ATI RADEON 3850/3870 (RV670)
320 шейдерных процессора с 256-битной шиной памяти
Часть 1: Теория и архитектура
Недавно мы писали о Geforce 8800 GT — отличном решении среднего ценового диапазона от компании Nvidia, и теперь настало время и для рассмотрения аналогичной продукции AMD. В очередной раз вспоминаем, насколько неудачными оказались предыдущие mid-end решения от AMD и Nvidia, основанные на чипах RV630 и G84, соответственно. Они страдали от слишком большого урезания их возможностей по сравнению с топовыми видеокартами, имели на борту слишком малое количество разнообразных исполнительных блоков: ALU, TMU и ROP. Также их производительность ограничивалась и «узкой» 128-битной шиной памяти, которая особенно слабо смотрелась у RADEON HD 2600 XT на фоне 512-битной у топового RADEON HD 2900 XT.
Архитектура AMD R6xx была анонсирована в мае, тогда вышло только решение верхнего ценового диапазона на основе чипа R600, видеокарты среднего и нижнего ценовых диапазонов на основе чипов унифицированной архитектуры R6xx были отложены до лета. И уже тогда стало ясно, что ни от одного из производителей видеочипов мы не дождемся действительно сильных mid-end решений на чипах, произведенных по 80/90 нм техпроцессу. Поддержка DirectX 10 и унифицированность архитектур накладывали определенные ограничения на сложность видеочипов, и даже в дешевых GPU должны были быть включены довольно сложные блоки, например, те же диспетчеры потоков. Поэтому на исполнительные блоки оставалось не так много места в пределах бюджета по количеству транзисторов, и на основе 80/90 нм техпроцесса быстрый mid-end сделать было очень сложно.
И теперь, с переходом Nvidia на технологию производства 65 нм, а AMD даже на 55 нм, появились действительно мощные mid-end видеочипы и решения на их основе. По сути, это предыдущие топовые чипы, переведенные на более «тонкий» техпроцесс. С соответствующей мощностью, отличающейся в худшую сторону разве что в поддержке меньшей ширины шины памяти. Именно так, основным отличием чипов RV670 и G92 от предыдущих топовых R600 и G80 является технология производства 55 и 65 нм, которая снизила себестоимость сложных чипов, важную для недорогих продуктов и позволила выпустить подобные решения. Мало того, новые GPU производства AMD выгодно отличаются от R600 ещё и поддержкой обновленного DirectX 10.1, PCI Express 2.0 и включают в себя улучшенный блок аппаратного ускорения воспроизведения и обработки видеоданных.
Перед прочтением данного материала мы рекомендуем внимательно ознакомиться с базовыми теоретическими материалами DX Current, DX Next и Longhorn, описывающими различные аспекты современных аппаратных ускорителей графики и архитектурные особенности продукции Nvidia и AMD (ранее ATI).
- [06.06.05] Longhorn — ускорители и шейдеры для DirectX 10
- [01.03.05] DirectX.Update — Ускорители 3D-графики: полшага вперед
- [09.04.04] DX.Next: ближайшее и ближнее будущее аппаратного ускорения 3D-графики
Эти материалы достаточно точно спрогнозировали текущую ситуацию с архитектурами видеочипов, оправдались многие предположения о будущих решениях. Подробную информацию об унифицированной архитектуре AMD R6xx на примере предыдущих чипов можно найти в следующих статьях:
- [14.05.07] Долгожданное появление DirectX 10-семейства от AMD/ATI
- [04.07.07] ATI RADEON HD 2400-2600-серии: новые решения от AMD для среднего и бюджетного секторов с поддержкой DirectX 10
Итак, обновленный чип RV670 основан на известной архитектуре RADEON HD 2000 (R6xx). Этот GPU включает в себя все основные особенности этого семейства, такие как унифицированная шейдерная архитектура, полная поддержка DirectX 10 (теперь в версии 10.1), качественные методы анизотропной фильтрации и новый алгоритм антиалиасинга с увеличенным количеством выборок и т.п. RV670 выгодно отличается в лучшую сторону по своим возможностям, на его основе анонсированы решения среднего ценового диапазона по цене от $179 до $229. Ещё раз отметим, что основное технологическое изменение — технология производства 55 нм, позволившая снизить себестоимость и вывести решения в данный ценовой сектор.
Одним из важных положительных изменений, по сравнению с R600, стало включение в состав нового чипа блока аппаратного декодирования видео — UVD, которого нет (или он не работает нормально, что практически одно и то же) в R600. Всё так же, как и у Nvidia, low-end и mid-end чипы линейки обладают лучшими возможностями по декодированию видео. К исследованию производительности и качества декодирования видеоданных новыми решениями AMD и Nvidia мы обязательно вернемся, продолжив наши исследования по этой теме.
Графические ускорители RADEON HD 3850 и HD 3870
- Кодовое имя чипа RV670
- Технология 55 нм
- 666 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10.1, в том числе и новой шейдерной модели — Shader Model 4.1, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 256-битная шина памяти: четыре контроллера шириной 64 бита, соединенных шиной ring bus
- Частота ядра 670-775 МГц
- 320 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 точности в рамках стандарта IEEE 754)
- 4 укрупненных текстурных блока, с поддержкой FP16 и FP32 компонент в текстурах
- 32 блоков текстурной адресации (см. подробности в базовой статье)
- 80 блоков текстурной выборки (см. подробности в базовой статье)
- 16 блоков билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 16 блоков ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 16 отсчетов за такт, в режиме без цвета (Z only) — 32 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI, HDTV
Спецификации карты RADEON HD 3870
- Частота ядра 775 МГц
- Количество универсальных процессоров 320
- Количество текстурных блоков — 16, блоков блендинга — 16
- Эффективная частота памяти 2250 МГц (2*1125 МГц)
- Тип памяти GDDR4
- Объем памяти 512 мегабайт
- Пропускная способность памяти 72 гигабайта в сек.
- Теоретическая максимальная скорость закраски 12.4 гигапикселя в сек.
- Теоретическая скорость выборки текстур 12.4 гигатекселя в сек.
- Два CrossFireX разъема
- Шина PCI Express 2.0 x16
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI адаптер
- Энергопотребление до 105 Вт
- Рекомендуемая цена $219
Спецификации карты RADEON HD 3850
- Частота ядра 670 МГц
- Количество универсальных процессоров 320
- Количество текстурных блоков — 16, блоков блендинга — 16
- Эффективная частота памяти 1660 МГц (2*830 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 53 гигабайта в сек.
- Теоретическая максимальная скорость закраски 10.7 гигапикселя в сек.
- Теоретическая скорость выборки текстур 10.7 гигатекселя в сек.
- Два CrossFireX разъема
- Шина PCI Express 2.0 x16
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI адаптер
- Энергопотребление до 95 Вт
- Рекомендуемая цена $179
Как видите, начиная с RADEON HD 3870 и 3850, компания AMD решила сменить традиционную маркировку видеокарт ATI RADEON. Так, в названии модели RADEON HD 3870 первая цифра (3) означает поколение видеокарт, видимо, начиная с серии X1000 (X1800, X1600 и т.п.), вторая цифра (8) — семейство видеокарт (принадлежность к рыночному диапазону, иными словами), а третья и четвертая (70 в данном случае) — конкретную модель видеокарты в пределах поколения и семейства. Как обычно, большая цифра означает большую производительность решения. На данный момент, для упрощения ориентации в новых моделях, AMD приводит такое соответствие новой и предыдущей маркировок: 50 — означает то же, что и суффикс PRO ранее, а приставка 70 эквивалентна суффиксу XT.
Важно сделать традиционное уже отступление по поводу необходимого современным играм количества видеопамяти. Как показало наше недавнее исследование, многие современные игры очень требовательны к объему видеопамяти, они используют до 500-600 мегабайт. И хотя это не означает, что все ресурсы игр должны обязательно находиться именно в локальной памяти видеокарты, менеджмент ресурсов зачастую может отдаваться в управление API, тем более что в Direct3D 10 используется виртуализация видеопамяти. Тем не менее, в современных 3D-приложениях прослеживается четкая тенденция к увеличению требуемых объемов локальной памяти, и 256 мегабайт теперь являются минимально необходимым объёмом, а оптимальным количеством памяти на данный момент является 512 Мбайт. И при выборе между двумя моделями линейки HD 3800 это нужно обязательно принимать во внимание. Разница в цене между ними не такая уж большая.
Итак, AMD опять выходит на рынок графических решений среднего уровня технологическим лидером, их новые чипы выполнены по 55 нм технологическим нормам. Такие переходы важны, так как более совершенные технологические процессы дают преимущества, позволяя добиться меньшего размера ядра или большего количества транзисторов при той же площади, увеличивая частотный потенциал чипов и процент выхода годных на высоких тактовых частотах, а также снижая себестоимость производства. В сравнении площадей ядер R600 (80 нм) и RV670 (55 нм), имеющих близкое количество транзисторов (700 и 666 миллионов, соответственно), можно отметить даже более чем двукратную разницу: 408 и 192 кв.мм, соответственно!
Конечно, большая плотность транзисторов сказалась на так называемой энергетической эффективности, RV670 потребляет в два раза меньше энергии, по сравнению с R600, обладая примерно той же производительностью! К сожалению, преимущество более «тонкой» технологии в этот раз не очень заметно на фоне конкурирующего продукта от Nvidia, старшее mid-end решение AMD потребляет примерно столько же энергии и выделяет столько же тепла, по сравнению с конкурирующей видеокартой на основе чипа G92, выполненного на 65 нм техпроцессе и имеющего большую площадь.
Архитектура
В предыдущих статьях (R600, RV630), посвященных анонсу архитектуры R6xx и выходу RADEON HD 2900, HD 2600 и HD 2400, мы подробно описали все архитектурные особенности новой линейки видеочипов с унифицированной архитектурой от компании AMD, в этом материале будет лишь их краткое описание, за остальными данными обращайтесь по указанным выше ссылкам. В RV670 есть всё то же, что и в предыдущих решениях (320 универсальных блоков по обработке данных, 16 блоков текстурных выборок, 16 блоков растровых операций, программируемый тесселятор и т.п.), лишь с небольшими изменениями, предназначенными для поддержки возможностей Direct3D версии 10.1, о которой подробно написано далее.
Архитектура R6xx сочетает в себе некоторые решения из предыдущих: R5xx и Xenos, и дополнена новыми: мощным диспетчером потоков, суперскалярной архитектурой шейдерных процессоров с выделенными блоками ветвления и т.п. Схема нового чипа RV670 абсолютно идентична схеме R600:
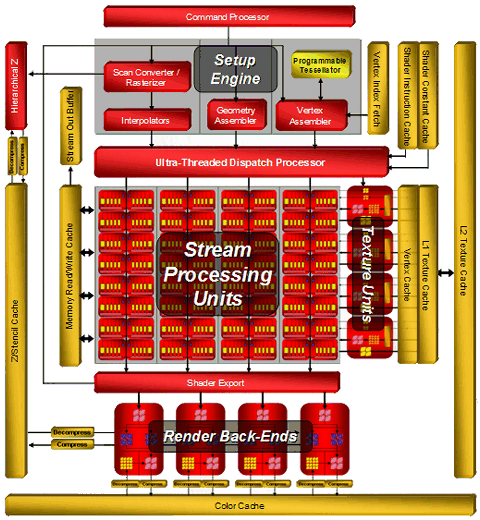
По сути, RV670 не отличается от R600 ничем, количество всех блоков (ALU, ROP, TMU) у него точно такое же. Обо всех остальных архитектурных подробностях R600 можно узнать из базового материала, ссылка на который приведена выше. Единственное ухудшающее характеристики отличие нового mid-end чипа в том, что у него нет поддержки 512-битной шины, она «всего лишь» 256-битная, но всё остальное, написанное в том материале, относится к нему полностью.
Конечно, AMD заявляет, что контроллер памяти в RV670 был оптимизирован для более эффективного использования полосы пропускания, что 256-битная шина снаружи является 512-битной внутри и т.п. На одном из слайдов презентации даже написана любопытная фраза о том, что HD 3870 обладает равной производительностью с RADEON HD 2900 при одинаковых тактовых частотах. Если они учитывали, в том числе и эффективность использования ПСП, то не значит ли это, что R600 попросту не может использовать все возможности 512-битной шины? Или всё-таки это RV670 такой эффективный вдруг стал? Постараемся проверить в следующих частях.
Поддержка Direct3D 10.1
AMD называет свой чип RV670 первым GPU с поддержкой DirectX 10.1, превознося нововведения в этой обновленной версии API почти до небес, обещая глобальное освещение и прочий ambient occlusion в реальном времени. Nvidia, пока не имеющая подобных решений, называет версию 10.1 небольшим обновлением, не особенно важным для индустрии. Всё, как обычно, привычная игра маркетологов, которую мы не раз видели. Попробуем разобраться, есть ли настолько важные особенности в 10.1 или нет?
Сразу отмечаем, что эта версия DirectX будет доступна только в первом полугодии следующего года, вместе с обновлением для операционной системы MS Windows Vista. Service Pack 1 для неё, в состав которого и должен войти DirectX 10.1, появится нескоро, не говоря уже о том, когда обновленный API принесёт что-то новое в реальные игровые проекты. Основным изменением в этой версии стало улучшение некоторых возможностей: обновленная шейдерная модель Shader Model 4.1, независимые режимы блендинга для MRT, массивы кубических карт (cube map arrays), чтение и запись значений в буферы с MSAA, одновременная текстурная выборка нескольких значений Gather4 (ранее известная как FETCH4 у чипов ATI), обязательное требование блендинга целочисленных 16-битных форматов и фильтрации 32-битных форматов с плавающей запятой, а также поддержка MSAA как минимум с четырьмя выборками и другое.
Новые возможности, которые появятся в DirectX 10.1, облегчат реализацию некоторых техник рендеринга (например, глобального освещения в реальном времени). Все нововведения можно поделить на группы: улучшения, связанные с шейдингом и текстурированием, изменения антиалиасинга и спецификаций. Что каждое из них даёт на практике — сейчас разберёмся.
- Массивы кубических карт — чтение и запись нескольких кубических карт за один проход рендеринга. Упрощает эффективные техники глобального освещения в реальном времени для сложных сцен. Глобальное освещение включает в себя расчет отраженного (непрямого) освещения, мягких теней, преломлений, размытых отражений и переноса или перетекания цвета (color bleeding).
- Независимые режимы блендинга для MRT — при выводе данных пиксельными шейдерами в несколько буферов сразу (MRT), каждый из них может использовать свой режим блендинга. Это улучшает эффективность и быстродействие алгоритмов отложенного затенения («deferred shading»), часто применяющихся в современных игровых проектах.
- Увеличенное количество регистров для вершинных шейдеров — количество входных и выходных регистров вершинных шейдеров в DX 10.1 увеличено вдвое, с 16 до 32. Это позволит увеличить производительность сложных шейдеров и упростит их оптимизацию.
- Поддержка текстурной выборки Gather4 — текстурная выборка 2x2 нефильтрованного пиксельного блока вместо одного билинейно отфильтрованного значения. Эта возможность была ранее известна как FETCH4, она используется в алгоритмах качественной фильтрации карт теней, также может быть полезна в процедурном текстурировании и неграфических расчетах на GPU.
- Новая инструкция LOD — новая шейдерная инструкция, возвращающая уровень детализации для отфильтрованной текстурной выборки. Может использоваться в алгоритмах специфической текстурной фильтрации в шейдерах и в алгоритмах parallax occlusion mapping.
- Улучшения антиалиасинга: маски покрытия пикселя (Pixel Coverage Masks) и чтение/запись мультисэмплового буфера — чтение и запись буфера позволяет читать и записывать данные цвета и глубины отдельных сэмплов в/из буфера из шейдеров, а pixel coverage masks позволяют использовать программируемый антиалиасинг из пиксельного шейдера. Это даёт возможность создания собственных edge detect фильтров для нахождения пикселей, требующих применения сглаживания, то есть быстрого и качественного адаптивного алгоритма антиалиасинга. Также новые возможности полезны для улучшения качества антиалиасинга буферов при HDR рендеринге и отложенном затенении, и некоторых других эффектах.
- Программируемые положения выборок при мультисэмплинге — возможность дает разработчикам приложений определять своё размещение субпиксельных выборок, что полезно при temporal и мультичиповом антиалиасинге, например.
- Стандартные сетки расположения субпикселей при антиалиасинге — сетки с заранее заданным стандартным положением субпикселей для всех режимов антиалиасинга. Это гарантирует, что антиалиасинг будет выглядеть идентично на всех совместимых с DirectX 10.1 решениях.
- Улучшенные фиксированные спецификации API — включают в себя обязательную поддержку фильтрации для 32-битных форматов с плавающей запятой и блендинг для 16-битных целочисленных, а также минимально необходимую поддержку MSAA с четырьмя сэмплами (4x MSAA). Для DirectX 10.1 видеочипов поддержка этих возможностей обязательна, а не опциональна, как в DX10. Хотя преимуществ это не даёт, но разработчикам не нужно будет задумываться, поддерживает ли та или иная карта такую фильтрацию и блендинг такого формата, или нет.
- Увеличенная точность расчетов для операций с плавающей запятой — увеличенная точность расчетов для математических расчетов (сложение, вычитание, деление, умножение) и операций блендинга.
Как мы уже сказали выше, некоторые из новых возможностей DirectX 10.1 упрощают реализацию техник и алгоритмов, повышающих качество 3D-графики. AMD в своих материалах приводит пример реализации глобального освещения (Global Illumination, GI). Так как в реальном времени полноценный расчет GI слишком сложен, большинство игр прошлого довольствуются непрямым освещением в виде постоянной ambient составляющей, самой грубой аппроксимацией GI. Иногда используются и более совершенные методики, некоторые описаны по ссылке выше.
Преимущество DirectX 10.1 в расчете GI состоит в том, что разработчики могут использовать массивы кубических карт совместно с геометрическими шейдерами в эффективном алгоритме GI реального времени. Работает он так: сцена делится на части, соответствующие трехмерному массиву кубических карт. Для каждой грани кубмапа отрисовывается упрощённая сцена с направлением камеры из центра куба наружу («light probe»), все шесть граней записываются в кубическую карту. Разрешение и детализация этих кубмапов не должны быть слишком велики для того, чтобы сцена рендерилась в реальном времени.

Каждый кубмап конвертируется в сферическое представление при помощи «spherical harmonics». Это даёт возможность определения интенсивности и цвета освещения для каждой точки в кубе. Для точек, лежащих между кубами, используется интерполяция значений из соседних кубмапов. Кроме того, массивы кубических текстур могут использоваться и для качественных отражений для большого количества объектов в сцене.
Описанный метод расчета GI хорошо масштабируется в зависимости от размера и количества кубов, на которые разделена сцена, а также разрешения и детализации кубических карт. Помощь от нововведений DirectX 10.1 заключается в возможном использовании массивов кубмапов. При этом большое количество кубических карт отрисовывается одновременно, что увеличивает эффективность техники.
Ещё одной интересной техникой, реализацию которой облегчают возможности DirectX 10.1, является «ambient occlusion». Эта техника рассчитывает количество света, достигающее определенной точки по всем направлениям и количество отраженного объектами света, не дошедшего до точки. То есть, участки сцены, окруженные со сторон объектами будут выглядеть темнее, чем точки, освещению которых ничто не мешает, что увеличивает реалистичность изображения. Возможности DirectX 10.1 облегчают задачу при помощи множественной текстурной выборки Gather4. В описанной технике для хранения данных используются одноканальные текстуры специального формата, в отличие от обычных RGB(A) текстур. Gather4 даёт возможность одновременной выборки четырех значений из таких текстур, что можно использовать как для улучшения фильтрации текстур, так и для увеличения производительности.
Далее поговорим об улучшениях антиалиасинга. На данный момент наиболее распространенным методом сглаживания является мультисэмплинг (MSAA), который работает только на краях полигонов, не сглаживая текстуры и вывод пиксельных шейдеров. В DX 10.1 появились возможности, облегчающие устранение этих проблем. Ещё в базовом материале мы писали, что семейство RADEON HD 2000 отличается новым алгоритмом антиалиасинга — custom filter anti-aliasing (CFAA), который является гибко программируемым методом.
В DirectX 10.1 ввели возможность использования специализированных фильтров антиалиасинга из пиксельных шейдеров. Такие методы улучшают качество в случаях, когда у обычного алгоритма MSAA есть определенные проблемы, например, при использовании HDR рендеринга или отложенного затенения. Подобные алгоритмы используют появившийся в DX 10.1 доступ ко всем экранным буферам из шейдеров, в то время как раньше можно было читать и писать данные только в мультисэмпловые буферы цвета. В Direct3D 10.1 стало возможно читать и писать информацию из буфера глубины для каждого сэмпла по отдельности, что позволяет 3D разработчикам использовать продвинутые техники антиалиасинга по своим алгоритмам, и даже комбинации методов привычного антиалиасинга и «шейдерного».
Естественно, многие перечисленные нововведения в DirectX 10.1 полезны и удобны, но в оценке их значения не нужно забывать, что сам обновленный API появится через полгода, распространение видеокарт с его поддержкой займет ещё какое-то время (кстати, у Nvidia поддержка DirectX 10.1 запланирована для следующего поколения архитектуры GPU, представители которой появятся не раньше Service Pack 1 для Vista). Кроме того, первые видеокарты явно не дадут возможности использования всех новинок API с приемлемой производительностью для реальных применений.
Интересно, что некоторые игровые разработчики высказались по поводу DirectX 10.1 в том ключе, что это небольшое обновление DirectX, которое они пока даже не планируют использовать. Вероятно, их мнение поменяется со временем, ведь некоторые возможности новой версии этого API действительно помогут в дальнейшем улучшении качества рендеринга реального времени.
PCI Express 2.0
Полноценным нововведением в RV670 стала поддержка шины PCI Express 2.0. Вторая версия PCI Express увеличивает стандартную пропускную способность в два раза, с 2.5 гигабит/с до 5 гигабит/с, в результате, по стандартному для видеокарт разъему x16 можно передавать данные на скорости до 8 ГБ/с в каждом направлении (в маркетинговых материалах любят суммировать цифры, указывая 16 ГБ/с), в отличие от 4 ГБ/с для версии 1.x. При этом PCI Express 2.0 совместим с PCI Express 1.1, старые видеокарты будут работать в новых системных платах, а новые видеокарты с поддержкой второй версии останутся работоспособными в платах без его поддержки. При условии достаточности внешнего питания и без увеличения пропускной способности интерфейса, естественно.
Реальное влияние большей пропускной способности шины PCI Express на производительность оценить непросто, нужны тесты в равных условиях, сделать которые довольно проблематично. Но большая пропускная способность точно не помешает, особенно для SLI/CrossFire систем, обменивающихся данными, в том числе и по PCI Express шине. Да и многие современные игры требуют большого объема быстрой памяти, и при недостатке локальной, будет использоваться системная, и тогда от PCI Express 2.0 точно будет толк.
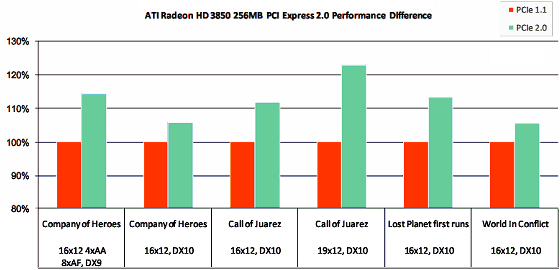
Компания AMD приводит такие данные для RADEON HD 3850 с 256 мегабайтами памяти: разница в производительности между системами с PCI Express 1.x и 2.0 в играх Company of Heroes, Call of Juarez, Lost Planet и World In Conflict меняется от 5% до 25%, в среднем составляя около 10%. Естественно, в высоких разрешениях, когда буфер кадра и сопутствующие буферы занимают большую часть локальной видеопамяти, а некоторые ресурсы хранятся в системной.
Для обеспечения обратной совместимости с существующими PCI Express 1.0 и 1.1 решениями, спецификация 2.0 поддерживает как 2.5 Гбит/с, так и 5 Гбит/с скорости передачи. Обратная совместимость PCI Express 2.0 позволяет использовать прошлые решения с 2,5 Гбит/с в 5,0 Гбит/с слотах, которые будут работать на меньшей скорости, а устройство, разработанное по спецификациям версии 2.0, может поддерживать и 2,5 Гбит/с и 5 Гбит/с скорости. Как обычно, абсолютно гладко бывает разве что на бумаге, и кто-нибудь на практике сталкивается с проблемами совместимости с некоторыми сочетаниями системных плат и карт расширения.
ATI CrossFireX
Видимо, чтобы хоть как-то удивлять пользователей при выпуске бывших топовых чипов на обновленном техпроцессе, обе компании, и AMD и Nvidia, ударились в улучшения, связанные с многочиповыми конфигурациями и системами на основе двух и более видеокарт. Решения на базе RV670 заявлены как первые видеокарты с поддержкой одновременной работы четырех карт (или двух карт на основе двух чипов каждая). Мало того, что смысл от совместной работы четырех видеокарт есть лишь в сверхвысоких разрешениях и в оптимизированных приложениях с оптимизированными для них драйверами, так ещё и в некоторых режимах CrossFire играбельность не улучшится реально, даже если частота кадров и возрастёт.
Впрочем, это дело отдельного разговора, раз производители GPU говорят нам «Надо!», значит, так и есть, против них не пойдешь. Они видят в многочиповых конфигурациях путь роста производительности (в бенчмарках, прежде всего, надо отметить). Так, начиная с версии CATALYST 7.10, для всех DirectX 9 и 10 приложений по-умолчанию включен специальный режим «Compatible AFR». Это не избавит от некоторых проблем и ошибок, но производительность должно поднимать чаще, чем CrossFire системы до этого великого момента. А насколько сильно скорость увеличится — вопрос. Нам очень нравятся заявления обеих компаний о том, что эффективность их технологий CrossFire и SLI очень высока, до 80% (в реальности скорее 50%) в сверхвысоких разрешениях типа 2560x1600, да и всё больше в бенчмарках, а не в первой попавшейся игре. Жаждущим рекордов в 3DMark посвящается.
Из нововведений CrossFireX, помимо шикарной возможности установки сразу четырех видеокарт, потребляющих более чем 100 Вт каждая, можно отметить возможность разгона на мультичиповых решениях, в том числе и автоматическое определение рабочих частот, а также поддержку неких новых мультимониторных режимов, до восьми штук одновременно. Эту очередную весьма важную возможность обещают включить в драйверах, которые выйдут в начале 2008 года.
ATI PowerPlay
В отличие от CrossFire, реальным улучшением, которое сразу могут прочувствовать на своей шкуре рядовые пользователи, стала технология ATI PowerPlay — технология динамического управления питанием, пришедшая с видеочипов для ноутбуков. Суть технологии в том, что специальная управляющая схема в чипе отслеживает загрузку видеочипа работой (процент загрузки GPU, к слову, показывается на панели Overdrive в CATALYST Control Center) и определяет необходимый рабочий режим, управляя рабочей частотой чипа, памяти, напряжением питания и другими параметрами, оптимизируя энергопотребление и тепловыделение.
Иными словами, в 2D режиме, при невысокой загрузке GPU, напряжение и частоты будут максимально снижены, как и частота вращения вентилятора, охлаждающего радиатор видеокарты (в некоторых случаях теоретически возможно и полное выключение вентилятора), в режиме небольшой 3D-нагрузки все параметры установятся на средние значения, а при максимальной работе GPU и частоты с напряжением будут выставлены в наибольшее значение. В отличие от предыдущих решений AMD и Nvidia, эти режимы управляются не драйвером, а аппаратно, самим чипом. То есть более эффективно, с меньшими задержками и без известных проблем, связанных с определением 2D/3D режимов, когда 3D-приложение, запущенное в оконном режиме, не считается драйверами 3D-приложением.
В своей презентации AMD сравнивает потребление HD 2900 XT и HD 3870, если в 2D и интенсивном 3D-режимах разница между потребляемой и выделяемой мощностью решений составляет привычные два раза, то в так называемом «легком игровом» режиме (честно говоря, непонятно, что за игры имеются в виду, видимо, игры многолетней давности и современные casual игры в 3D) разница достигает уже четырех крат, что весьма и весьма много.
Итак, мы познакомились с теоретическими особенностями нового mid-end чипа RV670, далее идёт практическая часть исследования, в которой мы узнаем, как производительность новых решений на основе RV670 соотносится со скоростью предыдущих решений компании AMD и конкурирующих видеокарт Nvidia на основе чипа G92. Также мы проверим, насколько сильно «урезание» ширины шины памяти сказалось на их скорости, по сравнению с топовой картой семейства — RADEON HD 2900 XT.
Комментарии