Особенности архитектуры AMD/ATI Radeon
Это похоже на рождение новых биологических видов, когда при освоении сфер обитания живые существа эволюционируют для улучшения приспособленности к среде. Так и GPU, начав с ускорения растеризации и текстурирования треугольников, развили дополнительные способности по выполнению шейдерных программ для раскраски этих самых треугольников. И эти способности оказались востребованы и в неграфических вычислениях, где в ряде случаев дают значительный выигрыш в производительности по сравнению с традиционными решениями.
Проводим аналогии дальше — после долгой эволюции на суше млекопитающие проникли в море, где потеснили обычных морских обитателей. В конкурентной борьбе млекопитающие использовали как новые продвинутые способности, которые появились на земной поверхности, так и специально приобретенные для адаптации к жизни в воде. Точно так же GPU, основываясь на преимуществах архитектуры для 3D-графики, все больше и больше обзаводятся специальными функциональными возможностями, полезными для исполнения далеких от графики задач.
Итак, что же позволяет GPU претендовать на собственный сектор в сфере программ общего назначения? Микроархитектура GPU построена совсем иначе, чем у обычных CPU, и в ней изначально заложены определенные преимущества. Задачи графики предполагают независимую параллельную обработку данных, и GPU изначально мультипоточен. Но эта параллельность ему только в радость. Микроархитектура спроектирована так, чтобы эксплуатировать имеющееся в наличии большое количество нитей, требующих исполнения.
GPU состоит из нескольких десятков (30 для Nvidia GT200, 20 — для Evergreen, 16 — для Fermi) процессорных ядер, которые в терминологии Nvidia называются Streaming Multiprocessor, а в терминологии ATI — SIMD Engine. В рамках данной статьи мы будем называть их минипроцессорами, потому что они исполняют несколько сотен программных нитей и умеют почти все то же, что и обычный CPU, но все-таки не все.
Маркетинговые названия запутывают — в них, для пущей важности, указывают количество функциональных модулей, которые умеют вычитать и умножать: например, 320 векторных «cores» (ядер). Эти ядра больше похожи на зерна. Лучше представлять GPU как некий многоядерный процессор с большим количеством ядер, исполняющих одновременно множество нитей.
Каждый минипроцессор имеет локальную память, размером 16 KБ для GT200, 32 KБ — для Evergreen и 64 KБ — для Fermi (по сути, это программируемый L1 кэш). Она имеет сходное с кэшем первого уровня обычного CPU время доступа и выполняет аналогичные функции наибыстрейшей доставки данных к функциональным модулям. В архитектуре Fermi часть локальной памяти может быть сконфигурирована как обычный кэш. В GPU локальная память служит для быстрого обмена данными между исполняющимися нитями. Одна из обычных схем GPU-программы такова: в начале в локальную память загружаются данные из глобальной памяти GPU. Это просто обычная видеопамять, расположенная (как и системная память) отдельно от «своего» процессора — в случае видео она распаяна несколькими микросхемами на текстолите видеокарты. Далее несколько сотен нитей работают с этими данными в локальной памяти и записывают результат в глобальную память, после чего тот передается в CPU. В обязанность программиста входит написание инструкций загрузки и выгрузки данных из локальной памяти. По сути, это разбиение данных [конкретной задачи] для параллельной обработки. GPU поддерживает также инструкции атомарной записи/чтения в память, но они неэффективны и востребованы обычно на завершающем этапе для «склейки» результатов вычислений всех минипроцессоров.
Локальная память общая для всех исполняющихся в минипроцессоре нитей, поэтому, например, в терминологии Nvidia она даже называется shared, а термином local memory обозначается прямо противоположное, а именно: некая персональная область отдельной нити в глобальной памяти, видимая и доступная только ей. Но кроме локальной памяти в минипроцессоре есть ещё одна область памяти, во всех архитектурах примерно в четыре раза бо́льшая по объему. Она разделена поровну между всеми исполняющимися нитями, это регистры для хранения переменных и промежуточных результатов вычислений. На каждую нить приходится несколько десятков регистров. Точное количество зависит от того, сколько нитей исполняет минипроцессор. Это количество очень важно, так как латентность глобальной памяти очень велика, сотни тактов, и в отсутствие кэшей негде хранить промежуточные результаты вычислений.
И ещё одна важная черта GPU: «мягкая» векторность. Каждый минипроцессор обладает большим количеством вычислительных модулей (8 для GT200, 16 для Radeon и 32 для Fermi), но все они могут выполнять только одну и ту же инструкцию, с одним программным адресом. Операнды же при этом могут быть разные, у разных нитей свои. Например, инструкция сложить содержимое двух регистров: она одновременно выполняется всеми вычислительными устройствами, но регистры берутся разные. Предполагается, что все нити GPU-программы, осуществляя параллельную обработку данных, в целом движутся параллельным курсом по коду программы. Таким образом, все вычислительные модули загружаются равномерно. А если нити из-за ветвлений в программе разошлись в своем пути исполнения кода, то происходит так называемая сериализация. Тогда используются не все вычислительные модули, так как нити подают на исполнение различные инструкции, а блок вычислительных модулей может исполнять, как мы уже сказали, только инструкцию с одним адресом. И, разумеется, производительность при этом падает по отношению к максимальной.
Плюсом является то, что векторизация происходит полностью автоматически, это не программирование с использованием SSE, MMX и так далее. И GPU сам обрабатывает расхождения. Теоретически, можно вообще писать программы для GPU, не думая о векторной природе исполняющих модулей, но скорость такой программы будет не очень высокой. Минус заключается в большой ширине вектора. Она больше, чем номинальное количество функциональных модулей, и составляет 32 для GPU Nvidia и 64 для Radeon. Нити обрабатываются блоками соответствующего размера. Nvidia называет этот блок нитей термином warp, AMD — wave front, что одно и то же. Таким образом, на 16 вычислительных устройствах «волновой фронт» длиной 64 нити обрабатывается за четыре такта (при условии обычной длины инструкции). Автор предпочитает в данном случае термин warp, из-за ассоциации с морским термином warp, обозначающим связанный из скрученных веревок канат. Так и нити «скручиваются» и образуют цельную связку. Впрочем, «wave front» тоже может ассоциироваться с морем: инструкции так же прибывают к исполнительным устройствам, как волны одна за другой накатываются на берег.
Если все нити одинаково продвинулись в выполнении программы (находятся в одном месте) и, таким образом, исполняют одну инструкцию, то все прекрасно, но если нет — происходит замедление. В этом случае нити из одного warp или wave front находятся в различных местах программы, они разбиваются на группы нитей, имеющих одинаковое значение номера инструкции (иначе говоря, указателя инструкций (instruction pointer)). И по-прежнему выполняются в один момент времени только нити одной группы — все выполняют одинаковую инструкцию, но с различными операндами. В итоге warp исполняется во столько раз медленней, на сколько групп он разбит, а количество нитей в группе значения не имеет. Даже если группа состоит всего из одной нити, все равно она будет выполняться столько же времени, сколько полный warp. В железе это реализовано с помощью маскирования определенных нитей, то есть инструкции формально выполняются, но результаты их выполнения никуда не записываются и в дальнейшем не используются.
Хотя в каждый момент времени каждый минипроцессор (Streaming MultiProcessor или SIMD Engine) выполняет инструкции, принадлежащие только одному warp (связке нитей), он имеет несколько десятков активных варпов в исполняемом пуле. Выполнив инструкции одного варпа, минипроцессор исполняет не следующую по очереди инструкцию нитей данного варпа, а инструкции кого-нибудь другого варпа. Тот варп может быть в совершенно другом месте программы, это не будет влиять на скорость, так как только внутри варпа инструкции всех нитей обязаны быть одинаковыми для исполнения с полной скоростью.
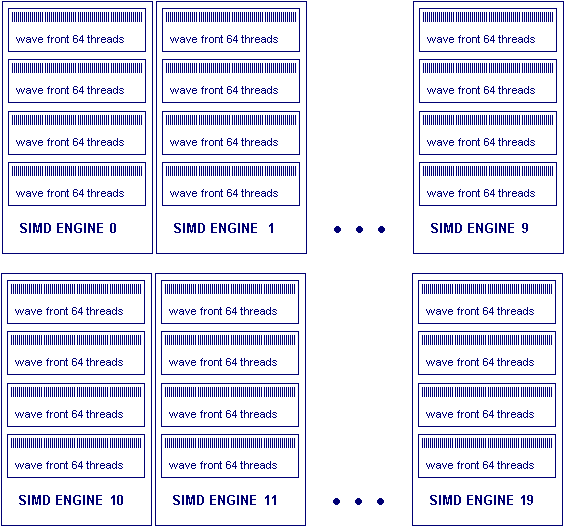
В данном случае каждый из 20 SIMD Engine имеет четыре активных wave front, в каждом из которых 64 нити. Каждая нить обозначена короткой линией. Всего: 64×4×20=5120 нитей
Таким образом, учитывая, что каждый warp или wave front состоит из 32-64 нитей, минипроцессор имеет несколько сотен активных нитей, которые исполняются практически одновременно. Ниже мы увидим, какие архитектурные выгоды сулит такое большое количество параллельных нитей, но сначала рассмотрим, какие ограничения есть у составляющих GPU минипроцессоров.
Главное, что в GPU нет стека, где могли бы хранится параметры функций и локальные переменные. Из-за большого количества нитей для стека просто нет места на кристалле. Действительно, так как GPU одновременно выполняет порядка 10000 нитей, при размере стека одной нити в 100 КБ совокупный объем составит 1 ГБ, что равно стандартному объему всей видеопамяти. Тем более нет никакой возможности поместить стек сколько-нибудь существенного размера в самом ядре GPU. Например, если положить 1000 байт стека на нить, то только на один минипроцессор потребуется 1 МБ памяти, что почти в пять раз больше совокупного объема локальной памяти минипроцессора и памяти, отведенной на хранение регистров.
Поэтому в GPU-программе нет рекурсии, и с вызовами функций особенно не развернешься. Все функции непосредственно подставляются в код при компиляции программы. Это ограничивает область применения GPU задачами вычислительного типа. Иногда можно использовать ограниченную эмуляцию стека с использованием глобальной памяти для рекурсионных алгоритмов с известной небольшой глубиной итераций, но это нетипичное применение GPU. Для этого необходимо специально разрабатывать алгоритм, исследовать возможность его реализации без гарантии успешного ускорения по сравнению с CPU.
В Fermi впервые появилась возможность использовать виртуальные функции, но опять-таки их применение лимитировано отсутствием большого быстрого кэша для каждой нити. На 1536 нитей приходится 48 КБ или 16 КБ L1, то есть виртуальные функции в программе можно использовать относительно редко, иначе для стека также будет использоваться медленная глобальная память, что замедлит исполнение и, скорее всего, не принесет выгод по сравнению с CPU-вариантом.
Таким образом, GPU представляется в роли вычислительного сопроцессора, в который загружаются данные, они обрабатываются некоторым алгоритмом, и выдается результат.
Преимущества архитектуры
Но считает GPU очень быстро. И в этом ему помогает его высокая мультипоточность. Большое количество активных нитей позволяет отчасти скрыть большую латентность расположенной отдельно глобальной видеопамяти, составляющую порядка 500 тактов. Особенно хорошо она нивелируется для кода с высокой плотностью арифметических операций. Таким образом, не требуется дорогостоящая с точки зрения транзисторов иерархия кэшей L1-L2-L3. Вместо неё на кристалле можно разместить множество вычислительных модулей, обеспечив выдающуюся арифметическую производительность. А пока исполняются инструкции одной нити или варпа, остальные сотни нитей спокойно ждут своих данных.
В Fermi был введен кэш второго уровня размером около 1 МБ, но его нельзя сравнивать с кэшами современных процессоров, он больше предназначен для коммуникации между ядрами и различных программных трюков. Если его размер разделить между всеми десятками тысяч нитей, на каждую придется совсем ничтожный объем.
Но кроме латентности глобальной памяти, в вычислительном устройстве существует ещё множество латентностей, которые надо скрыть. Это латентность передачи данных внутри кристалла от вычислительных устройств к кэшу первого уровня, то есть локальной памяти GPU, и к регистрам, а также кэшу инструкций. Регистровый файл, как и локальная память, расположены отдельно от функциональных модулей, и скорость доступа к ним составляет примерно полтора десятка тактов. И опять-таки большое количество нитей, активных варпов, позволяет эффективно скрыть эту латентность. Причем общая полоса пропускания (bandwidth) доступа к локальной памяти всего GPU, с учетом количества составляющих его минипроцессоров, значительно больше, чем bandwidth доступа к кэшу первого уровня у современных CPU. GPU может переработать значительно больше данных в единицу времени.
Можно сразу сказать, что если GPU не будет обеспечен большим количеством параллельных нитей, то у него будет почти нулевая производительность, потому что он будет работать с тем же темпом, как будто полностью загружен, а выполнять гораздо меньший объем работы. Например, пусть вместо 10000 нитей останется всего одна: производительность упадет примерно в тысячу раз, ибо не только не все блоки будут загружены, но и скажутся все латентности.
Проблема сокрытия латентностей остра и для современных высокочастотных CPU, для её устранения используются изощренные способы — глубокая конвейеризация, внеочередное исполнение инструкций (out-of-order). Для этого требуются сложные планировщики исполнения инструкций, различные буферы и т. п., что занимает место на кристалле. Это все требуется для наилучшей производительности в однопоточном режиме.
Но для GPU все это не нужно, он архитектурно быстрее для вычислительных задач с большим количеством потоков. Зато он преобразует многопоточность в производительность, как философский камень превращает свинец в золото.
GPU изначально был приспособлен для оптимального исполнения шейдерных программ для пикселей треугольников, которые, очевидно, независимы и могут исполняться параллельно. И из этого состояния он эволюционировал путем добавления различных возможностей (локальной памяти и адресуемого доступа к видеопамяти, а также усложнения набора инструкций) в весьма мощное вычислительное устройство, которое все же может быть эффективно применено только для алгоритмов, допускающих высокопараллельную реализацию с использованием ограниченного объема локальной памяти.
Пример
Одна из самых классических задач для GPU — это задача вычисления взаимодействия N тел, создающих гравитационное поле. Но если нам, например, понадобится рассчитать эволюцию системы Земля-Луна-Солнце, то GPU нам плохой помощник: мало объектов. Для каждого объекта надо вычислить взаимодействия со всеми остальными объектами, а их всего два. В случае движения Солнечной системы со всеми планетами и их лунами (примерно пара сотен объектов) GPU все еще не слишком эффективен. Впрочем, и многоядерный процессор из-за высоких накладных расходов на управление потоками тоже не сможет проявить всю свою мощь, будет работать в однопоточном режиме. Но вот если требуется также рассчитать траектории комет и объектов пояса астероидов, то это уже задача для GPU, так как объектов достаточно, чтобы создать необходимое количество параллельных потоков расчета.
GPU также хорошо себя проявит, если необходимо рассчитать столкновение шаровых скоплений из сотен тысяч звезд.
Ещё одна возможность использовать мощность GPU в задаче N тел появляется, когда необходимо рассчитать множество отдельных задач, пусть и с небольшим количеством тел. Например, если требуется рассчитать варианты эволюции одной системы при различных вариантах начальных скоростей. Тогда эффективно использовать GPU удастся без проблем.
Детали микроархитектуры AMD Radeon
Мы рассмотрели базовые принципы организации GPU, они общие для видеоускорителей всех производителей, так как у них изначально была одна целевая задача — шейдерные программы. Тем не менее, производители нашли возможность разойтись в деталях микроархитектурной реализации. Хотя и CPU различных вендоров порой сильно отличаются, даже будучи совместимыми, как, например, Pentium 4 и Athlon или Core. Архитектура Nvidia уже достаточно широко известна, сейчас мы рассмотрим Radeon и выделим основные отличия в подходах этих вендоров.
Видеокарты AMD получили полноценную поддержку вычислений общего назначения начиная с семейства Evergreen, в котором также были впервые реализованы спецификации DirectX 11. Карточки семейства 47xx имеют ряд существенных ограничений, которые будут рассмотрены ниже.
Различия в размере локальной памяти (32 КБ у Radeon против 16 КБ у GT200 и 64 КБ у Fermi) в общем не принципиальны. Как и размер wave front в 64 нити у AMD против 32 нитей в warp у Nvidia. Практически любую GPU-программу можно легко переконфигурировать и настроить на эти параметры. Производительность может измениться на десятки процентов, но в случае с GPU это не так принципиально, ибо GPU-программа обычно работает в десять раз медленней, чем аналог для CPU, или в десять раз быстрее, или вообще не работает.
Более важным является использование AMD технологии VLIW (Very Long Instruction Word). Nvidia использует скалярные простые инструкции, оперирующие со скалярными регистрами. Её ускорители реализуют простой классический RISC. Видеокарточки AMD имеют такое же количество регистров, как GT200, но регистры векторные 128-битные. Каждая VLIW-инструкция оперирует несколькими четырехкомпонентными 32-битными регистрами, что напоминает SSE, но возможности VLIW гораздо шире. Это не SIMD (Single Instruction Multiple Data), как SSE — здесь инструкции для каждой пары операндов могут быть различными и даже зависимыми! Например, пусть компоненты регистра А называются a1, a2, a3, a4; у регистра B — аналогично. Можно вычислить с помощью одной инструкции, которая выполняется за один такт, например, число a1×b1+a2×b2+a3×b3+a4×b4 или двумерный вектор (a1×b1+a2×b2, a3×b3+a4×b4).
Это стало возможным благодаря более низкой частоте GPU, чем у CPU, и сильному уменьшению техпроцессов в последние годы. При этом не требуется никакого планировщика, почти все исполняется за такт.
Благодаря векторным инструкциям, пиковая производительность Radeon в числах одинарной точности очень высока и составляет уже терафлопы.
Один векторный регистр может вместо четырех чисел одинарной точности хранить одно число двойной точности. И одна VLIW-инструкция может либо сложить две пары чисел double, либо умножить два числа, либо умножить два числа и сложить с третьим. Таким образом, пиковая производительность в double примерно в пять раз ниже, чем во float. Для старших моделей Radeon она соответствует производительности Nvidia Tesla на новой архитектуре Fermi и гораздо выше, чем производительность в double карточек на архитектуре GT200. В потребительских видеокарточках Geforce на основе Fermi максимальная скорость double-вычислений была уменьшена в четыре раза.
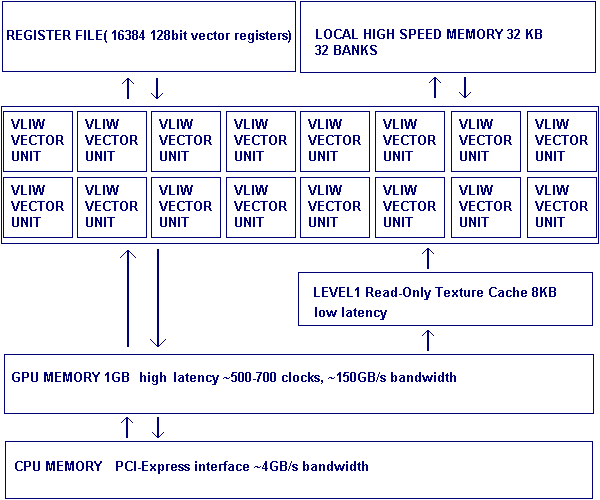
Принципиальная схема работы Radeon. Представлен только один минипроцессор из 20 параллельно работающих
Производители GPU, в отличие от производителей CPU (прежде всего, x86-совместимых), не связаны вопросами совместимости. GPU-программа сначала компилируется в некий промежуточный код, а при запуске программы драйвер компилирует этот код в машинные инструкции, специфичные для конкретной модели. Как было описано выше, производители GPU воспользовались этим, придумав удобные ISA (Instruction Set Architecture) для своих GPU и изменяя их от поколения к поколению. Это в любом случае добавило какие-то проценты производительности из-за отсутствия (за ненадобностью) декодера. Но компания AMD пошла ещё дальше, придумав собственный формат расположения инструкций в машинном коде. Они расположены не последовательно (согласно листингу программы), а по секциям.
Сначала идет секция инструкций условных переходов, которые имеют ссылки на секции непрерывных арифметических инструкций, соответствующие различным ветвям переходов. Они называются VLIW bundles (связки VLIW-инструкций). В этих секциях содержатся только арифметические инструкции с данными из регистров или локальной памяти. Такая организация упрощает управление потоком инструкций и доставку их к исполнительным устройствам. Это тем более полезно, учитывая что VLIW-инструкции имеют сравнительно большой размер. Есть также секции для инструкций обращений к памяти.
| Секции инструкций условных переходов | ||||
|---|---|---|---|---|
| Секция 0 | Ветвление 0 | Ссылка на секцию №3 непрерывных арифметических инструкций | ||
| Секция 1 | Ветвление 1 | Ссылка на секцию №4 | ||
| Секция 2 | Ветвление 2 | Ссылка на секцию №5 | ||
| Секции непрерывных арифметических инструкций | ||||
| Секция 3 | VLIW-инструкция 0 | VLIW-инструкция 1 | VLIW-инструкция 2 | VLIW-инструкция 3 |
| Секция 4 | VLIW-инструкция 4 | VLIW-инструкция 5 | ||
| Секция 5 | VLIW-инструкция 6 | VLIW-инструкция 7 | VLIW-инструкция 8 | VLIW-инструкция 9 |
GPU обоих производителей (и Nvidia, и AMD) также обладают встроенными инструкциями быстрого вычисления за несколько тактов основных математических функций, квадратного корня, экспоненты, логарифмов, синусов и косинусов для чисел одинарной точности. Для этого есть специальные вычислительные блоки. Они «произошли» от необходимости реализации быстрой аппроксимации этих функций в геометрических шейдерах.
Если бы даже кто-то не знал, что GPU используются для графики, и ознакомился только с техническими характеристиками, то по этому признаку он мог бы догадаться, что эти вычислительные сопроцессоры произошли от видеоускорителей. Аналогично, по некоторым чертам морских млекопитающих ученые поняли, что их предки были сухопутными существами.
Но более явная черта, выдающая графическое происхождение устройства, это блоки чтения двумерных и трехмерных текстур с поддержкой билинейной интерполяции. Они широко используются в GPU-программах, так как обеспечивают ускоренное и упрощенное чтение массивов данных read-only. Одним из стандартных вариантов поведения GPU-приложения является чтение массивов исходных данных, обработка их в вычислительных ядрах и запись результата в другой массив, который передается далее обратно в CPU. Такая схема стандартна и распространена, потому что удобна для архитектуры GPU. Задачи, требующие интенсивно читать и писать в одну большую область глобальной памяти, содержащие, таким образом, зависимости по данным, трудно распараллелить и эффективно реализовать на GPU. Также их производительность будет сильно зависеть от латентности глобальной памяти, которая очень велика. А вот если задача описывается шаблоном «чтение данных — обработка — запись результата», то почти наверняка можно получить большой прирост от ее исполнения на GPU.
Для текстурных данных в GPU существует отдельная иерархия небольших кэшей первого и второго уровней. Она-то и обеспечивает ускорение от использования текстур. Эта иерархия изначально появилась в графических процессорах для того, чтобы воспользоваться локальностью доступа к текстурам: очевидно, после обработки одного пикселя для соседнего пикселя (с высокой вероятностью) потребуются близко расположенные данные текстуры. Но и многие алгоритмы обычных вычислений имеют сходный характер доступа к данным. Так что текстурные кэши из графики будут очень полезны.
Хотя размер кэшей L1-L2 в карточках Nvidia и AMD примерно сходен, что, очевидно, вызвано требованиями оптимальности с точки зрения графики игр, латентность доступа к этим кэшам существенно разнится. Латентность доступа у Nvidia больше, и текстурные кэши в Geforce в первую очередь помогают сократить нагрузку на шину памяти, а не непосредственно ускорить доступ к данным. Это не заметно в графических программах, но важно для программ общего назначения. В Radeon же латентность текстурного кэша ниже, зато выше латентность локальной памяти минипроцессоров. Можно привести такой пример: для оптимального перемножения матриц на карточках Nvidia лучше воспользоваться локальной памятью, загружая туда матрицу поблочно, а для AMD лучше положиться на низколатентный текстурный кэш, читая элементы матрицы по мере надобности. Но это уже достаточно тонкая оптимизация, и для уже принципиально переведенного на GPU алгоритма.
Это различие также проявляется в случае использования 3D-текстур. Один из первых бенчмарков вычислений на GPU, который показывал серьезное преимущество AMD, как раз и использовал 3D-текстуры, так как работал с трехмерным массивом данных. А латентность доступа к текстурам в Radeon существенно быстрее, и 3D-случай дополнительно более оптимизирован в железе.
Для получения максимальной производительности от железа различных фирм нужен некий тюнинг приложения под конкретную карточку, но он на порядок менее существенен, чем в принципе разработка алгоритма для архитектуры GPU.
Ограничения серии Radeon 47xx
В этом семействе поддержка вычислений на GPU неполна. Можно отметить три важных момента. Во-первых, нет локальной памяти, то есть она физически есть, но не обладает возможностью универсального доступа, требуемого современным стандартом GPU-программ. Она эмулируется программно в глобальной памяти, то есть её использование в отличие от полнофункционального GPU не принесет выгод. Второй момент — ограниченная поддержка различных инструкций атомарных операций с памятью и инструкций синхронизации. И третий момент — это довольно маленький размер кэша инструкций: начиная с некоторого размера программы происходит замедление скорости в разы. Есть и другие мелкие ограничения. Можно сказать, только идеально подходящие для GPU программы будут хорошо работать на этой видеокарточке. Пусть в простых тестовых программах, которые оперируют только с регистрами, видеокарточка может показывать хороший результат в Gigaflops, что-то сложное эффективно запрограммировать под нее проблематично.
Преимущества и недостатки Evergreen
Если сравнить продукты AMD и Nvidia, то, с точки зрения вычислений на GPU, серия 5xxx выглядит, как очень мощный GT200. Такой мощный, что по пиковой производительности превосходит Fermi примерно в два c половиной раза. Особенно после того, как параметры новых видеокарточек Nvidia были урезаны, сокращено количество ядер. Но появление в Fermi кэша L2 упрощает реализацию на GPU некоторых алгоритмов, таким образом расширяя область применения GPU. Что интересно, для хорошо оптимизированных под прошлое поколение GT200 CUDA-программ архитектурные нововведения Fermi зачастую ничего не дали. Они ускорились пропорционально увеличению количества вычислительных модулей, то есть менее чем в два раза (для чисел одинарной точности), а то и ещё меньше, ибо ПСП памяти не увеличилась (или по другим причинам).
И в хорошо ложащихся на архитектуру GPU задачах, имеющих выраженную векторную природу (например, перемножении матриц), Radeon показывает относительно близкую к теоретическому пику производительность и обгоняет Fermi. Не говоря уже о многоядерных CPU. Особенно в задачах с числами с одинарной точностью.
Но Radeon имеет меньшую площадь кристалла, меньшее тепловыделение, энергопотребление, больший выход годных и, соответственно, меньшую стоимость. И непосредственно в задачах 3D-графики выигрыш Fermi, если он вообще есть, гораздо меньше разницы в площади кристалла. Во многом это объясняется тем, что вычислительная архитектура Radeon с 16 вычислительными устройствами на минипроцессор, размером wave front в 64 нити и векторными VLIW-инструкциями прекрасна для его главной задачи — вычисления графических шейдеров. Для абсолютного большинства обычных пользователей производительность в играх и цена приоритетны.
С точки зрения профессиональных, научных программ, архитектура Radeon обеспечивает лучшее соотношение цена-производительность, производительность на ватт и абсолютную производительность в задачах, которые в принципе хорошо соответствуют архитектуре GPU, допускают параллелизацию и векторизацию.
Например, в полностью параллельной легко векторизуемой задаче подбора ключей Radeon в несколько раз быстрее Geforce и в несколько десятков раз быстрее CPU.
Это соответствует общей концепции AMD Fusion, согласно которой GPU должны дополнять CPU, и в будущем интегрироваться в само ядро CPU, как ранее математический сопроцессор был перенесен с отдельного кристалла в ядро процессора (это случилось лет двадцать назад, перед появлением первых процессоров Pentium). GPU будет интегрированным графическим ядром и векторным сопроцессором для потоковых задач.
В Radeon используется хитрая техника смешения инструкций из различных wave front при исполнении функциональными модулями. Это легко сделать, так как инструкции полностью независимы. Принцип аналогичен конвейерному исполнению независимых инструкций современными CPU. По всей видимости, это дает возможность эффективно исполнять сложные, занимающие много байт, векторные VLIW-инструкции. В CPU для этого требуется сложный планировщик для выявления независимых инструкций или использование технологии Hyper-Threading, которая также снабжает CPU заведомо независимыми инструкциями из различных потоков.
| такт 0 | такт 1 | такт 2 | такт 3 | такт 4 | такт 5 | такт 6 | такт 7 | VLIW-модуль | |
| wave front 0 | wave front 1 | wave front 0 | wave front 1 | wave front 0 | wave front 1 | wave front 0 | wave front 1 | ||
|---|---|---|---|---|---|---|---|---|---|
| → | инстр. 0 | инстр. 0 | инстр. 16 | инстр. 16 | инстр. 32 | инстр. 32 | инстр. 48 | инстр. 48 | VLIW0 |
| → | инстр. 1 | … | … | … | … | … | … | … | VLIW1 |
| → | инстр. 2 | … | … | … | … | … | … | … | VLIW2 |
| → | инстр. 3 | … | … | … | … | … | … | … | VLIW3 |
| → | инстр. 4 | … | … | … | … | … | … | … | VLIW4 |
| → | инстр. 5 | … | … | … | … | … | … | … | VLIW5 |
| → | инстр. 6 | … | … | … | … | … | … | … | VLIW6 |
| → | инстр. 7 | … | … | … | … | … | … | … | VLIW7 |
| → | инстр. 8 | … | … | … | … | … | … | … | VLIW8 |
| → | инстр. 9 | … | … | … | … | … | … | … | VLIW9 |
| → | инстр. 10 | … | … | … | … | … | … | … | VLIW10 |
| → | инстр. 11 | … | … | … | … | … | … | … | VLIW11 |
| → | инстр. 12 | … | … | … | … | … | … | … | VLIW12 |
| → | инстр. 13 | … | … | … | … | … | … | … | VLIW13 |
| → | инстр. 14 | … | … | … | … | … | … | … | VLIW14 |
| → | инстр. 15 | … | … | … | … | … | … | … | VLIW15 |
128 инструкций двух wave front, каждый из которых состоит из 64 операций, исполняются 16 VLIW-модулями за восемь тактов. Происходит чередование, и каждый модуль в реальности имеет два такта на исполнение целой инструкции при условии, что он на втором такте начнет выполнять новую параллельно. Вероятно, это помогает быстро исполнить VLIW-инструкцию типа a1×a2+b1×b2+c1×c2+d1×d2, то есть исполнить восемь таких инструкций за восемь тактов. (Формально получается, одну за такт.)
В Nvidia, по-видимому, такой технологии нет. И в отсутствие VLIW, для высокой производительности с использованием скалярных инструкций требуется высокая частота работы, что автоматически повышает тепловыделение и предъявляет высокие требования к технологическому процессу (чтобы заставить работать схему на более высокой частоте).
Недостатком Radeon с точки зрения GPU-вычислений является большая нелюбовь к ветвлениям. GPU вообще не жалуют ветвления из-за вышеописанной технологии выполнения инструкций: сразу группой нитей с одним программным адресом. (Кстати, такая техника называется SIMT: Single Instruction — Multiple Threads (одна инструкция — много нитей), по аналогии с SIMD, где одна инструкция выполняет одну операцию с различными данными.) Однако Radeon ветвления не любят особенно: это вызвано бо́льшим размером связки нитей. Понятно, что если программа не полностью векторная, то чем больше размер warp или wave front, тем хуже, так как при расхождении в пути по программе соседних нитей образуется больше групп, которые необходимо исполнять последовательно (сериализованно). Допустим, все нити разбрелись, тогда в случае размера warp в 32 нити программа будет работать в 32 раза медленней. А в случае размера 64, как в Radeon, — в 64 раза медленней.
Это заметное, но не единственное проявление «неприязни». В видеокарточках Nvidia каждый функциональный модуль, иначе называемый CUDA core, имеет специальный блок обработки ветвлений. А в видеокартах Radeon на 16 вычислительных модулей — всего два блока управления ветвлениями (они выведены из домена арифметических блоков). Так что даже простая обработка инструкции условного перехода, пусть её результат и одинаков для всех нитей в wave front, занимает дополнительное время. И скорость проседает.
Компания AMD производит к тому же и CPU. Они полагают, что для программ с большим количеством ветвлений все равно лучше подходит CPU, а GPU предназначен для чисто векторных программ.
Так что Radeon предоставляет в целом меньше возможностей для эффективного программирования, но обеспечивает лучшее соотношение цена-производительность во многих случаях. Другими словами, программ, которые можно эффективно (с пользой) перевести с CPU на Radeon, меньше, чем программ, эффективно работающих на Fermi. Но зато те, которые эффективно перенести можно, будут работать на Radeon эффективнее во многих смыслах.
API для GPU-вычислений
Сами технические спецификации Radeon смотрятся привлекательно, пусть и не стоит идеализировать и абсолютизировать вычисления на GPU. Но не менее важно для производительности программное обеспечение, необходимое для разработки и выполнения GPU-программы — компиляторы с языка высокого уровня и run-time, то есть драйвер, который осуществляет взаимодействие между частью программы, работающей на CPU, и непосредственно GPU. Оно даже более важно, чем в случае CPU: для CPU не нужен драйвер, который будет осуществлять менеджмент передачи данных, и с точки зрения компилятора GPU более привередлив. Например, компилятор должен обойтись минимальным количеством регистров для хранения промежуточных результатов вычислений, а также аккуратно встраивать вызовы функций, опять-таки используя минимум регистров. Ведь чем меньше регистров использует нить, тем больше нитей можно запустить и тем полнее нагрузить GPU, лучше скрывая время доступа к памяти.
И вот программная поддержка продуктов Radeon пока отстает от развития железа. (В отличие от ситуации с Nvidia, где откладывался выпуск железа, и продукт вышел в урезанном виде.) Ещё совсем недавно OpenCL-компилятор производства AMD имел статус бета, со множеством недоработок. Он слишком часто генерил ошибочный код либо отказывался компилировать код из правильного исходного текста, либо сам выдавал ошибку работы и зависал. Только в конце весны вышел релиз с высокой работоспособностью. Он тоже не лишен ошибок, но их стало значительно меньше, и они, как правило, возникают на боковых направлениях, когда пытаются запрограммировать что-то на грани корректности. Например, работают с типом uchar4, который задает 4-байтовую четырехкомпонентную переменную. Этот тип есть в спецификациях OpenCL, но работать с ним на Radeon не стоит, ибо регистры-то 128-битные: те же четыре компоненты, но 32-битные. А такая переменная uchar4 все равно займет целый регистр, только еще потребуются дополнительные операции упаковки и доступа к отдельным байтовым компонентам. Компилятор не должен иметь никаких ошибок, но компиляторов без недочетов не бывает. Даже Intel Compiler после 11 версий имеет ошибки компиляции. Выявленные ошибки исправлены в следующем релизе, который выйдет ближе к осени.
Но есть ещё множество вещей, требующих доработки. Например, до сих пор стандартный GPU-драйвер для Radeon не имеет поддержки GPU-вычислений с использованием OpenCL. Пользователь должен загружать и устанавливать дополнительный специальный пакет.
Но самое главное — это отсутствие каких бы то ни было библиотек функций. Для вещественных чисел двойной точности нет даже синуса, косинуса и экспоненты. Что ж, для сложения-умножения матриц этого не требуется, но если вы хотите запрограммировать что-то более сложное, надо писать все функции с нуля. Или ждать нового релиза SDK. В скором времени должна выйти ACML (AMD Core Math Library) для GPU-семейства Evergreen с поддержкой основных матричных функций.
На данный момент, по мнению автора статьи, реальным для программирования видеокарт Radeon видится использование API Direct Compute 5.0, естественно учитывая ограничения: ориентацию на платформу Windows 7 и Windows Vista. У Microsoft большой опыт в создании компиляторов, и можно ожидать полностью работоспособный релиз очень скоро, Microsoft напрямую в этом заинтересована. Но Direct Compute ориентирован на нужды интерактивных приложений: что-то посчитать и сразу же визуализировать результат — например, течение жидкости по поверхности. Это не значит, что его нельзя использовать просто для расчетов, но это не его естественное предназначение. Скажем, Microsoft не планирует добавлять в Direct Compute библиотечные функции — как раз те, которых нет на данный момент у AMD. То есть то, что сейчас можно эффективно посчитать на Radeon — некоторые не слишком изощренные программы, — можно реализовать и на Direct Compute, который гораздо проще OpenCL и должен быть стабильнее. Плюс, он полностью портабельный, будет работать и на Nvidia, и на AMD, так что компилировать программу придется только один раз, в то время как реализации OpenCL SDK компаний Nvidia и AMD не совсем совместимы. (В том смысле, что если разработать OpenCL-программу на системе AMD с использованием AMD OpenCL SDK, она может не пойти так просто на Nvidia. Возможно, потребуется компилировать тот же текст с использованием Nvidia SDK. И, разумеется, наоборот.)
Потом, в OpenCL много избыточной функциональности, так как OpenCL задуман как универсальный язык программирования и API для широкого круга систем. И GPU, и CPU, и Cell. Так что на случай, если надо просто написать программу для типичной пользовательской системы (процессор плюс видеокарта), OpenCL не представляется, так сказать, «высокопродуктивным». У каждой функции десять параметров, и девять из них должны быть установлены в 0. А для того, чтобы установить каждый параметр, надо вызывать специальную функцию, у которой тоже есть параметры.
И самый главный текущий плюс Direct Compute — пользователю не надо устанавливать специальный пакет: все, что необходимо, уже есть в DirectX 11.
Проблемы развития GPU-вычислений
Если взять сферу персональных компьютеров, то ситуация такова: существует не так много задач, для которых требуется большая вычислительная мощность и сильно не хватает обычного двухъядерного процессора. Как будто бы из моря на сушу вылезли большие прожорливые, но неповоротливые чудовища, а на суше-то и есть почти нечего. И исконные обители земной поверхности уменьшаются в размерах, учатся меньше потреблять, как всегда бывает при дефиците природных ресурсов. Если бы сейчас была такая же потребность в производительности, как 10-15 лет назад, GPU-вычисления приняли бы на ура. А так проблемы совместимости и относительной сложности GPU-программирования выходят на первый план. Лучше написать программу, которая работала бы на всех системах, чем программу, которая работает быстро, но запускается только на GPU.
Несколько лучше перспективы GPU с точки зрения использования в профессиональных приложениях и секторе рабочих станций, так как там больше потребности в производительности. Появляются плагины для 3D-редакторов с поддержкой GPU: например, для рендеринга с помощью трассировки лучей — не путать с обычным GPU-рендеренгом! Что-то появляется и для 2D-редакторов и редакторов презентаций, с ускорением создания сложных эффектов. Программы обработки видео также постепенно обзаводятся поддержкой GPU. Вышеприведенные задачи в виду своей параллельной сущности хорошо ложатся на архитектуру GPU, но сейчас создана очень большая база кода, отлаженного, оптимизированного под все возможности CPU, так что потребуется время, чтобы появились хорошие GPU-реализации.
В этом сегменте проявляются и такие слабые стороны GPU, как ограниченный объем видеопамяти — примерно в 1 ГБ для обычных GPU. Одним из главных факторов, снижающих производительность GPU-программ, является необходимость обмена данными между CPU и GPU по медленной шине, а из-за ограниченного объема памяти приходится передавать больше данных. И тут перспективной смотрится концепция AMD по совмещению GPU и CPU в одном модуле: можно пожертвовать высокой пропускной способностью графической памяти ради легкого и простого доступа к общей памяти, к тому же с меньшей латентностью. Эта высокая ПСП нынешней видеопамяти DDR5 гораздо больше востребована непосредственно графическими программами, чем большинством программ GPU-вычислений. Вообще, общая память GPU и CPU просто существенно расширит область применения GPU, сделает возможным использование его вычислительных возможностей в небольших подзадачах программ.
И больше всего GPU востребованы в сфере научных вычислений. Уже построено несколько суперкомпьютеров на базе GPU, которые показывают очень высокий результат в тесте матричных операций. Научные задачи так многообразны и многочисленны, что всегда находится множество, которое прекрасно ложится на архитектуру GPU, для которого использование GPU позволяет легко получить высокую производительность.
Если среди всех задач современных компьютеров выбрать одну, то это будет компьютерная графика — изображение мира, в котором мы живем. И оптимальная для этой цели архитектура не может быть плохой. Это настолько важная и фундаментальная задача, что специально разработанное для неё железо должно нести в себе универсальность и быть оптимальным для различных задач. Тем более что видеокарточки успешно эволюционируют.
Дополнительные материалы:
- Подробная презентация архитектуры Evergreen
- Ещё одна презентация с акцентом на программирование OpenCL
- Страница с разнообразными публикациями и документами, посвященными вычислениям общего назначения на видеокарточках AMD
- Ссылка на сам SDK для программирования на Radeon


