Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer
Часть 15: процессоры AMD Phenom X4
Не так давно компания AMD объявила о выпуске новых серийных моделей процессоров Phenom X4, основанных на новой архитектуре, знакомой пользователям под официальным названием «AMD Family 10h Processors» (кодовое название «AMD K10», ранее известное как «AMD K8L»). Отметим ключевые моменты новой процессорной архитектуры от AMD, почерпнутые из официальной документации на эту архитектуру (Software Optimization Guide for AMD Family 10h Processors, Publication #40546), в сравнении с архитектурой предыдущих моделей процессоров AMD K8.
- Реализация 128-битных (против 64-битных у AMD K8) исполнительных устройств с плавающей точкой (FP), количество которых осталось прежним (3 шт. — блоки FADD, FMUL и FSTORE);
- Расширение шины L1-LSU (Load-Store Unit) до 2x128 бит (чтение) и 2x64 бит (запись);
- Расширение шины L1-L2 кэша ядра процессора до 128 бит (при этом тип ее организации официально не разглашается);
- Реализация предвыборки данных в L1-кэш процессора (как мы увидим ниже, действующей на всех уровнях кэша процессора, а также оперативной памяти);
- Наличие объединенного кэша инструкций/данных третьего уровня (L3) эксклюзивной (неинклюзивной) архитектуры, расположенного в интегрированном контроллере памяти и общего по отношению к ядрам процессора;
- Наличие интегрированного двухканального контроллера памяти (2x64-бит, с возможностью «спаренного» (ganged) либо «распаренного» (unganged) режимов работы), поддерживающего память типа DDR2 и DDR3 (в первых моделях процессоров — только DDR2).
В распоряжении нашей тестовой лаборатории оказался инженерный образец процессора AMD Phenom X4 9700 с частотой 2.4 ГГц, который мы уже имели возможность протестировать в нашем недавнем исследовании, посвященном эффективности утилизации пропускной способности памяти. В этом исследовании уже были затронуты некоторые архитектурные аспекты нового поколения процессоров AMD, в частности, связанные с его шиной L1-L2 кэша. В настоящей статье мы более детально рассмотрим представленные выше ключевые моменты новой процессорной архитектуры, сопоставив их с характеристиками типичного представителя последнего поколения архитектуры AMD K8 — процессора Athlon 64 X2 5200+ платформы «AM2» (или официально — NPT, New Platform Technology).
Конфигурация тестовых стендов
Стенд №1 (платформа АМ2)
- Процессор: AMD Athlon 64 X2 5200+ (2.6 ГГц, CPUID 40F32h, ядро Windsor rev. F2)
- Чипсет: NVIDIA nForce 590 SLI
- Материнская плата: ASUS CROSSHAIR, версия BIOS 0702 от 20.06.2007
- Память: 2x1 ГБ Corsair XMS2-6400 DDR2-800, тайминги 5-5-5-18
Стенд №2 (платформа АМ2+)
- Процессор: AMD Phenom X4 9700 (инженерный образец, 2.4 ГГц, CPUID 100F22h, ядро Barcelona rev. B2)
- Чипсет: AMD 790FX
- Материнская плата: MSI K9A2 Platinum, версия BIOS V1.1B3 от 16.11.2007
- Память: 2x1 ГБ Corsair XMS2-6400 DDR2-800, тайминги 5-5-5-18, ganged mode
Характеристики CPUID
Начнем изучение новой процессорной архитектуры AMD с рассмотрения кратких характеристик процессора, выдаваемых инструкцией CPUID и представленных в табл. 1.
Таблица 1. Phenom X4 CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 100F22h | Семейство 16, модель 2, степпинг 2 |
| Brand ID | 10000000h | Неизвестно (инженерный образец) |
| Дескрипторы кэшей/TLB | FF30h FF10h FF30h FF20h 40020140h 40020140h 2080h 0000h 4200h 4200h 02008140h 0010A140h | L1 D-TLB: 4-МБ стр., 24 записи, полноасс. L1 I-TLB: 4-МБ стр., 8 записей, полноасс. L1 D-TLB: 4-КБ стр., 48 записи, полноасс. L1 I-TLB: 4-МБ стр., 32 записи, полноасс. L1-D кэш: 64 КБ, 2-асс., 64-байтн. строка L1-I кэш: 64 КБ, 2-асс., 64-байтн. строка L2 D-TLB: 4-МБ стр., 64 записи, 2-асс. L2 I-TLB: 4-МБ стр., не поддерживается L2 D-TLB: 4-КБ стр., 512 записей, 4-асс. L2 I-TLB: 4-КБ стр., 512 записей, 4-асс. L2 кэш: 512 КБ, 16-асс., 64-байтн. строка L3 кэш: 2048 КБ, 32-асс., 64-байтн. строка |
| Количество логических процессоров | 04h | 4 логических процессора |
| Количество ядер | 03h | 4 ядра |
| Basic Features, ECX | 802009h | Bit 0: SSE3 Bit 3: Инструкции MONITOR/MWAIT Bit 13: Инструкция CMPXCHG16B Bit 23: Инструкция POPCNT |
| Extended Features, EDX | EFD3FBFFh | Bit 26: Поддержка 1-ГБ страниц памяти Bit 27: Инструкция RDTSCP |
| Extended Features, ECX | 07FFh | Bit 0: Инструкции LAHF/SAHF Bit 1: Многоядерный процессор Bit 2: Расширения SVM (Secure Virtual Mode) Bit 3: Расширенное пространство APIC Bit 4: Инструкция MOV CR8 Bit 5: Advanced Bit Manipulation (инструкция LZCNT) Bit 6: SSE4A (инструкции EXTRQ, INSERTQ, MOVNTSS, MOVNTSD) Bit 7: Невыровненный режим SSE Bit 8: Инструкции 3DNow!-предвыборки (PREFETCH и PREFTECHW) Bit 9: OS Visible Workaround Bit 10: Instruction Based Sampling |
Итак, перед нами — процессор AMD нового семейства 16 (10h), самой компанией именуемого «Family 10h». Номер модели (2) и степпинга (2) соответствуют ревизии процессорного ядра B2. Дескрипторы кэшей и TLB процессора полностью поддаются расшифровке, согласно имеющейся на данный момент документации на процессоры (BIOS and Kernel Developer's Guide (BKDG) For AMD Family 10h Processors, Publication #31116). Среди расширений процессора можно отметить поддержку инструкций MONITOR/MWAIT в дополнение к расширениям SSE3, присутствующим в последних моделях процессоров Athlon 64 X2, вспомогательных инструкций для манипуляции с битами (Advanced Bit Manipulation — POPCNT, LZCNT), расширений «SSE4A» (версия SSE4 от AMD, поддерживаемые инструкции перечислены в табл. 1) и невыровненного режима SSE (операций SSE с данными, невыровненными по естественной 16-байтной границе).
Реальная пропускная способность кэша данных/памяти
Перейдем к результатам тестирования нового процессорного ядра, которые, как обычно, начнем с тестов реальной пропускной способности (ПС) всех уровней кэша данных и оперативной памяти.
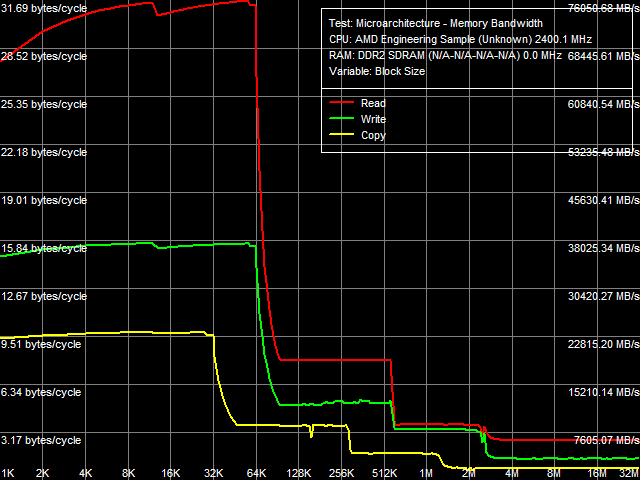
Рис. 1. Средняя реальная ПС кэша данных и оперативной памяти, SSE2
Наиболее показателен результат этого теста, полученный с использованием 128-битного доступа к данным с помощью инструкций SSE/SSE2 (см. рис. 1). Налицо наличие трехуровневой эксклюзивной архитектуры кэша данных. Размер L1-кэша данных составляет 64 КБ (первый перегиб), второй перегиб в области примерно 576 КБ соответствует объединенному размеру L1+L2 кэша процессора (64 + 512 КБ), наконец, последний перегиб в области примерно 2.5 МБ соответствует суммарному размеру всех уровней кэша процессора (64 + 512 + 2048 КБ = 2624 КБ). Интересно отметить, что L3-кэш процессора, который, как известно, относится к области его интегрированного контроллера памяти и является общим для всех четырех ядер процессора, при исполнении данного теста целиком оказывается в распоряжении первого ядра процессора, исполняющего код тестового приложения и осуществляющего доступ к данным. Также интересно отметить, что скоростные характеристики L3-кэша данных, особенно при операциях чтения, несильно превосходят скоростные характеристики оперативной памяти — это видно даже на качественном уровне по относительно слабому перегибу на соответствующей кривой между областями L3-кэша и оперативной памяти. Это может говорить, с одной стороны, о достаточно высокой эффективности контроллера памяти (что подтверждается результатами нашего недавнего исследования), в частности, аппаратной предвыборки данных из оперативной памяти, а с другой стороны, — достаточно невысокой эффективности обмена данными между L3-кэшем контроллера памяти процессора и одним, отдельно взятым ядром процессора.
Таблица 2
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| Athlon 64 X2 | Phenom X4 | |
| L1, чтение, MMX L1, чтение, SSE2 L1, запись, MMX L1, запись, SSE2 | 15.68 8.00 8.00 8.00 | 15.69 31.69 7.98 15.67 |
| L2, чтение, MMX L2, чтение, SSE2 L2, запись, MMX L2, запись, SSE2 | 4.10 4.02 3.94 3.92 | 7.66 7.98 4.94 5.10 |
| L3, чтение, MMX L3, чтение, SSE2 L3, запись, MMX L3, запись, SSE2 | — | 3.69 3.71 3.38 3.38 |
| RAM*, чтение (SSE2) RAM, запись (SSE2) | 3.89 ГБ/с (32.7%) 3.27 ГБ/с (27.5%) | 6.38 ГБ/с (49.9%) 3.49 ГБ/с (27.3%) |
*в скобках указаны значения относительно теоретического предела ПС шины памяти
Более интересны количественные оценки ПС различных уровней кэша процессора, представленные в табл. 2, в сравнении с характеристиками процессора Athlon 64 X2, типичного представителя платформы АМ2.
Наибольшие различия наблюдаются в ПС L1-кэша данных рассматриваемых процессоров. В условиях 64-битного доступа с использованием регистров MMX ПС этого уровня кэша у Phenom X4 и Athlon 64 X2 практически совпадает (~15.7 байт/такт на чтение, ~8.0 байт/такт на запись). Однако использование 128-битного доступа с использованием инструкций SSE или SSE2 принципиально меняет картину: в новом процессоре ПС L1 на чтение возросло с 8.0 байт/такт до ~31.7 байт/такт (то есть практически в 4 раза!), а на запись — с тех же 8.0 байт/такт до ~15.7 байт/такт (примерно в 2 раза). Попробуем разобраться в причинах наблюдаемых различий (а также их отсутствий при 64-битном доступе к данным).
Согласно документации, L1-кэш данных новых процессоров семейства Phenom обладает двумя 128-битными портами (по сравнению с двумя 64-битными портами L1-кэша процессоров семейства Athlon 64). При этом блок LSU (Load-Store Unit) за один такт процессорного ядра способен осуществлять две 128-битные операции чтения, либо две 64-битные операции записи (при этом 128-битная операция записи разбивается на две 64-битные операции). Таким образом, пиковая ПС связки «регистры процессора — L1 кэш данных» может составлять 256 бит (32 байта) на такт при операциях чтения, и 128 бит (16 байт) на такт при операциях записи. Соответствующие скоростные характеристики процессоров Athlon 64 ограничены возможностью осуществления за один такт двух 64-битных операций чтения (128 бит, или 16 байт/такт), либо двух 64-битных операций записи (128 бит, или 16 байт/такт).
Однако этих данных пока недостаточно для объяснения реальных значений ПС, наблюдаемых в нашем тесте, — близкие к предельным значения наблюдаются только на процессоре Phenom X4 и только при использовании SSE/SSE2, но не во всех остальных случаях. Для объяснения этого факта необходимо рассмотреть предельную скорость исполнения инструкций загрузки/выгрузки данных MMX и SSE/SSE2 обоими процессорами. Для процессоров семейства Athlon 64 она составляет до 2-х инструкций загрузки данных MMX (MOVQ reg, [mem]) и одной инструкции выгрузки данных (MOVQ [mem], reg). Инструкции загрузки/выгрузки данных SSE/SSE2 (MOVAPS или MOVDQA) способны исполняться лишь со скоростью 1 инструкция / 2 такта. Это полностью объясняет наблюдаемые величины ПС L1-кэша на процессорах этого семейства: исполнение 2-х инструкций MMX при чтении данных обеспечивает ПС на чтения порядка 16 байт/такт, одной инструкции MMX при записи данных — ПС на запись в 8 байт/такт, а исполнение инструкций SSE/SSE2 со скоростью 1/2 ограничивает реальную ПС L1-кэша на уровне 8 байт/такт как при чтении, так и при записи данных.
Иначе обстоит дело в новых процессорах Phenom, в которых разрядность исполнительных модулей FP (операций с плавающей точкой, в которых обрабатываются все инструкции SSE/SSE2, даже не связанные с вычислениями) была расширена до 128 бит. Ядро этих процессоров способно исполнять инструкции SSE/SSE2 с внушительной скоростью — до 2 инструкций/такт при загрузке данных (конвейеры FADD и FMUL), и до 1 инструкции/такт при выгрузке данных (конвейер FSTORE). При этом скорость исполнения инструкций MMX остается такой же, как и в процессорах семейства Athlon 64. Таким образом, можно сказать, что в этих процессорах, при пересылке данных L1-кэш и исполнительные модули работают согласованно: два 128-битных порта L1-кэша/LSU обеспечивают ПС (256 бит, или 32 байта/такт), равную предельной скорости исполнения инструкций SSE/SSE2 при чтении данных (две за такт); при записи данных возможность осуществления до двух 64-битных операций пересылки данных из LSU в L1-кэш (128 бит, или 16 байт/такт) соответствует предельной скорости исполнения SSE/SSE2-инструкций записи данных (одна за такт).
Рассмотрим ПС 2-го уровня кэша данных, которая на процессорах нового семейства возросла ощутимо — почти в 2 раза при операциях чтения (7.66-7.98 байт/такт против 4.02-4.10 байт/такт) и примерно на 25-30% при операциях записи (4.94-5.10 байт/такт против 3.92-3.94 байта/такт). В нашем первом исследовании, посвященном эффективности взаимодействия новых процессоров с подсистемой памяти, мы уже отмечали, что эффективная ширина шины L1-L2 кэша данных на чтение возросла до 128 бит, что подтверждается и результатами данных измерений.
Изучая величины ПС L3-кэша Phenom в цифрах (ее качественное рассмотрение мы сделали выше), интересно отметить, что она не сильно уступает ПС L2-кэша предыдущего поколения процессоров Athlon 64 X2 — несмотря на тот факт, что L3-кэш является архитектурным элементом, отдельным от ядра процессора, тогда как L2-кэш и в Athlon 64, и в Phenom интегрирован в ядро. Разумно предположить (а далее — проверить это предположение), что разрядность шины L2-L3 составляет 64 бита, то есть равна разрядности шины L1-L2 процессоров семейства Athlon 64.
Что касается пропускной способности памяти (ПСП), недавно мы уже показали, что по сравнению с Athlon 64 X2 она возросла значительно при операциях чтения, оставаясь примерно на том же уровне при операциях записи. С одной стороны, это можно объяснить значительным увеличением ПС шины L1-L2 кэша процессора, а с другой — более высокой эффективностью реализации аппаратной предвыборки данных из памяти в процессорах семейства Phenom. При этом следует, однако, заметить, что реально достижимая величина ПСП составляет не более 50% от теоретической ПСП двухканальной DDR2-800 (тесты проводились в «спаренном» (ganged) режиме работы интегрированного контроллера памяти, обеспечивающем именно такую теоретическую ПС шины памяти даже при «одноядерном» доступе). Заметим также, что ПС L3-кэша на чтение данных одним ядром процессора (примерно 3.7 байт/такт, то есть примерно 8.9 ГБ/с) также оказывается ниже теоретической ПСП двухканальной DDR2-800, что подтверждает сделанное в нашем раннем исследовании предположение о наличии предела эффективности «обслуживания» одного ядра процессора его интегрированным контроллером памяти, преодолеть который, однако, можно при «многоядерном» доступе в память.
Предельная реальная пропускная способность памяти
Оценим предельно достижимую ПСП при одноядерном доступе в память, полученную с помощью оптимизации операций чтения (программная предвыборка данных) и записи (методом прямого сохранения).
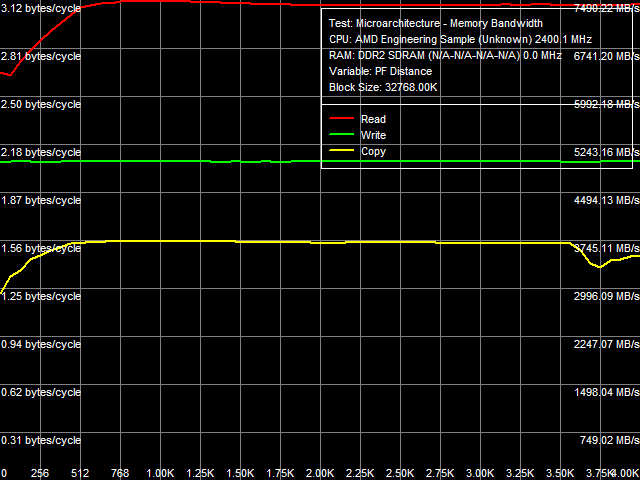
Рис. 2. Максимальная реальная ПСП, SSE2, Software Prefetch/Non-Temporal Store
Результат теста представлен на рис. 2 и в табл. 3. Максимальная эффективность программной предвыборки наблюдается при дистанции предвыборки 768 байт и выше. Однако ее эффективность оказывается довольно невысокой — достижимая величина ПСП составляет ~7.5 ГБ/с (58.5% от теоретической ПСП), что всего на 17% выше по сравнению с «обычным» чтением данных. Для сравнения, эффективность программной предвыборки на Athlon 64 X2 значительно выше — ПСП возрастает примерно в 2 раза. Скорее всего, это связано с высокой эффективностью реализации аппаратной предвыборки данных в Phenom — настолько, что программной предвыборке уже «негде развернуться», и она становится… как бы ненужной. Особенно отчетливо это было заметно в нашем недавнем исследовании эффективности утилизации ПСП DDR2-800 и DDR2-1066 при изучении «многоядерного» доступа в память. Нам остается добавить, что высокую эффективность аппаратной предвыборки, делающую «ненужным» программную предвыборку, можно считать большим плюсом новой архитектуры процессоров AMD — разработчикам ПО можно практически не заботиться о проблемах организации программной предвыборки данных (вычислении дистанции предвыборки и размещения инструкций PREFETCHx) в коде своих приложений.
В то же время, нас не могут не огорчать результаты измерений максимальной реальной ПСП на запись данных, которая демонстрирует весьма низкую эффективность реализации метода прямого сохранения данных (минуя всю иерархию кэшей). Она составляет лишь 39% от теоретической ПСП, и примерно 69% от величины, наблюдаемой на Athlon 64 X2. Можно предположить, что «виноват» в данном случае L3-кэш процессора, общий для всех ядер и расположенный в северном мосту процессора, который в данном случае также требуется «обходить», то есть организовывать прямой путь поступления данных из ядра процессора непосредственно в оперативную память.
Таблица 3
| Операция | Максимальная реальная ПСП, ГБ/с* | |
|---|---|---|
| Athlon 64 X2 | Phenom X4 | |
| Чтение, Software Prefetch | 7.87 (65.9%) | 7.49 (58.5%) |
| Запись, Non-Temporal Store | 7.26 (60.8%) | 4.99 (39.0%) |
*в скобках указаны значения относительно теоретического предела ПС шины памяти
Средняя латентность кэша данных/памяти
Перейдем к тестам латентности кэша данных и памяти, способных выявить некоторые новые интересные подробности реализации архитектуры процессоров AMD Phenom.
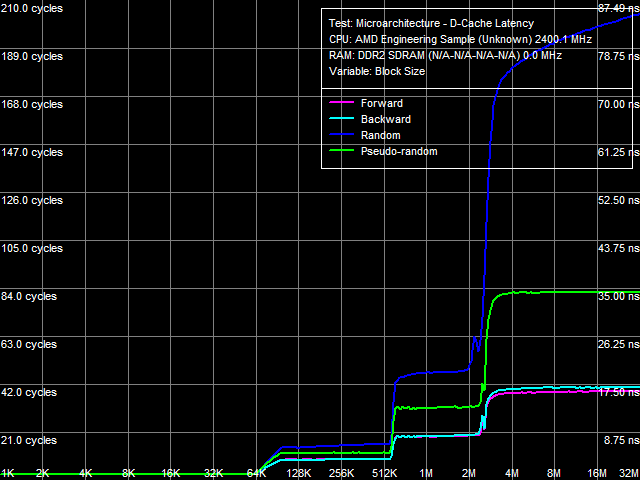
Рис. 3. Латентность кэша данных и памяти
Результат теста на качественном уровне (см. рис. 3) совпадает с результатом теста измерения ПСП различных уровней кэша процессора с точки зрения их объема и типа организации (эксклюзивной). Но уже на качественном уровне характерно отметить, что величины латентности всех уровней кэша, за исключением L1, различаются в зависимости от того, какой режим доступа используется (прямой, обратный, псевдослучайный или случайный). Это говорит о реализации аппаратной предвыборки данных на всех уровнях кэша процессора (из L2-кэша, из L3-кэша и из оперативной памяти) — впервые для процессоров AMD (во всех предыдущих поколениях процессоров семейств AMD K7 и K8 аппаратная предвыборка данных присутствовала лишь на уровне оперативной памяти).
Таблица 4
| Уровень, режим доступа | Средняя латентность, тактов (нс) | |
|---|---|---|
| Athlon 64 X2 | Phenom X4 | |
| L1-кэш, во всех случаях | 3.0 | 3.0 |
| L2-кэш, прямой L2-кэш, обратный L2-кэш, псевдослучайный L2-кэш, случайный* | ~17.0 | ~9.2 ~9.0 ~12.1 ~14.5 |
| L3-кэш, прямой L3-кэш, обратный L3-кэш, псевдослучайный L3-кэш, случайный* | — | ~19.4 ~19.5 ~31.9 ~47.5 |
| RAM, прямой RAM, обратный RAM, псевдослучайный RAM, случайный* | 21.4 нс 21.2 нс 32.3 нс 86.0 нс | 16.2 нс 17.0 нс 34.4 нс 85.3 нс |
*размер блока 32 МБ
В количественных оценках эти различия представлены в табл. 4. Средняя латентность L1-кэша данных в новых процессорах остается на уровне 3 тактов. Средняя латентность L2-кэша зависит от режима доступа: для прямого и обратного обхода (когда эффективность аппаратной предвыборки максимальна) она составляет примерно 9 тактов, при случайном обходе — примерно, 14.5 тактов, псевдослучайный обход дает значение «где-то посередине» (примерно 12 тактов), что говорит о том, что даже в этом случае аппаратная предвыборка данных способна проявить себя в достаточной мере. Соответствующая величина в процессорах Athlon 64 X2 не зависит от режима обхода и составляет примерно 17 тактов. С величинами средней латентности L3-кэша наблюдается похожая картина: она минимальна (примерно, 19.5 тактов) при прямом и обратном обходе, и максимальна — при случайном (примерно, 47.5 тактов), а при псевдослучайном обходе находится, примерно, посередине между этими значениями. И, наконец, то же, но с существенно большим разбросом, наблюдается и при доступе в память: величины средней латентности памяти разбросаны в пределах от 16-17 до 85 нс. Заметим также, что все возрастающая величина латентности случайного доступа в память связана со все возрастающим количеством промахов L2 D-TLB, размер которого составляет 512 записей 4-КБ страниц памяти, то есть способен «покрыть» до 2 МБ случайных обращений к памяти (соответствующий перегиб на кривой не заметен, поскольку попадает в область перегиба, связанного с размером L3-кэша процессора).
Минимальная латентность кэша данных и памяти
Попытаемся определить минимальные латентности различных уровней кэша данных процессора. На первый взгляд, это может показаться тривиальной задачей, однако наличие аппаратной предвыборки данных на всех уровнях существенно затрудняет проведение этого точного количественного исследования.
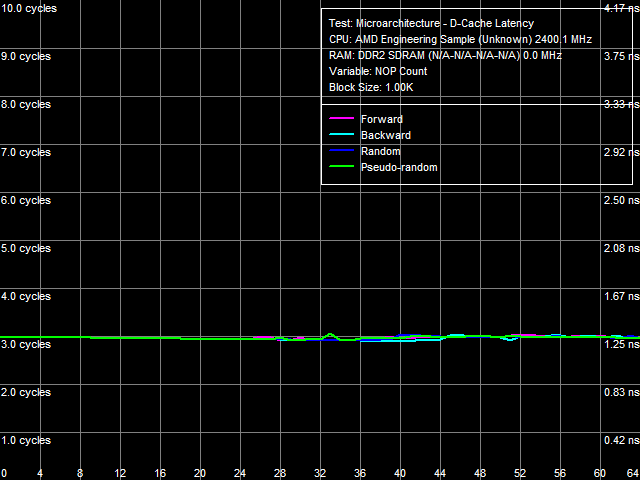
Рис. 4. Минимальная латентность L1-кэша
Легче всего обстоит дело с L1-кэшем данных, результат измерения латентности которого представлен на рис. 4. Во всех случаях она равна средней латентности этого уровня и составляет 3 такта (см. табл. 5).
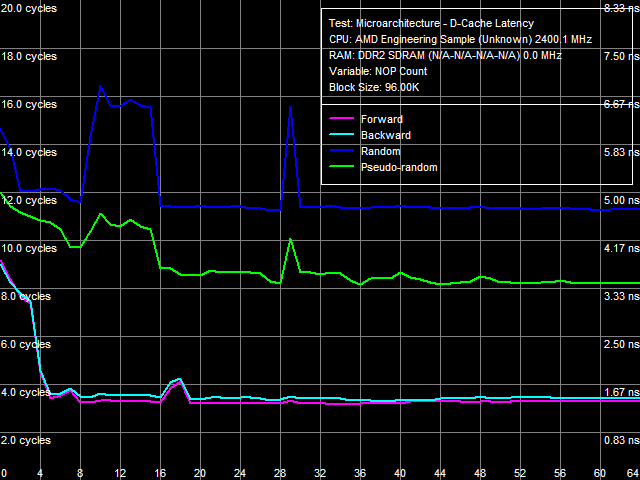
Рис. 5. Минимальная латентность L2-кэша, метод 1
Попытка оценить минимальную латентность L2-кэша тем же методом не приводит к ощутимо хорошему результату — картину существенно осложняет аппаратная предвыборка данных (см. рис. 5). Уже при вставке 5 «пустых операций» («NOP-ов», не связанных с доступом в кэш) между двумя соседними обращениями она приводит к полной «разгрузке» L2-кэша, и его латентность понижается практически до уровня латентности L1-кэша и составляет примерно 3.3 такта. При псевдослучайном обходе требуется уже 16 «NOP-ов», а минимально достижимая латентность составляет примерно 8.2 такта. И только при случайном обходе для полной «разгрузки» требуется не менее 30 «NOP-ов», а достигаемый минимум составляет 11.5 тактов, что наиболее близко к результату, ожидаемому, согласно документации (9 тактов латентности сверх L1, то есть общая латентность 12 тактов).
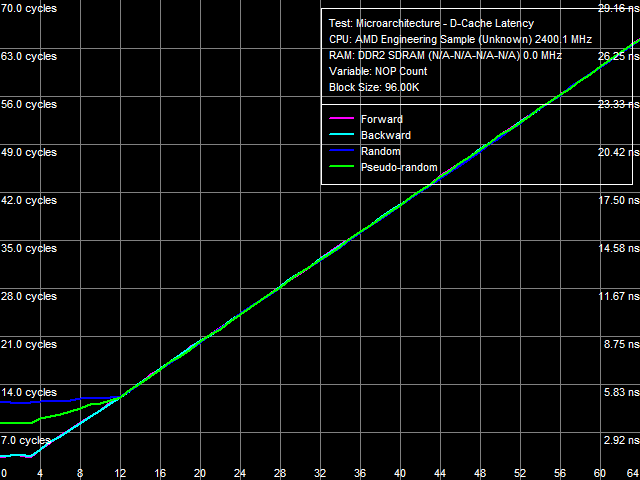
Рис. 6. Минимальная латентность L2-кэша, метод 2
Попробуем оценить минимальную латентность L2 и достичь ее реальную величину методом 2 (см. рис. 6), изначально разработанным для процессоров со спекулятивной загрузкой данных (класса Intel Pentium 4 Prescott и более старших моделей). Напомним, что в этом методе мерой латентности следует считать количество используемых для разгрузки шины «NOP-ов», при котором наблюдается перегиб на кривой, помноженное на скорость их исполнения в зависимой цепи инструкций (для рассматриваемых процессоров это 1 инструкция/такт). Что характерно, перегиб на кривых прямого и обратного, а также псевдослучайного обхода наблюдается в области 3 «NOP-ов», то есть минимальная латентность этих уровней, вследствие аппаратной предвыборки данных, равна латентности L1 и составляет 3 такта. Правильную оценку истинной латентности L2, без участия предвыборки, дает истинно случайный обход — перегиб на соответствующей кривой наблюдается в области 12 тактов. Интересно также отметить, что точка 12 «NOP-ов» является точкой, в которой все 4 кривые «сливаются воедино». Как будет показано ниже, эта точка может являться более надежным критерием достижения истинной латентности рассматриваемого уровня кэша данных процессора.
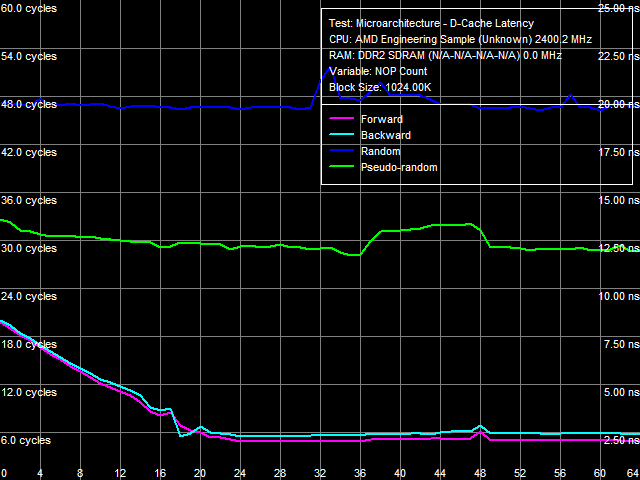
Рис. 7. Минимальная латентность L3-кэша, метод 1
По аналогии с тестами латентности L2, попытаемся оценить минимальную латентность L3-кэша процессора Phenom. Для этого воспользуемся модифицированным вариантом тестов «Minimal L2 D-Cache Latency, Method 1/Method 2», увеличив размер блока с 96 до 1024 КБ (для попадания в область L3). Результат этого теста методом 1 представлен на рис. 7. Аналогично, при прямом и обратном обходе при вставке примерно 24 и более «NOP-ов» наблюдается полная «разгрузка» L3-кэша, приводящая к его минимальной эффективной латентности порядка 5.0-5.5 тактов. Однако при псевдослучайном обходе разгрузка шины уже практически не происходит, и минимальная латентность (~28.2 такта) не сильно отличается от своего среднего значения (~32 такта). То же можно сказать и о случайном доступе, при котором минимально достижимая величина составляет примерно 46.7 тактов.
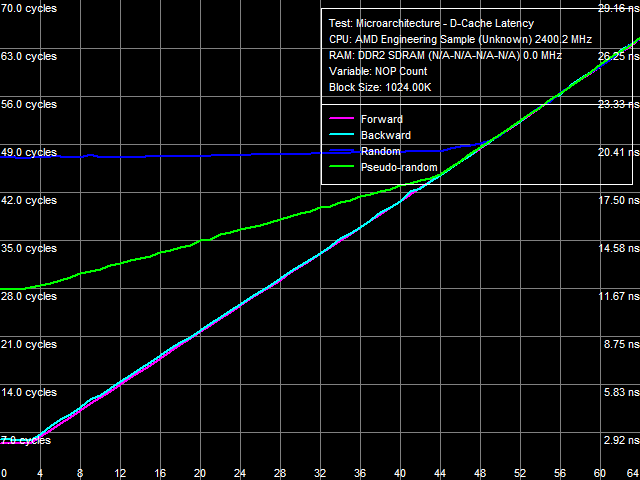
Рис. 8. Минимальная латентность L3-кэша, метод 2
Для попытки более точной количественной оценки истинной латентности L3-кэша вновь попробуем обратиться к измерению методом 2, результат которого приведен на рис. 8. Как и в случае L2-кэша, наличие аппаратной предвыборки в случае прямого, обратного и псевдослучайного обхода приводит к эффективной величине латентности L3, равной латентности L1-кэша (3 такта). Теоретически такой результат можно считать верным — в условиях бесконечно высокой эффективности аппаратной предвыборки (при бесконечно большой разгрузке шины данных) действительно, все запрашиваемые данные как бы сразу окажутся в L1-кэше, и эффективная задержка их считывания будет равняться задержке именно этого уровня кэша процессора. В то же время, перегиб на кривой случайного доступа (когда эффективность аппаратной предвыборки близка к нулю) оказывается достаточно нечетким — эта кривая изначально плавно возрастает по мере увеличения количества «NOP-ов», а более резкий скачок наблюдается в области 44-48 «NOP-ов». И именно в этом случае более надежным критерием оценки реальной латентности L3-кэша выступает точка слияния всех кривых, на которую приходится примерно 48-49 «NOP-ов». Учитывая полученные выше данные по средней латентности L3-кэша, будем считать, что истинная латентность этого уровня кэша составляет 48 тактов (с погрешностью ±1 такт).
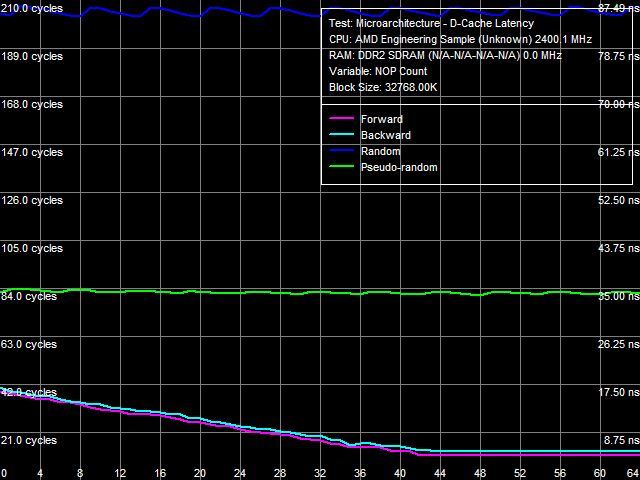
Рис. 9. Минимальная латентность памяти
В заключение, оценим минимальную латентность оперативной памяти, достижимую на платформе с процессором Phenom X4. Как и во всех рассмотренных выше случаях, аппаратная предвыборка данных понижает ее до весьма низких значений при прямом и обратном обходе (4.6-5.4 нс, то есть всего 11-13 процессорных тактов), однако при псевдослучайном и случайном обходе практически минимальные величины латентности практически равны средним. В противоположность этому, следует отметить, что на платформе Athlon 64 X2 разгрузка шины L2-RAM приводит к некоторому снижению латентности случайного доступа к памяти (с 86 до 74 нс, то есть примерно на 14%).
Таблица 5
| Уровень, режим доступа | Минимальная латентность, тактов (нс) | |
|---|---|---|
| Athlon 64 X2 | Phenom X4 | |
| L1-кэш, во всех случаях | 3.0 | 3.0 |
| L2-кэш*, прямой L2-кэш, обратный L2-кэш, псевдослучайный L2-кэш, случайный** | 12.0 | ~3.3 (3.0) ~3.3 (3.0) ~8.2 (3.0) ~11.3 (12.0) |
| L3-кэш*, прямой L3-кэш, обратный L3-кэш, псевдослучайный L3-кэш, случайный** | — | ~5.0 (3.0) ~5.5 (3.0) ~28.2 (3.0) ~46.7 (48.0) |
| RAM, прямой RAM, обратный RAM, псевдослучайный RAM, случайный** | 7.2 нс 7.8 нс 29.4 нс 74.1 нс | 4.6 нс 5.4 нс 33.9 нс 84.6 нс |
*в скобках указаны значения, полученные методом №2
**размер блока 32 МБ
Ассоциативность кэша данных
Ассоциативности всех трех уровней кэша процессора (L1-D, L2 и L3) известны из характеристик CPUID: они составляют 2, 16 и 32 такта, соответственно. В этой связи реальная картина измерения ассоциативности, представленная на рис. 10, выглядит особенно интересно.
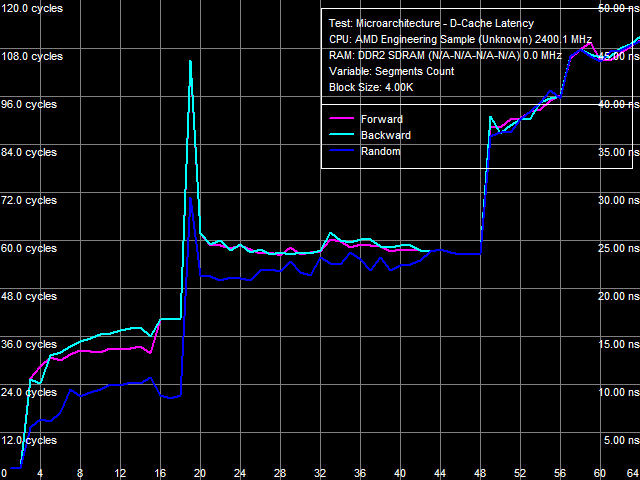
Рис. 10. Ассоциативность кэша данных
Первый перегиб наблюдается в области 2-х сегментов кэша (используемый в этом тесте размер сегмента составляет 1 МБ) и соответствует ассоциативности L1-кэша данных. Второй перегиб наблюдается при превышении 18 сегментов кэша, что характерно для эксклюзивной организации последнего — это соответствует «объединенной ассоциативности» L1-D и L2-кэшей процессора (2+16). Однако наиболее интересен последний перегиб, наблюдаемый в области 48 сегментов кэша. По аналогии, он должен соответствовать «суммарной ассоциативности» всех трех уровней кэша, которая, однако, должна равняться 50 (2+16+32). Получается, что в этом тесте L3-кэш проявляет свою «эффективную» ассоциативность, равную лишь 30. Пока до конца не понятно, почему так происходит, однако это может быть связано с особенностью локализации L3-кэша (в контроллере памяти, но не ядре процессора) и связанным с нею «разделением» этого уровня кэша всеми ядрами процессора.
Реальная пропускная способность шины L1-L2 кэша
Мы уже затрагивали эту «архитектурную деталь» новых процессоров Phenom в ходе нашего первого исследования, посвященного изучению подсистемы памяти на новой платформе ввиду ее крайней важности для эффективной утилизации высокой ПСП двухканальной DDR2-800 и DDR2-1066.
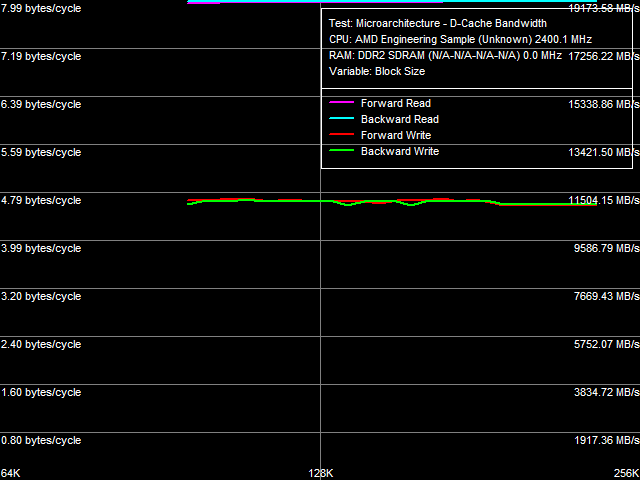
Рис. 11. Реальная пропускная способность шины L1-L2 кэша
Результат теста реальной ПС шины L1-L2 кэша приведен на рис. 11, а количественные ее оценки в сравнении с Athlon 64 X2 — в табл. 6.
Таблица 6
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт | |
|---|---|---|
| Athlon 64 X2 | Phenom X4 | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 4.67 4.85 4.55 4.55 | 7.98 7.99 4.71 4.67 |
Напомним, что «полная» ширина шины L1-L2 кэша у процессоров семейства Athlon 64 составляет 128 бит, однако эта шина организована как 128-битная двунаправленная шина (иными словами, две 64-битные шины), что обеспечивает ее ширину «в одну сторону», равную всего 64 битам. Ее «полная» разрядность может быть продемонстрирована в рассматриваемом тесте, количественные результаты которого необходимо умножить на 2 для учета эксклюзивной организации кэша процессора (пересылка любой строки из L2 в L1 сопровождается вытеснением строки из L1 в L2). Таким образом, ПС шины L1-L2 кэша на чтение строк кэша составляет примерно 9.34-9.70 байт/такт, то есть достигает примерно 58-61% от теоретического значения. ПС этой шины при записи строк кэша несколько ниже — примерно 9.10 байт/такт, то есть 57% от теоретической ПС.
Как показывают результаты теста, «полная» ширина шины L1-L2 в новых процессорах Phenom также составляет 128 бит (предельное значение ПС — 16 байт/такт), однако эффективность ее утилизации значительно возросла. Так, при считывании строк кэша ПС этой шины достигает почти предельного значения (15.96-15.98 байт/такт), однако ПС этой шины на запись строк кэша возросла ненамного и составляет 9.34-9.42 байт/такт (58-59% от теоретической).
Для более детального изучения способа организации шины L1-L2 воспользуемся тестом прибытия данных по этой шине (№1), результат которого представлен на рис. 12.
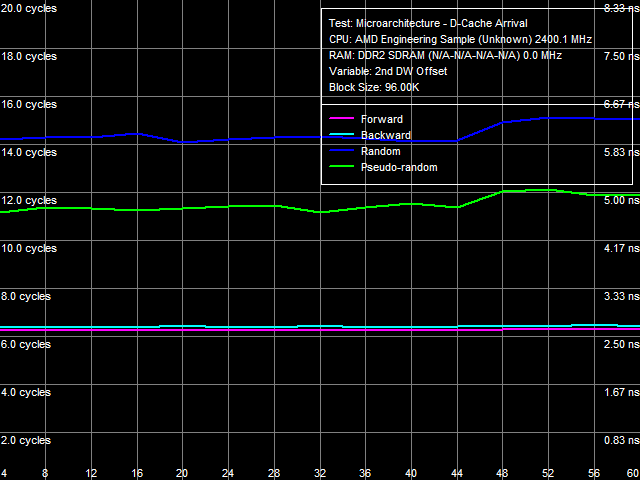
Рис. 12. Тест прибытия данных по шине L1-L2 кэша №1
Вследствие наличия аппаратной предвыборки данных на всех уровнях, результаты данного теста в случае прямого и обратного обхода (и, в некоторой степени, псевдослучайного) нельзя считать достоверными. При случайном обходе «суммарная латентность» двух обращений к элементам одной и той же строки L2-кэша в области смещений 2-го элемента относительно 1-го составляет примерно 14-14.5 тактов (теоретическое значение — 15 тактов, равное сумме латентностей L1- и L2-кэша). При величине смещения 2-го элемента 48 байт и выше она увеличивается на 1 такт. Это означает, что максимальное количество данных, которое способна переслать шина L1-L2 без задержек в пределах времени доступа к L1-кэшу (3 такта) составляет 48 байт, то есть предельная пропускная способность этой шины «в одну сторону» составляет 48/3 = 16 байт/такт (128 бит). С учетом того, что ее «полная» разрядность также составляет 128 бит (как было показано выше), шину L1-L2 кэша данных ядра процессоров Phenom можно считать однонаправленной 128-битной шиной. Напомним, что такой же способ организации шины, но вдвое меньшей разрядности, встречался в процессорах семейства AMD Athlon (K7).
Заметим, что можно представить себе и альтернативную трактовку данных, полученных в этой серии тестов. 128-битная разрядность шины в «одну сторону» надежно доказана тестом прибытия данных (№1), но можно предположить, что ее «полная» разрядность все же составляет 256 бит, то есть она представляет собой двунаправленную шину (две 128-битные шины), аналогичную шине L1-L2 процессоров семейства Athlon 64, но вдвое большей ширины. При этом ее эффективность при считывании/записи строк кэша по не совсем понятным причинам оказывается вдвое ниже наблюдаемой в предыдущем тесте, то есть составляет примерно 50% при чтении строк кэша и примерно 29% при записи строк кэша. К сожалению, никаких реальных подтверждений этому предположению нам найти не удалось, и оно может быть оправдано разве что с точки зрения здравого смысла (развитие идеи двунаправленной шины AMD K8 выглядит более логичным, нежели возврат к однонаправленной шине AMD K7). К тому же, в этом случае придется как-то объяснить, почему ее реальная ПС укладывается в предел теоретической ПС 128-битной шины и, соответственно, не превышает половины ПС 256-битной шины (тогда как реальная ПС шины L1-L2 процессоров предыдущего поколения с таким же способом ее организации достигает примерно 60% от теоретического значения).
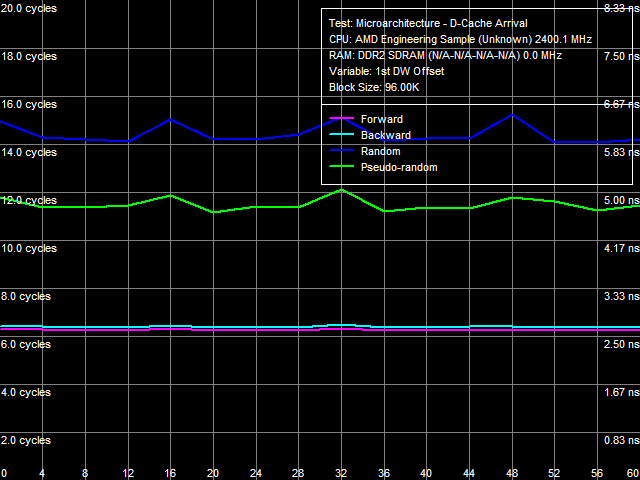
Рис. 13. Тест прибытия данных по шине L1-L2 кэша №2
Ради интереса, рассмотрим результаты теста прибытия данных по шине L1-L2 кэша №2, в котором переменной величиной оказывается смещение первого элемента строки кэша. Этот тест позволяет оценить, каким образом возможно считывание строки кэша из L2 в L1 — только от ее начала и до конца, или же считывание возможно с какого-либо промежуточного ее участка? Методология этого теста подробно описана в нашем первом исследовании процессоров AMD K7/K8, поэтому мы не будем здесь на ней подробно останавливаться. Отметим лишь, что характерные пики на кривой латентности случайного доступа при смещениях, равных 0, 16, 32 и 48 байтам означают, что считывание строки кэша возможно с ее каждого 16-го байта (например, в такой последовательности байт: 32-47, 48-63, 0-15, 16-31). То же самое, но с шагом 8 байт, наблюдалось и в вышеупомянутых процессорах AMD K7/K8, причем кратность шага соответствует разрядности шины L1-L2 «в одну сторону»: 64 бит для AMD K7 и K8, 128 бит для Phenom.
Реальная пропускная способность шины L2-L3 кэша
По аналогии с изложенными выше тестами шины L1-L2, оценим также разрядность и скоростные характеристики шины L2(ядро)-L3(контроллер памяти) процессора. Для этого воспользуемся теми же тестами, увеличив размер блока с 96-240 до 640-2048 КБ.
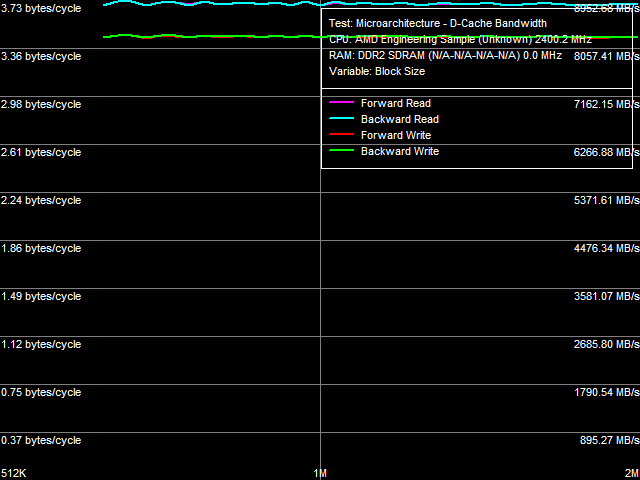
Рис. 14. Реальная пропускная способность шины L2-L3 кэша
Результат теста реальной ПС шины L2-L3 представлен на рис. 14 и в табл. 7.
Таблица 7
| Режим доступа | Реальная пропускная способность L2-L3, байт/такт | |
|---|---|---|
| Athlon 64 X2 | Phenom X4 | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | — | 3.73 3.73 3.46 3.46 |
Что интересно, величины ПС шины L2-L3 «сами по себе» очень близки к величинам реальной ПС L3-кэша на чтение/запись, полученных в соответствующем тесте. Однако, как и в случае шины L1-L2, полученные в этом тесте величины необходимо умножить на 2 для учета эксклюзивной организации и этого уровня кэша процессора. Таким образом, ПС L2-L3 составляет 7.46 байт/такт при чтении строк кэша и 6.92 байт/такт при записи. Трактовка полученных результатов вновь может оказаться двоякой: либо это 64-битная однонаправленная шина с пиковой ПС 8 байт/такт (а реально достижимая ПС составляет 86-93% от теоретического максимума), либо это 128-битная двунаправленная шина (то есть полный аналог шины L1-L2 процессоров Athlon 64), реальная утилизация которой составляет лишь 43-47%. Предпочтение тому или иному варианту вновь можно отдавать лишь руководствуясь здравым смыслом, согласно которому использование более «старого» способа реализации шины на уровне связки отдельного ядра с контроллером памяти выглядит, по крайней мере, странным. К тому же, если принять во внимание, что шина L2-L3 кэша фактически представляет собой шину обмена данными между отдельным ядром процессора и интегрированным контроллером памяти, намного разумнее предполагать двунаправленную организацию такой шины, обеспечивающую возможность одновременного чтения (из оперативной памяти или L3-кэша) и записи данных (либо вытеснения данных из L1/L2-кэша в L3-кэш).
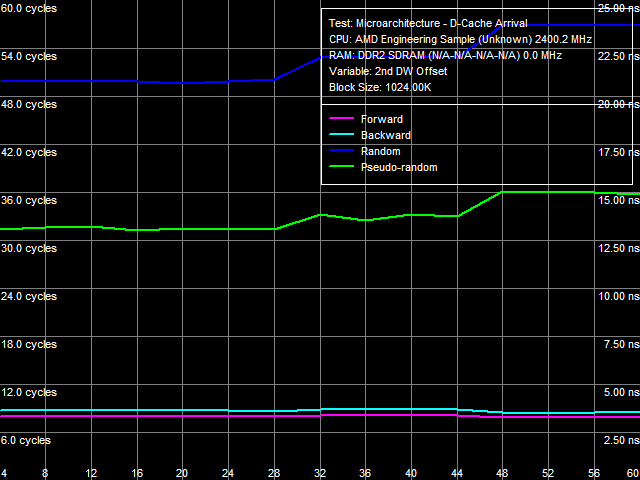
Рис. 15. Тест прибытия данных по шине L2-L3 кэша №1
Для подтверждения того, что разрядность шины L2-L3 «в одну сторону» составляет не менее 64 бит, воспользуемся тестом прибытия данных №1, результат которого приведен на рис. 15. Количественная оценка этого результата (кривые псевдослучайного и случайного обхода) несколько затруднена, поскольку увеличение латентности наблюдается при смещении 2-го элемента относительно 1-го на 32 байта и более, поскольку для 64-битной шины оно должно наблюдаться в области 24-байтного смещения (8 байт, помноженные на 3 такта доступа к данным). В то же время, при 128-битной ширине шины «в одну сторону», как было показано выше, и как предсказано теорией, возрастание латентности должно наблюдаться в области смещения от 48 байт и выше. Таким образом, разрядность шины L2-L3 «в одну сторону» не превышает 64 бит.
Кэш инструкций, реальная пропускная способность декодирования/исполнения кода
Оценим эффективность L1-кэша инструкций (L1-I) и объединенных L2/L3-кэшей инструкций/данных при декодировании и исполнении простейших ALU-инструкций в независимой цепочке. Наиболее показательный результат, с точки зрения ПС L1-I кэша, полученный при декодировании/исполнении 8-байтных «префиксных» инструкций CMP ([F3h][67h]cmp eax, 00000000h) приведен на рис. 16.
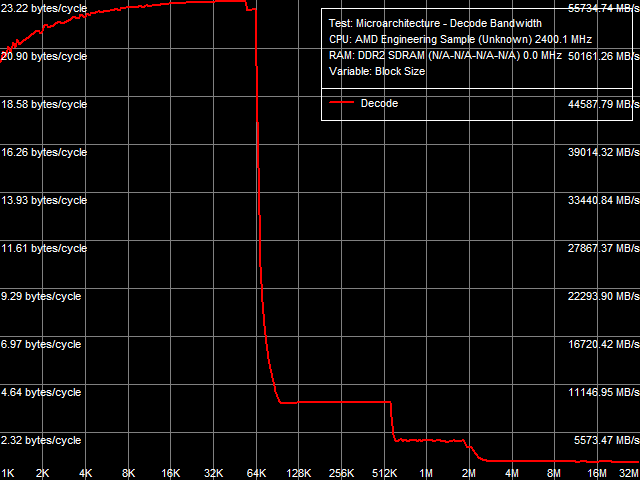
Рис. 16. Эффективность декодирования/исполнения 8-байтных префиксных инструкций CMP
Из этого рисунка видно, что эксклюзивная организация L1/L2 и L2/L3-кэшей проявляет себя и при кэшировании потока инструкций (наблюдаются перегибы в областях, соответствующих суммарному объему L1+L2 и L1+L2+L3-кэшей), что, впрочем, выглядит вполне естественно. Максимальная реальная ПС L1-I кэша, достигаемая в этом тесте, составляет 23.22 байта/такт (против не более 16 байт/такт у процессоров семейства Athlon 64, см. табл. 8), что говорит о том, что пиковая ПС (разрядность) L1-кэша инструкций, как и L1-кэша данных, составляет 32 байта/такт (256 бит). Недостижимость столь большой величины теоретической ПС L1-I кэша связана с ограничениями, накладываемыми декодером и исполнительными ALU-устройствами процессора, способными обеспечить пропускную способность не более 3 инструкций/такт (в данном случае она оказывается несколько ниже — порядка 2.9 инструкций/такт, в связи с необходимостью «отсечения» «ненужных» префиксов REP (F3h) и Address Override (67h)).
Таблица 8
| Тип инструкций (размер, байт) | Реальная пропускная способность декодирования / исполнения, байт/такт (инструкций/такт) | ||||
|---|---|---|---|---|---|
| Athlon 64 X2 | Phenom | ||||
| L1-I-кэш | L2-кэш | L1-I-кэш | L2-кэш | L3-кэш | |
| NOP (1) SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) CMP 2 (4) CMP 3-6 (6) Prefixed CMP 1-4 (8) | 3.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 11.98 (3.00) 15.97 (2.66) 15.97 (2.00) | 3.00 (3.00) 3.28 (1.64) 3.28 (1.64) 3.28 (1.64) 3.28 (1.64) 3.28 (1.64) 3.28 (0.82) 3.19 (0.53) 3.28 (0.41) | 3.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 6.00 (3.00) 11.99 (3.00) 17.97 (3.00) 23.22 (2.90) | 3.00 (3.00) 3.78 (1.89) 3.78 (1.89) 3.78 (1.89) 3.78 (1.89) 3.78 (1.89) 3.78 (0.95) 3.78 (0.63) 3.78 (0.47) | 1.88 (1.88) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.50) 1.99 (0.33) 1.99 (0.25) |
Количественные характеристики ПС L1-I, L2- и L3-кэшей процессора, а также его исполнительных устройств, приведены в табл. 8. Эффективность декодирования/исполнения большинства простейших ALU-инструкций из L1-I кэша не изменилась — она по-прежнему ограничена величиной в 3 инструкции/такт, связанной с наличием ровно трех ALU-исполнительных устройств в ядре процессора. В то же время, как уже было отмечено выше, ПС декодирования/исполнения «крупных» инструкций вроде 6-байтных CMP (cmp eax, 32-bit value) и 8-байтных префиксных CMP ([F3h][67h]cmp eax, 32-bit value) возросла до своих предельных значений (3.0 и 2.9 байт/такт, соответственно) в связи с расширением шины L1-I кэша до 256 бит. В связи с увеличением ПС шины L1-L2 кэша возросла также скорость исполнения кода из L2-кэша (максимальная реальная ПС этого уровня составляет 3.78 байт/такт против 3.28 байт/такт у Athlon 64 X2), а скорость исполнения кода из общего L3-кэша процессора составляет примерно 2 байта/такт.
Ассоциативность кэша инструкций
Оценим поведение L1-кэша инструкций и объединенных L2/L3-кэшей инструкций/данных в тесте ассоциативности кэша инструкций, преподнесшим нам довольно интересную картину, представленную на рис. 17.
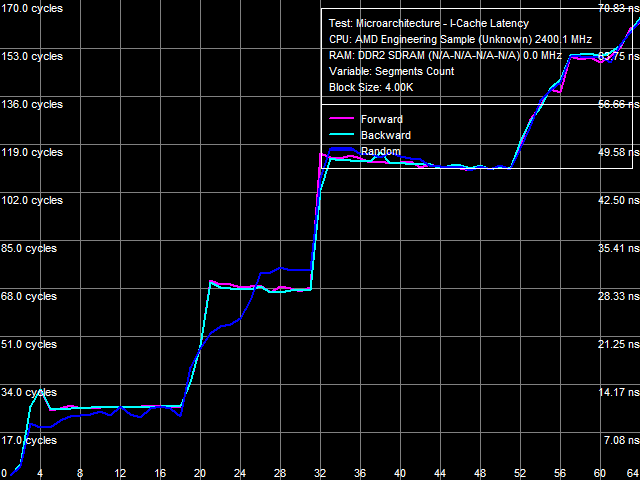
Рис. 17. Ассоциативность кэша инструкций
Первый перегиб наблюдается в области 2 сегментов кэша и соответствует ассоциативности L1-кэша инструкций. Второй перегиб также соответствует заявленным характеристикам: он наблюдается в области 18 сегментов кэша и соответствует «суммарной» ассоциативности L1-I и L2-кэшей ядра процессора. Наиболее интересный результат связан с ассоциативностью L3-кэша, общего для всех ядер процессора. Напомним, что истинная (заявленная) ассоциативность этого уровня кэша равна 32, тогда как в тесте ассоциативности кэша данных реально наблюдаемая ассоциативность L3 равнялась 30 (в связи с чем было сделано предположение, что это может быть связано именно с «общностью» L3-кэша по отношению ко всем ядрам процессора, тогда как все рассматриваемые тесты исполняются лишь на одном ядре). В случае же исполнения кода на кривых ассоциативности можно отметить 2 перегиба: первый в области примерно 32 сегментов кэша (что соответствует ассоциативности L3 = 14), а второй — в области примерно 50 сегментов кэша, соответствующий истинной ассоциативности L3 = 32. Причины такого поведения L3-кэша остаются непонятными, и сделанное выше предположение является единственным разумным объяснением.
Характеристики TLB
В заключение, подтвердим характеристики уровней TLB процессора, известные из дескрипторов CPUID, результатами реальных тестов. Начнем с тестов размера и ассоциативности TLB данных (D-TLB).
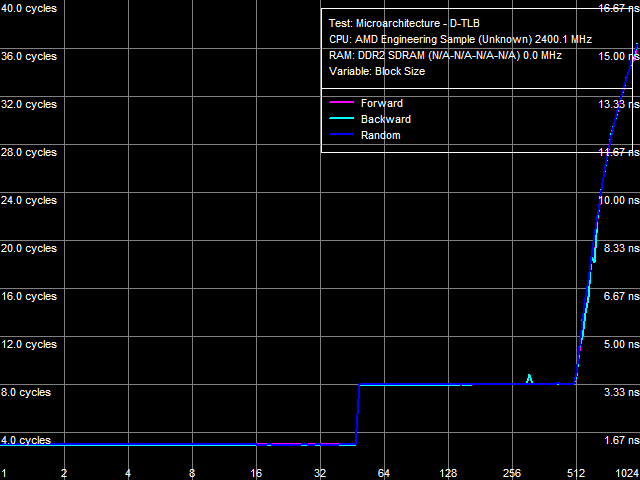
Рис. 18. Размер D-TLB
Из рис. 18 видно, что размер первого уровня D-TLB составляет 48 записей (стандартных для 32-битной ОС 4-КБ страниц), штраф промаха этого уровня D-TLB во всех случаях составляет 5 тактов. Размер L2 D-TLB составляет 512 записей (что соответствует 2 МБ данных), а штраф промаха зависит от количества используемых страниц памяти и при 1024 страницах (4 МБ) составляет примерно 28 тактов процессора (несколько выше по сравнению с процессорами семейства Athlon 64, где штраф промаха составляет примерно 17 тактов).
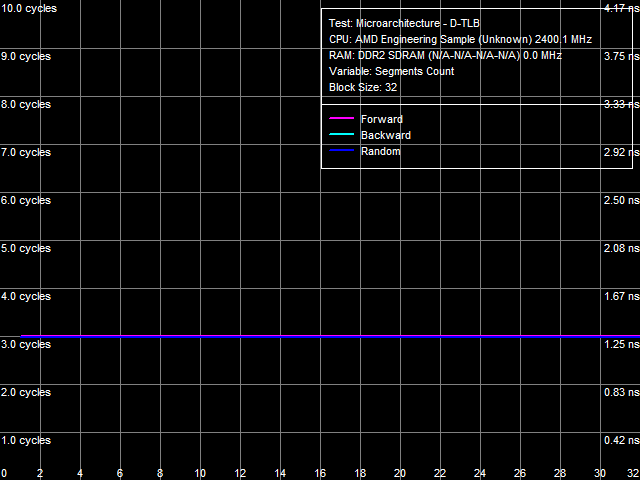
Рис. 19. Ассоциативность L1 D-TLB
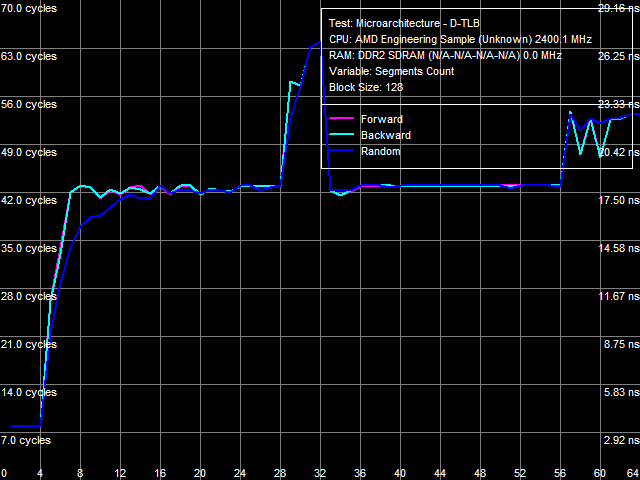
Рис. 20. Ассоциативность L2 D-TLB
Тесты ассоциативности L1 и L2 D-TLB приведены на рис. 19 и 20, соответственно. Первый тест подтверждает полную ассоциативность L1 D-TLB, второй показывает, что ассоциативность L2 D-TLB равна 4, а штраф промаха «по ассоциативности» составляет примерно 34 такта (выше по сравнению со штрафом промаха «по размеру», что наблюдается и на процессорах семейства Athlon 64).
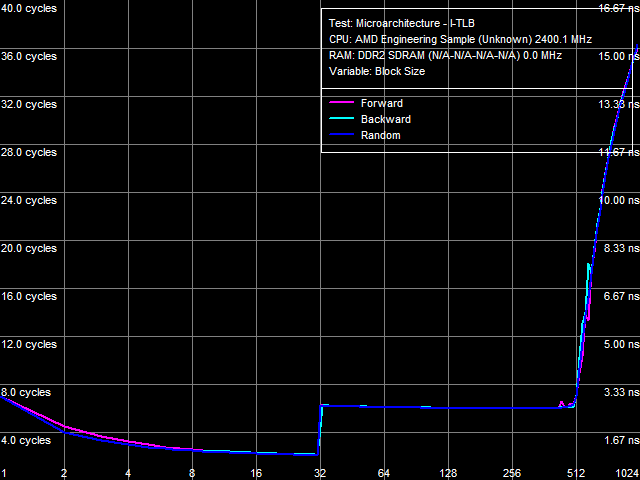
Рис. 21. Размер I-TLB
Результат теста размера уровней TLB инструкций (I-TLB) представлен на рис. 21. Как и в случае D-TLB, видна двухуровневая организация I-TLB. Размер первого уровня (L1 I-TLB) составляет 32 записи, штраф промаха — 4 такта. Размер L2 I-TLB составляет 512 записей, а штраф промаха также зависит от количества страниц памяти и составляет примерно 30 тактов — также выше по сравнению с семейством Athlon 64 (24-26 тактов, в зависимости от модели процессора).
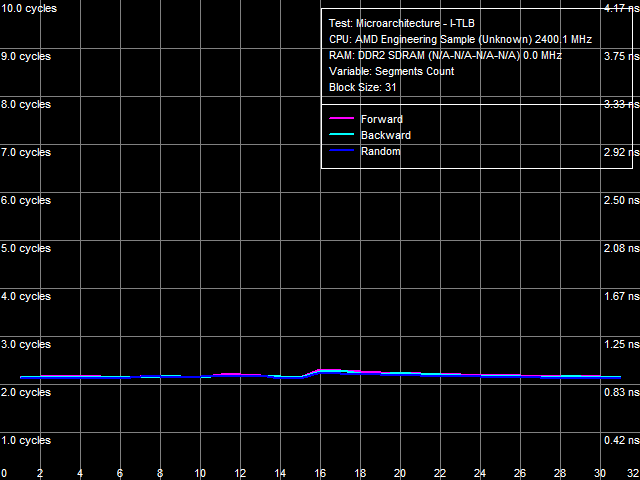
Рис. 22. Ассоциативность L1 I-TLB
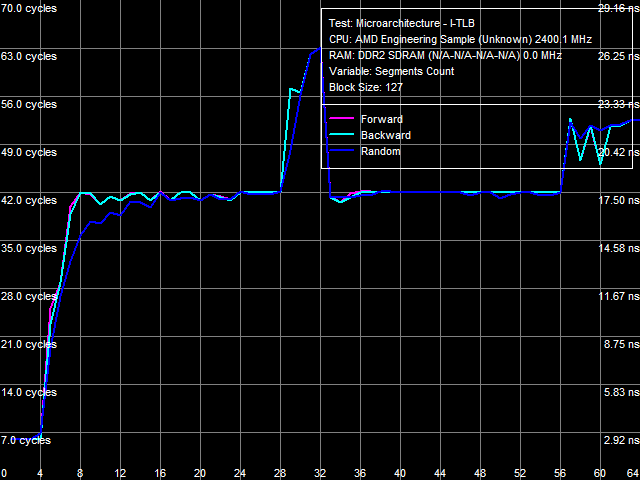
Рис. 23. Ассоциативность L2 I-TLB
Приведенный на рис. 22 результат теста ассоциативности L1 I-TLB показывает полную ассоциативность этого уровня, а рис. 23 подтверждает ассоциативность L2 I-TLB, равную четырем, со штрафом промаха «по ассоциативности» порядка 36 тактов.
Следует отметить, что, несмотря на появившееся в Сети сообщение о содержащейся ошибке в блоке TLB L3-кэша(?) текущей ревизии процессоров AMD Phenom, подробности которой неизвестны, проведенные и представленные выше тесты D- и I-TLB рассматриваемой модели процессора не подтвердили каких-либо аномалий указанных блоков процессора. Их размеры и ассоциативности соответствуют заявленным характеристикам, а штрафы промаха укладываются в разумные значения (чего не скажешь, кстати, о TLB рассмотренных нами недавно «энергоэффективных» моделей процессоров Athlon 64 X2). Вполне возможно, что ошибка действительно находится где-то на уровне L3-кэша (интегрированного контроллера памяти) процессора и способна проявить себя лишь в специально подобранных условиях. В ближайшее время мы попытаемся изучить этот вопрос (в частности, влияние «заплатки» BIOS, исправляющей эту ошибку, на низкоуровневые характеристики процессора) в отдельном исследовании.
Заключение
Рассмотренная в настоящей статье архитектура новых процессоров AMD Phenom (AMD K10) получилась, на наш взгляд, достаточно удачной. Ее главным достоинством, по сравнению с архитектурой предыдущего поколения процессоров AMD семейства Athlon 64 (AMD K8), можно считать ее сбалансированность, проявляющуюся на всех уровнях. Так, расширенная до 256 (2x128) бит шина L1-кэша данных ядра процессора хорошо согласуется с реализацией 128-битных FP-блоков вычисления, обеспечивая равную пропускную способность при чтении данных с использованием 128-битных мультимедийных инструкций SSE/SSE2 (32 байта/такт). Да и сами по себе 128-битные FP-блоки, хотя их рассмотрение и выходит за рамки настоящего исследования, способны обеспечить ощутимую прибавку производительности процессора в большинстве синтетических и реальных приложений, оперирующих с этим типом данных (к которым можно отнести научные вычислительные программы, пакеты 3D-моделирования, компьютерные игры и многое, многое другое). Напомним, что в нашем простейшем случае — тесте чтения данных с использованием 128-битных инструкций SSE/SSE2 скорость исполнения таких инструкций возросла в 4 раза.
В то же время, расширенная до 128 бит «в одну сторону» шина L1-L2 кэша данных (тип организации которой пока что остается под вопросом) устраняет «узкое место» при обмене данных между ядром процессора и оперативной памятью (трудно представить, что шины данных L1-L2 и «L2-контроллер памяти» в процессорах AMD K8 имели одинаковую ширину!). Большим плюсом новой архитектуры также можно считать реализацию эффективной аппаратной предвыборки данных на всех уровнях (L2-, L3-кэш и оперативная память). Как было показано нами в нашем отдельном исследовании, она способна максимально проявить себя при «многоядерном» доступе в оперативную память, впервые достигая существенное раскрытие (до 85%) скоростного потенциала высокоскоростных категорий двухканальной памяти DDR2.
Что касается L3-кэша процессора, локализованного в области его интегрированного контроллера памяти и являющегося общим для всех ядер, наличие этого уровня кэша нельзя считать однозначным преимуществом новых процессоров. Как показали наши тесты в условиях «одноядерного» доступа, пропускная способность этого уровня кэша не сильно опережает пропускную способность оперативной памяти в тех же условиях доступа (8.9 против 6.4 ГБ/с), что связано с высокой пропускной способностью двухканальной DDR2 самой по себе. Несколько выигрывает L3-кэш разве что по латентности, да и то только при случайном доступе к данным (в остальных случаях латентности всех уровней эффективно маскируются аппаратной предвыборкой данных), поэтому его преимущества могут быть более заметны в приложениях, оперирующих с данными, расположенными в различных областях памяти, к которым осуществляется доступ в случайном порядке (например, базы данных).
Комментарии