или "Опять двадцать пять"
томит нас ожиданьем,
NV справляет 25,
возможно, с опозданьем… "

В наших руках — NV25. Этот чип ждали многие. Кто-то как отголосок славных дел 3dfx (холодно); кто-то как достойный ответ на ATI RADEON 8500 (теплее); кто-то как вторую, оптимизированную и обогащенную инкарнацию NV20 (жарко). Пожалуй, на этот раз мы не будем злоупотреблять лирическими отступлениями, а сразу подойдем к сути вопроса…
Внимание! Прежде, чем приступить к прочтению данного материала, рекомендуем ознакомится с предыдущими полновесными обзорами NVIDIA GeForce3 (NV20) и ATI Radeon 8500 (R200).
Линейка продуктов
Линейка GeForce 4 базируется на двух чипах — NV17 (подробный обзор которого появится на нашем сайте несколько позже) и NV25 — главном герое этой статьи:
- GeForce 4 Ti4600 — NV25 300 МГц ядро, 128 МБ 325(650) МГц 128 бит DDR памяти.
- GeForce 4 Ti4400 — NV25 275 МГц ядро, 128 МБ 275(550) МГц 128 бит DDR памяти.
- Еще одна, младшая карта на базе NV25, будет анонсирована позже.
- GeForce 4 MX460 — 300 МГц ядро, 64 МБ 275(550) МГц 128 бит DDR памяти.
- GeForce 4 MX440 — 270 МГц ядро, 64 МБ 200(400) МГц 128 бит DDR памяти.
- GeForce 4 MX420 — 200 МГц ядро, 64 МБ 166 МГц 128 бит SDR памяти.
- Линейка GeForce 3 будет максимально быстро заменена новой GeForce 4 линейкой.
- NV17 не поддерживает (и не будет поддерживать) пиксельные и вершинные шейдеры.
- NV17 будет иметь аппаратный декодер MPEG2 и систему динамического управления питанием, а NV25 нет.
- NV17 имеет только два конвейера закраски, а NV25 четыре.
- NV25 имеет суперскалярный (двойной) T&L, NV17 только один.
- NV17 и NV25 имеют схожие контроллеры памяти (двухканальный у NV17 и четырехканальный у NV25).
- Оба чипа снабжены одинаковым набором систем повышения эффективной пропускной полосы памяти второго поколения (сжатие и быстрая очистка Z буффера, MSAA, HSR).
- NV17 имеет два встроенных контроллера LCD панелей.
- Оба чипа имеют два независимых RAMDAC, CRTC контроллера, интегрированные TV-Out и DVI интерфейс.
Вот такой "милый" вервольф будет оказывать наглядную силовую поддержку анонсу продуктов на базе NV25, демонстрируя передовые возможности мягкого освещения, скелетной анимации, сгенерированной вершинными шейдерами шерсти и попиксельного рельефа:


Теория
Структурная схема NV25
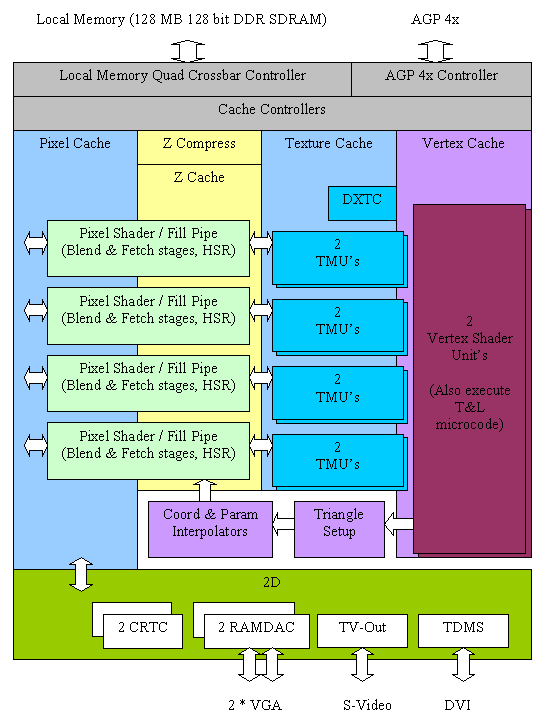
Основные архитектурные новшества NV25 (в сравнении с NV20)
Для начала посмотрим, каким предстает перед нами новый чип после прочтения массы сопутствующих его анонсу спецификаций и кратких обзоров технологий:
- Два независимых контроллера отображения (CRTC). Гибкая поддержка всевозможных режимов с выводом двух независимых по разрешению и содержанию буферов кадра на любые доступные приемники сигнала.
- Два полноценных интегрированных в чип 350 МГц RAMDAC (с 10 битной палитрой).
- Интегрированный в чип интерфейс TV-Out.
- Интегрированный в чип TDMS трансмиттер (для DVI интерфейса).
- Два блока интерпретации и исполнения вершинных шейдеров. Они сулят существенное увеличение скорости обработки сцен со сложной геометрией. Блоки не могут испольнять различный микрокод шейдеров, единственное назначение подобного дублирования — обработка двух вершин одновременно — служит для увеличения производительности.
- Усовершенствованные конвейеры закраски обеспечивают аппаратную поддержку пиксельных шейдеров до версии 1.3 включительно.
- По заявлениям NVIDIA, увеличена эффективная скорость закраски в режимах MSAA, теперь режимы 2x AA и Quincunx AA вызовут существенно меньшее падение производительности. Немного усовершенствован Quincunx AA (смещены позиции выборки семплов). Появился новый метод AA — 4xS.
- Усовершенствованная система раздельного кеширования (4 раздельных кеша для геометрии, текстур, буфера кадра и Z буфера).
- Усовершенствованное сжатие без потерь (1:4) и быстрая очистка Z буфера.
- Усовершенствованный алгоритм отброса невидимых поверхностей (Z Cull HSR).
Далее, по ходу нашего повествования, мы тщательно сверим, проверим и замерим все декларированные здесь преимущества нового чипа, дабы собственноручно убедится в степени их реальной эффективности.
Подводя итог этого списка, хочется отметить скорее эволюционный, нежели революционный характер изменений в сравнении с предыдущим творением NVIDIA (NV20). Впрочем, это неудивительно — исторически NVIDIA вначале предлагала продукт, несущий множество новых технологий, а затем выпускала более совершенный (оптимизированный) вариант на его основе, устраняя привлекшие основное внимание (за время присутствия продукта на рынке) недостатки. Вспомним TNT и TNT2, GF256 и GF2 — точно такой же парой являются на наш взгляд GF3 и GF4. И, как показывает практика предыдущих "пар", именно вторую, доведенную версию архитектуры ждет наибольший успех и признание, а следовательно и долгая (скажем так, сравнительно долгая :-) ) жизнь.
Тактико-технические характеристики
Для начала небольшое пояснение:
- Ускоритель нельзя рассматривать в отрыве от драйверов. Для конкретных приложений любые возможности чипа существуют лишь в меру их поддержки драйверами для двух основных API. Многие из приведенных в этой таблице характеристик могут зависеть от драйверов и верны в первую очередь для указанной версии. Более того, некоторые возможности, о наличии которых драйверы не сообщают, на проверку оказываются доступными для приложений (например, плоскости отсечения в D3D для карт NVIDIA). Мы все равно будем считать эти возможности отсутствующими — корректно написанные приложения не должны пытаться использовать вызовы и параметры, о наличии которых не отрапортовал драйвер.
- Большинство информации относится к Direct3D, в OpenGL эти параметры могут иметь иные значения (впрочем, это происходит крайне редко). Тому есть несколько причин, в том числе и более тесное взаимодействие этого игрового API с железом ускорителей. А также тот факт, что возможности современных ускорителей достаточно четко продиктованы спецификацией D3D.
А теперь — сводная таблица ключевых ТТХ участвующих в дальнейшем тестировании чипов и карт. Отметим, что в ближайший календарный квартал следует рассматривать ATI RADEON 8500 как основного конкурента карт на базе NV25 (GeForce 4 Ti 4600 и Ti 4600) ввиду отложенного (возможно, навсегда) запуска RADEON 8500XT и достаточно существенного промежутка времени, оставшегося до выхода первых продуктов на базе R300.
| Название карты | GeForce3 Ti 500 | RADEON 8500 | GeForce 4 Ti 4600 (GeForce 4 Ti 4400) |
|---|---|---|---|
| Чип, ревизия, версия драйверов | |||
| Чип | NV20 | R200 | NV25 |
| Ревизия | A5 | A23 | A03 |
| Версия драйверов | 27.30 | 6.018 | 27.30 |
| Основные параметры | |||
| Число конвейеров | 4 | 4 | 4 |
| Текстурных блоков на конвейер | 2 | 2 | 2 |
| Текстур за проход | 4 | 6 | 4 |
| Частота ядра, МГц | 240 | 275 | 300 (275) |
| Филрэйт (млн. пикселей) | 960 | 1100 | 1200 (1100) |
| Филрэйт (млн. текселей) | 1920 | 2200 | 2400 |
| RAMDAC, МГц | 350 | 400 (+внешний 240) | 350*2 |
| Параметры локальной памяти | |||
| Частота памяти, МГц | 250 | 275 | 325 (275) |
| Шина памяти, бит | 128 (DDR) | 128 (DDR) | 128 (DDR) |
| Технология, мкм | 0.15 | 0.15 | 0.15 |
| Объем памяти, МБ | 64 | 64 | 128 |
| Скорость памяти, нс | 3.8 | 3.6 | 2.8 (3.6) |
| Версия OpenGL | 1.3 | 1.3 | 1.3 |
| Версия DirectX | 8.1 | 8.1 | 8.1 |
| Ускорение GDI+ | Да | Да | Да |
| Пиксельный конвейер | |||
| Пиксельные шейдеры | 1.0, 1.1 | 1.0.,1.4 | 1.0.,1.3 |
| Диапазон вычисляемых значений цвета | -1.0..+1.0 | -8.0..+8.0 | -1.0..+1.0 |
| Текстурных стадий | 4 | 8 | 4 |
| Комбинационных стадий | 8 | 8 | 8 |
| Multisampling | 2,3,4 сэмпла | Нет | 2,3,4 сэмпла |
| Число плоскостей отсечения | 0 | 6 | 0 |
| Вершинный конвейер | |||
| Вершинные шейдеры | 1.0, 1.1 | 1.0, 1.1 | 1.0, 1.1 |
| Число потоков вершин | 16 | 8 | 16 |
| Число констант вершинного шейдера | 96 | 192 | 96 |
| Максимум матриц для блендинга | 4 | 4 | 4 |
| Индексированный блендинг | Нет | До 57 матриц | Нет |
| Число источников света | 8 | 8 | 8 |
| N-Patches | Нет | Да | Нет |
| RT-Patches | Нет | Нет | Нет |
| Число примитивов | 1048575 | 65536 | 1048575 |
| Число вершин | 1048575 | 16777215 | 1048575 |
| Прочие параметры | |||
| Pure Device | Да | Да | Да |
| Масштабирование спрайтов до | 64 | 256 | 8192 |
| 3D текстуры | Да (с анизотропией) | Да (без MIPMAP) | Да (с анизотропией) |
| Карты отражения (среды) | Да (с анизотропией) | Да (без MIPMAP) | Да (с анизотропией) |
| Анизотропная фильтрация | Да | Да (только билинейная) | Да |
| Степень анизотропии до | 2,3,4 би/три линейных выборки | 2,3 упрощенных билинейных выборки | 2,3,4 би/три линейных выборки |
| Туман | FOGVERTEX FOGRANGE FOGTABLE | FOGVERTEX FOGRANGE | FOGVERTEX FOGRANGE FOGTABLE |
| Буфер кадра | |||
| Форматы буфера рендеринга | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 | A8R8G8B8 X8R8G8B8 R5G6B5 A1R5G5B5 A4R4G4B4 R3G3B2 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 |
| Форматы буфера глубины | D32 D24S8 D16 D24X8 | D32 D24S8 D16 D24X8 | D32 D24S8 D16 D24X8 |
| Форматы текстур | |||
| Максимальный размер текстур (максимальный повтор) | 4096x4096(8192) | 2048x2048(2048) | 4096x4096(8192) |
| Форматы 2D текстур | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 V8U8 L6V5U5 X8L8V8U8 DXT1 DXT2 DXT3 DXT4 DXT5 D24S8 D16 D24X8 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 R3G3B2 L8 A8L8 V8U8 L6V5U5 X8L8V8U8 Q8W8V8U8 V16U16 W11V11U10 DXT1 DXT2 DXT3 DXT4 DXT5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 V8U8 L6V5U5 X8L8V8U8 DXT1 DXT2 DXT3 DXT4 DXT5 D24S8 D16 D24X8 |
| Форматы 3D текстур | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 R3G3B2 L8 A8L8 Q8W8V8U8 W11V11U10 DXT1 DXT2 DXT3 DXT4 DXT5 | A8R8G8B8 X8R8G8B8 R5G6B5 X1R5G5B5 A1R5G5B5 A4R4G4B4 P8 |
Прокомментируем существенные пункты:
- GeForce4 Ti4600 обладает более высокой тактовой частотой ядра и памяти, нежели RADEON 8500. GeForce4 Ti4400 обладает равной тактовой частотой ядра и памяти по отношению к RADEON 8500.
- Наконец-то, передовые продукты NVIDIA получили полноценную поддержку вывода изображений на два монитора, причем, в отличие от R200, оба полноценных 350 МГц RAMDAC интегрированы в чип NV25.
- Более низкая у NV25 частота RAMDAC по сравнению с первичным RAMDAC R200 (350 против 400 МГц)
- Схожая с NV20 и R200 организация внутренней архитектуры NV25 — 4 конвейера закраски, по два текстурных блока на каждом. Однако у R200 результаты их работы могут накапливаться два раза, в результате чего мы получаем возможность комбинировать до 6 текстур за один проход, а у NV25 мы по прежнему ограничены 4 текстурами. Впрочем, пока на рынке нет ни одного игрового приложения, способного получить существенное преимущество при использовании 6 текстур за проход. По слухам, в будущем на роль такого приложения претендует Next Doom.
- NVIDIA по-прежнему не поддерживает пиксельные шейдеры 1.4 (подробнее о них см. в превью R200) и, следовательно, более гибкий механизм зависимой выборки значений текстур. Реально шейдеры транслируются в настройки конвейеров выборки и комбинации, число стадий конвейера выборки текстур осталось прежним - 4 у NV25/NV20 против 8 у R200; Небольшие изменения комбинационного конвейера позволили аппаратно поддержать шейдеры 1.2 и 1.3. Отличия последних от шейдеров 1.1 не имеют отношения к организации более гибкой зависимой выборки (как хотелось бы), а связаны в основном с использованием и модификацией значений Z и другими мелкими "удобствами".
- Комбинационные конвейеры всех чипов имеют 8 стадий и поддерживают все декларированные DirectX 8.1 операции.
- Несмотря на ожидания, в доступных на данный момент драйверах для NV25 не увеличено ни число констант, которые можно задействовать в вершинных шейдерах (все так же 96 против 192 у R200), ни число команд вершинного шейдера (все так же 128). Судя по всему, никаких существенных качественных изменений, кроме дублирования T&L блока (он же интерпретатор вершинных шейдеров в одном лице) в геометрический конвейер не внесено.
- Ликвидировано отставание от R200 в плане стабильной работы контроллера памяти на близких к номинальным частотах — память NV25 успешно работает на одинаковой с R200 частоте при том же номинальном времени доступа. Само по себе это еще не говорит о равной эффективности — подходы R200 и NV20/NV25 в вопросах работы с памятью существенно разнятся. NV25 предпочитает мелкие блоки и эффективный четырех канальный перекрестный контроллер, R200 — крупные блоки и интенсивное совместное кеширование. Какой из подходов оказался более жизнеспособен в современных тестах и приложениях, мы увидим далее.
- Все карты имеют полноценные DirectX 8.1 и OpenGL 1.3 драйверы. Общепризнано, что OpenGL драйвер ATI не столь эффективен, как творение программистов NVIDIA. Однако различие между ними постепенно сокращается, и в данный момент во многом определяется тем, как работает с геометрией OpenGL программа и использует ли она индексные буферы — сам по себе R200 заметно менее эффективен в вопросах передачи геометрии через AGP нежели NV20/NV25.
- У NV20 и NV25 сложилась достаточно интересная ситуация в области плоскостей отсечения. По той или иной причине текущие драйверы рапортуют, что плоскостей отсечения нет, хотя на поверку оказывается, что они прекрасно работают. Причина столь странного поведения следующая: для реализации плоскостей отсечения NVIDIA использует специальный пиксельный шейдер. Т.е. при этом задействуется большая часть слотов комбинационного конвейера и приложение теряет возможность использовать собственный пиксельный шейдер и некоторые другие ресурсы. Что, в свою очередь, не соответствует стандарту DirectX — именно поэтому плоскости отсечения и были отключены на уровне рапортуемых драйвером возможностей.
- В NV25 по прежнему не реализована аппаратная поддержка N-Patches, скорее всего, по политическим соображениям.
- Драйверы NV20 и NV25 уже достаточно давно перестали поддерживать аппаратную тесселяцию гладких поверхностей (HOS на основе RT-Patches). Причина этого кроется в DirectX — в случае, когда карта не поддерживает аппаратно N-Patches, API пытается эмулировать их с помощью RT-Patches. Что, несомненно, вызывает очень медленную работу N-Patches, даже более медленную чем толковая программная эмуляция. NVIDIA была вынуждена отключить RT-Patches, дабы игры с поддержкой N-Patches не впадали в трудно объяснимый для рядового пользователя ступор на ее последних продуктах.
- NV25, как и NV20, не поддерживает индексированный матричный блендинг — приоритет в этом вопросе отдан шейдерам, через них можно гибко организовать любые схемы матричного блендинга.
- Multisampling не претерпел никаких изменений по сравнению с NV20 — все те же 2..4 сэмпла, на которые R200 по-прежнему не способен.
- Реализация анизотропии у NV25/NV20 и R200 существенно различаются, и каждый подход имеет свои преимущества и недостатки. Чуть далее мы уделим этому вопросу больше внимания.
- Диапазон значений пиксельных шейдеров NV25 по-прежнему от -1.0 до 1.0 — повышенная точность R200 осталась без ответа.
- Все карты поддерживают стандартный джентельменский набор форматов текстур, однако, в дополнение к нему, R200 имеет поддержку нескольких экзотических форматов для использования в шейдерах дополнительных данных (карт нормалей и смещений) с повышенной точностью передачи компонент (11 и 16 бит - V16U16, W11V11U10); NV25 и NV20, в свою очередь, позволяют использовать текстуры с форматом буфера глубины (D32, D24S8, D16, D24X8), необходимые для реализации алгоритмов затенения на основе буфера глубины (Depth Buffer Shadows). То, как этот специфичный для продуктов NVIDIA алгоритм используется приложениями в драйверах для DirectX, является некоторым отступлением от стандарта — своеобразным хаком.
- NV25 по-прежнему не позволяет сжимать объемные текстуры. Учитывая существенные размеры 3D-текстур, этот факт можно считать заметным недостатком драйверов или чипа. По крайней мере, когда эти пресловутые объемные текстуры наконец начнут применяться в реальных приложениях :-). В то же время, OpenGL драйвер NVIDIA предоставляет свой собственный формат сжатия 3D-текстур.
- NV25 поддерживает все разновидности тумана, как и NV20.

Приведем, для полноты картины, полный список OpenGL расширений поддерживаемых NV25 с текущими драйверами:
GL_VENDOR: NVIDIA Corporation
GL_RENDERER: GeForce4 Ti 4400/AGP/SSE2
GL_VERSION: 1.3.1
GL_EXTENSIONS:
- GL_ARB_imaging
- GL_ARB_multisample
- GL_ARB_multitexture
- GL_ARB_texture_border_clamp
- GL_ARB_texture_compression
- GL_ARB_texture_cube_map
- GL_ARB_texture_env_add
- GL_ARB_texture_env_combine
- GL_ARB_texture_env_dot3
- GL_ARB_transpose_matrix
- GL_S3_s3tc
- GL_EXT_abgr
- GL_EXT_bgra
- GL_EXT_blend_color
- GL_EXT_blend_minmax
- GL_EXT_blend_subtract
- GL_EXT_compiled_vertex_array
- GL_EXT_draw_range_elements
- GL_EXT_fog_coord
- GL_EXT_multi_draw_arrays
- GL_EXT_packed_pixels
- GL_EXT_paletted_texture
- GL_EXT_point_parameters
- GL_EXT_rescale_normal
- GL_EXT_secondary_color
- GL_EXT_separate_specular_color
- GL_EXT_shared_texture_palette
- GL_EXT_stencil_wrap
- GL_EXT_texture3D
- GL_EXT_texture_compression_s3tc
- GL_EXT_texture_edge_clamp
- GL_EXT_texture_env_add
- GL_EXT_texture_env_combine
- GL_EXT_texture_env_dot3
- GL_EXT_texture_cube_map
- GL_EXT_texture_filter_anisotropic
- GL_EXT_texture_lod
- GL_EXT_texture_lod_bias
- GL_EXT_texture_object
- GL_EXT_vertex_array
- GL_EXT_vertex_weighting
- GL_HP_occlusion_test
- GL_IBM_texture_mirrored_repeat
- GL_KTX_buffer_region
- GL_NV_blend_square
- GL_NV_copy_depth_to_color
- GL_NV_evaluators
- GL_NV_fence
- GL_NV_fog_distance
- GL_NV_light_max_exponent
- GL_NV_multisample_filter_hint
- GL_NV_occlusion_query
- GL_NV_packed_depth_stencil
- GL_NV_point_sprite
- GL_NV_register_combiners
- GL_NV_register_combiners2
- GL_NV_texgen_reflection
- GL_NV_texture_compression_vtc
- GL_NV_texture_env_combine4
- GL_NV_texture_rectangle
- GL_NV_texture_shader
- GL_NV_texture_shader2
- GL_NV_texture_shader3
- GL_NV_vertex_array_range
- GL_NV_vertex_array_range2
- GL_NV_vertex_program
- GL_NV_vertex_program1_1
- GL_SGIS_generate_mipmap
- GL_SGIS_multitexture
- GL_SGIS_texture_lod
- GL_SGIX_depth_texture
- GL_SGIX_shadow
- GL_WIN_swap_hint
- WGL_EXT_swap_control
И, для сравнения, такой же список в исполнении последних драйверов R200:
GL_VENDOR: ATI Technologies Inc.
GL_RENDERER: Radeon 8500 DDR x86/SSE2
GL_VERSION: 1.3.2475 WinXP Release
GL_EXTENSIONS:
- GL_ARB_multitexture
- GL_ARB_texture_border_clamp
- GL_ARB_texture_compression
- GL_ARB_texture_cube_map
- GL_ARB_texture_env_add
- GL_ARB_texture_env_combine
- GL_ARB_texture_env_crossbar
- GL_ARB_texture_env_dot3
- GL_ARB_transpose_matrix
- GL_ARB_vertex_blend
- GL_ARB_window_pos
- GL_S3_s3tc
- GL_ATI_element_array
- GL_ATI_envmap_bumpmap
- GL_ATI_fragment_shader
- GL_ATI_map_object_buffer
- GL_ATI_pn_triangles
- GL_ATI_texture_mirror_once
- GL_ATI_vertex_array_object
- GL_ATI_vertex_streams
- GL_ATIX_texture_env_combine3
- GL_ATIX_texture_env_route
- GL_ATIX_vertex_shader_output_point_size
- GL_EXT_abgr
- GL_EXT_bgra
- GL_EXT_blend_color
- GL_EXT_blend_func_separate
- GL_EXT_blend_minmax
- GL_EXT_blend_subtract
- GL_EXT_clip_volume_hint
- GL_EXT_compiled_vertex_array
- GL_EXT_draw_range_elements
- GL_EXT_fog_coord
- GL_EXT_packed_pixels
- GL_EXT_point_parameters
- GL_ARB_point_parameters
- GL_EXT_rescale_normal
- GL_EXT_secondary_color
- GL_EXT_separate_specular_color
- GL_EXT_stencil_wrap
- GL_EXT_texgen_reflection
- GL_EXT_texture_env_add
- GL_EXT_texture3D
- GL_EXT_texture_compression_s3tc
- GL_EXT_texture_cube_map
- GL_EXT_texture_edge_clamp
- GL_EXT_texture_env_combine
- GL_EXT_texture_env_dot3
- GL_EXT_texture_lod_bias
- GL_EXT_texture_filter_anisotropic
- GL_EXT_texture_object
- GL_EXT_vertex_array
- GL_EXT_vertex_shader
- GL_KTX_buffer_region
- GL_NV_texgen_reflection
- GL_NV_blend_square
- GL_SGI_texture_edge_clamp
- GL_SGIS_texture_border_clamp
- GL_SGIS_texture_lod
- GL_SGIS_generate_mipmap
- GL_SGIS_multitexture
- GL_WIN_swap_hint
- WGL_EXT_extensions_string
- WGL_EXT_swap_control
Закончив с представлением новых графических процессоров, обратим внимание на видеоплаты, которые базируются на двух вариантах NV25: GeForce4 Ti 4400 и 4600.
Платы
Мы рассматриваем двух представителей новой линейки продуктов от NVIDIA. Обе платы — это опытные образцы (reference cards) на базе NVIDIA GeForce4 Ti 4400 и 4600. Внешне платы очень схожи, однако есть небольшие различия, о которых мы поговорим ниже. Кроме того, заострим ваше внимание на отличии тактовой частоты чипа нашего образца Ti 4400 — 300 МГц вместо 275 МГц, запланированных для серийных карт. Т.к. результаты тестов были получены еще до окончательного определения финальных параметров серийных карт, необходимо не забывать о небольшом внеплановом преимуществе нашего образца Ti 4400. Частоты Ti 4600 точно соответствуют плановым.
Карты снабжены


На картах установлены микросхемы памяти марки Samsung, BGA форм-фактора.
| Время выборки у Ti 4400 — 3.6 нс, что соответствует примерно 275 (550) МГц. |  |
| Время выборки у Ti 4600 — 2.8 нс, что соответствует примерно 357 (714) МГц. | .  |
Впервые на обычных видеокартах были использованы микросхемы памяти в новой BGA-упаковке. Этот форм-фактор обеспечивает более эффективное охлаждение чипов и память не перегревается, работая на своей штатной частоте (правда, на GeForce4 Ti 4600 память работает на частоте, чуть ниже номинальной частоты для 2.8ns). Напомним частоты наших образцов (ядро/память):
Продолжая тему перегрева, отметим, что несмотря на столь высокие частоты памяти и ядра (для уже знакомого нам по NV20 и R200 техпроцесса 0.15 мкм), обе карты нагреваются весьма умеренно, особенно это касается чипов памяти. Поэтому, можно предположить, что на серийных платах какое-либо дополнительное охлаждение на память устанавливаться также не будет. Вернемся к отличиям между рассматриваемыми картами:
NVIDIA GeForce4 Ti 4400


NVIDIA GeForce4 Ti 4600


Различия касаются лишь правой части карт, где расположен блок, отвечающий за преобразование напряжений питания. На платах используются микросхемы памяти и GPU, имеющие разные номинальные параметры (вольтаж и потребляемый ток), это и обуславливает визуальные отличия.
В глаза бросается необычного вида и форм-фактора кулер, установленный на GPU.


Видно, что для охлаждения используется продув воздуха сквозь канал с гребенчатым радиатором с помощью вентилятора, расположенного не в центре над чипом, а несколько левее.
Интересно отметить значительно возросшие размеры reference card на базе NVIDIA GeForce4 Ti (на снимке ниже для сравнения с новинкой была использована карта Hercules 3D Prophet III Titanium 500, полностью повторяющая эталонный дизайн GeForce3 Ti 500):

Нам было интересно сравнить размеры GeForce4 Ti с 3dfx Voodoo5, которая до сего момента является самой большой по размеру игровой видеокартой:

Мы видим, что новейшая плата лишь немного недотянула до размеров двухчипового монстра былых времен. Впрочем, это наконец проясняет вопрос: как отразилась покупка активов 3dfx компанией NVIDIA? Видеокарты последней стали расти на глазах, становясь все больше похожими на флагман почившей 3dfx (разумеется, речь идет только о размерах PCB) :-) 
Если радиатор — это заметная, но не существенная для обычного пользователя новинка, то поддержка новыми продуктами вывода изображения на два приемника (так называемая "двуголовость") — значительно отличает эти карты от предыдущих. Никогда ранее самые мощные акселераторы от NVIDIA не поддерживали TwinView (теперь эта технологическая марка трансформировалось в nView).
Обратите внимание на размер гнезда VGA (d-Sub). Точно такие же гнезда использовала фирма Matrox для G450 — это гнездо перешагивает через место на PCB, оставленное для распайки выводов второго DVI разъема, спрос на который может появится в ближайшем будущем.
Ниже VGA-разъема расположен TV-out с S-Video разъемом. Видеоинтерфейсный чип, обслуживающий эту функцию, расположен на обороте карты и маркирован как CX25871 (поддерживаются разрешения до 1024х768 включительно), чип изготовлен фирмой Conexant. Факт наличия внешнего интерфейсного чипа кажется как минимум странным, поскольку, согласно заявленным характеристикам, законченный интерфейс TV-out встроен в сам GPU (возможно, что в текущих драйверах/BIOS еще нет поддержки "нового" TV-out, и поэтому референс-карты были снабжены внешним видеоинтерфейсным чипом). Посмотрим, как будут обстоять дела с серийными картами.
Внизу карты расположен полный (цифра+аналог) DVI разъем, который и служит источником сигнала для второго аналогового CRT-монитора, как правило, при использовании стандартного переходника DVI-to-VGA:

Чуть далее мы подробно рассмотрим самую интересную особенность новых карт (если не касаться 3D-части) — возможность вывода картинки на два приемника. Благо, для этого у нового GPU есть все что надо, в т.ч. и два встроенных RAMDAC. Перед тем, как подробно рассмотреть эти функции, мы закончим описание самих плат, рассказав об их "разгонном" потенциале.
Разгон
Само собой разумеется, в нашем случае разгонять младшую модель (Ti 4400) не имело никакого смысла. Поэтому мы повышали частоты только у старшей карты — GeForce4 Ti 4600. Карта смогла устойчиво работать на частотах 320 МГц GPU и 365 (730) МГц память. Как можно видеть, чип смог разогнаться только на 20 МГц (пока мы не можем сказать, типичный ли это предел для данной технологии и архитектуры чипа, или нам просто попался такой экземпляр), а вот память продемонстрировала неплохой запас "прочности", тем более, учитывая, что это Samsung. Отметим также, что на TI 4400 мы также разгоняли память, которая со временем выборки 3.6ns смогла спокойно работать на частоте 300 (600) МГц (вновь порадовав нас — ведь раньше модули от Samsung никогда не отличались приличным потенциалом разгона).
Подчеркнем два важных момента:
- при разгоне обязательным условием является наличие дополнительного охлаждения, в частности, обдувающего карту (прежде всего, ее память) вентилятора:

- разгон любой карты зависит от конкретного экземпляра, и поэтому нельзя слепо обобщать вышеприведенные частоты на все видеокарты этой марки и даже серии. Показатели разгона мы приводим только как интересное явление; они ни в коей мере не входят в состав объективно тестируемых нами параметров видеокарты.

Установка и драйверы
Рассмотрим конфигурацию тестовых стендов, на которых проводились испытания карт:
- Компьютер на базе Pentium 4 (Socket 478):
- процессор Intel Pentium 4 2100;
- системная плата ASUS P4T-E (i850);
- оперативная память 512 MB RDRAM PC800;
- жесткий диск Quantum FB AS 20GB;
- операционные системы Windows XP, Windows ME.
- Компьютер на базе Athlon XP:
- процессор AMD Athlon XP 1800+;
- системная плата EPoX 8KHA+ (VIA KT266A);
- оперативная память 512 MB DDR SDRAM PC2100;
- жесткий диск Fujitsu 20GB;
- операционные системы Windows XP, Windows ME.
На стендах использовались мониторы
При тестировании применялись драйверы от NVIDIA версии 27.20, 27.30. VSync отключен, технология S3TC активирована.
Для сравнительного анализа приведены результаты уже знакомых читателям видеокарт:
- Reference card NVIDIA GeForce3 Ti 500 (240/250 (500) МГц, 64 МБ);
- ATI RADEON 8500 (RADEON 8500, 275/275 (550) МГц, 64 МБ, driver 9.008 (Windows ME) / 6.014 (Windows XP)).
Настройки драйверов и nView
Как уже было отмечено выше, при тестировании использовались драйверы версий 27.20 и 27.30 (с точки зрения интерфейса и скоростных показателей обе версии практически идентичны, поэтому мы рассмотрим настройки на примере 27.20 для Windows XP).
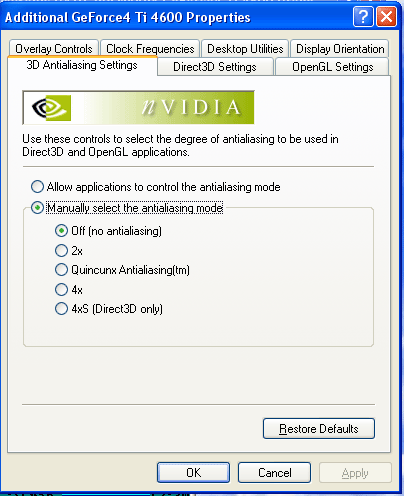
На данной закладке можно видеть среди имеющихся уровней анти-алиасинга и новый вид — 4xS. О том, что скрывается под этой абревиатурой мы расскажем далее, а сейчас отметим тот факт, что для пользователя эта возможность появляется только на новых картах на базе NV25, несмотря на то, что через ключи реестра может быть активирована и на GeForce 3.
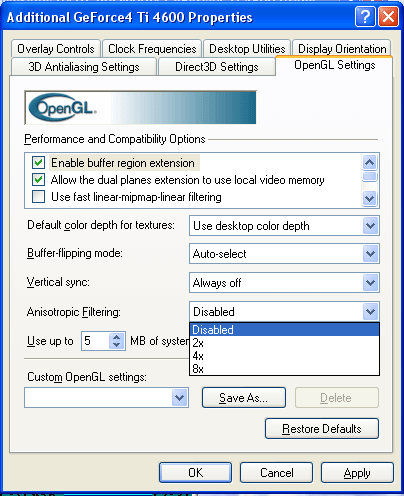
Наконец-то появилась реальная (а не декларированная как это было ранее) возможность настройки анизотропии в OpenGL. Впрочем, эта возможность доступна начиная с 23.* версий.
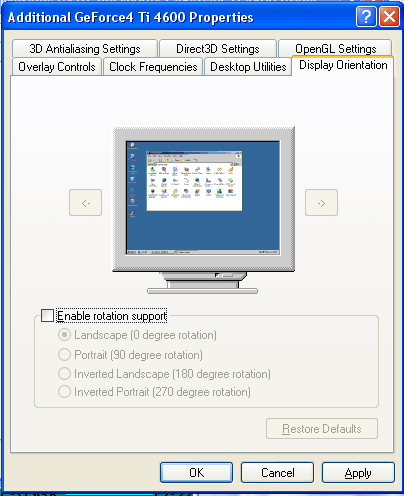
Новая возможность по смене типа (ориентации) изображения, крайне удобна не только для профессиональных верстальщиков и оформителей, но и просто для любителей побродить по сети, ЖК монитор которых может быть развернут на 90 градусов. Интересно, что, в отличие от программных пакетов, разворачивающих изображение на 90 градусов, эта возможность выполняется на уровне GPU, и поэтому не только не замедляет вывод 2D графики, но, и судя по всему, не грозит проблемами несовместимости с новыми версиями операционных систем. Для карт на базе предыдущих GPU эта возможность, к сожалению, недоступна.
И вот, наконец, мы подошли к возможностям расширенного менеджмента рабочего стола. Собственно, отсюда и начинается nView.
nView
nView — это целая система управления выводом информации на монитор(ы). Разделена на две части:
- Менеджер рабочих столов;
- Поддержка двумониторных конфигураций (включая TV-out).
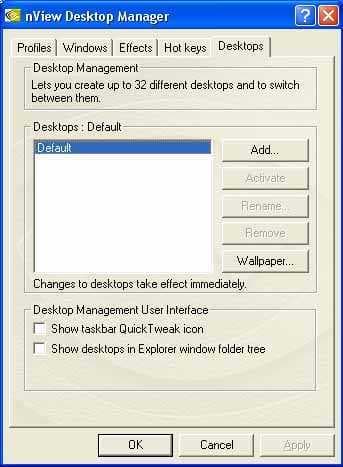
Начнем с первого. При активизации Desktop Manager мы получаем возможность создавать несколько (до 32-х) рабочих столов на одном экране (разумеется, виртуальных):
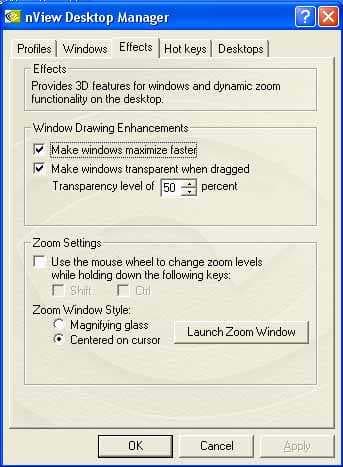
Кроме того, мы можем управлять окнами, эффектами при работе с последними и т.д.:
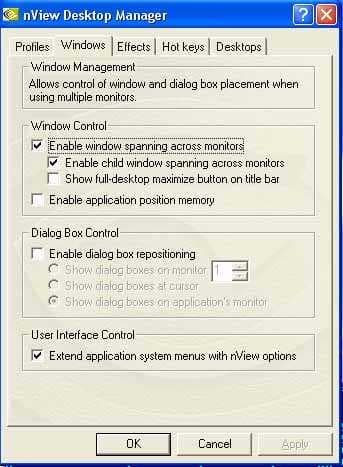
Ну и, разумеется, можно создать свой профиль и в нем сохранить все выбранные настройки:
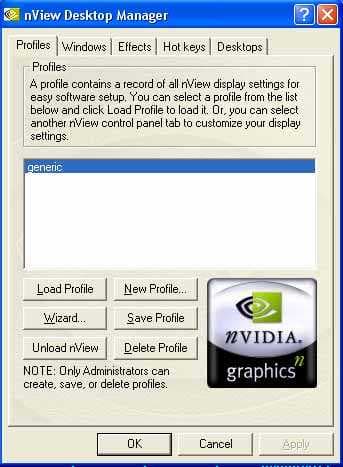
Самая интересная часть nView — это поддержка двумониторных конфигураций. Мы уже сталкивались с подобным на видеокартах класса GeForce2 MX, обладающих технологией TwinView. Поэтому закладка драйверов по настройке этой части nView выглядит вполне привычно для обладателей таких плат:
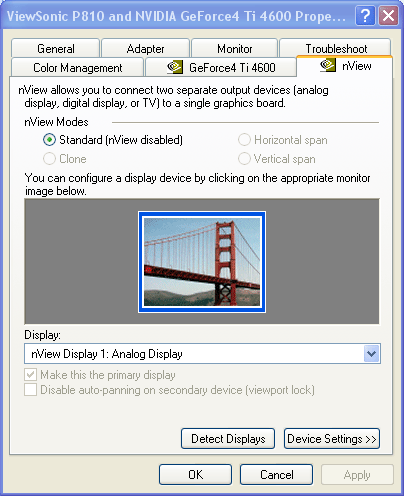
Однако сразу можно заметить отличия от TwinView. Кроме обычного режима Clone (то есть копирования изображения
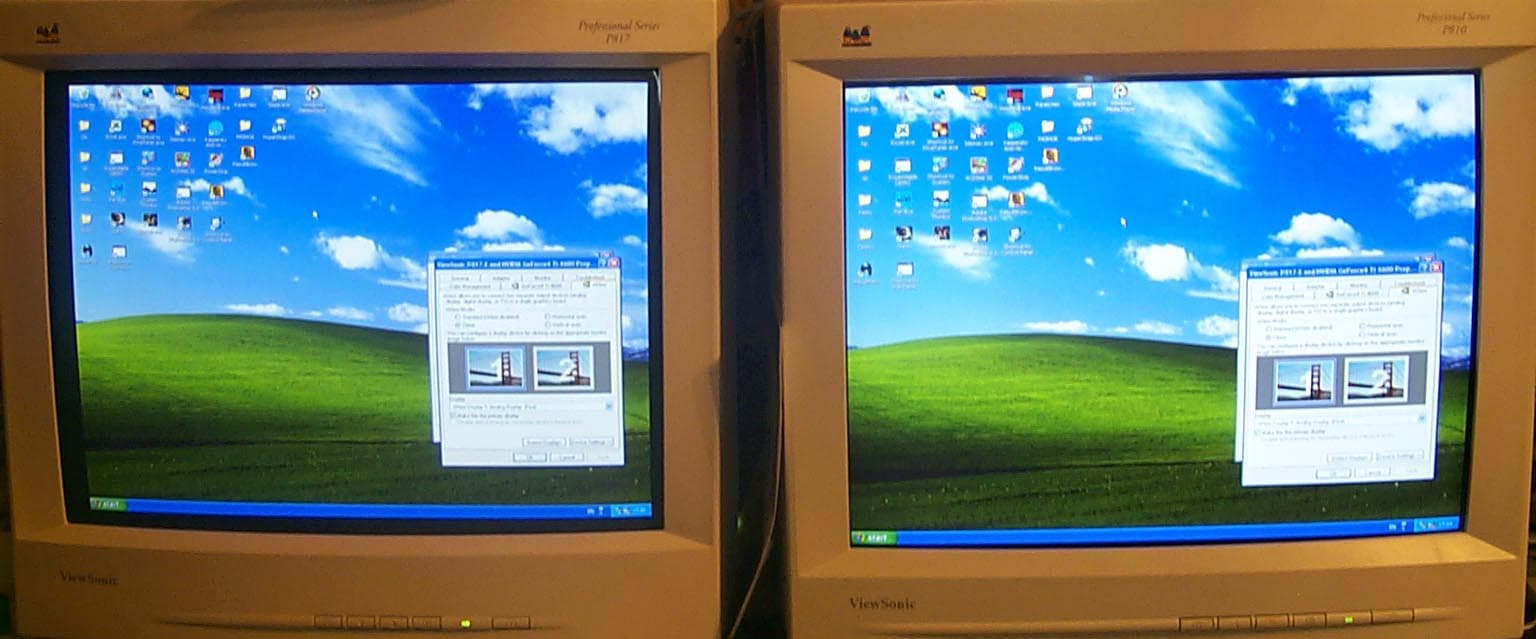
на два приемника), имеются и другие режимы. Разумеется, есть и возможность растянуть рабочий стол на два монитора, а также регулировать настройки DVC (digital vibrance control) для каждого монитора отдельно (на снимках ниже это продемонстрировано: вначале DVC включена на левом экране, а затем на правом):
Возможно также растянуть рабочий стол по горизонтали (от расширения десктопа на второй экран это отличается тем, что рабочий стол не обзаводится дополнительным полем, а вместе с панелью задач просто растягивается на два экрана),
имеется возможность сделать то же самое по вертикали (рабочий стол как бы становится вдвое выше)

Надо сказать, что расширение рабочего стола на второй монитор позволяет осуществить мечту многих пользователей: на одном мониторе работать, а на втором смотреть кино (в частности, DVD). Особенно актуально это становится, если в качестве второго монитора использовать TV-out. И это возможно!
На снимке выше это наглядно продемонстрировано. Участвовал плеер WinDVD для проигрывания DVD, который можно запустить на основном мониторе и перетащить окно на второй, а затем раскрыть на весь экран.
Если вдруг в каком-либо плеере включится защита от демонстрации DVD на втором приемнике, то можно на первом приемнике открыть окно с DVD, а на втором подготовить рабочий стол для деловых нужд. Затем в драйверах поменять местами первый и второй приемники и таким образом "обмануть" защиту.
Кстати о DVD. В отличие от NV17, спецификация NV25 не содержит аппаратного декодера MPEG2. С появлением первых плат на NV17 мы подробно исследуем эту возможность, а пока лишь отметим, что в нашем "программном" случае при использовании последней версии WinDVD процент загрузки процессора не превышал 18% (с учетом активизации nView).
Результаты тестов
2D-графика
Традиционно начнем с 2D. С большим удовольствием отметим, что никаких замечаний к обеим картам в этом отношении нет. Качество изображения замечательное (разумеется, при наличии высококачественного монитора). Работать можно с прекрасным комфортом в разрешении 1600х1200 при 85Гц. Мне кажется, что качество Matrox G400/G450 в этом отношении достигнуто.
Подчеркну, что оценка 2D-качества есть вещь субъективная, не подвластная никаким измерительным инструментам, также она сильно зависит от конкретной карты и даже от связки карта-монитор. Поэтому никто и никогда не сможет дать подобную общую оценку для всей серии или марки видеокарт.
3D-графика, MS DirectX 8.1 SDK — предельные тесты
Для тестирования различных предельных характеристик чипов мы использовали модифицированные (для большего удобства и контроля) примеры из последней версии DirectX SDK (8.1, релиз). Без лишних преамбул перейдем к уже хорошо знакомым нашим постоянным читателям тестам:
Optimized Mesh
Этот тест призван выяснить практический предел пропускной способности ускорителя по треугольникам. Для этого используется несколько одновременно выводимых в небольшом окне моделей, каждая из которых состоит из 50 тысяч треугольников. Текстурирование отсутствует. Размеры моделей минимальны — каждый треугольник не превышает одного пиксела. Хочется сразу отметить, что результат этого теста, разумеется, останется недостижим для реальных приложений, где размеры треугольников значительны, присутствуют текстуры и освещение. Приведем результаты этого теста для трех методов отрисовки — оптимизированной для оптимальной скорости вывода (в том числе с учетом размера внутреннего кеша вершин на чипе) модели — Optimized, неоптимизированной исходной модели — Unoptimized и той-же неоптимизированной модели, выводимой в виде одного Triangle Strip — Strip:
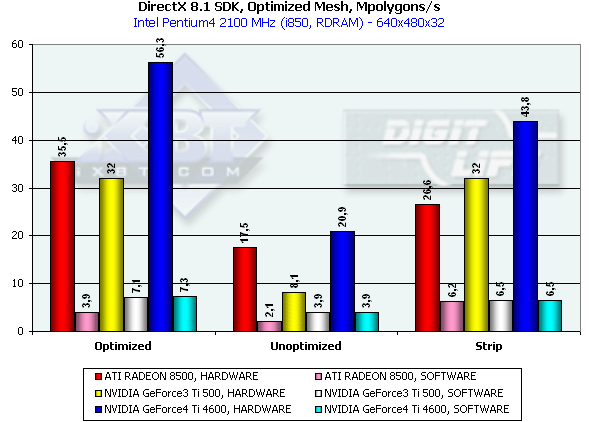
В случае полностью оптимизированной модели, когда влияние подсистемы памяти минимально, мы измеряем практически чистую производительность трансформации и установки треугольников. Налицо безоговорочное, лидерство Ti 4600 на базе NV25. 56 миллионов треугольников в секунду — цифра нешуточная, практически вдвое превосходит результаты RADEON 8500 и Ti 500. Что ж, именно так и должен был отразится на производительности второй блок T&L. В случае неоптимизированной модели, мы имеем дело скорее с эффективностью кеширования и пропускной полосой памяти. Но и здесь NV25 "на высоте", пропорциональной разнице частот между R 8500 и Ti 4600. Кроме того, очевидна существенная "работа над ошибками", проделанная по сравнению с более чем вдвое (!) менее эффективной в этом тесте NV20. В случае Strip-а из треугольников R200 чувствует себя хуже всего, а NV25, как и положено, заметно преумножает преимущество NV20, вновь на сравнимую с разницей частот величину. Итак, в этом тесте NV25 выступает безусловным лидером.
Кроме того, отметим существенное преимущество NV20 и NV25 в случае принудительной активации программного расчета геометрии. Причина этого явления кроется во взаимодействии процессора и ускорителя при передаче рассчитанных процессором данных — чипы NVIDIA получили значительное преимущество благодаря FastWrites механизму, позволяющему напрямую передавать геометрические данные из процессора в ускоритель, минуя системную память. В случае Strip модели это преимущество нивелируется из-за существенного (вдвое) снижения объема передаваемых данных.
Производительность блока вершинного шейдера
Этот тест позволяет определить предельную производительность блока вершинных шейдеров. Выполняется достаточно сложный шейдер, вычисляющий как видовые преобразования, так и геометрические функции. Тест проводится в минимальном разрешении, дабы минимизировать влияние закраски. Z-буфер отключен, так что HSR также не может влиять на результаты:
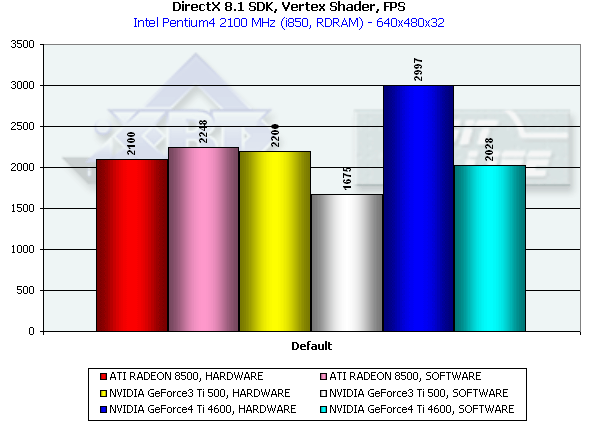
И вновь налицо существенное преимущество "двойного" T&L NV25. Более того, впервые мы наблюдаем картину, когда один из самых производительных (на момент анонса ускорителя) CPU заметно проигрывает по скорости обработки геометрических данных. Кроме того, мы можем сделать косвенный вывод о небольшом повышении у NV25 эффективности передачи рассчитанной программно геометрии (по сравнению с NV20) — благо драйверы для обоих чипов использовались совершенно одинаковые.
Интересно, что со времени прошлого большого обзора R200 скорость выполнения им вершинных шейдеров выросла более чем вдвое. При этом она подозрительно сравнялась со скоростью программной эмуляции, и в том обзоре мы уже наблюдали подобный скачок у NV20. На этот раз мы вновь решили проверить, не исполняются ли шейдеры R200 программно, и для этого понизили тактовую частоту процессора до 1 ГГц. Результаты (HARDWARE 1860, SOFTWARE 1470) свидетельствуют скорее в пользу истинно аппаратного исполнения. Что ж, ATI тоже не лыком шиты, и вполне успешно выжали из чипа новые соки за счет оптимизации драйверов (вероятно, в первую очередь компилятора шейдеров в микрокод).
Вершинный матричный блендинг
Эта возможность T&L используется для правдоподобной анимации и скиннинга моделей. Мы протестировали блендинг с использованием двух матриц как в жестком "аппаратном" варианте, так и с использованием вершинного шейдера, выполняющего ту же функцию. Кроме того, мы, как обычно, "подстраховались" результатами, полученными в режиме програмной эмуляции T&L:
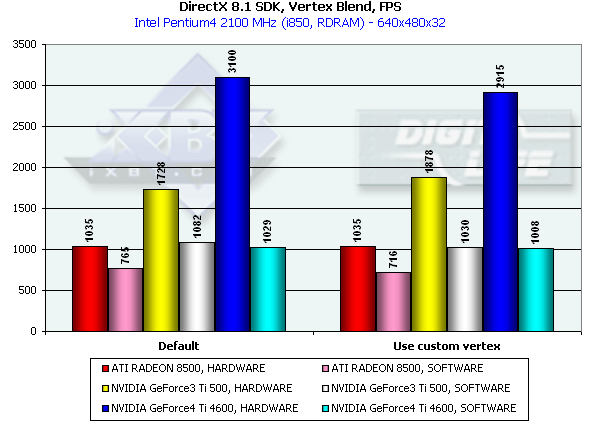
На сей раз, программная эмуляция везде проигрывает аппаратному исполнению, упираясь, судя по всему, (обратите внимание на похожести результатов с шейдером и без) в скорость передачи геометрии по AGP. Где, как уже было отмечено, продукты NVIDIA обладают некоторым преимуществом благодаря FastWrites. В случае аппаратного исполнения, на сей раз (по сравнению с прошлым большим тестом R200) шейдеры сравнялись с полностью аппаратным блендингом, который, таким образом, ввиду своей ограниченной гибкости, полностью потерял смысл на современных чипах. Интересно, что жесткий аппаратный блендинг на NV20 чуть медленнее, а на NV25 чуть быстрее шейдерного, но отличия крайне малы, что вполне естественно, учитывая отсутствие у NV20 и NV25 фиксированного T&L. Фактически, его роль играет специальный шейдерный микрокод, и равенство результатов предстает перед нами в новом свете — как признак того, что оптимизация компилируемых драйвером шейдеров близка к оптимуму.
EMBM рельеф
В этом тесте мы измеряем производительность, а точнее ее падение, возникающее при использовании наложения карт отражения (Environment) и рельефа на основе карт отражения (EMBM — Environment Bump). Для тестирования использовалось разрешение 1280*1024 — т.к. именно в нем различия между картами и разными режимами текстурирования выражено наиболее резко:
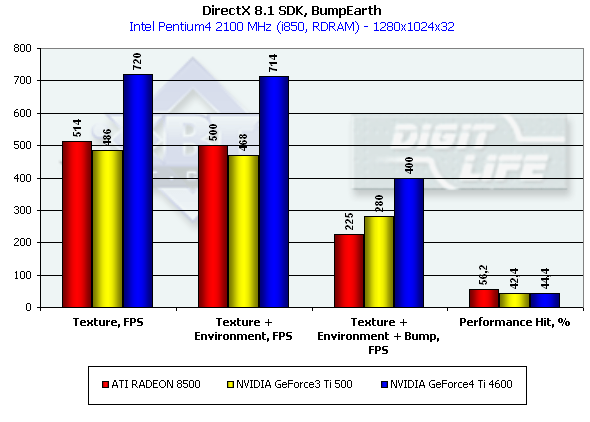
Ti 4600 вновь занимает четкую лидирующую позицию, заметно опережая остальные карты по эффективной скорости закраски во всех трех режимах. Сильнее всего EMBM бьет по R200, однако, сама по себе разница в падении не столь существенна, сколь низка эффективность любой (даже без EMBM) закраски на R200. Чипы NVIDIA красят гораздо эффективнее, особенно при пересчете на единицу тактовой частоты — 240 МГц NV20 практически сравнялась с 275 МГц R200.
Производительность пиксельных шейдеров
Мы вновь использовали модифицированный пример MFCPixelShader, измерив производительность карт в высоком разрешении при выполнении 5 различных по сложности шейдеров, для билинейно фильтрованных текстур:
Ti 4600 на коне, и характер зависимости от сложности шейдера и числа текстур полностью повторяет предыдущий чип (NV20). А вот R200 демонстрирует печальную слабость, существенно сдавая на сложных заданиях. Повторное использование текстурных блоков стоит ему гораздо дороже, нежели творениям NVIDIA.
Итак, подведем первый промежуточный итог. По сумме тестов DX 8.1 SDK карта NVIDIA GeForce4 Ti 4600 выходит очевидным, четким победителем. Что, впрочем, от нее и ожидалось — удивительно, если бы разница в полгода не сказалась именно таким образом. Однако не будем забывать, что только результаты реальных приложений позволят нам судить об общей сбалансированности этого чипа. Оставайтесь с нами.
3D-графика, VillageMark (Тестирование эффективности HSR)
Для того, чтобы оценить эффективность реализации HSR, мы использовали тест с большим уровнем OverDraw — VillageMark v.1.17. Приводим результаты обеих карт со включенным и отключенным HSR:
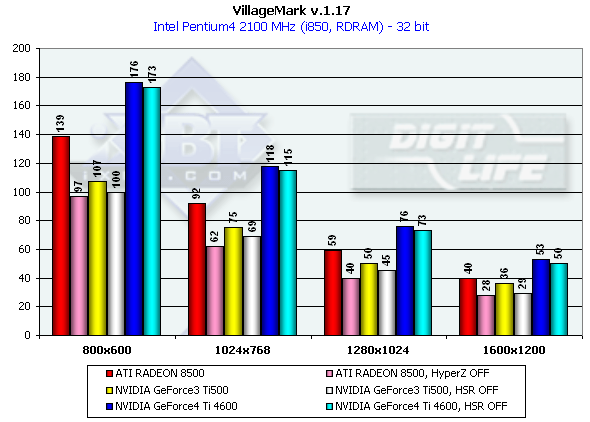
Кроме очевидного преимущества NV25, особенно ярко выраженного в разрешении 1280х1024, в глаза бросается интересный факт — падение производительности при отключенном HSR для NV25 и NV20 очень мало. Особенно по сравнению с R200. Говорит ли это о более низкой эффективности HSR? Нет, и вот почему. Если в случае R200 мы отключаем весь HyperZ, т.е. целый комплекс оптимизаций на основе иерархического представления Z буфера (в том числе, HSR, сжатие Z, быстрая очистка Z), то в случае NVIDIA, как выяснилось при более детальном анализе, нам удалось выключить только сжатие Z, а сам HSR (Z-Cull) в драйверах 27.ХХ на данный момент включен по умолчанию и активируется вне зависимости от состояния ключей в реестре. Как бы там ни было — общая эффективность NV25 в сценах с высоким overdraw налицо.
Следует отметить, что сцена в этом тесте выводится не в порядке глубины, а просто "как есть", и поэтому HSR нетайловых чипов, наиболее эффективно справляющийся с выводимыми по мере удаления сценами, не получает на этом тесте эффекта, сравнимого с полностью тайловыми архитектурами, которые аппаратно сортируют сцену по мере ее вывода. Но, т.к. большинство реальных приложений изначально выводит сцены не сортируя полигоны, мы считаем этот тест вполне правомерным.
3D-графика, предварительный тест на основе iXBT/Digit-Life RightMark Video Analyser
В данный момент мы разрабатываем тестовый пакет, исходные тексты которого будут доступны всем желающим (OpenSource). Мы создали небольшой предварительный тест на основе одной сцены и движка, который ляжет в основу этого пакета. Отличительными особенностями этого теста является большая сложность геометрии (более 150000 полигонов в кадре) и широкое использование возможностей DirectX 8.1. Все освещение базируется на вершинных шейдерах, закраска — на пиксельных, практически повсеместно используются карты среды и рельефа, т.е. накладывается до 4 текстур на точку. Кроме того, в этом примере рассчитывались в реальном времени тени от предметов с использованием Shadow Buffer технологии. Положительной особенностью теста является низкая зависимость от процессора — большинство процессорного времени он проводит в Direct3D и драйверах, в ожидании ускорителя.
Приведем несколько скриншотов:



И результаты теста:
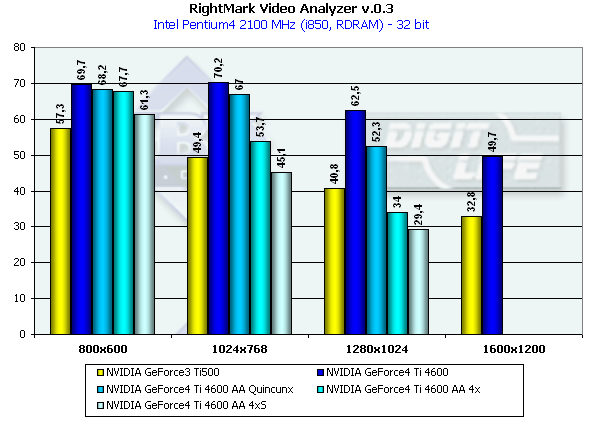
Как мы видим, тест не сильно зависит от разрешения, ввиду очень высокой сложности сцен и большой нагрузки на геометрическую часть ускорителя. Впрочем, при включении AA, очень благодатно влияющего на визуальное качество сцен с большим количеством мелких полигонов, мы, наконец, начинаем чувствовать влияние разрешений. Более того, мы думаем, что в скором будущем акценты всех приложений сместятся в сторону геометрической сложности сцен, и разрешение уже не будет играть такой роли — мощность ускорителя будет достаточна для закраски любых разрешений, а рост будет направлен в основном в область реализма (гибкости) и все более возрастающей сложности геометрии. Интересно, что вновь именно в разрешении 1280*1024 отрыв NV25 от NV20 наиболее существенен — карта словно проектировалась в расчете на это разрешение. И возросшая пропускная способность памяти, и ее удвоенный объем сильнее всего сыграли на руку NV25 в этом режиме. Учитывая все большее распространение 17 и 18 дюймовых ЖК, для которых этот режим является родным, мы можем только приветствовать этот факт.
3D-графика, 3DMark2001 — синтетические тесты
Скорость закраски
Мы измеряли этот параметр только для 32 битной глубины цвета:
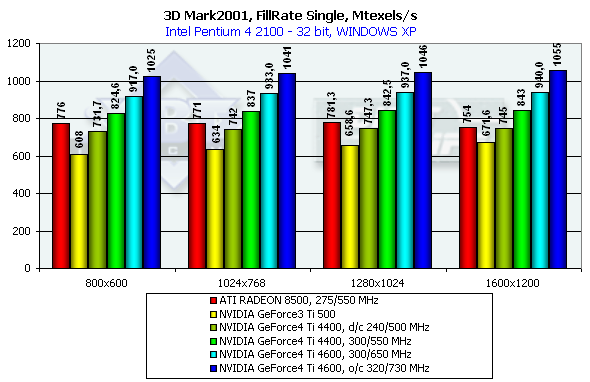
NV25 вновь лидер (на что несколько ранее уже намекал нам EMBM тест из раздела DX SDK). Особенно интересно наглядно сравнить эффективность закраски в исполнении NV25, установленного на штатную частоту Ti500 (240/500). Налицо заметный прирост, а, следовательно, и наличие архитектурной оптимизации конвейера закраски и контроллера памяти. Напомним, что теоретические пределы для данного теста составляют 960 миллионов пикселей в секунду для Ti 500, 1100 для RADEON 8500 и 1200 для Ti 4600 соответственно. На сей раз архитектура NV25 достигла сравнимой с R200 степени приближения к теоретическому максимуму филрэйта, исправив небольшое отставание NV20 в этом вопросе. В какой раз мы убеждаемся в целенаправленной и эффективной "работе над ошибками", проделанной специалистами из NVIDIA. Не забываем, что, несмотря на ту же самую технологию производства и лишь незначительно возросшее число транзисторов, NV25 существенно превосходит NV20 как по предельной рабочей частоте, так и по эффективности работы на равных частотах. Редкий случай, когда удалось и рыбку съесть, и ничего не уколоть (прозрачный намек в сторону производителей центральных процессоров).
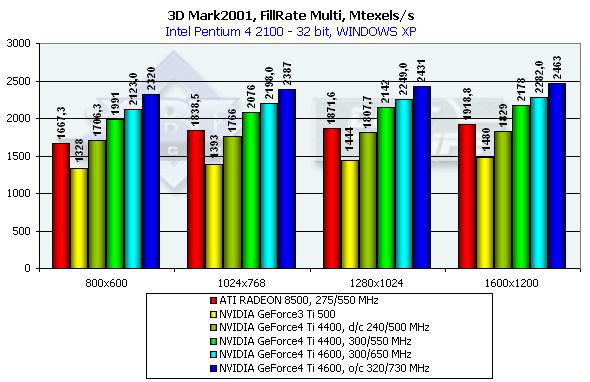
В случае нескольких текстур чипы еще немного приблизились к теоретическому пределу, сохранив общую картину взаимного расположения. Наибольший результат этого теста всегда достигается при максимальном разрешении — здесь чипу остается только красить, красить и еще раз красить бескрайние поля экрана.
Сцена с большим количеством полигонов
На этом тесте особое внимание следует уделить минимальному разрешению — именно там зависимость от закраски практически нивелируется:
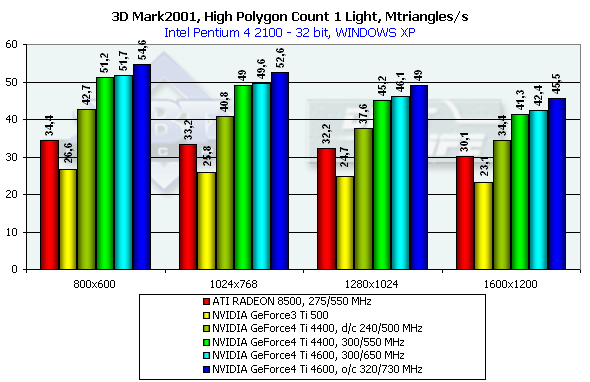
При наличии одного источника света NV25 показывает себя абсолютным лидером. Его результат не только значительно (более, чем на разницу частот) превосходит Ti 500, но и (что более важно) вплотную приблизился к значению практического предела пропускной способности по треугольникам, полученному ранее с помощью Optimized Mesh из DX8.1 SDK. Еще одно свидетельство мощи двойного T&L NV25 и прекрасного баланса всей архитектуры чипа. Общий прирост эффективности, достигнутый благодаря появлению второго шейдерного блока, можно наблюдать, сравнив результаты NV25 и NV20 на одинаковой частоте (более чем в полтора раза!). Впрочем, не будем умалять достоинств R200, также приблизившегося к предельной цифре, полученной в тесте из SDK, но значительно отстающего по абсолютным значениям, несмотря на близкую к NV25 частоту ядра.
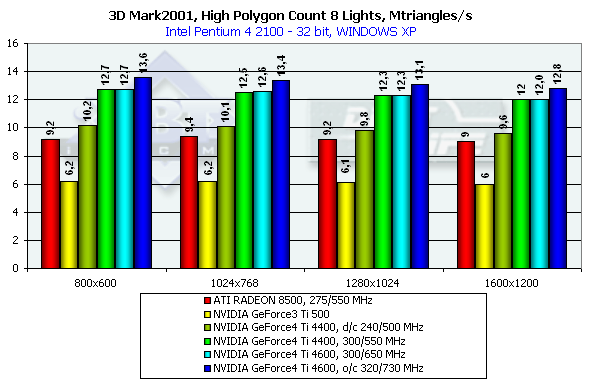
В случае 8 источников света R200 немного реабилитирует себя: с ростом числа источников его производительность падает чуть более медленно чем у NV20 и NV25. Но абсолютное лидерство по-прежнему за NVIDIA.
Рельефное текстурирование
Посмотрим на результаты синтетической EMBM сцены:
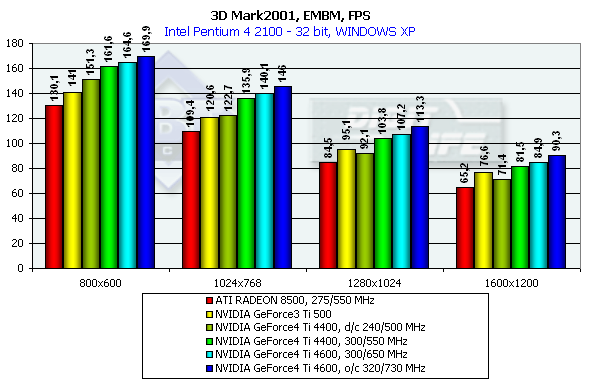
Наибольшее отношение собственно к EMBM результаты этого теста имеют в высоких разрешениях, в 800х600 все определяет зависимость от геометрии. Интересно, что на одинаковой частоте собственно EMBM выполняется NV25 чуть медленнее NV20 — вероятно, это расплата за оптимизацию конвейера закраски, гораздо более эффективного при обыкновенной закраске и, особенно, при использовании MSAA (об этом далее). А теперь DP3 рельеф:
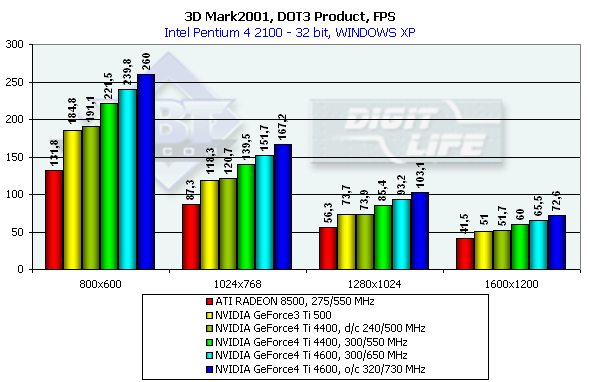
Здесь все встает на свои места и никаких досадных исключений из общей победоносности NV25 не возникает.
Вершинные шейдеры
Мы приводим результаты этого теста в нескольких разрешениях. Читатель легко подметит интересную зависимость:
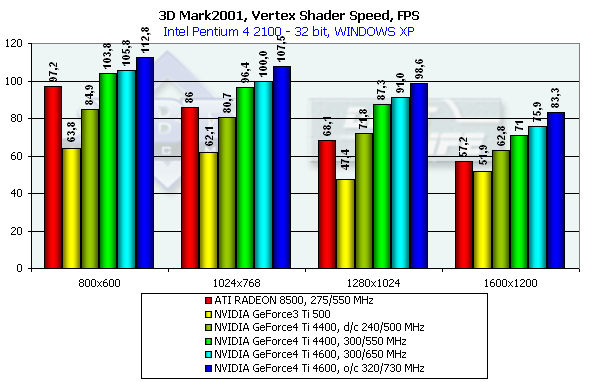
С ростом разрешения R200 стремительно сдает свои позиции, упираясь в недостаточную эффективность закраски, в то время как скорость NV25 падает существенно медленнее. Кроме того, вновь четко выражено архитектурное преимущество двойного T&L NV25 над NV20 на одинаковой частоте.
Пиксельный шейдер
Руководствуясь высказанными выше соображениями о том, что слишком малые разрешения "упираются" в геометрию, а слишком большие — в пропускную полосу памяти, обратим основное внимание на 1024х768 и 1280х1024:
Картина вполне узнаваема: NV25 вновь на коне, в том числе и на равной NV20 частоте. Впрочем, архитектурное преимущество в исполнении пиксельных шейдеров минимально, и это ожидаемый результат: простор для аппаратной оптимизации на этом поприще значительно уже, чем в случае вершинных шейдеров (если не затрагивать простое увеличение числа конвейеров закраски, которое не имеет смысла из-за ограничений на пропускную способность памяти).
Спрайты
В этой области NV25 значительно опережает NV20 на равной частоте. В маленьких разрешениях наибольший вклад в этот тест вносит скорость геометрической обработки, а в средних все встает на свои места. В принципе — нельзя говорить о четком преимуществе NV25 над R200 или наоборот, на штатных частотах разница минимальна. Как бы там ни было — работа над ошибками (в отношении того, что наблюдалось ранее у NV20) налицо. Следует отметить и возросшие возможности по масштабированию спрайтов (см. ранее таблицу с параметрами чипов).
Итак, подведем первый промежуточный итог. По сумме синтетических тестов карта NVIDIA GeForce4 Ti 4600 выходит очевидным, "четким" победителем. Что, впрочем, от нее и ожидалось — удивительно, если бы разница в полгода не сказалась именно таким образом. Однако не будем забывать, что только результаты реальных приложений позволят нам судить об общей сбалансированности этого чипа. Оставайтесь с нами.
3D-графика, 3DMark2001 — игровые тесты
3DMark2001, 3DMARKS
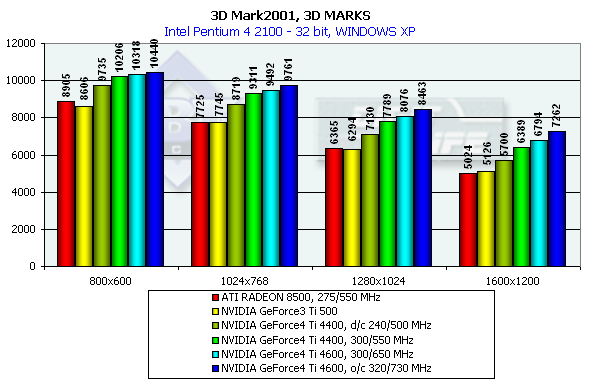
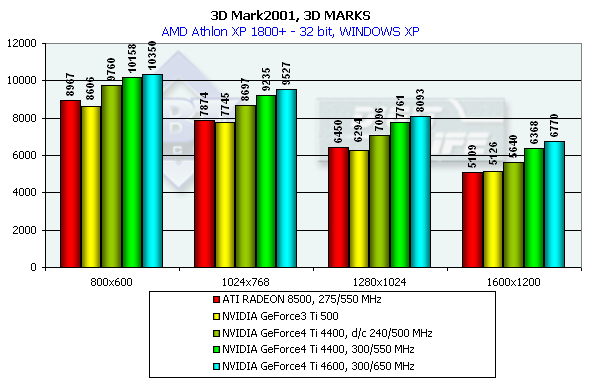
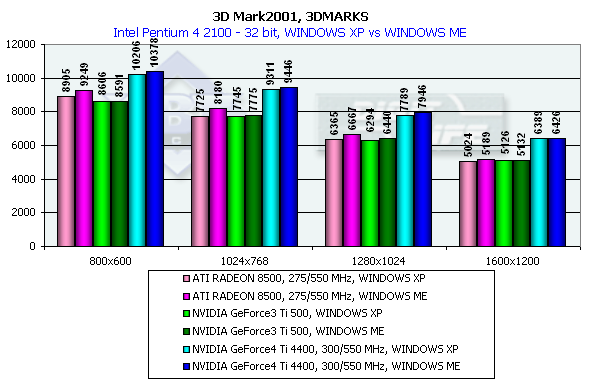
На основании общих "марков" можно отметить, что GeForce4 обгоняет своего предшественника более, чем на 30%. Интересно отметить, что RADEON 8500 утратил былое яркое преимущество над GeForce3 Ti 500 по общему "зачету" в 3DMark2001. А теперь посмотрим более подробно.
Как известно, в состав 3DMark2001 входит 4 игровых теста, 3 из которых присутствуют в 2-х вариантах: так называемой низкой и высокой детализации графики. Высокая детализация в этих тестах сводится, в основном, к усилению нажима на процессор и видеоускоритель дополнительными эффектами и повышением полигональной сложности сцен. Однако движок этих тестов сделан таким образом, что высокий уровень детализации в игровых тестах приводит к "упиранию" в частоту CPU в случае очень производительного ускорителя. Что мы, к сожалению, и наблюдали (в достаточно жесткой форме) на примере результатов GeForce 4. Мы были вынуждены исключить High Detail тесты из нашего рассмотрения в данном материале. Надеемся, что обновленная версия 3D Mark, которая, по слухам, готовится к выходу, разрешит эту проблему.
3DMark2001, Game1 Low details
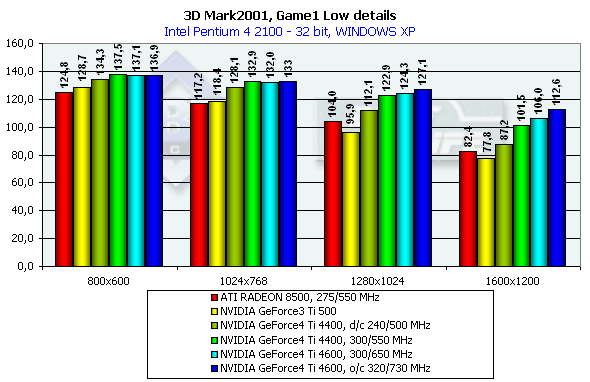
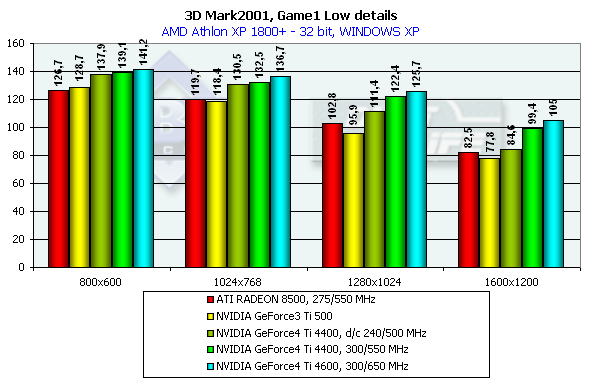
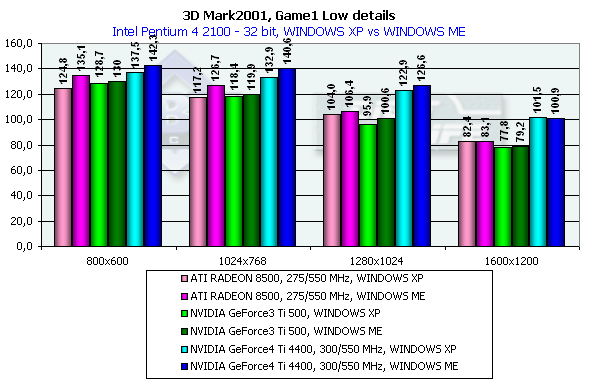
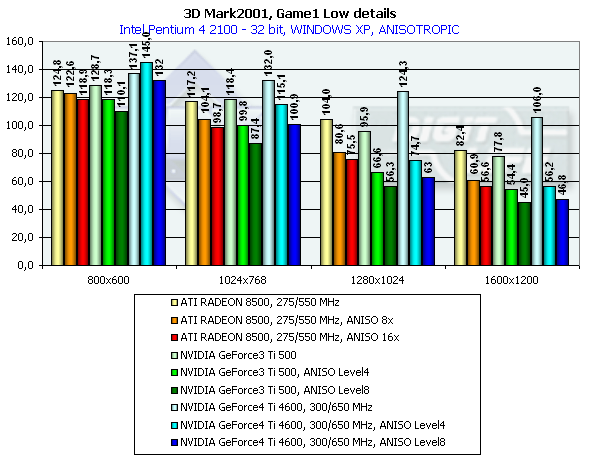
Боевой авто-симулятор, навеянный нетленной антиутопией о войне с роботами (Terminator 1 и 2). Создатели теста утверждают, что эта игровая сцена честным образом тратит процессорное время на расчет физики и поведения объектов, как это сделала бы любая реальная игра. Что ж, это несомненно плюс — мы сможем не только говорить о скорости ускорителя, но и прикинуть, как он покажет себя в будущих играх. Характеристики:
- Rendered triangles per frame (min/avg/max): 19773/33753/143422
- Rendered textures per frame with 16 bit textures (min/avg/max): 7.5/8.8/16.5 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 15.1/17.7/30.3 MB
- Rendered textures per frame with texture compression (min/avg/max): 10.7/12.2/21.0 MB
Превосходство над GeForce3 Ti 500 в разрешении 1600х1200х32 таково: у GeForce4 Ti 4400 — 30.5%, у GeForce4 Ti 4600 — 36.2%.
Что касается сравнения Windows ME и Windows XP, то здесь наблюдается некоторое отставание результатов XP от ME.
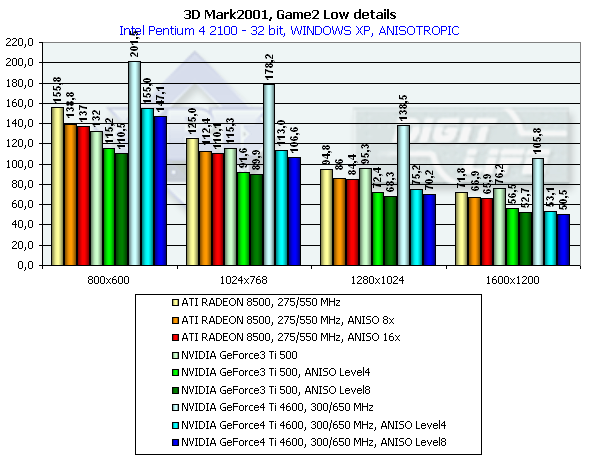
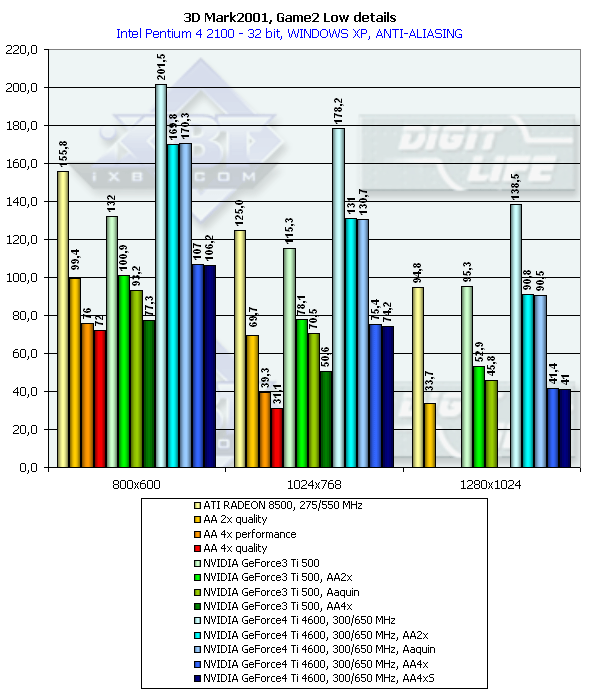
3DMark2001, Game2 Low details
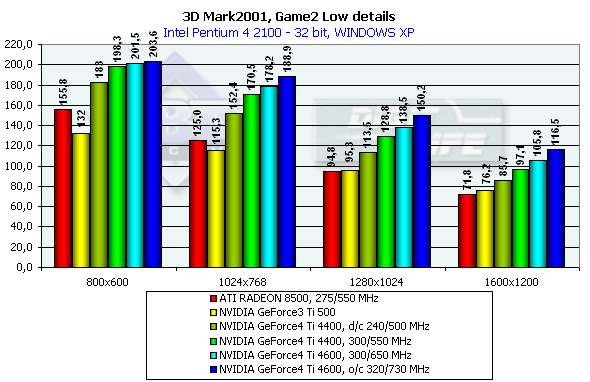
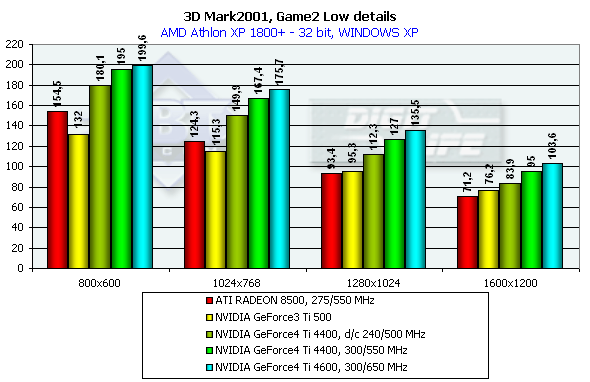
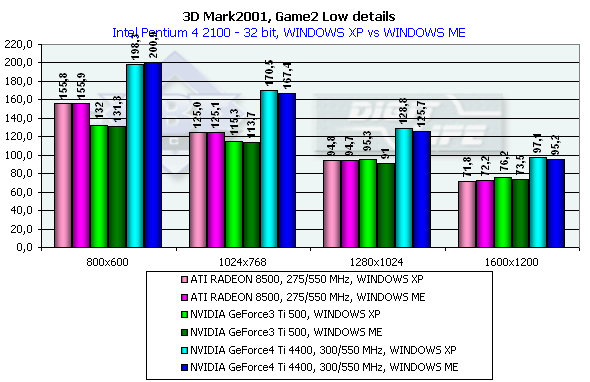
Cказочно-историческая фэнтези с драконом, красивой наездницей оного, городом, кораблем и нещадно опаляемыми огнем людьми. Так как жанр этой игры определить сложно, будем считать, что это — аркадная сцена из какой-то 3D Adventure или стратегии. Судя по всему, сцены имеют высокое значение overdraw и достаточно слабую оптимизацию геометрии при выводе. От ускорителя требуется оптимизация работы с Z-буфером. Характеристики:
- Rendered triangles per frame (min/avg/max): 46159/51440/147828
- Rendered textures per frame with 16 bit textures (min/avg/max): 8.0/8.8/10.1 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 15.6/17.2/19.8 MB
- Rendered textures per frame with texture compression (min/avg/max): 9.3/10.9/13.5 MB
Превосходство над GeForce3 Ti 500 в разрешении 1600х1200х32 таково: у GeForce4 Ti 4400 — 27.4%, у GeForce4 Ti 4600 — 38.8%, в 1280х1024х32 — 35.1% и 45.3% cоответственно. Интересно заметить, что в очередной раз пик прироста наблюдается в 1280х1024 (вспомним описанные ранее синтетические тесты), и затем спадает в 1600х1200.
Сравнение Windows ME vs Windows XP в этом тесте показало, что у ATI RADEON 8500 производительность в обеих ОС равна, а у NVIDIA-карт чуть-чуть выше у второй.
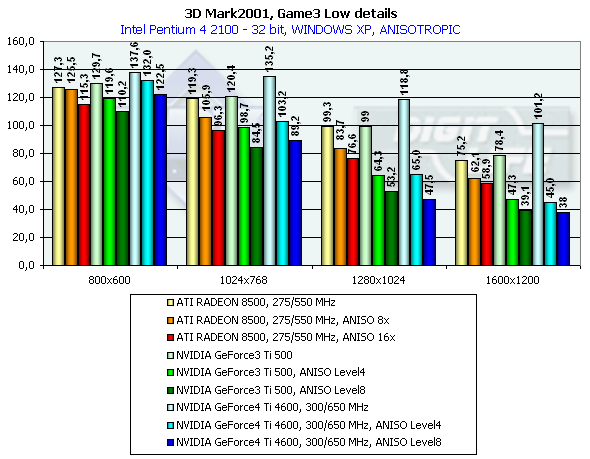
3DMark2001, Game3 Low details
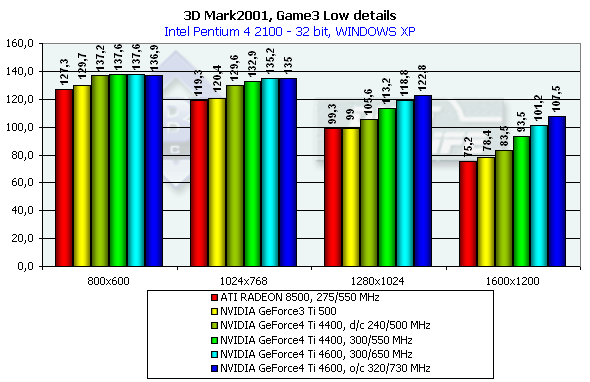
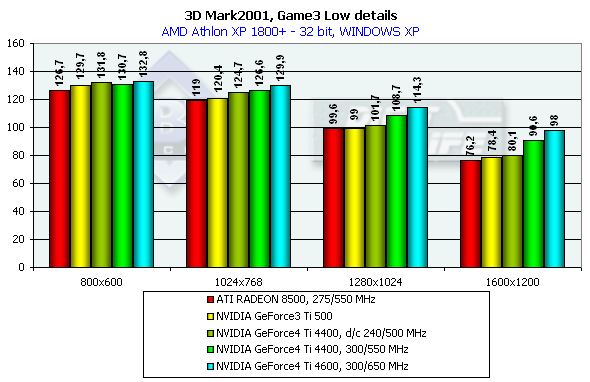
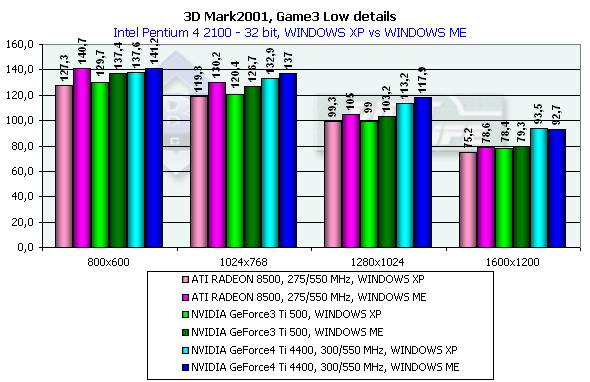
Сцена навеяна "Mатрицей". Надо отметить, что детальность самих моделей невысока — где-то на уровне Quake2. Судя по всему, присутствует скининг (матричный блендинг) и скелетная анимация. В активе — детальные текстуры и огромное количество всяческих гильз, осколков и прочих мелочей, они значительно нагружают ускоритель. Назовем этот жанр киношутером. Характеристики:
- Rendered triangles per frame (min/avg/max): 16681/21746/39890
- Rendered textures per frame with 16 bit textures (min/avg/max): 2.8/4.1/4.7 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 5.7/8.2/9.4 MB
- Rendered textures per frame with texture compression (min/avg/max): 5.0/7.2/8.4 MB
Превосходство над GeForce3 Ti 500 в разрешении 1600х1200х32 таково: у GeForce4 Ti 4400 — 19.3%, у GeForce4 Ti 4600 — 29.1%.
Сравнение Windows ME vs Windows XP в этом тесте показало, что у всех карт производительность чуть-чуть выше под первой — ME.
3DMark2001, Game4
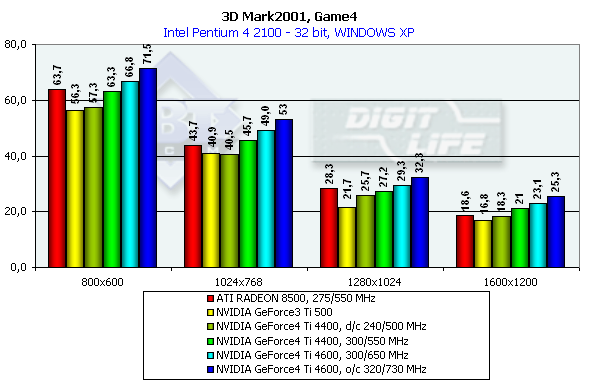
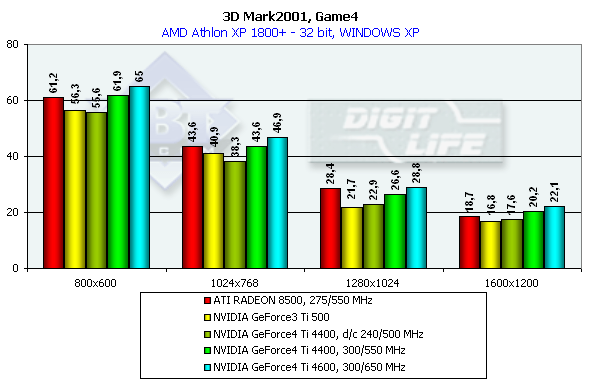
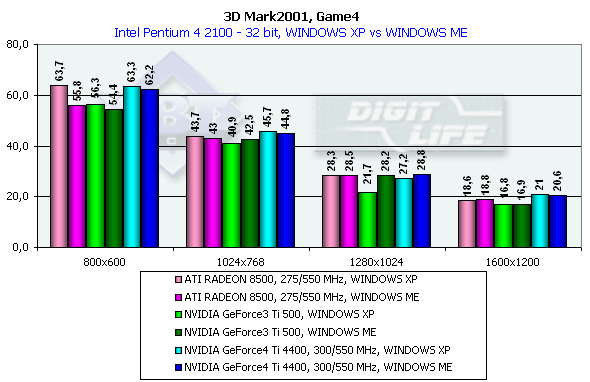
Безусловно, это самый красивый из всех игровых тестов. Главная его особенность, что он использует пиксельные шейдеры, вершинные шейдеры и кубическое текстурирование для формирования водных поверхностей (кроме быстро бегущей речки). Поэтому лицезреть эту игру во всей красе можно пока только на GeForce3/4 и RADEON 8500 (в демо-режиме водные поверхности не отображаются). Характеристики:
- Rendered triangles per frame (min/avg/max): 55601/81714/180938
- Rendered textures per frame with 16 bit textures (min/avg/max): 14.9/17.4/20.7 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 28.4/33.5/40.0 MB
- Rendered textures per frame with texture compression (min/avg/max): 28.4/33.5/40.0 MB
Превосходство над GeForce3 Ti 500 в разрешении 1600х1200х32 таково: у GeForce4 Ti 4400 — 25%, у GeForce4 Ti 4600 — 37.5%.
Сравнение Windows ME vs Windows XP в этом тесте показало, что у NVIDIA-карт производительность чуть-чуть выше под первой ME, а у ATI RADEON 8500 она одинаковая под обеими ОС.
3D-графика, игровые тесты
Приступаем к оценке производительности видеокарты в 3D-играх. В качестве инструментария мы использовали:
- Quake3 Arena v.1.17
(id Software/Activision) — игровой тест, демонстрирующий работу плат в OpenGL с использованиемдемо-бенчмарка уровня Q3DM9 с огромнымитекстурами — Quaver; - Return to Castle Wolfenstein
(id Software/Activision) — игровой тест, демонстрирующий работу плат в OpenGL с использованиемдемо-бенчмарка Checkpoint; - Serious Sam v.1.05 (Croteam/God Games) — игровой тест, демонстрирующий работу плат в OpenGL с использованием
демо-бенчмарка Karnak demo; - GLMark (Vulpine) — синтетический тест, демонстрирующий работу плат в OpenGL с использованием возможностей GeForce3 (это единственный тест — исключение из игровых программ);
- AquaMark v.2.2 (Massive Development) — игровой тест, демонстрирующий работу плат в DirectX 8.1 с использованием пиксельных шейдеров;
Giants: Citizen Kabuto (Planet Moon Studios/Digital Mayhem/Interplay) — игровой тест, демонстрирующий работу платы в Direct3D с использованиемдемо-бенчмарка gamegauge.
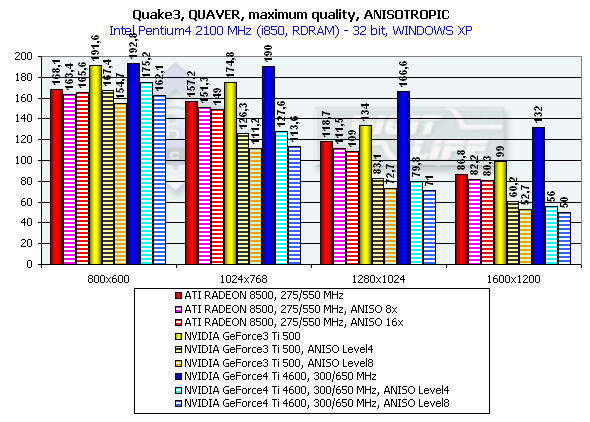
Quake3 Arena
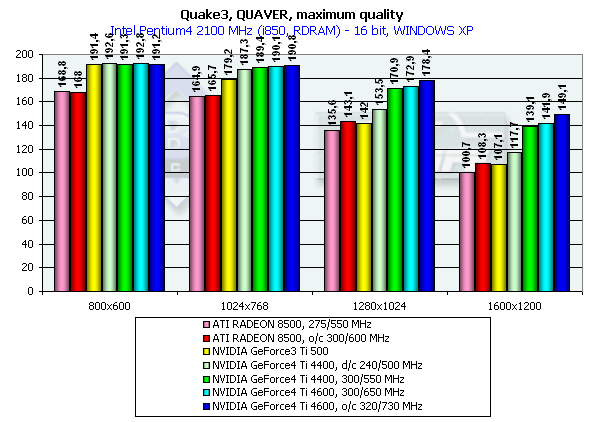
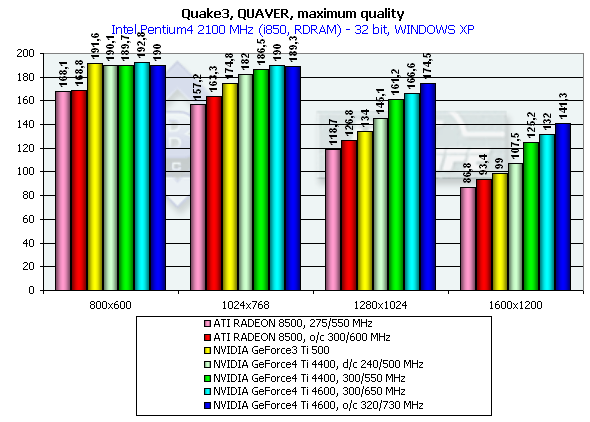
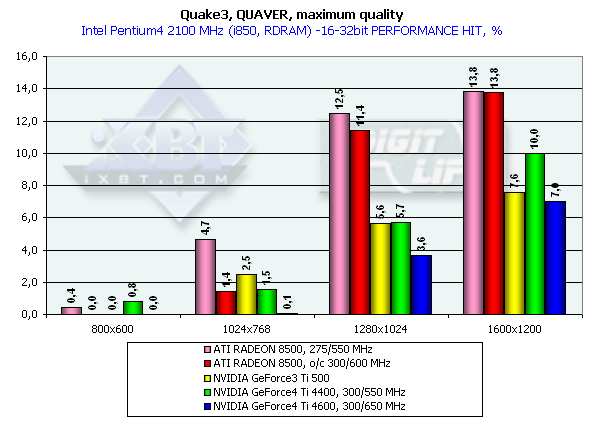
Quaver, режимы максимального качества
Тестирование на примере Quaver проводилось в режиме 16- и
Pentium 4 2100
Athlon XP 1800+
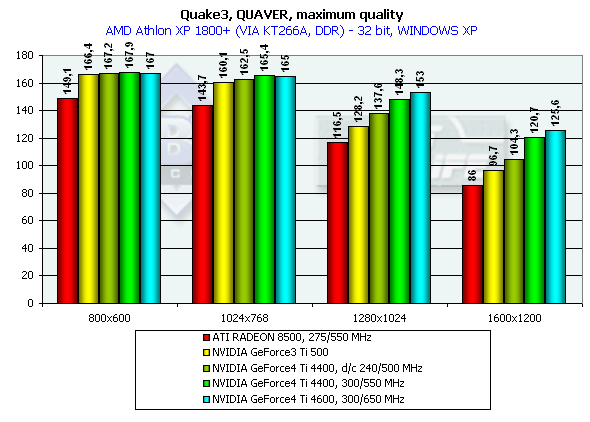
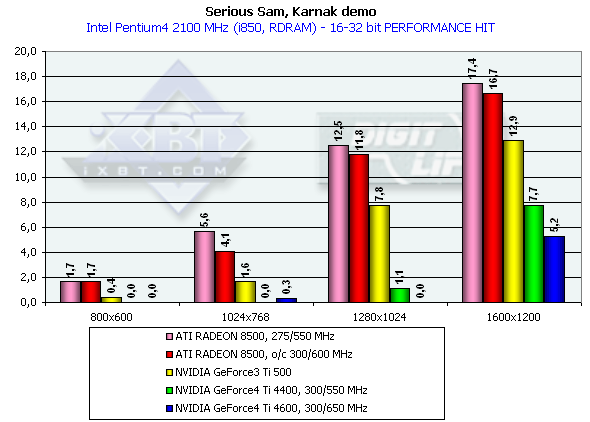
Эти тесты нам продемонстрировали производительность новинок в 16-, 32-битном цвете, а также падение скорости при переходе от 16- к 32-битному цвету, где прекрасно видно, что 16-битный цвет заслуженно нами отправлен в историю при рассмотрении видеокарт даже уровня GeForce3 Ti. Обратите внимание на то, что специально заторможенная нами до частот Ti 500 (d/c 240/500 MHz) GeForce4 показывает значительно более высокую производительность, чем Ti 500, что свидетельствует о том, что GeForce4 — не просто увеличение диапазона рабочих частот предыдущего продукта, но и значительная оптимизация различных блоков (о чем мы писали вначале).
Также хочу заметить, что мы разогнали ATI RADEON 8500 до уровня предполагаемых частот следующей ревизии этой карты (если она всетаки будет) — 300/300 (600) МГц. Отлично видно, что этот чип такой прирост частот не спасает.
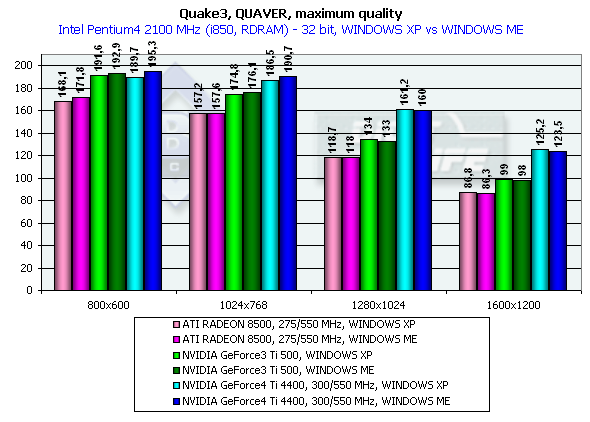
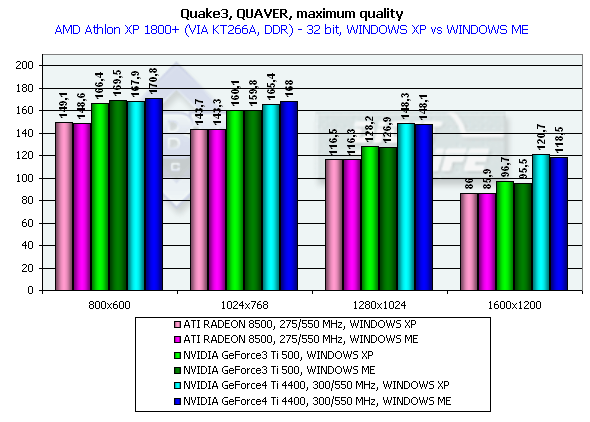
На этой диаграмме хорошо видно, что оба производителя видеочипсетов потрудились над OpenGL ICD, сравняв производительность Windows XP c Windows ME, а драйверы NVIDIA для Windows XP демонстрируют даже более высокую скорость.
Думаю, что оценка производительности GeForce4 не нуждается в комментариях, в 1280х1024х32 мы видим превосходство над GeForce3 Ti 500 у GeForce4 Ti 4400 в 20.3%; у GeForce4 Ti 4600 — 24.3%. В 1600х1200х32 соответственно - 26.5% и 33.3%. Замечу, что частота чипа выросла с 240 до 300 МГц, что составляет 25%.
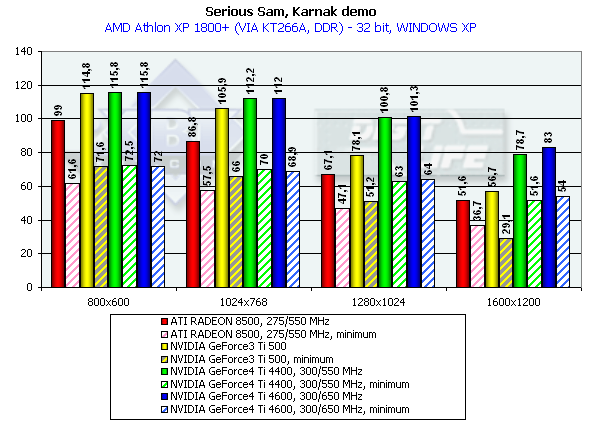
Serious Sam
Karnak demo, режим Quality
Поскольку конфигурация настроек этой игры очень сложна, и ее трудно описать словами, я приведу скриншоты установок:





Итак, что же мы получили:
Pentium 4 2100
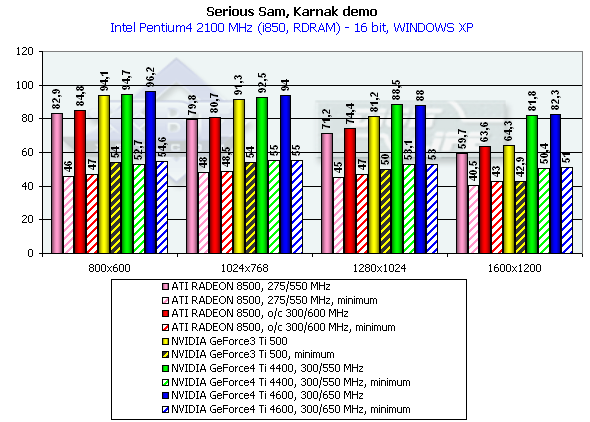
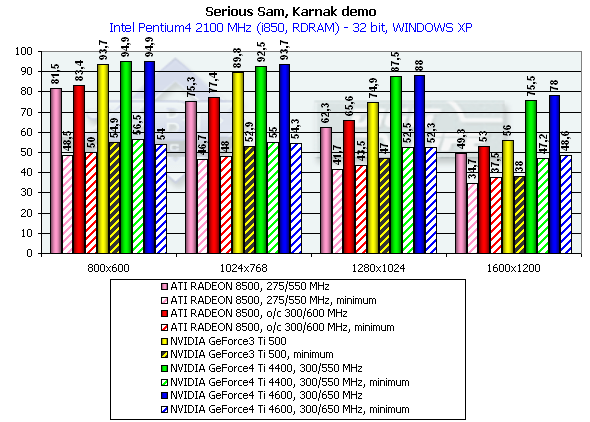
Athlon XP 1800+
Вначале замечу, что мы привели на диаграммах не только средние, но и минимальные значения производительности, полученные при тестировании. В целом, выводы по результатам этого исследования схожи со сделанными нами в Quake3 — тестировании. Падение производительности 16-32бит лишний раз подтвердило, что 16-битный цвет изжил себя и ушел в историю (разумеется, в случае наличия акселераторов класса GeForce3 и выше). По минимальным значениям производительности можно сказать, что ни один акселератор даже в 1600х1200х32 не выдает скорость ниже предела играбельности (хотя наиболее близко к ней подобрался ATI RADEON 8500).
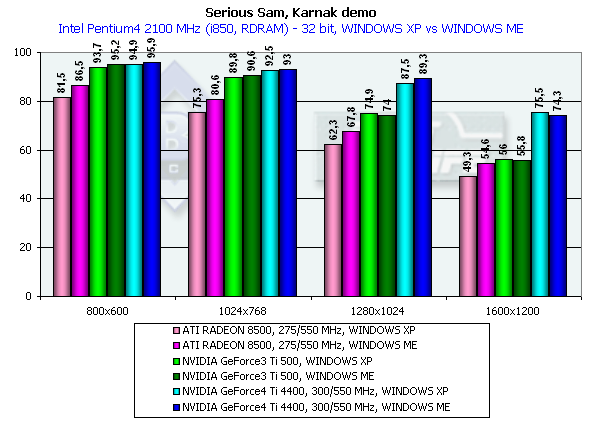
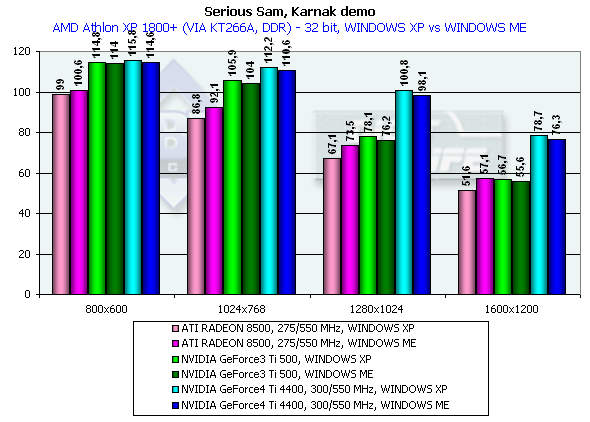
В целом, картина по сравнению производительности в Windows XP и Windows ME схожа с той, что мы видели ранее на примере Quake3.
Итак, мы получили прирост относительно GeForce3 Ti 500 в разрешении 1600х1200х32 такой: у GeForce4 Ti 4400 — 34.8%, у GeForce4 Ti 4600 — 39.3%, что опять-таки просто превосходный результат.
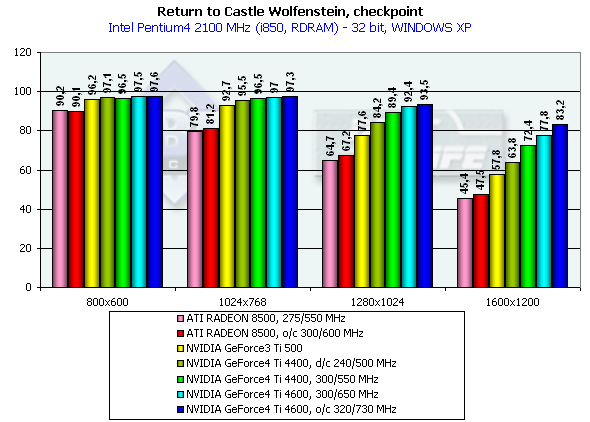
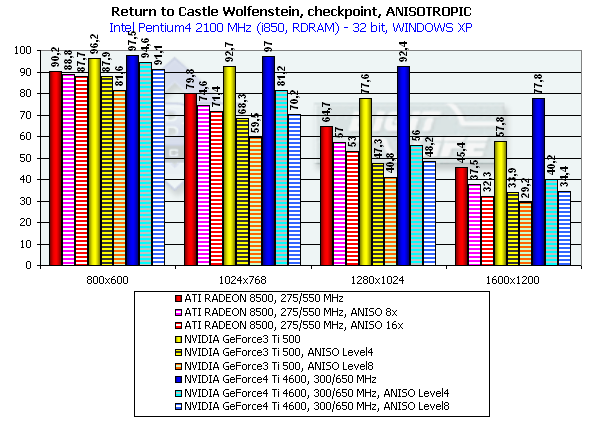
Return to Castle Wolfenstein (Multiplayer)
Checkpoint, режимы максимального качества
Тестирование проводилось в режиме
Pentium 4 2100
Athlon XP 1800+
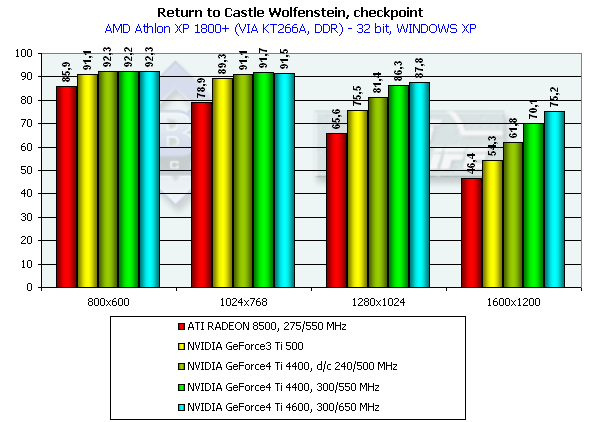
Несмотря на то, что эта игра намного более требовательна к ресурсам акселератора (да и CPU тоже), расклад сил остался на том же уровне.
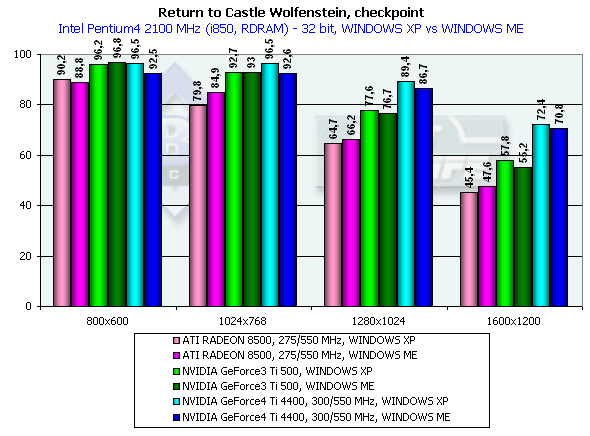
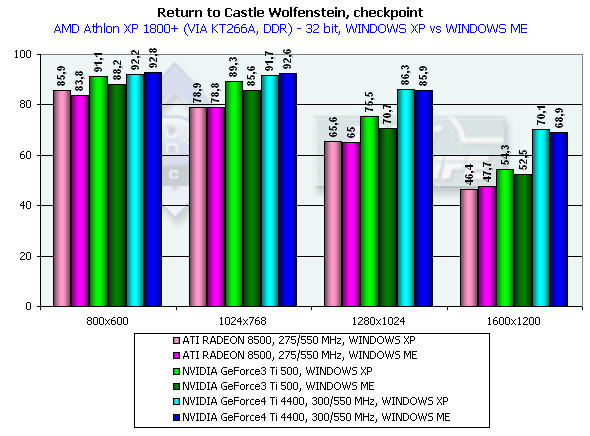
Отметим, что ранее сделанный вывод об отличной отлаженности ICD OpenGL под Windows XP и на примере этого теста получил четкое подтверждение. Видеокарты на базе процессоров от NVIDIA демонстрируют четкое превосходство по скорости в Windows XP над производительностью в Windows ME. OpenGL, детище серъезных открытых операционных систем, чувствует себя в NT среде более комфортно, нежели ведущий родословную от MSDOS DirectX :-)
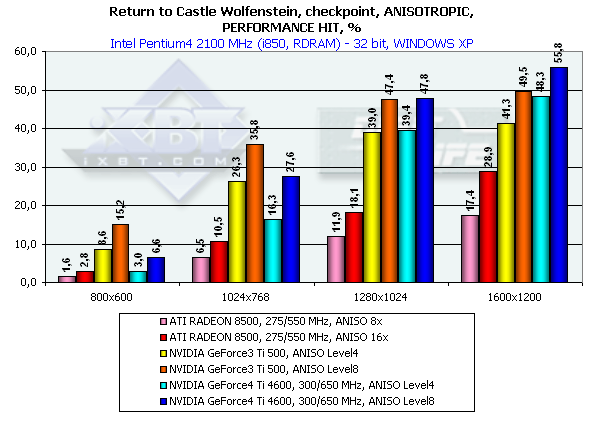
Итоги таковы: в 1600х1200х32 GeForce4 Ti 4400 опередил Ti 500 на 25.6%, а GeForce4 Ti 4600 на 34.6%, что очень даже отлично для GPU, частота которого выше на 25%. Как можно видеть, пропускная способность памяти на таком тесте играет значительную роль (собственно, этим только и отличаются Ti 4400 и 4600).
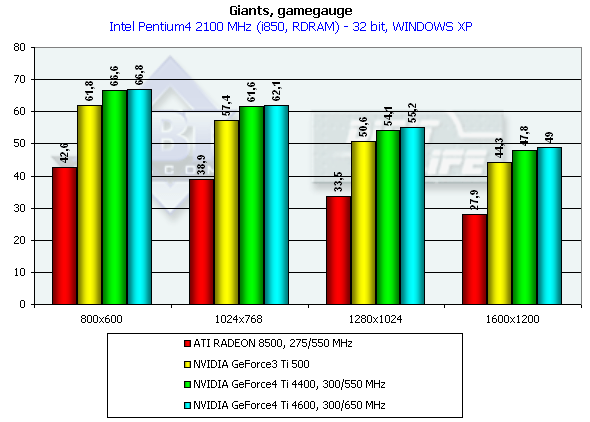
Giants
Gamegauge, режимы максимального качества
Эта игра давно уже принимает участие в наших обзорах в качестве теста в DirectX. Несмотря на нарекания многих читателей к этому тесту, как якобы заточенному под отдельные акселераторы, мы считаем, что из всего скудного списка игр с бенчмарками под DX этот тест весьма ярко показывает мощь и возможности современных видеокарт при достаточно сложной графике (конечно, 25000 полигонов в сцене — уже не удивительное число, но игра примечательна еще и тем, что широко использует технику рельефного текстурирования по методу Dot3 и наложения карт среды, а это накладывает на ускорители, владеющие таковыми функциями, серьезные требования к скорости заполнения сцены). Недостатком этого теста является отзывчивость на частоту CPU, а также зависимость от платформы (явно прослеживается любовь создателей игры к 3DNow!).
Pentium 4 2100
Athlon XP 1800+
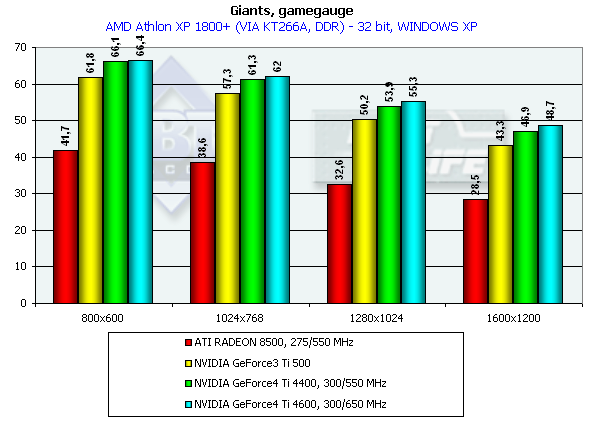
Что и подтвердилось при тестировании. Приросты уже не столь впечатляющие, однако на фоне общей производительности выделяются.
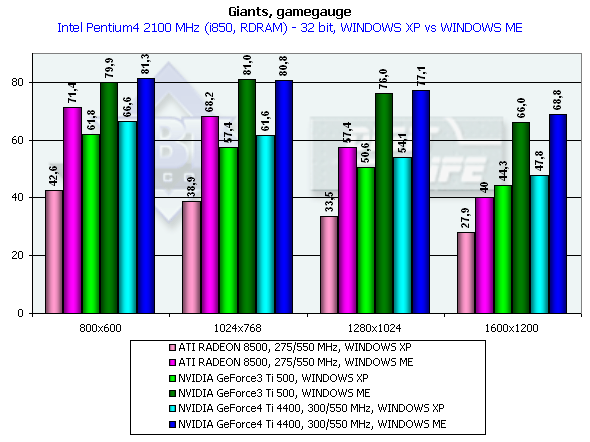
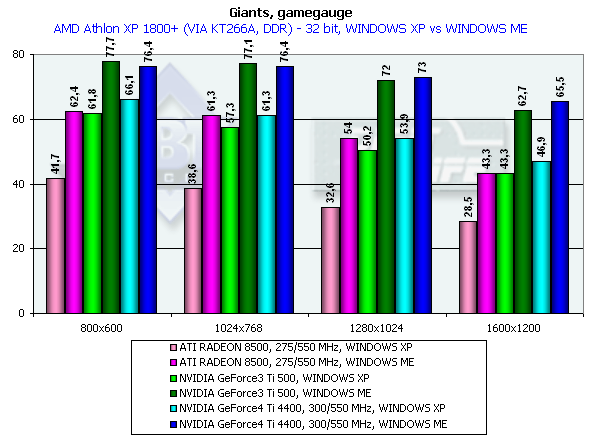
Обратите внимание на то, как заточена эта игра под Windows ME, как вырастает скорость на этой ОС по сравнению с Windows XP. Мы могли бы говорить об отлаженности драйверов, но DirectX — вещь универсальная, и по сути одна и та же в любой ОС (если номер версии DX одинаков). Тем более, что наблюдается удивительная слаженность таких различий у разных ускорителей, что как раз и наводит на мысли, что виноваты уже не драйверы, а сама игра. Впрочем, от этого не легче, иных игровых тестов под DirectX днем-с-огнем не найти.
Итак, победа над Ti 500 у GeForce4 Ti 4400 заключается в 7.9%, у GeForce4 Ti 4600 — 10.6% (разрешение 1600х1200х32). Подчеркну, что это — в Windows XP, где наблюдается общая относительная низкая производительность. Слабые проценты прироста еще обусловлены и влиянием самого движка игры, который слабо реагирует на увеличение мощности карты (вернее, реагирует до какого-либо предела). Возможно, виновата зависимость игры от CPU.
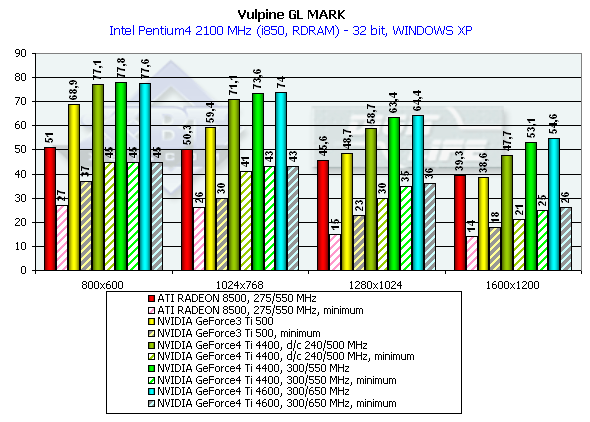
GLMark
режимы максимального качества
Данный тест мы уже рассматривали около года назад, поскольку он вышел почти одновременно с появлением GeForce3 на рынке. GLMark использует расширения OpenGL от NVIDIA, специфичные для GeForce3, поэтому на примере этого теста хорошо сравнивать GeForce3 и GeForce4, однако мы привели и значения по ATI RADEON 8500 с той оговоркой, что эта карта не может использовать некоторые функции бамп-маппинга, специфичные для GeForce3 (что, вероятно, повышает скорость RADEON 8500 из-за меньшей нагрузки), как не могут быть применены и некоторые расширения NVIDIA по ускорению работы GeForce3/4-карт (что, в свою очередь, не снижает скорость RADEON 8500). Карты тестировались только в 32-битном цвете.
Pentium 4 2100
Athlon XP 1800+
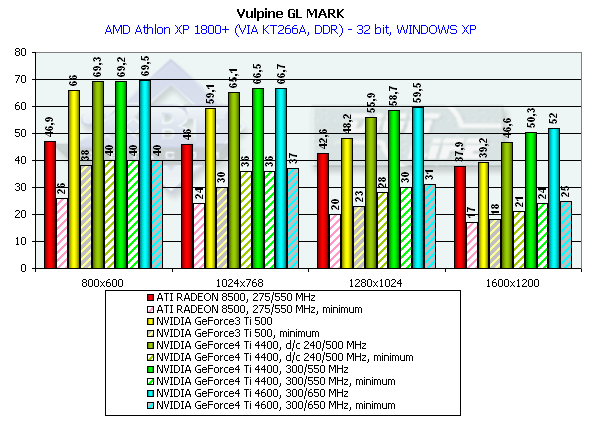
Этот сложнейший тест (особенно по числу полигонов в сцене и по наличию эффектов рельефного текстурирования) заставил "прогнуться" даже самые новейшие платы. По минимальным значениям видно, что только разрешение 1280х1024х32 дает GeForce4 хорошую играбельность (ну, если предположить, что на этом движке была бы создана игра с такими же сложными сценами). Посмотрим, какие же приросты мы получили относительно Ti 500: GeForce4 Ti 4400 — 37.5%, GeForce4 Ti 4600 — 41.5%. Очень даже неплохо!
Тестирование GeForce4 на частоте Ti 500 — 240/500 МГц еще раз продемонстрировало технологическое усовершенствование архитектуры нового GPU.
AquaMark
режимы качества по умолчанию
При установке качества по умолчанию используется набор текстур в 24 мегабайта, активизированы пиксельные шейдеры, карты тестировались только в 32-битном цвете.
Pentium 4 2100
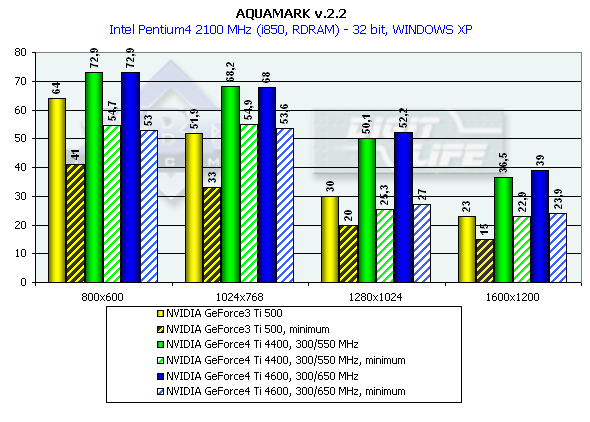
Athlon XP 1800+
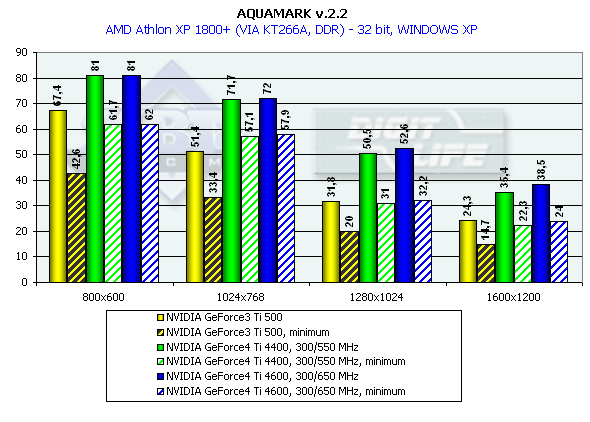
Игра AquaNox была анонсирована еще при выходе GeForce3, но вышла только в ноябре прошлого года. Еще почти год назад на нее движке был создан бенчмарк — AquaMark, который был чрезвычайно сложен даже для новейшего на ту пору GeForce3. Сложность сцен в AquaMark-е достигала подчас 130 тысяч полигонов. Поэтому нам было весьма интересно посмотреть, как справится с такой задачей новейший GeForce4. И с удовлетворением можно отметить, что справился блестяще. Прирост в 1600х1200х32 относительно Ti 500 составил у GeForce4 Ti 4400 - 58.7%, у GeForce4 Ti 4600 — 69.5% ! Любопытно, что данный тест предъявляет сильные требования именно к графическому процессору (сложная геометрия и шейдеры), а не к пропускной способности памяти. Разница между 4400 и 4600-ми моделями минимальна.
АНИЗОТРОПНАЯ ФИЛЬТРАЦИЯ
Уже на протяжении года мы уделяем этой функции самое пристальное внимание. И это неудивительно, поскольку она позволяет значительно улучшить качество восприятия трехмерных сцен. Кратко я напомню, что для устранения артефактов (т.н. песка) по мере удаления текстурированных объектов от наблюдателя применяется технология MIP-mapping-а, создающая для каждой текстуры набор ее копий разной детализации (т.н. MIP-уровней), выбираемых при построении изображения в зависимости от расстояния от масштаба с которым текстура в результате закраски проецируется на экран. Чем дальше от нас удаляется треугольник, тем менее детализованный и, следовательно, более размытый MIP-уровень текстуры будет использован. Это соответствует нашему зрению (дальние объекты мы видим уже не такими четкими, как близкие). Резкими границами между MIP-уровнями "занимается" трилинейная фильтрация, сглаживая эти переходы с помощью линейной интерполяции между двумя соседними уровнями. Таким образом, билинейная фильтрация занимается удалением резких границ между пикселами текстуры (дабы мы видели стены и пол покрытыми не квадратиками, а сглажеными и более похожими на естественную плавно меняющуюся окраску материалами), а трилинейная дополнительно размывает картину, еще раз интерполируя результаты двух билинейно фильтрованных MIP-уровней. В результате четко видны только самые близко расположенные объекты. При этом расположенные под достаточно острым углом к направлению взгляда стены черезмерно смазываются. Справляться с такими "неудобными" для обычной билинейной и трилинейной фильтрации объектами и призвана анизотропная фильтрация, сохраняющая четкую картинку для расположенных под углом плоскостей и одновременно не допускающая "песок" на текстурах при черезмерном удалении от объекта.
Мы знаем, что реализация этой функции у разных фирм-производителей видеопроцессоров — различная. Да и скоростные характеристики анизотропий, скажем, от ATI и от NVIDIA, сильно отличаются. Схоже только результирующее качество.
Так ли это? Постоянные читатели наших материалов знают, что анизотропия от NVIDIA (речь идет о GeForce3) отличается высоким качеством, но и чрезмерным аппетитом. Падение производительности может достигать до 50%! Анизотропия от ATI (речь идет о RADEON 8500) гораздо более дешевая и, как считалось до недавнего времени, имеет не меньшее качество.
Как обычно, качество анизотропии оценивается на примерах стен, полов, площадей и т.п. Читатели видят четкие линии и радуются качеству этой функции. Но вот бдительные читатели заметили, что не все гладко в "канадском государстве". На некоторых поверхностях, находящихся под разными углами, отличными от 90 градусов, RADEON 8500 просто не воспроизводит анизотропию. Посмотрите на скриншоты, полученные в игре Serious Sam при повороте наблюдателя относительно стены:
ATI RADEON 8500
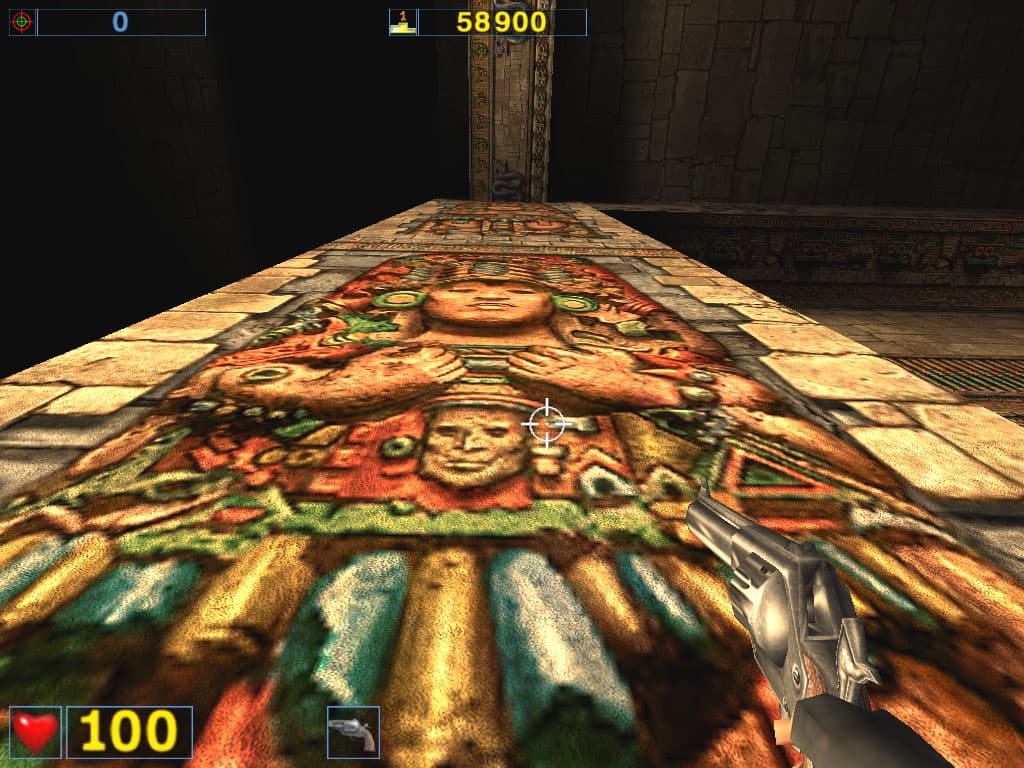
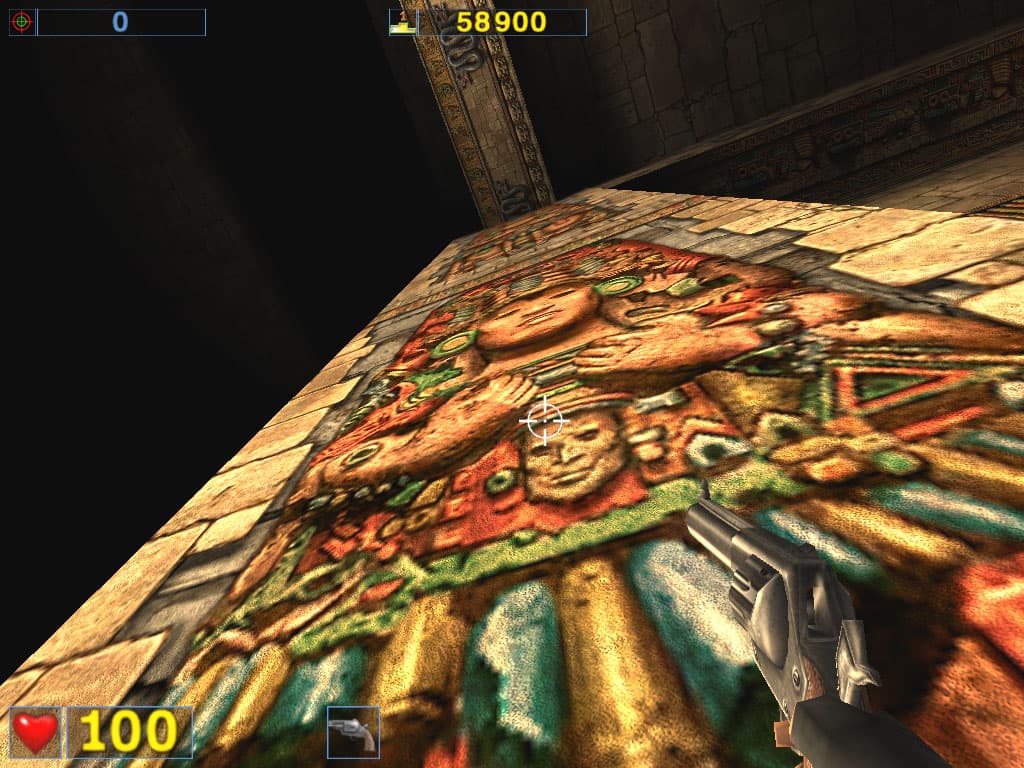
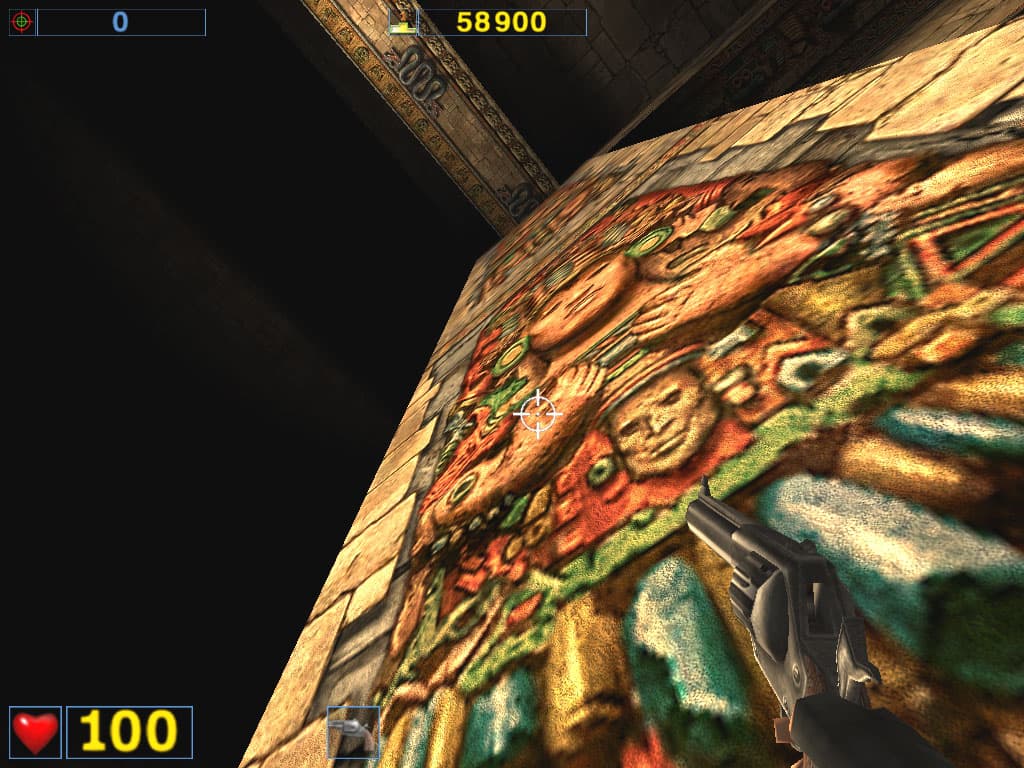
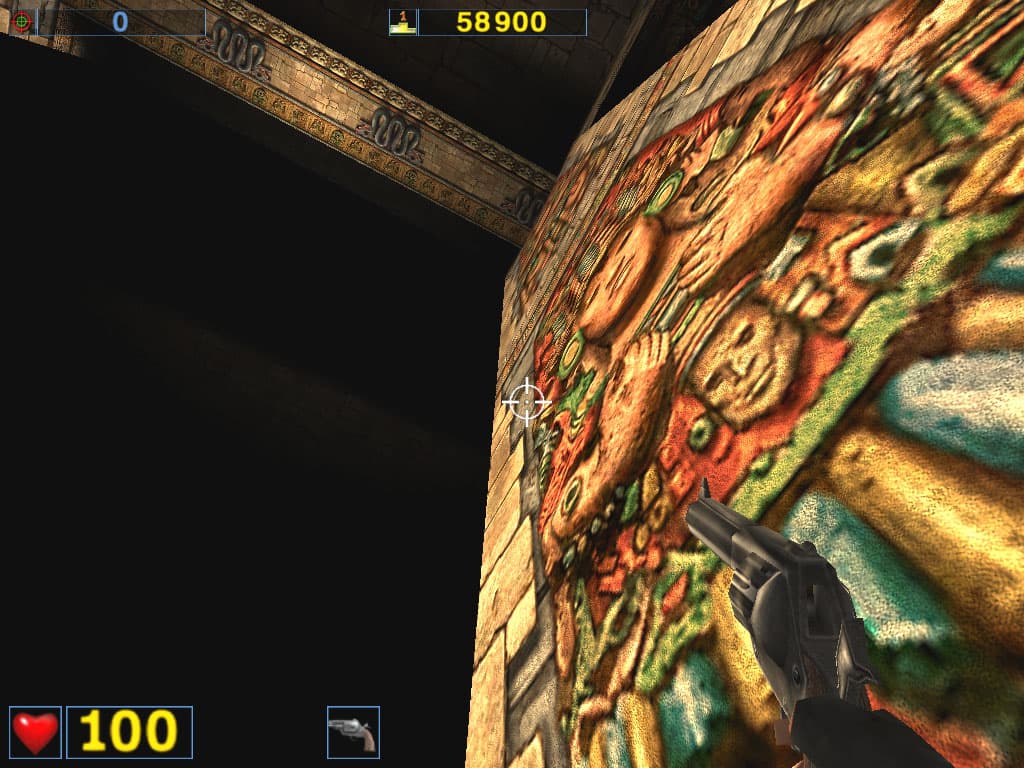
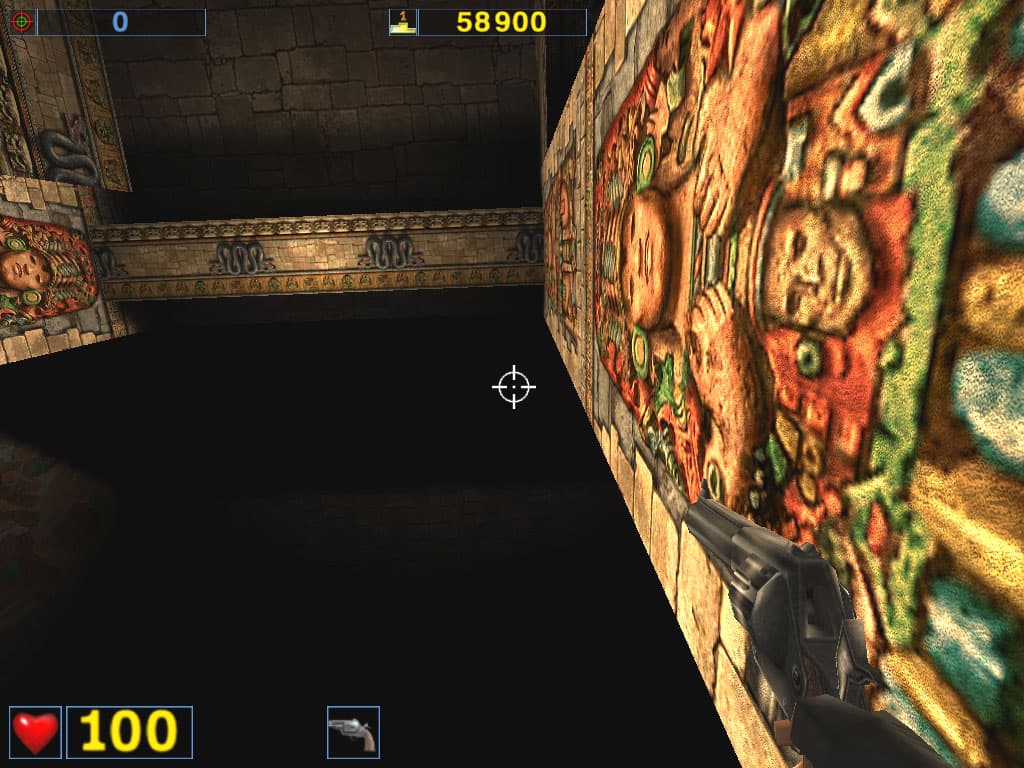
NVIDIA GeForce4





Для удобства восприятия я сделал анимированные GIF-файлы:
| ATI RADEON 8500 | NVIDIA GeForce4 |
|---|---|
 |  |
Прекрасно видно, что на ряде углов зрения четкости у RADEON 8500 как ни бывало. Не это ли и является причиной вычислительной дешевизны анизотропии от ATI? А вот у NVIDIA GeForce3 и GeForce4 все "честно", если можно, конечно, считать способы реализации этой функции честными и нечестными. Плохо, что производители не предоставляют пользователям сознательного выбора: использовать честную анизотропию с большими потерями или "аппроксимацию", но более дешевую. Пока такой выбор может быть осуществлен только косвенно — выбором карты.
И все же нельзя напрямую оперировать понятием "честности" в отношении анизотропии. Если трилинейку мы можем достаточно строго оценивать, поскольку ее алгоритм однозначен и хорошо описан, то технология осуществления анизотропной фильтрации не разглашается производителем, а базовых подходов для выполнения такой фильтрации известно как минимум пол десятка. И это не считая нюансов реализации! Давайте подробно остановимся на реализациях этой функции у двух компаний.
Различия подходов NVIDIA и ATI к практической реализации анизотропной фильтрации
Если билинейная и трилинейная фильтрация достаточно четко опеределены математически (что, впрочем, не помешало NVIDIA в свое время называть в некоторых документах трилинейной фильтрацией некий метод аппроксимации — дизеринг значений из разных MIP уровней), то термин "анизотропная фильтрация" не подразумевает каких-то конкретных алгоритмов ее реализации. Подходы NVIDIA и ATI в этом вопросе существенно разнятся. Давайте (схематически) познакомимся с ними:
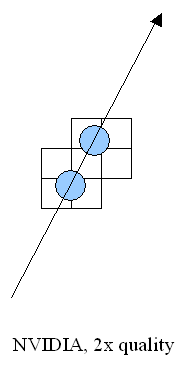
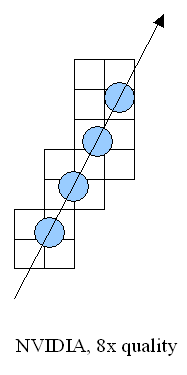
NVIDIA поступает довольно прямолинейно. На схеме показано, как происходит в пространстве текстуры выборка билинейных семплов в процессе анизотропной фильтрации. В зависимости от установок качества фильтрации и угла наклона поверхности относительно плоскости экрана, выполняется от одного до четырех раз стандартная би- (или три-) линейная фильтрация для точек, лежащих на прямой, проведенной по делящей проектируемый из экрана в поверхность текстуры пиксель вдоль его длинной стороны (на схеме изображена стрелкой). Полученные таким образом значения (синие кружки) усредняются — это и будет результатом фильтрации. Каждое значение основывается на четырех ближайших дискретных значениях текстуры (прямоугольники) и может иметь собственные независимые координаты. Такой подход годится для произвольно ориентированных текстур, но требует изрядной производительности — для заметной части непараллельных экрану треугольников в несколько раз возрастает число выбираемых текстурных семплов, и, соответственно, время закраски.
Подход ATI более ограничен, но и более производителен:
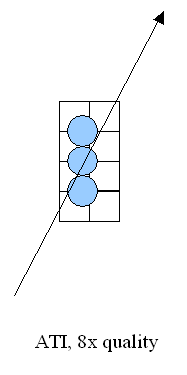
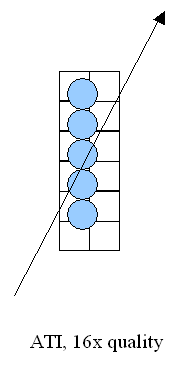
Как мы видим, значения выбираются цепочкой, причем она может быть ориентирована в плоскости текстуры строго горизонтально или вертикально. Т.е. для близких к ортам значений проекционного вектора (стрелка на схеме) качество фильтрации будет высоким, но по мере его поворота эффект будет сходить на нет, вплоть до полной потери смысла в использовании такого метода. В реальных приложениях это выразится следующим образом — на стенах или потолках фильтрация будет работать на все сто, в то время как на наклоненных под непрямыми углами поверхностях ее результат будет все менее и менее заметен по мере приближения к критическому углу в 45 градусов (что мы и наблюдали выше). Но, с другой стороны, подобный подход гораздо более выгоден с вычислительной точки зрения. Во-первых, мы выбираем организованные цепочки размером от 2хN точек текстуры (на схеме квадратики), которые можно эффективно выбрать за N/2 тактов с помощью стандартных, рассчитанных на билинейную фильтрацию текстурных блоков. Затем, мы фильтруем значения (на схеме кружки), используя каждый раз одни и те же смещения относительно дискретных точек исходной текстуры. Подобная операция может быть выполнена за один такт специальной схемой из десяти умножителей, встроенной в текстурный блок, благо само значение параметров интерполяции вычисляется один раз и остается неизменным для всех 1..5 вычисляемых точек. Кроме того, мы можем существенно ускорить этот и так достаточно производительный алгоритм, заранее вычислив специально сжатые по осям варианты текстуры (т.н. RIP mapping).
Суммируя вышесказанное, отметим, что подход NVIDIA требует большее время на вычисление результата, но и является более "честным", одинаково хорошо справляясь с объектами, расположенными под любыми углами наклона, а не только строго горизонтально или вертикально по отношению к наблюдателю. В методе ATI заложено свое рациональное зерно — большинство современных игр изобилуют в основном горизонтальными и вертикальными поверхностями.
Вернемся к GeForce4 и его анизотропии. По сути, мы имеем тот же способ, какой увидели у GeForce3, то-есть три уровня, за которыми может скрываться максимально возможное для каждого уровня число выборки текстурных сэмплов для реалиазации анизотропной фильтрации (Level2 — 8, Level4 — 16, Level8 — 32 сэмпла). В наших обзорах по GeForce3 вы сможете подробно узнать, чем отличаются эти уровни в плане качества, да и падения по скорости имеет смысл изучить :-).
Давайте посмотрим, что дает потенциальным пользователям GeForce4 анизотропия в плане производительности:
Quake3
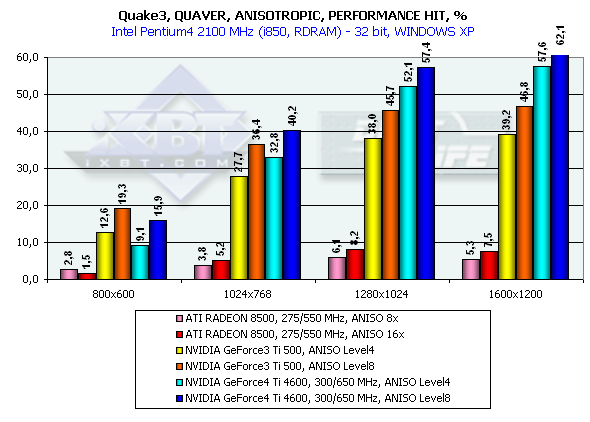
Return to Castle Wolfenstein
3DMark2001, Game1 Low details
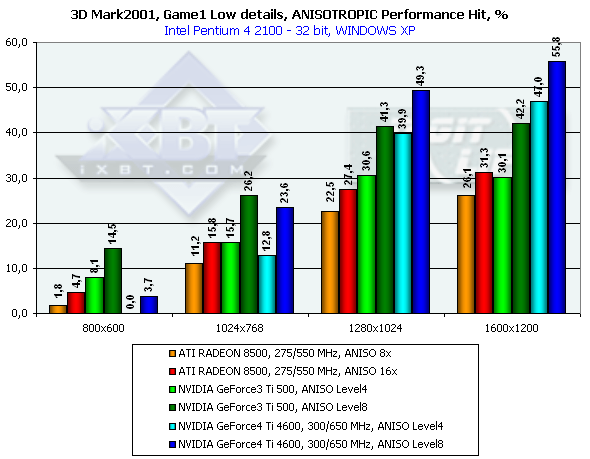
3DMark2001, Game2 Low details
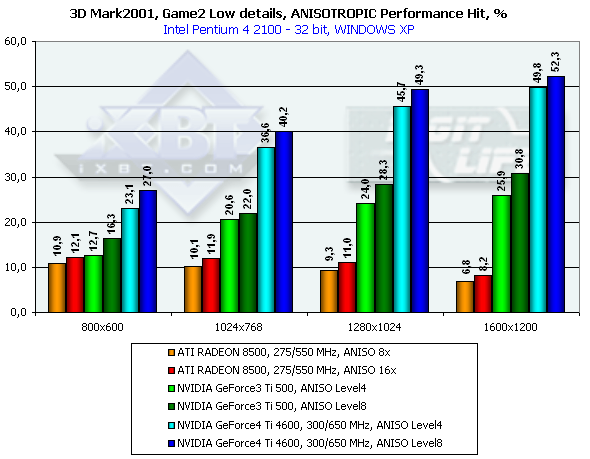
3DMark2001, Game3 Low details
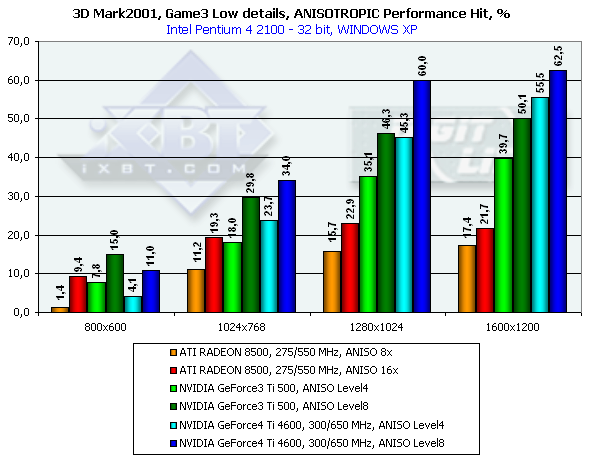
3DMark2001, Game4
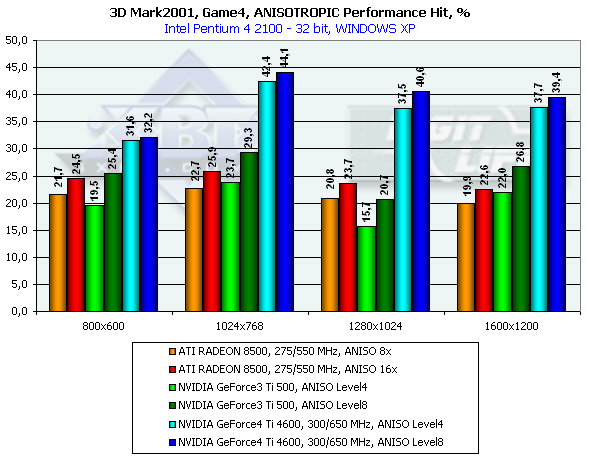
Думаю, что такого большого количества тестов достаточно для того, чтобы получить печальное представление о том, как такая функция, как анизотропия, может "убить" даже сверхмощный ускоритель. Важно отметить, что пока по неясным причинам мы можем наблюдать гораздо более сильное падение производительности у GeForce4, чем было у GeForce3. Возможно, что виноваты еще не доведенные до ума драйверы, возможны и иные причины. Но пока факт остается фактом: Level8 просто уничтожает все преимущества GeForce4 в плане скорости перед GeForce3 Ti 500. Возникает вопрос — а можно ли хотя бы при помощи Level4 получить почти такое же качество, как у RADEON 8500? Ответ — да! Потери относительно Level8 будут, но получить достаточно высокий уровень качества возможно при помощи изменения LOD BIAS в отрицательную сторону. К сожалению, до последнего времени существовала возможность менять этот параметр только в Direct3D, и то только через твикеры, например RivaTuner. В 27.* версиях драйверов появилась такая же возможность и в OpenGL, но, к сожалению, пока только при помощи правки в Registry (автор RivaTuner в ближайшее время выпустит новую версию этой программы, обладающую уже возможностями изменения LOD BIAS в OpenGL). Давайте посмотрим, что нам даст смещение LOD BIAS до значения -1 на примере игры Serious Sam: The Second Encounter.
Анизотропная фильтрация Level 8


Анизотропная фильтрация Level 4, LOD BIAS = 0


Анизотропная фильтрация Level 4, LOD BIAS = -1


Анизотропная фильтрация Level 2, LOD BIAS = -1


Как мы видим, эффект достигнут! Побочными явлениями можно назвать появление муара, того самого шума текстур ("песка"), который обычно и вызывается понижением LOD BIAS (т.е. смещением MIP-уровней), но примерно то же самое мы можем видеть и у RADEON 8500 при активной анизотропии (да, разумеется, когда мы говорим про эту функцию у RADEON 8500, то имеется ввиду максимально возможный уровень анизотропной фильтрации). Здесь падение велико, но уже не столь катастрофично. А вот при степени анизотропии Level2 понижение LOD BIAS уже не помогает, хотя качество Level4 при LOD BIAS = 0 и достигается.
АНТИ-АЛИАСИНГ (АА)
Эта функция борьбы с "лестницами по краям объектов", называемыми артефактами алиасинга, также имеет давнюю и сложную историю. Дело в том, что у АА аппетиты еще выше, чем у анизотропии (если имеем дело с существенными уровнями АА, дающими заметное визуальное улучшение картинки).
Как известно еще из материалов по GeForce3, год назад NVIDIA дала жизнь новому методу АА — Quincunx, который имеет свои плюсы и минусы. К плюсам относится быстрота этого АА, несмотря на приличный уровень сглаживания; к минусам относится "замыливание" текстур во многих случаях, что приводит к размытию картинки в целом. Поэтому рост производительности GeForce4 относительно предыдущего продукта может сделать более востребованным следующий уровень АА (4х), отличающийся великолепным качеством.
Давайте посмотрим на качество двух наиболее интересных видов АА у GeForce3 Ti 500 и GeForce4, и сравним их.
| GeForce3 Ti 500 | GeForce4 |
|---|---|
| 3DMark2001, Game 1 | |
| No AA | |
 | |
 | |
 | |
| AA Quincunx | |
 |  |
 |  |
 |  |
| AA 4x | |
 |  |
 |  |
 |  |
| AA 4x | AA 4xS |
|  |
|  |
|  |
| 3DMark2001, Game 2 | |
| No AA | |
 | |
 | |
 | |
| AA Quincunx | |
 |  |
 |  |
 |  |
| AA 4x | |
 |  |
 |  |
 |  |
| AA 4x | AA 4xS |
|  |
|  |
|  |
| 3DMark2001, Game 3 | |
| No AA | |
 | |
 | |
| AA Quincunx | |
 |  |
 |  |
| AA 4x | |
 |  |
 |  |
| AA 4x | AA 4xS |
|  |
|  |
Прекрасно видно, что по АА 4х и AA Quincunx каких либо заметных отличий между GeForce3 и GeForce4 (несмотря на заявленное NVIDIA для GeForce 4 смещение позиций выбираемых семлов для повышения качества AA Quincunx) нет. А что же такое АА 4xS?
Новый гибридный режим АА: 4xS
Давайте познакомимся с новым гибридным (MS и SS одновременно) режимом полноэкранного сглаживания, доступным для карт на базе NV25. Фактически, этот режим можно назвать "Мичуринским гибридом" — в каждом исходном 2х2 блоке сглаживания усредняется два расположенных друг над другом "подблока" (2х1), полученных стандартным для 2х MSAA образом (для сравнения справа приведен обычный 4х MSAA блок):
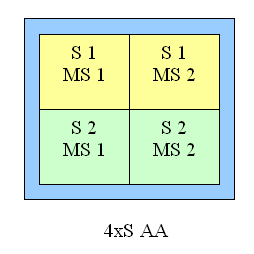
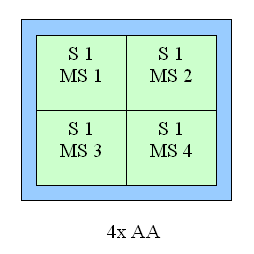
Здесь, S1 — первый 2х1 подблок, S2 соответственно второй. Внутри подблока семплы рассчитываются методом мултисамплинга, т.е. из одного выбранного значения текстуры, однако, в отличие от обычного 4x MSAA, значения текстуры для верхнего и нижнего подблоков могут отличаться. Т.е., с точки зрения ускорителя, мы просто рассчитываем удвоенное по вертикали изображение в стандартном 2x MSAA (блоки 2х1) режиме. Данный режим может быть установлен и на NV20, но только через недокументированные значения параметров драйвера в реестре. С картами же на базе NV25 эта установка становится доступной из панели настроек драйверов. Отметим, что на NV25 этот режим показывает себя очень хорошо, несмотря на вдвое большее число интерполируемых текстурных значений, производительность отличается от 4х на считанные проценты, а визуальное качество, несомненно, выше. Конечно, подобный метод не может существенно изменить ситуацию на границах полигонов — там SSAA и MSAA выглядят практически одинаково, но вот сами текстуры должны стать менее размытыми. Более того, для горизонтально расположенных поверхностей (ландшафты, пол, потолок) этот метод подспудно выполняет роль анизотропной фильтрации (с качеством 2х).
А теперь посмотрим, сколько мы теряем в скорости, включив тот или иной вид АА.
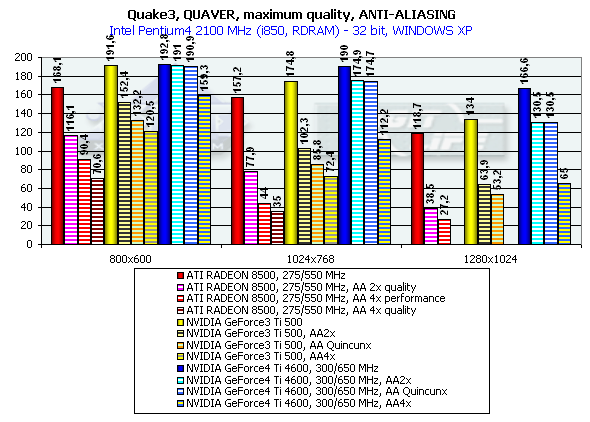
Quake3
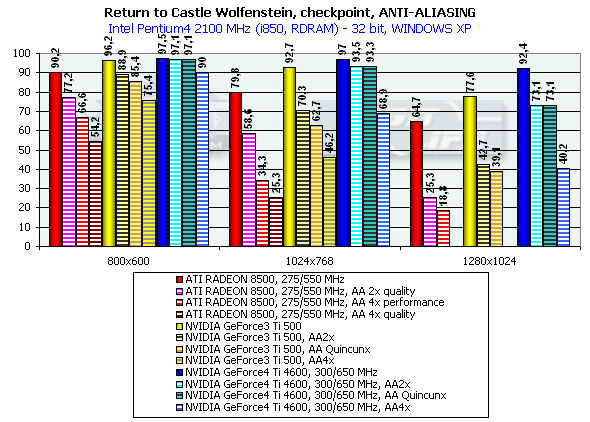
Return to Castle Wolfenstein
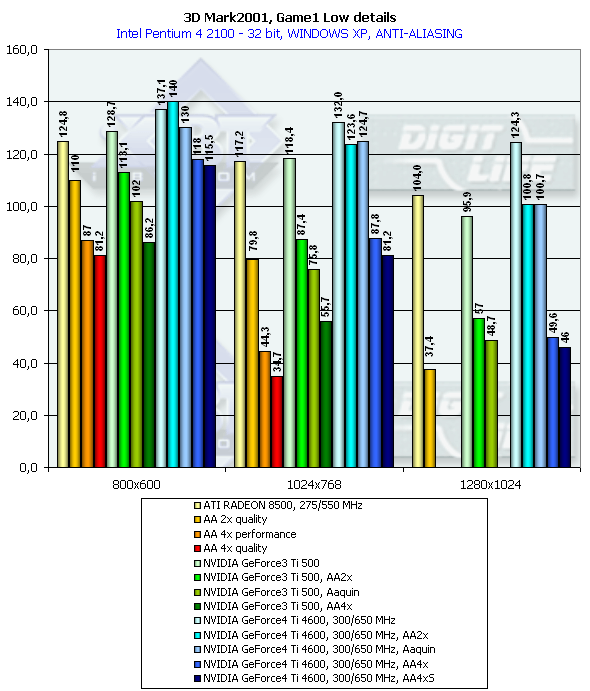
3DMark2001, Game1 Low details
3DMark2001, Game2 Low details
3DMark2001, Game3 Low details
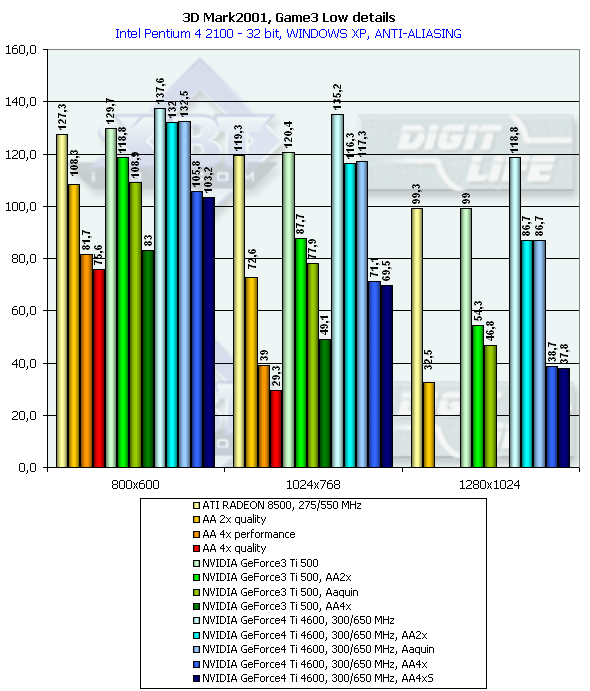
Интересно отметить, что производительность АА 2x и AA Quincunx почти сравнялась (благодаря огромной пропускной способности памяти и оптимизации работы GeForce4 Ti 4600 в режиме мултисэмплинга). В остальных режимах также дает себя знать увеличенная производительность GeForce4 — многие ранее недоступные из-за низкой играбельности режимы стали более привлекательными.
Режим 4xS (напомню, что он работает только в Direct3D) достаточно успешен — падение скорости на уровне обычного 4x, качество сглаживания границ также. А вот четкость текстур, как и ожидалось, возросла — на лицо эффект схожий с применением анизотропной фильтрации.
Совместную работу анизотропной фильтрации и АА мы рассмотрим в одном из последующих обзоров по серийным видеокартам на базе GeForce4 Ti.
Выводы
- Налицо добротная "работа над ошибками" — все, что в NV20 заметно проигрывало по сравнению с R200, теперь оптимизированно и доведено до равного или превышающего уровня.
- Несмотря на ту же технологию и лишь небольшое увеличение числа транзисторов, чип гораздо более эффективен, особенно в интенсивных задачах на равной предыдущему частоте, и имеет существенно возросший частотный потолок.
- АА придвинулся ближе к бесплатному идеалу, особенно в случае Quincunx.
- Прекрасно выполнена поддержка работы с двумя мониторами, как с аппаратной, так и с програмной стороны.
- Чип нельзя рассматривать как новое (с точки зрения архитектуры) поколение ускорителей — это доведенный и оптимизированный вариант предыдущего поколения.
- Сходная технология и сложность обещают, что цена карт на базе этого чипа будет не сильно превышать цену Ti500. В таком случае его, несомненно, можно назвать удачным — гораздо больше производительности и возможностей за практически те же деньги.
- Применение BGA памяти является удачным и оправданным ходом.
- Некоторые возможности (анизотропия, EMBM) слегка сдали по сравнению с NV20, что, даже учитывая заметно возросшую тактовую частоту, следует признать недостатком. Нет в этой жизни совершенства :-).
- Подсознательно, многие поклонники и владельцы NVIDIA ожидали от этого чипа большего, ведь с момента появления GeForce3 прошел практически целый год. Но, несмотря на желание как можно скорее увидеть в продаже новые революционные архитектуры и новшества, мы считаем подобную стратегию постепенного роста и оптимизации более оправданной в условиях значительного спада активности на IT рынке. Вспомним, что большинство новых возможностей DirectX 8, представленных вместе с GeForce3, еще только начинают пробивать себе путь в реальные приложения.
Вероятно, Ti 4400 будет позиционироваться как прямой конкурент RADEON 8500 128 МБ, в том числе и по ценовому диапазону. Этот факт не может не радовать. Ti 4600 займет позицию повыше, и прямых конкурентов иметь не будет — следовательно, и цена на него будет установлена заметно более серьезная.
Подводя общий итог, отметим, что новый чип NVIDIA (NV25) способен уверенно закрепиться в верхнем секторе игрового рынка, успешно подготовленным к его приходу GeForce3, и, возможно, станет в скором времени основным проповедником передовых технологий DX8.


