Идеальный компьютер-2 или «начнем с чистого листа и забудем для простоты о совместимости»
написан в порядке полемики со статьей Владимира Рыбникова
«10 GHz на сундук мертвеца или Записки на крышке системного блока»,
в которой также затрагивается тема «идеального компьютера».
Поэтому по ходу изложения автор намерен иногда ссылаться на
указанную статью, и предполагает, что эти ссылки
в состоянии восприниматься читателями.
Для начала я бы хотел сформулировать те задачи, которые, с моей точки зрения, необходимо решить в ходе разработки концепции, и определить их приоритеты. Основная цель очевидна: создать сбалансированную архитектуру, отвечающую современным и перспективным представлениям о решаемых компьютерами задачах. Для этого, с моей точки зрения, следует найти решение следующих проблем:
- 1. В архитектуре процессора и подсистемы процессор-память:
- 1.1. Обеспечить процессору максимально быстрый доступ к памяти
- 1.2. Снабдить его максимально оптимизированной последовательностью команд (чтобы не тратить транзисторы на оптимизацию непосредственно при исполнении)
- 2. Снять с CPU задачи организации ввода / вывода, для чего:
- 2.1. Ввести в архитектуру компьютера дополнительный процессор для решения исключительно этих задач
- 2.2. Общение программы, выполняемой CPU, с процессором ввода / вывода, привести к виду высокоуровневых вызовов
- 3. Сократить задержки ввода / вывода и упростить организацию компьютера в целом, для чего:
- 3.1. Использовать в качестве системы ввода / вывода какую-либо гибкую и хорошо масштабирующуюся технологию передачи данных с единым форматом пакета (для исключения задержек преобразования)
- 3.2. Исключить из компьютера все нецифровые способы передачи сигнала, чтобы исключить задержки АЦП / ЦАП
- 4. Создать гибкую, масштабируемую архитектуру с единым стандартом на систему команд, подключение периферии, коммуникаций и всего, что только можно придумать :).
Что ж, вопросы заданы, приступим к ответам.
Сокращение задержек и уход от влияния шин
На мой взгляд, основным потребителем пропускной способности памяти и сейчас, и в обозримом будущем есть и останется процессор. Причем, именно пропускная способность и задержки работы оперативной памяти наиболее негативно отражаются на производительности системы (задержка обращения к дискам, например, и так велика, но ее можно избежать, просто увеличив объем ОЗУ). Именно поэтому я предлагаю расположить контроллер оперативной памяти на кристалле процессора и «запустить» его на полной частоте ядра (несколько гигагерц).
Там же я разместил и главный системный коммутатор, ведающий доступом ядра процессора и устройств ввода / вывода к оперативной памяти. Естественно, контроллер устройства ввода / вывода может через коммутатор адресовать непосредственно области памяти, равно как и ядро процессора. Впрочем, и процессор может обращаться непосредственно к любому устройству, подключенному к разъемам ввода / вывода. Я вполне поддерживаю и идею «умного» контроллера памяти, способного, например (по команде процессора), передать блок информации устройству ввода / вывода. Кроме того, расположение контролера памяти на процессорном кристалле дает возможность сделать шину памяти предельно короткой — к примеру, разместив ее модули непосредственно рядом с процессорным разъемом.
Новым в предлагаемой структуре является кэш коммутатора. Его назначение состоит в том, чтобы за счет буферизации поступающих запросов (если их много) обеспечить максимально возможное заполнение полосы пропускания как RAM, так и FSB и канала ввода / вывода. Выполнить его я предлагаю в виде двухпортовой памяти SRAM с ПСП не меньшей, чем суммарная ПСП RAM и FSB.
Сверхглубокая компиляция и явный параллелизм против ЯВУ-ассемблера
На первый взгляд процессор, имеющий в качестве ассемблера ЯВУ, выглядит очень привлекательно. Действительно — если он будет просто «напрямую» исполнять вашу программу — то все должно быть хорошо и быстро. Однако, тут есть один почти фатальный для данной концепции «подводный камень»: дело в том, что при переводе текста на ЯВУ в микрокод (который уже выполняется непосредственно ядром процессора) так или иначе нужно проделать вполне определенный цикл операций.
В настоящий момент эти этапы (компиляция) отделены от этапа исполнения, и это правильно, т. к. позволяет компилировать программу на ЯВУ однократно. Более того — в идеале исходные тексты должны транслироваться даже не в некий промежуточный код (архитектура х86), а прямо до уровня микроопераций процессора, как это делается в случае с VLIW-архитектурой. Только такой подход позволит (при неизменном числе транзисторов на кристалле, замечу) наиболее полно использовать кристалл процессора для выполнения именно вычислений.
А вот в случае, если ассемблером процессора является ЯВУ, кристалл процентов на 80 будет занят преобразованием текста ЯВУ в микрооперации. И я еще умолчал о том, что при компиляции текстов отслеживаются все связи, зависимости и т. п. — что принципиально невозможно для ЯВУ-ориентированного процессора, который, фактически, работает в режиме интерпретатора кода. Подытоживаем: чем глубже компиляция — тем меньшая часть кристалла отвлекается на решение задач, непосредственно не связанных с выполнением вычислений. Таким образом, перспективным является тот путь, по которому движется компания Intel — то, что называется словом EPIC. Конечно, этот путь не лишен недостатков и подводных камней — но всё же, его принципиальной правильности отрицать нельзя.
Впрочем, есть и позитивный опыт использования чего-то вроде ЯВУ в качестве процессорного языка. Называется он IBM AS/400 — знакомое название, не правда ли? А если еще взглянуть вот на этот рисунок — то не отпускает впечатление, что что-то он очень сильно напоминает :) Фактически, в AS/400 (и уже давно) частично воплощены обе идеи — и ЯВУ, и высокоуровневость. Приложение для этой системы представляет собой набор неких высокоуровневых системных вызовов, которые по мере поступления инициируют передачу на исполнение процессору неких заранее готовых подпрограмм, реализующих ту или иную функцию. Данный подход позволил сделать CPU незаметным для приложений, обеспечить мгновенную миграцию на иные типы процессоров… но в расчетных задачах производительность AS/400 невелика. И не в последнюю очередь — из-за сравнительно большой задержки между поступлением высокоуровневой команды и доступностью её результатов (из-за длительности процесса декодирования вызова в последовательность команд ядра). На потоках, или при большом (а также очень большом) количестве пользователей, это незаметно — (пока декодируется один вызов, другой — из другой программы, уже попал в обработку), а вот в однопользовательском режиме и при сильных ветвлениях AS/400 как-то «не очень». А вот при обработке БД их преимущество не в последнюю очередь обеспечивается тем самым «умным» каналом ввода / вывода. Кстати, число процессоров ввода/вывода у старших моделей IBM i-series 400 может доходить до 200. Фактически, каждое устройство ввода/вывода может быть снабжено своим процессором.
{kind=link}
Отдельно хочется обсудить вопрос о работе многозадачной системы. Вполне очевидно, что несмотря на предельно возможную глубину компиляции в многозадачной системе придется отдельно решать проблему гладкого совместного выполнения нескольких задач, каждая из которых возможно полно использует функциональные устройства процессора. Представляется разумным создание такой структуры процессора, которая сможет исполнять параллельно как минимум два потока VLIW-слов (иметь достаточно большой регистровый файл, некоторое избыточное количество ФУ) — для того, чтобы исключить ситуацию блокирования процессора одной задачей. Пропускная способность кэшей так же должна рассчитываться исходя из предельно возможного темпа доступа всеми ФУ. Интересным представляется и одновременное исполнение обеих веток алгоритма с отбрасыванием ненужного результата — команды, реализующие обе ветки, можно даже упаковать в одно VLIW слово. Опять-таки — такой подход позволяет экономить транзисторы, расходуемые обычно для предсказания ветвлений.
Самой «интересным» (и опасным — для всей концепции) аспектом развития VLIW-архитектур можно считать проблему статической оптимизации кода в сочетании с возможными изменениями внутренней архитектуры процессоров. Вполне очевидно, что оптимизированная для одного процессора программа может оказаться совершенно непригодной (малоэффективной) для работы на следующем поколении.
Тем не менее, существует метод, позволяющий изящно обойти данную проблему. Суть идеи состоит в том, что распространяемый «дистрибутив» приложения содержит не готовый к исполнению код, и не исходные тексты (по идее OSF), а результат некоторого промежуточного этапа компиляции: с описанными зависимостями, формализованным описанием процессов, развернутыми циклами… В общем — именно то, что традиционно считается самой сложной частью работы компилятора и, собственно, определяет его качество. Инсталлятор же в процессе установки программы вызывает некий специфический уже для данного процессора компилятор, преобразующий этот промежуточный код в исполняемый — причем, оптимальным для данного CPU (и даже данной конфигурации) образом. Развивая эту мысль, можно предложить вариант составления финального компилятора (опций его работы) на основании библиотек, описывающих используемые подсистемы.
Итогом такого подхода может стать, во-первых, «выжимание» максимально возможной производительности из каждой конкретной конфигурации компьютера, а, во-вторых — исчезновение понятия «аппаратно-программная платформа». Любая ОС сможет быть установлена на любой процессор, если только есть набор требуемых драйверов (описаний).
Альтернативой предложенным вариантам можно назвать Crusoe-подобную систему с динамической компиляцией приложений, поставляемых в виде промежуточного кода непосредственно во время исполнения. С одной стороны, очевидно, что ее производительность из-за дополнительной нагрузки в виде динамической компиляции будет ниже, а с другой — простота такого решения и его очевидно большая гибкость (например, динамический транслятор может учитывать поведение одновременно исполняющихся в системе приложений), делают такой способ достаточно привлекательным. Опять-таки, подобный динамический компилятор вполне может (и даже должен) руководствоваться во время работы информацией об имеющемся оборудовании.
В развитие данной идеи могу предложить например, создание семейства процессоров с различным соотношением ALU и FPU. Например, «3+3» — для универсального процессора, «4+2» — для офисного, и «2+4» — для научного. Более того — могут быть даже такие варианты как «1+1» для PDA и «2+0» для встроенного процессора периферии. И это при 100% программной совместимости!
Выполнение же всей нагрузки по преобразованию ЯВУ в микрооперации должно обязательно производиться отдельно от этапа исполнения — что, как я уже говорил выше, позволит эффективно использовать транзисторы.
Идем дальше… Некоторый опыт работ убедил меня в том, что даже самый большой кэш не в состоянии скомпенсировать задержки памяти. Причем критичны как раз задержки доставки данных в ветвящихся, событийно управляемых алгоритмах типа БД, где невозможно обычно произвести эффективную предвыборку — как в силу непредсказуемости оной, так и в силу объемов данных, которые нужно предварительно втянуть в кэш. Именно в силу этого схема с «ЯВУ-ассемблером» вызывает у меня сомнения в способности достичь высокой производительности на малопредсказуемых алгоритмах обработки большого объема данных большим по объему кодом (особенно в однопрограммном режиме — в мультипрограммном, за счет разделения времени все не так уж плохо). С другой стороны — ее способности к быстрой обработке потоков или программ с сильной локальностью данных, я сомнению не подвергаю.
Итак, подытожим: выше я, как мне кажется, убедительно обосновал бесперспективность использования в качестве ассемблера процессора какого либо ЯВУ в силу того, что преобразование его выражений в набор микроопераций конвейера — процедура более чем затратная как с точки зрения расхода транзисторов, так и с точки зрения быстродействия на некоторых операциях. Кроме того, существует и проблема невозможности предварительного профилирования программы с целью оптимального выполнения. Частично исправить положение мог бы большой (многомегабайтовый) trace-кэш, хранящий готовые последовательности микроопераций — но проблему затрат транзисторов и невозможности анализа кода в целом не решит и он. Предвидя лежащие на поверхности возражения, хотел бы сразу заметить: имеющиеся примеры процессоров использующих в качестве ассемблера байт-код Java (Majic от SUN) — для нашего случая не вполне корректны. Во-первых — они совершенно не нацелены на рекорды производительности, а во-вторых — используют при работе результаты компиляции исходных текстов в тот самый промежуточный байт-код.
Работа с периферийными устройствами
При обращении к периферии, напротив, целесообразно использовать как можно более высокоуровневые обращения. Далее я продемонстрирую подобный вариант в отношении систем дискового и сетевого ввода / вывода.
Как снять с CPU нагрузку по вводу/выводу? «Все новое — хорошо забытое старое». Одной из основных проблем, которую хотелось бы решить является непропорционально высокая загрузка процессора операциями по вводу/выводу данных. В этой области сложно предложить что-либо оригинальное, поэтому я позволю себе предложить вернуться к старому (не очень сильно, но все же забытому). Суть идеи называется просто — интеллектуальный канал ввода/вывода. Фактически — некий самодостаточный (и самостоятельный) компьютер, специфически ориентированный на ввод/вывод данных. Содержащий, разумеется, свой процессор, память, каналы связи с центральным процессором и периферийными устройствами.
Однако, что же использовать в качестве связующего звена между процессором и тем самым каналом ввода/вывода? Напомню, что желательно использовать технологию, исключающую преобразование форматов, и, естественно, достаточно производительную. В качестве интерфейса, связывающего между собой различные части компьютера я могу предложить технологию Hyper Transport. Не в последнюю очередь, ввиду весьма неплохой производительности и масштабируемости оной. В частности, на нижеприведенном рисунке процессор снабжен одним каналом HT, пропускной способности которого (уже сегодня реально — 3,2 Gb/s в full duplex, дальше будет больше) достаточно для обслуживания всех устройств ввода/вывода типичного персонального компьютера. В дальнейшем вполне возможен переход на HT2 с пропускной способностью до 20 Gb/s. Итак, что же у нас получается? Как будет выглядеть блок-схема придуманного компьютера? А вот так:
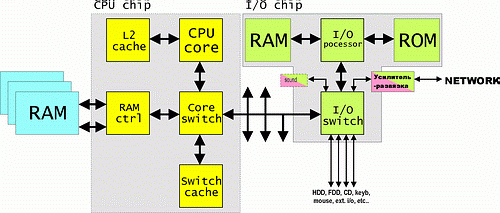
Как видно из рисунка, шина HT (в том варианте развития событий, который мне кажется разумным) имеет некоторое количество разъемов, служащих для прямого подключения к ней периферийных устройств (как то: видеоадаптеров, высокопроизводительных RAID-контроллеров и прочих). С другой стороны эта шина упирается в контроллер канала ввода/вывода который содержит в себе следующие компоненты:
- Многопортовый коммутатор HT с одним высокопроизводительным каналом HT и несколькими (1-10) каналами меньшей пропускной способности (вплоть до последовательных). Другими словами, каналы одинаковые (пускай 800 Mb/s), а скорость выбирает подключаемое устройство.
- Оперативной памяти, содержащей, собственно, программу, описывающую работу редиректора системы ввода/вывода, дисковой системы ввода вывода, стека сетевых протоколов и пр. (возможно, и кэш дисковой системы).
- ПЗУ, хранящего, помимо начального загрузчика OS, неизменные компоненты системы ввода/вывода (стека IP, например, VLAN или протокол работы с клавиатурой/«мышкой», конфигурацию RAID массива и пр.).
- Процессор ввода/вывода (что-то вроде StrongARM / XScale на 200-400 MHz, или Crusoe с частотой около гигагерца, или просто-напросто P6 Celeron по технологии 0,13 (0,09) с частотой около 700 MHz). Он выполняет функции интеллектуального контроллера жестких дисков (получает на вход высокоуровневые команды типа «create_ file()», «read_file()» и пр.), и заодно реализует (если нужно) RAID алгоритмы, выполняет львиную часть работы по обслуживанию стека IP, возможно, RIP для принтеров и т. п. Замечу, что производительность этого процессора много больше того, что обычно бывает в принтерах, RAID-контроллерах и т. п. — но за счет того, что он один — цена решения может быть меньше, чем для отдельных процессоров в каждом ПУ.
- Опционные системы ввода вывода как то: усилитель и гальваническую развязку, служащую для использования канала HT для организации LAN, звуковой кристалл (на начальном этапе, потом следует использовать колонки, по принципу современных USB колонок — простой ЦАП непосредственно в корпусе колонок) и т. п.
Естественно, что интерфейсом жестких дисков, CD-ROM, клавиатуры и прочей периферии должна являться та же самая HT, разве что меньшей разрядности — чтобы формат пакета был единым во всей системе. Никаких преобразований форматов — никаких задержек.
Что следует отметить: загрузка OS-специфической программы управления файловой системой в память контроллера канала ввода/вывода должна производится в процессе запуска конкретной операционной системы. Например — с единого, стандартного места размещения на дисках, или из ППЗУ перезаписываемого инсталлятором на материнской плате, или (реверанс в сторону поборников охраны авторских прав) — во внешнем ключе ОС. С одной стороны, это дает определенную гибкость для написания различных файловых систем (конкуренция, совершенствование и т. п.), а с другой — независимость канала ввода/вывода от системы CPU <—> memory в процессе работы, и полное снятие с центрального процессора нагрузки по выполнению операций ввода/вывода.
Графическая подсистема
А теперь — самое интересное. Первый вариант — традиционный. Просто-напросто банальный видеоадаптер, но подключенный напрямую к шине HT, минуя всяческие мосты. Единственное преимущество перед предлагаемыми системами на Hammer от AMD — отсутствие лишнего моста HT-AGP. Ему просто нет места, он лишний. Соответственно, исключается задержка преобразования (понимаю, что небольшая, но ведь и не нулевая же?), сокращается (примерно вдвое) число транзисторов, реализующих интерфейс GPU с RAM.
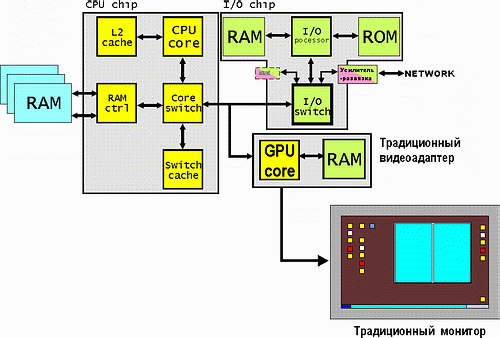
А вот теперь — предложу вашему, господа читатели, вниманию кое-что поинтереснее: умный монитор. В общем-то суть идеи в перенесении комплекса GPU + memory в корпус монитора. Соединение же системного блока с этим «умным» монитором предлагается производить по каналу HT достаточно большой пропускной способности. В принципе, не возбраняется размещение в корпусе монитора доп. коммутатора ввода/вывода для подключения других устройств ввода/вывода (клавиатуры, сканера, колонок и т. п.), но это увеличивает требования к каналу «системный блок — монитор», что не очень правильно идеологически (хотя с другой стороны — дополнительный трафик от перечисленный устройств по сравнению с графическим настолько мал…).
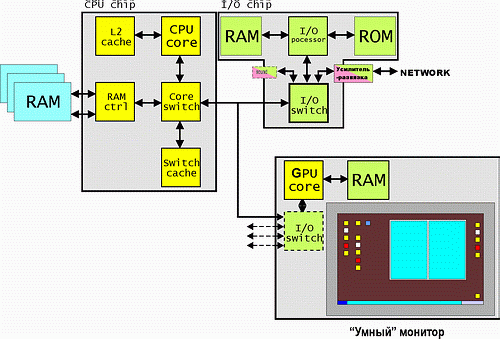
Что же необычно в этом рисунке? Да собственно, все видно и так. «Умный монитор» полностью берет на себя функции отображения информации (замечу, что при этом он избавляет системный блок от необходимости питать весьма прожорливый видеоадаптер). Может показаться, что данная архитектура закрыта и модернизация компьютера (видеосистемы) невозможна, но это не так. Вполне возможно ввести стандартный конструктив разъема видеоакселератора в корпусе монитора. В данный разъем и можно будет вставлять различные видеоадаптеры (замечу, возможно стандартизированные по вызовам API, что «убьет» понятие аппаратно-зависимого драйвера), и даже больше — по конструктиву разъема модуля процессора и отдельно — модулей памяти (любой GPU может быть укомплектован любым размером локального ОЗУ!). Фактически, монитор превращается в самодостаточное, гибко конфигурируемое, устройство вывода всех типов графической информации. Этакий отдельный «компьютер для вывода на экран», соединенный с хостом цифровым каналом с высоким уровнем абстракции.
При таком варианте вырисовывается и еще одна интересная возможность — программный монитор. Предположим такую неприятную ситуацию — разъем видеоадаптера в мониторе пуст. Но, особенно если у нас плоскопанельный монитор, мы можем установить сравнительно небольшой буфер (для разрешения 1024×768×32 у стандартной 15″ матрицы всего около 3,5 МБ, для 19″ монитора с разрешением 1600×1200×32 — меньше 8 МБ) и простенькую схему — для отображения этого поля на элементы экрана.
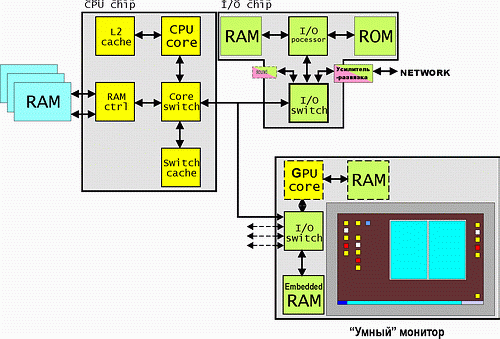
Грубо говоря, возможна банальная передача битовых карт экрана в память «умного монитора». Более того, этот монитор может и сам «вычитывать» требуемые данные из основной памяти. Понятно, что это не в пример медленнее решения с автономным высокоуровневым видеоадаптером, особенно в сложном 3D (и из-за большей загрузки процессора, и из-за «выкусывания» части ПСП, и из-за отсутствия отдельного GPU). Но как бюджетное (для офиса) или в качестве решения для временной эксплуатации при выходе из строя/замене видеоадаптера, для работы в режиме отладки/ремонта системы, на мой взгляд, вполне пригодно.
Когда же специализированный видеоадаптер установлен — буферная память становится фрейм-буфером нормального видеоадаптера. Для нее меняется только источник данных — из непосредственно компьютера в локальный видеоадаптер. А наличие у видеосистемы отдельной памяти для работы и для фрейм-буфера — в свою очередь снижает требования и к скорости видеопамяти открывая пути как к снижению цены решения, так и (при сохранении цены) к росту производительности.
Единственным препятствием для качественной реализации идеи могут оказаться несоразмерно высокие требования к пропускной способности кабеля связывающего системный блок с «умным монитором». Причем в отсутствие специального видеоадаптера, в режиме «программного монитора», эти требования как раз, не особенно велики — 3,5 МБ, пускай 100 раз в секунду (при 100 раз в секунду меняющейся картинке) — всего 350 МБ/с. Впрочем, применение 16 дифференциальных, индивидуально экранированных пар с частотой передачи данных в 800 МГц уже позволит передавать в монитор до 1,6 GB/s (в полтора раза больше, чем AGP 4x). И это, я полагаю, не предел… Ну, а 2-3 метра для этого соединения не проблема, как мне кажется. Для особо требовательных приложений можно предложить соединение монитора с системным блоком двумя (и более) шнурами с удвоением (умножением соответственно количеству каналов) доступной пропускной способности.
Очень интересным вариантом использования такой системы может стать, как мне кажется, эксплуатация «умного монитора» укомплектованного клавиатурой, мышкой, звуковыми устройствами и, возможно, принтером в качестве удаленного (на длину кабеля) терминала. При определенном сокращении пропускной способности канала — банальная витая пара при использовании существующих кабельных сетей категории 5 и 5е может передать до 37,5 MB/s к терминалу и 12,5 MB/s от терминала, что более чем достаточно для 99% приложений. Смотрите: если у нас монитор содержит концентратор ввода/вывода, да еще и самостоятельно выполняет отрисовку изображения (используя высокоуровневые функции), то что мешает (укомплектовав его сетевой платой) удлинить канал, связывающий этот монитор с системным блоком? Как раз до длинны кабеля локальной сети? Практически та же идея реализована в терминальном режиме, например, Windows+Citrix или реализациях X11 (как для универсальных ПК со специальным клиентским ПО, так и для специфических аппаратных решений). У нас получается практически то же самое — только любой «умный монитор» изначально способен быть удаленным терминалом (укомплектовать его сетевой платой за $7-10 несложно). Более того, эта плата может быть просто встроена во все мониторы «по умолчанию». Естественно, что для современных операционных систем число таких мониторов может быть больше единицы.
Более того, даже и 100 Mb/s канал позволит использовать такие мониторы в качестве терминалов в офисе. Для некоторых задач (неинтенсивное 3D) вполне возможно и использование беспроводного канала с пропускной способностью около 10 Mb/s. Понятно, что декодирование потоков mpeg должно производиться полностью аппаратно, что позволит нормально использовать «удаленные мониторы» и для, например, вещания видео, тем более, что задача ЦАП для звука и так решается в рамках колонок. Кстати, за прошедшее со дня написания статьи время фирма apple подсуетилась и чтобы не платить за идею срочно предложила похожую идею: «Беспроводной экран Apple: альтернатива Mira? — Archont @ 16:36 14.04.2003. Судя по некоторым слухам, в ближайшем будущем Apple может выпустить беспроводной экран для своих настольных ПК. Этот экран, оснащенный присоединяемой клавиатурой, будет напоминать планшетный ПК, но пока не известно, планируется ли включить распознавание перьевого ввода и вообще какой-либо ввод информации непосредственно с экрана».
Я бы вот с удовольствием стал владельцем такого выносного экрана, чтобы сидя на диване с кнопками на коленях что-то ваять, пока ребенок играет. И процессор не очень сильно нагружен, и производительность для меня вполне даже приемлемая (хоть кино смотри). Да даже и по квартире развесить несколько таких мониторов (с одним единственным системным блоком) — это в любом случае получается дешевле нескольких ноутбуков. Жена на кухне смотрит какую-нибудь кулинарную энциклопедию, я что-то ваяю у себя (или кино смотрю), ребенок играет… А один системник стоит тихонько где-то под столом. Причем, в невыключамом режиме, просто «засыпает».
Скажу даже больше! К коммутатору ввода-вывода умного монитора вполне можно (как я писал выше) подключить и некоторую периферию. А CD-ROM (DVD-RW, Memory Stick, или, страшно подумать, жесткий диск!) — так и вовсе — интегрировать в конструктив, получив полуавтономный интерфейсный модуль! Другими словами, я ношу с собой этакий «ноутбук без процессора» — и подключаю его к тому процессору, который есть поблизости. Либо кабелем, либо по радио. Получая при этом возможность пользоваться своими данными. Правда, остается вопрос защиты данных — но это можно решать на уровне операционной системы, аппаратных ключей для данных и т. п., как мне кажется. Вот как может выглядеть сеть, в которой сочетаются все перечисленные выше технологии:
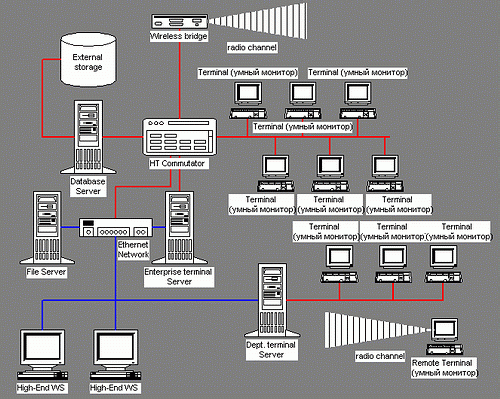
Красным тут изображены каналы HT, синим — традиционный Ethernet. Коммутатор Ethernet содержит внутри один (не один?) мост HT-Ethernet (по аналогии с коммутаторами с 24*10+1*100 Ethernet).
О «другой периферии»
К слову — язык описания изображения вообще может быть унифицирован т.е. применяться везде где имеет место работа с графической информацией, независимо от типа устройства. Например, он может быть одним и тем же для видеоадаптеров и принтеров — GDI принтеры, рассчитанные на работу под управлением ОС Windows и использующие ее GDI-механизм, дают нам пример такого решения. В качестве взятого «с потолка» предложения могу сказать, что, например, формат PostScript (дополненный тем, что нужно для оконного интерфейса, трехмерной графики, и т. п.) — вполне может дать представление о предлагаемом способе общения с периферийными устройствами. Впрочем, я не настаиваю на PS — возможно, есть и другие решения. Например, в MacOS X от описания экранных объектов на PostScript (как это было сделано в NeXT OS) отказались в пользу другого формата — PDF. Хотя, честно говоря, решение тоже из разряда спорных — все-таки PDF — это формат менее гибкий.
Однако каким бы ни был наш язык, на общих принципах организации всего процесса это никак не сказывается. В любом случае, при инициализации ОС производится загрузка в локальную видеопамять битовых карт используемых в GUI примитивов (фонов, в соответствии со схемой, рисунков кнопок, курсоров и т. п.). При работе же ОС передает видеоадаптеру вместе с командой типа, например, «draw_window()» помимо положения и размеров окна, размещения элементов управления (сейчас, вроде, по составу более-менее консенсус) еще и указание, какие битовые карты использовать для отрисовки стандартных элементов интерфейса (рамок, кнопок, фонов и т. п.). Между прочим, такая схема хороша еще и тем, что несколько сдерживает «неуемный полет фантазии» дизайнеров интерфейса, мягко поворачивая их в сторону стандартных решений, и делая различные «интерфейсные извращения» не то что бы совсем невозможными (гибкость все-таки терять нельзя ни в коем случае!), но гораздо более хлопотными. Как по мне — это только на пользу.
Повторюсь — все вышеизложенное вовсе не требует, чтобы таким же высокоуровневым был ассемблер центрального процессора (CPU). Процессор вполне традиционным способом формирует пакет с командой, каковой и отправляется видеоадаптеру на исполнение. Вывод же на принтер выглядит как формирование такого же набора команд в виде файла (массива в памяти) с последующей отсылкой его (командой «умному» контроллеру канала или памяти) в соответствующий порт. Кстати, растеризацию может выполнить и процессор ввода-вывода. Скорость канала, связывающего системный блок с принтером такова (примем условно 50 MB/s, что соответствует 3145728000 (!) байтам в минуту), что управление лазером принтера может осуществляться непосредственно в процессе печати — вся битовая карта формата А4 при разрешении 600 dpi составляет всего 4350316 байт (при печати без полей), соответственно, для формата А4 скорость печати может составлять до 723 (!) страниц в минуту. Для разрешения 1200 dpi — тоже немало — 180 страниц в минуту. В случае 1200 dpi и формата А3 меньше, но тоже приемлемо — 90 стр./мин. Для цветного лазерного принтера формата А3 нужно передать 4 битовых карты (CMYK) на одно изображение, соответственно, делим производительность на 4 — получаем «всего» 22,5 стр./мин (45 стр./мин для формата А4). Принтеру нужен только небольшой буфер, а его цена при этом падает до стоимости самого механизма печати + $20 за элементарную электронику. Примерно такую же, как сейчас у струйных принтеров. Я полагаю, что стоимость типичного монохромного принтера A4 с разрешением 1200*1200 и скоростью 10-20 стр./мин составит не более $70-120. Буферизация изображения (как PS варианта, так и битовой карты) производится в памяти контроллера канала ввода/вывода. Плюс — никаких драйверов. Принтер просто сообщает при включении системе свой формат печати и дополнительные возможности на основании информации, хранимом в нем самом — в простейшем ПЗУ.
Интересно выглядит в таком случае работа сетевого интерфейса. Получив указание от редиректора на открытие (к примеру) файла на другом компьютере, процессор ввода-вывода отправляет соответствующий пакет соседнему узлу (процессору ввода-вывода), у которого находится требуемый файл. Тот, получив пакет, проверяет (от своего имени) права запрашивающего, после чего более не напрягая свой процессор производит затребованные коллегой операции. Таким образом, например, для файлового сервера роль CPU сводится к проверке прав пользователя и (возможно) использованию основной памяти в качестве кэша для контролера канала ввода/вывода (то же самое, что при нормальной работе — но с точностью до наоборот). Кстати, замечу, что эта концепция позволит создать целый спектр чипсетов для различного применения с различной мощностью (и, возможно, количеством) процессоров ввода/вывода и объемом памяти. Для серверных чипсетов можно предположить даже и внешний ECC DIMM в качестве кэша большой ёмкости. Много нового и интересного вырисовывается и в области построения специфических систем узкого применения — тонких серверов, принт-серверов и тому подобного. Даже больше того — вынесенный в отдельный корпус модуль ввода-вывода может по шине HT соединяться непосредственно с процессорными коммутаторами нескольких серверов. Реализуя кроме высокой пропускной способности еще и минимальные задержки и нагрузку на ОС.
Есть и еще одна возможность о которой не хочется молчать. В качестве выносного модуля может выступать PDA имеющий и свой процессор (совместимый по набору команд с CPU, но с меньшим количеством исполнительных устройств и частотой) и свою память. При подключении его к системе тем или иным образом, операционная система определяет его производительность и скорость связи (установка в слот системного блока или иной способ внешнего подключения). После чего накопитель PDA включается в иерархию носителей, а процессор задействуется для выполнения различных счетных задач (тех, что ему по плечу). Возможен и другой вариант. Несколько PDA могут быть при необходимости связаны между собой (проводными или радио каналами, либо подключены к одному системному блоку) образуя систему высокой производительности. Например, несколько (4-8-30 устройств — школьный класс или студенческая группа, просто несколько сотрудников в офисе) PDA с гигагерцовыми Crusoe и 128 МБ памяти, связанные 400 mbyte/s (проводными) или 100 mbit/s (радио) каналами образуют весьма солидный «кластер» и сами по себе. Так, что для офиса, например, отпадает необходимость в какой-либо вычислительной инфраструктуре. Каждый приходящий в офис сотрудник автоматически увеличивает доступную совокупную производительность компьютеров. Причем, именно на необходимую величину. Ну, а студентам уже не надо будет искать доступа к суперкомпьютерам, достаточно сбиться в кучку побольше и потеснее (для максимальной скорости радиоканалов).
Такой PDA становится не просто помощником, а многофункциональным устройством, используемым для, например, реализации функций факса и автоответчика для сотового телефона (с «голубым зубом» для связи с трубкой), мобильной рабочей станцией для работы с почтой, www и иными приложениями с доступом по радиоканалу через тот же сотовый телефон, фотокамерой с носителем неограниченной емкости (при заполнении локальной памяти данные через сотовый сбрасываются на диск домашнего компьютера), PDA может быть установлен не только в системный блок стационарного компьютера, но и подключен непосредственно к переносному «умному монитору», превратив его (и себя) в обычный ноутбук с большим экраном и клавиатурой. Впрочем, не исключаю и того, что «поумнение» сотовых телефонов вытеснит PDA «как класс» (единственное что — проблематичен большой экран и клавиатура — размер сотового определяет рука человека), но и в этом случае возможность подключения его к PC и совместного использования ресурсов остается привлекательной возможностью.
Итак, как будет выглядеть задняя панель компьютера предлагаемой архитектуры? Очень просто — всего три типа разъемов. Универсальные, к которым подключается всё, кроме монитора и «дальних» соединений, разъем монитора и «LAN» разъемы с дифференциальным сигналом (для «дальнобойности»).
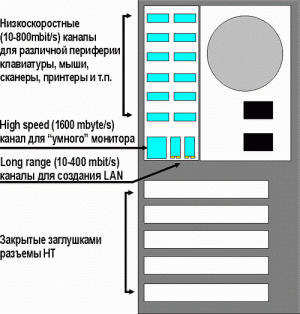
Заключение
Вот так, как мне кажется, может выглядеть идеальный (ну или близкий к таковому) компьютер. От разнообразия интерфейсов, шин, разъемов — к единообразной масштабируемой универсальной архитектуре. Разнородность интерфейсов, выполнение процессором навязанных ему излишних функций (по вводу/выводу, например) — это не только проблемы с подключением, оборудования, это еще и неминуемые задержки преобразования, лишние транзисторы — короче, это, практически, цепи на ногах вычислительных систем, которые не дают им заниматься их прямым делом — СЧИТАТЬ. Быстро и эффективно. Один из возможных вариантов решения проблемы я и представил вниманию читателей. Естественно, автор не претендует на абсолютную истину, рад буду выслушать (и обсудить) альтернативную точку зрения.
Комментарии