Данный материал является продолжением статьи «Файловая система NTFS». В этом обзоре будут подробно рассмотрены вопросы, рассмотрение которых в прошлой статье было поверхностным или отсутствовало вообще. Хотелось бы сразу сказать, что дисковая система NT настолько сложна, что говорить о ней можно еще достаточно долго — и эта статья не опишет всего, что можно было бы рассказать. Так что это лишь попытка координировано и подробно ответить на все вопросы, которые вызвала предыдущая публикация.
Часть 4. Журналирование NTFS
Описание того простого факта, что NTFS является журналируемой системой, повергло многочисленных поклонников других файловых и операционных систем в искреннее возмущение. В многочисленных письмах, адресованных мне, NTFS называли системой с квази-журналированием или даже без журналирования вообще, ставя в противовес многочисленные файловые системы Unix. Мне пришло также много писем, указывающих на фатальные сбои NTFS, восстановится от которых не удалось — данные были потеряны. В данной части я попытаюсь, в меру своих сил и понимания, объяснить философию журналирования и средств защиты от сбоев NTFS, а также пояснить причины появления фатальных сбоев. Я постараюсь оправдать подход корпорации Microsoft, которая сделала всё именно так, как сделала — по крайней мере, я изложу причины реализованных технологических решений и те компромиссы, на которые пришлось пойти коллективу разработчиков NTFS.
Журналируемые операции
Прежде всего, хотелось бы рассказать о том, какие именно операции журналируются. Совершенно очевидно, что полный undo-файл, способный откатить абсолютно все операции, абсолютно невозможен как с точки зрения быстродействия, так и с точки зрения здравого смысла. Да, такое журналирование дало бы возможность восстановить большее число данных — например, при осуществлении перезаписи трех мегабайт в середине файла мы могли бы сначала сохранить новые данные в логе, затем переписать туда же предыдущие три мегабайта файла, и уж только затем осуществлять операции с реальными данными. Такой подход гарантировал бы полную определенность с судьбой информации — мы всегда смогли бы понять, какая часть данных уже записалась на диск, а какая находится в исходном, не обновленном состоянии. Он имеет всего один скромный недостаток — небольшая накладочка по быстродействию: для записи на диск трех мегабайт мы вынуждены будем осуществить разнообразные дисковые операции на объем в три раза больший — девять мегабайт. Да, полное журналирование также применяется — но в основном при работе с базами данных. Если вы желаете обеспечить полное журналирование каких-либо данных, вы можете поставить MS SQL или даже Oracle, который вообще не будет пользоваться средствами какой либо файловой системы и обеспечит сохранность ваших данных в любых разумных условиях. Сторонникам же полного журналирования файловой системы я могу ответить одно: решение сократить быстродействие операций записи в три раза, на мой взгляд, является слишком смелым для обязательного применения — и на домашних компьютерах, и на серверах.
Подход разработчиков NTFS был принципиально иным. Главный девиз был, видимо, не «надежность любой ценой», а «неизменность быстродействия». Журналирование просто не должно было помешать работе файловой системы. Первый логичный шаг — отменить полное журналирование как абсолютно неприемлемое с точки зрения быстродействия. В NTFS применяется журналирование логических структур, а не данных пользователя — отсюда и идет фраза, что сохранность данных не гарантируется, но, тем не менее, корректное состояние самой системы будет поддерживаться. То, что NTFS не журналирует данные файлов, приводит на практике к одному варианту потери данных — в том же гипотетическом случае записи трех мегабайт, в случае сбоя в процессе записи никогда уже не удастся установить, какая часть данных записалась, а какая осталась неизменна. Операции, которые, тем не менее, журналируются системой — это операции со структурами самой системы, то есть с файлами и каталогами: добавление файлов, переименование, перенос, создание и удаление (освобождение свободного места). Журналируются также и операции дефрагментации — то есть перемещения фрагментов файлов. Одним словом, все логические операции журналированы.
Отложенная запись и контрольные точки журналирования
Известно, что любая современная система для ускорения файловых операций вынуждена использовать кэширование, в том числе — кэширование операций записи. Так называемая отложенная запись — принцип кэширования, при котором данные, предназначенные для записи на диск, некоторое время сохраняются в кэше и лишь в свободное от других занятий время сохраняются физически. Отложенная запись существенно повышает эффективность дисковых операций, так как такое кэширование группирует множество операций в одну — это особенно эффективно, если запись производится в компактные участки диска. Еще один плюс отложенной записи — не мешать более нужным операциям чтения, и осуществлять запись только тогда, когда система свободна и ей не требуется доступ к диску для других нужд. Как согласовать отложенную запись с журналированием? Это довольно сложный вопрос, так как откладывание записи делает возможным потерю тех данных, которые находились в очереди на физическую запись и не успели записаться на диск до сбоя. Самое неприятное здесь даже не потеря данных, а то, что происходит рассогласование времени записи: какие-то служебные области могут быть обновлены, а какие-то смежные по смыслу — еще нет, так как их обновление могло отложится еще на пару секунд и не состоятся из-за сбоя.
NTFS справляется с этими проблемами с помощью смысловой интеграции операций отложенной записи и ведения журнала. При попытке начать журналируемую операцию в лог тут же записывается намерение — например, стереть файл. Это случается без задержек — на этом этапе отложенная запись не работает: это плата за присутствие журналирования, которой нельзя избежать. Но вот все остальные операции уже идут в задержанном режиме — то есть они могут состояться частично (могут еще в придачу и не в том порядке) или не состоятся вообще. Единственная задержанная операция, работа которой несколько отличается от простой записи — запись в лог об удачном завершении предыдущих транзакций, так называемая контрольная точка. Через определенные промежутки времени — обычно через каждые несколько секунд — система в обязательном порядке сбрасывает абсолютно все задержанные операции на диск. После произведения этой операции в журнал записывается простейшая запись — контрольная точка — которая говорит о том, что все предыдущие операции выполнены корректно на всех уровнях — как на логическом, так и на физическом.
Такой режим работы — с помощью записей и контрольных точек — с одной стороны, по прежнему гарантирует полностью корректную работу журналирования, а с другой стороны практически совершенно не приводит к замедлению работы: простановка контрольных точек производится, считай, мгновенно, а запись в журнал о начале операции соответствует по трудозатратам записи самих данных без отложенного кэширования. Реальная же запись, осуществляемая позже, в подавляющем числе случаев не мешает никаким операциям и не идет в ущерб производительности системы.
Проблемы отложенного журналирования: концепция дублирования информации
Вся вышеописанная теория достаточно хороша, но способна, тем не менее, вызвать очень неприятные последствия, если не учесть еще нескольких вещей, о которых и пойдет речь.
Рассмотрим такой случай: мы стираем файл. Журнал получил запись — «файл N стирается». Затем запаздывающему кэшу стало угодно осуществить сначала физическую пометку о том, что место, занимаемое файлом, освободилось, а уж только затем удалить файл из физических структур MFT и каталога. Допустим, диск находится в активной работе, и на освободившееся место тут же записывается другой файл. В этот момент происходит сбой. Система, загружаясь, исследует журнал и видит незавершенную операцию «файл N стирается» — вернее, как я уже описал выше, не незавершенную, а просто операцию, контрольная точка после которой отсутствует, что автоматически говорит о её незавершенности. Следующая фаза была бы «откат операции» — то есть восстановление файла. Одна незадача — место, физически занимаемое файлом, содержит уже другие данные.
Для недопущения таких ситуаций система, желающая ограничиться логическим журналированием, вынуждена применять принцип «временно занятого места». Место, освобожденное каким-либо объектом или записью о нем, не объявляется свободным до тех пор, пока физически не завершились все операции с логическими структурами. Данный механизм в NTFS, по видимому, не синхронизирован даже с проставлением контрольных точек, так как типичное время освобождения временно занятого места — около 30 секунд, точки же идут чаще.
Данный механизм применяется не только при стирании файла, но и при самых разных операциях: принцип журналирования — объект, убранный или перемещенный на новое место, должен иметь возможность корректно откатить своё «отбытие» — то есть данные, на которые ссылаются логические структуры удаляемого или перемещаемого объекта, необходимо еще на некоторое время зарезервировать как занятое место (диска/каталога). Это еще один шаг NTFS к полному журналированию, где специфическим журналом файловой информации служат сами данные освобождаемых областей, не уничтожаемые физически.
Допущения, обеспечивающие надежность
Ну хорошо, скажете вы, всё так замечательно — но почему же тогда разделы NTFS всё же летят?.. Сейчас я постараюсь объяснить принципы, которые приводит к тому, что вышеописанная модель сможет обеспечить полную восстанавливаемость логических структур.
- Жесткий диск, в штатном режиме, должен записать именно то и именно туда, что и куда ему сказано было записать операционной системой. Данный принцип нарушается в случае, если система имеет ненадежный шлейф, процессор, память или контроллер — и это самая распространенная причина сбоев NTFS. Вам поможет: неразогнанный процессор, дорогая (качественная) память, хорошая материнская плата и протокол UDMA, обеспечивающий контроль и восстановление ошибок на участке контроллер-диск.
- Жесткий диск, в случае аварии, отключения питания или получения от контроллера сигнала «сброс» (в случае внезапной перезагрузки материнской платы) обязан корректно завершить запись данных текущего физического сектора, если таковая производилась на момент аварии. Промежуточное состояние сектора не допускается. Вам помогут современные винчестеры, которые могут осуществить данную операцию даже в случае полного пропадания питания — у них хватит буферизированной в конденсаторах энергии, и их логика рассчитана на корректное поведение в случае отказа питания при записи.
- Диск обязан мгновенно осуществить запись данных, отправленных с флагом «не кэшировать». Дело в том, что многие современные диски или контроллеры обеспечивают задержанную запись. Метафайлы NTFS обновляются в режиме «писать сразу», и контроллер/диск обязан выполнять это требование.
- Жесткий диск обязан обеспечить чтение именно тех данных, которые были записаны. В случае невозможности прочесть данные выдается сигнал «ошибка». Диск не имеет права возвращать ошибочные данные (возможно, лишь частично некорректные) без сигнала об ошибке. Все современные жесткие диски имеют контрольные суммы секторов и жестко следуют этой логике поведения.
Четкое выполнение этих требований полностью гарантирует надежную работу NTFS. Структура файловой системы не будет содержать существенных ошибок даже после сбоя. Некоторые несущественные ошибки всё же появляются из-за того, что логика журналирования часто пытается завершить недоделанные операции — например, то же удаление файла — тогда как полную надежность обеспечивал бы только безусловный откат всего, что находится после последней контрольной точки. Малые несоответствия, рождающиеся из этих попыток, относятся к избыточной информации системы безопасности, не представляют никакой реальной опасности для данных — они действительно незначительны. Суть этих несоответствий чаще всего заключается в том, что на диске остаются «лишние» данные о тех режимах доступов, которые уже не понадобятся системе. Их прочистка — дело сугубо повышения производительности, как, например, дефрагментация, поэтому их наличие не является на самом деле ошибкой. В случае же обнаружения серьезных, реальных, проблем драйвер сам установит флажок тома «грязный», что проинструктирует систему проверить том при следующем его монтировании.
Я с большим сожалением должен сказать, что подавляющее большинство фатальных ошибок NTFS происходит по вине аппаратуры, не выполняющей эти элементарные требования. Да, я понимаю, абсолютной надежности не бывает. Но Microsoft пошел по пути разделения труда — за надежность вашей аппаратуры корпорация ответственности не несет. Мой компьютер на 70% не попадает в список совместимого с Windows 2000 оборудования, и то же самое можно сказать про почти любую реальную машину, функционирующую на просторах бывшего СССР. Особенно это относится к любителям разгонять компьютеры. Запомните раз и навсегда: вы с огромной степенью вероятности угробите NTFS в первый же год работы, если ваш процессор — 333, разогнанный на 415. И даже не раз... Мне очень жаль, но это действительно так. От любых сбоев корректного компьютера NTFS защитит, но вот от записи случайных данных в бут-сектор (копия которого, кстати, хранится в самом конце раздела) и в MFT система просто не страхуется. Извините.
Часть 5. Программный RAID
Журналирование NTFS, как уже указывалось ранее, ни в коей мере не гарантирует от сбоев с потерей пользовательской информации. Между тем, NT предлагает несколько вариантов создания систем, где, в разумных условиях, гарантируется абсолютно всё. Можно также использовать большее число дисков для обеспечения не повышенной надежности, а, наоборот, повышенной скорости — или того и другого одновременно. О таких конфигурациях и пойдет речь в этой части статьи.
RAID (Redundant Array of Inexpensive Disks) — избыточный массив недорогих дисков. Технология, заключающаяся в одновременном использовании нескольких дисковых устройств для обеспечения характеристик надежности или скорости, отсутствующих у накопителей в отдельности.
Windows NT поддерживает на программном уровне три уровня RAID (так называются стратегии работы дисковых массивов), краткие характеристики которых сведены в следующую таблицу.
| Быстродействие, по сравнению с обычными дисками | Надежность | Общее дисковое пространство | |
| RAID 0 Параллельные диски Существенное повышение производительности за счет дублирования дисков. | Теоретически, в условиях некоторых (например, линейных) операций скорость чтения/записи, повышается во столько раз, сколько дисков задействовано в системе. Реально увеличение быстродействия меньше — процентов 50%-90% от этого числа, что всё равно очень существенно. | Понижается — фатальный сбой одного из дисков вызовет потерю данных. | Равно сумме объемов составляющих массив дисков |
| RAID 1 Зеркальные диски Повышение надежности за счет дублирования информации. | Скорость чтения теоретически повышается в число раз, соответствующее числу дисков. Реализованный в NT алгоритм не оптимален и приводит к гораздо более скромному увеличению быстродействия. Скорость записи снижается, особенно в случае не до конца многозадачных дисковых контроллеров. | Потеря данных возможна лишь в случае отказа сразу всех дисков или повреждения одного и того же участка информации на всех дисках. | Остается неизменным (увеличение доступного дискового пространства за счет добавочных дисков не происходит). |
| RAID 5 Параллельные диски с четностью Комбинация RAID 1 и RAID 0 — более эффективное использование дополнительных дисков. | Скорость чтения повышается аналогичным RAID 0 образом, но число дисков, влияющих на быстродействие, следует уменьшить на один. Т.е. три диска RAID 5 обладают примерно такой же скоростью чтения, как и два диска RAID 0. Скорость записи больше, чем у каждого диска в отдельности, но в целом невысока. | Потеря данных возможна при выходе из строя двух дисков набора. Выход из строя одного из дисков существенно снижает скорость работы всего массива и является, по сути, аварийной ситуацией, хоть и без потери данных. | Увеличивается. Потеря от суммарного дискового объема составляет объем одного диска. Например, пять дисков по 10 Гб дают RAID 5 объемом 40 Гб. |
Остановимся подробнее на каждом из типов RAID-а.
RAID 0 (параллельные диски)
Данная стратегия направлена исключительно на повышение производительности. Несколько дисков хранят части дисковой структуры, которые собираются в один том лишь при наличии всех дисков массива.
Простейшая реализация RAID 0 из двух, например, дисков — указание на то, что каждый первый сектор тома (или любой другой объем информации) расположен на физическом диске A, а каждый второй — на диске B. Такая жесткая стратегия дает возможность избежать каких-либо дополнительных структур для хранения информации о том, где находятся какие данные. Скорость чтения, как и записи равны и зависят от числа дисков:
- Быстродействие операции по работе со случайно расположенными данными подчиняются следующей схеме: всё зависит от вероятности того, что диск, на который мы хотим записать очередную порцию информации, свободен и готов мгновенно выполнить наш запрос. Например, RAID 0 из двух дисков: при осуществлении операции одним из дисков и поступлении дополнительной команды на работу с дисковой системой вероятность того, что для выполнения команды нам придется тревожить свободный в данный момент диск составляет 50% — это соответствует общему увеличению производительности случайных операций в полтора раза. Если же используется, к примеру, массив из десяти дисков, то вероятность какой-либо операции попасть на уже занятый накопитель составляет всего 10% — то есть производительность повышается в девять раз. Любителям строгой теории вероятности хочу заметить, что при таких подсчетах не учитываются некоторые факторы реальной работы систем, но цифры, тем не менее, имеют именно такой порядок.
- Последовательные операции — чтение или запись последовательных участков — проходят практически всегда в n раз быстрее, чем на отдельном физическом диске, где n — число дисков в наборе. Это происходит потому, что вероятность в следующей операции попасть на свободный диск составляет 100% — ведь операции осуществляются последовательными блоками, которые равномерно раскидываются по дискам.
В качестве некоторого вывода — RAID 0 в любом случае существенно повышает быстродействие линейных операций, а с увеличением количества дисков, входящих в набор, существенно повышается скорость работы и со случайными данными. Для эффективной работы с дисковой системой в режиме RAID 0 просто необходим многозадачный режим работы контроллера, а желательно даже разных контроллеров, обеспечивающих доступ к разным дискам. Обязательным условием такой работы на интерфейсах IDE являются Bus-Mastering драйвера. Windows 2000 имеет встроенные драйвера, автоматически включающие этот режим для всех распространенных IDE контроллеров, для NT4 же могут понадобится дополнительные драйвера или изменения ключей реестра.
Надежность RAID 0 низка — отказ каждого диска является фатальным сбоем, точно так же, как и отказ накопителя в случае работы с обычными разделами.
Вероятность сбоя системы в целом только повышается — чем больше дисков вы используете, тем выше вероятность отказа хоть одного из них и, соответственно, потери какой-то части данных тома.
RAID 1 (зеркальные диски)
Самый простой способ обеспечения безопасности данных — создать копию двух дисков. Запись осуществляется на оба диска сразу, что приводит к замедлению этого процесса, тогда как чтение — с того диска, который в данный момент свободен — если, конечно, система способна эффективно осуществить такое чтение (необходимо наличие Bus-Mastering). Реализованный в NT алгоритм, к сожалению, не совсем оптимален и приводит к гораздо более скромному увеличению быстродействия чтения.
Некоторая сложность работы RAID 1 в программном режиме заключается в том, что часто система не может быть до конца уверена в идентичности данных двух дисков. Операция сверки двух физических дисков после серьезного сбоя может затянутся на часы и быть очень некстати, поэтому использовать программный RAID 1 следует очень осмотрительно. Если вы решаетесь на увеличение дисковых массивов в несколько раз только ради надежности, возможно, вам стоит приобрести аппаратный RAID контроллер, который, к тому же, обеспечит замену вышедших из строя дисков прямо на ходу и будет следить за синхронностью данных сам.
В любом случае, даже полный отказ одного из дисков не приводит к потере данных, так как диски полностью зеркальны.
RAID 5 (параллельные диски с четностью)
Данная стратегия представляется в настоящее время наиболее удачной и эффективной схемой работы RAID, состоящих из трех и более дисков. Информация дополняется так называемыми данными четности (parity), которые размещаются на другом физическом диске, нежели реальные данные, контролируемые этой информацией.
Концепцию четности можно понять, например, так: допустим, у нас есть пять бит — например, набор {0, 1, 1, 0, 1}. Мы формируем еще бит — бит четности, шестой, по такому правилу — если число единиц в предыдущих пяти битах четно, он будет равен 1, если нет — 0. В нашем случае число единиц равняется трем, т. е. нечетному числу — наш набор дополнился числом 0 и превратился в {0, 1, 1, 0, 1, <0>}.
Допустим, набору данных причинен урон — {0, X, 1, 0, 1, <0>}. С помощью правила, гласящего нам, что число единиц должно быть нечетно (последний бит), мы можем догадаться, что на месте X стояла единичка. Наш получившийся набор из шести бит (5 бит данных и 1 бит четности) избыточен и может грамотно скорректировать потерю любого из своих шести бит.
Операции четности могут осуществляться не только с битами, но и с любыми объемами данных, что применяется в простейших алгоритмах восстановления данных.
Возвращаемся к устройству RAID 5:
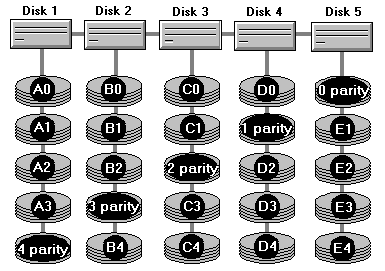
На рисунке изображен массив из пяти дисков. Видно, что каждый диск хранит четыре (условные) части реальных данных и один блок данных четности. Блок четности — скажем, 0 parity — способен восстановить потерю одного из фрагментов — любого, но одного — среди A0, B0, C0 и D0. Все вместе они, в свою очередь, способны восстановить блок 0 parity. Из изображенной структуры RAID видно, что данные, необходимые для полного восстановления всего столбика — то есть информации любого диска в случае сбоя — находятся на других дисках. В этом и заключается восстановление — при записи данных на любой из дисков обновляется также блок четности другого диска, соответствующего текущему блоку (например, при записи в A2 обновляется еще и блок 2 parity). Чтение данных с исправного диска происходит без использования блоков четности, т. е. почти в том же режиме, в каком работает RAID 0. Быстродействие RAID 5 в том виде, в каком это реализовано в NT, даже немного выше, чем у RAID 0.
Единственная накладка — в случае сбоя производительность массива снижается в огромное количество раз, так как при невозможности напрямую считать, например, D4, нужно будет восстанавливать данные этого блока с использованием всех других дисков одновременно — в нашем случае это будут блоки 4 parity, B4, C4 и E4.
Как видно, выход из строя одного из дисков RAID 5 является хоть и не фатальной, но резко аварийной ситуацией — хотя бы из соображений быстродействия чтения с массива. Нетрудно догадаться также, откуда исходит требования как минимум трех дисков — в случае двух накопителей RAID 5 просто вырождается в RAID 1, так как единственный способ создать информацию четности списка из одного элемента — это тем или иным образом дублировать этот элемент.
Допущения, обеспечивающие надежность
Как, опять? Да, опять — RAID также не является панацеей от абсолютно всех бед аппаратуры. Я должен сказать очень неожиданную для некоторых людей вещь: на ненадежном (некорректном) компьютере RAID грохнуть почти так же легко, как и однодисковую систему. RAID совершенно не спасет в следующих случаях:
- Корректная запись некорректных данных, а также запись данных мимо ожидаемой области. К этому приводят, как и ранее, сбойная память, процессор, шлейф, контроллер, питание привода.
- Если диск не способен сообщить об ошибке чтения.
RAID предназначен для минимизации ущерба всего в одном случае — при физическом отказе жесткого диска или, возможно, контроллера (в случае многоконтроллерного RAID). Отказы памяти, операционной системы, да и вообще всего остального RAID-ом не предусмотрены — точно так же, как и стратегией работы одиночной NTFS.
И, напоследок, аксиома работы вышеописанных уровней RAID-а — любой сбой одного из дисков системы считается аварией, которую необходимо как можно быстрее ликвидировать. Особенно это относится к RAID 0 и RAID 5, штатная работа которых в условиях аварии одного из дисков практически невозможна.
Более подробно с системой программных RAID Windows NT можно ознакомится в справке к программе (или модулю — в Windows 2000) Disk Administrator, где, собственно, и создаются эти типы дисков. Обращаю ваше внимание, что способности рабочих станций в создании и использовании RAID-ов сильно ограничены — рабочая станция NT4, к примеру, поддерживает только RAID 0 (параллельные диски), тогда как все описанные варианты работают лишь на серверных вариантах операционных систем.
Часть 6. Стратегия восстановления томов NTFS
Компьютер с NTFS не загружается. Что делать в этом случае? Как восстановить данные? Возможны два случая, действия в которых несколько отличаются друг от друга. К сожалению, простых стратегий восстановления NT и, соответственно, NTFS не существует — система достаточно сложна и не имеет простейших загрузочных средств, как, например, DOS или Windows95/98.
1. Первый вариант — система находилась на том же NTFS диске. Система просто-напросто перестала загружаться. Что же, тогда нам в 90% случаев предстоит поднимать не NTFS, а просто-напросто саму NT. Данная операция выходит далеко за рамки данной статьи, поэтому описываю лишь способ поставить рядом (на тот же NTFS раздел) еще одну систему NT, на которой можно будет в дальнейшем работать (и которая сможет считать ваши данные).
Пользователи NT4 смогут поставить систему прямо на NTFS, каким-либо образом загрузившись в программу установки.
Вам понадобится CD диск, который представляет собой корректный дистрибутив NT4. Такими свойствами, скорее всего, обладают диски, на которых NT4 находится в каталоге под именем i386, расположенном в корневом каталоге. Команда winnt /?, запущенная в этом каталоге, поможет вам выбрать ключи для создания трех загрузочных дискет, с которых можно будет запустить установку NT4 прямо на диск NTFS. Можно выбрать другой каталог установки — например, winnt2, чтобы затем попытаться реанимировать вашу собственную инсталляцию NT4, если вы видите подходы к этой специфической проблеме, которая под силу только специалистам. Устанавливаемая заново операционная система корректно впишет себя в список загрузи и нисколько не помешает вашему старому NT4.
В случае отсутствия CD в соответствующем формате (симптомы — надпись «вставьте диск с дистрибутивом NT4», не реагирующая на наличие вашего CD) — вам остается только поставить NT на какой-нибудь другой раздел, так как диск с NTFS недоступен из систем, отличных от NT.
Стоит учесть, что NT4 нельзя поставить на NTFS, прошедшую преобразование в новый формат от Windows2000. NT4 всё же читает такой NTFS, но только при наличии пакета обновления SP4 или выше.
Пользователи Windows2000 будут вынуждены найти загрузочный CD диск с Windows2000 (таким является официальный дистрибутив), который сам предложит вам либо поставить систему с нуля, или попытаться восстановить старую инсталляцию. Считать диск NTFS, с которым работал Windows2000, можно только самим Windows2000 или NT4 с пакетом обновления SP4 или выше.
Имейте в виду: восстановить какую-либо NT, не обладая либо диском аварийного восстановления (создается в NT4 командой rdisk /s, в Windows2000 — программой резервного копирования), практически невозможно — это работа для специалиста. К слову говоря, даже при наличии диска восстановления, вам скорее всего очень не понравится работа «восстановленной» системы, поэтому переустановка всей системы практически неизбежна. Если вы не являетесь опытным специалистом по NT, советую вам не пытаться пользоваться починяющими опциями установщика NT, т.к. результат вас, скорее всего, крайне не удовлетворит. Попытка, конечно, не пытка, но комплекс операций по полноценной реанимации системы очень велик и мало где описан, поэтому вы останетесь в каком-то промежуточном, хотя, наверное, и загружабельном, состоянии.
2. Система сама по себе работает, но доступа к диску (не загрузочному, а какому-то другому) нет. Disk Administrator показывает для вашего раздела тип unknown (неизвестный). В подавляющем большинстве случаев это означает, что каким-то образом была осуществлена перезапись загрузочной области (boot sector-а) раздела, и NT действительно не догадывается, что это вообще NTFS. Операционная система NT на всякий случай хранит копию загрузочного сектора в конце раздела — если его скопировать обратно в надлежащее место, в подавляющем большинстве случаев диск опознается как NTFS и починится самостоятельно.
Процесс вычисления правильных адресов достаточно сложен, поэтому я не буду его описывать. Для получения исчерпывающих инструкций для данного случая вам придется пойти на сайт MSDN и найти там статью Knowledge Base под номером Q153973 (скорее всего, вы сможете сделать это простым поиском) — после корректного следования этим инструкциям система по крайней мере опознается как NTFS, и дальнейшая судьба раздела зависит от внутренних средств восстановления NT, которые в таком случае возьмут его в оборот. Вам также поможет скромная на вид команда chkdsk, являющаяся неким ярлычком к системе внутреннего восстановления дисковых систем NT.


