DX.Next: Ближайшее и ближнее будущее аппаратного ускорения графики

Предупреждение: данная статья посвящена еще разрабатываемым (или разработанным, но еще не анонсированным) технологиям и поэтому, во многом, базируется на неофициальной информации. Общая картина скомпилирована из более-менее официальных источников (таких как опубликованные презентации ATI и NVIDIA на GDC для разработчиков) и слухов публикуемых различными сетевыми СМИ. При этом следует учитывать что любая, даже прозвучавшая из уст ATI или NVIDIA информация о будущей версии API DirectX не является окончательной хотя бы потому, что ее разработка еще не завершена. Любые параметры и требования могут быть изменены по тем или иным соображениям, даже в последние дни перед релизом.
Таким образом, читайте эту статью на свой страх и риск, здесь и сейчас, а все последующие совпадения с реальными событиями можно будет считать удачной случайностью. Впрочем, говорят что «удача улыбается подготовленным», и я старался подготовить эту компиляцию на основе данных, которые показались мне наиболее разумными и правдоподобными.
То ли еще будет
Для начала — небольшое отступление. Известно, что анонс нового поколения продуктов ожидается в скором времени (факт приближающихся анонсов несколько раз упоминался официальными источниками ATI и NVIDIA, пускай и без конкретных дат, но с вполне конкретными рамками). Некоторые сайты в сети уже публикуют слухи о названиях и конкретных датах, например, Anandtech:
«Recently we received confirmation that the first retail samples of ATI's R420 (AGP Radeon X800) will debut April 26 as Radeon X800 Pro. NVIDIA's NV40 (GeForce 6800) officially launches April 13th, but retail availability will occur around April 26th. Notice the NV40 product to be released April 13th is GeForce 6800, not GeForceFX 6800. ATI's naming scheme for R420 has been closely guarded as well, but the open term we hear from vendors is Radeon X800.»
Предполагает что анонс нового продукта NVIDIA под названием GeForce 6800 запланирован на 13 апреля, а анонс нового продукта ATI — Radeon X800 Pro на 26 число того же месяца. Что ж, в скором времени мы сможем убедиться, соответствуют ли эти слухи действительности. А теперь, перейдем непосредственно к темам нашей статьи.
Шинный вопрос
C места в карьер! Для начала обсудим стремительно свершающийся факт перехода графических платформ на новую шину — PCI Express (далее сократим ее до PCX). Здесь особых секретов нет, а есть вполне озвученная картина того, что мы увидим в ближайшем поколении графических чипов NVIDIA и ATI.
Итак, ATI предпочли выпустить две версии чипа (R420 и R423). Первая версия поддерживает шину AGP 8x, вторая — PCX (согласно слухам анонс PCX версии чипа будет несколько позже, в начале лета). Больше принципиальных отличий эти чипы не имеют. Как мы уже неоднократно писали, первое поколение настольных PCX решений будет иметь один выделенный для графики слот (16х) и несколько периферийных (1х). Напомним, что пропускная способность 16х слота PCX — по 4 гигабайта в секунду в обоих направлениях передаваемых одновременно (т.н. полный дуплекс). Пропускная способность AGP 8x — 2.1 гигабайта в секунду от системы к ускорителю и значительно меньше (~200 мегабайт) обратно.
NVIDIA делает ставку на отдельный чип (мост) осуществляющий преобразование PCX->AGP. Данный мост может использоваться как с будущими чипами, так и с текущей серией NV3Х. Однако все не так просто — выясняется, что пропускная способность такой схемы (AGP чип + PCX бридж) не ограничена типичными для AGP 8х значениями. Как такое может быть? Схема:
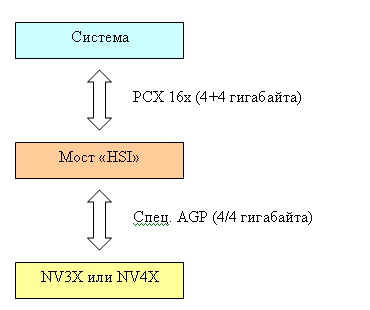
Итак, сверху у нас система, затем 16х PCX слот, затем чип моста называемый NVIDIA «HSI» (High Speed Interconnect — высокоскоростное соединение). Чип моста соединен с графическим чипом серии NV3Х или чипом будущего поколения через его стандартные AGP выводы. Однако, в случае, когда графический чип работает с HIS мостом, расположенным на минимальном расстоянии рядом с самим чипом на плате ускорителя, мы можем позволить себе двукратное увеличение скорости, на которой функционирует AGP 8х шинный интерфейс графического чипа. Таким образом, мы получаем аналог (по пропускной способности) несуществующей в виде стандарта шины AGP 16х. Таким образом, пропускная способность достигает 4 гигабайта в секунду. Но и это еще не все — если типичная система, согласно стандарту AGP, умеет передавать данные с максимальной скоростью только в одном направлении, то усовершенствованный AGP интерфейс между HIS мостом и ускорителем от NVIDIA передает данные со скоростью 4 гигабайта в секунду в обоих направлениях (!). Но, важно понимать, что не одновременно. В каждый конкретный момент времени передача идет только в одном направлении, и пиковая полоса будет всегда 4 гигабайта в секунду. Кроме того, требуется время на переключение из состояния передачи в состояние приема данных.
Интересно, что чип моста является двунаправленным — при желании его можно развернуть «наоборот» и он будет выполнять функции моста для создания AGP 8х карт на основе PCX чипов, которые NVIDIA планирует начать производить через некоторое время (есть слухи что менее чем через год).
Какие теоретические минусы подобного решения мы можем указать:
- Конструкция платы с мостом сложнее и дороже, вероятность отказа или брака выше. Дело не столько в цене самого чипа моста, сколько в факте его монтажа. Лишнее энергопотребление.
- При частом переключении направления передачи данных и/или большом обратном потоке данных от ускорителя, решение без моста будет (теоретически) более производительным.
C другой стороны, налицо практические плюсы: подход NVIDIA позволяет фирме не запускать два различных варианта ускорителя в производство ( процесс весьма дорогой). Кроме того, можно гибко регулировать соотношение PCX и AGP карт в зависимости от текущих требований рынка. Аспекты возможной потери производительности кажутся мне не важными, по крайней мере, в рамках поколения NV4X и текущей версии API (DX9). Как сам API, так и большинство приложений созданы (и еще как минимум два года будут создаваться) с расчетом на характерные особенности AGP и с учетом максимально возможного размещения данных в локальной памяти ускорителя.
Итак, основной вопрос стоит в области сложности карты (дополнительный чип моста, дополнительная ответственность на производителях карт) для NVIDIA и в области поставок (возможные дефицит или перепроизводство PCX или AGP версий чипа) для ATI. Время покажет, чей подход был выбран вернее.
Вопрос третьих шейдеров
В случае ближайшего поколения продуктов NVIDIA вопрос видится нам вполне предсказуемым. В материалах для разработчиков и презентациях на последнем GDC было однозначно дано понять, что новые продукты NVIDIA будут аппаратно поддерживать вершинные и пиксельные шейдеры версии 3.0.
Начнем с вершинных. Согласно стандарту, для версии 3.0 требуется возможность выборки значений текстур не только из пиксельного, но и из вершинного шейдера. Эту возможность нельзя недооценивать. Ее можно применять для множества техник, начиная с DM (Displacement Mapping) на уровне вершин и заканчивая той или иной степенью искажения или даже генерации новой геометрии (правда, пока только с заранее известным числом вершин) на основе различных таблиц и расчетов. Удобство неоспоримо. Как быть с практическими аспектами реализации? Два основных вопроса — будет ли поддерживаться фильтрация значений текстур при выборке, и какие форматы текстур будут возможны (поддерживаются ли плавающий формат). Пока сказать, что-то конкретное по этому поводу мы не можем, однако очевидно, что при современном подходе к построению архитектуры пиксельного конвейера использование тех же TMU, что обслуживают пиксельные конвейеры для обслуживания вершинных пока еще маловероятно и, скорее всего, в ближайшем поколении ускорителей будут присутствовать отдельные, TMU для вершинных процессоров. Как следствие — так или иначе обрезанные в своей функциональности (например, возможно отсутствие фильтрации, не столь критичной в данном случае). После официального анонса новых продуктов мы подробно исследуем этот аспект.
Другая важная особенность шейдеров 3.0, как вершинных, так и пиксельных — наличие динамического управления исполнением команд, т.е. истинно динамических условий и ветвлений, как в полноценных CPU. Если в случае вершинных шейдеров картина вполне очевидна (чипы NV3X позволяли использовать динамические ветвления в уже в вершинных шейдерах 2.х и, разумеется, в OpenGL) то с пиксельными шейдерами с точки зрения практической реализации не все так просто. На первом месте вопрос производительности. Если Вы внимательно читали статью DX Current, Вы, вероятно, помните схему пиксельного конвейера семейства 3X и подробный разбор его работы, приведенные в ней. Если нет — рекомендуем освежить этот аспект архитектуры NV3X в памяти
Итак, вспоминаем, что пиксели в пиксельном конвейере обрабатываются четверками (квадами). Как нам в этом случае быть с динамическими переходами и условиями? Есть различные потенциальные решения этого вопроса:
- Всегда обрабатывать пиксели по отдельности, забыв об оптимизациях на основе квадов;
- Выполнять над квадом всевозможные ветки условий, воспользовавшись расширенным так или иначе механизмом предикации (см статью DX Current)
- Деградировать квад до одного пиксела в случае исполнения истинно динамических ветвлений.
Наиболее вероятен второй или третий подход (возможно оба в разной степени в зависимости от кода шейдера — т.к. выгода переменна), а первый несомненно потребует чрезмерных транзисторных ресурсов — отказываться от квадов пока рано. Тем более, что в реальных приложениях реальные динамические ветвления в шейдерах будут возникать не часто, особенно в течении «лидерской» жизни этого поколения ускорителей. Итак, скорее всего мы получим компромиссное решение — шейдеры 2.0 быстро, простые шейдеры 3.0 с небольшими ветвлениями — приемлемо быстро, шейдеры 3.0 с интенсивными динамическими переходами и ветвлениями — достаточно медленно. Но, зато без каких либо ограничений в гибкости. Для будущего поколения такое решение видится мне оптимальным, а в последующих архитектурах (R5XX и NV5X) подход может и должен быть несколько другим, но об этом мы поговорим далее.
Что ж, это вполне естественная тенденция — за гибкость приходится расплачиваться производительностью. Чем сильнее нарушается специфическая однородность графических алгоритмов (однородные, взаимозаменяемые наборы примитивов и однородные операции над ними), тем слабее проявляется выгода от массивно параллельных решений, столь широко реализованных в различных блоках ускорителя. Кроме того, нарушение однородности команд и данных приводит к все более и более хаотическому доступу к исходным данным в памяти, что резко снижает эффективность кэширования (вспомним про небольшие кэши графических процессоров).
Однако, не все так мрачно. В случае второго подхода, можно реализовать определенные оптимизации — например, если все пиксели квада принадлежат одной конкретной ветке условия, нет необходимости пропускать их через команды другой ветки. Во многих алгоритмах это условие будет соблюдаться — соседние пикселы имеют хорошие шансы получить одинаковые значения условий, и, таким образом, падение производительности будет существенно снижено.
С другой стороны хранение предикатов и параметров условий требует временных регистров связанных с каждым пикселем квада и, скорее всего, на эту задачу будут тратиться биты временных регистров общего назначения. Т.е. при большой сложности ветвлений у нас появляется еще один снижающий производительность фактор.
Как бы там ни было, после выхода соответствующих продуктов мы внимательно исследуем все аспекты производительности пиксельных шейдеров 3.0, и попытаемся сделать выводы о конкретных особенностях реализации.
Интересно, что, судя по распространившимся в сети слухам (которые косвенно подтверждаются некоторыми формулировками из презентаций ATI для разработчиков) пиксельные процессоры ускорителей следующего поколения ATI (R420 и основанные на его архитектуре варианты) не будут поддерживать динамические ветвления в пиксельных шейдерах. Доступны будут только статические (т.е. заданные извне, из вершинного шейдера) условия, циклы и ветвления и при этом производительность все равно будет заметно снижаться при их использовании. Есть некоторая неопределенность, достаточно ли статических ветвлений, для того чтобы признать пиксельные шейдеры соответствующим 3.0. Здесь все зависит от Microsoft, которые могут либо ввести новый профиль для вторых шейдеров — назовем его «2.B», наподобие 2.Х, либо определить достаточно мягкие требования, для того чтобы называть продукт совместимым с пиксельными шейдерами 3.0. Все эти новшества появятся в DirectX 9.0c — релиз которого следует ожидать в скором времени после анонсов новых продуктов от ATI и NVIDIA. Еще один возможный вариант — компромиссное решение для ATI — когда вершинные процессоры будут исполнять шейдеры 3.0 аппаратно, а пиксельные только расширенную в той или иной степени разновидность шейдеров 2.0 (2.B или 2.X). Принципиальных помех этому нет, но текущая версия DX SDK такую возможность еще не поддерживает.
Радует другой аспект — точность пиксельных вычислений доведена в R420 до стандартных 32 бит.
Итак, со стороны NVIDIA мы увидим поддержку шейдеров 3.0 везде и без исключений, со стороны ATI мы можем получить что угодно — начиная от базовых вторых шейдеров в вершинном и пиксельном процессорах, затем тандем более продвинутых вершинных и компромиссных пиксельных и заканчивая 3.0 и там и там, но, возможно с существенными ограничениями на длину шейдера или без динамических переходов в пиксельных шейдерах.
Увидим! В некотором роде повторяется ситуация с пиксельными шейдерами 1.4 — когда один производитель поддержал это новшество а второй его проигнорировал. В итоге, множество разработчиков приложений настроились на наибольшее общее кратное, т.е. на 1.1. Сейчас ситуация более многогранна и возможны несколько сценариев развития, однако, в любом случае отсутствие неограниченных пиксельных шейдеров 3.0 может свдинуть ATI с пьедестала популярной карты разработчиков, вновь водрузив туда продукт NVIDIA. Реальные же приложения, разработанные на NV4X увидят свет лишь к моменту появления следующего поколения архитектур (через полтора года и более), но, т.к. эти архитектуры будут нацелены на шейдеры 4.0, очевидно, что и любой 3.0 код они будут исполнять без каких либо ограничений. В обычных играх же, в ближайший год или даже два, пиксельные шейдеры 3.0 мы если и увидим, то только как дополнительную, не обязательную и не особенно любимую опцию. Что, впрочем, не умаляет их ценности для DCC приложений и различных систем реалистической графики.
Итак, суммируем предполагаемую ситуацию:
| Следующее поколение | ATI | NVIDIA |
|---|---|---|
| VS 2.0 | Да (быстро) | Да (быстро) |
| VS 2.X/2.B | Очень вероятно (быстро) | Да (быстро, умерено быстро для динамических переходов) |
| VS 3.0 | Вероятно (умерено быстро, возможны ограничения) | Да (умерено быстро) |
| PS 2.0 | Да (быстро) | Да (быстро) |
| PS 2.X/2.B | Да (быстро или умеренно) | Да (быстро) |
| PS 3.0 статические переходы | Да, но с ограничениями (умеренно быстро или средне) | Да (быстро) |
| PS 3.0 динамические | Скорее всего нет | Да (скорее всего средне) |
В скором времени, по мере анонса карт, мы на практике проверим все эти предположения.
Вопрос прочих возможностей DX9 в ближайшем поколении
Пока мы можем только догадываться какие новые алгоритмы анизотропии и антиалиасинга мы увидим в новом поколении ускорителей. А вот некоторые другие параметры можно уже сейчас предсказать на основе презентаций с GDC. Новая архитектура NVIDIA, наконец то, получит столь желаемую и отсутствовавшую ранее возможность MRT — записывать из одного пиксельного шейдера несколько разных значений цвета в разные буфера. Кроме того, упоминается широкая поддержка плавающего формата буфера кадра — как записи, так и операций блендинга. Таким образом, именно в этом поколении можно будет говорить о полноценной работе с плавающими значениями цвета, как во время вычислений, так и в буфере кадра. Наверняка, мы увидим и какие то новые возможности для плавающих текстур в пиксельных шейдерах, например, билинейную фильтрацию. Не ясно как с этим будут обстоять дела у ATI, но наиболее вероятно, что блендинг плавающих форматов буфера кадра также будет реализован. Кроме того, это будет уже второе поколение ускорителей со встроенной гамма-коррекцией при пиксельных вычислениях.
До остальных подробностей осталось потерпеть немного, а мы с грустью отметим очевидный факт — первое поколение каких либо возможностей всегда комом. Только во втором поколении архитектур с плавающей точкой в пиксельных вычислениях мы наконец то получим более менее ровную (ортогональную) картину возможностей по работе с этим форматов, в продуктах обоих лидеров графического рынка.
Вопрос времени и места DX Next
Название следующей версии DirectX еще неизвестно и потому мы будем называть ее «DX Next» (просьба не путать с будущим официальным именем продукта которое мы еще не знаем). А вот время выхода приблизительно определено — начало 2006 года. Да да, старый добрый DirectX 9 просуществует еще целую уйму времени, вот почему в него сразу были заложены в некотором роде «опередившие» время шейдеры 3.0. В начале 2006 года, вместе с новой операционной системой Longhorn, судя по всему достаточно революционной, в плане внутренних изменений, столь существенных впервые со времен Windows NT 4. Во многом, эти изменения и вызваны новой концепцией работы с различными устройствами и в том числе с графическими ускорителями — выход следующей версии DX неразрывно связан с новым ядром новой ОС и, наиболее вероятно, что мы вообще не увидим этот API на предыдущих системах (XP, 2000 и иже). Почему? Давайте обсудим этот вопрос подробнее:
Вопрос виртуальной памяти и интерфейса софт-железо
До сих пор, решение, где хранить те или иные данные (локальная память карты, системная память) и как осуществлять их обновление во многом зависит от программиста. Можно переложить этот вопрос на плечи DX, но он зачастую почти ничего не знает о характере использования данных заранее (часто, редко, будут ли обновляться или перезаписываться) и поэтому программисты указывают различные флаги, обозначающие место хранения вершинных буферов, текстур и других объектов DX. Однако парадокс в том что и сами программисты не всегда могут определить оптимальным образом что и где должно храниться. Особенно с учетом того, что локальная память варьируется от ускорителя к ускорителю, популярность тех или иных ресурсов меняется от уровня к уровню и более того, непостоянна в каждом конкретном кадре, а какие либо настройки игры могут кардинально изменить всю предполагаемую картину. Доверять в такой ситуации человеку опасно и нерационально : но в замен необходимы продуманные алгоритмы загрузки данных по необходимости и учета производительности (частоты обращений к ресурсам). Ничего не вспомнили? Правильно - виртуальная память, основанная на страничной подкачке с учетом частоты обращений. Хорошо известная в современных CPU технология.
В продуктах 3dlabs уже предпринималась попытка создать механизм виртуальной памяти с аппаратной поддержкой, когда с точки зрения внутренних блоков ускорителя (за пределами контроллера памяти) его локальная память и системная память компьютера являются одним целым. Однако такая попытка не может считаться полноценной — действительно прозрачный механизм потребует поддержки не только со стороны API DirectX (или OpenGL где его можно реализовать даже силами одного вендора) но и со стороны операционной системы, а последнее до сих пор было невозможно. Новая OS с кодовым названием Longhorn будет содержать все необходимые для этого механизмы, а DX Next во многом будет ориентирован на этот, новый для классических API подход к менеджменту ресурсов. Графические чипы, нацеленные на DX Next (вероятно это будут R5XX, NV5X и далее) будут поддерживать аппаратную подкачку данных в локальную память из системной и аппаратную выгрузку данных в системную, по мере надобности, на основе независимого (фонового) анализа обращений к данным:
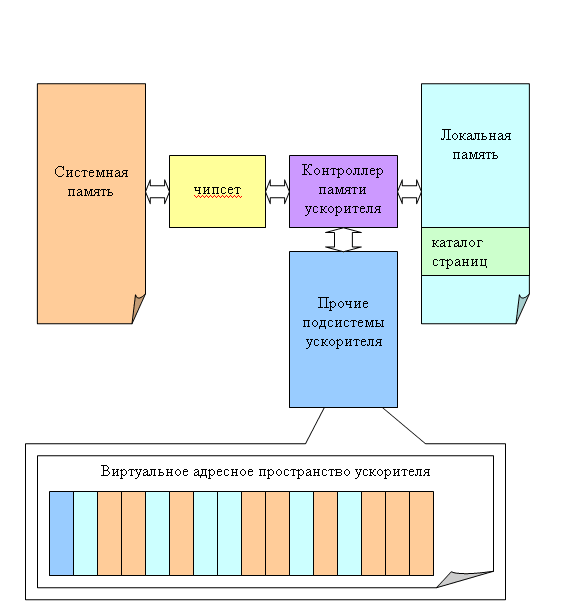
В результате с точки зрения шейдеров, программы и во многом API все данные будут находиться в едином линейном виртуальном адресном пространстве, и их конкретное физическое положение в данную минуту будет определяться железом ускорителя, с учетом характера обращений к этим данным. Для этого, судя по всему, будет использован классический подход каталога страниц, знакомый нам по CPU. Разумеется, есть и отдельные тонкие моменты, например не обязательно выгружать при высвобождении памяти те данные, которые не изменялись с момента загрузки, кроме того, некоторые типы данных, такие как буфер глубины можно будет с уверенностью навсегда привязать к локальной памяти ускорителя. Было бы нерациональным пытаться гонять содержимое буфера глубины в системную память и обратно — это слишком дорого для приемлемой скорости закраски.
Очевидно, что многие типы данных, такие как текстуры, выгоднее хранить в виде тайлов того или иного размера, соответствующего оптимальной гранулярности подкачки. По некоторым данным минимальная порция подкачки (т.н. размер страницы первого уровня) будет равна типичной странице операционной системы — 4 килобайта.
Еще одна проблема современных API — низкая производительность смены различных состояний (установки новых текстур, смены шейдеров и их параметров, и тем более смены активного буфера кадра) также подлежит решению в той или иной мере. Разрабатываются новые формы интерфейса железо-API, приближенные к современным реалиям и во многом ускоряющие менеджемент (создание и выбор) новых объектов DirectX, в первую очередь, шейдеров, текстур и активных буферов кадра. Основная политика проста — все, что может быть обработано заранее будет обработано заранее, а не во время построения кадра. Приоритетом нового API является существенное повышение скорости обработки небольших наборов треугольников — самое больное место современных ускорителей, зачастую не позволяющее программистам развернуться на все 100% и реализовать множество одновременно применяемых и различных для разных объектов эффектов на одной сцене, по крайней мере, без заметной потери производительности. Все что может быть переложено с процессора на ускоритель, будет переложено, в том числе и та или иная начальная подготовка текстур и буферов с геометрическими данными. Будет оптимизирована и конвейеризирована работа с небольшими наборами примитивов. Подобные новшества способны во многом сдвинуть акценты оптимизации в будущих приложениях, возможно, сделав более выгодным другие, считавшиеся ранее неэффективными, подходы к построению изображения. Поживем — увидим! Все это несет новые возможности программистам, но ясно, что перспектива появления приложений изначально рассчитанных на DX Next достаточно отдалена. Можно надеяться, что через три года, первые игры, сбалансированные с учетом нового API достигнут полок официальных магазинов и пиратских ларьков :-).
Самый важный вопрос четвертых шейдеров, генерации примитивов и произвольного доступа
Основная сила DX Next — шейдеры версии 4.0 и все связанные с ними архитектурные особенности. Интересно, что во многом современное виденье этого вопроса совпадает с моими досужими гаданиями на кофейной гуще годичной давности.
Впрочем, все достаточно логично — пути развития графики не приносят пока никаких глобальных сюрпризов. Итак, что можно (вероятно) ожидать в этой области:
- 1. Три логических типа шейдеров:
- 1.1 Новый геометрический шейдер (может генерировать новые вершины)
- 1.2 Вершинный шейдер (трансформирует вершины)
- 1.3 Пиксельный шейдер (закрашивает пиксели)
- 2. Единый набор ограничений, команд и поддерживаемых типов данных для всех трех шейдеров, включая доступ к текстурам, регистры, форматы представления чисел и т.д.
- 3. Более или менее произвольная коммутация потоков данных из шейдера в шейдер
- 4. Произвольный доступ к данным из шейдеров (наконец то) в виртуальном адресном пространстве ускорителя. Разумеется, ценой снижения производительности
- 5. Поддержка характерных для CPU типов данных — в том числе целочисленных данных и смешанных структур данных.
- 6. Полноценная реализация IEEE стандарта на операции с плавающей точкой (поддержка знакового нуля, денормализованных чисел, бесконечности и т.д.), причем, видимо, требуемой и достаточной пока останется точность в 32 бита.
- 7. Фактически ускоритель будет массивом совершенно одинаковых процессоров, динамически конфигурируемых на исполнения того или иного рода шейдеров над тем или иным потоком данных.
- 8. Все равно сохранятся некоторые ограничения связанные с потоковой природой ускорителя.
Итак, давайте поясним подробнее эти пункты. Ускоритель превратится в некий набор совершенно одинаковых векторных процессоров достаточно общего назначения, поддерживающих работу как с плавающим, так и с целочисленным форматом, ветвления, генерацию новых данных, а также те или иные формы произвольного доступа к данным. Конечно, эти процессоры по-прежнему будут снабжены большим числом специфических блоков (текстурные блоки выборки и фильтрации, интерполяторы параметров, оптимизации HSR разного рода для отбрасывания примитивов до обработки и т.д.). Но, степень их универсальности резко возрастет. Возможно, что эти процессоры по-прежнему будут собраны в группы по квадам, но теперь, каждый квад сможет обрабатывать не только пиксельные, но и иные (геометрические) данные.
При столь высокой унификации шейдеров (единая архитектура) принципиальной разницы нет. Более того, унификация позволит создавать достаточно сложные цепочки для обработки потоков данных:
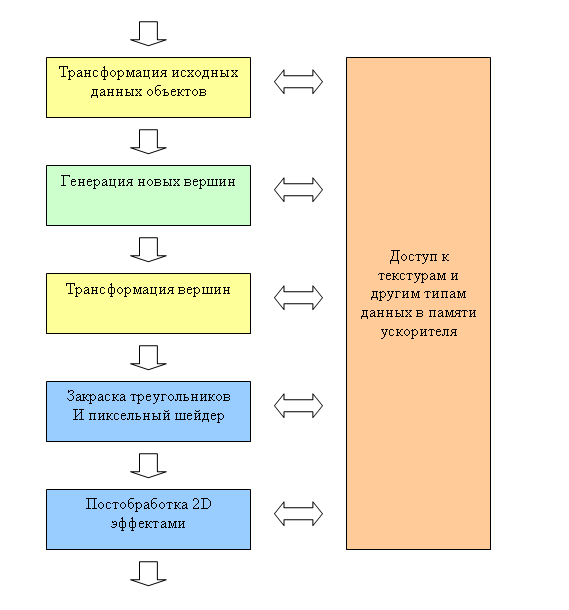
Число шейдеров в такой цепочке может быть достаточно велико, каждый из них принадлежит к одному из ранее описанных типов, и структуры данных, буферезируемые между ними могут иметь различные гибко задаваемые форматы. Реально, DX Next может наложить существенные ограничения на эту схему, но, как минимум, можно ожидать допустимости следующей цепочки:
- 0. Выборка данных из памяти
- 1. Вершинный шейдер
- 2. Геометрический шейдер
- 3. Вершинный шейдер (после генерации новой геометрии)
- 4. Установка треугольников и квадов, HSR
- 5. Пиксельный шейдер
- 6. Запись результатов
Причем пункты 0 и 4 и 6 выполняются непрограммируемыми аппаратными блоками, а все остальные — стандартными шейдерными процессорами. Разумеется, что в других API (например, OpenGL) будет возможна и другая конфигурация, в том числе более гибкая или разветвленная - это лишь вопрос логического представления очень гибкой аппаратной структуры состоящей из массива процессоров, с возможностью произвольной коммутации потоков между ними.
Подобная архитектура раз и навсегда снимет вопрос неравномерной нагрузки на различные шейдерные подсистемы ускорителя. Можно будет аппаратно перераспределять ресурсы, динамически и даже совершенно автоматически (!). Подобное распределение может происходить с гранулярностью вплоть до одного конкретного объекта (вершины или пиксела) и тогда процессоры ускорителя всегда будут загружены на 100% (конечно, если не произойдет упора в один из специальных аппаратных блоков). Такой подход в очередной раз облегчит жизнь программистам, тратящим сейчас немало времени на экспериментальный поиск узких мест, в графическом конвейере, исполняющем их приложение.
Интересно, что с точки зрения программиста конфигурацию такого ускорителя можно записать в виде набора шейдерных функций, снабженного указанием соответствия входных и выходных данных для каждой из них. Все остальное сделает за вас компилятор и API.
Вся эта райская гибкость ставит перед нами множество вопросов эффективной аппаратной реализации. Произвольный доступ к памяти — надо существенно увеличить кэши. Много шейдеров — надо существенно увеличить промежуточные буфера и кэш память команд. Доступ к текстурам возможен из всех процессоров — следовательно, вопрос борьбы с латентностью встает еще более остро (хотя и по-прежнему так или иначе обходится методом «одна команда исполняется над многими примитивами» описанным в DX Current, но эффективность подхода стремительно падает из-за ветвлений и произвольного доступа к памяти).
Итак, вокруг проблемы, проблемы и еще раз проблемы, которые только предстоит решить. Но мы не сомневаемся, они решаются, и будут решены, а DX Next увидит свет в 2006 году.
Интересно другое — CPU и GPU необратимо идут на встречу друг другу. Для CPU это SIMD и MIMD (т.е. VLIW) возможности, HT и несколько ядер на одном чипе, для GPU это произвольный доступ к памяти и все более и более общие наборы инструкций и типы данных. Нет сомнений, что рано или поздно эти паровозы столкнутся.
Лет через 10? Я думаю через 7..8. Впрочем увидим!
Чем мне нравится эта индустрия — всегда можно сказать «увидим!» — все развивается так стремительно, что порою кажется, что уж кто кто, а мы — работники хайтека, стареем медленнее других :-)
Комментарии