Теоретический обзор Nvidia GeForce RTX 4090 и RTX 4080: еще больше производительности всеми возможными методами

Особенности архитектуры
В уже довольно далеком 2018 году компания Nvidia анонсировала архитектуру Turing, заметно изменившую индустрию 3D-графики реального времени, как бы громко это ни звучало. Именно решения той поры предложили абсолютно новые возможности, постепенно раскрывающиеся в играх, профессиональной графике и вычислительных задачах, включающих нейросети. Turing впервые предложил рынку аппаратное ускорение не только растеризации, но и трассировки лучей, что позволило использовать ее и в приложениях реального времени. Также большим нововведением GPU той архитектуры стало аппаратное же ускорение задач искусственного интеллекта посредством перемножения матриц на специализированных тензорных ядрах.
Еще двумя годами позднее Nvidia представила решения архитектуры Ampere, которые до недавнего времени были наиболее совершенными графическими процессорами компании. Они продолжили дело Turing, и практически все в их следующих GPU получило значительно более высокую производительность: математические вычисления, RT-ядра и тензорные ядра — все это стало намного быстрее, по сравнению с Turing. В среднем все тогдашние изменения привели к росту общей производительности на 70%-100%, и особенно это хорошо заметно было в играх с применением трассировки лучей.
Представленная недавно архитектура Ada Lovelace (далее Ada для краткости) встала в этот ряд — как и предшествующие, она взяла имя одного из великих ученых прошлых лет — в этот раз это Ада Лавлейс — известный британский математик, которая создала первую в мире программу и считается первым программистом в истории. В ее честь также назван и один из языков программирования. Очередное громкое имя для графической архитектуры продиктовано ее возросшими возможностями — пусть в ней и нет таких революционных инноваций, как были в Turing, но это в очередной раз заметно улучшенная и усиленная архитектура, по сравнению с предыдущими.
Чтобы понять, какой путь был пройден той же трассировкой лучей в играх за последние годы, достаточно привести один пример. Если в первой игре с гибридным рендерингом, сочетающим растеризацию и трассировку — Battlefield V — было в среднем всего лишь 39 операций трассировки на пиксель, то четыре года спустя, в улучшенной версии Cyberpunk 2077 (режим RT Overdrive, который использует трассировку пути для рендеринга, то есть растеризация не используется вообще) используется уже 635 вычислений на пиксель — рост более чем в 16 раз! Понятно, что трассировка — не единственное, что есть в этих играх, но разница налицо. И для того, чтобы поддерживать приемлемый уровень производительности, новые графические процессоры Ada стали в полтора-два раза производительнее в растеризации и до четырех раз — в играх и приложениях с активным применением трассировки лучей, по сравнению с Ampere.
Nvidia называет Ada революционной архитектурой, но мы все же считаем, что она продолжательница действительно новаторских идей Turing (ну и Ampere). Да, она гораздо производительнее и эффективнее, в нее есть новые и очень интересные особенности и возможности, но это все же продолжение предыдущих GPU, по сути. Кроме чисто архитектурных улучшений можно отметить то, что создать довольно большой GPU с 76,3 млрд транзисторов и двукратной производительностью, по сравнению с RTX 3090 Ti при том же потреблении энергии, позволил новый техпроцесс.
При производстве новых чипов Ada используется техпроцесс тайваньской компании TSMC — некий специально модифицированный под потребности Nvidia процесс с названием 4N. Это не совсем 4 нм техпроцесс, точнее совсем не — а просто неким образом улучшенный 5 нм техпроцесс. Впрочем, все эти числа с количеством нанометров давно стали маркетинговыми и куда важнее реальные параметры производительности и потребления. И тут все просто отлично, новый техпроцесс позволил Nvidia сделать большой шаг в топовых GPU — по сложности, производительности и энергоэффективности.
Вкратце отметим некоторые новые возможности RT-ядер архитектуры Ada, которые появились впервые. По заявлению Nvidia, RT-ядра новой архитектуры обеспечивают вдвое большую производительность теста пересечения луча и треугольника, но также имеют и дополнительные аппаратные блоки: Opacity Micromap Engine — ускоряющий трассировку полупрозрачной геометрии до двух раз, а также Displaced Micro-Mesh Engine — генерирующий дополнительные микротреугольники для большей геометрической сложности (помните же еще такой термин — тесселяция?). Микромеши позволяют повысить геометрическую сложность сцены без снижения производительности и повышения накладных расходов на хранение и передачу сложных объектов. Для использования и того и другого необходима поддержка со стороны графических API и дополнительный код со стороны разработчиков приложения, но выглядят эти возможности весьма перспективно.
Вероятно, даже еще более важным изменением в Ada, связанным с трассировкой лучей, является изменяемый порядок шейдерных вычислений — Shader Execution Reordering. Новые GPU поддерживают динамическое переупорядочение данных — например, материалов, в которые попадают лучи, для увеличения эффективности работы трассировки. К этой простой, но одновременно сложной возможности мы еще вернемся, ну а вкратце она хороша тем, что дает до 44% прироста в том самом режиме трассировки пути RT Overdrive в игре Cyberpunk 2077.
Значительные изменения произошли и в деле метода повышения производительности — DLSS. Все графические процессоры архитектуры Ada поддерживают новую версию этого метода — DLSS 3, которая отличается генерацией дополнительных кадров на основе существующих, что работает примерно как «уплавнялки» в телевизорах, только лучше. Для этого в Ada, помимо модернизированных тензорных ядер, есть улучшенный движок Optical Flow Accelerator, который и занимается синтезом новых кадров, что дает прирост до двух раз, по сравнению с DLSS 2.0 — при схожем или аналогичном качестве. Довольно логичное продолжение развитие метода увеличения производительности, которое потребовало множества улучшений в программной и аппаратной части, чтобы поддерживать не только высокую частоту кадров, но и низкие задержки.
Сегодня мы рассмотрим сразу три графических процессора: AD102, AD103 и AD104, на основе которых созданы видеокарты GeForce RTX 4090 и два варианта GeForce RTX 4080, соответственно. Это первые графические процессоры архитектуры Ada, предназначенные для обеспеченных игроков и профессионалов, которые хотят получить максимум производительности при самых богатых возможностях. Все они предназначены исключительно для 4K-разрешения и максимальных графических настроек.
Так как графическая архитектура Ada Lovelace во многом схожа с архитектурой Ampere, на которой основаны различные модификации чипов GA10x, обе эти архитектуры имеют достаточно много общего и с предыдущими архитектурами Turing и Volta, то перед прочтением материала будет полезно ознакомиться с нашими предыдущими статьями по теме:
- [30.09.20] Nvidia GeForce RTX 3090: самое производительное, но не чисто игровое решение
- [16.09.20] Nvidia GeForce RTX 3080, часть 1: теория, архитектура, синтетические тесты
- [19.09.18] Nvidia GeForce RTX 2080 Ti — обзор флагмана 3D-графики 2018 года
- [14.09.18] Игровые видеокарты Nvidia GeForce RTX — первые мысли и впечатления

| Графический ускоритель GeForce RTX 4090 | |
|---|---|
| Кодовое имя чипа | AD102 |
| Технология производства | 5 нм (TSMC 4N) |
| Количество транзисторов | 76,3 (28,3 у GA102) млрд |
| Площадь ядра | 608,5 (628,4 у GA102) мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 384-битная: 12 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6X |
| Частота графического процессора | до 2520 (1860 у GA102) МГц |
| Вычислительные блоки | 128 (из 144 в полном чипе) потоковых мультипроцессоров, включающих 16384 (из 18432) CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32/FP64 |
| Тензорные блоки | 512 (из 576) тензорных ядра для матричных вычислений INT4/INT8/FP16/FP32/BF16/TF32 |
| Блоки трассировки лучей | 128 (из 144) RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 512 (из 576) блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 22 (из 24) широких блока ROP на 176 (из 192) пикселей с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка HDMI 2.1 и DisplayPort 1.4a (со сжатием DSC 1.2a) |
| Спецификации референсной видеокарты GeForce RTX 4090 | |
|---|---|
| Частота ядра | 2230/2520 МГц |
| Количество универсальных процессоров | 16384 |
| Количество текстурных блоков | 512 |
| Количество блоков блендинга | 176 |
| Эффективная частота памяти | 21 ГГц |
| Тип памяти | GDDR6X |
| Шина памяти | 384-бит |
| Объем памяти | 24 ГБ |
| Пропускная способность памяти | 1008 ГБ/с |
| Вычислительная производительность (FP32) | до 82,6 терафлопс |
| Теоретическая максимальная скорость закраски | 444 гигапикселей/с |
| Теоретическая скорость выборки текстур | 1290 гигатекселей/с |
| Шина | PCI Express 4.0 x16 |
| Разъемы | по выбору производителя |
| Энергопотребление | до 450 Вт |
| Дополнительное питание | один 16-контактный разъем |
| Число слотов, занимаемых в системном корпусе | по выбору производителя |
| Рекомендуемая цена | $1599 |
| Графический ускоритель GeForce RTX 4080 16 ГБ | |
|---|---|
| Кодовое имя чипа | AD103 |
| Технология производства | 5 нм (TSMC 4N) |
| Количество транзисторов | 45,9 млрд |
| Площадь ядра | 378,6 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 256-битная: 8 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6X |
| Частота графического процессора | до 2510 МГц |
| Вычислительные блоки | 76 (из 80 в полном чипе) потоковых мультипроцессоров, включающих 9728 (из 10240) CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32/FP64 |
| Тензорные блоки | 304 (из 320) тензорных ядра для матричных вычислений INT4/INT8/FP16/FP32/BF16/TF32 |
| Блоки трассировки лучей | 76 (из 80) RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 304 (из 320) блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 14 широких блоков ROP на 112 пикселей с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка HDMI 2.1 и DisplayPort 1.4a (со сжатием DSC 1.2a) |
| Спецификации референсной видеокарты GeForce RTX 4080 16 ГБ | |
|---|---|
| Частота ядра | 2210/2510 МГц |
| Количество универсальных процессоров | 9728 |
| Количество текстурных блоков | 304 |
| Количество блоков блендинга | 112 |
| Эффективная частота памяти | 22,4 ГГц |
| Тип памяти | GDDR6X |
| Шина памяти | 256-бит |
| Объем памяти | 16 ГБ |
| Пропускная способность памяти | 717 ГБ/с |
| Вычислительная производительность (FP32) | до 48,7 терафлопс |
| Теоретическая максимальная скорость закраски | 281 гигапикселей/с |
| Теоретическая скорость выборки текстур | 762 гигатекселей/с |
| Шина | PCI Express 4.0 x16 |
| Разъемы | по выбору производителя |
| Энергопотребление | до 320 Вт |
| Дополнительное питание | один 16-контактный разъем |
| Число слотов, занимаемых в системном корпусе | по выбору производителя |
| Рекомендуемая цена | $1199 |
| Графический ускоритель GeForce RTX 4080 12 ГБ | |
|---|---|
| Кодовое имя чипа | AD104 |
| Технология производства | 5 нм (TSMC 4N) |
| Количество транзисторов | 35,8 млрд |
| Площадь ядра | 294,5 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 192-битная: 6 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6X |
| Частота графического процессора | до 2610 МГц |
| Вычислительные блоки | 60 потоковых мультипроцессоров, включающих 16384 (из 18432) CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32/FP64 |
| Тензорные блоки | 240 тензорных ядер для матричных вычислений INT4/INT8/FP16/FP32/BF16/TF32 |
| Блоки трассировки лучей | 60 RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 240 блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 10 широких блоков ROP на 80 пикселей с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка HDMI 2.1 и DisplayPort 1.4a (со сжатием DSC 1.2a) |
| Спецификации референсной видеокарты GeForce RTX 4080 12 ГБ | |
|---|---|
| Частота ядра | 2310/2610 МГц |
| Количество универсальных процессоров | 7680 |
| Количество текстурных блоков | 240 |
| Количество блоков блендинга | 80 |
| Эффективная частота памяти | 21 ГГц |
| Тип памяти | GDDR6X |
| Шина памяти | 192-бит |
| Объем памяти | 12 ГБ |
| Пропускная способность памяти | 504 ГБ/с |
| Вычислительная производительность (FP32) | до 40,1 терафлопс |
| Теоретическая максимальная скорость закраски | 209 гигапикселей/с |
| Теоретическая скорость выборки текстур | 626 гигатекселей/с |
| Шина | PCI Express 4.0 x16 |
| Разъемы | по выбору производителя |
| Энергопотребление | до 285 Вт |
| Дополнительное питание | один 16-контактный разъем |
| Число слотов, занимаемых в системном корпусе | по выбору производителя |
| Рекомендуемая цена | $899 |
Имена анонсированных моделей видеокарт нового семейства сами по себе вполне соответствует принципу наименования решений компании — изменилась первая цифра поколения. GeForce RTX 4090 является топовой моделью в существующей линейке, а RTX 4080 стоит на шаг ниже. Но есть одно большое или даже огромное но — в Nvidia зачем-то решили одинаково назвать две абсолютно разные видеокарты. У них даже чипы разные, причем отличаются они довольно сильно. Если в случае тех же GeForce GTX 1060 на 3 ГБ и 6 ГБ, которые также отличались не только объемом памяти, хотя бы GPU был тот же, да и шина памяти была одинаковая, то в случае RTX 4080 с 16 ГБ и 12 ГБ из одинакового у них только название и архитектура — посмотрите на таблички, AD103 и AD104 отличаются почти по всем показателям раза в полтора.
Зачем Nvidia нужно вносить такую путаницу в собственную линейку? Неужели расчет на то, что покупатели будут ориентироваться на бенчмарки старшей модели, но затем купят младший вариант, так как он банально дешевле? Тогда дальше можно выпустить RTX 4080 10 ГБ и RTX 4080 8 ГБ, которые станут как бы RTX 4060 и RTX 4050, но с более привлекательным маркетинговым наименованием. Такой подход мы точно не поддерживаем, вариант RTX 4080 с 12 ГБ явно должен был называться RTX 4070.
Хотя, скорее всего, это просто такой относительно мягкий вариант повышения цен на всю линейку. И пусть RTX 3090 также была весьма дорога, так что действительно топовую RTX 4090 мы трогать не будем, она предназначена для самых-самых энтузиастов, но RTX 4080 16 ГБ и RTX 4080 12 ГБ «4070» явно ожидались публикой по несколько меньшей цене. Но и тут есть пара объяснений. Во-первых, у новинок пока что нет конкуренции, причем от слова совсем. Решения нового семейства AMD ожидаются позднее в этом году, а линейка Radeon RX 6000 при всем уважении на соперников RTX 40 не тянет, особенно учитывая производительность в трассировке лучей.
Во-вторых, во всем мире цены в последние месяцы действительно растут, причем вообще на все. Наверняка и себестоимость производства GPU и карт на их основе для Nvidia заметно повысилась, вот они и корректируют, как могут. Посмотрим, что выкатит их конкурент и по каким ценам, но не советуем рассчитывать на подарки — AMD тоже коммерческая компания, которая своего не упустит. Пока же, в виде условного конкурента младшим новинкам Nvidia можно рассматривать разве что Radeon RX 6950 XT — она пусть во многих задачах и медленнее, но и заметно дешевле.
С объемом видеопамяти новых решений Nvidia в целом сделала все верно, хотя это и было продиктовано во многом шириной шины памяти — 24 ГБ у топового (больше просто не нужно), 16 ГБ у предтопового и 12 ГБ у RTX «4070» — все это полностью обосновано. И хотя 16 ГБ против 12 ГБ вряд ли принесут преимущество в нынешних играх, но это дает некоторый запас прочности на будущие проекты — массовое применение трассировки лучей и все большая геометрическая и текстурная сложность сцен в играх со временем потребуют большего объема видеопамяти.
Многих пугает энергопотребление RTX 4090 в 450 Вт. Но позвольте, это — топовая видеокарта с максимальной производительностью, даже без всех этих DLSS 3 обеспечивающая вдвое больше производительности, по сравнению с RTX 3090 Ti (вот где монстр то) хотя бы на бумаге. Да, в производстве GPU используется более совершенный техпроцесс, но никуда мы от высокого потребления уже не денемся, постоянный рост вычислительных запросов не даст. Если вас не устраивают 450 Вт, то никто не запрещает купить RTX 4080 — с 320 Вт или даже 285 Вт. Другое дело, что некоторые модели видеокарт RTX 4090 в исполнении партнеров наверняка дойдут и до полукиловатта, если не больше. Но если спрос есть, то появляется и предложение.
Как и их предшественницы, RTX 4090 и RTX 4080 (только вариант с 16 ГБ) будут предлагаться и в дизайне самой Nvidia — в виде решений специального издания Founders Edition. Дизайн новинок очень похож на то, что мы видели в предыдущей серии, но были увеличены размер и эффективность вентиляторов (на 20% лучшие по параметрам), улучшена система питания и т. п. Важно, что обещано и снижение температуры видеопамяти — бич многих видеокарт серии RTX 30, включая референсные варианты.
Логично, что для питания новых карт самой Nvidia используется новый 16-контактный разъем питания PCIe 5.0, обкатанный на GeForce RTX 3090 Ti, который стал стандартом для ATX 3.0 и позволяет сократить количество кабелей в корпусе игрового ПК. Блоки питания с подобным разъемом уже представлены на рынке, ну и всегда можно обойтись переходником с трех или четырех привычных 8-контактных разъемов.

Партнеры компании Nvidia, производящие видеокарты, уже анонсировали и выпустили по несколько решений собственного дизайна, включая разогнанные варианты, имеющие весьма массивные системы охлаждения. Модели GeForce RTX 4090 и 4080 будут доступны в разных модификациях у партнеров Nvidia: Asus, Colorful, Gainward, Galaxy, Gigabyte, Innovision 3D, MSI, Palit, PNY и Zotac. Кроме этого, на RTX 40 будут основаны и готовые игровые системы Acer, Alienware, Asus, Dell, HP, Lenovo и MSI.
Архитектурные особенности
В линейке видеокарт GeForce RTX 40 применяются новые графические процессоры AD10x, основанные на графической архитектуре Ada Lovelace. При создании новой архитектуры у инженеров компании Nvidia была четкая цель — на фоне очень мощных и инновационных для своего времени Turing и Ampere создать графическую архитектуру, которая бы не только кратно повышала производительность операций трассировки лучей и машинного вычисления на тензорных ядрах, но и предоставляла некоторые новые возможности, позволяющие еще больше повысить качество и производительность до 2-4 раз (включая хитрости DLSS 3) над лучшими из Ampere.
В этом им серьезно помог переход на продвинутый технологический процесс 4N тайваньской компании TSMC, занимающей львиную долю рынка производства микрочипов. Название техпроцесса наводит на мысль о том, что это 4 нм технологические нормы, но нет — это улучшенный 5 нм техпроцесс, просто так названный, вероятно, с маркетинговой точки зрения — эти нанометры в названиях все равно давно уже не говорят ни о чем, они у всех разные. Так вот, инженеры Nvidia работали совместно со специалистами из TSMC чтобы оптимизировать техпроцесс для производства столь продвинутых GPU. Единственное, что мы еще знаем — по данным Nvidia, улучшения техпроцесса TSMC относительно «обычного» TSMC 5N обеспечивают на несколько процентов лучшую производительность и энергоэффективность.

Но и 5 нм — это отлично, и во многом именно техпроцесс позволил «засунуть» в AD102 на 70% больше CUDA-ядер, по сравнению с GA102 прошлой архитектуры Ampere. Новый чип получился очень сложным, он содержит 76,3 миллиарда транзисторов и при этом его физический размер даже меньше, чем у TU102 и GA102. И даже тактовая частота не пострадала — чипы Ada работают на высоких частотах — турбо-частота для топовой модели GeForce RTX 4090 составляет 2,52 ГГц, что заметно выше, чем у предыдущих решений. Самое важное, что большое количество исполнительных блоков, работающих на высокой частоте, дало неплохой показатель энергоэффективности — при том же потреблении, что и у RTX 3090 Ti, новый RTX 4090 GPU до двух раз производительнее.
Как и все графические процессоры компании Nvidia, чип состоит из укрупненных кластеров Graphics Processing Cluster (GPC), которые включают несколько кластеров текстурной обработки Texture Processing Cluster (TPC), содержащих потоковые процессоры Streaming Multiprocessor (SM), блоки растеризации ROP и контроллеры памяти. Рассмотрим диаграмму графического процессора.
Полная версия графического процессора AD102 содержит 12 крупных вычислительных кластеров GPC, 72 кластеров текстурной обработки TPC, 144 потоковых мультипроцессоров SM. Как и в предыдущих архитектурах, кластер GPC самостоятельно производит все основные вычисления внутри кластера, и включает свой движок растеризации Raster Engine, шесть кластеров TPC, состоящих из 12 мультипроцессоров SM. Количество блоков растеризации ROP также серьезно возросло по сравнению с Ampere, что должно сказаться при упоре в скорость растеризации, что иногда встречается и в играх.
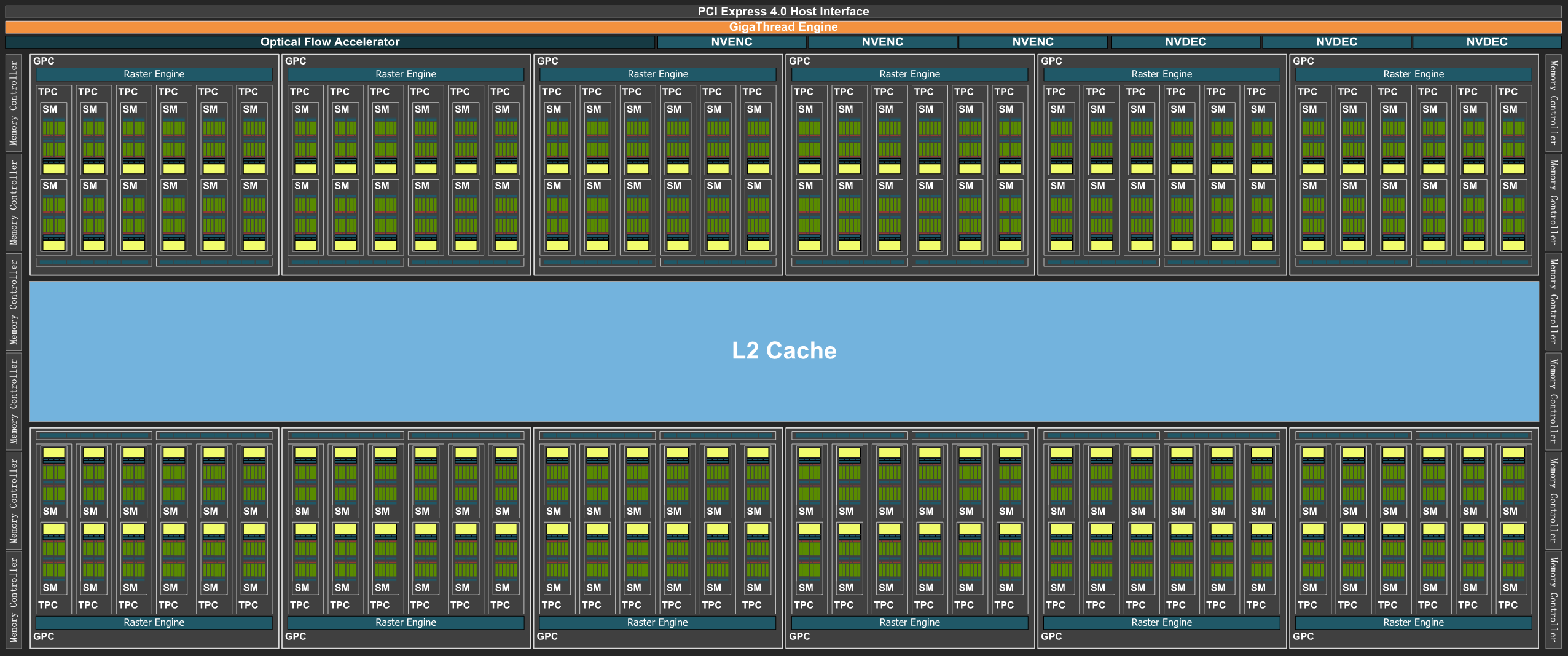
Всего полный чип AD102 содержит 18432 CUDA-ядер, 144 RT-ядра, по 576 тензорных ядер и текстурных модулей TMU. Кроме обозначенных на диаграмме, в AD102 есть и блоки для FP64-вычислений повышенной точности — по два на мультипроцессор SM, что дает 288 блока на чип. FP64-вычисления нужны для серьезных научных задач и в игровых решениях имеются в основном для обеспечения совместимости, поэтому производительность FP64 составляет лишь 1/64 от скорости FP32-вычислений.
Также в чипе есть 12 контроллеров памяти по 32-бит, что в результате дает общую 384-битную шину памяти — в этом новый GPU не отличается от GA102 архитектуры Ampere. Да и память применяется уже знакомая нам с GeForce RTX 3090 и RTX 3080 — GDDR6X производства Micron. Но в те времена эффективная частота памяти была 19,5 ГГц, а в случае RTX 4090 это уже 21 ГГц — то есть, общая пропускная способность памяти в случае GeForce RTX 4090 превышает 1 ТБ/с. Впрочем, это мы уже видели в RTX 3090 Ti. Общий объем видеопамяти также не изменился еще с RTX 3090, ее тут столько же — 24 ГБ
А вот что было улучшено очень серьезно, по сравнению с Ampere, так это объем кэш-памяти второго уровня. В полный чип AD102 смогли вместить аж 96 МБ L2-кэша, что в 16 раз больше, чем всего лишь 6 МБ у GA102! К слову, если говорить о части GPU, которую занимают транзисторы кэш-памяти, то 96 МБ — это почти 5 млрд транзисторов — приличная часть кристалла. Это все еще не так много, как L3-кэша в RDNA2 с учетом соотношения производительности и объема кэш-памяти, но значительно больше, чем в Ampere, да и L3 имеет меньшую пропускную способность и более высокие задержки. Многие приложения получат преимущество от столь объемной кэш-памяти — в частности, большой объем L2-кэша положительно сказывается в сложных вычислительных задачах, при аппаратной трассировке лучей, да и при растеризации — особенно в играх и тестах с большим количество полупрозрачных частиц, вроде бенчмарка FireStrike из пакета 3DMark.
Каждый мультипроцессор в чипах AD10x содержит по 128 CUDA-ядер, по одному RT-ядру третьего поколения, по четыре тензорных ядра четвертого поколения, по четыре текстурных блока TMU, регистровый файл на 256 КБ и 128 КБ L1-кэша или разделяемой памяти, объем которых конфигурируется по необходимости. Полный чип AD102 содержит 18432 КБ кэш-памяти первого уровня, по сравнению с 10752 КБ в GA102.

Каждый мультипроцессор SM разделен на четыре подраздела, каждый из которых содержит по 64 КБ регистрового файла, L0-кэша для инструкций, а также блоки управления warp scheduler и dispatch unit. 16 CUDA-ядер в разделе выделены исключительно для FP32-вычислений, а еще 16 CUDA-ядер способны производить или FP32- или INT32-вычисления с той же скоростью. Также в блоке есть тензорное ядро, четыре блока загрузки данных и блок специальных функций Special Function Unit (SFU) для исполнения сложных инструкций.
Ранее мы рассматривали полную версию чипа AD102, а даже в топовой модели GeForce RTX 4090 применяется заметно урезанный вариант с меньшим количеством исполнительных блоков в следующей конфигурации — отключен не только один GPC, но еще в паре кластеров заблокированы по одному кластеру TPC:
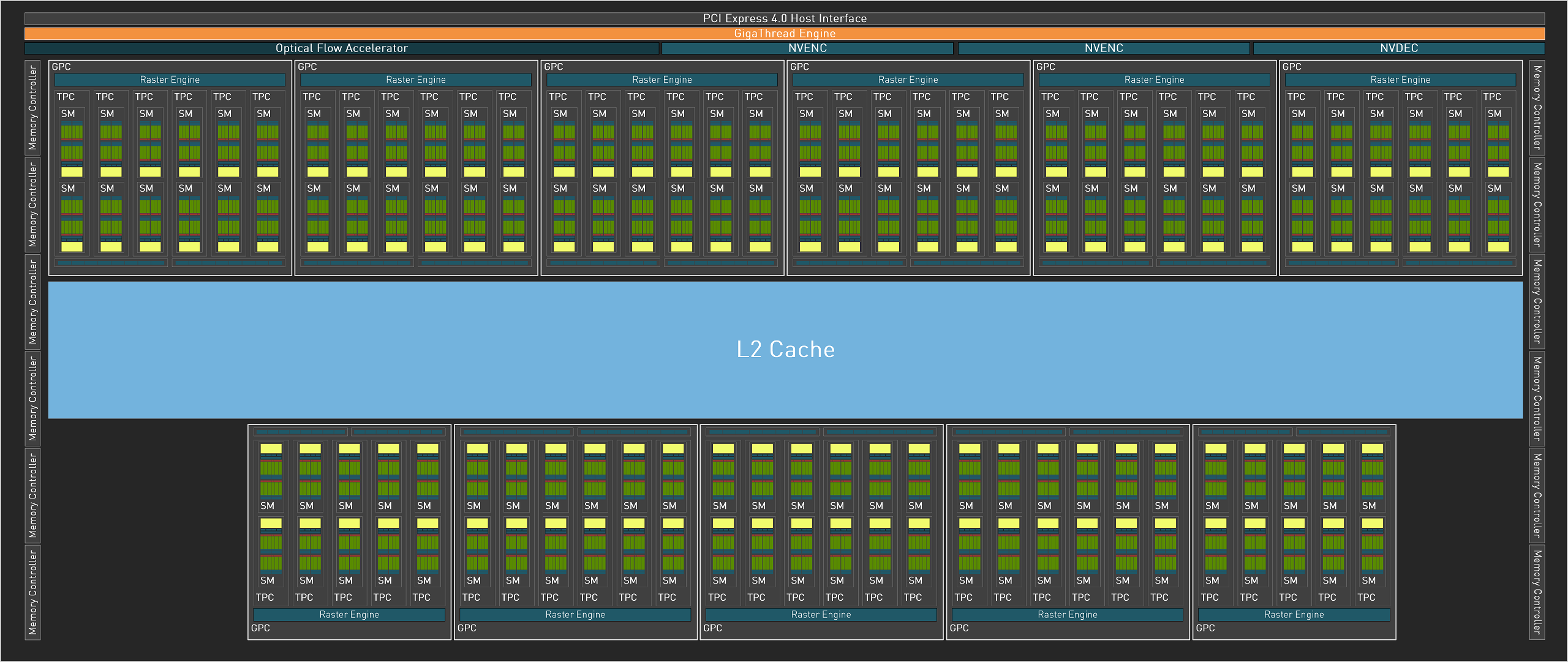
Сравним некоторые из теоретических показателей всех анонсированных моделей видеокарт серии GeForce RTX 40, основанных на разных чипах AD10x, с некоторыми моделями из Ampere, это позволит наглядно оценить разницу между ними.
| RTX 4090 | RTX 4080 16 ГБ | RTX 4080 12 ГБ | RTX 3090 Ti | RTX 3080 Ti | |
|---|---|---|---|---|---|
| CUDA-ядра | 16384 | 9728 | 7680 | 10752 | 10240 |
| Тензорные ядра | 512 | 304 | 240 | 336 | 320 |
| RT-ядра | 128 | 76 | 60 | 84 | 80 |
| Базовая частота, ГГц | 2,23 | 2,21 | 2,31 | 1,56 | 1,37 |
| Турбо-частота, ГГц | 2,52 | 2,51 | 2,61 | 1,86 | 1,67 |
| Объем памяти, ГБ | 24 | 16 | 12 | 24 | 12 |
| Шина памяти, бит | 384 | 256 | 192 | 384 | 384 |
| ПСП, ГБ/с | 1008 | 717 | 504 | 1008 | 912 |
| Потребление, Вт | 450 | 320 | 285 | 450 | 350 |
Что сразу бросается в глаза — большая разница между RTX 4090 и RTX 4080, даже старшим вариантом. Как по количеству исполнительных блоков, так и по энергопотреблению. То есть, RTX 4090 это явно бескомпромиссная топовая модель, а ведь она еще и не на полном варианте AD102 основана. Во-вторых, сразу видны серьезно повысившиеся рабочие частоты GPU у новой линейки Ada, по сравнению с Ampere, и заметно меньшее потребление энергии у той же RTX 4080 с 12 ГБ по сравнению с RTX 3090 Ti, хотя их производительность должна быть близкой — за это спасибо скажем новому 5 нм техпроцессу TSMC.
Еще интересна ничуть не увеличившаяся пропускная способность видеопамяти у RTX 4090, по сравнению с RTX 3090 Ti, да и ПСП у младших вариантов Ada не особенно впечатляет на фоне указанных видеокарт предыдущей серии. Вероятно, Nvidia смогла себе позволить это в том числе и из-за серьезно (в 16 раз для топовой модели) увеличившегося объема L2-кэша, который как раз и позволяет нивелировать относительный недостаток ПСП.
К слову, о младших видеокартах. Графический процессор AD103 включает в себя все способности AD102, включая RT-ядра третьего поколения и тензорные ядра четвертого — то есть, поддерживает и DLSS 3 и новый ускоритель оптического потока OFA. AD103 в виде модели видеокарты GeForce RTX 4080 16 ГБ обеспечивает высокий уровень производительности более чем у флагманского решения на чипе GA102 — GeForce RTX 3090 Ti.
Полный чип AD103 содержит 45,9 млрд транзисторов и включает 7 кластеров GPC, 40 кластеров TPC, 80 мультипроцессоров SM и восемь 32-битных контроллеров памяти (256-бит всего). В целом, полноценный GPU содержит 10240 CUDA-ядра, 80 RT-ядер, 320 тензорных ядер, 320 текстурных блока TMU и 112 блоков ROP. Подсистема памяти включает 10240 КБ L1-кэша, 20480 КБ регистрового файла и 64 МБ L2-кэша.
На основе графического процессора AD103 выпущена модель видеокарты GeForce RTX 4080 16 ГБ, имеющая GPU с парой отключенных кластеров TPC и четыре неактивных SM. Соответственно снижено и количество большинства исполнительных блоков: осталось 9728 CUDA-ядер, 304 блока TMU и столько же тензорных ядер, 76 RT-ядер. А вот подсистему памяти не тронули — все контроллеры активны и это 256-битная шина. То же самое и с блоками ROP, их тут тоже 112 штук, как и в полном чипе.
Графический процессор AD104 — самая недорогая на момент выхода линейки модель для игроков и создателей контента, которые хотят использовать новые возможности архитектуры Ada. На чипе AD104 основана модель GeForce RTX 4080 12 ГБ («RTX 4070»), которая появится в продаже в ноябре. Она использует полную версию этого графического процессора, которая состоит из 5 кластеров GPC, 30 кластеров TPC, 60 мультипроцессоров SM и шести 32-битных контроллеров памяти (всего 192-бит на чип). Этот GPU состоит из 35,8 млрд транзисторов и содержит 7680 CUDA-ядер, 60 RT-ядер, 240 тензорных ядер и блоков TMU, а также 80 блоков ROP. Подсистема памяти включает 7680 КБ L1-кэша, 15360 КБ регистрового файла и 48 МБ L2-кэша.
Улучшения аппаратной трассировки лучей
RT-ядра в чипах архитектуры Turing и Ampere включают выделенные блоки для ускорения нахождения пересечений лучей со специальными структурами — ограничивающими объемами Bounding Volume Hierarchy (BVH) и тестирования пересечений луча с треугольником и луча с ограничивающей структурой BVH, что критически важно для трассировки лучей. В RT-ядрах Ampere прохождение BVH ускоряется движком поиска пересечений Box Intersection Engine, а тестирование пересечений луча и треугольника ускоряется блоком Triangle Intersection Engine. Эти блоки выполняют значительную работу трассировки лучей и разгружают SM от выполнения этих задач и у них остается больше времени над операциями с пикселями, вершинами и т. д.
В RT-ядрах третьего поколения, которые включены в графические процессоры Ada, в дополнение к этим двум блокам были добавлены еще два — Opacity Micromap Engine и Displaced Micro-Mesh Engine. Они выполняют довольно специфические задачи: первый блок ускоряет трассировку лучей для полупрозрачных объектов, вроде растительности, а второй разбивает объекты на микротреугольники (микромеши) — метод известен как Displaced Micro-Meshes для трассировки сложных геометрических объектов с высокой производительностью за счет упрощенных структур BVH.

Эти возможности нужно еще поддержать в графических API, затем их должны использовать программисты — то есть, это дело скорее завтрашнего дня. А сразу сегодня важно то, что само по себе тестирование пересечения луча и треугольника в графических процессорах Ada стало вдвое быстрее, чем в Ampere, и вчетверо быстрее, чем в Turing. А с учетом выросшей рабочей частоты GPU, трассировка в Ada уже до 2,8 раз быстрее, чем в лучших графических процессорах предыдущего поколения. Эти улучшения делают RT-ядра третьего поколения наиболее мощными блоками для ускорения трассировки лучей в исполнении Nvidia.
Но давайте подробнее остановимся на двух аппаратных улучшениях, которые выглядят перспективно, но требуют программной поддержки. Вообще, почему понадобились подобные обходные решения, связанные со специфическими деталями, вроде прозрачных объектов? Трассировка лучей очень требовательная и поглотит столько ресурсов, сколько есть в наличии, особенно если 3D-сцена богатая, со сложными объектами и эффектами, и путей для простой универсальной оптимизации тут не слишком много, поэтому и приходится ускорять частные случаи.
3D-разработчики нередко используют альфа-канал текстур для того, чтобы придать сложную форму плоскому объекту, отбросив невидимые пиксели, заданные значением альфа-канала — этот метод очень часто используется для рендеринга растительности — листьев, травы, а также языков пламени. Самый простой случай — целый лист растения может быть представлен лишь двумя треугольниками со сложной формой его краев, описанных в альфа-канале текстуры — там же задается и степень прозрачности. Вы наверняка видели такую растительность в играх — в каждой первой из них.
Это неплохо работает в растеризации, но приносит проблемы при трассировке. В RT-ядрах предыдущих поколений в описании сцены при трассировке лучей разработчики представляют такие объекты в виде непрозрачных, и когда луч попадает в лист, то для определения пересечения всегда вызывается шейдер, прозрачный ли тот участок или нет, что влечет излишние затраты производительности — вызовов шейдера требуется слишком много, а это выполняется неэффективно.
Для лучшей обработки подобного контента, инженеры Nvidia добавили движок Opacity Micromap Engine в RT-ядра Ada. Микрокарта непрозрачности в его названии — это виртуальная сетка из микротреугольников, каждый из которых имеет состояние непрозрачности, которое и используется при тестировании пересечения лучей. Состояние непрозрачности каждого микротреугольника может быть непрозрачным, прозрачным или неизвестным. Если микротреугольник непрозрачный, то попадание луча записывается и возвращается, а если прозрачный, то это пересечение игнорируется и поиск дальнейшего пересечения продолжается. Если же статус прозрачности неизвестен, только тогда управление переходит к SM и вызывается шейдер для программного определения пересечения.
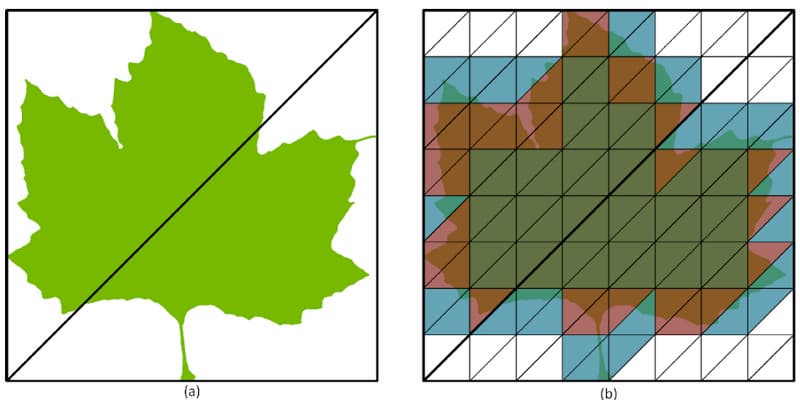
Маска непрозрачности из треугольной сетки может иметь размер от одного до 16 млн микротреугольников, и статус прозрачности для каждого из них определяется одним или парой бит. Рассмотрим кленовый лист, описанный в 3D-сцене парой треугольников и альфа-текстуры. В процессе обработки к кленовому листу, состоящему из пары треугольников, применяется маска непрозрачности, движок Opacity Micromap Engine определяет, какие секции непрозрачные, прозрачные или неизвестные.
Темно-зеленым цветом отмечены непрозрачные микротреугольники, белым — прозрачные, а красным и синим — области смешанной непрозрачности (то есть, неизвестной прозрачности, которая требует дополнительного определения пересечения луча шейдером). В этом примере 30 микротреугольников помечены как прозрачные, 41 — как непрозрачные, а 57 — как неизвестные. То есть, больше половины лучей, пересекающих эти треугольники, или точно не проходят через лист или точно проходят, и эти лучи RT-ядро может охарактеризовать без вызова кода шейдера, а лишь при обнаружении неизвестного состояния управление возвращается шейдеру для точного определения пересечения.
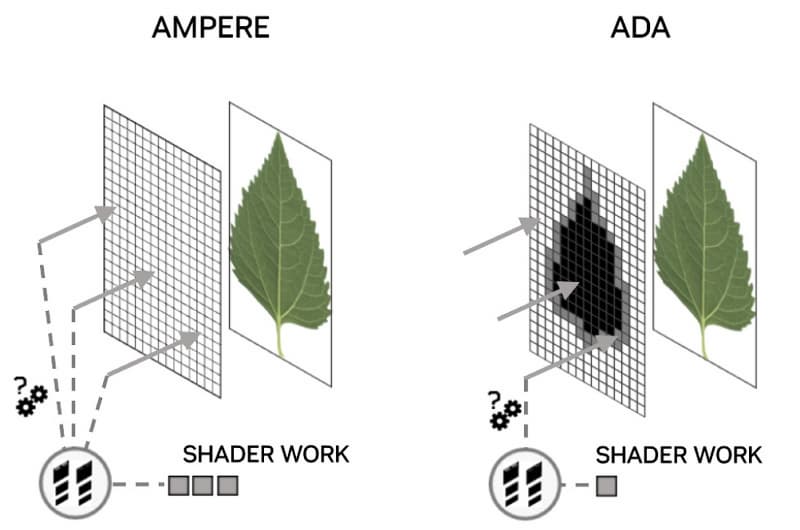
То есть, движок Opacity Micromap Engine существенно снижает шейдерную работу при обработке таких объектов, по сравнению с предыдущими поколениями RT-ядер. По оценке специалистов Nvidia, добавление Opacity Micromap Engine в RT-ядра позволяет удвоить производительность обхода сцены при трассировке лучей, когда используется альфа-тестирование. Конечно, прирост производительности зависит от сцены, но наибольший рост должен быть при обсчете теней, отбрасываемых на геометрию с альфа-тестированием (ветки деревьев, языки пламени).
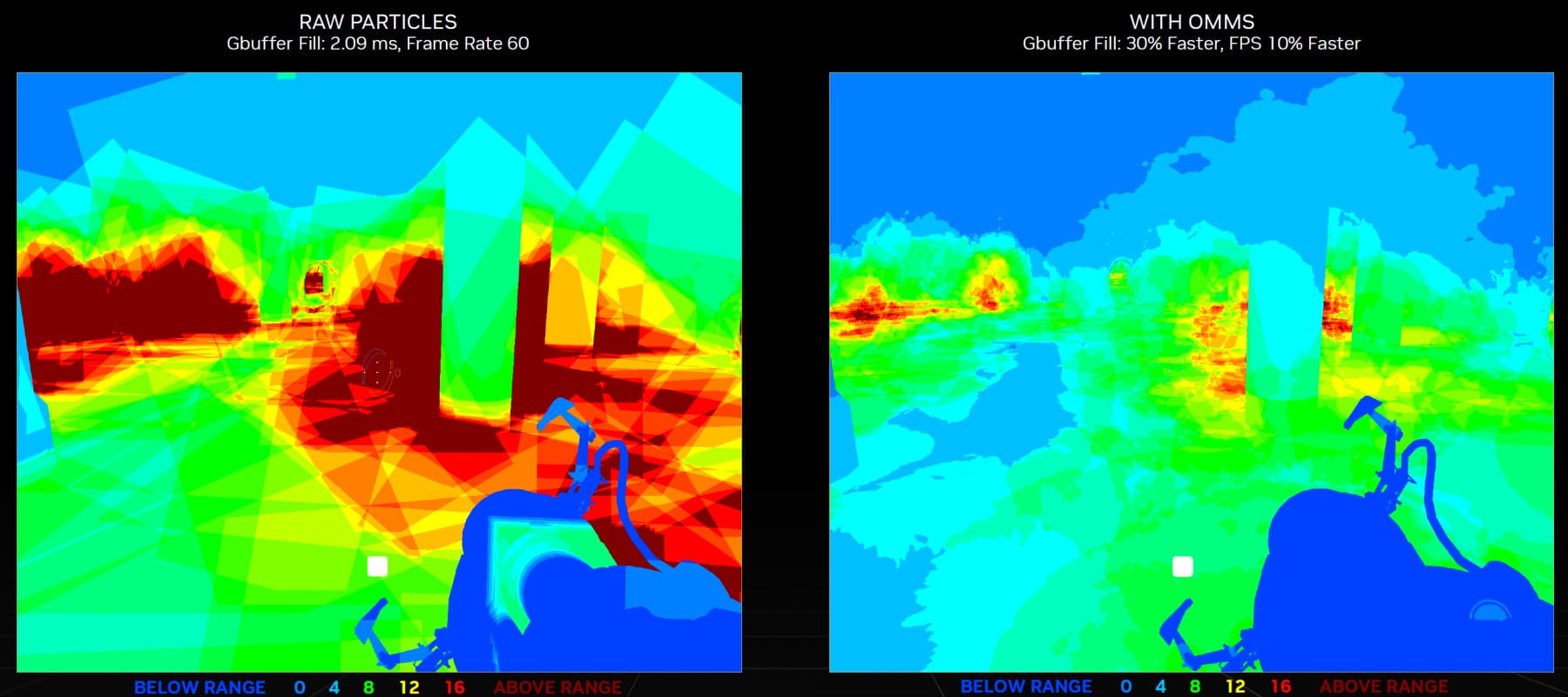
Поддержка маски непрозрачности при трассировке может значительно увеличить или производительность или детализацию геометрии в сценах. Вот наглядный пример из Portal RTX, использование OMM в котором дает 10% прироста в частоте кадров при наличии большого количества геометрии с альфа-тестом в виде пара от воды:
Второй аппаратный блок в RT-ядрах нового поколения — Displaced Micro-Mesh Engine, он связан с новым (на самом деле — не очень, но аппаратной поддержки ранее нигде не было) методом повышения геометрической сложности сцены без прироста требовательности к вычислительной мощи — Nvidia заявляет до 10-кратного ускорения при построении структур ускорения BVH и в 20 раз меньший объем в памяти для хранения и передачи геометрических данных одинаковой сложности.
Геометрическая сложность сцен в играх и других приложениях постоянно растет, но ресурсоемкость трассировки лучей повышается с увеличением сложности геометрии не столь заметно — затраты на трассировку более сложных сцен растут не настолько быстро, как сложность. Например, можно увеличить количество геометрии в 100 раз, а увеличение времени трассировки сцены не превысит 2-4 раз. Но вот создание ускоряющих структур BVH потребует почти линейного увеличения времени на обработку, не говоря уже о требуемом для хранения и обработки объеме памяти, которые также могут увеличиться в 100 раз.
Используемые сейчас примитивы неидеально подходят для очень сложных поверхностей и органических объектов, а в играх геометрии все больше и больше. Микромеши позволяют эффективнее использовать сложные объекты и материалы — вплоть до нескольких десятков раз больше треугольников, заполняя ими фотореалистичные сцены при меньшем использовании памяти и места на накопителе. Это работает как сжатие геометрических данных с автоматической возможностью получать регулируемые уровни детализации. Для обработки микромешей в RT-ядра третьего поколения добавлен движок DMM — создающих и обрабатывающих смещенные микросетки. Производительность создания BVH и объем памяти при этом растет незначительно, снижаются и затраты на хранение и передачу геометрических ресурсов.

Смещенная микросетка представляет геометрию в компактном структурированном виде для более эффективного рендеринга с изменяемым уровнем детализации (LOD) и упрощенной деформацией и анимацией. При трассировке лучей используется смещенная микросетка — для того, чтобы снизить затраты на построение BVH, а при растеризации используется необходимый уровень детализации микросетки для растеризации примитивов при помощи вычислительных или mesh-шейдеров. На иллюстрации выше указан разный уровень детализации краба.
Микромеши DMM — это новый тип графического примитива для сложной геометрии, предназначенный для применения в трассировке лучей реального времени. Новый геометрический примитив определяется базовым треугольником и картой смещения — displacement map — текстурой, в которой записаны необходимые смещения для вершин внутри треугольника. Блок Micro-Mesh Engine при трассировке лучей генерирует микротреугольники так, чтобы находить пересечения лучей с геометрией вплоть до отдельного микротреугольника.
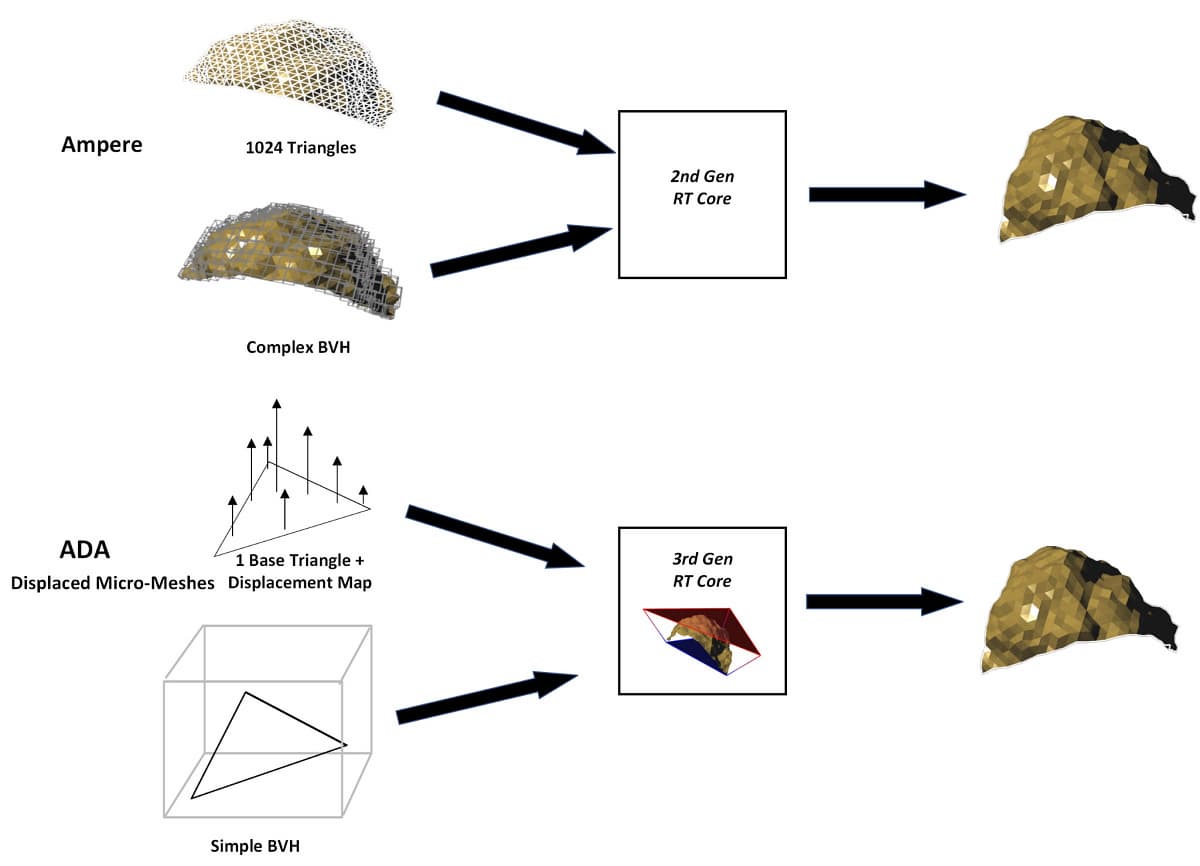
Новые RT-ядра третьего поколения при помощи движка DMME используют в работе упрощенную структуру BVH, один базовый треугольник и карту смещений — для того, чтобы создать высокодетализированную геометрию с использованием меньших вычислительных ресурсов, по сравнению с RT-ядрами предыдущих поколений. Такой подход позволяет получить преимущество в объеме геометрии в 5—20 раз, а время на создание BVH-структуры уменьшится в 7—15 раз.
Но самый важный вопрос в деле внедрения этой новой возможности с микромешами — поддержка со стороны разработчиков. Кроссплатформенные микромеши с открытым кодом доступны для всех разработчиков на всех платформах, и Nvidia утверждает, что представлением геометрии в виде микромешей уже заинтересовались партнеры в виде компаний Adobe и Simplygon — это часть Xbox Game Studios, которая занимается как раз оптимизацией представления геометрии, уровнями ее детализации и т. п. Если инициатива будет поддержана индустрией, а поддержка появится в распространенных API, то ее будущее выглядит весьма неплохим.
И это еще не все нововведения в блоках аппаратной трассировки лучей, есть еще кое-что. Например, известно, что чем сложнее 3D-сцена с эффектами, тем менее когерентными становятся лучи. Вторичные лучи, использующиеся для отражений, непрямого освещения, эффектов прозрачности и других, все чаще имеют разную направленность и поэтому попадают в различные материалы, что делает вторичные попадания все менее упорядоченными и эффективными. Потеря этой упорядоченности лучей приводит к значительному снижению эффективности использования ресурсов графического процессора, его шейдерных мультипроцессоров, которым желательно подавать одинаковую работу сразу над группой пикселей, а не несколько программ для каждого.
Прямолинейным подходом нехватку вычислительных ресурсов не решить, неупорядоченные шейдеры при трассировке все чаще становятся основным ограничителем производительности, особенно в алгоритмах множественного отскока, вроде трассировки пути (path tracing). И эта дивергенция (расхождение, разветвление) бывает двух форм: когда разные потоки выполняют разные шейдеры или когда потоки обращаются к сложно кэшируемым ресурсам в памяти. Такие расхождения естественны при трассировке лучей, и чем сложнее трассировка, тем больше их возникает. А графические процессоры работают эффективнее только тогда, когда обрабатываемые данные однородны.
В архитектуре Ada появилась дополнительная система планирования — изменение порядка выполнения шейдеров (Shader Execution Reordering — SER), которая предназначена для повышения эффективности выполнения RT-шейдеров при помощи решения указанной проблемы расхождения. Эта система переупорядочивает работу по затенению для более эффективного исполнения шейдеров и лучшей локальности данных. Пока что Nvidia не раскрывает все возможности и особенности SER, но утверждает, что система разрабатывалась годами, а архитектура Ada разработана с учетом применения SER — это включает оптимизации мультипроцессоров SM и подсистемы памяти.
Планировщик SER не работает автоматически, а контролируется из ПО при помощи небольшого API, что позволяет разработчикам применять переупорядочивание именно там, где это будет полезно. Им нужно вставить в код определенный вызов и планировщик в GPU переупорядочит шейдеры материалов так, чтобы в потоках команд (варпах) были одинаковые материалы, а не расположенные в случайном порядке, что исполняется неэффективно. Автоматически такой планировщик будет работать плохо, так как если переупорядочивать работу затенения вообще всегда, то во многих случаях будет наблюдаться падение производительности. Поэтому нужно, чтобы сам программист вставил нужную функцию в код, чтобы гарантировать ускорение.
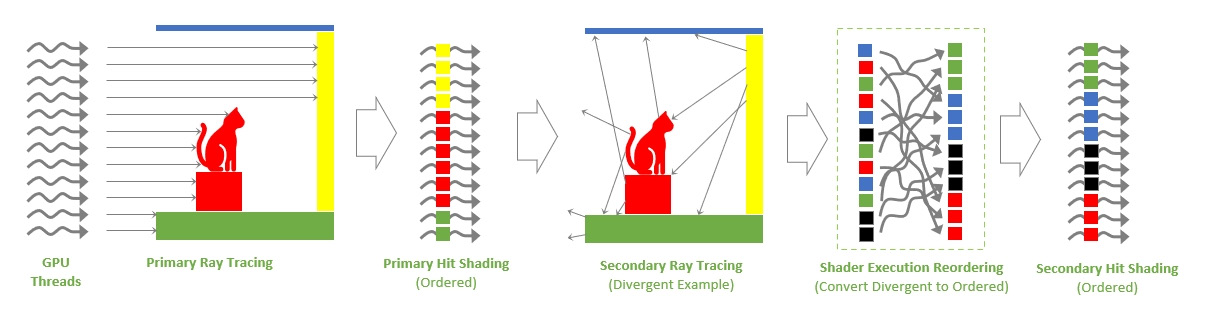
На иллюстрации выше показана работа планировщика изменения порядка выполнения шейдеров на примере продвинутого метода трассировки пути, которая вызывает заметно расхождение шейдеров для вторичных лучей, которые отражаются от объектов сцены и обозначены разным цветом. В этих сценариях SER переупорядочивает работу по затенению для повышения эффективности.
GPU выпускает первичные лучи в сцену, они попадают в одни и те же объекты, и поэтому запускают один и тот же шейдер в каждом из потоков — эти лучи хорошо упорядочены и данные для них локализованы, поэтому затенение первичных попаданий будет исполняться очень эффективно и без SER. Вторичные же лучи генерируются в точках попадания первичных лучей, и разлетаются в разные стороны, попадая уже в совершенно разные объекты вокруг. И затенение вторичных попаданий будет гораздо менее упорядоченным и менее эффективным для выполнения на GPU, так как разные шейдеры выполняются в разных потоках, да и данные часто будут плохо кэшируемые.
Планировщик SER дополняет трассировку лучей новой стадией, в которой он переупорядочивает и группирует вторичные лучи так, чтобы они были лучше упорядочены и локализованы. И чем сложнее процесс затенения, тем выше будет прирост производительности при работе новой технологии. Примеры с вторичными лучами, которые сильно выигрывают при работе SER, включают трассировку пути, все отражения, непрямое освещение и эффекты полупрозрачности — в них очень часто возникает та самая неупорядоченность вторичных лучей, и ее поможет решить SER.
Что касается примерной оценки производительности, то Nvidia утверждает, что включение SER может увеличить производительность для RT-шейдеров до двух-трех раз при трассировке пути. Понятно, что в более привычных для нас играх с гибридным рендерингом с применением растеризации и трассировки, этот прирост будет заметно меньше. Но в уже не раз упомянутом режиме «RT: Overdrive Mode» в игре Cyberpunk 2077 разработчики получили впечатляющий 44% прирост скорости рендеринга именно при включении планировщика SER.
Что касается реального применения новой технологии, то на начальной стадии разработчики ПО могут использовать эту возможность через расширения NVAPI, но в будущем возможно появление управления возможностями этого планировщика и в стандартных API — Nvidia работает над этим с Microsoft и другими компаниями — это важный момент, так как сейчас подобная технология есть только у Nvidia, и если она будет поддержана в том же DirectX, то и другие производители графических процессоров подтянутся.
В качестве примера того, что могут обеспечить при трассировке новые GeForce RTX 4090 и RTX 4080, приводятся следующие проекты: Portal with RTX — с полной трассировкой пути, весьма впечатляющая демонстрация Nvidia Racer RTX — также с полной трассировкой пути (см. ролик ниже), а также новый режим игры Cyberpunk 2077 — «Ray Tracing: Overdrive Mode».
Изменения графики игры Cyberpunk 2077 в режиме Ray Tracing: Overdrive Mode включают следующее: непрямое освещение RTX Direct Illumination (RTXDI) дает каждому источнику света (неоновая вывеска, уличный фонарь, автомобильные фары и т. п.) качественно трассированные освещение и тени, трассированное непрямое освещение и отражения теперь обсчитывают лучи, отраженные несколько раз, а в обычной версии игры было лишь одно отражение — глобальное освещение, отражения и переотражения будут более точными и реалистичными, трассированные отражения просчитываются в полном разрешении, что улучшает их качество.
Еще один интересный проект — Portal with RTX — будет представлен в виде бесплатного дополнения к классической игре в ноябре — на 15-летие оригинальной игры. В нем используется полная трассировка пути и многие из описанных выше технологий трассировки. Так как все эти проекты весьма требовательны к производительности трассировки лучей, то для них весьма полезны все улучшения Ada: быстрые RT-ядра с новыми возможностями, а также применение DLSS 3, к которой мы и переходим.
Технология повышения производительности DLSS 3
Если раньше мы называли DLSS технологией масштабирования разрешения, пусть и продвинутой, то с версии DLSS 3 так ее называть уже некорректно, так как она перешла в другое измерение и не просто растягивает меньшее разрешение в большее, используя детали из предыдущих кадров, но еще и добавляет дополнительные кадры, исходя из информации в существующих. Как утверждает сама Nvidia, над технологией генерации кадров специальная группа Applied Deep Learning Research работала уже более четырех лет, этот метод использует комбинацию привычной для нас DLSS 2.0 с вычислением оптического потока (optical flow estimation) — для добавления новых кадров в видеоряд. Новая версия технологии добавляет синтезированные ей кадры между существующими, тем самым увеличивая их частоту.
Вычисление (или оценка) оптического потока часто используется в приложениях компьютерного зрения для определения направления и скорости движения пикселей в последовательных кадрах видеоряда. В 3D-графике и обработке видеоданных этот метод используется для снижения задержек в дополненной и виртуальной реальности, улучшения плавности воспроизведения видеороликов, повышения эффективности видеосжатия и стабилизации видеоряда. Для этого часто используются методы глубокого обучения и применяются они в автопилотах, робототехнике, а также при анализе видеоданных.
Оптический поток схож с оценкой движения при кодировании видеоданных, но он предъявляет заметно более высокие требования к точности и согласованности. Начиная с архитектуры Turing, графические процессоры Nvidia имеют специализированный движок оптического потока (Optical Flow Accelerator — OFA), который использует современные алгоритмы для качественной оценки оптического потока. Но в Turing этот ускоритель был еще в очень упрощенном виде, ему не хватает возможностей и производительности для реализации таких сложных задач, как в DLSS 3.
В Ampere этот блок улучшили, появилась поддержка тайлов по 1×1 пикселей, но и он имеет недостаточно высокую производительность для работы в реальном времени, а вот блок OFA в графических процессорах Ada обеспечивает более чем вдвое большую производительность, по сравнению с OFA в Ampere — 300 TOPS при работе с оптическим потоком. В итоге, только в Ada производительности OFA достаточно для генерации кадров в реальном времени и с высокой частотой, что и необходимо для полноценной реализации DLSS 3.
На рисунке ниже показан пример работы метода DLSS 3 и его коренное отличие от других методов интерполяции и вставки промежуточных кадров, работу которых вы могли наблюдать в своих телевизорах при просмотре кино с 24 кадрами в секунду, которые преобразовывались в 50/60 FPS, создавая эффект просмотра телевизионного сериала, которые часто снимают с реальными 50/60 FPS.

DLSS 3 работает куда хитрее этих методов, и все для того, чтобы избежать появления неприятных артефактов при генерации промежуточных кадров. Метод комбинирует использование векторов движения, которые он получает от игрового движка, с полем оптического потока, которое генерирует движок OFA. Именно эта комбинация и позволяет точнее определять предполагаемое движение в кадре. Алгоритмы анализа векторов движения и OFA — основа эффективной генерации качественных дополнительных кадров в DLSS 3. В примере, показанном выше, алгоритмы анализа позволяют воссоздать тень от мотоцикла с большей точностью, чем при использовании только векторов движения или только оптического потока.
Алгоритм генерации промежуточных кадров DLSS 3 использует в качестве входных данных готовые текущий и предыдущий кадры, поле оптического потока от движка OFA и данные от игрового движка: буферы глубин и векторов движения. Движок OFA анализирует два последовательных кадра и выдает поле оптического потока, в которое захватывается направление и скорость движения пикселей от первого кадра ко второму. Так как OFA работает с тайлами 1×1 пиксель, то он способен захватывать даже такие мелкие объекты, как частицы, а также отражения, тени и освещение, чего не делают вычисления векторов движения в игровом движке. В примере с мотоциклом показано, как при помощи этого анализа аккуратно воссоздается его тень в правильном месте, по отношению к самому мотоциклу.
Вместе с попиксельным анализом поля оптического потока, умный алгоритм DLSS 3 также использует векторы движения для точного отслеживания геометрии в сцене — в примере выше это помогает отследить движение дорожного полотна, но не тени на ней. Если не использовать оптический поток при генерации промежуточных кадров, то будут видны артефакты, вроде дергающейся тени. Для каждого пикселя умная нейросеть DLSS 3 решает, как использовать информацию из буфера векторов движения, из поля оптического потока, и кадр за кадром генерирует промежуточные кадры. Использование двух типов данных о движении в сцене дает DLSS 3 возможность точного воссоздания движения и геометрических и пиксельных данных в сгенерированных кадрах.
Вот так это выглядит на практике — видеоряд становится заметно плавнее, особенно если сравнивать с родным разрешением. Еще одно преимущество нового метода DLSS 3 состоит в том, что он не добавляет остаточные следы (так называемый ghosting), так как нейронная сеть генератора кадров создает промежуточные кадры, а не накапливает пиксели из серии предыдущих кадров, как это работает в случае DLSS 2.
Новый метод вставки кадров на основе алгоритмов глубокого обучения, увеличивает частоту кадров в два раза по сравнению с DLSS 2 — в дополнение к тому, что делает умное масштабирование разрешения. На диаграмме Nvidia можно увидеть, что в современных играх прирост от включения DLSS 3 (учитывается и масштабирование разрешения и генерация дополнительных кадров) достигает 2-2,5 раз, а в приложениях будущего он может достигать и 4-5-кратного.
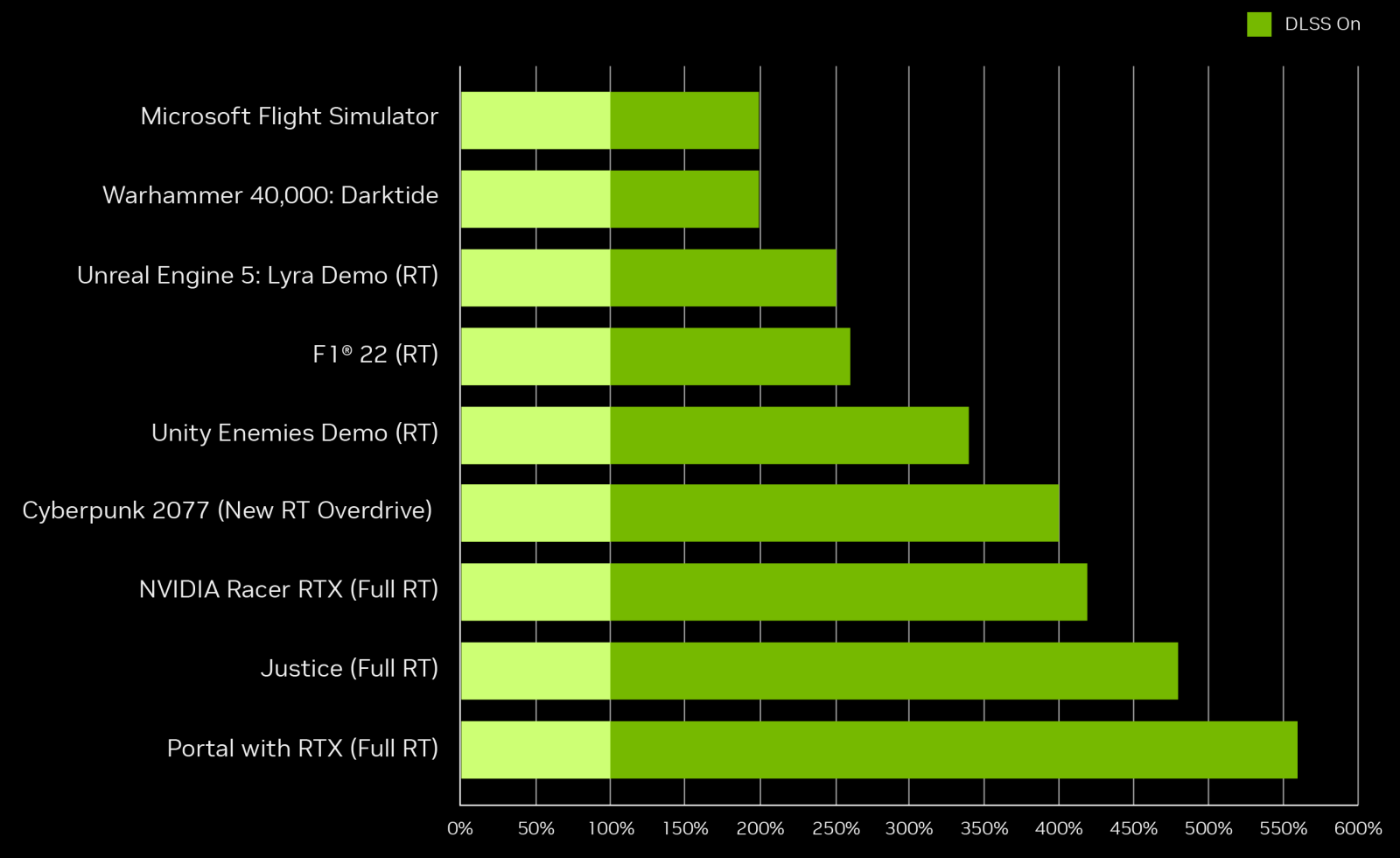
Также DLSS 3 может повысить производительность и в тех случаях, когда она ограничена мощностью центрального процессора. Ведь генерация кадров в DLSS 3 исполняется как постфильтр полностью на GPU, что позволяет увеличить частоту кадров когда производительность ограничена CPU.
В таких играх, как стратегии реального времени или авиасимулятор Microsoft Flight Simulator, общая частота кадров зачастую ограничена процессором — из-за сложных физических расчетов и большого расстояния прорисовки кадра. И система не может отрисовать большее количество кадров, на которое способен CPU, даже если GPU мог бы и больше. В этом случае способность DLSS 3 по генерации кадров все равно будет работать и обеспечит двукратное повышение частоты кадров, что будет восприниматься мозгом как большая плавность.
Но тут возникает важный вопрос — а что станет с задержками при работе новой технологии, ведь вставка промежуточных кадров хоть и принесет визуальную плавность, но не даст более точного управления. Nvidia утверждает, что в связке с их же технологией Reflex они добились того, что задержки получаются хоть и выше, чем при работе DLSS 2, но ниже, чем при родном разрешении рендеринга. Reflex используется для синхронизации GPU и CPU, чтобы обеспечить как можно более низкие задержки, помогающие более точному управлению в играх.
Ускоритель OFA в графических процессорах Ada — это фиксированный блок, одинаковый для всех уже вышедших моделей GPU, и поэтому та часть DLSS 3, которая связана с работой именно генерации дополнительных кадров, на RTX 4080 и на RTX 4090 не должна слишком отличаться по производительности. Важно отметить и то, что в играх с поддержкой DLSS 3 технология будет работать и на решениях предыдущего поколения — но в пределах возможностей DLSS 2.0, то есть с масштабированием разрешения, но без генерации дополнительных кадров. Для последнего у Ampere и Turing недостаточно продвинутые ускорители OFA.
Конечно же, при работе DLSS 3 графическим процессорам архитектуры Ada помогают и улучшенные тензорные ядра четвертого поколения. По сравнению со своими предшественниками архитектуры Ampere, новые GPU обеспечивают более чем вдвое большую производительность при вычислениях с разной точностью: FP16, BF16, TF32, INT8 и INT4.
Так когда нам ждать DLSS 3 в играх и в каких? Так как процесс внедрения DLSS 3 довольно прост для игровых разработчиков, то проблем с этим не будет — уже объявлено о 35 играх, в которых появится DLSS 3 и первые проекты получат его уже в октябре. В число игр с поддержкой входят: A Plague Tale: Requiem, Atomic Heart, Cyberpunk 2077, Dakar Rally, Dying Light 2 Stay Human, F1 22, Hitman 3, Microsoft Flight Simulator, Racer RTX, Portal with RTX, S.T.A.L.K.E.R. 2: Heart of Chornobyl, The Witcher 3: Wild Hunt, Warhammer 40,000: Darktide. Также поддержка DLSS 3 добавлена и в движки Unreal Engine, Unity и Nvidia Omniverse.
К слову, ускорители OFA используют сложные алгоритмы для определения поля оптического потока, которые применяются не только в технологии DLSS 3, но и в таких задачах, как преобразование частоты кадров (FRUC — frame rate up conversion), интерполируя кадры с использованием векторов оптического потока, при отслеживании движения объектов в анализе видеоданных, интерполяции и экстраполяции видеокадров в реальном времени (используется в VR-шлемах, телевизорах и т. д.)
Работа с видеоданными и стриминг
Ни для кого не секрет, что из-за пандемии коронавируса в индустрии стриминга за пару лет произошел взрывной рост, и пользователи стали еще чаще использовать такие сервисы, как Twitch и Youtube. И если несколько лет назад настройка стриминга была очень сложной задачей, для которой часто использовали выделенный ПК, то современные системы упростили настройку потоковой передачи настолько, что каждый желающий может с легкостью транслировать видео прямо со своих ПК. Такие вещи, как аппаратный кодировщик NVEnc и оптимизации для стримингового ПО, например Open Broadcaster Software (OBS), устранили необходимость в выделенном ПК и позволили получить качественную трансляцию с одной системы.
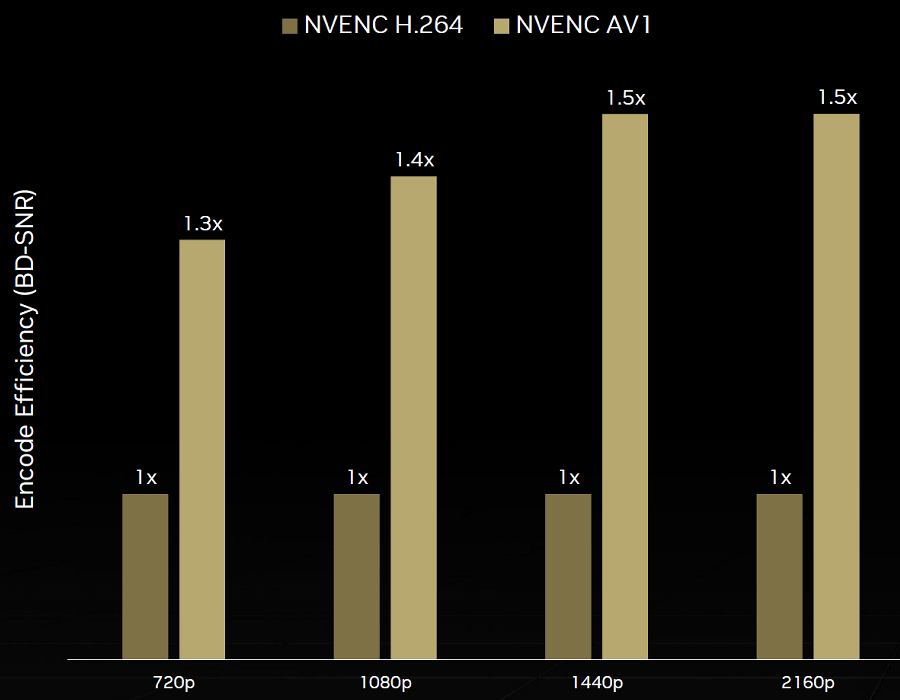
А такие утилиты, как Nvidia Broadcast, использующая мощь искусственного интеллекта, предоставляют пользователям удобные и простые инструменты для подавления шума и эха, вставки виртуального фона, удаления шумов в изображении и т. д. Графические процессоры семейства Ada умеют больше предыдущих и в этом направлении — в специализированном аппаратном кодировщике NVEnc восьмого поколения появилась поддержка кодирования видео в формате AV1, а Ampere умели только декодировать такие данные. Кодировщик AV1 в Ada на 40%-50% эффективнее кодировщика H.264, используемого в графических процессорах предыдущей серии, и новый формат AV1 позволит увеличить разрешение видеопотока при стриминге с 1080p до 1440p при том же битрейте.
Для того, чтобы добавить поддержку AV1 в ПО, Nvidia сотрудничает с OBS Studio, и в конце года ожидается выпуск новой версии этого ПО с поддержкой кодирования в AV1 — в дополнение к недавно появившейся поддержке HEVC и HDR. OBS также оптимизирует ПО, чтобы ускорить кодирование на всех графических процессорах Nvidia, в новой версии будут представлены обновленные эффекты Nvidia Broadcast, включая шумоподавление и удаление эха, а также улучшенный виртуальный фон. Также в Nvidia работают и с Discord, и в скором обновлении появится возможность использования AV1 для заметного улучшения качества.
Кроме того, графические процессоры Ada серии GeForce RTX 40 с объемом памяти 12 ГБ и более имеют сразу два аппаратных кодировщика NVEnc на борту, что позволяет кодировать видео с разрешением 8K при 60 FPS или сразу четыре видео разрешения 4K при 60 FPS. Двойной кодировщик и AV1 для таких популярных приложений, как DaVinci Resolve, плагин Voukoder для Adobe Premiere Pro и Jianying, будут доступны уже в октябре. Nvidia также сотрудничает и с разработчиками приложения видеоэффектов Notch и Topaz — чтобы внедрить поддержку AV1 и двух кодировщиков. Естественно, в GeForce Experience захват видео в формате 8K HDR при 60 FPS также поддерживается.

Кроме NVEnc, в графические процессоры архитектуры Ada включен аппаратный декодер пятого поколения NVDec, который появился в Ampere. Он поддерживает декодирование видеоданных с аппаратным ускорением в форматах: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9 и AV1. Также полностью поддерживается и декодирование в разрешении 8K при 60 FPS.
Выводы
Графическая архитектура Ada Lovelace приносит приличный прирост производительности — за это нужно благодарить и более совершенный техпроцесс и технические усовершенствования, выполненные инженерами Nvidia. Техпроцесс TSMC 4N позволил инженерам Nvidia интегрировать в GPU не самого крупного размера довольно большое количество исполнительных блоков и ячеек памяти. В топовом графическом процессоре AD102 на 70% больше CUDA-ядер, чем в лучшем из Ampere, в 16 раз больше кэш-памяти, чем в Ampere: 18 МБ L1-кэша и 96 МБ L2-кэша и большой регистровый файл на 36 МБ. Весь GPU содержит более 76 млрд транзисторов, и в этом он уступает только Nvidia H100. При этом графический процессор в GeForce RTX 4090 работает на частоте в 2,5 ГГц — на 660 МГц выше, чем предыдущее топовое решение GeForce RTX 3090 Ti, а потребление у них одинаковое — 450 Вт. Если считать, что RTX 4090 вдвое быстрее лучшего из предшественников, то Ada получается вдвое энергоэффективнее, по сравнению с Ampere.
Но изменения Ada коснулись не только увеличения количества исполнительных блоков, их возможности также были улучшены. В мультипроцессорах SM сделаны важные модификации, особенно заметные в задачах трассировки лучей. Да и само по себе определение пересечений луча и треугольника в третьем поколении RT-ядер было ускорено вдвое, по сравнению с RT-ядром Ampere, а это одна из самых важных вычислительных задач при трассировке лучей. Но еще интереснее пара дополнительных аппаратных блока в RT-ядрах: Opacity Micromap Engine, ускоряющий обработку полупрозрачных объектов, вроде языков пламени и листьев, и Displaced Micro-Mesh Engine, способный снизить время построения структур BVH и сократить требования к объему геометрических данных для очень сложных геометрически объектов.
Обе технологии требуют поддержки со стороны разработчиков ПО, и мы надеемся, что они этим заинтересуются. А что точно должно их заинтересовать, так это новая возможность по переупорядочиванию выполнения шейдеров при трассировке лучей — Shader Execution Reordering. Планировщик SER способен на лету оптимизировать загрузку вычислительных блоков мультипроцессора SM и это очень важное новшество для графических процессоров, потенциально обеспечивающее двух-трехкратное ускорение для многих алгоритмов трассировки лучей.
Комбинация всех улучшений и ускорений в RT-ядрах дает преимущество по сравнению с Ampere примерно вдвое — в задачах, где широко применяется трассировка лучей, естественно. Так почему в Nvidia заявляют о четырехкратном ускорении? Речь идет о применении новой версии DLSS 3, использующей ускоритель оптического потока Optical Flow Accelerator, заметно улучшенный в архитектуре Ada. DLSS 3 использует как масштабирование разрешения из DLSS 2, так и удвоение частоты кадров при помощи вставки промежуточных, используя поле оптического потока. Данные от OFA комбинируются с векторами движения и искусственный интеллект при помощи тензорных ядер генерирует качественные промежуточные кадры. А для того, чтобы задержки не слишком увеличивались, используется еще одна технология компании — Reflex. В результате игрок получает вдвое больше кадров в секунду при визуальном качестве, сравнимом с DLSS 2, и задержками точно меньшими, чем при родном разрешении рендеринга.
Все графические процессоры Ada поставляются с кодировщиком NVEnc 8-го поколения, который добавляет поддержку кодирования AV1. AV1 на 40% эффективнее популярного формата H.264, который широко используется сейчас. Для стримеров это позволит трансляциям выглядеть так, как будто они используют битрейт на 40% выше. Также уже вышедшие GPU нового семейства имеют сдвоенный NVEnc-кодировщик, повышающий планку до 8K при 60 FPS и способный на кодирование сразу четырех видеопотоков в 4K при 60 FPS. Со всеми разработчиками важного ПО сотрудничают и поддержка новинок Nvidia скоро в них появится.
GeForce RTX 4090 поступает в продажу с 12 октября по цене $1599 — это решение до двух раз производительнее предыдущего чемпиона GeForce RTX 3090 Ti — при том же энергопотреблении. Новинка предназначена для игр в разрешении 4K при самых высоких графических настройках и впечатляющей частоте кадров. Лучше всего новый GPU раскроется в будущих играх с более активным применением трассировки лучей, но и нынешние игры с трассировкой получат прирост производительности до двукратного, по сравнению с GeForce RTX 3090 Ti.
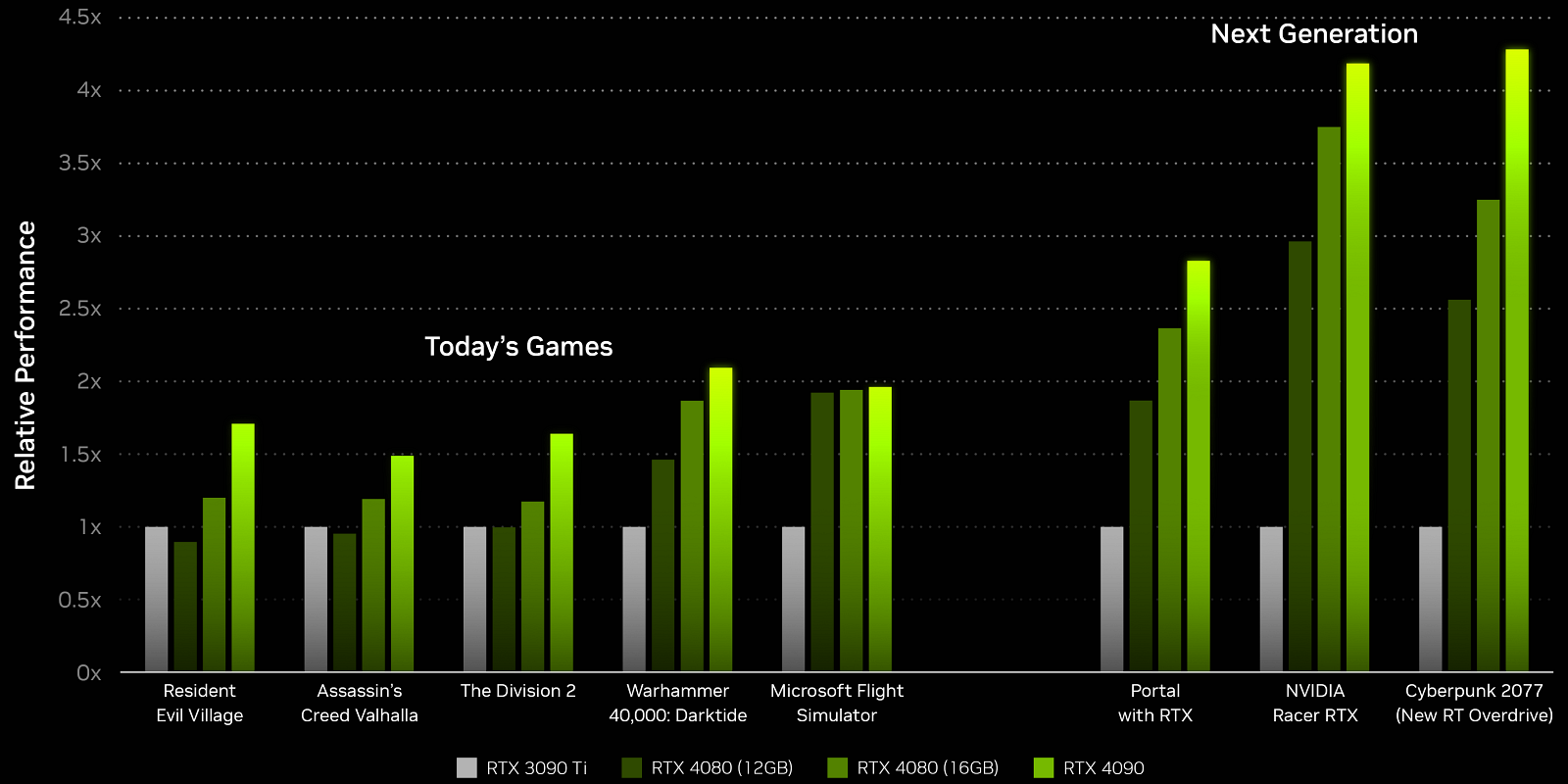
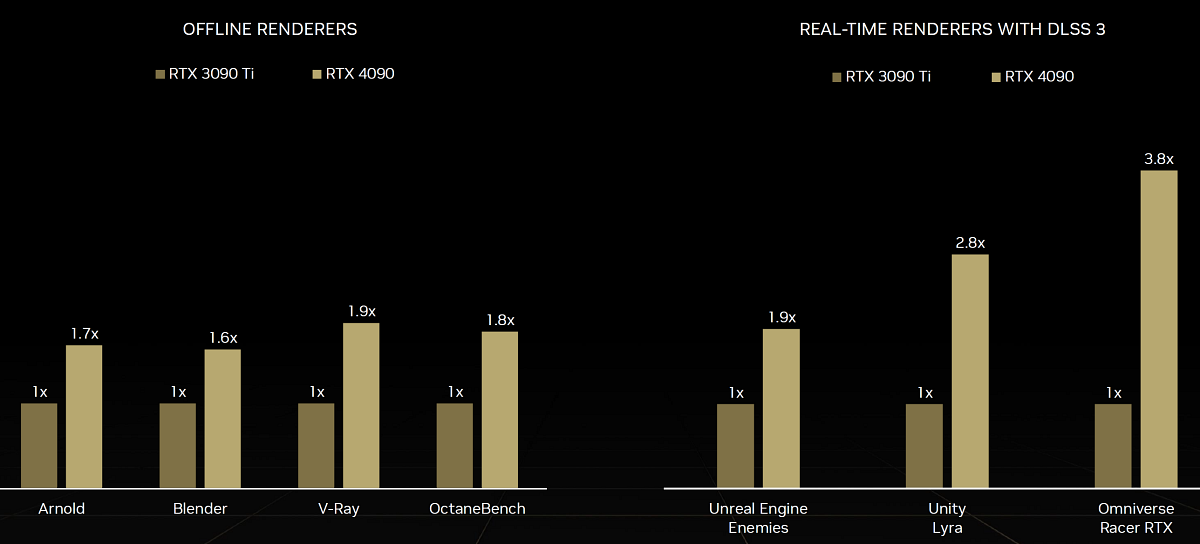
А игры будущего, которые сейчас представлены в виде специального режима Cyberpunk 2077, а также Portal with RTX и Nvidia Racer RTX, с применением всех инноваций Ada дадут прирост скорости до четырехкратного. В приложениях создания контента, таких как 3D-рендеринг, обработка видео и искусственный интеллект, серия GeForce RTX 40 также обеспечивает производительность до двух раз выше, чем лучшие представители Ampere. То же самое касается и Nvidia Omniverse — Ada увеличивает производительность примерно вдвое, а вместе с DLSS 3 получится и того больше:
Что касается GeForce RTX 4080, то эта модель предлагается как вдвое более производительная видеокарта, по сравнению с GeForce RTX 3080 Ti. Нужно быть особенно внимательным, потому что GeForce RTX 4080 с ноября будет предлагаться в двух конфигурациях, которые очень сильно друг от друга отличаются, хотя в название вынесено только отличие в объеме видеопамяти: GeForce RTX 4080 (16 ГБ) и RTX 4080 (12 ГБ). Пусть это вас не смущает, две эти видеокарты с почти одинаковым названием отличаются не меньше, чем условные RTX *070 и RTX *080 из прошлых поколений.
GeForce RTX 4080 с 16 ГБ содержит 9728 CUDA-ядер, а модель с 12 ГБ — лишь 7680 CUDA-ядер, шина памяти у первой — 256-битная, у второй — 192-битная. Остальные параметры приведены в таблицах, но даже из этих значений очевидно, что разница в производительности будет огромной, несмотря на схожее наименование. Но и цены серьезно отличаются: рекомендованные для США — $1199 и $899 соответственно. Первую из них рекламируют как вдвое более производительную, чем GeForce 3080 Ti, а вторую — как просто более производительную, чем GeForce RTX 3090 Ti, и тут у нас есть некоторые сомнения, связанные с разницей в теоретических показателях этих GPU. Конечно, если включить DLSS 3, то будет и больше, наверное, но это уже не совсем корректное сравнение.
По понятным причинам (уход компании Nvidia с российского рынка, включая закрытие московского офиса) у нас пока что нет на руках карт новой линейки, и мы не сможем предложить вам обзор рассмотренных новинок еще какое-то время. Но мы уже работаем над этим и обещаем как можно быстрее протестировать один из вариантов GeForce RTX 4090, например Palit GeForce RTX 4090 GameRock с необычным дизайном.

Комментарии