16 TMU на 16 пикселей.
А теперь, увеличим степень детализации в самых интересных местах:
Вершинные процессоры и выборка данных
Интересное новшество — поддержка разных т.н. « делителей частоты» для потоков исходных данных вершин. Напомним, как в общем случае строится выборка данных для вершин в современных ускорителях:
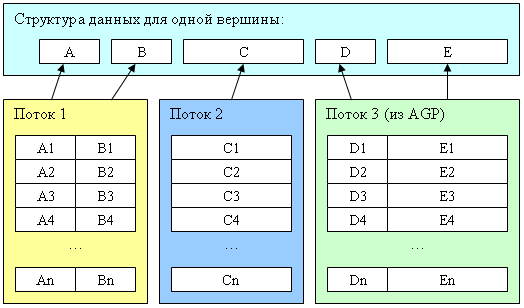
Итак, структура состоит из некоего числа параметров допустимых типов: скаляры и векторы разных размерностей до 4D включительно, плавающего или целочисленного формата, включая специальные типы данных, такие как координаты вершины или вектор нормали, значение цвета, текстурные координаты и т.д. Интересно, что « специальными» они являются только с точки зрения API, само железо допускает произвольную коммутацию параметров в микрокоде вершинного шейдера, но для программиста важно четко задать, в какие исходные регистры вершинного процессора эти данные попадут после выборки, например, чтобы не осуществлять лишних пересылок в шейдере.
В памяти данные для вершины не обязательно хранятся в виде непрерывного фрагмента — они могут быть разбиты на некоторое число потоков (для NV40 — до 16) в каждом из которых может быть один или несколько параметров. При этом, какие-то потоки могут находить в адресном пространстве AGP (т.е. будут выбираться из системной памяти) а прочие могут быть расположены в локальной памяти ускорителя. Такой подход позволяет повторно использовать одни и те же наборы данных для разных объектов (например, мы можем разделить геометрическую и текстурную информацию по разным потокам и использовать с одной геометрической моделью разные наборы текстурных координат и других параметров поверхности, таким образом, обеспечив внешнее отличие). Кроме того, можно пересылать по AGP (и генерировать в системной памяти) в отдельном потоке только те параметры модели, которые действительно изменились, остальные достаточно один раз загрузить в локальную память ускорителя. Для доступа к параметрам той или иной вершины используется текущий индекс, общий для всех потоков. Этот индекс или хаотически меняется (представление исходных данных в виде индексного буфера) или планомерно увеличивается (отдельные треугольники, полоски и веера).
Новшество блока выборки вершинных данных NV40 состоит в том, что всем потокам не обязательно иметь одинаковое число наборов данных. Теперь, каждый поток может иметь свой собственный делитель значения индекса (т.н. Frequency Stream Divider). Таким образом, иногда отпадает необходимость дублировать данные, и мы экономим объем и ПСП локальной памяти и системной памяти адресуемой через AGP :
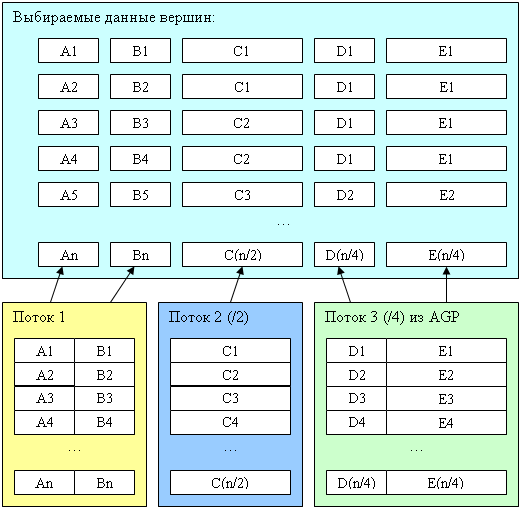
Кроме того, теперь можно подсунуть в качестве потока буфер меньшего размера, чем максимальное значение индекса даже с учетом делителя. Индекс будет просто заворачиваться вокруг границы буфера того или иного потока. Эта возможность тоже может найти вполне конкретные полезные применения, например, для сжатия геометрии с использованием иерархических представлений или копирования свойств на массив объектов (общая для каждого дерева в лесу информация хранится только один раз и т.д.). А теперь приведем блок схему вершинного процессора NV40:
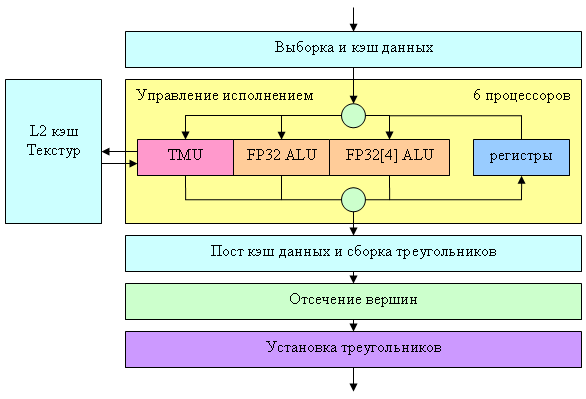
Собственно сам процессор на схеме обозначен желтым прямоугольником, остальные окружающие его блоки показаны для более полной картины. Заявлено, что NV40 содержит 6 независимых процессоров (мысленно скопируем желтый блок 6 раз), каждый из которых исполняет свои команды и имеет собственную контрольную логику (т.е. разные процессоры могут одновременно исполнять различные ветки условий над разными вершинами). За один такт вершинный процессор NV40 может выполнить одну векторную операцию (до 4-х компонент FP32) одну скалярную FP32 операцию и осуществить один доступ к текстуре. Поддерживаются целочисленные и плавающие форматы текстур и мип-маппинг. В одном вершинном шейдере может быть задействовано до четырех различных текстур. Однако, фильтрация не производится — возможен только самый простой, дискретный доступ к ближайшему значению по заданным координатам. Это позволило существенно упростить TMU и как следствие весь вершинный процессор (проще TMU — меньше длина конвейера — меньше транзисторов). В случае надобности можно самостоятельно выполнить фильтрацию в шейдере, но, разумеется, это потребует нескольких выборок значения текстуры и последующие вычисления, т.е. займет вполне заметное число тактов. Каких либо жестких аппаратных ограничений на длину микрокода шейдера нет — он выбирается из локальной памяти ускорителя по мере исполнения. Однако конкретные API (а именно DX) могут накладывать такие ограничения. Вот так выглядит сводная табличка параметров вершинного процессора NV40 с точки зрения вершинных шейдеров DX9 в сравнении с семействами R3XX и NV3X:
Версия вершинных шейдеров | 2.0 (R 3 XX) | 2. a (NV 3 X) | 3.0 (NV40) |
Число инструкций в коде шейдера | 256 | 256 | 512 и более |
Число исполняемых инструкций | 65535 | 65535 | 65535 и более |
Предикаты | Нет | Есть | Есть |
Временных регистров | 12 | 13 | 32 |
Константных регистров | 256 и более | 256 и более | 256 и более |
Статические переходы | Да | Да | Да |
Динамические переходы | Нет | Да | Да |
Глубина вложенности динамических переходов | Нет | 24 | 24 |
Выбор значений текстур | Нет | Нет | Да (4) |
Фактически, если оглядываться на архитектуру NV3X становится ясно, что разработчикам из NVIDIA было достаточно увеличить число временных регистров и добавить модуль TMU. Далее, по результатам синтетических тестов, мы проверим, насколько архитектура вершинных модулей NV40 близка к оной NV3X с точки зрения производительности.
Еще один интересный аспект, который мы исследуем далее — производительность эмуляции FFP (фиксированного T&L). Интересно узнать, сохранились ли в железе NV40 специальные блоки, дававшие NV3X столь заметный прирост на FFP геометрии.
Пиксельные процессоры и организация закраски
Рассмотрим пиксельную архитектуру NV40 в порядке следования данных. Итак, после установки параметров треугольника нас ждет:
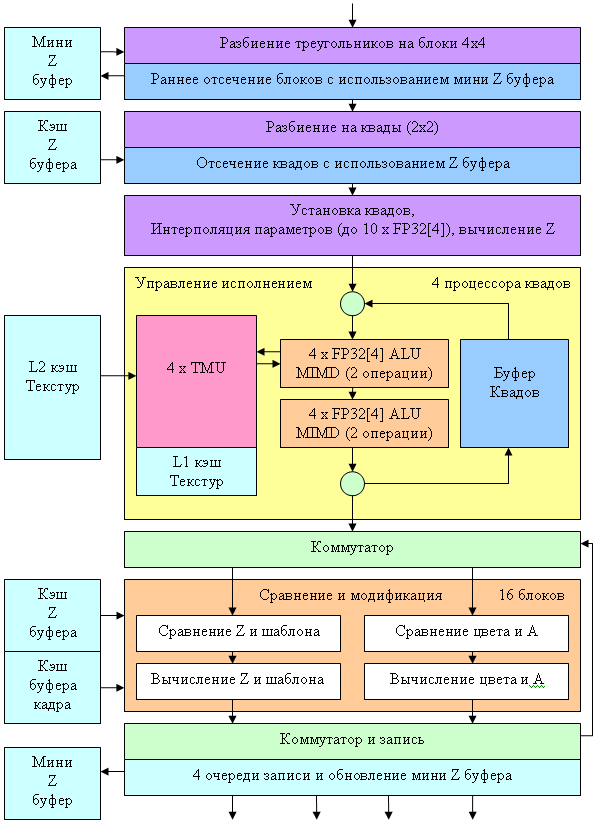
Остановимся на самых интересных фактах. Во-первых, если ранее в NV3X был лишь один процессор квадов, обрабатывающий за такт блок из четырех пикселов (2х2) то теперь таких процессоров стало четыре. Они полностью независимы и каждый из них может исключаться из работы (например, для создания облегченной версии чипа с тремя процессорами при наличии брака в одном из них). По-прежнему сохранилась очередь для « карусели» квадов (см. DX Curent), своя в каждом процессоре. Соответственно, сохранился и схожий с NV3X подход на исполнение пиксельных шейдеров: прогон через одну настройку (операцию) более чем сотни квадов и последующей смены настройки в соответствии с кодом шейдера. Но есть и заметные отличия. В первую очередь — это число TMU — теперь у нас только по одному TMU на каждый пиксель квада. Всего у нас 4 процессора квадов, в каждом по 4 TMU, таким образом, всего их 16.
Новые TMU поддерживают анизотропную фильтрацию с соотношением сторон до 16:1 включительно (т.н. 16х, у NV3X было до 8х) и, наконец-то, научились выполнять все виды фильтрации с плавающими форматами текстур. Правда, при условии 16 битной точности компонент (FP16). Для FP32 фильтрация по-прежнему недоступна, однако и FP16 можно считать заметным прогрессом — теперь плавающие текстуры станут « полноправной» альтернативой целочисленным в любых применениях, тем более что сама фильтрация FP16 текстур происходит без снижения скорости (впрочем, повышенный поток данных может и должен сказаться на производительности реальных приложений).
Отметим двухуровневую организацию кэширования текстур — каждый процессор квада имеет свой собственный кэш текстур первого уровня. Необходимость наличия оного вызвана двумя фактами — четырехкратным увеличением числа обрабатываемых одновременно квадов (очередь квадов в одном процессоре не выросла, но процессоров теперь четыре) и наличием конкурентного доступа к кэшу текстур из вершинных процессоров.
На каждый пиксель приходится по два ALU, причем каждое из них может выполнить две различные(!) операции над разным числом произвольно выбираемых компонент вектора (до 4х). Т.е. возможны схемы 4, 1+1, 2+1, 3+1 (как в R3XX), и новая конфигурация 2+2 ранее недоступная. Подробнее об этом вопросе см. DX Current. Поддерживается произвольное маскирование и перестановка компонент после операции. Кроме того, ALU способно выполнять нормализацию вектора как одну операцию, что может существенно сказаться на производительности некоторых алгоритмов. Аппаратное вычисление значений SIN и COS было изъято из новой архитектуры NVIDIA — опыт показал, что потраченные на эту возможность транзисторы были потрачены зря — все равно доступ по простейшей таблице (1D текстуре) способен дать лучшие результаты с точки зрения скорости, тем более, учитывая отсутствие такой поддержки у ATI.
Таким образом, в зависимости от кода, может быть выполнено от одной до 4х различных FP32 операций за такт, над векторами и скалярами. На схеме видно, что первое ALU задействуется для служебных операций во время выборки значений текстур, таким образом, за один такт мы можем либо выбрать одно значение текстуры и задействовать второе ALU для одной или двух операций, либо задействовать оба ALU, если мы не выбираем текстуру в этот заход. Производительность такой связки напрямую зависит от компилятора и кода, но очевидно, что мы имеем:
Минимум: одну выборку текстуры за такт
Минимум: две операции за такт без выборки текстуры
Максимум: четыре операции за такт без выборки текстуры
Максимум: одну выборку текстуры и две операции за такт
По некоторым данным, число временных регистров для каждого квада было увеличено вдвое, т.е. теперь мы имеем 4 временных FP32 регистра на пиксель или 8 временных FP16 регистров. Этот факт должен существенно увеличить производительность сложных шейдеров. Кроме того, сняты какие либо аппаратные ограничения на длину пиксельных шейдеров и число выборок текстур — теперь все будет зависеть только от API. Самое главное усовершенствование — поддержка динамического управления исполнением. Позже, с выходом нового SDK и новой версии DirectX 9 (9.0c) мы тщательно исследуем вопрос реализации и производительности пиксельных шейдеров 3.0 и динамических ветвлений. А теперь — сводная таблица возможностей:
Версия пиксельного шейдера | 2.0 (R3XX) | 2.a (NV3X) | 2.b (R420?) | 3.0 (NV40) |
Вложенность выборок текстур до | 4 | Без ограничений | 4 | Без ограничений |
Выборок значений текстур до | 32 | Без ограничений | Без ограничений | Без ограничений |
Длинна кода шейдера | 32 + 64 | 512 | 512 | 512 и более |
Исполняемых инструкций шейдера | 32 + 64 | 512 | 512 | 65535 и более |
Интерполяторы | 2 + 8 | 2 + 8 | 2 + 8 | 10 |
Предикаты | нет | да | нет | да |
Временных регистров | 12 | 22 | 32 | 32 |
Константных регистров | 32 | 32 | 32 | 224 |
Произвольная перестановка компонент | нет | да | нет | да |
Инструкции градиента (D D X/ D DY) | нет | да | нет | да |
Глубина вложенности динамических переходов | нет | нет | нет | 24 |
Присутствующий в компиляторе шейдеров профиль 2.b видимо будет поддерживаться будущей архитектурой ATI (R420), анонс которой не за горами. Не будем делать скороспелых выводов, но отметим, что гибкость и возможности программирования NV40 пока находятся вне конкуренции.
А теперь вернемся к нашей схеме и обратим внимание на ее нижнюю часть. Там расположен блок, отвечающий за сравнение и модификацию значений цвета, прозрачности, глубины и буфера шаблонов. Всего у нас 16 таких блоков. Ввиду достаточной однотипности задачи сравнения и модификации, мы можем использовать этот блок в двух режимах:
Стандартный (за один такт производится):
- Сравнение и модификация значения глубины
- Сравнение и модификация значения буфера шаблона
- Сравнение и модификация значения компоненты прозрачности и цвета (блендинг)
Турбо режим (за один такт производится):
- Сравнение и модификация двух значений глубины
- Сравнение и модификация двух значений буфера шаблона
Разумеется, что последний режим возможен только в случае отсутствия вычисленного и записываемого значения цвета. Вот откуда в спецификации указано, что в случае отсутствия цвета, чип может закрасить (точнее заполнить) 32 пикселя за один такт, причем рассчитывается как значение глубины, так и значение буфера шаблонов. Подобный « турбо» режим полезен в первую очередь для ускорения построения теней на основе буфера шаблонов (алгоритм, принятый в Doom III) и для предварительного прохода рендеринга в котором рассчитывается только Z буфер (зачастую такая техника позволяет сэкономить время на длинных шейдерах, т.к. фактор перекрытия будет гарантированно уменьшен до единицы).
Наконец то исправлено досадное упущение с отсутствием в семействе NV3X поддержки MRT (Multiple Render Targets — рендеринг в несколько буферов) — т.е. возможности расчета и записи в одном пиксельном шейдере до четырех различных значений цвета, которые будут затем помещены в разные буфера (одинакового размера). Отсутствие такой функции у NV3X было серьезным аргументом в пользу R3XX для разработчиков. Теперь, в NV40, эта возможность появилась. Еще одно важное отличие от предыдущих поколений — интенсивная поддержка этим блоком плавающей арифметики. Все операции по сравнению, блендингу и записи цвета могут проходить в формате компонент FP16. Наконец то мы имеем, что называется, полную (ортогональную) поддержку операций с 16 битной плавающей точкой — как в плане фильтрации и выборки текстур, так и в плане работы с буфером кадра. На очереди FP32, но, видимо это вопрос следующего поколения.
Еще один интересный факт — поддержка MSAA . Как и его предшественники (NV 2Х и NV 3 X), NV40 может осуществлять 2 × MSAA без потери скорости (генерируется и сравнивается два значения глубины на один пиксель) а в случае 4 × MSAA необходимо добавить один штрафной такт (впрочем, на практике, нет необходимости вычислять все четыре значения за такт — все равно будет проблематично записать в буфер глубины и кадра столько информации за один такт — полоса пропускания памяти достаточно ограничена. Более 4х MSAA не поддерживается — как и в предыдущем семействе, все более сложные режимы гибриды между 4х MSAA и последующим SSAA того или иного размера. Но, теперь, наконец-то поддерживается RGMS (повернутая решетка отсчетов MSAA):
Что, способно заметно улучшить качество сглаживания наклонных линий. На этом мы заканчиваем описание пиксельного процессора NV40 и переходим к следующей части:
2D и Видеопроцессор
Вот такой отдельный программируемы блок NV40 берет на себя задачи обработки видео потоков:
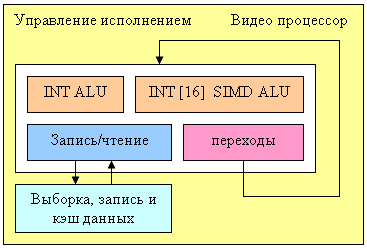
Процессор содержит четыре функциональных блока (целочисленное ALU, векторное целочисленное ALU с 16 компонентами, блок загрузки и выгрузки данных и блок управления переходами и условиями) и может таким образом выполнять до четырех различных операций за такт. Формат данных — целые числа, видимо 16 битной или 32 битной точности (точно не известно, но для некоторых алгоритмов 8 бит было бы недостаточно). Для удобства процессор включает специальные возможности выборки, коммутации и записи потоков данных. Классические задачи декодирования и кодирования видео (IDCT, деинтерлейсинг, преобразование цветовых моделей и т.д.) могут быть выполнены без участия CPU. Однако, управление со стороны центрального процессора все равно требуется — подготовку данных и выбор параметров преобразований надо выполнять на CPU, особенно в случае достаточно сложных алгоритмов сжатия, включающих в себя распаковку как один из промежуточных шагов.
Такой процессор способен существенно разгрузить CPU, особенно в случае больших разрешений видео, таких, как все более набирающие популярность форматы HDTV. Не известно, используются ли возможности этого процессора для ускорения 2D графики, особенно некоторых достаточно сложных функций GDI+ — было бы логично задействовать его на этом поприще, но точной информации об этом аспекте у нас нет. Как бы там ни было, NV40 соответствует высочайшим требованиям к аппаратному ускорению 2D — все необходимые вычислительно интенсивные функции GDI и GDI+ выполняются аппаратно.
Расширения OpenGL и свойства D3D
Приведем список расширений поддерживаемых OpenGL (Драйверы 60.72):
- GL_ARB_depth_texture
- GL_ARB_fragment_program
- GL_ARB_fragment_program_shadow
- GL_ARB_fragment_shader
- GL_ARB_imaging
- GL_ARB_multisample
- GL_ARB_multitexture
- GL_ARB_occlusion_query
- GL_ARB_point_parameters
- GL_ARB_point_sprite
- GL_ARB_shadowGL_ARB_shader_objects
- GL_ARB_shading_language_100
- GL_ARB_texture_border_clamp
- GL_ARB_texture_compression
- GL_ARB_texture_cube_map
- GL_ARB_texture_env_add
- GL_ARB_texture_env_combine
- GL_ARB_texture_env_dot3
- GL_ARB_texture_mirrored_repeat
- GL_ARB_texture_non_power_of_two
- GL_ARB_transpose_matrix
- GL_ARB_vertex_buffer_object
- GL_ARB_vertex_program
- GL_ARB_vertex_shader
- GL_ARB_window_pos
- GL_ATI_draw_buffers
- GL_ATI_pixel_format_float
- GL_ATI_texture_float
- GL_ATI_texture_mirror_once
- GL_S3_s3tc
- GL_EXT_texture_env_add
- GL_EXT_abgr
- GL_EXT_bgra
- GL_EXT_blend_color
- GL_EXT_blend_equation_separate
- GL_EXT_blend_func_separate
- GL_EXT_blend_minmax
- GL_EXT_blend_subtract
- GL_EXT_compiled_vertex_array
- GL_EXT_Cg_shader
- GL_EXT_depth_bounds_test
- GL_EXT_draw_range_elements
- GL_EXT_fog_coord
- GL_EXT_multi_draw_arrays
- GL_EXT_packed_pixels
- GL_EXT_pixel_buffer_object
- GL_EXT_point_parameters
- GL_EXT_rescale_normal
- GL_EXT_secondary_color
- GL_EXT_separate_specular_color
- GL_EXT_shadow_funcs
- GL_EXT_stencil_two_side
- GL_EXT_stencil_wrap
- GL_EXT_texture3D
- GL_EXT_texture_compression_s3tc
- GL_EXT_texture_cube_map
- GL_EXT_texture_edge_clamp
- GL_EXT_texture_env_combine
- GL_EXT_texture_env_dot3
- GL_EXT_texture_filter_anisotropic
- GL_EXT_texture_lod
- GL_EXT_texture_lod_bias
- GL_EXT_texture_mirror_clamp
- GL_EXT_texture_object
- GL_EXT_vertex_array
- GL_HP_occlusion_test
- GL_IBM_rasterpos_clip
- GL_IBM_texture_mirrored_repeat
- GL_KTX_buffer_region
- GL_NV_blend_square
- GL_NV_centroid_sample
- GL_NV_copy_depth_to_color
- GL_NV_depth_clamp
- GL_NV_fence
- GL_NV_float_buffer
- GL_NV_fog_distance
- GL_NV_fragment_program
- GL_NV_fragment_program_option
- GL_NV_fragment_program2
- GL_NV_half_float
- GL_NV_light_max_exponent
- GL_NV_multisample_filter_hint
- GL_NV_occlusion_query
- GL_NV_packed_depth_stencil
- GL_NV_pixel_data_range
- GL_NV_point_sprite
- GL_NV_primitive_restart
- GL_NV_register_combiners
- GL_NV_register_combiners2
- GL_NV_texgen_reflection
- GL_NV_texture_compression_vtc
- GL_NV_texture_env_combine4
- GL_NV_texture_expand_normal
- GL_NV_texture_rectangle
- GL_NV_texture_shader
- GL_NV_texture_shader2
- GL_NV_texture_shader3
- GL_NV_vertex_array_range
- GL_NV_vertex_array_range2
- GL_NV_vertex_program
- GL_NV_vertex_program1_1
- GL_NV_vertex_program2
- GL_NV_vertex_program2_option
- GL_NV_vertex_program3
- GL_NVX_conditional_render
- GL_SGIS_generate_mipmap
- GL_SGIS_texture_lod
- GL_SGIX_depth_texture
- GL_SGIX_shadow
- GL_SUN_slice_accum
- GL_WIN_swap_hint
- WGL_EXT_swap_control
Параметры D3D вы можете посмотреть здесь:
D3D RightMark: NV40, NV38, R360
DX CapsViewer: NV40, NV38, R360
Внимание! Заметьте, что в текущей версии DirectX в паре с текущими драйверами NVIDIA (60.72) возможности пиксельных и вершинных шейдеров 3.0 пока не доступны. Возможно, этот вопрос разрешится с выходом DirectX 9.0c или для этого достаточно текущей версии DirectX, но с перекомпиляцией программ с библиотеками новой версии SDK, которая также скоро будет доступна — поживем, увидим. Как бы там ни было, пока эта возможность отключена.
Плата
| NVIDIA GeForce 6800 Ultra 256MB |  |
NVIDIA GeForce 6800 Ultra 256MB | |
Kарта имеет интерфейс AGP x8/x4, 256 МБ памяти GDDR3, размещенной в 8-ми микросхемах на лицевой стороне PCB. Микросхемы памяти производства Samsung (маркировка K4J55323QF). Время выборки у микросхем памяти 1,6 ns, что соответствует частоте работы 600 (1200) МГц, память же работает на частоте 550 (1100) МГц. Частота работы GPU — 400 MHz. Интерфейс обмена с памятью — 256 бит. |  |
| Сравнение с GeForce FX 5950 Ultra, вид спереди | |
|---|---|
| GeForce 6800 Ultra | Reference card GeForce FX 5950 Ultra |
 |  |
 | |
| Сравнение с GeForce FX 5950 Ultra, вид сзади | |
|---|---|
| GeForce 6800 Ultra | Reference card GeForce FX 5950 Ultra |
 |  |
 | |
Очевидно, что дизайн карты претерпел весьма значительные изменения. Использование памяти GDDR3 дало возможность разместить все 256 МБ на лицевой стороне платы, что в будущем даст возможность установить на карту и 512 МБ видеопамяти (при условии изменения дизайна PCB, ибо на тыльной стороне платы нет посадочных мест для дополнительных 256 МБ, хотя на первый взгляд кажется, что эти места присутствуют. Однако если изучить большое фото, видно, что это уже не та ситуация, что была с GeForce FX 5900 не-Ultra, у которой микросхем памяти на оборотной стороне не было, но посадочные места для неё присутсвовали.
Далее следует отметить координально переработанную систему питания. Она стала гораздо более компактной, появился второй разъём питания… Да и вообще карта совершила небольшую "революцию" — NVIDIA настоятельно рекомендует использовать вместе с GeForce 6800 Ultra блоки питания мощностью не менее 480 Вт!!! Это может стать серьёзной помехой распространению карты на рынке.
А теперь рассмотрим систему охладжения:
NVIDIA GeForce 6800 Ultra | |
| Здесь мы наблюдаем планомерное развитие системы охлаждения 5950 Ultra. Разница лишь в том, что забор воздуха теперь производится не извне, а изнутри корпуса. Кроме того, в системе охлаждения памяти появилась тепловая трубка для наиболее быстрого отвода тепла от микросхем к массивному игольчатому радиатору. В целом охлаждение карты весьма эффективно. Также отметим, что весьма велика вероятность использования вендорами кулеров не занимающих соседний с AGP слот. |  |
 | |
Раз уж сняли кулер, давайте поближе посмотрим на сам GPU:

Сразу бросается в глаза огромных размеров красталл. Действительно, 16 конвейеров, 222 млн. транзисторов — это не шутка. Отметим ещё одно новшество — рамку, аналогичную той, что уже давно применяет ATI для защиты ядра GPU от скола. Столь большому кристаллу NV40 подобная защита уж точно не помешает.
На этом знакомство с картой мы заканчиваем и переходим, наконец, к тестам.
Синтетические тесты D3D RightMark
Использованная нами версия пакета синтетических тестов D3D RightMark Beta 4 (1050) и ее описание доступна на сайте 3d.rightmark.orgКонфигурации тестовых стендов:
- Компьютер на базе Pentium 4 3200 MHz:
- процессор Intel Pentium 4 3200 МГц;
- системная плата ASUS P4C800 Delux (i875P);
- оперативная память 1024 MB DDR SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1; DirectX 9.0b;
- мониторы
ViewSonic P810 (21") иMitsubishi Diamond Pro 2070SB (21"); - драйверы NVIDIA верии 60.72;
- драйверы ATI версии 6.436 (CATALYST 4.4).
Для начала исследуем соответствие заявленных характеристик (16 пикселей за такт, 16 TMU и т.д.) действительности. Итак :
Тест Pixel Filling
Пиковая производительность выборки текстур (texelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
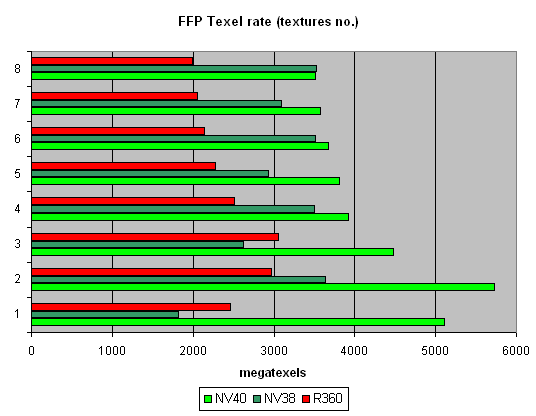
Теоретический максимум NV40 в этом тесте 6.4 гигатекселов в секунду. В действительности мы почти достигли 6 гигатекселов, что однозначно свидетельствует о наличии 16 текстурных модулей. В случае одной текстуры результат чуть меньше чем в случае двух — видимо мы страдаем от недостаточной полосы пропускания буфера кадра, а далее на лицо плавная зависимость — с каждой новой текстурой скорость закраски постепенно падает. Скачков между четными и нечетными числами (как у NV38) свойственных конфигурациям с двумя TMU на пиксель нет, и наоборот, картина очень похожа на R360. Таким образом, можно сделать вывод о соответствии схемы 16х1 действительности. Интересно, что максимум достигается R360 на трех текстурах, а NV40 на двух — это говорит о более оптимальной работе последней с буфером кадра при закраске. Интересно, что по мере роста числа текстур NV38 догоняет старший чип — в случае четного числа текстур эффективность выборки NV38 близка к теоретическому пределу. Однако, мы помним, что в реальных задачах все не так просто — более слабый на выборке текстур R360 порою выигрывал у NV38 числом конвейеров и вычислительной мощью. Далее мы посмотрим как с этим обстоят дела у NV40.
А сейчас — скорость закраски буфера кадра (fillrate, pixelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
Итак, NV40 новый король горы. Пиковая скорость работы с буфером кадра (0 текстур –закраска цветом и одна текстура) вдвое выше, чем у R360 и в два с половиной раза выше, чем у NV38. Впрочем, на четном числе текстур (2 и более) этот чип реабилитирует себя. И, хотя теоретический предел 6.4 гигапикселя в секунду не достигнут, налицо возможность записывать 16 пикселей за такт. Итак, обрабатывается целых 4 квада (2х2) за один такт, т.е. 16 пикселей. Интересно, что с увеличением числа текстур скорость закраски падает быстрее, чем у предыдущего поколения — сказывается небольшая частота ядра и увеличение числа текстурных блоков вдвое, по сравнению с пикселями, число которых возросло вчетверо.
Посмотрим, как скорость закраски зависит от версии шейдеров:
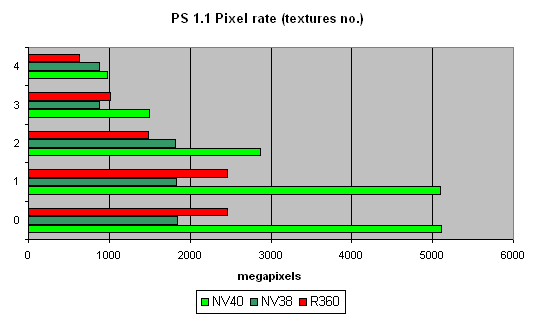
та же картина что и в случае FFP,
Посмотрите на курьез судьбы, на родном детище ATI, шейдерах 1.4 ныне NVIDIA является четким лидером. Такова селяви.
Отлично, если NV38 в силу своих архитектурных тонкостей досадно замедлялся в этом тесте на пиксельных шейдерах 2.0 (дополнительные такты уходили на некоторые команды шейдеров 2.0 реализованные в NV38 как макросы) что делало более выгодным использование на NV38 шейдеров 1.4, чем 2.0 (вот парадокс — на R360 все наоборот, 2.0 производительнее 1.4). Теперь справедливость восстановлена, а просчеты исправлены — NV40 показывает себя ровно во всех версиях шейдеров. Отметим, что старичок R360 не так уж и плохо смотрится на фоне NV40.
Сводный график NV38 и NV40 для некоторого числа текстур, как доказательство успешной работы над ошибками:
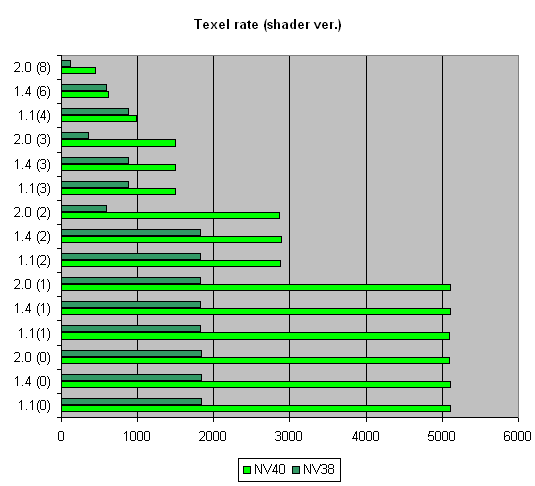
Итак, вырисовывается следующая картина предпочтений:
Версия | 1.1 | 1.4 | 2.0 |
NV40 | Оптимально | Оптимально | Оптимально |
NV38 | Оптимально | Оптимально | Не оптимально |
R360 | Оптимально | Не оптимально | Оптимально |
А теперь посмотрим, как текстурные модули справляются с кэшированием и билинейной фильтрацией реальных текстур различных размеров:
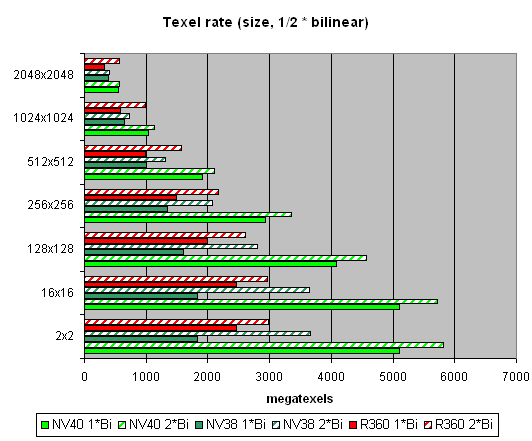
Приведены данные для разных размеров текстур, одна и две текстуры на пиксель. На размерах вплоть до 512х512 преимущество 16 текстурных модулей NV40 налицо. Результаты близки к теоретическому пределу. А далее, по мере роста размера текстур, все упирается в пропускную полосу памяти. Эффективность кэширования достойна похвал — на самом ходовом размере 128х128 мы достигаем более чем четырех гигатекселей. Посмотрим, как изменится картина в случае трилинейной фильтрации:
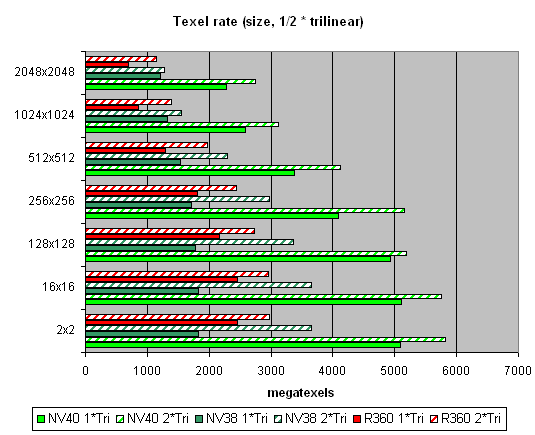
Вот это да! Здесь преимущество NV40 еще более заметно. Все правильно — больше текстурных блоков — больше результатов трилинейной фильтрации, кроме того, наличие мип уровней позволяет эффективно кэшировать данные текстур. А двукратное преимущество однозначно показывает, что в этом аспекте NV40 пока нет равных.
Напоследок предельный случай восьми трилинейно фильтруемых текстур:
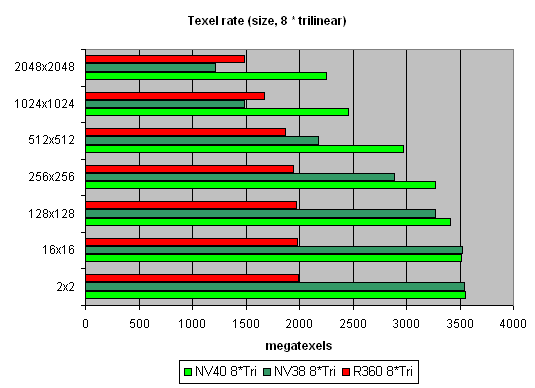
Лишний раз показывает нам, что реализация выборки текстур — сильная сторона NVIDIA.
А теперь посмотрим на зависимость производительности текстурных модулей от формата текстур:
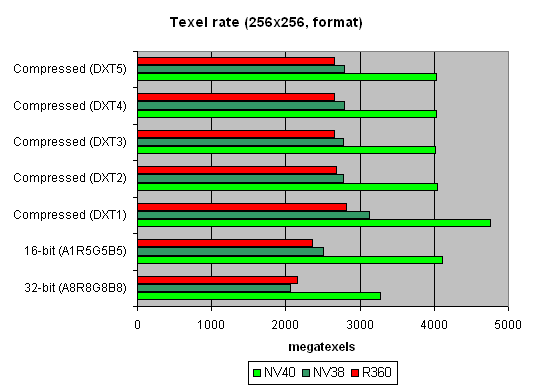
Больше размер:
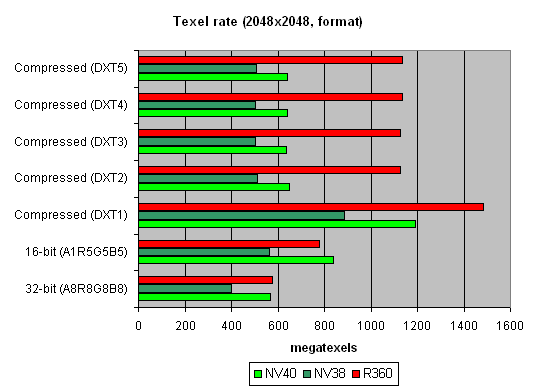
Интересная картина. Почему R360 так выигрывает, даже у NV40 в случае больших размеров сжатых текстур? Ответ прост — в текстурном кэше NVIDIA хранятся уже распакованные текстуры, приведенные к формату 32 бита. В текстурном кэше ATI — все еще сжатые. С одной стороны эффективность выборки текстур NVIDIA будет выше — меньше простоев во время распаковки, меньше задержка, с другой стороны при большом размере текстур фактор занимаемого ими места может вывести ATI в лидеры — NV40 упрется в пропускную полосу памяти и даже 16 TMU его не спасут. Что собственно и происходит на втором графике. В реальных приложениях баланс может склониться как в ту, так и в иную сторону, в зависимости от шейдеров, числа и размера текстур и прочих параметров сцены.
Итак, в общем и целом, можно констатировать два факта:
- NV40 чемпион по закраске и выборке текстур, 16 пикселей за такт, 16 TMU, да и легендарная эффективность работы TMU и буфера кадра от NVIDIA по прежнему в силе.
- Досадные неравномерности поведения предыдущего поколения NVIDIA на пиксельных шейдерах 2.0 устранены.
Тест Geometry Processing Speed
Самый простой шейдер — предельная пропускная способность по треугольникам:
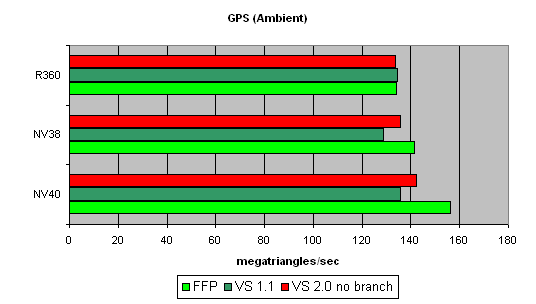
Почему результаты NV40 почти не превышают предыдущего поколения? Вопрос сложный. Судя по всему вершинные процессоры чипа просто не разворачиваются в полную силу на столь примитивной задаче. Проверим наше предположение далее, на более сложных задачах. А пока отметим, что характер зависимости скорости NV40 от версии шейдера очень точно повторяет NV38 — как мы уже предполагали, может оказаться, что в вершинных процессорах этих чипов много общего.
Более сложный шейдер — один простой точечный источник света:
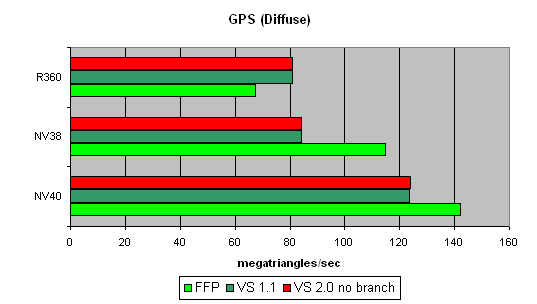
Вот здесь преимущество NV40 уже начинает проявляться. Все верно, слишком короткий шейдер просто упирался в скорость работы буферов и механизма выборки вершин, а здесь у вершинного процессора NV40 появилась возможность поработать в плане вычислений и результат не замедлил сказаться. Интересно, что по-прежнему FFP является лучшим вариантом для NVIDIA и худшим для ATI — сказываются дополнительные аппаратные блоки для ускорения расчета освещения в рамках стандартных требований FFP.
Усложняем задачу далее:

Здесь FFP лидер даже в случае ATI — алгоритм FFP несколько проще того, что был использован в вершинном шейдере. Здесь NV40 явный лидер.
А теперь самая сложная задача, три источника света, причем, для сравнения в вариантах без переходов, со статическим и динамическим управлением исполнением:

Статические переходы заметно ударяют по чипам NVIDIA . Причем, характер падения одинаковый как в NV38, так и в NV40 — можно предположить, что их вершинные процессоры устроены в этом плане одинаково. Парадокс в том, что динамические переходы на чипах от NVIDIA выгоднее статических. В случае ATI все достаточно ровно.
Итак :
- FFP значительно быстрее на чипах NVIDIA, зачастую вдвое.
- Характер зависимости от типа шейдера одинаковые для NV38 и NV40 — видимо архитектура вершинных процессоров очень близка.
- Статические переходы на ускорителях NVIDIA исполняются не оптимально.
Тест Pixel Shaders
Первая группа шейдеров — достаточно простых для исполнения в реальном времени, 1.1, 1.4 и 2.0:
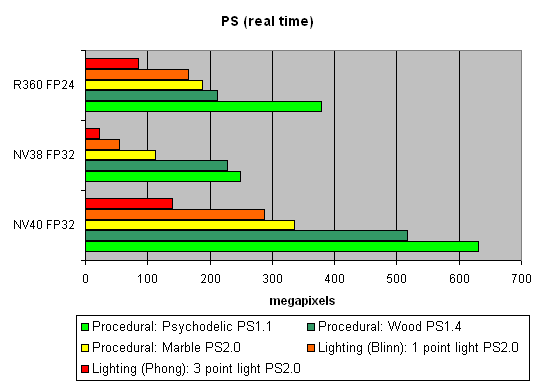
Что еще сказать — свершилось. Четкое преимущество NV40 и соответственно работа над ошибками NV38 налицо. Новая топология пиксельного процессора, новые ALU и текстурный модуль прекрасно справляются с различными версиями шейдеров.
Посмотрим, каков прирост при использовании 16 битной точности плавающих чисел:
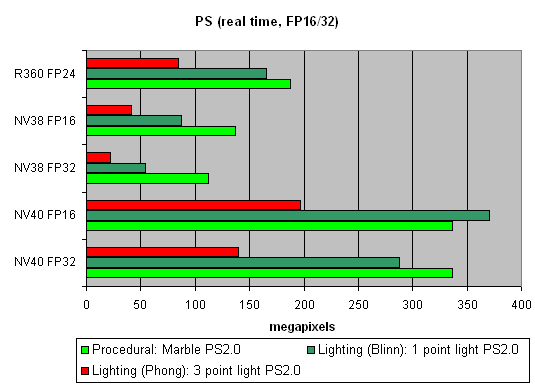
Преимущество 16 битной точности для NV40 есть, в некоторых шейдерах больше, в некоторых меньше. И, что самое интересное, порой более заметное чем в случае NV38. Впрочем, здесь может играть роль компилятор — со временем, по мере его оптимизации, будет уменьшаеться число задействованных временных переменных и проходов карусели пиксельного процессора и, как следствие, разница может уменьшиться — FP32 подтянется к результатам FP16.
А теперь посмотрим на действительно сложные, « кинематографичные» шейдеры:
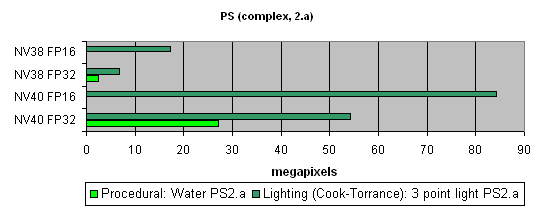
Здесь NV40 демонстрирует просто феноменальную производительность в несколько раз превышающую результаты предыдущего поколения. Есть где развернуться — десятки зависимых выборок текстур, множество временных переменных, сложный код. Вот почем разница 16 и 32 бит столь заметна.
На последок, исследуем зависимость скорости от использования арифметических или табличных методов вычисления sin, pow и нормализации векторов, отдельно для всех чипов:
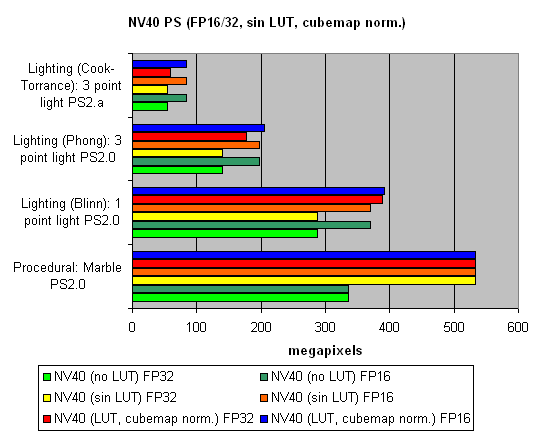
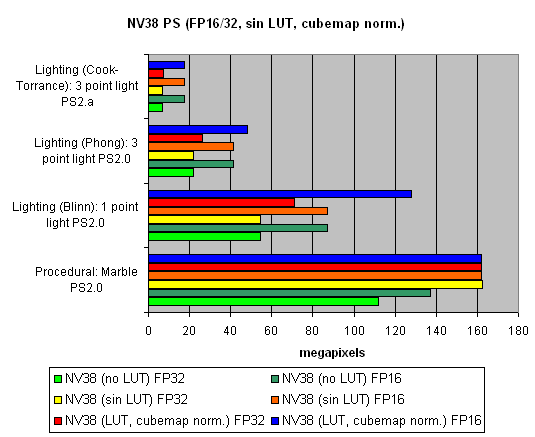
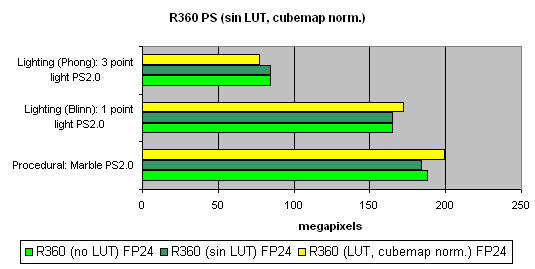
Общая мораль такова :
- Лучше 16 бит, чем 32
- Лучше таблицы, чем арифметические вычисления для NVIDIA (эффективная выборка текстур)
- Лучше вычисления, чем таблицы для ATI (выборка текстур менее эффективна)
Итого, по пиксельным шейдерам :
- Производительность вне конкуренции, с печальным прошлым предыдущего поколения покончено.
- Наличие возможности динамического управления вычислениями не сказалось на производительности обычных шейдеров в худшую сторону.
- Исправлены слабые места, связанные с временными переменными, но все еще можно ждать прироста от компилятора в новых версиях драйверов — он пока не столь эффективен, как у NV38
Тест HSR
Для начала пиковая эффективность (без текстур и с текстурами) в зависимости от сложности геометрии: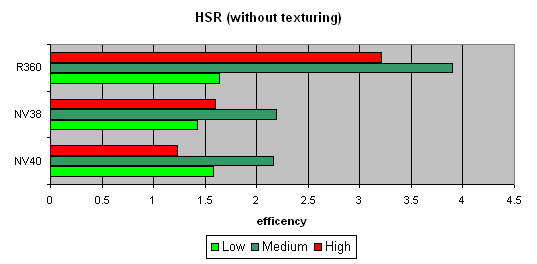
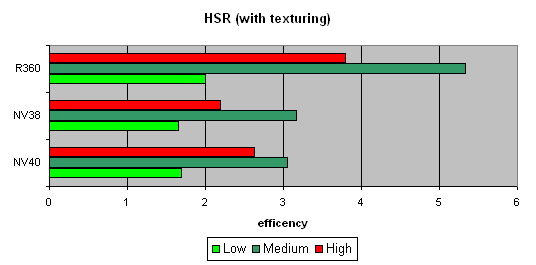
Заметно, что ATI лучше переносит средние и сложные сцены — сказывается наличие двух уровней уменьшенных Z буферов (кроме базового). У NVIDIA традиционно один дополнительный уровень, поэтому эффективность HSR в случае оптимального баланса сцены (средняя сложность) несколько ниже. Кроме того, более эффективная закраска и текстурирование также снижает пиковую эффективность HSR (точнее уменьшается штраф за не отброшенные зоны).
Характер зависимости показывает, что алгоритм со времен NV38 не изменился. Зато абсолютные цифры существенно возросли:
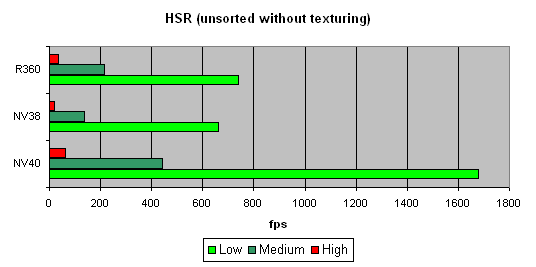
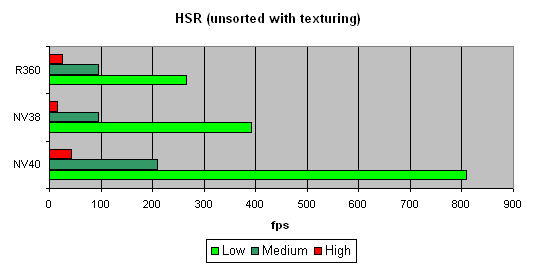
Видно, что NV40 вне конкуренции, как минимум вдвое опережая других участников.
Вывод :
- Алгоритм HSR не претерпел серьезных изменений
- Но его общая производительность увеличилась, что нормально, учитывая большее число отправляемых на отрисовку (или отбрасываемых) за такт квадов.
Тест Point Sprites.
Я думаю, читателям не составит труда самим сделать выводы. Спрайты давно перестали быть популярным новшеством и зачастую проигрывают треугольникам по скорости вывода.
Качество трилинейной фильтрации и анизотропии
Трилинейная фильтрация (Угол 0) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
High Quality | ||
- |  |  |
Quality | ||
 |  |  |
Performance | ||
 |  | 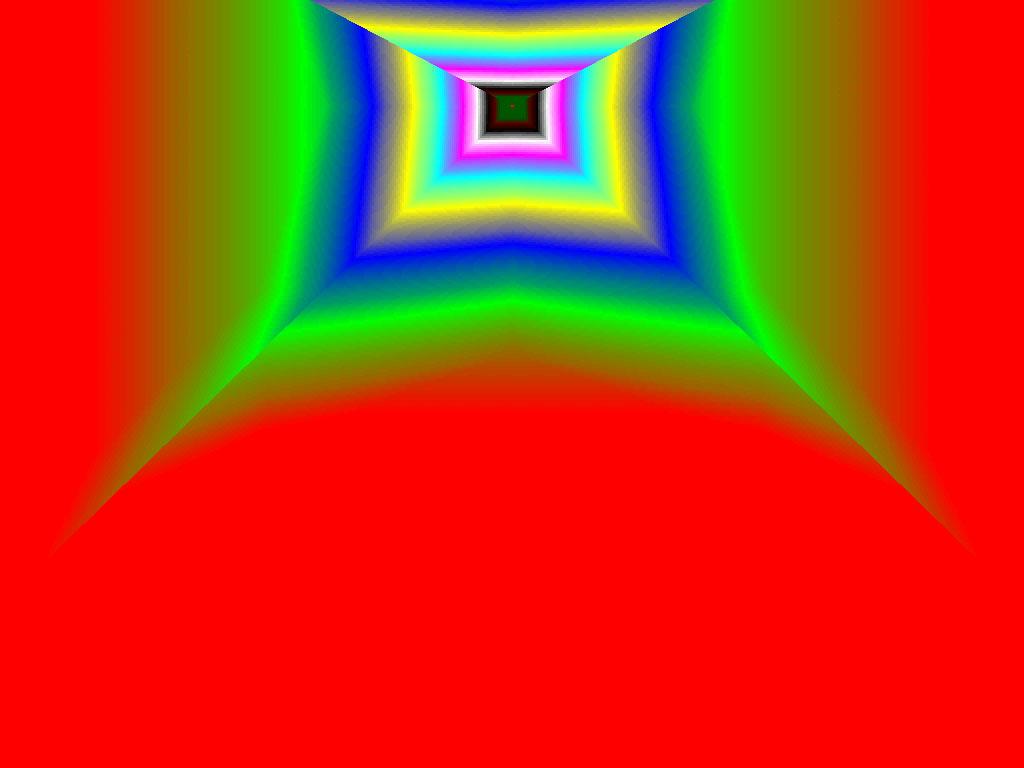 |
High Performance | ||
 |  |  |
Трилинейная фильтрация (Угол 30) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
High Quality | ||
- | 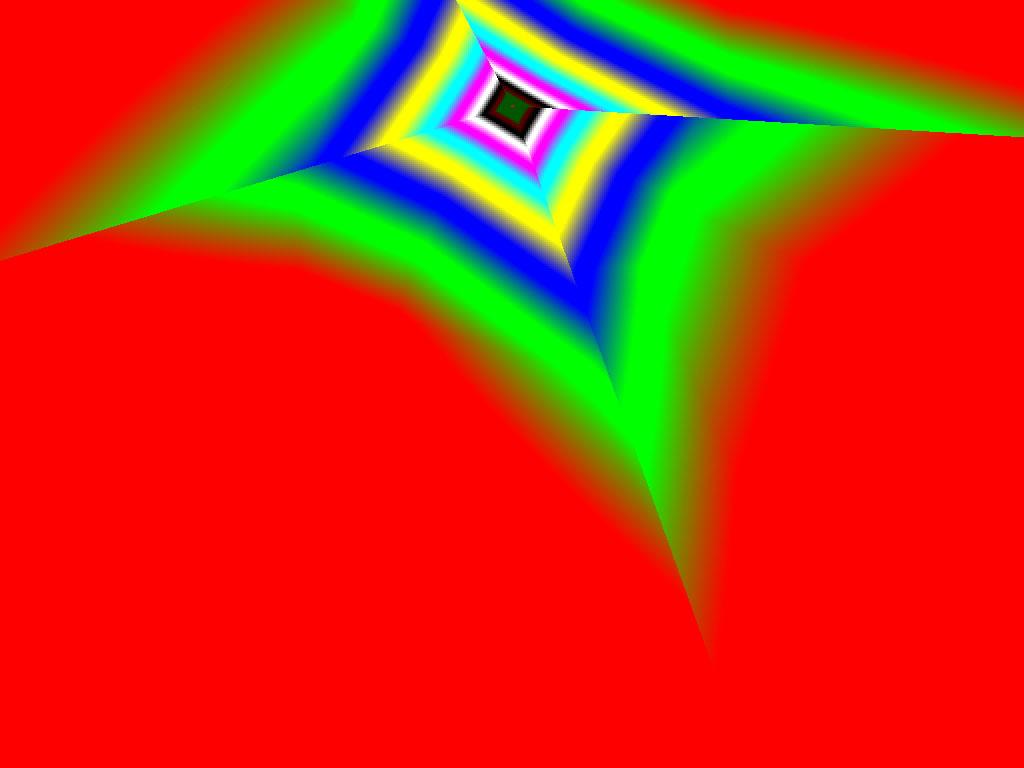 | 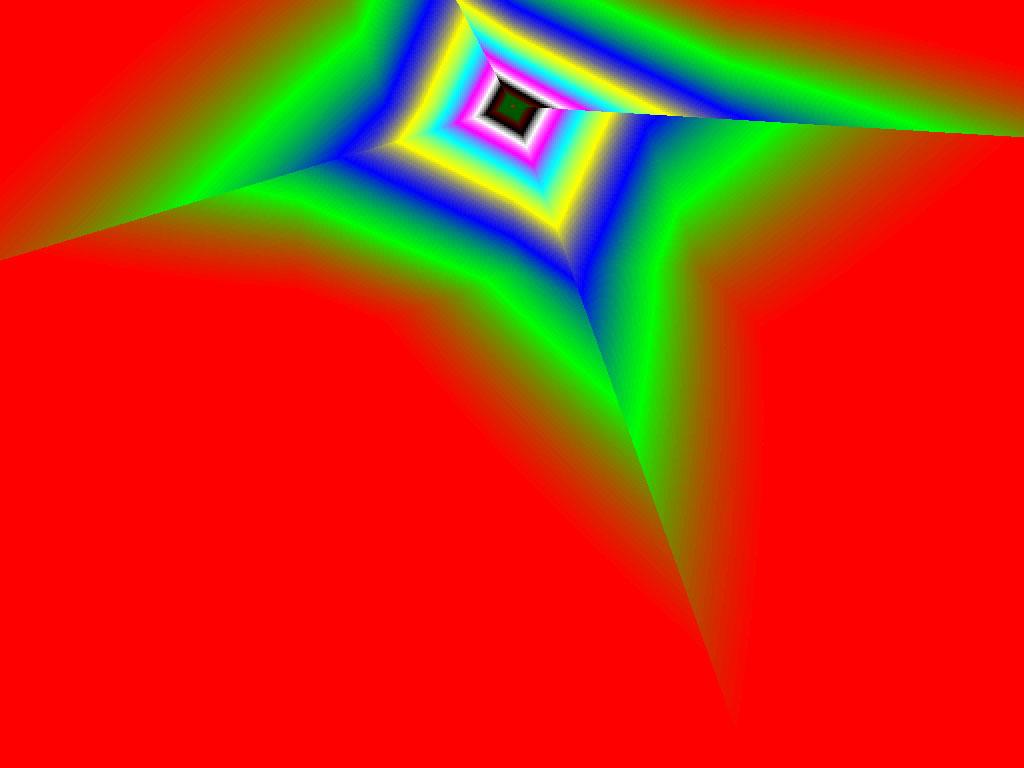 |
Quality | ||
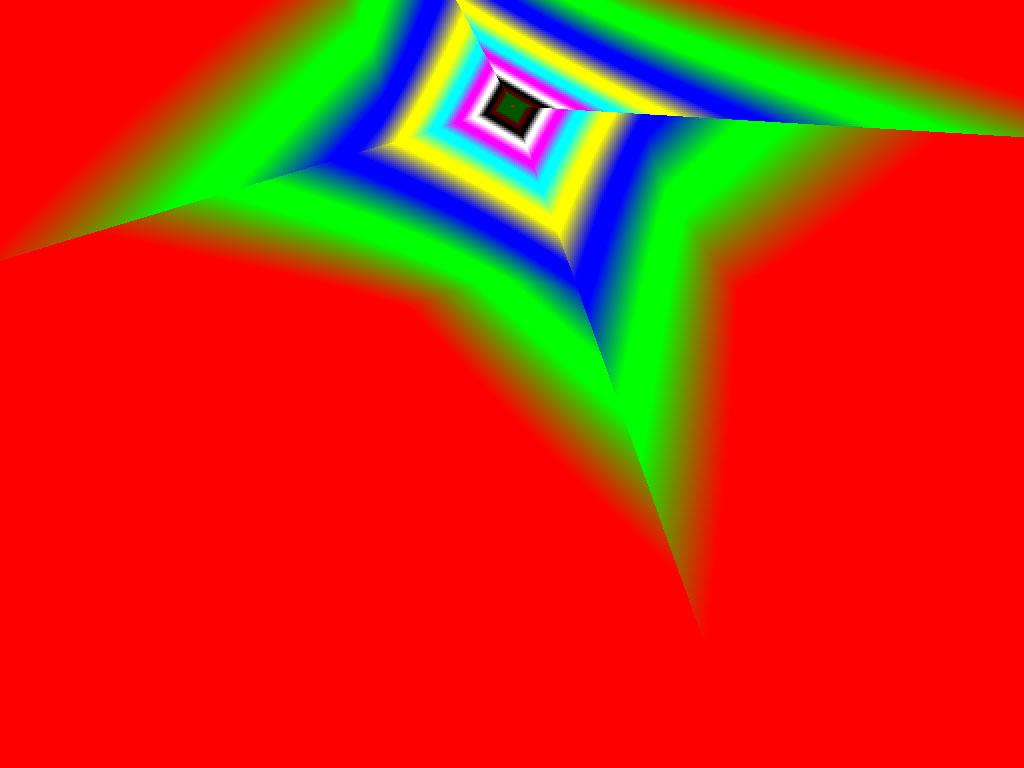 | 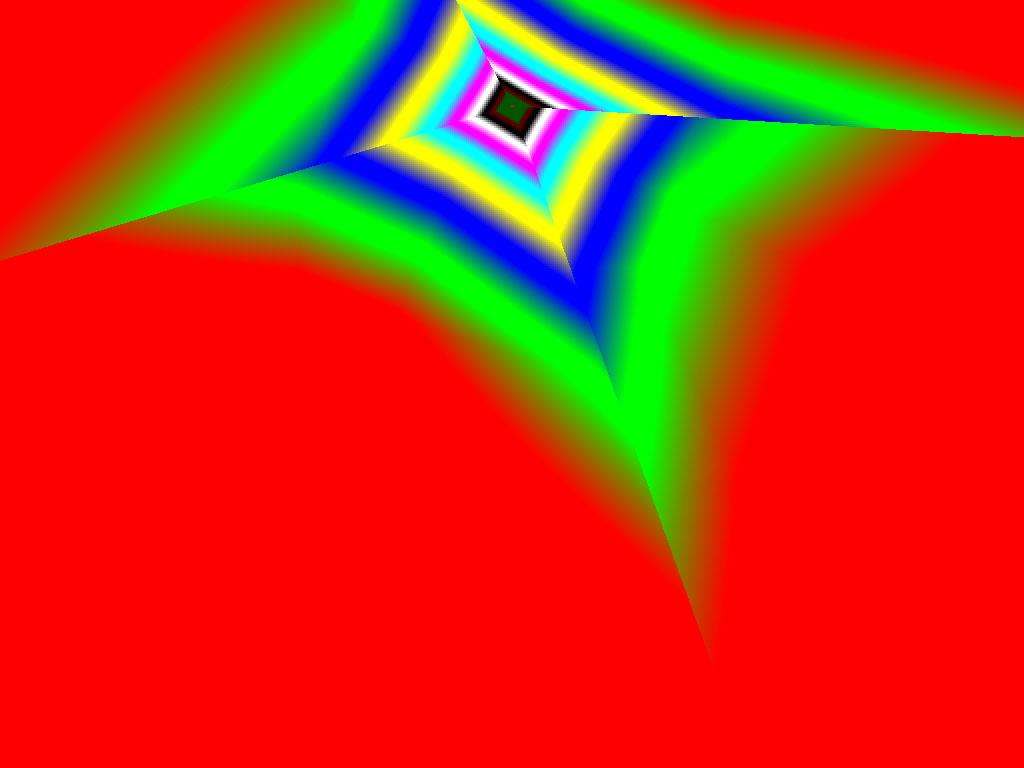 | 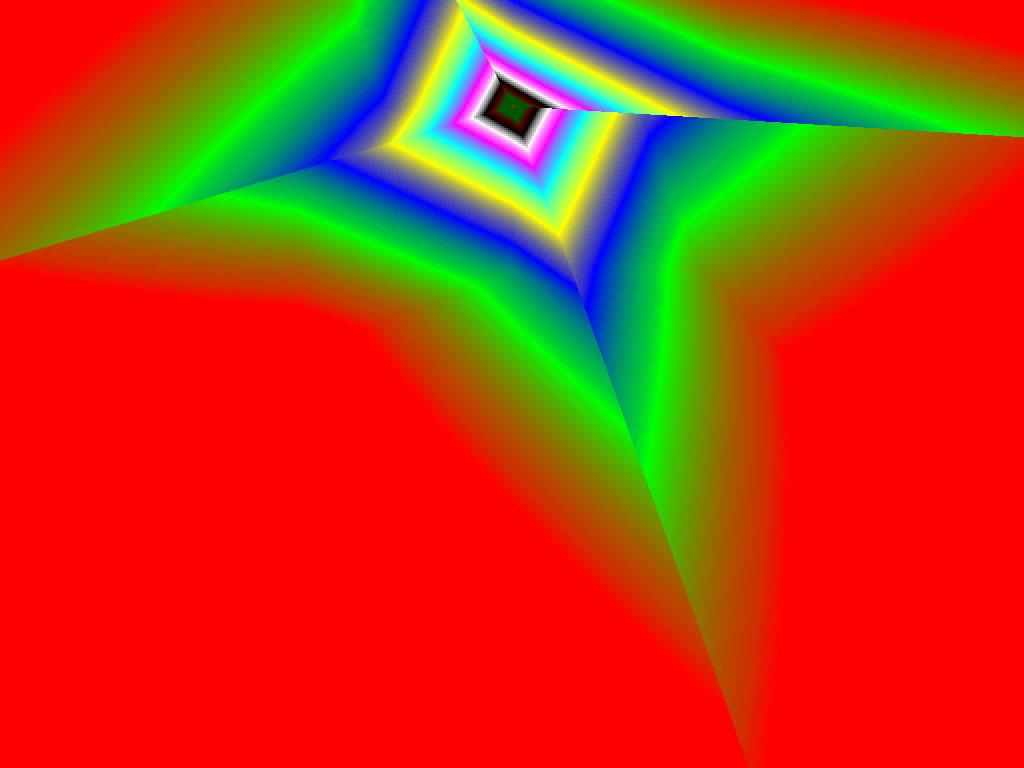 |
Performance | ||
 | 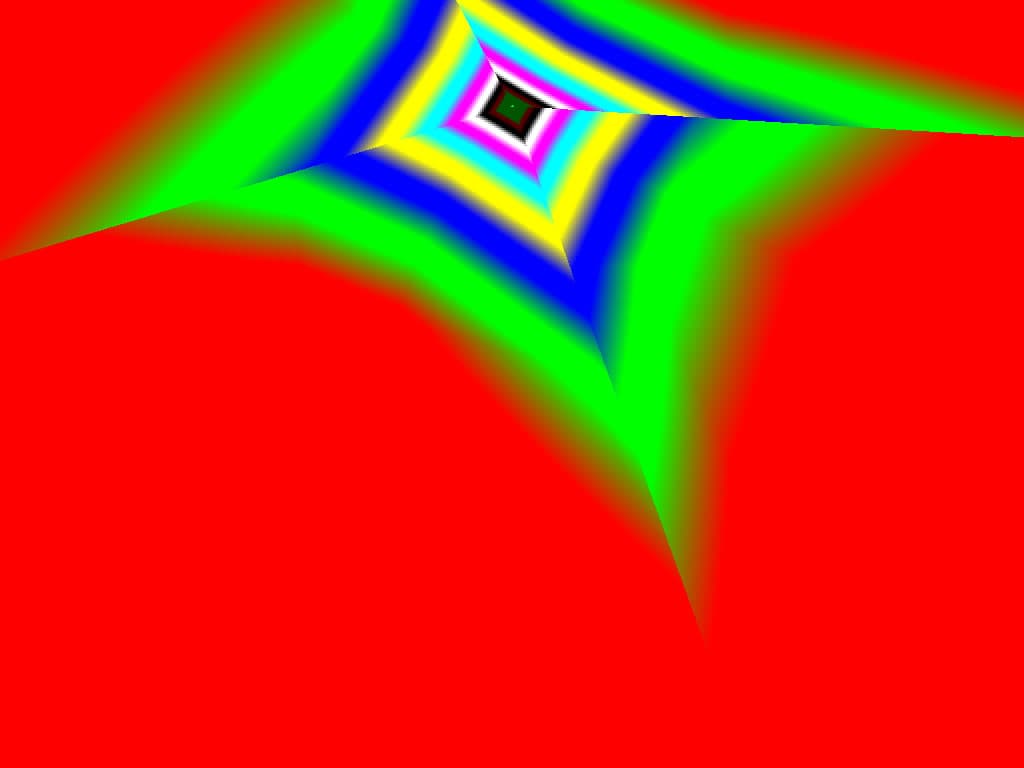 | 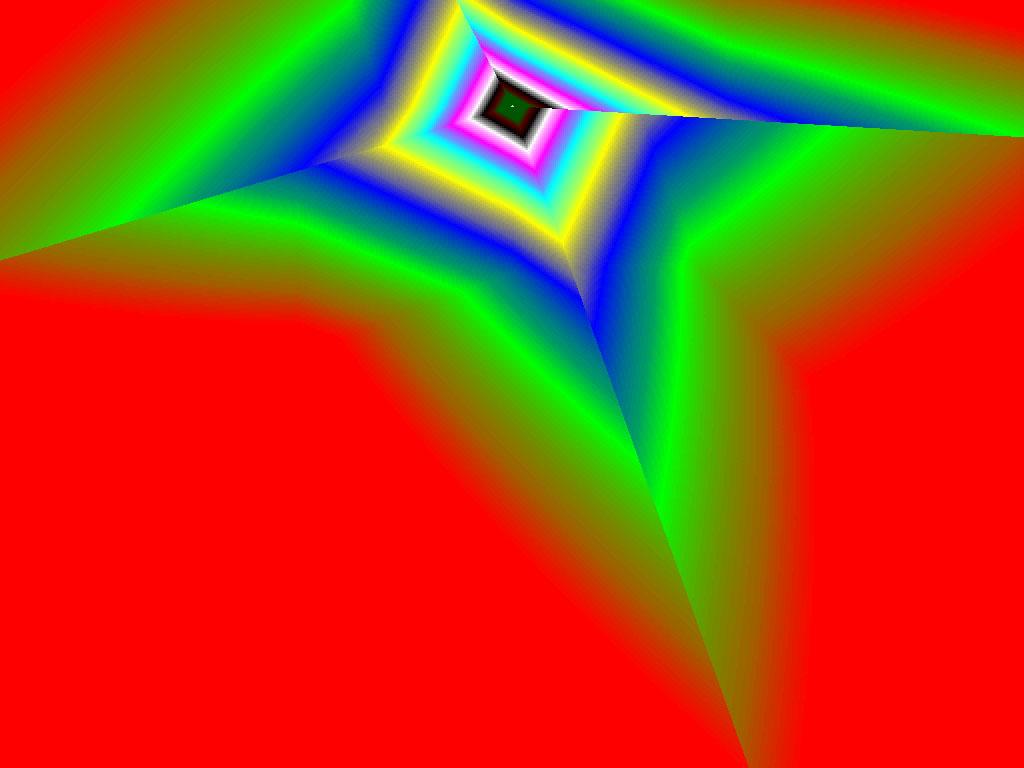 |
High Performance | ||
 |  | 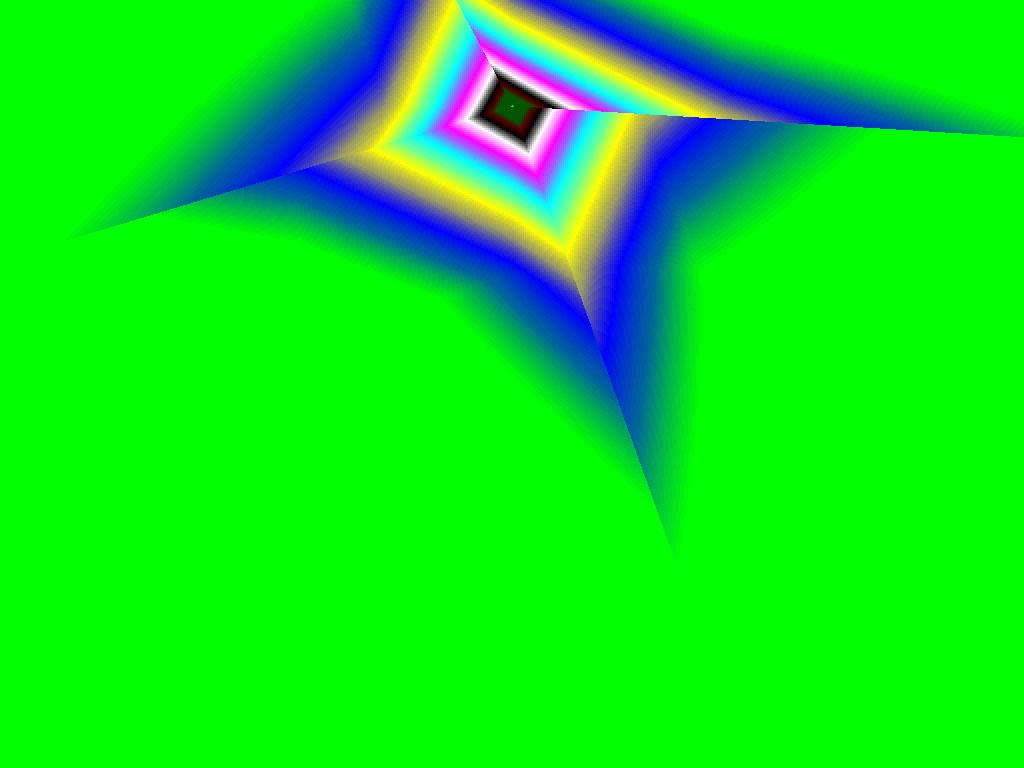 |
Трилинейная фильтрация (Угол 45) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
High Quality | ||
- | 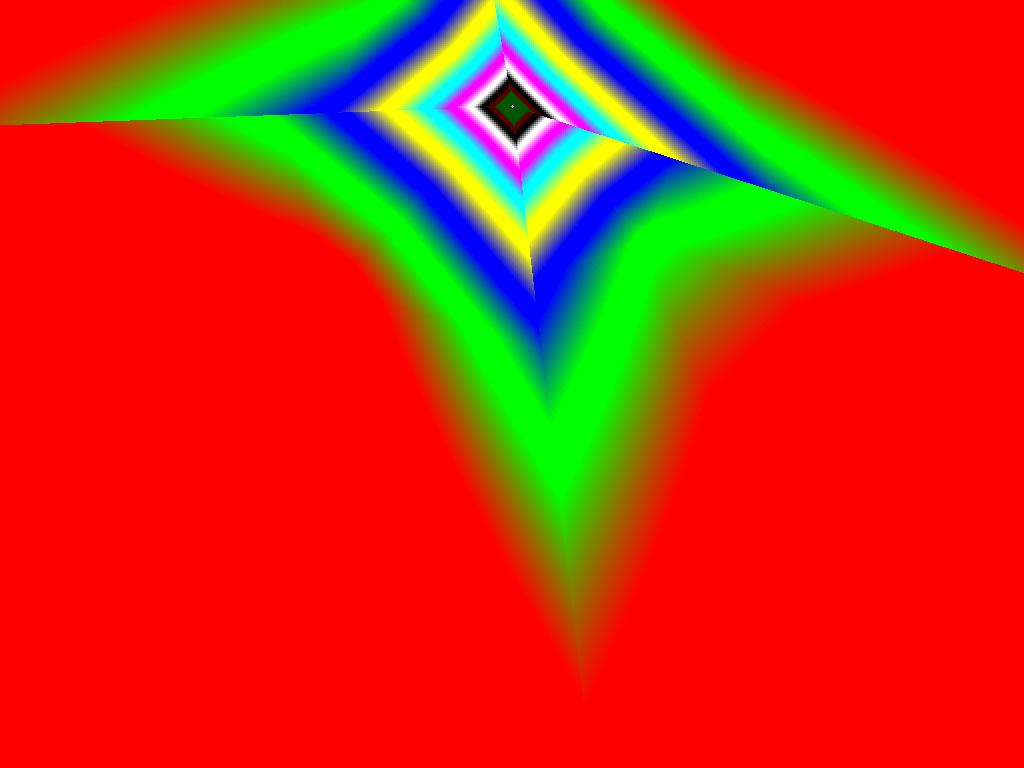 | 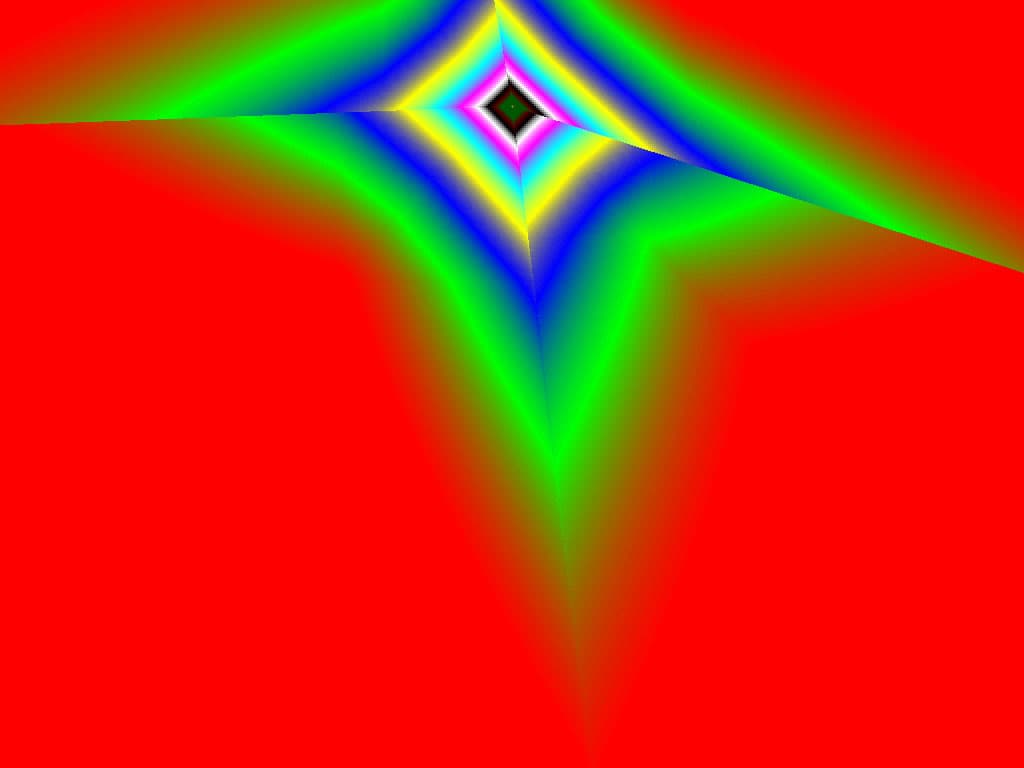 |
Quality | ||
 | 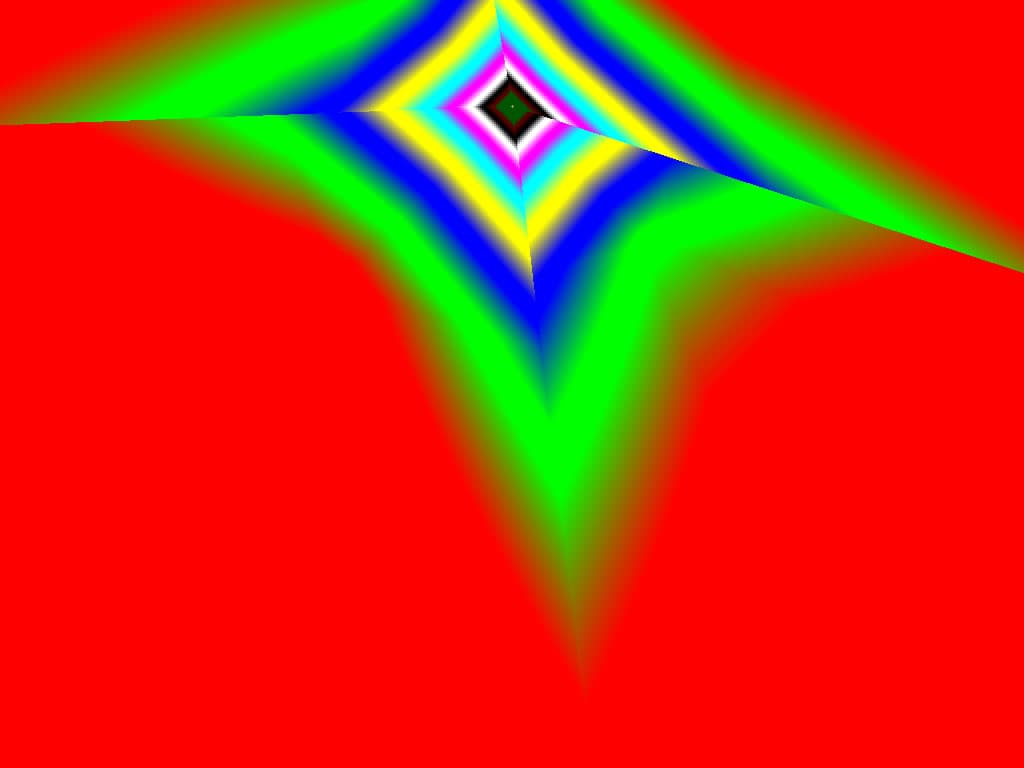 |  |
Performance | ||
 |  |  |
High Performance | ||
 |  |  |
Трилинейная фильтрация (Угол 60) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
High Quality | ||
- |  | 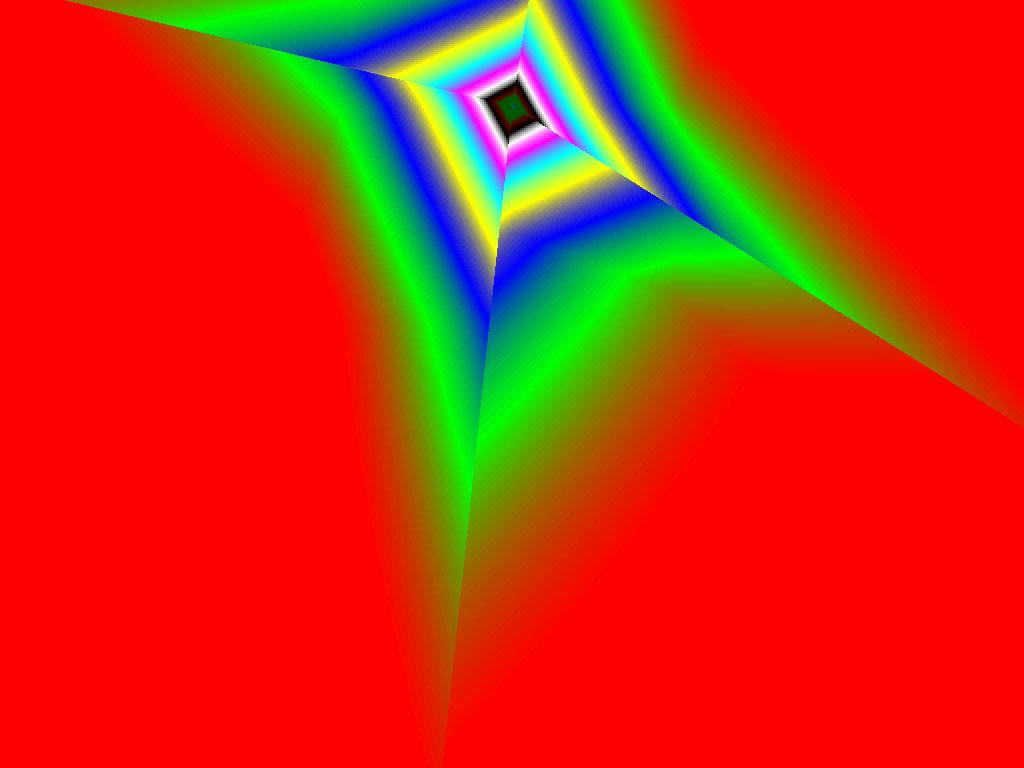 |
Quality | ||
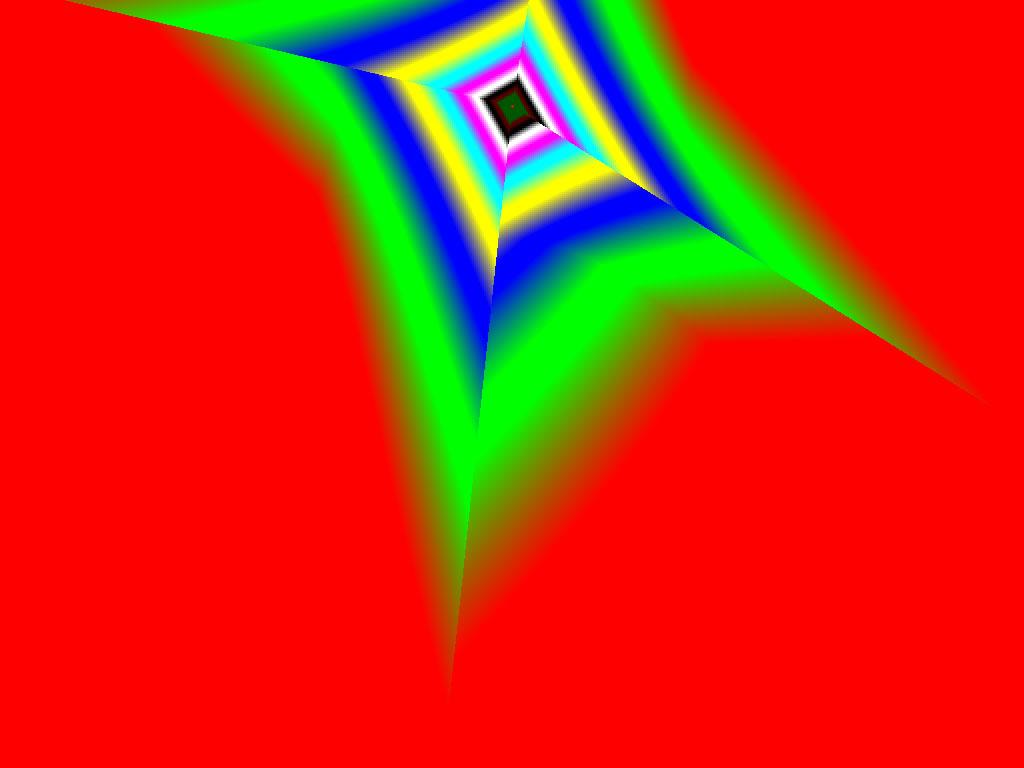 | 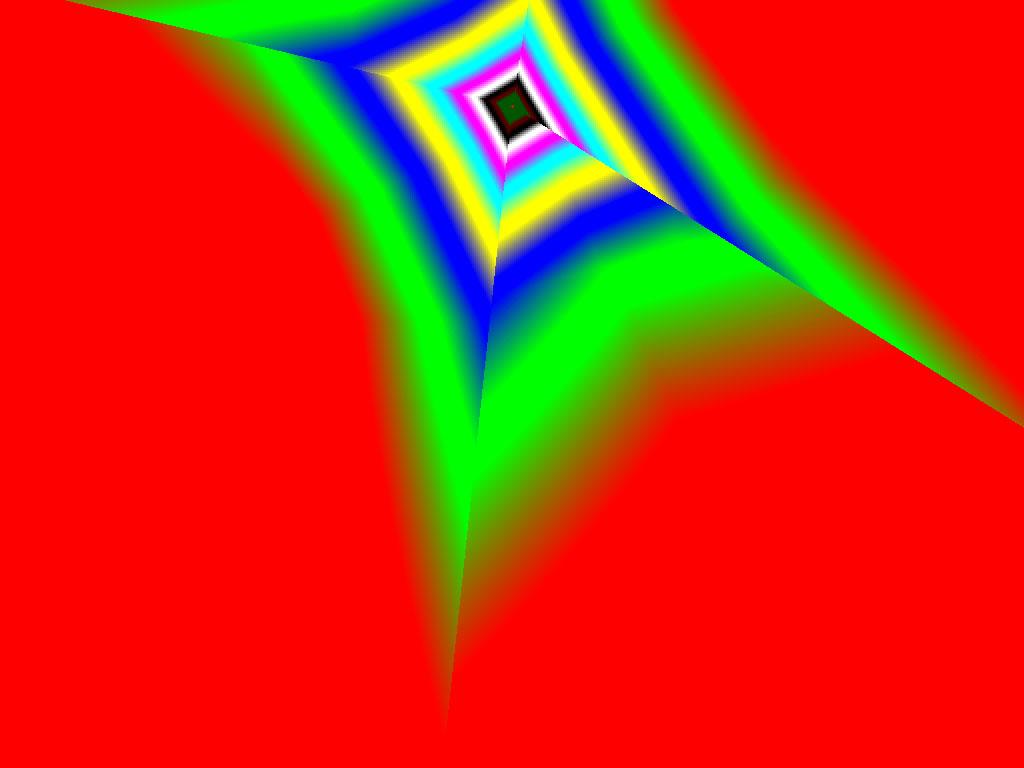 | 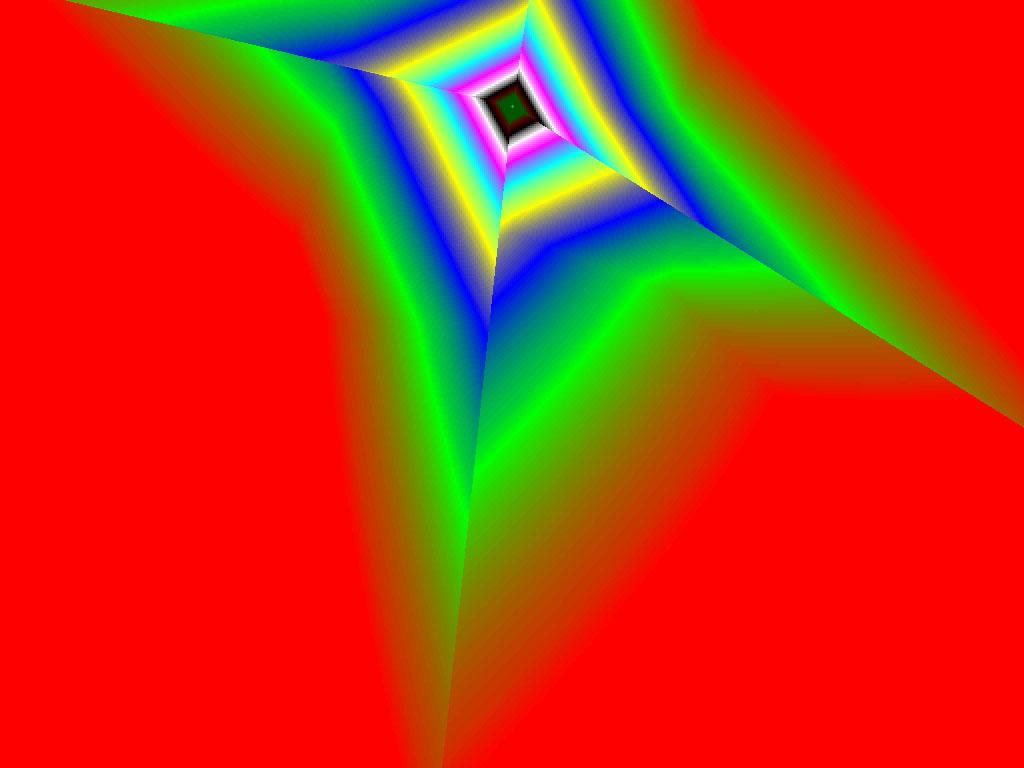 |
Performance | ||
 | 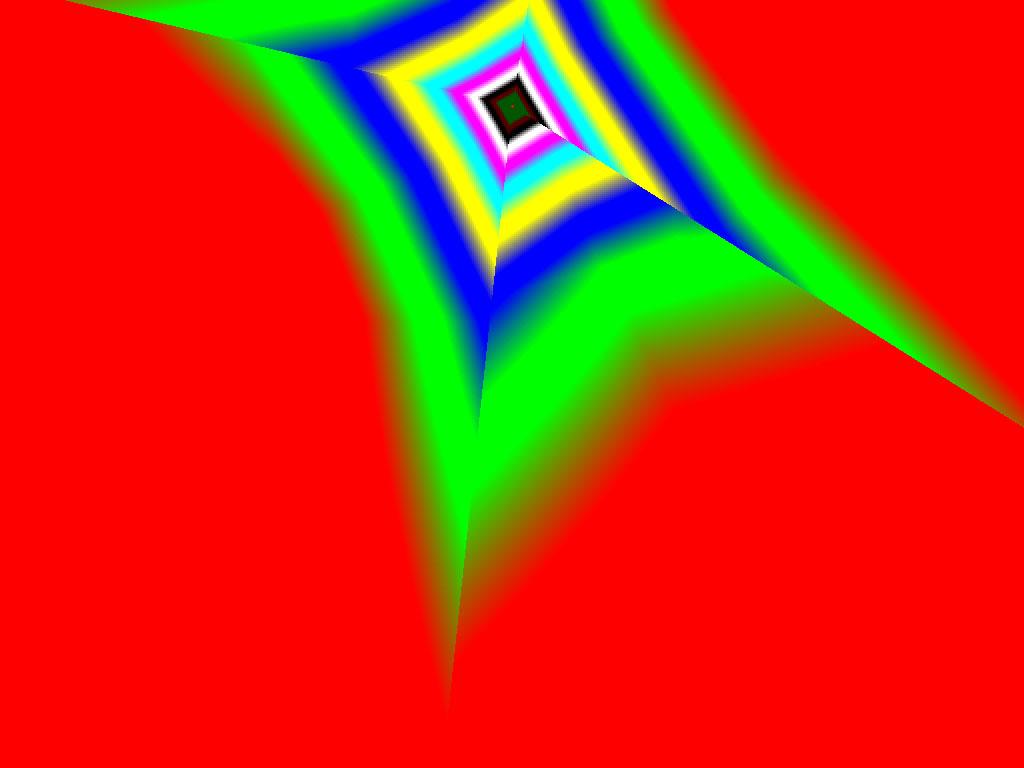 | 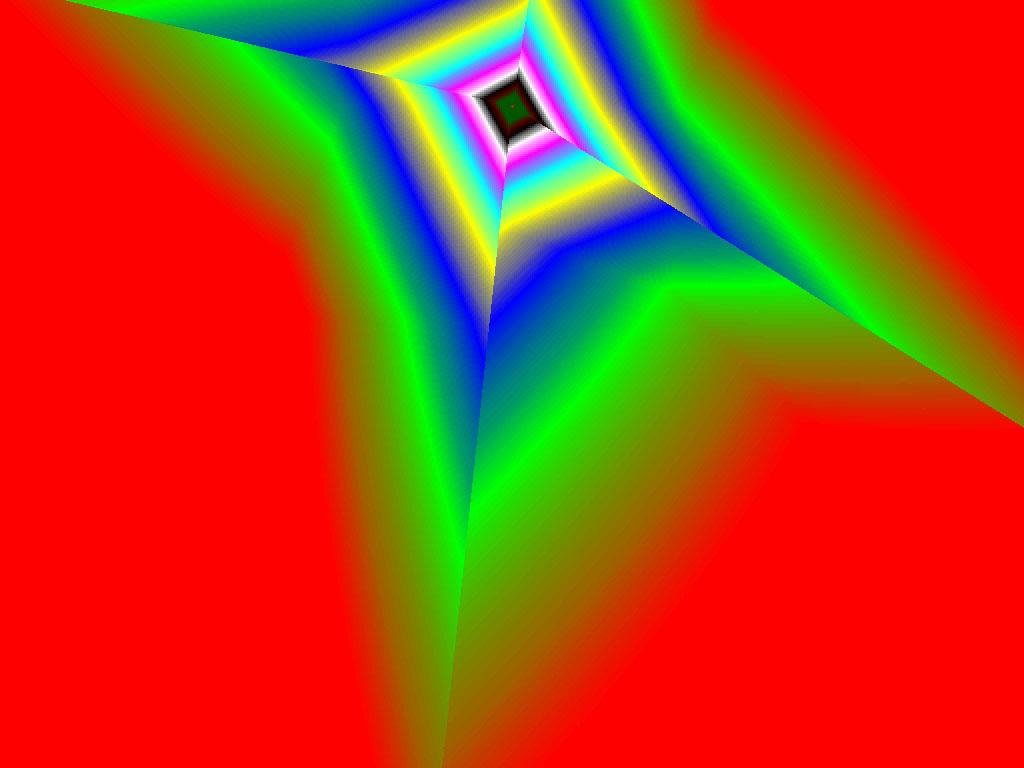 |
High Performance | ||
 |  | 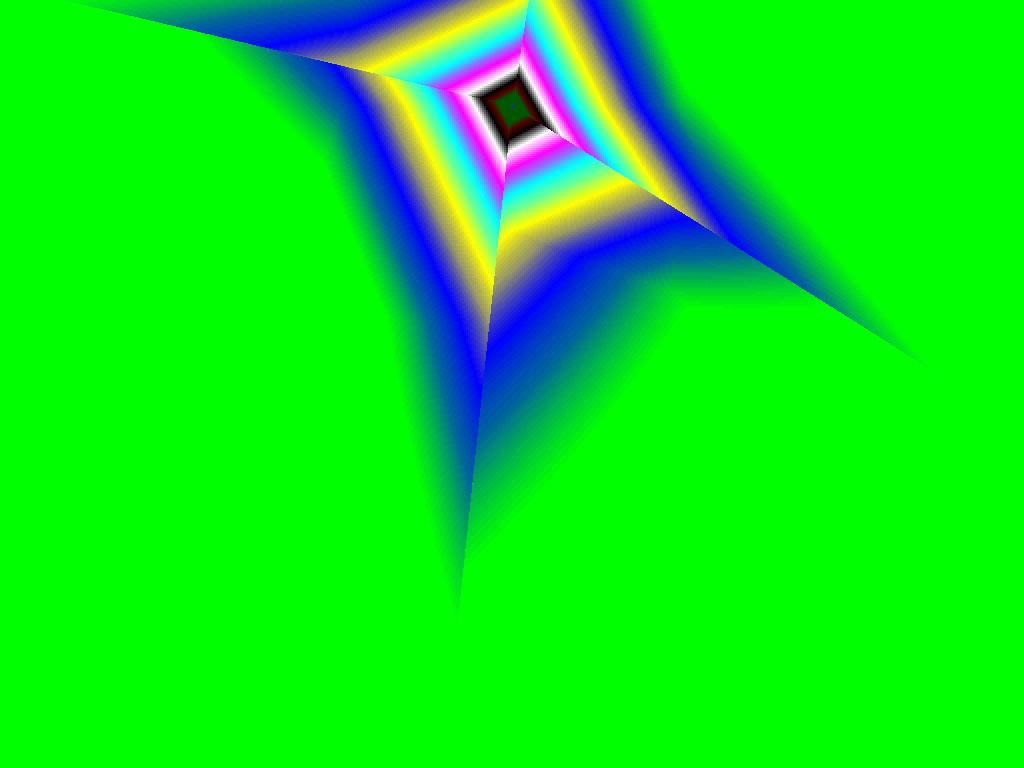 |
Трилинейная фильтрация (Угол 90) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
High Quality | ||
- | 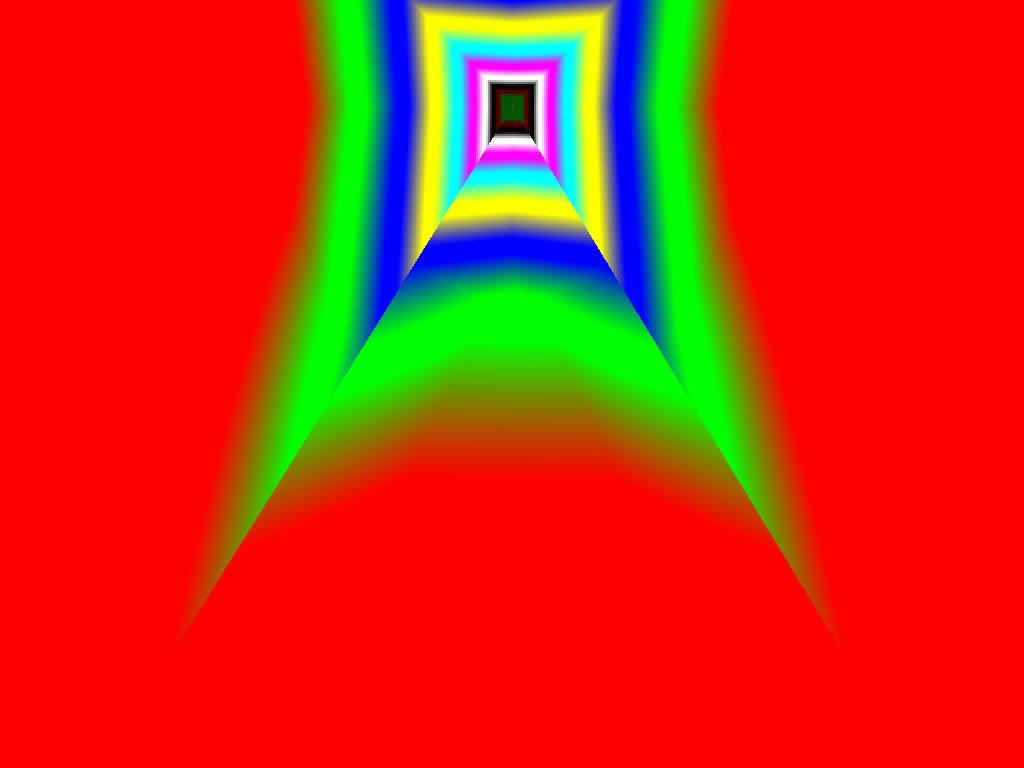 | 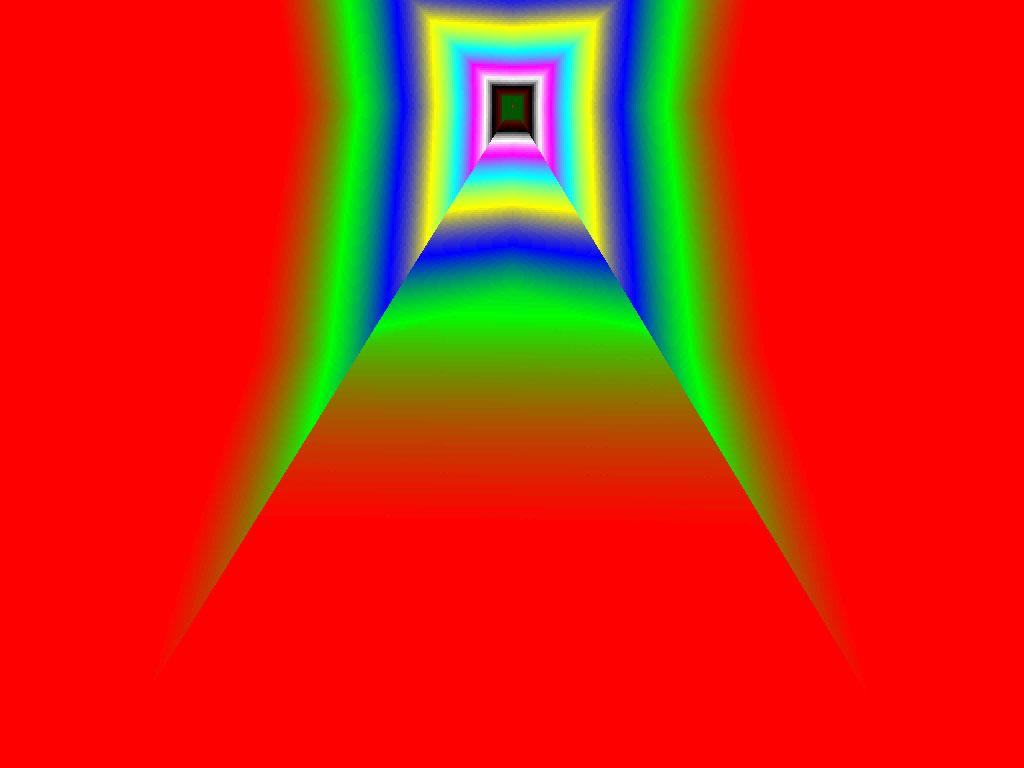 |
Quality | ||
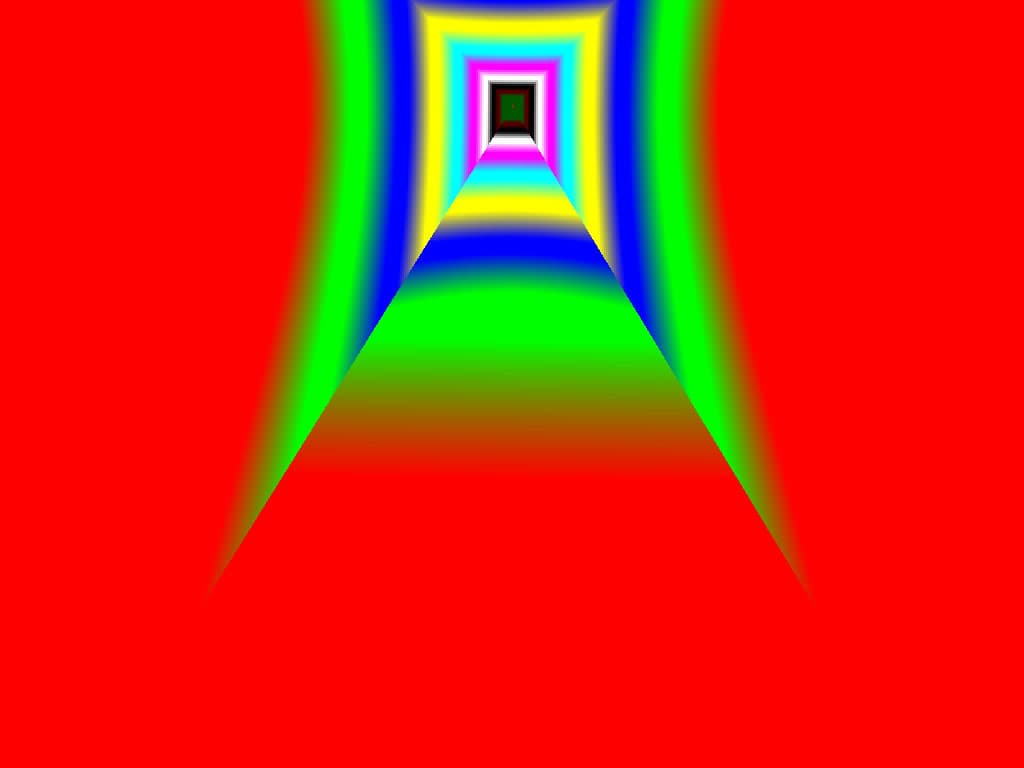 | 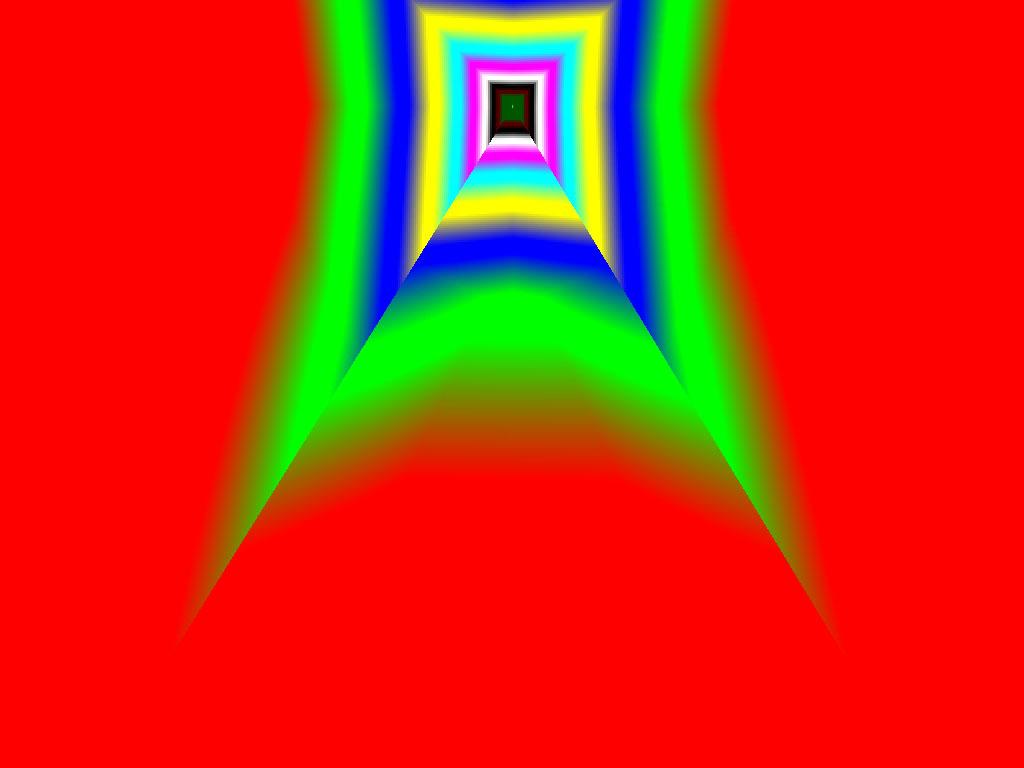 | 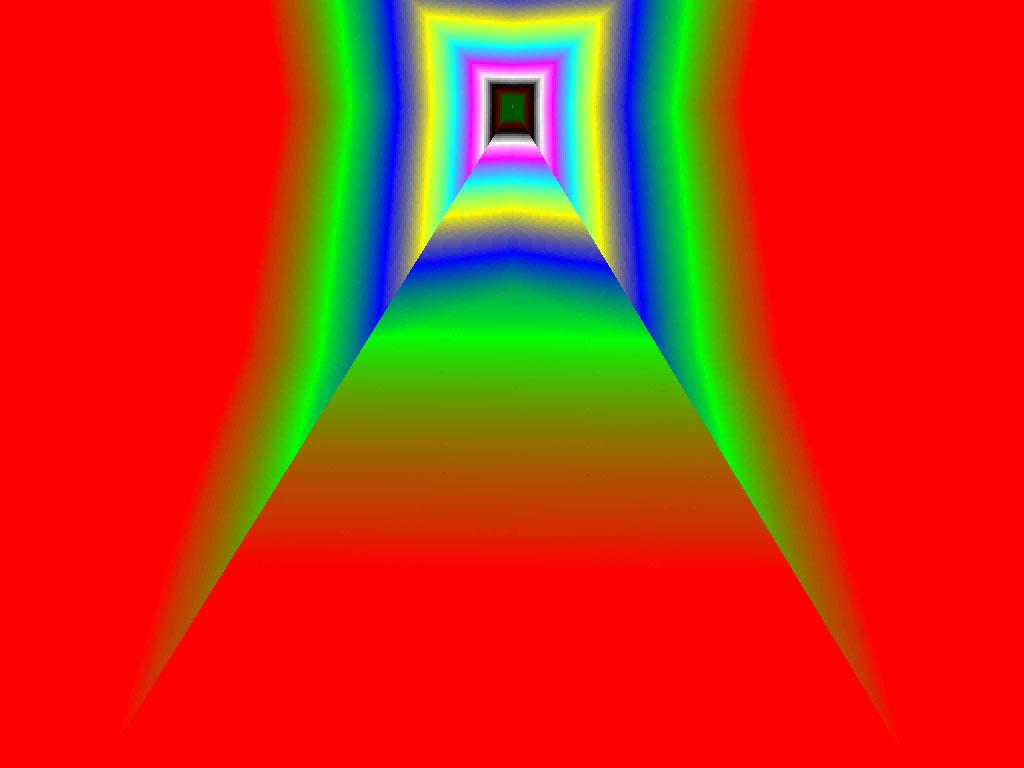 |
Performance | ||
 |  | 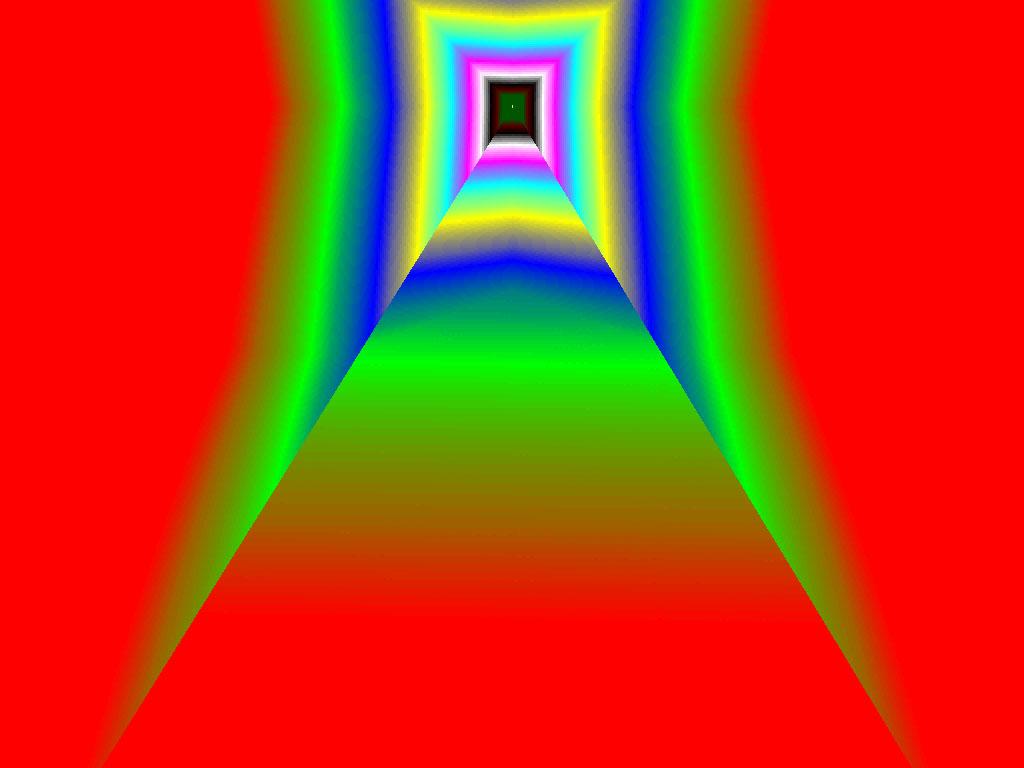 |
High Performance | ||
 |  | 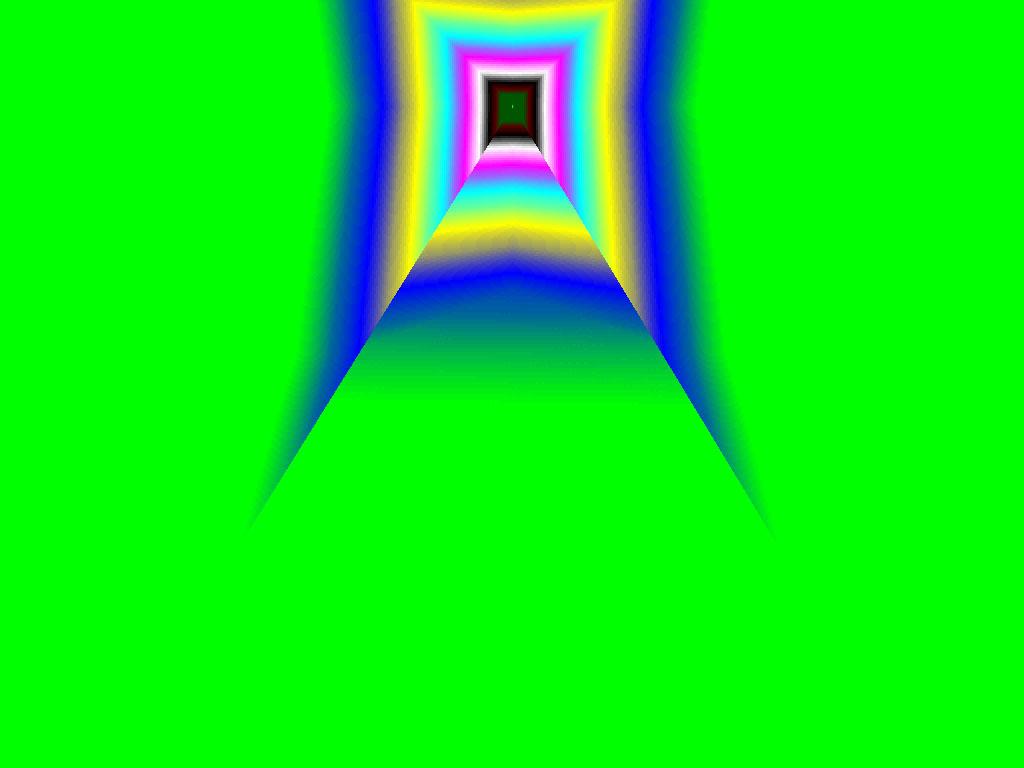 |
Анизотропная фильтрация (Угол 0) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
Anisotropic 0x | ||
 |  |  |
Anisotropic 8x | ||
 | 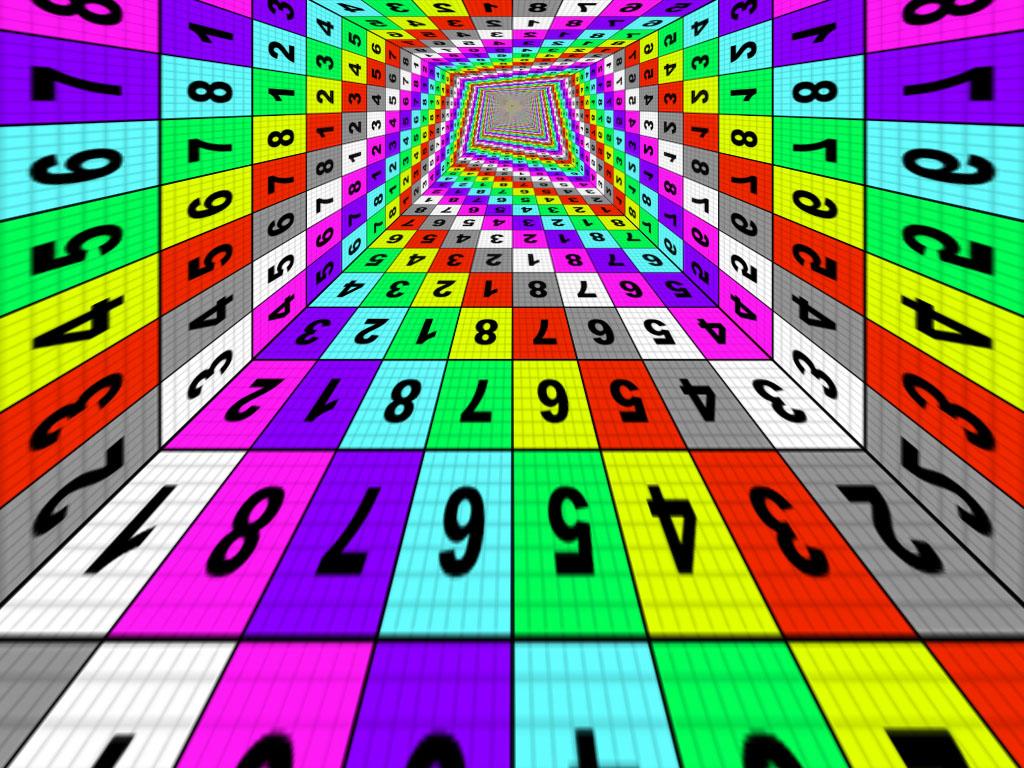 |  |
Anisotropic 16x | ||
- | 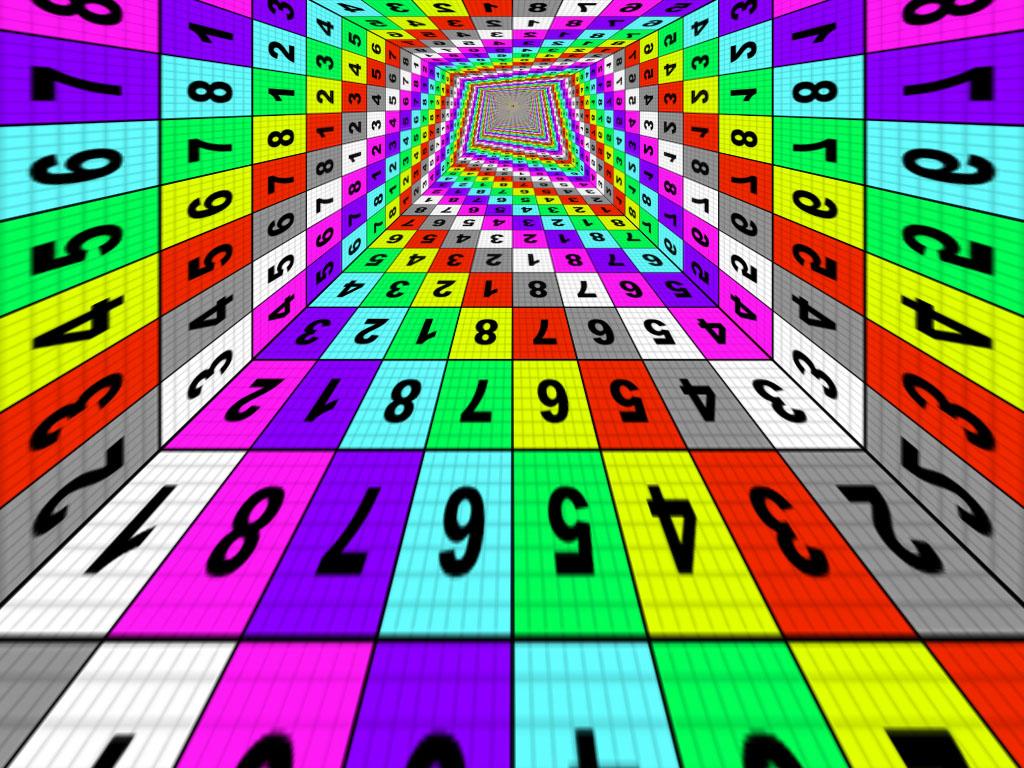 |  |
Анизотропная фильтрация (Угол 30) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
Anisotropic 0x | ||
 |  |  |
Anisotropic 8x | ||
 |  |  |
Anisotropic 16x | ||
- |  |  |
Анизотропная фильтрация (Угол 45) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
Anisotropic 0x | ||
 |  |  |
Anisotropic 8x | ||
 |  |  |
Anisotropic 16x | ||
- |  |  |
Анизотропная фильтрация (Угол 60) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
Anisotropic 0x | ||
 |  |  |
Anisotropic 8x | ||
 |  |  |
Anisotropic 16x | ||
- |  |  |
Анизотропная фильтрация (Угол 90) | ||
GeForce FX 5950 Ultra | GeForce 6800 Ultra | RADEON 9800XT |
Anisotropic 0x | ||
 |  |  |
Anisotropic 8x | ||
 |  |  |
Anisotropic 16x | ||
- |  |  |
Итак, алгоритм выбора мип-уровней изменился по отношению к NV38. Кусочно-линейная аппроксимация выполняется теперь с большим числом сегментов, что можно назвать положительным моментом, однако в случае плоскостей под углами 0 и 90 градусов (пол и стены) NV38 использовал другое, более точное (видимо квадратичное) приближение, нежели для остальных углов наклона. И в этом, надо отметить достаточно распространенном и важном для некоторых типов игр, случае NV38 выглядит немного выгоднее NV40. В остальных случаях NV40 обеспечивает заметно более лучшую апроксимацию идеальной кривой. Кроме того, при сходных установках качества увеличелась протяженность зон в которых реально выполняется трилинейная фильтрация. В NV38 установки более агрессивны, и, возможно это было продиктовано недостаточно успешной конкуренцией с R3XX в различных тестах. Впрочем, после выхода R420 эти могут появиться новые драйверы, в которых и настройки NV40 станут более жесткими — ориентированными на скорость а не на качество. Что касается R360 — налицо меньшее число линий, аппроксимирующих кривую изолинию расстояния до наблюдателя, но зато более широкие зоны трилинейной фильтрации. Лучше это или хуже — можно решить, глядя на скриншоты конкретных игровых приложений, но как бы там ни было, разница на лицо.
Что касается анизотропии — ее алгоритм изменился. Пока сложно сказать насколько, но очевидно что это шаг в сторону подхода принятого в ATI. При этом на некоторых критических углах наблюдается увеличение замыливания на некоторых других наоборот, есть ощущение что NV40 дает более четкую картинку чем NV38 и в этом характер его поведения похож на R360, хотя есть и различия в конкретных моментах. Во многом эта разница между анизотропной фильтрацией в NV38 и NV40 может определяться изменившимся алгоритмом выбора мип уровня. Во второй части статьи мы исследуем влияние этого факта на качество графики конкретных приложений.
Выводы
- Работа над ошибками состоялась.
- Задел на будущее ощутим.
- Производительность вне конкуренции (пока).
- NV40 видится нам более успешным, чем NV30 в момент ее анонса.
Однако, чтобы сделать окончательные выводы мы ждем:
- Выхода ATI R420
- Результатов игровых тестов
- Возможности сравнительно протестировать скорость и качество AA и анизотропии у NV40 и R420
- Возможности задействовать шейдеры 3.0 и исследовать их производительность.
Комментарии