Пришло время очередного анонса новой версии универсального тестового пакета RightMark Memory Analyzer. Пожалуй, главное, что можно сказать о ней — это то, что тенденция, намеченная с момента предыдущего релиза RMMA 3.0, сохранилась и, будем надеяться, сохранится и далее. А именно, количество нововведений вновь больше, чем какой бы то ни было «работы над ошибками». Изменения, конечно, также имеются, но в основном такие, чтобы сделать некоторые тесты более понятными, а, следовательно, более удобными в использовании. Их рассмотрением мы и откроем это небольшое приложение.
Изменения в тестах RMMA
Первое изменение коснулось теста латентности кэша данных/памяти (D-Cache Latency), первоначально обладающего довольно большим количеством настроек.
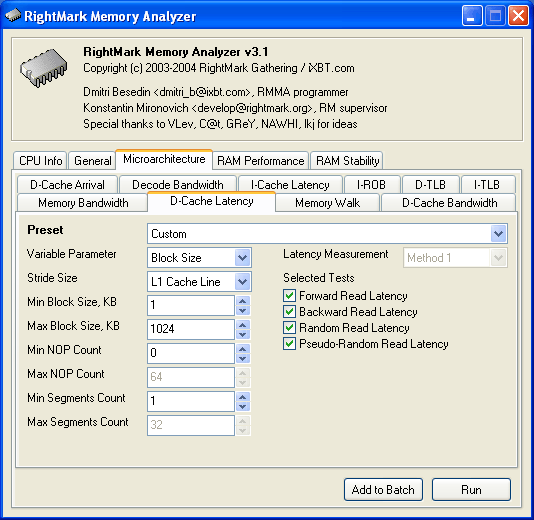
Из представленного рисунка видно, что из этого теста исчезли параметры Mininal Walk Step Size и Maximal Walk Step Size, а вместе с ними — одна из разновидностей этого теста (Variable Parameter = Walk Step Size). На самом деле, мы ничего не удалили — просто реализовали эту функцию в виде отдельного подтеста, представленного ниже.
Второе изменение также затрагивает тест латентности кэша, только не данных, а инструкций (I-Cache Latency).
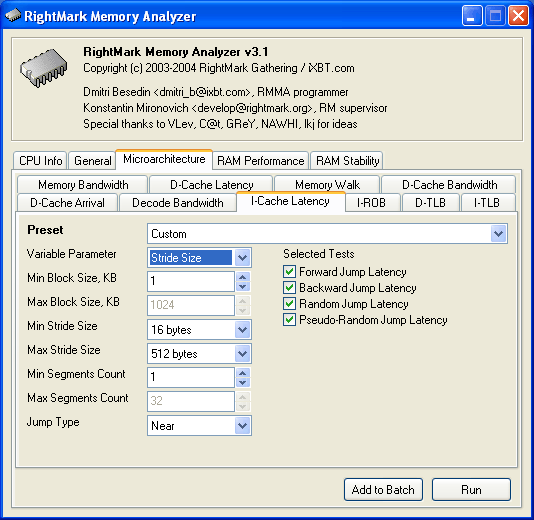
В этот тест, напротив, была добавлена новая разновидность (Variable Parameter = Stride Size), позволяющая строить зависимость латентности исполнения инструкций перехода по цепочке от величины шага между двумя последующими переходами. Данная опция может быть полезна для измерения «эффективной» длины строки кэша инструкций.
Новые тесты RMMA
Вот, собственно, и все, что касается изменений в тестах RMMA 3.1. Самое время теперь рассмотреть новые тесты, реализованные в этой версии тестового пакета.
Тест «ходьбы» по памяти (Memory Walk)
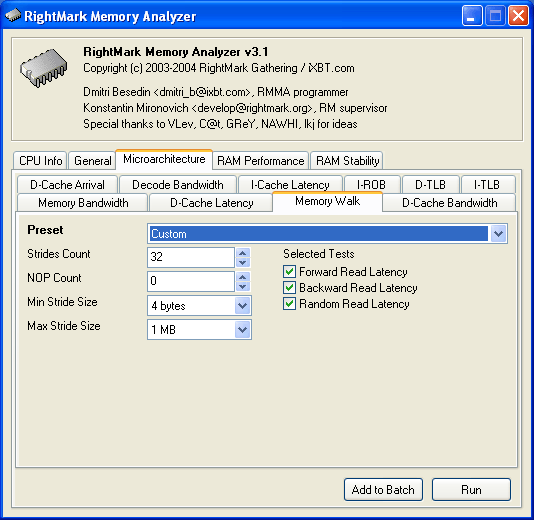
Как уже было сказано выше, этот тест, по сути, является одним из вариантов теста латентности кэша данных (D-Cache Latency), вынесенным в отдельную закладку с целью упрощения его настроек. Параметры этого теста следующие.
Strides Count
Strides Count — количество шагов по зависимой цепочке доступа. Поскольку сам размер шага в этом тесте является переменной величиной, варьируемой в очень широких пределах, в случае данного теста гораздо более разумно задавать именно этот параметр, а не размер блока, как это сделано во всех остальных тестах.
NOP Count
NOP Count — количество «пустых» операций (не связанных с доступом в кэш/память), вставленных между каждыми последующими обращениями к кэшу данных/памяти.
Minimal Stride Size
Min Stride Size — минимальная величина шага по зависимой цепочке, в байтах.
Maximal Stride Size
Max Stride Size — максимальная величина шага по зависимой цепочке, в байтах.
Selected Tests
Selected Tests — выбор способов обхода цепочки при тестировании латентности.
Forward Read Latency — латентность прямого последовательного доступа;
Backward Read Latency — латентность обратного последовательного доступа;
Random Read Latency — латентность случайного доступа.
Итак, в тесте Memory Walk осуществляется обход фиксированного количества элементов цепочки, расположенных друг относительно друга со смещением, находящимся в интервале от Minimal Stride Size до Maximal Stride Size. Данная процедура позволяет определить размер сегмента интересующего нас уровня кэша данных, что проявляет себя в виде значительного увеличения латентности доступа к этому уровню. Очевидно, что для того, чтобы «увидеть» размер одного сегмента определенного уровня кэша данных, необходимо выбрать количество шагов (Strides Count), превышающее ассоциативность этого уровня как минимум на единицу.
Тест буфера переупорядочивания инструкций (I-ROB)
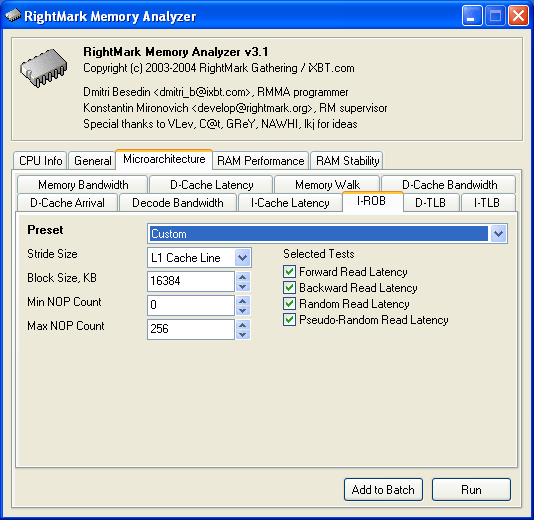
Следующий микроархитектурный тест предназначен для определения размера буфера переупорядочивания инструкций, присутствующего во всех современных процессорах, исполняющих код внеочередным (out-of-order) образом.
Принцип этого теста следующий. Для того, чтобы «заставить» процессор переупорядочивать ход исполнения инструкций, достаточно просто «загрузить» его какой-нибудь очень медленной, но в то же время, простой операцией, не занимающей его исполнительные ресурсы, после чего сразу «предоставить» ему длинную серию других простых инструкций, причем не зависящих как от результата первой операции, так и между собой. В нашем случае само собой в качестве «простой, но медленной» операции напрашивается использование операции зависимой загрузки данных из памяти, а в качестве «простых независимых» инструкций — самые обычные NOP-ы (они же xchg eax, eax). Таким образом, исполняемая этим тестом последовательность команд выглядит так:
// простая, но медленная операция, связанная с доступом в память
mov eax, [eax]
// переменное количество пустых операций
nop
…
nop
Поскольку исполнение первой инструкции в правильно подобранных условиях (большой размер обходимой цепочки данных, случайный режим обхода) будет исчисляться как минимум сотней тактов процессора, подобной нагрузки окажется вполне достаточно для того, чтобы переупорядочить исполнение (т.е., запустить его параллельно с доступом в память) как минимум двух-трех сотен NOP-ов (учитывая, что современные CPU исполняют их со скоростью 2-3 операции/такт) — количества, заведомо большего, чем размер любого существующего на сегодняшний день буфера переупорядочивания инструкций (I-ROB). При этом исчерпание I-ROB будет проявлять себя в виде возрастания латентности доступа к памяти, начиная с определенного количества NOP-ов, поскольку повлечет за собой последовательное (по отношению к операции доступа в память) исполнение оставшейся части NOP-ов, не поместившихся в этот буфер.
Параметры этого теста во многом повторяют настройки, типичные для тестов латентности кэша/памяти.
Stride Size
Stride Size — величина шага по цепочке зависимого доступа, в байтах.
Block Size
Block Size, KB — объем памяти, используемый для построения и обхода цепочки, в килобайтах.
Minimal NOP Count
Min NOP Count — минимальное количество исполняемых процессором пустых операций.
Maximal NOP Count
Max NOP Count — максимальное количество исполняемых процессором пустых операций.
Selected Tests
Selected Tests — выбор способов обхода цепочки:
Forward Read Latency — прямой последовательный обход;
Backward Read Latency — обратный последовательный обход;
Random Read Latency — случайный обход.
Pseudo-Random Read Latency — псевдослучайный обход.
Рекомендуемые для этого теста режимы обхода — два последних, связанные со случайным доступом к элементам памяти в целом (Random Read Latency) либо в пределах одной страницы памяти (Pseudo-Random Read Latency), поскольку латентность доступа в память в этих условиях, как правило, заметно выше, чем в случае прямого/обратного последовательного обхода, дающего возможность эффективной работы алгоритма Hardware Prefetch.
Тесты производительности памяти
Следующие тесты, введенные в новую версию RMMA 3.1, относятся к «состязательным» тестам, предназначенным для сравнительного тестирования производительности подсистемы памяти. Важно отметить, что эти тесты предъявляют значительные требования не только к реальной пропускной способности памяти, но и к вычислительной мощности процессора, в связи с чем их скорее можно рассматривать как «смешанные» тесты, измеряющие производительность связки CPU/RAM в целом.
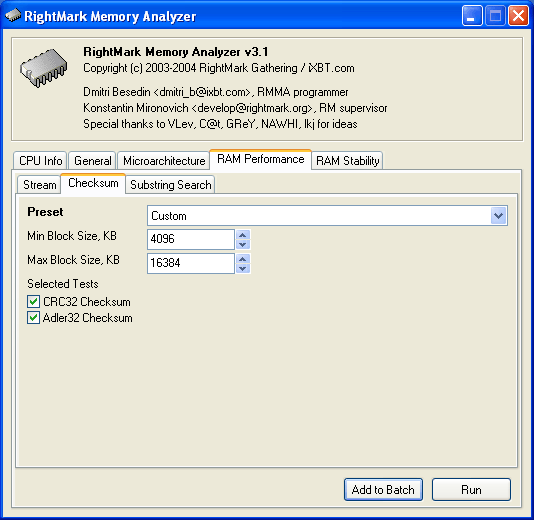
В первом из этих тестов (Checksum) осуществляется вычисление контрольных сумм CRC32 и Adler32 по алгоритмам, реализованным Марком Адлером (Mark Adler) в библиотеке zlib. Параметры этого теста — минимальный (Min Block Size, KB) и максимальный (Max Block Size, KB) размер блока, выбор способов тестирования (Selected Tests — CRC32 Checksum и Adler32 Checksum). По умолчанию этим тестом используются большие объемы данных, заведомо превышающие размер кэша данных процессора.
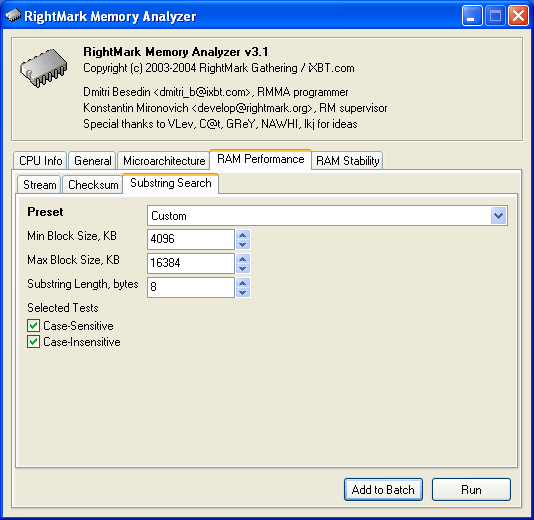
Второй из новых тестов производительности подсистемы памяти (Substring Search) представляет собой простую реализацию задачи поиска подстроки текста заданной длины (параметр Substring Length, bytes) в текстовом массиве большого размера (границы которого задаются параметрами Min Block Size, KB и Max Block Size, KB). В данной версии теста массив «текста» представляет собой массив случайных символов, попадающих в интервал (0x20 — 0x7F), т.е. типичных для текста, состоящего из цифр, заглавных и прописных латинских букв, знаков пунктуации и т.п., а «подстрока» представляет собой фрагмент текста, составленный из названия программы. Для примера, подстрока длиной 64 символа будет выглядеть следующим образом:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 00 | R | i | g | h | t | M | a | r | k | M | e | m | o | r | y | |
| 10 | A | n | a | l | y | z | e | r | R | i | g | h | t | M | ||
| 20 | a | r | k | M | e | m | o | r | y | A | n | a | l | y | ||
| 30 | z | e | r | R | i | g | h | t | M | a | r | k | M | e |
Поддерживаются два режима поиска (задаваемые параметром Selected Tests) — с учетом регистра символов (Case-Sensitive) и без такового (Case-Insensitive). Поскольку во втором случае необходимо преобразование регистра каждого символа, относящегося к текстовому массиву, скорость исполнения такого теста является гораздо меньшей по сравнению с первым тестом, в котором подобное преобразование не применяется.


