Главная особенность будущего графического процессора компании AMD

Содержание
- Введение
- Проблемы существующих типов графической памяти
- Устройство и специфика HBM
- Преимущества и недостатки нового стандарта памяти
- Заключение
Введение
В скором времени в мире стандартов оперативной памяти грозят произойти несколько важных изменений, и первопроходцами должны стать производители графических процессоров, как самые заинтересованные в получении максимальной пропускной способности и энергоэффективности. У обоих основных производителей GPU есть планы по внедрению нового стандарта скоростной памяти High Bandwidth Memory (HBM), хотя существуют и другие варианты: Wide I/O (Samsung) и HMC, Hybrid Memory Cube (Intel и Micron).
Для чего вообще вдруг понадобились новые типы памяти, почему не обойтись использованием GDDR5 в видеокартах и DDR4 в других системах? Оба указанных типа памяти, универсальной и графической, являются всего лишь эволюционным развитием давно известных стандартов, и хотя они имеют улучшенные характеристики по производительности и энергопотреблению по сравнению с DDR3 и GDDR3/GDDR4, но улучшения эти не столь значительны, как многим хотелось бы.
Основам ныне применяемых стандартов DRAM уже не один десяток лет, и их улучшение позволило повысить пропускную способность далеко не настолько, насколько выросла производительность CPU и GPU за это время. Двадцать лет улучшения стандартов позволили поднять пропускную способность памяти (ПСП) всего лишь примерно в 50 раз, в то время как скорость вычислений за это время выросла много больше. Особенно это касается графических процессоров, скачок в производительности которых за это время произошел весьма существенный. И индустрии требуются новые типы памяти, которые дадут совершенно иные возможности, вроде Wide I/O, HMC и HBM.
Все эти стандарты основываются на так называемой stacked DRAM — размещении чипов памяти слоями, с одновременным доступом к разным микросхемам, что расширяет шину памяти, значительно повышая пропускную способность и немного снижая задержки. Описание разницы между указанными стандартами выходит за рамки данной статьи, но все указанные стандарты имеют множество схожих черт, хотя и с некоторыми особенностями.
Стандарт Hybrid Memory Cube, предлагаемый Intel и Micron, можно назвать наиболее универсальным, он должен позволить получить ПСП до 480 ГБ/с при несколько бо́льших энергопотреблении и себестоимости по сравнению с Wide I/O 2. Появление продукции с использованием HMC ожидается в следующем году. На данный момент стандарт HMC не является стандартом JEDEC, но в консорциум входят такие крупные компании, как Samsung, Micron, Microsoft, Altera, ARM, Intel, HP, Xilinx, SK Hynix и другие, так что поддержка со стороны индустрии у стандарта достаточная. Однако среди поддерживающих HMC нет (пока?) компаний AMD и Nvidia, выпускающих графические процессоры — они выбрали для себя конкурирующий (условно) стандарт компании Hynix — High Bandwidth Memory.
Стандарт HBM не настолько универсальный, как HMC, это специализированная версия Wide I/O 2, которая лучше всего подходит именно для графических процессоров, хотя может применяться и в будущих гибридных процессорах APU компании AMD, например. Хотя компании AMD и Nvidia уже анонсировали применение HBM в будущих поколениях GPU, Nvidia ожидает выхода своего Pascal с поддержкой этой памяти лишь в 2016-м, тогда как AMD планирует выпуск первого графического процессора, оснащенного HBM-памятью, уже в середине текущего года.
Что касается сравнения со стандартами Wide I/O и HMC, то HBM — это среднее решение по цене и производительности, специализированное для применения в связке с высокопроизводительными GPU, которое дороже в производстве, чем Wide I/O, но дешевле HMC. Кроме того, очень похоже, что HBM станет первой из перечисленных технологий stacked DRAM, которая появится на пользовательском рынке в виде графических решений. Применение же технологии Micron HMC пока что будет ограничено серверами и суперкомпьютерами, вроде семейства Knights Landing (Xeon Phi) Intel.
Новые стандарты полностью изменят рынок памяти, предлагая значительно бо́льшую ПСП и серьезное улучшение энергоэффективности. Кроме этого, немного снизятся и задержки доступа, что не так важно для применения в графических задачах, зато будет полезно в гибридных APU. Да и Intel вполне может начать применять stacked-память в своих будущих решениях, предназначенных для рынка настольных ПК, когда это станет экономически целесообразно. Такие типы памяти, как HMC и HBM, откроют гибридным процессорам совершенно новые возможности, и производительность встроенного графического ядра значительно вырастет.
Еще в 2011 году компании AMD и Hynix анонсировали совместные планы по разработке и внедрению нового стандарта памяти — High Bandwidth Memory (HBM). Новый тип памяти должен был стать огромным шагом вперед по сравнению с применяющейся до сих пор GDDR-памятью, и среди главных преимуществ HBM значились серьезное увеличение пропускной способности и увеличение энергетической эффективности (снижение потребления вместе с ростом производительности).
Компания AMD, как и компания ATI в годы своей жизни, в последние несколько лет была лидером по освоению новых типов графической памяти. Хотя продукты с поддержкой GDDR2 и GDDR3 первыми выпустили не они, но именно эта компания первой оснастила свои решения видеопамятью последних двух существующих стандартов (GDDR4 и GDDR5). Соответственно, в 2011 году в партнерстве с Hynix они решили продолжить свои инициативы по приоритетной разработке и внедрению новых стандартов видеопамяти для будущих GPU. И вот, после четырех лет разработки подошло то самое время, когда эти компании наконец-то готовы предложить рынку графический процессор, оснащенный совершенно новым типом графической памяти.
В своем отчете с мероприятия AMD под названием 2015 Financial Analyst Day мы уже рассказывали читателям о том, что компания анонсировала первое в индустрии применение HBM-памяти в своем следующем графическом процессоре, который должен выйти еще в этом квартале (то есть до конца июня).
В то время AMD еще не была готова поведать технические подробности применения HBM-памяти, да и сейчас многие технические характеристики основанного на HBM графического чипа остаются неизвестными, но заинтересованным представителям технической IT-прессы уже рассказали определенные детали. Видимо, в AMD захотели превратить свое первое в индустрии применение HBM-памяти в отдельное событие, заранее раскрыв некоторые карты. Давайте посмотрим, что же мы узнали.
Проблемы существующих типов графической памяти
За четыре поколения GDDR-памяти ее разработчики продолжали увеличивать тактовые частоты, на которой она способна работать, для увеличения пропускной способности. В итоге родилась GDDR5-память с эффективной рабочей частотой более чем 7 ГГц. Но первый графический ускоритель, использующий память GDDR5 (ATI Radeon HD 4870, если кто забыл), был выпущен еще в июне аж 2008 года! С тех пор прошло уже почти семь лет — больше, чем продержались другие типы графической памяти.
А расти то уже больше особо и некуда — из возможностей GDDR выжато почти все. В стандарте GDDR5 нынешний тип памяти достиг своего предела, и хотя небольшие возможности для роста ПСП еще есть, но они требуют слишком больших усилий и не изменят ситуацию кардинально. Но самое главное — вопрос высокого потребления не решился до сих пор. А ведь энергоэффективность — главный параметр для любого современного чипа. Даже текущие поколения GDDR5-памяти уже потребляют слишком много энергии из-за сложных механизмов тактования и работы на очень высокой частоте, а любые улучшения производительности GDDR5 связаны с дальнейшим повышением частоты и сложности чипов, а значит, и энергопотребления.
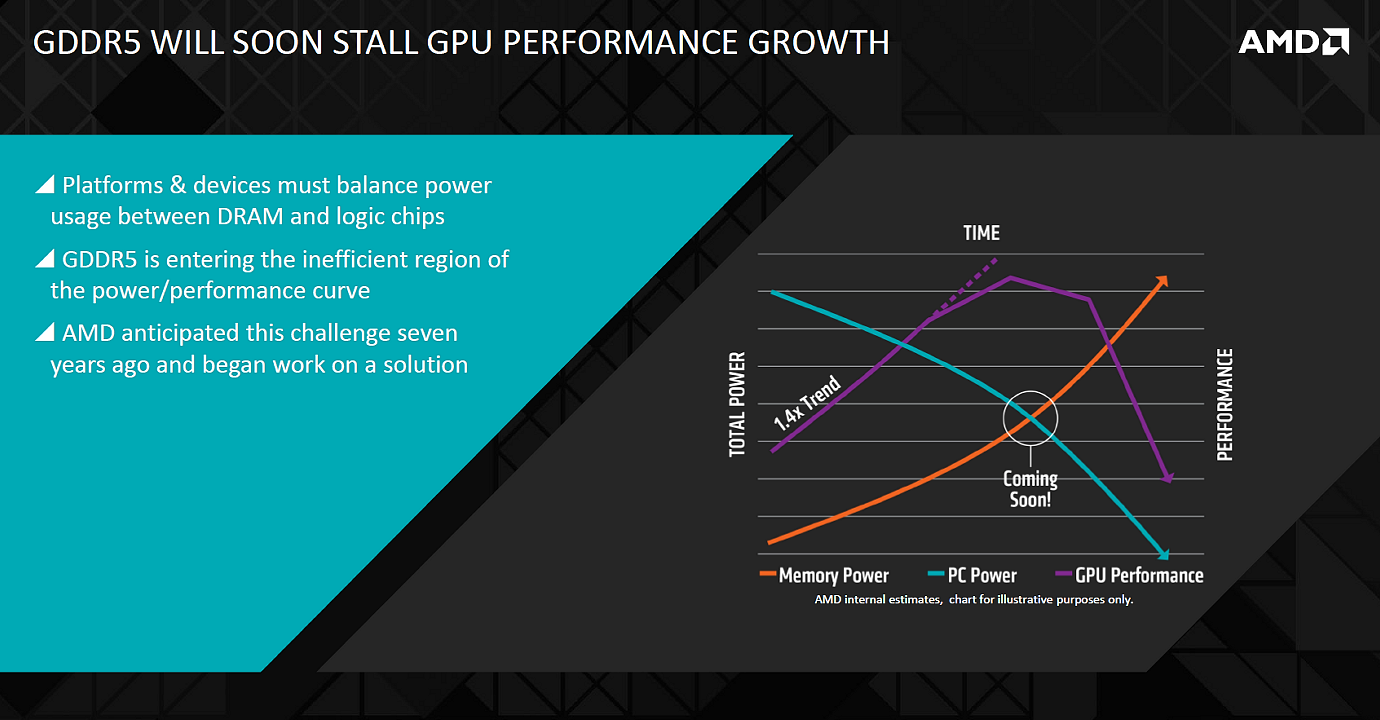
Потребление энергии исключительно чипами GDDR5-памяти в современных топовых видеокартах по оценке компании AMD уже сейчас составляет около 15-20% — то есть из 250 Вт потребления видеокарты Radeon R9 290X где-то до 40-50 Вт тратится на обеспечение работы чипов памяти. Такие данные получились даже с учетом того, что в AMD намеренно выбрали более широкую 512-битную шину памяти в GPU и использовали не слишком быструю GDDR5-память, работающую на частоте 5 ГГц — как раз для того, чтобы снизить потребление энергии видеопамятью.
А если представить точно такой же графический процессор, но с GDDR5-памятью, работающей уже на частоте в 7 ГГц? Видеопамять в таком случае будет потреблять еще больше энергии, что лишь усугубит проблему энергоэффективности и оставит GPU без необходимой доли энергии. Компания AMD показывает диаграмму изменения потребления питания GPU и RAM — если ничего не менять, то скоро они сравняются по пожиранию энергии, что приведет к снижению общей производительности.
Мы уже не раз говорили о том, что в настоящее время вопрос энергопотребления стал важнейшим из параметров для любой электроники, так как он напрямую связан с энергоэффективностью и производительностью, и его важность лишь продолжит усиливаться в будущем. Возьмем мобильные устройства, часто работающие в автономном режиме — время их работы полностью зависит от энергоэффективности внутренней начинки, так как объем батарей увеличивать уже просто некуда, ведь на этот параметр накладываются физические ограничения.
Но не только популярные мобильные устройства нуждаются в энергоэффективных решениях. Высокое потребление энергии ограничивает производительность и настольных CPU и GPU, ведь пределы потребления энергии ими неизменны уже несколько лет, расти может лишь производительность (а вместе с ней и энергоэффективность). И основной тренд на рынке сейчас такой, что ему требуются все более энергоэффективные устройства и чипы.
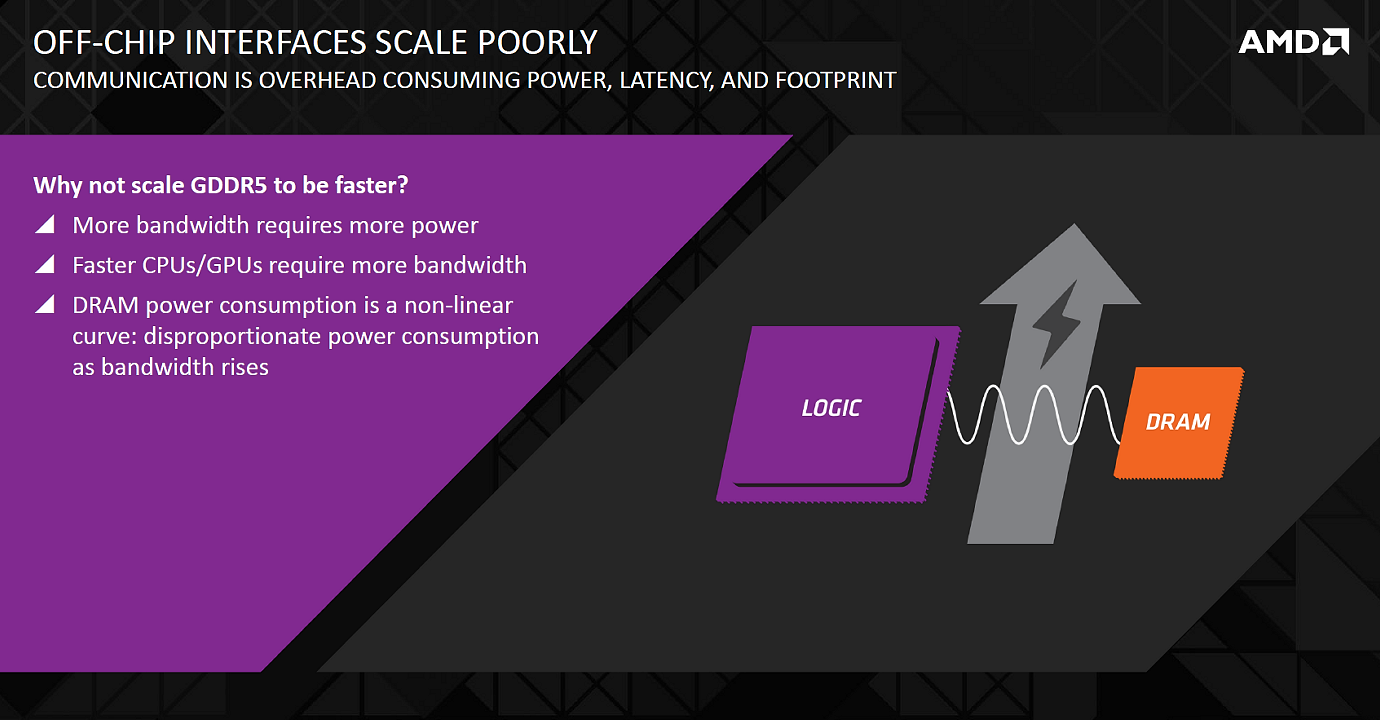
И это еще не все проблемы нынешнего стандарта памяти GDDR5. Также эти чипы занимают слишком много места на плате и требуют применения нескольких каналов памяти, что усложняет сам графический процессор. Особенно если говорить о топовых GPU с 384-битной или даже 512-битной шиной памяти. Не то чтобы сам по себе размер видеокарт имел слишком большое значение для игровых ПК, но ведь в последнее время появляется довольно много компактных корпусов, применять в которых нынешние видеокарты весьма сложно, а минимизация размера платы в этом как раз и поможет.

Теоретически, можно было бы встроить DRAM прямо в кристалл видеочипа, но это не будет эффективным решением, так как параметры технологических процессов для производства кристаллов GPU и RAM нужны совсем разные, и интеграция на одном чипе не будет оправданной с точки зрения производства.
То есть такой вариант тоже не подходит, но и с GDDR5 продолжать прогрессировать вскоре будет невозможно из-за снижения энергоэффективности этого типа памяти. Именно поэтому инженеры сразу нескольких компаний несколько лет назад и начали разработку новых поколений стандартов памяти со сверхширокой шиной, в том числе и HBM.
Устройство и специфика HBM
Исходя из сложностей и проблем развития и совершенствования GDDR5-памяти и аналогичных технологий памяти, разработка новых стандартов с широкой шиной в последние годы привела к появлению «широких», но медленных интерфейсов. Это можно представить как переход от быстрой последовательной работы микросхем памяти к медленным параллельным интерфейсам. Если в прошлые годы было проще увеличить тактовую частоту, чем расширить шину памяти, то теперь мы уперлись в скорость передачи данных с каждого чипа и пришло время распараллеливать сам интерфейс. Пусть этот путь и связан с определенными сложностями, но когда-то к нему все равно пришлось бы переходить.
В стандарте HBM и аналогичных ему, вместо массива очень быстрых чипов памяти (7 ГГц и выше), соединенных с графическим процессором по сравнительно узкой шине от 128 до 512 бит, применяются очень медленные чипы памяти (порядка 1 ГГц эффективной частоты), но ширина шины памяти при этом получается шире в несколько раз. Как и в случае с GDDR5, ширина шины для различных GPU будет разной и она зависит как от поколения стандарта HBM (первого или второго на данный момент), так и конкретного воплощения.
Компания AMD говорит о применении четырех стеков (stacks, стопок или пачек) чипов памяти, каждая из которых состоит из четырех микросхем и дает 1024-битный интерфейс памяти. То есть в итоге на GPU получаются просто широченная по меркам GDDR5-памяти шина в 4096 бит. Естественно, что при этом чипам памяти не обязательно работать на таких высоких частотах, как в случае GDDR5 — даже низких частот будет достаточно, чтобы по полосе пропускания памяти (ПСП) заметно обойти привычные доселе интерфейсы.

Конечно, интересующимся технической стороной дела хотелось бы узнать не только цифры ПСП, но и то, каким образом они достигаются. Сама по себе идея сверхширокой шины памяти лежит на поверхности, но одно дело теория, а совсем другое — практика. Именно сложности с практической реализацией присоединения очень широкой шины и не давала воплотить все это ранее.
4096-битная шина памяти требует значительно большее количество соединений, по сравнению с привычной GDDR5, и все они должны поместиться физически, чтобы такая шина работала. Именно эти параллельные соединения и являются главной проблемой в воплощении GPU с HBM-памятью, и для успешного решения задач по их размещению в новом типе памяти применяется несколько новых технологий, о которых мы сейчас и расскажем.
Самым важным вопросом, который встал перед инженерами, является эффективная разводка 4096-битной шины памяти. Ведь даже самые последние технологии производства чипов имеют свои ограничения, и графические процессоры никогда не переходили предел в 512 бит, даже в самых последних топовых графических чипах вроде Hawaii. Организовать еще более широкую шину памяти на больших GPU теоретически можно, но решение этой очень сложной задачи будут ограничивать физические возможности по размещению такого количества соединений и на печатной плате и в самом чипе, не говоря уже о необходимом количестве контактов на корпусах типа BGA.
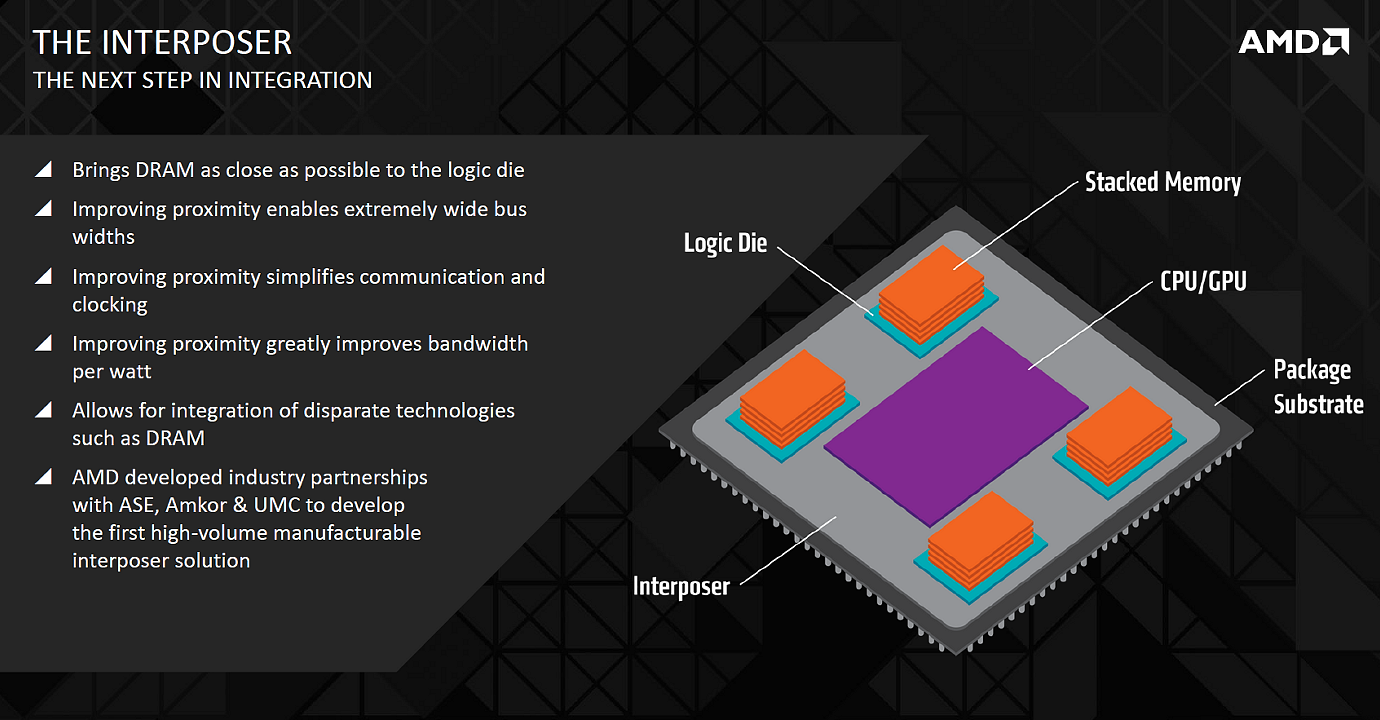
Решением первой части этой задачи стала разработка специального слоя, который способен вместить соединения большой плотности — кремниевой подложки (interposer). Этот слой похож на обычный кремниевый кристалл, в котором вместо некоей внутренней логики размещены исключительно металлические слои для передачи сигналов и питания между различными компонентами — этакий переходник. При производстве interposer используются возможности современных литографических процессов, позволяющих разместить очень тонкие проводники, которые практически невозможно вместить на традиционных печатных платах.
Использование такого слоя-переходника решает часть фундаментальных проблем по размещению широкой шины памяти, а также дает и другие преимущества. Так, вместе с решением проблемы маршрутизации проводников, эта кремниевая подложка позволяет разместить чипы памяти очень близко к GPU, но не прямо на кристалле, как применяется в случаях мобильных систем-на-чипе, например. Ведь подобное решение (package on package, или PoP) попросту невозможно для выделяющих значительное количество тепла графических процессоров.
А если поместить микросхемы памяти близко к графическому чипу, то и длинных соединений между ними не требуется, что упрощает конструкцию и предъявляет менее жесткие требования по питанию. Помещение чипов памяти вместе с основной логикой также выигрывает в повышении степени интеграции — большее количество функциональной логики можно собрать в одной упаковке, что уменьшает количество необходимой внешней обвязки. А достижение высокой степени интеграции — давний тренд в индустрии. Все постепенно интегрировалось в кристаллы: сначала кэш-память и FPU, затем чипсетная логика и графические ядра, а теперь вот и память перебирается поближе к вычислительным ядрам.
Конечно, у решения с промежуточным слоем интерпозера есть и свои недостатки — это усложнение конструкции и повышение себестоимости производства. Естественно, что никто из AMD пока что не говорит о стоимости производства первых чипов с HBM, но очевидно, что добавление дополнительного слоя, а также его соединение и тестирование всего продукта, включающего сложнейшую логику, может лишь увеличить его себестоимость, особенно в самом начале его производства. И особенно — по сравнению с давно отработанными технологиями производства традиционных печатных плат и чипов без кучи слоев, соединенных друг с другом.
Ну хотя бы сам по себе слой интерпозера не столь сложен, как сам графический процессор и он не требует столь же сложного и современного производственного процесса. Отработанного годами и весьма недорогого по современным меркам техпроцесса 65 нм здесь более чем достаточно. И все-таки интерпозер явно добавляет некоторую сумму к себестоимости всего продукта с поддержкой HBM, так что абсолютно логичным выглядит первое применение этого типа памяти пока что лишь исключительно в топовых GPU. Про менее дорогие видеокарты и уж тем более гибридные процессоры APU можно говорить пока что лишь теоретически и с большой осторожностью.
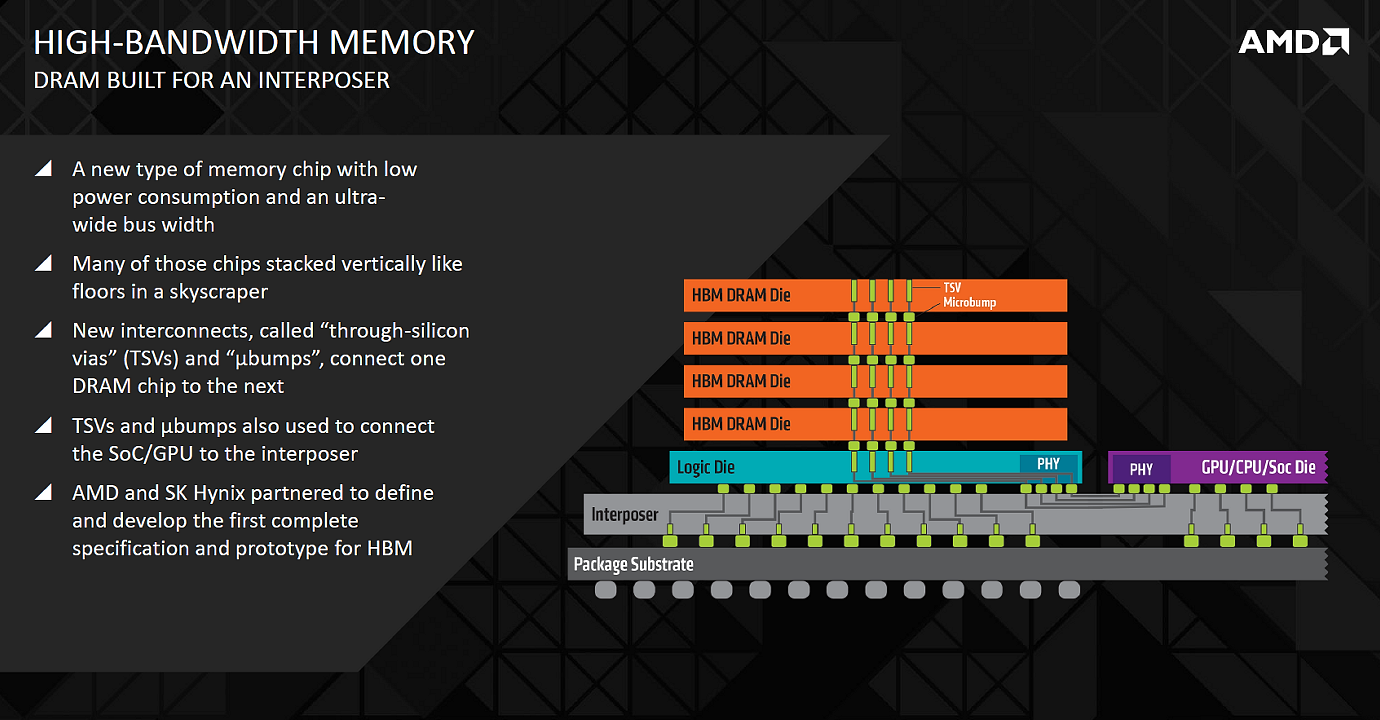
Рассматривая весь «бутерброд» в разрезе, можно увидеть, что интерпозер становится новым слоем между традиционной упаковкой и чипами DRAM с дополнительной управляющей логикой, смонтированными прямо на интерпозере. Для связи чипов памяти и логики с интерпозером используются специальные соединения типа microbump и TSV (through-silicon vias), далее интерпозер соединяется с основным кристаллом, а тот уже привычно соединен с печатной платой контактами BGA.
Само по себе присоединение чипа с HBM-памятью к печатной плате несколько упрощается, так как в данном случае на PCB не будет никаких соединительных линий к микросхемам памяти, останутся только линии для передачи данных (по шине PCI Express и т. п.), а также для питания графического процессора и микросхем памяти. Часть этих сложностей переходит на слой интерпозера, поэтому его тестирование при производстве становится одной из самых важных задач.
Еще один важный технологический момент в присоединении чипов HBM-памяти друг к другу заключается в создании соединений типа through-silicon vias (TSV). Если интерпозер решает задачу маршрутизации широкой ширины памяти для GPU, то этот тип соединений позволяет соединить стопку микросхем памяти в единый 1024-битный стек. Причины для такого объединения нескольких чипов просты — облегчение производства и снижение количества отдельных устройств в системе. Главная сложность в том, что традиционные методы соединений, какие используются в упаковке PoP, не способны обеспечить достаточную плотность соединений, их должно быть очень много и они очень маленькие.
Поэтому проблема объединения стопки чипов DRAM была решена при помощи TSV-соединений. Обычные типы соединений позволяют соединить два слоя вместе, а TSV расширяет эти возможности, соединяя и дальнейшие кремниевые слои. С точки зрения производственного процесса, соединения типа TSV сложнее в производстве и объединение чипов DRAM в стеки является непростой технологической задачей. К стопке чипов памяти снизу присоединено еще и логическое ядро, которое отвечает за работу всех чипов DRAM в стеке и управляет шиной HBM между стеком и GPU.
Главным ограничителем для дальнейшего роста производительности сейчас являются возможности по изготовлению слоя интерпозера — в нем нужно сделать много очень маленьких соединений для нескольких слоев памяти. Именно поэтому количество слоев пока что ограничено четырьмя, а размещения восьми слоев придется немного подождать — в HBM второго поколения уже будет восемь слоев (и вдвое больше ПСП при прочих равных условиях, соответственно). В остальном HBM2 будет мало отличаться от HBM1. Разве что еще ожидается поддержка коррекции ошибок ECC, важная для применения в профессиональных решениях.
Преимущества и недостатки нового стандарта памяти
После рассмотрения технических вопросов о том, как именно устроена HBM-память, переходим к характеристикам ее производительности и другим преимуществам HBM. Хотя сходу может показаться, что тут все просто, но кроме банального прироста в полосе пропускания памяти, более низкое потребление и физически меньший размер дают дополнительные плюсы перед GDDR5-памятью.
Но сначала поговорим о чистой производительности. Что даст применение HBM? Ответ не так прост и зависит от того, сколько стеков (стопок) чипов памяти установлено в данном продукте, от количества чипов памяти в стеке и от частоты работы этих чипов. Тут важно отметить разницу между двумя поколениями HBM-памяти. Первое поколение, которое и ожидается к применению в следующем топовом GPU AMD, позволяет использовать 1024-битные стеки из четырех чипов, работающих с частотой до 500 МГц, которая соответствует эффективной частоте в 1 ГГц для DDR-памяти. То есть каждый стек способен обеспечить до 128 ГБ/с полосы пропускания видеопамяти.
В теории, HBM позволяет использовать и восемь стеков на один чип, когда каждый из стеков включает 1 ГБ памяти. Но AMD приводит пример, в котором используется четыре стека, что дает нам итоговую пропускную способность в 512 ГБ/с. Конечно, это больше, чем 320 ГБ/с у Radeon R9 290X и 336 ГБ/с у лучшей карты конкурента Geforce GTX Titan X, но обеспечивает лишь до 60% прироста в ПСП — не слишком много для абсолютно нового типа памяти с такой широкой шиной, ведь чисто теоретически можно предположить появление GPU с 512-битной шиной и применением очень быстрой GDDR5-памяти, которая по ПСП не уступит первому варианту HBM-памяти.
Любопытно, что представитель AMD уверил нас, что и задержки доступа к памяти в случае с HBM получаются чуть ниже — на 15-20% по сравнению с GDDR5. Это не так уж важно для графических задач, но очень важно для CPU и некоторых вычислительных задач на GPU. Кроме того, в будущих продуктах HBM-память можно будет применять в том числе и в качестве кэш-памяти последнего уровня, например, но это скорее вопрос к разработчикам CPU, чем GPU.
Кроме повышения ПСП и небольшого снижения задержек, применение HBM обеспечивает и снижение потребления энергии всей подсистемой памяти. Мы уже писали выше о том, что в текущем топовом решении Radeon R9 290X до 15-20% из 250 Вт общего потребления энергии, расходуется на питание чипов GDDR5. Если посчитать, то это будет до 37,5-50 Вт в абсолютных цифрах. Хотя из следующей диаграммы AMD следует, что GDDR5 обеспечивает 10,66 ГБ/с ПСП на 1 Вт, то есть по этим расчетам потребление GDDR5-памяти получается несколько ниже — 30 Вт. HBM же память дает более 35 ГБ/с на ватт, то есть обеспечивает более чем втрое лучшую энергоэффективность, по сравнению с GDDR5.
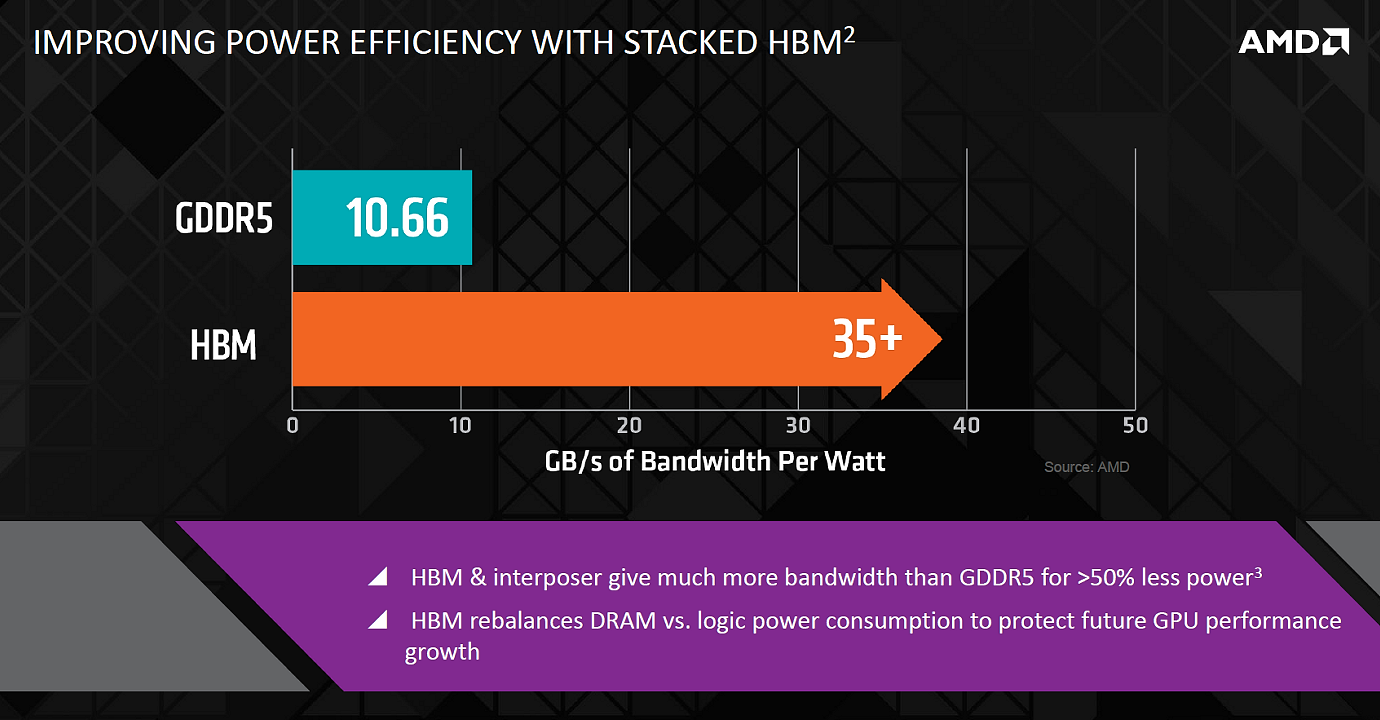
Доля памяти в общем энергопотреблении видеокарт пока что может быть и не слишком велика, но она постоянно растет, и чем дальше — тем будет только хуже. Ведь рост потребления энергии чипами GDDR5 в зависимости от ПСП нелинейный, потребление энергии растет быстрее, чем тактовая частота и обеспечиваемая ПСП, и в будущем такая ситуация начала бы ограничивать общую производительность видеокарт.
Преимущество в энергоэффективности позволяет или улучшить производительность или сэкономить энергию. Последнее важно скорее для мобильных решений, а для ожидаемого топового GPU можно повысить ПСП при отсутствии роста потребления энергии. Так что вряд ли энергопотребление снизится настолько уж сильно. Если взять предполагаемое значение итогового ПСП в 512 ГБ/с при четырех стеках HBM-памяти, то такие чипы будут потреблять около 15 Вт против 30 Вт у 320 ГБ/с GDDR5 в случае Radeon R9 290X.
Это преимущество в 15 или даже 20-25 Вт (с учетом разницы в ПСП) можно потратить на разные вещи, но для топового GPU вероятнее именно увеличение производительности. Ведь та же технология управления питанием PowerTune ограничивает общее потребление видеокартой, и большая доля питания, выделенная для GPU, позволит компании AMD повысить тактовые частоты для следующего топового графического процессора с HBM. Увы, конкретных цифр у нас пока что нет, ни итоговой ПСП конечного продукта, ни тактовых частот, ни цифр энергопотребления. Так что мы можем только гадать, что в итоге получится у AMD.
В любом случае, все графические процессоры в большей или меньшей степени страдают от недостатка в пропускной способности памяти — во многих случаях это негативно влияет на общую производительность 3D-рендеринга. И у нас нет никаких сомнений в том, что резкое увеличение ПСП будет благом, и применение HBM лишь улучшит итоговую производительность.
Но тут есть одна оговорка — даже имея преимущество по ПСП, существующие решения компании AMD зачастую или не быстрее соперничающих видеокарт Nvidia, или даже несколько медленнее их. Так что мы бы хотели предостеречь от слишком больших ожиданий от внедрения HBM-памяти, по крайней мере в игровых задачах. Похоже, что у соперника AMD лучше работают технологии по сжатию информации во фреймбуфере (применяются методы без потерь, разумеется).
Но если новый GPU AMD будет основан на архитектуре GCN 1.2 или более новой, то есть шанс к улучшению ситуации, так как именно в этой версии архитектуры были внедрены новые методы сжатия данных, что должно выправить ситуацию. Так что ожидаемый топовый графический процессор AMD получит высокую ПСП физически, да еще и улучшенную эффективность ее использования, что должно дать некоторое преимущество в условиях ограничения общей скорости рендеринга полосой пропускания — например, в высоких разрешениях.
С точки зрения проектирования самого графического процессора, с применением HBM можно сэкономить и площадь кристалла GPU, которую занимают контроллеры памяти — так как протоколы памяти сильно упрощены, по сравнению с GDDR5. Отсюда же следует некоторая экономия энергии, потребляемой этими контроллерами памяти — есть преимущество по энергоэффективности в том числе и со стороны GPU — видеочип с HBM-памятью также потребляет меньше энергии при прочих равных, а не только сами чипы памяти.
Еще одним преимуществом памяти стандарта HBM, отмечаемым компанией AMD в своих материалах, является компактность в смысле физических размеров всего устройства — GPU вместе с чипами DRAM занимает очень мало места, по сравнению с привычными для нас форм-факторами с большой печатной платой, отдельным GPU и микросхемами памяти, размещенными на ней на некотором отдалении. Естественно, что замена чипов GDDR5-памяти на маленькие HBM-стеки даст итоговое уменьшение размеров всей видеоплаты.

Насколько велика разница в размерах, и важна ли она? Как видно по иллюстрации выше, каждый гигабайт GDDR5-памяти, состоящий из четырех двухгигабитных микросхем, занимает до 672 мм², а такое же количество HBM-памяти в виде HBM-стеке займет лишь 35 мм² — это почти в 20 раз меньше! Даже если пересчитать цифры с применением четырехгигабитных микросхем, то разница по занимаемой площади останется почти на порядок.
Даже если брать площадь, занимаемую на PCB всеми микросхемами, то по расчетам AMD получается, что упаковка GPU с HBM-памятью займет порядка 4900 мм² против 9900 мм² у нынешней видеокарты Radeon R9 290X. Эту дополнительную экономию места можно также использовать в разных целях, особенно учитывая еще и то, что стеки HBM-памяти не нуждаются в отдельной сложной подсистеме питания, поэтому на практике разница будет еще больше.

К слову, конкурент AMD также уже показывал картинки аналогичного решения и рассказывал об экономии места и возможном появлении новых форм-факторов. Хотя экстремальным игровым энтузиастам на ПК не особенно нужно уменьшение физических размеров видеокарт, но для остальных людей уменьшение размеров одного из основных компонентов системы будет только на пользу — можно будет в маленький корпус засунуть мощный GPU с быстрой HBM-памятью. Главное — не забыть хорошо охладить такую систему.
И тут также есть некоторые вопросы, так как в случае подобного решения чипы DRAM и сам GPU будут в одной упаковке, которая наверняка будет накрыта единой теплоотводящей крышкой, покрывающей и HBM-стеки и ядро GPU. Будет ли в таком случае обеспечиваться достаточно эффективное охлаждение для всей системы и не повлияет ли на работу чипов памяти соседство с крайне горячим ядром графического процессора? Остается лишь ждать появления финального продукта AMD.
В этом же контексте интересно утверждение AMD о том, что разгон HBM-памяти будет осуществить даже проще, чем GDDR5, из-за сравнительно простой системы тактирования и меньшего напряжения питания. При этом, разгон HBM принесет большую пользу, так как даже маленькое увеличение частоты работы чипов памяти выльется в серьезное повышение ПСП из-за очень широкой шины памяти. Но это мы тоже сможем проверить лишь когда выйдет соответствующая видеокарта с новым GPU.
Но неужели у HBM-памяти и первого GPU с ее применением нет недостатков? На наш взгляд, главным минусом предполагаемой конфигурации из четырех стеков HBM-памяти станет общий объем видеопамяти — ведь четыре стека по 1 ГБ дают лишь 4 ГБ в целом. Мы до сих пор не уверены в том, что будущий продукт AMD будет включать лишь четыре стека HBM-памяти, но вероятность этого весьма велика. И запуск нового топового графического процессора, имеющего доступ лишь к 4 ГБ памяти, пусть и очень быстрой, потенциально может стать довольно большой проблемой, ведь решения конкурента будут иметь больше видеопамяти, хотя и медленной GDDR5, но с весьма эффективным ее использованием.
Причина этого ограничения в 4 ГБ во многом заключается в том, что в будущем топовом GPU AMD они решили применить HBM-память первого поколения, имеющую некоторые ограничения. Главным из которых является лишь четыре микросхемы DRAM на стек, что дает объем 1 ГБ на стек. И, судя по всему, текущий дизайн AMD позволяет разместить вокруг GPU всего лишь четыре стека, что и ограничивает общий объем четырьмя гигабайтами.
Возможно, дело в том, что размер вскоре выходящего GPU слишком мал для того, чтобы разместить на нем восемь стеков HBM, или дело в снижении себестоимости, так как новый тип памяти очень сложен в производстве, а значит и дорог. Ведь хотя применение HBM и обойдется дешевле, чем аналогичный стандарт stacked-памяти HMC, но такое решение явно дороже, чем подобный же объем GDDR5, что делает использование большего количества стеков еще менее практичным.
С одной стороны, объем видеопамяти в 4 ГБ до сих пор очень часто применяется даже в топовых решениях, и его может быть достаточно во многих условиях. С другой, самые современные игры вроде GTA V уже частенько желают больше памяти, чем 4 ГБ, особенно в самых высоких разрешениях, вроде 4K. И при нехватке видеопамяти под буферы, игровые текстуры будут то загружаться в память, то освобождать ее, что вызовет снижение производительности и неплавность частоты кадров. А ведь сейчас именно 4K и VR являются главными двигателями индустрии, и все они лишь увеличивают требования к объему видеопамяти. Как и многомониторные конфигурации, поддержкой которых славятся решения компании AMD.
Получается, что для игр решение с 4 ГБ HBM-памяти может быть спорным. А что с профессиональным рынком вычислений и рендеринга? Ситуация аналогичная, даже еще хуже — для профессионального рынка поддержка всего лишь 4 ГБ памяти — как насмешка, ведь для сложного рендеринга в реальном времени и множества вычислительных задач лимит в 4 ГБ памяти будет смерти подобен! Тем более, что конкурент предлагает полупрофессиональные и профессиональные решения, имеющие пусть и не столь шуструю память, но зато в три раза большего объема — 12 ГБ у той же Geforce GTX Titan X.
Может быть в AMD решились на применение такой памяти слишком рано и нужно было подождать коммерческой доступности второго поколения HBM-памяти, ведь его главное отличие в том, что будет удвоено число чипов DRAM на стек, а значит возрастет объем до 2 ГБ на стек, что позволит выпустить графический чип с 8 ГБ видеопамяти. Но это будет возможно лишь в будущем году, не раньше, и второе поколение будет доступно не только AMD, а они явно хотят стать первыми.
Заключение
Будущие стандарты памяти серьезно изменят несколько рынков, в том числе и графических процессоров, ведь тот же стандарт HBM предлагает значительно большую ПСП и заметное улучшение энергоэффективности. Такие типы памяти откроют для GPU новые возможности по росту пропускной способности — одного из важнейших препятствий для дальнейшего повышения производительности в графических задачах.
В стандарте памяти HBM используются 128-битные каналы, которые можно стыковать друг с другом до восьми микросхем в стопке, получая 1024-битный или даже 2048-битный интерфейс на каждый стек в итоге. Полная пропускная способность стека при этом будет 128 ГБ/с или 256 ГБ/с в зависимости от количества чипов памяти в нем: четыре или восемь. И будущие графические процессоры с HBM-памятью смогут иметь ПСП от 512 ГБ/с до 1 ТБ/с, тогда как текущий рекорд равен 336 ГБ/с (для Geforce GTX Titan Black и Titan X).
В общем смысле, стандарт stacked-памяти HBM абсолютно точно можно считать благом — он даст как повышенную производительность, так и снижение потребления, а энергоэффективность является самым важным параметром для всех современных решений. Гипотетическому GPU, чтобы достичь 512 ГБ/с, возможных с применением HBM первого поколения, нужно иметь 512-битную шину памяти и GDDR5-память, работающую на эффективной частоте в 8 ГГц. Теоретически, это вполне достижимые показатели, но при этом чипы памяти будут потреблять энергии порядка 50 Вт, в отличие от 15 Вт потребления аналогичной HBM-памятью. А ведь эти 35 Вт разницы можно отдать в пользу GPU, чтобы его исполнительные устройства работали на более высокой частоте, например. А для и так немало потребляющих графических процессоров архитектуры GCN 1.x это довольно важно.
Но вот что касается конкретно применения первого поколения HBM-памяти в будущем топовом графическом процессоре компании AMD, тут есть одно «но» — ограничение по объему видеопамяти с HBM первого поколения довольно жесткое. Как мы предполагаем, на следующую видеокарту AMD смогут установить всего лишь 4 ГБ HBM-памяти, что для продукта из топового сегмента крайне мало. Особенно с учетом популяризации 4K-разрешения, систем виртуальной реальности и распространения многомониторных конфигураций. И уж тем более — в требовательных играх, которые вполне могут использовать 5-6 ГБ и даже больше.
Еще один момент — да, у памяти стандарта HBM даже в первом поколении есть явное преимущество по энергоэффективности, которое можно потратить или в сторону повышения ПСП или снижения потребления (для мобильных GPU, например) — это надо решать в каждом конкретном случае отдельно. Но вот стоит ли овчинка выделки в первом поколении при не столь уж существенной разнице по ПСП для топовых решений? Ведь проблем при производстве добавляется очень много, да и себестоимость растет.
Что касается использования stacked-памяти в общем, то AMD не станет компанией, первой выпустившей на рынок продукт с использованием многослойной памяти, так как Samsung и Hynix уже выпускают модули DDR4 высокой плотности, использующие подобное решение и соединения типа TSV, но AMD точно станет первой на рынке с графическим процессором, поддерживающим HBM-память.
Хотя у первого поколения HBM есть явные недостатки, но новый стандарт абсолютно точно станет будущим общепринятым стандартом для видеопамяти по крайней мере для топовых GPU. Новая память даже первого поколения имеет значительное преимущество по производительности в плане пропускной способности, а также энергоэффективности.
Более того, компания AMD будет не просто первым производителем графического процессора с памятью стандарта HBM, но единственным производителем, кто освоит HBM память первого поколения. Ведь стандартом, одобренным комитетом JEDEC, станет лишь второе поколение — HBM2, а HBM первого поколения будет использоваться исключительно совместно AMD и Hynix. И до появления продуктов, использующих уже второе поколение HBM (HBM2), у AMD есть примерно с год форы по применению этой технологии, за это время только в их GPU мы увидим такую память. Вполне возможно, кстати, что и второе поколение они освоят быстрее конкурента — ведь опыт по работе с HBM-стеками то у них уже будет.
Но компания AMD постарается получить преимущество и в первом же графическом процессоре с поддержкой HBM. Хотя AMD пока что не разглашает подробных данных о производительности подсистемы памяти будущего графического процессора, зато о планах на использование HBM-памяти даже в будущих APU они рассказывают охотно, хотя это пока что является лишь теоретической возможностью.
Но когда применение HBM станет сравнительно недорогим, от AMD можно ожидать выпуска как бюджетных GPU с такой памятью, так и даже гибридных чипов APU с подобным типом памяти, так как нынешние поколения APU сильно страдают в том числе из-за малой ПСП их 128-битных интерфейсов памяти и применения DDR3-памяти. Представьте себе APU с несколькими CPU-ядрами нового поколения, относительно мощным GPU-ядром и общей HBM-памятью с огромной ПСП — это мечта многих разработчиков, и особенно хорошо такой чип подойдет для игровых консолей. Но для начала давайте дождемся топового GPU с памятью HBM — благо, ждать осталось совсем недолго.


