Использование AMD Core Math Library
История склонна развиваться по спирали, постоянно возвращаясь в одну и ту же точку, но каждый раз на новом уровне. И история компьютерной техники не будет исключением из этого правила, а эволюция GPU может стать замечательным примером тенденции истории повторять себя в новой форме на новом витке.
В свое время первые процессоры для PC серии x86, модели 8088, 286, 386 не поддерживали нативно операции с вещественными числами. Они поддерживали только целочисленные вычисления, а для операций над числами с плавающей запятой (это специальный формат для приближенной записи в компьютере вещественного числа) — сложения, умножения — вызывались специальные подпрограммы. Они реализовывали вычисления с вещественными числами через целочисленные операции. Соответственно, скорость расчетов с нецелочисленными типами данных (float, double) была на порядок ниже.
Для ускорения этих вычислений существовал специальный математический сопроцессор (FPU — floating point unit). Он размещался на материнской плате в отдельном сокете, имел свою систему команд и умел умножать и складывать вещественные числа на аппаратном уровне, обеспечивая, таким образом, значительное ускорение расчетов. Intel выпускал сопроцессоры для своих CPU, существовали модели математических сопроцессоров и у сторонних производителей, которые тоже можно было поставить в пару к интеловскому центральному процессору. Некоторые из них по определенным параметрам превосходили сопроцессоры Intel — например, сопроцессор одной из фирм был в несколько раз быстрее, но только в вычислениях с вещественными числами одинарной точности. Некоторые сопроцессоры имели свою собственную, более удобную систему команд, позволяющую достичь более высокой производительности, но требовавшую специальной поддержки программистов.
Первым шагом интеграции математического сопроцессора и CPU стало размещение их на одном кристалле в Intel 486DX. Но сопроцессор все ещё был, по сути, отдельным модулем, имевшим такую же схему работы, как и сопроцессор для 386SX/DX — просто они стали размещаться ближе. Выпускались и модели серии 486 без сопроцессора, они назывались 486SX. Полностью сопроцессор растворился в CPU уже в процессорах семейства Pentium.
А сегодня GPU начинает выступать в роли математического сопроцессора для CPU. Только вместо чисел идут векторы, вместо ускорения умножения вещественных чисел происходит ускорение перемножения вещественных и комплексных матриц, а вместо вычисления квадратного корня — нахождение собственных значений. И мы находимся на таком промежутке истории, когда современный «математический сопроцессор» тоже находится в отдельном слоте, но уже начинают появляться и первые модели с «интегрированным» GPU: совсем недавно был выпущен первый APU.
Одна известная фирма-производитель современных «сопроцессоров», наоборот, вынашивает планы интегрировать CPU в свой продукт, если не удастся расширить функциональность их моделей GPU таким образом, чтобы она включала полную функциональность CPU. Параллельно увеличивается скорость соединения между CPU и GPU. Так или иначе, они имеют тенденцию сливаться. The Future is Fusion — тем или иным образом.
И в данной статье мы рассмотрим реальную производительность видеоускорителей семейства Radeon при их использовании в качестве математических сопроцессоров для ускорения матричных операций.
GPU превращаются в математические сопроцессоры
Во времена 8086 считалось, что быстрые вычисления с вещественными числами не очень нужны на персональных компьютерах, и можно обойтись медленной программной эмуляцией. Но развитие и распространение компьютерных игр, прежде всего трехмерных, сделало это мнение неактуальным и катализировало тесную интеграцию CPU и FPU.
Сегодня нужды игровой графики породили новую генерацию специализированных устройств, и «графическое» происхождение современных сопроцессоров наложило сильный отпечаток на их вычислительные характеристики. В первую очередь, GPU были слабы в вычислениях с числами двойной точности, которые широко используются в научных расчетах, тогда как в графике используются числа одинарной точности — и это ограничивало внеграфические применения GPU. Но последние модели GPU всех производителей обзавелись полноценной поддержкой типа double именно с прицелом на научные вычисления, и при анализе производительности мы обратим особое внимание на реализацию вычислений с двойной точностью.
Современные процессоры имеют специальные инструкции для вычисления квадратного корня, синуса, косинуса и других математических функций, но внутри самого CPU, в силу его архитектуры, ориентированной на высокие частоты, они реализованы как подпрограммы, выполняющие набор более простых операций. То есть вычисление, скажем, косинуса, заданное конкретной командой, производится не чисто аппаратно. Более того, иногда вычисление таких сложных функций даже выгодно заменить на набор более простых инструкций (умножения и сложения) в коде программы, чтобы процессор выполнял один непрерывный поток инструкций. Даже столь «очевидная» операция, как деление, в некоторых CPU выполняется программно.
Аналогично, в системе команд GPU нет специальной инструкции перемножения матриц; эту и другие функции надо программировать. Однако когда уже есть реализация, перемножить две матрицы в коде программы не сложнее, чем извлечь квадратный корень, так как всё сводится к вызову одной единственной функции с несколькими аргументами.
Производители CPU явно или неявно предоставляют реализации математических функций: либо они могут быть прямо вшиты в процессор для базовых функций, либо оптимизирующий компилятор подставляет инструкции при создании кода, и есть специальные библиотеки вроде Intel Math Core Library с оптимизированными под конкретный CPU широко используемыми математическими функциями.
И конечно, самым удобным способом задействовать в своей программе возможности GPU будет просто вызов библиотечной функции, оптимизированной для выполнения на видеокарте. Для программирования GPU нужны специальные знания, а вот использование готовых библиотек никаких дополнительных навыков не требует.
ACML
AMD Core Math Library изначально была ориентирована на CPU, она включает оптимизированные для процессоров AMD реализации широко известного набора программ для вычислений линейной алгебры BLAS (Basic Linear Algebra Subroutines), самое главное в котором — это перемножение матриц, и LApack (методы решения линейных матричных уравнений, нахождения собственных значений матриц, метод наименьших квадратов и т. п.), причем LApack использует функции BLAS, как строительные кирпичики, и его производительность прямо зависит от реализации BLAS. ACML так же включает реализации быстрого преобразования Фурье и некоторые вспомогательные функции, вроде генераторов случайных чисел.
Новая версия библиотеки получила полноценную поддержку последних моделей GPU AMD Radeon: с помощью GPU была ускорена самая ресурсоемкая функция BLAS — перемножение матриц. (Естественно, в форме D=α×A×B+β×C, где α и β — числа, а A, B и С — матрицы.) А эта функция, в свою очередь, используется в алгоритмах решения более сложных задач, входящих в LApack, и они тоже получают ускорение от использования GPU.
Причем GPU-версия полностью совместима с CPU, то есть пользователю не требуется как-либо изменять код и даже перекомпилировать его — просто нужно прилинковать ACML GPU, и вызовы библиотеки будут заменены на GPU-оптимизированные, если такие имеются.
Далее мы рассмотрим детали использования ACML GPU, а сейчас перейдем непосредственно к тестам производительности.
Производительность
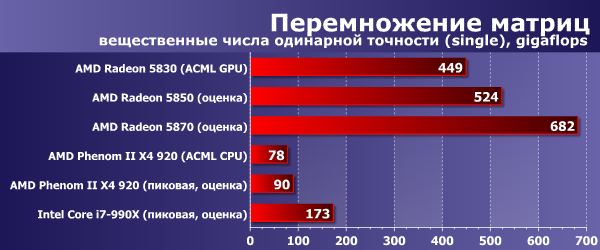
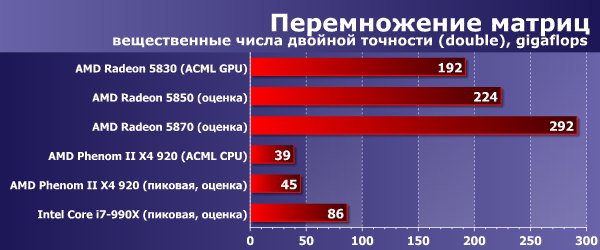
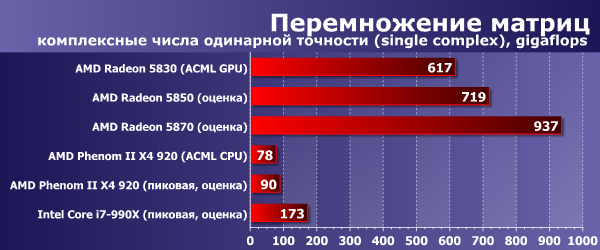
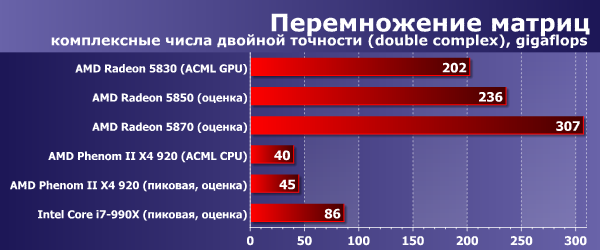
Ниже на диаграммах приведена производительность в gigaflops при перемножении матриц размером 5000×5000, с использованием вещественных чисел одинарной и двойной точности, а так же комплексных чисел одинарной и двойной точности.
Сразу необходимо отметить, что ACML GPU работает с матрицами любого размера, лишь бы они помещались в системной памяти. Объем же набортной памяти видеоускорителя не является ограничивающим фактором для использования GPU, так как библиотека сама автоматически разбивает матрицу на блоки, которые помещаются в видеопамять.
Более того, проведенные автором тесты показали, что производительность при увеличении размера матрицы почти не падает. Она скорее может уменьшаться при малом размере матрицы, так как тогда накладные расходы на передачу данных в GPU и обратно начинают доминировать, и к тому же возрастают расходы на запуск программы на GPU. Помимо этого, очень малые размеры матрицы не позволят создать достаточное количество нитей, которое, как мы знаем, необходимо для эффективной работы GPU (подробнее — в статье «Особенности архитектуры AMD/ATI Radeon»).
Кстати, матрицы могут размещаться в памяти любым образом, построчно или по столбцам — библиотека по необходимости транспонирует матрицы тоже без потери производительности. Таким образом, никакого специального формата (и никакой специальной подготовки) для вычислений на GPU не требуется.
Однако ACML автоматически определяет, при каком размере матриц эффективнее использовать CPU, и сама переключается при необходимости на CPU-реализацию. Конкретные размеры матрицы, при которых становится невыгодно использовать имеющийся GPU, зависят от параметров работы шины PCI Express (1.0 или 2.0, x8 или x16), производительности установленного CPU, а также размера используемого типа данных (он влияет на объем данных, передаваемых по шине).
Исследование показало, что начиная примерно с 1000 элементов производительность GPU (в гигафлопсах) быстро приближается к своему максимуму.
Тестирование библиотеки проводилось на Radeon 5830, для сравнения приведены результаты CPU-варианта на процессоре AMD Phenom II X4 920 (2800 МГц, 4 ядра, 4 МБ L3). Также приведена пиковая теоретическая производительность этого процессора и Intel Core i7-990X и виртуальные результаты Radeon 5850 и Radeon 5870. (Так как GPU-приложения в целом масштабируются по количеству SIMD Engine и частоте шейдеров, оценка производительности более мощных карточек будет недалека от истины.) Экстремальный процессор Intel взят для оценки максимальной производительности настольной платформы (без учета Sandy Bridge) в CPU-варианте: у него 6 ядер, работающих в режиме Turbo Boost на частоте 3,6 ГГц.
Максимальная теоретическая производительность AMD K10 и Intel Nehalem в вычислениях с вещественными числами считается как произведение частоты процессора, количества [физических] ядер и количества операций за один такт. А нынешние процессоры обеих компаний в идеале могут исполнять SSE-операции с темпом 2. То есть получается две 4-компонентные SIMD-операции в случае использования чисел одинарной точности или две 2-компонентные SIMD-операции в случае чисел двойной точности.
Пиковая производительность новых процессоров Intel семейства Sandy Bridge считается иначе из-за появления набора инструкций AVX, работающего с более широкими регистрами, чем SSE. Но пока особенности реализации ещё мало исследованы, и мы их в данной статье учитывать не будем.
Что ж, даже младшая видеокарточка из серии Radeon 58xx демонстрирует производительность примерно в 5 раз большую, чем пиковая мощность современных настольных CPU (и в 2,5 раза большую, чем пиковая мощность топовых настольных CPU). Надо отметить, что ACML CPU очень хорошо оптимизирована и выдает очень близкие к теоретически возможному пику результаты. А вот ACML GPU ещё далека от теоретического максимума GPU, который составляет примерно полтора терафлопса в случае Radeon HD 5830. Собственно, версия для Radeon Evergreen вышла всего несколько месяцев назад, ее производительность ещё возрастет, тем более что сейчас она тормозится несовершенным драйвером Windows. А вот производительности CPU уже расти некуда: на этой (на самом деле, выгодной для демонстрации вычислительных возможностей процессоров) задаче и так удалось выжать практически всю доступную скорость. Можно ещё раз отметить, что в данном случае учитывается также время копирования данных в память видеокарты и результата обратно, то есть это реальная конечная производительность GPU.
Можно отметить также преимущество GPU в соотношении цены и производительности: топовые или предназначенные для мультипроцессорных конфигураций модели CPU стоят гораздо дороже практически любой видеокарты, не говоря уж о младших видеоускорителях в линейке, так что разница в цене гигафлопса будет просто неприличной (не в пользу CPU). То есть если собирать на основе CPU систему с равной производительностью, это потребует совсем других денег, так как нужны будут серверные процессоры и платы.
При вычислениях с double картина, в целом, аналогична ситуации с числами одинарной точности — прирост (в случае использования видеокарты) чуть меньше, но все равно составляет разы. Таким образом, дешевая потребительская видеокарточка радикально опережает в математических расчетах самые быстрые CPU…
Падение скорости по сравнению с вычислениями с single составляет примерно два раза, аналогично CPU.
Тем, кто слышал о стократном превосходстве GPU в скорости, прирост всего в пять раз может показаться каким-то незначительным, но в этой задаче и 5% прироста очень важны, 50% — невероятно важны и являются значительным преимуществом, а 500% — уже нечто выдающееся. Тем более, что задача оптимизирована для CPU максимально возможным образом.
А вот в вычислениях с комплексными числами одинарной точности преимущество GPU ещё больше увеличивается. В задаче перемножения матриц (с оговоренными условиями) скорость видеокарточки очевидно в некоторой степени ограничена скоростью доступа к памяти, поэтому можно относительно бесплатно выполнить лишние арифметические операции, отличающие умножение комплексных чисел (каждое комплексное число состоит из двух вещественных, и для перемножения двух комплексных чисел нужно 6 элементарных операций).
CPU же, который использует 4-компонентные инструкции SSE, наоборот испытывает некоторые затруднения, так как умножение и сложение комплексных чисел хуже векторизуется. Для перемножения матриц необходимо покомпонентно умножить строки одной матрицы на столбцы другой и сложить N произведений. Тут проявляется преимущество видеокарточек в грубой вычислительной мощности: код становится более «арифметически интенсивным», то есть с меньшим процентом операций доступа к памяти, и такой код очень удобен для GPU, он позволяет достичь максимума.
Тут ситуация почти полностью аналогична соотношению в single. 2-компонентные регистры SSE2 все же более удобны для операций с комплексными числами, чем 4-компонентные регистры обычного SSE.
А в случае GPU относительный прирост в скорости меньше, чем соотношение single/complex — вероятно, из-за того, что скорость вычислений с double примерно в 4 раза меньше, чем с числами одинарной точности. Напомню, Radeon может перемножить 2 числа типа double или 4 пары чисел single за одно и то же время, один такт. И, таким образом, за время свободных тактов в ожидании данных из памяти можно выполнить меньше инструкций. Все логично.
Можно сказать, что теперь вычисления с двойной точностью превратились из слабого места GPU — в его преимущество.
Повышенная точность
В свое время вычисления на GPU критиковали за якобы низкую точность расчетов. То есть GPU считает, может быть, и быстро, но с невысокой точностью. Тому были две причины: опять-таки использование чисел одинарной точности в качестве базового типа и использование очень быстрых, но неточных функций вычисления квадратного корня, синуса и экспоненты. Эти функции были взяты из графических шейдеров, где высокая точность не нужна, но сразу можно было сказать, что это приходящее, просто наследство от игровой графики.
Так как GPU по своей природе низкочастотен, он может выполнять более сложные инструкции с повышенной точностью расчетов. В частности, у GPU есть инструкция FMA (fused multiply-add, умножение двух чисел и сложение с третьим) — она, кстати, выполняется за один такт. И она выдает более точный результат, чем последовательное выполнение инструкций умножения и сложения на CPU, так как каждая из них вносит небольшую погрешность, и в случае двух инструкций — погрешности складываются. А инструкция FMA имеет такую же погрешность, как инструкция одного сложения или умножения. Напомним, что в компьютере все операции с вещественными числами выполняются с некоторой погрешностью из-за представления вещественных чисел в сжатом приближенном формате.
Так что GPU перемножает матрицы даже чуточку точнее, чем CPU. Ничего принципиального, но приятно.
Установка и использование ACML
Как уже отмечалось выше, использование ACML GPU не представляет трудности. Но есть несколько тонких моментов, на которые стоит обратить внимание. Да, необходимо отметить, что эта библиотека полностью бесплатна, в отличие от многих других библиотек с высоким уровнем оптимизации, и свободно скачивается с сайта AMD. Она есть в варианте для Linux и для 64-битных систем Windows. 64-битность обязательна, что, в общем, неудивительно и совершенно оправдано.
После установки ACML можно сразу посмотреть примеры программ. Для использования ACML в своей программе необходимо только включить заголовочный файл с описанием функций и подключить две библиотеки, libacml_dll.lib и libCALBLAS.lib. Что интересно, если подключить только libacml_dll.lib, то программа скомпилируется и будет работать, причем будет использовать GPU и даже получит некий прирост в скорости — однако он будет меньше, чем если подключить обе необходимые библиотеки. На это надо обратить внимание, так как если второй библиотечный файл не подключен, никаких сообщений не выдается.
ACML есть в вариантах для C++ и для Фортрана, причем для наиболее популярных современных компиляторов Фортрана есть отдельные дистрибутивы — в том числе и для Intel Fortran. Кстати, ACML CPU несколько лучше оптимизирована для CPU Intel, чем MKL Intel — для CPU AMD.
Мульти-GPU
ACML GPU автоматически поддерживает конфигурации мульти-GPU и способна сама распределить работу между всеми установленными видеокарточками, однако из-за дополнительных накладных расходов требования к «оптимальному» размеру матрицы становятся несколько выше. Надо обратить внимание, что для использования видеокарт в вычислениях CrossFire должен быть отключен.
Но есть и другой способ использования нескольких GPU: можно запустить несколько программ, и привязать каждую к своему GPU. Для этого существует специальная переменная среды, которая указывает для контекста приложения, какой GPU следует использовать — её нужно установить перед первым обращением к ACML GPU. Это особенно востребовано для управления узлом кластера, имеющего несколько GPU.
В Windows эту переменную можно установить вручную в свойствах значка «Мой компьютер» → Параметры системы → вкладка Дополнительно → Переменные среды. Она называется ACML_GPU и её значение задается в шестнадцатиричном формате 0xX. Подробнее о настройке можно прочитать в документации к библиотеке.
В рамках данной статьи масштабируемость по количеству GPU не исследовалась, но технических препятствий для хорошей мастшабируемости при использовании материнской платы, поддерживающей последние спецификации PCI Express на нескольких слотах, нет. Могут быть проблемы с драйверами OS, которые постепенно будут устраняться. Да, на момент работы над статьей были сложности сборки и настройки системы из нескольких двухчиповых Radeon 5790 (имеется в виду — не для игрового применения, а для вычислений). Мы не будем их рассматривать, потому что они должны быть устранены в новом релизе SDK и драйверов, который ожидается в ближайшие время. В крайнем случае, процесс конфигурации претерпит изменения, и появятся другие сложности. Сейчас, в частности, иногда требуется ставить заглушки на видеовыходы карт, чтобы система их опознавала и задействовала. (Заглушки дешевые, просто это неудобно.)
Таким образом можно очень недорого и легко получить систему с очень большой вычислительной мощностью на задачах линейной алгебры. Аналогичная по мощности система на основе CPU будет стоить более десяти тысяч долларов.
Обычное программирование
Интересен вопрос: насколько важна «хардкорная» оптимизация для достижения высокой скорости GPU? И какой прирост скорости дает использование специальных библиотек по сравнению со стандартной реализацией?
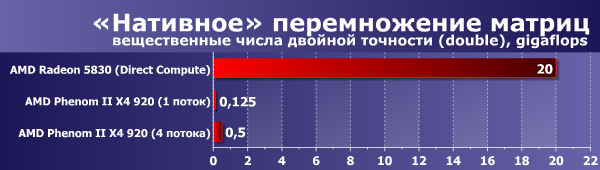
Для сравнения была протестирована производительность так называемой «нативной» реализации алгоритма перемножения матриц на языке C. То есть просто несколько строчек кода, выполняющих перемножение элементов матриц «по определению»
Был рассмотрен случай использования чисел типа double, но можно точно сказать, что в других случаях картина была бы примерно аналогичной. Да, так как GPU-вариант мультипоточен изначально, CPU-вариант тоже был распараллелен средствами OpenMP. Это добавило в код буквально одну строчку — директиву автоматической параллелизации главного цикла по элементам матрицы (и директиву установки количества создаваемых потоков).
Для программирования GPU использовался Direct Compute (точнее, просто был модифицирован простейший пример из DirectX 11 SDK), для CPU — MSVS 8 с включенной оптимизацией.
Размер матриц установлен в 1000 элементов.
Результаты очень показательные: скорость перемножения матриц с использованием GPU упала в 10 раз по сравнению с оптимизированным вариантом, а вот скорость CPU-реализации упала в 80 раз! CPU и GPU в данном варианте исполняют практически одинаковый код на языке C. Таким образом, оптимизация оказалась даже более важной в случае использования обычного процессора. Кстати, тесты показали, что масштабируемость по количеству ядер у CPU в этой задаче просто прекрасная, 100%. То есть скорость увеличилась по сравнению с однопоточным вариантом в 4 раза.
Как видите, даже безо всякой оптимизации недорогой GPU приближается по производительности к теоретическому максимуму средних настольных процессоров.
Почему скорость перемножения матриц так сильно упала в случае CPU? Общая причина заключается в том, что для приближения к теоретическому максимуму производительности процессоров в подобных вычислительных задачах действительно нужна хардкорная оптимизация на уровне ассемблерных инструкций с использованием векторизации. Конкретно: мы ведь считаем чистые гигафлопсы, то есть количество операций сложения и умножения при использовании вещественных чисел, но в коде есть ещё масса инструкций вычисления адресов, загрузки и выгрузки данных и т. п. И процессору нужно также выполнять все это, а время выполнения вспомогательных инструкций не меньше, чем вычислительных. Далее, в этой задаче доступ к данным не локален, так как мы сканируем одну из матриц по столбцам, а она располагается в памяти построчно. То есть каждый новый элемент считывается из новой строки, где он находится (в памяти) далеко от предыдущего, что затрудняет кэширование, и процессор простаивает в ожидании данных. В принципе, даже задержка доступа к данным из L3-кэша, который имеет высокую латентность по сравнению с L2, и тем более L1, не позволит CPU приблизиться к своему пику.
| 1 (1) | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 (2) | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 (3) | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 (4) | 32 | 33 | 34 | 35 |
При оптимизации перемножения матриц на CPU прежде всего разбивают матрицу на тайлы, изменяя стандартный порядок нахождения элементов результирующей матрицы на более дружественный по отношению к кэшу. Также применяют другие сложные приемы оптимизации доступа к памяти, специально вставляют инструкции предвыборки данных в кэш, и т. п. И лишь потом выполняется векторизация с использованием SSE и достигается полный темп в 2 SSE-инструкции за такт. Все это требует изощренного программирования и глубокого знания специфики конкретных процессоров. Не случайно сами производители CPU выпускают высокооптимизированные библиотеки для каждого семейства процессоров.
А в случае GPU большое количество нитей позволяет отчасти скрыть латентность доступа к памяти, который в «нативной» реализации неоптимизирован, и GPU легко «проглатывает» все дополнительные инструкции вычисления индексов. В оптимизированной GPU-реализации для ускорения чтения данных из памяти матрицы разбиваются на тайлы, и тайлы загружаются в локальную память каждого SIMD Engine (AMD) или Streaming Multiprocessor (Nvidia). Матрицы перемножаются кусочками, что аналогично приемам оптимизации для CPU.
Кстати, размер матрицы в 1000×1000 был выбран в этом тесте потому, что матрицы большего размера CPU обрабатывает слишком медленно. Но есть ещё одна неприятная особенность: при размере матрицы кратном 1024 производительность CPU-реализации сильно падала из-за конфликтов в кэш-памяти, так как та не может хранить много данных с одинаковыми последними цифрами (битами) адреса. За этим тоже надо следить при программировании на CPU: с одной стороны, удобно использовать кратные степени двойки размеры, а с другой — вот такие вот вещи происходят. И в целом при увеличении размера матрицы время работы увеличивалось непропорционально сильно, так как чем больше матрицы в этой тривиальной реализации, тем больше рабочая область данных программы и тем больше дорогих кэш-промахов. Даже примитивная GPU-реализация в этом отношении была гораздо более стабильна — спокойно переносила любое изменение кратности и масштабирование размера матрицы.
Правда, надо отметить такой момент: при выполнении программы Direct Compute (собственно вычислительного шейдера) экран полностью замирал. А если вычисления производились достаточно долго, то срабатывал сторожевой таймер (watchdog timer), который восстанавливал обычный режим функционирования GPU, прерывая исполнение вычислительного шейдера. Вероятно, использование отдельной видеокарты для отображения рабочего стола Windows решит эту проблему. Или можно вручную разбивать задачу на кусочки — это, как правило, несложно (а в данном случае — совершенно точно несложно).
Кстати, при использовании ACML GPU подобных проблем во время работы нет, а вот курсор движется прерывисто, параллельно работать совсем некомфортно, так что отдельная видеокарта для рабочего стола и здесь бы оказалась хорошим решением. Но, что интересно, четырехпоточная CPU-реализация практически блокировала 64-битную Windows 7, забирала все ресурсы себе и делала параллельную работу невозможной вообще.
Сравнительные результаты
Итак, при использовании просто языка С и тривиальной параллелизации (без каких-либо оптимизаций кода или подключения оптимизированных библиотек) GPU оказался в 40 раз быстрее, чем CPU. Этот результат ближе к тому, что молва говорит о производительности GPU. И он не менее важен, чем скорость полностью оптимизированных библиотечных функций: ведь библиотечные функции создаются только для наиболее популярных задач, это сложный, трудоемкий процесс, требующий специальных навыков, а для оптимизации всего и вся просто не хватит программистов. Поэтому в научных работах, посвященных переводу некоторого алгоритма на GPU, часто фигурируют цифры именно такого порядка, и это вполне оправдано, так как сравнивается работа кода, написанного на языке программирования высокого уровня с одинаковым подходом к оптимизации.
На самом деле, скорость очень многих вычислительных программ далека от теоретически возможной. Сейчас зачастую важно хоть как-нибудь реализовать параллелизацию, чтобы воспользоваться несколькими ядрами (или процессорами), а программировать на низком уровне и тратить время на хардкорную оптимизацию — экономически невыгодно. И оказывается, что GPU тоже подходят для такого обычного стиля программирования, причем, может быть, даже лучше, чем CPU — то есть неоптимизированная программа будет менее медленно работать на видеокарточке, чем на процессоре.
Пример с «нативным» перемножением матриц на самом деле важен. Пусть в случае простого алгоритма его относительно несложно оптимизировать на низком уровне, более сложный алгоритм может иметь такой же нерегулярный доступ к некоторым массивам, а там проводить оптимизацию будет гораздо сложнее, чем в случае матричного умножения с простым циклом. Однажды автора статьи попросили оптимизировать с использованием SSE некую счетную задачу, чтобы получить четырехкратный прирост в скорости. Но после анализа кода выяснилось, что оптимизация под SSE ничего не даст, так как доступ к памяти осуществляется ещё более «неправильно», чем в случае стандартного перемножения матриц. Вот мультипоточный GPU был бы в том случае весьма эффективен, хотя, конечно, для использования GPU на полную мощность нужно оптимизировать чтение данных, чтобы нити одного wavefront считали данные из одного блока памяти. Однако и приведенный пример показывает, что для достижения высокой скорости лучше воспользоваться оптимизированной функцией, прирост в скорости может быть очень большой.
И необходимо отметить, что на данный момент обычное программирование GPU с использованием OpenCL и Direct Compute сложно с точки зрения организации средств разработки, овладения программным интерфейсом, просто инициализации приложения. Пока ещё программная поддержка не устоялась и не достигла уровня развития средств разработки для CPU, так что для программирования GPU нужно быть квалифицированным разносторонним программистом, а не только уметь придумывать алгоритмы, как многие ученые. Это болезни роста, которые будут преодолены, но сейчас некоторые аспекты работы по созданию GPU-программ заставляют опытных разработчиков вспомнить молодость, когда среды программирования были не очень развиты.
Развитие
Использование AMD Radeon в научных расчетах на данный момент может быть актуально прежде всего для небольших научных лабораторий. Сейчас, в основном, для построения суперкомпьютеров на основе GPU выбирают Nvidia Tesla из-за наличия ECC, а также более продвинутых средств управления кластерными узлами. Но Tesla дороже на порядок, чем младшие модели Radeon — собственно, эти видеокарты Nvidia конкурируют с соответствующими серверными процессорами, которые тоже сто́ят на порядок дороже настольных.
В то же время, для использования «в личных целях» ECC не нужно, а по сравнению с Geforce в Radeon не ограничена производительность вычислений с числами типа double. И в частности, в описанной задаче перемножения матриц Radeon значительно быстрее и дешевле, тем более что в некоторых новых моделях Geforce для потребительского рынка максимальная скорость вычислений в double ограничена ещё больше — не в 4 раза, а в 6. Не во всех задачах ограничение в скорости работы с double прямо транслируется в производительность, так как программа может быть ограничена производительностью памяти, но в случае оптимизированных библиотек даже теоретически возможный максимум «настольных» Geforce меньше, чем результаты Radeon.
Многие исследователи были расстроены ограничением производительности в double у потребительских карточек Nvidia, но пока это компенсируется наличием у этой компании большего количества оптимизированных библиотек. С другой стороны, поддерживаемый AMD стандарт ОpenCL, в отличие от CUDA, является открытым, и вскоре можно ожидать появления большого количества OpenCL-оптимизированных математических библиотек, многие из которых будут доступны бесплатно, как, например, реализация FFT компании Apple. И только что вышла первая версия библиотеки FFT на OpenCL, написанная самой AMD.
Заключение
На данный момент, когда рост частоты CPU очень сильно замедлился (практически прекратился), но, тем не менее, однопоточная производительность остается очень важной, невозможно создать вычислительный дизайн, который был бы универсален и одинаково хорош и для серверных задач, и для настольных, и для научных вычислений. В такую эпоху индустрия переходит к специализации, подобно дереву, которое уперлось в потолок и начало разрастаться в разные стороны: появляются специализированные устройства, оптимальные для тех или иных задач.
GPU архитектурно быстрее для широкого класса вычислительных алгоритмов, что наглядно демонстрируется результатами тестов на известных задачах, так что он будет играть роль математического сопроцессора. Особенно удобно применение GPU при использовании готовых оптимизированных библиотек, таких как рассмотренная в данной статье ACML GPU. Возможно, в будущем GPU и CPU полностью сольются, как это произошло 20 лет назад с первыми математическими сопроцессорами для PC — это сулит многие выгоды и ещё больше расширит области применения GPU. Для такого развития событий архитектура у AMD уже готова.
Дополнительная информация
- Статья «Общее описание архитектуры Radeon с точки зрения неграфических вычислений»
- Страничка загрузки ACML и ACML GPU на сайте AMD — кстати, для работы с ACML в принципе не требуется Stream SDK
- Сторонняя высокоэффективная реализация умножения матриц с вещественными числами двойной точности. По заявлению разработчиков, она почти выбирает всю теоретически доступную производительность видеокарточки, что позволяет достичь в тесте Linpack ещё более высоких результатов
- OpenCL-код Apple, реализующий FFT (float)
- Математические библиотеки AMD на OpenCL, включая FFT




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}