Общая информация
Не секрет, что 27 февраля на Intel's Developer Forum (IDF) должен быть официально анонсирован новый GPU от NVIDIA, известный под кодовым именем NV20. Всем интересно узнать, что же будет нового в этом графическом процессоре. У нас появилась возможность приподнять завесу тайны и предоставить вам массу интересной информации. Сразу оговорюсь, что результаты замеров производительности приводиться не будут, т.к. существующий инженерный образец еще довольно сырой, да и драйверы еще находятся в стадии, далекой от финальной. Зато про функциональные особенности NV20 мы можем поговорить уже сейчас в полном объеме.
Начнем мы с общей спецификации NV20, причем мы выделим самые интересные параметры, чтобы не повторять все то, что поддерживается в GeForce2. Обратите внимание, что это обновленная версия статьи, где синим цветом выделено все новое.
Спецификация NV20
- Технология: 0.15 мкм
- около 60 миллионов транзисторов
- Частота графического ядра: 200+ МГц (позже, вероятны "Ultra" и "Pro" варианты, например на 250 МГц)
- Число пиксельных конвейеров рендеринга: четыре
- Число текстурных блоков на конвейер рендеринга: два
- Возможность наложения четырех текстур на один пиксель (требуется два такта)
- Интерфейс памяти: 128 бит
- Поддерживается память типа DDR SDRAM/SGRAM
- На момент выхода первые карты на базе NV20 будут оснащаться памятью, работающей на частоте 250 (500) МГц
- Пиковая пропускная способность шины памяти при 250 Мгц шине: 8 Гб/с
- Поддерживаемый объем локальной видеопамяти: до 128 Мб (первые карты, как и наш образец, будут иметь 64 Мб)
- RAMDAC: 350 МГц
- Максимальное разрешение: 2048x1536@75Hz
- Интегрированный в чип TMDS трансмиттер позволяет подключать цифровые мониторы и поддерживает разрешение вплоть до 1600x1200
- Интерфейс внешней шины: полная поддержка AGP x2/x4 (включая SBA, DME и Fast Writes) и PCI 2.2 (включая Bus mastering).
- Аппаратный T&L: эффективная производительность порядка 40+ млн. полигонов в секунду (у нашего образца чуть меньше 40 млн. полигонов в секунду на синтетическом тесте)
- Полная аппаратная поддержка всех возможностей MS DirectX 8.0 и OpenGL 1.2
- Полностью поддерживаются аппаратные вершинные шейдеры (VertexShaders) DX8, версия 1.1
- Полностью поддерживаются аппаратные пиксельные шейдеры (PixelShaders) DX8, версия 1.0
- Имеется поддержка объемных текстур
- Имеется поддержка кубических карт среды (Cube environment mapping)
- Поддерживается проекция текстур (projective textures)
- Имеется поддержка аппаратной тесселяции гладких поверхностей (прямоугольных и треугольных патчей)
- Имеется аппаратная поддержка рельефного текстурирования следующих типов: Embosing, Dot Product3 и EMBM (наконец-то!)
- Имеется поддержка S3TC и всех пяти DXTC методов сжатия текстур
- Имеется поддержка отсечения примитивов по произвольно заданным плоскостям
- Имеется поддержка FSAA методом OGMS
- Аппаратные средства для экономии полосы пропускания видеопамяти: поддержка сжатого формата буфера глубины (compressed Z) и раннего определения видимости точек (HSR на базе early Z test)
- Поддерживаются текстуры вплоть до 4096x4096 @ 32 bit
Даже при беглом взгляде на список возможностей можно сделать вывод о том, что в NV20 реализована принципиально новая архитектура, позволяющая обеспечить полную аппаратную поддержку DirectX 8.0. Можно констатировать, что поддержка DX8 сделана своевременно, и, наверняка, именно этот факт будет использован в качестве базиса при рекламе NV20 и карт на его основе.
NVIDIA не пошла по пути прямолинейного наращивания мощности (например увеличения числа конвейеров рендеринга). Наоборот, все усилия инженеров были сосредоточены на реализации новой архитектуры, позволяющей обеспечить полную аппаратную поддержку DX8, но при этом без существенного увеличения числа транзисторов в чипе. Прибавьте к этому использование 0,15 мкм технологического процесса, что позволило без создания гигантских размеров чипа уместить в нем около 60 млн. транзисторов. Многие из которых, несомненно, были потрачены на более вместительные кэши для различных видов данных. Быстрый переход на NV20 гарантирует то, что у NVIDIA очень хорошо налажены отношения с вендорами, также надежно отлажены каналы поставок памяти в комплекте с GPU. Референс дизайн карт для NV20 не сильно отличается от дизайна PCB для GeForce2 — чипы памяти передвинуты на несколько миллиметров ближе к графическому ядру и изменено расположение стабилизаторов питания. В остальном все без изменений. DDR память доступна в промышленных масштабах, так что тут нет причин для беспокойства.
Можно заметить, что частота графического ядра NV20, число пиксельных конвейеров и текстурных блоков соответствует чипам серии GeForce2. Это значит, что потенциальная величина пиксельного fillrate у карт на базе NV20 будет как у карт на базе GeForce2, но в этом нет никакой трагедии. На самом деле проблема всех GPU, начиная с GeForce 256, не в величине потенциально возможного fillrate, а в эффективной (читай, реальной) величине fillrate, которая напрямую связана с пропускной способностью локальной видеопамяти. Именно видеопамять является главным "узким местом" всех современных графических ускорителей. Впрочем, все это вам хорошо известно из наших обзоров. На мой взгляд, NVIDIA поступила правильно, пойдя путем повышения эффективности архитектуры вместо прямолинейного увеличения мощностей.
Отметим еще одну интересную особенность NV20 — возможность наложения четырех текстур на один пиксель, что позволит раскрыть потенциал программируемых пиксельных шейдеров, подняв реализм 3D графики на качественно новый уровень. Однако, будучи по-прежнему ограниченными шириной полосы пропускания локальной видеопамяти, создатели чипа не стали тратить транзисторы, реализуя 4 текстурных блока на каждый пиксельный конвейер. Они поступили иначе: позволили сохранять результаты работы двух текстурных блоков для комбинирования с результатами, полученными на следующем такте. Т.е. при использовании трех или четырех текстур предельно достижимая величина генерируемых пикселей падает вдвое. Но в реальных приложениях, где все упирается в пропускную способность шины видеопамяти, а не в fillrate, реальное падение производительности из-за пропущенных тактов, скорее всего, будет некритичным.
Тут стоит немного отвлечься и вспомнить XBox. Официальные спецификации X-Box звучат удивительно: величина пиксельного fillrate соотвествует 4000 млн. pix/sec! Частота графического ядра, используемого в XBox, чипа NV2A, будет порядка 250 МГц. Даже если допустить наличие 8 пиксельных конвейеров, мы не получим этой цифры (250*8=2000 млн. пикселей). Но 8 конвейеров маловероятны — пропускная полоса памяти XBox будет явно недостаточной, в текущей спецификации она порядка 6.4 GByte/sec, следовательно, их вновь 4. Более того, известно, что у NV2A также по 2 текстурных модуля на пиксельный конвейер. Откуда же взялась в спецификации XBox цифра 4000 млн. pix/sec? В действительности, речь идет о 4x Multi-Sample режиме, в котором реализуется FSAA. Там возникает ситуация, когда для одного полученного значения цвета соответствуют 4 положения, т.е. можно сказать, что число генерируемых пикселей возрастает вчетверо по сравнению с картами, не поддерживающими мультисэмплинг аппаратно (хотя, на самом деле, просто один пиксель с одной и той же текстурой используется четыре раза, меняются лишь его координаты). В итоге Microsoft с NVIDIA нашли очень изящный способ, как заявить большие значения fillrate :-)
Мы знаем, что увеличить величину эффективного fillrate без применения новых и/или дорогих технологий памяти можно только с использованием модифицированных алгоритмов закраски примитивов, снижающих требования к ее пропускной полосе. Очевидно, что игры будущего, созданные с учетом XBox и DX8, будут еще больше полагаться на T&L и аппаратное удаление невидимых поверхностей, нежели на собственные эффективные алгоритмы. Да и повышенная сложность моделей, несомненно, дополнительно увеличит OverDraw. В NV20 реализована несложная аппаратная поддержка HSR (ранняя проверка Z). Ее эффективность сильно зависит от сцены, передаваемой на ускоритель. Если примитивы отсортированы в порядке удаления от наблюдателя, то это позволит существенно снизить потребность в вычислении скрытых точек примитивов и значение эффективного fillrate вырастет в несколько раз. Также у NV20 в наличии сжатие Z буфера. Причем, по нашим данным, это несколько иной алгоритм, нежели иерархический Z, но сжатый буфер также делится на тайлы, которые читаются, записываются, обрабатываются и кэшируются целиком в чипе. Остается дождаться финальных образцов карт на базе NV20, релизной версии драйверов и проверить эффективность этих решений в реальных играх. Аналогичные алгоритмы будут иметь место и в XBox, но, возможно, в более "продвинутом" варианте (особенно если принять во внимание меньшую ширину полосы пропускания его памяти).
Настал черед блока HW T&L — его производительность по сравнению с GeForce2 существенно увеличилась, причем несомненно, что в NV20 применена эффективная схема кэширования информации о вершинах (vertex cache), а также механизм преобразования и выполнения списков вершин и примитивов, хранимых в локальной памяти, вообще без обращения к основной памяти системы. Эти меры позволили снизить до минимума (а во втором случае полностью обойти) ограничения, связанные с пропускной полосой AGP шины. Более мощный T&L позволит получить ощутимое (почти вдвое) преимущество в играх, которые могут его использовать. Особенно заметный результат будет наблюдаться в играх, рассчитанных на API DX 8.0 — в этих играх нас ждет высокая детализация и основанные на шейдерах эффекты. Речь идет и о тех играх, которые разрабатываются к выходу XBox, и, несомненно, будут успешно исполняться на NV20 и последующих за ним ускорителях "поколения X" 8.0. Старые игры будут идти практически с той же скоростью, что и на GeForce2-семействе. Некоторый прирост в виде увеличения fps будет наблюдаться во всех играх, которые могут использовать HW T&L, например, Quake3, но лишь в низких разрешениях.
NVIDIA делает ставку на то, что новые эффекты и возможности заставят людей покупать новые карты на базе NV20. И XBox, несомненно, поможет реализовать эти планы. Он спровоцирует появление игр нового визуального уровня, пользователи PC потянутся вслед, раскупая практически идентичные с XBox (с точки зрения игр) ускорители. Это настоящий шанс продать не только множество NV2A (прибыль от которых будет не так высока), но и новых, дорогих карт на базе NV20.
Для энтузиастов
Ну а теперь приготовимся к восприятию нелегкой на подъем, но практически бесценной информации о внутреннем потенциале NV20 (и как следствие, NV2A). Разумеется, новые возможности NV20 тесно завязаны на DX8. И я опишу их в соответствующих терминах. Перед вами сравнительная таблица:
| Параметр | NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| Max Texture Size | 4,096*4,096 | 2,048*2,048 | 2,048*2,048 |
| Max Textures Count | 4 | 3 | 2 |
| Point Sprites | аппаратно, масштабируемые (до 64х) | аппаратно (?), немасштабируемые | эмуляция, немасштабируемые |
| Max Texture Stages | 8 | ||
| Max Simultaneous Lights | |||
| Max Clip Planes | 8 | 6 | 0 |
| Max Vertex Blend Matrices | 4 | 2 | |
| Max Primitive Count / Max Vertex Index | 16,777,215 | 65,535 | |
| Vertex Shader Version | 1.1 | 0.0 | |
| Max Vertex Shader Const | 96 | 0 | |
| Pixel Shader Version | 1.0 | 0.0 | |
| Quintic/RT Patches | Да/Да | Нет/Нет | |
| W Depth Values | Да | ||
| Stencil Buffer | |||
| Anisotropy Filtering | |||
| Cubic Texturing | |||
| Volume Texturing | Да | Нет | |
| Z test | Нет | Да | |
| Shade modes | Color and Specular Gouraud, Alpha Gouraud blend, Fog goraud | ||
| MultiSample Types (включая FSAA методом OGMS) | 2x, 4x | Нет | Нет |
| SSAA Types | Нет | OGSS | |
| Z/MIPMAP Bias | Да/Да | ||
| Vertex/Table/Range Fog | Да/Да(Эмуляция?)/Да | Да/Да/Да | Да/Эмуляция/Да |
| W/Z Fog | Да/Да | ||
| Bandwidth Saving | Early Z test / Compressed Z | Hierarhical optimized Z | Нет |
Если вы еще не перестали читать
Итак, пояснения к пунктам, по порядку:
- Max Texture Size — максимальный размер текстуры.
- Max Textures Count — максимальное число текстур, участвующее в формировании результирующего пикселя. В DX8 это число определяется как максимальное количество текстур, которые могут быть одновременно задействованы на различных текстурных стадиях конвейера.
- Point Sprites — поддержка плоских спрайтов, предназначенных для быстрой отрисовки частиц. Подробнее про них см. наш DirectX 8.0 FAQ. Масштабируемые спрайты могут менять размер, немасштабируемые всегда отображаются 1:1. При отсутствии специальной аппаратной поддержки спрайты эмулируются двумя небольшими треугольниками, что сводит на нет их потенциальное преимущество (высокая скорость отрисовки).
- Max Texture Stages — длина конвейера, т.е. количество операций, которое может быть применено для формирования цвета результирующего пикселя из исходных параметров (цвета выбранных точек текстуры, интерполированные по поверхности треугольника значения прозрачности и освещенности вершин, параметры рельефа и пр.) Причем, в случае поддержки шейдеров, число текстурных стадий может и определять длину программы шейдера. По крайней мере, длину эффективно без задержки исполняемой программы. Каждый простой конвейера (если архитектура допускала бы оный) штрафует нас падением производительности. Один простой - и закраска идет вдвое медленнее, два простоя — втрое и т.д. Поэтому, наверняка, все шейдерные ускорители первой волны ограничатся шейдерами, не превышающими длиной количество текстурных стадий. О шейдерах чуть позже, а пока приведем таблицу операций, возможных на каждой стадии:
| NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| DISABLE SELECTARG 1 SELECTARG 2 MODULATE MODULATE 2X MODULATE 4X ADD ADDSIGNED ADDSIGNED 2X SUBTRACT ADDSMOOTH BLENDDIFFUSEALPHA BLENDTEXTUREALPHA BLENDFACTORALPHA BLENDTEXTUREALPHAPM BLENDCURRENTALPHA PREMODULATE MODULATE ALPHA_ADDCOLOR MODULATE COLOR_ADDALPHA MODULATEINVALPHA_ADDCOLOR MODULATEINVCOLOR_ADDALPHA BUMPENVMAP BUMPENVMAPLUMINANCE DOTPRODUCT3 MULTIPLYADD LERP | DISABLE SELECTARG 1 SELECTARG 2 MODULATE MODULATE 2X MODULATE 4X ADD ADDSIGNED ADDSIGNED 2X SUBTRACT BLENDDIFFUSEALPHA BLENDTEXTUREALPHA BLENDFACTORALPHA BLENDTEXTUREALPHAPM BLENDCURRENTALPHA MODULATEALPHA_ADDCOLOR MODULATECOLOR_ADDALPHA MODULATEINVALPHA_ADDCOLOR MODULATEINVCOLOR_ADDALPHA BUMPENVMAP DOTPRODUCT3 MULTIPLYADD LERP | DISABLE SELECTARG 1 SELECTARG 2 MODULATE MODULATE 2X MODULATE 4X ADD ADDSIGNED ADDSIGNED 2X SUBTRACT ADDSMOOTH BLENDDIFFUSEALPHA BLENDTEXTUREALPHA BLENDFACTORALPHA BLENDTEXTUREALPHAPM BLENDCURRENTALPHA PREMODULATE MODULATEALPHA_ADDCOLOR MODULATECOLOR_ADDALPHA MODULATEINVALPHA_ADDCOLOR MODULATEINVCOLOR_ADDALPHA DOTPRODUCT3 |
| Все эти команды возможны, когда стадия отведена под обработку цвета или альфа значения (также стадия может быть отдана на интерполяцию или загрузку соответствующего параметра из текстуры/вершин и т.д.) | ||
Выясним, что эти операции делают:
- DISABLE — запрещает работу (выдачу результатов), начиная с этой стадии конвейера и далее.
- SELECTARG1 (или 2) — результатом этой стадии становится один из ее входных параметров (никак не модифицируемый)
- MODULATE — результат стадии есть умножение входных параметров. Out=In1*In2
- MODULATE2X (или 4X) — то же самое, но с масштабированием, Out=(In1*In2)*2 или *4, соответственно
- ADD — сложение Out=In1+In2
- ADDSIGNED — сложение со знаком Out=In1+In2-0.5
- ADDSIGNED2X — сложение со знаком и масштабирование Out=(In1+In2-0.5)*2
- SUBTRACT — вычитание Out=In1-In2
- ADDSMOOTH — хитрое сложение с комбинацией Out=In1+In2*(1-In1)
- BLENDDIFFUSEALPHA,
BLENDTEXTUREALPHA,
BLENDFACTORALPHA,
BLENDCURRENTALPHA — альфа смешение параметров с использованием одного из 4 возможных значений Alpha (взятое с предыдущей стадии CURRENT, интерполированное по поверхности треугольника значение из вершин FACTOR, значение из текстуры TEXTURE или константное значение DIFFUSE). Соответственно, Out=In1*Alpha+In2*(1-Alpha) - BLENDTEXTUREALPHAPM — специальная разновидность альфа смешения, значение Alpha берется из текстуры. Out=In1+In2*(1-Alpha)
- PREMODULATE — модулирует результат этой стадии результатом последующей (например, используется для создания бликов).
- MODULATEALPHA_ADDCOLOR — модулирует цвет второго параметра альфой первого. Out=In1RGB+In2RGB*In1Alpha
- MODULATECOLOR_ADDALPHA — умножает цвета и прибавляет альфу Out=In1RGB*In2RGB+In1Alpha
- MODULATEINVALPHA_ADDCOLOR,
MODULATEINVCOLOR_ADDALPHA — то же, что и два предыдущих, соответственно, но вместо Alpha используется 1-Alpha - BUMPENVMAP — поточечный EMBM, в качестве карты среды используется результат последующей стадии. См. далее описания форматов текстур, там есть специальные форматы для хранения карт высот/смещений для задания рельефа.
- BUMPENVMAPLUMINANCE — то же самое, но с учетом кэффициента освещенности, так же хранимой в текстуре релиефа.
- DOTPRODUCT3 — самый честный поточечный вид рельефа. Фактически — скалярное произведение двух векторов с учетом знаков, компоненты которых помещены в RGB входных параметров. In1R*In2R+In1G*In2G+In1B*In2B
- MULTIPLYADD — популярная операция Out=In1+In2*In3
- LERP — линейная интерполяция Out=(In1)*In2+(1-In1)*In3
На основе подобного механизма можно запрограммировать множество эффектов с использованием различного количества текстур. Но тот факт, что разные ускорители поддерживают разное число операций, сильно дискредитирует этот механизм управления эффектами (NV20 способен на все, Radeon молодец, а вот GeForce2 выглядит явно отстающим на их фоне). Как бы там ни было, пиксельные шейдеры более гибкий и удобный инструмент.
Продолжаю комментировать главную таблицу:
- Max Simultaneous Lights — максимальное количество источников света, обрабатываемых аппаратно. Здесь наблюдается редкое единодушие, 8 это уже стандарт. Но вот реализации, судя по результатам тестов, показывающих зависимость падения производительности от числа источников света, разнятся. Однако, мы договорились не обсуждать сегодня производительность. Раз уж мы заговорили о свете, посмотрим поподробнее, какие возможности по аппаратному расчету освещения и геометрии обеспечивают наши карты:
| NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| DIRECTIONALLIGHTS LOCALVIEWER MATERIALSOURCE7 POSITIONALLIGHTS TEXGEN | DIRECTIONALLIGHTS LOCALVIEWER MATERIALSOURCE7 POSITIONALLIGHTS TEXGEN | DIRECTIONALLIGHTS LOCALVIEWER POSITIONALLIGHTS TEXGEN |
И снова придется прокомментировать:
- DIRECTIONALLIGHTS — поддержка бесконечно удаленных, источников освещения, заданных только направлением
- POSITIONALLIGHTS — поддержка точечных и конусных источников
- LOCALVIEWER — поддержка расчета в локальных координатах
- MATERIALSOURCE7 — можно выбирать источник цвета вершин у примитива
- TEXGEN — аппаратная генерация текстурных координат
Окей, возвращаемся к главной таблице:
- Max Clip Planes — количество задаваемых пользователем плоскостей для отсечения примитивов. Плоскость определяется 4 коэффициентами (ABCD) и если для координат примитива выполняется условие Ax + By + Cz + Dw >= 0 (w — четвертная координата, это так называемое нормальное представление), то примитив отсекается и не передается на отрисовку. Здесь мы наблюдаем очевидный провал у GeForce2. И интересную избыточность в случае NV20 — даже произвольный кубический сектор можно задать 6 плоскостями. Но, впрочем, не трудно придумать случай, когда две оставшиеся плоскости пригодятся.
- Max Vertex Blend Matrices — максимальное число матриц, одновременно применяемых к вершине во время многоматричного смешения координат. В DX7 был возможен matrix blending (single-skin) с четырьмя матрицами. К сожалению, GeForce/GeForce2 поддерживают две. В DX8 можно использовать набор до 256 матриц, при этом на одну вершину остаётся ограничение в 4 матрицы, они выбираются из общего набора индексом. Но драйверы NV20, Radeon и GeForce2 на данный момент не поддерживают такое индексирование.
- Max Primitive Count / Max Vertex Index — все эти ускорители могут самостоятельно интерпретировать, трансформировать, освещать и отрисовывать списки примитивов, существенно разгружая центральный процессор. Этот параметр определяет максимальный размер списка примитивов или вершин. Создатели NV20 не пожалели лишний байт, а нам остается ждать от создателей игр сцен со сногсшибательным количеством треугольников.
- Vertex Shader Version — Вот мы и до брались до самого интересного. Итак, для начала иллюстрация из документации DX8 SDK:
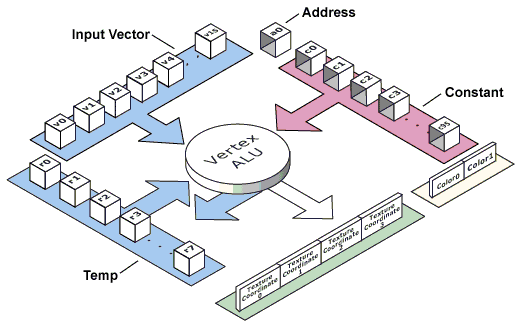
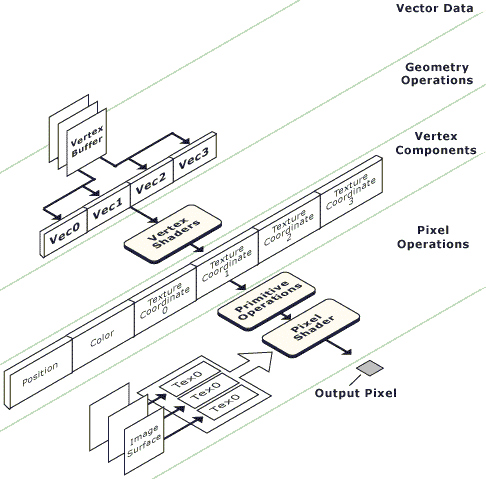
Перед нами некий черный ящик — версии 1.1 у NV20, в то же время у Radeon и GeForce2 отсутствующий вообще. Хотя, реально в Radeon и GeForce2 есть это самое Vertex ALU, способное интерпретировать шейдеры, они не совсем совместимы с окончательным стандартом. Т.е. можно сказать, что это шейдеры версии 0.5. Кстати, для Radeon их можно включить специальным ключом в реестре, но при этом большинство примеров из DX8 SDK будут виснуть, и лишь небольшое число простых шейдеров исполнится как положено. Что совершенно неудивительно — совместимость лишь частичная. Как бы там ни было, Microsoft понятие шейдеров "версии 0.5" не вводил, и мы будем считать, что оные присутствуют только у NV20. Итак, шейдер имеет дело с константами (сколько их, определяет следующая строчка таблицы — Max Vertex Shader Const) для NV20 их 96. С 16 входными и 8 переменными (временными) регистрами. Выполняя программу шейдера (размер которой у NV20 ограничен 128 командами, а у других чипов может быть иным) ускоритель оперирует с этими данными и создает на их основе 4 набора координат для текстур, два значения цвета для вершины и, разумеется, сами результирующие координаты вершины. C этими данными далее работают (во время отрисовки примитива) пиксельный шейдер или просто выбранная нами конфигурация текстурных стадий:
Вопрос о производительности этого блока мы деликатно оставим в стороне, до появления близких к финальным образцов NV20. Отмечу только (мое личное мнение), что очень легко (это не отнимет много ресурсов) сделать параллельный блок, обрабатывающий сразу несколько вершин параллельно, реально исполняя при этом одну программу шейдера. Скорее всего, так и было сделано.
Кстати, к вопросу о матрицах: при использовании шейдера будет доступно много констант (96 для NV20). Ничто не мешает нам самим написать шейдер, реализующий произвольной степени гибкости блендинг, например, с использованием 96/4 матриц. Впрочем, не забудем про ограничение на количество команд шейдера. С учетом оного у нас выйдет ~20 матриц на вершину. Хотя в случае одного скина это бессмысленно, можно придумать множество других применений более многоматричного блендинга. Да и сам по себе этот пример неплохо демонстрирует мощность вершинных шейдеров.
Вновь вернёмся к главной таблице:
- Pixel Shader Version — ага, вот и второй тип шейдеров. Картина с существованием версии 0.5 все та же. Что интересно, включив пиксельные шейдеры у Radeon, можно обнаружить, что на этот раз ситуация более оптимистична. То, что он имеет в железе, вероятно, весьма близко к версии 1.0 и многие примеры из DX8 успешно работают. Впрочем, это не удивительно, сам по себе пиксельный шейдер — штука гораздо более простая, нежели вершинный. Для желающих поэкспериментировать приведу ключи для Radeon:
HKEY_LOCAL_MACHINE\SOFTWARE\ATI Technologies\Driver\0000\atidxhal
(вместо 0000 может 0001 или т.п.)
строковый VertexShaderVersion = "10"
(правда, почти все примеры, которые их используют, виснут)строковый PixelShaderVersion = "10"
(это работает лучше, можно почти все примеры посмотреть в hardware исполнении)строчковый PureDevice = "1" — включает режим "PURE device"
В этом режиме (самом быстром) ускоритель хранит, преобразует и выполняет списки примитивов и вершин в локальной видео памяти.
Иллюстрируем место пиксельных шейдеров в общей картине закраски:
Тут и вправду все просто, но, отметим, со вкусом. Еще бы, шейдер вычисляется для каждой закрашиваемой точки треугольника, он должен выполняться максимально быстро и без затей. Есть 8 констант, два цвета (интерполированные по поверхности примитива), текстурные стадии, с которыми мы можем взаимодействовать. Есть два временных регистра. Наша задача посчитать результирующий цвет точки. Доступно изрядное количество команд, похожих на описанные ранее команды для вычислений на текстурной стадии, но более гибких. Команды достаточно продуктивны и выполняют сразу несколько дел. Это неудивительно — их максимальное число равно числу текстурных стадий (для NV20 это всего лишь 8). Пиксельный шейдер не интерпретируется в классическом понимании — это скорее настройка ступеней конвейера. Соответственно, и выполняется он эффективно, выдавая по одному результату за такт. И вновь ничто не мешает параллельному существованию в железе нескольких конвейеров, настроенных одинаковым образом.
В очередной раз вернемся к главной таблице:
- Quintic/RT Patches — аппаратная поддержка тесселяции гладких поверхностей! Вводится два новых примитива высокого порядка — прямоугольный и треугольный патчи. Для их отрисовки в DX8 есть два соответствующих вызова, причем можно управлять степенью детализации при разбиении гладких поверхностей патчей на треугольники. Судя по всему, NV20 аппаратно осуществляет тесселяцию. Не известно, как конкретно реализована эта возможность: может быть, результат тесселяции хранится в локальной памяти ускорителя в виде результирующего списка треугольных примитивов, а может, параметры треугольников генерируются динамически и сразу отправляются на отрисовку, нигде не сохраняясь. Во втором случае, эта возможность не только упростит работу программистов, но и существенно снизит нагрузку на память, в которой вместо огромного количества треугольников будут храниться более компактные патчи.
- W Depth Values — поддержка альтернативного формата значений глубины (W формат).
- Stencil Buffer — поддержка Stencil буфера. Конкретнее, ускорители могут выполнять следующие операции со значениями Stencil буфера:
| NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| KEEP ZERO REPLACE INCRSAT DECRSAT INVERT INCR DECR | KEEP ZERO REPLACE INCRSAT INVERT DECR | KEEP ZERO REPLACE INCRSAT DECRSAT INVERT INCR DECR |
А вот тут, очевидно, слегка сдал Radeon. Подробно про операции:
- KEEP — не менять значение в буфере
- ZERO — записать 0 во все отрисованные точки примитива
- REPLACE — записать некое конкретное значение
- INCRSAT — увеличить на единицу. При достижении максимального значения не менять.
- DECRSAT — уменьшить на единицу. При достижении 0 не менять.
- INCR, DECR — то же самое, но с заворачиванием через край. Например, при достижении максимума значение сбрасывается в 0
Вернемся к главной таблице:
- Anisotropy Filtering — поддержка анизотропной фильтрации. Судя по всему, у NV20 она реализована так же, как и у GeForce2, и выглядит хуже, нежели у Radeon. Чуть ниже мы приведем таблицу со всеми допустимыми режимами фильтрации для различных типов текстур.
- Cubic Texturing — аппаратная поддержка кубического текстурирования (наложения кубических карт среды).
- Volume Texturing — аппаратная поддержка объемных текстур. GeForce2 снова не у дел.
Приведем таблицу с допустимыми режимами фильтрации для трех возможных типов текстур, как с использованием MIP уровней, так и без:
| Фильтрация | NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| Standart Texture Filters (режимы фильтрации обычных текстур) | |||
| Min/Mag | Point, Linear, Anisotropic | ||
| MIPMAP | Point, Linear | ||
| Cube Texture Filters (режимы фильтрации кубических карт среды) | |||
| Min/Mag | Point, Linear, Anisotropic | Point, Linear | Point, Linear, Anisotropic |
| MIPMAP | Point, Linear | No | Point, Linear |
| Volume Texture Filters (режимы фильтрации объемных текстур) | |||
| Min/Mag | Point, Linear, Anisotropic | Point, Linear | No |
| MIPMAP | Point, Linear | No | No |
Здесь NV20 очевидный лидер, разве что анизотропную фильтрацию для объемных текстур не придумали :-). Ну да и нет в ней нужды...
Возвращаемся к параметрам:
- Z test — возможность после отрисовки примитива сообщить, была ли реально отрисована (видна ли) хотя бы одна его точка
- Shade modes — режимы закраски. Тут все три карты удивительно единодушны.
- MultiSample Types — допустимые режимы мультисэмплинга. Только у NV20
- SSAA (Super Sample Anti-Aliasing) Types — допустимые режимы полноэкранного сглаживания
- Z/MIPMAP Bias — возможность сдвига мип уровня или глубины.
- Vertex/Table/Range Fog — поддерживаемые разновидности тумана.
- W/Z Fog — допустимые для тумана форматы глубины.
- Bandwidth Saving — методы экономии пропускной полосы памяти.
Взглянем на таблицу с параметрами текстурирования:
| NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| PERSPECTIVE POW2 ALPHA ALPHAPALETTE PROJECTED CUBEMAP VOLUMEMAP MIPMAP MIPVOLUMEMAP MIPCUBEMAP CUBEMAP_POW2 VOLUMEMAP_POW2 | PERSPECTIVE POW2 ALPHA PROJECTED CUBEMAP VOLUMEMAP MIPMAP CUBEMAP_POW2 VOLUMEMAP_POW2 | PERSPECTIVE POW2 ALPHA PROJECTED CUBEMAP MIPMAP MIPCUBEMAP CUBEMAP_POW2 |
Тут снова хорошо бы пояснить:
- PERSPECTIVE — аппаратная коррекция перспективы.
- POW2, CUBEMAP_POW2, VOLUMEMAP_POW2 — текстуры соответствующего типа должны иметь размеры равные степеням двойки.
- MIPMAP — поддержка mipmap текстурирования для обычных текстур
- CUBEMAP, VOLUMEMAP — поддержка кубических карт среды и объемных текстур, соответственно
- MIPVOLUMEMAP, MIPCUBEMAP — то же самое, но еще и с mipmap уровнями. Здесь NV20 снова отличился.
- ALPHA — поддержка альфа каналов в текстуре и
- ALPHAPALETTE — в палитре текстуры, соответственно.
И, напоследок — возможные форматы для буфера кадров, буфера глубины и различных типов текстур:
| NVIDIA NV20 драйвер 7 серии | Radeon DDR драйвер 5 серии | NVIDIA GeForce2 Ultra драйвер 7 серии |
| Depth/Stencil Formats | ||
| D24S8 D16 D24X8 | D32 D24S8 D16 D24X8 | D24X8 D24S8 D16 (standart/lockable) |
| Render Target Formats | ||
| A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 | A8R8G8B8 X8R8G8B8 R5G6B5 A1R5G5B5 A4R4G4B4 R3G3B2 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 |
| Texture Formats | ||
| A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 V8U8 L6V5U5 X8L8V8U8 Q8W8V8U8 DXT1 DXT2 DXT3 DXT4 DXT5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 R3G3B2 V8U8 DXT1 DXT2 DXT3 DXT4 DXT5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 DXT1 DXT2 DXT3 DXT4 DXT5 |
| Cube Texture Formats | ||
| A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 V8U8 L6V5U5 X8L8V8U8 Q8W8V8U8 DXT1 DXT2 DXT3 DXT4 DXT5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 R3G3B2 DXT1 DXT2 DXT3 DXT4 DXT5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 DXT1 DXT2 DXT3 DXT4 DXT5 |
| Volume Texture Formats | ||
| A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 R5G6B5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 R3G3B2 DXT1 DXT2 DXT3 DXT4 DXT5 | - |
Пояснения к форматам текстур и буферов:
- Буквы обозначают тип хранимых значений (например, R/G/B — компоненты цвета). Цифра после буквы — количество бит (R8G8B8 True color)
- RGB — компоненты цвета.
- D — глубина в форме Z или W
- A — альфа канал, т.е. прозрачность
- X — неиспользуемое значение
- DXT1..5 — сжатые соответствующим методом текстуры
- QWUV — параметры рельефа (BumpMap)
- L — освещенность
- P — индекс в палитре
Ну что же, с радостью могу констатировать: по возможностям NV20 удался (не в пример GeForce2)! Корпорация NVIDIA вновь подтверждает свое звание технологического лидера.
Со скоростью пока не все ясно, многое будет зависеть от памяти (как всегда) и программистов (что на этот раз в новинку). Хочется отметить все более тесную интеграцию API (DX8) и железа, а также множество технологических новинок. Очевидно, что вкупе с XBox, серия NV2x способна спровоцировать настоящую революцию спецэффектов в играх. Главное, чтобы разработчики игр успели сделать новые игры или переделать уже существующие, радует, что грядущий XBox гарантирует собою наличие игр, рассчитанных на возможности API DX8.
Ожидается, что первые карты на базе NV20 уже в марте выпустят ASUS, Leadtek, Elsa, Hercules, а чуть позднее, примерно в апреле-мае, подтянется и второй эшелон: GigaByte, MSI и многие другие.
В самом начале продаж карты на базе NV20 с 64 Мб памяти будут стоить в районе $450-500, но уже через месяц цены начнут плавно снижаться. Что интересно, у некоторых уважаемых производителей видеоакселераторов на данный момент заявлены карты на базе NV20 исключительно со 128 Мб локальной видеопамяти :-).


