Введение
Parallel Composer является одним из четырех инструментов, входящих в состав набора Intel Parallel Studio. Composer – это не просто компилятор С++ от Intel. Он интегрируется в Microsoft Visual Studio вместе с библиотекой производительности IPP и параллельной библиотекой TBB, что значительно облегчает процесс разработки параллельного кода для новичков, т.е. тех, кто еще не пользовался продуктами Intel, такими, например, как Compiler Pro, и только собирается попробовать улучшить производительность своих приложений с помощью технологий Intel.
Наличие сразу нескольких компонент в пакете позволит сразу же начать оптимизировать свою программу с использованием параллельных технологий, которые содержит Composer:
- Вычислительные примитивы, реализованные в виде функций в библиотеке IPP, гарантируют высокую производительность алгоритмов на платформах Intel;
- Поддержка новой версии стандарта OpenMP 3.0 позволит использовать multitasking, недоступный в предыдущих версиях, которые поддерживаются в том числе и компилятором Microsoft;
- Новый тип данных Valarray немного упростит код, реализующий векторные операции, а компилятор сгенерирует эффективный бинарный код, задействующий SIMD-инструкции для увеличения производительности;
- Поддержка компилятором элементов стандарта С++ 0х облегчит кодирование программистам.
В данной статье мы рассмотрим встроенный в Composer механизм Parallel Debugger Extension (PDE) – расширение стандартного отладчика Microsoft, позволяющее эффективно отлаживать параллельный код, посредством лучшего представления и понимания следующих сущностей:
- данные, разделяемые между потоками приложения, скомпилированного с помощью Intel C++ Compiler;
- векторизированные данные, обрабатываемые в блоке инструкций SIMD;
- использование и зависимости между реентерабельными процедурами;
- информация о блокировках в задачах OpenMP и иерархия созданных потоков.
Продвинутые технологии параллельного программирования требуют соответствующих инструментов и технологий отладки приложений. Интеграция Parallel Debugger Extension в Microsoft Visual Studio позволяет наряду с обычной отладкой применять специальные методики, которые облегчают программисту представление о выполнении параллельных потоков и обработке данных.
Как обнаруживаются разделяемые между потоками данные
Несколько слов о терминологии. Состояние, когда некоторая область памяти доступна двум или более потокам, выполняемым в процессе, называется разделение данных между потоками (data sharing). Если протоки осуществляют доступ с модификацией к разделяемым данным, при этом этот доступ не защищен объектами синхронизации, то имеет место событие, называемое нарушение доступа к разделяемым данным (data sharing violation). Для того, чтобы отслеживать состояние памяти и доступ к ней потоками, необходимо использовать специальные ключи компиляции /Qopenmp и /debug:parallel. Механизм инструментации включается с помощью ключа /debug:parallel, однако специальные расширения библиотеки run-time OpenMP также должны быть задействованы, чтобы отслеживать события управления потоками (рис.1).
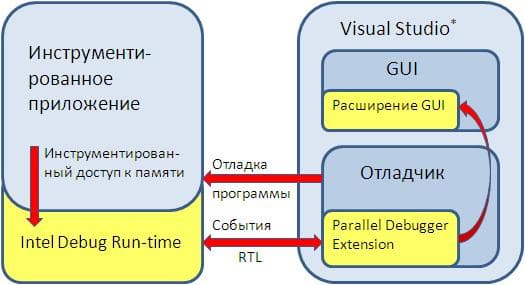
Если включить "Enable Detection" в меню Intel Parallel Composer -> Thread Data Sharing Detection, то в процессе отладки при доступе к разделяемым данным будет срабатывать исключение, которое перехватывается отладчиком, и которое можно обработать различными способами, в зависимости от того, какая стоит задача. Например, можно отфильтровать все события доступа к разделяемым данным, оставив только те переменные, которые представляют интерес или внушают опасения с точки зрения потоковой безопасности.
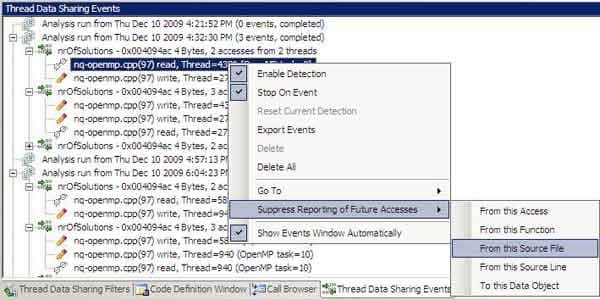
Указанные события регистрируются в базе событий и отображаются в специальном окне Thread data sharing events (рис.2). Понятно, что не все события являются ошибками, поэтому можно включить обнаружение только тех событий, которые ведут к нарушению доступа, или оставить отображения событий, связанных с какой-то конкретной переменной, доступ к которой необходимо отслеживать на протяжении дальнейшей модификации кода. При необходимости с помощью контекстного меню можно установить опцию остановки отладчика на том или ином событии. Кликнув по любому из событий можно переместиться в редактор исходного кода или окно дизассемблера.
Обнаружение реентерабельных процедур
Реентерабельная процедура или повторно входимая функция – это функция, которая может быть вызвана из другого потока до завершения её исполнения в предшествующем вызове в первом потоке. При этом такая такая функция должна исполняться корректно, иначе она не будет обладать свойством реентерабельности. Отладчик спотобен обнаруживать те функции, которые вызываются потоками одновременно. Для этого необходимо включить опцию обнаружения в меню отладчика и указать адрес интересующей вас функции, или адрес внутри функции. Использование адреса несколько неудобно, поэтому можно воспользоваться контекстным оператором, используемым отладчиком Microsoft, ситаксис которого определяется выражением
{[function],[source],[module] } expression (более продробно здесь)
Например, можно указать конкретную строку исходного кода, на которой отладчик должен остановиться:
{my_func,sample.cpp,TestApp.exe}@152
Как только вызов функции будет обнаружен, отладчик остановит процесс и позволит исследовать возможные последствия одновременного вызова функции несколькими потоками. Необходимым условием для обнаружения реентерабельных функций является использование тех же опций компиляции, что и для обнаружения доступа потоков к разделяемым данным.
Окно отображения содержимого регистров SSE
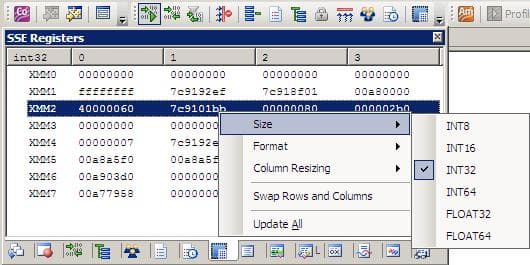
Дополнительным инструментом для низкоуровневой отладки приложений служит окно, отображающее значения регистров, используемых SIMD инструкциями (рис.3). Значения регистров отображаются в виде векторов по столбцам (или строкам), а не просто в виде отдельных значений. Это помогает лучше воспринимать изменения векторизованных данных в процессе пошаговой отладки.
Отладка OpenMP приложений
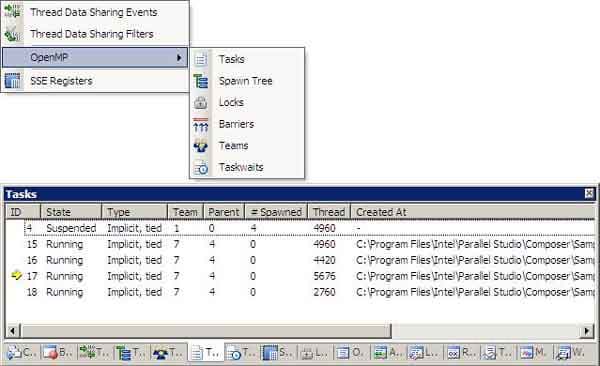
Если приложение было скомпилировано с использованием Intel OpenMP run-time библиотеки, то становится доступным меню для отображения структур OpenMP (рис.4): задачи (tasks), списки ожидания задач (task wait lists), дерево порожденных задач (task spawn trees), барьеры (barriers), блокировки (locks) и группы потоков (thread teams).
Сериализация параллельных регионов
Параллельным регионом называется тот участок кода, который выполняется несколькими потоками. Для OpenMP приложений параллельные регионы легко определить, так как они описываются явно с помощью скобок при указании какой-либо параллельной прагмы. Известно, что параллельное программирование вносит новый вид ошибок, влияющих на корректность исполнения приложения. В таких случаях результаты выполнения прараллельного кода могут не совпадать с результатами выполнения того же кода, но в однопоточном режиме. Последний, как правило, является эталоном, с которым мы сравниваем результат параллельного исполнения и делаем вывод о том, внесло ли распараллеливание ошибку в исполнение алгоритма. Однако для того, чтобы проверить значения на выходе однопоточного алгоритма, необходимо перекомпилировать весь модуль, а может и всю программу. Сериализация параллельных регионов позволяет избежать этих действий, и проверить значение выполнения алгоритма в однопоточном режиме только для какого-либо конкретного параллельного региона "на лету". Для этого необходимо выделить необходимый регион точками останова, а при останове отладки в первой точке, включить опцию Serialize Parallel Regions в меню или панели инструментов, и отладчик сам переопределит переменную окружения OMP_NUM_THREADS, для того чтобы run-time библиотека использовала только один поток для исполнения.
Пример отладки демонстрационного приложения
Рассмотрим особенности отладчика на примере демонстрационного приложения NQueens, которое поставляется вместе с Intel Parallel Composer. Программа NQueens моделирует решение задачи расположения ферзей на шахматной доске, при котором ни одна из фигур не должна атаковать какую-либо другую. В задаче необходимо решить, какое максимальное количество ферзей можно расставить на шахматной доске и сколько существует решений для различных размеров шахматной доски. Очевидно, что решение задачи начинается с определения условия, при котором фигуры не должны находиться в одном столбце, в одном ряду или на одной диагонали.
Интерес предствляют параллельные реализации решения данной задачи. В демонстрационной версии они представлены в виде проектов с использованием различных параллельных технологий: потоков Win32, OpenMP и Intel TBB.
Открыв NQueens.sln в Microsoft Visual Studio, находим проект nq-openmp-intel – реализация решения задачи с помощью OpenMP. Необходимо помнить, что для отладки проекта нужно установить следующие опции:
/ZI /DEBUG /debug:parallel – для генерирования отладочной информации и дополнительной информации о параллельных структурах приложения (инструментирование)
/Qopenmp – линковка с библиотекой Intel OpenMP run-time.
Также необходимо включить перехватывание отладчиком исключений PDE: Menu Debug -> Exceptions -> Win32 Exceptions -> Intel Parallel Debugger Extension Exception 0-2.
Включаем опцию обнаружения доступа к разделяемым данным, при этом можно также активировать опцию останова отладчика при наступлении такого события.
Чтобы работа обнаружения нарушений доступа к разделяемым данным была наглядной, можно специально закомментировать какой-нибудь объект синхронизации, защищаюший переменную.
Например, процесс инкрементации переменной nrOfSolutions (подсчет количества найденных решений задачи), защищен прагмой #pragma omp atomic. Закомментируем ее и пересоберем приложение. Запустив его на отладку (F5), мы увидим, что отладчик остановился в коде напротив строки
nrOfSolutions++;
располагающейся прямо под строкой
#pragma omp atomic
которую мы закомментировали ранее.
В открывшемся окне Thread Data Sharing Events мы видим события, зарегистрированные при исполнении программы. Если продолжить выполнение программы (Continue, F5), то мы увидим, как новые события добавляются в список при каждом последующем останове. В окне содержится информация о том, в каком файле исходного кода произошло событие, какая переменная участвовала и какова ее длина, в какой строке она находится, какие потоки и сколько раз осуществляли доступ к ней, и был ли доступ по записи или чтению.
Из контекстного меню, появляющегося по нажатию правой кнопки мышки над событием, можно перейти либо к исходному коду, либо в окно дисассемблера к инструкции, где произошло нарушение доступа. Там же можно выбрать переход к окну фильтров, и если они определены, и изменить критерии фильтрации. Также можно подавить вывод конкретного события в окно, если вы считаете что данный конфликт доступа не влияет на корректность выполнения приложения, и так было задумано изначально. Для этого необходимо выбрать в контекстном меню Suppress Reporting of Future Accesses и указать либо объект памяти, либо контекст доступа.
Решив, что какой-то участок кода или участок памяти свободен от ошибок разделяемого доступа, вы можете указать целый регион, который должен игнорироваться. Для этого открыв окно фильтров либо из контекстного меню, либо из панели инструментов, задаем соответственно Code Range Filter (фильтр по коду) или Data Range Filter (фильтр по данным).
Например, если вы хотите создать фильтр событий, относящихся к доступу потоков к переменной nrOfSolutions, то в окне New Data Range Filter вы указываете имя переменной, и оставляете определение ее размера через функцию sizeof(). Однако если необходимо исключить целый массив данных, то можно указать размер массива, а имя переменной будет служить его начальным адресом. При необходимотсти, можно вместо имени указать непосредственно начальный адрес данных.
Для фильтрации целых участков кода используется Code Range Filter. Если вы уверены, что доступ потоков к разделяемым данным безопасен, то можно отфильтровать полностью функцию или даже целый файл исходного кода. Для некоторых особых случаев можно указывать диапазон адресов исполняемого кода, котоый подлежит фильтрации.
При отладке реального приложения, количество событий, зарегистрированных и отображенных в окне Thread Data Sharing Events, может быть огромным, тем более если производилось несколько запусков отладки. Для того чтобы освободиться от событий, которые были накоплены ранее, используйте кнопку Reset Detection.
Необходимо отметить, что подобный функционал обнаружения нарушений доступа к разделяемым данным реализован в Intel Parallel Inspector, который входит в состав Intel Parallel Studio. Однако, Inspector работает уже с готовым приложением, осуществляя инструментацию "на лету", в то время как Composer анализирует инструментированное приложение, скомпилированное специально для процесса отладки. С точки зрения обнаружения подобных ошибок, оба инструмента выполняют одну и ту же задачу.
Пример обнаружения реентерабельных процедур
Для того, чтобы проверить функцию setQueen, в которой мы закоментировали объект синхронизации, нажиаем кнопку Break on Re-entrant Call и в появившемся диалоге указываем имя функции в соответствии с нотацией, описанной ранее.
После запуска приложения на отладку появится окно с сообщением, что обнаружен вызов функции одновременно из нескольких потоков, с указанием этих потоков.
Нажав OK, мы попадаем в окно дизассемблера с аннотацией исходным кодом, откуда можно либо продолжить отладку, либо остановить ее для обдумывания дальнейших действий, например, должна ли эта функция вызываться из разных потоков одновременно и является ли она реентерабельной. Каждый раз, как будет обнаруживаться re-entrant call, отладчик будет останавливаться в этой точке.
Пример анализа OpenMP приложения
Во время анализа нашего приложения можно остановиться в функции setQueen и вывести окна Task Spawn Tree, Tasks и Teams, чтобы понять структуру, каким образом организованы задачи и как они объединены в группы в приложении. В данном случае в основной задаче были порождены четыре дополнительных, выполняющихся в отдельных потоках, и объединенных в одну группу.
Картинка выглядит довольно простой и малоинформативной для несложного приложения. Однако в реальных программах, где количество потоков может измеряться десятками, а задач – сотнями, понять их структуру непросто без такого представления данных.
Рассмотрим пример использования сериализации параллельных регионов для обнаружения ошибок в коде. Допустим, что в процессе анализа результатов работы приложения, мы обнаружили неверное значение количествра решений при заданном размере шахматной доски.
Для того чтобы убедиться, что неправильный результат получается из-за вычислений в нескольких потоках, рассмотрим параллельный регион в функции solve(), исключив строки, не определенные препроцессором (листинг 1).
void solve() { int myid;#pragma omp parallel for private(myid) for(int i=0; i// try all positions in first row // create separate array for each recursion // started here setQueen(new int[size], 0, i, myid); }}
Прагма omp parallel for определяет выполнение цикла в различных потоках, то есть функция setQueen вызывается одновременно. При этом незащищенная глобальная переменная nrOfSolutions из прошлого примера может быть инкрементирована в функции setQueen некорректно в результате конфликта доступа.
Необходимо поставить точку останова отладчика перед входом в параллельный регион, то есть до начала цикла. Когда отладчик остановится в этой точке, активизируем сериализацию параллельных регионов: Menu Debug -> Intel Parallel Debugger Extension -> Activate/Deactivate Serialize Parallel Regions.
В результате OpenMP run-time библиотека получит команду выполнять регион в однопоточном режиме, а результаты вычислений будут избавлены от ошибок, которые может внести многопоточность.
После выхода из параллельного региона можно поставить еще одну точку останова и возобновить исполнение программы в многопоточном режиме. Таким образом можно быстро проверить, является ли некорректный результат следствием параллельного исполнения кода именно в этом регионе.
Заключение
The Intel Parallel Debugger Extension для Microsoft Visual Studio является дополнительным инструментом, расширяющим возможности отладки многопоточных приложений и позволяющим эффективно находить как ошибки доступа к разделяемым переменным из разных потоков, так и причины некорректных вычислений в результате распараллеливания алгоритмов. Используя отладчик совместно с интрументам анализа корректности Intel Parallel Inspector, разработчики получают возможность быстро и эффективно обнаруживать ошибки многопроточности, сокращая время, затрачиваемое на отладку и сопровождение продукта. В случае затруднений разработчики Intel Parallel Composer будут рады вам помочь, а также услышать мнения пользователей о продукте и обсудить те недостатки, которые еще есть в нем, на ISN форумах, как англоязычном, так и русскоязычном.


