Intel решила брать размером? Топовый GPU Intel получился крупнее конкурирующих решений AMD и Nvidia
Пока о производительности новинок Intel ничего сказать нельзя
Представленные вчера видеокарты Intel Arc, как мы давно знаем, опираются на два GPU. Старший имеет 512 вычислительных блоков, и видеокарты на его основе якобы должны конкурировать с GeForce RTX 3070 и Radeon RX 6700 XT.
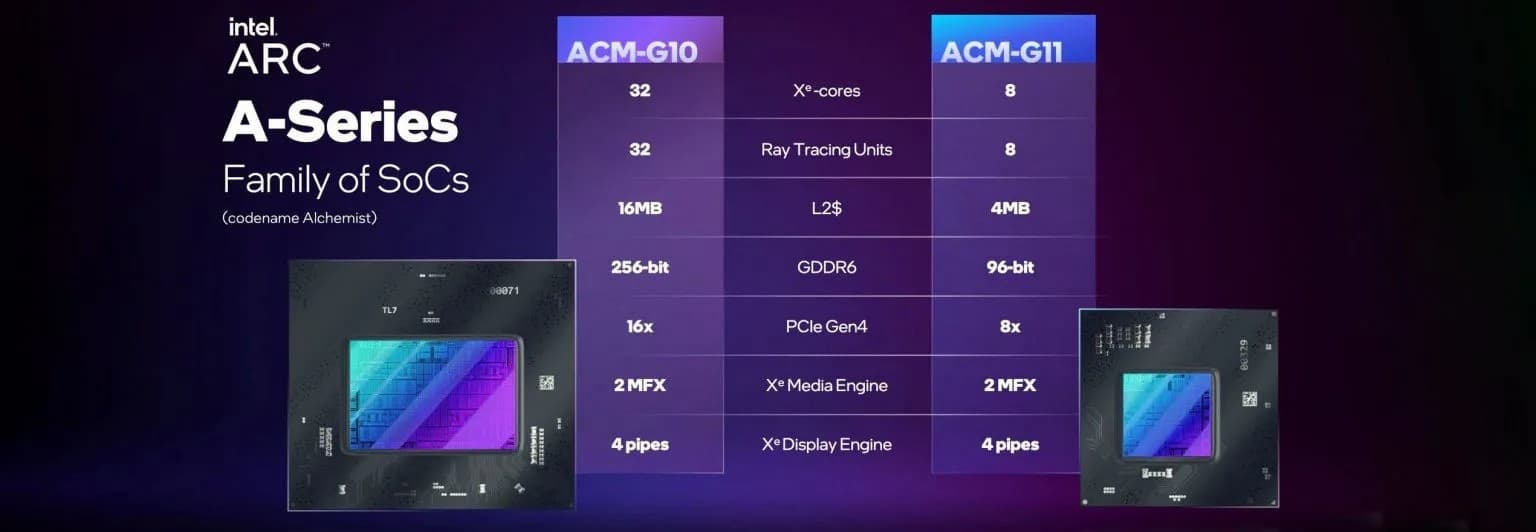
Как сообщается, GPU ACM-G10, который ранее мы знали под именем DG2-512, имеет площадь 406 мм2 и содержит 21,7 млрд транзисторов. То есть он крупнее, чем Navi 22 и GA104, и имеет ощутимо больше транзисторов. Кроме того, плотность транзисторов у него также выше.
Напомним, GPU Intel производятся на мощностях TSMC по техпроцессу 6 нм, то есть по этому параметру они современнее, чем конкурирующие решения AMD и Nvidia.

Что касается GPU ACM-G11 (DG2-128), он имеет площадь 157 мм2 и содержит 7,2 млрд транзисторов. То есть он опережает Navi 24, а вот относительно GA107 говорить сложно, так как его площадь известна лишь приблизительно (200 мм2), а количество транзисторов Nvidia вообще не раскрывала.
Комментарии