Серия первая: MP3-кодек LAME
Разумеется, выводы и комментарии к результатам тестов, которые вы читаете в наших статьях, строятся не на пустом месте и не высасываются из пальца. Все высказываемые в них предположения и гипотезы, а также объяснения поведения различных программ основаны, прежде всего, на опыте инженеров-тестеров, которые не первый день занимаются измерениями производительности различных компьютерных комплектующих и приобрели за это время большой опыт, позволяющий трактовать результаты, опираясь на анализ статистики предыдущих. Однако с ростом количества тестового ПО все чаще возникает мысль о необходимости как-то упорядочить эту «полуинтуитивную базу знаний», более жестко формализовать ее. Этой статьей мы открываем серию под условным названием «Ящики Пандоры», в которой будут детально исследоваться аспекты производительности различных архитектур в часто используемом при тестированиях программном обеспечении. Для начала мы решили взять достаточно простую (с тестовой точки зрения) программу MP3-кодек LAME. Все-таки «закон первого блина», как правило, оказывается верным, поэтому нелишним было подстраховаться и не браться с самого первого раза за что-либо сложное. Впрочем не таким уж и простым оказался даже этот внешне совершенно «безобидный» пример.
Для начала хотелось бы четко обрисовать цели данного тестирования. Его ни в коем случае не следует рассматривать в качестве «руководства по кодированию MP3», и даже в качестве «руководства по кодированию MP3 с помощью кодека LAME». Нас данный кодек интересовал исключительно как «черный ящик», на вход которого поступает одна информация, на выходе получается другая, и, кроме того, доступны некоторые параметры обработки информации, которые можно менять. Более того, нас интересовала исключительно скорость работы, которую демонстрирует этот «черный ящик» с различными процессорами и при различных параметрах обработки. Анализ качества звучания закодированной информации, рекомендации по особенностям применения LAME для сжатия различного рода аудиопотоков всего этого вы в данном материале не найдете. Впрочем, если кто-то из занимающихся кодированием MP3 сочтет приведенную в статье информацию полезной для себя мы не возражаем. :)
На первом этапе тестирования мы использовали систему на базе чипсета i875P и процессора Intel Pentium 4 3,2 ГГц, оснащенную 512 (2x256) МБ DDR400 SDRAM, в двухканальном режиме контроллера памяти, с включенной технологией PAT. Кодируемый WAV-файл, одинаковый для всех тестов, имел размер 146 МБ (153275180 байт) и частоту дискретизации 44,1 кГц (разрядность дискретизации, соответственно, 16 бит). Для особо интересующихся: исполнитель Nick Cave, альбом «Murder Ballads», трек «O`malley`s bar», длительность звучания 00:14:26. Изменение частоты дискретизации в зависимости от получаемого битрейта (кодек LAME по умолчанию пытается подобрать ее автоматически) было принудительно запрещено с помощью указания опции «--resample 44.1», для обеспечения чистоты экспериментов с другими опциями. По идее, ресэмплинга в этом случае не должно происходить вообще, так как в качестве требуемой результирующей указана та же частота дискретизации, что и у исходного файла. Также принудительно для всех тестов был включен режим Joint Stereo, опять-таки с целью исключения «неподконтрольной самодеятельности» встроенных механизмов автоматической оптимизации кодека и ее влияния на чистоту эксперимента. Соответственно, опций, неизменных на протяжении всего тестирования, было две: «-m j --resample 44.1». Изменяемые опции указаны в комментариях к подтестам и диаграммам, а также (частично, самые важные) прямо на диаграммах.
Кодирование с постоянным битрейтом
Самая простая операция это кодирование MP3 с постоянным битрейтом (CBR, Constant BitRate). Здесь нас, разумеется, может интересовать только одно: насколько сильно зависит время кодирования от собственно битрейта. Впрочем, есть у кодека LAME еще один параметр: «q». По заявлениям разработчиков, это параметр, определяющий «
choice of algorithms to determine the best scalefactors and Huffman encoding (noise shaping) for a given bitrate
», то есть выбор алгоритма, предусматривающего либо лучшее качество, либо большую скорость. Для начала мы взяли q=0, что соответствует наивысшему качеству, но замедляет процесс кодирования. Ну и, естественно, для того чтобы отследить какую-то предполагаемую закономерность, нам требовалось достаточное количество данных, поэтому мы измерили время кодирования с CBR от 64 до 320, с минимально возможным шагом. Также следует заметить, что битрейт 144 нами был исключен (как тут, так и в дальнейшем), поскольку пара из LAME 3.93.1 и RazorLame 1.1.5 реагировала на это значение выдачей сообщения об ошибке.
Легко заметить, что самой сложной задачей является кодирование с низкими битрейтами, причем чем ниже битрейт тем сложнее оказывается задача. Однако есть и нюанс необъяснимый «горб» на графике в районе битрейтов 96128 Кбит/с. Можно предположить, что он связан с каким-то узким местом в алгоритме по крайней мере, другие причины кажутся еще более невероятными. Также заметно, что различия между битрейтами выше 224 в скорости кодирования практически отсутствуют (впрочем, мы использовали достаточно высокочастотный процессор). Однако поэкспериментировать с качеством нам тоже хотелось, поэтому мы понизили его наполовину (q=4) и повторили в полном объеме все тот же эксперимент с кодированием в CBR от 64 до 320.
Понижение качества сказалось очень сильно: теперь практически все битрейты кодируются с примерно одинаковой скоростью, различия между ними минимальны. Интересно, что для почти идеального выравнивания графика хватило даже понижения качества наполовину (по идее, такого эффекта можно было бы ждать от его снижения до минимума). В связи с таким забавным результатом нам показалось необходимым отследить влияние параметра «q», так сказать, «в полном объеме», поэтому мы измерили время кодирования с граничными битрейтами (64 и 320), изменяя q в пределах всего доступного диапазона от 0 до 9.
Видно, что для низкого битрейта разница во времени кодирования между максимальным качеством и просто «высоким» (для LAME параметр «-h», задающий «оптимизацию по качеству» выставляет q равным не 0, как можно было бы ожидать, а 2) довольно велика более чем в два раза. А вот на высоком битрейте разницы между максимумом и оптимумом (примем на веру установки авторов кодека, согласно которым достаточно «качественным» является q=2) практически никакой. Установки q от 3 до 8 в обоих случаях по скорости почти идентичны, а в конце, при q=9, на обоих графиках наблюдаем синхронный «скачок вниз» видимо, для самого низкого качества применяется алгоритм намного более «тупой и простой», чем даже для предыдущей ступеньки.
Общий вывод очевиден: при повышении качества (q) скорость кодирования однозначно падает, а вот при повышении качества получаемого продукта (то бишь MP3-файла) путем выбора более высокого битрейта скорость, наоборот, растет. Что, с одной стороны, не может не радовать (более качественный продукт оказывается и более быстр «в производстве»), но, с другой стороны, применять MP3-кодек LAME в роли бенчмарка, оказывается, более оправдано при кодировании с особо низким битрейтом что на практике практически не востребовано.
Кодирование с переменным битрейтом
Ну а дальше нас, естественно, заинтересовало поведение LAME в режиме кодирования с переменным битрейтом (VBR, Variable BitRate). При этом начать мы решили с экспериментов с «шириной диапазона», для чего выбрали основным значением битрейта 128 и задали верхний и нижний пределы кодирования, отступив по два шага в обе стороны (получилось от 96 до 160). Далее же мы принялись расширять диапазон «веером», отступая с каждым следующим разом еще на шаг (в обе стороны). Параметр качества VBR («V») мы для начала взяли равным 0 (наивысшее качество). По идее (которая на момент начала тестирования выглядела здравой), расширение диапазона должно было сказаться на производительности отрицательно, так как, во-первых, алгоритму нужно будет тратить больше усилий на определение того, в каком битрейте кодировать каждый конкретный звуковой фрагмент, а во-вторых будет увеличиваться доля низких битрейтов, которые кодируются медленнее. Но это все было по идее
Вышло все с точностью до наоборот: чем шире диапазон тем меньше время кодирования. Логическое (основываясь на результатах предыдущих тестов) объяснение может быть только одно: чем шире диапазон тем больший «вес» в получаемом файле имеют высокие битрейты, которые, как это нам уже известно, кодируются быстрее низких. Но, быть может, есть способ переломить ситуацию? Как и в прошлый раз, нас заинтересовали параметры управления качеством, поэтому мы снова повторили эксперимент в полном объеме, но с пониженным качеством VBR (V=4). Заметьте, что качество VBR (V) и качество CBR (q) это разные параметры. Сразу оговорим, что при всех «играх с VBR» q мы не трогали, этот параметр оставался всегда равным нулю (максимально качественный алгоритм кодирования). За что же тогда отвечает V? Это тоже интересный вопрос
Итак, с понижением качества VBR мы получили примерно такую же картину, как и при понижении качества CBR (q) различная ширина диапазона перестала влиять на скорость. Опять-таки, вспоминая результаты экспериментов со скоростью кодирования CBR, логично будет предположить, что при более низком качестве VBR «низкобитрейтные» куски при расширении диапазона стали иметь примерно одинаковый вес с «высокобитрейтными», поэтому увеличение скорости кодирования за счет расширения диапазона «вверх» стало компенсироваться ее уменьшением за счет одновременного расширения диапазона «вниз».
Ну и, наконец, в завершение, для полноты картины, мы взяли фиксированный диапазон «по два шага в обе стороны от начального значения» и «прошлись» по всему диапазону битрейтов с 64 до 320. Сначала, как всегда, с наилучшим качеством VBR (V=0).
Что ж, картинка, в общем-то, слегка напоминает аналогичный «проход» при кодировании CBR. Даже «горб» в районе 96128 Кбит/с остался, только за счет того, что мы имеем дело уже не с фиксированным битрейтом, а с диапазоном, он стал более пологим и протяженным. А вот резкий уход графика вверх на низших битрейтах пропал. Опять-таки, можно предположить, что при V=0 большую долю в файле, кодированном с диапазоном 4896, занимает именно битрейт 96 Кбит/с, поэтому битрейт 80 Кбит/с и более низкие, которым и обязан резким скачком вверх график CBR-кодирования, просто не смогли внести свою лепту в замедление процесса. Ну а теперь посмотрим, что нам даст понижение качества VBR (до V=4) при сохранении прочих условий эксперимента
Нет, такого сглаживания, как при уменьшении q, все-таки не наблюдается. Впрочем, это естественно ведь V, судя по всему, влияет лишь на «баланс» между битрейтами, поэтому общая картина кодирования с VBR при q=0 должна быть похожей на кодирование с CBR при том же q. Также кого-то может заинтересовать сравнение из серии «VBR vs. CBR». Это нетрудно сделать, ведь вы помните, что «наш» VBR с постоянной шириной диапазона рассчитывался как раз исходя из соответствия некоему CBR ±2 шага диапазона. Таким образом, VBR от 48 до 96 мы будем рассматривать как «примерную аналогию» CBR 64 (<48>56[64]80<96>). Посмотрим на этот график.
В общем-то, ничего особенного. Вполне вписывается в наши гипотезы. Для справки (и чтобы вы не подумали, что наши выводы относительно специфики работы параметра V в кодеке LAME чисто умозрительны) мы приведем гистограммы кодирования MP3 с переменным битрейтом для большого диапазона и разного качества VBR (благо, RazorLame выводит их в весьма понятной и доступной форме). Четко видно, как меняется «весовой состав битрейтов» в итоговом MP3 при сохранении одного и того же диапазона, но разном значении параметра V.
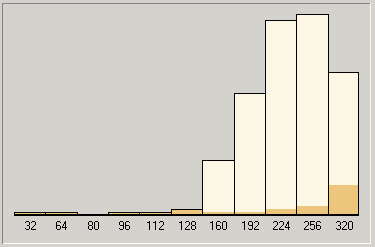
Диапазон 64320, наивысшее качество (V=0)
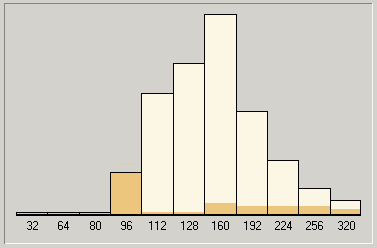
Диапазон 64320, пониженное качество (V=4)
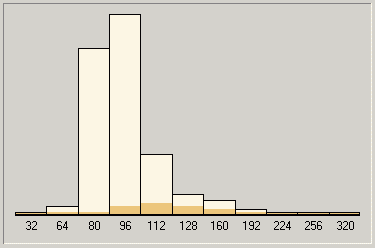
Диапазон 64320, наихудшее качество (V=9)
Четко видно, что именно за баланс между битрейтами в результирующем файле и отвечает параметр V. Разумеется, мы не можем утверждать, что это его единственное назначение: будем помнить, что для нас LAME это всего лишь «черный ящик», исследуемый с точки зрения скорости, поэтому мы можем констатировать только то, что видим на диаграммах, но это не значит, что в поле нашего зрения попало абсолютно все.
Зависимость скорости от частоты CPU и подсистемы памяти
Ну а теперь приступим к сравнению производительности различных систем на Pentium 4. Для этого мы отобрали самые, как нам кажется, типичные варианты: кодирование с постоянным битрейтом и наивысшим качеством (первая диаграмма) и кодирование с переменным битрейтом, фиксированной «шириной диапазона» и наивысшим качеством VBR (седьмая диаграмма). Вот как выглядят кривые различных процессоров Pentium 4 в этих случаях:
Легко заметить, что никаких «взбрыков» не наблюдается скорость кодирования меняется в зависимости от частоты строго линейно. Однако только ли от частоты CPU она зависит? Мы решили задаться вопросом о влиянии на скорость работы исследуемого нами кодека быстродействия подсистемы памяти. Благо, чипсет i875P позволяет «играться» с режимами работы памяти достаточно гибко: при сохранении частоты FSB 800 (физические 200) МГц память может тактоваться на 400, 333 или 266 МГц. Кроме того, в зависимости от распределения модулей по разъемам DIMM становятся доступны двухканальный или одноканальный режимы работы контроллера памяти. Мы решили ограничиться четырьмя «пороговыми» парами: DDR400 и DDR266 в одно- и двухканальном режиме в обоих случаях. Ну а для тестов были взяты самые «долгие» (подразумевается самые сложные) задания: кодирование с CBR 64, и кодирование VBR 4896, все с наивысшим качеством (q=0, V=0). Однако для начала следовало убедиться, что различия в пропускной способности и латентности подсистемы памяти действительно присутствуют. Убеждаемся:
Низкоуровневый бенчмарк подсистемы памяти CacheBurst32 утверждает: различия есть. И существенные. Ну а теперь приступаем к кодированию
Эээ Да, нам тоже было смешно :). Однако раз уж обещали привести диаграммы то вот, приводим. Думаем, всем достаточно хорошо видно, что какая-либо существенная разница отсутствует, более того разница в 1 секунду на таком временном интервале покрывается погрешностью даже при весьма тщательных измерениях. То есть попросту можно констатировать, что скорость кодирования с помощью LAME от пропускной способности подсистемы памяти и ее латентности не зависит. Ну, или, по крайней мере, зависит в столь малой степени, что этой зависимостью можно смело пренебречь. Заметим, что использование самого мощного процессора по всем теоретическим выкладкам обязано было подчеркнуть разницу, если бы она имела место. Так что с менее высокочастотными CPU ситуация будет еще «сглаженнее» хотя куда уж больше, как говорится.
Сравнение различных процессорных архитектур
Ну а теперь пришло время сравнить производительность Pentium 4 3,2 ГГц и Athlon XP 3200+. Последний работал в составе системы на базе чипсета NVIDIA nForce2 Ultra 400, с теми же 512 (2x256) МБ DDR400 SDRAM, в двухканальном режиме. Для этого теста мы отобрали несколько уже хорошо знакомых примеров: кодирование с постоянным битрейтом при наивысшем и пониженном качестве (диаграммы 1 и 2), кодирование с постоянным битрейтом при плавном понижении качества (диаграмма 3) и кодирование VBR при фиксированной ширине диапазона с повышением битрейта (диаграмма 7).
Итак, даже принципиально другая архитектура процессора AMD не принесла никаких сюрпризов графики Pentium 4 и Athlon XP практически идентичны по характеру. Остается выяснить, как влияет на скорость кодирования изменение частоты у Athlon XP, хотя наверняка вы уже поняли, что никаких сюрпризов нам, скорее всего, этот тест не преподнесет. Поэтому чисто для проформы мы ограничимся всего двумя графиками сравнения производительности различных Athlon XP. Для удобства сопоставления в данном случае мы указали в подписях не название модели, а частоту процессора (2200 и 2000 МГц). Помните, что частоту Pentium 4 мы понижали каждый раз на 400 МГц? В случае с Athlon XP мы решили, что вполне хватит и 200, так как его производительность сильнее зависит от частоты такова особенность архитектуры.
Комментировать, по сути, нечего: все результаты именно такие, каких мы и ожидали. И даже «интуитивное» приравнивание разницы в 400 МГц на Pentium 4 к 200 МГц на Athlon XP, кажется, почти «попало в точку».
Выводы
Они будут краткими. Скорость кодирования MP3 с помощью LAME зависит в рамках одной процессорной архитектуры практически исключительно от частоты работы ядра CPU. Сопоставление разных архитектур указывает на то, что «коэффициент перевода частоты в скорость» для них также является разным. При этом можно подсчитать и «коэффициент перевода производительности одной архитектуры в производительность другой», и, скорее всего, он позволит нам на основе имеющихся результатов весьма точно оценить скорость кодирования для любого процессора любой архитектуры (из протестированных) и любой частоты как доступных на данный момент, так и будущих. Таким образом, получается, что, во-первых, использовать LAME при сравнении производительности чипсетов нет никакого смысла (к скорости подсистемы памяти он индифферентен), а во-вторых даже при сравнении CPU он употребим, только если мы в первый раз имеем дело с сопоставлением различных процессорных архитектур, поскольку во всех остальных случаях поведение данного теста (и его результаты, соответственно) на 100% предсказуемо. Остался открытым пока только один вопрос: влияет ли на скорость работы этого кодека объем кэша? У обоих исследованных нами процессоров объем L2 равен 512 КБ. А если меньше? Впоследствии мы планируем изучить этот вопрос дополнительно на примере P4-Celeron с разными частотами.
Вместо P.S.
LAME, увы, похоже, остановился в развитии последняя версия вышла аж в декабре 2002-го года, то есть почти год назад. Поддержка дополнительных наборов инструкций тоже не внушает оптимизма: у официального релиза данного кодека она застыла на лохматой давности MMX/3DNow!, а «самопальные переделки» от энтузиастов широкого хождения не имеют для Windows нам вообще не удалось отыскать ни одной. Хотя под Linux, по слухам, версии LAME с поддержкой SSE кому-то скомпилировать удавалось, «поправив кое-что руками в makefile». Однако вряд ли подобные несанкционированные вмешательства в авторский код имеет смысл использовать в повседневной практике тестирований, так что в качестве опции мы решили попробовать оценить производительность различных архитектур на примере другого кодека GOGO, который развивается достаточно активно. В отличие от «официального» LAME GOGO поддерживает все самые последние наборы SIMD-команд (Extended 3DNow!, SSE, SSE2) и даже «косвенно» поддерживает Hyper-Threading (умеет распараллеливать процесс кодирования на два потока). К сожалению, пока что существуют некоторые проблемы с «реальной» тестовой процедурой дело в том, что кодек GOGO работает слишком быстро! Настолько быстро, что наш 146-мегабайтный файл «проскакивает» через него почти в любом режиме не более чем за 20 секунд. А это уже та самая опасная область, где начинает существенно влиять на результат производительность дисковой подсистемы.
Пока что мы нашли только один выход: воспользоваться специальным бенчмарком для GOGO, который так и называется GOGO Bench. Эта программа «эмулирует» работу кодека в памяти, не записывая ничего на диск, и выдает в результате соответствующие производительности баллы. Также удобно то, что можно легко «играться» с наборами процессорных инструкций, разрешая или запрещая использование некоторых из них. Подчеркнем, что данный подтест является в нашем материале исключительно опцией, то есть детально мы не «прорабатывали» ни сам бенчмарк, ни его результаты. Такой вот, своего рода, «эксперимент внутри эксперимента» получился. Можете ознакомиться с показателями тестовых систем.
Что ж, как и следовало ожидать, результаты этого кодека демонстрируют совершенно другую картину: тут налицо и преимущество от задействования различных дополнительных наборов команд, и даже ощутимый прирост при использовании распараллеливания кодирования на несколько потоков (что становится востребованным в случае поддержки процессором Hyper-Threading). Однако несомненную интересность (с тестовой точки зрения) кодека GOGO отчасти умаляет тот факт, что GOGO Bench это все-таки именно бенчмарк, то есть синтетика, пусть и на основе реального продукта. А вот тестировать кодирование MP3 с помощью самого кодека пока что не представляется возможным причины мы изложили выше.


