Ложное солнце / Parhelia-512
17 мгновений весны
Положение компании Matrox на рынке вообще, и на российском в частности, довольно странное. Отношение к этому рынку еще более странное. Небольшой пример компания не удосужилась сообщить (sic!) своим дистрибуторам (за исключением очень отдельных товарищей) о выходе нового продукта. Что уж говорить о прессе… Но, как говорится, кто ищет… Мы нашли и желаем компании вместе с ее дистрибуторскими каналами больших успехов…
Почему мы сделали это сегодня, а не 14 мая? Все очень просто у нас нет никаких обязательств перед господами из Канады и их европейскими коллегами. Им НЕ ИНТЕРЕСНА Россия. Точка. Поставим точку и мы. Поехали…
14 мая 2002, уже забытая энтузиастами 3D визуализации компания Matrox Graphics Inc. анонсирует чип Parhelia-512, принадлежащий к новому поколению архитектур графических ускорителей. Вернее всего будет охарактеризовать это поколение как «Generation X9». Можно сказать, что новый чип от Matrox является вторым представителем этого поколения приоритет за 3Dlabs (с некоторыми оговорками) уже анонсировавшей свой гибко программируемый VPU под именем P10.
Прежде чем вплотную перейти к новому детищу Matrox основного виновника данной статьи, обсудим еще одного знакового героя:
Мистер икс, девятый (DirectX 9)
Сохраняя свойственный хорошему секретному досье стиль, приведем ключевые новшества (с точки зрения ускорителей) будущей версии популярного игрового API.
Повышенная точность представления данных
Введены новые форматы текстур и буферов кадра. Каждая компонента из четырех (RGBA) теперь может быть представлена в виде 32 или 16 битного числа с плавающей точкой в стандартных форматах IEEE F32 и F16. Каждая точка будет занимать 128 или 64 бита и это существенно поднимет требования к объему локальной памяти графических ускорителей. Впрочем, использовать подобные форматы «везде и вся» пока нет необходимости. Основное назначение точных форматов реализация различных эффектов и моделей освещения (например, хранение таблиц используемых в пиксельных шейдерах). Содержимое буферов кадра в плавающем формате не могут быть выведены напрямую на монитор через RAMDAC или цифровой интерфейс они используются только для внутренних целей. Для повышенной точности представления целочисленной информации выводимой на экран введен новый формат 10:10:10:2 (RGBA), где каждая цветовая компонента передается с точностью 10 бит. Подобная точность с избытком покрывает возможности современных устройств отображения и существенно расширяет динамический диапазон, а, следовательно, и качество результирующего изображения.
Карты смещения (Displacement Mapping)
Лицензированная у Matrox Graphics Inc. (и, разумеется, реализованная в Parhelia-512) технология Displacement Mapping позволяет существенно увеличить степень реалистичности и детальности рельефных поверхностей. В отличие от привычных уже разновидностей рельефа, наносимого на поверхности треугольников при закраске и не влияющего на видимость тех или иных точек (картой рельефа моделируется только освещенность точки, а не ее реальное положение в пространстве) карты смещения позволяют создавать геометрически корректные рельефы, пересечение которых в пространстве не будет выглядеть идеальной прямой. Фактически эта технология модифицирует положение вершин треугольников, сдвигая их в направлении нормали к поверхности на величину, пропорциональную значению из специальной текстуры (карта смещения):

Карта смещений отвечает за «грубый» рельеф, смещая вершины треугольников в направлении нормали, заданной для этой вершины. При необходимости, совместно с картой смещений можно использовать и традиционную карту рельефа (bump map) для создания более тонких «попиксельных» деталей.
Разумеется, число треугольников должно быть достаточным для передачи всех нюансов грубого рельефа, задаваемого картой смещений. Для того чтобы эти треугольники создать автоматически (не забивая головы программистов, ресурс центрального процессора и AGP шину) используется хорошо знакомые нам N-патчи:
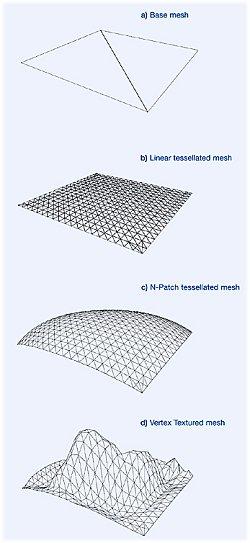
Т.е. технология увеличения детализации моделей на основе дополнительной тесселяции треугольников. Без аппаратной поддержки N-патчей карты смещения не могут быть использованы с точки зрения DX9 эта технология лишь существенное дополнение к алгоритму N-патчей:

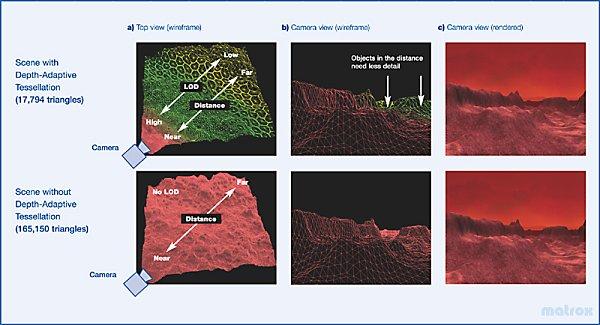
Интересно, что в DX9 патчи претерпели существенные улучшения, например степень детализации (число разбиений) теперь может выбираться автоматически в зависимости от расстояния от треугольника до наблюдателя. Таким образом, достигается более оптимальное, близкое к равномерному (с точки зрения наблюдателя) разбиение сцены все треугольники имеют примерно одинаковый видимый размер:
Кроме того, для карт смещения, также как и для обычных текстур, можно использовать кратную фильтрацию (mip-mapping):
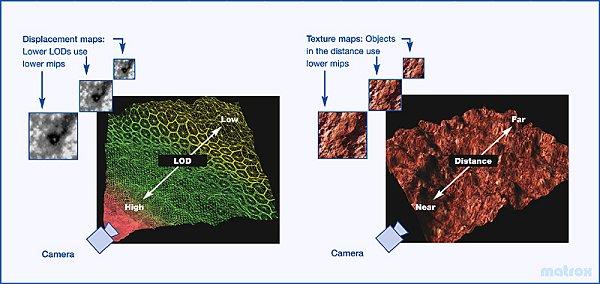
В сумме получая прекрасный результат «без особых хлопот»:

Разумеется, карты смещений можно применять не только для плоских поверхностей но и для объемных моделей:
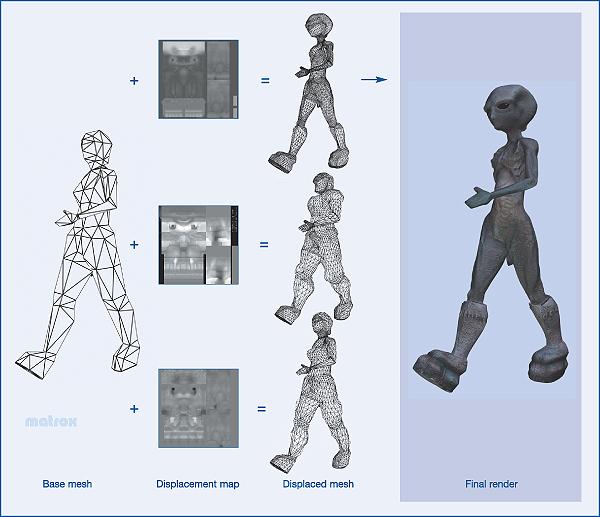

По сравнению с традиционными картами рельефа (включающим попиксельный рельеф на основе шейдеров), карты смещения, несомненно, более ресурсоемки шутка ли сказать, все детали рельефа передаются треугольниками. Но и более реалистичны:

Разумеется, в реальных игровых приложениях, для получения динамичной и реалистичной графики необходимо разумно сочетать эти технологии.
Вершинные шейдеры второго поколения (Vertex Shader 2.0)
Кратко охарактеризуем возможности новых вершинных программ:
- 256 ассемблерных команд
- Как минимум 256 констант
- 12 регистров общего назначения
- Управление исполнением условия, циклы, переходы, подпрограммы. Существенные ограничения: управление возможно только на основе значений констант. Условные переходы только вперед. Циклы только назад. Вызовы подпрограмм не могут быть вложенными.
- 1 регистр со значением параметра цикла
- 16 регистров с константами для задания параметров циклов
- 16 регистров с логическими константами для переходов
- Возможность, при желании, записать шейдеры на «С» подобном языке высокого уровня, компилируемом в ассемблерный код автоматически
Пиксельные шейдеры второго поколения (Pixel Shader 2.0)
Кратко охарактеризуем возможности новых пиксельных программ:
- Все вычисления только с вещественными числами (с плавающей точкой) от начала и до конца шейдера. Если нужно, результат преобразуется к целочисленному формату только при записи в память.
- Возможность, при желании, записать шейдеры на «С» подобном языке высокого уровня, автоматически компилируемом в ассемблерный код.
- До 8 текстурных итераторов (т.е. вычисляемых для каждой точки треугольника соответствующих ей текстурных координат).
- До 16 выборок из текстур, в том числе зависимые выборки по предварительно рассчитанным в шейдере координатам. Степень вложенности таких выборок не больше 4.
- Шейдер может включать до 32 ассемблерных команд адресации текстур и до 64 ассемблерных арифметических команд в произвольном порядке.
- Появились связанные с плавающими вычислениями команды (exp, log, rsq и т.д.)
- 12 временных векторных регистров общего назначения
- 32 константы
- Гамма-коррекция значений. Позволяет повысить реалистичность передачи тонких цветовых нюансов, особенно в тенях синтезированных изображений. Проводится прямая гамма-коррекция при записи результатов шейдера в буфер кадра и обратная коррекция при поступлении исходных данных из буфера кадра или текстуры, можно управлять значением гамма.
Кроме того, появился столь актуальный формат компрессии объемных текстур DXVC, лицензированный у NVIDIA.
Подведем итоги. Существенная ставка сделана (как и в случае OpenGL 2.0) на программируемость ускорителя. Появление языка высокого уровня и существенное увеличение гибкости программируемых блоков сыграет свою положительную роль. Мечта многих компаний, разрабатывающих графические чипы переложить большинство сложностей (алгоритмов) из железа на плечи программистов воплощается семимильными шагами. Теперь, внутри конвейеров ускорителя, все данные передаются и обрабатываются с высокой точностью, обеспечиваемой плавающим форматом.
Появление стабилизированной версии MS DX9 ожидается в конце лета, а ее официальный выход, судя по всему, будет рождественским подарком.
А теперь позвольте представить вам во всей красе новый чип от Matrox Graphics:
Parhelia-512 GPU

Блок схема:
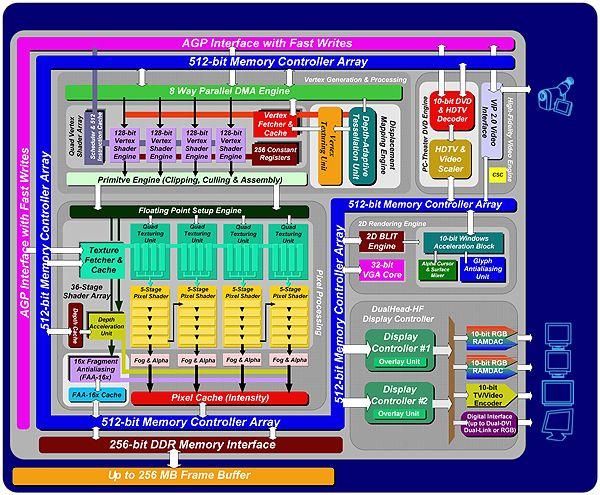
Спецификация:
- 80 миллионов транзисторов
- Технологическая норма 0.15 мкм
- Графическое ядро с частотой 250 МГц (оринтировочно) и до DDR 325 (650) МГц частота памяти
- Полноценная 256 бит (!) DDR шина памяти
- Пропускная способность локальной памяти порядка 20 ГБ/сек
- Объем локальной памяти 64/128/256 МБ
- AGP 2x/4x/8x включая режимы SBA и FastWrites
- 4 пиксельных конвейера
- 4 текстурных блока на каждом конвейере (!)
- Скорость закраски — около 1 Гигапикселя и около 4 Гигатекселей
- Вершинные шейдеры версии 2.0 (Vertex Shader 2.0), четыре параллельных исполняющих блока
- Пиксельные шейдеры версии 1.3 (Pixel Shader 1.3), 4 текстурных + 5 комбинационных стадий на каждом пиксельном конвейере, с возможностью объединения конвейеров попарно (получаем 2 конвейера по 10 комбинационных стадий)
- EMBM и DOT3 наложение рельефа
- Фиксированный T&L DX8 (включая расширенные возможности матричного блендинга и скининга). Фактически представляет собой специальный вершинный шейдер
- Построение, хранение в локальной памяти и вывод на монитор изображения с точностью 10 бит на компоненту цвета (!). Технология 10-bit GigaColor
- Два встроенных в чип, 400 МГц, 10 бит на канал RAMDAC, использующих технологию UltraSharp
- Полноценная 10 бит > 10 бит таблица для произвольной гамма-коррекции выводимого изображения
- DVD и HDTV видео декодер с точностью (на выходе) 10 бит
- Поддерживается вывод изображения в разрешениях вплоть до 2048x1536x32bpp@85 Гц
- Встроенный в чип интерфейс TV-Out с 10 битной точностью формирования сигнала
- Два цифровых TMDS интерфейса для цифровых выходов или внешних RAMDAC. Поддерживается разрешение вплоть до 1920x1200x32bpp
- Два полностью независимых CRTC
- Возможность вывода одного изображения, растянутого на два или даже три (!) приемника. Например, на 2 встроенных и один внешний RAMDAC или на оба встроенных RAMDAC и TV-Out. Суммарное разрешение в тройном режиме до 3840x1024x32bpp. Технологии TripleHead Desktop, Surround Gaming и DualHead-HighFidelity (HF)
- Адаптивная разновидность суперсэмплинга (не мултисэмплинг!) 16x Fragment SSAA с числом сэмплов до 16 включительно. Активируется только на краевых точках полигонов.
- Аппаратная поддержка N-патчей с адаптивной тесселяцией (!) и картами смещения (Displacement mapping)
- Glyph Antialiasing технология аппаратного краевого сглаживания и гамма-коррекции шрифтов (!)
- Microsoft DirectX 8 и OpenGL 1.3. Потенциально некоторые возможности DirectX 9.
Большое число транзисторов при такой технологической норме знаменует собой как большие возможности, так и существенную себестоимость чипа Parhelia-512. Вообще странно, что такой сложный графический процессор планируется выпускать по 0.15 мкм технологическому процессу и еще неизвестно, как будет обстоять дело с тепловыделением. Еще более дорогим удовольствием, присущим всем чипам последнего поколения (P10, R300, NV30) является полноценная 256 бит DDR шина памяти.
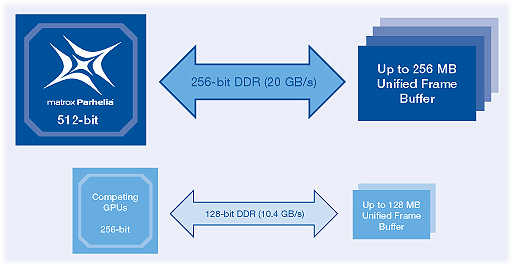
Теоретически, подобный технологический скачок позволяет вдвое увеличить производительность графического ускорителя. Причем, сугубо за счет увеличения себестоимости продукта, без применения каких либо новых технологий в архитектурном плане. Видимо, на данный момент подобное решение экономически выгоднее, нежели архитектурные изыски цены на память и печатные платы позволят применять «широкую» шину в широких масштабах.
Кроме того, в DX9, OpenGL 2.0 и последующих версиях основных API все больше данных будет храниться в памяти ускорителя в плавающем (неохотно и непросто сжимаемом) формате. Все больше данных будут представлять собой геометрическую (и другую неграфическую) информацию. Решившись на столь широкую шину памяти не надо вкладывать деньги в разработку и отладку сложных тайловых технологий закраски и сжатия, экономящих пропускную полосу локальной памяти (они существенно удорожают и увеличивают время разработки чипа и драйверов). Говоря о цене разработки Parhelia-512, самое время задуматься над причинами, побудившими Matrox выпустить этот GPU. Согласитесь, уже год, как почти никто не ждал от этой компании претендующего на hi-end решения. Сюрприз!
Со слов одного из инженеров компании Matrox: «Мы сделали этот чип, чтобы показать всем мы по-прежнему способны разработать передовое решение». Другой работник ответил менее серьезно: «Just for fun». Очевидно, что в ближайшее время столь дорогое решение не сможет повлиять на передел рынка, а вот улучшить реноме компании Matrox способно. Даже если число проданных карт на базе Parhelia-512 не превысит 10000. Один только анонс чипа содержащего передовые (не имеющие пока аналогов) технологические решения способен привлечь к себе пристальное внимание.
Итак, по сравнению с предыдущим поколением ускорителей, вдвое увеличится пропускная полоса локальной видеопамяти. Но скорость не главный конек продуктов от Matrox. На удивление, чип Parhelia-512 не оснащен какими-либо технологиями экономии пропускной полосы памяти. Этот факт удивителен подобные технологии присутствуют во всех последних продуктах от ATI и NVIDIA, но видимо Matrox решила ускорить и удешевить разработку чипа, являющегося для них скорее символом, чем попыткой завоевать рынок.
Поясним подробнее: В отличии от ATI и NVIDIA, Matrox не снабдила свой последний чип технологиями сжатия Z буфера или раннего удаления невидимых поверхностей. В наличии только быстрая очистка Z буфера. Чип и так слишком сложен — такое количество транзисторов просит более тонкой .13 технологии, но, видимо пока она не доступна для Matrox в необходимых количествах и/или с необходимой себестоимостью. Можно прогнозировать появление через некоторое время (в начале 2003 года или позже) обновленной версии чипа выполненой по технологии .13 и с полной поддержкой DX9.
Тесты инженерных образцов на еще очень сырых драйверах показывают лишь 20..30% преимущество Parhelia-512 над NVIDIA GeForce 4 Ti4600. Даже при условии успешного тюнинга программного обеспечения, двукратное превосходство вряд ли станет возможным. Полтора раза вот верхний предел. Очевидно, что при существенной стоимости карт на базе нового GPU от Matrox, обычным потребителям имеет смысл покупать их ради качества и уникальных возможностей, но не скорости. С другой стороны, Matrox не может претендовать на успех на профессиональном рынке без сертифицированных OpenGL драйверов (возможно, они появятся вместе с профессиональной линейкой карт на базе Parhelia-512 выпуск которой планируется). Для ниши «просто любителей качественного 2D» карта неоправданно дорога. Итак, на первое время остаются энтузиасты, полупрофессионалы, фанаты марки и мы специалисты по видеокартам :-).
Интересно, что ускоритель можно назвать лишь «частично» DX9 совместимым. Известно, что Parhelia-512 сможет исполнять вершинные шейдеры второго поколения. Но, при этом Parhelia-512 не соответствует второму поколению пиксельных шейдеров! Максимум, на что чип способен в этом вопросе версия 1.3, т.е. до 4 текстур за проход. Давайте посмотрим на детальную схему пиксельных конвейеров чипа:
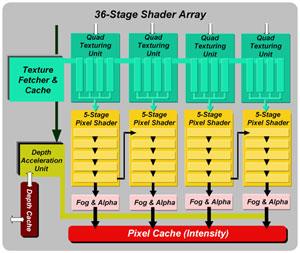
Исполнение пиксельных шейдеров версии 2.0 невозможно хотя бы из-за явно недостаточного числа стадий пиксельного конвейера, и отсутствия текстурных лупбеков (нельзя использовать более 4-х значений текстур за один проход). Интересно, что в документах Matrox говорится о 36 стадиях, но на четыре пиксельных конвейера в сумме. Реально возможны две конфигурации:
- Работают все четыре пиксельный конвейера, на каждом доступны 4 текстурных и 5 пиксельных (арифметических) шейдерных стадий.
- Работают только два конвейера, закраска двух точек за такт. Доступны 4 текстурных и 10 пиксельных стадий на каждом.
В результате, пиксельные шейдеры с числом команд более 5 будут исполнятся вдвое медленнее. Справедливости ради отметим, что типичные пиксельные шейдеры версии 1.3 (и ниже) часто состоят из 5 и менее команд.
Фактически, маркетологи Matrox хотят запутать потенциальных покупателей внушительной цифрой в 36 стадий, совершенно не нужных ускорителю, ограниченному 4-мя текстурами за проход. Максимум что мы можем получить на практике 4 текстурные и 10 пиксельных стадий. Приложениями будут использоваться только 8 из 10 в четком соответствии с ограничениями шейдеров версии 1.3.
В тех же документах от Matrox идет речь о 64 (!) отсчетах текстур, выбираемых за такт чипом Parhelia-512, но при ближайшем рассмотрении становится понятно, что это число вновь лишь суммарная характеристика по всем 16 текстурным блокам чипа сразу. Неприятно, когда тебя стремятся запутать большими цифрами, полученными в обход общепринятых норм :-(.
Итак, Parhelia-512 не является полноценным DX9 ускорителем. Надеяться на поддержку собственных нестандартных возможностей (находящихся между DX8 и DX9) со стороны разработчиков приложений нет смысла новый GPU от Matrox просто не займет достаточной для этого доли рынка.
С другой стороны, Parhelia-512 полноценно реализует уже подробно описанные нами карты смещений, и N-патчи с адаптивной тесселяцией. И то и другое реализовано строго в понимании DX9. Чип работает с введенным в DX9 10-ти битным форматом буфера кадров и имеет некоторые другие специфичные для именно для DX9 возможности. В наличии полностью соответствующий DX9 блок вершинных шейдеров (версия 2.0), способный параллельно обрабатывать четыре вершины:
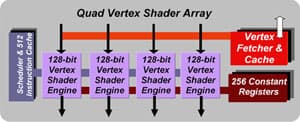
Не первый раз мы наблюдаем рождение чипа на стыке версий API железо развивается практически вдвое интенсивнее работающего с ним программного обеспечения. Будем, наедеяться, что еще одна цель разработки этого чипа создание и обкатка ядра, которое послужит основой для будущих mainstream продуктов Matrox, вполне возможно, уже полностью DX9 совместимых, с соответствующим второй версии, «плавающим» блоком пиксельных шейдеров.
Кроме широкой шины и повышенной точности обработки данных, чипы нового поколения просто обязаны отличаться качественными и «недорогими» с точки зрения производительности антиалиасингом (АА) и анизотропной фильтрацией. У Parhelia-512 тут все в норме, если не считать маркетингового заскока с цифрой 64. На практике в наличии по четыре блока выборки билинейных значений, и гибко конфигурируемый интерполятор на каждом пиксельном конвейере (вернее было бы сказать один гибко конфигурируемый текстурный блок, способный выбирать четыре билинейных сэмпла, в том числе из различных текстур, за такт). Каждый такой блок может выбрать и интерполировать 16 дискретных отсчетов за такт (а всего, для четырех пиксельных конвейеров 64). Вот пример реального использования наложения четырех текстур за один проход:
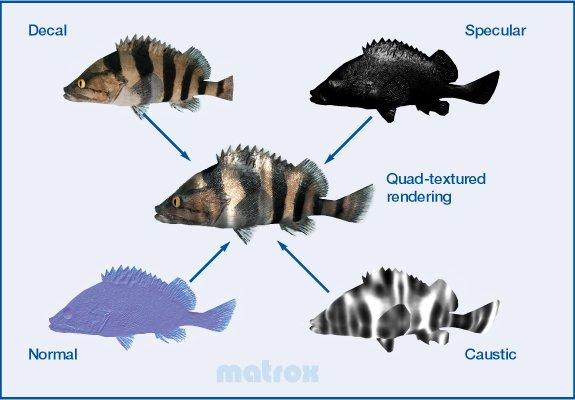
В зависимости от используемой фильтрации мы получим четыре билинейно фильтрованных, две трилинейно или анизотропно (8 отсчетов) или одну анизотропно (16 отсчетов) текстуры за такт. Соответственно, для старых, «двутекстурных» приложений анизотропная фильтрация на базе 8 отсчетов будет проходить без потери скорости. Но, технология анизотропной фильтрации близка к реализации от NVIDIA, а вот практически бесплатной анизотропки (на основе RIP маппинга), свойственной ATI мы у Parhelia-512 не увидим. Приведем скриншот из Quake III c максимальной анизотропией:

Подробнее о качестве анизотропной фильтрации мы расскажем позже. Но сразу отметим, что падение производительности будет слегка сглажено вдвое большим числом выбираемых за такт текстурных данных. Но, только на старых, не использующих за один проход 4 текстуры, приложениях.
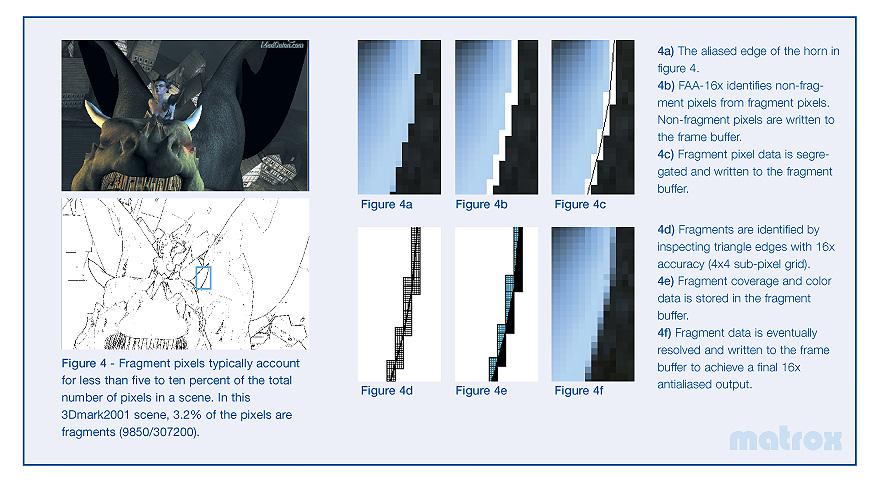
Технология полноэкранного сглаживания, реализованная в Parhelia-512 на сегодняшний день аналогов не имеет. Посему, должна быть похвалена, и несомненно может считаться достаточно близкой к идеалу. По своей сути, это суперсэмплинг, до 16 отсчетов на одну точку экрана. Но, выполняется он ТОЛЬКО (!) для точек принадлежащих краям полигонов (всего 3..5% типичной сцены):
Сравним с распространенными методами полноэкранного сглаживания:
Основное преимущество очевидно: в отличие от мултисэмплинга избыточные данные не хранятся в памяти и не пересылаются по шине! Суммарный размер буфера кадра возрастает лишь незначительно, не более чем вдвое, даже при максимальной 16x установке. Для определения граничных пикселей используется специальный быстрый проход рендеринга, когда ускоритель в отдельном буфере помечает только граничные пиксели полигонов, не вычисляя значения текстур и не закрашивая промежуточных точек. Кроме того, т.к. обрабатываются только края полигонов, не возникает свойственной FSAA и некоторым гибридным MSAA техникам потери четкости текстур:
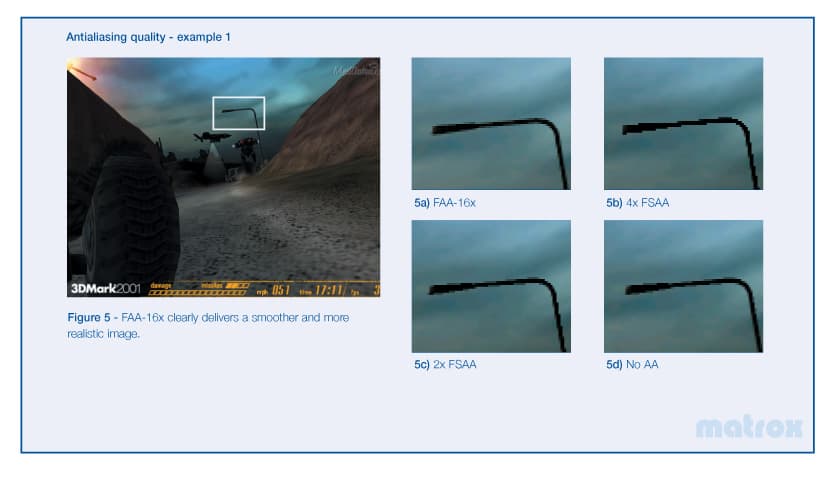
Давайте сравним полученый с применением этой технологии сглаживания скриншоты:


Слева: 3D Mark 2001 Without FAA-16x; Справа: 3D Mark 2001 With FAA-16x


Слева: Seaplane Without FAA-16x; Справа: Seaplane With FAA-16x
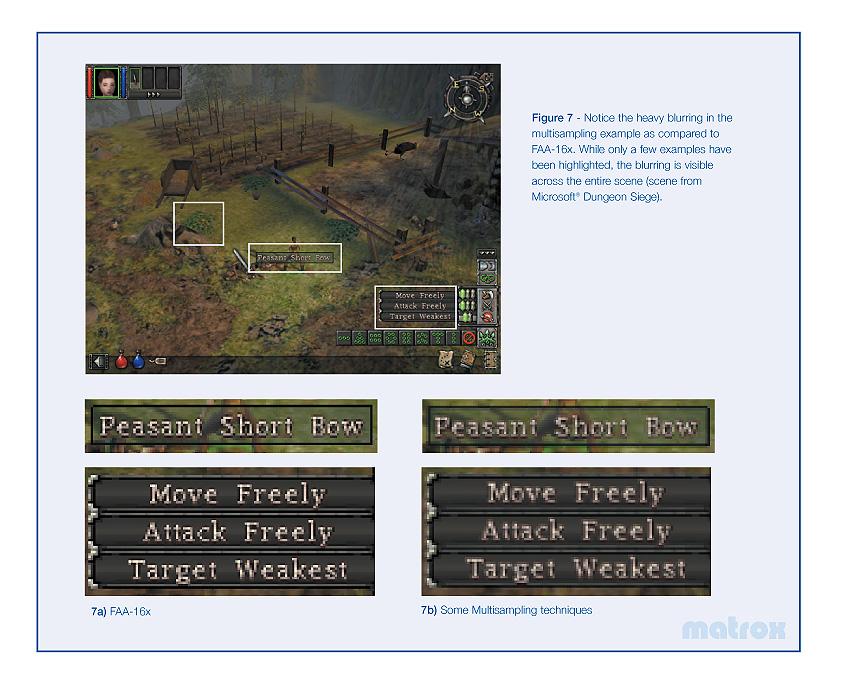
Однако, столь интеллектуальный метод AA способен вызывать артефакты в некоторых случаях. Кроме того, он не может корректно обрабатывать сглаживание границ перемешаных с полупрозрачными полигонами (например облака, туман, стекла, огонь в играх). Пользователь может переключится на хорошо знакомый классический 4х (2х2) MSAA также поддерживаемый чипом.
Несомненный плюс чипа богатство интерфейсов. В наличии два полноценных, традиционно качественных 400 МГц RAMDAC, два TMDS трансмиттера, интегрированный TV-Out и два контроллера (CRTC) обеспечивающие возможность вывода различных изображений на два приемника одновременно:
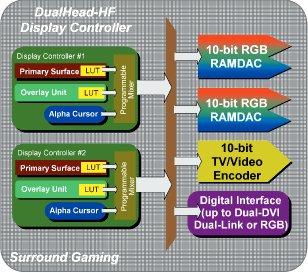
Поддерживается полный набор двуголовых возможностей:

А также новая возможность вывода одного изображения по частям на три (!) приемника сигналов одновременно. Например, на три монитора, при использовании внешнего, третьего, RAMDAC):
Ожидается, что на выставке E3 в этом году будет демонстрироваться много разных игр в широком (180 градусов охвата зрения) исполнении, сразу на трех мониторах. Как вы уже догадались на карте, на базе Parhelia-512. В комплекте программного обеспечения идет специальная утилита, позволяющая играть во многие популярные игры в широком дву- или трехэкранном режиме.


Как говорится, почувствуем разницу (слева обычный режим, справа режим Surround Gaming):

Return to Castle Wolfenstein


Soldier of Fortune II


Haegemonia: Legions of Iron


Jedi Knight II: Jedi Outcast
Осталось разрешить только один бытовой вопрос: где обычному игроку взять три монитора? И где их потом поставить :-)
К слову о качестве RAMDAC. Matrox всегда славилась качественным 2D компания даже приводит результаты испытаний (!) частотной характеристики своих RAMDAC в сравнении с основными конкурентами. Первичный:
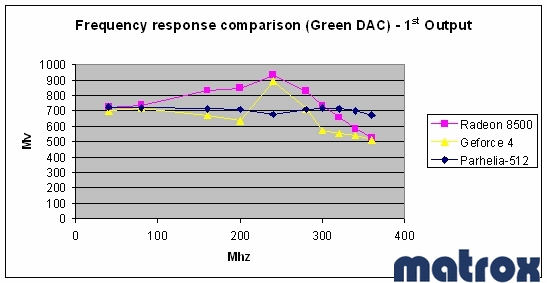
и вторичный RAMDAC:
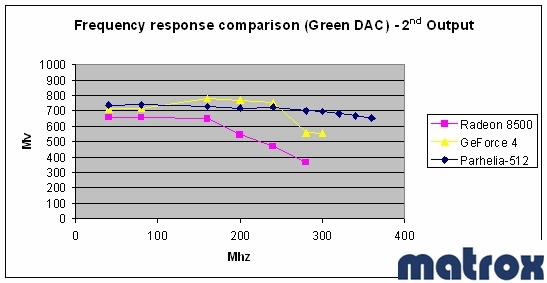
На карте в свою очередь присутствует качественный выходной фильтр пятого порядка:

Кроме всего прочего, чип Parhelia-512 содержит аппаратное «вспоможение» для DVD и HDTV декодера. Теперь можно будет посмотреть DVD в 10 битном качестве, вопрос только в целесообразности такой точности представления для сигнала исходно хранимого и сжатого с учетом 8 бит.
Светит! Греет?
На последок, приведем достаточно бесполезную сравнительную таблицу:
| Чип | Parhelia-512 | 3Dlabs P10 | GeForce4 Ti | RADEON 8500 |
|---|---|---|---|---|
| Шина памяти, бит | 256 DDR | 256 DDR | 128 DDR | 128 DDR |
| Частота памяти, МГц | 325(?) | 250(?) | 325 | 275 |
| Частота ядра, МГц | 250(?) | 250 | 300 | 275 |
| Полоса пропускания | ~20 Гб | ~20 Гб | 10.4 Гб | 9.6 Гб |
| Макс. доступный объем локальной памяти | 256 Мб | 256 Мб | 128 Мб | 128 Мб |
| Вершинные шейдеры, версия | 2.0 (4 блока) | 2.0 (4 блока) | 1.1 (2 блока) | 1.1 |
| Пиксельные шейдеры, версия | 1.3 | 1.3 (2.0?) | 1.3 | 1.4 |
| Текстур за проход, до | 4 | 8 (до 16 выборок) | 4 | 6 |
| Текстурных блоков | 4 | 2 | 2 | 2 |
| Пиксельных конвейеров | 4 | 4 | 4 | 4 |
| Анизотропия | 8, 16 | ? | 8, 16, 32 | RIP-маппинг |
| Встроенные RAMDAC | 2 (10 бит!) | 2 (10 бит?) | 2 | 2 |
| Встроенный TV-Out | 1 (10 бит!) | нет | нет | нет |
| Число CRTC | 2 (+ режим растяжения на 3 экрана) | 2 | 2 | 2 |
| FSAA | 16x FAA (фрагментный) | 8x MSAA | 4x MSAA | 6x pattern MSAA |
| N-Patches | DX9 (адаптивные) | Нет | Нет | DX8 |
| Карты смещения | Да | Нет | Нет | Нет |
Бесполезную потому, что нет смысла делать выводы о технологическом лидерстве Parhelia-512 раньше времени подождем анонсов и образцов игровых чипов нового поколения от конкурентов, а именно, ориентированных на DX9 чипов NVIDIA NV30 и ATi R300.
Интересно, не повторится ли история с пиксельными шейдерами GF2 и Radeon по сути «перечеркнутыми» Microsoft, в результате долгого развития и утряски ключевых параметров шейдеров DX8, в том числе и после завершения разработки чипов. Будут ли эти два основных конкурента полностью совместимыми с DX9? Их создатели утверждают что да, но только осенью, мы сможем проверить их слова.
Не стоит забывать и анонсированный 3Dlabs профессиональный чип P10. Он является физическим воплощением еще не принятого стандарта OpenGL 2.0 (в понимании 3Dlabs), стандарта, развивающегося по сходному с DX9 пути. Пускай медленнее, но более последовательно и продуманно. Необходимая для реализации OpenGL 2.0 архитектура потенциально (с большой вероятностью) сможет соответствовать и требованиям DX9. Но, не наоборот.
Итак, в скором времени будут анонсированы 64, 128 и 256 МБ карты на базе Parhelia-512, старшая в линейке плата будет стоить порядка $500, за плату со 128 МБ памяти вы заплатите уже около $400. Реально доступны первые карты будут в июле. Все карты снабжены полноценной 256 бит шиной памяти разница только в скорости работы памяти и ее объеме. Карты на базе Parhelia-512 будут выпускатьcя только самой Matrox, по словам представителей компании опыт сотрудничества с Gigabyte был большой ошибкой.
Ожидается и отдельная профессиональная линейка карт на базе Parhelia-512. В продаже карты появятся в самом конце лета, приблизительно в то же время, что и карты на базе NV30/R300. И конкурировать, разумеется, продукт Matrox будет именно с ними, а не с предыдущим поколением ускорителей в лице GeForce4 Ti4600 и, тем более, RADEON 8500, что, согласитесь, несколько меняет картину.
Parhelia (в переводе «ложное солнце») начинает светить нам 14 мая. Сможет ли оно согреть нас?
Комментарии