После нашего обзора VSA, в котором было поставлено несколько вопросов,
мы получили несколько ответов. Часть информации мы получили по собственным конфиденциальным каналам, а часть ответов дал, как это водится относительно продуктов 3dfx и некоторых продуктов от конкурентов, известный проповедник Скотт Селлерс (Scott Sellers). К сожалению, Скотт дал свои ответы не нам персонально, а нашим друзьям Dave Barron и Van Mardian (свободный художник), которые любезно поделились информацией с нами. По понятным этическим причинам, мы не могли опубликовать никаких дополнений по VSA до того, как это сделают наши друзья.
Прежде, чем перейти собственно к вопросам и ответам, дадим некоторые пояснения в виде предисловия.
Что такое вообще превью, или первый взгляд? Как мне кажется, это обзор, посвященный анонсированному, но еще не появившемуся на рынке продукту. Может ли такой обзор дать точную информацию о будущем продукте? На мой взгляд, это почти невозможно. Дело в том, что такого рода статьи пишутся только на основе информации, имеющейся на момент написания. Причем доступная информация исходит от производителя, анонсировавшего продукт. Никто не может гарантировать, что информация от производителя является полной и достоверной. Кроме того, при недостатке разъяснений разные факты могут интерпретироваться по-разному. Поэтому, если у нас есть какие-либо сомнения или вопросы, то в таких статьях мы всегда об этом указываем. Как правило, настоящая правда о том, как все обстоит на самом деле, выясняется только после тестирования реального продукта. В результате данные из предварительных обзоров могут не совпадать с тем, что есть на самом деле. Означает ли это, что превью не имеет смысла писать? Думаю, что нет. Во-первых, такой обзор позволяет составить общую картину о том, что нас ждет. Во-вторых, несоответствие того, что написано в превью, реальности показывает честность политики производителя по отношению к пользователям. Если все, что было обещано в превью, соответствует действительности, значит, производитель говорил в своих обещаниях правду и не умалчивал важных деталей. Если есть несоответствия, значит, производитель нас умышленно или неумышленно пытался ввести в заблуждение. Как правило, при написании предварительных обзоров любые возникающие сомнения мы трактуем в пользу создателя нового продукта. Почему? Ну, например, потому что если какие-то предположения оказались чересчур оптимистичными, критика получается более язвительной. Кроме того, всем нам хочется увидеть готовый продукт таким, каким нам этого хочется. К сожалению, действительность оказывается прозаичной.
Обычно мы не практикуем дополнений к превью, потому
что, как правило, производители предоставляют достаточный объем информации о своих новых продуктах. Затем, уже в обзоре готового продукта, мы показываем, какие из своих обещаний производитель выполнил. В случае с обзором VSA наблюдалась масса неопределенностей. Фактически 3dfx не раскрыла некоторых деталей своего нового продукта. Вследствие чего осталось много вопросов и пришлось сделать несколько предположений. Замечу, что все свои предположения мы делали на основе имеющейся информации и все сомнительные моменты трактовали в пользу 3dfx. Так как после получения ответов на заданные вопросы выяснилось, что некоторые детали о чипах VSA-100 и функционировании технологии VSA изменились, мы решили отступить от правил и написать это дополнение.
Теперь вернемся к превью VSA. И посмотрим на новые факты, которые стали известны.
Самый интересный вопрос, который волновал многих: возможно ли одновременное использование технологии SLI и T-Buffer. Прежде всего, под термином SLI в случае с VSA компания 3dfx подразумевает нечто отличное от старой техники SLI, применявшейся во времена Voodoo2. Фактически 3dfx использовала старое раскрученное имя для обозначения новой технологии. Новая версия SLI — это гораздо больше, нежели обычное чередование строк кадра.
Теперь наряду с традиционной техникой чередования строк кадра введено понятие чередования полос, состоящих из нескольких строк. Далее, технология SLI представляет собой протокол коммуникации или взаимодействия от двух до 32 чипов VSA-100, в этом смысле SLI используется всегда, если на карте установлено два или более чипов VSA-100. При этом возможна ситуация, когда техника чередования полос может не применяться.
Подобно традиционной технике SLI, в новой технологии используется понятие Master-чипа (или главного чипа). При этом в конфигурациях из двух и более чипов VSA-100 один из графических процессоров является Master, а остальные — Slave. Комбинирование результатов работы нескольких чипов — фактически содержимого их кадровых буферов — происходит в порядке очереди в кадровом буфере Master-чипа, откуда и происходит вывод данных на экран монитора. Заметим, что могут комбинироваться как отдельные пиксели, так и полосы, если чипы работают в режиме чередования полос, сформированные разными чипами VSA-100, в результате чего получается полный кадр, который и отображается на экране монитора. При этом пиксели, из которых состоят полосы, могут быть получены в результате работы T-Buffer, т.е. когда для формирования одного пикселя используется несколько пиксельных семплов.
Кроме управления процессом вывода готового кадра на экран монитора, Master-чип VSA-100 обеспечивает синхронизацию работы со Slave-чипами. Slave-чипы занимаются распределением данных, полученных от CPU системы. В некоторых случаях, например, при конфигурации из четырех чипов VSA-100, в режиме T-Buffer в системе один из Slave-чипов выполняет и роль ведущего, или Master-чипа, синхронизируя процесс комбинирования пиксельных семплов. Подробнее об этом мы поговорим ниже.
Прежде чем показать, как все это работает более детально, сделаем важное отступление.
3dfx дала следующее описание своему чипу VSA-100:
- выводит 2 full featured пикселя за такт
- обладает всеми теми же возможности, как и Voodoo3
- fillrate 333-366 млн. пикселей в секунду
- поддерживает single-pass, single-cycle multi-texturing
- поддерживает single-pass, single-cycle bump mapping
- поддерживает single-pass, single-cycle tri-linear mip-mapping
Из всего этого можно было сделать вывод, что каждый из двух конвейеров рендеринга в VSA-100 обладает двумя блоками текстурирования. Ни одного намека на то, что в режиме мультитекстурирования VSA-100 может выводить лишь один пиксель за такт, нет. Все сомнения мы трактовали в пользу 3dfx, разумеется, из самых благородных побуждений. Но немногим позже официального анонса VSA-100 и после выхода нашего превью появилась информация от 3dfx, из которой следовало, что VSA-100 в режиме мультитекстурирования может выводить лишь один пиксель за такт. Фактически в VSA-100 применили решение, которое с 1998 года используется в чипах от NVIDIA, т.е. один конвейер рендеринга имеет один блок текстурирования. С одной стороны, такое решение обеспечивает полную загрузку конвейера во всех режимах работы. С другой стороны, в режиме мультитекстурирования, а этот режим используют практически все современные игры, теоретическая величина fillrate снижается вдвое. Интересно, что 3dfx считает, что такие игры как Quake3Arena не являются по настоящему использующими мультитекстурирование, приводя в качестве примера небо в игре, которое формируется в результате наложения трех текстур за три прохода. Не буду комментировать это, замечу лишь, что если игра поддерживает режим мультитекстурирования, это не означает, что в игре не могут использоваться полигоны с одной наложенной текстурой или десятью наложенными текстурами. Вся суть в том, что чем больше текстур накладывается на пиксель, тем больше времени на это уходит, а значит, общая производительность видеоакселератора снижается. В дальнейшем мы будем рассматривать предельные случаи, т.е. когда в приложении всегда используется мультитекстурирование или всегда на один пиксель накладывается две текстуры, чтобы показать, как все будет работать в принципе. Когда появятся реальные карты на базе VSA-100, мы сможем провести комплексное тестирование и посмотреть на реальные цифры производительности.
Теперь посмотрим, как работают два чипа VSA-100 в режиме T-Buffer и без него. Сначала приведем иллюстрацию работы двух чипов VSA-100 на одной карте.
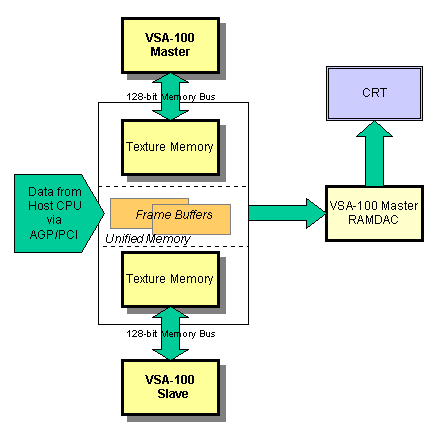
В режиме, когда T-Buffer не используется, применяется технология SLI в традиционном качестве, но с некоторыми отличиями.
Отличия в том, что кроме техники чередования строк, применяется техника чередования полос из строк. При этом полоса может содержать от одной до 128 строк кадра, и количество строк в полосе может динамически изменяться. Напомню, что изменение числа строк в полосе позволяет равномерно распределять число покрываемых одной полосой вершин полигонов, что обеспечивает равномерную загрузку VSA-100. Выигрыш в производительности получается за счет применения раздельных шин памяти и благодаря использованию доступной локальной видеопамяти специальным образом.
Каждый из чипов VSA-100 имеет собственную 128-разрядную шину
памяти, что позволяет равномерно распределить нагрузку при передаче данных и снизить требования к полосе пропускания каждой из шин. Локальная видеопамять используется следующим образом: текстуры для каждого чипа VSA-100 хранятся раздельно и являются одинаковыми, т.е. на практике происходит дублирование загруженных в локальную видеопамять текстур для каждого чипа. Все остальные данные, такие, как координаты вершин треугольников и информация о глубине (z), не копируются и едины для обоих чипов, они располагаются в общей памяти, т.н. unified memory. При этом каждый из чипов VSA-100 формирует в общей памяти собственный кадровый буфер. Каждый из двух чипов VSA-100 осуществляет формирование готовых пикселей в своем кадровом буфере (точнее, рендеринг происходит во вторичном буфере, back buffer). Эти пиксели формируют строки кадра, из которых формируются полосы кадра. Затем полосы комбинируются в кадровом буфере Master-чипа VSA-100, потом данные передаются в RAMDAC, а оттуда в монитор и отображаются в виде пикселей на его экране.
Заметим, что во всех режимах представления цвета данные будут передаваться по двум шинам в два процессора, при этом каждый графический процессор обрабатывает лишь часть информации, в идеальном случае — половину. В результате нагрузка на шину памяти снижается, что должно обеспечить высокую общую производительность видеокарты, в частности, в режиме 32-битной глубины представления цвета. Преимущества такой реализации режима SLI будут особенно заметны в играх, требовательных к величине fillrate и при высоких разрешениях.
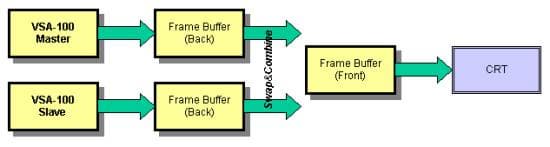
Если пользователь задействует T-Buffer, то тогда картина несколько меняется.
В режиме T-Buffer для получения готового кадра, который выводится на экран монитора, необходимо сформировать несколько версий этого кадра, а затем определенным образом скомбинировать их. Иными словами, для формирования одного пикселя используется несколько пиксельных семплов, или sub-pixels. Так как все эффекты T-Buffer являются различными вариациями на тему пространственного или временного сглаживания объектов или всей сцены (anti-aliasing), то рассмотрим все на примере реализации full-scene anti-aliasing (FSAA), т.к. этот эффект полностью прозрачен для приложений и интерфейсов.
Для формирования сглаженного пикселя используются несколько семплов, или sub-pixel, которые представляют собой данные о цвете соседних пикселей, выбранных с некоторым смещением от пикселя, который нужно сгладить. За счет комбинирования цветов пиксельных семплов получается цвет сглаженного пикселя, что и требуется. Ввиду того, что в режиме мультитекстурирования VSA-100 может сформировать лишь один пиксель, 3dfx решила использовать для конфигураций плат с двумя чипами VSA-100 маску 1х2 для реализации FSAA.
Это означает, что для формирования одного сглаженного пикселя (anti-aliased pixel) используется два пиксельных семпла или два субпикселя. При этом в случае использования мультитекстурирования сглаженный пиксель получается за два прохода, либо за первый проход формируется два субпикселя с одной текстурой, а за второй проход накладывается вторая текстура. Какой именно метод формирования пиксельных семплов будет использоваться, решается оперативным путем. По словам 3dfx, будет выбираться наиболее эффективный способ. При этом каждый из двух чипов формирует полосы, состоящие из сглаженных пикселей в собственно кадровом буфере (вторичном).
Затем полосы, сформированные обоими чипами, комбинируются в кадровом буфере Master-чипа - получается полный кадр, затем происходит вывод сглаженных пикселей на экран монитора. Замечу, что мы описали самый общий случай работы T-Buffer. На самом деле, возможны вариации.
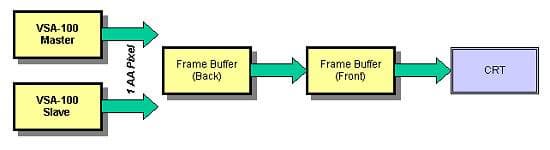
Например, можно использовать маску 2х2, в этом случае чередования полос не будет. За каждые два такта оба чипа VSA-100 формируют по два пиксельных семпла, затем значения четырех пиксельных семплов комбинируются, и получается один сглаженный пиксель. Такая ситуация позволит повысить качество эффекта FSAA, однако снизит величину fillrate до уровня 83-92 млн. пикселей в секунду. В результате использовать такой режим можно будет лишь в низких разрешениях.
Понятно, что пользователь будет решать сам, какой метод сглаживания использовать или вообще отказаться от FSAA. Но и это еще не все. Если при реализации FSAA можно пойти на компромисс, выиграв в производительности, но пожертвовав качеством, и использовать маску 1х2 при формировании сглаженного пикселя, то при реализации других эффектов T-Buffer этот метод не подходит.
Дело в том, что для реализации таких эффектов, как Motion Blur или Depth of Field для формирования одного пикселя или конечного кадра, нужно использовать не менее четырех пиксельных семплов или комбинировать четыре немного различающихся кадра. В результате пользователь, по сути, не будет иметь возможности использовать различные эффекты T-Buffer, за исключением FSAA с маской 1х2 при конфигурации из двух чипов VSA-100. Только если в игре не используется мультитекстурирование, появится возможность использовать эффекты T-Buffer при приемлемом уровне производительности. Если принять во внимание, что для использования таких эффектов, как Motion Blur требуется, чтобы приложение было рассчитано на этот эффект, то есть все основания предположить, что у пользователя просто может не возникнуть потребности в использовании таких эффектов.
Сомнительно, что сразу после выхода на рынок карт серии Voodoo5 мы увидим игры, использующие эффекты T-Buffer (кроме FSAA) или патчи для игр, добавляющие поддержку таких эффектов. Почему? Во-первых, пока что-то не видно анонсов от разработчиков игр. Во-вторых, на примере с поддержкой HW T&L мы видим, что даже при самом благоприятном стечении обстоятельств только через три месяца после начала продаж карт на базе GeForce 256 на рынке есть буквально единичные игры, поддерживающие аппаратный расчет T&L. Прибавьте к этому то, что NVIDIA тратит массу сил и денег, проповедуя среди разработчиков приложений поддержку T&L, вспомните, что HW T&L поддерживается в DirectX 7.0 и в OpenGL. В тоже время T-Buffer хотя и заявлен в качестве открытого инструмента, пока является новинкой от 3dfx, и его уровень поддержки среди разработчиков выглядит очень низким.
Так что маркетологи 3dfx не случайно вынесли в списке поддерживаемых функций у карт серии Voodoo5 эффект FSAA в качестве отдельной возможности, отделив его от остальных эффектов T-Buffer. К слову, нет никаких препятствий к комбинированному использованию разных эффектов T-Buffer, например, можно одновременно использовать эффект FSAA и Motion Blur, применяя их к разным частям кадра. Это возможно благодаря тому, что в обоих случаях для формирования готового пикселя используются несколько пиксельных семплов, а процесс комбинирования субпикселей происходит на аппаратном уровне.
Итак, посмотрим на примере, как все работает в том режиме, который, скорее всего, и будет использоваться. Скажем, мы хотим играть в разрешении 1024х768 с использованием FSAA с маской 1х2. Тогда каждый из двух чипов VSA-100 формирует полосы, при этом можно говорить о том, что каждый чип выполняет работу по формированию лишь примерно половины кадра. Полосы из строк формируются в отдельных кадровых буферах (точнее, во вторичных буферах), а затем полосы комбинируются в первичном буфере Master-чипа, и уже оттуда происходит вывод данных на экран монитора.
Заметим, что качество такой реализации FSAA будет хуже, чем при использовании маски 2х2, причем разница будет особо заметна на наклонных линиях, где должен исчезать лестничный эффект. Иначе говоря, сглаживание будет недостаточным, и обещанных ровных наклонных линий мы не увидим. Плюс к этому, в режиме мультитекстурирования снизится теоретическая величина fillrate. Например, в режиме мультитекстурирования и с использованием эффекта FSAA с маской 1х2 величина fillrate будет соответствовать 166-183 млн. пикселей в секунду. Такой величины должно хватить для игры в разрешении 1024х768 при 32-битной глубине представления цвета и 60 fps. Посмотрим, что покажут реальные тесты.
Теперь посмотрим, как работают четыре чипа VSA-100 в режиме T-Buffer и без него. Сначала приведем иллюстрацию работы четырех чипов VSA-100 на одной карте, тем более, что в случае с двумя чипами VSA-100 все аналогично.
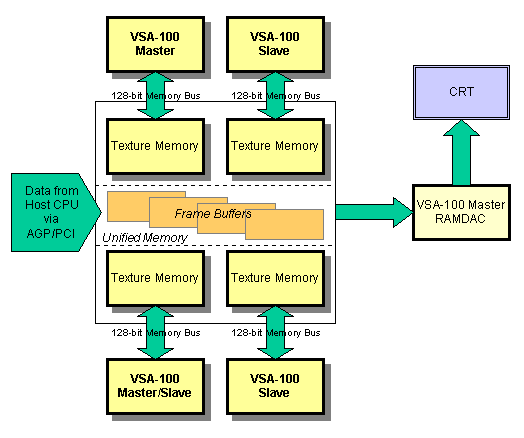
Замечу, что в данной конфигурации в зависимости от используемого режима работы может быть один Master-чип, который управляет синхронизацией работы остальных трех чипов, либо может быть еще один Master/Slave-чип, который с одной стороны подчиняется основному Master чипу, а с другой стороны управляет совместной работой второй пары чипов в режиме использования T-Buffer.
В режиме без использования T-Buffer все обстоит примерно как и в случае с конфигурацией платы с двумя чипами.
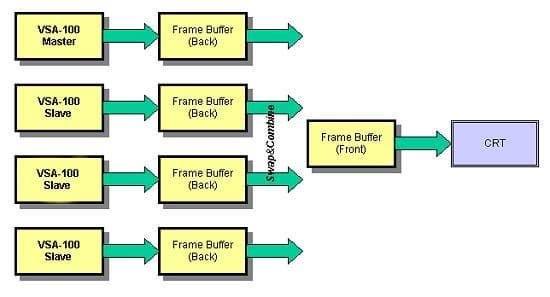
Каждый из чипов VSA-100 формирует полосы из строк кадра в своем кадровом буфере (точнее, во вторичном, или back буфере), затем данные из вторичных кадровых буферов Slave-чипов передаются во кадровый буфер Master-чипа, где и происходит их комбинирование. После чего содержимое кадрового буфера Master-чипа выводится на экран монитора. Ввиду того, что весь обмен данными между кадровыми буферами происходит внутри общей памяти (unified memory), все происходит очень быстро и не должно сказываться отрицательным образом на производительности в целом. В таком случае величина fillrate может достигать пиковых значений 664-732 млн. пикселей в режиме мультитекстурирования. Если пользователь решит использовать T-Buffer, например, для реализации эффекта FSAA, то четыре чипа VSA-100 будут взаимодействовать следующим образом.
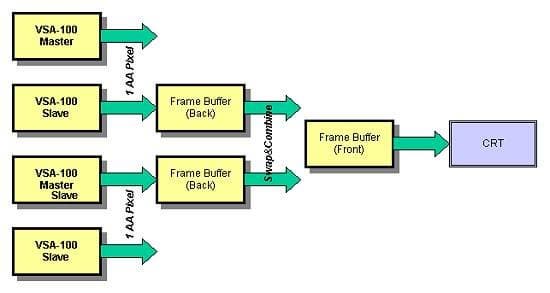
Каждая пара чипов занимается формированием строк из сглаженных
пикселей, т.е. фактически каждая пара чипов формирует лишь примерно половину всего кадра. При этом для реализации FSAA с маской 2х2, которая обеспечивает действительно полноценное сглаживание, для формирования каждого сглаженного пикселя используются 4 семпла или субпикселя. В этой ситуации в режиме мультитекстурирования каждая пара чипов VSA-100 формирует один сглаженный пиксель за два прохода, т.к. за один такт два чипа могут сформировать два пиксельных семпла. К слову, скорее всего, будет предусмотрена возможность применения эффекта FSAA с маской 1х2. Так что, у пользователя будет возможность выбора.
В режиме без мультитекстурирования сглаженный пиксель формируется за один такт. Благодаря тому, что каждая пара чипов VSA-100 формирует лишь часть кадра, нагрузка распределяется равномерно и падение величины fillrate в режиме мультитекстурирования будет не сильно отражаться на величине fps. Даже в режиме с мультитекстурированием и при использовании эффекта FSAA теоретическая пиковая величина fillrate будет соответствовать 166-183 млн. пикселей в секунду, что довольно много по современным меркам. Для сравнения: карта на базе GeForce 256 при штатных частотах в режиме мультитекстурирования, но без FSAA, обладает пиковой величиной fillrate, равной 240 млн. пикселей в секунду.
Если принять во внимание все то, что мы уже написали относительно работы T-Buffer в случае конфигурации с двумя чипами VSA-100, можно констатировать, что только карты серии Voodoo5 с четырьмя чипами VSA-100 на борту (Vooodoo5 6000) будут обеспечивать возможность использовать все эффекты T-Buffer с приемлемым качеством и приемлемой скоростью. Почему мы говорим о приемлемом качестве? Потому что хотя для реализации таких эффектов, как Motion Blur, достаточно использовать комбинацию четырех пиксельных семплов, при комбинировании 8 пиксельных семплов (или восьми кадров) или более, результат будет лучше.
Замечу, что играть в низких разрешениях с использованием эффекта FSAA вряд ли кто-то захочет, так как размытости будут явно различимы, и общие ощущения от этого могут быть совсем не самые приятные. Фактически, оптимальным разрешением для игры с использованием FSAA является 1024х768, тем более что величины fillrate карт серии Voodoo5 должно как раз хватить для игры в этих разрешениях. Но если пользователь отключит T-Buffer, у него появится возможность вполне комфортно играть в разрешениях вплоть до 1600x1200 при 60 fps. При этом в высоких разрешениях за счет большей детализации необходимость в использовании эффекта FSAA, в принципе, отпадает. Что предпочтет пользователь? Трудно сказать. Можно напомнить, что большинство обычных любителей поиграть все равно используют разрешения вплоть до 1024х768. Есть, конечно, те, кто имеют мониторы с большой диагональю. Возможно даже, что кому-то будет по карману купить карту за $600, которая позволит использовать все эффекты T-Buffer при приемлемом уровне производительности. Только число таких пользователей будет явно невелико. Но, как правило, эти пользователи, или т.н. hardcore gamers, имеющие мониторы с большой диагональю, наверняка предпочтут высокое разрешение низкому, но с FSAA. В итоге, купив карту за $600 они, скорее всего, не будут использовать всех ее возможностей. В общем, радужных перспектив для Voodoo5 совсем немного.
Теперь еще некоторые подробности о чипе VSA-100.
В спецификации VSA-100 заявлялось об аппаратной поддержке рельефного текстурирования. На практике оказалось, что поддерживается только метод выдавливания (Embossing), который является наименее эффективным из всех. Никакой поддержки Dot Product и тем более EMBM нет.
В спецификации чипа VSA-100 заявлено о полной поддержке AGP x4 (full AGP x4 support), на самом деле, под полной поддержкой 3dfx понимает поддержку всего, за исключением такой малости, как DME или AGP-текстурирования, а также режима Fast Writes. Радует, что хотя бы SBA поддерживается. Отказ от поддержки DME компания 3dfx мотивирует тем, что практически нет игр, которые этот режим используют. 3dfx пока вообще не собирается поддерживать этот режим в своих будущих продуктах. Если же игре потребуется загружать огромные объемы текстур, то 3dfx рекомендует использовать технологии компрессии текстур. Позиция 3dfx не лишена оснований, однако возникает вопрос, а что мешает реализовать поддержку DME? Может, проблемы технического плана?
Всем был интересен вопрос о том, как 3dfx собирается реализовать работу при использовании 32-битной глубины представления цвета. Было интересно, будет ли использоваться какой-либо пост-фильтр при этом. На сегодня есть информация о том, что никакого пост-фильтра при работе с 32-битным цветом применяться не будет. И это хорошо, т.к. во-первых, избавит 3dfx от лишних вопросов и нападок, а во-вторых, хватит и стандартного, но хорошо реализованного решения. Опыт с рендерингом в 32 -итном цвете для 3dfx первый, так что лучше лишний раз не экспериментировать. Пост-фильтр будет использоваться только во время рендеринга при 16-битном представлении глубины цвета. Пост-фильтр будет такой же, как и в случае с Voodoo3.
К вопросу о том, почему в чипе VSA-100 используется так много транзисторов. 3dfx объясняет это сложностью аппаратной реализации работы T-Buffer, т.е. процесса комбинирования значений пиксельных семплов и увеличением объемов текстурного кэша. Правда, традиционно для всех производителей объем текстурного кэша не называется. Можно предположить, что текстурный кэш в чипе VSA-100 имеет объем не менее 32 Кбайт.
Заметим, что при работе в конфигурации из двух или более чипов VSA-100, некоторые функциональные части чипов могут вообще не использоваться. Например, каждый чип VSA-100 имеет интегрированный RAMDAC, но используется RAMDAC только Master-чипа. Аналогично обстоит дело и с блоком, отвечающим за аппаратную поддержку T-Buffer, т.е. тем блоком, который осуществляет комбинирование пиксельных семплов. Почему же 3dfx не стала использовать один внешний RAMDAC и отдельный чип, отвечающий за аппаратную поддержку T-Buffer? Объяснение этому чисто экономическое. Выгоднее дублировать часть функций во всех чипах, чем тратить деньги на производство отдельных чипов со специальными функциями. То же относится и к RAMDAC — его дешевле интегрировать во все чипы, чем использовать один внешний.
В режиме 2D-графики, работает только один чип VSA-100. Возможности других чипов не задействуются. В принципе, есть информация о том, что у 3dfx есть планы по установке второго VGA выхода на картах серии Voodoo5, в этом случае в режиме 2D будут работать два чипа. В случае с конфигурацией из четырех чипов VSA-100 будет возможность поддержки вывода на два монитора 3D-графики.
Что касается вопроса о том, какой чип с маркировкой Intel используется на карте Voodoo5 6000, то тут практически ничего нового не выяснилось. Единственно, появилась информация о том, что чип от Intel (похоже, это все-таки будет нечто вроде non-transparent PCI-to-PCI bridge, но не обязательно) нужен в частности для того, чтобы, сохранив работоспособность карты в системе, полностью отказаться от использования питания через AGP-порт.
По поводу вопроса о том, зачем все-таки 3dfx решила делать карты с PCI-интерфейсом. Все просто. Во всем виновата корпорация Intel (так и хочется добавить: как всегда). Почему Intel? Потому что в настоящее время Intel не предлагает ничего нового по приемлемой цене вместо уже несколько устаревшего чипсета i440BX, за исключением вариаций на тему чипсета i810. Напомню, что i440BX не имеет поддержки AGP x4, UDMA/66, PC133, т.е. тех функциональных возможностей, которые стали необходимыми (например, в силу хорошей рекламы). Чипсет i820 рассчитан на использование очень дорогой памяти DR DRAM, а появление на рынке чипсета i815 (Solano), которого ждут многие пользователями, может отложиться на неопределенный срок. В результате пользователь вынужден покупать системные платы на базе i810, т.е. без AGP-порта или покупать платы на базе чипсета Apollo Pro 133A от VIA. Если пользователь купит плату на базе i810, он не сможет установить внешний графический акселератор с интерфейсом AGP. Вот тут серия карт Voodoo5 5000 может оказаться очень кстати. Тем не менее, пока сложно судить о том, угадала ли 3dfx будущее состояние дел на рынке, ведь до появления первых карт серии Voodoo5 еще не менее трех месяцев.
Небольшой комментарий по ценам на карты серии Voodoo5. Представители 3dfx зявляют, что карты серии Voodoo5 будут оснащаться памятью типа SDR SDRAM. Мотивируется это тем, что данный тип памяти самый дешевый. Вместе с тем, высокая цена на карты серии Voodoo5 мотивируется именно ценами на память. Однако тут есть один интересный момент. Да, всем известно, что цены на память типа SDRAM за последние 3-4 месяца существенно изменились в сторону повышения. Но цены на память выросли лишь на свободном рынке. Вряд ли 3dfx покупает память именно на свободном рынке и не имеет долгосрочных контрактов. Цены на память по контрактам практически не изменились, по крайней мере, они не повышались в разы. Так что, 3dfx немного лукавит, оставляя себе место для маневра. Поэтому есть все основания предполагать, что к моменту начала продаж карт серии Voodoo5 цены на них будут установлены несколько ниже заявленных сейчас.
Недавно 3dfx объявила о том, что их собственный закрытый интерфейс Glide становится открытым для всех. Пока трудно однозначно оценить, какие выгоды принесет это 3dfx. На мой взгляд, разработчики приложений вряд ли перейдут на Glide или вернутся к его использованию. Во-первых, если конкуренты 3dfx не будут поддерживать в драйверах для своих продуктов API Glide, то у разработчиков не будет причин поддерживать хотя и открытый, но нераспространенный интерфейс. Во-вторых, за спинами разработчиков очень часто видна тень Microsoft, которая вряд ли будет способствовать распространению Glide. В-третьих, интерфейс Glide строго ориентирован на возможности чипов от 3dfx, набор поддерживаемых им функций ограничен числом аппаратно поддерживаемых функций чипами от 3dfx серии Voodoo. Если сравнивать количество поддерживаемых функций с количеством функций, которые поддерживает OpenGL в смысле возможностей API, то Glide выглядит довольно узкоспециализирванным подмножеством OpenGL, хотя никакой прямой связи между этими двумя API нет. Скорее можно сказать, что эти интерфейсы похожи, но не совместимы. Отметим, что у API Glide есть низкоуровневые функции, которых нет в OpenGL, например, функции управления текстурной памятью (grTexMinAddress, etc). OpenGL не дает возможности контролировать распределение текстурной памяти. Если эти функции — возможные комбинации режимов вычисления цветов пикселей типа texture*alpha, то и здесь из Glide доступны режимы, не достижимые в OpenGL за один проход, например, iterated rgb + texture. Интерфейсы OpenGL и Glide имеют достаточно большое множество общих поддерживаемых функций. При этом отметим, что OpenGL является API гораздо более высокого уровня, нежели Glide, и позволяет описывать задачу в терминах источников света, mesh`ей, положений и поворотов, в то время как Glide является своего рода wrapper`ом на Voodoo, и, фактически, просто упрощает задачу программирования ускорителя на самом низком уровне. Говорить о том, что Glide является подмножеством OpenGL, наверное, можно в том смысле, что под OpenGL можно писать также как под Glide — не используя встроенных в OpenGL преобразований координат, источников света и т.п. Нельзя не отметить сходную идеологию этих API, многие функции являются общими с разными префиксами (gl у OpenGL и gr у Glide) и немного разными именами, например, glBlendFunc/grAlphaBlendFunc и т.п. С каждой версией Glide потихоньку приближается к OpenGL, например, в Glide 3.0 grSstIdle() была заменена на grFinish() (выполняемые функции сходны с glFinish()). Однако в способе представления вертексов между OpenGL и Glide общего мало, здесь Glide больше похож на Direct3D с его flexible vertex format. Теперь прибавте к этому то, что OpenGL и так используют некоторые разработчики, и переходить на Glide они вряд ли захотят. Тем более, что OpenGL уже является мультиплатформенным и портируемым. В общем, единственно, где возможно Glide получит широкое распространение это операционные системы типа Linux, что позволит запускать часть игр в этих ОС. Правда, если игра использует Direct3D, то под Linux от поддержки Glide толку не будет. Тем не менее, будет интересно наблюдать за развитием событий.
Теперь давайте посмотрим на перспективы использования эффектов
T-Buffer в реальной жизни. Если не принимать во внимание возможности T-Buffer и аппаратной поддержки компрессии текстур, то карты серии Voodoo5 представляют собой лишь вариации конкурирующих продуктов типа NVIDIA GeForce 256, но только с очень большой величиной fillrate и без аппаратной поддержки T&L. Фактически пользователь будет иметь возможность выбора между игрой в высоких разрешениях при высоких показателях fps и игрой в разрешениях вплоть до 1024х768 при 60 fps и при использовании только одного эффекта T-Buffer, а именно FSAA. Остальные эффекты T-Buffer не являются прозрачными для приложений и интерфейсов. Это значит, что использовать эти эффекты будет возможно только в том случае, если этого захотят разработчики игр. Процесс поддержки T-Buffer разработчиками приложений может несколько ускориться, если T-Buffer будет поддерживаться в стандартных интерфейсах, например в Direct3D. Пока известно только, что 3dfx ведет переговоры с Microsoft на эту тему, но на какой стадии все находится в данный момент, неизвестно. При самых оптимистичных прогнозах, такая поддержка возможна лишь к осени 2000 года, а тогда ожидается появление следующего поколения чипов от 3dfx. В результате нам предлагают купить то, что мы не будем использовать.
Что предпочтет пользователь? Сложный вопрос. Так как нет однозначного ответа, преимущества от использования T-Buffer становятся далеко не очевидными. Что касается аппаратной поддержки компрессии текстур, то тут возникает проблема поддержки этой функциональной возможности в приложениях. Пока широкой поддержки не предвидится. В результате, коммерческие перспективы карт серии Voodoo5 выглядят совсем не радужно. Теперь прибавьте к этому то, что 1999 год 3dfx заканчивает с серьезными убытками и с анонсом продуктов с высокой стоимостью и неясными перспективами объемов продаж.
Раз уж многие из нас любят прогнозы, то представьте себе ситуацию на рынке в марте 2000 года. 3dfx начинает продажи своих новых карт, со свойствами, которыми конкуренты обладают уже с конца 1998 года, обладающих уникальными функциями, но с неясными перспективами их применения, такими, как T-Buffer, аппаратная компрессия текстур, и хорошими возможностями по масштабируемости за дополнительные деньги. Фактически, 3dfx опоздала с выпуском на рынок новых продуктов. Если бы карты серии Voodoo5 появились на рынке осенью 1999, как этого все ожидали (включая конкурентов 3dfx), то 3dfx, по крайней мере, осталась бы на рынке в числе лидеров. Но кто-то в 3dfx сильно просчитался, и даже очень умный и обаятельный Скотт Селлерс (Scott Sellers) не может убедить всю общественность, что проблем у 3dfx нет, а все, что мы считаем проблемами, нам просто кажется. Лично я бы сейчас не стал покупать себе акции 3dfx.
Итак, перенесемся в будущее, скажем, в март 2000. В это время 3dfx с гордостью представляет свои новые продукты. В это же время NVIDIA представляет свой новый GPU GeForce 256 II (NV15), обладающий fillrate на уровне 600-800 млн. пикселей в секунду в режиме мультитекстурирования и аппаратной поддержкой T&L. Может сложиться ситуация, когда NVIDIA окажется безусловным лидером, по крайней мере, в смысле производительности. Если чисто гипотетически предположить, что к тому моменту на рынок не будут предложены другие сильные конкурентные решения, а S3 так и не решит свои проблемы с Savage2000, то мы можем стать свидетелями появления нового монополиста в лице NVIDIA. Причем никто не может гарантировать, что NVIDIA не будет использовать свое монопольное положение исключительно во благо себе. Это может означать для всех нас, например, существенное повышение цен на продукцию NVIDIA. Все это, возможно, будет происходить на фоне медленного ухода со сцены 3dfx.
Конечно, мы нарисовали наиболее пессимистичный вариант развития событий и немного сгустили краски. Но такой вариант развития событий также не исключен, особенно если 3dfx не предпримет в ближайшее время энергичных действий и не расскажет убедительно о своих планах на будущее. Так или иначе, сейчас лучше представить себе наихудший вариант развития событий, зато позднее, если все будет лучше, чем мы предполагали, чувство удовлетворения будет более полным.
Подведем итоги.
Ну, что сказать. На мой взгляд, все беды 3dfx — из-за отсутствия грамотного руководства. Причем прежде всего руководства верхнего звена. Ведь именно высшие руководители принимают стратегические решения. На мой взгляд, в 1998 году 3dfx выбрала неправильную стратегию. В результате в начале 2000 года нам будут предложены продукты по завышенной цене и с сомнительными преимуществами над конкурентами. Как говорится, вожак стаи выбрал свой курс и летит по нему, да вот стаи позади давно нет, все остальные летят в другом направлении.
Конечно, если быть совсем объективными, 3dfx скорее проигрывает прежде всего в маркетинговом плане. Конкурентам удалось убедить публику в том, что продукты 3dfx не обладают необходимыми на современном этапе функциональными возможностями. В результате 3dfx проигрывает рынок. Пока проигрывает.
Судя по всему совет директоров 3dfx, наконец, осознал, что руководство
нужно менять и сделал это. Удастся ли новому президенту исправить ситуацию в лучшую сторону, пока трудно судить. Будет очень разумным решением сменить состав маркетингового отдела. Пока мы можем уверенно прогнозировать, что первая половина 2000 года будет самой тяжелой для 3dfx как в технологическом, так и в финансовом плане. На мой взгляд, удержаться на рынке 3dfx удастся только за счет низких цен, грамотной поддержки своих клиентов, умной рекламы и жесткой экономии на всем. Будем надеяться, что у нового руководства 3dfx хватит воли, чтобы переломить ситуацию, и в скором времени мы увидим анонс VSA-200 с возможностью рендеринга четырех пикселей за такт и с аппаратной поддержкой T&L наряду с аппаратной поддержкой T-Buffer и компрессии текстур.


