
Non-Uniform Memory Architecture (NUMA)
Часть 2: исследование подсистемы памяти четырехпроцессорных платформ AMD Opteron с помощью RightMark Memory Analyzer
Не так давно, мы рассмотрели основные преимущества и недостатки простейшего варианта организации неоднородной архитектуры памяти (NUMA), реализуемой в двухпроцессорных платформах AMD Opteron. В этом случае, подсистема памяти платформы была построена всего из двух двухканальных контроллеров памяти («узлов»), каждый из которых либо содержал (конфигурация «2+2»), либо не содержал (конфигурация «4+0») собственную оперативную память. При этом связь между контроллерами осуществлялась посредством одной двунаправленной шиной HyperTransport.
Теперь настало время (а точнее, выдалась возможность) изучить более сложную организацию NUMA, которую можно реализовать на четырех контроллерах памяти процессоров AMD Opteron. Для наглядности, представим ее в виде блок-схемы.
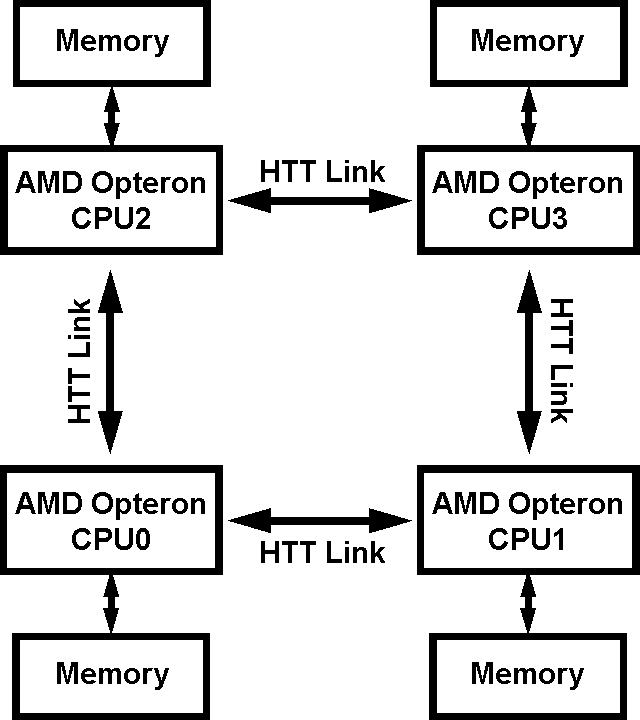
Упрощенная блок-схема 4-узловой NUMA-системы
Итак, что мы имеем: каждый контроллер памяти наделен собственной оперативной памятью (более «дешевые» варианты, с отсутствием собственной памяти у того или иного узла здесь не рассматриваем, поскольку такие предложения, пожалуй, практически невозможно встретить на рынке для сравнительно дорогих четырехпроцессорных платформ AMD Opteron), при этом каждый из узлов связан с двумя соседними посредством двух свободных шин процессора HyperTransport (напомним, что процессоры AMD Opteron имеют три шины HyperTransport, однако в данном случае одна из них отводится на связь с периферическими устройствами посредством моста PCI-X чипсета).
Такая организация подсистемы памяти имеет одно важное обстоятельство: по отношению к каждому заданному процессору (для примера, CPU0) оперативная память может быть не только «своей» (принадлежащей самому контроллеру памяти этого процессора) и «чужой» (принадлежащей соседнему контроллеру, в рассматриваемом примере — CPU1 и CPU2), но и, назовем это так, «дважды чужой» (CPU3). Действительно, в последнем случае, чтобы получить доступ с процессора CPU0 к оперативной памяти, находящейся в адресном пространстве контроллера процессора CPU3, электрическим сигналам необходимо пройти уже через две последовательно подключенные шины HyperTransport (CPU0 -> CPU1 -> CPU3 или CPU0 -> CPU2 -> CPU3, что, по идее, должно обеспечивать дополнительную гибкость при передаче данных).
Таким образом, усложнение организации неоднородной архитектуры памяти неизбежно увеличивает и меру ее неоднородности. Так это выглядит в теории, но мы, как всегда, проверим это на практике, проведя реальные количественные оценки.
Конфигурация тестового стенда и ПО
- Платформа: сервер STSS QDD4400
- Процессоры: 4x AMD Dual Core Opteron 875, 2.2 ГГц, ревизия ядра E1
- Материнская плата: NEWISYS 3U4P, версия BIOS V2.34.5.1, 11/08/2005
- Чипсет: AMD 8111 & 8131 PCI-X Tunnel
- Память: 16x Corsair 1ГB DDR-333 ECC Registered
- Видео: Trident Blade3D
- HDD: Seagate ST336807LC, Ultra320 SCSI, 10000 rpm, 36Gb
- ОС: Windows Server 2003 SP1
Результаты исследований
Исследование проводилось в стандартном режиме тестирования подсистемы памяти любой платформы. Измерялись: средняя реальная пропускная способность памяти (ПСП) при операциях простого линейного чтения и записи данных из памяти/в память, максимальная реальная ПСП при операциях чтения (с программной предвыборкой данных, Software Prefetch) и записи (методом прямого сохранения данных, Non-Temporal Store), а также латентность памяти при псевдослучайном и случайном обходе 16-МБ блока данных.
Как и в случае нашего предыдущего исследования NUMA-архитектуры, отличием от общепринятой методики явилась «привязка» потока, исполняющего тест к определенному физическому процессору. При этом размещение блока данных в памяти всегда осуществляется первым процессором (т.е. блок выделяется в физической памяти первого процессора), после чего запуск тестов может быть осуществлен как на том же, первом, так и на любом другом присутствующем в системе процессоре. Это позволяет оценить параметры обмена данными между процессором и памятью, принадлежащей как собственному, так и любому другому процессору.
Симметричная 4-узловая NUMA, SRAT, No Node Interleave
В настройках BIOS оказавшегося в нашем распоряжении сервера STSS QDD4400 можно варьировать три параметра, относящихся к подсистеме памяти: включение/выключение режима SRAT («Enabled/Disabled»), режима Node Interleave («Auto/Disabled») и Bank Interleave («Auto/Disabled»).
Несколько слов, по порядку, о каждом из них: SRAT означает System Resource Affinity Table, и включение этого режима приводит к созданию в данных ACPI особой таблицы с одноименным названием, которая позволяет операционной системе правильно ассоциировать процессоры и принадлежащие им области памяти — что, в случае NUMA-систем, оказывается крайне полезным и нужным. Конечно, все это выполняется при условии поддержки данной технологии со стороны ОС. К счастью, Windows Server 2003 SP1 относится к числу таких операционных систем. Заметим, однако, что для нашего сегодняшнего тестирования такая возможность совершенно не существенна, ибо, как мы уже писали выше, мы осуществляем ручную «привязку» нашего тестового приложения к данному конкретному процессору, тогда как SRAT актуальна для обычных приложений, не осуществляющих подобную «привязку».
Node Interleave, напротив, можно считать интересным решением для ОС и приложений, ничего не знающих об архитектуре NUMA. Суть этого решения, как мы уже писали, заключается в чередовании памяти по 4-КБ страницам между модулями, находящимися на разных узлах (контроллерах памяти процессоров). В результате чего достигается практически полная симметризация изначально несимметричной архитектуры NUMA, поскольку любой выделяемый блок данных в памяти будет равномерно «раскинут» по адресному пространству всех контроллеров памяти. Отметим, что рассматриваемая платформа не позволяет включить режим Node Interleave при включении режима SRAT, что, в общем-то, вполне естественно.
Наконец, Bank Interleave есть просто чередование доступа к логическим банкам модуля памяти. Поскольку наши предыдущие тесты показали некоторое увеличение производительности подсистемы памяти при включении этого режима («Auto»), мы решили оставить этот параметр неизменным.
Итак, первая серия тестов: SRAT включен, Node Interleave выключен (в силу включения SRAT), Bank Interleave включен («Auto»). Еще раз отметим, что такие же результаты мы получили бы и без задействования режима SRAT, просто отключив режим Node Interleave.
| Характеристика | CPU 0 | CPU 1 | CPU 2 | CPU 3 |
|---|---|---|---|---|
| Средняя реальная ПСП на чтение, МБ/с* | 2424 (48.2%) | 2003 (39.8%) | 1917 (38.1%) | 1666 (33.1%) |
| Средняя реальная ПСП на запись, МБ/с* | 2187 (43.5%) | 1645 (32.7%) | 1551 (30.8%) | 1437 (28.6%) |
| Максимальная реальная ПСП на чтение, МБ/с* | 4779 (95.0%) | 2992 (59.5%) | 2870 (57.1%) | 3001 (59.7%) |
| Максимальная реальная ПСП на запись, МБ/с* | 4133 (82.2%) | 2548 (50.7%) | 2317 (46.1%) | 2457 (48.9%) |
| Минимальная латентность псевдослучайного доступа, нс** | 56.1 | 58.9 | 59.7 | 73.0 |
| Максимальная латентность псевдослучайного доступа, нс** | 59.5 | 63.1 | 64.4 | 78.5 |
| Минимальная латентность случайного доступа, нс** | 104.4 | 114.0 | 119.0 | 146.7 |
| Максимальная латентность случайного доступа, нс** | 105.7 | 118.2 | 123.2 | 150.5 |
*в скобках указаны величины относительно теоретического предела ПСП
(5028 МБ/с)**размер блока 16 МБ
Доступ процессора CPU0 (учитывая, что процессоры двухъядерные, здесь и далее под «процессором» будем всегда понимать первое ядро данного физического процессора; впрочем, с равным успехом можно было бы рассмотреть и второе ядро, главное — рассматривать разные физические процессоры) к собственной памяти характеризуется вполне приемлемыми величинами ПСП и латентностей. Так, при операциях чтения с Software Prefetch достигается 95% теоретической ПСП, которая в данном случае равна 5028 МБ/с (частота памяти составляет 2200 / 14 = примерно 157 МГц). Вследствие асинхронного режима работы подсистемы памяти, латентности оказываются заметно выше по сравнению с результатами предыдущих тестов, в которых использовалась память DDR-400.
Доступ CPU0 к «чужой» памяти соседних процессоров CPU1 и CPU2, как и следовало ожидать, имеет сходные характеристики в обоих случаях, с некоторым преимуществом в пользу CPU1. При этом максимальная реальная ПСП на чтение снижается до уровня 57-59% от теоретической. Снижение ПСП оказывается менее выраженным по сравнению с тем, что наблюдалось ранее с памятью DDR-400, ибо здесь важен сам факт снижения ПСП до уровня 3.0 — 3.2 ГБ/с, который, по-видимому, является реальным пределом скорости передачи данных по шине HyperTransport, имеющей теоретическую ПС 4.0 ГБ/с. Не может не удивлять весьма незначительное возрастание латентностей для этого случая: при псевдослучайном обходе они возрастают всего на 2-5 нс, при случайном — на 10-17 нс. Заметим, что в проведенных ранее тестах 2-узловой симметричной NUMA латентности при доступе к «чужой» памяти возрастали весьма существенно — в среднем, с 45 нс при доступе к «своей» памяти до 70 нс при доступе к «чужой». Чем вызвано столь незначительное увеличение латентностей в данном случае — не очень понятно, по-видимому, все-таки серьезно сказывается асимметричный режим работы памяти, вносящий заметные задержки уже при доступе к «своей» памяти, которые отчасти маскируются при доступе к «соседней» памяти.
Наконец, нам осталось рассмотреть доступ процессора CPU0 к «дважды чужой», совсем удаленной памяти процессора CPU3, который осуществляется последовательно по двум шинам HyperTransport. Как ни странно, такой режим доступа практически не уступает по максимальной реальной ПСП доступу к соседней памяти — она сохраняется на уровне 3.0 ГБ/с для операций чтения и 2.4 ГБ/с для операций записи. Несколько снижается лишь средняя реальная ПСП, примерно с 2.0 ГБ/с (чтение «соседней» памяти) до 1.67 ГБ/с (чтение «дважды удаленной памяти»). Кроме того, здесь дополнительно возрастают задержки, но вновь незначительно. При псевдослучайном обходе увеличение задержек составляет 18-19 нс относительно доступа к «своей» памяти (14-15 нс относительно доступа к «соседней»), а при случайном — 42-45 нс относительно доступа к «своей» памяти (32-37 нс относительно доступа к «соседней» памяти).
Симметричная 4-узловая NUMA, No SRAT, Node Interleave
Переходим ко второй серии тестов: отключаем режим SRAT, оставляем настройки режимов Node Interleave и Bank Interleave в положении «Auto».
| Характеристика | CPU 0 | CPU 1 | CPU 2 | CPU 3 |
|---|---|---|---|---|
| Средняя реальная ПСП на чтение, МБ/с* | 1960 (39.0%) | 1976 (39.3%) | 1970 (39.2%) | 1979 (39.3%) |
| Средняя реальная ПСП на запись, МБ/с* | 1715 (34.1%) | 1754 (34.9%) | 1719 (34.1%) | 1740 (34.6%) |
| Максимальная реальная ПСП на чтение, МБ/с* | 3290 (65.4%) | 3291 (65.5%) | 3293 (65.5%) | 3289 (65.4%) |
| Максимальная реальная ПСП на запись, МБ/с* | 2671 (53.1%) | 2701 (53.7%) | 2671 (53.1%) | 2696 (53.6%) |
| Минимальная латентность псевдослучайного доступа, нс** | 104.5 | 103.2 | 102.9 | 102.0 |
| Максимальная латентность псевдослучайного доступа, нс** | 105.7 | 104.8 | 105.1 | 104.2 |
| Минимальная латентность случайного доступа, нс** | 123.9 | 122.9 | 123.1 | 122.5 |
| Максимальная латентность случайного доступа, нс** | 125.0 | 124.0 | 123.9 | 123.4 |
*в скобках указаны величины относительно теоретического предела ПСП
(5028 МБ/с)**размер блока 16 МБ
Как и следовало ожидать, включение Node Interleave позволяет достичь практически полной симметризации NUMA и в случае ее 4-узловой организации. Заметим, что максимальная реальная ПСП на чтение и в этом случае оказывается ограниченной на уровне 65-66% от теоретической ПСП, по остальным показателям пропускной способности симметризация 4-узловой, да вдобавок — асинхронной конфигурации NUMA несколько проигрывает симметризации простой симметричной синхронной 2-узловой NUMA (так, становится более заметно снижение ПСП при операциях записи, а также неоптимизированного чтения).
Интересно также отметить значительное возрастание латентностей при псевдослучайном обходе — почти в два раза по сравнению с латентностью псевдослучайного доступа процессора к «собственной» памяти. Кроме того, среднюю величину латентности (104-106 нс) в этом случае уже нельзя получить простым усреднением величин, полученных при доступе к памяти, принадлежащей CPU0, со стороны всех четырех процессоров — такое среднее значение составило бы всего 62-66 нс. Вероятно, здесь виновато более сложное чередование страниц памяти, принадлежащих всем четырем контроллерам, что делает данный режим отчасти похожим на случайный обход (напомним, что основой псевдослучайного обхода, реализованного в RMMA, является линейный, прямой последовательный обход на уровне страниц памяти при условии случайности обхода внутри самой страницы — однако в данном случае нарушается линейность на уровне физических страниц памяти, ибо каждые четыре последовательно расположенные, на логическом уровне, страницы памяти принадлежат разным физическим адресным пространствам).
Заключение
В нашей предыдущей статье, посвященной архитектуре NUMA в виде простейшего 2-узлового варианта, мы уже показали ее превосходство над традиционным SMP-подходом. Наши сегодняшние тесты показывают, что данное утверждение можно распространить и на случай более сложной, 4-узловой конфигурации NUMA.
Чтобы продемонстрировать это, приведем таблицу, аналогичную представленной в нашей прошлой статье. Рассмотрим в ней традиционные SMP-системы (многопроцессорные, в т.ч. двухъядерные или многопроцессорные двухъядерные платформы Intel Xeon/Pentium D), 2-узловые NUMA-системы (двухпроцессорные, в т.ч. двухпроцессорные двухъядерные платформы AMD Opteron) и 4-узловые NUMA-системы (четырехпроцессорные, в т.ч. четырехпроцессорные двухъядерные платформы AMD Opteron). Для двух последних рассмотрим режим их работы как при включенном, так и отключенном Node Interleave. Для наглядности, дабы не быть привязанным к количественным характеристикам того или иного типа памяти, представим относительные величины пиковой пропускной способности (в виде числа раз). Наконец, отметим, что цифры для неоптимизированных многозадачных/многопоточных случаев на NUMA-системах получены простым масштабированием, т.е. в предположении отсутствия коллизий при передаче данных по шинам HyperTransport.
| Платформа | Пиковая пропускная способность подсистемы памяти* | ||||
|---|---|---|---|---|---|
| Однопоточное приложение, количество копий | Многопоточное приложение** | NUMA-aware многопоточное приложение** | |||
| 1 | 2 | 4 | |||
| SMP | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Симметричная 2-узловая NUMA | 0.65 (1.00**) | 1.30 (2.00**) | 1.30 (2.00**) | 1.00 | 2.00 |
| Симметричная 2-узловая NUMA, Node Interleave | 0.65 | 1.30 | 1.30 | 1.30 | 1.30 |
| Симметричная 4-узловая NUMA | 0.65 (1.00**) | 1.30 (2.00**) | 2.60 (4.00**) | 1.00 | 4.00 |
| Симметричная 4-узловая NUMA, Node Interleave | 0.65 | 1.30 | 2.60 | 2.60 | 2.60 |
*относительно максимальной теоретической ПСП для одного контроллера памяти
**число потоков, обращающихся к памяти, не менее 4
Пройдемся вкратце по всем типам систем. Итак, SMP-системы: максимально возможная пропускная способность подсистемы памяти не зависит от типа и количества запущенных приложений и всегда составляет единицу — т.е. пропускную способность единственного присутствующего в системе контроллера памяти.
2-узловые NUMA-системы: реальный проигрыш SMP-системам наблюдается лишь в случае однопоточных приложений, если они не привязаны к определенному процессору — в этом случае примерно 50% обращений осуществляется к «собственной» памяти, а оставшиеся 50% — к «чужой», в результате чего максимальная реальная ПСП снижается до уровня, наблюдаемого при включении режима Node Interleave. Не демонстрируют преимущества также неоптимизированные многопоточные приложения, которые выделяют память в пространстве лишь одного из контроллеров, в результате чего оказываются ограниченными по пропускной способности именно этого контроллера. Как видно из таблицы, подобное ограничение можно устранить оптимизацией многопоточного приложения под NUMA-архитектуру (при этом каждый из процессоров, в идеале, работает исключительно со «своей» памятью), либо задействовать режим Node Interleave, симметризующий подсистему памяти (однако его полезность ограничена лишь этим случаем).
4-узловые NUMA-системы ведут себя аналогично 2-узловым, за одним важным исключением — они позволяют достичь еще больших величин пиковой пропускной способности подсистемы памяти, при условии запуска нескольких приложений, правильно «раскиданных» по процессорам, либо в случае NUMA-оптимизированных многопоточных приложений (при наличии не менее 4 потоков, ведущих обмен с памятью). Не лишены эти системы и недостатков, присущих 2-узловым NUMA-системам. А именно, они не показывают преимущества над SMP-системами при запуске всего одного однопоточного, либо неоптимизированного многопоточного приложения. Впрочем, для последнего случая и здесь существует решение в виде уже хорошо известного нам режима Node Interleave, однако вновь напомним, что его полезность ограничена этим и только этим случаем, вряд ли широко встречающимся на практике. Нетрудно убедиться, что во всех остальных случаях включение Node Interleave способно не только не улучшить, но и ухудшить скоростные показатели подсистемы памяти.
Комментарии