(М.Амстердам)

Весна уже здесь. Метнув лучик своего взгляда, на секунду показалась она из-за угла часовых стрелок, запахом жизни пронеслась мимо нас и вновь была припорошена снежком. Но мы то знаем, что она рядом, ждет своего часа, свернувшись в пружину, готовится выскочить, раскидав во все стороны фейерверк зеленых листьев, осветить землю солнцем, подарить нам новую любовь. А может быть и не одну… Кто знает, каким еще словом можно охарактеризовать чувства человека, питаемые им по отношению к только что приобретенному графическому ускорителю последнего поколения? Как же еще можно потратить столько денег, если не по любви…
Представляем NVIDIA GeForce3
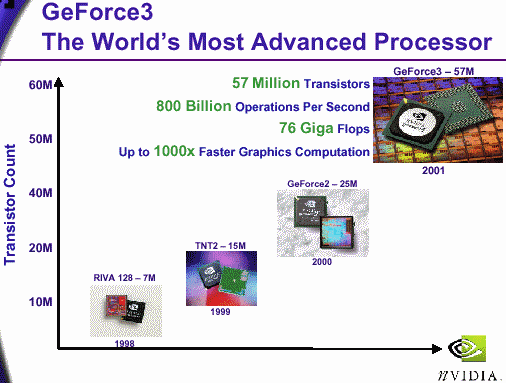
Предоставим нашим читателям возможность самим спокойно и вдумчиво прочитать пресс-релизы уважаемой компании NVIDIA, представители которой, кстати, посетили недавно нашу гостеприимную столицу. Мы же обратим свой взгляд на "технические" параметры, скрывающиеся за лозунгами Light-speed Memory Architecture и nfiniteFX engine. Итак:
Спецификации GPU GeForce3
- технологический процесс производства: 0.15 мкм
- число транзисторов: 57 миллионов
- частота графического ядра: 200 МГц
- число пиксельных конвейеров рендеринга: четыре
- число текстурных блоков на каждом конвейере рендеринга: два
- возможность наложения до четырех текстур на один пиксель за один проход (требуется два такта, если число комбинируемых текстур больше двух)
- интерфейс памяти: 128 бит
- поддерживаемые типы памяти: DDR SDRAM/SGRAM
- на момент выхода карты на базе GeForce3 будут оснащаться 3.8 нс памятью, работающей на частоте 230 (460) МГц
- пиковая пропускная способность шины памяти (230 МГц DDR): 7 Гб/с
- поддерживаемый объем локальной видеопамяти: до 128 Мб (большинство первых карт будут иметь 64 Мб)
- RAMDAC: 350 МГц
- максимальное разрешение: 2048x1536@75Hz
- интегрированный в чип TMDS трансмиттер позволяет подключать мониторы по цифровому интерфейсу (DVI), разрешение до 1600x1200 включительно
- интерфейс внешней шины: полная поддержка AGP x2/x4 (включая SBA, DME и Fast Writes) и PCI 2.2 (включая Bus mastering).
- Аппаратный T&L с производительностью эквивалентной 76 миллиардам операций с плавающей точкой в секунду.
- полная аппаратная поддержка всех возможностей MS DirectX 8.0 и OpenGL 1.2
- полностью поддерживаются аппаратные вершинные шейдеры (VertexShaders) DX8, версия 1.1
- полностью поддерживаются аппаратные пиксельные шейдеры (PixelShaders) DX8, версия 1.1
- имеется поддержка объемных текстур
- имеется поддержка кубических карт среды (Cube environment mapping)
- поддерживается проективные текстуры (projective textures)
- имеется поддержка аппаратной тесселяции гладких поверхностей — прямоугольных и треугольных патчей (RT Patches)
- аппаратная поддержка рельефного текстурирования следующих типов: Embosing, Dot Product3 и EMBM
- имеется поддержка S3TC и всех пяти DXTC методов компрессии текстур
- имеется поддержка отсечения примитивов по произвольно заданным плоскостям
- имеется поддержка FSAA на основе различных методик мультисэмплинга (MSAA)
- аппаратные средства для экономии полосы пропускания видеопамяти: поддержка сжатого формата буфера глубины (compressed Z) и раннего определения видимости точек (HSR на базе early Z test)
- поддерживаются текстуры с размером вплоть до 4096x4096 @ 32 bit
Нетрудно заметить, что в финальной спецификации практически ничего не изменилось (читайте наш "Анализ функциональных возможностей GPU NV20"). Уточнения коснулись точного числа транзисторов и параметров памяти, которой будут оснащаться карты на основе GeForce3. Желающим более подробно узнать о программируемых графическом и геометрическом конвейерах GeForce3 (пиксельные и вершинные шейдеры) рекомендуем прочитать "DX8 FAQ" и "Анализ функциональных возможностей GPU NV20".
Мы же непринужденно обсудим различные аспекты реализации новых технологий в GeForce3 и дадим обширный и подробный анализ производительности, а также рассмотрим, как изменяется производительность при использовании различных технологических новшеств. Для проведения анализа мы воспользуемся набором специальных синтетических тестов и, разумеется, реальных приложений.
Фильтрация и fillrate
Как мы уже знаем, чип имеет два текстурных блока на каждом из четырех пиксельных конвейеров (как и GeForce2 GTS/Ultra). Есть и отличие — реализована возможность накопления результатов работы текстурных блоков: можно комбинировать до 4-х текстур за один проход. В случае использования трилинейной или анизотропной фильтрации задействуются одновременно два блока, уменьшается число текстур, комбинируемых одновременно (пример: одна трилинейная и две билинейных текстуры). Даже с учетом того, что современные игры строят сцену в 2-4 прохода, используя при этом, как минимум, по 2 текстуры, причин для паники нет. Да, нас ожидает заметное падение производительности, особенно при использовании 32-х точечной анизотропной фильтрации, но положение спасает тот факт, что в реальных приложениях лишь одна основная текстура фильтруется с такими потерями. Карты освещения и отражения, текстуры детализации и прочее не требуют даже трилинейной фильтрации. Итак, включая анизотропную фильтрацию, мы должны быть морально готовы к падению скорости на проценты (при наихудшем раскладе вдвое), но никак не больше. Далее мы подробно исследуем вопросы скорости и качества анизотропии на конкретных приложениях, а пока давайте посмотрим на различные вариации комбинированных фильтраций, которые можно получить на различных чипах за один проход:
| Методы фильтрации | GeForce3 | RADEON | GeForce2 |
|---|---|---|---|
| 1 билинейная текстура | 1 такт (800) | 1 такт (366) | 1 такт |
| 2 билинейные текстуры | 1 такт (800) | 1 такт (366) | 1 такт |
| 3 билинейные текстуры | 1 такт (800) | 1 такт (366) | - |
| 4 билинейные текстуры | 2 такта (400) | - | - |
| 1 трилинейная | 1 такт (800) | 1 такт (366) | 1 такт |
| 1 трилинейная + 1 билинейная | 2 такта (400) | 1 такт (366) | - |
| 1 трилинейная + 2 билинейных | 2 такта (400) | - | - |
| 1 анизотропная (8 точек) | 1 такт (800) | - | 1 такт |
| 1 анизотропная (16 точек) | 2 такта (400) | 2 такта (183) | - |
| 1 анизотропная (24 точки) | - | 2 такта (183) | - |
| 1 анизотропная (32 точки) | 4 такта | - | - |
| 1 анизотропная (8 точек) + 1 билинейная | 2 такта (400) | - | - |
| 1 анизотропная (8 точек) + 2 билинейных | 2 такта (400) | - | - |
| 1 анизотропная (16 точек) + 1 билинейная | 3 такта (266) | 2 такта (183) | - |
| 1 анизотропная (16 точек) + 2 билинейных | 3 такта (266) | - | - |
* В скобках указаны теоретические значения пиксельного fillrate.
Полноэкранное сглаживание
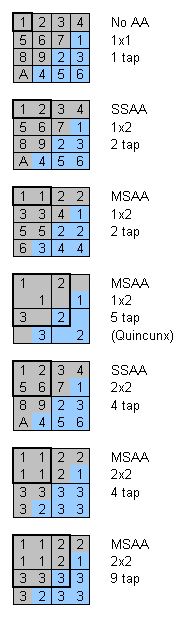
Пришло время уделить особое внимание технологиям полноэкранного сглаживания (FSAA), ведь именно с появлением GeForce3 у них есть все шансы стать повсеместно применяемыми. В отличие от предыдущих чипов, где мы имели дело с суперсэмплингом (SS FSAA или SSAA), GeForce3 обладает возможностью проводить полноэкранное сглаживание на основе мультисэмплинга (MS FSAA или MSAA). Этот метод существенно экономит текстурный fillrate — используя одно вычисленное значение цвета для всех пикселов сглаживаемого блока (как правило, 1x2 или 2x2). Приведем схему (слева), иллюстрирующую различные методы полноэкранного сглаживания.
Серым и голубым цветом обозначены два соседних полигона. Мы наблюдаем за тем, что происходит на их границе. Именно границы, порождающие пресловутую ступенчатость, требуют сглаживания больше всего. Цифрами обозначены различные вычисляемые значения цвета. Если на полигоне цифра встречается несколько раз — мы имеем дело с мультисэмплингом, и вычисленное значение цвета записывается сразу в несколько позиций. GeForce3 способен записать одно значение в 1, 2 или 4 результирующих точки буфера кадра. Черными линиями выделен блок сглаживания, в пределах которого записываются одинаковые значения для мультисэмплинга и различные для суперсэмплинга. Жирным выделена область, используемая для формирования результирующего цвета точки выводимой на экран монитора. Отметим, что эта область не обязательно совпадает с одним блоком сглаживания, она может заходить и на территорию соседних, для обозначения этого указывается число точек, используемых в формировании окончательного значения (например, 5 или 9 tap). Таким образом, мы реализуем некий постфильтр, сглаживающий также и все изображение целиком.
Не следует думать, что мультисэмплинг совершенно "бесплатен" с точки зрения производительности. Во-первых, необходима постобработка, превращающая буфер, рассчитанный с избыточным разрешением, в результирующее изображение. Во-вторых, увеличение (в 2 или 4 раза) размера исходного буфера существенно нагружает шину памяти. В-третьих, на краях полигонов мы все же вынуждены рассчитывать несколько значений цвета для каждого блока сглаживания, следовательно, чем больше мелких полигонов, тем выше потери производительности. Но, как бы там ни было, подобный подход (на реальных приложениях) получает преимущество в сравнении c методами SSAA, что мы и покажем на практике, но чуть позже. Кроме того, запатентованный NVIDIA метод 1x2 MSAA метод с подозрительным названием Quincunx позволяет получить близкое к 2x2 SSAA качество сглаживания, при существенно более низком падении производительности.
Кэширование и сбалансированность
Огромное количество транзисторов в GeForce3 не пропало даром. Результаты тестов показывают, что архитектура чипа существенно лучше сбалансирована, нежели предыдущие творения NVIDIA. Чип уже не упирается "чуть что" в пропускную полосу памяти. Инженеры NVIDIA говорят, что множество кэшей (для значений текстур, буфера кадра, глубины и геометрических данных) и специальная "кроссбар" архитектура (позволяющая оптимизировать доступ различных блоков чипа к выбираемым из памяти или получаемым от процессора данным, а также к результатам работы предыдущих блоков) помогают GeForce3 не тратить впустую ни единого такта на реальных задачах. Чип использует свой потенциал почти на 100%. Мы проверим это заявление на практике и посмотрим, на что были потрачены миллионы транзисторов и десятки человеко-лет разработки.
Нет сомнений, что хорошо сбалансированный чип ровно проявит себя в любых задачах, в то время как излишняя мощь, таящаяся лишь в отдельных блоках — пустая трата денег покупателя. Эта скрытая мощь вряд ли будет высвобождена в большинстве реальных применений. Именно поэтому не имело никакого смысла дальше увеличивать число конвейеров и/или текстурных блоков. Что же было сделано вместо этого?
Но сначала скинем покров тайны и представим миру долгожданные карты на базе GeForce3!
Карты, установка и драйверы
Расскажем о тех видеокартах, которые мы успели исследовать в нашей лаборатории. Отметим сразу, что эти образцы, по заявлениям производителей, на 99% соответствуют серийными картам (возможно, слегка будет изменена разводка PCB и чипы памяти будут иметь радиаторы охлаждения), которые вскоре поступят в продажу.
ASUS AGP-V8200
Карта имеет AGP x2/x4 интерфейс, 64 Мб DDR SDRAM памяти, размещенной в 8-ми микросхемах на лицевой стороне PCB.

Микросхемы памяти произведены компанией Elite Semiconductor Memory Technology (марки EliteMT и ESMT принадлежит этой фирме) и имеют время выборки 4 ns, т.е. чипы памяти рассчитаны на рабочую частоту 250 (500) МГц.  На самом деле память функционирует на частоте 230 (460) МГц. Аналогичная ситуация наблюдается и у карт, основанных на GeForce2 Ultra, где частота памяти снижена с целью повышения стабильности работы.
На самом деле память функционирует на частоте 230 (460) МГц. Аналогичная ситуация наблюдается и у карт, основанных на GeForce2 Ultra, где частота памяти снижена с целью повышения стабильности работы.
Отметим, что данный сэмпл карты от ASUS более ранний, нежели все остальные, рассмотренные нами в этом обзоре. Именно поэтому на этой карте установлена 4 ns память, тогда как на всех остальных картах используется память с временем выборки 3.8 ns. На модулях памяти у всех рассматриваемых карт нет радиаторов охлаждения, а у серийных карт радиаторы на чипах памяти будут.
Представленная плата выполнена точно по эталонному дизайну, и все серийные карты будут иметь такой же вид. Тем не менее, не исключены некоторые изменения в разводке у серийных плат. 
На графическом процессоре установлен обычный кулер, которого в свое время было совершенно достаточно для охлаждения GPU GeForce2 GTS. Имели место слухи, что GeForce3 очень сильно греется, но это неверно. Несмотря на колоссальное количество транзисторов в чипе, новый технологический процесс 0.15 мкм с семислойным дизайном позволил создать процессор с довольно низким энергопотреблением и тепловыделением. Если взглянуть на фотографию корпуса GPU (справа), то видно, что он все еще маркирован кодовым названием "NV20".
Отметим еще одну особенность нового дизайна PCB карт на базе GeForce3 — он предусматривает два способа монтажа TV-out: как непосредственно на самой PCB, так и посредством дочерней платы с TV-out (такой способ мы уже видели у карт на базе GeForce2). Дизайн PCB карт на GeForce3 предусматривает наличие DVI-I интерфейса (на данной видеокарте есть только разводка, а самого разъема DVI нет). Интересно отметить, что разработчики поменяли местами гнезда VGA и DVI, перенеся первое наверх PCB.

Поскольку мы рассматриваем опытные образцы карт, то речь о комплекте поставки Retail вариантов не идет. Тем не менее, вы можете посмотреть на дизайн коробки (справа), в которой будут поставляться видеокарты ASUS AGP-V8200 Pure. Дизайнеры ASUSTeK решили полностью перейти на абстрактные изображения, символизирующие новые веяния в 3D графике.
Разгон
При наличии дополнительного охлаждения данный экземпляр карты стабильно работал при частотах ядра и памяти 220/255(510) МГц соответственно. Забегая вперед, скажу, что это самый низкий результат разгона из всех рассмотренных в данном обзоре видеокарт.
ASUS AGP-V8200 Deluxe
Карта имеет AGP x2/x4 интерфейс, 64 Мб DDR SDRAM памяти, размещенной в 8-ми микросхемах на лицевой стороне PCB.


Микросхемы памяти производства компании Elite Semiconductor Memory Technology имеют время выборки 3.8 ns и рассчитаны на рабочую частоту 263(526) МГц.  Несмотря на рекордно низкое время выборки в 3.8 ns, память функционирует на частоте 230 (460) МГц, что сделано с целью повысить стабильность работы карты в целом. Охлаждающие радиаторы на модулях памяти отсутствуют.
Несмотря на рекордно низкое время выборки в 3.8 ns, память функционирует на частоте 230 (460) МГц, что сделано с целью повысить стабильность работы карты в целом. Охлаждающие радиаторы на модулях памяти отсутствуют.
Карта AGP-V8200 Deluxe полностью спроектирована инженерами ASUSTeK с целью реализовать поддержку традиционных для серии Deluxe функций, таких как прием и оцифровка видеопотоков, вывод изображения на телевизор и работа со стерео-очками. Подчеркну еще раз, что мы рассматриваем сэмпл - опытный образец, поэтому у серийных видеокарт могут быть некоторые отличия.
ТВ-функции и стерео-режим мы не рассматриваем в данном материале, поскольку пока еще нет соответствующего программного обеспечения от ASUSTeK.
На графическом процессоре установлен уже ставший привычным активный кулер, но более эффективный, нежели у карты серии Pure, рассмотренной выше. Я еще раз подчеркну, что несмотря на огромное число транзисторов, графический процессор греется очень умеренно.

Несмотря на то, что мы рассматриваем лишь сэмплы карт на GeForce3, у нас есть возможность продемонстрировать дизайн коробки (справа), в которой будут поставляться видеокарты ASUS AGP-V8200 Deluxe.
Разгон
При наличии дополнительного охлаждения у данного экземпляра карты мы добились стабильной работы ядра и памяти на нештатных частотах 225 и 260(520) МГц соответственно. Это самый высокий результат разгона среди всех рассмотренных в данном обзоре карт.
Leadtek WinFast GeForce3
Карта имеет AGP x2/x4 интерфейс, 64 Мб DDR SDRAM памяти, размещенной в 8-ми микросхемах на лицевой стороне PCB.


Микросхемы памяти EliteMT 3.8 ns рассчитаны на рабочую частоту 263(526) МГц.
Как и положено по спецификациям, память функционирует на частоте 230 (460) МГц. Охлаждающие радиаторы на модулях памяти отсутствуют, но на серийно выпускаемых картах они будут.
Как и в случае ASUS AGP-V8200, представленная плата выполнена точно по эталонному дизайну от NVIDIA, и все серийные карты будут иметь почти такой же вид. Интересно отметить, что начиная с выпуска видеокарты на базе GeForce2 Ultra, компания Leadtek отказалась от традиционного для нее лимонно-желтого цвета PCB и остановилась на темно-зеленом оттенке.
Видеокарта Leadtek WinFast GeForce3 оснащена полным набором дополнительных функций, таких как TV-out (причем, он смонтирован на самой PCB, а не на дочерней карте) и DVI-интерфейс для подключения цифровых мониторов. Обращаю внимание на то, что новый дизайн предусматривает смещение VGA-гнезда в верхнюю часть PCB, а DVI, наоборот, в нижнюю.
И еще, несмотря на то, что у GeForce3 нет второго RAMDAC или второго CRTC, у него есть интегрированный TDMS передатчик, что позволяет выводить изображение как через цифровой, так и через аналоговый интерфейс. Кроме того, аналоговый сигнал с RAMDAC дублирован и на аналоговые выходы DVI-I разъема. Если подключить к DVI-I разъему переходник DVI-to-VGA (которыми комплектуются некоторые видеокарты), мы увидим копию картинки, выдаваемой на VGA монитор. Это сделано для возможности подключения аналоговых мониторов, имеющих только DVI-I коннектор. Этот факт наводит на мысли о перспективе окончательного вымирания VGA разъемов.
На графическом процессоре установлен традиционный для Leadtek огромный радиатор с вентилятором, который обеспечивает эффективное охлаждение.

Несмотря на то, что в нашей лаборатории побывал лишь сэмпл карты Leadtek WinFast GeForce3, мы можем продемонстрировать дизайн коробки (справа), в которой будут поставляться эти видеокарты.
Разгон
При наличии дополнительного охлаждения для данного экземпляра карты мы добились стабильной работы графического ядра и видеопамяти на частотах 220 и 255(510) МГц соответственно. Это средний результат разгона среди всех рассмотренных нами карт.
Gigabyte GA-GF3000D
Карта имеет AGP x2/x4 интерфейс, 64 Мб DDR SDRAM памяти, размещенной в 8-ми микросхемах на лицевой стороне PCB.


Микросхемы памяти от компании Elite Semiconductor Memory Technology имеют время выборки 3.8 ns и рассчитаны на рабочую частоту 263(526) МГц.
Как и положено по спецификациям для карт на базе GeForce3 от NVIDIA, память функционирует на частоте 230 (460) МГц с целью повышения стабильности при работе. Охлаждающие радиаторы на модулях памяти отсутствуют, но на серийно выпускаемых картах они будут установлены.
Видно, что по дизайну GA-GF3000D практически не отличается от предыдущей карты, т.е. карта от Gigabyte выполнена эталонному дизайну от NVIDIA. Впрочем, почти все серийные карты на базе GeForce3 будут производиться именно по эталонному дизайну. Зато карты от Gigabyte всегда можно будет узнать по ярко-лазурному цвету PCB, что является визитной карточкой этой уважаемой компании.
Видеокарта Gigabyte GA-GF3000D оснащена полным набором функций: TV-out (на этот раз TV-out смонтирован на дочерней карте) и DVI-интерфейс для подключения цифровых мониторов.
Если найти переходник DVI-to-VGA, то видеокарта GA-GF3000D будет способна выводить через гнездо DVI на дополнительный монитор копию картинки как на основном мониторе. При этом нет никаких опций в настройках драйверов и нельзя менять даже разрешение на втором мониторе, ибо он лишь копирует данные, выводимые на первый.
На графическом процессоре установлены очень эффективные радиатор и вентилятор.

Мы рассматриваем опытный образец GA-GF3000D, который поставляется без специального Retail комплекта поставки, однако вы можете оценить дизайн коробки (справа), в которой будут поставляться серийные видеокарты от Gigabyte.
Разгон
При использовании дополнительного охлаждения данный экземпляр карты стабильно работал при нештатных частотах графического ядра и памяти 225/255(510) МГц соответственно. Это средний результат разгона среди всех рассмотренных нами в данном обзоре видеокарт. Впрочем, опыт тестирования ранних экземпляров карт на базе GeForce2 говорит о том, что графическое ядро на серийных картах разгоняется лучше. Ниже мы покажем на практике, насколько эффективен разгон карт на базе GeForce3.
Установка и драйверы
Перед рассмотрением работы программного обеспечения и результатов тестирования следует ознакомить читателя с конфигурацией тестового стенда:
- процессор Intel Pentium III 1000 MHz:
- системная плата Chaintech 6OJV (i815);
- оперативная память 256 MB PC133;
- жесткий диск IBM DPTA 20GB;
- операционная система Windows 98 SE;
На стенде использовались мониторы ViewSonic P810 (21") и ViewSonic P817 (21").
Относительно полноценной поддержкой нового графического процессора обладают пока только драйверы версии 10.50 (бета). Сразу после релиза драйверов для GeForce3 мы проведем их анализ. Более подробно обо всех тонкостях драйверов для GeForce3 читатель сможет узнать из предстоящего выпуска 3DGiТогов. Сейчас я лишь отмечу, что некоторая "сырость" текущей версии драйверов имеет место.
Тестирование проводилось при отключенном VSync, а для сравнительного анализа были использованы видеокарты ATI RADEON 64MB (Retail-поставка, частоты 183/183 МГц) и Leadtek WinFast GeForce2 Ultra.
Ввиду того, что все четыре видеокарты на базе GeForce3, исследуемые в рамках данного обзора, показали полностью идентичную производительность, в дальнейшем мы будем использовать в наших тестах результаты только одной из карт, абстрактно обозначая как NVIDIA GeForce3.
Возможности GPU GeForce3 на примерах из DirectX 8.0 SDK
Итак, попробуем подробно рассмотреть все технологические новшества нового графического процессора. Для тестирования мы будем использовать различные примеры из DirectX 8.0 SDK, некоторые из которых были нами модифицированы, дабы получить возможность наглядно продемонстрировать выигрыш, получаемый благодаря использованию сжатого формата Z буфера или HSR. Но для начала продемонстрируем несколько скриншотов из прекрасных технологических демо-программ NVIDIA, использующих пиксельные шейдеры:



На скриншотах выше последовательно демонстрируются попиксельные отражение, преломление и тени. Итак, первое, с чем нам предстоит иметь дело, — это пиксельные шейдеры. Для начала отметим, что физически, в GeForce3 нет никакого интерпретатора для пиксельных шейдерных команд — последовательное исполнение слишком медлительно для подобных задач. Код пиксельного шейдера транслируется в параметры настройки 8 стадий комбинационного конвейера чипа, которые, по сравнению с предыдущим поколением ускорителей, были обогащены множеством новых возможностей, позволяющих не только исполнять все шейдерные команды, но и реализовывать некоторые другие, дополнительные эффекты, которые вскоре станут доступны через соответствующие расширения OGL, а позже, возможно, и в виде новой версии ассемблера для пиксельных шейдеров. Итак, важно понимать, что это лишь 8 ступенчатый конвейер, хотя и чрезвычайно гибко настраиваемый.
Мы модифицировали программу mfcpixelshader, так, чтобы она позволяла нам измерить производительность исполняемого шейдера. Также мы добавили в нее загрузку четырех текстур:
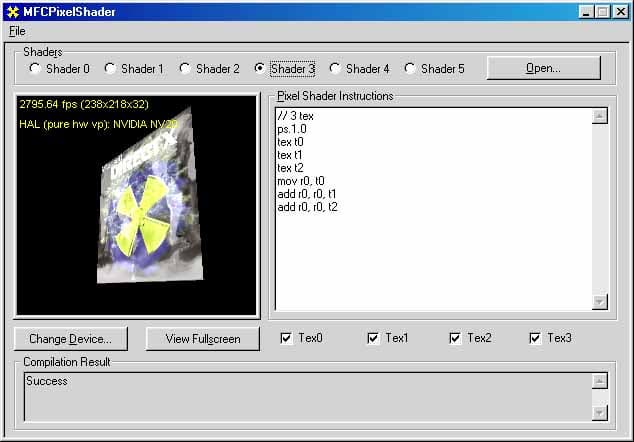
Тестирование проводилось с использованием нескольких шейдеров, начиная с самого простого, не использующего ни одной текстуры и заканчивая достаточно сложным шейдером из 8 команд, задействующим все текстурные блоки и оба значения освещения. Итак:
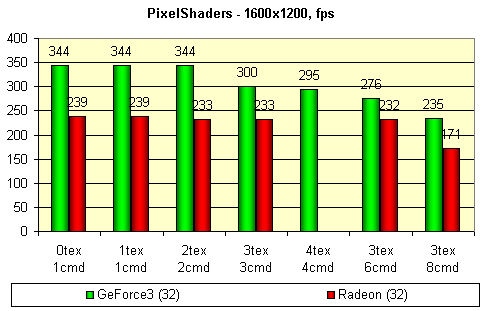
Для сравнения приведены результаты, полученные на RADEON. Тест проводился в режиме 1600x1200@32, дабы максимально снизить зависимость результатов от параметров, связанных с геометрическими преобразованиями. Внизу приведены кодовые обозначения шейдеров в виде Xtex Ycmd — где X количество одновременно используемых текстур, а Y — длина шейдера в стадиях конвейера.
На результатах хорошо заметна задержка в такт, вызываемая использованием более 2-х текстур одновременно у GeForce3 и странное, резкое падение производительности в случае шейдера максимальной длины. Я не нашел этому никакого разумного объяснения, кроме как наличия перезагрузки комбинационного конвейера, например, при достижении края полигона. Как известно, время перезагрузки зависит от количества стадий. Но, в таком случае неясно, почему результаты первых 4 шейдеров практически идентичны.
Как бы там ни было, желающие поэкспериментировать могут самостоятельно скачать SDK с сайта Microsoft и проверить все свои предположения.
Следующий тест измеряет скорость выполнения достаточно сложного вершинного шейдера:

Для сравнения мы приведем значения, полученные в режиме с программной эмуляцией вершинных шейдеров (напомню, что наш стенд оснащен процессором Pentium III 1000 MHz).
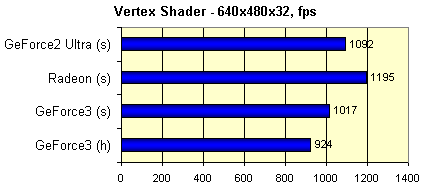
Где (h) обозначает использование аппаратного, а (s) программного исполнения шейдера. Как мы видим, аппаратная реализация шейдеров GeForce3 сравнима по производительности с самыми мощными из современных процессоров. Но не следует забывать, что при программном исполнении шейдера в данном синтетическом тесте ресурсы центрального используются по максимуму, а в случае программной эмуляции в реальном приложении мы получили бы заведомо более низкие значения, т.к. ресурсы CPU пришлось бы делить между множеством других, не менее важных задач, нежели эмуляция шейдера.
Кстати, вершинные шейдеры являются настоящей программой, последовательно выполняемой блоком HW T&L. И здесь, от ее длины, или используемых команд зависит многое. Однако столь подробное исследование выходит за рамки данной статьи.
Следующий тест — матричный блендинг, с использованием двух матриц:

Для сравнения мы приведем значения полученные аппаратным блендингом, и программной эмуляцией, как для самого матричного блендинга, так и для эквивалентного ему шейдера.
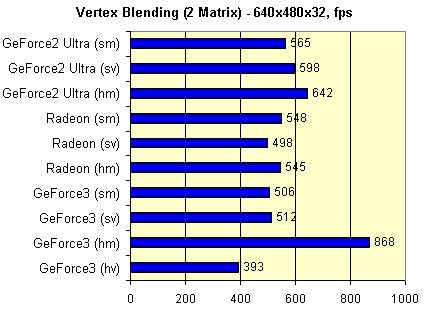
Здесь (hm) обозначает аппаратный двухматричный блендинг, (hv) эквивалентный вершинный шейдер, а (sm) и (sv) их программную эмуляцию соответственно. Цифры удивительно близки, но как бы там ни было, следует отметить, что в случае программной эмуляции выгоднее вершинный шейдер, а в случае аппаратного исполнения — простой матричный блендинг. Здесь GeForce3 существенно производительнее чипов предыдущих поколений. Очевидно, что для получения наибольшей отдачи программистам необходимо комбинировать аппаратный матричный блендинг и шейдеры (для прочих геометрических нужд), исполняя их на аппаратном уровне.
Далее мы детально протестировали производительность HW T&L и его взаимодействие с растеризатором, использовав для этой цели модифицированный пример optimized mesh:

Мы получили предельные значения для этого несложного синтетического теста с непростой моделью, состоящей из 40000 полигонов, выводя одновременно 32 уменьшенных модели в маленьком окне, изменение размера которого уже переставало сказываться на количестве обрабатываемых в секунду треугольников. Это верный признак "насыщения" системы CPU-HW T&L. Но не следует забывать, что с появлением новых, более производительных центральных процессоров, GeForce3 может показать несколько большие результаты. Для сравнения мы приводим максимальные значения, полученные на программной эмуляции:
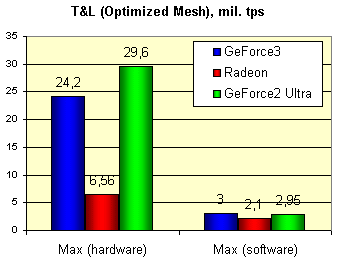
Цифры означают миллионы треугольников в секунду. Что интересно, для GeForce2 Ultra мы практически достигли заявленного производителем значения (31 миллион). А вот до цифры 60 млн. GeForce3 еще далеко. На подобном незатейливом тесте карта на базе GeForce3 проигрывает GeForce2 Ultra строго в соответствии с разницей в тактовой частоте, что наводит на мысль о практически идентичной валовой производительности блока HW T&L. RADEON смотрится бедным родственником на этом фоне, но мы то знаем, что современные игры (за исключением считанных единиц, таких как Giants) еще не исчерпали потенциала его HW T&L. Когда же они будут способны переварить GeForce3, нам остается только догадываться. Далее мы измерили это же число в реальных разрешениях, дабы проследить, насколько растеризация оказывается сдерживающим фактором для HW T&L. Приведем величину падения производительности в процентах для различных разрешений:
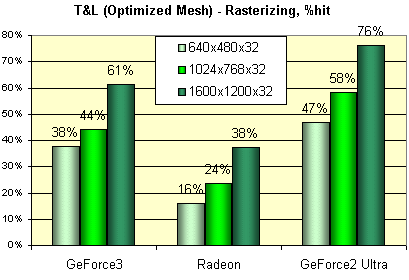
Видно, что с этой точки зрения наиболее сбалансированной картой (в данном синтетическом тесте) является RADEON. А GeForce2 Ultra явный аутсайдер — производительность ее HW T&L практически всегда остается невостребованной.
Теперь выполним три эксклюзивных теста. Отключим Z буфер и исследуем влияние этого фактора на скорость вывода сцены, а также отключим отсечение обратных граней и оптимизацию модели перед выводом (оптимизация — сортировка ее вершин так, чтобы вершины, используемые одним треугольником, находились поблизости в буфере вершин, упрощая жизнь кэшу вершин и блоку их выборки):
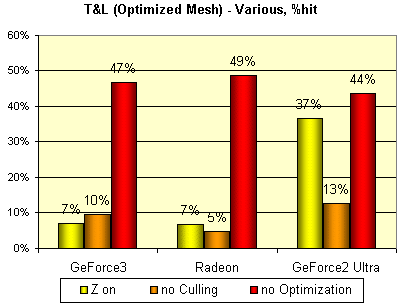
Полученные результаты говорят о том, что по сравнению с GeForce2 Ultra работа RADEON и GeForce3 c Z буфером организована чрезвычайно эффективно. И, что самое главное, вероятно, они используют схожие технологии сжатия Z — величина падения производительности совершенно идентична. Наиболее эффективное (с точки зрения оптимизированной модели) кэширование имеют RADEON и GeForce3, а GeForce2 Ultra вновь аутсайдер. От технологии HSR в данном тесте зависело немного, но все равно, сознательно внесенные обратные грани меньше всего ударили по RADEON. Позднее мы попробуем найти более весомое подтверждение гипотезе о высокой эффективности реализованного в GeForce3 метода HSR.
Приведем изображение модели, нарисованное с отключенным Z буфером (1) и обратными гранями (2):


В заключение, посмотрим на величину падения производительности при использовании (средствами DX, из самой программы) 2х и 4х FSAA:
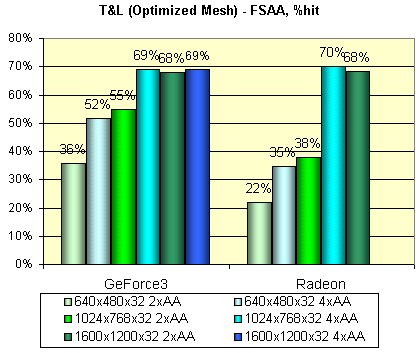
Очевидно, что в случае GeForce3, MSAA абсолютно не бесплатен на подобных сценах — большое количество полигонов дает о себе знать. Кроме того, есть подозрение, что 2x MSAA режим, активизируемый из DX 8 программ, есть не просто 1х2 MSAA, а полноценный Quincunx, о качестве которого будет сказано чуть ниже.
Теперь протестируем производительность аппаратной тесселяции гладких поверхностей.


Сравнивать тут, к сожалению, не с чем — программная эмуляция HW T&L эту возможность не поддерживает. Поэтому просто приведем зависимость производительности от числа разбиений сторон патча:
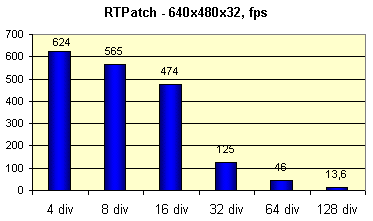
Видно, что где-то после значения 16 наступает перелом и производительность заметно снижается, но уже и при такой детализации модель выглядит весьма гладкой.
Еще один тест — PointSprites. Система частиц, отражающихся от поверхности. Результаты приведем без комментариев, отметив только, что реализация оных у RADEON очень хороша с точки зрения производительности (если принять во внимание его тактовую частоту), но подкачала в качестве — текущие драйверы накладывают текстуру на спрайты неединичного размера неверно.
Следующий тест измеряет производительность закраски для наложения карт среды (EM) и EMBM:

У всех карт, участвующих в этом тесте, EMBM не бесплатен:
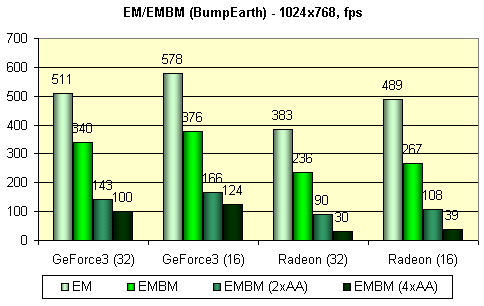
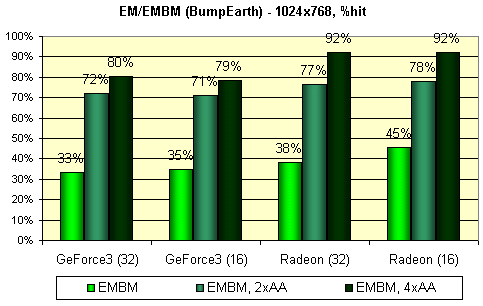
Налицо практически идентичные результаты в 16 и 32 бит цвете и несколько меньшее падение производительности для GeForce3. Также удивляет существенное падение скорости при включенном FSAA - даже у GeForce3 в 2х режиме. Как мы видим, существуют несложные DX 8 приложения, способные, по той или иной причине, существенно проиграть при включенном FSAA. Возможно, причина в том, что хотя они и несложны, но построение изображения занимает сравнимое с проходом сглаживания время.
Теперь проведем несколько распространенных синтетических тестов. 3DMark 2000 позволил нам проследить за зависимостью производительности HW T&L от числа источников света:
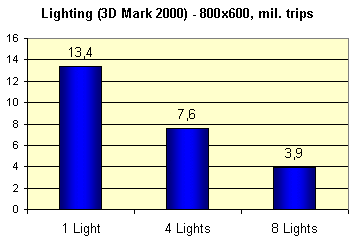
Все то же существенное линейное падение, хорошо знакомое нам по картам на базе GeForce2. Но, не следует забывать, что вершинные шейдеры позволяют нам подсластить этот факт возможностью использовать большее число источников света или более сложные техники освещения на наш выбор. Для GeForce3 он ограничен только длиной программы шейдера (до 128 команд) и нашей фантазией. Приведем значения fillrate, теоретические и измеренные на практике:
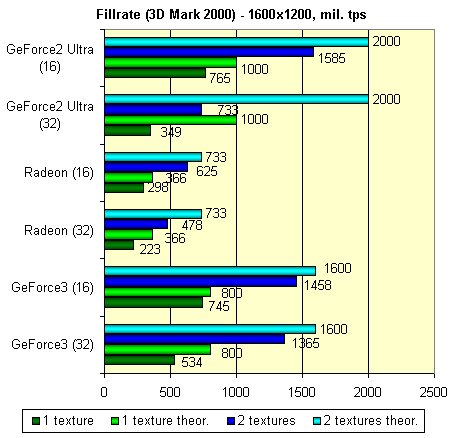
Наименее сбалансированной архитектурой оказался GPU GeForce2 Ultra, наиболее сбалансированными являются GPU RADEON и GeForce3, с попеременным успехом. Именно величины их fillrate наиболее близки к теоретическим значениям, а, следовательно, сильнее раскрывают потенциал своей тактовой частоты и числа конвейеров.
А этот тест (на основе несложного скринсэйвера) позволяет проследить падение производительности GeForce3 в различных принудительных режимах MSAA, описанных нами ранее и выбираемых в панели настроек драйвера:
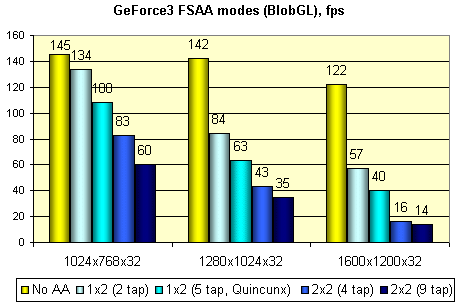
Как видно, в разрешении 1024x768 мы вольны выбирать любые методы сглаживания, режим 1280x1024 оставляет нам метод 1x2 и Quincunx, а в 1600x1200 лучше использовать "как есть". Эта картина очень характерна для GeForce3, но об этом чуть позднее, при обсуждении результатов реальных игровых тестов. И, напоследок, хорошо известный тест эффективности HSR, VillageMark (сцена с огромным значением overdraw):

А вот и полученные в этом тесте результаты:
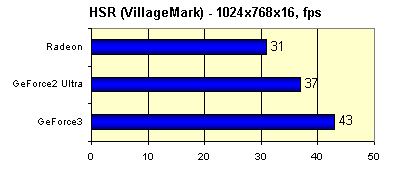
Высокая эффективность реализации HSR у GeForce3 — вне всяких сомнений. А близость к нему значения, полученного у карты на базе GeForce2 Ultra, объясняется более высокой тактовой частотой ядра у этого GPU. Но и RADEON, что называется, приятно удивил… Схожесть результатов снова наводит на мысли о схожести реализованных аппаратно методик — вероятно, GeForce3 также имеет дело с иерархическим Z буфером и HSR на его основе.
А теперь запустим TreeMark — родное детище NVIDIA. Ну разве можно не померить им их же новый GPU?
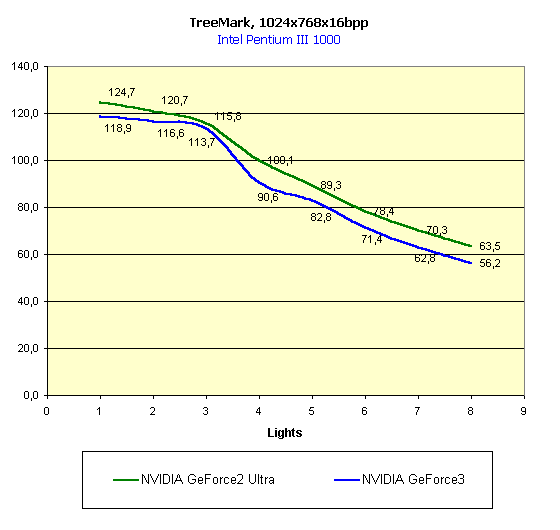
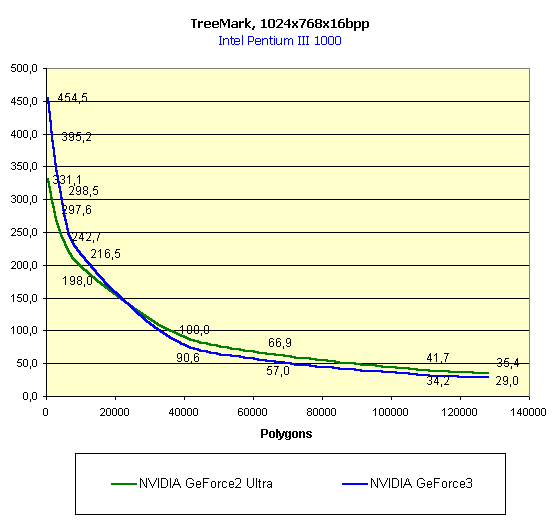
Грубо говоря, HW T&L у GeForce2 Ultra снова впереди, а вот малое число полигонов, наоборот, дает фору GeForce3 — есть где развернуться HSR и Z компрессии. Что же, на этом все, перейдем к немногочисленным реальным приложениям.
Результаты тестирования в игровых приложениях
Quake3 Arena, OpenGL
Для тестирования мы использовали версию 1.17 игры Quake3 Arena от id Software с использованием двух бенчмарков: demo002 и quaver.
Производительность при максимальном качестве графики и анизотропная фильтрация
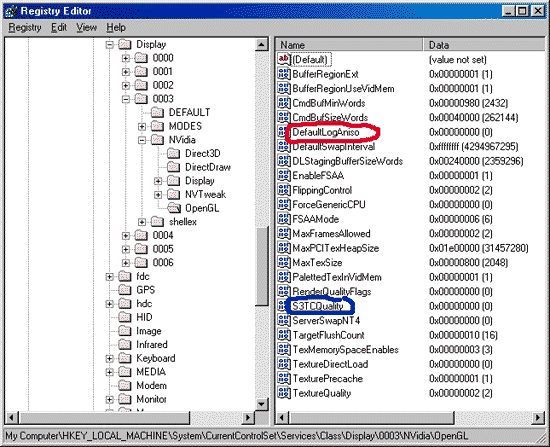
Я не случайно привел скриншот из registry. Обратите внимание на переменную, выделенную красным цветом — DefaultLogAniso. Именно через нее и можно включить анизотропную фильтрацию в OpenGL. К сожалению, сырость новых драйверов сказывается на удобстве настройки такой важной функции, как анизотропная фильтрация. Включить ее привычным способом через настройки дисплея в данном случае не получится. После тщательных исследований была найдена формула получения "степени" анизотропной фильтрации, то есть число используемых текстурных сэмплов:
AF=2^(DefaultLogAniso+2)
Таким образом, анизотропная фильтрация на GeForce3 может образовываться 8-ю, 16-ю или 32-мя сэмплами. В Сети гуляла информация о возможности 64-сэмпловой анизотропии, однако это практически невероятно. Два объединенных TMU могут выбирать до 8 сэмплов за такт, то есть за 2 такта можно осуществить 16-сэмпловую анизотропию, а за 4 такта — 32-сэмпловую (точно также на ATI RADEON можно наблюдать максимальную выборку в 24 сэмпла, учитывая наличие 3-х TMU на каждом конвейере).
Качество 32 сэмпловой анизотропии выше всяких похвал. Ниже мы покажем, какое падение по скорости вызывает использование максимального числа сэмплов, и станет ясно, что 64-сэмпловая анизотропия просто иррациональна. К тому же, опытным путем было установлено, что переменная DefaultLogAniso имеет максимальное значение 3.
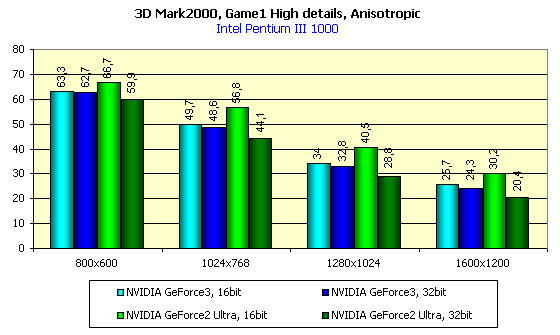
Подчеркну, что все тесты проводились при максимально возможном качестве (уровень детализации геометрии — High, детализация текстур №4, трилинейная фильтрация включена):
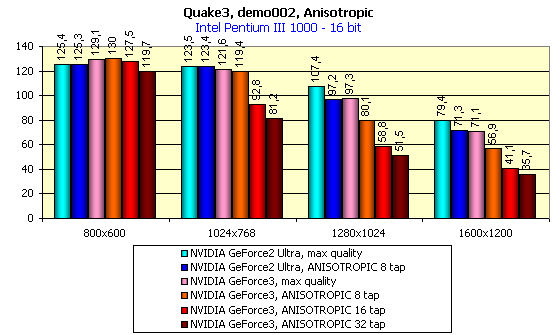
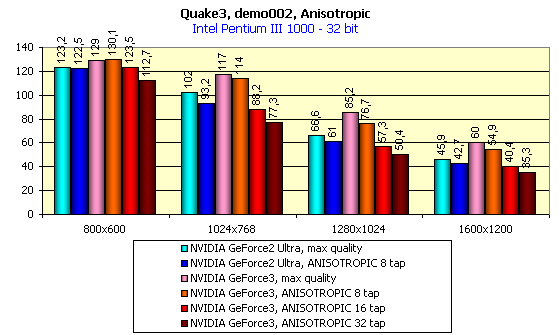
Всем хорошо видно, как приходиться жертвовать скоростью для достижения лучшего качества. Возникает вопрос: "А оно того стоит?"
Давайте посмотрим:
Анизотропная фильтрация по 8-ми текстурным сэмплам


Анизотропная фильтрация по 16-ти текстурным сэмплам


Анизотропная фильтрация по 32-м текстурным сэмплам


Я думаю, что последний скриншот наглядно показывает, какого великолепного качества и четкости можно добиться на GeForce3, правда, отдав за это около 30 fps производительности в 1024х768х32. Тут уж каждому придется выбирать самостоятельно. Кстати, о потерях производительности. Давайте посмотрим на картину в целом:
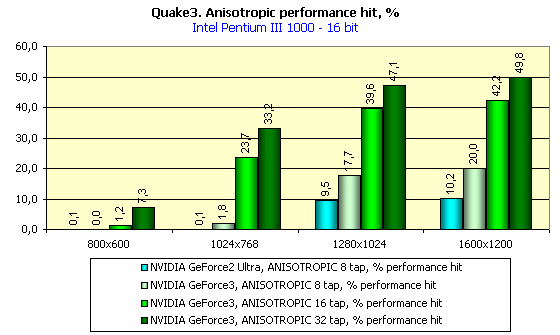
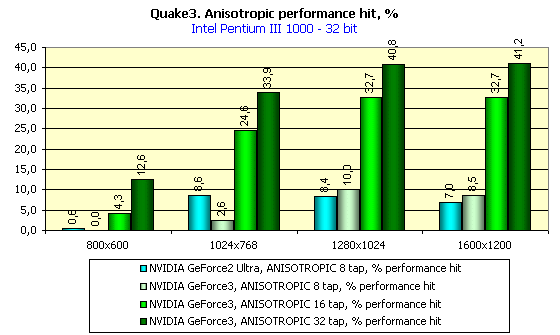
Да, действительно, цена за красоту и качество довольно велика. Но повторю, что каждый волен выбрать компромиссное решение между наилучшим качеством и великолепной производительностью, GeForce3 предоставляет в полной мере и то и другое (в отличие от GeForce2 Ultra — ориентированной скорее на скорость и Radeon — ориентированного более на качество).
Теперь рассмотрим производительность GeForce3 без анизотропной фильтрации при максимально возможном качестве. Надо обратить внимание на то, что в 16-битном цвете GeForce3 почти не получает преимущества, здесь наблюдается проигрыш более скоростному сопернику в лице GeForce2 Ultra. Зато в 32-битном цвете мы видим прямо противоположную, отрадную картину. Посмотрите, насколько сильно обогнала карта на GeForce3 оппонента! И при этом частота графического ядра ниже, чем у GeForce2 Ultra.
Налицо действие новых технологий кэширования и наглядная демонстрация сбалансированной архитектуры - то, о чем мы говорили выше, при представлении нового графического процессора — GeForce3. Теперь мы имеем возможность играть в разрешении 1280х1024@32bpp при максимальном качестве, совершенно забыв про то, что когда-то 3D-акселераторы постоянно подтормаживали там, где нам хотелось бы наблюдать всю красоту трехмерной графики. Более того, даже в режиме 1600х1200@32 карты на GeForce3 обеспечивают прекрасный уровень играбельности в играх типа Single Play (я сам с удовольствием поиграл в Giants в таком разрешении).
В игре Quake3 есть один уровень, который стал весьма любимым для многих тестеров. Это Q3DM9, в котором используется много текстур большого размера, общий объем которых, как правило, превышает 32 мегабайта даже в низких разрешениях. Когда-то был изготовлен демо-бенчмарк QUAVER, при помощи которого многие измеряли и измеряют производительность графических акселераторов в "тяжелых" условиях при сильной нагрузке. Когда мы исследовали карты на базе GeForce2 Ultra, то этот бенчмарк был нам хорошим помощником. Посмотрим, как поведет себя в этом тесте GeForce3:
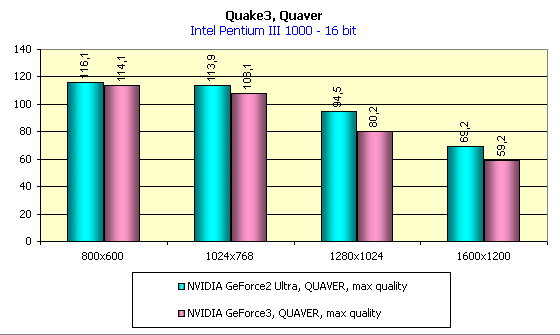
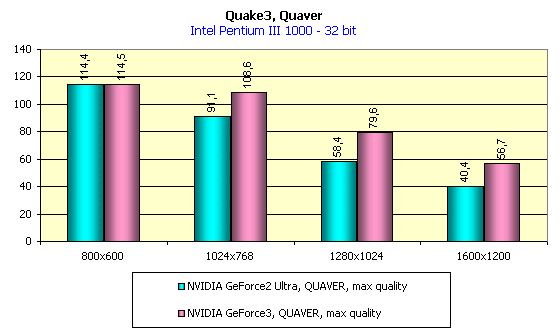
Видно, что картина полностью повторяется с 16-битным цветом, а при 32-битном цвете вновь наблюдаем первенство GeForce3. Теперь оценим в целом величину падения производительности при переходе с 16- на 32-битный цвет:
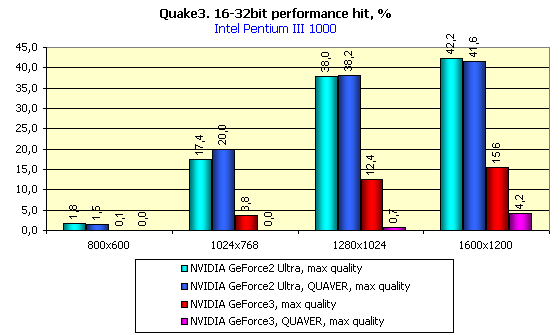
У GeForce3 просто блестящие результаты, не правда ли? Конечно, скептики сразу же возразят, что, мол, за счет более низкой скорости в 16-битном цвете и получилась такая небольшая разница в производительности. А нужно ли вообще использовать 16-битный цвет с картами на базе GeForce3? Может быть, пора вообще забыть о нем, как о тяжелом сне? Видеокарты класса GeForce3 (да и GeForce2 Ultra) могут обеспечить отличные результаты и в "труколоре". Если же у вас монитор не поддерживает высокие разрешения (вроде 1600х1200), то мы советуем вам обратить внимание на такую вещь, как анти-алиасинг.
Общая производительность и анти-алиасинг
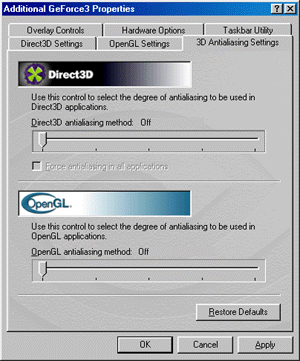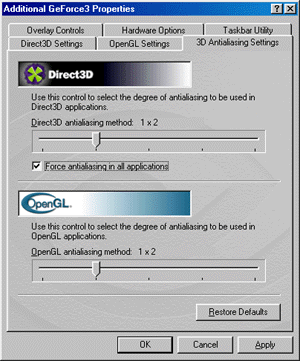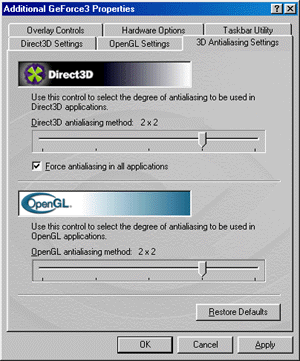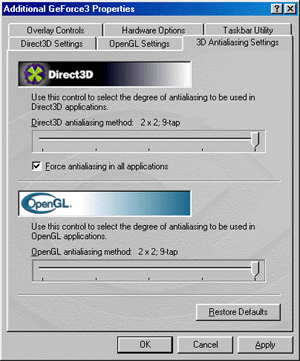
В драйверах версии 10.50 настройка эффекта сглаживания (анти-алиасинг, АА) вынесена в отдельную закладку, объединяя в одном месте регулировки АА для Direct3D и OpenGL приложений. Возможности настроек для обоих API полностью идентичны. Напомню, что NVIDIA GeForce3 использует новый метод мультисэмплинга для реализации АА, о котором было рассказано выше. Мы можем использовать следующие режимы АА:
- MSAA 1x2
- Quincunx (метод, запатентованный NVIDIA)
- MSAA 2x2
- MSAA 2x2tap9
С каждым из способов читатель уже познакомился выше (в теоретическом смысле), мы же покажем, что все это дает на практике:
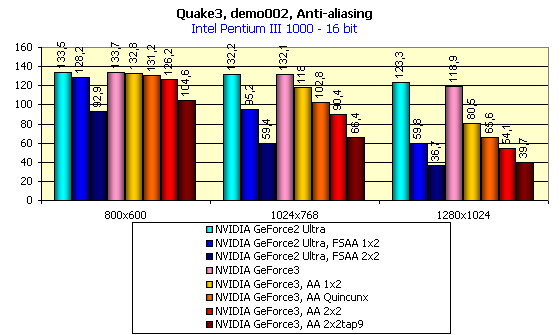
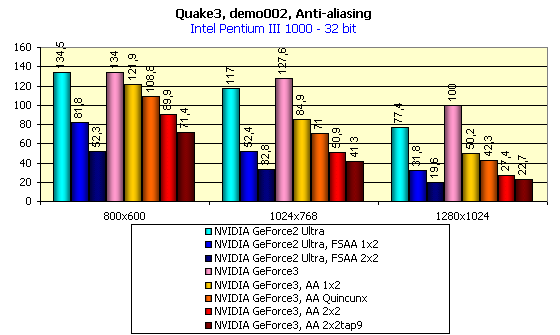
Прежде всего, надо отметить, что в этой части обзора тестирование при 16-битном цвете проводилось в режиме Fast, а при 32-битном цвете использовался режим High Quality.
Рассмотрим производительность NVIDIA GeForce3 при отключенном АА. В 16-битном цвете какие-либо отличия от GeForce2 Ultra отсутствуют, а вот 32-битный цвет показал всю силу нового графического процессора. Мы уже говорили об оптимизациях в этом GPU, которые дают возможность 200-мегагерцовому графическому ядру GeForce3 легко обходить 250-мегагерцовый GeForce2 Ultra, имея при этом эквивалентное количество конвейеров рендеринга и текстурных модулей.
Теперь бросим взгляд на качество, которое может нам дать использование того или иного режима АА:
Анти-алиасинг 1х2


Анти-алиасинг Quincunx


Анти-алиасинг 2х2

Посмотрите внимательно и убедитесь, что новый режим АА — Quincunx обеспечивает превосходное качество картинки. Теперь взглянем на диаграммы выше. Если на GeForce2 Ultra мы можем получить примерно аналогичное качество только в режимах FSAA 2x2 и выше, потеряв при этом колоссальную долю производительности (например, в 1024х768х32 мы получим скорость всего около 33 fps), то на GeForce3 режим Quincunx дает нам 71 fps в том же разрешении. При этом качество АА в большинстве случаев выше! Полагаю, что будущим владельцам GeForce3 будет весьма приятно иметь широкий выбор режимов работы карты: можно использовать высокое разрешение 1600х1200 или низкое разрешение в паре с АА.
Однако вернемся к общей оценке влияния АА на производительность:
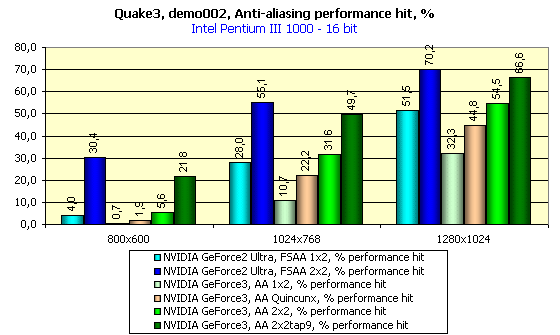
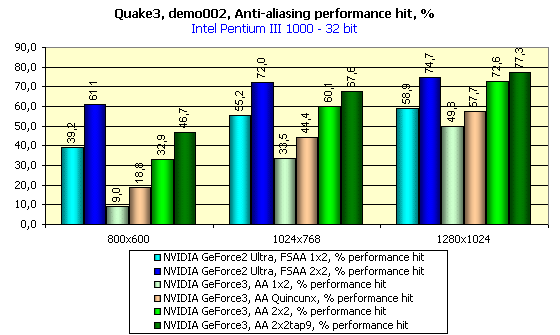
Мы помним, что по качеству анти-алиасинг у GeForce3 в режиме Quincunx (розовый столбец) примерно соответствует и даже превосходит режим 2х2 SSAA у GeForce2 Ultra (синий столбец на диаграмме). Даже в относительных единицах видно, что SSAA проигрывает везде. Конечно, MSAA далеко не бесплатный, как обещалось в рекламных материалах, однако при мощи GeForce3 он дает отличные результаты по производительности.
Производительность при разгоне
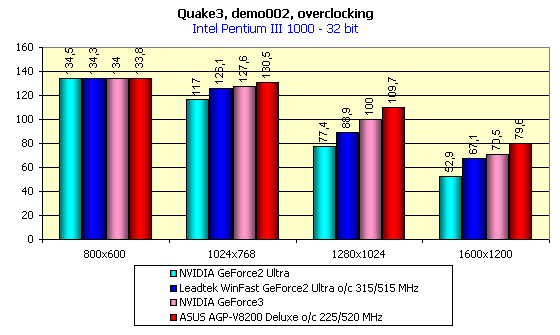
Как следует из описаний рассматриваемых в данном обзоре акселераторов, самой разгоняемой оказалась карта ASUS AGP-V8200 Deluxe, она-то и представлена на диаграмме выше. Обратите внимание на то, что даже самый максимальный разгон GeForce2 Ultra не смог поднять производительность этой карты до уровня GeForce3. Прирост производительности от разгона GeForce3 не стал весьма существенным ввиду незначительной разгоняемости самого GPU. Более подробно вопросы разгона и влияния частот работы памяти и графического ядра по отдельности мы рассмотрим несколько позже в отдельном материале. Сейчас я хочу лишь отметить, что по итогам проведенных исследований разгона можно сделать вывод о переносе центра "тяжести" производительности с частоты работы памяти на частоту графического процессора. Плата на GeForce3 уже намного более сбалансирована, и дальнейший рост производительности уже упирается не в пропускную способность видеопамяти, а в скорость работы самого графического процессора. Зато какие возможности по выпуску без особых усилий модификаций GeForce3 с приставкой Pro или Ultra :-)
Болевая точка — S3TC…
Многие владельцы видеокарт на базе GeForce/GeForce2 знают, что при включении S3TC в OpenGL в 32-битном цвете наблюдается очень неприятная картина, о которой я рассказывал уже в 3DGiТогах:


Проблема низкого качества сжатых текстур на у карт на базе GeForce/GeForce2 связана с неприятной особенностью аппаратной распаковки текстур, упакованных в формате DXT1. При распаковке таких текстур чип оперирует с 16-битным текселем. Такая реализация декомпрессии приводит к бандингу при распаковке текстур, которые содержат плавные цветовые градиенты (именно этот эффект мы и наблюдаем на текстурах неба в Quake3 на скриншоте выше). К огромному сожалению, эта проблема досталась в наследство и GeForce3. Однако не все так плохо. Если посмотреть по тексту этой статьи немного выше, то при рассмотрении анизотропии приводился скриншот из Registry, где можно увидеть переменную S3TCQuality, обведенную синим цветом. По умолчанию она равна 0, а если ей присвоить 1, то картина довольно сильно меняется:


Ключ S3TCQuality влияет на динамическую упаковку текстур. Установка этого ключа в значение 1 приводит к тому, что OpenGL драйвер начинает упаковывать текстуры в формат DXT3 вместо формата DXT1. При этом наблюдается небольшая потеря в скорости. Общее влияние использования S3TC на производительность мы покажем на диаграмме ниже (16-битный цвет не привожу, так как, во-первых, эта глубина цвета для GeForce3 уже не актуальна, а во-вторых, включение S3TC в этом случае дает крайне незначительный прирост в скорости):
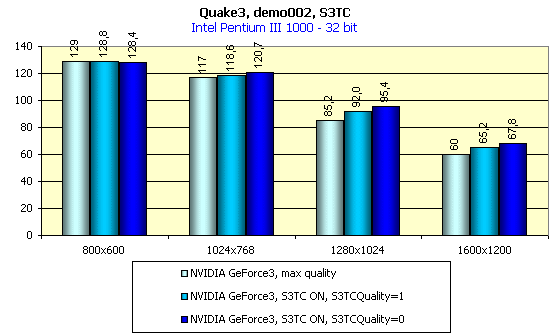
Выводы очевидны и комментариев не требуют, хотя я лично не включал бы S3TC без надобности (дивидендов это приносит мало, если только не играть на специальных уровнях от Diamond). Вопросы использования S3TC в OpenGL в целом на ряде акселераторов мы подробно рассматриваем в 3DGiТогах, где читатели смогут с ними ознакомиться.
3DMark 2000 Pro, DirectX
Для тестирования мы использовали версию 1.1 популярного бенчмарка 3DMark 2000 Pro от MadOnion с использованием двух тестов: Game1 и Game2. Оба теста прогонялись при максимальном уровне детализации (High Details).
Производительность и анизотропная фильтрация
Вначале рассмотрим скоростные показатели GeForce3 в Direct3D. Если в OpenGL уже давно имеется такой универсальный и популярный бенчмарк, как Quake3, а также есть игры на этом движке, где имеется возможность измерения средней производительности (FAKK2, например), то в Direct3D в этом плане совсем все плохо. Есть 2.5-летней давности Expendable, который не выдерживает уже никакой критики с точки зрения нагрузки акселераторов новыми функциями и эффектами, да и все… В 3DGiТогах мы еще используем Unreal в Direct3D, который на высоких разрешениях хоть как-то отражает возможности ускорителей, однако сырость драйверов версии 10.50 сделала невозможность использования этого бенчмарка из-за отсутствия в Unreal какого-либо текста. Нет, он есть, конечно, но его не видно, в т.ч. и timedemo. Поэтому пришлось обратиться к синтетическим тестам. В принципе, игровые тесты из 3DMark 2000 довольно реально отражают ситуацию по нагрузке акселератора. Особенно если это режим High Details. Именно в нем мы и проводили тестирование:
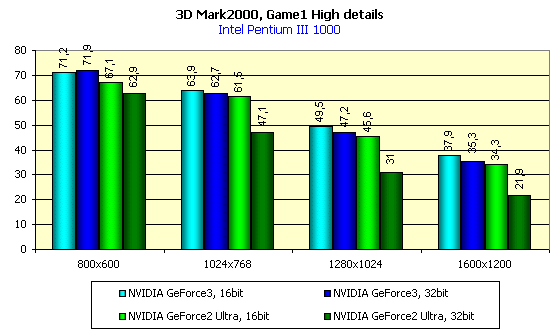
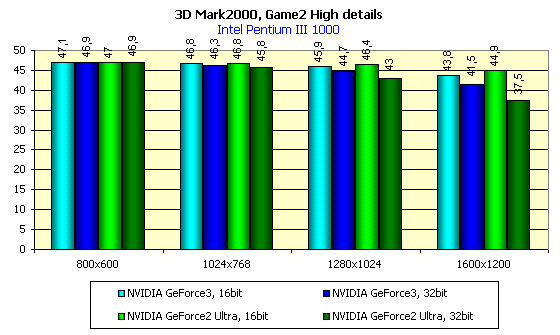
Видно, что в 16-битном цвете GeForce3 незначительно опережает GeForce2 Ultra, а вот в 32-битном цвете это преимущество становится очевидным и осязаемым.
Отмечу, что наконец-то в драйверах от NVIDIA появилась возможность форсирования (принудительного включения) анизотропной фильтрации в Direct3D. До сего момента только само приложение могло управлять этой фильтрацией, однако игр с поддержкой анизотропии практически нет. Теперь, внеся изменение в Registry, создав переменную FORCEANISOTROPICLEVEL (выделено зеленым) и дав ей значение 2, мы получаем в Direct3D анизотропную фильтрацию, правда, пока лишь самого минимального уровня — на основе выборки из 8-ми сэмплов:
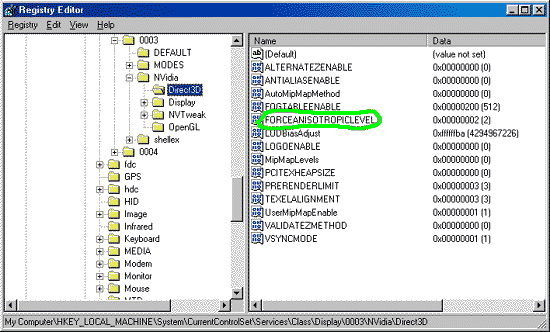
Что же мы при этом получаем?
Анизотропная фильтрация отсутствует, FORCEANISOTROPICLEVEL=0
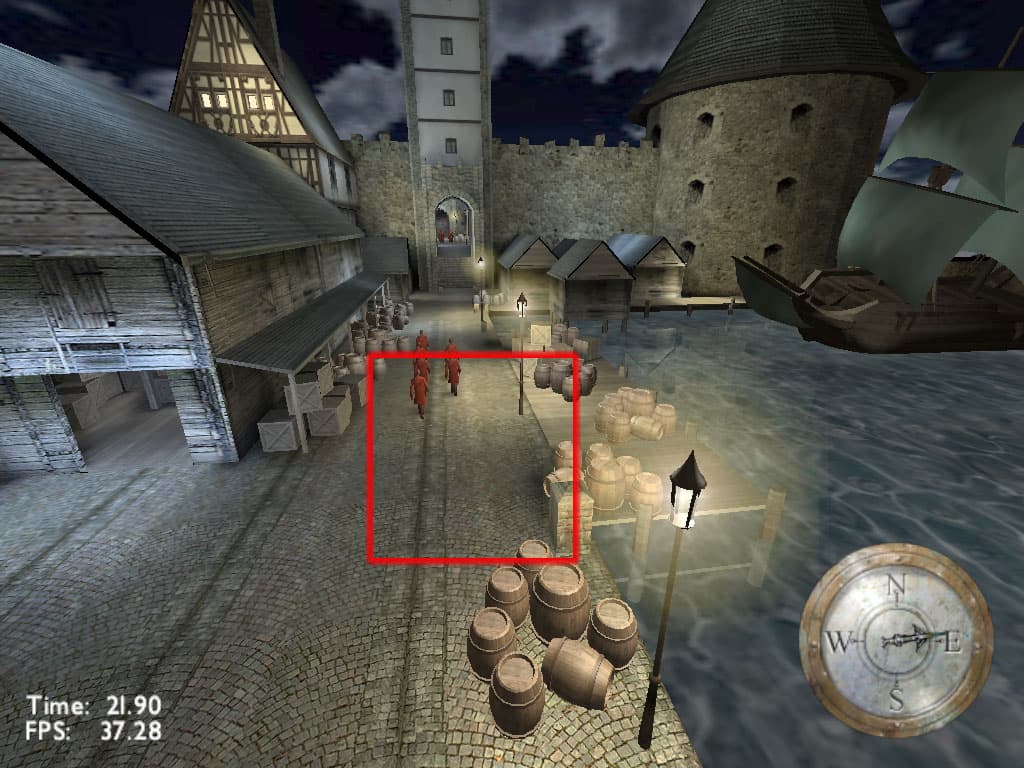

Анизотропная фильтрация присутствует, FORCEANISOTROPICLEVEL=2


Разница в качестве весьма наглядна. Но как это скажется на производительности? Ведь еще из раздела по Quake3 стало понятно, что "бесплатный сыр бывает только в мышеловках".
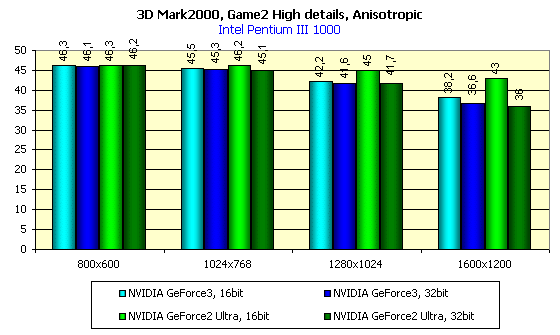
Интересно отметить, что на GeForce2 Ultra в 16-битном цвете включение анизотропии минимальным образом снижает производительность. Впрочем, интересно оценить влияние использования анизотропной фильтрации на производительность в целом:
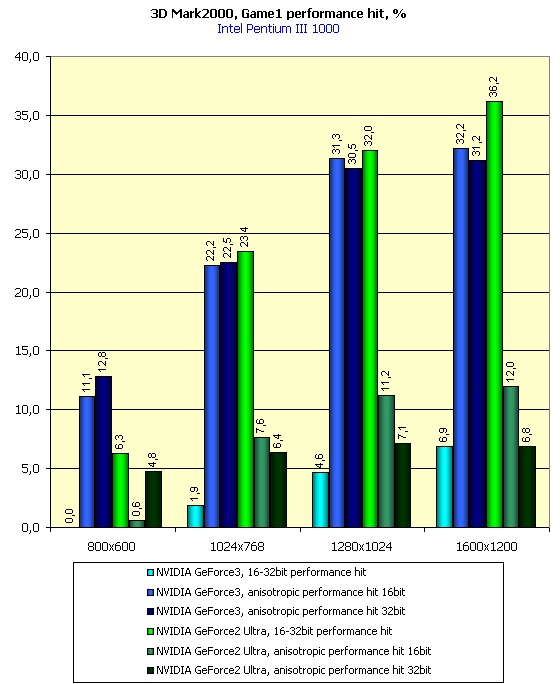
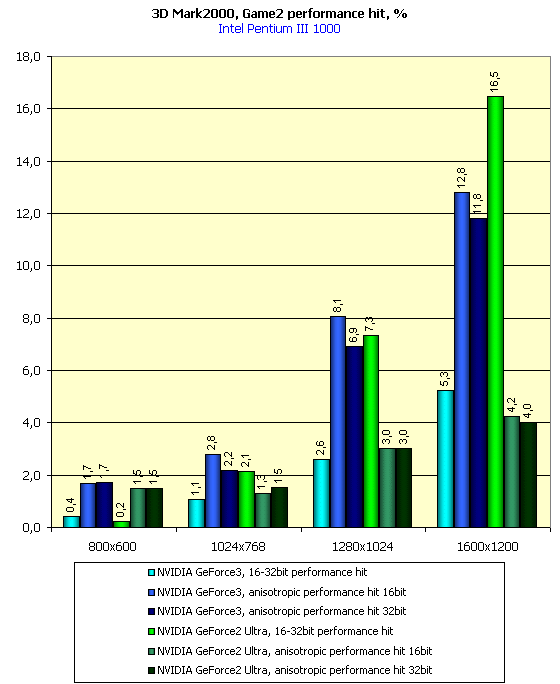
Из приведенных диаграмм видно, что величина падения скорости у GeForce3 при активизации анизотропии намного выше, чем у GeForce2 Ultra. Этот момент пока несколько непонятен. Возможно, что одно и то же значение переменной FORCEANISOTROPICLEVEL по-разному влияет на истинную "степень" анизотропной фильтрации на различных акселераторах, хотя я особых отличий визуального плана не усмотрел.
На тех же диаграммах можно увидеть и величину падения производительности при переходе с 16- на 32-битный цвет. И опять мы констатируем, что разница в производительности при переходе у GeForce3 очень мала по сравнению с тем, насколько падает производительность у GeForce2 Ultra.
Есть еще один весьма хороший пример, где наглядно видно, что дает включение анизотропной фильтрации, это демо NV Gothic:
Анизотропная фильтрация отсутствует, FORCEANISOTROPICLEVEL=0


Анизотропная фильтрация присутствует, FORCEANISOTROPICLEVEL=2


К сожалению, это приложение лишено встроенного бенчмарка, поэтому мы можем лишь ограничиться визуальным сравнением.
Некоторые аспекты качества 3D-графики
Можно много и нудно говорить про важность полноценной поддержки DirectX 8.0, а также о тех возможностях для разработчиков игр, которые открывает перед ними новый движок nFinite Engine у GeForce3, однако многим пользователям хочется уже сейчас хоть какие-то из новшеств увидеть в вышедших играх. Пока нет в релизах ни одной игры "под DirectX 8.0", мы вспоминаем про технологию EMBM (Environment Mapped Bump Mapping). Наконец-то появился первый чип от NVIDIA, который может полноценно напрямую поддерживать эту ценнейшую технологию. Не один год уже (скоро будет два) это понятие тесно было связано с "родителем", фирмой Matrox, которая активно использовала EMBM в своих рекламных целях, привязывая все вновь выходящие игры или патчи с поддержкой EMBM к своим G400/G450. В результате оказалось, что, когда летом 2000 года вышел в свет ATI RADEON, также поддерживающий EMBM, ни одна соответствующая игра на этом графическом процессоре не запустилась, требуя непременно Matrox Hardware.
К некоторому нашему удовлетворению, все же стали появляться игры, где технология EMBM не только применяется, но и никак не привязана к имени Matrox. Например, это Battle Isle4: The Andosia War от Blue Byte:
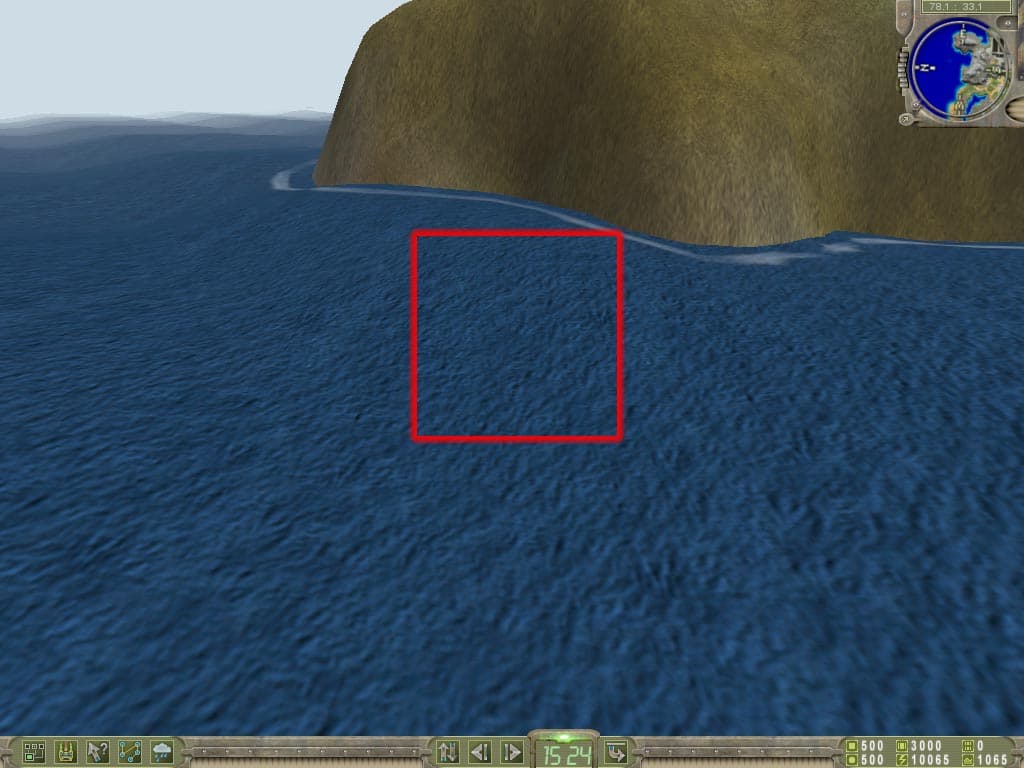


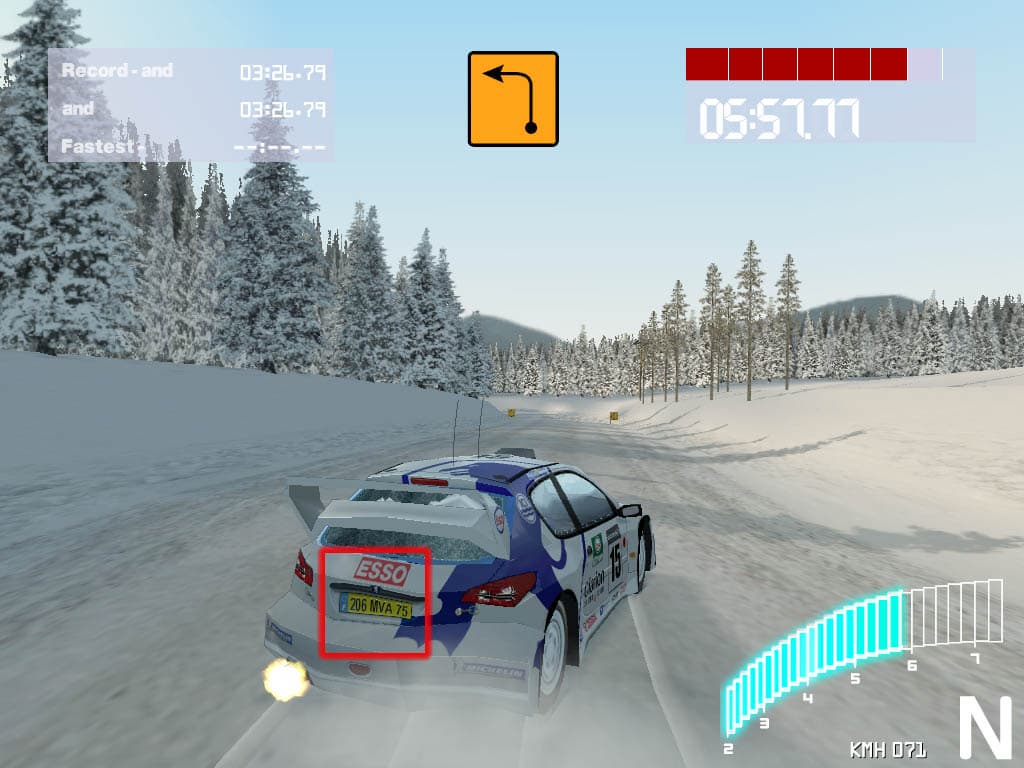
В этой игре EMBM довольно широко используется для более реалистичного отображения всевозможных поверхностей на больших площадях. А вот в игре Colin McRae Rally2 от Codemasters применение EMBM можно увидеть только на автомобиле, да и то практически лишь на номере и на разбитых окнах:

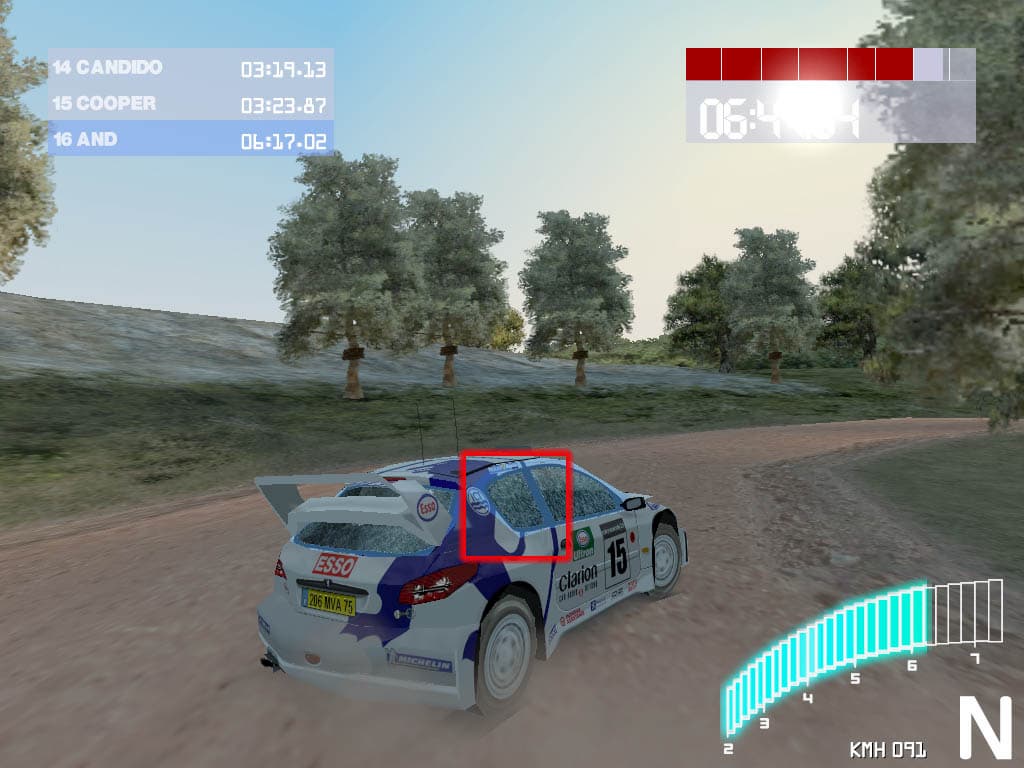

Остальные вопросы качества 3D-графики подробно и ежемесячно рассматриваются нами в 3DGiТогах, где есть целые галереи скриншотов из многих игр, полученные на большом количестве видеокарт разных поколений.
Вернемся к теме данной статьи. Надо сказать, что вообще-то наступает эпоха активного внедрения в игры элементов реалистичности изображения. Вот мы поговорили о EMBM, однако способов получения рельефной поверхности уже довольно много. Новые технологии шейдеров дают в этом плане разработчикам просто невероятные возможности:


Сразу предупреждаю, что это не фотографии, и не репродукции с картин :-) Эти лица построены в реальном времени при помощи GeForce3 и новых возможностей, которые дает DirectX 8.0. Конечно, далеко еще до тех времен, когда в играх мы сможем общаться с героями, имеющими настолько выразительную мимику и тщательно прорисованные черты лица, однако уже в следующем году мы сможем реально увидеть персонажей с разной мимикой:




Это кадры из предстоящего хита от id Software — DOOM3. Мы просим извинить за такое неважное качество скриншотов. Дело в том, что они были получены с видеоролика из презентации NVIDIA GeForce3 на Macworld, на которой Джон Кармак продемонстрировал некоторые кадры из DOOM3.
Выводы
Как совершенно верно заметил Джон Кармак после презентации GeForce3 на MacWorld, следовало бы назвать GeForce2 другим именем, например чем-то вроде GeForce256 Pro, ввиду отсутствия в этом чипе революционных изменений относительно предшественника, а вот цифру "2", как символ нового поколения GPU, имеющего вполне революционные технологии, присвоить нынешнему GeForce3. Ну да ладно, это лирика, а мы подведем итоги рассмотрению новейшего графического процессора GeForce3 от NVIDIA.
- Полноценная аппаратная поддержка Microsoft DirectX 8.0, которая дает разработчикам приложений широкие возможности по программированию очень интересных эффектов и их использованию в играх, а пользователям впоследствии наслаждение превосходной графикой.
- Новый уникальный движок NVIDIA nFinite FX, дающий разработчикам игр большие возможности по гибкому использованию механизма HW T&L, который отныне стал полностью программируемым. В конечном итоге выиграет от этого опять пользователь, поскольку производители игр уже не станут использовать HW T&L "для галочки", то есть, чтобы просто было, раз это в моде. Более полноценная нагрузка GPU по операциям HW T&L даст реальное высвобождение ресурсов центрального процессора под иные нужды, например, расчеты физики движения тех или иных объектов или частей (то же управление мимикой лиц, например, требует от центрального процессора немало вычислений, чтобы корректно выставить задачу для акселератора).
- Наконец-то мы видим действительно сбалансированный 3D-ускоритель, у которого относительно низкая пропускная способность видеопамяти не урезает добрую половину потенциала GPU. Применение технологий кэширования и оптимизация работы с Z-буфером обеспечивают феноменальный успех GeForce3 в реальных приложениях. GeForce3, даже имея меньшую тактовую частоту, чем у его предшественника в лице GeForce2 Ultra (а конвейерную архитектуру точно такую же), продемонстрировал великолепную производительность, сбросив в архив истории такое понятие, как 16-битный цвет в 3D-графике. Действительно, уже нет ни малейшей нужды использовать эту глубину цвета, от которой уже года два как все пытаются освободиться, и до сего момента это никак не удавалось из-за сильного падения производительности в 32-битном цвете.
- Новая технология анти-алиасинга методом мультисэмплинга, а особенно патентованный режим Quincunx, дают пользователям прекрасное качество 3D-картинки при отсутствии катастрофического падения производительности. В самом деле, ну какой еще ускоритель даст возможность получить практическое отсутствие "лестниц" по краям объектов в разрешении 1024х768х32 и при скорости в 70 fps! Только GeForce3.
- Отрадно видеть, что уже много производителей собираются выпускать свои карты на базе нового GPU. В данном обзоре мы представили ряд самых передовых вендоров, идущих в ногу со временем. Совсем скоро представленные в данном обзоре карты появятся в свободной продаже.
- Ложкой "дегтя" остается, безусловно, стоимость карт на базе GeForce3. Разумеется, как не пытайся обойти этот вопрос, он будет постоянно напоминать, что данные изделия, мягко говоря, не очень популярны среди пользователей компьютеров именно из-за их цены. С другой стороны, есть такое понятие, как рынок. Он формирует цены. Опыт показывает, что если какая-либо фирма начинает бездумно и неоправданно завышать цены, то рано или поздно ее ждет провал или даже крах (Hercules, 3dfx). Директор по продажам европейского представительства NVIDIA Рой Тейлор на недавней конференции партнеров фирмы ASUSTek так ответил на вопрос о росте цен на их продукцию: "Мы выставляем цену в $50 — нас ругают, предрекают забитые склады и т.п. А мы продаем все чипы до последнего. Потом мы выставляем цену в $75 - нас еще больше ругают, кто-то бьется в конвульсиях, а мы продаем все чипы опять до последнего. Что мы будем делать на следуюшем этапе? — Догадаться несложно. Мы не были бы бизнесменами, если бы не поступали так. Вот когда продажи резко сократятся, когда образуется масса товара, не имеющего сбыта, вот тогда мы уже будем думать, а не завысили ли мы цены… Впрочем, мы всегда сможем снизить цены"
Итак, мы рассмотрели новейший GPU GeForce3 от NVIDIA и протестировали в реальных и синтетических условиях сразу несколько карт на его базе. Да, карты на GeForce3 — это сэмплы, на 99% не отличающиеся от серийных карт, которые совсем скоро пойдут в свободную продажу. Разумеется, мы проверим в деле и серийные платы и, конечно же, мы ждем релизных драйверов для GeForce3. В общем, этот обзор закончен, но тема GeForce3 только открывается, впереди еще много интересного. Читайте наши 3DGiТоги, в которых отныне будет участвовать и карта на базе GeForce3.


