С одной стороны, время в IT-индустрии летит настолько быстро, что не успеваешь замечать новые продукты и технологии, а с другой ну-ка, вспомним сколько лет мы не видели нового ядра от Intel? Не старого с переделками: тут частоту FSB подняли, там виртуальную многопроцессорность с серверного процессора на десктопный перенесли (на самом деле просто разрешили последнему честно рассказать, что она у него есть), но действительно полностью нового? Если не с нуля разработанного, то хотя бы не латаного, а заново по тем же лекалам сшитого, но с другими рюшечками и по последней моде? А ведь целых два года, оказывается! Даже с хвостиком небольшим. И все это время горячие головы рассуждали на излюбленную тему: а каким же оно будет, новое ядро? Чего только не предсказывали вплоть до полной анафемы архитектуре NetBurst и воцарения сплошного Banias на декстопной платформе. Правда (как часто бывает), оказалась менее сказочной: новое ядро оказалось честным и последовательным продолжателем Northwood. Разумеется, с некоторыми архитектурными нововведениями, но стремления «до основанья, а затем » в нем не прослеживается. Поэтому чисто эмоционально Prescott можно оценивать по-разному: кто-то похвалит инжереров Intel за последовательность и целеустремленность, кто-то, наоборот посетует на отсутствие свежих идей. Однако эмоции личное дело каждого, мы же обратимся к фактам.
Теория
Основные изменения в ядре (Prescott vs. Northwood)
Для начала мы предлагаем вам небольшую табличку, в которой сведены воедино наиболее существенные различия между ядрами Prescott и Northwood во всем что касается «железа» (а точнее кремния, и прочих «минеральных составляющих»).
| Ядро | Northwood | Prescott |
|---|---|---|
| Техпроцесс | 0,13 мкм (130 нм) | 0,09 мкм (90 нм) |
| Медные соединения, слоев | 6 | 7 |
| Диэлектрик | low-k, SIOF | low-k, CDO |
| Материал затвора | Силицид кобальта | Силицид никеля |
| Площадь ячейки памяти, мм2 | 2 | 1,15 |
| Литография | 248 нм | 193 нм |
| Кремниевая решетка | Обычный кремний | Напряженный кремний |
Остается только добавить, что новое ядро содержит 125 миллионов транзисторов (куда там бедному Northwood с его 55 миллионами!), и его площадь равна 112 кв. мм (немного меньше площади Northwood 146/131 кв. мм, в зависимости от ревизии). Произведя несложный арифметический подсчет, видим, что увеличив количество транзисторов в ~2,3 раза, за счет нового техпроцесса инженерам Intel удалось, тем не менее, уменьшить площадь ядра. Правда, не так значительно «всего» в 1,3 (1,2) раза.
Что же касается технологии «напряженного» (некоторые предпочитают термин «растянутый») кремния то она, если объяснять на пальцах, довольно проста: с целью увеличения расстояния между атомами кремния, он помещается на подложку, расстояние между атомами у которой больше. В результате, для того чтобы «хорошо усесться», атомам кремния приходится растягиваться по предложенному формату. Выглядит это примерно вот так:
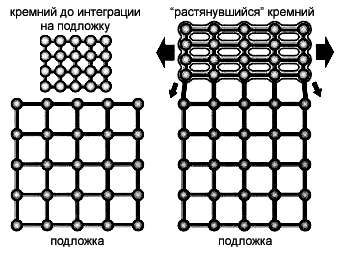
Ну а понять, почему электронам проще проходить через напряженный кремний, вам поможет вот этот простенький рисунок:

Как видите, геометрическая ассоциация в данном случае вполне уместна: путь электрона просто становится короче.
Ну а теперь рассмотрим гораздо более интересные отличия: в логике ядра. Их тоже немало. Однако для начала будет нелишним напомнить об основных особенностях архитектуры NetBurst как таковой. Тем более что не так уж и часто мы это делали в последнее время.
Немного предыстории
Итак, одним из основных отличий ядер, разработанных в рамках архитектуры NetBurst, сама компания Intel считает уникальную особенность, выражающуюся в разделении собственно процесса декодирования x86-кода во внутренние инструкции, исполняемые ядром (uops), и процедуры их выполнения. Между прочим, такой подход породил в свое время немало споров относительно корректности подсчета стадий конвейера у Pentium 4: если подходить к данному процессору с классической точки зрения (эпохи до-NetBurst), то стадии декодера следует включать в общий список. Между тем, официальные данные Intel о длине конвейера процессоров Pentium 4 содержат информацию исключительно о количестве стадий конвейера исполняющего блока, вынося декодер за его рамки. С одной стороны «крамола!», с другой это объективно отражает особенность архитектуры, поэтому Intel в своем праве: она же ее и разработала. Спорить, можно, разумеется, до посинения, однако какая, собственно, разница? Главное понимать суть подхода. Не нравится вам, что декодер исключен? Ну так прибавьте его стадии к «официальным» и получите искомую величину конвейера по классической схеме, вместе с декодером.
Таким образом, основная идея NetBurst асинхронно работающее ядро, в котором декодер инструкций работает независимо от Execution Unit. С точки зрения Intel, существенно большая, чем у конкурентов, частота работы ядра, может быть достигнута только при асинхронной модели т.к. если модель синхронная, то расходы на синхронизацию декодера с исполняющим блоком возрастают пропорционально частоте. Именно поэтому вместо обычного L1 Instructions Cache, где хранится нормальный x86-код, в архитектуре NetBurst применяется Execution Trace Cache, где инструкции хранятся уже в декодированном виде (uops). Trace это и есть последовательность uops.
Также в историческом экскурсе хотелось бы окончательно развеять мифы, связанные с излишне упрощенной формулировкой, согласно которой ALU у Pentium 4 работает на «удвоенной частоте». Это и так
и не так. Однако для начала взглянем на условную блок-схему процессора Pentium 4 (уже Prescott):
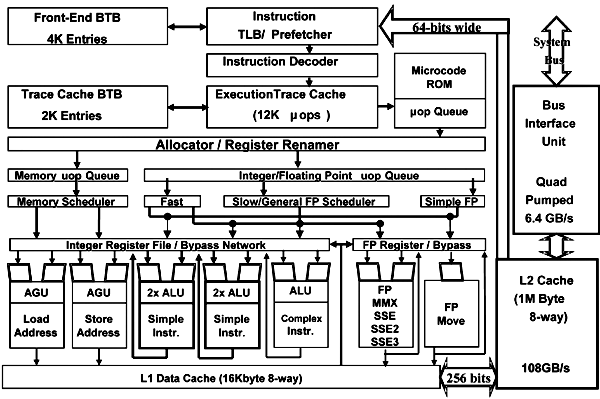
Легко заметить, что ALU состоит из нескольких частей: в нем присутствуют блоки Load / Store, Complex Instructions, и Simple Instructions. Так вот: с удвоенной скоростью (0,5 такта на операцию) обрабатываются лишь те инструкции, что поддерживаются исполняющими блоками Simple Instructions. Блок ALU Complex Instructions, исполняющий команды, отнесенные к сложным наоборот, может тратить до четырех тактов на исполнение одной инструкции.
Вот, собственно, и все, что хотелось бы напомнить относительно внутреннего устройства процессоров сконструированных на базе архитектуры NetBurst. Ну а теперь перейдем к нововведениям в самом свежем NetBurst-ядре Prescott.
Увеличение длины конвейера
Вряд ли это изменение можно назвать усовершенствованием ведь общеизвестно, что чем длиннее конвейер, тем большие накладные расходы вызывает ошибка механизма предсказания ветвлений, и, соответственно, уменьшается средняя скорость выполнения программ. Однако, видимо, другого способа увеличить разгонный потенциал ядра, инженеры Intel найти не смогли. Пришлось прибегнуть к непопулярному, но проверенному. Итог? Конвейер Prescott увеличен на 11 стадий, соответственно, общее их количество равняется 31. Честно говоря, мы намеренно вынесли эту «приятную новость» в самое начало: фактически, описание всех последующих нововведений можно условно назвать «а вот теперь мы вам расскажем, как инженеры Intel боролись с последствиями одного-единственного изменения, чтобы оно окончательно не угробило производительность» :).
Усовершенствования в механизме предсказания ветвлений
В основном, тонкий тюнинг коснулся механизма предсказания переходов при работе с циклами. Так, если ранее по умолчанию обратные переходы считались циклом, то теперь анализируется длина перехода, и исходя из нее механизм пытается предсказать: цикл это, или нет. Также было обнаружено, что для ветвей с определенными типами условных переходов, независимо от их направления и расстояния, использование стандартного механизма предсказания ветвлений чаще всего неактуально соответственно, теперь в этих случаях он не используется. Однако кроме теоретических изысканий, инженеры Intel не побрезговали и голой эмпирикой т.е. просто-напросто отслеживанием эффективности работы механизма предсказания ветвлений на примере конкретных алгоритмов. С этой целью было исследовано количество ошибок механизма предсказания ветвлений (mispredictions) на примерах из теста SPECint_base2000, после чего по факту были внесены изменения в алгоритм с целью их уменьшения. В документации приводятся следующие данные (количество ошибок на 100 инструкций):
| Подтест SPECint_base2000 | Northwood (130 nm) | Prescott (90 nm) |
|---|---|---|
| 164.gzip | 1.03 | 1.01 |
| 175.vpr | 1.32 | 1.21 |
| 176.gcc | 0.85 | 0.70 |
| 181.mcf | 1.35 | 1.22 |
| 186.crafty | 0.72 | 0.69 |
| 197.parser | 1.06 | 0.87 |
| 252.eon | 0.44 | 0.39 |
| 253.perlbmk | 0.62 | 0.28 |
| 254.gap | 0.33 | 0.24 |
| 255.vortex | 0.08 | 0.09 |
| 256.bzip2 | 1.19 | 1.12 |
| 300.twolf | 1.32 | 1.23 |
Ускорение целочисленной арифметики и логики (ALU)
В ALU был добавлен специализированный блок для исполнения инструкций shift и rotate, что позволяет теперь исполнять данные операции на «быстром» (двухскоростном) ALU, в отличие от ядра Northwood, где они исполнялись в блоке ALU Complex Instructions, и требовали большего количества тактов. Кроме того, ускорена операция целочисленного умножения (integer multiply), ранее исполнявшаяся в блоке FPU. В новом ядре для этого выделен отдельный блок.
Также есть информация о присутствии некоторого количества мелких усовершенствований, позволяющих увеличить скорость обработки инструкций FPU (и MMX). Впрочем, ее мы лучше проверим в практической части при анализе результатов тестов.
Подсистема памяти
Разумеется, одним из основных плюсов нового ядра являются увеличенные размеры L1-кэша данных (в 2 раза т.е. до 16 килобайт) и кэша второго уровня (также в 2 раза т.е. до 1 мегабайта). Однако есть и еще одна интересная особенность: в ядро введена специальная дополнительная логика, обнаруживающая page faults в инструкциях software prefetch. Благодаря этому нововведению, инструкции software prefetch теперь имеют возможность осуществлять не только предвыборку данных, но и предвыборку page table entries т.е., другими словами, prefetch умеет не останавливаться на загруженной странице, но еще и обновлять страницы памяти в DTLB. Разбирающиеся в вопросе наверняка заметят на этом примере, что Intel внимательно следит за отзывами программистов, пусть даже и не кается прилюдно по поводу каждого обнаруженного ими негативного фактора, влияющего на производительность.
Новые инструкции (SSE3)
Кроме всего прочего, в Prescott добавлена поддержка 13 новых инструкций. Назван этот набор, по устоявшейся традиции, SSE3. В их числе присутствуют команды преобразования данных (x87 to integer), работы с комплексной арифметикой, кодирования видео (правда, всего одна), новые команды, предназначенные для обработки графической информации (массивов вершин), а также две инструкции, предназначенные для синхронизации потоков (явно последствия появления Hyper-Threading). Впрочем, о SSE3 мы в скором времени выпустим отдельную статью, поэтому рассматривать возможности данного набора в этом материале воздержимся, чтобы не портить излишней популяризацией серьезную и интересную тему.
Ну а теперь, пожалуй, довольно с нас теории и спецификаций. Попытаемся, как говорилось в одном известном анекдоте, «вместе со всем этим взлететь» :).
Тестирование
Конфигурации стендов и ПО
Тестовый стенд
- Процессоры:
- AMD Athlon 64 3400+ (2200 МГц), Socket 754
- Intel Pentium 4 3,2 ГГц «Prescott» (FSB 800/HT), Socket 478
- Intel Pentium 4 2,8A ГГц «Prescott» (FSB 533/нет HT), Socket 478
- Intel Pentium 4 3,4 ГГц «Northwood» (FSB 800/HT), Socket 478
- Intel Pentium 4 3,2 ГГц «Northwood» (FSB 800/HT), Socket 478
- Материнские платы:
- ABIT KV8-MAX3 (версия BIOS 17) на чипсете VIA K8T800
- ASUS P4C800 Deluxe (версия BIOS 1014) на чипсете Intel 875P
- Albatron PX875P Pro (версия BIOS R1.00) на чипсете Intel 875P
- Память:
- 2x512 МБ PC3200 DDR SDRAM DIMM TwinMOS (тайминги 2-2-2-5)
- Видеокарта: Manli ATI Radeon 9800Pro 256 МБ
- Жесткий диск: Western Digital WD360 (SATA), 10000 об/мин


Pentium 4 2,8A ГГц «Prescott»
Единственный Prescott с частотой FSB 533 МГц
и без поддержки Hyper-Threading


Pentium 4 3,2E ГГц «Prescott»
Здесь уже все нормально: FSB 800 МГц,
Hyper-Threading в наличии


Pentium 4 3,4 ГГц «Northwood»
Просто еще один Northwood
Системное ПО и драйверы устройств
- Windows XP Professional SP1
- DirectX 9.0b
- Intel Chipset Installation Utility 5.0.2.1003
- VIA Hyperion 4.51
- VIA SATA Driver 2.10a
- Silicon Image Driver 1.1.0.52
- ATI Catalyst 3.9
| Плата | ABIT KV8-MAX3 | ASUS P4C800 Deluxe | Albatron PX875P Pro |
|---|---|---|---|
| Чипсет | VIA K8T800 (K8T800 + VT8237) | Intel 875 (RG82004MC + FW82801ЕB) | Intel 875 (RG82875 + FW82801ЕB) |
| Поддержка процессоров | Socket 754, AMD Athlon 64 | Socket 478, Intel Pentium 4, Intel Celeron | Socket 478, Intel Pentium 4, Intel Celeron |
| Разъемы памяти | 3 DDR | 4 DDR | 4 DDR |
| Слоты расширения | AGP/ 5 PCI | AGP Pro/ 5 PCI | AGP/ 5 PCI |
| Порты ввода/вывода | 1 FDD, 2 PS/2 | 1 FDD, 2 COM, 1 LPT, 2 PS/2 | 1 FDD, 2 COM, 1 LPT, 2 PS/2 |
| USB | 4 USB 2.0 + 2 разъема по 2 USB 2.0 | 4 USB 2.0 + 2 разъема по 2 USB 2.0 | 2 USB 2.0 + 3 разъема по 2 USB 2.0 |
| FireWire | 1 порт + 2 разъема на 2 порта (планка в комплекте), Texas Instruments TSB43AB23 | 1 порт + 1 разъем на 1 порт (нет планки в комплекте), VIA VT6307 | |
| Интегрированный в чипсет ATA-контроллер | ATA133 + SATA RAID (0, 1) | ATA100 + SATA | ATA100 + SATA |
| Внешний ATA-контроллер | Silicon Image Sil3114CT176 (SATA RAID 0, 1, 0+1, Spare) | Promise PDC20378 (ATA133+SATA RAID 0, 1, 0+1) | |
| Звук | AC'97-кодек Avance Logic ALC658 | AC'97-кодек Analog Devices AD1985 | AC'97-кодек Avance Logic ALC655 |
| Сетевой контроллер | 3Com Marvell 940-MV00 (Gigabit Ethernet) | 3Com Marvell 940-MV00 (Gigabit Ethernet) | 3Com Marvell 920-MV00 (Fast Ethernet) |
| I/O-контроллер | Winbond W83627HF-AW | Winbond W83627THF-A | Winbond W83627THF |
| BIOS | 4 Мбит Award BIOS v6.00PG | 4 Мбит AMI BIOS v2.51 | 3 Мбит Phoenix AwardBIOS v6.00 |
| Форм-фактор, размеры | ATX, 30,5x24,5 см | ATX, 30,5x24,5 см | ATX, 30,5x24,5 см |
| Средняя текущая цена (количество предложений) | Н/Д(0) | Н/Д(0) | Н/Д(0) |
В завершение описания, хотелось бы разъяснить алгоритм подбора участников тестирования. С одной стороны, полностью исключить из тестов процессоры AMD было бы неправильно, ведь эта платформа основной конкурент Intel, как сейчас, так и в обозримом будущем. С другой стороны совмещать в одной статье сравнение двух поколений Pentium 4 с процессорами другого производителя, означало бы не сравнить толком ни то, ни другое. Поэтому мы решили в первом материале, посвященном Prescott, пойти на определенный компрормисс: во-первых, полностью исключить всевозможные «экстремальные» варианты в виде Pentium 4 eXtreme Edition и Athlon 64 FX, во-вторых же, взять в качестве представителя альтернативной платформы только один, но быстрый из обычных десктопных процессоров AMD: Athlon 64 3400+.
Да и то, по большому счету, его результаты здесь приводятся лишь в качестве опции. В этом материале нас более всего интересует сравнение нового ядра Intel со старым. Если кто-то желает получить одновременно информацию о том, как производительность Prescott соотносится с ближайшим конкурентом что ж, она представлена на диаграммах. Комментарии? Пожалуй, они просто излишни. Вы сами в этом убедитесь. Зная, какова производительность Prescott и Northwood, работающих на одинаковой частоте, и то, как соотносятся производительность Northwood и топовых процессоров AMD (а этот вопрос мы уже неоднократно освещали) вы знаете вполне достаточно для того, чтобы самостоятельного сделать все остальные выводы.
Кроме того, хотелось бы разъяснить наличие на диаграммах двух столбиков для Prescott 3,2 ГГц. Дело просто в том, что мы решили
подстраховаться. Всем известно, что с выходом процессора на другом ядре, среди производителей системных плат сразу же начинается суматоха с обновлением BIOS, всяческих microcode update, и прочего «железно-ориентированного» ПО. Нам показалось логичным использовать такой ресурс нашей тестовой лаборатории как «официально Prescott-ready» системные платы максимально полно, чтобы уберечься от возможных последствий некорректной работы конкретной модели. Впрочем, как вы увидите далее, опасения оказались напрасными: в большинстве случаев новый процессор вел себя на обеих платах совершенно одинаково.

Все характеристики Prescott 2,8A ГГц программа
CPU-Z определяет вполне корректно:
как наличие SSE3, так и шину 533 МГц

Разумеется, не ошиблась она и в случае с
Prescott 3,2E ГГц
Низкоуровневые тесты в CPU RightMark
Для начала, мы решили проверить функционирование нового ядра в двух режимах традиционно самом лучшем для процессоров Pentium 4 и самом худшем: SSE/SSE2 и MMX/FPU. Начнем с вычислительного блока (Math Solving).
Результаты неутешительные. Новое ядро медленнее старого, более того в режиме MMX/FPU его отставание даже больше, чем при использовании SSE/SSE2. Делаем первый вывод: если что-то в FPU и «подкручивали», то явно в CPU RightMark используются другие команды. Ну а что у нас с рендерингом?
Во-первых, рассмотрим варианты работы модуля рендеринга в однопоточном и двухпоточном режимах с максимальной производительностью (SSE/SSE2). Картина достаточно интересная: если используется один поток преимущество Prescott минимально, а больший по частоте Northwood его легко обгоняет. Однако стоит нам задействовать Hyper-Threading, как Prescott тут же резко вырывается вперед, причем настолько, что обгоняет всех других участников. Возникает впечатление, что некая работа над ядром в плане улучшения обработки параллельно выполняющихся потоков, была проведена, и заключалась она не только в расширении набора команд. Посмотрим теперь, как себя ведут те же процессоры в режиме MMX/FPU.
Абсолютно аналогичная картина. Причем если сопоставить ее с предыдущей хорошо видно, что тщательность анализа себя оправдала: если бы, к примеру, мы ограничились рассмотрением лучшего (двухпотокового) результата, можно было бы ошибочно сделать вывод о том, что ядро Prescott быстрее в плане исполнения инструкций, причем даже в режиме MMX/FPU. Сейчас же хорошо видно, что быстродействие возросло исключительно благодаря оптимизации использования ресурсов виртуальных CPU.
Тесты в реальных приложениях
Перед тем как начать рассмотрение результатов тестов в реальных приложениях, сделаем небольшое вводное разъяснение. Дело в том, что процессор Pentium 4 на ядре Prescott с частотой 3,4 ГГц, к сожалению, до сих пор для нас недоступен, поэтому то, что вы видите на диаграммах под названием "Virtual" Prescott 3,4 ГГц это не более чем аппроксимация результатов Prescott 3,2 ГГц, рассчитанная исходя из идеальных условий роста производительности пропорционально частоте. Кто-то может заметить, что это слишком топорный подход. Дескать, намного корректнее было бы, к примеру, разогнать имеющийся Prescott 3,2 ГГц с помощью выставления большей частоты FSB, или хотя бы выстроить кривую аппроксимации по трем точкам: Prescott 2,8 ГГц -> 3,0 ГГц -> 3,2 ГГц. Разумеется, так было бы корректнее. Однако «на всякого мудреца довольно простоты», и просто обратите внимание на то, какие поправки вносит в общую картину наличие на диаграммах даже «идеального» Prescott 3,4 ГГц (а реальный будет либо таким же, либо медленнее третьего не дано). Рискуя навлечь на себя немилось преждевременным разглашением тайны, скажем сразу: да практически никаких. Где ядро Prescott выигрывает там это и так видно. А где проигрывает не помогают ему даже идеализированные 3,4 ГГц
Работа с графикой
Самые предсказуемые результаты у Northwood 3,4 ГГц (немного лучше, чем у Northwood 3,2 ГГц) и Prescott 2.8 ГГц (отсутствие поддержки Hyper-Threading сразу же выбросило его в аутсайдеры). Prescott 3,2 ГГц пытается быть хотя бы наравне с одночастотным Northwood, но у него не получается даже это. Ну а наш «виртуальный Prescott 3,4 ГГц», в свою очередь, не смог обогнать реальный Northwood 3,4 ГГц что тоже естественно. C другой стороны, можно заметить, что все процессоры кроме Prescott 2,8 ГГц почти равны. Вряд ли это будет аргументом для апгрейда на Prescott, но хотя бы не станет существенным доводом против его покупки для тех, кто задумывается над приобретением новой системы.
В Lightwave ситуация аналогичная, только Prescott отстает еще больше. Здесь уместно будет вспомнить, что Lightwave (судя по сравнению результатов 6-й ветки с 7-й), затачивался под Pentium 4 очень тщательно и скрупулезно. Можно предположить, что именно поэтому он оказался так чувствителен к малейшим архитектурным изменениям в ядре. Также отметим, что впервые протестированный нами в этой программе Athlon 64 3400+ демонстрирует пусть и не лучший, но вполне приличный результат.
Для Photoshop в современных процессорных архитектурах, видимо, самым главным параметром является размер кэша. Мы уже неоднократно обращали внимание на то, что эта программа весьма «кэшелюбива», и результаты Prescott это подтверждают.
Кодирование медиаданных
Вообще, поскольку мы тестируем новую (или существенно модифицированную, если вам так больше нравится) архитектуру то для нас любое приложение может стать маленьким открытием. По сути, сейчас количество даже важнее качества, потому что нам просто необходимо набрать как можно больше данных о том, как старые (еще не оптимизированные под Prescott) программы ведут себя с новым процессорным ядром. Вот, тот же LAME: оказывается, для него Prescott по всем статьям новый процессор результаты совершенно не ложатся на то, что мы ранее знали про Northwood. Правда, они стали хуже. Что ж, бывает. Продолжаем коллекционировать
Ogg Encoder демонстрирует практически идентичную картину: Prescott существенно проигрывает всем остальным процессорам без исключения, несмотря на удвоенный кэш данных первого уровня и L2. Остается предположить, что виновато увеличение длины конвейера при оставшемся неизменным объеме Trace Caсhe.
Даже тяготеющий к архитектуре NetBurst кодек DivX невзлюбил новое ядро. Не то что бы очень сильно, но все-таки оно ему не понравилось. Впрочем, тут есть определенная надежда на SSE3 разработчики DivX просто обожают различные оптимизации (во всяком случае, судя по анонсам), поэтому весьма велик шанс, что единственная и неповторимая инструкция, предназначенная для ускорения кодирования видео, найдет свое место в будущем релизе данного кодека. Однако это все в будущем, а пока увы
А вот результаты XviD мы опять не приводим по причине совершенно невообразимого «фортеля», который в очередной раз выкинула эта нежно нами любимая программа. Дело в том, что прирост производительности Prescott по отношению к Northwood в ней составил 232%! Такие тесты, пардон, мы использовать просто отказываемся. Похоже, что их результаты могут зависеть вообще от чего угодно
Ну, вот и первая победа. Впрочем, возвращаясь к теме о предпочтениях различного ПО, можно заметить, что Windows Media Video 9 весьма неплохо поддерживает Hyper-Threading, а данные низкоуровневых тестов показали, что эффективность задействования виртуальных CPU в случае с новым ядром возрастает. Похоже, что это первый положительный результат, достигнутый за счет качественного, а не количественного изменения в Prescott. Во всех предыдущих случаях он «выезжал» исключительно за счет большого объема кэша
Очень, очень интересный результат. Mainconcept MPEG Encoder, которому мы пеняли за «корявую» работу с Hyper-Threading при кодировании в формат MPEG1 вполне адекватно работает с виртуальными процессорами, если они эмулируются Prescott, а не Northwood! Впору даже задуматься: быть может, программисты не виноваты, просто «затык» был в процессорном ядре, которое некорректно распараллеливало потоки? Вполне возможно, по крайней мере, глядя на результаты Prescott, понимаешь, что и это предположение имеет право на жизнь. C другой стороны вполне неплохо себя показал Prescott 2,8A ГГц, про Hyper-Threading и слыхом не слыхавший. Забавная ситуация. Пожалуй, мы находимся на пороге интересного открытия: напрашивается предположение, что вся «оптимизация работы Hyper-Threading в Prescott» сводится всего лишь к тому что этой технологии в Northwood не хватало объема кэша, чтобы развернуться в полную силу!
И снова можно порадоваться за новое ядро: в Mainconcept MPEG Encoder не только пропал «глюк» с кодированием MPEG1, но и преобразование в MPEG2 стало работать существенно быстрее. Имея в виду результаты предыдущих тестов, можно почти однозначно утверждать, что основным виновником торжества является улучшенная работа Hyper-Threading (и не забываем о том, за счет чего она могла стать лучше если наши предположения верны). Что самое интересное не понадобились даже специальные команды для управления потоками из набора SSE3, процессор сам отлично разобрался (поддержку SSE3 в данной версии кодировщика предполагать не приходится она вышла довольно давно).
А вот Canopus ProCoder просто почти ничего не заметил. В принципе, небольшая разница в производительности присутствует, и она даже в пользу Prescott. Но, по сути, это копейки, мелочь. Учитывая «кэшелюбивость» ProCoder, можно даже сказать так: весь большой кэш, судя по всему, ушел на компенсацию других недостатков нового ядра. Он просто вытянул Prescott на ту же высоту, что и Northwood, но, увы не более.
Архивирование
Традиционно, мы протестировали 7-Zip как со включенной поддержкой многопоточности, так и без нее. Ожидаемый эффект достигнут в этой программе не был: не заметно, чтобы многопоточность на Prescott давала намного больший эффект, чем на Northwood. Да и вообще особой разницы между старым и новым ядром не видно. Похоже, что мы наблюдаем упомянутый выше эффект: все, что смогли сделать количественные показатели Prescott (объемы кэша L1 Data и L2) это компенсировать его же удлиненный конвейер.
К слову: один из немногих тестов, где хоть как-то видна разница между платами. В остальном все та же картина: Prescott и Northwood одинаковой частоты идут рядом, практически не отличаясь по скорости. Пессимисты скажут: «плохо», оптимисты: «могло быть и хуже» :). Мы просто промолчим
Игры
Картина во всех трех играх схожая, поэтому особенно расписываться нет нужды: Prescott все же медленнее. Правда, ненамного.
Обобщая результаты
Что ж, если делать какие-то выводы на основании тех тестов, что присутствуют в статье, то ситуация выглядит следующим образом: ядро Prescott в целом медленнее Northwood. Иногда это удается компенсировать большим объемом кэша, вытянув производительность на уровень старого ядра. Ну а если программа особенно чувствительна к объему L2, Prescott даже способен выиграть. Кроме того, несколько улучшилась эффективность Hyper-Threading (но похоже, что причина снова кроется в увеличении объема L2-кэша). Соответственно, если программа умеет использовать обе сильные стороны нового ядра большой кэш и виртуальную многопроцессорность то выигрыш получается ощутимым. В целом же, производительность Prescott примерно такая же, как у Northwood, а применительно с старому, неоптимизированному ПО даже более низкая. Ожидаемой революции, увы, не получилось. С другой стороны а был ли мальчик? Но об этом ниже.
Что же касается Prescott 2,8A ГГц с 533-мегагерцевой системной шиной и без поддержки Hyper-Threading, то как раз тут все предельно ясно. Во-первых, для Intel это просто очень хороший способ сделать хотя бы что-то из тех экземпляров, которые в «настоящем Prescott'овском» режиме банально не заработали. Этакий «Celeron среди Prescott'ов» (хотя будет, судя по всему, на базе этого ядра и официальный Celeron). Во-вторых отсутствие Hyper-Threading скорее всего свидетельствует о принципиальном нежелании Intel видеть HT на устаревшей, низкоскоростной шине. Действительно: единственным представителем 533 МГц FSB + HT так и остался первый процессор с поддержкой этой технологии Pentium 4 3,06 ГГц. Да и то по вполне понятной, извиняющей его причине: не было еще на тот момент CPU с 800-мегагерцевой шиной.
Таким образом, да простят нам инженеры Intel эту вольность, Pentium 4 2,8A ГГц это «как бы не Prescott». А просто сравнительно недорогой (другим его выпускать нельзя не купит ведь никто ), но высокочастотный Pentium 4. И совершенно неважно, на каком он сделан ядре, не в этом суть. Честно говоря, было искушение его в этот материал вообще не включать, но потом мы решили поступить наоборот: дать ему один раз «засветиться», и более к данному чудному процессору не возвращаться. Из простого сравнения одночастотных ядер Prescott и Northwood понятно, что без Hyper-Threading Prescott 2.8 ГГц даже с Pentium 4 2.8C (800 МГц FSB + HT) по усредненным показателям производительности соперничать не сможет.
Версии
Да, именно «версии», а не «выводы». Слишком неоднозначным получился этот материал. Проще было бы ограничиться анализом диаграмм и сделать напрашивающийся, лежащий на поверхности вывод: «если новое не быстрее (а то и медленнее) старого значит, оно хуже». Списать, так сказать, в расход. Однако самый простой ответ не всегда самый правильный. Поэтому мы решили коснуться аналитики, и рассмотреть выход Prescott в исторически-рыночной перспективе. Получилось, что ответов на вопрос «в чем для Intel состоит смысл выпуска Pentium 4 на ядре Prescott?» на самом деле несколько, и каждый из них можно логично аргументировать.
Версия первая или Большая ошибка
Почему бы и нет? Жила-была компания Intel, и появилась у нее идея: сделать процессорное ядро, ориентированное не на максимальный КПД (если рассматривать КПД как соотношение производительности к частоте), а на легкую масштабируемость. Дескать, если наши 2000 МГц проигрывают 1000 МГц от конкурента не беда, догоним частоту до 4 ГГц и оставим всех позади. Между прочим, с чисто инженерной точки зрения, это вполне адекватное решение. Не все ли равно? Пользователя-то (грамотного) все равно интересуют не мегагерцы, а производительность, какая ему разница, за счет чего она достигается? Главное чтобы масштабируемость оказалась именно такой, какую предполагалось достичь. И вот, выясняется, что с масштабируемостью начались большие проблемы. Догнали до 3,4 ГГц, остановились и пришлось придумывать новое ядро, у которого КПД еще ниже и неизвестно, какими темпами будет расти у него частота и так далее. Напомним, что это версия. Рассмотрим ее внимательнее в сопоставлении с реальными фактами.
Факт, свидетельствующий в пользу данной версии рост частоты Pentium 4 за прошедший 2003 год. Все-таки 200 МГц, да еще и по отношению к такой «частотолюбивой» архитектуре как NetBurst явно мало. Однако как общеизвестно, рассматривать какой-то факт в отрыве от других не очень хорошая практика. Был ли смысл в активном наращивании частоты Pentium 4 в прошлом году? Вроде бы нет Основной конкурент решал другие вопросы у него новая архитектура, новое ядро, ему нужно наладить массовое производство процессоров на базе этого ядра, обеспечить им соответствующую обвязку в виде чипсетов, системных плат, программного обеспечения, в конце концов! Поэтому один из вариантов ответа на вопрос «почему практически не росла частота (и производительность) Pentium 4 в 2003 году» звучит просто: не было особого смысла ее наращивать. Ни догонять, ни перегонять вроде некого. Стало быть, можно особенно не торопиться.
Получить ответ на главный вопрос мы, увы, пока не можем: как будет «гнаться» новое ядро? Пока что, если судить по внешним признакам, фактов, подтверждающих хорошую масштабируемость Prescott нет. Впрочем, равно как и опровергающих ее. Анонсированы 3,4-гигагерцевые версии как Prescott, так и Northwood. Northwood 3,4 ГГц, наверное, будет последним процессором на этом ядре (хотя, официальных подтверждений этого предположения нет). А то, что Prescott стартовал с 3,4 ГГц, а не с 3,8 или 4,0 тоже легко объяснимо: зачем прыгать через ступеньки? Подводя итог: версия «Большой ошибки», в принципе, имеет право на существование. Но если частота (а еще точнее, производительность) Prescott будет быстро расти, это однозначно подтвердит ее несостоятельность.
Версия вторая или Переходное ядро
Ни для кого не секрет, что иногда производителю требуется выпустить некое устройство, достаточно ординарное само по себе (в другой ситуации совершенно не заслуживающее звания релизного продукта). Но в том-то и дело, что выпуск данного устройства необходим для продвижения на рынок других, анонсируемых одновременно с ним или чуть позже. Таким был Pentium 4 Willamette, вряд ли достойный звания «хорошего и быстрого процессора», однако явно обозначивший факт перехода одного из самых крупных игроков на процессорном рынке, на новое ядро, и под конец своего существования сменивший «промежуточный» Socket 423 на «долгоиграющий» Socket 478. Что, если аналогичная роль уготована Prescott?
Уже всем известно, что с выходом Grantsdale-P, нас ждет появление еще одного процессорного разъема для Pentium 4 (Socket T / Socket 775 / LGA775), и поначалу устанавливаться в него будут именно CPU на ядре Prescott. Лишь впоследствии Pentium 4 «Tejas» начнет постепенно их замещать. И тут вполне логично задаться вопросом: а насколько быстро будет происходить это замещение? Поскольку мы все равно лишь выдвигаем версии, ограничивать свою фантазию не будем, и предположим, что Intel желает этот процесс максимально ускорить. С помощью чего? Скорее всего оставив Socket 478 мирно почивать в нижних строчках на диаграммах производительности, и сделав Socket 775 символом обновленной, мощной и скоростной платформы для Pentium 4. Тогда все становится ясно: Prescott нужен для того, чтобы на рынке присутствовал процессор, способный работать как в платах с разъемом Socket 478, так и с новым Socket 775. Tejas же, если наши предположения верны, будет устанавливаться только в Socket 775, и станет, таким образом, могильщиком как для Prescott, так и для устаревшей платформы Socket 478. Логично? Нам кажется, что да. В таком случае, правдоподобно смотрится и следующее предположение: жизнь Prescott’у уготована весьма недолгая
Версия третья или «Кто с мечом к нам придет »
Не секрет, что соперничество между двумя основными конкурентами Intel и AMD, почти всегда строилось на противопоставлении двух основных аргументов. Intel: «наши процессоры самые быстрые!», AMD: «зато у наших лучше соотношение цены и производительности!». Соперничество давнее, аргументы тоже. Причем, они не изменились даже с выходом процессоров AMD на ядрах K7/K8, несмотря на то, что у последних с производительностью дела обстоят намного лучше, чем у K6. Ранее Intel не делала исключений из основного своего правила: продавать свои CPU с производительностью, аналогичной процессорам конкурента, немного дороже. Рынок местами очень прост, поэтому причина такого поведения понятна: если их и так покупают то зачем снижать цену? Опять-таки: хоть участвовать в ценовых войнах Intel и приходилось, но развязывала их всегда AMD, это уже стало традицией. Третья версия базируется на очевидном предположении: а что если на этот раз Intel решила повести себя агрессивнее, чем обычно, и развязать ценовую войну первой?
В списке достоинств нового ядра Prescott числится не только новизна, объемы кэшей, и потенциально хорошая (правда, пока не подтвержденная) масштабируемость, но и цена! Это сравнительно дешевое в производстве ядро: если при использовании 90-нанометровой технологии будет достигнут показатель выхода годных чипов хотя бы такой же, как у Northwood то, ничуть не теряя в абсолютных показателях прибыли, Intel сможет продавать свои процессоры за гораздо меньшую цену. Напомним одну очевидную зависимость: такую характеристику CPU как «соотношение цена / производительность», можно улучшать, не только повышая производительность, но и снижая цену. Вообще-то, никто не мешает быстродействие даже понизить (!) главное, чтобы цена упала еще больше :). Судя по появляющимся в Сети неофициальным анонсам цен на Pentium 4 Prescott, стоить они будут намного дешевле Pentium 4 Northwood. Таким образом, мы можем предположить, что Intel решила осуществить своего рода «обход с флангов»: пока основной конкурент, по старинке, все гонится и гонится за производительностью, ему будет нанесен удар в секторе middle-end систем, где пользователи тщательно анализируют именно такой показатель как price / performance.
Версия четвертая или Тайное оружие
Здесь следует сделать небольшое лирическо-историческое отступление для тех, кто «во времена оные» не очень активно отслеживал разные мелкие нюансы в процессорном секторе. Так, к примеру, можно вспомнить, что сразу после появления первых процессоров с поддержкой Hyper-Threading (а ими были вовсе не Pentium 4 «Northwood» + HT, а Xeon «Prestonia»), многие задались вопросом: «если ядра Prestonia и Northwood настолько похожи, что практически не отличаются по основным характеристикам, но у Prestonia поддержка Hyper-Threading присутствует, а у Northwood ее нет то не логично ли предположить, что и у Northwood она тоже есть, просто искусственно заблокирована?». Впоследствии это предположение косвенно подтвердилось анонсом Pentium 4 3,06 ГГц на все том же ядре Northwood, но уже с Hyper-Threading. Более того, самые смелые выдвигали и вовсе крамольную мысль: Hyper-Threading была даже в Willamette!
А теперь вспомним: что у нас в последнее время известно по части новых технологических инициатив Intel. Сразу всплывают два названия: «La Grande» и «Vanderpool». Первое технология аппаратной защиты приложений от вмешательства извне, которую вкратце можно описать словами «сделать так, чтобы одно ПО не могло вмешиваться в функционирование другого». Впрочем, о La Grande вы можете почитать на нашем сайте отдельную статью. Об Vanderpool информации меньше, но исходя из обрывков доступной на сегодня, можно сделать вывод, что она представляет собой вариацию на тему полной виртуализации PC, включая все без исключения аппаратные ресурсы. Таким образом (самый простой, но и самый эффектный пример), на одном компьютере смогут работать параллельно две операционные системы, причем одна из них может быть даже перезагружена но это совершенно не отразится на работе другой.
Так вот: есть очень большие подозрения, что и La Grande и Vanderpool в ядре Prescott уже реализованы, но (как было ранее с Hyper-Threading) пока не активированы. Если это предположение истинно, то многое относительно самого ядра становится понятным. В частности то, почему оно такое большое, почему так долго разрабатывалось, но, несмотря на это, не выирывает в скорости у предыдущего. Если исходить из гипотезы «Тайного оружия», можно предположить, что основные ресурсы команды разработчиков были направлены вовсе не на достижение быстродействия, а на отладку новых функций. Частично данная версия перекликается со второй так или иначе, но мы имеем дело с переходным ядром. Соответственно, быть совершенным оно вовсе не обязано, ибо не в том его основное предназначение. Между прочим, также удачно вторую и четвертую версии дополняет третья: низкая цена в данном случае является именно той конфеткой, что подсластит для конечного пользователя пилюлю «переходности».
Подводя итоги
Мы не зря назвали эту статью «полшага вперед». Prescott получился более сложным и неоднозначным, чем ожидаемый «Northwood с увеличенным объемом кэша и более высокой частотой» (как многие его воспринимали). Разумеется, можно обвинить производителя в том, что прирост скорости в среднем близок к нулю (а местами и отрицательный), в очередной чехарде с поддержкой процессоров на базе нового ядра системными платами И, между прочим, вполне справедливо это сделать. Это, в конце концов, не наши проблемы а между тем, именно мы с ними и столкнемся. Поэтому просто поставим в конце статьи «жирное троеточие». На стоп-кадре видно только начало шага: нога, зависшая в воздухе, или, если угодно, лайнер на взлете. Что нас ждет дальше? Благоприятным ли окажется «приземление» (Tejas?..) Пока можно только догадываться.


