
Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer
Часть 9 двуядерный процессор Intel Pentium Extreme Edition 840 (Smithfield)
18 апреля состоялся анонс первого двуядерного процессора Intel Pentium Extreme Edition 840, основанного на новом ядре с кодовым названием Smithfield, поддерживающем технологию Extended Memory 64-bit Technology (EM64T). Заметим, что в названии нового процессора отсутствует привычное сочетание «Pentium 4» оно заменено на просто «Pentium», хотя нет никаких сомнений в том, что процессорное ядро Smithfield основано на микроархитектуре NetBurst. Во-вторых, новый процессор являет собой очередную смену идеологии «экстремальности» процессоров с микроархитектурой NetBurst. Напомним, что «экстремальность» первых Pentium 4 Extreme Edition заключалась в наличии 2-МБ кэша третьего уровня. В дальнейшем, с относительно недавним выходом в свет процессора Pentium 4 Extreme Edition 3.73 ГГц это понятие уже было ассоциировано исключительно с увеличенной до 266 МГц (1066 МГц Quad-Pumped) частотой системной шины. В новом же процессоре «экстремальность», очевидно, связана с его двуядерностью (ибо больше-то ее связать попросту не с чем). В то же время, в будущем ожидается появление новой серии двуядерных процессоров компании Intel под торговой маркой «Pentium D», что в очередной раз потребует пересмотра понятия «экстремальности» процессора. Что ж, это заботы производителя, наши же заключаются в исследовании новых процессоров, в частности особенностей реализации их микроархитектуры. В настоящей статье, по традиции, будут рассмотрены основные низкоуровневые характеристики нового «двуядерного ядра», в сопоставлении с его предыдущими одноядерными аналогами ядрами Prescott, Nocona и «Prescott/2M», рассмотренными в статьях «Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer. Часть 6 платформа Intel Xeon (Nocona)» и «Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer. Часть 8 процессоры Intel Pentium 4 и Pentium 4 Extreme Edition с новой ревизией ядра Prescott».
Конфигурация тестового стенда
- Процессор: Intel Pentium Extreme Edition 840 (3,2 ГГц, ядро Smithfield, Socket 775, FSB 200 МГц)
- Материнская плата: Intel D955XBK на чипсете Intel 955X, версия BIOS от 04/04/2005
- Память: 2x512 МБ PC2-4300 DDR2-533 Samsung (тайминги 4-4-4-11)
Программное обеспечение
- Windows XP Professional SP2
- Intel Chipset Installation Utility 7.0.0.1019
- DirectX 9.0c
- RightMark Memory Analyzer 3.5 pre-release
Характеристики CPUID
Исследование нового процессорного ядра Smithfield начнем с анализа важнейших характеристик, выдаваемых инструкцией CPUID.
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0F44h | Семейство 15, модель 4, степпинг 4 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | 50h 5Bh 60h 40h 70h 7Ch | I-TLB: полноассоциативный, 64 записи D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12K-uops, 8-ассоциативный L2-кэш: 1 МБ, 8-ассоц., 64-байтн. строка |
| Количество логических процессоров | 04h | 4 логических процессора |
| Basic Features, ECX (наиболее значимые характеристики) | 0000641Dh | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 2: Неизвестно Bit 13: Неизвестно |
| Extended Features, EDX | 20000000h | Bit 29: Поддержка Intel (R) EM64T (x86-64) |
Итак, по сигнатуре процессора (0F44h) новое ядро Smithfield можно считать продолжением, как бы новой ревизией линейки ядер Prescott и Nocona/Irwindale (последняя ревизия N0 которых имеет сигнатуру 0F43h). Тем не менее, ядро Smithfield, реализованное в Pentium Extreme Edition 840 (далее Pentium EE 840), получило официальное буквенно-цифровое обозначение ревизии A0, т.е. является первым ядром подобной серии.
Содержимое дескрипторов кэшей/TLB выглядит самым что не наесть привычным образом для ядер Prescott/Nocona с 1-МБ кэшем второго уровня (общий заявленный объем L2-кэша данных в Pentium EE 840 составляет 2 МБ, но, как нетрудно догадаться, это понятие весьма условно, т.к. L2-кэш является не общим ресурсом для обоих ядер, а изолированным по 1 МБ на каждое ядро).
Не отличаются чем-то принципиальным и избранные характеристики дополнительных «фич» процессора легко заметить, что новое ядро не поддерживает ни Thermal Monitor 2, ни технологию управления энергопотреблением Enhanced Intel SpeedStep (Demand-Based Switching), ни Execute Disable Bit, однако в полной мере поддерживает технологию Extended Memory 64-bit Technology (EM64T), а также улучшенный режим состояния простоя C1E (наличие/отсутствие которого не имеет какого-либо способа представления в данных CPUID). Весьма привычно также присутствие двух «неизвестных» технологий (согласно нашим предположениям, LaGrande и VanderPool), обозначаемых битами 2 и 13 Basic Features, регистр ECX. Таким образом, по основным характеристикам новое ядро Smithfield можно расположить где-то посередине между последней ревизией E0 ядра Nocona (если мысленно «отключить» в нем технологии TM2 и DBS) и «экстремальной» версией ядра «Prescott/2M», реализованной в Pentium 4 Extreme Edition 3.73 ГГц, но с 1 МБ кэша второго уровня и отключенной технологией XD bit.
Тем не менее, главное отличие на уровне процессора в целом, конечно, касается количества логических процессоров, реализованных в одной физической «упаковке» (именно в «упаковке», а не в ядре) оно возросло до четырех (каждое физическое ядро представляется двумя логическими процессорами, благодаря поддержке технологии Hyper-Threading).
Реальная пропускная способность кэша данных/памяти
Переходим к результатам тестирования нового процессора с помощью новейшей pre-release версии 3.5 тестового пакета RMMA. Отметим, что на момент тестирования поддержка нового процессора и чипсета в компоненте SysInfo тествого пакета еще не была окончательно «доведена до ума», в связи с чем процессор представляется нам «обычным» Intel Pentium 4 540 (собственно, таковым, с точки зрения тактовой частоты и объема L2-кэша на ядро, он и является если мысленно «закрыть глаза» на двуядерность и наличие EM64T). Расшифровка же значений таймингов по конфигурационным регистрам чипсета i955X, выполненная в соответствии с официальной документацией, дает ошибку в параметре tRAS его значение представляется вдвое меньшим по отношению к реальному (что связано, по всей видимости, с ошибкой в документации). Тем не менее, эти недочеты уже устранены в готовящейся к выходу release-версии 3.5 данного тестового пакета.
Общая картина реальной пропускной способности уровней подсистемы памяти (L1/L2/RAM) на Pentium EE 840 представлена на рисунке.
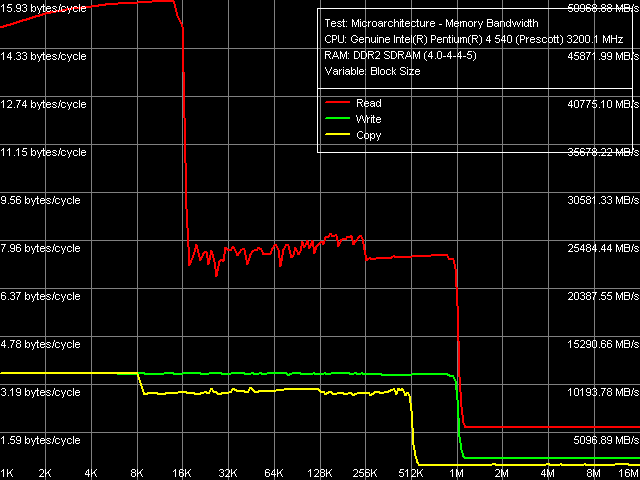 Реальная пропускная способность кэша данных и оперативной памяти,
Реальная пропускная способность кэша данных и оперативной памяти,Pentium EE 840
Основные черты, которые можно отметить на графике, следующие: объем L2-кэша данных действительно составляет 1 МБ (т.е. никакого «вмешательства» L2-кэша соседнего ядра здесь нет и быть не может), однако уже при обращении к 256-КБ блокам данных ПС этого уровня подсистемы памяти заметно «проседает». Напомним, что это связано с исчерпанием ресурса буфера D-TLB, размер которого по-прежнему остается без изменений 64 записи, т.е. 256 КБ «покрываемого» им виртуального адресного пространства. Отсутствие различий в эффективности L1 и L2 кэша на запись (т.е. отсутствие характерного перегиба в области 16 КБ) свидетельствует о «сквозной» организации записи данных (Write-Through), реализованной во всех предыдущих ядрах процессоров Pentium 4/Xeon.
| Уровень | Средняя пропускная способность, байт/такт (МБ/с) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.98 15.93 2.91 3.56 | 7.96 15.93 2.90 3.54 | 7.98 15.93 2.91 3.56 | 7.98 15.93 2.91 3.56 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.41 8.02 2.91 3.56 | 4.39 7.84 2.89 3.54 | 4.53 8.13 2.91 3.56 | 4.57 8.21 2.91 3.56 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 3901.4 МБ/с 4457.4 МБ/с 1750.0 МБ/с 1760.6 МБ/с | 3215.2 МБ/с 3620.1 МБ/с 1863.0 МБ/с 1855.0 МБ/с | 5187.3 МБ/с 5490.6 МБ/с 2061.8 МБ/с 2057.8 МБ/с | 5361.4 МБ/с 5649.6 МБ/с 2408.9 МБ/с 2430.9 МБ/с |
Количественные характеристики ПС L1- и L2-кэшей данных Smithfield совпадают с полученными ранее на последней ревизии ядра «Prescott/2M» следует отметить несколько большую эффективность L2-кэша на чтение по сравнению с более ранними ревизиями (D0) ядер Prescott/Nocona.
Еще более заметные изменения продолжают наблюдаться в величинах средней реальной ПС оперативной памяти. И если реальная ПСП на чтение по сравнению с Pentium 4 660 возросла незначительно, то реальная ПСП на запись весьма ощутимо (примерно на 20%). Как обычно, это может быть либо следствием доработки интерфейса BIU процессорного ядра, либо следствием использования более усовершенствованного контроллера памяти в новом чипсете i955X.
Предельная реальная пропускная способность памяти
Как обычно (для процессоров Pentium 4), метод Software Prefetch позволяет достичь наибольших значений ПСП, в то время как остальные методы не обладают столь высокой эффективностью.
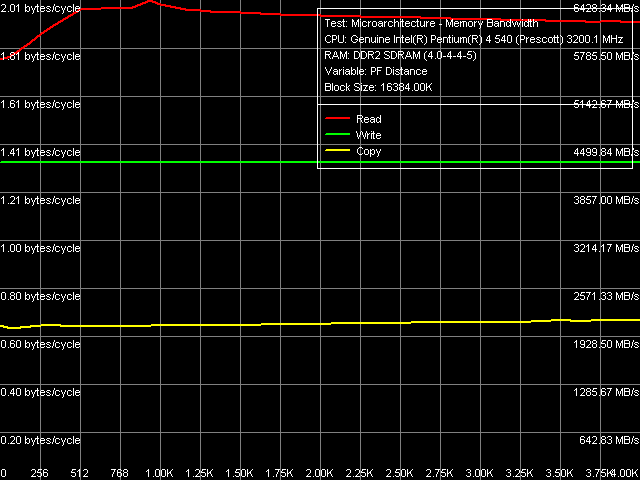 Максимальная реальная ПСП, Software Prefetch, Pentium EE 840
Максимальная реальная ПСП, Software Prefetch, Pentium EE 840 Кривые зависимости реальной ПСП от дистанции программной предвыборки на Pentium EE 840 характерны для ядер Prescott (внешне они совпадают с теми, которые мы получили ранее, на предыдущих ревизиях этого ядра). Следует отметить лишь более плавный спад значений относительно максимума по мере увеличения дистанции префетча. Скорее всего, это связано не с префетчем как таковым, а с предположенным выше усовершенствованием контроллера памяти чисета i955X.
| Режим доступа | Предельная ПСП на чтение, МБ/с* | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэша, прямое Чтение строк кэша, обратное | 3901.4 (61.0%) 4457.4 (69.6%) 6311.3 (98.6%) 6334.2 (99.0%) 4191.0 (65.5%) 4614.8 (72.1%) 3948.3 (61.7%) 4517.2 (70.6%) 5180.9 (81.0%) 5178.7 (80.9%) | 3215.2 (50.2%) 3620.1 (56.6%) 5334.2 (83.3%) 5329.9 (83.3%) 3302.2 (51.6%) 3524.3 (55.1%) 3392.3 (53.0%) 3784.5 (59.1%) 3313.5 (51.8%) 3315.8 (51.8%) | 5187.3 (81.1%) 5490.6 (85.8%) 6521.3 (101.9%) 6679.7 (104.4%) 4630.6 (72.4%) 5046.4 (78.9%) 5146.9 (80.4%) 5492.2 (85.8%) 5968.8 (93.3%) 5957.7 (93.1%) | 5361.4 (83.8%) 5649.6 (88.3%) 6404.7 (100.1%) 6438.3 (100.6%) 4729.7 (73.9%) 5245.2 (82.0%) 5350.9 (83.6%) 5681.4 (88.8%) 6213.0 (97.1%) 6208.1 (97.0%) |
*в скобках указаны значения относительно теоретического предела ПСП (6.4 ГБ/с для 200-МГц FSB)
Это предположение дополнительно подтверждается фактом больших значений (по сравнению с предыдущими исследованиями) предельной реальной ПСП, полученных при использовании других методов, не затрагивающих программную предвыборку, в особенности и в частности методом чтения строк кэша (значения ПСП в этом случае лишь немного не дотягивают до теоретического предела).
| Режим доступа | Предельная ПСП на запись, МБ/с* | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэша, прямая Запись строк кэша, обратная | 1750.0 (27.3%) 1760.6 (27.5%) 4265.9 (66.7%) 4266.0 (66.7%) 2283.9 (35.7%) 2254.2 (35.2%) | 1863.0 (29.1%) 1855.0 (29.0%) 4236.2 (66.2%) 4235.9 (66.2%) 2380.2 (37.2%) 2386.1 (37.3%) | 2061.8 (32.2%) 2057.8 (32.2%) 4255.0 (66.5%) 4254.9 (66.5%) 2527.7 (39.5%) 2435.0 (38.0%) | 2408.9 (37.6%) 2430.9 (38.0%) 4266.0 (66.6%) 4266.0 (66.6%) 3114.4 (48.7%) 3112.8 (48.6%) |
*в скобках указаны значения относительно теоретического предела ПСП (6.4 ГБ/с для 200-МГц FSB)
Наиболее поразительные изменения видны в значениях максимальной реальной ПСП на запись. Конечно, использование метода прямого сохранения данных во всех случаях позволяет достичь 2/3 от максимальной теоретической ПС процессорной шины, не больше и не меньше. Эффективность же метода записи строк кэша на новой платформе возросла значительно поученные величины ПСП составляют примерно половину от предельного теоретического значения. Вновь сказывается улучшенный контроллер памяти нового чипсета i955X.
Латентность кэша данных/памяти
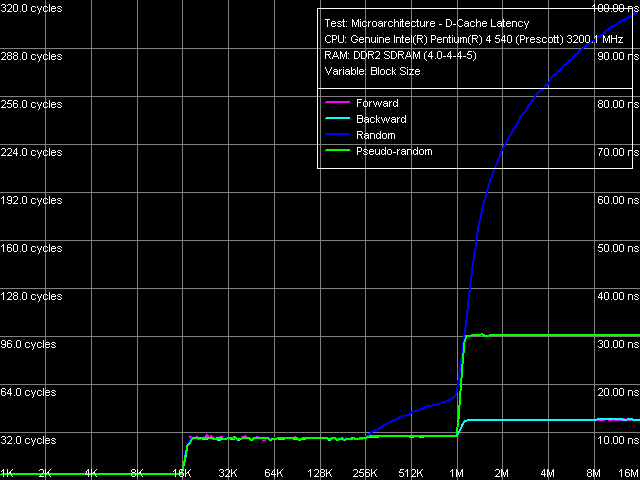 Латентность кэша данных/памяти, Pentium EE 840
Латентность кэша данных/памяти, Pentium EE 840 Характерные черты организации кэшей данных и D-TLB проявляются в этом тесте не менее отчетливо: перегибы в области 16 КБ и 2 МБ, соответствующие размерам L1 и L2 кэшей, а также плавное возрастание латентности случайного доступа в L2-кэш при размере блока 256 КБ и более.
| Уровень, доступ | Средняя латентность, тактов (нс) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| L1 | 4.0 | 4.0 | 4.0 | 4.0 |
| L2 | ~28.5 | ~28.5 | ~28.5 | ~28.5 |
| RAM, прямой RAM, обратный RAM, случайный* RAM, псевдослучайный | 37.3 нс 41.1 нс 126.0 нс 56.1 нс | 50.3 нс 52.6 нс 134.1 нс 75.8 нс | 32.5 нс 36.8 нс 106.1 нс 52.0 нс | 32.3 нс 35.7 нс 100.9 нс 51.5 нс |
*Размер блока 4 МБ
Количественные характеристики латентности первого и второго уровней кэша одинаковы для всех перечисленных в таблице процессоров. Относительно латентности памяти отметим, что приведенные в таблице величины получены в отдельном тесте, в котором осуществляется обход цепочки данных с шагом 128 байт, т.е. «эффективной» длиной строки L2-кэша. Нетрудно видеть, что значения средней латентности памяти при всех режимах обхода на платформе Pentium EE 840 практически не отличаются от величин, полученных на платформе Pentium 4 660. Несколько меньшая латентность случайного доступа (101 нс против 106 нс), при котором алгоритм аппаратной предвыборки процессора практически бездействует, может являться дополнительным признаком усовершенствования контроллера памяти, реализованного в чипсете i955X, которое мы неоднократно упоминали выше.
Минимальная латентность кэша данных/памяти
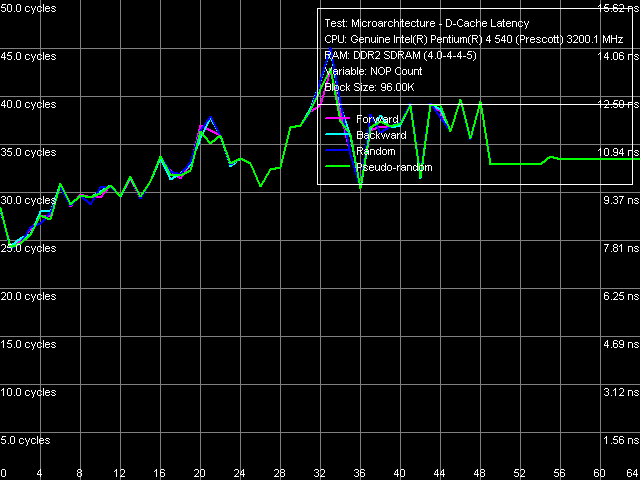 Минимальная латентность L2 кэша, Pentium EE 840, метод 1
Минимальная латентность L2 кэша, Pentium EE 840, метод 1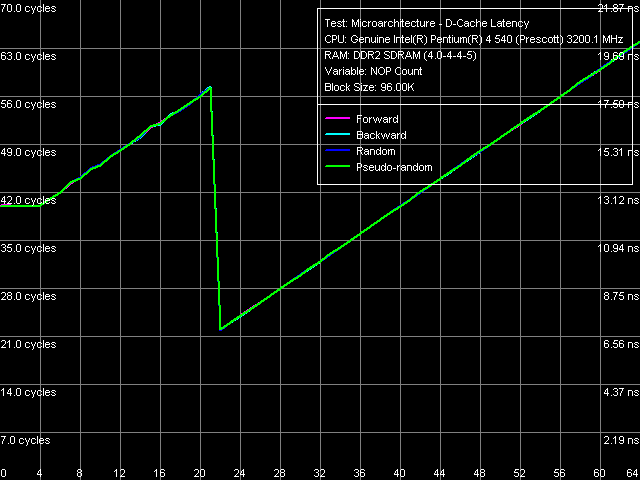 Минимальная латентность L2 кэша, Pentium EE 840, метод 2
Минимальная латентность L2 кэша, Pentium EE 840, метод 2 Кривые разгрузки шины L1-L2, т.е. достижения минимальной латентности L2-кэша ядра Smithfield выглядят привычно, поскольку они аналогичны кривым, полученным ранее на процессорных ядрах Prescott: латентность этого уровня не достигает минимума при «стандартной» разгрузке шины L1-L2 вставкой «пустых» операций (метод 1), и снижается до 22 тактов при «нестандартной» разгрузке, разработанной специально для процессоров с выраженной спекулятивной загрузкой данных (метод 2).
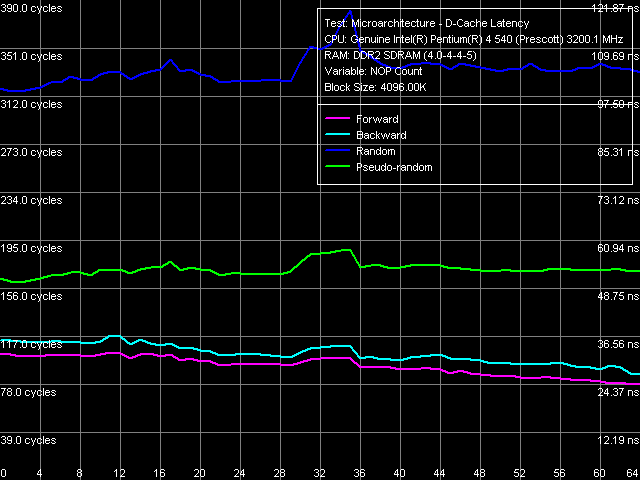 Минимальная латентность памяти, Pentium EE 840
Минимальная латентность памяти, Pentium EE 840 Не менее привычный вид имеют и кривые «стандартной» разгрузки шины L2-RAM процессора Pentium EE 840.
| Уровень, доступ | Минимальная латентность, тактов (нс) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| L1 | 4.0 | 4.0 | 4.0 | 4.0 |
| L2* | 24.0 (22.0) | 24.0 (22.0) | 24.0 (22.0) | 24.0 (22.0) |
| RAM, прямой RAM, обратный RAM, случайный** RAM, псевдослучайный | 28.7 нс 31.1 нс 125.2 нс 55.0 нс | 38.4 нс 41.2 нс 134.0 нс 74.5 нс | 27.0 нс 31.1 нс 105.4 нс 50.9 нс | 24.6 нс 27.0 нс 98.9 нс 50.5 нс |
*В скобках указаны значения, полученные методом 2
**Размер блока 4 МБ
Минимальные значения латентности памяти, полученные при достаточной разгрузке шины L2-RAM, оказываются несколько меньшими по сравнению с результатами исследований платформы Pentium 4 660. Учитывая абсолютно одинаковый характер разгрузки шины (так сказать, «разгрузочные кривые») на этих процессорах, данное обстоятельство вновь следует приписать к усовершенствованию контроллера памяти нового чипсета.
Ассоциативность кэша данных
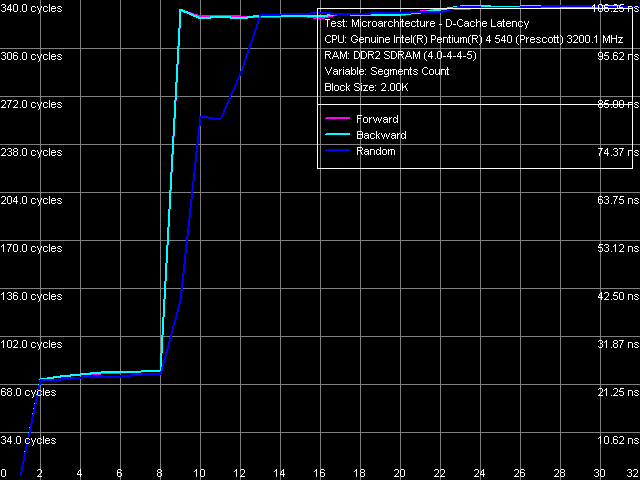 Ассоциативность кэша данных, Pentium EE 840
Ассоциативность кэша данных, Pentium EE 840Тест ассоциативности L1/L2 кэша данных обоих процессоров, результат которого приведен на рисунке, в очередной раз указывает на отсутствие изменений по данному параметру. Как и у всех остальных исследованных нами процессоров семейства Pentium 4/Xeon с ядрами Prescott и Nocona, «эффективная» ассоциативность L1-кэша данных получается равной единице, ассоциативность объединенного L2-кэша инструкций/данных восьми.
Реальная пропускная способность шины L1-L2 кэша
| Режим доступа | Пропускная способность, байт/такт* | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 16.42 (51.3%) 16.40 (51.3%) 4.76 (14.9%) 4.75 (14.9%) | 16.42 (51.3%) 16.42 (51.3%) 4.79 (15.0%) 4.78 (14.9%) | 14.50 (45.3%) 14.53 (45.4%) 3.99 (12.5%) 4.00 (12.5%) | 16.75 (52.3%) 16.58 (51.8%) 4.89 (15.3%) 4.85 (15.2%) |
*в скобках указаны значения относительно теоретического предела
По сравнению с предыдущим исследованным нами ядром «Prescott/2M» ревизии N0, результаты которого по данному тесту оказались ощутимо хуже по сравнению с более ранними ревизиями ядер, новое ядро Smithfield ревизии A0 в этом тесте преподносит нам приятный сюрприз. А именно, величины реальной ПС шины L1-L2 кэша данных не только вернулись до прежних значений, привычных для ядер Prescott, но и даже немного возросли по сравнению с ними. Таким образом, причина «просадки» рассматриваемых величин на процессоре Pentium 4 660 теперь становится очевидной она связана с увеличенным вдвое объемом L2-кэша данных. Стоило снизить его до 1МБ на ядро (в Pentium EE 840), как все встало на свои места… и даже немного выше :).
Trace Cache, эффективность декодирования/исполнения
Не обойдем стороной изучение еще одной, наиболее интересной детали микроархитектуры NetBurst его специализированного кэша микроопераций, поставляемых ему предекодером, именуемый Execution Trace Cache.
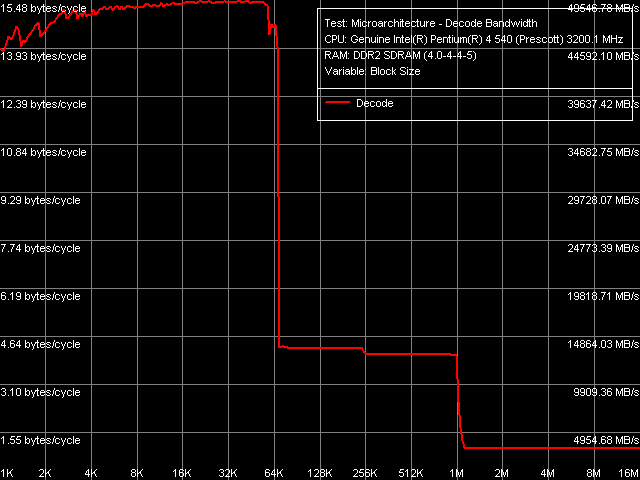 Эффективность декодирования/исполнения, Pentium EE 840
Эффективность декодирования/исполнения, Pentium EE 840Общая картина скорости декодирования/исполнения «крупных» 6-байтных инструкций CMP, как всегда, наиболее показательна. В этом тесте, как и во всех других тестах этого типа, качественных отличий в поведении изучаемого ядра Smithfield и ранее изученных Prescott/Nocona не наблюдается. Так что перейдем к количественным оценкам.
Эффективность декодирования/исполнения, Xeon (Nocona D0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.5 (10.5) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.85 (2.85) 5.70 (2.85) 3.97 (1.98) 3.64 (1.82) 5.70 (2.85) 5.40 (2.70) 10.29 (2.57) 15.50 (2.58) 15.50 (2.58) 15.50 (2.58) 8.62 (1.44) 20.66 (2.58) 20.66 (2.58) 20.66 (2.58) 11.53 (1.44) | 0.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.98 (0.99) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.25 (0.71) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) 4.40 (0.55) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) | 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 1.99 (0.99) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Для отслеживания весьма загадочной и интересной тенденции изменений Execution Trace Cache, приведем, так сказать, хронологию наших исследований. В качестве опорной точки рассмотрим данные, полученные ранее на платформе Xeon (ядро Nocona ревизии D0). Напомним, что в этом процессорном ядре, оснащенном технологией EM64T, впервые наметилась тенденция ухудшения эффективности исполнения некоторых команд в частности, простейших операций типа TEST (test eax, eax) и CMP 1 (cmp eax, eax). Для удобства, значения, претерпевающие изменения в последующих ядрах, выделены красным цветом.
Эффективность декодирования/исполнения, Pentium 4 660 (Prescott N0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.5 (10.5) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.87 (2.87) 5.73 (2.87) 3.99 (2.00) 3.42 (1.71) 5.73 (2.87) 5.16 (2.58) 10.32 (2.58) 15.48 (2.58) 15.48 (2.58) 15.48 (2.58) 8.67 (1.45) 20.62 (2.58) 20.60 (2.58) 20.60 (2.58) 11.56 (1.45) | 1.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 3.99 (1.00) 4.00 (0.67) 4.00 (0.67) 4.00 (0.67) 4.00 (0.67) 4.14 (0.52) 4.14 (0.52) 4.14 (0.52) 4.14 (0.52) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 2.01 (1.00) 2.01 (1.00) 2.01 (1.00) 2.00 (1.00) 3.00 (1.00) 3.00 (1.00) | 2.01 (1.00) 2.01 (1.00) 2.01 (1.00) 2.00 (1.00) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Намеченная тенденция ухудшения производительности процессоров (исполнения ряда команд) продолжает свое развитие в ядре «Prescott/2M» ревизии N0 (процессоры Pentium 4 660 и Pentium 4 Extreme Edition 3.73 ГГц). Прежде всего, здесь заметно дальнейшее снижение эффективности исполнения команд TEST и CMP 1. Второе значимое изменение это снижение максимальной скорости исполнения всех операций CMP из L2-кэша до 4.0 байт/такт (1.0 или 0.67 инструкций/такт, в зависимости от длины команды), а также «префиксных» CMP до 4.14 байт/такт (0.52 операций/такт).
Эффективность декодирования/исполнения, Pentium EE 840 (Smithfield A0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP SUB XOR TEST XOR/ADD CMP 1 CMP 2 CMP 3 CMP 4 CMP 5 CMP 6* Prefixed CMP 1 Prefixed CMP 2 Prefixed CMP 3 Prefixed CMP 4* | 10.5 (10.5) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 22.0 (11.0) 44.0 (11.0) 63.0 (10.5) 63.0 (10.5) 63.0 (10.5) 32.0 (10.6) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 63.0 (7.9; 10.5**) 44.0 (11.0; 14.7**) | 2.87 (2.87) 5.73 (2.87) 3.99 (2.00) 3.42 (1.71) 5.73 (2.87) 5.16 (2.58) 10.32 (2.58) 15.48 (2.58) 15.48 (2.58) 15.48 (2.58) 8.67 (1.45) 20.62 (2.58) 20.60 (2.58) 20.60 (2.58) 11.56 (1.45) | 1.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 2.00 (1.00) 3.99 (1.00) 4.26 (0.71) 4.26 (0.71) 4.26 (0.71) 4.26 (0.71) 4.45 (0.56) 4.45 (0.56) 4.45 (0.56) 4.45 (0.56) |
| Зависимые | |||
| LEA MOV ADD OR SHL ROL | - - - - - - | 2.01 (1.00) 2.01 (1.00) 2.01 (1.00) 2.00 (1.00) 3.00 (1.00) 3.00 (1.00) | 2.01 (1.00) 2.01 (1.00) 2.01 (1.00) 2.00 (1.00) 3.00 (1.00) 3.00 (1.00) |
*2 микрооперации
**в предположении, что префиксы отбрасываются до помещения в Trace Cache
Переходим к данным, полученным на новейшем Pentium EE 840. С TEST и CMP 1 все остается по-прежнему эффективность их исполнения из Trace Cache такая же, как у процессоров с ядром «Prescott/2M». Зато эффективность исполнения операций CMP3-CMP6, а также префиксных CMP1-CMP4 из L2-кэша вновь возросла, причем даже до несколько больших значений по сравнению с Nocona. Ничего не напоминает? Очень похожую картину мы только что видели в предыдущем тесте реальной пропускной способности кэша L1-L2. И дело здесь, очевидно, именно в ней. Становится ясно: снижение скорости исполнения ряда «крупных» команд из L2-кэша на процессорах с 2-МБ ядром Prescott ревизии N0 следствие увеличенного объема объединенного L2-кэша инструкций/данных.
Второе значимое ухудшение эффективности декодера/конвейера ядер Prescott/Nocona с поддержкой EM64T заключалось в снижении эффективности отбрасывания «бессмысленных» префиксов в тесте исполнения инструкций вида [0x66]nNOP, n = 0..14.
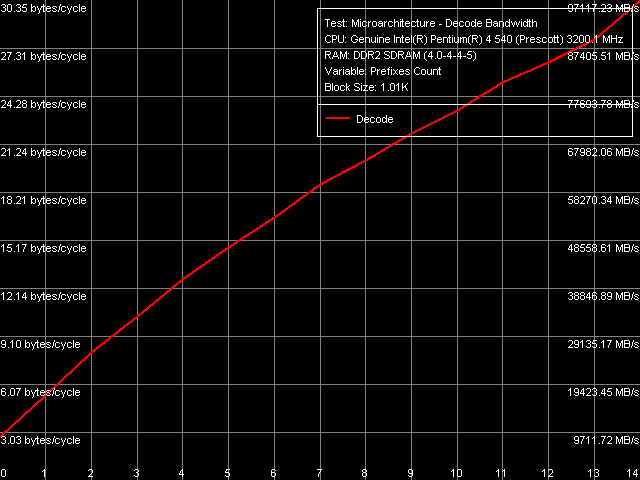 Эффективность декодирования/исполнения префиксных инструкций, Pentium EE 840
Эффективность декодирования/исполнения префиксных инструкций, Pentium EE 840| Количество префиксов | Эффективность декодирования/исполнения, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| Pentium 4 (Prescott D0) | Xeon (Nocona D0) | Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | |
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 2.84 (2.84) 5.68 (2.84) 8.52 (2.84) 11.34 (2.84) 14.09 (2.82) 16.89 (2.82) 19.51 (2.79) 22.30 (2.79) 24.87 (2.76) 27.54 (2.75) 30.76 (2.80) 33.24 (2.77) 35.86 (2.76) 38.18 (2.73) 40.85 (2.72) | 2.79 (2.79) 5.41 (2.71) 8.16 (2.72) 10.48 (2.62) 12.73 (2.55) 14.73 (2.46) 16.63 (2.38) 18.75 (2.34) 20.63 (2.29) 21.93 (2.19) 23.44 (2.13) 25.78 (2.15) 27.14 (2.09) 28.64 (2.05) 30.33 (2.02) | 2.80 (2.80) 5.43 (2.72) 8.13 (2.71) 10.42 (2.61) 12.74 (2.55) 14.74 (2.46) 16.64 (2.38) 18.76 (2.35) 20.23 (2.25) 21.96 (2.20) 23.45 (2.13) 25.17 (2.10) 26.46 (2.04) 27.89 (1.99) 30.35 (2.02) | 2.80 (2.80) 5.43 (2.72) 8.13 (2.71) 10.42 (2.61) 12.74 (2.55) 14.74 (2.46) 16.64 (2.38) 18.76 (2.35) 20.23 (2.25) 21.96 (2.20) 23.45 (2.13) 25.17 (2.10) 26.46 (2.04) 27.89 (1.99) 30.35 (2.02) |
Напомним, что в этом плане в новой ревизии ядер Prescott N0 с EM64T изменения были весьма незначительными: это необъяснимая, но хорошо воспроизводимая «просадка» при наличии ровно 13 префиксов перед инструкцией NOP. Легко видеть, что та же характерная особенность присуща и новому ядру Smithfield.
Характеристики TLB
На изучении характеристик D-TLB и I-TLB подробно останавливаться не будем, учитывая, что они (по значениям дескрипторов CPUID) совпадают у всех рассматриваемых процессоров.
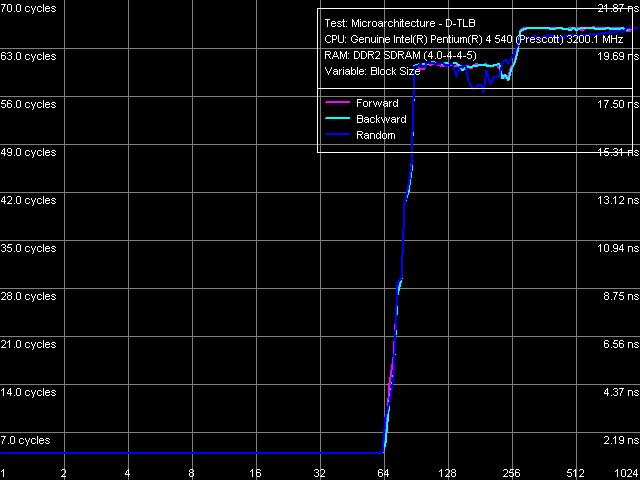 Объем D-TLB, Pentium EE 840
Объем D-TLB, Pentium EE 840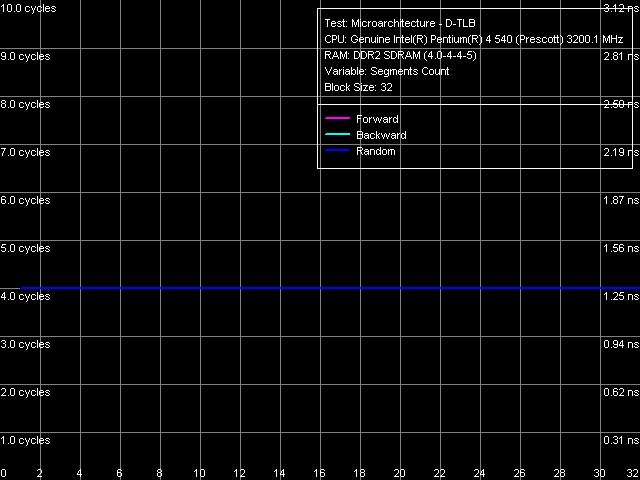 Ассоциативность D-TLB, Pentium EE 840
Ассоциативность D-TLB, Pentium EE 840 Объем D-TLB составляет 64 записи страниц (что мы уже видели по результатам других тестов), его промах при исчерпании объема «обходится» процессору минимум в 57 тактов. Ассоциативность полная.
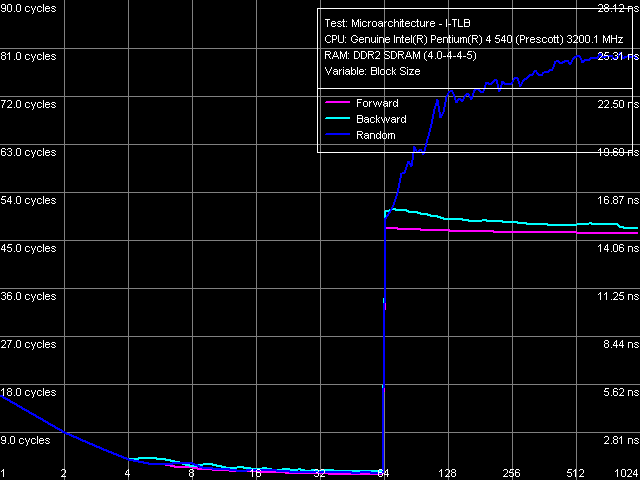 Объем I-TLB, Pentium EE 840
Объем I-TLB, Pentium EE 840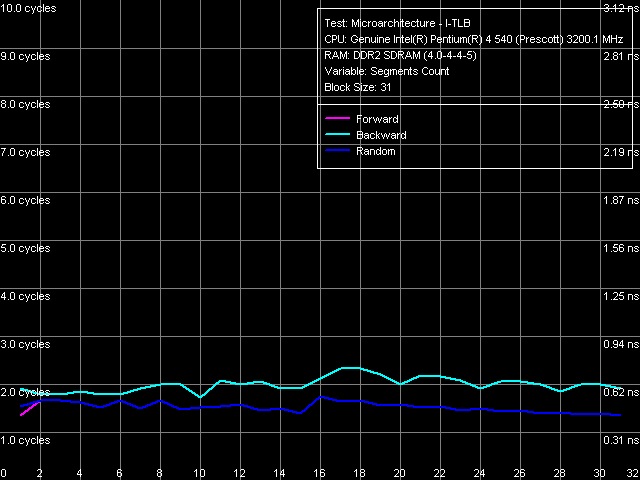 Ассоциативность I-TLB, Pentium EE 840
Ассоциативность I-TLB, Pentium EE 840Объем I-TLB 64 записи, штраф промаха буфера 45 тактов (прямой, обратный обход) и более (случайный обход), ассоциативность полная. Важно отметить, что объем этого буфера (который является «разделяемым» ресурсом) при отключении технологии Hyper-Threading в рассматриваемом процессоре не увеличивается до 128 записей (как по данным CPUID, так и по результатам этого теста), что наблюдалось ранее на всех процессорах Pentium 4. Данная поведенческая особенность является достаточно странной, по крайней мере, она не должна быть неизбежной ввиду двуядерности процессора, учитывая, что каждое из ядер представляет собой как бы отдельный, независимый физический процессор со своими собственными ресурсами вроде буфера I-TLB. Не исключено, что в нынешней, первой ревизии ядра Smithfield были замечены какие-либо проблемы, не позволяющие использовать полный объем I-TLB при отключении технологии Hyper-Threading, либо же этот момент был просто… забыт производителем :).
Заключение
Проведенное нами исследование показывает, что новое ядро Smithfield можно считать полноправным продолжением микроархитектурной линейки NetBurst, реализованной в ядрах Prescott, Nocona и Irwindale. Как по характеристикам CPUID, так и по результатам наших сегодняшних исследований новое ядро (точнее, его «одноядерную половинку») можно расположить где-то посередине между последней ревизией ядра Nocona (E0) и последними ревизиями ядер «Prescott/2M» и Irwindale (N0). А именно, новое ядро Smithfield A0 характеризуется абсолютно таким же устройством Trace Cache, декодера, конвейера и исполнительных модулей, которое реализовано в ядрах «Prescott/2M» и Irwindale, но благодаря вдвое меньшему объему L2-кэша (в пересчете на ядро) обладает улучшенными скоростными характеристиками шины L1-L2, которые даже несколько превосходят характеристики ядра Nocona E0.
Учитывая вышесказанное, а также способ организации многоядерной архитектуры процессора (два независимых, изолированных ядра, «посаженных» на общую системную шину), следует ожидать, что с точки зрения производительности новая платформа будет по крайней мере не уступать производительности двухпроцессорной платформы с равночастотными процессорами Intel Xeon, основанными на ядрах Nocona E0, а то и превосходить ее благодаря усовершенствованиию контроллера памяти, интегрированного в чипсет Intel 955X.
Комментарии