Реализация аппаратного сглаживания с использованием модифицированного А-буфера
Вместо предисловия
Весь заинтересованный компьютерный мир с нетерпением ожидает выхода в свет нового детища nVidia — графического чипсета NV20, ориентированного на профессионалов и серьезных фанатов компьютерных игр. Официально его характеристики пока не объявлены, но по некоторым данным этот графический процессор будет иметь в себе встроенные схемные решения, позволяющие осуществить аппаратную реализацию полноэкранного сглаживания (FSAA) на базе интегрированного A-буфера. Как ожидается, такой подход даст возможность производить качественное удаление краевых искажений при дискретизации пикселя сеткой с размерностью 4х4 или 8х8. При этом падение производительности будет составлять не более 40% для самых тяжелых сцен.
Давайте рассмотрим один из наиболее вероятных вариантов реализации вышесказанного на базе специально разработанного акселератора. Учитывая нынешние возможности интеграции элементов на кристалле, описанная ниже архитектура может быть легко встроена в NV20 целиком, в виде самостоятельного функционального блока.
В данной статье будут рассмотрены алгоритмы сглаживания (antialiasing), которые можно реализовать на специально разработанном 3D акселераторе с невысокой стоимостью. Для просчета освещения и отсечения невидимых поверхностей способом "от ближнего к дальнему" (front-to-back) будут использованы многопроходные методы. Для ускорения просчета сложных трехмерных объектов и их композиции в пространстве будут применены охватывающие маски (coverage masks). Главные преимущества такой реализации сглаживания:
- не требует много памяти;
- для большинства изображений падение производительности будет составлять всего 30-40%. Алгоритм основан на разбиении изображения на части (partition) и является легко масштабируемым с точки зрения производительности и затрат.
1. Введение
В процессе изложения мы рассмотрим структуру недорогого в исполнении 3D акселератора, предназначенного для рендеринга трехмерной графики с аппаратным сглаживанием. Его архитектура базируется на описанной ранее M. Kelley [10]. Акселератор реализует новаторский алгоритм на базе А-буфера, который объединяет в себе высокопроизводительный front-to-back алгоритм композиционирования* объектов с охватывающими масками. Акселератор также обеспечивает базовый просчет треугольников, сортировку по глубине, наложение текстур, прозрачность, просчет теней и CSG** операции.
Прим.: * Композиционирование, (композитинг, compositing) — это процесс совмещения двух изображений для получения одного нового. Операция совмещения выполняется путем смешивания цветов пиксельных сэмплов (пикселей), а в качестве весового коэффициента выступает значение прозрачности (альфа) пикселей.
** CSG — Constructive Solid Geometry — процесс построения одного геометрического объекта из двух других. Этот процесс реализуется тремя операциями — объединения, пересечения и разности. Последняя операция отличается от первых двух тем, что для производства вычитания необходимо сначала указать, что из чего вычитать, и только затем производить операцию.
Скорость растеризации без задействования алгоритмов сглаживания составляет 1 млн. пикселей в секунду (100M pix/s), обеспечивая обработку 2 млн. текстурированных треугольников в секунду. При включенном сглаживании снижение производительности для сложной сцены составляет 30%, обеспечивая скорость растеризации в 70М pix/s.
Уже разработан целый ряд аппаратных алгоритмов, позволяющих получить хорошее качество изображения и высокую производительность, не требующих значительных ресурсов памяти в отличие от сглаживания на основе избыточной выборки [11,8]. Аккумулирующий, или накопительный, буфер требует только малую часть ресурсов, выделяемых для обеспечения избыточной выборки, но вынужден использовать несколько проходов, т.е. несколько раз перегонять через конвейер объектные* данные (по разу на каждую пиксельную выборку). Подробнее про формирование и суть выборок при сглаживании можно почитать здесь. Результирующее изображение получается очень высокого качества, но скорость растеризации уменьшается пропорционально количеству субпиксельных сэмплов, используемых конечной функцией фильтрации.
*Прим. Понятие объекта в статье трактуется авторами очень широко и в зависимости от контекста может иметь значения от пикселя (субпикселя) до полигона или даже законченной геометрической фигуры. Так, например, говоря про композиционирование объектов, авторы имеют в виду пиксель, описывая модуль подготовки списка объектов, под объектом будет подразумеваться полигон.
Реализация сглаживания на основе А-буфера* не требует множественных проходов акселератора, но требует предварительной сортировки объектов по глубине перед тем как перейти к их композиционированию. Количество памяти, необходимое для хранения отсортированных по глубине пиксельных слоев, определяется количеством используемых пиксельных выборок и, в конечном счете — велико, т.к. каждый слой требует своих собственных данных о цвете, прозрачности и масках. Операции композитинга используют функции смешения (blending function) на основе трех возможных компонент (маска, тень и z), определяющих перекрытие для конкретного пикселя, и требуют более интенсивных вычислений по сравнению со смешением, применяемым в случае аккумулирующего буфера. Сложности, возникающие при аппаратной реализации А-буфера, описаны в работе Молнара [12].
*Прим. Иное название алгоритма А-буфера — метод мультисэмплинга. В отличие от суперсэмплинга, вместо того, чтобы рендерить в более высоких разрешениях или использовать несколько проходов, вычисляется среднее покрытие полигонами каждой ячейки сетки координат. Программная реализация А-буфера впервые была описана Carpenter и Loren, в статье "The A-buffer, an Antialiased hidden Surface Method" и применялась для неинтерактивного рендеринга изображений.
Вариант аппаратной реализации А-буфера, описанный в данной статье, позволяет обеспечить высокую производительность алгоритма, сохраняя при этом низкие требования к количеству необходимой памяти. В некоторых случаях неоднократная пересылка объектных данных через конвейер (проход) все же может потребоваться для обеспечения front-to-back композитинга, даже в случае отключенного сглаживания. При включенном сглаживании количество необходимых проходов увеличится и в самом худшем случае будет равно количеству пиксельных выборок (восемь, в случае нашей архитектуры). Также, для корректной рендеризации пересекающихся объектов вполне возможно усовершенствовать алгоритм, как описано в [2,3]. Текущая реализация не включает в себя указанных улучшений. Однако, алгоритм корректно рендеризует изображения сцен средней степени сложности с перекрывающимися прозрачными поверхностями, не налагая при этом каких либо ограничений на порядок поступления данных для обработки.
2. Обзор архитектуры акселератора
Функционально акселератор строится на базе одиночного ASIC*, полностью осуществляющего 3D рендеризацию и базовый просчет треугольников. Такой подход обеспечит недорогое решение для 3D ускорения в персональном компьютере.
*Прим. ASIC — широко распространенное сокращение от Application Specific Integrated Circuit, что означает специально спроектированную для выполнения конкретной задачи интегральную микросхему ("чип").
Второй ASIC выполняет функции интерфейса с системной шиной или PCI/AGP. Растеризатор использует принцип деления экрана на части, или доли (partition). Размер каждой доли (тайла) составляет 16х32 пикселя. Деление экрана снижает требования к количеству памяти, необходимой для сортировки по глубине и композиционирования изображения до размеров, которые без усилий можно интегрировать в сам чип. При таком подходе нет необходимости использовать внешнюю память для реализации Z-буфера и буфера изображения. Высокая пропускная способность, малые задержки между растеризатором и интегрированными буферами положительно влияют на производительность.
Конструкция акселератора должна обеспечить выполнение трех главных условий:
- Сбалансированность вычислительной нагрузки между центральным процессором и акселератором;
- Минимальное количество прерываний для CPU и невысокие требования к пропускной способности шины данных;
- Удовлетворительная производительность при объеме памяти в 2 Мб и возможность масштабирования для конфигураций с большим объемом памяти и большей производительностью.
Выполнение перечисленных условий обеспечивается следующим:
- Акселератор берет на себя базовый просчет треугольников, чем значительно снижает количество данных, перекачиваемых через шину данных и выравнивает нагрузку между центральным процессором (процессорами) и самим акселератором. Для осуществления подгонки под мощный центральный процессор возможно использование нескольких ASIC, работающих параллельно;
- Акселератор вырабатывает прерывание для центрального процессора только в случае полного завершения обработки кадра. Это дает возможность CPU заняться обработкой и подготовкой геометрии для следующего кадра, в то время как ASIC растеризует текущий;
- Деление экрана на доли (тайлы) размерностью 16х32 пикселя позволяет хранить двойной Z- буфер и буфер изображения в ячейках памяти интегрированных в сам ASIC
В дополнение к этим трем конструктивным особенностям, еще одной задачей является реализация аппаратного сглаживания. При разработке учитывалась необходимость обеспечить два варианта сглаживания: быстрое сглаживание для интерактивного рендеринга*, и медленное, но повышенного качества.
*Прим. Понятие интерактивного рендеринга означает формирование конечной анимации с такой скоростью, что дискретность выводимых кадров становится незаметной человеческому глазу (~30 кадров/сек).
Для сглаживания с повышенным качеством, ASIC использует традиционный аккумулирующий (накопительный)* буфер для сглаживания каждого тайла экрана путем просчета тайла для всех субпиксельных смещений, а затем аккумулируя результат в накопительном буфере. Так как этот алгоритм хорошо известен [8], то алгоритм сглаживания с повышенным качеством здесь рассматриваться не будет.
*Прим. Аккумулирующий буфер это буфер с тем же разрешением, что и конечное изображение, но с большей разрешающей способностью на каждый пиксель. Для реализации дискретизации с маской 2х2 создается 4 изображения, но со сдвигом на пол пикселя по оси × или у. В общем случае, каждое изображение создается для разной позиции семплов (отсчетов дискретизации) относительно сетки координат. Полученные изображения суммируются в аккумулирующем буфере. После рендеринга изображение усредняется (в нашем случае делением на 4) и отправляется на экран.
Гораздо более интересной кажется задача реализации высокого качества сглаживания при интерактивных скоростях за время, не более чем в 2 раза большее, чем время, требуемое для рендеринга обычными методами без сглаживания. При этом нам надо постараться сделать так, что бы избежать хранения информации о пространстве, покрываемом пикселем и прозрачности индивидуально для каждого слоя изображения (в противном случае резко возрастут требования к количеству памяти для хранения этих данных. Прим.).
Наше решение для этой задачи состоит в разработке ASIC, выполняющего просчет цветности и освещенности пикселя на основе и в порядке, определяемом Z уровнем (глубиной) выбранного слоя, при помощи алгоритма, реализующего несколько проходов (псевдокод алгоритма рендеринга приведен в Приложении). Такой подход позволяет просчитывать неограниченное количество слоев для каждого пикселя. А. Mammen уже описывал подобную реализацию рендеринга [11]. Однако, для того, чтобы успешно сгладить изображение, алгоритм Маммена использовал количество проходов, равное количеству субпиксельных позиций (отсчетов). Например, для сглаживания изображения используя типовой фильтр, работающий с 8-ю отсчетами (samples), требовалось время в 8 раз большее, чем для просчета того же изображения, но без сглаживания. Такое падение производительности вряд ли совместимо с понятием интерактивной графики.
Используя наш алгоритм с модифицированным А-буфером, количество проходов определяется только сложностью изображения (прозрачностью и коэффициентом перекрытия маски для пикселя) в каждом тайле экрана и не зависит от количества сэмплов. Самый худший случай, когда конкретный пиксель тайла будет формироваться не менее чем 8 пиксельным слоями, каждый слой будет содержать различную маску, и при этом каждая маска равна одному субпиксельному отсчету.
Прим. Описанная ситуация может возникнуть только тогда, когда края 8 различных полигонов совместятся с точностью до одного пикселя, при этом края полигонов должны будут проходить через пиксель под различными углами.
Такое случается очень редко, если вообще может случиться на практике. Фактически, в среднем нам необходимо 1,4 прохода для того, чтобы произвести рендеринг доли размерностью 16х32 с использованием 8 битовой маски.
2.1 Сглаживание методом front-to-back
| Практическая реализация алгоритма сглаживания происходит в трех главных функциональных модулях ASIC: — базового просчета поверхностей, отсечения невидимых поверхностей и композиционирования (совмещения) (см. Рис.1). Модуль базового просчета поверхностей производит вычисление параметров плоскости для каждого треугольника и сохраняет для их дальнейшего использования. Scan conversion модуль для каждого пиксельного фрагмента (пиксель фрагментируется на субпиксели в случае, если он перекрывает край полигона) генерирует соответствующую субпиксельную охватывающую маску и передает ее в рендеризующий конвейер для дальнейшей работы. В процессе отсечения невидимых поверхностей фрагменты частично перекрытых объектов помечаются для применения к ним специализированных операций цветового смешивания в модуле просчета затенения и наложения текстур. Модуль композиционирования определяет конечный цветовой оттенок пикселя путем композиции (совмещения), охватывающей маски с alpha значением. | 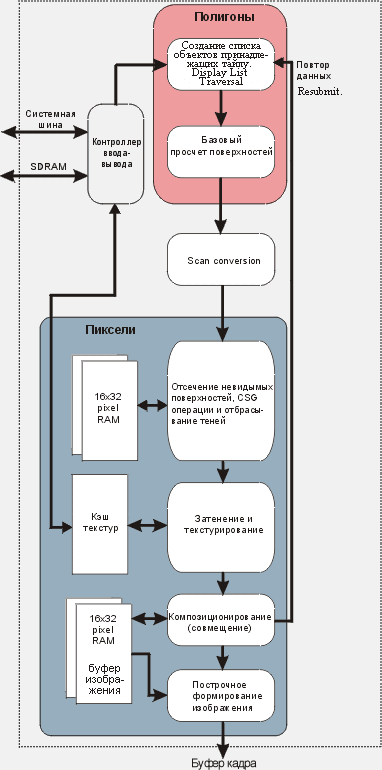 Рис. 1 Растеризующий конвейер микросхемы (растеризатор) |
2.2 Генерация охватывающих масок
Мы будем использовать чередующуюся (в шахматном порядке) субпиксельную маску. (См. Рис.2)
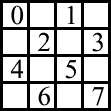 Рис.2 Чередующаяся охватывающая маска | Каждый пиксель делится на 16 субпикселей (являющихся отсчетами), но только половина из этих 16 будет использована нами. Маска хранится в виде 8 битового значения, соответствие битов конкретным субпикселям определяется из Рис. 2. Чередующаяся маска очень похожа на маску, используемую в схеме процессора треугольников [5]. Такая маска требует в два раза меньше памяти по сравнению со стандартной 4х4, но обеспечивает практически аналогичное качество сглаживания. Улучшенное сглаживание может быть достигнуто использованием 64 отсчетов и 32 битовой маски. Для поддержки такого режима объем интегрированного буфера изображения должен быть на 60% больше. |
Генерация маски осуществляется в процессе scan conversion. При этом стандартная линия сканирования (шириной в пиксель) рассматривается в виде 4-х сублиний (шириной в 4 раза меньше), каждая из них, пересекая полигон (треугольник), сформирует свой собственный сегмент.
В первую очередь производится определение × координаты начальной и конечной точки пересечения базовой линии сканирования с треугольником.
где, Y0, Y1, Х0, Х1 — координаты конечных точек краев треугольника. Slope — коэффициент* определяющий степень наклона края треугольника.
*Прим. Для вертикальной линии этот коэффициент равен 0, для горизонтальной 1. Для всех других наклонов — соответствующие промежуточные значения.
Далее вычисляются начальные и конечные точки 4-х сублиний. Пиксели, соответствующие краям треугольника, "подрезаются" получившимися сегментами. Соответствующий бит в маске устанавливается в 1 в том случае, если он попал в сегмент. Проиллюстрируем это на Рис. 3. Это фрагмент линии сканирования, пересекающей треугольник. Она состоит из четырех сублиний. Каждый отдельный малый квадрат представляет собой субпиксель. Фрагменты, состоящие из 16 субпикселей (размерностью 4х4), представляют исходные пиксели, выделены отдельным цветом и по размеру соответствуют нашей чередующейся охватывающей маске. Колонка цифр слева представляет собой начальные и конечные значения каждого сегмента. Бит в маске будет установлен в 1 в том случае, если его положение будет больше начального значения сегмента и меньше конечного. Соответствующая охватывающая маска для каждого пикселя приведена в нижней части рисунка.
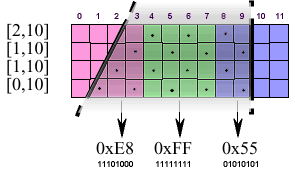
Рис.3 Генерация охватывающих масок.
Одиночное линейное арифметическое устройство способно обеспечить производительность в 1 пиксель за такт даже для небольших треугольников, например размерностью 2Х2. При аппаратной реализации с точки зрения скорости и площади, занимаемой на кристалле, применение линейного арифметического устройства более оправдано, чем поддержка своеобразных справочных таблиц (lookup tables), описанных Шиллингом [16]. Точно так же, как в работах Шиллинга [14] и Reality Engine Graphics [2] мы в своих исследованиях пришли к выводу, что генерация масок значительно лучше сочетается с алгоритмом scan conversion, что делает возможным повторное использование той же самой схематики на кристалле.
2.3 Совмещение фрагментов
Блок отсечения невидимых поверхностей включает в себя интегрированный буфер памяти для хранения двух слоев с информацией о глубине пикселей (значение Z, тень и текущий статус CSG операций).
Когда объекты рендеризуются за один проход, используется всего один слой. Когда необходимо использование нескольких слоев, в одном буфере хранится слой с информацией, полученной в результате предыдущих операций совмещения слоев; в другом буфере находится информация о наиболее ближнем (front-most) слое, взятом для дальнейшего совмещения (композиционирования).
Пиксели, целиком принадлежащие непрозрачной поверхности, определяются за один проход. В том случае, если пиксель содержит фрагменты двух или более треугольников, то очень желательно совместить фрагменты пикселя для того, чтобы окончательные параметры пикселя были просчитаны за один проход. Мы проработали и исследовали несколько методов, но так и не нашли удобного решения, позволяющего просчитать фрагментированный пиксель за один проход.
Так, например, мы рассматривали применение объектных тэгов, которые помогли бы нам на этапе сортировки, но отказались от этого подхода ввиду огромной нагрузки, ложащейся на центральный процессор. Тэги требуют выделения дополнительной памяти для их хранения — они хранятся вместе с данными о глубине пикселей. Поэтому количество возможных тэгов будет ограничиваться количеством памяти, имеющейся у акселератора. Работающая программа должна снабдить каждый объект своим уникальным тэгом, а также обеспечить их эффективную подмену в случае, когда количество объектов превысит максимальное количество тэгов, поддерживаемых аппаратно.
Другой метод, который был исследован для обеспечения слияния фрагментированных пикселей, основан на выявлении фрагментов с одинаковой глубиной. Их слияние осуществлялось бы только в случае, когда их цветовые характеристики идентичны [17]. Но в нашем случае, на этапе операций отсечения невидимых плоскостей информация о цвете еще не доступна, поэтому мы располагаем только информацией о глубине. Располагая только глубиной, принять решение об идентичности фрагментов проблематично. Однако, на уровне программного обеспечения при реализации рендеринга возможно использование минимального значения градиента глубины, при помощи которого можно определить толерантность (tolerance), некоторую область, внутри которой считается, что объекты имеют одинаковую глубину. Так как градиенты по × и Y доступны (соответственно, значения a и b в примере параграфа 3.2), то это кажется отличным выбором.
К сожалению, на практике вполне возможно создать такую сцену, где размер треугольника будет стремиться к размеру пикселя, а градиент глубины будет достаточно велик для того, что бы можно было безошибочно провести сортировку. Градиенты глубины, генерируемые в фазе просчета поверхностей, будут аккуратными только для случая, когда пиксель не фрагментирован. Таким образом, вырабатываемые градиенты будут нерепрезентативными для пиксельных фрагментов. Просчет репрезентативного градиента для фрагмента — задача еще более трудная, поэтому мы решили использовать фиксированную толерантность. Но даже в случае фиксированной толерантности, в многопроходном режиме возможны случаи некорректного просчета фрагментов и отброс правильных данных при сортировке глубины от ближнего к дальнему.
Проанализировав ситуацию, мы решили отказаться от вариантов, которые могли сформировать серьезные артефакты на конечном изображении и предпочли использовать надежное и испытанное решение, найдя удовлетворяющий нас компромисс между производительностью и качеством.
2.4 Передача цветности пикселей при сглаживании
Операции затенения, shading (т.е. передача пикселям нужных цветовых оттенков) реализованы в блоке композиционирования, который, подобно блоку отсечения невидимых поверхностей, имеет двойной буфер для хранения информации о цветности пикселей и масок. В каждом буфере хранится по одному слою. Так как буферы реализованы непосредственно на "чипе", то необходимо принять меры для того, чтобы количество информации, предназначенной для помещения в них, было минимальным. Поэтому цветность пикселей, альфа (прозрачность) и маска хранятся в виде единого 40 битного значения (24 бит на цветность и по восемь бит на значение альфа и маску). Плюс добавочный бит (бит управления) используемый функцией смешивания для цвета, альфа и маски. Подробности функционирования блока композиционирования будут рассмотрены чуть позже.
Рассмотрим пример, приведенный на Рис. 4. На нем представлены фрагменты из трех различных слоев, но принадлежащих одному и тому же пикселю на экране. Объект А имеет значение альфа 0.5 (полупрозрачен) и полностью покрывает пиксель, следовательно, значение маски для данного пикселя максимально и равно 0хFF. По завершению первого прохода слой будет содержать информацию о цвете объекта А, значении альфа и маске.
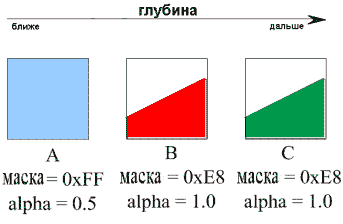
Рис. 4 Композиционирование (совмещение) слоев
Объект В — непрозрачен (alpha 1.0), но он не полностью перекрывает пиксель и имеет маску 0хE8 (11101000). Поэтому сначала цветность и альфа, принадлежащие B, масштабируются в соответствии с охватом маски (коэффициентом перекрытия).
Прим. маска указывает, какая часть площади формируемого пикселя принадлежит объекту В. В нашем случае охват маски составляет 0.5 пикселя, т.к. количество единиц и нулей в маске одинаково. Отсюда, на данном этапе, интенсивность цвета и значение альфа пикселя уменьшаются в два раза.
Исходя из структуры и способа использования охватывающей маски, всего возможно восемь фиксированных значений коэффициентов охвата 0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1 — в десятичном выражении.
Далее, результат подвергается смешиванию с данными, полученными на предыдущем проходе функцией AoverB (А поверх В) [14]:
где, IBack — интенсивность цветовых составляющих нижнего объекта (В); IFront - интенсивность цветовых составляющих объекта находящегося выше (А) с учетом значения собственного альфа (aFront); выражение (1-aFront) — переходной коэффициент прозрачности между слоями.
Смешивание масок — более сложная задача. В алгоритме с А-буфером, новая маска это результат побитового логического ИЛИ двух масок. В нашем алгоритме коэффициенты охвата и переходные коэффициенты сравниваются и в зависимости от результата сравнения результирующая маска будет либо "логическим ИЛИ" двух масок, либо копией одной из них. Так, когда маска, принадлежащая ближнему объекту, будет полностью перекрывать вторую маску, а данные о втором слое считаются менее прозрачными, то маска второго объекта будет записана на место прежней без применения операции ИЛИ. Для этого пикселя бит управления устанавливается в единицу, и является флагом "маска непрозрачна" (opaqueMask flag).
Совмещение данных объекта C с предыдущим результатом производится при третьем проходе. Объект непрозрачен, ему соответствует маска 0xE8. Когда флаг opaqueMask установлен, маска C подрезается по маске, полученной при предыдущем проходе. В нашем случае результатом подрезки будет маска 0x00. Далее цветность пикселя C и значение альфа масштабируются в соответствии с коэффициентом охвата подрезанной маски и смешивается с результатами предыдущего прохода функцией, аналогичной AoverB [Ф.2].
Рисунок 5a создан с учетом управляющего бита opaqueMask flag. Сцена содержит почти прозрачный слой (альфа очень близка, но не равна нулю), который покрывает черный непрозрачный треугольник, который, в свою очередь, расположен ближе идентичного белого треугольника. Фоном является непрозрачный красный слой. Рисунок 5b создан без учета значения бита управления opaqueMask. Обратите внимание на появившуюся светлую паразитную бахрому, которая явилась результатом отсутствия подрезки масок, принадлежащих белому треугольнику.
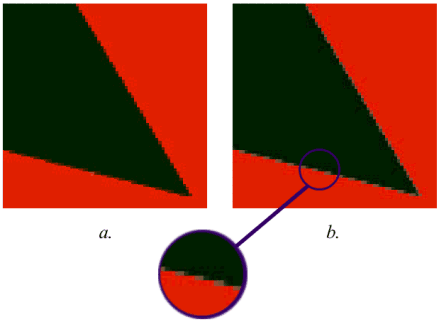
Рис.5 Черный треугольник полностью закрывает собой белый. a) флаг opaqueMask использован b) флаг opaqueMask отключен.
Реализация А-буфера аппаратно требует хранения маски для каждого слоя. Количество слоев может быть огромным, соответственно возрастают и требования к количеству памяти для их хранения. Это нас не совсем устраивает. Поэтому использование управляющего флага opaqueMask дает возможность экономить на памяти, имея при этом хорошее качество изображений, содержащих элементы прозрачности.
На Рис.6 показаны два конуса, рендеризованных с применением сглаживания. Визуальные артефакты, которые видны в месте пересечения голубого и красного конусов, являются результатом потери начальных значений маски и альфа, когда при послойном композиционировании методом front-to-back (от ближнего к дальнему) производится комбинирование альфа значения с коэффициентом охвата маски. Как утверждалось ранее в [2], используя сглаживание на основе значений альфа, корректно сгладить конуса невозможно.
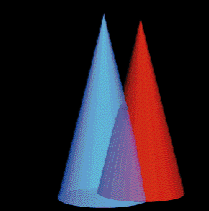
Рис.6 Визуальные артефакты сглаживания
На рисунке 7 приведены два одинаковых изображения рендеризованных с применением сглаживания и без.

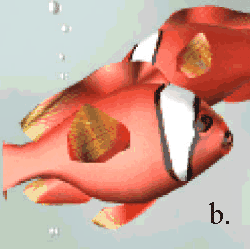
Рис.7 a) без сглаживания b) со сглаживанием
2.5 Сглаживание перекрывающихся объектов
Сглаживание в местах пересечений объектов возможно реализовать путем просчета и восстановления субпиксельной глубины для каждого слоя. Методы, реализующие такой подход, подробно описаны в "Reality Engine Graphics"[2] и "The A-buffer, an Antialiased Hidden Surface Method. [3]. Алгоритм с использованием А — буфера прекрасно работает на пересечениях двух объектов, но неработоспособен в случае трех и более объектов до тех пор, пока мы не обеспечим хранение значений Zmin и Zmax для каждого из слоев. Сглаживание перекрывающихся объектов, реализованное в Reality Engine, использует значения уклонов по × и Y и единую для всего слоя выборку значений Z для восстановления величин субпиксельной глубины. Это более аккуратный метод, но требует значительных вычислительных ресурсов и хранения величин субпиксельной глубины в Z- буфере.
Оба этих метода непригодны для использования в аппаратных решениях с ограниченным количеством памяти, в особенности если сглаживание CSG геометрии и теней требует хранения субпиксельных значений CSG операций и теней в буфере глубины. Для хранения информации о текущем статусе CSG и тени в пределах одного субпикселя требуется 12 бит, таким образом для 8 субпикселей потребуется 84 бита, в пересчете на два слоя — 168 бит. И это на каждый пиксель. Для того, чтобы обеспечить размещение такого большого количества данных внутри чипа, мы вынуждены уменьшать размер тайла, что в свою очередь снизит производительность при выводе обычных изображений без сглаживания.
Сглаживание с повышенным качеством…
Существуют два основных метода, применяемых для просчета сцен с повышенным качеством сглаживания. Суперсэмплинг, сглаживание на основе избыточной выборки* может быть реализовано путем рендеризации каждого тайла с разрешением выше, чем требуется и затем преобразованием его к нужному разрешению (используя дополнительный, специально выделенный для этого ASIC).
*Прим. Методы сглаживания на основе избыточной выборки подробно описаны здесь
Второй метод основан на использовании накопительного буфера. Сцена рендеризуется несколько раз для различных субпиксельных смещений. В накопительном буфере производится аккумулирование результатов каждого из проходов. Эта операция производится последовательно для каждого из тайлов изображения.
2.6 Отсечение невидимых поверхностей
Спроектированное нами аппаратное решение позволяет растеризовать неограниченное количество видимых слоев путем многопроходного рендеринга. Реализации, способные работать с множеством слоев, уже описывались by Abraham Mammen [11] и Michael Kelley [10]. Алгоритм Маммена требует раздельного рендеринга прозрачных и непрозрачных объектов; Келли, наоборот, не разделяет эти два процесса в своем алгоритме, что очень важно, т.к. значение альфа для объекта с наложенной текстурой может быть определено только после извлечения текстуры из памяти.
Сортировка объектов при первичном проходе
Сцена без прозрачных объектов, теней и CSG может быть просчитана за один проход через конвейер. В ином случае, для каждого пикселя потребуются дополнительные проходы для определения его окончательного цвета. Вычислительные операции, которые производятся во втором и последующих проходах, отличаются от тех, которые реализуются при первичном проходе.
Во время выполнения первичного прохода, информация о глубине поступившего на обработку пикселя сравнивается с глубиной самого ближайшего объекта, данные о котором уже имеются (см. псевдокод в Приложении). Глубина представляется 25 битовым числом с плавающей точкой. Из них 19 отведено под мантиссу, 6 — под экспоненту. Этап композиционирования не дожидается полного завершения сортировки всех объектов по глубине, и как только конкретный объект прошел проверку на глубину, он сразу передается на растеризацию, вниз по конвейеру.
На этапе композиционирования, как только будут получены значения маски, прозрачности и цветности пикселя, они сохраняются в буфере изображения. Ранее записанные данные в буфере отбрасываются и заменяются новым значением. Перед тем, как отбросить предыдущие данные, производится проверка, могут ли они влиять на окончательный цвет пикселя, и если так, то для этого пикселя устанавливается специальный флаг. Этот флаг используется в конце прохода для того, чтобы инициировать дополнительный цикл рендеринга той же самой доли (partition) экрана.
После того, как последний объект в тайле (доле) поступит на обработку, перед тем, как перейти к обработке следующего тайла, модуль создания списка полигонов (Display List Traversal, см. схему Рис.1.) вырабатывает специальный синхросигнал. Блок композиционирования, получив синхросигнал, вырабатывает прерывание для модуля создания списка и пересылает ему данные, обозначенные Resubmit на Рис.1. Получив прерывание и данные, Display List Traversal принимает решение: перейти к следующему тайлу или инициировать дополнительный проход для текущего тайла. Задержка в ожидании прерывания должна быть минимизирована алгоритмами предсказывания, которые обеспечивали бы сбор информации для дополнительного прохода или подготовку данных для работы с новым тайлом.
Неограниченное количество слоев с одинаковой глубиной
Архитектура акселератора позволяет композиционировать неограниченное количество слоев, имеющих одинаковую глубину за один проход. Эквивалентные слои определяются на этапе сортировки по глубине и после того, как новый слой подрезан по маскам другого слоя, композиционируются путем аддитивного смешивания. В рассматриваемой нами реализации равенство слоев по глубине устанавливается тогда, когда величины глубин полностью совпадают. Значительный прирост производительности будет возможен при изобретении надежного алгоритма, позволяющего определить эквивалентность слоев даже при отсутствии точного совпадения по глубине (см. также предыдущий раздел о совмещении фрагментированных пикселей).
Сортировка объектов на втором и последующем проходах
Когда для обработки данных требуется два и более проходов, операции композиционирования несколько модифицируются. Сохранение данных в первичных буферах глубины и изображения происходит в конце каждого прохода. Вторичные буферы используются для хранения параметров, поступающих на обработку пикселей.
В процессе сортировки каждый объект сравнивается со значением конечной глубины (final depth) из предыдущих проходов и самой минимальной глубиной (front-most depth) в текущем проходе. Если глубина объекта находится между ними или совпадает с минимальной, то объект пересылается в модуль композиционирования. Модуль смешивает цвета всех объектов, имеющих одинаковые глубины, используя функцию AoverB. Маски объектов комбинируются вместе и результат хранится во вторичном буфере. Как и в случае с одиночным проходом, запись новых данных во вторичный буфер иногда может вызвать потерю еще нужной для текущего прохода информации. Необходимо определить, может ли перезаписываемая информация влиять на конечный цвет пикселя и если да, то пометить флагом данный пиксель и в дальнейшем инициализировать дополнительный цикл для данного тайла.
В случае, когда глубина объекта равна значению конечной глубины из предыдущих циклов композиционирования, то охватывающая маска этого объекта подрезается маской из предыдущего прохода и смешивается функцией AoverB с данными, хранящимися в буфере композиционирования.
Каждый проход акселератора требует полных данных о просчитываемом тайле. В случае совпадения глубин очень важно обеспечить исходный порядок подачи данных, так как первый объект, поданный на обработку, будет считаться наиболее ближайшим и лежащим выше всех остальных, подаваемых на обработку позже, "первым пришел, первым просчитан" (first-come-first-rendered).
2.7 Разбиение изображения на доли (тайлы)
Существует несколько вариантов разработанных и построенных архитектур растеризаторов, использующих разбиение изображения на тайлы [13,6,15,8]. Главное достоинство такого подхода — это возможность реализации буферов глубины и изображения непосредственно на чипе. Такое решение позволяет выиграть в производительности за счет снижения нагрузки на шину памяти и уменьшить количество ножек на микросхеме ASIC.
Основным же недостатком тайловой архитектуры являются присущие ей задержки, связанные с необходимостью создания списков объектов для каждого тайла, отсортированных в пакеты. Также недостатком разбиения изображения можно считать неизбежность многократного обращения к одним и тем же данным, находящимся в системной памяти (например, в случае, когда объекты из разных тайлов используют одинаковую текстуру), что может дополнительно потребовать проработки механизмов локального кэширования таких данных.
Для снижения требований к пропускной способности шины памяти важно предусмотреть алгоритмы, утилизирующие присущую двумерным изображениям когерентность.
Сортировка в пакеты
После того, как треугольники спроецированы на плоскость экрана, плоскость разбивается на части (тайлы) размерностью 16х32, которые неизбежно пересекают некоторые из полигонов. Так как процедура определения принадлежности треугольника определенному тайлу требует очень интенсивных вычислений, то применяется два различных алгоритма, в зависимости от размеров треугольников. Маловероятно, что треугольники, по размеру близкие к размеру тайла или целиком умещающиеся внутри тайла, будут принадлежать одновременно более чем 1 — 2 тайлам, поэтому сортировка таких полигонов сравнительно легка. Небольшие треугольники внутри тайла объединяются в пакеты с размерами, равными размерам прямоугольника, содержащего эти треугольники (triangle's bounding box).
Значительно сложнее выглядит сортировка треугольников, которые значительно больше размеров тайла, т.к. от ориентации полигона в пространстве зависит и его принадлежность определенному тайлу. Очень важно избежать случаев, когда треугольник будет неоправданно ассоциироваться с тайлом, который его не пересекает. В конечном итоге результат ренедеризации будет все равно правильным, но это вызовет излишний расход памяти, перегрузку шины и отрицательно скажется на производительности. Чтобы определить принадлежность треугольника своему тайлу, применяются коэффициенты уклона краев полигона.
Для достижения минимального размера списка объектов (display list) обеспечивается совместное использование треугольниками общих вершин. Используя структуры данных TriMesh, генерируемых Quick Draw 3D и Quick Draw 3D RAVE, совмещения вершин треугольников легко достигнуть даже после подрезки под экран и проецирования. В идеальном варианте каждая новая вершина будет принадлежать двум новым треугольникам и количество треугольников будет равно удвоенному количеству используемых вершин.
3. Архитектура акселератора
Функционально, для выравнивания вычислительной нагрузки выполнение различных задач рендеринга распределено между центральным процессором (CPU) и 3D акселератором. Центральный процессор осуществляет геометрические преобразования, подрезку под экран и шейдинг (затенение, т.е. определение цветового оттенка пикселя). Алгоритмы, реализующие вышеперечисленные функции представлены в [1, 4, 9]. CPU подготавливает списки объектов, связанные с конкретным тайлом. Акселератор производит растеризацию в соответствии с созданными списками. Он извлекает данные об объектах непосредственно из памяти, используя интерфейс DMA, и вырабатывает прерывание процессору только в конце обработки списка или целого кадра. Реализация конвейера растеризации в ASIC представлена на Рис. 1. На входе он получает данные о треугольниках, на выходе формируются законченные пиксели, имеющие цветность с учетом текстур, освещения и т.д. Буферы глубины и изображения реализованы непосредственно на кристалле ASIC, что снижает латентность (задержки) и увеличивает пропускную способность. ASIC рассчитан на тактовую частоту в 100 МГц.
3.1 Модуль подготовки списков
Этот модуль считывает данные о вершинах треугольников, последовательно следуя записям в списочном массиве объектов. Массив (список) был сформирован центральным процессором на этапе деления экрана на тайлы (см. п.2.7, выше по тексту).
3.2 Модуль просчета поверхностей
Работа алгоритма scan conversion с треугольниками основана на использовании математического уравнения плоскости и функционирует аналогично PixelPlanes design [7]. Уравнение плоскости используется для установления взаимосвязи между плоскостью в пространстве и любыми тремя точками, принадлежащими плоскости. Алгебраически плоскость можно описать следующим уравнением:
Это уравнение можно применить для любой точки (x, y, z) в пространстве, проецируемом на экране.
*Прим. Коэффициенты a, b, c — являются постоянными для конкретной плоскости и, по сути, задают вектор нормали.
Линейная зависимость между тремя точками (x0, y0, z0), (x1, y1, z1), (x2, y2 ,z2) и приведенным выше уравнением следующая:
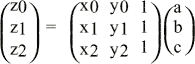 [Ф.3]
[Ф.3]Модуль просчета поверхностей получает данные о вершинах треугольников и вычисляет коэффициенты a, b, c. На базе этих коэффициентов модуль генерирует связанные коэффициенты для всего остального набора параметров, как-то цветность, прозрачность (альфа), глубина и координаты текстур.
Функционирование модуля на основе уравнения плоскости исключает необходимость использования двух стандартных циклов линейной интерполяции (lirp) по × и Y и является более точным. Расчет коэффициентов реализован в систолической матрице, поэтому производится быстрее, чем типичные двухпроходные реализации lirp [10].
Как только происходит вычисление коэффициента, он передается далее по конвейеру и сохраняется в модуле, занимающемся работой с соответствующим параметром; например, коэффициенты глубины хранятся в модуле Отсечения невидимых поверхностей. Коэффициенты могут передаваться посредством отдельных, самостоятельных конвейеров (цепей) с частотой один коэффициент за такт и далее подвергаться двойной буферизации в соответствующем модуле. Такой подход значительно снизит возникающую при передаче нагрузку на внутреннюю шину данных, а использование коэффициентов для параметров освещенности (строго на определенной стадии) значительно эффективнее, чем постоянный прогон этих параметров для каждого пикселя в каждом такте.
3.3 Модуль отсечения невидимых поверхностей
Модуль сортирует по глубине один пиксель за такт. Он снабжен интегрированной на кристалле памятью, достаточной для хранения информации о глубине, тени, статусе CSG для двух слоев. При первичном проходе тайла модуль работает только с одним слоем.
3.4 Работа с текстурами
Модуль наложения текстур реализует традиционное мип-мэп текстурирование с билинейной* или трилинейной фильтрацией [19].
*Прим. Подробнее о принципах осуществления билинейной и трилинейной фильтрации при мип-мэппинге можно почитать здесь и здесь.
Заданная текстура может быть как квадратной, так и не квадратной и иметь вплоть до 2048 текселей на сторону при кодировании 16-ю или 32-мя битами на тексель. Текстурированный пиксель (пиксель, просчитанный с учетом текстуры), формируемый на выходе — это результат работы фильтра по четырем (билинейная фильтрация) или по восьми (трилинейная фильтрация) текселям. Функция фильтрации представляет собой линейную интерполяцию между этими текселями, где весовыми коэффициентами являются дробные части горизонтальных (u) и вертикальных (v) индексов. Наша цель — обеспечить трилинейную фильтрацию при средней скорости в один пиксель за такт. Сложность достижения такой цели заключается в том, что на входе требуется обеспечить подачу четырех или восьми 32 битных текселей за такт. Построение текстурной подсистемы памяти с такой пропускной способностью (1600 Мбайтс для билинейной и 3200 Мбайтс для трилинейной фильтрации) является слишком дорогим удовольствием для персонального компьютера. Вместо этого мы применим специальный интегрированный тексельный кэш, который в значительной мере позволит компенсировать описанную выше проблему.
Тексельный кэш работает с двумя видами (типами) пиксельных комбинаций, образующихся при билинейном подходе к выборке соседствующих текселей. Будем называть эти типы как "последние четыре" и "межлинейные". Оба типа комбинаций — результат нашего подхода к реализации мип-мэппинга, который ограничивает шаг дискретизации до одного пикселя. Кэш состоит из двух различных, но работающих одновременно модулей. Один модуль отслеживает событие повторного использования "последних четырех" текселей, второй занимается фиксированием повторного использования текселей соседними линиями сканирования треугольника. Для трилинейной фильтрации необходимо применить две пары таких модулей.
Использование комбинации "последние четыре" изображено на Рис. 8.
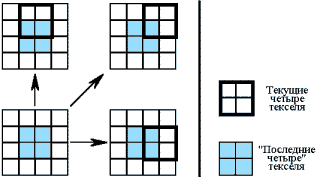
Рис. 8 Использование "последних четырех"
Для осуществления билинейной фильтрации пикселя берется блок из четырех соседних текселей (2х2) текстуры с центром, соответствующим прорисовываемому пикселю (выделено голубым цветом). Следующий пиксель треугольника потребует аналогичный блок из четырех текселей (выделено жирной линией). Но ввиду того, что шаг дискретизации ограничен одним пикселем, мы гарантированно получим повторное использование хотя бы одного текселя из четырех использованных для формирования предыдущего пикселя. Можно предположить, что в среднем, кэш "последних четырех" текселей обеспечит коэффициент попаданий, равный 2 текселям на пиксель. Структура кэш модуля должна обеспечить хранение 4 записей и иметь 4 порта. Любая новая запись должна замещать старую.
Использование "межлинейных" совпадений при сканировании треугольника показано на Рис. 9. Рисунок отображает связь между плоскостью экрана и текстурой, возникающую в процессе билинейной дискретизации треугольника. Координата × каждого последующего пикселя увеличивается на единицу вдоль линии сканирования (scanline). Так, линия А имеет начало Х=1 и заканчивается в Х=8. Приведенный на рисунке треугольник состоит из 6 линий (от А до F). Пересечения линий сканирования А-F с координатами × от 1 до 8 соответствуют единичным отсчетам (сэмплам) билинейной дискретизации. Тексели, необходимые для формирования линии А на экране, выделены. Красным цветом выделены тексели, соответствующие одновременно линии А в Х=4 и линии B в Х=4.
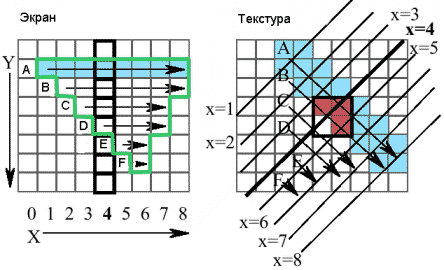
Рис. 9
Четырехпортовый, полностью ассоциативный кэш, с возможностью перезаписи данных только в случае, если они использовались в предыдущем такте, может отслеживать повторное использование "четырех последних" текселей и "межлинейных" совпадений. Однако, архитектуру кэш можно еще упростить, исходя из следующих соображений: "межлинейные" совпадения всегда коррелированны по X. Так, в нашем примере на Рис.9, два текселя, принадлежащие линии А (верхние два, выделенные красным) были сэмплированны по линии X=4; оставшийся повторно использованный тексель сэмплирован по X=5. Ограничив апертуру поиска только близлежащими текселями со значениями X, равными X-1, X, X+1, мы можем реализовать более компактный кэш. Теперь нам достаточно реализовать кэш модуль для хранения тексельных адресов (тэгов), с тремя портами для чтения, одним (двумя) портами записи и двенадцатью (максимум) компараторами. В отличие от такого решения, реализация полностью ассоциативного кэш потребовала бы 4 порта для чтения, четыре порта записи и 16 компараторов.
Путем селективного (выборочного) сохранения одного (двух) из четырех текселей для каждого пикселя (индексированного по X), мы сделаем их доступными для следующей линии текущего прорисовываемого объекта. Решение о том, какой именно тексель сохранять, можно легко принять, основываясь на знаковых битах U и V градиентов объекта. Так, например, если следующая линия проходит ниже и правее текущей линии в текстуре, мы сохраним нижний правый из четырех текущих текселей (или два нижних текселя, в случае применения двух портов записи).
Для отслеживания попаданий в модуле "межлинейного" кэширования индексы пикселей X-1, Х, Х+1 сравниваются с сохраненными в кэш тэгами (адресами текселей) для выбранного текселя, ассоциированного с соответствующим Х. Соответствие укажет на попадание. В завершение цикла новый тэг (адрес выбранного текселя) записывается в ячейку на место попадания.
В нашей архитектуре мы разрешили фиксировать только одно "межлинейное" попадание из трех возможных в X-1, X, X+1. Чтобы уменьшить падение общей производительности кэш памяти ввиду возможного дублирования попаданий "межлинейным" модулем и модулем "последних четырех", кэш "последних четырех" вырабатывает блокирующий сигнал для "межлинейного". В этом случае, "межлинейный" будет фиксировать только свои уникальные попадания, которые не были зафиксированы другим модулем.
Кэш "последних четырех" в среднем фиксирует попадания двух текселей на пиксель. "Межлинейный" модуль с высокой вероятностью обеспечит еще один тексель на каждый пиксель. Таким образом, в самом общем случае мы будем иметь от двух до трех текселей из четырех, необходимых для мип-мэппинга с высоким разрешением. На текстурах с низким разрешением частота попаданий будет еще выше. Недостающие один или два текселя для обеспечения билинейной или трилинейной фильтрации (при удвоенном количестве модулей) можно вполне комфортно извлечь непосредственно из pipelined SDRAM.
Ввиду того, что процесс чтения из SDRAM сопряжен с задержкой на 10 -12 тактов, необходимо реализовать раздельную работу блоков, работающих с тэгами и данными. Блок кэширования тэгов, показанный на Рис. 10 содержит полный набор тэгов для данных, которые поступят и будут кэшированы чуть позже, в блоке кэширования данных. Блок синхронизации производит временнОе выравнивание поступления данных о цвете текселя из SDRAM — с моментами подачи тэгов из блока кэширования. Текстурное арифметическое логическое устройство (Рис. 10) производит расчет адресов тексельных сэмплов и передает их в блок кэширования тексельных тэгов. Оно обеспечивает генерацию четырех адресов за такт, необходимых для осуществления билинейной фильтрации пикселя. Для трилинейного пикселя будет сформировано восемь адресов за такт. | 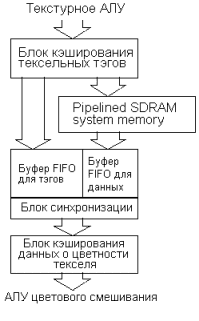 Рис. 10 Архитектура кэш с раздельными конвейерами для тэгов и данных |
На выходе всего конвейера формируется информация о четырех цветах (или о восьми для трилинейной фильтрации). Дальше она поступает в АЛУ, где происходит смешивание с исходным цветом пикселя. Полученная таким образом информация об окончательном цвете билинейного или трилинейного пикселя передается дальше по графическому конвейеру акселератора в модуль композиционирования с другими пикселями.
3.5 Композиционирование методом front-to-back (от ближнего к дальнему)
Окончательная обработка пикселя осуществляется путем композиционирования поступающих на обработку пиксельных слоев в порядке от самого ближнего к дальним. После этого результирующие значения ARGB (alpha + RGB) передаются в буфер кадра. Модуль композиционирования имеет собственные ячейки памяти в количестве, достаточном для хранения информации о двух слоях изображения. При первичном проходе используется только один слой, записываемый в первый буфер памяти. Второй буфер в этот момент содержит законченное изображение, полученное в результате работы с предыдущим тайлом, и оно может быть считано кадровым буфером в то время пока идет обработка следующего тайла (по крайней мере, в течение первичного прохода). Это стандартный прием двойной буферизации.
3.6 Масштабируемая производительность
Реализация 3D ускорителя в виде самостоятельной и недорогой карты представлена на Рис. 11. Хранение текстур реализовано в модулях памяти SDRAM, непосредственно подключенной к микросхеме акселератора. К контроллеру ввода-вывода, обеспечивающему интерфейс с шиной PCI, также подключены модули памяти SDRAM. Они могут использоваться для хранения дополнительных текстур или информации о вершинах треугольников. Эти модули — элементы необязательные, но очень желательные, так как хранение текстур непосредственно на карте значительно снижает нагрузку на шину PCI при текстурировании. Локальное хранение вершин разгрузит шину в те моменты, когда просчитываемые треугольники пересекают границы тайла, ввиду того, что вершины будут загружаться на карту всего один раз. Более того, наличие такой памяти снижает нагрузку на PCI при повторных циклах обработки тайла внутри акселератора.
Прим. Можно предположить, что использование шины AGP снимет вышеперечисленные проблемы, присущие PCI, и данные можно будет вполне комфортно получать непосредственно из системной RAM компьютера.
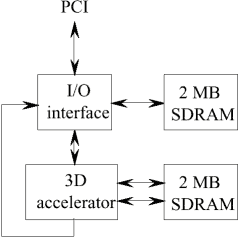
Рис.11 Блок схема недорогого 3D ускорителя
Для того, чтобы увеличить производительность, можно применить несколько растеризующих ASIC, работающих параллельно [16]. Микросхема контроллера ввода — вывода (I/O interface) способна обеспечить работу до 4-х ASIC, как показано на Рис. 12.
Информация, формирующаяся в буферах изображения каждого из растеризаторов, через специальный интерфейс, объединяющий изображения отдельных тайлов, передается в кадровый буфер (функционирование указанного интерфейса не является предметом статьи и поэтому не рассматривается).
Кадровый буфер (VRAM), должен находится на самом ускорителе, т.к. PCI не может обеспечить пропускную способность в 177 Мбайт/сек, необходимую для формирования тридцати 1280х1152 pix кадров в секунду. Типовая пропускная способность 32bit 33 МГц PCI шины составляет около 100 Мбайт/сек.
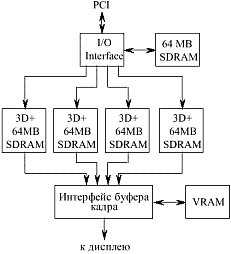
Рис. 12 Блок-схема высокопроизводительного ускорителя
4. Заключение
Разработав архитектуру акселератора, мы достигли следующих главных целей проекта:
Высокопроизводительное сглаживание
Снижение производительности при сглаживании с использованием модифицированного А-буфера составляет не более 40% от производительности, получаемой без сглаживания. Использование сглаживания с аккумулирующим буфером или на основе избыточной выборки (supersampling) дает значительно большее падение.
Невысокие требования к памяти и ее пропускной способности
В нашей архитектуре отсутствует необходимость реализации буфера глубины вне чипа. Интегрированные в кристалл чипа буферы изображения передают информацию в буфер кадра в режиме "только запись". Тексельный кэш также интегрирован, что значительно снижает нагрузку на память при текстурировании. Можно использовать дополнительные модули памяти для организации хранения вершин треугольников и текстур, что позволит снизить нагрузку на системную память и увеличить общую производительность акселератора (последнее имеет смысл только для PCI).
Равномерное распределение нагрузки между CPU и акселератором
Графический ASIC вырабатывает прерывание процессору только в случае завершения обработки кадра. Это позволяет процессору полностью переключиться на обработку 3D геометрии. Применение дополнительной памяти, подключенной к контроллеру ввода вывода, увеличивает общую производительность работы акселератора и снимает излишнюю нагрузку с системной памяти.
5. Будущие разработки
Как было сказано выше, предстоит разработать надежный и корректный алгоритм для совмещения пиксельных фрагментов. Это снизит количество проходов, необходимых для реализации сглаживания при улучшенном качестве и производительности. Качество сглаживания может быть еще более высоким, если увеличить количество субпиксельных отсчетов с 16 до 64. Предстоит разработать метод корректного сглаживания для проникающих друг в друга объектов (таких, как пересекающиеся конусы, например). Ну и, наконец, для безупречного сглаживания теней и результатов CSG нужно постараться увеличить количество данных хранимых в Z буфере и буфере изображения.
Благодарности
Авторы выражают признательность Paul Baker и Jack McHenry за поддержку проекта в Apple's Interactive 3D Graphics group и благодарят Bill Garrett и Sun-Inn Shih за подготовку обзоров.
Приложение: псевдокод
Представленный ниже псевдокод демонстрирует алгоритм рендеринга.
RenderFrame()
{
/* object loop: transform, shade, sort */
foreach (object)
{
Transform (object);
Shade (object);
PartitionSort (object);
}
/* partition loop: rasterize */
foreach (partition)
{
InitPartition (partition);
Rasterize (partition);
}
}
Object loop выполняется на CPU, partition loop (тайловый цикл) функционально встроен в ASIC 3D ускорителя. Приведенный ниже псевдокод представляет собой упрощенный вариант цикла многопроходной растеризации.
/* rasterize loop: first layer первый слой */
foreach (object)
{
foreach (pixel)
{
if (depth_pixel[x][y] <= depth_buf[x][y])
{
depth_buf[x][y] = depth_pixel[x][y];
composite_buf[x][y] = Composite(pixel);
}
}
}
while ( Resubmit )
{
firstDepth = depth_buf;
firstComposite = composite_buf;
clear(depth_buf);
clear(composite_buf);
foreach (object)
{
foreach (pixel)
{
if (depth_pixel[x][y] > firstDepth[x][y])
{
if (depth_pixel[x][y] !>
depth_buf[x][y])
{
depth_buf[x][y] = depth_pixel[x][y];
composite_buf[x][y] = CompositeFirst+pixel(pixel);
}
}
}
}
} Статьи и литература
[1] Kurt Akeley and T. Jermoluk. High-Performance Polygon Rendering. Computer Graphics (SIGGRAPH 88 Conference Proceedings), volume 22, number 4, pages 239-246. August 1988.
[2] Kurt Akeley. RealityEngine Graphics. SIGGRAPH 93 Conference Proceedings, pages 109-116. August 1993. ISBN 0-89791-601-8.
[3] Loren Carpenter. The A-buffer, an Antialiased Hidden Surface Method. Computer Graphics, (SIGGRAPH 84 Conference Proceedings), volume 18, number 3, pages 103-108. July 1984. ISBN 0-89791-138-5.
[4] Michael Deering and S. Nelson, Leo: A System for Cost Effective 3D Shaded Graphics. SIGGRAPH 93 Conference Proceedings, pages 101-108. August 1993.
[5] Michael Deering, S. Winner, B. Schediwy, C. Duffy and N. Hunt. The Triangle Processor and Normal Vector Shader: A VLSI System for High Performance Graphics. Computer Graphics, (SIGGRAPH 88 Conference Proceedings), volume 22, number 4, pages 21-30. August 1988
[6] Henry Fuchs. Distributing a Visible Surface Algorithm over Multiple Processors. Preceeding of the 6th ACM-IEEE Symposium on Computer Architecture, pages 58- 67. April, 1979.
[7] Henry Fuchs et al. Fast Spheres, Shadows, Textures, Transparencies, and Image Enhancements in Pixel-Planes. Computer Graphics, (SIGGRAPH 85 Conference Proceedings), volume 19, number 3, pages 111-120. July 1985.
[8] Paul Haeberli and Kurt Akeley. The Accumulation Buffer: Hardware Support for High-Quality Rendering. Computer Graphics, (SIGGRAPH 90 Conference Proceedings), volume 24, number 4, pages 309-318. August 1990. ISBN 0-89791-344-2.
[9] Chandlee Harrell and F. Fouladi. Graphics Rendering Architecture for a High Performance Desktop Workstation. SIGGRAPH 93 Conference Proceedings, pages 93-100. August 1993.
[10] Michael Kelley, K. Gould, B. Pease, S. Winner, and A. Yen. Hardware Accelerated Rendering of CSG and Transparency. SIGGRAPH 94 Conference Proceedings, pages 177-184. 1994.
[11] Abraham Mammen. Transparency and Antialiasing Algorithms Implemented with the Virtual Pixel Maps Technique. IEEE Computer Graphics and Applications, 9(4), pages 43-55. July 1989. ISBN 0272-17-16.
[12] Steven Molnar, John Eyles, and John Poulton. PixelFlow: High-Speed Rendering Using Image Composition. Computer Graphics, (SIGGRAPH 92Conference Proceedings), volume 26, number 2, pages 231-240. July 1992.
[13] F. Park. Simulation and Expected Performance Analysis of Multiple Processor Z-Buffer Systems. Computer Graphics, (SIGGRAPH 80 Conference Proceedings), pages 48-56. 1980.
[14] Thomas Porter and Tom Duff. Compositing Digital Images. Computer Graphics, (SIGGRAPH 84 Conference Proceedings), volume 18, number 3, pages 253-259. July 1984. ISBN 0-89791-138-5.
[15] PowerVR, NEC/VideoLogic 1996.
[16] Andreas Schilling. A New Simple and Efficient Antialiasing with Subpixel Masks. Computer Graphics, (SIGGRAPH 91 Conference Proceedings), volume 25, number 4, pages 133-141. July 1991.
[17] Jay Torborg and James Kajiya. Talisman: Commodity Realtime 3D Graphics for the PC. SIGGRAPH 96 Conference Proceedings, pages 353-363. 1996.
[18] G. Watkins. A Real-Time Visible Surface Algorithm. Computer Science Department, University of Utah, UTECH-CSC-70-101. June 1970.
[19] Lance Williams. Pyramidal Parametrics. SIGGRAPH 83 Conference Proceedings, pages 1-11. July 1983.
Mike Kelley, Silicon Graphics Computer Systems, Mountain View, CA USA
Brent Pease, Bungie West, San Jose, CA USA
Bill Rivard, 3Dfx Interactive, San Jose, CA USA
Alex Yen, Silicon Graphics Computer Systems, Mountain View, CA USA
Комментарии