Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer
Часть 5: Платформа Intel Pentium M (Dothan)
Сегодня, 10 мая, корпорация Intel официально представила три новых модели процессора Pentium M, известных под кодовым названием Dothan. Новое поколение процессоров Pentium M Dothan (кстати, впервые получивших маркировку в виде Processor Number), согласно пресс-релизам Intel, выполнено по 90-нм технологическому процессу с применением технологии напряженного кремния, что создает резерв для дальнейшего повышения производительности и снижения энергопотребления. Ядро «Dothan» содержит 140 млн. транзисторов (что почти вдвое больше, чем у предыдущей модели Pentium M «Banias», при практически неизменившейся площади кристалла 83.6 мм2), оснащено удвоенным объемом (2 МБ) «энергосберегающей» кэш-памяти второго уровня (под этим, очевидно, понимается то, что уже реализовано в Banias — неиспользуемые части L2 кэша не получают питания), а также представляет ряд микроархитектурных новшеств. К последним относится улучшенная система доступа к регистрам, повышающая эффективность управления регистрами при операциях чтения/записи данных переменной длины и улучшенная предварительная выборка (prefetch) данных, которая обеспечивает более эффективную выборку и загрузку в кэш-память данных, которые с большой вероятностью могут потребоваться центральному процессору.
Цель настоящего исследования, по сути, заключается в ответе на вопрос, является ли новое ядро Dothan просто «90-нм Banias с 2 мегабайтами L2 кэша» или же действительно представляет собой нечто большее. Для этого воспользуемся новой, недавно анонсированной версией 3.1 универсального тестового пакета RightMark Memory Analyzer. Результаты тестов Dothan мы сопоставим с тестами, полученными ранее для Banias, которые были представлены в статье, посвященной исследованию микроархитектуры процессоров Pentium III/Pentium M.
Конфигурации тестовых стендов и ПО
Тестовый стенд №1 (ноутбук ASUS A6000Ne)
- Процессор: Intel Pentium-M (ядро Dothan, 2000 МГц)
- Чипсет: Intel 855PM (Montara)
- Память: 1 ГБ PC2700 DDR, 333 МГц
- Видео: ATI M11
Программное обеспечение
- Windows XP Professional SP1
- RightMark Memory Analyzer 3.1
Тестовый стенд №2 (ноутбук MaxSelect TravelBook Z4)
- Процессор: Intel Pentium-M (ядро Banias, 1300 МГц)
- Чипсет: Intel 855PM (Montara)
- Память: 512 МБ PC2100 DDR, 266 МГц
- Интегрированная видеосистема
Программное обеспечение
- Windows XP Professional SP1
- RightMark Memory Analyzer 2.4
Характеристики CPUID
Начнем наше исследование с анализа «заявленных» Intel значений, выдаваемых инструкцией CPUID процессора. Основное внимание уделим параметрам кэшей и TLB — то есть тем низкоуровневым характеристикам, измерением которых мы и займемся ниже.
Для начала, перечислим основные характеристики нынешней реализации Pentium M — ядра Banias.
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0x695 | Семейство 6, модель 9, степпинг 5 |
| Brand ID | 0x16 | Процессор Intel(R) Pentium(R) M |
| Дескрипторы кэшей/TLB | 0xB0 0xB3 0x02 0x87 0x30 0x04 0x2C | I-TLB: 4-КБ стр., 4-ассоц., 128 записей D-TLB: 4-КБ стр., 4-ассоц., 128 записей I-TLB: 4-МБ стр., полноассоц., 2 записи L2 кэш: 1 МБ, 8-ассоц., 64-байтн. строка L1-I кэш: 32 КБ, 8-ассоц., 64-байтн. строка D-TLB: 4-МБ стр., 4-ассоц., 8 записей L1-D кэш: 32 КБ, 8-ассоц., 64-байтн. строка |
А вслед за ними — параметры CPUID новой, анонсируемой модели Pentium M Dothan.
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0x6D6 | Семейство 6, модель 13, степпинг 6 |
| Brand ID | 0x16 | Процессор Intel(R) Pentium(R) M |
| Дескрипторы кэшей/TLB | 0xB0 0xB3 0x02 0x7D 0x30 0x04 0x2C | I-TLB: 4-КБ стр., 4-ассоц., 128 записей D-TLB: 4-КБ стр., 4-ассоц., 128 записей I-TLB: 4-МБ стр., полноассоц., 2 записи неизвестно L1-I кэш: 32 КБ, 8-ассоц., 64-байтн. строка D-TLB: 4-МБ стр., 4-ассоц., 8 записей L1-D кэш: 32 КБ, 8-ассоц., 64-байтн. строка |
Легко заметить, что изменения важнейших низкоуровневых параметров CPU нельзя назвать кардинальными. Разумеется, в первую очередь переменилась сигнатура процессора, причем не только на уровне степпинга (он увеличился на единицу), но и на уровне номера модели. Новое ядро 6-го семейства процессоров Intel получило сразу 13-й номер (предыдущий действительный номер модели этого семейства — 11-й — относится к процессорам Pentium III на ядре Tualatin). На первый взгляд, не самое удачное число для обозначения нового ядра :), но куда привлекательнее выглядит его шестнадцатеричное представление — 0xD. И сама собой напрашивается интерпретация, что это число соответствует первой букве его кодового имени — Dothan.
Что касается дескрипторов кэшей/TLB, здесь заметно лишь одно изменение, которое, как нетрудно догадаться, относится к L2-кэшу процессора. Значение этого дескриптора (0x7D) в настоящее время отсутствует в официальном руководстве Intel по идентификации процессоров (документ 241618-025, датированный февралем 2004 г.), но легко предположить (по аналогии с нынешней моделью Banias), что оно соответствует 8-входовому наборно-ассоциативному объединенному L2 кэшу данных/инструкций объемом 2 МБ с длиной строки 64 байта. Впрочем, как оно обстоит на самом деле, как всегда покажет тестирование, выполненное в соответствующих тестах RMMA.
Реальная пропускная способность кэша данных/памяти
А начнем мы его, не нарушая традиций, с рассмотрения реальной пропускной способности L1/L2-кэша данных и оперативной памяти (тест Memory Bandwidth, пресеты D-Cache/RAM Bandwidth, MMX/SSE/SSE2). Результаты, полученные с использованием MMX-, SSE- и SSE2-инструкций для доступа в оперативную память, внешне оказались идентичными, в связи с чем представим здесь общую картину, полученную в тесте с MMX-инструкциями.
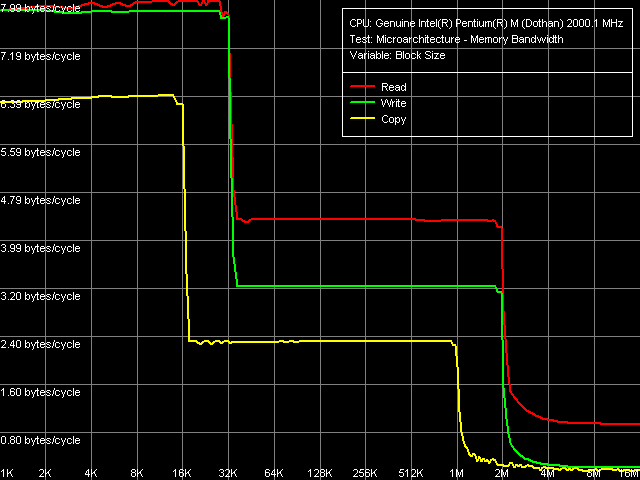
Легко видеть, что объем L2-кэша Pentium M Dothan действительно составляет 2 МБ, а его архитектура является инклюзивной, что присуще всем процессорам Intel. В данном случае это никак нельзя считать ее существенным недостатком, ибо дублирование данных, содержащихся в 32-КБ L1 кэше, занимает лишь 1.5% объема L2. Перейдем к количественным оценкам производительности различных уровней подсистемы памяти рассматриваемой платформы.
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.94 7.98 7.96 7.52 | 7.99 7.99 7.83 7.88 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.58 4.58 4.27 4.27 | 4.36 4.36 3.24 3.24 |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 1740.3 МБ/с (81.6%) 1737.4 МБ/с (81.4%) 482.5 МБ/с (22.6%) 477.4 МБ/с (22.4%) | 1885.1 МБ/с (70.7%) 1885.8 МБ/с (70.7%) 440.2 МБ/с (16.5%) 440.1 МБ/с (16.5%) |
Реальная пропускная способность L1 кэша данных при операциях чтения достигает почти своего максимума — 7.99 байт/такт, что по-прежнему соответствует пересылке за такт одного 64-разрядного значения из кэша процессора в его регистры. По этому показателю Dothan практически не отличается от Banias, который также способен считывать значения из L1-D кэша с почти 100% эффективностью. Но относительно записи значений из регистров процессора в L1 кэш у рассматриваемых платформ уже имеются заметные отличия. Так, запись из MMX-регистров идет эффективнее у Banias (7.96 байт/такт против 7.83), а в операциях записи из SSE/SSE2-регистров лидером выступает Dothan, причем с ощутимым отрывом (7.88 байт/такт против 7.52).
Более значимые различия наблюдаются в области L2 кэша — того самого микроархитектурного компонента процессора Pentium M, который претерпел изменения при переходе к новому ядру. С сожалением отметим, что не в лучшую сторону. Эффективность чтения из L2 снизилась на 5%, записи — намного больше, на 24%. Ниже мы исследуем аспекты работы L2-кэша и шины L1-L2 более детально.
А пока обратимся к данным по реальной пропускной способности оперативной памяти. Эффективность тотального чтения данных из RAM у платформы Dothan несколько ниже (70.7% от теоретического максимума против 81.6% у Banias), также как и тотальной записи (440 МБ/с, 16.5% против 22.5%). Тем не менее, подобный результат никак нельзя связать напрямую с деталями реализации микроархитектуры процессоров, поскольку он связан, прежде всего, с настройками чипсета (в частности, таймингов памяти) и собственно используемой памятью.
Предельная реальная пропускная способность памяти
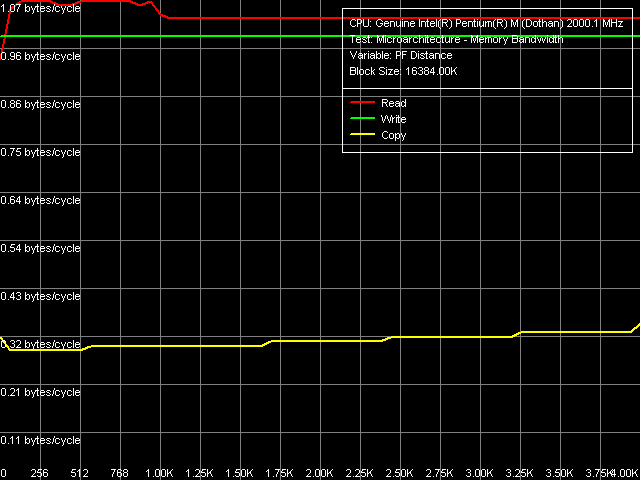
Как бы там ни было, весьма интересно оценить предельную величину реальной ПСП, достигаемой на практике различными методами. Для оценки максимальной реальной ПСП на чтение, таковыми являются Software Prefetch, Block Prefetch 1 и 2, а также метод чтения целых строк кэша, вместо тотального чтения данных. Представим здесь наиболее показательную картину, полученную в методе Software Prefetch с использованием MMX-регистров.
А также, чтобы продемонстрировать влияние большого объема L2 кэша — кривые чтения/записи строк кэша, при размере блока данных 4-16 МБ.
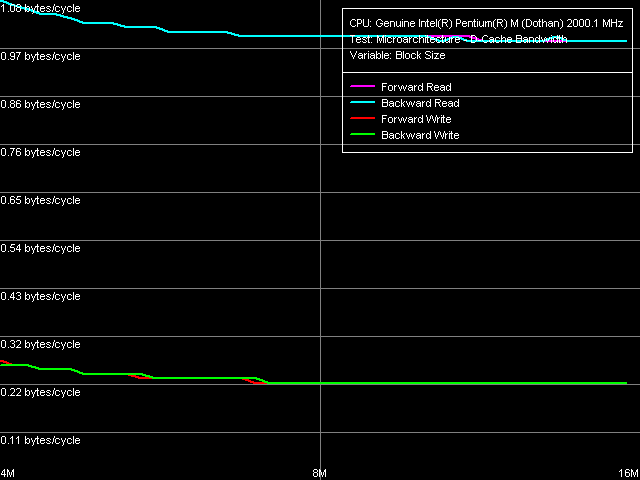
Влияние L2 очевидно — кривые выходят на постоянные значения только при размере блока 8 МБ и выше. Что неудивительно, поскольку «построчное» чтение/запись 4-МБ блока данных сопровождается 50% попаданием данных в L2 кэш процессора.
Вернемся к данным Software Prefetch. Максимум его эффективности наблюдается при длине префетча от 64 до 960 байт, и достигает примерно 81% теоретической ПСП PC2700 DDR. Кстати, реализация Software Prefetch у Dothan заметно отличается от таковой у Banias. По рисунку, приведенному в нашей предыдущей статье, посвященной исследованию его микроархитектуры, видно, что эффективность Software Prefetch у Banias достигает своего максимума при длине префетча 64 байт и выше, после чего сохраняется на постоянном уровне. Второе значимое отличие — это выигрыш от использования Software Prefetch, который в случае Banias составляет величину порядка 1.08 раз. Тогда как на Dothan достигается больший прирост в скорости — примерно в 1.14 раз. Таким образом, одним из важных микроархитектурных отличий Dothan от Banias является усовершенствование алгоритма Sofware Prefetch. Заметим, что подобную картину мы наблюдали и у Prescott в ходе тестирования платформ Pentium 4. Не исключено, что Intel реализовала те же задумки, которые были с успехом применены в Prescott, или хотя бы некоторые из них, в своем новом ядре Dothan.
| Режим доступа | Предельная реальная ПСП на чтение, МБ/с* | |
|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэш, прямое Чтение строк кэш, обратное | 1740.3 (81.6 %) 1737.4 (81.4 %) 1881.4 (88.2 %) 1883.7 (88.3 %) 1515.4 (71.0 %) 1517.5 (71.1 %) 1795.0 (84.1 %) 1800.3 (84.4 %) 1791.0 (84.0 %) 1786.9 (83.8 %) | 1885.1 (70.7 %) 1885.8 (70.7 %) 2149.3 (80.6 %) 2157.0 (80.9 %) 1771.4 (66.4 %) 1771.8 (66.4 %) 1996.2 (74.9 %) 1996.9 (74.9 %) 1991.8 (74.7 %) 1991.7 (74.7 %) |
*в скобках указаны значения относительно теоретического предела для данного типа памяти
Об остальных методах, в особенности Block Prefetch 1 и 2, скажем вкратце. Действительно, зачем подробно останавливаться на них, если выигрыш от их использования либо незначительный (Block Prefetch 2), либо вовсе является… проигрышем! (Block Prefetch 1). Столь же незначительный выигрыш наблюдается у обоих ядер и при использовании «построчного» чтения данных. Относительные показатели (в процентах от теоретического предела) во всех случаях у Dothan несколько ниже по сравнению с теми, что наблюдаются у Banias. Подобное поведение вполне естественно, учитывая, что первая платформа характеризуется меньшими относительными величинами средней реальной ПСП на чтение.
Посмотрим, как обстоит дело с записью данных. Вариантов оптимизации записи, как и ранее, всего два — это метод прямого сохранения данных (Non-Temporal Store) и «построчной» записи. Несмотря на то, что Dothan характеризуется меньшими величинами средней реальной ПСП на запись, выигрыш от использования прямого сохранения оказывается выше именно на этой платформе — в 4.50 раз, против 3.65 раз у Banias. Таким образом, в алгоритме прямого сохранения данных в Dothan также имеются определенные улучшения, достигнутые, предположим, за счет увеличения количества или размера буферов комбинирования записи.
| Режим доступа | Предельная реальная ПСП на запись, МБ/с* | |
|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэш, прямая Запись строк кэш, обратная | 482.5 (22.6 %) 477.4 (22.4 %) 1746.2 (81.9 %) 1746.3 (81.9 %) 491.5 (23.0 %) 484.6 (22.7 %) | 440.2 (16.5 %) 440.1 (16.5 %) 1981.6 (74.3 %) 1981.5 (74.3 %) 439.9 (16.5 %) 439.9 (16.5 %) |
*в скобках указаны значения относительно теоретического предела для данного типа памяти
Тем не менее, напоследок мы вынуждены несколько испортить полученную картину, поскольку никак нельзя обойти стороной результаты по копированию данных, полученные при совместном использовании лучших вариантов оптимизации (Software Prefetch и Non-Temporal Store). Максимальная реальная ПСП при операциях копирования данных у платформы Dothan составляет лишь 700.4 МБ/с (величина полной максимальной действительной ПСП — соответственно, 1400.8 МБ/с, а это лишь 52.2% от теоретического максимума). Кстати, подобным недостатком страдает и Banias — он характеризуется полной максимальной действительной ПСП при операциях копирования данных в 1372 МБ/с (64.3% от теоретического предела). Впрочем, подобная эффективность (2/3 от теоретической и ниже), похоже, присуща всем процессорам семейства Pentium III, архитектура которых была унаследована процессорами Pentium M, в противоположность Intel Pentium 4 и AMD K7/K8, характеризующихся намного большей эффективностью при операциях копирования.
Средняя латентность кэша данных/памяти
Приступим к изучению следующей важной характеристики — латентности кэша данных рассматриваемых процессоров. Сначала посмотрим на вид кривых, полученных в тесте D-Cache Latency, пресет D-Cache/RAM Latency.
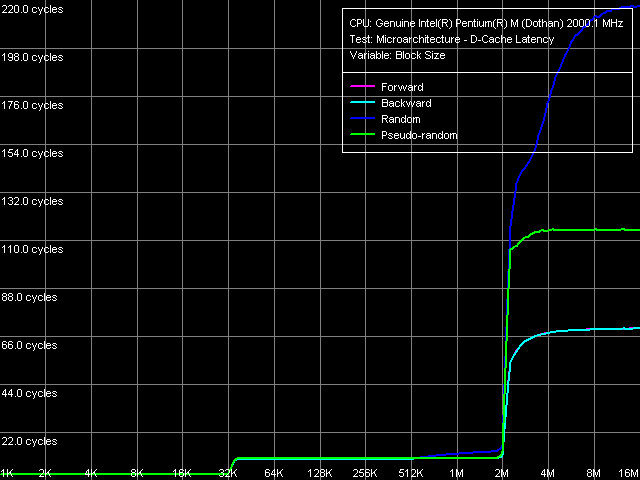
По ним заметно, что Dothan, как и его предшественник, снабжен алгоритмом Hardware Prefetch, эффективность которого можно оценить примерно в 40% (путем сравнения значений, полученных при прямом/обратном последовательном обходе и псевдослучайном обходе памяти). Кстати, отметим, что псевдослучайный режим обхода является новой возможностью теста RMMA, появившейся в версиях 2.5 и выше, тогда как данные для Banias были получены в версии 2.4, в связи с чем оценить эффективность Hardware Prefetch у последнего предложенным способом в данном исследовании не представляется возможным. Тем не менее, посмотрим на количественные характеристики латентности кэшей данных/памяти.
| Режим доступа | Средняя латентность, тактов | |
|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |
| L1, прямой L1, обратный L1, случайный L1, псевдослучайный | 3.0 3.0 3.0 - | 3.0 3.0 3.0 3.0 |
| L2, прямой L2, обратный L2, случайный L2, псевдослучайный | 9.5 9.5 9.5 - | 10.0 10.0 10.0 10.0 |
| RAM*, прямой RAM, обратный RAM, случайный RAM, псевдослучайный | 66.5 (51.2 нс) 66.5 (51.2 нс) 190.3 (146.7 нс) - | 70.0 (35.0 нс) 70.0 (35.0 нс) 175.8 (87.9 нс) 114.8 (57.4 нс) |
*Размер блока 4 МБ
Латентность L1-D кэша, что приятно, осталась равной трем тактам (новое ядро Pentium 4 Prescott, как мы помним, весьма и весьма «порадовало» нас двукратным возрастанием латентности L1 кэша данных). В то же время, средняя латентность L2-D кэша возросла, правда, весьма незначительно — до 10 тактов. Латентность доступа к памяти на платформе Dothan значительно меньше — 35.0 нс (против 51.2 нс) при прямом/обратном обходе и 87.9 нс (против 146.7 нс) при случайном обходе 4-МБ блока памяти. Тем не менее, не будем считать это заслугой микроархитектурных улучшений процессора, не забывая про остальные компоненты платформы — чипсет и оперативную память как таковую. Прежде всего потому, что на рассматриваемой платформе Dothan установлена память PC2700 DDR, тогда как на Banias — PC2100 DDR.
Минимальная латентность L2 кэша данных/памяти
Оценим несколько более важную характеристику — минимальную латентность L2 кэша данных и памяти, для чего, как обычно, будем последоваетльно разгружать шину L1-L2 (L2-RAM) вставкой «пустых» операций (тест D-Cache Latency, пресеты Minimal L2 D-Cache Latency, Method 1 и Minimal RAM Latency, 4MB Block). Для начала посмотрим, как при этом меняется латентность кэша L2.
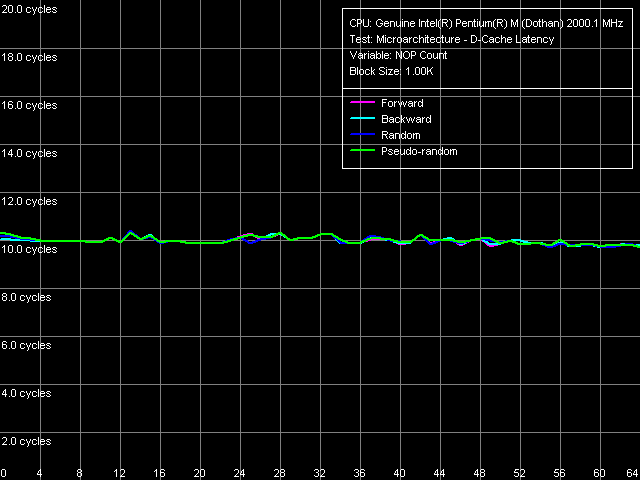
И увидим, что она вовсе не меняется, а сохраняет свое среднее значение, равное 10 тактам. Таким образом, увеличение размера L2 в Dothan не обошлось «без жертв» — время поиска нужной строки в столь большом кэше увеличилось на 1 такт. Что, на самом деле, смотрится просто смешно по сравнению с тем, что было сделано той же компанией в новом ядре Pentium 4 Prescott (где латентность L2 возросла с 9 до 22 тактов). Посмотрим теперь на то, как меняется латентность доступа к памяти при разгрузке соответствующей шины.
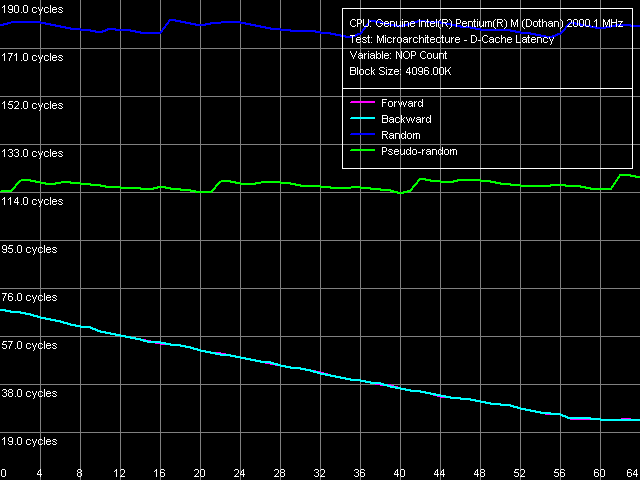
Последовательные (прямой и обратный) режимы обхода в этом случае предоставляют возможность Hardware Prefetch работать на максимум своей эффективности, в результате чего достигается латентность в 24 такта процессора (12.0 нс). Заметим, что Banias характеризуется подобным видом кривых, но разгрузка там достигается чуть менее эффективно, да и сами величины латентности выше. Значит, Hardware Prefetch в Dothan также был немного улучшен по сравнению с его реализацией в Banias. Что касается случайного и псевдослучайного обхода — легко видеть, что соответствующие минимальные латентности практически совпадают со средними. Важно упомянуть уже хорошо знакомый нам «зубчатый» вид этих кривых, шаг которых (20 «NOP»-ов) соответствует коэффициенту умножения процессора. В свою очередь, это означает возможность осуществления обмена с памятью на каждом такте 100-МГц Quad Pumped системной шины процессора.
| Режим доступа | Средняя латентность, тактов | |
|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |
| L2, прямой L2, обратный L2, случайный L2, псевдослучайный | 9.0 9.0 9.0 - | 10.0 10.0 10.0 10.0 |
| RAM*, прямой RAM, обратный RAM, случайный RAM, псевдослучайный | 30.0 (23.1 нс) 30.2 (23.3 нс) 184.7 (142.5 нс) - | 24.0 (12.0 нс) 24.0 (12.0 нс) 175.6 (87.8 нс) 114.0 (57.0 нс) |
*Размер блока 4 МБ
Ассоциативность кэша данных
Для анализа ассоциативности кэша данных Dothan представим кривые, полученные в тесте D-Cache Latency с использованием пресета, получившего название L1 D-Cache Associativity.
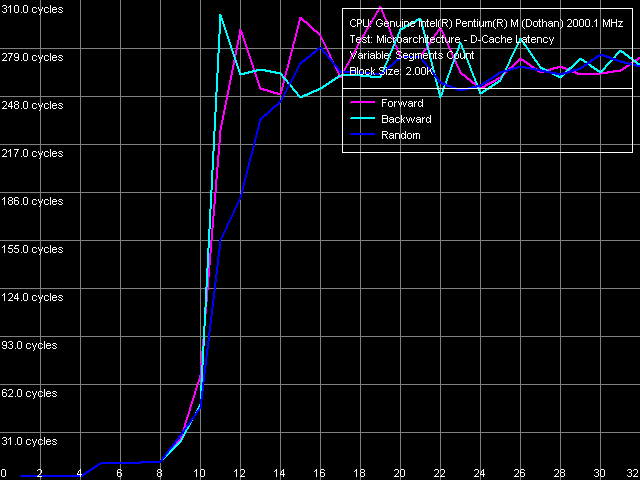
На графике довольно ясно видно 2 перегиба, которые соответствуют ассоциативности L1 кэша, равной четырем (область 1-4 сегментов), и L2 кэша, равной восьми (область 5-8 сегментов). Таким образом, серьезных изменений по сравнению с Banias (а также Pentium III Tualatin) здесь не имеется. Значительно увеличив объем L2 кэша, Intel не позаботилась об увеличении степени ее ассоциативности, что, вообще говоря, не очень хорошо для столь большого кэша. Впрочем, увиденная картина не нова для процессоров Intel — например, Pentium 4 XE (Gallatin) также наделен 8-ассоциативным двухмегабайтным кэшем (только не второго, а третьего уровня). Что более странно, и чему мы не уделили внимание при тестировании Banias — это то, что заявленная величина ассоциативности кэша L1 (8, согласно дескрипторам кэша/TLB в CPUID) не имеет ничего общего с действительностью. Можно было бы предположить, что L1 кэш все-таки является 8-ассоциативным, а L2 кэш — 4-ассоциативным (что было бы очень странно для кэша такого размера), но тест L2 D-Cache Associativity, в котором осуществляется «многосегментный» обход 96-КБ блока данных, не подтверждает такое предположение — ассоциативность L2 кэша по результатам этого теста также равна 8. Значит, первый скачок, наблюдаемой на представленной выше кривой в области 4 сегментов, действительно соответствует 4-ассоциативному L1 кэшу данных.
Реальная пропускная способность шины L1-L2
Оценим реальную ПС шины L1-L2 кэша данных, воспользовавшись тестом D-Cache Bandwidth, пресет L1-L2 D-Cache Bus Bandwidth.
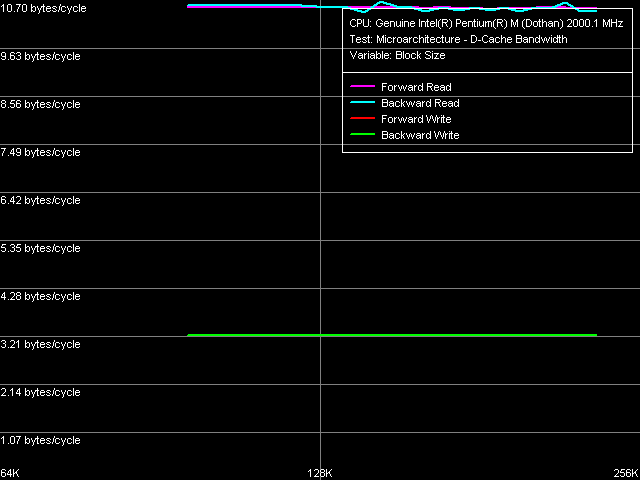
И сопоставим полученные результаты с теми, которые мы получили при тестировании Banias.
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт | |
|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 10.75 10.77 4.27 4.27 | 10.58 10.70 3.24 3.24 |
Разрядность этой шины по-прежнему осталась равной 128 битам (предельная ПС такой шины — 16.0 байт/такт). Ее эффективность на чтение строк из L2 в L1 практически не изменилась (точнее, уменьшилась, но весьма мало), а вот на запись — снизилась значительно (с 4.27 до 3.24 байт/такт, т.е. на 24%). Впрочем, этот результат для нас не стал неожиданностью #151; подобную картину мы наблюдали выше, при рассмотрении эффективности L2 кэша при операциях тотального чтения/записи данных.
Заметим, что 128-разрядная шина данных, присущая всем процессорам семейства Pentium III/Pentium M, для Dothan оказывается так же недостаточно эффективной, как и для Banias, учитывая, что размер строки L1/L2-кэша у этих процессоров составляет 64 байта. В самом деле, для пересылки такого количества байт данных даже с предельной скоростью в 16 байт/такт потребовалось бы целых 4 такта процессора. Но латентность первого уровня кэша, как мы видели выше, составляет 3 такта, так что запрашиваемая строка даже в идеальных условиях должна быть доступной не сразу, а с задержкой как минимум в один такт. Как это проявляет себя в действительности, позволит ответить специальный тест прибытия данных (D-Cache Arrival). Проанализируем, как зависит суммарная латентность двух обращений к одной и той же строке кэша при увеличении расстояния между этими обращениями от 4 до 60 байт. Для этой цели используем пресет L1-L2 Cache Bus Data Arrival Test 1, 64 bytes.
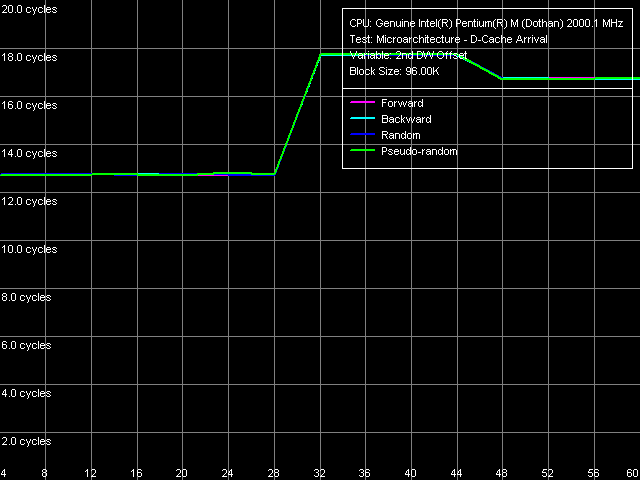
Результат получился таким же, как и на Banias, за исключением количественных характеристик (с разницей в 1 такт, соответствующей увеличенной латентности L2 кэша). А именно, латентность двух обращений остается минимальной (13 = 3 + 10 тактов) при смещениях второго элемента до 28 байт включительно, после чего она возрастает на 5 тактов, и снижается на 1 такт при дальнейшем увеличении смещения (от 48 байт и выше). Полученный результат означает, что запрашиваемая 64-байтная строка действительно оказывается доступной L1 кэшу процессора не сразу.
Кэш инструкций, эффективность декодирования
Для оценки эффективности работы кэша инструкций, декодера, конвейера и исполнительных модулей Dothan воспользуемся тестом Decode Bandwidth. Как всегда, наиболее показательный результат получился при декодировании простых, но «крупных» 6-байтовых инструкций CMP (пресет L1 I-Cache Size / Decode Bandwidth, CMP Instructions 3).
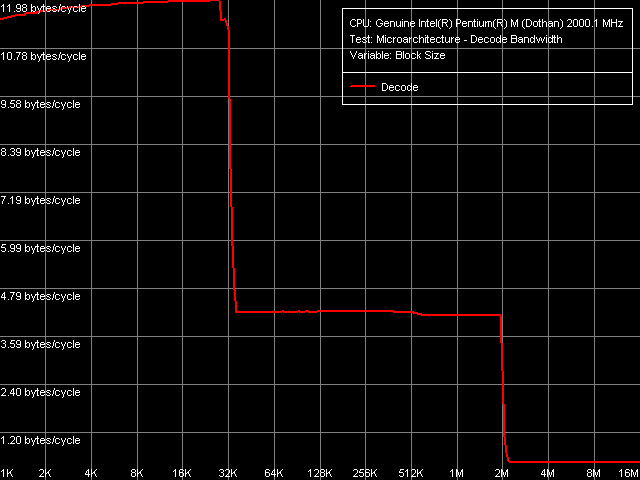
Эффективность их декодирования/исполнения из L1-I кэша достигает 12 байт/такт, что соответствует исполнению двух инструкций двумя исполнительными ALU-модулями процессора. Эффективности декодирования/исполнения остальных инструкций приведены в таблице.
| Тип инструкций (размер, байт) | Эффективность декодирования, байт/такт (инструкций/такт) | |||
|---|---|---|---|---|
| Pentium M (Banias) | Pentium M (Dothan) | |||
| L1-I кэш | L2 кэш | L1-I кэш | L2 кэш | |
| NOP (1) SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) CMP 2 (4) CMP 3-6 (6) Prefixed CMP 1-4 (8) | 2.00 2.02 2.02 3.99 2.02 3.99 7.98 11.97 2.00 | 1.94 1.98 1.98 3.65 1.98 3.65 4.12 4.36 1.78 | 2.00 2.02 2.02 4.00 2.02 4.00 7.98 11.98 2.00 | 1.94 1.98 1.98 3.55 1.98 3.55 3.99 4.22 1.78 |
Прежде всего, следует сказать, что устройство исполнительных модулей Dothan, по всей видимости, осталось таким же, каким оно было реализовано в Banias. Об этом свидетельствуют идентичные показатели скоростей декодирования различных простых ALU-инструкций двумя рассматриваемыми процессорами. По-прежнему важно, что далеко не все независимые операции исполняются на этих процессорах с максимально возможной скоростью. Действительно, темп исполнения независимых операций SUB, XOR и XOR/ADD составляет всего лишь одну операцию за такт. Поскольку это никак нельзя назвать нехваткой исполнительных ресурсов (способных исполнять NOP, TEST и CMP с предельной скоростью 2 операции/такт), имеет место «неумение» процессора разрешать подобные ложные зависимости. Вторым важным моментом является темп исполнения простейших инструкций CMP, содержащих два «бессмысленных» префикса (Prefixed CMP 1-4). Он оказывается крайне низким — на обоих Pentium M одна такая операция исполняется за четыре такта процессора! К сожалению, новое ядро Dothan не имеет каких-либо усовершенствований по отношению к указанным недостаткам. Вместо этого наследуется старая, существующая со времен Pentium III микроархитектура, дополненная SSE2-командами в первой модели Pentium M (Banias). Вдобавок к этому, новый Dothan характеризуется меньшей эффективностью декодирования инструкций из объединенного L2 кэша, что заметно при декодировании/исполнении «крупных» инструкций CMP 3-6 (4.22 байт/такт против 4.36 у Banias). Впрочем, полученный результат хорошо согласуется с нашими предыдущими находками, свидетельствующими о снижении эффективности шины L1-L2 кэша процессора.
Ассоциативность кэша инструкций
Для измерения ассоциативности L1-I/L2 кэша воспользуемся новым тестом (появившемся в RMMA 3.0 и выше) I-Cache Latency, выбрав пресет I-Cache/RAM Latency, Near Jump.
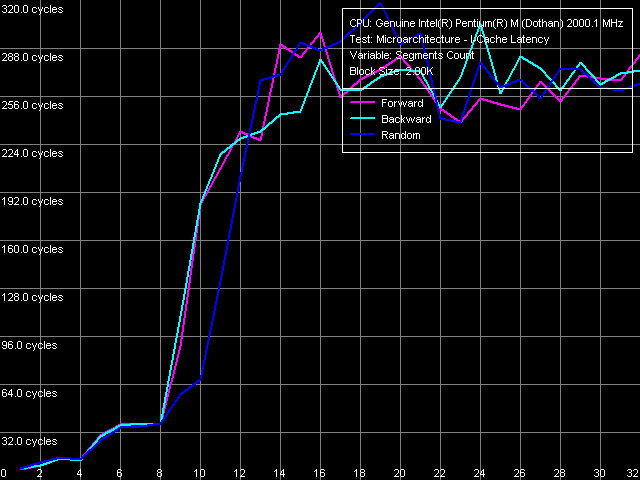
Наши выводы об ассоциативности L1-D кэша, равной четырем, и ассоциативности L2 кэша, равной восьми, распространяются и на случай кэша инструкций. Действительно, согласно результатам этого теста ассоциативность L1-I кэша также равна четырем (в противоположность заявленному в CPUID значению 8), а ассоциативность объединенного кэша L2 инструкций/данных равна восьми.
Характеристики D-TLB
Согласно значениям дескрипторов кэша/TLB, выдаваемых функцией CPUID, в новом ядре Dothan нет каких-либо изменений параметров D-TLB и I-TLB, вроде их размера и ассоциативности. В этих, заключительных тестах мы проверим это утверждение, а также оценим, как сказывается промах D-TLB/I-TLB на величинах латентности доступа в L1-D/L1-I кэш процессора. Для начала воспользуемся тестом D-TLB, пресет D-TLB Size.
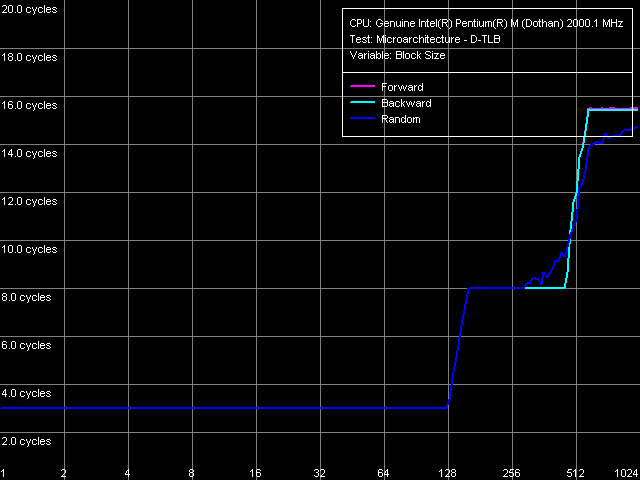
Полученные кривые выглядят достаточно четко. Размер D-TLB действительно составляет 128 записей (кстати, внимательный читатель наших статей мог вполне уже определить этот параметр, изучив вид кривой латентности случайного доступа в области L2 — в ней заметно плавное возрастание латентности при размере блока 512 КБ и выше, что как раз соответствует (512 КБ / 4 КБ) = 128 записям страниц). Промах D-TLB сопровождается увеличением латентности доступа в L1-D кэш на 5 тактов, что характерно для всех процессоров семейств Pentium III, включая Pentium M. Второй скачок, наблюдающийся в области 512 страниц, связан с выходом за пределы L1 кэша данных, способного вместить (32 КБ / 64 байта) = 512 строк.
Для определения ассоциативности D-TLB выберем пресет D-TLB Associativity, 64 Entries, задействуя тем самым рассматриваемый буфер ровно на половину.
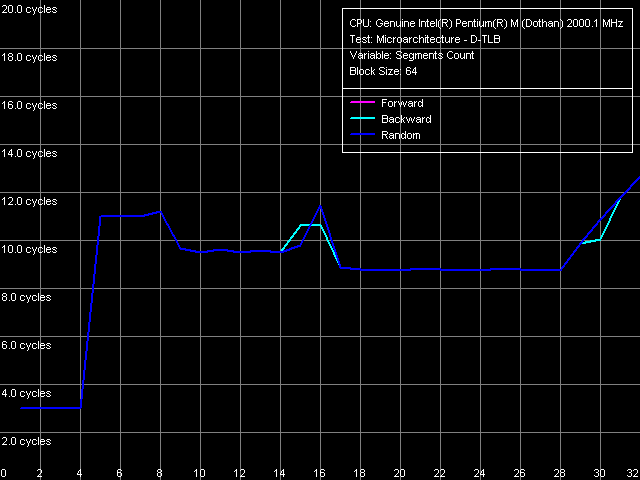
Из представленных кривых видно, что ассоциативность D-TLB равна четырем, а ее «исчерпание» сопровождается увеличением латентности L1-D кэша в среднем до 9 тактов. Такую же картину мы наблюдали при тестировании нынешней реализации Pentium M — ядра Banias. Таким образом, реализация D-TLB у Dothan и Banias является абсолютно идентичной.
Характеристики I-TLB
Посмотрим напоследок, что можно сказать об аспектах реализации I-TLB у рассматриваемых ядер процессора Pentium M — Dothan и Banias. Начнем с определения размера этого буфера (тест I-TLB, пресет I-TLB Size, Near Jump).
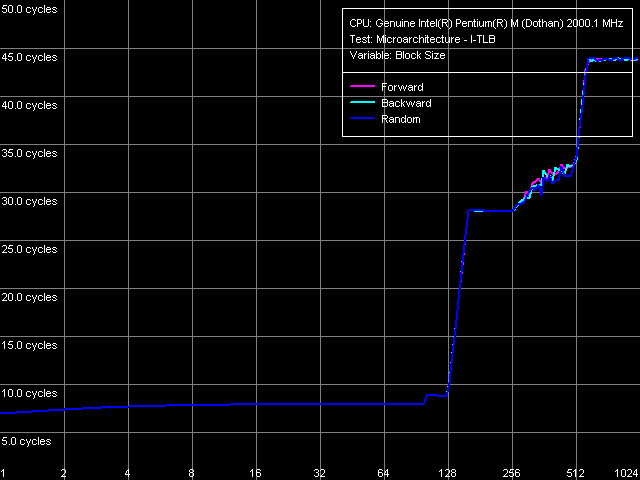
Он в точности соответствует заявленному значени — 128 записей, а его промах «обходится» L1-I кэшу процессора порядка в 20 тактов.
Для оценки ассоциативности I-TLB воспользуемся пресетом I-TLB Size, Near Jump, 64 Entries.
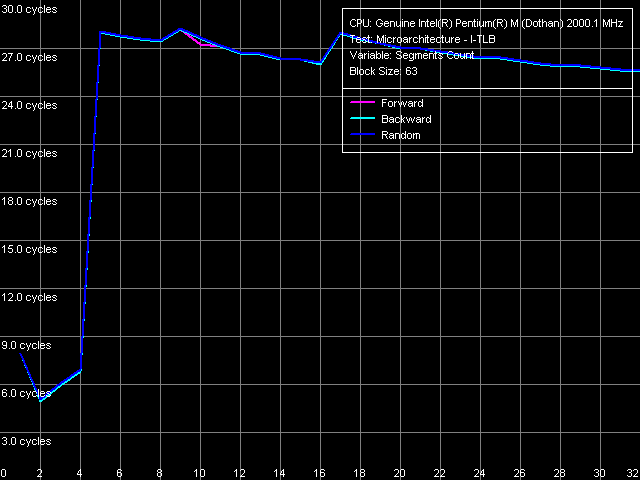
Как и ожидалось, ассоциативность I-TLB у Dothan равна четырем. Ее «исчерпание» приводит к увеличению латентности доступа в L1-I кэш в среднем до 27 тактов, так же, как и выход за пределы его размера. Представленные характеристики I-TLB совпадают с полученными ранее для Banias. То есть, реализация I-TLB также не претерпела каких-либо изменений при переходе от Banias к Dothan.
Заключение
Подводя итог, рассмотрим основные аспекты микроархитектуры нового ядра Dothan, которые так или иначе были модифицированы по сравнению с нынешней реализацией микроархитектуры Pentium M, получившей свое воплощение в виде ядра Banias.
Первое, что бросается в глаза, да и, несомненно, главное — это увеличенный вдвое, до 2 МБ, объем объединенного L2 кэша данных/инструкций. С одной стороны, это определенно идет на пользу новому ядру, с другой, все же имеется ряд недостатков. Первый заключается в том, что ассоциативность этого уровня кэша осталась точно такой же, как и в предыдущей реализации (Banias) — она равняется восьми, что явно маловато для столь большого кэша. Недостаточная эффективность такого кэша станет особенно заметной в случае необходимости кэширования данных, пусть даже не занимающих столь большой объем, но сильно разделенных в пространстве виртуальной памяти. Другой ощутимый недостаток реализации L2 кэша в Dothan напрямую связан с увеличением его объема, и проявляется в виде двух тесно связанных между собою следствий — увеличения латентности доступа в L2 и уменьшения эффективной пропускной способности шины L1-L2, особенно при операциях записи. Тем не менее, ухудшение этих параметров выглядит куда менее значимым по сравнению с тем, что мы наблюдали в новом ядре Prescott. Так что новое 90-нм воплощение Pentium M можно назвать куда более удачным, чем его 90-нм NetBurst-собрата.
Второй положительный момент — усовершенствование алгоритмов Software и Hardware Prefetch. Первое проявляется в увеличенной эффективности чтения из памяти при использовании такой оптимизации (а используется она довольно часто), второе — в уменьшении латентности последовательного доступа к памяти (который также можно встретить на практике гораздо чаще по сравнению со случайным доступом).
Тем не менее, нельзя не упомянуть и о недоработках ряда моментов, присущих процессорам Pentium M в целом, которые, однако, можно было бы как-нибудь усовершенствовать с выпуском нового ядра. Здесь прежде всего следует отметить довольно низкую эффективность копирования больших объемов данных, даже при использовании наилучших вариантов оптимизации. А также — отсутствие каких-либо изменений на уровне конвейера и исполнительных модулей процессора, проявляющее себя «неумением» эффективно исполнять независимые операции, и очень большим (по сравнению с Pentium III) временем исполнения инструкций безусловного перехода. Что, вообще говоря, выглядит несколько странно — ведь алгоритмы предсказания ветвлений в современных CPU имеют тенденцию становиться все более и более «продвинутыми» с выпуском новых ядер.
Тем не менее, результаты представленного исследования позволяют сказать, что новое ядро Pentium M Dothan — это все же нечто принципиально иное, чем просто «90-нм Banias с двумя мегабайтами L2 кэша», в связи с чем его выпуск можно считать весьма удачным шагом со стороны Intel.
Комментарии