Non-Uniform Memory Architecture (NUMA): исследование подсистемы памяти двухпроцессорных платформ AMD Opteron с помощью RightMark Memory Analyzer
Неоднородная архитектура памяти (NUMA) как особый вид организации подсистемы памяти существует уже довольно давно. Ее наиболее наглядный и доступный вариант представлен подсистемой памяти многопроцессорных платформ AMD Opteron, и существует он, можно сказать, с момента анонса самих процессоров AMD Opteron 200-х и 800-х серий, поддерживающих многопроцессорные конфигурации. Вместе с тем, изучение этой архитектуры памяти (здесь и далее мы будем иметь в виду исключительно ее «AMD-шный вариант») на низком уровне, анализ ее преимуществ и недостатков до сих пор не проводились. Этим мы и решили заняться в настоящей статье, благо в распоряжении нашей тестовой лаборатории оказалась очередная двухпроцессорная система на базе процессоров AMD Opteron. Но для начала, напомним основные особенности этой архитектуры.
Большинство типовых многопроцессорных систем реализовано в виде симметричной многопроцессорной архитектуры (SMP), предоставляющей всем процессорам общую системную шину (а, следовательно, и шину памяти).
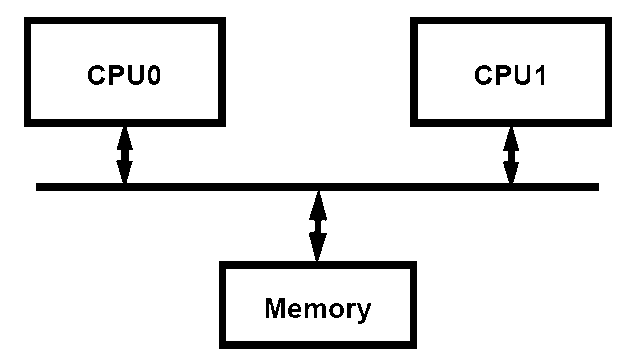
Упрощенная блок-схема SMP-системы
С одной стороны, эта схема обеспечивает практически одинаковые задержки при доступе к памяти со стороны любого процессора. Но с другой стороны, общая системная шина является потенциальным узким местом всей подсистемы памяти по такому не менее (и даже намного более) важному показателю, как пропускная способность. Действительно, если многопоточное приложение оказывается требовательным к пропускной способности, его производительность будет во многом сдерживаться такой организацией подсистемы памяти.
Что же предлагает AMD в своем варианте неоднородной архитектуры памяти NUMA (ее полное название Cache-Coherent Non-Uniform Memory Architecture, ccNUMA)? Все предельно просто поскольку процессоры AMD64 обладают интегрированным контроллером памяти, каждый процессор в многопроцессорной системе наделен своей «собственной» памятью. При этом, процессоры связаны между собой посредством шины HyperTransport, не имеющей прямого отношения к подсистеме памяти (чего не скажешь о традиционной FSB).
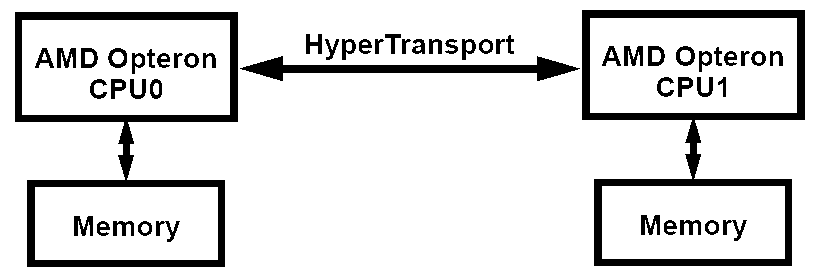
Упрощенная блок-схема NUMA-системы
В случае NUMA-системы задержки при обращении процессора к «своей» памяти оказываются невысоки (в особенности, по сравнению с SMP-системой). В то же время, доступ к «чужой» памяти, принадлежащей другому процессору, сопровождается более высокими задержками. Понятие «неоднородности» такой организации памяти берет свое начало именно отсюда. Вместе с тем, нетрудно догадаться, что при правильной организации доступа к памяти (когда каждый процессор оперирует данными, находящимися исключительно в «своей» памяти) такая схема будет выгодно отличаться от классического SMP-решения благодаря отсутствию ограничения по пропускной способности общей системной шины. Суммарная пиковая пропускная способность подсистемы памяти в этом случае будет равняться удвоенной пропускной способности используемых модулей памяти.
Однако «правильная организация доступа к памяти» здесь — ключевое и критически важное понятие. Платформы с архитектурой NUMA должны поддерживаться как со стороны ОС (хотя бы для того, чтобы сама система и приложения могли «увидеть» память всех процессоров, как единый блок памяти), так и со стороны приложений. Последние версии Windows XP (SP2) и Windows Server 2003 полностью поддерживают NUMA-системы (для 32-разрядных версий необходимо включение режима Physical Address Extension (ключ /PAE в boot.ini), который, к счастью, для AMD64-платформ включен по умолчанию, поскольку необходим для реализации Data Execution Prevention). Что касается приложений, здесь, прежде всего, имеется в виду нежелательность возникновения ситуации, когда приложение размещает свои данные в области памяти одного процессора, после чего обращается к ним с другого процессора. А как влияет соблюдение или несоблюдение этой рекомендации, мы сейчас и рассмотрим.
Конфигурация тестового стенда и ПО
- Процессоры: 2x Opteron 250, 2.4 ГГц
- Материнская плата: TYAN Thunder K8WE (S2895), BIOS версии 2003Q2 от 03/28/2005
- Чипсет: NVIDIA nForce Professional 2200 & 2050, AMD 8131 PCI-X Tunnel
- Память: 4x Corsair 512MB DDR-400 ECC Registered, 3-3-3-8
- Видео: Leadtek PX350 TDH, nVidia PCX5900
- HDD: WD Raptor WD360, SATA, 10000 rpm, 36Gb
- Драйверы: NVIDIA Forceware 77.72
Результаты исследований
Исследование проводилось в стандартном режиме тестирования подсистемы памяти любой платформы. Измерялись: средняя реальная пропускная способность памяти (ПСП) при операциях простого линейного чтения и записи данных из памяти/в память, максимальная реальная ПСП при операциях чтения (с программной предвыборкой данных, Software Prefetch) и записи (методом прямого сохранения данных, Non-Temporal Store), а также латентность памяти при псевдослучайном и случайном обходе 16-МБ блока данных.
Некоторым отличием от общепринятой методологии явилась «привязка» тестов к определенному физическому процессору возможность, уже давно реализованная в RMMA, да все никак не опробованная на практике. Ее суть такова: размещение блока данных в памяти всегда осуществляется первым процессором (что для NUMA-aware OS означает, что блок будет выделен в физической памяти первого процессора), после чего запуск тестов может быть осуществлен как на том же, первом, так и на любом другом присутствующем в системе процессоре. Это позволяет нам оценить скорость обмена данными между процессором и памятью (и прочие характеристики) как «своей», так и «чужой», принадлежащей соседнему процессору.
Симметричный режим «2+2», No Node Interleave
Настроек подсистемы памяти в BIOS двухпроцессорной системы AMD Opteron оказалось довольно много. А именно, настраиваются как минимум три параметра (по принципу Disabled/Enabled, или Disabled/Auto), что дает нам общее число вариантов — 8. Это: Node Interleave (чередование памяти между «узлами», то есть интегрированными контроллерами процессоров — замечательная возможность, которую мы подробно рассмотрим ниже), Bank Interleave (классическое чередование доступа к логическим банкам модулей памяти), а также Memory Swizzle (нечто похожее на Bank Interleave, но так до конца и не понятое :)). Поскольку изменение последнего параметра не оказывало ощутимого влияния на результаты тестов, было решено оставить его по умолчанию (Enabled). Остальные параметры варьировались, и в первой серии тестов была выбрана симметричная конфигурация «2+2» (по 2 модуля на каждый процессор), Node Interleave был отключен, а параметр Bank Interleave варьировался между Disabled и Auto (последнее означает, что чередование банков осуществляется в соответствии с характеристиками самого модуля).
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 3618 (±3) | 2369 (±2) | 3654 (±5) | 2387 (±2) |
| Средняя реальная ПСП на запись, МБ/с | 1616 (±2) | 1415 (±2) | 2417 (±56) | 1878 (±29) |
| Максимальная реальная ПСП на чтение, МБ/с | 6286 | 3116 | 6344 | 3133 |
| Максимальная реальная ПСП на запись, МБ/с | 5924 | 3032 | 6143 | 3033 |
| Минимальная латентность псевдослучайного доступа, нс | 45.6 | 70.9 | 44.1 | 70.5 |
| Максимальная латентность псевдослучайного доступа, нс | 48.3 | 74.7 | 47.3 | 74.3 |
| Минимальная латентность случайного доступа, нс | 74.7 | 112.3 | 74.7 | 112.3 |
| Максимальная латентность случайного доступа, нс | 78.6 | 116.3 | 78.6 | 116.3 |
Доступ процессора к «своей» памяти (CPU 0) дает вполне привычную картину, пожалуй, даже отлично выглядящую, учитывая, что используется регистровая память DDR-400 с не самыми быстрыми таймингами (3-3-3-8). Включение Bank Interleave приводит к улучшению некоторых показателей ПСП (особенно средней реальной ПСП на запись, с одновременным увеличением разброса ее величины) и практически не влияет на задержки.
Обращение процессора к «чужой» памяти (CPU 1) приводит к заметному ухудшению всех показателей подсистемы памяти. Прежде всего, это двукратное падение максимальной реальной ПСП на чтение/запись (получается как бы одноканальный режим доступа, но с чем связано такое ограничение не совсем понятно, поскольку частота HyperTransport в нашем случае составляет 1000 МГц, что обеспечивает пиковую пропускную способность межпроцессорного соединения 4.0 ГБ/с). Снижение средней реальной ПСП менее ощутимо, а задержки возрастают на 50-60%.
Таким образом, «неоднородность» подсистемы памяти, о которой мы упоминали в теоретической части — налицо (и, разумеется, не только в терминах латентности, но и ПСП). Что подтверждает необходимость использования не только NUMA-aware OS, но и специально оптимизированных многопоточных приложений, в которых каждый поток самостоятельно выделяет память под свои данные и работает со своей областью памяти. В противном случае (однопоточные приложения и многопоточные, «не задумывающиеся» о правильном с точки зрения NUMA размещении данных в памяти) следует ожидать снижение производительности подсистемы памяти. Рассмотрим это на примере однопоточных приложений, на сегодняшний день по-прежнему представляющих большинство ПО. Известно, что в многопроцессорной системе диспетчер ОС назначает приложениям процессорное время так, чтобы разделить его поровну между всеми имеющимися процессорами (таким образом, в случае двухпроцессорной системы примерно 50% приходится на первый процессор, и 50% — на второй). Таким образом, момент размещения памяти обязательно придется на какой-нибудь из процессоров (например, CPU0), в то время как код приложения, осуществляющий доступ к этим данным, будет исполняться как на CPU0, так и на CPU1. И половину времени подсистема памяти будет работать с полной эффективностью, а половину — со вдвое сниженной, как показывают наши тесты. Поэтому, как это ни странно, эффективность работы с памятью таких приложений можно повысить, принудительно «привязав» их к одному из процессоров (задав Process Affinity), что, в общем-то, сделать не так и сложно.
Хуже будет обстоять дело в случае неоптимизированных под NUMA многопоточных приложений, так же размещающих свои данные в памяти лишь одного из процессоров. Такая конфигурация может даже уступать традиционным SMP-вариантам суммарная пропускная способность будет ограничена пропускной способностью одного из контроллеров памяти, а задержки доступа будут неравномерными. Тем не менее, даже в этом непростом случае архитектура NUMA в ее AMD-шном воплощении предусматривает выход из ситуации, о котором ниже...
Несимметричный режим «4+0»
А пока мы решили немного... «удешевить» систему — то есть имитировать ситуацию, преобладающую среди более дешевых двухпроцессорных плат под AMD Opteron, когда модули памяти можно установить всего для одного процессора — для второго процессора такая память принудительно становится «чужой». Собственно, исходя из теоретических предположений, ожидать сильно отличающихся результатов в этом случае явно не стоит — ситуация отличается ровно тем, что у «своего» процессора памяти стало в 2 раза больше, а у «чужого» ее как не было, так и нет. Поэтому приводим мы их исключительно для полноты картины.
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 3623 (±5) | 2375 (±2) | 3684 (±33) | 2397 (±3) |
| Средняя реальная ПСП на запись, МБ/с | 1611 (±2) | 1418 (±2) | 2090 (±136) | 1932 (±31) |
| Максимальная реальная ПСП на чтение, МБ/с | 6249 | 3128 | 6358 | 3128 |
| Максимальная реальная ПСП на запись, МБ/с | 5878 | 3032 | 6234 | 3032 |
| Минимальная латентность псевдослучайного доступа, нс | 44.3 | 70.6 | 43.9 | 70.0 |
| Максимальная латентность псевдослучайного доступа, нс | 47.6 | 74.4 | 47.1 | 73.7 |
| Минимальная латентность случайного доступа, нс | 74.7 | 111.8 | 77.0 | 111.8 |
| Максимальная латентность случайного доступа, нс | 78.6 | 116.0 | 80.7 | 115.9 |
Так оно и есть теория подтверждается практикой. Небольшие отличия наблюдаются лишь при включении Bank Interleave в этом случае несколько снижается ПСП и увеличивается ее разброс (столь сильный разброс связан с плавным возрастанием ПСП на запись при увеличении размера блока от 4 до 16 МБ). Вместе с тем, в рамках нашего исследования это не столь важно, поскольку отражает лишь внутренние особенности функционирования Bank Interleave при использовании либо двух, либо четырех конкретных модулей памяти.
Зададимся лучше более важным вопросом: означают ли наши результаты то, что можно сэкономить и использовать более дешевый вариант построения подсистемы памяти? Делать этого однозначно не стоит, причем как в случае NUMA-оптимизированных приложений, так и без них. В первом случае причина ясна хорошо оптимизированные многопоточные приложения, если они требовательны к ПСП, получат максимум от симметричной организации подсистемы памяти. А во втором случае, симметричная организация «2+2» вместо асимметричной «4+0» позволяет задействовать режим Node Interleave... или просто выиграть от правильной «привязки» приложений к процессорам.
Симметричный режим «2+2», Node Interleave
Вот мы и добрались до самого интересного момента — решения для обычных приложений, ничего не знающих об архитектуре NUMA. Суть его весьма проста, и заключается она в чередовании памяти по 4-КБ страницам между модулями, находящимися на разных «узлах» (контроллерах памяти). В случае двухпроцессорной системы можно сказать, что все четные страницы «достаются» первому процессору, а все нечетные — второму. В результате получается — независимо от того, на какой из процессоров приходится момент размещения данных в памяти, данные будут размещены поровну в пространстве памяти обоих процессоров. И независимо от того, на каком из процессоров исполняется код, половина обращений к памяти будет относиться к «своей» памяти, а половина — к «чужой». Что же, посмотрим, как это проявляет себя на практике.
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 2893 (±3) | 2890 (±3) | 2899 (±5) | 2914 (±3) |
| Средняя реальная ПСП на запись, МБ/с | 1897 (±20) | 1895 (±20) | 2065 (±34) | 2070 (±34) |
| Максимальная реальная ПСП на чтение, МБ/с | 4211 | 4217 | 4220 | 4231 |
| Максимальная реальная ПСП на запись, МБ/с | 4029 | 4026 | 4029 | 4025 |
| Минимальная латентность псевдослучайного доступа, нс | 57.5 | 58.0 | 57.4 | 58.0 |
| Максимальная латентность псевдослучайного доступа, нс | 60.5 | 60.2 | 60.4 | 60.0 |
| Минимальная латентность случайного доступа, нс | 94.5 | 94.3 | 94.5 | 94.2 |
| Максимальная латентность случайного доступа, нс | 96.3 | 96.0 | 96.6 | 95.9 |
Полная симметрия по всем показателям, «неоднородности» архитектуры памяти как не бывало! Задержки при доступе к памяти при этом составляют истинно среднюю величину (например, при псевдослучайном доступе: (45 + 70) / 2 = 57.5 нс), с ПСП дела обстоят несколько хуже вместо ожидаемой теоретической величины (6.4 + 3.2 / 2) = 4.8 МБ/с мы наблюдаем лишь 4.2 МБ/с.
Заметим, однако, что примерно такие же величины мы получили бы и без включения Node Interleave для простого однопоточного приложения, не «привязанного» к определенному процессору. Более того, принудительная «привязка» приложения к процессору, как мы говорили выше, позволяет даже увеличить ПСП и снизить латентности. Таким образом, единственная адекватная область применения Node Interleave это лишь неоптимизированные многопоточные приложения, которые в противном случае будут упираться в ПСП одного из контроллеров памяти.
Заключение
В заключение, проведем краткий сравнительный анализ всех возможных вариантов платформ, оснащенных двухканальной памятью DDR-400 (на самом деле, с одинаковым успехом можно говорить и о двухканальной DDR2-400, -533, -667 и т.д., если не забывать, что 200-МГц процессорная шина по-прежнему ограничивает ПСП на уровне 6.4 ГБ/с), и приложений однопоточных (одного или нескольких) и многопоточных (обычных и NUMA-оптимизированных).
| Платформа | Пиковая пропускная способность подсистемы памяти, ГБ/с (двухканальная DDR-400) | |||
|---|---|---|---|---|
| Однопоточное приложение | Несколько однопоточных приложений | Многопоточное приложение | NUMA-aware многопоточное приложение | |
| SMP | 6.4 | 6.4 | 6.4 | 6.4 |
| Несимметричная NUMA | 4.2 (6.4*) | 6.4 | 6.4 | 6.4 |
| Симметричная NUMA | 4.2 (6.4*) | 8.4 (12.8*) | 6.4 | 12.8 |
| Симметричная NUMA, Node Interleave | 4.2 | 8.4 | 8.4 | 8.4 |
*в случае «привязки» приложения к одному из процессоров
Итак, SMP-системы (двухпроцессорные Intel Xeon, а также... любые существующие на сегодняшний день двухъядерные процессоры) теоретическая ПСП во всех случаях ограничена цифрой 6.4 ГБ/с, ибо это пиковая ПС единой и единственной процессорной шины.
Недорогие, несимметричные NUMA-системы выглядят не многим лучше, а то и хуже традиционных SMP-систем. Хуже — в случае однопоточных приложений, если их не «привязывать» к тому процессору, который обращается с памятью. Пиковая ПСП во всех остальных случаях здесь также ограничена цифрой 6.4 ГБ/с — то есть пропускной способностью единственного имеющегося в системе интерфейса памяти.
Симметричные NUMA-системы практически во всех случаях обладают преимуществом как над SMP, так и несимметричными NUMA-системами. Достигнуть пиковой ПСП 12.8 ГБ/с на таких платформах могут либо специальные NUMA-оптимизированные приложения, либо... два обычных, однопоточных приложения, «раскиданных» каждое по своему процессору.
Наконец, что же дает симметричным NUMA-платформам включение режима Node Interleave? Преимущество можно увидеть только в одном случае неоптимизированных многопоточных приложений (да еще и, конечно же, при условии, что каждый из потоков будет интенсивно обращаться с данными, находящимися в памяти). Если же грамотно запускать однопоточные приложения, либо использовать NUMA-оптимизированные включение этого режима однозначно не нужно, оно может лишь ухудшить производительность.
Таким образом, результаты проведенных нами исследований и их анализа позволяют заключить, что NUMA однозначно более совершенная архитектура памяти по сравнению с традиционными SMP-решениями, способная в большинстве случаев обеспечить над ними преимущество по низкоуровневым характеристикам подсистемы памяти.
Комментарии