Двухъядерный процессор Yonah:
уже не Pentium III, ещё не Conroe
Last but not least
Итак, мы наконец-то дождались выхода последнего представителя долгоиграющего семейства процессоров Pentium Pro — Pentium II — Pentium III — Pentium M, растянувшегося по времени более чем на десятилетие (с 1995 по 2006 гг.). Выходит он под странным и несолидным именем Intel Core Duo. Но это не меняет сути: перед нами по-прежнему Pentium M — правда, сильно модифицированный и исполненный в виде двухъядерного процессора с общим кэшем второго уровня.

Чтобы не выбиваться из общего ряда имён процессоров архитектуры P6 и при этом подчеркнуть заметные микроархитектурные отличия нового процессора от своего непосредственного предшественника Pentium M (Dothan), будем называть его в тексте настоящей статьи «Pentium M2». Также будем для удобства использовать сокращённые названия для всех процессоров цепочки: PPro, P-II, P-III, P-M, P-M2.
Но для начала договоримся о терминологии в связи с неоднозначностью понятий «двухъядерный» и «двухпроцессорный». С лёгкой руки компании Intel в популярной литературе устоялась следующая трактовка: всё, что размещено в одном корпусе (и вставляется в один разъём), называют процессором, а каждое из двух устройств, находящихся в этом корпусе (не обязательно на одном кристалле), не связанных микроархитектурно друг с другом и исполняющих независимые потоки инструкций, называют ядром. С другой стороны, каждое из этих ядер является полноценным процессором в самом строгом смысле слова. Компания IBM, например, использует только строгую терминологию: «two processors on one POWER4 chip» («два процессора на одном чипе POWER4»). Поэтому, чтобы избежать двусмысленностей и при этом не слишком отклоняться от нарождающейся терминологии, в необходимых случаях будем говорить «процессорное ядро», либо «CPU» для обозначения каждого такого «независимого процессора», и «процессорный чип», либо «разъём» (сокет) для обозначения собственно «двухъядерного процессора». В связи с этим систему, содержащую два процессорных разъёма, будет правильнее называть «двухсокетной», а не «двухпроцессорной» (вне зависимости от числа ядер на каждом процессорном чипе).
В предыдущей статье про двухъядерные процессоры новой архитектуры этот терминологический момент был обозначен не совсем чётко, и это вызвало некоторые нарекания.
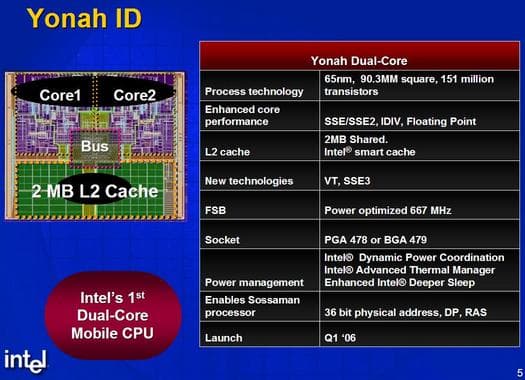
Основные характеристики двухъядерного процессора Yonah показаны на приведенном выше рисунке (на всякий случай уточним: по-русски это слово правильно произносится как «йона», а не «йонах», как это делают многие). На первый взгляд, новый процессор не содержит ничего особенного. Ожидаемый размер кристалла при переходе на технологические нормы 65 нм, ожидаемый общий кэш второго уровня размером 2 МБ, ожидаемое улучшение технологий энергопотребления. Тактовая частота тоже вполне ожидаемая — 2.16 ГГц сейчас и 2.33 во втором квартале. Однако если копнуть глубже, то можно увидеть, что Yonah имеет на удивление много важных микроархитектурных отличий от своего предшественника, процессора P-M на ядре Dothan. Информация о них появилась ещё на весеннем и осеннем форумах IDF-2005, но на фоне новостей о новой процессорной архитектуре Merom/Conroe она не была замечена и оценена по достоинству. Самое интересное, что ничто не предвещало таких изменений в микроархитектуре процессора для мобильных применений. Похоже, что компания Intel выбрала путь осторожного эволюционного развития существующей архитектуры P6+ (P-M), чтобы обкатать различные новшества перед внедрением их в процессоры следующего поколения Merom/Conroe. Вполне возможно, что эти новшества не внесут существенного вклада в увеличение производительности, поскольку они не затрагивают многие «слабые места» архитектуры процессоров P-III/P-M. Однако они касаются как раз тех подсистем процессора, которые представлялись «критическими» для будущей высокопроизводительной архитектуры и относительно которых делались различные предположения.
В настоящей статье новый процессор будет рассматриваться в основном с микроархитектурной точки зрения — то есть, с точки зрения функционирования внутренних блоков процессора и эффективности исполнения программ пользователей. А такие его характеристики и новшества, как управление энергопотреблением (Power management) и технологии виртуализации (Virtualization Technology, VT), будут лишь кратко упомянуты.
Что изменилось?
Основные отличия нового процессора
Основные микроархитектурные изменения в новом процессоре объединены под названием «Digital Media Boost» (что-то вроде «Мультимедийного разгона»).

Изменения эти довольно разрозненные и практически не затрагивают функциональных устройств. В их число входит:
- реализация слияния микроопераций (micro-ops fusion) для инструкций SSE всех типов (SSE/SSE2/SSE3);
- обработка инструкций SSE во всех трёх каналах декодера;
- добавление набора инструкций SSE3;
- ускорение исполнения некоторых инструкций SSE2, а также целочисленного деления;
- улучшение механизма предвыборки из памяти.

Наиболее радикальные изменения коснулись декодера инструкций в части обработки инструкций SSE. Как отмечалось в предыдущей статье, в процессоре P-M появился механизм слияния микроопераций (micro-ops fusion) при декодировании x86-инструкций, суть которого заключается в том, что в ряде случаев вместо двух микроопераций (МОПов) порождается одна (называемая иногда «макрооперацией»), содержащая два элементарных действия. В основном это относится к инструкциям загрузки из памяти с последующим исполнением (Load-Op), когда одна макрооперация замещает МОПы чтения из памяти и выполнения операции. Такая макрооперация расщепляется на два отдельных действия на более поздней стадии прохождения, непосредственно перед запуском на исполнение. Данный механизм похож на аналогичный в процессорах AMD K7/K8, где любой МОП может содержать в себе загрузку из памяти, либо выгрузку в память.
Однако в процессоре P-M механизм слияния микроопераций не был реализован для инструкций SSE с загрузкой и исполнением (Load-Op). Такие инструкции по-прежнему расщеплялись на отдельные МОПы загрузки и исполнения. Помимо увеличения числа МОПов, это приводило к снижению пропускной способности декодера, поскольку такие инструкции могли обрабатываться только в первом, «сложном» канале декодера (остальные два «простых» канала способны порождать лишь по одной микрооперации). Кроме того, и обычные инструкции SSE, не содержащие в себе загрузку из памяти, могли обрабатываться только в первом канале декодера (начиная с процессора P-III). Причём это ограничение относилось не только к упакованным инструкциям SSE, для которых порождается два МОПа 64-битовых операций, но и к скалярным операциям SSE тоже. Вероятно, данное ограничение было связано с трудностями радикальной переделки декодера для поддержки операций SSE в процессоре P-III (кстати, одним из руководителей работы по созданию расширений SSE был наш соотечественник В. Пентковский).
В процессоре P-M2 (Yonah) декодер инструкций был полностью переделан — и теперь он поддерживает слияние микроопераций для инструкций «Load-Op» всех типов (включая SSE), а также обработку инструкций SSE (как скалярных, так и упакованных) во всех трёх каналах декодера. Таким образом, предельная пропускная способность декодера увеличилась в три раза — с одной инструкции SSE за такт до трёх таких инструкций.

На этом рисунке показан пример обработки самого сложного варианта инструкции SSE — упакованной (128-битной) инструкции с загрузкой из памяти и исполнением (Load-Op). В процессоре P-M (Dothan) такая инструкция расщеплялась на 4 МОПа. Согласно рисунку, в процессоре P-M2 (Yonah) образуется лишь один, «склеенный» МОП, содержащий 128-битную загрузку регистра XMM из памяти и 128-битную упакованную операцию. На основании рисунка трудно судить, действительно ли на выходе из декодера будет получена только одна комбинированная «128-битная» макрооперация, которая будет расщеплена на 4 отдельных действия на более поздней стадии, или всё же породятся две «64-битные» макрооперации (каждая с последующим расщеплением на 2 действия). Но в любом случае можно считать, что декодер нового процессора работает по схеме «4-2-2», так как каждый канал декодера теперь может обрабатывать упакованные 128-битные инструкции SSE, которые в функциональных устройствах рассматриваются как две 64-битные. Это усовершенствование роднит P-M2 (Yonah) с процессором AMD K8.
Помимо изменений в декодере, в новом процессоре появился набор инструкций SSE3. Также были ускорены некоторые инструкции распаковки и упаковки из набора SSE2. К сожалению, из доступных документов ничего не известно о темпе выполнения операций 64-битного умножения с плавающей точкой SSE2 (скалярной «mulsd» и упакованной «mulpd»). В процессоре P-M такие операции выполняются в половинном темпе, выдавая один результат в 2 такта для скалярных операций, и один результат в 4 такта — для упакованных. Это вдвое ниже темпа выполнения операций 64-битного сложения SSE2, а также операций 32-битного умножения и сложения SSE. Выполнение 64-битного умножения в полном темпе является совершенно необходимым для процессора, претендующего на конкурентоспособность в приложениях, использующих плавающую арифметику.
Судя по тому, что в рекламных материалах компании нет упоминания о таком усовершенствовании, можно считать, что эти операции выполняются по-прежнему медленно. С учётом этого предположения ситуация с производительностью нового процессора в плавающей арифметике напоминает ситуацию с процессором P-III на момент его появления: скорость 64-битной арифметики осталась невысокой из-за половинного темпа умножения (для P-III — в режиме x87, для P-M и P-M2 — x87 и SSE2), а весь упор сделан на повышение эффективности 32-битной арифметики (для P-III — через SSE, для P-M2 — также и через улучшение декодера, который перестал быть узким местом). Правда, следует отметить, что процессор P-III был многоцелевым, ориентированным на все сферы применения, а P-M2 (Yonah) — это процессор для мобильных применений.

На этом рисунке показан пример улучшения операции целочисленного деления для случаев, когда число значащих цифр в делимом и делителе ограничено 16, либо 24 двоичными разрядами. Особенно интересен самый распространённый случай деления 24-разрядного числа на 16-разрядное — время выполнения такой операции становится вполне приемлемым и составляет всего 4 такта.
Перейдём теперь от микроархитектурных изменений к функциональным, связанным с наличием двух процессорных ядер на одном кристалле. Главным элементом нового процессора, отличающим его как от одноядерного процессора P-M, так и от других двухъядерных процессоров архитектуры x86 (Intel Pentium D/XE и AMD Athlon 64 X2/FX-60), является общий кэш второго уровня.

Реализация общего L2-кэша обеспечивает более высокий уровень интеграции процессорных ядер. Если в системах с раздельными кэшами обмен данными между ядрами осуществляется через коммуникационный интерфейс (шину, либо коммутатор), объединяющий эти ядра за пределами L2-кэшей, то в системе с общим кэшем такие данные доступны обоим процессорным ядрам непосредственно из него. Такая организация позволяет значительно уменьшить время доступа к «чужим» данным, а также снизить трафик шины (коммутатора).
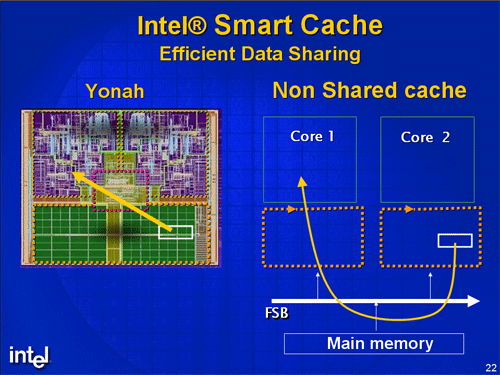
Однако этим преимущества общего кэша не исчерпываются. Процесс, исполняемый в одном CPU, может требовать больше места в L2-кэше для размещения своих данных, чем процесс в другом CPU, и общий кэш с адаптивной организацией позволяет обеспечить большую гибкость в их оптимальном размещении.
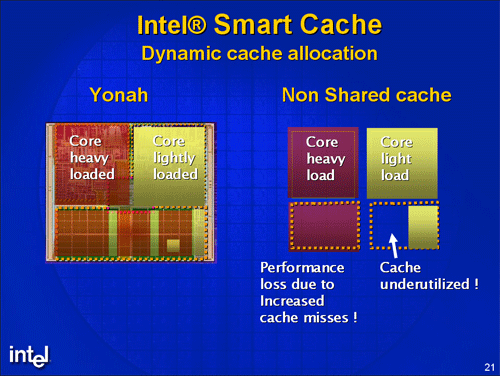
Потребность процесса в пространстве кэша определяется свойством алгоритма, называемом локальностью. Если объём данных, которые требуются процессу в течение определённого периода времени (размер рабочего множества), превышает размер подмножества L2-кэша, выделенного ему в данный момент, то процесс стремится «захватить» больше места в кэше и «отнять» его у процесса с меньшими потребностями. Рассмотрим эффективность использования общего L2-кэша в сравнении с раздельными кэшами такого же суммарного размера для различных сочетаний процессов.
- Исполняются два процесса с одинаковой локальностью — в этом случае каждому процессу достанется по половине кэша.
- Исполняется только один процесс — L2-кэш будет доступен этому процессу целиком.
- Исполняются два процесса с общими (пересекающимися) данными — в этом случае экономится место в кэше, так как исключается дублирование данных.
- Исполняются два процесса с различающейся локальностью — процессу с большими потребностями (худшей локальностью) достанется больше места в кэше.
Таким образом, в первом случае эффективность использования общего и раздельных кэшей не различается, а в остальных — общий кэш используется более эффективно. Лишь в ситуации, когда локальность одного процесса намного хуже, чем другого, первый процесс может вытеснить данные второго процесса из кэша практически полностью и тем самым существенно замедлить его выполнение. Подобные ситуации могут встречаться и в других системах с разделяемыми ресурсами. Например, в любом двухъядерном процессоре один из процессов может требовать намного больше обращений к оперативной памяти, чем другой, и также замедлять его исполнение. В целом, ситуации с сильно несимметричными процессами требуют дополнительного анализа с учётом различных критериев «справедливого» выделения ресурсов.
Согласно первым результатам измерений процессора Yonah, время доступа к общему L2-кэшу увеличилось до 14 тактов — в сравнении с 10 тактами в одноядерном процессоре Dothan. Эти дополнительные такты являются платой за реализацию общего кэша, обеспечение доступа к нему из двух процессорных ядер и затрат на арбитраж. Увеличение времени доступа способно, разумеется, снизить производительность процессора в некоторых применениях (при прочих равных условиях). Однако опыт эксплуатации и измерений различных процессоров показывает, что влияние времени доступа к L2-кэшу обычно не очень велико. Например, в процессорах AMD K7 и K8 при большой нагрузке на L2-кэш эффективное время доступа достигает 20 и 16 тактов, соответственно. Такое увеличение времени доступа связано с эксклюзивной организацией кэша — но оно не сильно влияет на производительность.
Полученные результаты измерений процессора Yonah потребуют подтверждения на других методиках. Также будет необходимо определить пропускную способность L2-кэша. Обеспечение общего доступа для двух процессорных ядер в идеале требует удвоения пропускной способности. Однако темп доступа к кэшу в 32 байта за такт, заявленный для одноядерных процессоров P-III и P-M, представляется несколько избыточным и обычно не подтверждается прямыми измерениями. Возможно, предельная пропускная способность кэша нового процессора не изменилась и по-прежнему составляет 32 байта за такт, а требуемые характеристики одновременного доступа двух CPU обеспечиваются более рациональной организацией и конвейеризацией обращений к кэшу.
Таким образом, благодаря общему L2-кэшу, Yonah является первым высокоинтегрированным двухъядерным процессором архитектуры x86. В связи с начинающимся внедрением двухъядерных процессоров на массовый рынок требования к таким процессорам, а также к методам распараллеливания прикладных задач, должны повышаться. Появление процессоров с общим кэшем второго уровня должно привести к появлению новых методов программирования, обеспечивающих более высокую интеграцию выполняемых процессов и общее повышение скорости их исполнения.
Что не изменилось?
Оставшиеся в наследство слабые места
К сожалению, в последнее время компания Intel не публикует подробных данных о микроархитектуре своих новых процессоров. Поэтому их характеристики приходится определять из кратких рекламных материалов и анонсов (где перечисляются лишь основные отличия от предыдущих моделей), а также средствами экспериментального исследования. Для мобильных процессоров проведение тестовых замеров также затрудняется тем обстоятельством, что такие процессоры не используются для построения серверов и не могут быть протестированы дистанционно — и в то же время они недостаточно распространены, чтобы исследователь мог найти процессор самостоятельно.
Дополнительной причиной «сокрытия» информации о процессорах Pentium M компанией Intel является, по-видимому, желание представить эти процессоры как самостоятельное поколение, отличающееся от старого семейства P6 (PPro, P-II, P-III) — поскольку признание принадлежности процессоров P-M к семейству P6 могло бы выглядеть как шаг назад в сравнении с основной десктопной архитектурой NetBurst (Pentium 4).
Действительно, процессор P-M сохраняет многие черты семейства P6, в том числе его слабые места. В новом процессоре P-M2 (Yonah) устранены очень важные ограничения архитектуры, связанные с декодером (они описываются в предыдущем разделе). Однако другие ограничения, унаследованные из процессоров P-III/P-M, остаются — и в первых результатах замеров это косвенно подтверждается тем фактом, что по производительности в однопоточных приложениях Yonah мало отличается от предшественника (Dothan), в одних случаях немного превосходя его, а в некоторых других — слегка уступая.
Главным недостатком процессоров P-M и P-M2 следует считать слабость блока плавающей арифметики. Этот блок является 80-битным при выполнении операций x87, и 64-битным — для операций SSE. Последнее означает, что 128-битные упакованные операции SSE (4 по 32 бита) и SSE2 (2 по 64 бита) расщепляются на две 64-битные и исполняются последовательно, с вдвое меньшим темпом.
Если бы все 64-битные операции могли выполняться в полном темпе, скорость работы FPU можно было бы считать приемлемой для процессоров такого класса. К сожалению, это требование не соблюдается для устройства умножения. Оно способно работать в полном темпе (выдавая один результат за такт) только в 32-битном скалярном режиме SSE. Также в оптимальном для этой архитектуры темпе устройство умножения работает в упакованном режиме SSE (выдавая четыре 32-битных результата каждые 2 такта). В режиме x87 и в 64-битном скалярном режиме SSE2 умножение выполняется в половинном темпе, а в упакованном режиме SSE2 — соответственно, ещё вдвое медленнее.
Таким образом, несмотря на способность декодера процессора P-M2 порождать достаточное количество микроопераций SSE2 в каждом такте, и, несмотря на возможность запуска МОПов на исполнение в раздельные устройства умножения и сложения через два независимых порта, предельная скорость выполнения 64-битных операций с плавающей точкой снижается вдвое, с двух операций за такт до одной (при равном количестве операций умножения и сложения).
Другой недостаток микроархитектуры процессоров P-III и P-M проявляется в невозможности достижения 100-процентной скорости выполнения даже при оптимальном потактовом планировании машинных инструкций программистом или транслятором. Это связано, вероятно, со схемой организации очереди (буфера) микроопераций, из которой МОПы выбираются для исполнения в функциональных устройствах внеочередным образом, по мере готовности операндов (такой буфер обычно называют «Reservation station»). В других современных процессорах (Intel Pentium 4, AMD K8, IBM PPC970) имеется несколько таких очередей (буферов), по одной очереди на группу близких функциональных устройств. Благодаря этому в каждом такте происходит поиск и выборка для исполнения только одного МОПа из каждой очереди (буфера). В процессоре P-III имеется единый буфер на 20 элементов, и в каждом такте из него извлекается до пяти МОПов. По-видимому, это действие является слишком сложным и не всегда выполняется оптимально, в необходимом темпе. Результаты замеров процессоров P-M (Banias, Dothan) показывают, что у них в этой части изменений не произошло. Предполагается, что организация этого буфера в процессоре P-M2 (Yonah) также не изменилась.
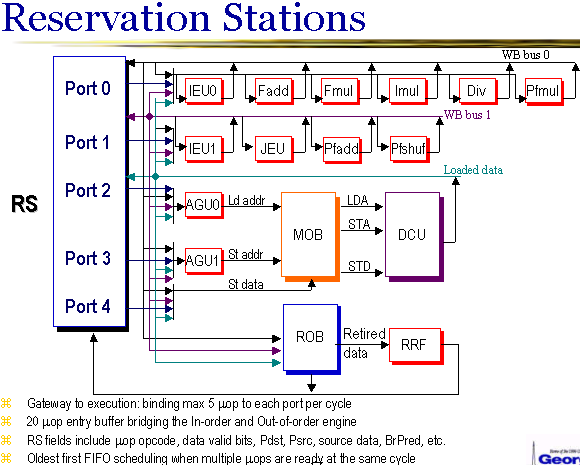
Можно отметить также ряд количественных ограничений, связанных с внеочередным исполнением операций (Out-of-Order execution) — в частности, относительно малую длину упомянутой выше очереди (буфера), равную 20, и небольшой размер «окна» для выполняемых операций («Reorder Buffer»), равный 40. Правда, есть предположения, что в процессоре P-M оба этих буфера несколько увеличены в сравнении с P-III, однако ни документация, ни общедоступные рекламные материалы, на это явно не указывают.
И, наконец, очень важным архитектурным недостатком процессора Yonah (как и его предшественников) является отсутствие поддержки 64-битного режима EM64T (x86-64). Введение такого режима потребовало бы значительной переделки функциональных устройств целочисленной и адресной арифметики, а также увеличения разрядности регистров и ширины внутрипроцессорных шин. Разумеется, в рамках эволюционного развития семейства P6+ такая переделка не могла быть проведена. Поэтому Yonah может в этой части рассматриваться лишь как временный, переходный по отношению к новому семейству универсальных процессоров Merom/Conroe/Woodcrest, в котором, помимо режима EM64T, будет внедрён целый комплекс мер по повышению производительности.
Итоги эволюции семейства P6
Итак, рассмотрим напоследок эволюцию процессоров семейства P6 и подведём её итоги. Для этого выделим пять основных представителей семейства, демонстрирующих развитие процессорной микроархитектуры: PPro, P-II, P-III, P-M, P-M2.
Pentium Pro
Первый суперскалярный процессор архитектуры x86 с внеочередным исполнением операций (Out-of-Order execution). Имеет незначительные архитектурные расширения в сравнении с процессором предыдущего поколения Pentium: добавлены инструкции условной пересылки и новые инструкции сравнения. Исполнен в виде сборки с раздельными кристаллами процессора и L2-кэша. Использовался в основном для серверных применений, выпускался с кэшами различного размера вплоть до 1 МБ.
Pentium II
Добавлен набор инструкций MMX. Увеличены кэши первого уровня, улучшено исполнение 16-разрядных кодов. Исполнен в виде дочерней платы с отдельным кристаллом L2-кэша, работающего на половинной частоте. Выпускался также в следующих вариантах: OverDrive, совместимый с разъёмом процессора Pentium Pro; Celeron без L2-кэша; Celeron и Dixon с интегрированным L2-кэшем уменьшенного размера; Xeon с полночастотным внешним кэшем увеличенного размера.
Pentium III
Добавлен набор инструкций SSE и инструкции предвыборки из памяти. Первоначально исполнен в виде дочерней платы с отдельным кэшем, в последующих вариантах имеет встроенный полночастотный L2-кэш с 256-разрядной шиной. Выпускался также в следующих вариантах: Celeron с L2-кэшем уменьшенного размера; Xeon с полночастотным внешним кэшем увеличенного размера.
Pentium M
Добавлен набор инструкций SSE2. Реализован механизм слияния микроопераций (micro-ops fusion), увеличены кэши первого уровня, ускорена работа с аппаратным стеком, существенно улучшен механизм предсказания переходов. В связи с ориентацией на мобильные применения внедрены радикальные технологии энергосбережения. Введена новая процессорная шина, заимствованная у процессора Pentium 4. Произведён ряд микроархитектурных усовершенствований, операции плавающего умножения и сложения разнесены на два отдельных порта запуска. Во второй модели процессора P-M (Dothan) устранены задержки из-за «частичной записи в регистр» («Partial register stall»), удвоен темп выполнения инструкции сложения MMX.
Pentium M2 (Core Duo)
Добавлен набор инструкций SSE3. Существенно улучшен декодер с поддержкой механизма слияния микроопераций для инструкций SSE и обработкой упакованных инструкций SSE во всех каналах декодера. Ускорено выполнение некоторых инструкций, усовершенствован механизм предвыборки из памяти. Содержит на кристалле два процессорных ядра и общий L2-кэш. Поддерживает технологию виртуализации VT и усовершенствованные технологии энергосбережения.
Развитие микропроцессоров семейства P6 сопровождалось совершенствованием электронных технологий и уменьшением технологических норм с одновременным увеличением размера L2-кэша. За счёт усовершенствования микроархитектуры, устранения узких мест, увеличения кэшей и повышения тактовой частоты производительность процессоров семейства выросла и по некоторым показателям приблизилась к производительности конкурирующих продуктов (AMD Athlon 64 и Intel Pentium 4).
Ниже приведена сводная таблица основных процессоров семейства P6.
| процессор |
Комментарии