Аппаратная графическая подсистема будущего
Не будем в очередной раз вспоминать пословицу о том, что «все новое это», а просто попробуем логическим путем рассудить, к чему придут ускорители трехмерной графики в ближайшем и (даже) более-менее отдаленном времени. Рассуждать будем не просто, а по частям. Итак.
Внешние интерфейсы и вывод изображения
Нет сомнений, что через некоторое время все системы отображения (мониторы, проекторы и пр.) будут подсоединяться к ускорителю по цифровому интерфейсу. В начале это будут плоды эволюции специализированного интерфейса (DVI), но позже, вполне логично ожидать постепенное замещение специализированной цифровой последовательной шины ее аналогом общего назначения, например одним из потомков USB или FireWire. Почему я в этом уверен?
Во-первых, разрешение и тем более частота кадров отображающих устройств не будут расти столь же стремительно, как вычислительная мощь ускорителя. Этому есть несколько причин, первая из них — ограниченное разрешение глаза, для которого изображение с 3..4 тысячами точек по горизонтали уже воспринимается (при условии разглядывания целиком) как монолитное и бесконечно детализированное. Во-вторых, кадровая частота выше 150..200 смен изображений в секунду не имеет смысла даже при условии отсутствия сглаживания движущихся объектов: почти десятикратное превосходство над кинематографической частотой обеспечит сглаживание движения за счет инерции восприятия в глазу, который невольно будет накапливать, и усреднять по нескольку кадров подряд. Разумеется, возможны варианты — такие как панорамные и сферические дисплеи, или стереодисплеи, требующие две картинки для разных глаз, но все они, так или иначе, могут довольствоваться разрешением порядка десяти тысяч точек по горизонтали. Дальнейшее увеличение разрешения возможно, но не видится приоритетной задачей — гораздо больше сил (уже сейчас) тратится на повышение реалистичности картинки, чем на ее сглаживание.
Итак, медленный (относительно) рост разрешения и кадровой частоты позволит в скором времени обычным шинам общего назначения служить каналом для передачи информации на монитор и другие устройства отображения. Почему это важно? Потому что это очень удобно. Представьте себе, что в каждый из 6 USB портов вы можете подключить (при желании по дисплею). Представьте, что самый элементарный фотоаппарат или КПК может быть при желании подсоединен к проектору или монитору через тот же интерфейс, через который вы осуществляете синхронизацию и передачу данных на PC. И т.д. и т.п.
В более отдаленном времени возможность соединять «все-со-всем», пользуясь одними и теме же интерфейсами (+ открытые протоколы передачи данных разных форматов) откроет прекрасные перспективы, причем не только в области отображения визуальной информации…
Итак, у нашего ускорителя будущего появился первый более-менее четкий элемент — один или несколько универсальных внешних портов на основе скоростных последовательных шин. Кстати, им не обязательно находится на самой плате (модуле, карте) ускорителя, он может использовать для передачи изображения и порты системной платы — тем паче, что системная шина заведомо будет опережать по пропускной способности внешние универсальные интерфейсы периферии.
В этом же ключе, логично ожидать появление дисплеев и проекторов со встроенными радиоинтерфейсами (уже существуют первые модели проекторов с разновидностями 802.11). Очевидно что все будущие ПК, КПК, ноутбуки и прочие устройства будут включать в себя те или иные беспроводные интерфейсы и передача изображений на ближайший экран, без какого-либо проводного соединения очень удобна, как в бизнес, так и в бытовых или персональных применениях. Кстати, о дисплеях:
Дисплеи и другие системы отображения
Обсудим вопрос демонстрации передаваемых с ускорителя картинок. Во-первых, очевидно, что в ближайшем будущем практически все дисплеи станут плоскими и будут использовать ту или иную технологию плоских панелей. Пока мы не говорим о проекторах, но и они в большинстве своем используют в наше время не сканирующие вакуумные трубки, а работающие на просвет миниатюрные высокотемпературные ЖК матрицы или матрицы с массивами микромеханических зеркал. Разрешение и размер дисплеев подрастут, но ничего особенно нового здесь ждать не приходится — слишком большие панели не удобны и даже вредны — они занимают много места и их не просто транспортировать (вес, хрупкость). Поэтому, размеры более 20 дюймов по диагонали по-прежнему будут сопутствовать только специфическим нишам. Идеальным решением для больших размеров являются те или иные разновидности проекторов — в паре с очень компактными экранами они могут обеспечивать изображение разных размеров в достаточно широких пределах и при этом являются сами по себе вполне компактными устройствами.
Итак, персональный дисплей будущего это плоская панель размером от 17 до 20..24 дюймов с разрешением порядка 3..4 тысяч точек по горизонтали и предельной физической частотой обновления информации около 100 кадров в секунду. Далее, в игру вступают различные проекторы и составные панели. Первые получат более высокое разрешение и яркость, опять таки до 3..4 тысяч точек — что не только позволит полноценно отображать на них фильмы очень высокого качества, но и потребует новых стандартов для съемки, сжатия и передачи движущегося изображения — даже передовые HDTV стандарты далеки от таких цифр. Именно в этой области и произойдет наиболее значимый прогресс, в плане качества захвата, хранения и передачи картинки. Но мы не должны забывать, что основная тема данной статьи — трехмерная графика в будущем.
Во-вторых, очень широкое, если не повсеместное, распространение получат панели способные создавать объемное изображение без применения дополнительных средств, таких как специальные стерео очки. Здесь могут дать результат различные технологии. В отдаленном будущем вероятны голографические ЖК матрицы (я лично знаком с бывшими сокурсниками занятыми такими исследованиями для компании LG), способные воспроизводить больше характеристик захваченного потока света, чем традиционные системы и давать объемную, цветную(!) голографическую картинку. Такие решения потребуют существенно большего разрешения матрицы и специальной формы представления данных, а потому не следует ожидать их появления в коммерческих количествах в ближайшие пять лет. Возможны и какие либо гибридные решения, в которых дифракционные динамически настраиваемые структуры разводят свет от матрицы для правого и левого глаза, следя при этом за положением головы и обеспечивая оптимальную глубину зоны устойчивого восприятия стереоизображения. И, наконец, наиболее вероятные уже в ближайшее время системы с простым разделением изображения для правого и левого глаза, на основе одной ЖК панели. Такие системы уже доступны коммерчески. Очевидно, что в ближайшее время появятся реконфигурируемые матрицы, способные работать как в режиме разделения изображения на два глаза, так и в режиме обычной плоской матрицы с широкими углами обзора — чисто технически это не представляет никакой трудности.
Итак, дисплеи будущего станут тоньше и легче, и, вероятно, получат стереорежим, как обязательную опцию. Но, в области больших размеров и разрешений куда как более впечатляющие качественные и количественные скачки будут происходить в проекционных устройствах.
Системная шина, шина памяти и передача данных
То, что системные шины вскоре все станут последовательными, уж не является секретом для большинства читателей. Проприетарные соединения между компонентами чипсета, HT, PCI-Express и даже LPC четко продемонстрировали реализацию уже не новой тенденции на перевод всего и вся на последовательные сигнальные каналы. Однако давайте прикинем, как конкретно этот процесс отразится на ускорителях. В ближайшее время появятся ускорители с PCI-Express интерфейсом с пропускной способностью 16х — именно такой слот для графических и других высокопроизводительных PCI-Express карт будут иметь первые PC. Однако гибкая возможность масштабирования этой шины позволяет пойти далее.
Представьте себе, что в чип заранее встроены 32 канала PCI-Express с возможностью динамической конфигурации. Во-первых, как только появятся производительные рабочие станции (и чипсеты) со слотами конфигурации 32х, можно будет сделать профессиональную карту на основе того же чипа. Во-вторых, можно сделать серверный вариант карты с 8х (типичный серверный разъем), и в сервер может быть одновременно установлено несколько таких карт. И, наконец, при необходимости можно сделать многочиповое решение, просто соединив двое или несколько чипов тем или иным образом, с участием вторых 16 каналов.
Но это только начало. В будущем шины памяти также станут более интеллектуальными и последовательными. Это позволит не только проще масштабировать пропускную способность памяти, но и упростить разводку на плате, т.к. данные разных каналов могут передаваться не синхронно и, соответственно, длинна проводников не обязательно должна быть одинаковой. Это позволит повысить тактовую частоту и снизить стоимость разводки. Кроме того, уже знакомые нам по PCI-Express одиночные двунаправленные каналы могут действовать независимо друг от друга и в дуплексном режиме — т.е. основная проблема задержек при интенсивных обращениях ускорителя к памяти — проблема переключения из режима чтения в режим записи и проблема параллельных потоков данных будет красиво и естественно решена. В итоге, снизится необходимость в интенсивном кэшировании некоторых типов данных и освободившиеся ресурсы на чипе можно будет бросить на самое главного — буфер кадров, полностью разместив его на чипе и связав с блоками закраски очень широкой шиной. Впрочем, мы несколько забегаем вперед.
А теперь самое интересное — а, собственно, почему последовательная шина памяти и последовательная системная шина должны быть разными? Рано или поздно мы можем ожидать схожую, при желании совместимую, а возможно и просто четко совместимую сигнальную технологию, которая позволит просто снабдить чип 256-ю (или скорее 256+32+8 - догадайтесь почему ;-) ) высокоскоростными последовательными каналами и, в зависимости от воли разработчиков конкретного продукта, раздавать их на общение с системой (процессором и чипсетом), на общение с локальной памятью, на общение с другими чипами в многочиповом решении, а также на различные интерфейсы ввода и вывода, например, один канал можно отдать на чип захвата видеосигнала. Изначально каналы равноправны, и каждый из них, например, может занимать 4-ку соседних выводов чипа. Это позволит расположить прочие элементы на плате ускорителя так, как того пожелает душа разработчика, а затем, не особенно задумываясь, протянуть к ним каналы с ближайших выводов чипа.
Очевидно, что подобный подход — обширный массив одинаковых и гибко распределяемых каналов передачи данных, имеет и более глобальные перспективы. Рано или поздно (скорее рано — см. материалы по HT) и системная логика (чипсеты) и процессоры тоже придут к подобной схеме, позволив в итоге создавать совершенно фантастические топологии вычислительных систем, как наборов активных компонент, соединенных различными по числу каналов шинами — словно игрушки собранные из детского конструктора «Лего».
Архитектура и программируемость ускорителя
Происходящая унификация хорошо заметна. Например, вершинные и пиксельные блоки (далее процессоры) внутри ускорителя уже сейчас имеют унифицированную систему команд и схожую программную архитектуру (отличается число регистров, но не методы работы с ними). Но, еще до общей унификации, нас ждет появление третьего типа процессоров — процессор генерации вершин или, иначе, «тесселяции». И, соответственно новый тип шейдеров — тесселяционные шейдеры. Его место в графическом конвейере — перед вершинными процессором:
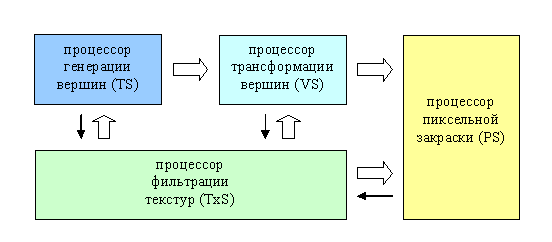
А так же, очень вероятно появление отдельного процессора для выборки, распаковки, фильтрации и генерации текстур.
Основная задача блока тесселяции, на основе гибкой программы (шейдера тесселяции, TS) создавать новые треугольники и вершины, и затем, передавать их вершинному шейдеру (VS) на уже привычную нам трансформацию и освещение. Этот подход позволит наиболее общим путем переложить на ускоритель построение примитивов более высокого порядка, нежели треугольники, например гладких сплайновых поверхностей. В первую очередь, наличие такого процессора позволит увеличить сложность сцен и реализовать адаптивную детализацию моделей и окружения без дополнительной нагрузки на центральный процессор и системный канал передачи данных. Например, хорошо известная разработчикам симуляторов задача построения ландшафта с адаптивной детализацией в данный момент не может быть решена эффективно только на ускорителе. Любые решения выглядят как компромисс, а с появлением тесселяционного процессора позволит генерировать адаптивное представление ландшафта на лету, не загружая системный процессор или шину.
Обратите внимание на зеленый блок — это процессор фильтрации, выборки и обработки текстур. На данный момент все нестандартные операции с текстурами, такие как специальные методы фильтрации или генерация процедурных текстур исполняются на уровне пиксельных шейдеров, а некоторые задачи, такие как распаковка сжатых форматов текстур реализованы только жестко аппаратно. Однако, гораздо эффективнее выделить для этого отдельный процессор и в будущем это будет сделано. Текстурные шейдеры (TxS) уже известные по программным пакетам реалистичной графики, будут отвечать за генерацию по запросу процедурных текстур, выборку, преобразование и модификацию значений обычных текстур, реализацию оптимальных методов сжатия и, самое главное, на специальные методы фильтрации, например продвинутую анизотропную, стохастическую или, очень важную для будущих приложений фильтрацию с учетом движения объекта для реализации эффективного и качественного сглаживания движущихся объектов.
Между процессорами расположены очереди данных, отмеченные на рисунке стрелками. Они позволяют накапливать (а по возможности и кэшировать для повторного использования) рассчитанные одним процессором для другого данные, и таким образом избежать задержек, позволив процессорам работать параллельно и в должной степени асинхронно. Именно наличие таких четких однонаправленных потоков данных позволяет эффективно распараллеливать задачи по построению изображения и одновременно именно этот факт накладывает на шейдеры существенные ограничения - например, они не могут иметь произвольный доступ к данным соседних примитивов или пикселей, т.к. они могут рассчитываться параллельно или еще не быть рассчитанными. Впрочем, обладая возможностью, так или иначе, записать поток данных с выхода шейдерного процессора и снова подав его на вход, мы можем (так сказать «в несколько проходов») реализовать более сложные алгоритмы, включая произвольный доступ, пускай и не самым удобоваримым путем.
На нашей схеме и процессор тесселяции и геометрический процессор, и пиксельный процессор могут получать данные у процессора выборки текстур, и тонкие черные стрелочки символизируют очередь запросов на получение таких данных. Например, при генерации ландшафта процессор тесселяции может таким образом получать доступ к карте высот, сохраненной в виде двумерной текстуры, а процессор трансформации может использовать текстуру как карту смешения (Displacement Map) вершин.
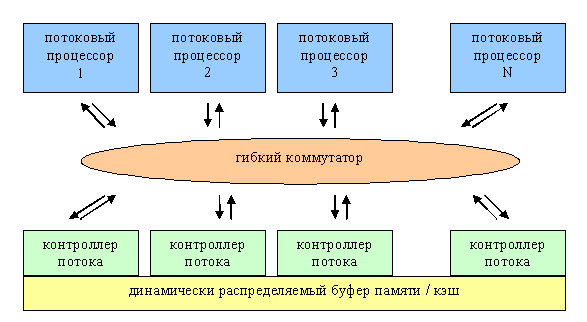
Перед нами графический ускоритель будущего. Основная концепция — набор из некоего числа одинаковых шейдерных процессоров (разумеется с неограниченной длинной программы, обширным набором команд включая динамическое управление исполнением команд — условия, циклы и подпрограммы). Во время построения изображения процессоры динамически соединяются между собой в некую топологию, например, так:
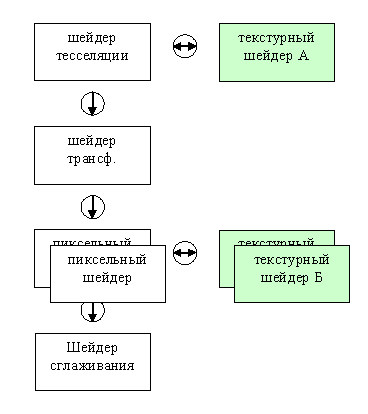
а между процессорами (кружки) организуются одно и двунаправленные асинхронные очереди данных, которыми фактически заведуют контроллеры потока (см. предыдущую схему). Каждый контроллер настраивается для того или иного метода хранения данных (стек, очередь, просто произвольный доступ) и получает в монопольное владение часть скоростной внутренней памяти (кэша) ускорителя или реализует доступ к потоку данных из внешней по отношению к чипу ускорителя локальной или системной памяти. Возможен и режим с произвольным, не потоковым доступом, но в реальных приложениях следует всячески избегать подобных настроек, ибо они способны существенно подорвать производительность в результате плохо оптимизируемых попыток доступа к внешней памяти. Однако, так или иначе, за счет интенсивного кэширования и использования предсказания паттернов доступа данная задача может быть решена на твердую «4», пусть и не в первом поколении таких ускорителей, открыв путь к более привычным программистам подходам, например, к произвольной индексации элементов массивов.
Итак, появляется множество возможностей. Не только альтернативные методы фильтрации, выбора и генерации вершин и пикселей, но и такие варианты как шейдер программирующий новый метод полноэкранного сглаживания, и даже шейдер отвечающий за динамическое перераспределение ресурсов (вычислительных и памяти) ускорителя, т.е. некая «операционная система». Понятно, что самому программисту крайне тяжело управлять всей коммуникацией блоков такого чипа, но это и не надо — этим будет заниматься API. Программист будет формулировать задачу в виде набора шейдеров различного назначения (фактически — функций на некоем языке программирования высокого уровня) и описания структур передаваемых и получаемых или параметров, а следовательно, и того, в каком порядке данные будут проходить через эти шейдеры. Остальное берет на себя API — DirectX или OpenGL будущего. API компилирует шейдерный код в машинные инструкции, оптимизирует их, настраивает взаимодействие очередей и блоков, распределяет кэш и другие ресурсы. Например, встает логичный вопрос — сколько процессоров отдать под шейдер А а сколько под шейдер Б, так, чтобы вся система была максимально сбалансирована и ни одного миллиметра силикона не простаивало без дела. Ответ на этот вопрос не однозначен. Можно грубо указывать важность шейдера в тех или иных единицах, еще при написании его на языке высокого уровня, а можно и создать API анализирующий по ходу построения кадров значения внутренних счетчиков производительности в чипе и динамически перераспределяющий процессоры по мере исполнения приложения каждую секунду или около того.
Представьте себе — играя в FPS, вы выходите к воде и больше процессоров отдается на пиксельные шейдеры, появляется детализированный монстр и чуть больше ресурсов уходит вершинным процессорам. Тонкая и кропотливая работа по балансу нагрузки на различные блоки ускорителей, реализуемая ныне во время программирования приложения путем достаточно утомительных итераций, проб и ошибок, будет автоматизирована на уровне API и железа!
Новые и улучшенные подходы к построению изображения
Разумеется, получив в свое распоряжение столь гибкую систему, мы не можем не обратить свой взгляд к альтернативным методам построения изображения. Новые примитивы, например объемные (3D) полигоны с заданным картой смещения рельефом (с точностью до одного пикселя!), шары или гладкие поверхности (на сей раз истинно гладкие, а не аппроксимированные треугольниками). И, конечно, мягкие тени: станет возможна трассировка лучей для расчета т.н. «глобального» освещения, в то время как закраска идет традиционным методом. Хотите? -Пожалуйста. Комбинированные методы с использованием Radiosity? — Нате. Да, и на худой конец, может быть легко реализована «стопроцентная» старая добрая обратная трассировка лучей. При условии, что сцена, пусть даже описанная примитивами достаточно высокого уровня, будет полностью размещена в локальной памяти ускорителя. Тогда она сможет интерпретироваться им практически без участия процессора.
Несомненно, важным видится сглаживание движущихся объектов. Именно оно отличает реалистичную кинематографическую графику от игровой аппаратной, и именно благодаря ему, мультфильмы с использованием компьютерных персонажей смотрятся при 25 кадрах в секунду куда как лучше, чем всем лучшие шутеры при 120. Подход к сглаживанию должен быть сбалансированным — грубая сила, выражаемая в расчете N кадров вместо одного и последующем их усреднении не допустима. Грамотное использование пиксельных, текстурных и специальных сглаживающих шейдеров вкупе с информацией о скорости каждой конкретной точки позволит создать очень аккуратно и качественно сглаженные движущиеся предметы, нарисовав при этом только одно (!) изображение за один проход. Ключ к этому — гибкая архитектура ускорителя описанная мной.
Толи еще будет, ой-ой-ой
Интересно, что вопросы питания, энергопотребления и теплорассеивания беспокоят конструкторов современных PC куда как сильнее вопросов надежности. Следует ожидать новых форм факторов для ускорителей, в виде некоего похожего на процессорный модуля (картриджа), такого, каким был в свое время процессор Pentium II или, например, такого, каким сконструирован ныне Itanium. Металлическая коробка, снизу контактный разъем, вертикальная установка оным на плату. Внутри, чип ускорителя и память. Интерфейсы перенесены на материнскую плату — все данные, включая захват видео и результирующую картинку, идут в цифровом виде по общей системной шине.
Итоги
- Динамическое распределение ресурсов
- Большой массив одинаковых по возможностям процессоров
- Общий коммутатор
- Большой набор контроллеров очередей и доступа к памяти
- Только цифровые интерфейсы, все на основе массива последовательных шин общего назначения
- Память, работающая напрямую с такими шинами
- Устройства вывода с общими периферийными интерфейсами, а также беспроводными интерфейсами
- Фокусировка на качестве, а не на разрешении или тем более кадровой частоте изображения
- Стерео дисплеи.
Итак, ставка сделана, придет время, и я смогу ответить, насколько процентов я был прав, а насколько ошибался ;-)
Ждать не так уж и долго.
Приложение
Вопрос, чем эта штука отличается от CPU?
Ответ 1 — ориентацией на эффективную параллельную обработку достаточно простых потоков данных, наличием специализации.
Ответ 2 — если рассуждать строго, то чем дальше, тем практически ничем.
Очень сложно сказать, кто первый придет к логической точке сращивания — или очередной CPU от Intel научится программно рассчитывать изображения уровня современных компьютерных мультфильмов (на что надо не так уж много — ~20 лет) или очередной ускоритель от NVIDIA или ATI научится исполнять Microsoft Windows или (на худой конец) один из клонов Linux. Может быть и такое.
Комментарии