Ввиду того, что новые технологии в области оперативной памяти в последнее время начали развиваться быстрыми темпами, думается, пришло время познакомиться с альтернативной DRDRAM (Direct Rambus DRAM) архитектурой динамической памяти — SLDRAM (SyncLink DRAM), работать над которой начали еще в начале 1995 года. Даже на сегодняшний день (по прошествию почти семи лет) SLDRAM не является массовым коммерческим продуктом и до сих пор находится в стадии доработки и отладки. Более того: идея SLDRAM чуть ли не целиком "портирована" в архитектуру нового поколения DDRII. Поскольку обзоров и статей, посвященных SLDRAM, крайне мало, то было бы несправедливо обойти стороной эту уникальнейшую во всех отношениях технологию и не познакомиться с ней подробнее. Весь последующий весьма объемный материал довольно детально и на достаточно высоком уровне описывает данную архитектуру. Таким образом, делается попытка собрать, упорядочить и систематизировать все имеющиеся на данный момент материалы, — как теоретические сведения из спецификаций, так и результаты тестов, — посвященные описанию этой блестящей идеи.
Основной показатель динамической памяти (DRAM или ДОЗУ), как известно, заключается в обеспечении как можно большей емкости и скорости за как можно более низкую цену. Это достигается двумя путями:
- Оптимизацией процесса разработки, обеспечивающей минимизацию конечной цены изделия
- Использованием как можно меньшей проектной нормы изготовления чипа, что позволяет увеличить объем памяти конечной микросхемы (информационная плотность — обеспечение как можно большего объема ОЗУ при использовании более совершенной технологии и уменьшении площади кристалла), сэкономить на производстве и обеспечить как можно меньшую цену за мегабайт

Память SLDRAM разработана для применения в самом широком спектре ПК — от настольных и мобильных компьютеров до высокопроизводительных рабочих станций и серверов. Это достигается благодаря высокой пропускной действительной способности и эффективности, маленьким задержкам, низкому энергопотреблению, легкой возможности наращивания объема и расширяемости (масштабирования) для обеспечения широкой и/или глубокой иерархии конфигурации подсистемы памяти. Микросхема SLDRAM предоставляет собой внутрикристальную конфигурацию множественных независимых логических банков, обеспечивает быстрые циклы обращения шины (Bus Turnaround) при проведении операций чтения/записи и способность работать в полностью конвейеризированном пакетном режиме. Адресация SLDRAM происходит согласно всем основным требованиям, предъявляемым к динамической памяти в целом, однако имеет довольно серьезные особенности, основанные на полностью пакетном протоколе, что исключает совместимость с любыми другими архитектурами, делая данную уникальной.
Если говорить точнее, то SLDRAM представляет собой эволюционирующую технологию ДОЗУ, являющуюся следующей ступенью в развитии динамической памяти от асинхронной EDO DRAM до синхронной DDR SDRAM, включающей некоторые основные моменты архитектурных особенностей, таких как множественные независимые внутренние банки с уникальной иерархической организацией, полная синхронизация с тактовым интерфейсом, односторонее терминирование, уникальный дифференциальный сигнальный протокол, 100% пакетный протокол с программируемыми длинами пакетов и полностью параллельный интерфейс. Схему эволюции можно представить следующим образом: EDO DRAM => {+ синхронизация операций и внутренних банков} => SDRAM => {+ передача данных по фронту/срезу синхросигнала} => DDR SDRAM => {+ пакетный протокол ввода/вывода, временная и температурная калибровки, полная обратная совместимость внутри архитектуры} => SLDRAM. Эти особенности стоят в основе концепции отделения шин команд/адреса, синхронизации и контроля DRAM от интерфейса данных, чем и достигается высокая эффективность работы и улучшенная помехозащищенность — момент, позаимствованный у лидера архитектурных инноваций динамической памяти — RDRAM. С появлением технологии эффективного удвоения пропускной способности (DDR — Double Data Rate), при котором данные передаются по фронту/срезу синхросигнала, стало возможным существенное повышение эффективности и скорости выполнения операций с возможностью улучшения такого параметра, как запас регулирования временных параметров (Time Margin) без какого-либо увеличения реальной частоты функционирования. Так, идея SLDRAM базируется на основных моментах технологии синхронной памяти и удвоения скорости передачи данных в совокупности со 100% пакетным протоколом, внутрисистемной и тайминговой (временные параметры) оптимизаций, а также полной совместимостью на всех уровнях предыдущего поколения устройств с последующими — так называемый гибкий интерфейс полной совместимости от поколения к поколению (GtG — Generation-to-Generation). На протяжении более 20 лет сменилось 9 поколений ДОЗУ, постоянно совершенствуясь и приобретая некоторые особенности. На текущий момент можно сказать, что SLDRAM включает все самые передовые идеи и самые лучшие черты, характеризующие самые современные типы динамической памяти, включая SDRAM, концепцию DDR и базисную идею RDRAM, и нацелена в первую очередь на обеспечение исключительно низкой стоимости.
Пакеты команд SLDRAM включают запасные биты (Spare Bits) для согласования операций адресации более чем на четыре поколения вперед (4G), в чем и заключается принцип GtG — протокол SLDRAM дает возможность микширования разноскоростных интерфейсов в одной системе: например, прибор (микросхема) памяти с "линейной" пропускной способностью (PBW — Pin BandWidth, скорость передачи информации по одной линии данных, выражаемая в мегабитах в секунду на вывод) 800 Mbps/p может свободно функционировать в системе с микросхемами, имеющими 400 Mbps/p с наименьшей из присутствующих пропускной способностью — в данном случае с 400Mbps/p. В рассмотрении технологии и принципов функционирования SLDRAM, равно как и других интерфейсов ДОЗУ, использовать именно "линейную" пропускную способность очень удобно — так более наглядно демонстрируется эффективность использования шины данных и загрузка протокола. В одной системе SLDRAM возможно использование до четырех различных генераций. Первые 64 Мбитные микросхемы SLDRAM, имея шину данных шириной 16 бит и пропускную способность 800 Мбайт/с (на частоте 200 MГц), обеспечивают PBW в 400 Mbps/p. Последующие четыре генерации обеспечивают "линейную" пропускную способность в 600 Mbps/p, 800 Mbps/p и 1.2 Gbps/p.
Отдельный интерес представляет собой вопрос цены/производительности, в данном случае подразумевающего "разумное" отношение "линейной" пропускной способности к объему микросхемы. Новый высокоскоростной интерфейс SLDRAM на данный момент намного опережает интерфейс стандартного синхронного ДОЗУ. Здесь имеется ввиду непосредственно внутренняя логика и интерфейсные цепи, поскольку ядро не претерпело абсолютно никаких изменений: основа ячейки памяти — все тот же транзистор с емкостью. Собственно, сама производительность ядра постоянно улучшается за счет применения совершенствующейся современной проектной нормы, уменьшения длин сигнальных трасс и оптимизации внутренней схемотехники, что улучшает фрагментацию матрицы массива.
Например, чипы SDRAM, DDR и SLDRAM используют ядро DRAM, имеющее время страничного цикла, грубо говоря, около 10 нс. Для того, чтобы получить высокоскоростной интерфейс с производительностью, большей, чем дает время страничного цикла ядра, необходимо использовать параллельную выборку нескольких слов (в данном случае слово — ширина внешней шины данных микросхемы памяти). Например, в х16 микросхеме DDR SDRAM (внешняя шина данных 16 бит) с "линейной" пропускной способностью 200 Mbps/p два слова должны быть считаны или записаны по внутренней шине шириной 32 бита за один 10 нс цикл ядра. Данное обстоятельство приводит к тому, что необходимо увеличивать ширину внутренней шины данных, что, понятно, увеличивает площадь кристалла. Так, например, 16 Mбитный прибор x16 SDRAM имеет PBW в 100 Mbps/p, что уравнивает производительность ядра и пропускную способность интерфейсной схемы. Интерфейс DDR с PBW 200 Mbps/p уже более привлекателен для 64 Мбитных приборов памяти, имеющих достаточное количество логических банков памяти для поддержки внутренней шины данных в 32 бита без необходимости существенного увеличения площади кристалла. Микросхема первого поколения х16 SLDRAM с "линейной" пропускной способностью 400 Mbps/p использует внутреннюю шину данных шириной 64 бита, что делает разумным использовать стартовый объем в 256 Мбит. Если рассматривать следующие поколения SLDRAM, то устройство с 800 Mbps/p, имеющее внутреннюю шину данных 128 бит (собственно говоря, микросхема памяти любой фундаментальной архитектуры с таким внутренним каналом), не будет иметь высокую эффективность, если его емкость будет менее 1 Гбита.
Вообще говоря, для архитектуры SLDRAM понятие «физический банк» неприменимо, поскольку один прибор памяти полностью перекрывает шину данных контроллера (управляющего устройства). Физическим ограничением в рассматриваемой архитектуре является нагрузка на канал — максимальное количество микросхем памяти на один канал с учетом используемой конфигурации (буферизируемые/не буферизируемые шины). Поэтому, понятие «банк» рассматривается исключительно как логическая основа — как составляющая часть ядра микросхемы памяти.
Вопрос низкой стоимости микросхем ДОЗУ упирается в такой показатель, как процент выхода годных микросхем, который должен быть как можно больше. Однако жесткие требования тайминговых схем, диктуемые очень высокой частотой функционирования, катастрофически снижают требуемый высокий показатель процента выхода годных. Несмотря на это, современный уровень технологии и норм производства в состоянии решить данную проблему.
С технической точки зрения, SLDRAM определяется как "интеллектуальная", высокоскоростная и вы-сокоточная память, базирующаяся на модели верньерного (Vernier) согласования, способная гибко, четко и бы-стро настраивать и перестраивать функциональные блоки под необходимую схему функционирования с учетом изменения температуры и возникновения флуктуаций напряжения — все эти особенности опираются на специ-альные разделы теории обратной связи и преобразований сигналов. Система способна буквально сразу же после включения питания самонастроиться, установив оптимально для текущей конфигурации все соответствующие параметры, вне зависимости от того, какой "микс" генераций микросхем SLDRAM используется — особенности схемы GtG. Пакетный протокол SLDRAM предусматривает настройку времени установки и ожидания, задержку данных, а также выходных управляющих уровней индивидуально для каждой микросхемы, чтобы адаптировать и согласовать режим функционирования подсистемы памяти с системными операциями.
Забегая вперед, важно отметить как это происходит. Все устройства (микросхемы отдельно или в составе модуля) подключаются к шинам команд/адреса и данных параллельно, и, чтобы избежать ответа на одну команду несколькими микросхемами, каждой из них в момент включения питания присваивается уникальный номер. В результате каждая микросхема всегда отвечает только на ту команду, которая предназначена специально для нее. Для передачи команд и адреса SLDRAM использует однонаправленный синхросигнал, в отличие от RDRAM, которая использует двунаправленный (CTM и CFM), и, чтобы избежать чрезмерного запаздывания сигнала от микросхем, находящихся дальше от контроллера, временные параметры (тайминги) каждой из них определяются при включении питания. При этом в управляющие регистры каждой микросхемы записывается время, через которое она должна реагировать на поступивший сигнал. Например, в микросхемы, находящиеся дальше от контроллера или более медленные, записывается меньшее значение задержки. Таким образом, ответ на команду, отправленную первой и последней микросхемам, поступит одновременно, так как первая микросхема ответит на него немного позже, что компенсирует время, затраченное сигналом на достижение последней. Время задержек определяется путем опроса всех устройств и измерения времени отклика от каждого из них.
Периодически осуществляется рекалибровка внутренних цепей (согласование по уровню напряжения и таймингам) и, соответственно, перестройка режима работы микросхем памяти, чтобы согласоваться с системными девиациями. Процесс ре-калибровки производится, учитывая условия функционирования и возможную нестабильность напряжения и частоты — еще одна отличительная особенность, частично позаимствованная у RDRAM. Гибкость пакетного протокола SLDRAM, определяющая уровень сложности внутрисхемной реализации интерфейса, позволяет обеспечивать достаточно высокий процент выхода годных и низкую стоимость.
Кроме вышеперечисленных факторов на низкую стоимость SLDRAM влияет использование обычного корпуса, методов упаковки микросхемы и технологии изготовления монтажной печатной платы (PCB — Printed Circuit Board) для модуля памяти. Микросхемы SLDRAM пакуются в стандартный 80pin корпус TSOP (Thin Small Outline Package) c 0.5mm расстоянием между соседними выводами, или в 64pin упаковку VSMP (Vertically Surface Mounted Package) для вертикального монтажа c шахматным расположением выводов, с 0.8mm расстоянием между соседними выводами по диагонали — некое подобие SVP, использующееся в Base/Concurrent RDRAM. С буферизирующими модулями контроллер (управляющее устройство) SLDRAM использует только 33 высокоскоростных сигнала для обеспечения гигабайтной конфигурации подсистемы памяти. "Ширина" модулей предусматривает канал данных шириной 16/18 бит без каких либо дополнительных изощрений со стороны контроллера. Для производства 2х- или 4х-слойных монтажных плат для модулей памяти с 5mil нормой трассы применяется стандартный FR4-материал.
Поскольку SLDRAM Incorporated — это целый консорциум, то стандарт является полностью открытым и сертифицирован на уровне IEEE (концепция интерфейса RamLink стандартизирована как IEEE Std 1594.4-1995, а SyncLink — как IEEE 1596.7-199x) и JEDEC. В группу вошли: Fujitsu Microelectronics, Hitachi Semiconductor, Hyundai Electronics, IBM Global Procurement, IBM Microelectronics Division, LG Semiconductors, Matsushita Electric, Micron Technology, Mitsubishi Electric, MOSAID Technologies, Mosel Vitelic, Motorola Corporate Communications, NEC Electronics, Siemens Components, Texas Instruments, Toshiba Electronic Components, Vanguard International Semiconductor. Открытость стандарта позволяет производителям изготавливать различные продукты каждые для своей ниши рынка и уровня приложений, кроме чего обеспечивается постоянное совершенствование и развитие данной уникальной технологии ДОЗУ. Интерфейс SyncLink (шина SLDRAM или SLBus — SyncLink Bus) является логическим продолжением и усовершенствованием шинной структуры RamLink, применяющейся при создании памяти RLDRAM (RamLink DRAM) — первого ответного хода нескольких корпораций на RDRAM от Rambus. Однако, сама SLBus — это разработка компании MicroGate Corporation, хотя и принадлежит к числу открытых стандартов. В настоящее время вся группа разработчиков почти полностью плавно "портировала" идею SLDRAM в дальнейшее развитие технологии синхронного ДОЗУ: со второй половины 1999 года проект SLDRAM, так и не преодолев "Show me the hardware"-синдром, официально считается закрытым, а вся его базовая концепция легла в основу другой архитектуры — DDRII, — на которую возлагают большие надежды.
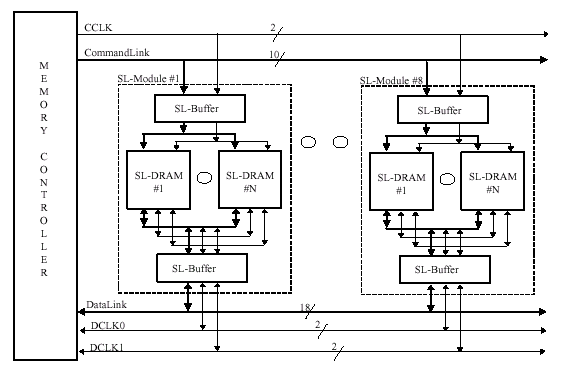
Составляющими подсистемы памяти SLDRAM являются контроллер (SLC — SLDRAM Controller) — очень сложное устройство — и микросхемы памяти (SLDRAM — SyncLink DRAM), которые могут использоваться как раздельно, так и в составе модуля (SLM — SLDRAM Module), вставляющегося в специальный коннектор (SLMC — SLDRAM Module Connector), объединенные общим интерфейсом, который и носит название SyncLink или SLBus (шина SLDRAM). Берущий начало от своего прародителя — RamLink, — именно SyncLink и является ключевым моментом в общей технологии SLDRAM. Однако сначала рассмотрим устройство микросхемы SLDRAM.
Микросхема памяти SLDRAM
Микросхема SLDRAM является довольно сложным устройством, содержащим в себе достаточно большое количество блоков с очень высокой интеграцией компонентов, несмотря на то, что общая политика SLDRAM — это как можно меньшее использование внутренних блоков в микросхеме памяти и как можно большая интеграция самого базового контроллера. Итак, микросхема состоит из следующих основных частей: регистра идентификации (ID Register), обработчика поступающих команд и адресов (Command & Address Capture), блока декодирования и планирования команд (Command Decoder & Sequencer), совмещенных цепей деления и формирования задержек синхросигнала (Clock Dividers & Delays), регистра адреса банка (Bank Address Register), регистра адреса строки (Row Address Register), счетчика регенерации (Refresh Counter), двух мультиплексоров (MUX), предекодера (PreDec), матриц соответствующих банков памяти (Rows x Columns x Internal WideBus) со встроенными усилителями уровня (SenseAmps), блока управления строками логических банков (BankX Row Latch/Dec/Driver), декодера адреса столбца (Column Decoder), шлюза ввода/вывода (I/O Gating), защелок чтения (Read Latch) и записи (Write Latch), буфера FIFO на чтение (Read FIFO) с блоком программирования задержки (Programming Delay), буфера FIFO на запись (Write FIFO) и входных регистров (Input Registers) в цепи внутреннего формирователя синхросигнала (Clock Generator).
Довольно внушительно и интересно выглядят основные общие параметры микросхем:
- Высокоскоростной интерфейс: 200/300/400/600 МГц соответственно для первых четырех поколений.
- Узкая магистраль: 16 бит для базового интерфейса и 18 бит для ECC-интерфейса.
- Высокая эффективность: при использовании шины шириной 16 бит и технологии DDR "линейная" пропускная способность составляет 400/600/800/1200 Mbps/p соответственно для первых четырех поколений.
- Конвейеризированное функционирование: возможность обработки до восьми транзакций в одном логическом банке или распределенных среди множественных банков.
- Восемь (первые образцы) или более (стандартно — 16) независимых логических банков для многократного улучшения эффективности доступа к строке, способности чередовать операции между несколькими внутренними банками и увеличения эффективности механизма регенерации массива.
- Программируемые длины пакетов (Burst Length): BL=4 или BL=8.
- 100% эффективность использования канала в случае выполнения операций произвольного (случайного) доступа даже с длительностью пакетов по 8 байт, что дает возможность обеспечить непрерывную передачу пакетов данных через случайные строку или столбец.
- Использование пакетно-ориентированного протокола (Packet Oriented Protocol) обеспечивает полную совместимость приборов памяти всех поколений по количеству выводов и информационной емкости.
- Полная поддержка режимов автоматической регенерации (AutoRefresh) и саморегенерации (SelfRefresh): например, для 64 Mбитной микросхемы с организацией 8x{1024x128x72} используется 64 мс регенерация, состоящая из 8192 циклов.
- Однонаправленный синхросигнал шины команд (CCLK) используется для синхронизации команд и адресов, а двунаправленный синхросигнал шины данных (DCLK) используется для стробирования чтения и записи данных.
- Сдвоенный синхросигнал (две синхропары) шины данных обеспечивает плавную передачу от одного источника данных к другому.
- Реализован управляемый временной сдвиг между данными и синхросигналом шины данных.
- Введены программируемые задержки чтения, регулируемые в грубых значениях приращений, соответствующие максимум одному информационному разряду (тактовому импульсу — половине тактового периода), и точных значениях приращений, которые являются фрагментом тактового импульса. Программируемые задержки учитывают смещение по времени (перекос, Skew) данных при задержке распространения сигнала от вывода контроллера по сигнальной трассе.
- Программируемые задержки записи, регулируемые в больших значениях приращений, соответствующие по длительности максимум одному тактовому импульсу, учитывают смещение по времени на выходных буферах контроллера памяти.
- Введена поддержка режима доступа к банку (цикл инициализации, или, как его еще называют, первоначальный холостой ход) и доступа к странице (банк активен, строка открыта).
- Сигнальный интерфейс SLIO (SyncLink I/O): калибрующиеся контроллером в момент подачи напряжения высокий 1.6 В выходной (VOH), низкий 0.9 В выходной (VOL) уровни с размахом (Swing) 700 мВ. Источники сигнала (управляющие устройства, Drivers) осуществляют калибровку логических уровней на выходе (Calibrated VOL/VOH levels), в то время как приемники (Receivers) снабжены интерфейсом узкого окна установки/захвата данных (Narrow Set-Up/Hold Windows). Структура SLBus использует серии 20W "изолирующих" резисторов для развязки модулей памяти и основной шины, и основан на подмножестве SSTL-логики (Stub Series Termination Logic), целью которой является обеспечение как можно более высокоскоростного интерфейса с малым временем переключения между логическими уровнями. Такая маленькая дискретизация выходных уровней специфична для высокоскоростных каналов и дает возможность улучшить помехозащищенность структуры. Напряжение (VDDQ <= VDD) функционирования интерфейсных схем (выходные цепи питания контроллера и микросхем памяти) составляет 2.5±0.125 В. Шины команд и данных терминированы в один конец (Single-End Termination) к средней точке опорного напряжения (VREF=1.25V) к концу шины. Терминирование в один конец (параллельная 28 Ом согласующая нагрузка) более экономно в потреблении энергии относительно двустороннего терминирования (Double-End Termination), применяемого, например, в схемах, использующих протоколы GTL/AGTL. Высокоскоростные сигналы интерфейса SLIO используют DDR-технологию обмена информацией (согласование по импульсам), в то время как в основе низкоскоростного LVCMOS-интерфейса лежит SDR-протокол (синхронизация по тактам).
- Общее количество выводов типичной микросхемы SLDRAM, например, в корпусе типа VSMP составляет 64 штуки, а сигнальный интерфейс состоит из 15 групп сигналов.
| Сигнальный интерфейс микросхемы памяти SLDRAM | |
| Сигнал | Назначение |
| CCLK, CCLK# | Входные дифференциальные синхросигналы шины команд интерфейса SLIO. Группа CCLK/CCLK# управляется непосредственно памяти или отдельно каждой микросхемой. Оба фронта CCLK являются началом передачи бита данных шины, определяя таким образом ее DDR-интерфейс. Синхроимпульсы команд, данных, а также другие внутренние синхросигналы управляются именно CCLK, являющимся в данном случае опорным. Все стробирующие сигналы имеют собственный инверсный дополнительный сигнал, из-за чего данная совокупность называется "синхропара" (SYNC Pair) — например, CCLK/CCLK#, где знак # указывает на активный низкий уровень сигнала. |
| DCLK0, DCLK0#, DCLK1, DCLK1# | Входные и выходные дифференциальные синхросигналы шины данных интерфейса SLIO. Получением доступа на чтение специфическими парами DCLK0/DCLK0# или DCLK1/DCLK1# управляет микросхема SLDRAM, а получением доступа на запись управляет непосредственно сам контроллер. Как и полагается в дифференциальном протоколе, разрешением на текущий доступ для чтения данных из микросхемы обеспечивают два пересечения на выбранных парах сигнала DCLK, и потом одно пересечение, соответствующее каждому считанному слову. В течение всего доступа для записи SLDRAM использует задержанные версии синхропар DCLK, принимаемые вместе с данными. |
| SI, SO | Низкоскоростные LVCMOS-сигналы выбора входа (Select In) и выхода (Select Out). Контроллер и все микросхемы памяти в канале соединяются в целые серии цепочечного типа при использовании этих сигнальных выводов. Данные соединения используются для инициализации микросхем памяти SLDRAM. |
| LINKON | Входной LVCMOS-сигнал, сигнализирующий о входе и/или выходе микросхемы в/из состояния низкого потребления (ShutDown) |
| RESET# | Входной LVCMOS-сигнал, обеспечивающий аппаратный сброс всей микросхемной логики, включая состояние регистров идентификации и суб-идентификации. Сигнал является "прозрачным", поскольку при этом данные из массива памяти не теряются. В течение действия цикла аппаратного сброса (или, как его еще называют, цикла переопределения) каждый прибор SLDRAM должен инициализироваться. |
| LISTEN | Входной LVCMOS-сигнал, сигнализирующий о входе/выходе микросхемы в/из состояния Stand-By. |
| FLAG | Входной сигнал интерфейса SLIO, высокое состояние которого указывает на начало передачи запрошенного пакета. После этого FLAG переходит в низкое состояние для передачи остатка пакета. В любое другое время сигнал интерпретируется как отсутствие операции (NOP — No OPeration), если находится в низком (неактивном) состоянии. |
| CA[9:0] | SLIO-входы передачи команд и адресов. Команды, адреса и/или данные для записи в регистр передаются именно по этим сигнальным выводам пакетами по четыре слова. |
| DQ[17:0] | Сигнальные выводы шины данных интерфейса SLIO. |
| TEST | Тестовый сигнал должен постоянно быть соединенным с интерфейсом VSS в течение всего цикла нормально функционирования. |
| VREF | Вывод опорного напряжения. |
| VDDQ | Линии питания шины данных, изолирующие питание выводов DQ[17:0] для улучшения помехозащищенности. |
| VSSQ | Линии экранирования шины данных, изолирующие выводы DQ[17:0] для улучшения помехозащищенности. |
| VDD | Линия питания. |
| VSS | Линия заземления. |
Так, восьмибанковый чип SLDRAM состоит из восьмибанковых квадрантов (Quadrant). Каждый банк использует общую 16/18 bit шину данных, маршрутизируемую для каждого квадранта отдельно. Соответственно, чтение/запись данных осуществляется по внешней шине DataLink шириной 16/18 bit пакетами по четыре, обеспечивая непрерывные прием/передачу пакета информации 64/72 bit — по полному слову от каждого квадранта, в сумме образующих пакет. Это осуществляется заполнением младшего байта внешнего интерфейса DQ[7:0]/DQ[8:0] данными из квадрантов 0 и 1, которые обеспечивают первых два слова пакета, а старшего байта DQ[15:8]/DQ[17:9] — данными из квадрантов 2 и 3, предоставляющих вторых два слова пакета. Шестнадцатибанковый чип строится по аналогичной схеме — разница заключается лишь в количестве банков одного квадранта.
Например, микросхема SLD4M18DR400 — это 4Мх18, восьмибанковое, синхронное, высокоскоростное, пакетно-ориентированное, конвейерное ДОЗУ, содержащее 75497472 бит массив и синхронизирующееся частотой 200 МГц при результирующей 400 MГц (400Mbps/p), обеспечивая пиковую пропускную способность 800 Мбайт/с. Данный прибор памяти внутренне организован как восемь логических банков по 128Кx72, каждый из которых содержит 1024 строки, 128 столбца с внутренней шиной 72 бита (1024x128x72) — соответственно, вся микросхема организована по схеме 8x{1024x128x72}. Эта шина передает по интерфейсу ввода/вывода в пакетном режиме по четыре 18-разрядных слова. Данный прибор поддерживает схему коррекции ошибки, поэтому имеет внешний интерфейс 18 бит. Обычная микросхема, понятно, имеет шину данных 16 бит.
Все транзакции начинаются с пакета запроса. Пакеты запроса на чтение или запись содержат специфическую команду и требуют информационный адрес. Читаемые и записываемые данные также передаются пакетами: одностолбцовый доступ включает передачу одиночного пакета данных, который является тем самым пакетом, состоящим из четырех 16/18-разрядных слов (пакет 64/72 бит соответственно). К данным от одного или двух столбцов в восьми страницах можно обращаться с одиночным пакетом запроса, что является результатом непрерывного пакета восьми 16/18-разрядных информационных слов (пакет 128/144 бит соответственно).
Запросы на чтение или запись могут быть применены к незанятым банкам или к открытой строке в активных банках, и указывают оставить ли строку открытой после доступа или исполнять самоустановленный цикл регенерации при завершении доступа (авторегенерация). Микросхема SLDRAM использует конвейерную архитектуру и множественные внутренние банки для достижения высокоскоростного выполнения операции и высокоэффективного использования протокола. Перезаряжая один банк при выполнении доступа к другому банку, циклы перезаряда скрываются, что достигается независимой внутренней логической структурой и гарантирует высокоскоростной произвольный доступ. Способность микросхемы SLDRAM выполнять программу авторегенерации обеспечивается наряду с двумя другими функциями управления питанием: Stand-By (пониженное потребление с готовностью полностью активизировать все цепи) и ShutDown (деактивация). Саморегенерация же выполняется в режиме деактивации.
Поскольку SLDRAM использует технологию DDR, был специально введен параметр, характеризующий единичную посылку — "тик" (Tick) или импульс сигнала, эквивалентный половине периода CCLK — tCK/2. Иными словами, период сигнала (длительность периода синхросигнала, Clock Period) разбивается на четыре части: положительный перепад (tR — Rise time) или фронт, продолжительность импульса (tW — Pulse Duration или Width), отрицательный перепад (tF — Fall time) или срез, и интервал или пауза. Собственно, термин "интервал" или "пауза" — это символическое о относительное понятие, поскольку оно в данном случае является все той же продолжительностью импульса. Идеальный тактовый период (Clock Period) подразумевает равенство длительностей фронта и среза (tR=tF) и равенство продолжительности импульса и паузы. На основе этой схемы равенства и было определено понятие "тик" — сумма длительностей первого и второго (по порядку, указываемому выше) или третьего и четвертого составляющих длительности цикла синхросигнала, за промежуток одной из сумм которых, при использовании технологии DDR, передается единица информации — бит. Поэтому, при использовании DDR, за тактовый период (сумма всех четырех составляющих) передается 2 бита — по положительному и отрицательному перепадам, или по фронту и срезу.
Все стробирующие сигналы (применительно к SLDRAM) рассматриваются как CCLK, DCLK0 и DCLK1. Важно понимать, что это дифференциальные сигналы и каждый их них имеет дополнительный инверсный (CCLK#, DCLK0# и DCLK1#). Поэтому любая ссылка к определенному фронту специфического строба имеет ввиду рассмотрение относительно реального синхроимпульса (например, CCLK), а не его дополнение (CCLK# соответственно).
Рассмотрим более детально описание основных команд микросхемы SLDRAM. Все пакеты команд должны стартовать по положительному перепаду CCLK (по фронту).
- Отсутствие операции (NOP — No OPoeration)
- Высокий уровень сигнала FLAG указывает на начало запрашиваемого пакета, после чего переходит в низкий уровень, чтобы продолжить пакет. Как только FLAG установился в низкий уровень, начинается цикл отсутствия операций (NOP, называемый еще циклом предотвращения конфликтов), который предотвращает выполнение нежелательных команд в течение выполнения текущей операции и относительно нее является «прозрачным».
- Открытие строки (Open Row)
- Используется для активизации строки в конкретном логическом банке для подготовки к последующей за этим команды доступа к столбцу. Страница (по-другому — строка) остается открытой (активной) для доступности до поступления команды закрытия строки (Close Row). После выполнения команды Open Row для данного банка должна быть исполнена команда Close Row до момента открытия доступа к другой строке в этом же банке. Open Row может быть также полезной, когда ожидается подача команды доступа к странице, но адрес столбца еще неизвестен.
- Закрытие строки (Close Row)
- Используется для закрытия страницы в конкретном банке, когда необходимо закрыть строку, которая ранее была открыта в ожидании последующего доступа к странице.
- Чтение (Read)
- Команды чтения из страницы (Page Read) и чтения из банка (Bank Read) используются для осуществления доступа для чтения открытой или закрытой строки соответственно.
- Запись (Write)
- Команды записи в страницу (Page Write) и записи в банк (Bank Write) используются для осуществления доступа для записи открытой или закрытой строки соответственно.
- Чтение из регистра (Register Read)
- Используется для чтения содержимого регистров устройства. Данные, считываемые из регистра, передаются по DataLink после задержки, определяемой значениями, записанными в регистр задержки чтения страницы (Page Read Delay Register), и программирования в микросхему значений точных (Fine Read Vernier) и компенсирующих (Data Offset Vernier) верньеров. Верньер (по-другому — нониус) является уточняющим параметром. В данном случае это временной интервал очень маленькой продолжительности — приблизительно на порядок меньше уточняемой им длительности. Иными словами, если речь идет о длительности, измеряемой в единицах наносекунд, то нониус будет иметь длительность сотни пикосекунд или еще меньше (в зависимости от требуемой точности). Схемы верньерного согласования носят индивидуальный характер для каждой конкретной операции, однако основаны на общей схеме взаимоотношения сигналов, синхронизируемых друг относительно друга. Так, точный верньер используется для грубой настройки (tCK/8, tCK/4 и tCK/2), а компенсирующий — для более точной (tCK/16, tCK/32 или еще меньше).
- Запись в регистр (Register Write)
- Используется для записи данных в регистры управления микросхемы памяти. Данные, записываемые в регистр, включают в себя пакет запроса, содержащий команду.
- Чтение образца синхронизации (Read SYNC/Stop Read SYNC)
- Команда, указывающая прибору памяти начать (закончить) передачу специфического синхронизирующего образца (определенная последовательность логических "0" и "1"), используемого контроллером для установки входных таймингов.
- Установка уровня DCLK (Drive DCLKs Low/High)
- Команда установки высокого/низкого уровней сигналов DCLK в противоположность другого DCLK (дифференциально).
- Совмещение DCLK (Drive DCLKs Toggling)
- Команда, указывающая микросхеме SLDRAM встречно направить выходные уровни сигналов DCLK: DCLKn/DCLKn# будут пересекаться в средней точке (уровень опорного напряжения) каждые tCK/2.
- Деактивация DCLK (Disable DCLKs)
- Команда перевода линий синхронизации шины данных в высокоимпедансное (High-Z) состояние (средняя точка), при котором ток не протекает (сопротивление стремиться к бесконечности)
- Событие (EVENT)
- Используется для выполнения команд не требующих специфической адресации микросхемы или микросхем памяти. Данная инструкция включает следующие процедуры:
- Жесткий сброс (Hard Reset) определяет последовательность установки регистра идентификации в значение 255, установки регистра субидентификации в значение 15 и сброса настроек устройства, включая откалиброванные и записанные значения выходных логических уровней (VOH/VOL levels).
- Мягкий сброс (Soft Reset) применяется для сброса значений регистров идентификации, субидентификации и значений логических уровней.
- Авторегенерация (AutoRefresh) осуществляет выполнение операции регенерации (обновления) содержимого строки или группы строк, адресуемое внутренним счетчиком регенерации, при чем все банки, в которых в данный момент происходит цикл регенерации, должны быть незанятыми.
- Закрытие всех строк (Close All Rows) выполняет закрытие всех открытых строк в любом банке.
- Вход в цикл саморегенерации (Enter SelfRefresh) используется для введения микросхемы памяти в режим выполнения программы саморегенерации, которая используется в периоды микропотребления, когда прибор памяти регенерируется самостоятельно путем инкрементирования своего внутреннего счетчика — в таком состоянии микросхема сама осуществляет обновление содержимого ячеек памяти, поскольку в ней запускается свой собственный генератор, синхронизирующий внутренние цепи.
- Выход из саморегенрации (Exit SelfRefresh) указывает на начало вывода микросхемы памяти из цикла SEREf, и внутренний генератор деактивируется.
- Установки настроек (Adjust Settings) используются для регулирования и настройки четких и компенсирующих верньеров, а также для проведения калибровки логических уровней.
Процедура назначения регистра представляет самый большой интерес, поскольку данные о определяемых таймингах и служебная информация записываются и/или хранятся именно в регистрах. Микросхема SLDRAM содержит две группы регистров, адресуемые сигналами REG[3:0]: 128 регистров управления (Control Registers) и 128 регистров состояния (Status Registers).
| Таблица наименований регистров и их адресации | |||||
| REG3 | REG2 | REG1 | REG0 | Регистры управления | Регистры состояния |
| 0 | 0 | 0 | 0 | Идентификация | Конфигурация |
| 0 | 0 | 0 | 1 | Субидентификация | Текущие задержки |
| 0 | 0 | 1 | 0 | Частота функционирования | Минимальные задержки |
| 0 | 0 | 1 | 1 | Тест | Максимальные задержки |
| 0 | 1 | 0 | 0 | Задержка чтения страницы | Тест |
| 0 | 1 | 0 | 1 | Задержка записи страницы | tRAS/tRP |
| 0 | 1 | 1 | 0 | Задержка чтения банка | tRC1/tRC2 |
| 0 | 1 | 1 | 1 | Задержка записи банка | tRRD/tXSR |
| 1 | 0 | 0 | 0 | Зарезервировано | tWR/tWRD |
| 1 | 0 | 0 | 1 | Зарезервировано | tPR/tBR |
| 1 | 0 | 1 | 0 | Зарезервировано | tPW/tBW |
| 1 | 0 | 1 | 1 | Зарезервировано | Зарезервировано |
| 1 | 1 | 0 | 0 | Зарезервировано | Зарезервировано |
| 1 | 1 | 0 | 1 | Зарезервировано | Зарезервировано |
| 1 | 1 | 1 | 0 | Зарезервировано | Зарезервировано |
| 1 | 1 | 1 | 1 | Зарезервировано | Зарезервировано |
Первая группа (регистры управления), носящая статус "только для записи" (Write-Only), имеет логическую "ширину" 20 бит. Физически же все регистры управления имеют поле 8 бит (или еще меньше), посему остаются резервные (DtC — Don't Care) биты. Для резервирования битовых позиций (для будущих расширений конфигурации) контроллер в DtC-поле должен внести "0", Данные записываются в регистр управления через шину команды/адреса как часть пакета записи данных в регистр (RWP — Register Write Packet).
- Регистр идентификации (ID Register) содержит 9-разрядное поле, устанавливаемое в "1" (ID=255) после выполнения процедуры аппаратного сброса (RESET#) и в последствии программируемое уникальным номером, определяемым процедурой инициализации. Каждая микросхема SLDRAM выполняет мониторинг шины команды/адреса для определения начала пакета запроса, а затем выполнения процедуры сравнения между содержащимся идентификатором в пакете запроса и собственным идентификационным номером, хранящимся во внутреннем регистре идентификации. Если все совпадает, то устройство отработает пакет запроса, если нет — пропустит. Девятый бит поля идентификации, содержащийся в пакете запроса, позволяет работать с каждым прибором индивидуально или как с частью целой группы микросхем — режим многоабонентской доставки или мультикаст (Multicast). Для записи в регистр и приема пакетов запроса события (Event Request Packets), значение, содержащееся в регистре суб-идентификации, должно также совпадать со значением данного выбранного прибора памяти.
- Регистр субидентификации (sub-ID Register) содержит 4-разрядное поле, которое после процедуры жесткого сброса установливается в "1" (sub-ID=15) и в последствии программируется уникальным номером, определяемым процедурой инициализации. Для процедуры записи в регистр и запроса события микросхема памяти после обнаружения совпадения по значениям, содержащимся в регистрах идентификации, выполняет сравнение значений, содержащихся в теле пакета запроса и во внутреннем регистре субидентификации. Если все совпадает, то устройство отработает пакет запроса, если нет — пропустит. Пятый бит поля суб-идентификации, содержащийся в пакете запроса, имеет назначение, аналогичное девятому биту в регистре идентификации. Регистр субидентификации программируется используя пакеты запроса на запись регистра субидентификации (Write SUB-ID Register Request Packets). Тело пакета состоит из двух частей: текущей инициализации и основной записи.
- Регистр частоты функционирования (Operating Frequency Register). Второе и последующие поколения микросхем памяти SLDRAM способны работать не только на одной конкретной частоте — они могут динамически (в фазе инициализации) перестраиваться на другую частоту (меньше собственной) в зависимости от "микса" генераций микросхем в подсистеме. Пакет, содержащий значения частоты функционирования, несет в своем теле 8-разрядное поле OF[7:0], которое и программируется данный регистр.
| Значения битового поля регистра частоты функционирования | ||
| OF[7:0] | Частота функционирования | "Линейная" пропускная способность |
| 00000001 | 100 MГц | 200 Mbps/p |
| 00000010 | 200 MГц | 400 Mbps/p |
| 00000100 | 300 MГц | 600 Mbps/p |
| 00001000 | 400 МГц | 800 Mbps/p |
| 00010000 | 500 МГц | 1.0 Gbps/p |
| 00100000 | 600 МГц | 1.2 Gbps/p |
| хх000000 | Зарезервировано | |
- Тестовый регистр (Test Register) применяется для тестирования микросхемы и выполнения фазы внутренней отладки памяти, и не может быть доступен для записи в режиме нормального функционирования.
- Регистр задержки чтения из страницы (Page Read Delay Register) предназначен для программирования количества целых тиков (полуциклов или "битов") между приемом пакета запроса на чтение из страницы (Page Read Request Packet) и последующим чтением данных. В данном случае этот 8-бит регистр определяет интервал 0-255 тиков, и значение программируется исходя из соответствующего состояния регистра. При этом разные значения программируются в разные микросхемы памяти на одном канале в порядке компенсации различных задержек, возникающих по внутренним и внешним маршрутам прохождения сигнала. Записанное в регистр значение может в последствии модифицироваться посредством инкремента/декремента четкого верньера. Такие модификации отображаются в значениях текущих задержек регистров состояния.
- Регистр задержки записи в страницу (Page Write Delay Register) используется для программирования количества целых тиков между приемом пакета запроса на запись в страницу (Page Write Request Packet) и последующей записью самих данных. Данный 8-бит регистр определяет интервал 0-255 тиков, и значение программируется исходя из соответствующего состояния регистра. Ожидается, но не требуется, что для всех приборов памяти в канале программируется одно и тоже значение. Данное специфическое значение, выбираемое из всего диапазона доступных значений, устанавливается согласно соотношения между задержкой на чтение и задержкой на запись.
- Регистр задержки чтения из банка (Bank Read Delay Register) применяется для программирования количества целых тиков между приемом пакета запроса на чтение из банка (Bank Read Request Packet) и соответствующим чтением данных. Этот 8-бит регистр определяет интервал 0-255 тиков, и значение программируется исходя из соответствующего состояния регистра. При этом различные значения могут быть запрограммированы в разные микросхемы памяти на одном канале в порядке компенсации различных задержек, возникающих по внутренним и внешним маршрутам прохождения сигнала. Записанное в регистр значение может в последствии модифицироваться посредством инкремента/декремента четкого верньера. Такие модификации отображаются в значениях текущих задержек регистра состояния.
- Регистр задержки записи в банк (Bank Write Delay Register) служит для программирования количества целых тиков между приемом пакета запроса на запись в банк (Bank Write Request Packet) и соответствующей записью данных. Данный 8-бит регистр определяет интервал 0-255 тиков, и значение программируется исходя из соответствующего состояния регистра. При этом различные значения могут быть запрограммированы в разные микросхемы памяти на одном канале. Данное специфическое значение, выбираемое из всего диапазона доступных значений, устанавливается согласно соотношения между задержкой на чтение и задержкой на запись.
Группа регистров состояния имеют свойство "только для чтения" (Read-Only) и 72bit логическую разрядность. Физически же они имеют "ширину" 32 бита, поэтому остальные резервные биты при чтении имеют значения "0". Данные из этих регистров считываются пакетами по четыре (BL=4) после промежутка, равного задержке чтения из текущей страницы (tRP или tAA — Actual Page Read Delay), ранее запрограммированной в соответствующий регистр микросхемы SLDRAM.
- Регистр конфигурации (Configuration Register) содержит уникальный код, идентифицирующий производителя микросхемы памяти, частоту ее функционирования, количество логических банков, число строк в банке, количество столбцов в странице и ширину шины данных. Поле производителя (Manufacturer Field) содержит уникальный код, идентифицирующий производителя прибора памяти. Компенсирующий бит (Data Offset Bit) определяется состоянием линии DQ0: DQ0=0 характеризует прибор памяти, поддерживающий только компенсацию "ширины" данных (Word-Wide Offset), а DQ0=1 определяет поддержку компенсации и уровня градации (Bit Level Offset). Поле определения частоты функционирования (Frequency Field) кодируется аналогично значениям битового поля идентификации частоты функционирования, записываемого в регистр частоты функционирования. Поля определения количества банков (Bank Field), строк (Row Field), столбцов (Column Field) ширины шины данных (DQ Field) говорят сами за себя.
- Регистр текущей задержки (Actual Delay Register) содержит установочную информацию о текущей задержке чтения из страницы, задержке записи в страницу, задержке чтения из банка и задержки записи в банк для конкретной микросхемы памяти — эти данные будут отображать любую последовательность изменения значений. Такие модификации происходят из-за программирования контроллером регистров управления или от процедуры настройки точного (четкого) верньера. Так, данный регистр содержит четыре поля. Поле текущей задержки чтения из страницы (Actual Page Read Delay Field) измеряется в количестве целых тиков между приемом пакета запроса на чтение из страницы и последующим чтением данных, и определяет поддерживаемую данной микросхемой памяти текущую задержку чтения из страницы. Поле текущей задержки записи в страницу (Actual Page Write Delay Field) измеряется в количестве целых тиков между приемом пакета запроса на запись в страницу и последующей записью данных, и определяет поддерживаемую данной микросхемой текущую задержку записи в страницу. Поля текущей задержки на чтение (Actual Bank Read Delay Field) и запись (Actual Bank Write Delay Field) из/в банк имеют свойства, аналогичные описываемым ранее, только для банка.
- Регистр минимальной задержки (Minimum Delay Register) содержит установочную информацию о минимальных значениях задержки чтения из страницы, задержки записи в страницу, задержки чтения из банка и задержки записи в банк. Значение, хранящееся в этом регистре, является суммой цифровых параметров соответствующих регистров тайминговых параметров (Timing Parameter Registers) и аналоговых значений, конвертируемых в цифровые (используя при этом минимальное время цикла CCLK), округляемых до ближайшего большего целого числа. Если прибор памяти используется на пониженных частотах, то контроллер должен будет вычислить эти значения, используя текущие тайминги и действительную частоту функционирования, и проигнорировать значение, записанное в регистре минимальной задержки. Как и в предыдущей ситуации, данный регистр состоит из четырех битовых полей, назначения которых определяются соответственно для данного регистра, аналогично описанию битовых полей для регистра текущей задержки: поля минимальной задержки чтения (Minimum Page Read Delay Field) и записи (Minimum Page Write Delay Field) из/в страницу, и поля минимальной задержки чтения (Minimum Bank Read Delay Field) и записи (Minimum Bank Write Delay Field) из/в банк.
- Регистр максимальной задержки (Maximum Delay Register) содержит установочную информацию о максимальных значениях задержки чтения из страницы, задержки записи в страницу, задержки чтения из банка и задержки записи в банк. Особенности этого регистра полностью аналогичны особенностям регистра минимальной задержки, с той лишь разницей, что в него вносятся максимальные параметры. Битовые поля по своему составу и назначению также аналогичны с той же самой разницей: поля максимальной задержки чтения (Maximum Page Read Delay Field) и записи (Maximum Page Write Delay Field) из/в страницу, и поля максимальной задержки чтения (Maximum Bank Read Delay Field) и записи (Maximum Bank Write Delay Field) из/в банк.
- Регистры тайминговых параметров (Timing Parameter Registers) содержат представление соответствующих таймингов параметров, предусматриваемых спецификацией микросхемы памяти. Контроллер может использовать эту информацию для программирования оптимальных временных параметров, базирующихся на возможном уровне производительности прибора памяти, установленного в подсистеме. Каждый регистр содержит значения для двух таймингов, состоящих из аналоговой и цифровой компонент. Цифровая компонента является целым числом, лежащем в диапазоне 0-255, не зависящим от частоты функционирования. Аналоговая компонента, выражаемая в наносекундах (нс), вычисляется умножением размера представления шага на десятичное представление значения (количество ступеней). Результирующее значение (аналоговая компонента + цифровая компонента) для данного параметра может быть получено преобразованием аналоговой компоненты в цифровую (методом деления на текущий интервал цикла CCLK и округления полученного результата до ближайшего большего целого числа) и добавлением полученного результата к имеющейся цифровой компоненте.
Теперь рассмотрим само функционирование подсистемы SLDRAM. Доступ на чтение или запись начинается с выдачи пакета запроса, который включает все необходимые адреса и команды. Пакет запроса следует за определенной специально запрограммированной задержкой, а сам пакет данных завершает транзакцию. Для обеспечения нормального функционирования каждая микросхема памяти SLDRAM проходит специальные фазы инициализации (Initialization), идентификации (Identification), синхронизации (Synchronization) и настройки временных параметров (Timing Adjust), после чего готова к нормальному функционированию. Рассмотрим данные фазы более подробно.
- Включение/аппаратный сброс (Power-Up/Hardware Reset)
- Приборы SLDRAM должны быть включены и инициализированы предопределенным способом. Нарушенный порядок действий, который определяется спецификацией этой ступени, может привести к возникновению неопределенной операции. Так, напряжение подается сначала на трассы VDD и VDDQ, а потом, после задержки инициализации основных интерфейсов питания (tVTD — VDD/VDDQ to VTERM Set Up time), определяемой конкретной микросхемой памяти, на интерфейс системного терминирования — VTERM. Интерфейс VTERM должен инициализироваться только после подачи напряжения на линии VDDQ, чтобы избежать "задвижки" устройства, которая может вызывать полное повреждение микросхемы памяти. Опорное напряжение VREF, номинально совпадающее с VTERM, может инициализироваться в любое время после окончания интервала подачи напряжения на VDDQ. Входные интерфейсы не активизируются, пока не пройдет полная фаза инициализации интерфейса напряжения микросхемы, заканчивающаяся на подаче опорного напряжения. На момент включения электропитания все линии DQ[17:0] и DCLK[1:0]/DCLK[1:0]# находятся в высокоимпедансном («третьем») состоянии (Hi-Z), а на выходе SO установлено низкое значение напряжения. Вход RESET# должен быть активным (низким) как минимум промежуток времени tRST (RESET# Pulse Width), равный длительности действия сигнала аппаратного сброса. Фаза жесткого сброса устанавливает внутренний регистр идентификации (ID Register) по значению 255, регистр субидентификации (sub-ID Register) по значению 15, программируемые задержки чтения и записи в минимальные значения, и активизирует интерфейс калибровки выходных уровней.
- Выход из деактивации/настройка управления контроллера (Exit ShutDown/Controller Driver Adjust)
- Низкий уровень сигнала LINKON при устойчивом CCLK должен установиться до окончания действия сигнала RESET#, после чего идет продолжение установленной последовательности инициализации, как при выполнении программы выхода из ShutDown: сначала сигнал LISTEN устанавливается в логический "0" до перехода LINKON в "1", после чего LINKON переходит в "1" и выполняется цикл ожидания tLHHC (Listen to Linkon High Hold time — Cold) для блокирования цепей автоподстройки длительности задержки сигнала (DLL — Delay Locked Loop), и, наконец, LISTEN переходит в активное состояние. Внешние буферные элементы могут требовать низкого уровня сигнала LISTEN до окончания действия RESET#, для чего необходимо введение дополнительной задержки блокировки между переходом LINKON и LISTEN в высокое состояние. После выхода из ShutDown микросхема памяти полностью активизируется, результатом чего является выполнение команды записи тайминга синхронизации. Тем не менее, до начала выполнения команды и записи тайминга синхронизации, контроллер должен выполнить внутреннюю самокалибровку уровней VOH и VOL интерфейса SLIO.
- Команда и запись тайминга синхронизации (Command and Write Timing Synchronization)
- Для команды и записи тайминга синхронизации контроллер передает определенный специфический образец (псевдослучайная синхронная последовательность, шаблон) на линии сигналов FLAG, CA[9:0], и DQ[17:0], постоянно его повторяя, пока в конечном счете не зафиксируется прямой переход "низкий-высокий" (LOW-to-HIGH) на входе SI контроллера — это происходит только после того, как все устройства на канале успешно синхронизированы. Выходной сигнал SO контроллера имеет высокий уровень после передачи первого цикла указываемого специфического образца. Шаблон передается на все устройства, соединенные непосредственно с контроллером, и идентифицируется последовательностью четырех "1" на входе FLAG. В течение этой операции, микросхемы SLDRAM используют SI/SO-соединение (последовательная связующая цепочка) с последовательным опросом, чтобы связаться с контроллером памяти и закончить запись тайминга синхронизации. Прохождение полной фазы определения и записи расчета синхронизации проходит по следующему маршруту: последовательный переход LOW-to-HIGH осуществляется от SO-выхода контроллера до входа SI первого прибора SLDRAM, затем от выхода SO первого прибора SLDRAM до входа SI второго прибора SLDRAM и т.д. через выход SO последней микросхемы SLDRAM ко входу SI контроллера. Каждое устройство SLDRAM начинает выполнение команды и записи тайминга синхронизации сразу после обнаружения на собственном входе специфического образца, но не направляет его к собственному выходу SOn, пока на входе действует переход и не завершился цикл отработки команды и записи тайминга синхронизации. Ответный сигнал по линии FLAG специального образца перехода LOW-to-HIGH на входе микросхемы дифференцирует эту активность от подобной процедуры, используемой в течение назначения идентификатора, чтобы однозначно разделить похожие фазы. Контроллер останавливает посылку специального образца после обнаружения на входе SI высокого уровня напряжения, и затем ждет 16 тиков до момента начала посылки необходимой команды или переопределения соединения SI/SO, при чем уровень сигнала FLAG все 16 тиков находится в низком состоянии. Эта задержка позволяет устройствам SLDRAM обнаруживать отсутствие посылки специального образца на входе FLAG и распознавать следующий высокий уровень на входе FLAG, как являющийся началом передачи действительного пакета команды. Контроллер переопределяет соединение SI/SO посредством передачи "0" на выход SO и ожидания момента перехода SI в аналогичное низкое состояние.
- Назначение идентификатора (ID Assignment)
- Далее, каждой микросхеме SLDRAM на канале(ах) последовательно назначается уникальный номер (идентификатор, ID) и суб-идентификационная (sub-ID) комбинация. Каждый прибор SLDRAM индивидуально выбирается по типу использования соединения SI/SO — этот режим работы идентифицируется переходом LOW-to-HIGH на входе SI, сопровождаемым пакетом запроса на запись (Write Request Packet) в регистр идентификации. Каждый запрос на запись в регистр идентификации обязательно сопровождается соответствующим пакетом запроса на запись в регистр суб-идентификации (встречные тайминги — tCC, Control Register Write to Next Command Set Up time, все логические банки закрыты), и N этих пар запросов будут результативными, где N соответствует количеству микросхем SLDRAM в подсистеме. Только прибор SLDRAM, который имеет высокий уровень на входе SI, ID=255 и sub-ID=15, среагирует на пакет запроса на запись в регистр идентификации в любой посланной паре запроса. Соответствующий пакет запроса на запись в регистр субидентификации в каждой паре запроса должен использовать только тот номер устройства, который был назначен пакетом запроса на запись в регистр идентификации в данной паре. Таким образом, только микросхема SLDRAM с тем идентификатором, где на входе SI присутствует "1" и sub-ID=15, отреагирует на пакет запроса записи в регистр субидентификации. Выбранная микросхема SLDRAM отреагирует на запись идентификатора, содержащегося в первом пакете к его внутреннему регистру идентификации, потом на запись субидентификатора, содержащегося во втором пакете к его внутреннему регистру субидентификации, а затем установит на выходе SO высокий уровень напряжения. Контроллер памяти, в свою очередь, обеспечивает достаточно времени задержки (tID — ID Write Request to SO Output Delay,- плюс максимальное значение задержки распространения) между установкой на SO логической "1" и первой выходящей парой запроса (а также между последующими парами запроса), чтобы учесть время прохождения сигнала от выхода SO данной микросхемы памяти до входа SI следующего устройства. Назначение идентификатора закончено, когда вход SI контроллера перешел в высокое состояние — тогда контроллер при необходимости снова переопределяет соединение SI/SO, как и прежде.
- Пре-конфигурация/настройка управления SLDRAM (Pre-configuration/SLDRAM Driver Adjust)
- На этой ступени микросхемы SLDRAM могут принимать команды, и каждый прибор памяти является уникально адресуемым. Затем программируется рабочая частота конкретного устройства SLDRAM и выполняется калибровка уровней VOH и VOL. Информация, указывающая соответствующую рабочую частоту микросхемы, будет содержаться непосредственно в контроллере или может быть получена опросом контроллера некоторых других компонент типа переходных устройств, микросхем, содержащих схему последовательного детектирования (SPD), и т.д. Таким образом, необходимые значения записываются в соответствующий регистр каждого устройства SLDRAM. Для запрограммированных частот функционирования, отличных от фактической частоты, команда и запись параметров синхронизации должна быть повторена для определения новой частоты. Калибровка уровня VOH выполняется для каждого устройства SLDRAM, посылая управляющие команды DCLK с высоким уровнем, итерационно направляя инкремент/декремент VOH команд и контролируя выходной уровень, пока не будет установлен необходимый. Калибровка уровня VOL выполняется аналогично, используя управляющие команды DCLK с уровнем. После завершения фпазы калибровки интерфейсов VOL/VOH контроллер посылает командный пакет прекращения подачи DCLK (Disable DCLKs).
- Считывание тайминга синхронизации (Read Timing Synchronization)
- Теперь контроллер может посылать команды отдельно каждому устройству SLDRAM, при чем происходит выбор рабочей частоты и выполняется чтение тайминга синхронизации. Для каждой микросхемы SLDRAM контроллер должен сначала послать как минимум 16 команд приращения точного верньера для интерфейса DQ[17:0] и DCLK0 так, чтобы счетчик с большой погрешностью отсчитывал приращение, начиная от минимального значения (0), устанавливаемого после отработки процедуры сброса, что дает возможность проведения последующих настроек. После этого контроллер должен послать пакет запроса на синхронизацию конкретной микросхемы SLDRAM, ответом которой является возвращенный образец специальных данных с задержкой, равной текущей задержке чтения из страницы. Такие специфические параметры на данном этапе обмена данными контроллеру пока неизвестны, поэтому контроллер должен немедленно после посылки команды запроса на считывание параметров синхронизации (Read Sync Request) активизировать цепи синхронизации. Далее контроллер должен настроить внутренние параметры синхронизации, чтобы фиксировать данные — это выполняется посредством точных и компенсирующих верньеров до тех пор, пока известный образец данных не зафиксирован и не оптимизированы параметры синхронизации. Окончательной настройкой для поступления считанных данных в контроллере является программирование задержки с довольно большим запасом времени, которое выполняется позже. В этот момент контроллер должен сформировать и отправить пакет прекращения считывания параметров синхронизации, который указывает микросхеме SLDRAM, что посылки шаблона прекращены. После того как такая процедура произведена для каждой микросхемы SLDRAM, контроллер может начать считывать данные с каждого прибора SLDRAM, но с неопределенной задержкой. Команда и запись тайминга синхронизации, запись тайминга синхронизации, чтение тайминга синхронизации или калибровка выходного уровня в случае необходимости могут периодически повторяться. Такие процессы ре-синхронизации и ре-калибровки должны выполняться в периоды простоя, когда не происходит никаких операций.
- Обнаружение и перепрограммирование задержек чтения и записи (Detecting and Reprogramming Read & Write Latencies)
- Теперь контроллер может обнаруживать текущую задержку чтения для каждой микросхемы SLDRAM, посылая управляющие команды перевода DCLK в активное состояние, сопровождаемые (после интервала tDD — Command to DCLK Delay for DCLK HIGH, LOW, Toggling or Hi-Z) запросом на чтение данных из регистра состояния (Read Status Register Request). Контроллер должен немедленно после выдачи запроса на чтение данных из регистра состояния активизировать контроль соответствующего сигнала DCLK и начать отсчитывать тактовые импульсы между посылкой команды и обнаружения первого перехода LOW-to-HIGH на этой линии DCLK — задержка записи может быть получена из этого перехода. После обнаружения задержки контроллер должен выдать команду прекращения подачи импульсов DCLK, чтобы перевести линии синхронизации шины данных в штатный режим функционирования. Данные из регистров состояния SLDRAM передаются пакетами по четыре с текущей задержкой чтения из устройства. После чтения данных из регистров состояния всех микросхем SLDRAM контроллер может их использовать для определения соответствующей задержки чтения, которая и будет запрограммирована в микросхемы. Для соблюдения правил соответствия параметры задержки первых приборов SLDRAM программируются с дополнительной задержкой, чтобы согласоваться по таймингам общей задержки с дальними микросхемами. Таким образом достигается согласование работы и ближних и дальних микросхем памяти.
Основные особенности интерфейса SYNCLINK
По причине улучшенной оптимизации для всевозможных конфигураций ОЗУ и интерфейса ввода/вывода SLDRAM был сделан ряд эволюционных изменений протокола RamLink, чтобы повысить эффективность, выделив одни положительные моменты, используемые в SyncLink. Модернизации SyncLink относительно RamLink включают:
- Нулевое состояние (No Status). Ответы SyncLink не включают абсолютно никакой информации о состоянии компонент системы. В особо жаростойких корпусах, где контроль состояния необходим, эта информация должна быть сохранена в микросхеме SLDRAM для последующего считывания через специальные регистры.
- Точное планирование (Exact Scheduling). Применяющийся в RamLink механизм, разрешающий преждевременный возврат ответа, устранен.
- Запрещение повтора (No Retry). Планирование SyncLink всегда точно, поэтому он не предусматривает никакого механизма или команды для микросхемы SLDRAM, чтобы запросить повторение, например, из-за неожиданного конфликта между циклом регенерации и доступом.
- Отсутствие заголовка ответа (No Response Header). Пакеты ответа проходят только когда намечено, поэтому им нет необходимости самоидентифицироваться по отношению к контроллеру. Пропускная способность остается неизменной, устраняя полностью заголовок и информацию о состоянии. Таким образом, ответы приходят только для чтения и содержат только данные.
- Отсутствие саморегенерации (No Self-Refresh). Чтобы планирование сделать полностью предсказуемым, устранена необходимость в повторе и максимально упрощена конструкция SyncLink. Саморегенерация не поддерживается в течение нормального режима функционирования, хотя данная фаза необходима во время перехода в режим низкого потребления энергии (STand-By).
- Компактные команды (Compact Commands). Чтобы повысить эффективность использования интерфейса SyncLink, заголовок пакета запроса RamLink сокращен до минимума, необходимого для выполнения приложений SLDRAM.
- Упрощенную модель устройства (Simplified Device Model). SyncLink DRAM не поддерживают внутренние запрос или ответ, а просто обходятся одним запросом и одним ответ на блок. Множественные блоки имеют те же самые тайминги чтения/записи, что и независимые SLDRAM устройства (микросхемы).
Система SLDRAM, имеющая "изолированную" конфигурацию с короткими длинами сигнальных линий и отличную помехозащищенность, может использовать шинные соединения намного эффективнее, чем прямой сигнальный интерфейс RingLink, основанный на схеме типа "точка-точка" (PtP — Point-to-Point) и применяемый в стандарте RamLink. Интерфейс SyncLink имеет меньше активных сигналов, меньше сигнальных линий и меньшую задержку передачи данных, чем структура RingLink. Назначение байт шины данных может быть арбитражно выбрано для выполнения доступа на чтение/запись из/в микросхемы памяти. Общий интерфейс шин команд и данных SLBus для удобства условно разделяет на приоритетные биты — более (MSB — Most Significant Bit) или менее (LSB — Less Significant Bit) важные, объединяемые в два аналогичных по условным приоритетам байта интерфейса dataLink. В общем, сигнальный интерфейс микросхемы памяти и шины SLBus абсолютно идентичен — разница только в используемом обозначении. Исключение составляет лишь не рассматриваемый ранее сигнал selectProm выбора идентификационного устройства — микросхемы ПЗУ, устанавливаемого на модуле SLM, — содержащего временные параметры, иначе, в случае отсутствия микросхемы PROM, определяемые в процессе настройки подсистемы SLDRAM по схеме, описываемой ранее.
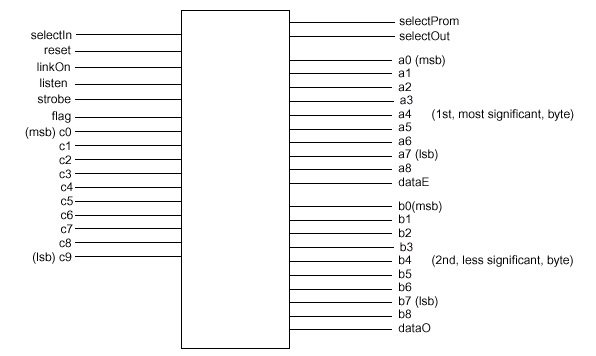
Приходящий основной задающий стробирующий сигнал strobe (дифференциальная группа CCLK/CCLK#) определяет границы бит данных, проходящих по командной шине, кроме чего, как уже отмечалось, используется как опорный синхронизирующий сигнал для синхрогруппы шины данных (dataE/dataO). Шины команд/адреса c[9:0] (аналог CA[9:0]) и данных a[8:0], b[8:0] (аналоги DQ[17:0]) функционируют на одной частоте, что контролируется компенсирующим верньерами относительно сигнала strobe. Транзакции по шине dataLink могут использовать двунаправленные синхросигналы dataE (дифференциальная группа DCLK0/DCLK0#) и dataO (дифференциальная группа DCLK1/DCLK1#) для точной передачи считываемых или записываемых данных.
Для определения точности настройки сигналов командной шины цепь задержки delayC должна будет выполнить фазу самонастройки при помощи самокалибровки или считать запрограммированные тайминги из соответствующих регистров, если их предусмотрел производитель микросхемы или модуля. Данные определения должны четко отработаться в порядке посылки команд к микросхемам памяти SLDRAM до момента начала процесса инициализации. CommandLink не так загружена, как шина данных, но для поддержания примерно одинаковой нагрузки на линии, шина команд/адреса буферизируется при помощи усилителей уровня, интегрирующихся непосредственно в чип памяти или использующихся в составе модуля в виде отдельной микросхемы. Задержка, вносимая данными буферами может быть разной для каждой микросхемы памяти, используемой в системе, поэтому для согласования по таймингам применяется схема сравнения по тикам, требующая выполнения фазы компенсации. Все сигналы командной шины, включая сигнал стробирования, должны быть по возможности идентично настроены с минимальным перекосом. Более сложные буферизирующие элементы могут изменять временные параметры для смещения фазы сигнала, если это необходимо в сложных системах, использующих сложную иерархию построения подсистемы памяти.
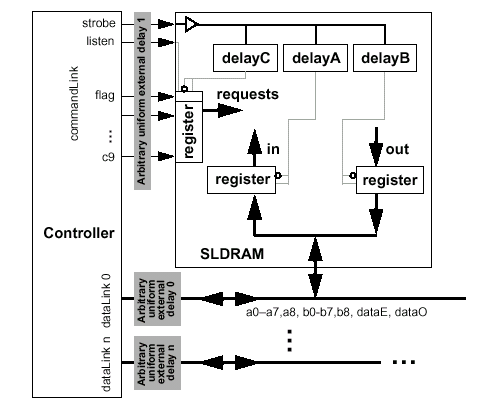
Для поддержания точности синхронизации на шине данных микросхема памяти имеет специальные цепи задержки (delayA и delayB), которые отвечают за "выравнивание" данных на входе и выходе микросхемы памяти. Эти задержки компенсируют разницу, вводимую для буферизируемых стробов, между маршрутами прохождения сигнала по адресной шине и шине данных. Значение задержки delayA устанавливается таким, чтобы обеспечить стабильность входных сигналов, когда их значения начинают "плавать". Значение delayB компенсирует задержки, возникающие на выходных регистрах, чтобы все сигналы поступали на выход одновременно. В момент включения питания внутренние цепи обратной связи микросхемы памяти настраивают задержку delayB таким образом, чтобы выходные сигналы синхронизировались со стробом, однако в течение нормального функционирования цепи обратной связи неактивны и значение delayB администрируется непосредственно контроллером. Контроллер в свою очередь заблаговременно посылает или прямые команды установки соответствующего временного параметра или команды события (EVENT), чтобы увеличить или уменьшить выходные тайминги микросхемы маленькими шагами, таким образом выравнивая временное смещение (перекос, Skew) на выходе микросхемы. Диапазон таких подстроек лежит как минимум в интервале ±1 тик, а длительность шага подстройки должна составлять приблизительно 1/16 тика (точная подстройка). Грубая подстройка может использоваться лишь как коррекция целым тиком (Integer-Tick Corrections).
Шина SLDRAM соединяет один контроллер памяти и до восьми нагрузок — в данном случае одна нагрузка подразумевает одну микросхему памяти или один буферизированный модуль. Модуль, содержащий две и более микросхемы памяти, должен быть буферизированным. Таким образом, в пределах стандартной конфигурации можно объединить максимум до 64 микросхем памяти в одном канале. Намного более сложные схемы позволяют объединять 128 и 256 запоминающих устройств при использовании 2 или 4 шин данных (а, следовательно — 2 или 4 контроллера) соответственно.
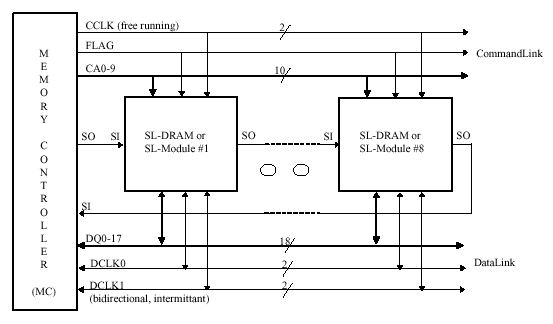
Протокол шины SLDRAM позволяет адресовать иерархическую подсистему памяти, позволяющую объединять гораздо больше микросхем памяти, чем стандартный интерфейс SyncLink. Буферизируемые модули позволяют создавать очень "глубокие" и "широкие" конфигурации, основанные на небуферизированном интерфейсе. Интересной особенностью является 100% совместимость буферизированных и небуферизированных модулей, что является подтверждением скрупулезно рассчитанной топологии, нагрузочных и временных характеристик, и уникальности всей системы в целом. В последовательности инициализации и синхронизации обязательно учитываются дополнительные задержки, вносимые буферами.
Буферизация командной шины (Buffered CommandLink) позволяет создавать "широкие" модули памяти с множественными шинами данных, что дает возможность получить гораздо большую пропускную способность (теоретически она должна возрастать кратно числу используемых шин данных, читай — каналов), чем при стандартной конфигурации.
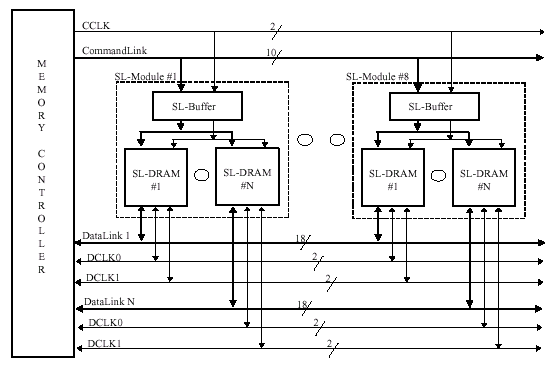
При использовании совместного буферизирования (Buffered CommandLink and DataLink) предоставляется возможность в рамках "единичного" SLDRAM интерфейса адресовать значительно более "глубокую" конфигурацию, нежели при использовании только буферизированной шины команд. Так, буфера шины команд и данных могут совмещаться в одном чипе, что позволяет обходиться без внешних буферизирующих элементов при производстве модулей памяти.
Для более высокой производительности используются многократные связи, чтобы улучшить результирующую пропускную способность (для "широких" передач), значительно уменьшить среднюю задержку (для небольших чередующихся передач) и улучшить надежность системы. Концепция надежных систем предусматривает сохранение избыточных копий данных так, чтобы сами данные могли быть быстро и точно восстановлены после возможных сбоев или выхода из строя массива ДОЗУ. Стандартные RAID-подобные методы, используемые в объединении дисковых массивов для создания быстрых и надежных конфигураций, могут применяться и к подсистеме памяти. Например, контроллер памяти может поддерживать пять матриц: четыре используются для сохранения чередующихся копий данных, а пятая — для сохранения копии контроля четности. Схемы движения в таких системах очень интенсивны, чтобы их можно было предсказать, но в качестве примера рассмотрим образец доступа типа "процессор-память".
Кэшируемый процессор формирует доступы к строкам кэша, которые, как предполагается, являются 64-байтными. Используя кэш с обратной записью (Write-Back), фаза чтения выполняется приблизительно в три раза больше, чем фаза записи. Все транзакции кэшируются в строку данных (те же 64 байта) — именно для таких случаев (модель первичной важности) и оптимизирована конструкция SyncLink.
Некэшируемый процессор генерирует доступы слова (4 или 8 байт) с частотой отработки циклов чтения приблизительно в три раза большей, чем циклов записи — эта модель трафика памяти является моделью вторичной важности по оптимизации конструкции SyncLink. Короткие записи в SyncLink включают в себя чтение пакета, модифицируя записанные части данных и записывая пакеты обратно. Данная схема оптимальна для самых простых запоминающих систем, кроме чего существенно упрощает и ускоряет контроль и доступ к памяти.
Важным моментом в конструкции SLDRAM является планируемый параллелизм (Scheduling Parallelism) — микросхема SLDRAM может иметь множественные суб-ОЗУ (sub-RAM) или блоки (Block). Если не принимать во внимание инициализацию, то действие блоков, по существу, подобно независимым ОЗУ. Блоки SyncLink не ожидают поступления основных множественных очередей запросов, как было принято для RamLink, но ожидают пока обработается по крайней мере один запрос.
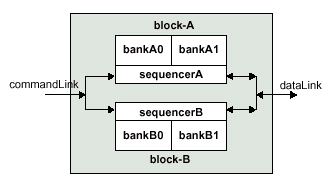
Стандартно банки содержат строки (Row), которые, в свою очередь, содержат столбцы (Column). Строка — это объем считываемых или записываемых данных в один из нескольких логических банков микросхемы. Столбцы — это подмножества строк, которые считываются или записываются в индивидуальных фазах операции чтения/записи, предусматриваемых интерфейсом самого чипа. Как уже говорилось ранее, типичная передача данных в SyncLink "связывает" четыре 16-разрядных столбца для того, чтобы создать пакет данных. Доступ к столбцам в пределах той же самой строки быстрее чем доступ к другой строке (произвольный или случайный доступ), что экономит время доступа, требуемое, чтобы доставить строку данных от конкретных ячеек ядра памяти.
Множественные банки в пределах каждой суб-ОЗУ могут обеспечивать дополнительный уровень параллелизма. При наличии множественных банков, данные могут многократно использоваться, что увеличивает производительность. Наконец, необходимо, чтобы банк соответствовал строке, которую можно держать в постоянной готовности для совместного доступа; суб-матрица соответствовала одному или большему количеству банков, совместно использующих один тайминговый контроллер, который может исполнять только одну операцию за раз; ОЗУ соответствовала нескольким суб-ОЗУ, которые могут иметь не только совместный доступ, но и которые также совместно используют общую инициализацию и средства адресации. Важно также отметить, что отдельная микросхема памяти SLDRAM для эффективного использования архитектуры и нормального функционирования должна иметь как минимум 16 независимых логических банков.
Поскольку интерфейс SLBus использует две разделенные шины общего доступа, то в сравнении с RamRing (интерфейс RamLink) число выводов уменьшилось. Обратной стороной медали является более низкая расширяемость, плюс реализация высокоскоростной шины возможна лишь в случае точно рассчитанной для конкретной топологии длинны сигнальных трасс и наличие относительно коротких выводов у самой микросхемы памяти — последствия функционирования подсистемы на очень высокой частоте. Использование коммуникаций с разделенными шинами (Shared-Link Communication) применяется для того, чтобы добиться высокой скорости передачи данных между контроллером и подчиненным устройством (Memory Slave — микросхема памяти на инженерном жаргоне). Топология базовой конфигурации подсистемы памяти, базирующейся на SyncLink, состоит из контроллера и до 64 подчиненных устройств.
Использование только одного контроллера для каждой подсистемы SyncLink (используется схема масштабирования "один контроллер на один канал", до четырех каналов максимум) значительно упрощает протоколы инициализации и арбитража. Ограничение в 64 микросхемы памяти на канал упрощает кодирование пакетов, потому как адресация SLDRAM или назначение slaveId (уникального номера, ID) может содержаться в первом байте каждого пакета, и часть 7-разрядного поля slaveId используется для упоминавшейся ранее мультикастовой адресации. На практике же используется ограничение по нагрузке, которое в значительной степени увеличивает используемый размер конфигурации. Адреса slaveId делятся на четыре группы: 0-63 — динамически назначаемые идентификаторы, 63 — назначение первоначального идентификатора, 64-126 — идентификаторы мультикаста и 127 — адрес псевдослучайной синхронной последовательности (шаблона). Микросхемы, входящие в мультикаст (расширение сверх 64 микросхем памяти), кроме базового идентификатора (Multicast ID) обязательно содержат суб-идентификатор (Multicast Sub-ID). Подсистемы, содержащие более 128 микросхем SLDRAM (до 256) имеют очень сложную схему адресации и логику распределения уникальных ID с применением механизма ретрансляции (Broadcast).
Существует несколько всевозможных схем построения системы памяти SLDRAM. Передача данных в этих конфигурациях требует выбора одной микросхемы памяти, а остальные требуют одновременного выбора специфического режима параллельных предустановок. Традиционно микросхемы синхронного ДОЗУ адресуются каждая самостоятельно, однако в этом случае корректное управление при использовании высокоскоростного протокола весьма проблематично. SyncLink же использует кодирование посылок выбора кристалла (CS — Chip Select) для всех микросхем по командной шине, что позволяет обходить эти проблемы.
Для поддержки "разношироких" соединений и варьирования "глубины" конфигураций используется логика сравнения адреса (Address-Compare Logic), выполняющая фазы выбора микросхемы. Данная логика поддерживает все разнообразие мультикастовой адресации (x2, x4, ...) и возможность адресной пересылки (ретрансляции). Декодирование мультикастовых slaveId адресов является более простой и гибкой схемой, чем использование стандартных отдельных сигналов выбора кристалла (CS#), использующихся в нынешних синхронных ДОЗУ. Кроме того, контролирование относительного смещения сигналов выбора кристалла и командных сигналов не применяется в ДОЗУ с большой частотой синхронизации.
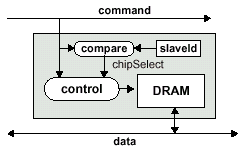
Так, кодирование адресов простой конфигурации ограничивается 64 микросхемами памяти. Значения 0-63 используются для адресации индивидуальных микросхем, а значения 64-127 (для конфигураций до 128 микросхем) специфичны для мультакастовых адресов. Логика сравнения и декодирования уникального номера (slaveId Comparision Logic) адресов выглядит следующим образом:
- Каждый из последующих 64 мультикастовых адресов определяют x2 мультикастовый адрес, где значения slaveId {0,1} назначают доступ к микросхеме, использующей мультикастовый адрес 64; {2,3} — доступ к микросхеме, использующей мультикастовый адрес 66; {4,5} — доступ к микросхеме, использующей мультикастовый адрес 68, и т.д.
- Оставшиеся 32 мультикастовых адреса определяют x4 мультикастовый адрес, где значения slaveId {0,1,2,3} назначают доступ к микросхеме, использующей мультикастовый адрес 65; {4,5,6,7} — доступ к микросхеме, использующей мультикастовый адрес 69; {8,9,10,11} — доступ к микросхеме, использующей мультикастовый адрес 73, и т.д.
- Оставшиеся 16 мультикастовых адреса определяют x8 мультикастовый адрес, где значения slaveId {0,1,…,6,7} назначают доступ к микросхеме, использующей мультикастовый адрес 67; {8,9,…,14,15} — доступ к микросхеме, использующей мультикастовый адрес 75; {16,17,...,22,23} — доступ к микросхеме, использующей мультикастовый адрес 83, и т.д.
- Оставшиеся 8 мультикастовых адреса определяют x16 мультикастовый адрес, где значения slaveId {0,1,...,14,15} назначают доступ к микросхеме, использующей мультикастовый адрес 71; {16,17,...,30,31} — доступ к микросхеме, использующей мультикастовый адрес 87; {32,33,...,46,47} — доступ к микросхеме, использующей мультикастовый адрес 103, и т.д.
Оставшиеся адреса 95 и 127 пересылаются и кодируются прямо, но из них для адресации используется только 95, поскольку адрес 127 применяется в псевдослучайном синхронном шаблоне для генерации модели согласования.
| Логика назначения мультикастовых slaveId адресов | |||||||
| SlaveId | "диапазон" | SlaveId | "диапазон" | SlaveId | "диапазон" | SlaveId | "диапазон" |
| 64 | 0-1 | 80 | 16-17 | 96 | 32-33 | 112 | 48-49 |
| 65 | 0-2 | 81 | 16-19 | 97 | 32-35 | 113 | 48-51 |
| 66 | 2-3 | 82 | 18-19 | 98 | 34-35 | 114 | 50-51 |
| 67 | 0-7 | 83 | 16-23 | 99 | 32-39 | 115 | 48-55 |
| 68 | 4-5 | 84 | 20-21 | 100 | 36-37 | 116 | 52-53 |
| 69 | 4-7 | 85 | 20-23 | 101 | 36-39 | 117 | 52-55 |
| 70 | 6-7 | 86 | 22-23 | 102 | 38-39 | 118 | 54-55 |
| 71 | 0-15 | 87 | 16-31 | 103 | 32-47 | 119 | 48-63 |
| 72 | 8-9 | 88 | 24-25 | 104 | 40-41 | 120 | 56-57 |
| 73 | 8-11 | 89 | 24-27 | 105 | 40-43 | 121 | 56-59 |
| 74 | 10-11 | 90 | 26-27 | 106 | 42-43 | 122 | 58-59 |
| 75 | 8-15 | 91 | 24-31 | 107 | 40-47 | 123 | 56-63 |
| 76 | 12-13 | 92 | 28-29 | 108 | 44-45 | 124 | 60-61 |
| 77 | 12-15 | 93 | 28-31 | 109 | 44-47 | 125 | 60-63 |
| 78 | 14-15 | 94 | 30-31 | 110 | 46-47 | 126 | 62-63 |
| 79 | 0-31 | 95 | 0-63 | 111 | 32-63 | 127 | 0-63 |
Архитектура SyncLink позволяет микшировать (использовать совместно в одной подсистеме) 16-бит и 18-бит микросхемы памяти, создавая гибкие конфигурации. Кроме того, 18-разрядные микросхемы можно использовать при наличии 16-разрядного контроллера, при чем дополнительные 2 бита будут просто логически «обрезаны».
Некоторые конфигурации разрабатываются для обеспечения механизма исправления ошибок, чтобы можно было корректировать ошибку в одном разряде или временные ошибки (Soft Errors приводят обычно к однократному изменению информации, однако чаще всего повторно данные записываются в ту же ячейку уже без ошибок) и постоянные ошибки (Hard Errors вызываются неисправностью самих микросхем памяти и зачастую приводят к потере информации в целом столбце или даже во всей микросхеме). Интерфейс SyncLink поддерживает на уровне контроллера памяти выполнение коррекции ошибок (ECC — Error-Correction Circuitry). Системы, не использующие механизм коррекции ошибок (Nonexistent ECC), являются более эффективными в плане производительности, но не в плане надежности.
Контроллер, поддерживающий ЕСС, читает пакеты, состоящие из нескольких 72-разрядных (4x18 бит) слов. Для небольших транзакций записи контроллер формирует транзакцию пакета чтения, вставляет модифицированные данные и регенерирует ЕСС, после чего уже формирует пакет записи. Также для ЕСС может использоваться 16-бит шина для планирования дополнительных бит и помощи в размещении дополнительных блоков в неиспользуемой части DRAM — в общем, выступать некоего рода "шаблоном". Используя ЕСС на широких блоках, типа 64-байтных кэшируемых линий, можно добиться значительной эффективности в ряде приложений. Так, микросхемы памяти ECC SLDRAM, которые обнаружат ошибку, заносят ошибочный бит (Fatal-Error Bit) в собственный специальный регистр, данные из которого будут считаны контроллером, когда управляющее устройство выполнит программу проверки количества "сбойных" бит.
Механизм проверки ошибок SyncLink позволяет контроллеру выполнять простую схему обнаружения ошибки байта четности (Byte-Parity Error-Detection Circuitry, EDC), используя аналогичный транспортный протокол, описываемый ранее. Протокол обнаружения ошибок является менее эффективным для небольших (менее, чем 8 байт) передач, кроме того ошибки в двух разрядах не определяются, а ошибки в одном разряде не могут быть исправлены.
Адресное пространство SyncLink делится на 64 узла — каждый со своим арбитражным пространством. Термин "узел" используется для описания SLDRAM, как контекст CSR-архитектуры. Узел ассоциируется со специфическими установками адресов контрольных регистров, включая идентификационное ПЗУ (ROM). В режиме нормального функционирования каждый узел может быть независимо доступен — модификация контрольного регистра одного узла происходит безо всяких воздействий на контрольный регистр другого узла.
Формат пакета данных позволяет добавлять адресные байты для неопределенного расширения, однако, учитывая 10-разрядную управляющую шину и 3 бита поля суб-команд, действительный размер адреса составляет 27, 37, 47,... бит. Выравнивание этих бит происходит по схеме "Left Justified", т.е. какое количество бит информации потребует микросхема памяти, начиная со старшего бита адресного поля во втором "байте" командного пакета. С момента, когда установка команды не требует байтовой адресации на уровне SLDRAM, микросхема памяти сама выбирает адрес, как точку действительного размера пакета наименьшей длины (BL=4) — таким образом, минимальный пакет выравнивает данные кратно своей собственной длине. Более длинные пакеты также могут выравнивать данные: пакеты двойной длительности минимального пакета (BL=8) должны иметь "0" значение менее важного бита адреса, а пакеты четырехкратной длины минимального пакета (BL=16) должны иметь нулевое значение двух менее важных бит адреса — это необходимо вводить с целью упрощения внутренней логики подчиненного устройства.
SyncLink использует транзакции с расщеплением данных (Split-Data Transactions), поскольку пакет чтения данных не возвращается немедленно, или не требуется немедленная запись данных. Другие (возможно, несвязанные) команды могут передаваться по шине команд (или данные по шине данных) пока конкретная микросхема памяти обрабатывает запрос. Тайминг потока данных, связанный с соответствующими пакетом запроса на шине команд, устанавливается во время процесса инициализации. Синхронизация приборов памяти в случае использования микросхем с различной частотой функционирования происходит согласно значений таймингов самого низкоскоростного устройства. Для того, чтобы установить эти параметры в микросхеме во время инициализации, контроллер использует заранее подготовленную команду для записи соответствующих значений в регистры управления.
Очень компактная (7 бит) команда события используется для обновления параметров синхронизации и управления определенными режимами функционирования. Для выполнения фазы чтения или загрузки задержка между командой и ответом микросхемы памяти устанавливается исходя из состояния соответствующего регистра управления. Для записей данных задержка между выдачей команды и моментом, когда микросхема начнет принимать данные (задержка отклика, Latency), устанавливается также исходя из состояния соответствующего регистра управления. В общем, транзакции SyncLink разделены на несколько групп.
- Транзакции чтения (Read Transactions), используемые для считывания пакета данных, расщепляются на две компоненты, являющимися пакетами запроса и ответа. Пакет запроса на чтение передает команду и адрес от контроллера к микросхеме памяти. Пакет данных возвращается через фиксированный интервал (tRC — Open Row to Open Row command period in Read в пределах одного логического банка), который устанавливается в процессе инициализации и является суммой задержек доступа к строке и доступа к столбцу в фазе выполнения операции записи, плюс цикл перезарядки строки (tRC=tRCD+tCAC+tRP) банка микросхемы памяти. Для обеспечения "портированности" параметров, используя схему GtG, значение этой задержки может быть установлено (более точно, чем номинальная) с запасом, учитывая значение, хранящееся в соответствующем регистре управления конкретной микросхемы. Чтение в определенный момент времени может осуществляться только из одной микросхемы памяти, а в пределах мультикаста — из нескольких (при использовании нескольких шин данных из одной микросхемы на каждой шине).
- Транзакции загрузки (Load Transactions) подобны транзакциям чтения, однако используют специальную адресацию для получения информации конкретно про каждый прибор памяти. Задержка для загрузки данных устанавливается как tRC. Загрузка в определенный момент времени может осуществляться только в одну микросхему памяти, а в пределах мультикаста — в несколько.
- Транзакции записи (Write Transactions). Пакет запроса на запись передает команду и адрес от контроллера к микросхеме памяти, а затем, после четко установленной задержки, передаются на запись в микросхему и сами данные. При этом никаких пакетов ответа на подтверждение записи данных не возвращается (No Acknowledge). Запись в определенный момент времени может осуществляться только в одну микросхему памяти, в пределах мультикаста — в подчиненную, а при использовании ретрансляции — во все. Так, микросхема памяти принимает данные, передаваемые контроллером, после задержки (tWC — Open Row to Open Row command period in Write в пределах одного логического банка), которая устанавливается в процедуре инициализации и представляет собой сумму задержек доступа к строке и доступа к столбцу в фазе выполнения операции записи, плюс цикл перезарядки строки банка микросхемы SLDRAM. Для улучшения эффективности планирования ожидается, что записываемые данные задержатся, чтобы попасть в тот же временной слот на шине данных, который будет использоваться при чтении данных с тем же адресом. Если предыдущая операция не выполнила запись строки, которую ожидалось записать (необходимая строка открыта), тайминги передачи остаются неизмененными, а потребляемая мощность микросхемы может быть уменьшена.
- Транзакции события (Event Transactions) подобны транзакциям записи, но используемый адрес сокращается и шина данных не используется. Транзакция события передает 7 бит (такой маленький размер поля объясняется спецификой применения с целью специального управления, типа синхронизация и операции регенерации) кодированной информации управления от контроллера памяти к микросхеме(ам).
- Резервные транзакции (Store Transactions) подобны транзакциям события, однако содержат данные, которые посылаются по командной шине для записи и хранения их в регистрах управления микросхемы. Данные транзакции используются в процессе текущей инициализации микросхемы для установки значений параметров функционирования, которые требуются для согласования с контроллером и другими микросхемами.
В фазе планирования ответов (Response Scheduling) контроллер отвечает за формирование таймингов в соответствии с пакетами запроса и планирование передачи считываемых и записываемых данных для устранения конфликтных ситуаций при передаче различных команд и данных. Изначально контроллер ожидает, что необходимые для инициализации и синхронизации данные запрограммированы в используемых устройствах — в некоторых конфигурациях модули памяти могут содержать ППЗУ (PROM) с уже прошитыми необходимыми параметрами.
Потенциальное количество "сквозных" транзакций (пакет запроса послан, однако ответа не последовало) довольно большое, поэтому контроллер проектируется с наименьшей сложностью, чтобы ограничить количество разрешенных "сквозных" транзакций до минимума — обычно до четырех.
Для обеспечения управляющего устройства эффективным алгоритмом планирования регенеративно-зависимые микросхемы памяти должны поддерживать механизм авторегенерации, подразумевающая адресацию, при которой содержимое ячеек памяти микросхемы автоматически обновляется и не зависит от тайминговых установок по выполнению программы регенерации, устанавливаемых контроллером. Используя схему совместимости со схемой авторегенерации, контроллер может абсолютно точно предугадывать время ответа конкретной микросхемы памяти и планировать момент начала выполнения текущей программы авторегенерации в периоды простоя. Точно выбранные специфические периоды ответа упрощают диагностику системы, после чего последовательности запросов доступа возобновляются. Кроме этого, точное планирование позволяет синхронизировать RAID-подобные массивы или обработку элементов массива в векторообрабатывающих приложениях.
Топология, транзакции и формат команды
Команды, адреса и контрольная информация (запись данных в регистры управления) посылается от контроллера к микросхемам памяти через однонаправленный командный интерфейс CommandLink, включающий шины команд/адреса (CA[9:0]), флага (FLAG) и дифференциальной синхропары (CCLK/CCLK#). Чтение и запись данных производится через двунаправленную шину DataLink, включающую линии данных (DQ[17:0]) и две дифференциальные синхропары данных (DCLK0/DCLK0# и DCLK1/DCLK1#). Шины команд и данных синхронизированы одной частотой и имеют параллельную схему включения относительно микросхем памяти.
Кроме вышеуказанных сигналов, командный интерфейс содержит низкоскоростные линии LISTEN, LINKON и RESET#. Команды состоят из четырех последовательных 10-разрядных слов (линия CA[9:0]). Первое слово команды указывается высоким уровнем на линии FLAG. Для "защелкивания" командных слов прибором SLDRAM используются оба фронта дифференциальной синхропары CCLK/CCLK#. Во время пребывания линии LISTEN в высоком состоянии микросхемы SLDRAM следят за поступающими командами по CommandLink. Когда LISTEN переходит в низкое состояние, командная шина "закрывается" и микросхемы переходят в режим экономии энергии (STBY). Выход микросхем из этого состояния возможен только по прошествии двух тактовых интервалов с момента подачи на трассу LISTEN высокого уровня. Когда LINKON переходит в низкое состояние, микросхемы памяти входят в фазу деактивации, где формирование сигналов по линиям CCLK может быть полностью отключено для полного сброса питания (ZPW — Zero PoWer) на шине. По команде RESET# микросхемы памяти активируют все цепи в рамках программы восстановления активности (PWUP — PoWer-UP).
Шина данных передает и принимает 16/18-разрядные слова пакетами по четыре, обязательно каждый сопровождающийся одной из дифференциальной пары DCLK0/DCLK0# или DCLK1/DCLK1#, сдвинутых друг относительно друга на 13N интервалов (тиков), длительность которых обратно пропорциональна удвоенной частоте следования синхросигналов. Две установочные пары DCLK применяются для контроля фаз приема/передачи по шине данных от одного устройства к другому с минимальными задержками.
| Интерфейс шины SLDRAM | ||||
| Шина | Сигнал | Назначение | Маршрутизация | Протокол |
| CommandLink | CCLK/CCLK# | Командный синхросигнал | MC=>SLDRAM | SLIO |
| CA[9:0] | Шина команд и адреса | MC=>SLDRAM | SLIO | |
| LISTEN | Режим экономии | MC=>SLDRAM | LVCMOS | |
| LINKON | Режим деактивации | MC=>SLDRAM | LVCMOS | |
| RESET# | Жесткий сброс | MC=>SLDRAM | LVCMOS | |
| DataLink | DCLK0/DCLK0# | Синхросигнал данных 0 | MC<=>SLDRAM | SLIO |
| DCLK1/DCLK1# | Синхросигнал данных 1 | MC<=>SLDRAM | SLIO | |
| DQ[17:0] | Шина данных | MC<=>SLDRAM | SLIO | |
| Serial | SI | Последовательный вход | MC=>SLDRAM SLDRAM=>SLDRAM | LVCMOS |
| SO | Последовательный выход | SLDRAM=>SLDRAM SLDRAM=>MC | LVCMOS | |
Последовательная шина инициализации цепочечной структуры интерфейса SLBus соединяется со входом SI и выходом SO в каждой микросхеме памяти и используется на стадии PWUP для коммуникации микросхем SLDRAM и выполнения фазы назначения уникальных собственных идентификаторов. Конфигурация "сквозной" последовательной SI/SO-цепочки (selectIn/selectOut Daisy Chain) в случае использования модульного расширения соединяет микросхемы собственной внутренней последовательной цепью, обеспечивая «сквозной» электрический интерфейс всех микросхем в составе модуля с внешней последовательной цепью. Частично расширяемая модульная система (некоторые разъемы SLMC могут быть пустыми) должна включать в цепь каждого разъема 1kW согласующий резистор, который является мостом последовательной цепочки — если разъем не заполнен, то в цепи разрыва не произойдет и система будет функционировать (в системах на базе Direct Rambus DRAM, например, для решения подобного рода проблемы разрыва шинной структуры используются специальные продолжители канала — D-RIMM-CONT, — представляющие собой печатную плату, не содержащую активных компонентов и обеспечивающую непрерывность сигнальных линий). Сигнал последовательного входа/выхода является низкоскоростным LVTTL-сигналом, контролируемый приемником с высоким входным сопротивлением, находящимся в контроллере или в следующей микросхеме SLDRAM. Поэтому 1 кОМ — это минимально необходимое сопротивление для прохождения сигнала, не приводящего к проблемам с рассеиванием мощности в короткие периоды, когда сигналы на двух выводах различаются если модуль установлен.
Особый интерес представляют конвейеризированные транзакции, отражающиеся на временной диаграмме ниже, где демонстрируются отработки серии команд чтения (Page Read) и записи (Page Write) из/в страницу памяти на выходе контроллера. С целью наглядности иллюстрирования все длины пакетов составляют длительность 4N (4 тика), несмотря на то, что основные пакеты 4N и 8N могут быть динамически смешаны. Более длинные пакеты могут быть получены путем "сцепления" 4N и/или 8N пакетов. Время доступа для чтения (tA(R) — Read Access Time) открытого банка, известное как задержка для чтения страницы (Page Read Latency), определяется интервалом длительностью 12 тиков (12N). Первые две команды являются командами чтения из страницы различных банков первой микросхемы памяти — SLDRAM#0. Считанные данные появляются на шине данных по приходу фронта DCLK0. До тех пор, пока первые две команды чтения из страницы предназначаются для одной и той же микросхемы памяти SLDRAM, нет необходимости для введения промежутка между двумя 4N-пакетами данных. При этом микросхема "самогарантирует", что DCLK0 будет управлять ею постоянно безо всяких перерывов и сбоев.
Пакет данных для последующего чтения страницы из страницы SLDRAM#1 должен быть разделен интервалом 2N для стабилизации состояния шины данных (период обращения шины, Bus Turnaround) и резервирования неопределенных таймингов между SLDRAM#0 и SLDRAM#1. Интервал 2N (или "правило 2N") требуется в любых операциях, производящихся по шине данных от одного устройства к другому, таких как чтения из различных микросхем SLDRAM или переходы "чтение-запись" и "запись-чтение" между приборами памяти и контроллером. Контроллер генерирует интервал 2N на шине данных, управляя формированием и передачей команд. Данные для команды Read1 сопровождаются стробом DCLK1, позволяя SLDRAM#1 начать управление линиями DCLK, передавая текущие пакеты данных.
Следующей командой является команда записи, использующая DCLK0 для стробирования записываемых данных в SLDRAM#2. Задержка для записи данных в страницу (Page Write Latency) программируется аналогично задержке для чтения из страницы. В порядке отработки 2N-промежутка между операциями Read1 и Write2 на шине данных команда Write2 должна быть задержана на 4 тика после прохождения команды Read1. Программируемая задержка записи в этом случае формируется как 4N-командный слот на шине команд, который может быть использован для команд, ориентированных не для данных (Non-Data Commands) — типа "строка открыта" или "строка закрыта", "запись в регистр" или "регенерация содержимого регистра", — без утилизации шины данных. Последующая команда чтения для SLDRAM#3 не требует никаких дополнительных задержек, чтобы выполнить "программу 2N".
Завершающий пакет этих трех последовательных команд записи показывает, что интервал 2N между пакетами данных не требуется когда происходит запись в различные микросхемы памяти SLDRAM. При этом должны использоваться все четыре копии DCLK, поскольку каждая микросхема памяти может устанавливать момент начала собственных пакетов записи. С этого момента все данные, которые требуется записать, начинают поступать из контроллера памяти без каких либо задержек или прерываний сигналов на линиях DCLK.
По окончании процедуры текущего контроля DataLink от одного устройства к другому шина остается в высокоимпедансном (третьем) состоянии (Hi-Z, соответствующее уровню опорного напряжения — средней точке) номинальный установленный интервал 2N. Это может являться результатом временной неопределенности текущего логического уровня и возможности возникновения множественных переходов у входных буферов, что допустимо для линий данных, но неприемлимо для синхропар данных, которые используются для постоянного стробирования. Для решения этой проблемы пары DCLK имеют 00010 преамбулу до переходящей ассоциации с первыми битами данных. Входной буфер приемника DCLK активизируется в течение первого 000 периода и сигнализирует о готовности принимать данные. "Пустой" переход 10 включается в преамбулу с целью компенсации временного перекоса длительности фронта сигнала DCLK. Принимающая микросхема памяти проигнорирует полностью первый тактовый интервал DCLK и начнет стробирование данных лишь по второму положительному перепаду. Два строба подряд обеспечивают промежуток в течение которого могут поступить 4N-пакета записи к различным приборам SLDRAM и отправиться 4N-пакета чтения от различных микросхем памяти. В каждом командном пакете контроллер указывает какую конкретно копию DCLK необходимо использовать.
Контроллер синхронизирует фронты синхропары CCLK с фронтами сигналов по шине команд CA[9:0] и флага FLAG. Фронты синхропар данных синхронизированы с фронтами сигналов по шине данных DQ[17:0]. Приборы SLDRAM вносят частичную задержку между приходящими CCLK и DCLK для выставления команды и записи данных за оптимальное время. Микросхема памяти программируется контроллером для внесения частичной задержки в пары DCLK, позволяя управляющему устройству читать данные с входных регистров, используя эталонный DCLK без необходимости регулировки любой внутренней задержки.
Интереснейшим моментом является процедура установки тайминга. Контроллер программирует каждый прибор SLDRAM четырьмя тайминговыми параметрами: к упоминавшимся ранее задержке для записи в страницу и задержке для чтения из страницы добавляются еще задержка чтения из банка (Bank Read Latency) и задержка записи в банк (Bank Write Latency). Понятие "задержка" (Latency) в данном случае определяется как промежуток времени между пакетом команды и началом ассоциируемого с командой пакета данных. Для согласованного функционирования подсистемы памяти рекомендуется программировать каждую микросхему SLDRAM таким образом, чтобы получать равные значения для четырех различных задержек, начиная от выводов контроллера SLC. Возникновение различных значений задержки Round-Trip (tRT — промежуток времени на от начала передачи пакета данных до момента получения подтверждения приема устройством) на шине у микросхем памяти, расположенных на различных участках шины, а также присутствие или отсутствие буферизирующих элементов и варьирование параметров различных приборов SLDRAM, может в значительной степени различать программируемые параметры для каждой микросхемы. При выполнении программы восстановления активности (постинициализация), регистры, хранящие параметры задержек (SLDRAM Latency Registers), устанавливают минимальные значения, предусмотренные программой предустановки производителя (внутренний блок хранения параметров, или внешние микросхемы SPD, или PROM). Контроллер может "наблюдать" за откликами каждой микросхемы SLDRAM и затем делать соответствующую регулировку для выполнения последующей операции.
Так, задержка чтения (Read Latency) регулируется грубыми приращениями длительности тика и точными приращениями дробных значений длительности тика. Контроллер моментально запрограммирует грубые и точные значения задержки чтения для каждой микросхемы памяти, учитывая электрическую разницу дистанций между ними, как только пакеты чтения вернутся обратно к управляющему устройству с одинаковой задержкой от момента начала поступления пакета команды. Задержка записи (Write Latency) настраивается только грубыми приращениями и ее значение определится сразу после того, как конкретная микросхема начнет поиски синхросигнала DCLK для стробирования записи данных.
Теперь рассмотрим на примере упоминавшейся ранее микросхемы SLD4M18DR400 с внутренней организацией 8x{1024х128x72} пакет команды, представляющий собой четыре 10-разрядных слова. Так, пакет команд содержит 40 бит информации, в пределах которой должны определяться приборы различной организации и емкости. Структура пакета представляет собой 3 бита адреса банка (BNK[2:0]), 10 бит адреса строки (ROW[9:0]) и 7 бит адреса столбца (COL[6:0]). Сразу после включения питания контроллер памяти выполняет "сквозной прострел" (Pool, пул) приборов SLDRAM с целью определения организации каждой микросхемы (количество банков, строк и столбцов). После этого контроллер уже может включать в пакет команды, предназначенный для конкретной микросхемы памяти, соответствующее количество адресных бит, определенное пулом.
| Формат пакета команды 64Mb SLD4M18DR400 8x{1024x128x72} | ||||||||||
| FLAG | CA9 | CA8 | CA7 | CA6 | CA5 | CA4 | CA3 | CA2 | CA1 | CA0 |
| 1 | ID8 | ID7 | ID6 | ID5 | ID4 | ID3 | ID2 | ID1 | ID0 | CMD5 |
| 0 | CMD4 | CMD3 | CMD2 | CMD1 | CMD0 | BNK2 | BNK1 | BNK0 | ROW9 | ROW8 |
| 0 | ROW7 | ROW6 | ROW7 | ROW4 | ROW3 | ROW2 | ROW1 | ROW0 | 0 | 0 |
| 0 | 0 | 0 | 0 | COL6 | COL5 | COL4 | COL3 | COL2 | COL1 | COL0 |
Первое слово пакета команд содержит биты идентификации микросхемы (Chip ID Bits), так что если любая проходящая команда содержит не тот локальный ID, микросхема ее просто проигнорирует. Как уже говорилось, идентификационный номер назначается непосредственно контроллером в момент подачи питания, используя пару SI/SO — это позволяет использовать "сквозные" транзакции без необходимости в дополнительной логике или индивидуальных командных сигналов для конкретного прибора памяти. Первые 8bit идентификатора позволяют адресовать до 256 (максимум) микросхем SLDRAM на одной иерархической шине данных (Hierarchical DataLink). Бит 9 поля идентификатора используется для мультикаста, который позволяет адресовать одной командой любые группы микросхем по 2, 4, 8, 16, 32, 64, 128 или все 256 приборов — это полезно для процессов инициализации, регенерации и конфигураций с использованием нескольких множественных шин данных.
Поле команды содержит 6 бит. Когда определяющий бит CMD5 установлен в 0, выполняются нормальные команды чтения или записи. Выбор операции адресации банка или страницы, длины пакета, чтения или записи, авторегенерации и стробирования (DCLK) независим. Доступ к странице требует, чтобы банк был открыт. Когда CMD5=1, происходит выбор операций со строкой, доступ к регистру или команд специальной синхронизации.
| Формат команды SLDRAM | ||||||
| Команда | CMD5 | CMD4 | CMD3 | CMD2 | CMD1 | CMD0 |
| Доступ к странице (Page Access) | 0 | 0 | x | X | x | x |
| Доступ к банку (Bank Access) | 0 | 1 | x | X | x | x |
| Длина пакета = 4 (Burst Length), BL=4 | 0 | x | 0 | X | x | x |
| Длина пакета = 8 (Burst Length), BL=8 | 0 | x | 1 | X | x | x |
| Чтение (Read) | 0 | x | x | 0 | x | x |
| Запись (Write) | 0 | x | x | 1 | x | x |
| Открытие страницы (Leave Page Open) | 0 | x | x | X | 0 | x |
| Автоподзаряд (Autoprecharge) | 0 | x | x | X | 1 | x |
| Использование DCLK0 | 0 | x | x | X | x | 0 |
| Использование DCLK1 | 0 | x | x | X | x | 1 |
| Специальные команды | 1 | x | x | X | x | x |
Поскольку индивидуальные приборы памяти не требуют "встречных" жестких соответствий параметров по постоянному и переменному току, микросхемы калибруются на системном уровне для возможности более широкой индивидуальной параметрической настройки. Так, инициализация и синхронизация проходит семь ступеней от момента подачи питания до момента начала нормального функционирования подсистемы памяти. Этот процесс ранее полностью подробно описывался, поэтому еще раз кратко основные моменты.
На линию сброса подается сигнал RESET# активного низкого уровня — ступень обнуления параметров, называемая "жестким сбросом" (Hard Reset). Это позволяет обнулить установленные ранее значения внутренней синхронизации, установить внутренний регистр идентификации в значение 255, выход SO в низкий уровень, а значения задержек чтения и записи — в минимум.
Поскольку фронты и срезы сигналов по шине команд (CA[9:0]) и данных (DQ[17:0]) синхронизированы со своими синхрогруппами (CCLK и DCLK соответственно), каждый прибор памяти должен внутренне согласоваться с фазой входящего тактового сигнала, чтобы скорректировать прием данных при помощи посылаемого в фазе настройки контрольного пакета (образца, шаблона). Для начала второй ступени, именуемой записью параметров синхронизации, контроллер начинает непрерывно передавать синхросигналы CCLK и DCLK, установив при этом сигнал выбора выхода в высокое состояние (SO=1). По линиям DQ[17:0], CA[9:0] и FLAG контролер начинает передавать инвертированную (Inverted) и неинвертированную (non-Inverted) версии 15 бит повторяющейся псевдослучайной синхронной (SYNC) последовательности — 000010100110111 и 111101011001000 соответственно. Приборы памяти "признают" эту последовательность по двум идущим подряд битам флага (FLAG). После этого микросхемы определяют оптимальные параметры внутренней задержки синхросигналов CCLK и DCLK[1:0], чтобы оптимизироваться под известный образец. Далее прибор памяти синхронизируется и программирует задержки, определенные в предыдущем шаге для CCLK, DCLK0 и DCLK1, "выровняв" состояния выборов входа и выхода (SI=SO). Контроллер перестает посылать образец, как только выбор входа установится в активное состояние (SI=1). После этого происходит "сброс" выходов (SO=0) для всех приборов памяти.
| Синхронизирующие шаблоны для линий команд, данных и флага | |||
| Сигнал | Шаблон | Сигнал | Шаблон |
| FLAG | 111101011001000... | DQ12 | 111101011001000... |
| CA9 | 000010100110111... | DQ11 | 000010100110111... |
| CA8 | 111101011001000... | DQ10 | 111101011001000... |
| CA7 | 000010100110111... | DQ9 | 000010100110111... |
| CA6 | 111101011001000... | DQ8 | 111101011001000... |
| CA5 | 000010100110111... | DQ7 | 000010100110111... |
| CA4 | 111101011001000... | DQ6 | 111101011001000... |
| CA3 | 000010100110111... | DQ5 | 000010100110111... |
| CA2 | 111101011001000... | DQ4 | 111101011001000... |
| CA1 | 000010100110111... | DQ3 | 000010100110111... |
| CA0 | 111101011001000... | DQ2 | 111101011001000... |
| DQ17 | 000010100110111... | DQ1 | 000010100110111... |
| DQ16 | 111101011001000... | DQ0 | 111101011001000... |
| DQ15 | 000010100110111... | DCLK1 | 101010101010101... |
| DQ14 | 111101011001000... | DCLK0 | 101010101010101... |
| DQ13 | 000010100110111... | ||
Далее контроллер устанавливает еще раз SO=1 и посылает команду записи в регистр идентификации со значением "0". Ответит на эту команду только прибор памяти, имеющий активный вход (SI=1) и идентификатор ID=255. Таким образом, эта микросхема памяти перезапишет в свой регистр идентификации значение "0" и установит SO=1. Контроллер повторит команду записи в регистр идентификации, но уже со значением "1", после чего, перебросив SI в высокий логический уровень, закроет третью ступень, выполняемую для назначения персонального идентификатора.
Следующая, четвертая ступень калибровки высокого и низкого уровней напряжения на выходе, соответствующих логическим "1" или "0", выполняется контроллером. Контроллер калибрует выходные уровни SLDRAM, посылая каждой микросхеме указания определить уровень соответствующих логических значений на шине данных по постоянному току. После этого контроллер выставит подходящие значения инкремента/декремента уровней VOL/VOH напряжения, подогнав существующие значения под опорные. Например, если обнаружилось положительное отклонение от номинального (опорного) значения на 7%, то контроллер выставит как минимум 2% декремент, чтобы "уложится" в схему ±5%.
Ступень определения тайминга синхронизации выполняется как бы в продолжение второй ступени. Контроллер формирует команду для каждой микросхемы памяти передавать совместно с непрерывным сигналом DCLK тот самый 15-разрядный псевдослучайный синхронизирующий образец по шине данных. Управляющее устройство выверяет позицию принятых бит, сравнивая по фазе относительно необходимой, и выравнивает значения инкрементированием верньера для чтения данных SLDRAM.
Теперь, для каждого прибора памяти контроллер выставляет на шину команду чтения, после чего производит постоянный мониторинг специального сигнала DCLK, который сопровождает передачи пакетов данных для определения задержки чтения — шестая ступень, предназначенная для калибровки параметра задержки чтения. После того, как минимальные значения задержек измерены для каждой микросхемы, выбирается одно подходящее значение (обычно это минимальное значение задержки самого медленного прибора памяти) и программируется, для каждого прибора SLDRAM, записывая установленное значение в один из регистров задержки чтения.
Далее, после определения задержки чтения, контроллер посылает к каждой микросхеме памяти команду записи с нулевой задержкой (Zero Write Latency) и передает расширенный 32N-пакет. Данные, содержащиеся в каждом последующем слове записываемого пакета, инкрементируются по схеме 0, 1, 2, 3,... 31. После выполнения команды записи контроллер начинает считывать обратные пакеты. Первое слово содержит минимальную задержку записи. Учитывая эту информацию, управляющее устройство может установить значения задержки записи для всех микросхем памяти и объединить их в одно значение, которое будет записано в один из регистров задержки записи. На этом заканчивается процесс согласования и калибровки подсистемы памяти и она готова для нормального функционирования.
Однако, в течение нормального функционирования откалиброванные тайминги и уровни напряжения могут смещаться из-за влияния температуры и нестабильности значения напряжения питания. Поэтому каждый прибор памяти должен периодически осуществлять ре-калибровку, чтобы обеспечивать стабильную работу. Процесс ре-калибровки "прозрачен", поскольку скрывается в периодах выполнения авторегенерации и саморегенерации, что никоим образом не отражается на производительности системы.
Реалии технологии SLDRAM
Теперь пришло время рассмотреть ключевые моменты функционирования подсистемы SLDRAM — источник синхронизации и методы верньерного согласования интерфейса. Поскольку на данный момент нет полностью рабочих систем SLDRAM, то в качестве примера разберем эксперимент, проведенный совместной исследовательской группой подразделений Mitsubishi Electric, Hyundai Electronics и IBM Microelectronics.
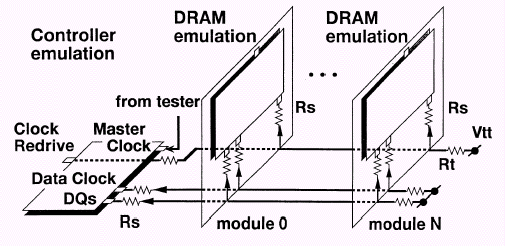
Интерфейс SLDRAM представляется установкой, включающей экспериментальный чип и системную плату эмуляции, на которую устанавливаются несколько эмулированных SLDRAM-модулей. Экспериментальный чип упакован в стандартный тип корпуса и установлен на стандартном PCB-модуле. 16bit интерфейс чипа синхронизируется 300MHz сигналом и обеспечивает пропускную способность 600Mbps/p (1.2GBps).
| Интерфейс используемого чипа SLDRAM | |
| Параметр | Значение |
| Интерфейс VDD и VDDQ | 2.5V±5% |
| Интерфейс SLIO | 1.6 В ("1"), 0.9 В ("0") |
| Размах активных уровней | 0.7 В |
| Средняя точка (опорное напряжение) | 1.25 В |
| Частота синхронизации | 300 MГц |
| "Линейная" и результирующая пропускная способность | 600Mbps/p (1.2 Гбайт/с) |
| Смещение данных на линиях DQ[15:0] относительно строба | 60 пс |
| Смещение данных на защелке приемника | 70 пс |
| Информационно-зависимый сдвиг | 300 пс |
| Максимальная/средний шаг верньера | 220 пс |
| Максимальный шаг калибровки уровня напряжения | 21 мВ |
| Рассеиваемая мощность | 150 мВт |
| Геометрические размеры чипа | 20.0х8.0 мм |
| Тип корпуса | 70pin, 400mil TSOP-II, 0.65mm pitch |
Как говорилось ранее, структура шины SLDRAM базируется на SSTL-подобной топологии, что дает возможность использования схемы с двухтактным выходным каскадом (Push-pull Drivers) и терминирования шины в один конец, чтобы генерировать небольшой "двусторонний" размах сигнала (±0.35 В) относительно уровня опорного напряжения (1.25 В). Топология шины использует серию коротких резисторов, чтобы снизить взаимное влияние соседних линий SLBus на материнской плате и на модуле памяти, а также улучшить целостность сигнала и помехозащищенность структуры. Это делается для того, чтобы была возможность без проблем использовать топологию шинного соединения, используемую в многокристальных и многоканальных модульных системах.
Интерфейс SLDRAM использует источник синхронизации и цепи верньерного согласования для осуществления высокоскоростной передачи данных без ошибок. Под источником синхронизации понимается устройство, которое передает данные на шину и управляет синхросигналами, стробирующими команды и данные. Эти синхросигналы данных используются, чтобы выровнять согласование данных в приемнике. Верньер согласования — программируемая единичная (чем меньше числовое значение, тем точнее отсчет) задержка, обеспечивающая точную балансировку временных параметров, чтобы в конечном итоге устранить разность фаз между модулями SLDRAM, расположенными на различном расстоянии от контроллера.
С момента поступления на соответствующие шины синхросигнала интерфейса CommandLink и начала передачи команды, внутри чипа формируется задержка сигнала CCLK для определения уровня дискретизации на входе и улучшения помехозащищенности (Noise Immunity). Внутренняя цепь подстройки задержки сигнала (DLL) устанавливает определенную длительность периода CCLK (tCK=3.3 нс в случае использования 300MHz синхросигнала) и обеспечивает его "разбиение" на 32 равных временных интервала — дискретизацию по фазе (Clock Phases Spanning). Результатом использования простейшей цепи DLL с фиксированными элементами задержки может являться искажение выполнения текущей операции под воздействием изменения окружающей температуры или вариаций питающего протокола, что может повлечь за собой формирование целой серии задержек от одного элемента к другому. Эта проблема решается при помощи 32-ступенчатой линии задержки (32-stage Delay Line), "разбивающей" длительность периода задержки на 32 одинаковых временных интервала, каждый их которых определяет минимально возможную единичную опорную задержку или минимально возможный единичных сдвиг по фазе — минимальный шаг верньера.
Применяемый в микросхеме 6-разрядный выходной ЦАП (DAC — Digital-to-Analog Converter) с токовым выходом и индивидуальным регистром управления (размером 6 бит) гарантирует подачу опорного тока для всех 32 ступеней задержки. В момент входа микросхемы в режим деактивации, 6-разрядное значение удерживается для немедленного возврата в активное состояние по требованию. Более простые аналоговые схемы требуют дополнительное время на ресинхронизацию цепей после выхода из ShutDown. Данный ЦАП, представляющий собой матрицу полевых транзисторов (FET), контролируемую термодатчиком, декодирует управляющее слово длиной 6 бит, сначала включая устройства из трех младших бит, управляющих строкой, а затем — из трех старших, контролирующие столбец. Первый полевой транзистор, который всегда активен, имеет соотношение W/L=1, и как только все устройства включатся, суммарный ток возрастает с коэффициентом S=1.055. Для обеспечения постоянного соотношения длительности задержки между изменением температуры и вариациями напряжения, в данном ЦАП используется нелинейная передаточная функция, которая обеспечивает изменение тока в диапазоне 1-26.6 по геометрической зависимости.
Схема внутренней синхронизации определяет фазу настройки цепей микросхемы относительно задающего синхросигнала CCLK. Во избежание искажений выполнения текущей операции, которые могут возникнуть во время прохождения сигнала от одного ответвителя к другому, цепь задержки сигнала содержит одинаковые параметры для всех ответвителей. Так, во время выполнения фазы инициализации выбирается первый ответвитель, реализующий виртуальный нулевой сдвиг по фазе (Virtual 0° Tap) синфазно с внешним CCLK. Шестиступенчатая задержка ввода компенсирует задержку синхросигнала, возникающую как на входных буферах, так и в процессе распространения по сигнальной трассе, поэтому в цикле инициализации управляющий ток для этой задержки устанавливается в среднее значение всего диапазона изменений на соответствующий элемент. В течение выполнения операции компенсации от возникновения температурных колебаний или флуктуаций напряжения задержка ввода устанавливается на уровне первой ступени цепи автоподстройки и поддерживается в фазе с внешним синхросигналом шины команд. Таким образом, 32-ступенчатая линия четко обеспечивает полную задержку, равную длительности периода CCLK, и постоянно поддерживает согласование по фазе сигналов интерфейса SLIO с формирователем внешнего синхросигнала шины команд.
Соответствующая линия задержки для каждого входа синхросигнала шины данных DCLK использует те же контрольные биты ЦАП, что и CCLK. С момента, когда синхропары группы DCLK используются только в режиме записи пакетов данных, любая возникающая задержка на данных входах, вызванная вариациями напряжения или температуры, компенсируется цепью DLL, выравнивающей фронты DCLK относительно опорного CCLK. В дополнение необходимо заметить, что несколько разных выходов берут свое начало от рассматриваемой цепи линии задержки сигнала: основной задатчик синхронизации CCLKH, который администрирует цепи управления и ядро ДОЗУ, командный вход модели синхронизации CLK_CAL, используемый для формирования псевдослучайного шаблона, READ_CLK, использующийся для настройки задержки чтения точного верньера, и пара RD_CLK[1:0], применяемая для независимой настройки двух исходящих синхросигналов.
Собственно, верньерное согласование представляет собой некое подобие юстировки. В фазе выполнения внутрисистемной синхронизации, как уже неоднократно писалось, контроллер посылает стробирующие сигналы совместно с шаблонами по линиям команд и данных, вычисляя временное смещение (разность фаз между синхроимпульсом и сопоставляемыми ему сигналами по шинам команд или данных) — опережающее/запаздывающее тау (t±). Как только разность определена, контроллер формирует фазовую компенсацию — верньер определенной длительности. После того, как выполнено соответствующее смещение (на длительность верньера) настраивающегося сигнала шины команд или данных относительно стробирующего импульса, контроллер снова выполняет мониторинг согласования. Фазовые смещения сигналов на линиях могут иметь очень разные значения, а верньер имеет точные программируемые, поэтому с первого раза требуемого согласования может не произойти. В этом случае контроллер контроллер повторит фазовую подстройку, но, как ожидается, уже верньером меньшей длительности. Такая процедура настройки происходит для всех линий команд, данных и линии флага. Как только все сигналы "выровнялись", управляющее устройство прекращает посылать шаблон.
SLBus использует различную методику калибровки для настройки уровней сигнала на выходе и поддержания его целостности, основанную на ряде импедансных характеристик всей сети устройств. Высокий (VOH) и низкий (VOL) выходные уровни изменяются непосредственно контроллером, который также обеспечивает передачу команды программирования верньера согласования к каждому чипу SLDRAM.
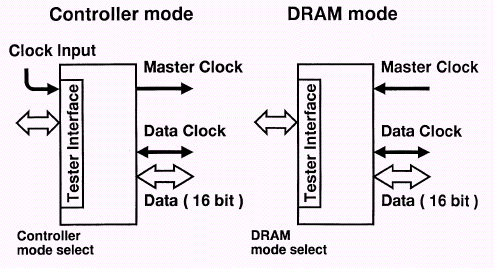
Для проведения эксперимента был использован чип с "урезанным" интерфейсом. Первичная цель этого эксперимента состоит в том, чтобы проверить интенсивность передачи по интерфейсу микросхемы SLDRAM, поэтому были реализованы только функции управления и приема данных. Таким образом, чип включает блок генерирования синхросигналов, блок формирования верньеров и цепи тракта данных — никаких прямых функций памяти и пакетизирования операций управления не выполняется. Также, для упрощения моделирования подсистемы, чип является эмулятором как контроллера так и самой микросхемы SLDRAM. Дополнительные тестовые функции измеряют такие характеристики передачи сигнала, как перекрестные помехи (Crosstalk) и одновременное переключение (Simultaneous Switching). Весь внешний сигнальный интерфейс в данном случае включает 16 линий ввода/вывода данных (DQ[15:0]) и линию синхронизации, выведенные с одной стороны чипа, а выводы тестового интерфейса расположены с другой. Программа верньерной синхронизации и калибровки выходного уровня осуществляется исключительно таким "усеченным" интерфейсом, а не командными пакетами. Для снижения уровня взаимного влияния соседних линий чип упакован в корпус TSOP, оснащенным специальным non-LOC-выводным окном для уменьшения собственной длины выводов.
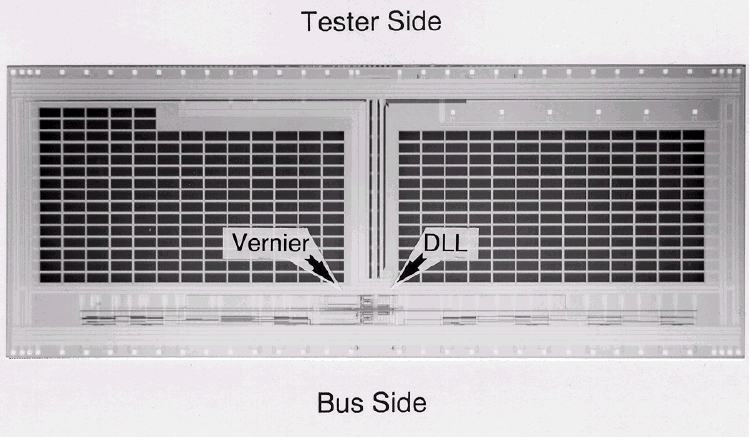
До начала передачи данных чип входит в режим отправителя (чтение из массива) или получателя (запись в массив), выбор которого осуществляется управлением сигнала интерфейса тестера. В режиме чтения согласование вывода данных определяется задержанным синхросигналом на входе задающего генератора. Значение задержки программируется непосредственно верньером, поэтому синхронизация данных на выходе также программируется верньером. Образцы данных подаются блоком тестирования через тестовый интерфейс: интерференционный образец и образец одновременного переключения могут быть сгенерированы, используя этот интерфейс ввода. В режиме записи данные запираются в чипе синхросигналами шины данных и посылаются в блок тестирования для оценки.
Поскольку источник синхронизирует передачу данных, то одновременное управление всеми синхросигналами и линиями данных осуществляется в режиме чтения. Внутренний синхросигнал цепи верньерной синхронизации подается на формирователь тактовых импульсов и на каждый вывод DQ[15:0]. Перекос между моментом начала действия DCLK и моментом начала поступления на выводы DQ[15:0] контролируется в пределах 60 пс. Калибровка уровня сигнала на выходе происходит исходя из значения удельной проводимости формирователя согласно запрограммированным данным VOH/VOL в соответствующий регистр управления.
В режиме записи коммутируемый синхросигнал на каждый входной буфер линии DQ[15:0] должен быть синхронизирован с каждым сигналом на шине данных. Сдвиг коммутируемого синхросигнала получается путем отслеживания таймингов задающего синхросигнала CCLK. Идеальной задержкой синхронизации является четверть длительности цикла синхросигнала формирователя (пол-тика) — tCK/4. Цепь фазового сдвига в рассматриваемом чипе реализует временной перекос в 70 пс.
Собственно, в рамках данной статьи придется ограничиться рассмотрением лишь этой экспериментальной модели, поскольку пока никакой информации о реально работающих системах на основе SLDRAM нет и, возможно, уже не будет. Однако приведенный пример все же наглядно демонстрирует результаты: при синхронизации в 300 МГц удалось добиться скорости передачи данных 1.2 Гбайта/с (600Mbps/p) при использовании внутреннего источника синхронизации и верньерного согласования — чип с урезанным интерфейсом показал просто идеальную пропускную способность, оправдывая свою 100% эффективность.
Исследования показывают, что вся система целиком если и будет обеспечивать падение производительности, то крайне низкое. Текущий интерфейс SLBus обладает отличными характеристиками и прекрасной помехозащищенностью, что в лабораторных гарантирует минимальную пропускную способность 800 Mbps/p. Таким образом, если контроллер памяти SLC будет иметь достаточно эффективные алгоритмы работы, а его сложнейшая внутренняя схемотехника будет в достаточной степени оптимизирована, то имеются абсолютно все шансы получить не только крайне высокопроизводительную архитектуру памяти, но и базовую концепцию архитектуры синхронного ДОЗУ ближайшего будущего. Остается только надеяться, что DDRII, «в жертву» которой и был принесена рассматриваемая в настоящей статье архитектура, будет именно такой, если основные концепции и идеи SLDRAM все же найдут практическое применение в конечном продукте, а не останутся лишь лабораторными тестами.
Информация получена из следующих источников:
- JESD8-9, Stub Series Terminated Logic For 2.5 Volts (SSTL_2)
- JEDEC Std JESD-21-C, Configuration of Solid-State Memories, DDR SDRAM Explained
- JESD79, Double Data Rate (DDR) SDRAM Specification
- JESD100-B, Terms, Definitions, and Letter Symbols for Microcomputers, Microprocessors, and Memory Integrated Circuits
- SLDRAM: High-Performance Open Standard Memory
- SLDRAM Architectural and Functional Overview
- SLDRAM: High-Performance Open Standard Memory
- IEEE Std 1594.4-1995, A RamLink Protocol Interface
- IEEE Std 1596.4-1996, Standard for Memory Interface based on SCI (RamLink)
- IEEE 1596.7-199x, Standard for A High-Speed Memory Interface (SyncLink)
- EIA/JEDEC Std JESD-21-C, Configuration of Solid-State Memories, DDR SDRAM Explained
- SLDRAM Preliminary Data Sheet
- SLD4M18DR400: 400Mbps/p 4Mx18 SLDRAM pipelined, 8-bank, 2.5V operation
- Source Synchronization and Timing Vernier Techniques for 1.2GBps SLDRAM Interface
- Outline Background SLDRAM Interface Evaluation System Demonstration Chip Experimental Results Conclusion
- A 800MBps 72Mb SLDRAM with Digitally-Calibrated DLL
- A 2.6GBps Multipurpose Chip-to-Chip Interface
- ANSI/IEEE Std 1596-1992, SCI: Scalable Coherent Interface (or IEC/ISO DIS 13961)
- IEEE P1285, Scalable Coherent Interface



{kind=link}
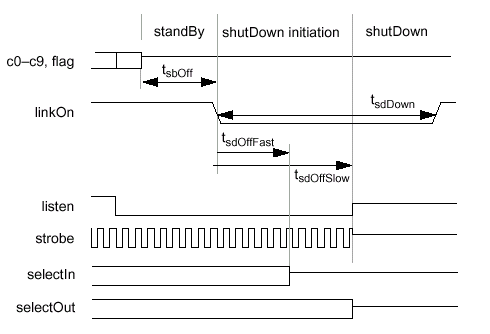{kind=link}
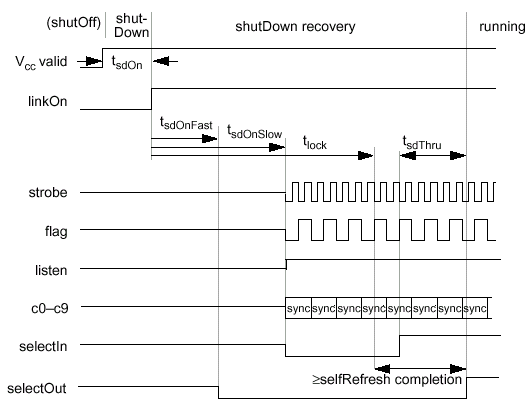{kind=link}
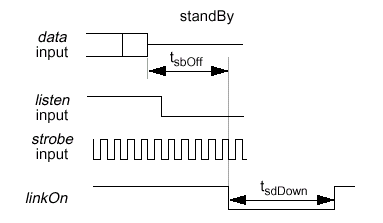{kind=link}
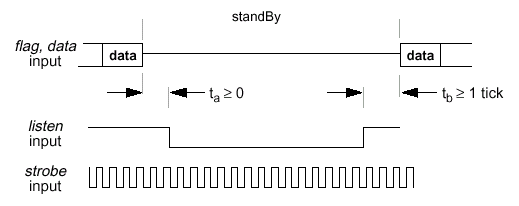{kind=link}
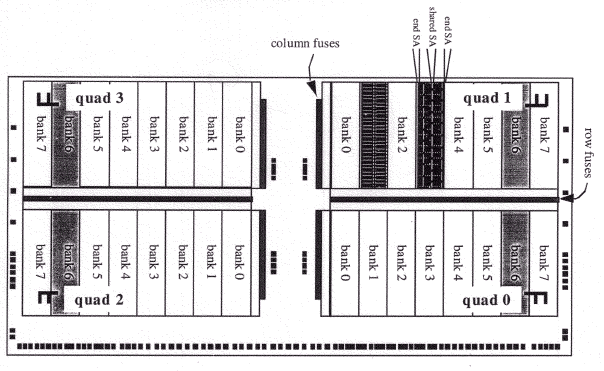{kind=link}
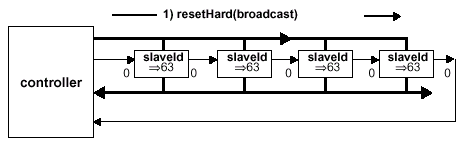{kind=link}
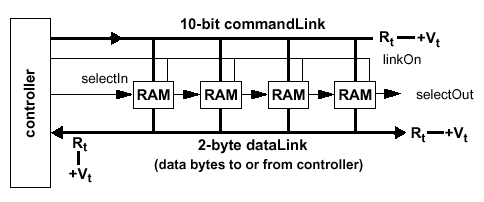{kind=link}
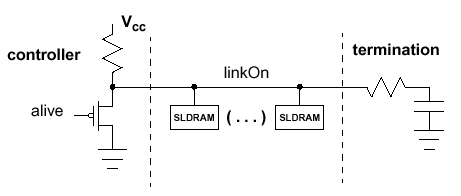{kind=link}
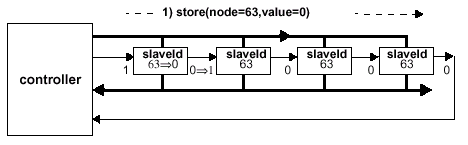{kind=link}
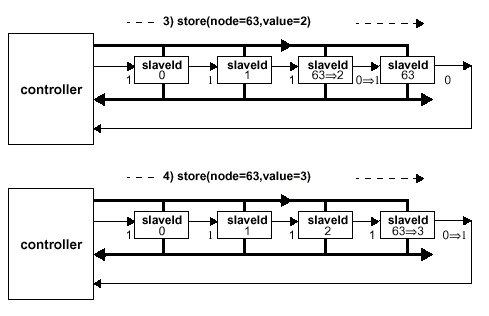{kind=link}
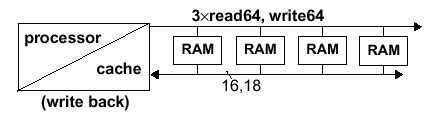{kind=link}
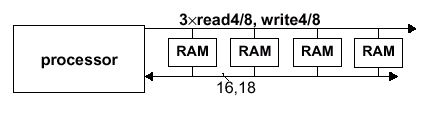{kind=link}
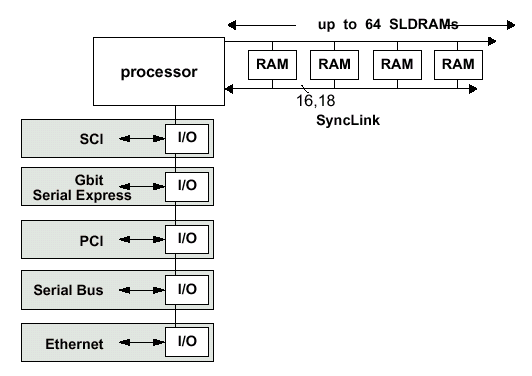{kind=link}
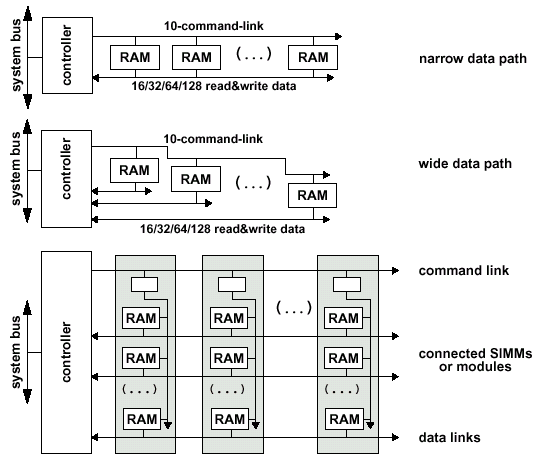{kind=link}
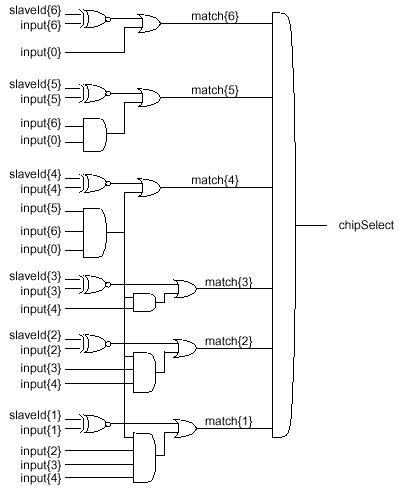{kind=link}
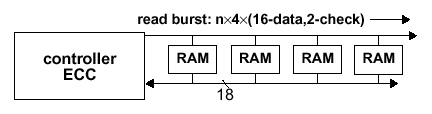{kind=link}
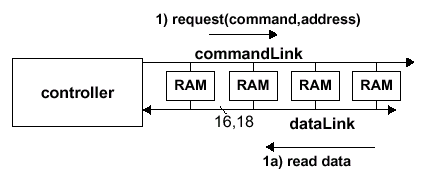{kind=link}
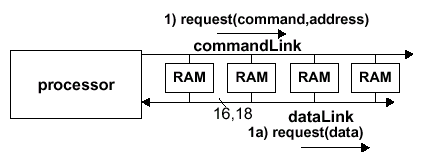{kind=link}
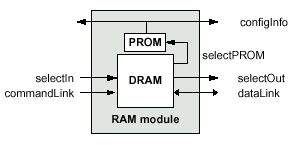{kind=link}
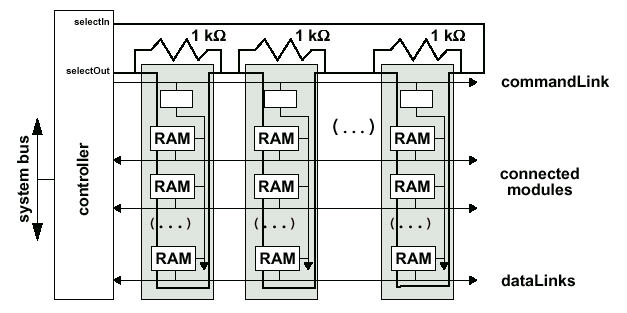{kind=link}
{kind=link}
{kind=link}
{kind=link}
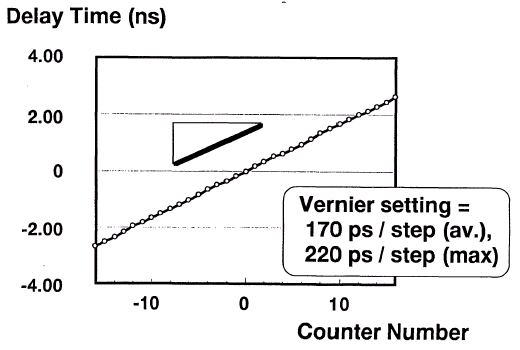{kind=link}
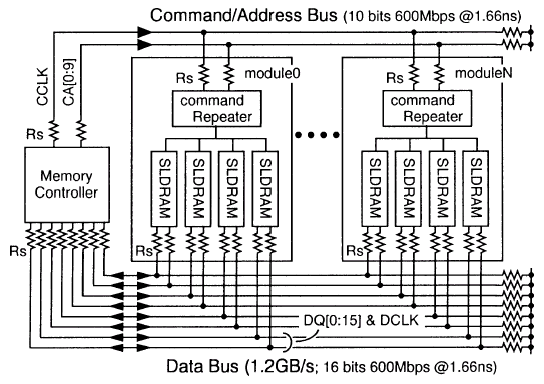{kind=link}
{kind=link}
{kind=link}
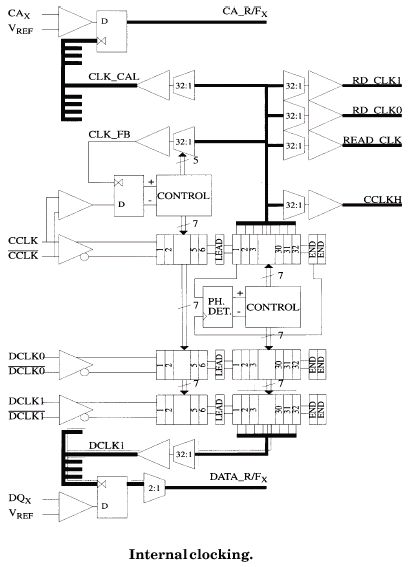{kind=link}
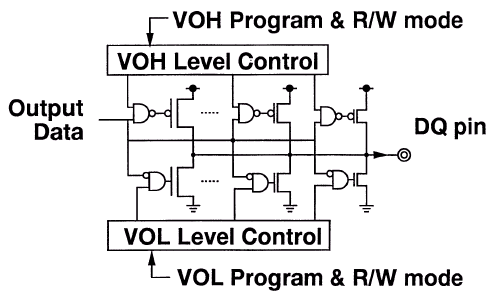{kind=link}
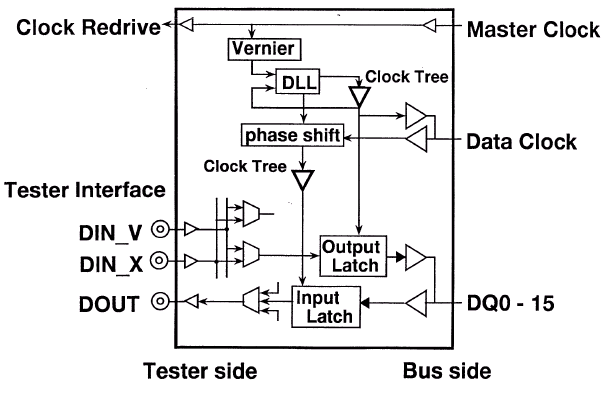{kind=link}
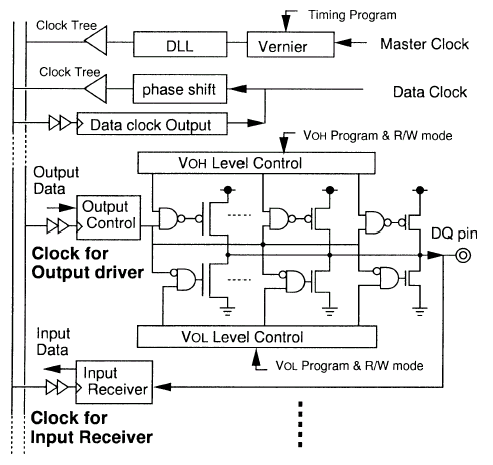{kind=link}
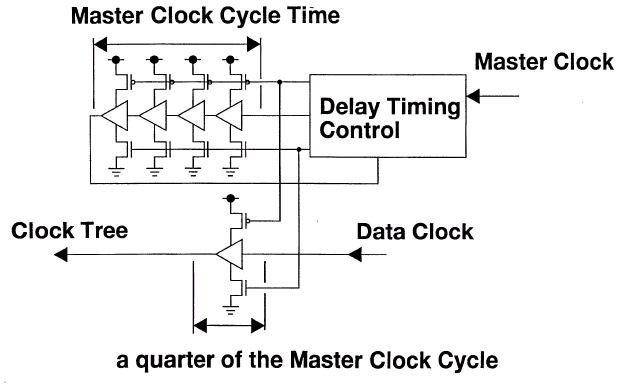{kind=link}
{kind=link}