Инструменты оптимизации приложений Intel
С выходом релиза Microsoft Windows Vista сообщество разработчиков программного обеспечения ощутило, на сколько важна производительность компьютера. Не смотря на то, что компания Microsoft тратит серьезные усилия на то, чтобы программы, входящие в состав системы работали максимально быстро, задача оптимизации производительности пользовательских приложений лежит на плечах их разработчиков. Компания Intel предлагает уникальный набор программных инструментов, которые помогут оптимизировать производительность приложений, критичных к вычислительным ресурсам, на платформах Intel. В данной статье рассматриваются принципы использования анализатора производительности Intel VTune Performance Analyzer версии 9.0 в процессе оптимизации приложений от системного уровня до уровня микроархитектуры процессора.
С выходом Windows Vista оживилось и сообщество разработчиков. На многочисленных девелоперских форумах и в персональных блогах известных специалистов во всю обсуждаются впечатления от новой ОС от Microsoft. И если в пользовательских разделах споры идут на темы вроде «рюшечеки» и «бантики» в Vista – зачем их так много?», то в серьезных обсуждениях все же появляются темы о производительности системы на современных аппаратных платформах и способах ее повышения.
Действительно, системные требования Vista к «железу» поражают своим размахом, подогревая разговоры о «всемирном заговоре» производителей «софта» и «железа». Однако не стоит забывать, что со стороны разработчиков Windows было бы неразумно не использовать всю мощь, которую могут предоставить современные платформы, и включить в состав системы «прожорливые фичи», которые требуют гигабайты оперативной памяти и гигагерцы процессора. Тем и хорош семейственный подход Microsoft, когда разные выпуски Windows соответствуют разным сегментам рынка, от Home до Enterprise, имеющим разные “усредненные” показатели производительности платформ.
Тем не менее, очевидно, что компания Microsoft осознает конечность аппаратных ресурсов и серьезно относится к производительности приложений, по крайней мере, встроенных в саму систему, и предоставляет большой набор системных инструментов, позволяющих «подтьюнить» OC, чтобы приложения выполнялись быстрее. Неспроста появились и такие инновационные технологии как ReadyBoost и ReadyBoot, которые призваны немного скомпенсировать недостатки такого «узкого места» в платформе как система ввода-вывода.
А что же пользовательские приложения? Будут ли они работать быстрее на Windows Vista? Как их сделать более производительными? Решение этих вопросов Microsoft оставляет нам, разработчикам приложений. Хотя, справедливости ради, надо сказать, что нам в помощь компания сделала серьезные изменения в ядре – переработанный диспетчер задач с более «справедливым» распределением временных слотов; модифицированная система операций ввода-вывода, как в плане распределения приоритетов, так и завершения и отмены; усовершенствованный диспетчер памяти с приоритетом страниц в очереди и функцией SuperFetch – все это поможет имеющимся приложениям работать эффективнее, а разрабатывающимся – использовать новые особенности системы в полной мере. Visual Studio .NET 2005, Platform SDK и высокопроизводительный компилятор С/C++ компании Microsoft помогут нам разрабатывать эффективные приложения, использующие мощь платформы. Но весь ли имеющийся потенциал будет использован? Сможет ли компилятор распознать все огрехи в коде программиста и оптимизировать код должным образом? Можем ли мы быть уверены, что все инновационные технологии, заложенные производителем процессора в чип, используются во время исполнения программы?
К сожалению, немногие разработчики задают себе такие вопросы. Если производительность вашего приложения вас не интересует, то можете дальше не читать эту статью... по крайней мере, до тех пор, пока ваши конкуренты не выпустят на рынок свое программное решение, но более эффективное и быстрое.
Вообще говоря, из опыта известно, что оптимизация приложений если и делается, то обычно этот этап оставляют на самый конец процесса разработки и тестирования, и то, если остается время. Однако ожидание конца разработки, для того чтобы начать оптимизацию, чревато большими трудностями в достижении результатов. Это примерно как имплементация новых фич или поиск багов – чем раньше начать, тем менее болезненным будет процесс и тем более приятным будет результат. Выпуск заплаток или обновлений программы – не самая лучшая технология оптимизации.
Для того чтобы приложение было эффективным и работало с максимальной скоростью, необходимо его производительность рассматривать как одну из фич. То есть в дизайнерской документации характеристики производительности должны быть внесены заранее перед началом кодирования. Программисты должны держать требования производительности в уме, вбивая код, а система тестирования должна быть организована таким образом, чтобы производительность, как параметр, содержалась в функциональных тестах наравне с другими тестами, и была включена в критерии релиза приложения.
Необходимо отметить, что крупнейшие компании производители софта уже отреагировали на тенденцию в развитии микропроцессорных технологий – эра галопирующего увеличения тактовых частот процессоров закончилась, наступила эпоха инновационных архитектур и мульти-ядерных процессоров. Adobe, Macromedia, Oracle, Pixar, SAP, Symantec, Yahoo – вот далеко не полный список компаний, которые включились в гонку за эффективностью своего кода, выполняемого на платформах IA-32 и Intel 64, и активно оптимизируют свои приложения с использованием инструментов.
Оптимизация программного обеспечения включает в себя несколько понятий. Прежде всего, это процесс, который представляет собой некий набор итераций в ходе разработки ПО (рис.1.) и требует дополнительных усилий для оценки производительности приложения. Следующее понятие – методология. На сегодняшний день методология оптимизации ПО для всех существующих платформ разработана и хорошо описана. Примером может служить отличная книга “The Software Optimization Cookbook” для платформ IA-32, написанная инженерами Intel [1], и изданная в издательстве Intel Press. И, наконец, инструменты, которые помогут оптимизировать ПО. Intel, как компания-производитель платформ, позаботилась о том, чтобы разработчики имели в своем распоряжении полный набор инструментов [2], позволяющих разрабатывать эффективные, а значит конкурентоспособные, приложения для современных платформ.
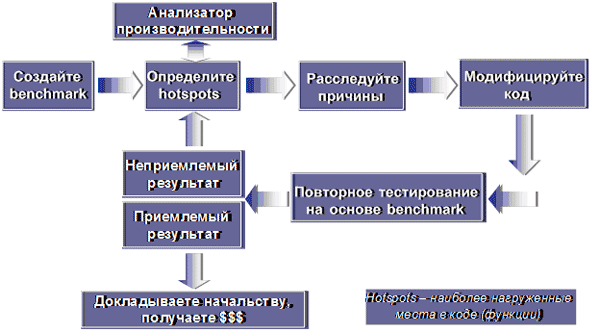
Перед тем как запускать анализатор производительности, создайте хороший тест (benchmark) для своего приложения. Хороший benchmark означает, что он должен быть повторяемым, легко запускаемым, поддающимся измерению, и моделирующим основной путь выполнения оптимизируемого приложения, т.е. репрезентативным. После того как benchmark создан, прогоните его для измерения производительности своего приложения. Это будет ваш базовый уровень производительности. Далее запускайте анализатор и находите узкие места в приложении. Найдя их, исправляйте код, пересоберите приложение и прогоните benchmark чтобы понять, увеличилась ли производительность. Повторяйте этот цикл до тех пор, пока не достигнете поставленной цели, либо пока у вас не закончатся ресурсы. Правильная постановка целей и осознание объема человеческих ресурсов и времени, которые можно потратить, всегда помогают сделать итерационные процессы более эффективными.
Сегодня мы поговорим об анализаторе производительности Intel VTune Performance Analyzer. Компания Intel приурочила к выпуску на рынок Windows Vista новый релиз VTune 9.0, основным маркетинговым преимуществом которого является поддержка 32- и 64-разрядных платформ, управляемых Microsoft Windows Vista и Microsoft Longhorn Server. Однако прежде чем переходить к рассмотрению возможностей инструмента, напомним базовые понятия методологии настройки производительности, так как именно на них опираются технологии, реализованные в VTune. Кстати, под «настройкой» здесь и далее будем понимать некие изменения как в в вычислительной системе, так и в программном коде, т.е. то, что принято называть «тьюнингом» (tuning).
Существует общепринятая методология, которая подразумевает подход к анализу и улучшению производительности приложения сверху вниз: от общесистемного уровня, к уровню микроархитектуры. VTune ориентирован именно на такой подход, что гарантирует максимальное увеличение производительности за минимальное время на вашей целевой платформе. Важно помнить, что этот подход эффективен только при последовательных анализе-настройке, от уровня к уровню, без пропусков:
- Настройки производительности общесистемного уровня
- Настройки на уровне приложения
- Настройки на уровне микроархитектуры
Начинайте всегда искать узкие места (bottlenecks) с общесистемного уровня. Бессмысленно оптимизировать исполнение кода, если ваше приложение потребляет всего 10% процессорного времени. Даже если вы увеличите эффективность исполнения кода в микропроцессоре в два раза, на общую производительность приложения это почти никак не повлияет, а ваши временные затраты на оптимизацию будут огромными. При этом, если окажется, что приложение просто «отдыхает» во время обработки запросов ввода-вывода и обмена данными на жестком диске, то замена дискового интерфейса в компьютере на более быстрый потенциально может уменьшить абсолютное время работы программы в 10 раз, тогда как усилия на архитектурном уровне дадут выигрыш в каких-нибудь 5%.
Как только вы разобрались с общесистемными проблемами (приложение должно «съедать» 100% процессорного времени во время выполнения основной нагрузки), сфокусируйтесь на узких местах в архитектуре своего проекта. Там обязательно найдется парочка ненужных функций, которые зачем-то вызываются несколько миллионов раз, а вы этого даже и не замечали. И, наконец, после того, как в проекте наведен полный порядок, можно приступать (если, конечно, еще есть желание или необходимость) к настройке на самом глубоком уровне – архитектурном. Здесь начинается все самое интересное, так как вы сможете узнать какие сюрпризы припас производитель микропроцессора или платформы, что там еще есть, помимо стандартной программной модели х86.
Опыт наших инженеров показывает, что следование данному подходу в целом может давать следующий примерный прирост производительности приложения:
- 3х – после общесистемной настройки;
- 2х – после настройки уровня приложения;
- 1.1 – 1.5х – после архитектурной настройки.
Причем часто бывает, что эти уровни взаимосвязаны. Например, обращение к памяти по невыровненным адресам приводит к неполным транзакциям записи (partial writes), что сильно перегружает системную шину, и чревато простоями процессора (CPU Stall). Казалось бы, выбор платформы с более высокой тактовой частотой системной шины решает проблему (общесистемный уровень), однако разумная организация обмена данными в коде программы (настройка на уровне микроархитектуры) даст прирост производительности на любой платформе.
Общесистемный уровень настройки
Целью настроек на общесистемном уровне является увеличение производительности приложения за счет улучшения эффективности его взаимодействия с системой. Обычно усилия на этом уровне дают максимальный результат при минимальных затратах времени. Это относится особенно к приложениям, которые интенсивно используют ввод-вывод с дисковыми или сетевыми интерфейсами. Хотя, если вы знаете, что ваша программа требует преимущественно вычислительных ресурсов, то, возможно, имеет смысл вообще пропустить этот этап.
Windows Vista, как и ее предшественники, содержит Менеджер Задач (Task Manager), который отображает данные мониторинга занятости процессора, распределения памяти и операций ввода-вывода. Анализатор производительности VTune тоже может отображать эту информацию, а также данные всех встроенных системных счетчиков, которые есть в операционной системе.
- Counter Monitor – это один из коллекторов данных производительности в VTune. Counter Monitor может отображать значения системных счетчиков в трех видах:
- Runtime Data view – отображает данные в реальном времени;
- Logged Data view – отображает графики значений счетчиков производительности системы, собранные за время работы приложения (на рис.2. представлен пример Logged Data вместе с легендой);
- Summary Data view – отображает bar graph суммарных данных, которые пользователь выделил в Logged Data view (рис.3).
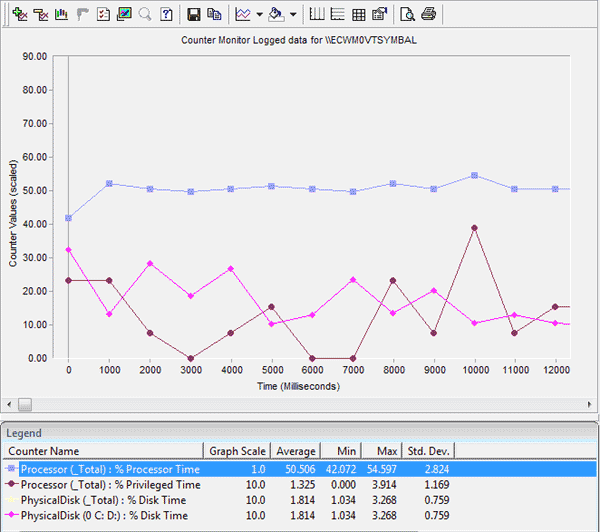

По большому счету не важно, каким вы пользуетесь инструментом, главное – это понять, используются ли ресурсы процессора по-максимуму, или он простаивает, ожидая какой-либо работы. Данные о занятости CPU помогают сориентироваться, какого прироста производительности следует ожидать после настройки на системном или архитектурном уровне. Если загрузка процессора низкая, то приложение имеет узкие места в системе ввода-вывода (диск, сетевой интерфейс) или памяти, и скорость его работы теоретически можно увеличивать до тех пор, пока не нагрузится полностью процессор. Если загрузка высокая, то приложение можно считать вычислительно нагруженным, и в общем случае в разы его уже не ускоришь.
После того, как сделаны настройки на общесистемном уровне, и загрузка процессора выросла, вы можете начинать оптимизацию на уровне приложения и микроархитектуры. И наоборот, после настройки приложения, может оказаться, что загрузка CPU понизилась, и возможно снова потребуется общесистемная настройка.
Вот несколько советов о том, как производить анализ и настройку на общесистемном уровне с помощью Counter Monitor:
- Запустите Counter Monitor Wizard (рис.4) для создания Активности (Activity), это некий аналог понятия эксперимента. Сконфигурируйте Counter Monitor коллектор, выбрав интересующие вас встроенные счетчики производительности (рис.5). Запустится коллектор данных, который, отображая данные в реальном времени, соберет всю выбранную информацию в течение работы приложения.
- По окончании работы запустится Logged Data view, в котором можно анализировать собранные данные, используя всевозможные представления (таблицы, чарты, графики, и т.д.). Анализируйте собранные данные и делайте выводы о работе своего приложения.
- Заинтересовавшие вас отрезки работы приложения можно увеличить (Zoom) для более детального анализа. А также можно отобразить результаты коллекции Sampling, если она была произведена, для конкретного участка, для более глубокого анализа на уровне микроархитектуры. В случае необходимости можно запросить контекстную подсказку в Tuning Assistant, который произведет собственный анализ ваших данных, сделает выводы о производительности приложения на данной платформе и даст Tuning Advice – подсказку по настройке системы или приложения (рис.6).
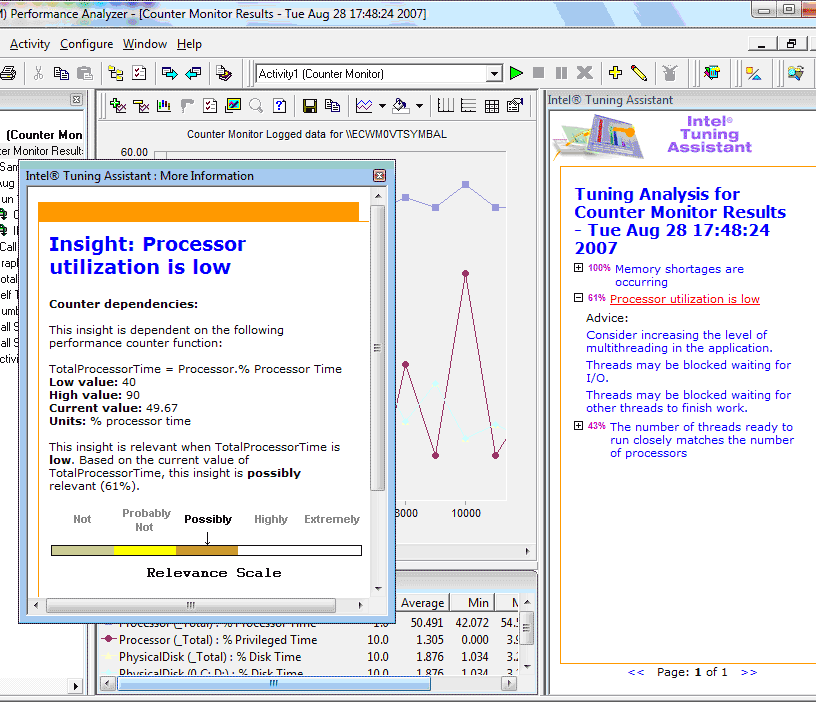
Щёлкните для увеличения
Не пропустите этот важный этап в процессе настройки и оптимизации вашего приложения. Те программисты, которые использовали встроенные в Windows счетчики производительности и раньше, нашли очень удобным использовать их в составе VTune. Для наиболее продвинутых любителей тьюнинга есть возможность создавать собственные счетчики, используя Performance DLL SDK. С его помощью можно создавать ловушки (hooks) в своем приложении, делая настройку производительности еще более эффективной и быстрой. Хотя Counter Monitor и считается третьей по используемости технологией в VTune после Sampling и Call Graph, его возможности широки, а работа над его усовершенствованием продолжается.
Настройки на уровне приложения
Целью настроек на уровне приложения является улучшение вычислительной эффективности алгоритмов, внедрение многопоточности, и/или использование производительных API, библиотек и примитивов. Для того, чтобы понять, где модифицировать приложение, необходимо идентифицировать те его участки, которые вносят наибольший отрицательный вклад в общую производительность приложения. Нахождение этих участков является самым важным шагом на пути улучшения производительности. Затрачивая свое время на оптимизацию «правильных» участков кода, вы получите хорошие результаты. И совсем не имеет значения, сколько времени вы потратили, оптимизируя не тот код, улучшение будет минимальным или совсем никаким. Это все равно что укреплять звенья цепи, находящейся под возрастающей нагрузкой: укрепите слабые звенья, и вся цепь окрепнет, а будете тратить время на и так сильные звенья, то толку от этого окажется мало.
Основополагающее понятие процесса оптимизации, Hotspot («Горячая точка») - это наиболее «слабое звено» в приложении в смысле его производительности. Hotspot может быть один во всем приложении. Их может быть и несколько. А может случиться и так, что, устранив один Hotspot, вы обнаружите в результате несколько новых.
Вообще приложения не выполняются равномерно на всем участке их работы. Некоторые части выполняются практически мгновенно, тогда как другие работают так долго, что кажется программа зависла. Эта неравномерность, очевидно, имеет три причины:
- Редкое исполнение: некоторые участки кода, такие как инициализация или ветки обработки ошибок, исполняются или один раз, или вообще никогда. Обычно приложение в этих местах отрабатывает очень быстро, и оптимизировать эти «холодные точки» не имеет смысла.
- Медленное исполнение: код, требующий значительных вычислительных ресурсов. Например, вычисление интегралов свертки или перемножение гигантских матриц заставят процессор «попотеть». Этот код является Hotspot’ом, если вычисление занимает довольно значительное время по сравнению со временем работы всего приложения.
- Частые исполнения: многие участки кода исполняются повторно много раз. Перерисовка экрана в игре или проверка орфографии во время набора текста – это пара простейших примеров. Но функции, выполняемые очень часто, не обязательно являются Hotspot’ами. Ими могут быть только те функции, кумулятивное время выполнения которых значительно по сравнению со временем работы всего приложения.
Если вы знаете, что является причиной Hotspot’ов в вашем приложении (медленный код, или частое его исполнение, или и то и другое), то вы сможете правильно выбрать методику оптимизации.
Sampling
Серьезный инструментарий для Hotspot-анализа предоставляет Intel VTune Performance Analyzer. Для первичной оценки ситуации с проблемными функциями в приложении используется технология Sampling, позволяющая идентифицировать Hotspot’ы в рамках всей системы, т.е. анализировать все процессы, выполняющиеся в системе, переходить от процессов в исполняемые модули, в модулях находить «горячие» функции, а в функциях идентифицировать строки кода, вызвавшие проблемы с производительностью. Дело в том, что Hotspot’ы – это не только участки, отнимающие время на их выполнение, это место кода, вызывающее любую интенсивную активность процессорных ресурсов. Поэтому в Sampling коллекции данных может быть собрана информация о количестве тиков процессора (CPU Clockticks), выполненных инструкций (Instructions Retired), промахах строк КЭШа процессора (Cache Miss), ошибках предсказания ветвления (Branch Misprediction), и т.д. Запустив Sampling коллекцию с приложением, мы получаем диаграмму (можно и в табличном виде) распределения событий (Events) процессора по модулям, исполняемым в системе, в абсолютном и относительном исчислении, а также некие относительные оценки производительности приложения, например CPI (рис.7). О значении показателя CPI мы поговорим в следующем подразделе.
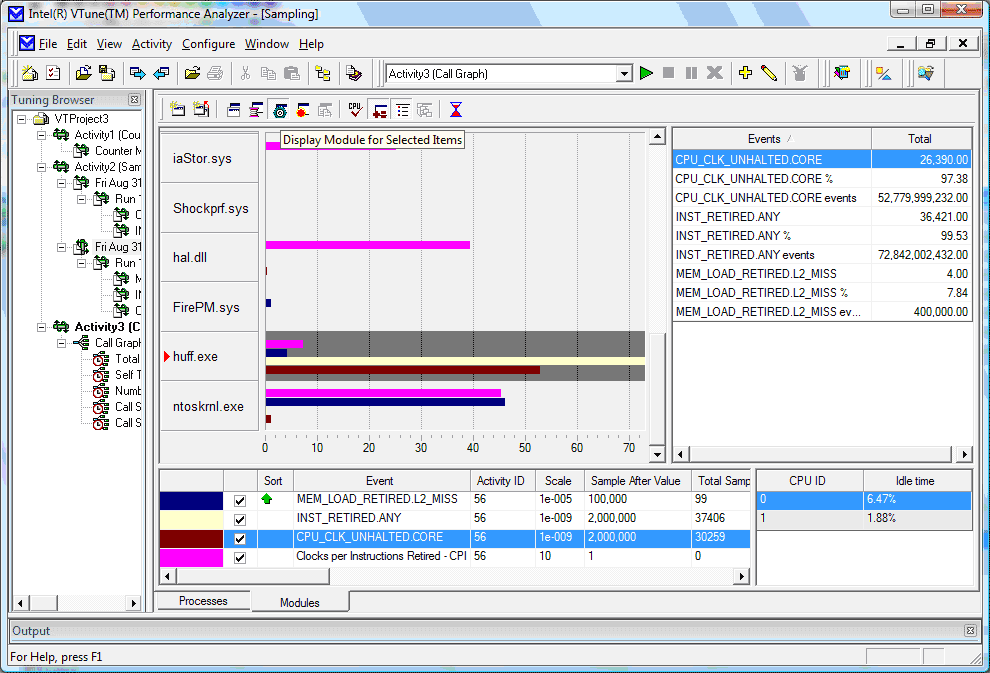
Щёлкните для увеличения
Идентифицировав интересующий нас модуль в Module View и изучив его показатели, углубляемся в Hotspot View, собственно главный режим определения Hotspot’ов в исполняемом модуле (рис.8). Здесь мы можем посмотреть, какие функции являются наиболее критичными к ресурсам процессора, причем привязку при поиске Hotspot’ов можно осуществлять не только к именам функций, но и к RVA (Relative Virtual Address), классам, или файлам исходного кода.
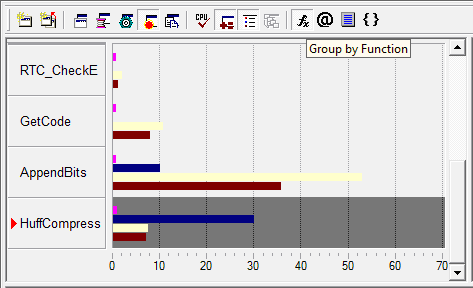
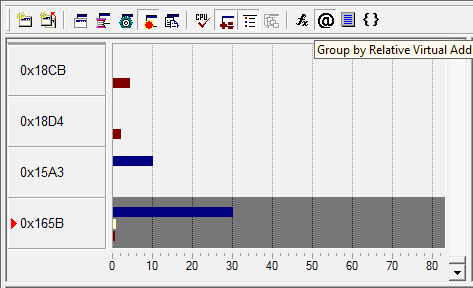
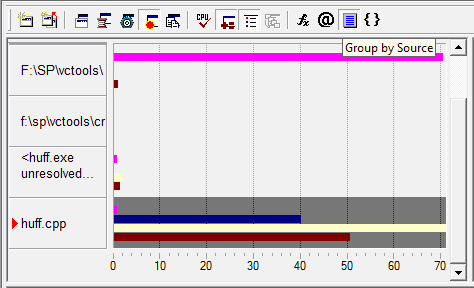
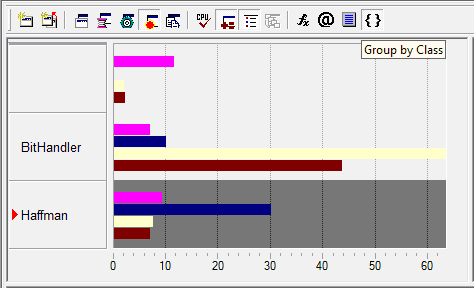
Чтобы определить, какая строка или строки кода стали причиной появления Hotspot’а, достаточно просто углубиться в Source View (рис.9), предоставляющий нам исходный код, строкам которого поставлены в соответствие те данные, которые были собраны в Sampling коллекции. Тем самым мы можем легко определить, какие вычисления и данные привели к каким событиям в процессоре, ущемляющим производительность.
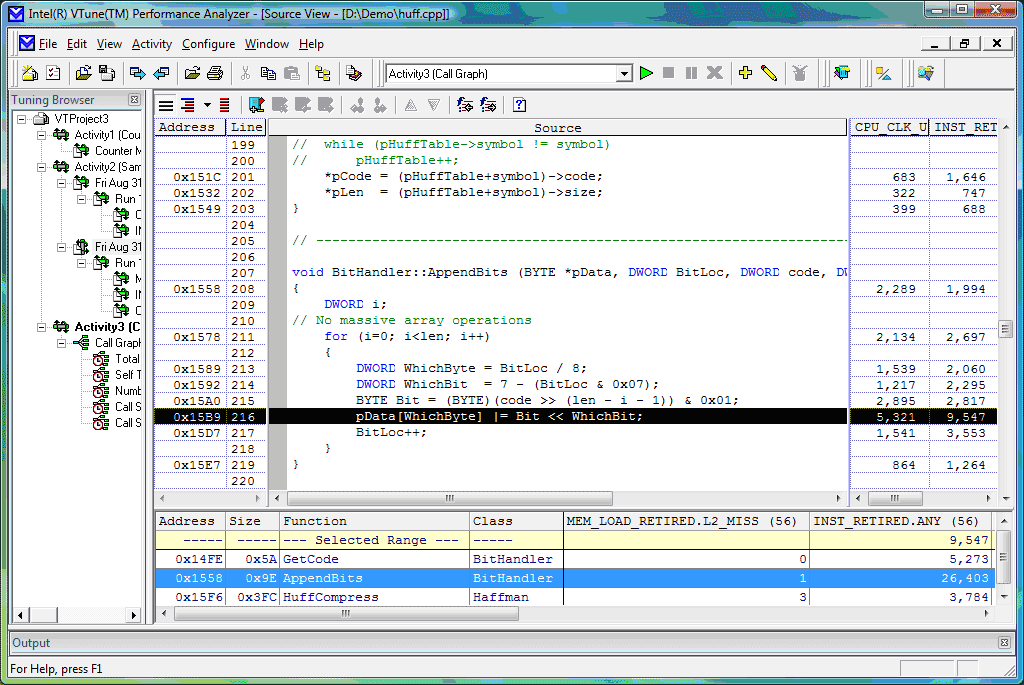
Щёлкните для увеличения
Алгоритмы
Выбор правильного алгоритма для вычислений является основополагающим фактором, влияющим на производительность приложения. Хороший алгоритм решает задачу эффективно и быстро, в то время как неудачно выбранный алгоритм будет тормозить всю программу, независимо от того как профессионально он имплементирован и настроен. Выбор «хорошего» алгоритма не так очевиден. Вычислительная сложность, использование памяти, зависимость по данным, выбор инструкций для реализации алгоритма – все это влияет на его эффективность. Поэтому время, затраченное на подбор алгоритма, окупится потом, так как у вас будут меньшие затраты на его оптимизацию.
Не сильно углубляясь в эту тему, приведем два примера влияния алгоритмов на производительность. Первый, самый тривиальный, и по идее его должны рассматривать еще на первых курсах по информатике.
Вычислительная сложность. Известно, что сортировку можно выполнить многими способами. Самый простейший, и при этом самый медленный их них – метод пузырьковой сортировки (bubble sort). Он обладает вычислительной сложностью O(n2), что означает, что если количество элементов сортируемой последовательности удвоится, то количество операций для вычисления потребуется в четыре раза больше. Метод быстрой сортировки (quick sort) имеет вычислительную сложность O(n log n), то есть с ростом элементов количество операций увеличивается по закону чуть быстрее линейного. И соответственно при достаточно большой последовательности quick sort будет гораздо эффективнее bubble sort, выполняя одну и туже задачу.
Когда вычислительная сложность альтернативных алгоритмов одинаковая, необходимо рассматривать другие факторы, влияющие на эффективность. С этим связан второй пример.
Зависимость по данным. Большинство современных процессоров имеют суперскалярную архитектуру и способны выполнять инструкции из кода последовательной программы параллельно. Так новейшие процессоры Intel Core2Duo способны выполнять в одном ядре до 4-х инструкций за один такт. Однако для этого должны быть выполнены определенные условия, одним из которых является независимость данных в инструкциях, выполняемых параллельно (параллелизм на уровне команд).
На рис.10 представлен пример, когда три инструкции умножения выполняются в процессоре параллельно.
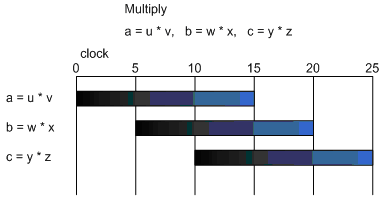
На рисунке предполагается, что между перемножаемыми аргументами нет зависимости, поэтому они могут быть помещены в конвейер для параллельного выполнения, правда с небольшим сдвигом, который называется throughput. В реальной жизни зависимость по данным часто существует. Например, если рассмотреть перемножение тех же независимых аргументов, но в виде выражения a = w x y z, то график исполнения несколько изменится (рис.11), поскольку результаты перемножения w x на результаты y z не будут готовы в течение 15 тиков процессора. На рисунке видно, что перемножение выполняется намного дольше, потому что полный параллелизм на уровне инструкций в данном случае невозможен.
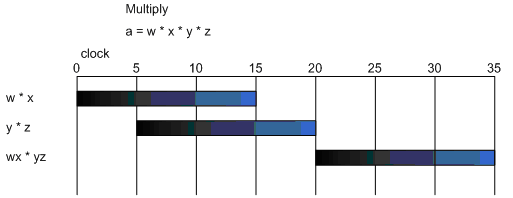
Как уже упоминалось ранее, настройки на уровне приложения и на архитектурном часто переплетены. Последний пример тому яркое подтверждение, когда эффективность реализации вычислений зависит от архитектуры процессора.
Необходимо отметить, что сегодня все более актуальным является выбор алгоритмов, способных эффективно выполняться на мультиядерных процессорах. Поэтому для сложных вычислительных приложений всегда предпочтительно выбирать те алгоритмы, которые линейно масштабируются в мультипроцессорной системе при параллельном выполнении. А оптимизация алгоритмов в основном сводится к их распараллеливанию или улучшению масштабируемости параллельных алгоритмов.
Callgraph
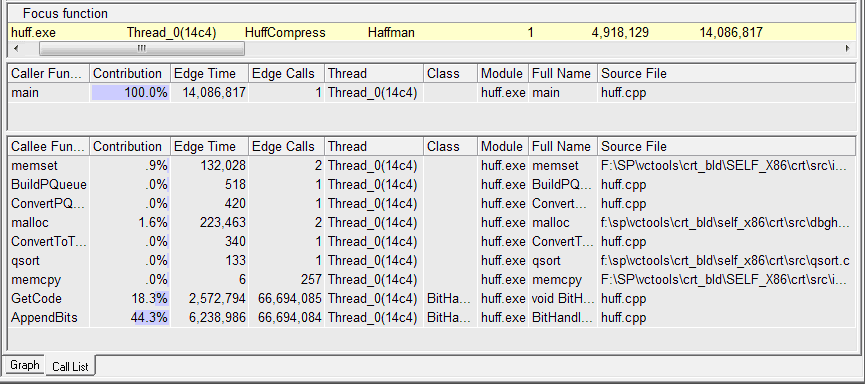
Проблемы с производительностью алгоритмов можно находить разными способами. Один из них – использование технологии Callgraph, которая, прежде всего, используется для анализа приложения на уровне алгоритмов или для выяснения общего потока исполнения в сложной программе. Callgraph комплементарно дополняет Sampling, так как профиль приложения, полученный с помощью сэмплирования, плоский (flat profile), то есть мы видим, какие функции являются Hotspot’ами, но вот как мы в них попали, сколько раз эта функция выполнялась, из скольких мест она вызывалась, и вызывает ли она другие функции мы не узнаем, пока не запустим Callgraph. Callgraph поможет вам найти функции, которые потребовали больше всего времени на их выполнение, предоставляя информацию о том, сколько времени было потрачено на выполнение кода самой этой функции, сколько - в функциях вызванных из нее, и время, потраченное на ожидание объектов синхронизации.
Дерево вызовов даст вам визуальную картину происходящего в приложении. VTune Callgraph построит критический путь исполнения (Critical Path) программы, то есть поток вызовов, исполнение которого заняло больше всего времени, а всплывающие подсказки укажут вам точные параметры вызовов функции (рис.12).
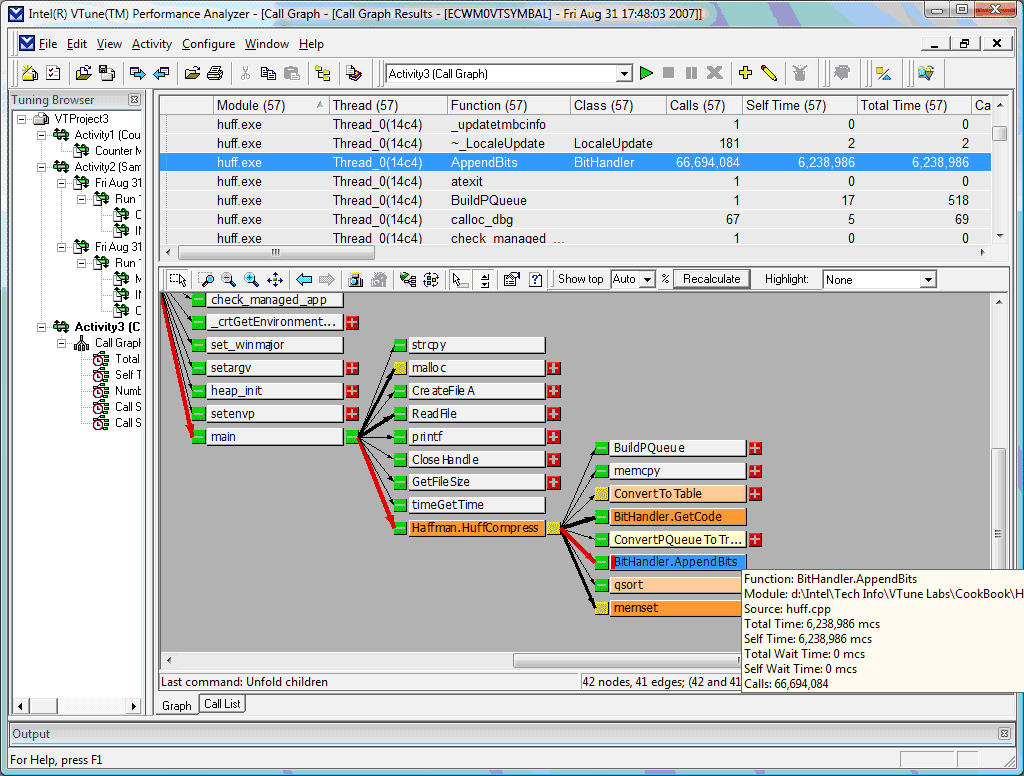
Щёлкните для увеличения
Здесь функция testoror1 была вызвана из testmain два миллиона раз, при этом из 223 мс в ней самой программа исполнялась только 45 мс, остальные 178 мс были проведены в функции dvid_rout, вызываемой из нее.
Если удобно просматривать результаты в табличном виде, то, перейдя по закладке Call List, можно получить список функций, которые вызвали текущую, или которые вызывались из текущей, с распределением вклада каждой (рис.13).
Щёлкните для увеличения
Настройки на уровне микроархитектуры
Сначала многим может показаться, что низкоуровневая оптимизация - это удел специализированных приложений, типа производительных библиотек, кодеков, фильтров и т.д., и заниматься настройкой обычного приложения под конкретную архитектуру процессора не имеет смысла. Действительно, практически весь специализированный софт, критичный к производительности, оптимизируется для конкретных типов или поколений процессоров. Однако необходимо отметить, что низкоуровневая настройка не ограничивается переписыванием критичных участков кода на ассемблере с использованием специализированных высокопроизводительных инструкций. Существует масса приемов оптимизации кода, написанного на языках высокого уровня, которые позволяют воспользоваться всем потенциалом архитектуры платформы. Для этого не всегда нужно изучать микроархитектуру конкретного процессора вплоть до регистров и исполнительных устройств, достаточно просто знать общие принципы построения платформы и конкретные параметры ее компонентов.
Так, например, любой высокопрофессиональный программист должен себе представлять структуру организации памяти в системе, порядок размеров кэш-памяти процессора и примерные соотношения затрат по доступу к ним, чтобы написать эффективную реализацию какого-либо алгоритма, активно использующего размещение временных данных в памяти. Как правило, наиболее интенсивные вычисления производятся в циклах. Если следовать правилу компактной организации и доступа к данным и держать суммарные размеры структур данных, задействованных в циклических вычислениях, соизмеримыми с размером кэша первого уровня, то скорость выполнения вычислений будет невероятно высока, и ограничена только тактовой частотой процессора (тогда как в большинстве приложений процессор просто простаивает в ожидании данных, которые должны быть доставлены в кэш из основной памяти).
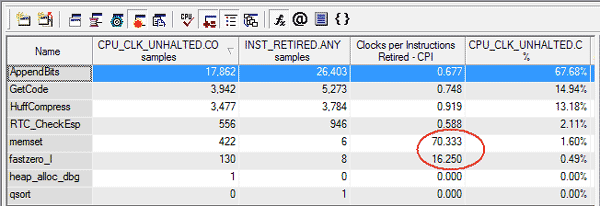
Кстати, упомянутый ранее показатель CPI (Clockticks per Instruction) – важное соотношение, индицирующее эффективность исполнения кода в процессоре. С учетом того, что в микроархитектуре Intel Core2Duo теоретически может выполняться до 4-х инструкций за один такт, идеальный CPI для участка кода с интенсивными вычислениями будет 0.25. После сбора данных с помощью Sampling VTune отобразит значения CPI на всех уровнях, от модуля исполнения до ассемблерной инструкции. Значительное превышение показателя CPI (выше 4-8) для вычислительных циклов, скорее всего, говорит о неправильной организации хранения данных, участвующих в вычислениях (рис.14).
Узнать в каком именно месте доступ к данным осуществляется не самым оптимальным образом с точки зрения микроархитектуры поможет коллекция процессорных событий. Например, исследование промаха КЭШа 2-го уровня (2nd-Level Cache Read Misses) позволит определить, какой участок кода приложения обращается к данным таким образом, что кэш-память все время приходится перезагружать из-за частого перепрыгивания через большие отрезки адресного пространства (Non-Unit Stride Memory Access) (рис.15).
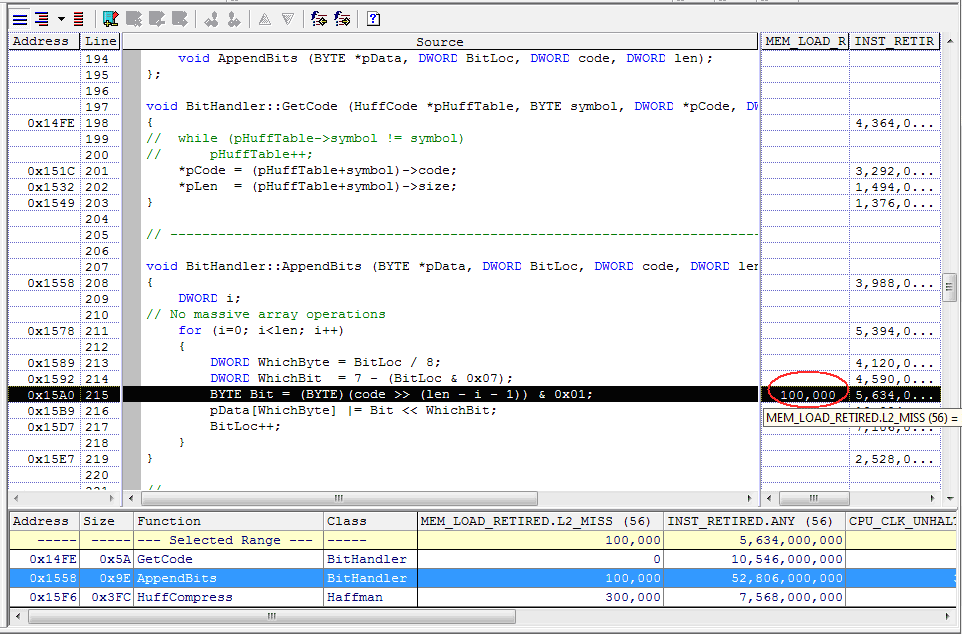
Щёлкните для увеличения
Примечательно то, что в данном примере компилятор Intel пытался предупредить разработчика о том, что текущий тяжелый цикл является хорошим кандидатом на векторизацию, т.е. он может быть исполнен как минимум в два раза быстрее с помощью SSE-инструкций. Однако автоматически векторизовать его не удалось по определенным причинам. Устранение таких причин («прыжки» по памяти, зависимость по данным в цикле, смешанные типы данных, не поддерживаемая структура цикла, и т.д.) действительно позволяет уменьшить время исполнения этого цикла в несколько раз (рис.16).
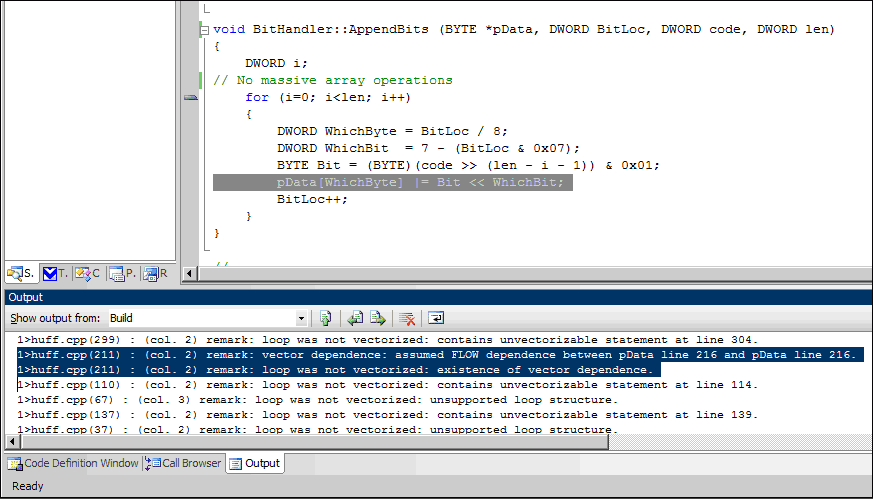
Щёлкните для увеличения
Вообще же стоит полистать IA-32 Architectures Optimization Reference Manual [3], в котором подробно описаны не только все события процессора, которые можно собрать с помощью VTune, но и примеры кода, из которых можно понять, как с помощью небольших модификаций С/С++ кода заставить выполняться приложение гораздо быстрее на архитектуре Intel. Описания этих же событий процессора есть в VTune On-line Help системе, в которой также описаны важнейшие соотношения событий процессора и приведены рекомендации по их улучшению.
Такие модификации могут казаться элементарными, однако программист может даже и не подозревать, насколько они облегчают исполнение кода процессору с архитектурой IA-32. Вот простой пример, Partial Register Stalls. Это ситуация, когда процессор перестает выполнять полезную работу, а вместо этого такты тратятся на реорганизацию внутренних данных. Происходит это в случае, если после операции записи данных в часть регистра следует операция чтения регистра целиком.
Следующий ассемблерный код приведет к Partial Register Stalls в процессоре:
mov al, 5; только 8 бит записываются в регистр eax
mov var, eax; процессор останавливается, пытаясь считать весь регистр eax
Проблема возникает тогда, когда процессор пытается считать весь 32-разрядный регистр, но при этом не знает, что за данные хранятся в верхних 24-х битах, поэтому он ожидает, когда первая инструкция пройдет по конвейеру и закончит исполнение, т.е. обновятся состояния флагов по операции записи. Такой код может быть сгенерирован компилятором, если «злоупотреблять» типами данных short/word.
Исправить ситуацию можно достаточно просто, нужно записывать в регистр 32-битное значение:
mov eax, 5; записывается весь регистр eax
mov var, eax; не возникает остановок процессора
Надо сказать, что на некоторых процессорах Intel проблема Partial Register Stalls не актуальна (P4), однако необходимо придерживаться общих рекомендаций руководства по производительности, это обеспечит равномерность производительности приложения на разных типах процессоров архитектуры IA-32. При этом анализатор VTune поможет обнаружить проблему, собирая события Partial Register Stalls, генерируемые микропроцессором. Отметим также, что если для компиляции приложения используется Intel C/C++ компилятор, то код с такого рода проблемами вряд ли будет сгенерирован. Однако в случае портирования оптимизированных «вручную» библиотек, или использования модулей, скомпилированных старыми компиляторами, возможность обнаружения подобных проблем делает VTune крайне полезным инструментом при оптимизации производительности.
Заключение
Тема оптимизации производительности приложений неисчерпаема. В разделе интернет-сайта Intel, посвященного разработчикам ПО, вы можете найти массу информации, статьи, книги, форумы, которые помогут вам овладеть методиками оптимизации и научиться пользоваться соответствующим инструментарием.
Среди всех инструментов VTune Performance Analyzer является уникальным не только благодаря способности собирать данные о внутренних событиях процессоров Intel, анализировать их, и находить наиболее тяжелые участки кода, восстанавливать дерево вызовов функций, определять временные характеристики вызовов, но и возможности определять наиболее подходящие места для распараллеливания приложений, максимально задействуя имеющиеся вычислительные ядра микропроцессора (multicore). О методиках анализа эффективности параллельных приложений и инструментах, которые предлагает Intel разработчикам, мы поговорим в следующих статьях.
Литература и ссылки:
- The Software Optimization Cookbook. High-Performance Recipes for IA-32 Platforms. Second Edition. Richard Gerber, Aart J.C. Bik, Kelvin B. Smith, and Xinmin Tian. – Intel Press, 2006.
- Intel Software Development Products
- Intel 64 and IA-32 Architectures Software Developer's Manuals
Комментарии