Обзор VPU 3Dlabs P10 и карты Wildcat VP870 на его основе
или "Наглядный процессор"
(А.Л. Гуртовцев, В.С. Гудыменко — "Программы для микропроцессоров", с.3.)

СОДЕРЖАНИЕ
- Общие сведения о P10 и позиционирование
- Линейка продуктов
- Спецификации P10
- Архитектура P10
- Особенности видеокарты 3Dlabs Wildcat VP870 128MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D и предельные тесты из DirectX 8.1 SDK
- Результаты тестов: Синтетические тесты 3DMark2001 SE
- Результаты тестов: Игровые тесты 3DMark2001 SE
- Качество 3D в играх
- Результаты тестов: Профессиональные тесты: SPECviewperf 7.0
- Результаты тестов: Профессиональные тесты: Discreet 3DS MAX 4.26
- Выводы
Р10 можно по праву приоритета считать основателем крепнущего племени гибко программируемых GPU. При ближайшем рассмотрении становится ясно, что этот чип занимает особенное положение. P10 — ничто иное, как железное воплощение проекта стандарта API OpenGL 2.0. В том понимании, в котором этот API видится 3Dlabs. Мы уже подробно писали о проекте OpenGL 2.0 и не раз уделяли внимание возможностям DirectX 9 (в аналитических материалах по Matrox Parhelia-512 и ATI RADEON 9700). Внимательный читатель заметил: несмотря на общность идей, связанную с возможностью гибко программировать работу графического ускорителя, можно легко найти отличия в реализации этих идей, даже на уровне API. Теперь, с появлением в нашей лаборатории карты на базе 3Dlabs P10, мы сделаем выводы об отличиях на уровне железа.
Позиционирование
Ни в коей мере не следует напрямую сравнивать эту карту (на уровне спецификаций, частот или скорости в игровых тестах и приложениях) с новейшими игровыми решениями — чип разрабатывался как профессиональный ускоритель OpenGL приложений, со всеми вытекающими отсюда последствиями. Известно, что игровые приложения, в своей основной массе, по-прежнему, нуждаются в скорости закраски и текстурирования, в то время как профессиональные — в скорости трансформации и освещения. Кроме того, игровые приложения (не будем пока вспоминать о будущих, завязанных на шейдеры играх, например, на основе движка Next Doom) пока не требуют какого-либо выдающегося набора дополнительных возможностей. Тем паче не идет разговор о краевом сглаживании или экзотических методах качественного мультисамплинга и AA. Даже максимальные установки анизотропной фильтрации редко задействуются обычными игроками.
Профессиональный ускоритель — таково позиционирование этого чипа разработчиками. Само собой разумеется, что Creative, купивший 3Dlabs, обращает свое внимание в первую очередь на массовый и, следовательно, игровой рынок (вспомните, что в свое время произошло с также приобретенным Creative разработчиком профессиональных звуковых решений EMU и его творениями). Очевидно, что чуть позже Р10 также будет выпущен на игровое поле, возможно, с некоторыми аппаратными модификациями (с архитектурной точки зрения этот GPU является очень легко масштабируемым в любом направлении — как в сторону увеличения fillrate, так и в любую другую). Возможно, что Creative на первых порах ограничится и просто заточенными под игры драйверами. С нашей точки зрения, подобный сценарий позволителен только при условии невысокой цены игровых решений на базе P10 — по некоторым причинам (мы вернемся к ним далее), конкурировать на игровом поле с будущими топовыми решениями NVIDIA и ATI им не под силу. Вне зависимости от степени оптимизации драйверов.
А теперь давайте посмотрим, как позиционируются карты на основе P10 внутри семейства профессиональных ускорителей 3Dlabs:
Линейка продуктов
- Wildcat VP970: 128 MB of 256-bit DDR SDRAM; 225M Vertices/Sec; 42G AA Samples/Sec; Решение предназначено для тяжелых процессов отрисовки в CAD/DCC приложениях всех видов.
- Wildcat VP870: 128 MB of 256-bit DDR SDRAM; 188M Vertices/Sec; 35G AA Samples/Sec; Решение также предназначено для CAD/DCC приложений (но более легкого плана).
- Wildcat VP760: 64 MB of 256-bit DDR SDRAM; 165M Vertices/Sec; 23G AA Samples/Sec; Это решение также позиционируется для CAD приложений и являет собою разумный компромисс между ценой и мощностью.
Вся линейка расположена в середине большой пирамиды, символизирующей охват различных секторов профессионального рынка продуктами от 3Dlabs.
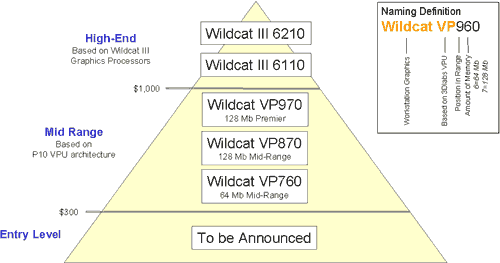
Как мы видим, несмотря на революционность нового изделия, это не High-End, в отличие от всех новинок от NVIDIA или ATI. Наверху сегмента по-прежнему тяжеловесы семейства Wildcat III, настоящие "львы" рынка профессиональной 3D-графики. Вместе с тем, как мы убедимся далее, даже "середнячок из середины" — Wildcat VP870 — способен соперничать с High-End продуктом от NVIDIA — Quadro4 900XGL. Хотя и позиционируется самой 3Dlabs, как конкурент Quadro4 750XGL.
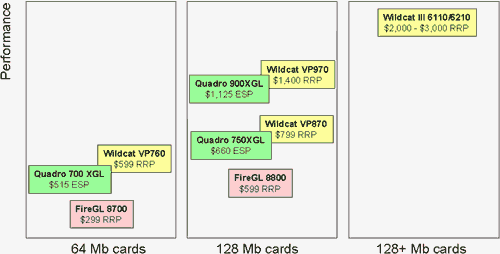
Ну а теперь приступим к рассмотрению характеристик P10.
Спецификации
Приведем уже традиционные ТТХ ускорителя и карты на его основе — VP870:
- Технология производства: 0.15 микрон;
- Число транзисторов: более 76 миллионов;
- Тактовая частота ядра: неизвестна (предположительно 200-250 МГц);
- Шина памяти: 256 бит DDR;
- Максимальный объем локальной памяти: 256 Мб;
- Объем локальной памяти на тестируемой карте: 128 Мб;
- Тактовая частота памяти: неизвестна (предположительно 250-300 DDR МГц), пропускная способность около 17-20 Гб/сек;
- Интерфейсная шина: AGP 4x, пропускная способность 1 Гб/сек;
- Полная поддержка всех возможностей проекта стандарта OpenGL 2.0 от 3Dlabs ;
- Оптимизированные для профессиональных приложений драйверы;
- 16 скалярных плавающих (F32) гибко конфигурируемых вершинных процессоров (более гибкий аналог четырех векторных 4D процессоров R300 или NV30);
- 64 плавающих (F32) процессора для генерации текстурных координат;
- 64 непрограммируемых блока для выборки и фильтрации значений текстур
- Поддержка трилинейной и анизотропной фильтрации;
- 64 целочисленных (фиксированная точка) процессора для исполнения пиксельных шейдеров;
- Возможность произвольно программировать (!) последние ступени пиксельного конвейера, отвечающие за чтение и запись значений в кадровый буфер, сглаживание и мултисамплинг;
- В буфер кадра может быть выведено (без учета мултисамплинга) не более 4 полностью рассчитанных пикселей за такт.
- Неполная (!) поддержка возможностей DX9 (пиксельные конвейеры на шейдерной стадии оперируют только с целочисленной арифметикой):
- Пиксельные шейдеры версии 1.4;
- Вершинные шейдеры версии 2.0 (?);
- Мультисамплинг до 8x включительно;
- Аппаратная тесселяция N-Patches с картами смещения (Displacement Mapping) и, по желанию, адаптивным уровнем детализации;
- Возможность многопоточного исполнения команд — построение изображения параллельно для нескольких приложений и окон с аппаратным менеджментом потоков команд;
- Технология экономии пропускной полосы памяти на основе поблочной закраски треугольников (блоки 8х8);
- HSR — возможность раннего отбрасывания невидимых блоков 8х8 и ранний Z тест на пиксельном уровне;
- Два независимых CRTC;
- Два встроенных 10 бит 400 МГц RAMDAC с аппаратной гамма коррекцией;
- Встроенный (два?) DVI (TMDS трансмиттер) интерфейс.
- Встроенный цифровой интерфейсный видео порт общего назначения.
| Ускоритель | R200(128 MB) | NV25(Ti 4600) | R300 | NV30 (1) | Parhelia 512 | P10(VP870) |
|---|---|---|---|---|---|---|
| Технология; число транзисторов, млн | 0.15; 62 | 0.15; 68 | 0.15; 107 | 0.13; 120 | 0.15; 96 | 0.15; 72 |
| AGP | 4x | 4x | 8x | 8x | 4х | 4х |
| Шина памяти, бит | 128 DDR | 128 DDR | 256 DDR (II) (2) | 256 DDR II | 256 DDR | 256 DDR |
| Частота памяти, МГц | 275 | 325 | >300 | >400 | 275 | 250…300 (?) |
| Частота ядра, МГц | 275 | 300 | 300 | 400 | 220 | 200…250 (?) |
| Пиксельных конвейеров | 4 | 4 | 8 | 8 | 4 | 64 (9) |
| Текстурных модулей | 4х2 | 4х2 | 8х1 (3) | 8х2 | 4х4 | 64 (10) |
| Текстур за проход | 6 | 4 | 16 (4) | 16 (4) | 4 | 8 (5) |
| Вершинных конвейеров | 2 | 2 | 4 | 4 | 4 | 16 (7) |
| Фиксированный блок T&L | Да | Нет | Нет | Нет | Нет | Нет |
| N-Patches | DX8 | Нет | DM (DX9) | DM (DX9) | DM (DX9) | DM (DX9) |
| Вершинные шейдеры | 1.1 | 1.1 | 2.0 | 2.0 (6) | 2.0 (?) | 2.0 (?) |
| Пиксельные шейдеры | 1.4 | 1.3 | 2.0 | 2.0 (6) | 1.3 | 1.2 (?) |
| Контроллер памяти | 2х64 | 4х32 | 4х64 | 4х64 | 1х256 | ? |
| RAMDAC, МГц | 400 | 400 | 2*400 | 2*400 (?) | 2*400 | 2*400 |
| Технологии экономии | Да(HyperZ II) | Да(LightSpeed II) | Да(HyperZ III) | Да (LightSpeed 3 ?) | Только ранний Z тест | Блоки 8х8 (8) |
Примечание:
- (1) Компиляция на основе официальных данных и слухов
- (2) Скорее всего, наравне с DDR будет поддерживаться и DDR II.
- (3) Каждый текстурный модуль способен самостоятельно делать трилинейную выборку.
- (4) Согласно требованиям DX9, за один проход может быть использовано до 16 различных текстур с 8 предварительно вычисленными (интерполированными по поверхности треугольника) полными 4D текстурными координатами. При этом, в пиксельном шейдере может быть сделано до 32 выборок конкретных значений из этих текстур.
- (5) Может быть использовано до 8 текстур с предварительно вычисленными или интерполированными полными текстурными координатами. В пиксельном шейдере может быть сделано до 16 выборок конкретных значений из этих текстур.
- (6) Судя по всему, в железе будут реализованы возможности, превышающие требования DX для вершинных и пиксельных шейдеров версии 2.0.
- (7) 16 скалярных плавающих процессоров объединяются по 2, 3 или 4 для обработки векторных величин. Т.е. полные 4D векторные команды выполняются по 4 за такт, так же, как и на R300 или NV30, а скалярные и 2D/3D векторные команды исполняются в большем числе, в зависимости от комбинации команд ждущих выполнения.
- (8) Закраска треугольников по блокам 8х8 для оптимизации кеширования и предварительного HSR на блочном и пиксельном уровне.
- (9) Число параллельных 32 бит целочисленных процессоров для обработки пиксельных шейдеров. Процессоры могут быть гибко переконфигурированы для поддержки того или иного формата вычислений, например, целочисленных форматов R10G10B10A2 или R16G16B16 . Во втором случае число параллельно обрабатываемых пикселей снизится вдвое (будут задействованы по два процессора на один пиксель). Кроме того, есть важное ограничение — чипом может быть записано в буфер кадра (т.е. физически закрашено) максимум 4 точки за такт. Из-за существенного числа процессоров и ограничений технологии .15 3Dlabs не смогли поддержать формат с плавающей точкой, однако планируют сделать это в будущих чипах.
- (10) Судя по всему, реальное число полноценных текстурных блоков ниже — 16 или даже 8.
Архитектура P10
P10 обладает очень специфической архитектурой — фиксированные блоки много раз чередуются с программируемыми, причем программируемые, как правило, организованы в виде широких массивов простых процессоров, гибко конфигурируемых для исполнения тех или иных задач в группы.
Приведем крупномасштабную блочную схему P10:
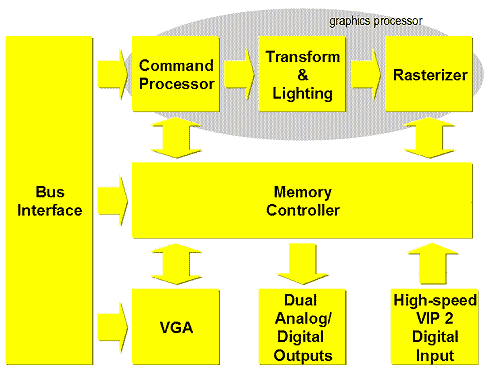
В наличии VGA совместимое графическое ядро, два CRTC, а также специальный цифровой интерфейс для импорта (захвата) видеоданных.
Интересной чертой, полезной для профессионального применения является способность P10 одновременно исполнять параллельные потоки команд от разных приложений. За эту возможность отвечает командный процессор:
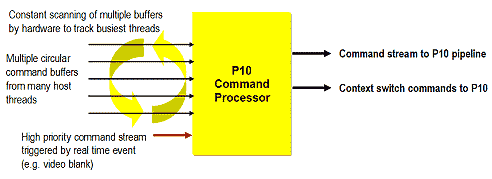
который не только дирижирует 3D конвейером, организуя некий графический аналог "многозадачности" (на основе переключения контекстов), распространенной в современных CPU, но и выполняет приоритетные команды, требующие немедленной реакции "вне очереди", такие, как переключение видеостраниц и пр.
P10 поддерживает так называемое виртуальное текстурирование, самостоятельно управляя блочным кешированием больших текстур в локальной памяти ускорителя:
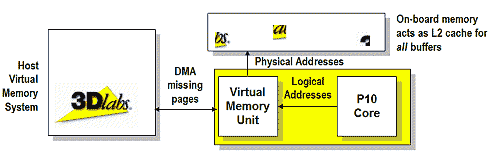
и вновь налицо четкая аналогия с современными CPU, снабженными MMU с поддержкой виртуальной памяти на основе страниц. Здесь роль страниц играют прямоугольные блоки текстур, кешируемые в локальной памяти ускорителя. Подкачка текстур через AGP DIME или PCI DMA осуществляется чипом автоматически, по мере надобности. Таким образом, мы получаем не только эффективное кеширование больших наборов текстур, но и важную для профессиональной графики возможность работать с отдельными текстурами, размер которых может превышать объем локальной памяти ускорителя (!).
Теперь, давайте посмотрим на полную схему трехмерного графического конвейера P10, отвечающего за построение трехмерных изображений:
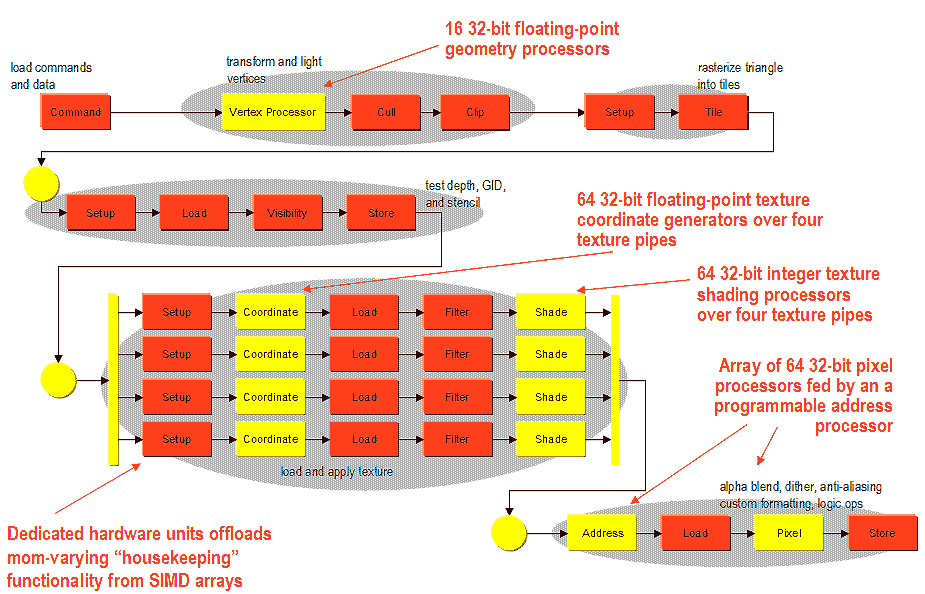
Как обычно в трехмерной графике, наблюдается четкая последовательность поточного прохождения данных через функциональные блоки ускорителя.
Вначале команды попадают в вершинный процессор:
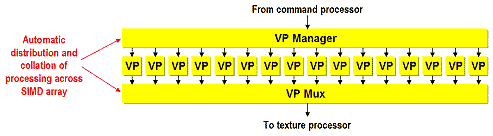
Способный, в отличие от прочих распространных ныне программируемых чипов, не только считывать, но и записывать в память обработанные параметры вершин. Подобная гибкость позволяет запрограммировать практически любые алгоритмы тесселяции сплайновых поверхностей или других представлений HOS и SS (Subdivision Surfaces), включая N-Patches. Интересно, что вершинный процессор способен считывать не только значения вершин и их атрибутов, но и значения текстур, что позволяет реализовать различные алгоритмы пертурбации и генерации геометрии на основе текстурных карт высот, нормалей и других считываемых из текстур значений. Характерный пример подобных алгоритмов — уже не раз описанный нами DM (Displacement Mapping). В этом плане совместимость P10 с DX9 беспокойства не вызывает. Интересно, что в отличие от NVIDIA, MATROX и ATI, в наличии не 4 векторных процессора, а 16 скалярных. Специальный блок (VP Manager) дирижирует этими процессорами на основе команд вершинного шейдера, объединяя их при необходимости для векторной обработки двух, трех или четырехмерных значений. По сравнению с общепринятыми четырьмя векторными процессорами, подобное решение гарантирует равную или превосходящую производительность. Разумеется, при условии одинаковой частоты и сходной производительности выполняющих атомарные операции АЛУ.
Далее полученные в результате работы массива вершинных процессоров координаты вершин и их атрибуты отправляются на закраску. Вначале выделенные аппаратные блоки отбрасывают обратные грани и выходящие за пределы области видимости треугольники (см. также общую схему, блоки Cull и Clip):
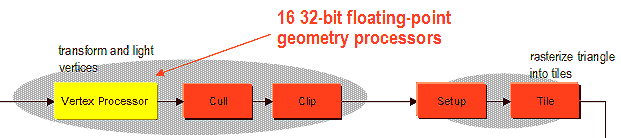
После отбрасывания треугольников, они попадают на установку (Setup) и разбиваются на тайлы 8х8 для последующей растеризации. За это вновь отвечают выделенные аппаратные блоки — подобным подходом разумного чередования программируемых и фиксированных блоков пропитан весь P10.
После разбиения на регионы (тайлы) закраска каждого тайла будет проходить по следующему сценарию:
Вначале проверяется видимость региона в целом и его отдельных пикселов, затем выполняется выборка необходимых значений текстур, затем вычисляются результирующие значения пикселей. Давайте посмотрим на этот процесс более подробно.
Вот так происходит раннее определение необходимости закрашивать блоки и отдельные пикселы (см. также общую схему):

Желтым кружочком обозначена очередь тайлов (фрагментов) 8х8, направляемых на растеризацию. В наличии специальные аппаратные блоки, которые определяют видимость — вначале каждого тайла, а затем и отдельных его пикселов, считывая значения глубины и буфера шаблонов и проводя необходимые сравнения. Далее, уже отдельные видимые пикселы отправляются в очередь на закраску.
Закраска выполняется параллельно для 64 пикселов, т.е. вплоть до целого блока 8х8 (!). Каждый из 64 пикселов проходит следующий путь через фиксированные и программируемые аппаратные блоки:
Программируемыми являются плавающий процессор для генерации координат (Coordinate) и целочисленный пиксельный процессор (Shader). Выбирающие и фильтрующие текстуры блоки Load и Filter реализованы аппаратно и способны выполнять билинейную и трилинейную фильтрацию. Но при необходимости их результаты могут возвращаться в процессор генерации координат, видимо, в том числе и для организации анизотропной фильтрации или более сложных методов выборки текстур. Разумеется, имея программируемый процессор для генерации текстурных координат, мы можем, в том числе, работать и с объемными текстурами и с кубическими или сферическими картами среды. Напомним, что, к сожалению, пиксельный процессор является целочисленным, и это не позволяет ему быть совместимым с пиксельными шейдерами версии 2.0 из DX9.
И наконец, после вычисления финального значения, как результата пиксельного шейдера, оно отправляется в один из специальных программируемых конвейеров:
Которые позволяют реализовывать произвольные методы заполнения буфера кадров, в том числе и различные методы AA и мультисамплинга, а также запись результатов рендеринга сразу в несколько буферов.
Напоследок, прежде чем приступить к тестам производительности, приведем список поддерживаемых текущими драйверами возможностей DirectX 8:
- Размер текстур — до 2048x2048, возможны неквадратные текстуры
- Максимальная степень анизотропии — 8
- Максимальное число источников света — 16
- Максимальное число текстур за один проход — 8
- Число плоскостей отсечения — 6
- Максимальный размер спрайтов — 127
- Максимальное число примитивов за один вызов — 1073741823 (много)
- Размер вершинного буфера — 65536
- Максимальное число потоков вершин — 8
- Версия вершинных шейдеров — 1.1
- Число констант вершинного шейдера — 128
- Версия пиксельных шейдеров — 1.2
- Максимальное значение пиксельного шейдера — 8
- Режимы мултисамплинга: нет, 2, 4, 8 сэмплов
- Форматы итогового буфера:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- Форматы буфера глубины:
- D3DFMT_D32
- D3DFMT_D24S8
- D3DFMT_D16
- D3DFMT_D24X8
- Форматы текстур:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_A8
- D3DFMT_L8
- D3DFMT_A8L8
- D3DFMT_A4L4
- D3DFMT_V8U8
- D3DFMT_L6V5U5
- D3DFMT_X8L8V8U8
- D3DFMT_Q8W8V8U8
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Форматы кубических текстур:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Форматы объемных текстур:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_A8
- D3DFMT_L8
- D3DFMT_A8L8
- D3DFMT_A4L4
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Режимы фильтрации обычных текстур:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MINFLINEAR
- D3DPTFILTERCAPS_MINFANISOTROPIC
- D3DPTFILTERCAPS_MIPFPOINT
- D3DPTFILTERCAPS_MIPFLINEAR
- D3DPTFILTERCAPS_MAGFPOINT
- D3DPTFILTERCAPS_MAGFLINEAR
- D3DPTFILTERCAPS_MAGFANISOTROPIC
- Режимы фильтрации кубических текстур:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MINFLINEAR
- D3DPTFILTERCAPS_MIPFPOINT
- D3DPTFILTERCAPS_MIPFLINEAR
- D3DPTFILTERCAPS_MAGFPOINT
- D3DPTFILTERCAPS_MAGFLINEAR
- Режимы фильтрации объемных текстур:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MAGFPOINT
В общем и целом — все на уровне, возможность использовать до 16 источников света и 8 текстур за проход выглядит привлекательно. Разумеется, поддерживается полный спектр операций с буфером шаблонов и полный набор режимов проверки глубины. Удивляет только отсутствие какой-либо (даже билинейной) фильтрации объемных текстур, но, возможно, это вопрос драйверов. Как бы там ни было, в пределах DX8 реализованы все необходимые базовые возможности, в том числе превышающие NV25. Ясно что с DX9 ситуация будет не столь безоблачна, хотя бы из-за пиксельных шейдеров, однако сказать что-либо точно можно будет только с выходом DX9 драйверов для P10.
Напоследок приведем список поддерживаемых на данный момент OpenGL расширений:
| Matrox, ICD for Parhelia version 1.2 | NVIDIA, GeForce4 Ti 4400/AGP/SSE2, version 1.3.1 | 3Dlabs, Wildcat VP870, version: 1.2.0 |
|---|---|---|
| GL_ARB_multitexture | GL_ARB_imaging | GL_ARB_multitexture |
| GL_ARB_point_parameters | GL_ARB_multisample | GL_ARB_texture_env_add |
| GL_ARB_texture_compression | GL_ARB_multitexture | GL_ARB_texture_env_combine |
| GL_ARB_texture_cube_map | GL_ARB_texture_border_clamp | GL_ARB_texture_env_crossbar |
| GL_ARB_texture_env_add | GL_ARB_texture_compression | GL_ARB_texture_border_clamp |
| GL_ARB_texture_env_combine | GL_ARB_texture_cube_map | GL_ARB_texture_cube_map |
| GL_ARB_texture_env_dot3 | GL_ARB_texture_env_add | GL_ARB_texture_env_dot3 |
| GL_ARB_transpose_matrix | GL_ARB_texture_env_combine | GL_EXT_bgra |
| GL_S3_s3tc | GL_ARB_texture_env_dot3 | GL_EXT_blend_subtract |
| GL_ATI_element_array | GL_ARB_transpose_matrix | GL_EXT_blend_minmax |
| GL_ATI_vertex_array_object | GL_S3_s3tc | GL_EXT_compiled_vertex_array |
| GL_EXT_bgra | GL_EXT_abgr | GL_EXT_polygon_offset |
| GL_EXT_blend_color | GL_EXT_bgra | GL_EXT_rescale_normal |
| GL_EXT_blend_func_separate | GL_EXT_blend_color | GL_EXT_separate_specular_color |
| GL_EXT_blend_logic_op | GL_EXT_blend_minmax | GL_EXT_secondary_color |
| GL_EXT_blend_minmax | GL_EXT_blend_subtract | GL_EXT_texture3D |
| GL_EXT_blend_subtract | GL_EXT_compiled_vertex_array | GL_EXT_texture_object |
| GL_EXT_secondary_color | GL_EXT_separate_specular_color | GL_EXT_texture_edge_clamp |
| GL_EXT_compiled_vertex_array | GL_EXT_fog_coord | GL_EXT_texture_env_add |
| GL_EXT_draw_range_elements | GL_EXT_multi_draw_arrays | GL_EXT_texture_env_combine |
| GL_EXT_element_array | GL_EXT_packed_pixels | GL_EXT_texture_env_dot3 |
| GL_EXT_fog_coord | GL_EXT_paletted_texture | GL_EXT_texture_cube_map |
| GL_EXT_multi_draw_arrays | GL_EXT_point_parameters | GL_EXT_texture_filter_anisotropic |
| GL_EXT_packed_pixels | GL_EXT_rescale_normal | GL_EXT_multi_draw_arrays |
| GL_EXT_point_parameters | GL_EXT_clip_volume_hint | GL_SGIS_multitexture |
| GL_EXT_rescale_normal | GL_EXT_draw_range_elements | GL_SGIS_texture_border_clamp |
| GL_EXT_secondary_color | GL_EXT_shared_texture_palette | GL_SGIS_texture_lod |
| GL_EXT_separate_specular_color | GL_EXT_stencil_wrap | GL_NV_register_combiners |
| GL_EXT_stencil_wrap | GL_EXT_texture3D | GL_NV_vertex_program |
| GL_EXT_subtexture | GL_EXT_texture_compression_s3tc | GL_NV_texgen_reflection |
| GL_EXT_texture3D | GL_EXT_texture_edge_clamp | GL_WIN_swap_hint |
| GL_EXT_texture_compression_s3tc | GL_EXT_texture_env_add | GL_KTX_buffer_region |
| GL_EXT_texture_cube_map | GL_EXT_texture_env_combine | - |
| GL_EXT_texture_edge_clamp | GL_EXT_texture_env_dot3 | - |
| GL_EXT_texture_env_add | GL_EXT_texture_cube_map | - |
| GL_EXT_texture_filter_anisotropic | GL_EXT_texture_filter_anisotropic | - |
| GL_EXT_texture_lod_bias | GL_EXT_texture_lod | - |
| GL_EXT_vertex_array | GL_EXT_texture_lod_bias | - |
| GL_EXT_vertex_array_object | GL_EXT_texture_object | - |
| GL_EXT_vertex_shader | GL_EXT_vertex_array | - |
| GL_EXT_texture_env_combine | GL_EXT_vertex_weighting | - |
| GL_EXT_texture_env_dot3 | GL_HP_occlusion_test | - |
| GL_KTX_buffer_region | GL_IBM_texture_mirrored_repeat | - |
| GL_MTX_fragment_shader | GL_KTX_buffer_region | - |
| GL_NV_texgen_reflection | GL_NV_blend_square | - |
| GL_SGIS_multitexture | GL_NV_copy_depth_to_color | - |
| GL_SGIS_texture_lod | GL_NV_evaluators | - |
| WGL_EXT_swap_control | GL_NV_fence | - |
| - | GL_NV_fog_distance | - |
| - | GL_NV_light_max_exponent | - |
| - | GL_NV_multisample_filter_hint | - |
| - | GL_NV_occlusion_query | - |
| - | GL_NV_packed_depth_stencil | - |
| - | GL_NV_point_sprite | - |
| - | GL_NV_register_combiners | - |
| - | GL_NV_register_combiners2 | - |
| - | GL_NV_texgen_reflection | - |
| - | GL_NV_texture_compression_vtc | - |
| - | GL_NV_texture_env_combine4 | - |
| - | GL_NV_texture_rectangle | - |
| - | GL_NV_texture_shader | - |
| - | GL_NV_texture_shader2 | - |
| - | GL_NV_texture_shader3 | - |
| - | GL_NV_vertex_array_range | - |
| - | GL_NV_vertex_array_range2 | - |
| - | GL_NV_vertex_program | - |
| - | GL_NV_vertex_program1_1 | - |
| - | GL_SGIS_generate_mipmap | - |
| - | GL_SGIS_multitexture | - |
| - | GL_SGIS_texture_lod | - |
| - | GL_SGIX_depth_texture | - |
| - | GL_SGIX_shadow | - |
| - | GL_WIN_swap_hint | - |
| - | WGL_EXT_swap_control | - |
Перейдем к рассмотрению непосредственно самой карты.
Плата
Подчеркну, что мы рассматриваем не опытный образец, а серийную карту.
Карта снабжена
 |  |
| На карте установлены микросхемы памяти Samsung, BGA форм-фактора. Время выборки — 3.3 нс, что соответствует примерно 300 (600) МГц. Память предположительно работает на частотах 250-300 МГц |  |
| 3Dlabs Wildcat VP870 | |
|---|---|
 |  |
| C кулером | |
 | |
Перед нами карта очень необычного дизайна. Разумеется, наличие 256-битной высокоскоростной шины не может не привести к усложнению PCB. Прежде всего мы заметим наличие экрана, предохраняющего от наводок:

В противоположность карте Matrox Parhelia 128MB, можно заметить, что на Wildcat VP870 практически "пусто", нет того огромного количества вспомогательных и буферных элементов на карте. Интересно то, что разработчики решили продемонстрировать число слоев на PCB (а их 8, ибо, как мы уже говорили, разводка довольно сложна из-за 256-битной шины памяти), сделав что-то наподобие контрольного "окна" на PCB и пронумеровав слои:



В наличии DVI выход, поэтому для подключения двух обычных CRT-мониторов обязательно потребуется переходник DVI-to-d-Sub. Разумеется, нельзя обойти вниманием и наличие TV-out (гнездо S-Video). В целом, PCB получилась весьма дорогая, но, вероятно, не настолько, как у Matrox. Мы полагаем, что относительно дешевую игровую карту можно создать и на базе такой PCB.
Микросхемы памяти расположены вокруг чипа, но на разном расстоянии, что выглядит необычно. Также интересно отметить, что расстояние между процессором и микросхемами сильно уменьшено, и из за этого карта выглядит совсем пустой — часть микросхем "спрятались" под кулером. Давайте посмотрим на сам VPU:

Несмотря на то, что VPU снабжен 256-битным интерфейсом памяти, используется обычный корпус, хотя и немного большего размера. Несмотря на сложность архитектуры, процессор не очень сильно греется, т.к. число транзисторов и технология сравнимы с чипами класса NV25, а тактовые частоты, в свою очередь, не столь велики.
Однако все равно для такого мощного чипа нужен весьма эффективный кулер. Обратите внимание на форму и размеры охлаждающего устройства.
| Как мы видим, используется уже привычный нашему глазу закрытый радиатор со смещенным относительно центра чипа вентилятором. Такую форму кулера мы уже видели на картах на базе GeForce4 Ti, в частности, компании MSI, Triplex используют точно такие же охлаждающие устройства (только с разной формой крышек). |  |
 |
Установка и драйверы
Рассмотрим конфигурацию тестового стенда, на котором проводились испытания карты:
- Компьютер на базе Pentium 4 (Socket 478):
- процессор Intel Pentium 4 2200 (L2=512K);
- системная плата ASUS P4T-E (i850);
- оперативная память 512 MB RDRAM PC800;
- жесткий диск Quantum FB AS 20GB;
- операционная система Windows XP.
На стенде использовались мониторы
При тестировании применялись драйверы от 3Dlabs версии 4.23. VSync отключен.
Для сравнительного анализа приведены результаты следующих видеокарт:
- ASUS V8460Ultra (GeForce4 Ti 4600, 300/325 (650) МГц, 128 МБ, driver 29.42);
- Matrox Parhelia 128MB (220/275 (550) МГц, 128 МБ, driver 2.31);
- Gigabyte MAYA AP128DG-H RADEON 8500 Deluxe (275/275 (550) МГц, 128 МБ, driver 6.118);
- Hercules 3D Prophet 9000 Pro (RADEON 9000 Pro, 275/275 (550) МГц, 128 МБ, driver 6.118);
- ATI RADEON 7500 (290/230 (460) МГц, 64 МБ, driver 6.118);
- Joytech Apollo Blade Monster Xabre 400 (250/250 (500) МГц, 128 МБ, driver 3.03);
- Leadtek Winfast A170V (GeForce4 MX 440, 270/200 (400) МГц, 64 МБ, driver 29.42);
- NVIDIA Quadro4 750XGL (275/275 (550) МГц, 128 МБ, driver 28.32(ViewPerf7),29.42(3DS MAX));
- NVIDIA Quadro4 900XGL (300/325 (650) МГц, 128 МБ, driver 28.32(ViewPerf7),29.42(3DS MAX));
- ATI FireGL 8800 (RADEON 8800, 250/300 (600) МГц, 128 МБ, driver 3.036).
Настройки драйверов
Перед нами главное меню настроек, как мы видим, это краткая информационная панель.
В качестве основной информационной панели служит эта закладка, позволяющая посмотреть как версии драйверов, так и поддерживаемые расширения (OpenGL) и возможности DirectX-драйвера (CAPS).
А здесь настройки OpenGL, они самые богатые, поскольку набор драйверов в данном исполнении оптимизирован под профессиональные пакеты, которые работают в OpenGL (кстати, внизу можно выбрать оптимизацию драйвера под тот или иной пакет, выбор огромен). Настройки Direct3D весьма скромны, и там можно только регулировать VSync и включать оптимизацию под игры (правда, никакого эффекта это не дает).
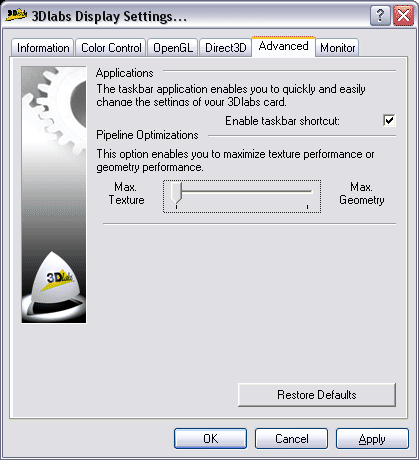
Эта закладка самая таинственная. Ниже, при тестировании в профессиональных приложениях, мы убедимся, что положение бегунка играет весьма существенную роль. А на играх оно вообще сказывается кардинально. Если сместить бегунок вправо (ускорение работы геометрического блока), то и без того низкая скорость работы карты в играх падает на 15-20%, а вот при положении бегунка в левой части (ускорение работы пиксельных конвейеров) в профессиональных приложениях производительность чуть падает, а в играх резко вырастает.
На этом рассмотрение особенностей драйверов от 3Dlabs мы заканчиваем.
Результаты тестов
2D-графика
Традиционно начнем с 2D. Совместно с ViewSonic P817 и кабелем BNC Bargo карта Wildcat VP870 продемонстрировала отменное качество в следующих разрешениях и частотах:
| 3Dlabs Wildcat VP870 | 1600x1200x85Hz, 1280x1024x100Hz, 1024x768x120Hz |
|---|
Пока такие карты выпускает только сама компания 3Dlabs, поэтому в повторе традиционной фразы о том, что оценка 2D-качества зависит от конкретного экземпляра, нет нужды. Но, хотя в данном случае качество и не зависит от конкретного экземпляра, связка карта-монитор могут по-прежнему играть огромную роль, прежде всего, качество монитора и кабеля.
3D-графика, MS DirectX 8.1 SDK — предельные тесты
Для тестирования различных предельных характеристик чипов мы использовали модифицированные (для большего удобства и контроля) примеры из последней версии DirectX SDK (8.1, релиз). Без лишних преамбул перейдем к уже хорошо знакомым нашим постоянным читателям тестам:
Optimized Mesh
Этот тест призван выяснить практический предел пропускной способности ускорителя по треугольникам. Для этого используется несколько одновременно выводимых в небольшом окне моделей, каждая из которых состоит из 50 тысяч треугольников. Текстурирование отсутствует. Размеры моделей минимальны — каждый треугольник не превышает одного пиксела. Хочется сразу отметить, что результат этого теста, разумеется, останется недостижим для реальных приложений, где размеры треугольников значительны, присутствуют текстуры и освещение. Приведем результаты этого теста для трех методов отрисовки — оптимизированной для оптимальной скорости вывода (в том числе, с учетом размера внутреннего кэша вершин на чипе) модели — Optimized, неоптимизированной исходной модели — Unoptimized и той-же неоптимизированной модели, выводимой в виде одного Triangle Strip — Strip. Кроме того, приведены значения в режиме программной эмуляции вершинного конвейера, дабы выяснить эффективность передачи геометрии от процессора к GPU:
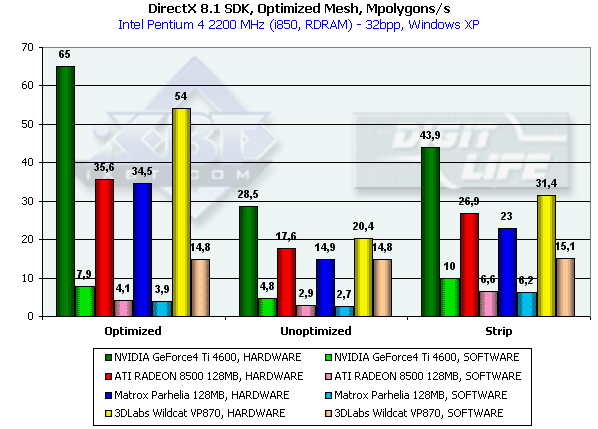
В случае полностью оптимизированной модели, когда влияние подсистемы памяти минимально, мы измеряем практически чистую производительность трансформации и установки треугольников. Налицо безоговорочное лидерство Ti 4600. 65 миллионов треугольников в секунду — цифра нешуточная, практически вдвое превосходит результаты RADEON 8500 и Parhelia. P10 занимает почетное второе место, вполне приемлемо отставая от NV25, в первую очередь, вероятно, из-за меньшей тактовой частоты ядра. Однако не будем забывать что не за горами NV30, геометрическая производительность которого вполне будет более чем вдвое выше предшественника — NV25. Отметим существенное преимущество P10 в случае принудительной активации программного расчета геометрии. Особенно заметно оно на неоптимизированной модели. Ранее безусловным лидером в этом вопросе всегда были решения NVIDIA, теперь же результаты NV25 в этом вопросе побиты вдвое! Основным сдерживающим фактором при передаче геометрии является, как правило, AGP шина и алгоритм взаимодействия ускорителя с процессором. P10 несомненно использует какие-то новые оптимизации передачи, возможно меньшую точность представления координат и атрибутов вершин или какие-либо иные техники сжатия геометрической информации. Интересно, что и в случае Strip модели двукратное преимущество сохраняется — видимо, полоса передаваемых данных действительно снижена вдвое для каждой вершины.
Производительность блока вершинного шейдера
Этот тест позволяет определить предельную производительность блока вершинных шейдеров. Выполняется достаточно сложный шейдер, вычисляющий как видовые преобразования, так и геометрические функции. Тест проводится в минимальном разрешении, дабы минимизировать влияние закраски:
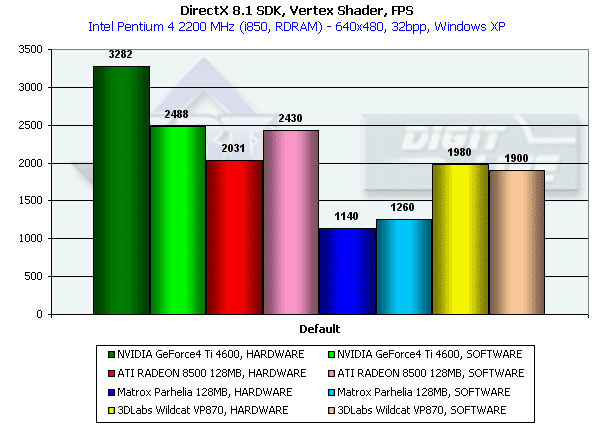
И вновь налицо существенное преимущество Ti 4600. P10 практически делит второе место с RADEON 8500.
Вершинный матричный блендинг
Эта возможность T&L используется для правдоподобной анимации и скиннинга моделей. Мы протестировали блендинг с использованием двух матриц как в фиксированном "аппаратном" варианте, так и с использованием вершинного шейдера, выполняющего ту же функцию. Кроме того, мы, как обычно, "подстраховались" результатами, полученными в режиме программной эмуляции T&L:
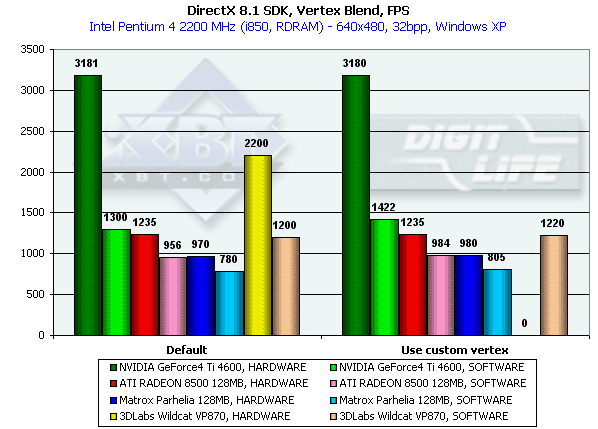
Интересно, что P10 по какой-то причине не смог выполнить аппаратный блендинг на основе вершинного шейдера, судя по всему, проблема в драйверах, т.к. все необходимые аппаратные возможности для исполнения вершинных шейдеров присутствуют. В случае полностью аппаратного блендинга (так же выполняемого лишенными фиксированного T&L GPU как некий шейдер) P10 вновь занимает почетное второе место.
EMBM рельеф
В этом тесте мы измеряем производительность, а точнее — ее падение, возникающее при использовании наложения карт отражения (Environment) и рельефа на основе карт отражения (EMBM — Environment Bump). Для тестирования использовалось разрешение 1280*1024 — т.к. именно в нем различия между картами и разными режимами текстурирования выражены наиболее резко:
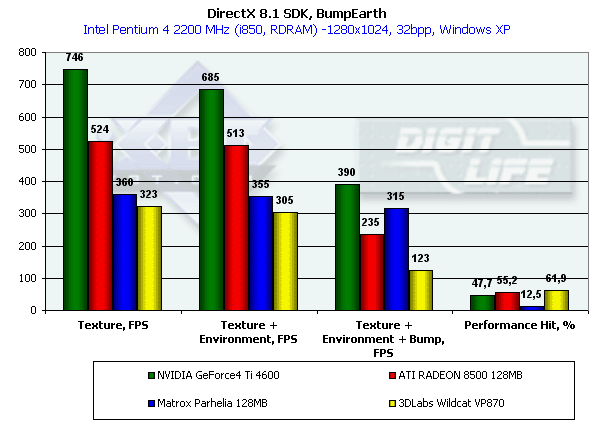
Что ж, результаты теста подтверждают наш постулат о вершинно ориентированном балансе производительности P10. В вопросах закраски он все время проигрывает, во многом из-за отсутствия развитых технологий экономии пропускной полосы памяти. Какой стыд, это происходит даже при наличии 256 бит шины! Сильнее всего активация EMBM бьет по P10. Чип от Matrox красит обычные режимы лишь чуть-чуть быстрее P10, но в EMBM заметно вырывается вперед.
Производительность пиксельных шейдеров
Мы вновь использовали модифицированный пример MFCPixelShader, измерив производительность карт в высоком разрешении при выполнении 5 различных по сложности шейдеров, для билинейно фильтрованных текстур:
На простом шейдере P10 впереди — 64 процессора и более широкая шина дают о себе знать. Но не забываем про расплату за гибкость — все это лишь последовательно выполняющие команды процессоры, а не массив выдающих по результату за такт стадий. В итоге, по мере роста сложности шейдера производительность остальных чипов падает скачками, по мере объединения конвейеров и не зависит от сложности самого шейдера, а только от числа задействованных в нем стадий. Скорость P10 падает с каждой новой командой — т.е. быстрее, чем у всех конкурентов, снабженных стадиями на пиксельном конвейере. Зависит она и от сложности используемых в шейдере команд. В итоге, будучи лидером на самом простом шейдере, на самом сложном P10 опережает только R200, известный нам своей неторопливостью в шейдерных делах еще по предыдущим обзорам.
Итак, подведем первый промежуточный итог. По сумме тестов DX 8.1 SDK карта VP870 выглядит очень уверенно (по сравнению с DX8 поколением игровых ускорителей) в вопросах обработки геометрии, но заметно сдает в вопросах закраски. Налицо четкая ориентация на профессиональные приложения. Судя по всему, эта карта не сможет составить конкуренцию поколению DX9 (R300 и NV30) даже в геометрических вопросах.
Мы еще вернемся к этим тестам несколько позже (осенью), когда будет возможность протестировать наличие шейдеров версии 2.0 и прочих возможностей DirectX 9.0.
3D-графика, 3DMark2001 SE — синтетические тесты
Подчеркну, что все замеры по всем 3D-тестам проводились в 32-битной глубине цвета.
Скорость закраски
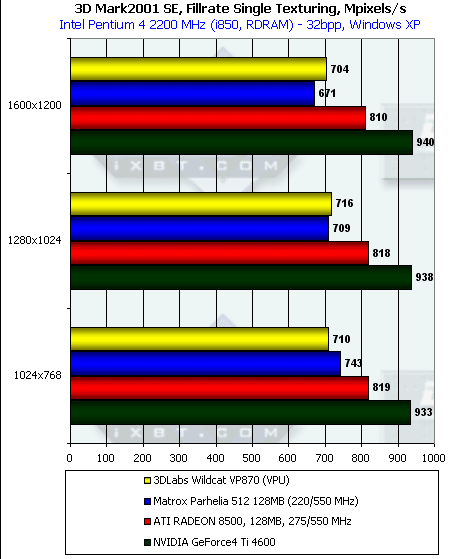
Напомним, что теоретические пределы для данного теста составляют 880 миллионов пикселей в секунду для Parhelia, 1100 для RADEON 8500 и 1200 для Ti 4600 соответственно. Как мы видим, по фактической скорости закраски Parhelia наиболее близко подошла к пиковым значениям, видимо, благодаря 256-битной шине памяти. Точное значение частоты ядра P10 неизвестно, однако, зная, что чип может записывать 4 точки за такт, можно предположить, что оно очень близко к Parhelia 512. Интересно, что с ростом разрешения эффективность закраски Parhelia чуть падает, что говорит о недостаточном совершенстве контроллера памяти.
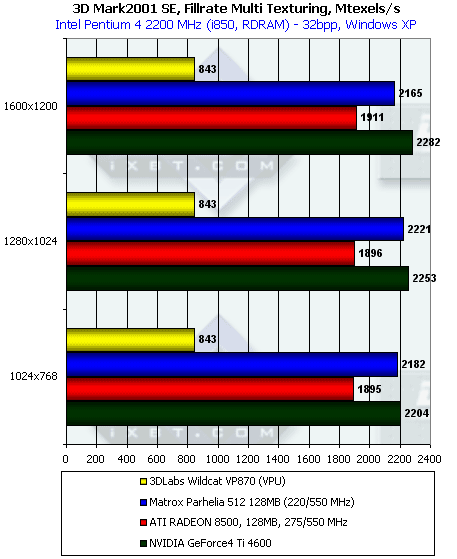
Также напомним, что пиковые значения для этого теста составляют 3520 (1760) миллионов текселей в секунду для Parhelia (в скобках указано значение при работе схемы 4 конвейера по 2 текстурника на каждом), 2200 - для RADEON 8500 и 2400 для Ti 4600. В случае мультитекстурирования большую роль играет сбалансированность чипа. На сей раз, около своей пиковой скорости оказался уже Ti 4600, чуть далее — RADEON 8500. P10 существенно проигрывает остальным картам — он не может похвастаться наличием нескольких текстурных блоков на конвейер закраски, и посему было вполне логично ожидать сравнимых с предыдущим тестом результатов. Интересно, наличие лишь одного текстурного блока столь же существенно скажется на R300?
Сцена с большим количеством полигонов
На этом тесте особое внимание следует уделить минимальному разрешению — именно там зависимость от закраски практически нивелируется:
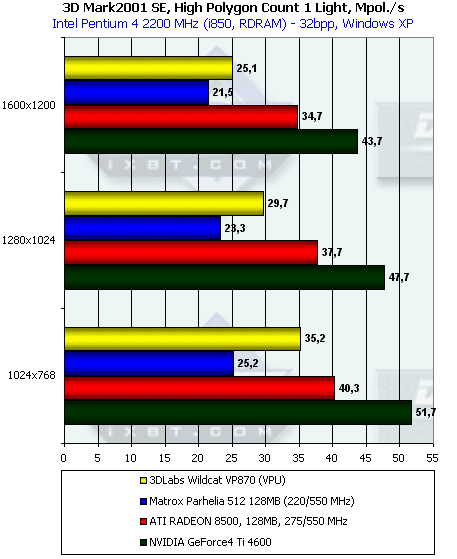
При наличии одного источника света Ti 4600 показывает себя абсолютным лидером. Его результат не только значительно (более, чем в 2 раза) превосходит Parhelia, но и (что более важно) вплотную приблизился к значению практического предела пропускной способности по треугольникам, полученному ранее с помощью Optimized Mesh из DX8.1 SDK. Впрочем, не будем умалять достоинств RADEON 8500, также приблизившегося к предельной цифре, полученной в тесте из SDK. А вот с P10 и Parhelia ситуация далека от идеала. Особенно далека от него Matrox Parhelia.
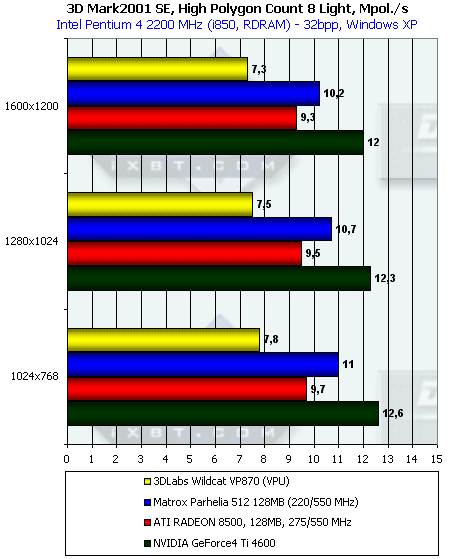
В случае 8 источников света Parhelia несколько реабилитирует себя: с ростом числа источников его производительность падает более медленно, чем RADEON 8500. Лидер — по-прежнему Ti 4600, аутсайдером теперь становится P10.
Интересно, это проблема драйверов или недостаточной производительности самого пула вершинных процессоров?
Рельефное текстурирование
Посмотрим на результаты синтетической EMBM сцены:
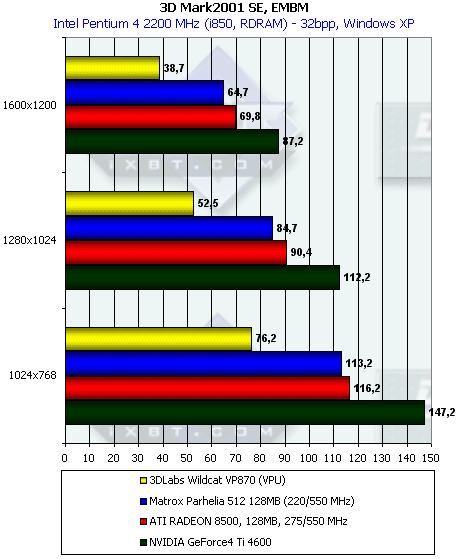
Печальная картина подтверждает тесты из SDK. А теперь DP3 рельеф:
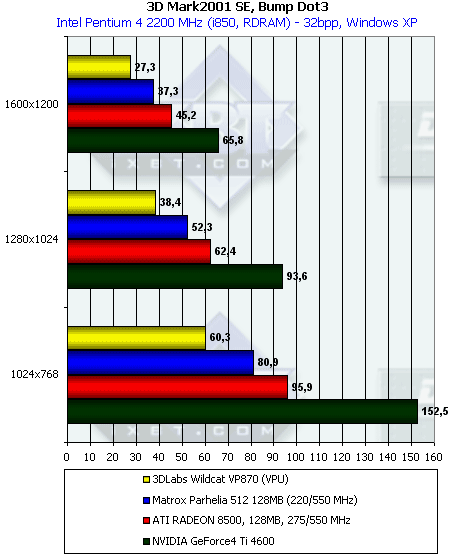
"Все те же лица".
Вершинные шейдеры
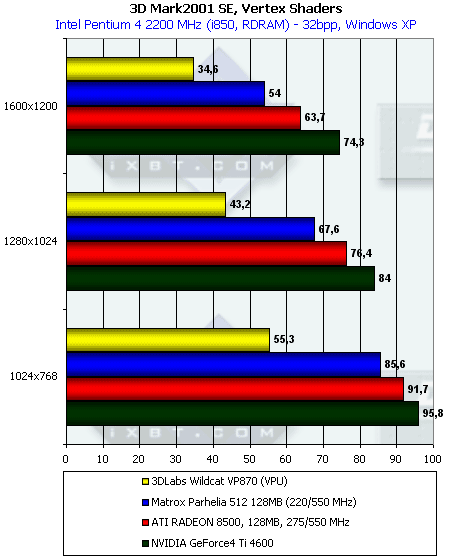
Проигрыш по всем статьям. И это при столь обещающих результатах теста на предельную пропускную способность по треугольникам. И это, при наличии 16 скалярных вершинных процессоров. Либо что-то не в порядке с драйверами, либо вершинное железо очень сильно заточено под OpenGL и не может конкурировать с DX ускорителями, либо оно просто-напросто недостаточно производительно. Последнее было бы крайне обидно, но маловероятно.
Пиксельный шейдер
Руководствуясь высказанными выше соображениями о том, что слишком малые разрешения "упираются" в геометрию, а слишком большие — в пропускную полосу памяти, обратим основное внимание на 1024х768 и 1280х1024:
На несложных пиксельных шейдерах P10 умудряется сохранять приемлемую производительность, несколько выигрывая у Parhelia. Это подтверждает полученные при тестировании пиксельных шейдеров в SDK результаты. Но посмотрим и на тест Advanced Pixel Shader.
Картина совершенно иная. Как уже отмечалось в секции SDK — чем длинее шейдер, тем хуже для P10. И вновь, интересно, как будут обстоять дела с этим вопросом у R300 и NV30.
Спрайты
В этой области у P10 все плохо — еще хуже чем у Parhelia. Очевидно, что спрайты эмулируются стандартными треугольниками. С другой стороны, не будем забывать, что подобные скоростные системы плоских частиц имеют пока сугубо игровые применения.
Итак, подведем второй промежуточный итог. По сумме синтетических тестов карта 3Dlabs P10 в основном проигрывает своим конкурентам. Впрочем, это и ожидалось — ускоритель не ориентирован на игровые приложения, а тест 3D Mark 2001 несомненно является игровым тестом, даже с точки зрения синтетических алгоритмов. Кроме того, судя по всему драйверы для DX8 не являлись первичной целью создателей P10 и до сих пор являются слишком слабо оптимизированными, чтобы соревноваться с продуктами ATI или NVIDIA.
3D-графика, 3DMark2001 — игровые тесты
3DMark2001, 3DMARKS
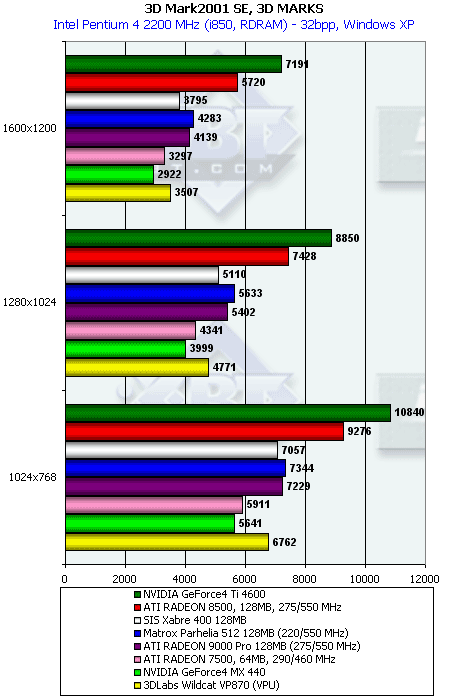
Как мы видим, в целом положение 3Dlabs Wildcat VP870 в игровых тестах DirectX 8.1 оказалось между ATI RADEON 7500 и RADEON 9000 Pro. Но это благодаря тому, что карта поддерживает пиксельные шейдеры, и поэтому Game4 функционирует. Ниже мы убедимся в том, что реальная скорость бывает даже ниже, чем у GeForce4 MX 440 (который по сумме баллов проиграл из-за отсутствия результатов по Game4).
3DMark2001, Game1 Low details
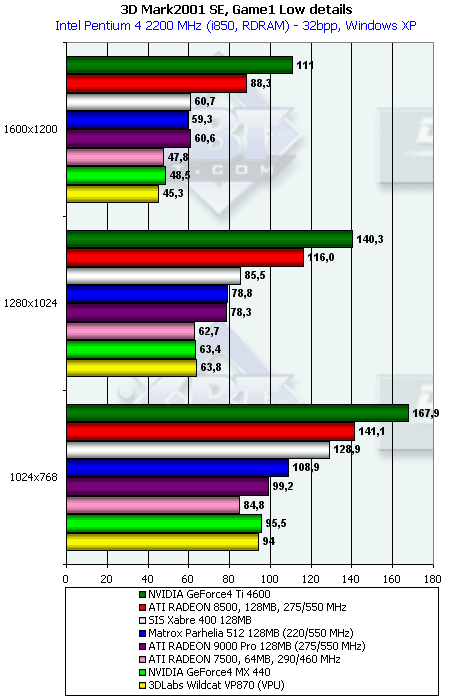
Характеристики теста:
- Rendered triangles per frame (min/avg/max): 19773/33753/143422
- Rendered textures per frame with 16 bit textures (min/avg/max): 7.5/8.8/16.5 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 15.1/17.7/30.3 MB
- Rendered textures per frame with texture compression (min/avg/max): 10.7/12.2/21.0 MB
А тут карта на P10 — аутсайдер, даже GeForce4 MX 440 смог показать чуть более высокую производительность.
3DMark2001, Game2 Low details
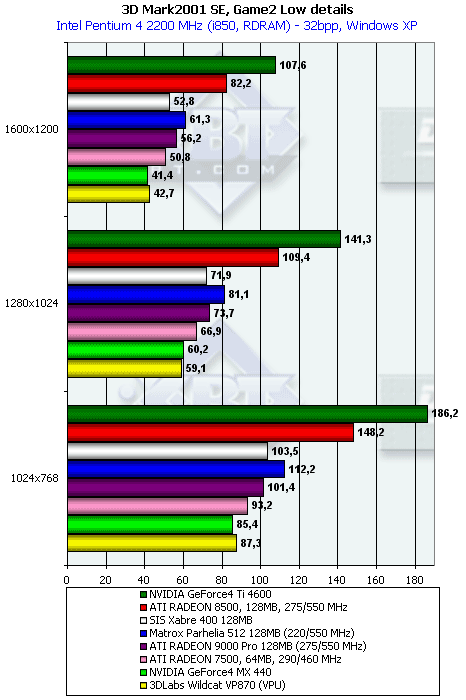
Характеристики теста:
- Rendered triangles per frame (min/avg/max): 46159/51440/147828
- Rendered textures per frame with 16 bit textures (min/avg/max): 8.0/8.8/10.1 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 15.6/17.2/19.8 MB
- Rendered textures per frame with texture compression (min/avg/max): 9.3/10.9/13.5 MB
Картина схожая, производительность где-то около той, что выдает GeForce4 MX 440.
3DMark2001, Game3 Low details
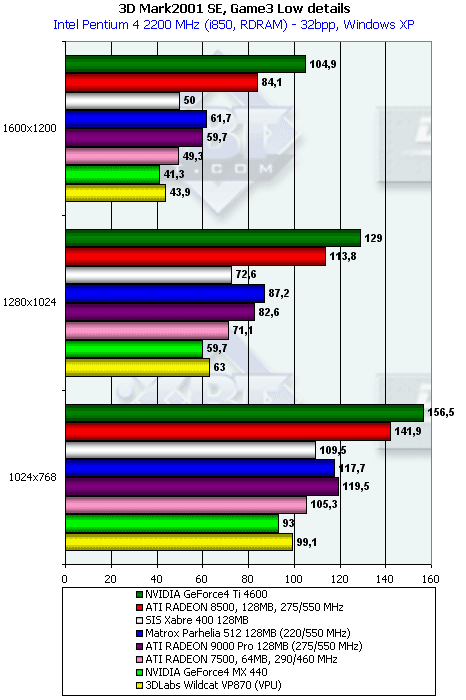
Характеристики теста:
- Rendered triangles per frame (min/avg/max): 16681/21746/39890
- Rendered textures per frame with 16 bit textures (min/avg/max): 2.8/4.1/4.7 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 5.7/8.2/9.4 MB
- Rendered textures per frame with texture compression (min/avg/max): 5.0/7.2/8.4 MB
Чуть-чуть скорость у P10 выросла, а толку все равно мало.
3DMark2001, Game4
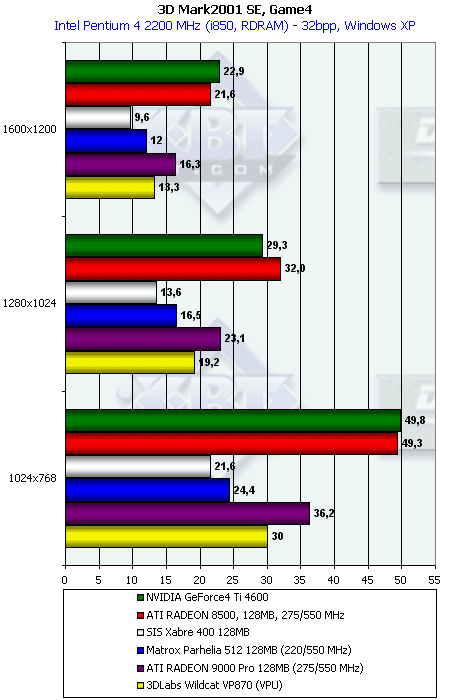
Характеристики теста:
- Rendered triangles per frame (min/avg/max): 55601/81714/180938
- Rendered textures per frame with 16 bit textures (min/avg/max): 14.9/17.4/20.7 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 28.4/33.5/40.0 MB
- Rendered textures per frame with texture compression (min/avg/max): 28.4/33.5/40.0 MB
Заметим, что в этом тесте, достаточно сложном и современном с точки зрения насыщеной эффетками реалистичной сцены P10 наконец-то хоть кого-то опередила :-). На сей раз в аутсайдерах осталась карта Matrox Parhelia.
В целом по 3DMark2001 можно сказать, что наши предварительные результаты тестирования в синтетике и выводы по ним полностью подтвердились практикой: 3Dlabs Wildcat VP870 и ее драйверы пока никоим образом не приспособлены к DirectX игровым приложениям. Пока невозможно даже четко сказать, кто больше виноват: драйверы или баланс возможностей самого P10. Будем ждать известий от Creative Labs — нынешнего хозяина 3Dlabs, который обещал выпустить на рынок игровой акселератор на базе P10. Тогда мы сможем подробно исследовать: что в этом вопросе изменилось в лучшую сторону.
Пока же постараемся утешить профессионалов-дизайнеров — они уже сейчас смогут в часы (или минуты) своего досуга поиграть на этой карте в любимые игры (пусть и с несколько меньшим комфортом в плане скорости: придется снижать разрешение).
Качество 3D-графики в играх
Однако и тут есть нарекания. Слава Богу, что их не так много, но вот пресловутая игра Morrowind, в которой практически впервые водная поверхность реализована через пиксельные шейдеры, выдала следующие картинки на 3Dlabs Wildcat VP870 (для сравнения приведены скриншоты, полученные на RADEON 8500):
P10


RADEON 8500
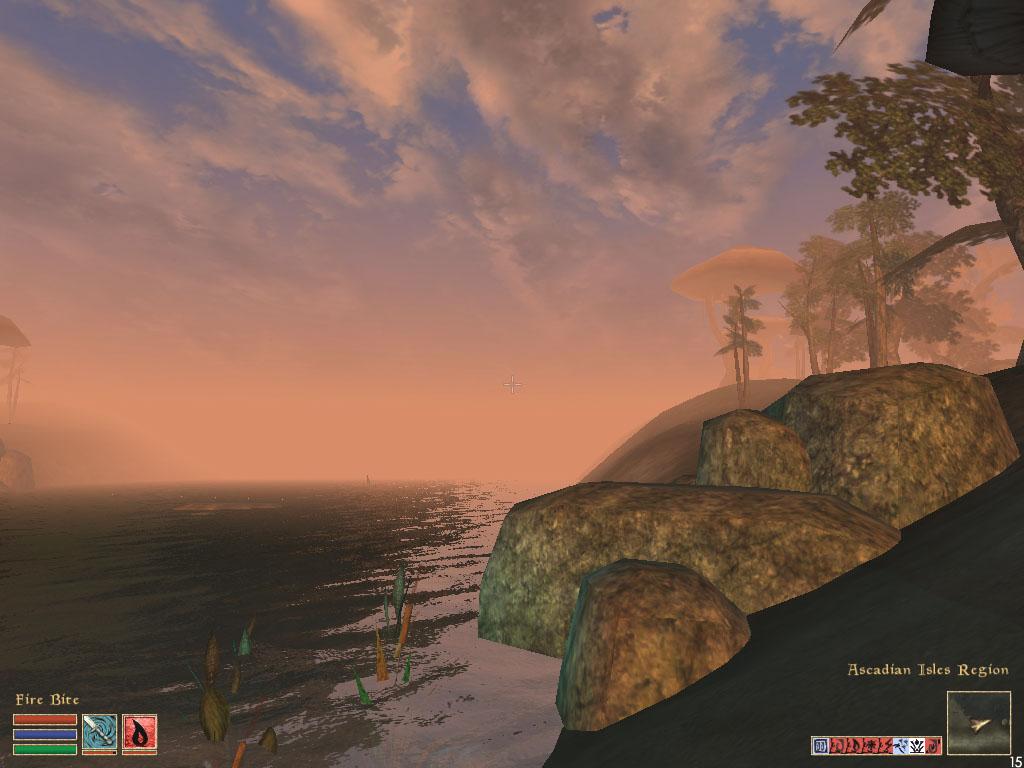
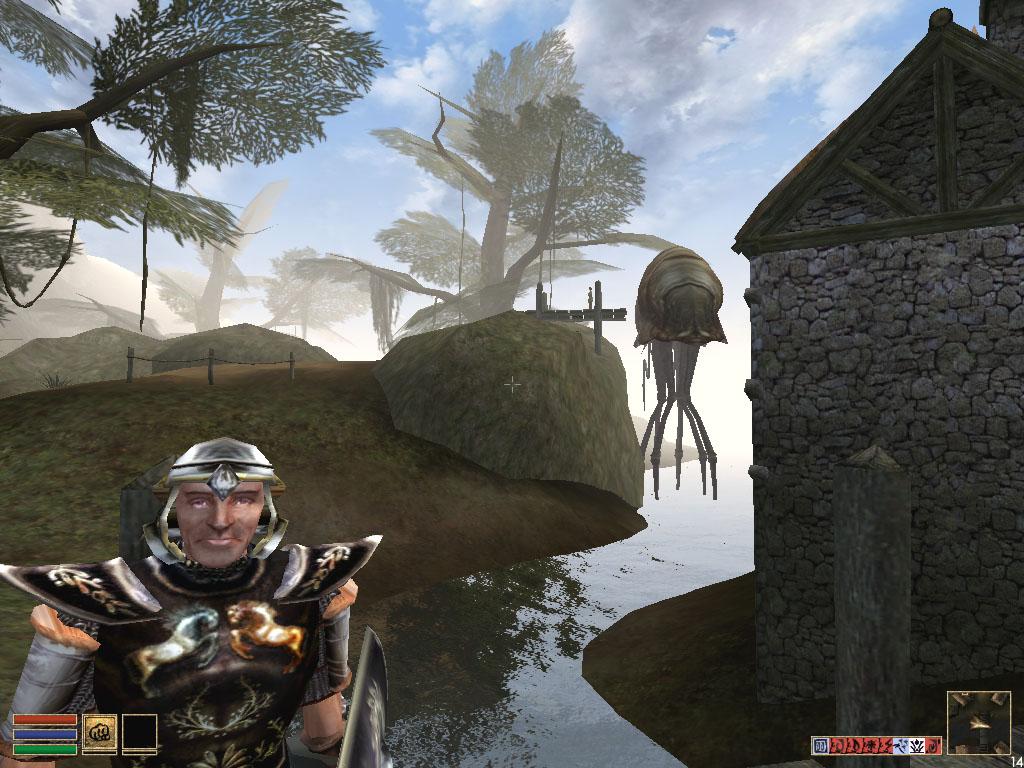
При этом игра была обновлена при помощи последнего патча до версии 1.02.0722.
Были замечены некоторые искажения и в других играх (правда малозначительные). Более подробно можно будет узнать о качестве из следующего (августовского) выпуска 3DGiТогов (в галерею скриншотов будут помещены кадры из многих игр, полученные на P10).
Профессиональные тесты, SPECviewperf 7.0
Итак, мы подробно рассмотрели работу VP870 в играх и DIRECTX 8. Однако главные выводы в обзоре профессиональной карты, несомненно, должны делаться на основе исследования ее в профессиональных тестах. В качестве инструментария мы выбрали два теста: новый SPECviewperf 7.0 и 3DS MAX 4.26. Новая версия SPECviewperf представляет из себя отличную "профессиональную" синтетику, а 3DS MAX — это отличный "живой" пример DCC приложения. Первый тест покажет нам баланс профессиональных возможностей карты, второй — ее реальные преимущества в реальной работе. Подробные описания тестов и методик можно посмотреть у нас на сайте.
Как мы тестировали: устанавливалась операционная система, потом устанавливались драйвера видеокарт, после чего запускались тесты и снимались показания. VP870 прошел все тесты из набора SPECviewperf без проблем - не было ни зависаний, ни нареканий по качеству. Впрочем, именно это мы и ожидаем в первую очередь от профессиональных, тщательно протестированных и сертифицированных драйверов. Давайте подробно посмотрим на результаты этого тестирования:
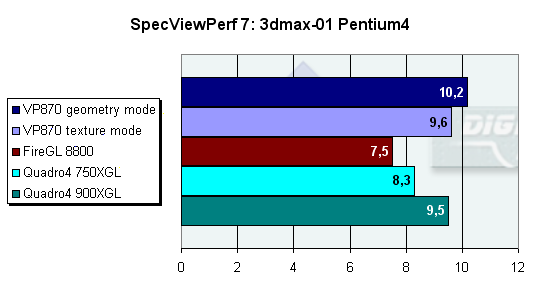
Первый тест, основанный на движке 3D MAX показывает четкое лидерство VP870, особенно если в драйверах установлен режим оптимизации для геометрии, что лишний раз подтверждает наш вывод о балансе P10 в эту сторону. VP870 быстрее ближайшего конкурента (900XGL) почти на 7%. Напомним, что последний при этом позиционируется в более высокую нишу, и сравнивать его результаты по-хорошему надо со следующей, более быстрой картой 3Dlabs. Безусловно, это нельзя назвать уверенным преимуществом, учитывая отличную масштабируемость карт на базе процессора Quadro4. Если выйдет более высокочастотная модель на базе Quadro4, преимущество P10 может быть сведено на нет. Однако сейчас, особенно при учете текущих цен, P10 выглядит привлекательно. Так ли это в реальном приложении, мы узнаем из результатов тестирования карты непосредственно в 3D MAX.
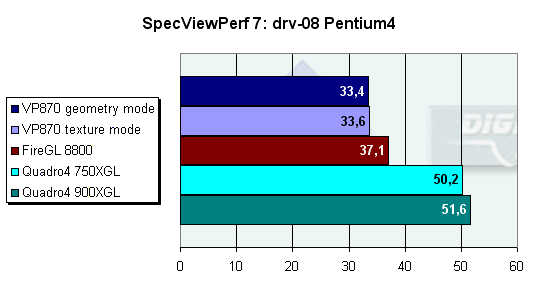
В этом ориентированном на закраску тесте VP870 показал себя крайне слабо. Отставание от лидера почти на 35%, причем практически неважно, какой режим оптимизации включен в драйверах. Учитывая что 3Dlabs позиционирует эту карту, как соперника Quadro4 750XGL, результаты этого синтетического теста можно признать провальными — VP870 даже близко не подошел к Quadro4 750XGL.
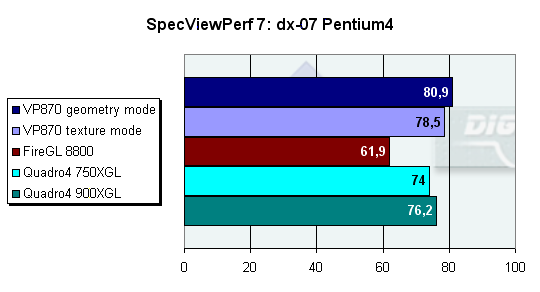
Новый тест, и совершенно другая картина. VP870 обгоняет самую быструю Quadro4 на 6%. Учитывая позиционирование карты от 3Dlabs, это весьма неплохой результат. Еще более отчетливо начинает проявляться разница между текстурным и геометрическим режимами оптимизации — если в ориентированных на закраску тестах текстурная оптимизация не особенно помогает (не забываем, что скорость закраски зависит не только от текстур), то в геометрических включение геометрической оптимизации сказывается весьма положительно. Можно сделать интересный вывод — в любых реальных приложениях, скорее всего, имеет смысл все время держать включенной только геометрическую оптимизацию.
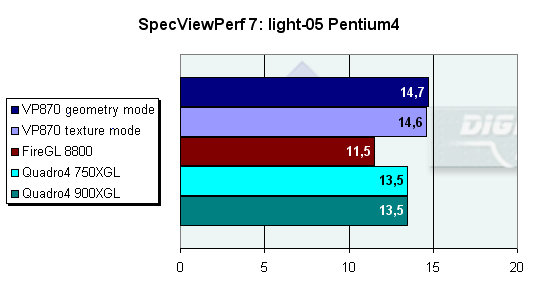
В этом сбалансированном тесте много как текстур, так и достаточно сложной геометрии, поэтому разницы между режимами практически нет, в целом же, картина опять в пользу VP870. На этот раз разница между VP870 и Quadro4 составила 8%. Это хороший знак для большинства реальных сбалансированных приложений.
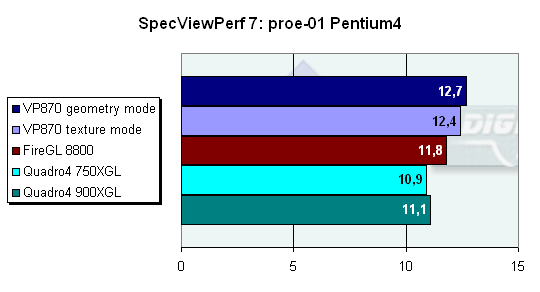
Расстановка сил кардинально поменялась, и в этом тесте мы будем сравнивать уже не VP870 vs Quadro4, а VP870 vs FireGL 8800, потому что FireGL 8800 быстрее, чем Quadro4 900XGL, в свою очередь, VP870 быстрее FireGL 8800. VP870 быстрее, чем FireGL 8800, на 7.6%, и быстрее Quadro4 900XGL на 14.4%. Тест несет смешанную нагрузку, и разница между геометрическим и текстурным режимом оптимизации невелика — составляет чуть более 2%.
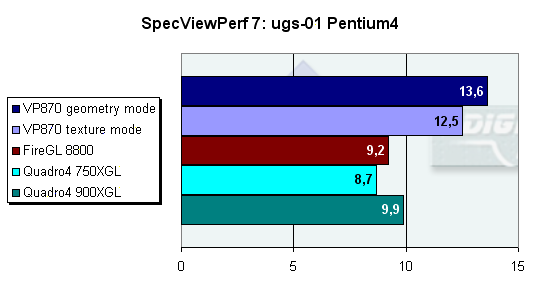
И в этом тесте VP870 оказывается на вершине, опережая абсолютно все карты фирм-конкурентов. Если выразить разницу в процентах, то получается, что VP870 в режиме оптимизации геометрии быстрее Quadro4 900XGL на 37%, быстрее FireGL 8800 на 47% и быстрее Quadro4 750XGL на 56%. И так же выразим процентное соотношение в режиме оптимизации текстур: VP870 vs Quadro4 900 XGL = 26%, VP870 vs FireGL 8800 = 35%, VP870 vs Quadro4 750 XGL = 43%. Разница между разными режимами оптимизации составляет 8%, опять в пользу оптимизации геометрии.
Теперь подведем общий итог по результатам тестирования в SPECviewperf 7.0. Как видно из приведенных диаграмм, в большинстве случаев лидирует карта от 3Dlabs на новом чипе P10. Как правило, она выигрывает в режиме оптимизации геометрии. Из этого факта можно сделать два вывода: во-первых, specviewperf в большинстве тестов упор делает именно на обработку геометрии. Точнее, этот упор делают реальные профессиональные приложения и задачи, а тест лишь отражает их популярные надобности. Во-вторых, имеет смысл раз и навсегда включить в драйверах режим оптимизации геометрии, хуже от этого не будет никогда, а вот лучше — достаточно часто.
В текущих условиях — при нынешних ценах и тактовых частотах в этом сегменте рынка лучшим выбором (на основе SPECviewperf 7.0) несомненно является VP870. Теперь посмотрим на результаты реального приложения:
Профессиональные тесты, Discreet 3DS MAX 4.26
После исследования в specviewperf, который все-таки является синтетическим тестом (хотя и эмулирует характерные для реальных приложений нагрузки на ускоритель), мы рассмотрим работу VP870 в 3DS MAX. В тестировании 3DS MAX мы исключили лишь моделирование работы дизайнера, но уверены, что "живая" работа будет более менее понятна, после количественных показателей нашего исследования. Мы несколько сократили отчет об исследовании качества в силу того, что все тестовые сцены рендерятся и отображаются правильно, и приводить множество скриншотов нет никакого смысла (положительно сказывается сертификация драйверов). Мы приведем только скриншоты результатов работы антиалиасинга.
Начнем исследования с тестирования скорости работы на стандартных демосценах, что идут в комплекте 3DS MAX. Поясним условные обозначения на диаграммах. Под термином "Special driver" мы понимаем специальный драйвер от производителя видеокарты, который предназначен только для работы в 3DS MAX. Драйвера от компании ATI называются MAXIMUM, драйвера от компании NVIDIA называются MAXTREME, а драйвер для VP870 от 3Dlabs никак не называется, более того, он не имеет каких-то своих функций управления, используя только стандартные настройки 3DS MAX. Под термином "OpenGL" подразумевается работа через стандартный OpenGL драйвер. Мы помним, о том, что в тесте SPECviewperf 3dmax-01, основанном на движке 3DS MAX, VP870 оказался первым и является вероятным кандидатом на звание наиболее предпочтительной карты для работы с этой системой трехмерного моделирования. Расставим же точки над i.
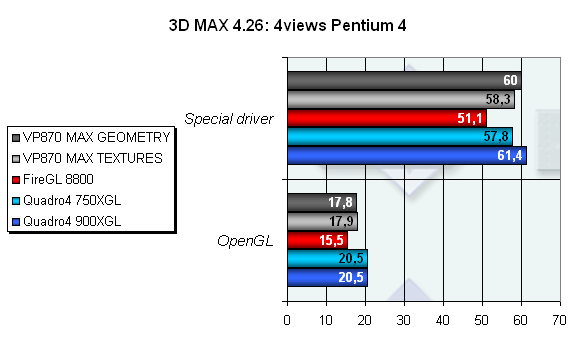
Тестовая сцена 4views, показывает нам, одновременное отображение в четырех областях проекции. И в этом тесте VP870 держится примерно на уровне своих соперников от NVIDIA. В разных режимах чуть лучше, чем Quadro4 750XGL, но чуть хуже Quadro4 900XGL, причем только при использовании специального драйвера. В чистом OpenGL он проигрывает картам линейки Quadro4. Отчасти это объясняется тем, что карты от NVIDIA обладают бОльшим числом поддерживаемых OpenGL расширений (см. таблицу расширений OpenGL).
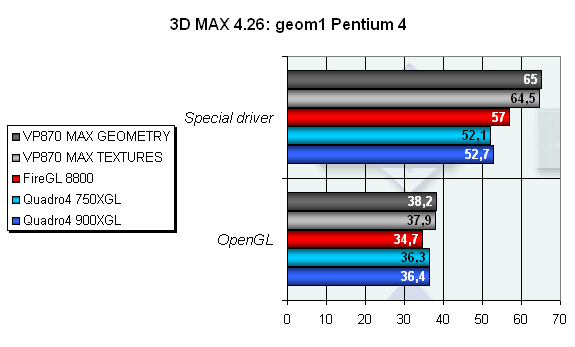
Тест на геометрические возможности подтверждает лидерство VP870 в области обработки сложной геометрии. Небольшое преимущество при работе в OpenGL и уверенное лидерство под управлением специального драйвера. Сделаем вывод: 3Dlabs очень ответственно подошли к специальному драйверу, он не является просто враппером, а существенно оптимизирует вывод изображения.
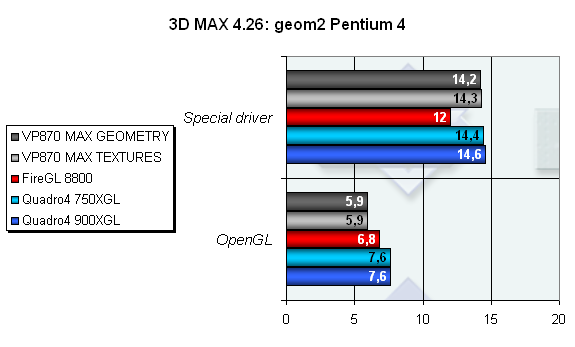
А вот усложнение геометрии до максимума показывает, что VP870 лидер лишь до определенного уровня сложности геометрии в сцене, после чего начинают сказываться уже другие причины (Карта упирается в пропускную способность AGP шины или сказываются какие-либо другие аспекты взаимодействия с процессором).
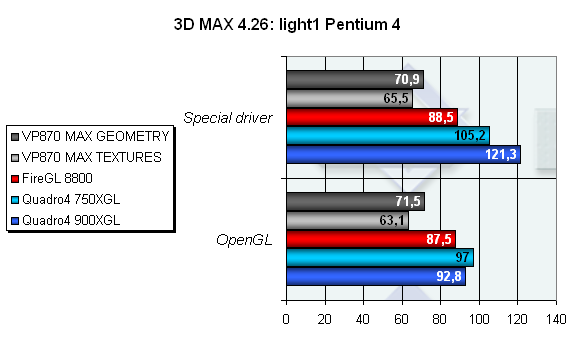
А вот тесты по работе с множеством источников света типа SPOT показывают нам, что этот вид освещения - не конек VP870, и хотя результаты достаточно высокие для комфортной работы с ними, общая картина несколько удручает тем, что по скорости этот чип проигрывает всем остальным ускорителям. Возможно, что картина изменится с выходом новых драйверов, причем достаточно кардинально, так как с остальными источниками света новое детище 3Dlabs справляется весьма успешно (судя по всему, все они реализуются в виде специальных шейдеров).
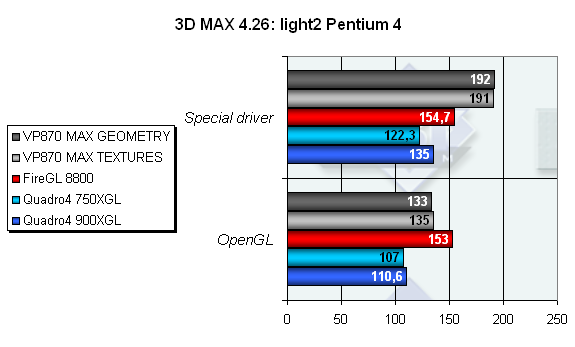
Как видно, с большим количеством источников света типа DIRECT лучше всех в OpenGL справляется карта от ATI (Вспомним DirectX синтетику — именно этот чип снабжен аппаратным блоком фиксированного T&L, что дает ему некоторое преимущество с ростом числа источников света). VP870 лишь немного уступает лидеру. Однако при использовании специального драйвера картина кардинально меняется — использование специального драйвера позволяет карте от 3Dlabs взять пальму первенства. Что примечательно, разные режимы оптимизации никак не влияют на результаты. Между ними есть разница в 1-2 fps, что, как вы и сами понимаете, скорее можно списать на погрешность в измерениях, чем именно на разницу оптимизации.
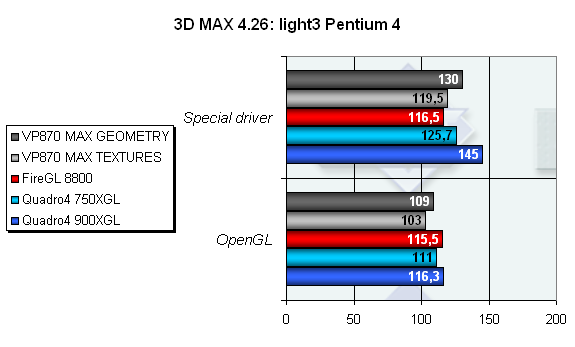
Последний тип источника света, применяемого в 3DS MAX, это источник света типа OMNI. Как видите, все карты примерно на одном уровне в OpenGL режиме, впрочем, разница невелика и под управлением специального драйвера.
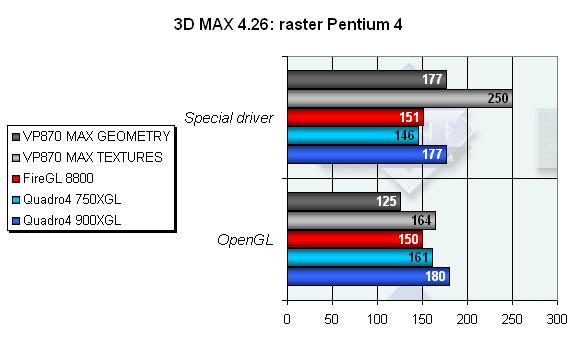
Очень важный тест растеризации. Вот где начинает сказываться оптимизация драйверов под разные режимы работы у карты VP870, вот где проявляется та самая, заявленная производителем, программируемость чипа. Под управлением OpenGL результат в принципе прогнозируемый, а вот под управлением специального драйвера результаты просто поражают воображение. Превосходство более чем на 40%! При этом обратите внимание, что у других карт скоростные показатели даже несколько выше в OpenGL режиме. Вывод — удачная реализация специального драйвера от 3Dlabs гармонично использует широкие возможности по гибкому программированию работы самого чипа. Именно в этом тесте мы можем почувствовать реальную пользу, приносимую действительно гибко программируемой архитектурой, несмотря на существенную зависимость этого теста от скорости закраски — которая, как известно, не является коньком P10.
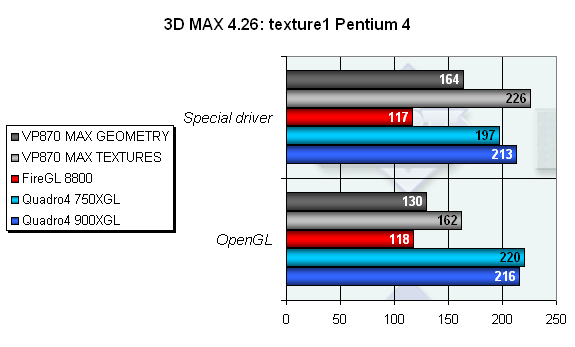
Далее идет набор тестов на текстуризацию. Посмотрите, как кардинально меняются результаты при включении разных режимов оптимизации в драйверах VP870! Причем при использовании специального драйвера скорости только возрастают, что позволяет карте от 3Dlabs находиться на вершине Олимпа. Разумеется, стандартные драйвера OpenGL не столь блистательны — они используются 3DS без учета специфики чипа.
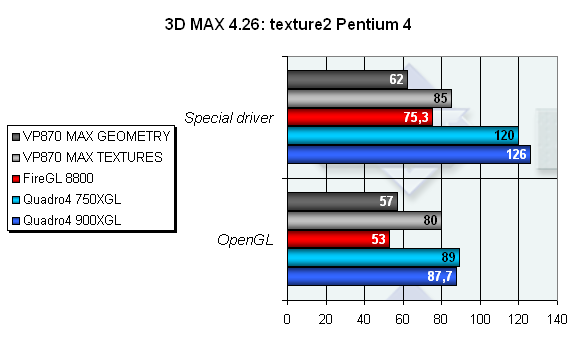
Этот тест просто-напросто "запутал" драйвера VP870. В нем используется и большое количество текстур, и достаточно сложная геометрия. Золотой середины не получилось — в этом тесте карта не показала ничего примечательно, несмотря на то, что со своей задачей она справляется на довольно высоком уровне.
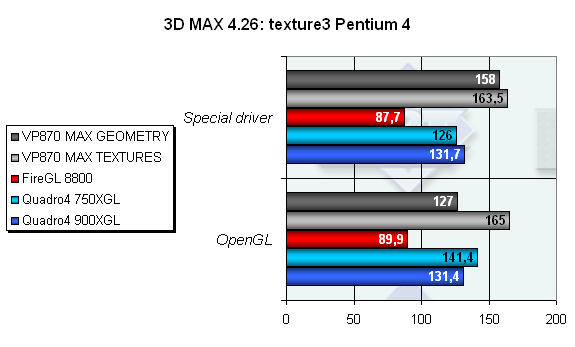
И последний режим текстурирования. В этом тесте также присутствует и достаточно сложная геометрия, и немалое количество текстур. Тем не менее, соблюдается некоторая пропорциональность — одно не довлеет над другим. За счет этого карта VP870 является абсолютным лидером в режиме оптимизации текстур. Чуть хуже дело обстоит с режимом оптимизации геометрии, особенно в OpenGL. В данном тесте мы исследуем именно текстурирование, а с ним у карты всё получилось хорошо.
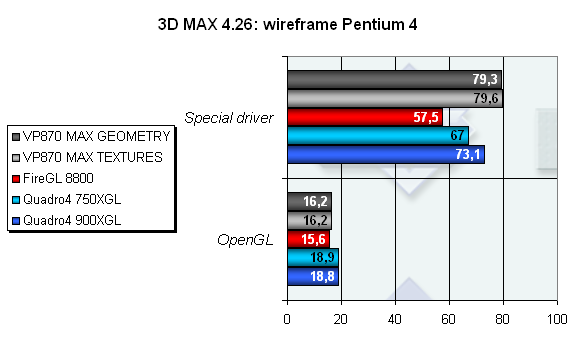
Важная часть тестирования — умение карты правильно и быстро прорисовывать большое количество прямых линий, так называемый каркасный режим работы. И при работе в OpenGL, и при работе под специальным драйвером результаты не зависят от типа оптимизации, причем результаты в OpenGL достаточно низкие. При использовании специального драйвера, в котором, очевидно, используется несколько иной, более выгодный для P10 алгоритм работы, скорость вырастает в разы. При этом прирост скорости позволяет карте забраться на вершину и стать лидером этого теста.
Важный момент — проверим работу Line Antialiasing.
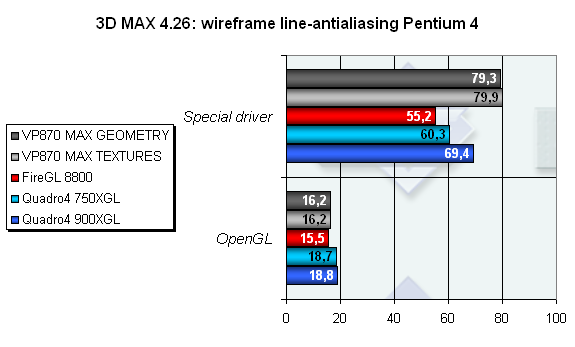
Как видно, падения в скорости не происходит. При этом ситуация практически ничем не отличается от предыдущего теста. Антиалиасинг линий для нового творения 3Dlabs является приятным и абсолютно бесплатным приложением.
И, поскольку речь зашла о антиалиасинге, а значит, и о качестве, мы приведем скриншоты, антиалиасинга в различных режимах работы.
Итак, сначала покажем, как отображает тестовую сцену карта без антиалиасинга линий.
Режим оптимизации под геометрию, управление — OpenGL:

Режим оптимизации геометрии, управление — special driver:

Как видно, визуальных отличий абсолютно никаких нет. Теперь включаем антиалиасинг:
Режим оптимизации под геометрию, управление — OpenGL:

Режим оптимизации геометрии, управление — special driver:

Глядя на эти скриншоты можно сделать следующий вывод: антиалиасинг более аккуратный под управлением OpenGL, нежели чем под управлением специального драйвера.Под управлением специального драйвера антиалиасинг выглядит более грубым. Антиалиасинг выполняется чипом весьма быстро, что говорит о том, что эта задача была успешно реализована инженерами компании, и можно смело постоянно использовать его в повседневной работе без ущерба производительности.
У карты есть огромный потенциал, который, возможно будет реализовываться с появлением новых драйверов.
Подведем итоги по 3DS MAX. Тестирование в SPECviewperf обнадежило и порадовало. Мы надеялись получить нового безусловного лидера. Однако тест в реальных приложениях показал, что не всё так просто. Да, карта получилась качественная и достаточно быстрая, чтобы претендовать на лидерство, но вместе с тем лидерство этой карты не может быть однозначным. В разных тестах результаты зависят от множества окружающих условий и подавляющего преимущества практически не наблюдается. Как минимум, мы можем констатировать добротность специального драйвера, рекомендовать его к применению и отметить существенное увеличение результатов при его использовании.
Выводы
- Прежде всего, эта карта является превосходным решением для профессионалов-дизайнеров, работающих в сфере 3D-моделирования. 3Dlabs Wildcat VP870, обладая ценой (по данным www.pricewatch.com), равной стоимости NVIDIA Quadro4 750XGL ($580 на начало августа), во многих тестах не отстает и даже побеждает куда более дорогую карту на базе Quadro4 900XGL.
- Карта изначально разрабатывалась как профессиональное решение, и очень хороша в режимах и сценах с акцентом на скорость расчета геометрии. Это же касается и режимов со сглаживанием, особенно линий.
- Что касается реализованных в P10 пиксельных и вершинных шейдеров, то пока их применение в профессиональной графике достаточно ограниченно, но мы уже можем наблюдать плоды гибкой программируемости чипа на примере высокооптимизированного драйвера специально для 3DS MAX. Как бы там ни было, потенциал данной карты в этом вопросе еще далеко не раскрыт, будем ждать появления OpenGL 2.0, DirectX 9 и с ними различных высокоуровневых языков для программирования графических ускорителей.
- Мы еще вернемся к исследованию 3Dlabs Wildcat VP870 в разных профессиональных приложениях, следите за анонсами сводных тестирований профессиональных карт (осень этого года принесет читателям ряд очень интересных статей в этом плане).
- С точки зрения игровых приложений 3Dlabs Wildcat VP870 выглядит крайне скромно. Впрочем, вполне естественно ожидать этого от профессиональной карты. Оптимизированные под профессиональные пакеты драйверы (достаточно посмотреть хотя бы на список расширений ICD OpenGL, чтобы убедиться в этом), достаточно слабый (неоптимизированный) DirectX 8 драйвер и особенности самого P10, сбалансированного с учетом неигровых применений, не позволяют рассчитывать на высокую скорость в играх.
- Мы считаем, что игровой потенциал этого чипа не раскрыт и на 50%, поэтому будем ожидать выхода игровой платы на базе P10 или его специальной игровой модификации, сбалансированной с учетом большей производительности закраски. Надеемся, что у этой карты будут уже полноценные с точки зрения игровых применений драйверы.
И еще раз отметим, что низкая относительно прочих участников тестирования DirectX производительность карты может заметно возрасти после выхода DirectX 9.0, поэтому мы не закрываем эту тему, а лишь ее несколько ее откладываем.
Комментарии