NVIDIA GeForce 7800 GTX 256MB PCI-E
Часть 1: Теория и архитектура

(дословный перевод строчки
из информации для прессы).
Итак, заканчивается затяжной период ожидания новых ускорителей. Вот она, новая верхняя модель от NVIDIA и, если все пойдет хорошо, то осенью мы сможем стать свидетелями ее конкуренции с новым топовым решением от ATI, которое (что уже не секрет) также будет способно исполнять шейдеры 3.0. Увидим кто кого! Пока же начнем наше всестороннее изучение GeForce 7800 GTX. Разумеется, как это уже стало традиционным, начнем мы его спецификациями, диаграммами и теоретической частью.
Спецификации GeForce 7800 GTX (кодовое название G70)
Новое кодовое название чипа. Что хотела сказать этим NVIDIA? Забегая вперед, отметим, что, несмотря на заметный рост производительности, эту архитектуру не следует считать принципиально новой — на лицо развитие и совершенствование хорошо знакомой нам по семейству NV4X архитектуры. Следовательно, новое кодовое название чипа введено по иной причине. Может, потому что NV47 звучало бы слишком рядовым образом, а архитектурные отличия от NV45 все-таки заметны, и сильнее, чем в случае привычного тюнинга, а может и по другим причинам, о которых мы можем только догадываться.
Перед прочтением рекомендуем внимательно ознакомиться с базовыми материалами DX Current, DX Next и Longhorn описывающими различные аспекты современных аппаратных ускорителей графики вообще, и архитектурные особенности продукции NVIDIA и ATI в частности. Информацию о предыдущей флагманской архитектуре NVIDIA также можно почерпнуть из соответствующей статьи:
NVIDIA GeForce 6800 Ultra (NV40).
А теперь, спецификации новинки:
Официальные спецификации GeForce 7800

- Кодовое имя чипа G70 (ранее известен как NV47)
- Технология 110 нм (предполагаемый производитель TSMC)
- 302 миллиона транзисторов (рекорд на данный момент)
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 256 бит интерфейс памяти
- До 1 гигабайта GDDR-3 памяти
- PCI Express 16х шинный интерфейс
- 24 Пиксельных процессора, по одному текстурному блоку на каждом, с произвольной фильтрацией целочисленных и плавающих FP16 текстур (в том числе анизотропия, степени до 16х включительно) и бесплатной нормализацией FP16 векторов. Пиксельные процессоры улучшены по сравнению с NV4X — увеличено число ALU, возможно эффективное выполнения MAD операции.
- 8 Вершинных процессоров, по одному текстурному блоку на каждом, без фильтрации выбираемых значений (дискретная выборка).
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 32 значений глубины и буфера шаблонов за такт (если не производятся операции с цветом)
- Поддержка «двустороннего» буфера шаблонов
- Поддержка специальных оптимизаций прорисовки геометрии для ускорения алгоритмов теней на основе буфера шаблонов и аппаратные карты теней (т.н. технология Ultra Shadow II)
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 3.0, включая динамические ветвления в пиксельных и вершинных процессорах, выбор значений текстур из вершинных процессоров и т.д.
- Фильтрация текстур в плавающем формате FP16.
- В вершинных шейдерах аппаратная фильтрация текстур не поддерживается, доступна только выборка значений без фильтрации.
- Поддерживается буфер кадра в плавающем формате (включая операции блендинга в формате компонент FP16 и только запись в формате FP32)
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- 2x RAMDAC 400 МГц
- 2x DVI интерфейса (требуются внешние интерфейсные чипы)
- TV-Out и HDTV-Out интерфейсы встроены в чип ускорителя
- TV-In интерфейс (требуется отдельный интерфейсный чип для видеозахвата)
- Программируемый аппаратный потоковый видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, с производительностью достаточной для качественного деинтерлейсинга HDTV
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка важных специальных возможностей графической драйверной модели Longhorn (степень поддержки пока неизвестна)
- Поддержка технологии SLI
Спецификации референсной карты GeForce 7800 GTX
- Частота ядра 430 МГц
- Эффективная частота памяти 1,2 ГГц (2*600 МГц)
- Тип памяти GDDR-3, 1,6 нс
- Объем памяти 256 мегабайт (будут варианты карты с 512 мегабайт, так как на предоставленной нам плате уже предусмотрены места для 512 мегабайт памяти)
- Пропускная способность памяти 38,4 гигабайта в сек.
- Теоретическая максимальная скорость закраски 6.9 гигапикселя в сек.
- Теоретическая скорость выборки текстур 10.4 гигатекселя в сек.
- Два DVI-I разъема
- SLI разъем
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
- Потребляет до 110 Ватт энергии (типовое потребление не превышает 100 Ватт, на карте один стандартный для PCI Express разъема дополнительного питания, рекомендуются источники питания суммарной мощностью 350 Ватт, для SLI режима — 500 Ватт).
Спецификации впечатляют, хотя в них и заметна некая преемственность по отношению к предыдущим флагманам на базе NV40 и NV45. Сразу отметим ключевые отличия в сравнении с ними:
- Более тонкая технология производства чипа, большее число транзисторов, меньшее энергопотребление карты (несмотря на большее число конвейеров и большую частоту!).
- Пиксельных процессоров не 16, а 24 (точнее, 6 процессоров квадов, вместо 4)
- Пиксельные процессоры стали производительнее — увеличено число ALU, ускорена работа со скалярными величинами и скалярным произведением/MAD.
- Вершинных процессоров стало 8 вместо 6, судя по всему, они не изменились
- Появилась производительная аппаратная поддержка для воспроизведения видео в формате HDTV и HDTV выход, совмещенный с TV-выходом.
Итак, очевидно, что при создании нового ускорителя преследовались две основные цели — снижение энергопотребления и существенное увеличение производительности. Так как шейдерная модель 3.0 была реализована уже в предыдущем поколении ускорителей NVIDIA, а следующая модель рендеринга (WGF 2.0) еще не детализирована окончательно, то картина выглядит вполне логичной и ожидаемой. Радует не просто увеличение числа пиксельных процессоров, но и увеличение производительности каждого. Единственный вопрос — почему не была реализована фильтрация при выборке значений текстур вершинными процессорами? Этот шаг казался нам вполне логичным, но, видимо, это решение забрало бы на себя слишком много ресурсов и инженеры NVIDIA решили направить их на другие цели — а именно на усиление пиксельных процессоров и увеличение их числа. Следующее поколение ускорителей, станет соответствовать WGF 2.0 и соответственно будет, наконец-то, лишено такой досадной асимметрии в возможностях текстурных блоков вершинных и пиксельных шейдеров. Еще одной целью можно считать широкое внедрение поддержки HDTV, как нового повсеместного (в будущем) стандарта.
Архитектура ускорителя
Теперь, по традиции, перейдем к общей диаграмме чипа:
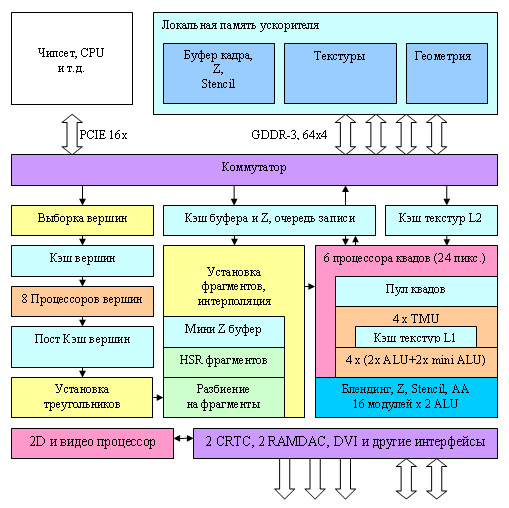
Основные отличия этой диаграммы от NV45 — наличие 8 вершинных процессоров и 6 процессоров квадов (всего, таким образом, обрабатывается 4*6=24 пикселя) вместо 4 с большим числом ALU для каждого процессора. Обратите внимание на вынесенный на схеме за пределы процессора квадов блок AA, блендинга и записи результатов. Дело в том, что, несмотря на увеличенное в полтора раза число пиксельных процессоров, число модулей отвечающих за запись результатов осталось прежним — их 16. То есть новый чип может существенно быстрее рассчитывать шейдеры, причем у 24 пикселей параллельно, но по-прежнему записывает не более 16 полноценных пикселей за такт. Что, впрочем, вполне достаточно — большее число пикселей за такт не пропустит память, да и современные приложения тратят несколько десятков команд, прежде чем вычислить и записать одно результирующее значение пикселя, поэтому рост числа пиксельных процессоров без роста числа модулей записи видится вполне сбалансированным и логичным решением. Такие решения применялись и ранее в бюджетных чипах NVIDIA (GeForce 6200, например), которые имели полноценный процессор квадов, но обрезанные модули записи (по числу блоков и по отсутствию FP16 блендинга).
Пиксельный конвейер
Итак, в наличии следующая архитектура пиксельной части:
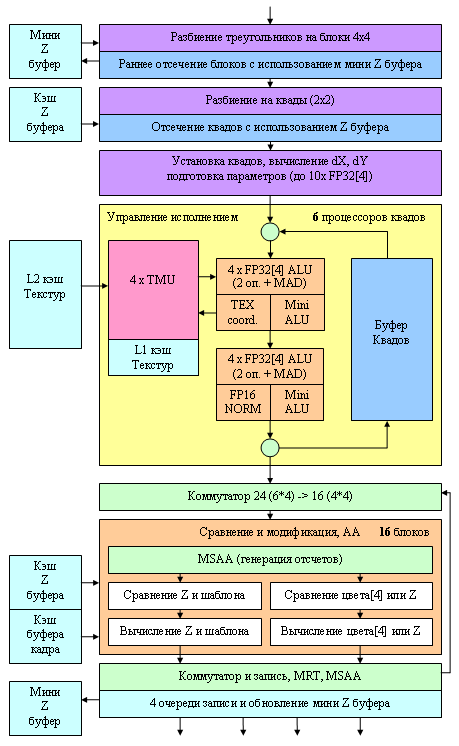
Посмотрим на желтый блок пиксельного процессора (процессора квадов). Можно сказать, что было произведено «турбирование» существовавшей ранее в NV40/45 схемы — к двум полным векторным ALU способным исполнять 2 разные операции над 4 компонентами были добавлены два скалярных mini ALU для параллельного исполнения простых операций. Теперь ALU умеют выполнить MAD операцию (одновременное умножение и сложение) без какого либо пенальти. Утверждается, что такая «расточка цилиндров» может привести к 2-х кратному росту производительности некоторых особенно тяжелых и удобных шейдеров (которым удается полностью загрузить и обычные ALU и mini-ALU) и к 1.5 кратному росту шейдерной мощи в среднем. Действительно, MAD очень популярная операция и встречаются в типовых пиксельных шейдерах по многу раз. К такой конфигурации ALU специалисты NVIDIA пришли после статистического исследования множества различных реальных игровых шейдеров, но, названная цифра (1.5 раза) выглядит слишком оптимистичной, что свойственно PR отделу NVIDIA, и далее мы проверим на практике, какое влияние этот архитектурный момент окажет на наши синтетические и игровые тесты.
Добавление небольших упрощенных и специализированных ALU — старый прием NVIDIA, уже не один раз позволявший компании малым числом транзисторов заметно увеличить производительность пиксельных блоков. Например, еще NV4X имели специальный блок для нормализации FP16[4] векторов (на схеме он пристыкован ко второму основному ALU и назван FP16 NORM), и в G70 эта традиция была продолжена - такой блок позволяет существенно увеличить производительность пиксельных шейдеров благодаря возможности бесплатной нормализации векторов на каждом проходе квада через конвейер процессора. Интересно, что операция нормализации кодируется в шейдерах в виде последовательности нескольких команд, и драйвер должен распознавать это действие, и подменять на одно обращение к этому специальному блоку. Однако на практике это распознавание происходит достаточно эффективно, особенно если шейдер был скомпилирован из HLSL, и таким образом пиксельные процессоры NVIDIA не тратят на нормализацию векторов несколько тактов как в случае ATI (важно не забывать об ограничении на формат - FP16, то есть половинная точность).
Что касается текстурных модулей — то тут все осталось прежним — по одному модулю на пиксель (то есть четыре модуля в процессоре квадов), собственный кэш первого уровня у каждого процессора квадов, фильтрация текстур с целочисленным или FP16 форматом компонент, до 4-х компонент включительно (FP16[4]). Выборка значений из текстур с форматом компонент FP32 возможна, но без аппаратной фильтрации — оную придется или не делать, или запрограммировать в пиксельном шейдере, потратив на это десяток и более инструкций. Впрочем, так было и раньше — полноценная поддержка FP32 компонент будет, видимо, только в следующем поколении архитектур.
За массивом из 6 процессоров квадов следует коммутатор, который перераспределяет рассчитанные квады по 16 блокам генерации глубины, AA и блендинга (а точнее по 4 связкам из 4-х блоков, обрабатывающим целый квад, так как геометрическая связанность не должна быть потеряна, так как понадобится при записи и сжатии цвета и буфера глубины). Каждый блок за один такт может сгенерировать, проверить и записать 2 значения глубины, или одно значение глубины и одно значение цвета. Обеспечивается работа с двусторонним буфером шаблонов. Кроме того, один такой блок бесплатно выполняет 2х мультисамплинг, для 4х режима требуется уже два прохода данных через блок, то есть два такта. Но и здесь есть исключения. Суммируем набор возможностей таких блоков:
- Запись цвета — FP32[4], FP16[4], INT8[4] за такт, в том числе в разные буфера (MRT).
- Сравнение и блендинг цвета — FP16[4], INT8[4], для формата компонент FP32 не поддерживается
- Сравнение, генерация и запись глубины (Z) — все режимы, при отсутствии цвета — два значения за такт (режим Z-only). В режиме MSAA — также, два значения за такт.
- MSAA — INT8[4], для плавающих форматов компонент не поддерживается.
Столько условий возникает в результате достаточно большого количества аппаратных ALU необходимых для операций MSAA, генерации значений глубины, сравнения и блендинга цвета. NVIDIA пытается оптимизировать расход транзисторов и использует одни и те же ALU в разных целях в зависимости от задачи, вот почему плавающий формат делает невозможным MSAA, а формат FP32 и блендинг. Большой расход транзисторов является и одной из причин к тому, чтобы оставить 16 модулей, а не сделать их 24 в соответствии с числом пиксельных процессоров. Ведь в таком варианте большинство транзисторов этих блоков может (и будет) простаивать в современных приложениях с длинными шейдерами, даже в режиме 4хAA, а память, пропускная полоса которой практически не увеличилась по сравнению с GeForce 6800 Ultra, все равно не даст записать даже 16 полноценных пикселей за такт в буфер кадра. Так как эти модули работают асинхронно с пиксельными процессорами (рассчитывают значения глубины и делают блендинг, в то время как уже идет расчет цвета следующих пикселей в шейдере), наличие 16 блоков можно считать не просто обоснованным, а очевидным решением. А вот некоторые ограничения, связанные с FP форматами, досадны, но характерны для нашего переходного периода, на пути к симметричным архитектурам, которые будут позволять производить все операции со всеми доступными форматами данных без какой-либо потери скорости, как это в большинстве случаев позволяют гибкие современные CPU.
Вершинный конвейер
Здесь никаких особенных изменений:
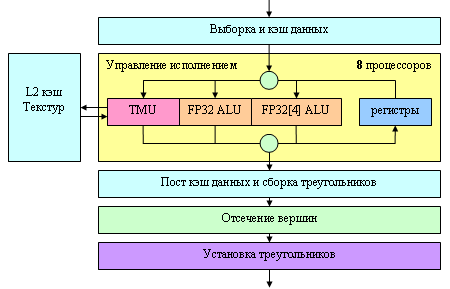
Все хорошо знакомо нам по семейству NV4x, и только число вершинных процессоров увеличилось с 6 до 8. По-прежнему выборка текстур в вершинных процессорах происходит достаточно номинально — как по скорости, так и по возможностям. Фильтрация недоступна ни для каких форматов — только точечная выборка, да и ее скорость (как показывают тесты) не велика, по сравнению с пиксельными процессорами. Впрочем, пока эта возможность SM 3.0 мало востребована в реальных приложениях и с таким статусом «золушки» можно смириться. Но в глубине души хочется поскорее увидеть воплощение светлого WGF 2.0 будущего, хотя бы в таких частностях, как симметричные возможности по работе с текстурами в вершинных и пиксельных процессорах. Забегая вперед, отметим, что некоторые аспекты работы с геометрией (кэширование вершин) все-таки были усовершенствованны, и во второй части статьи мы исследуем этот вопрос.
Форматы данных, с которыми работает ускоритель
Небольшая справочная глава. Доступны следующие форматы представления (хранения) данных (на компоненту, коих может быть от 1 до 4):
- VS 3.0 — FP32
- PS 3.0 — FP16, FP32
- Текстуры — INT8, FP16, FP32
- Буфер кадра — INT8, FP16, FP32
А обработка данных (вычисления) происходит в следующих форматах:
- VS 3.0 — FP32
- PS 3.0 — FP32
- Текстуры — INT8, FP16, FP32 (без фильтрации)
- Буфер кадра — INT8, FP16 (без MSAA), FP32 (без блендинга и MSAA)
Новая вкусная возможность для АА
А теперь поговорим о новых возможностях ускорителя, не нашедших места на вышеприведенных диаграммах но достаточно важных для нас. Впервые в наличии гамма-корректный MSAA (присутствовавший у чипов ATI со времен R3XX) и Transparent Supersampling — новшество в AA, впервые реализованное в этом чипе.
Как известно основная проблема MSAA состоит в том, что он сглаживает только края полигонов. Если полигон прозрачный или полупрозрачный (например, стекло, или решетка проволочного забора в игре, сделанная из текстуры, в которой прозрачные пиксели чередуются с непрозрачными), то сглаживания границ с тем, что проступает через этот полигон не происходит, и мы видим четкие ступеньки. Зато нам не приходится рассчитывать значения цвета для каждого отсчета (сэмпла), и мы обходимся только раздельными значениями глубины, а цвет один общий на все сэмплы. Основную проблему — ступеньки на краях полигонов такой метод устраняет эффективно. Но с прозрачными полигонами он не справляется. Второй метод — SSAA (суперсамплинг) честно рассчитывает все значения цвета для всех отсчетов, и мы получаем правильную картину даже через полупрозрачные полигоны с четкими границами прозрачных и непрозрачных областей. Однако тогда мы заметно проигрываем в скорости — нам надо выполнить пиксельные шейдеры в несколько раз больше — столько, сколько у нас отсчетов, 2 или 4 раза. Как быть? Предложен следующий выход:
На прозрачных полигонах автоматически включается полноценный SSAA (или, по выбору, специальная эмуляция - MSAA учитывающий прозрачность), на остальных производится обычный MSAA.
Решение простое и достаточно эффективное. Изменения в железе не очень большие — мы все равно храним глубину и цвет для отсчетов, как в том, так и в другом методе, и все что необходимо — автоматически переключать режим генерации AA отсчетов в зависимости от наличия или отсутствия прозрачности в настройках блендинга текущих треугольников. (вряд ли выбор происходит на уровне более точном, чем целый треугольник, и очевидно что он должен происходить автоматически). Далее мы исследуем его влияние на скорость и качество на практике, и более наглядно и подробно поговорим об этом нововведении.
Перейдем к первым практическим аспектам — описанию карты и исследованию ее с помощью синтетических тестов.
Комментарии