Сущность, сферы применения и особенности реализации
- Введение
- Список литературы
- Приложение
Двоичная трансляция (ДТ) — технология с достаточно длинной на данный момент историей, отсутствием каких-либо официальных документов, подробно описывающих достижения в этой области, и непредсказуемым будущим. Несмотря на то, что уже был реализован ряд систем двоичной трансляции и проведена серия исследований в этой области в различных научных центрах, до сих пор никто не использует такие системы в повседневной работе. Это и по сей день является многообещающей технологией и притягательным для многих инженеров направлением исследований. Уже давно витает в воздухе вопрос, где же реальные реализации в области двоичной трансляции, имеющие возможность стать всемирнопризнанными коммерческими продуктами?
Далее я планирую рассмотреть предпосылки возникновения двоичной трансляции и причины, по которым некоторые, наиболее известные продукты не смогли достичь коммерческого успеха, и отдельно сфокусировать внимание на двух, взаимодополняющих друг друга подходах — динамической и статической ДТ.
Классификация систем ДТ по типу (FBTS и ABTS)
ДТ традиционно понимается как полностью программная реализация или как сочетание последней с аппаратной поддержкой, но, в любом случае, такая система исполняет исходный код на некоторой целевой платформе, несовместимой с исходной (хотя это не всегда так, но это главная цель, которую преследовало большинство систем ДТ). Один из самых общих подходов к классификации систем ДТ заключается в их разделении на FBTS(Full Binary Translation Systems) и ABTS(Applications Binary Translation Systems). FBTS захватывает исполнение программного кода на целевой машине в момент её загрузки и затем контролирует исполнение всего ПО на данной машине, начиная от BIOS и ОС и заканчивая пользовательскими приложениями. ABTS, в отличие от FBTS, использует ОС целевой машины и транслирует только приложения, таким образом, ABTS увеличивает функциональность машины посредством добавления возможности выполнять «чужой» код (foreign code), а не является жизненно необходимым звеном всей машины. ABTS обеспечивает более гибкий способ использования аппаратуры. FBTS заходит в этом направлении дальше, создавая дополнительный слой между аппаратурой и программным обеспечением, полностью скрывая от последнего детали архитектуры, как, например, в проекте Code Morphing, Transmeta [14], [15].
Безусловно, можно предложить и другие методы классификации систем ДТ, например, на основе выполняемой ими задачи, что и будет рассмотрено в следующем разделе.
Классификация систем ДТ по выполняемой ими задаче
Межплатформенная совместимость
Сама идея бинарной трансляции появилась достаточно давно, когда объёмы написанного программного обеспечения стали настолько велики, что было уже нерационально переписывать программы для вновь появляющихся архитектур. Именно поэтому инженеры задумались о межплатформенной совместимости, которая и является главным применением технологии ДТ.
Первое, что было сделано, — это пошаговый интерпретатор (один из первых примеров: IBM-система System/360 обеспечивала эмуляцию для более старых машин IBM 1401, 1964 г.). Пошаговая интерпретация — наиболее примитивный метод, интерпретатор выбирал одну команду исходного кода и заменял её несколькими командами целевого кода. Этот подход чрезвычайно прост и надёжен, заодно и исчезает проблема точных прерываний (приложение), т.к. контекст исходной машины обновлялся сразу же после исполнения очередной исходной инструкции. К существенным недостаткам можно отнести, в первую очередь, колоссальное замедление по сравнению с исходной архитектурой. Спустя некоторое время IBM создала обновлённый симулятор, который уже интерпретировал не по одной инструкции, а группы инструкций, что было продиктовано эмпирически подтверждённым предположением о том, что трансляция инструкций группами способна значительно повысить эффективность.
Одними из первых систем, использовавших бинарную трансляцию и добившихся приемлемой производительности, стали VEST- и mx-трансляторы (OpenVMS—>OpenVMS Alpha AXP, MIPS ULTRIX—>DEC OSF/1 AXP). Они начали сочетать эмуляцию с бинарной трансляцией. В идеале, как предполагалось разработчиками, интерпретатор должен был запускаться только для динамически генерируемого кода, так как единицы трансляции (translation unit, TU) уже должны были находиться в памяти. Если всё-таки соответствующая единица трансляции не найдена в памяти, то запускался интерпретатор.
Развитие бинарных трансляторов было в значительной мере подстёгнуто распространением RISC-архитектур, которые, как считалось, должны были бы стать доминирующими на рынке компьютеров, поэтому начались разработки бинарных трансляторов CISC—>RISC.
Знаковой системой, появившейся на рынке в 1996 г., стала FX!32 (x86—>Alpha). Мечта об объединении эмуляции, бинарной трансляции и профилирования (приложение) впервые реализовалась в коммерческом продукте. Первый раз программа полностью эмулировалась, и записывался её профиль, который затем направлялся в фоновый транслятор, и последний транслировал исходный код в целевой, проводя дорогостоящие оптимизации на уровне TU. Производительность этой системы на самом мощном на тот момент процессоре Alpha сравнивалась со скоростью исполнения исходного кода на наилучшем чипе компании Intel.
И, наконец, одна из самых успешных разработок начала века — мобильный VLIW-процессор Crusoe от компании Transmeta. Он поддерживал выполнение x86 за счёт двоичной трансляции. Данный транслятор был на 3/4 реализован в виде программного продукта и оставшаяся 1/4 — в самом чипе. Результат оказался внушительным: 700 Мгц Cursoe по производительности сравнивался с Pentium 3 500-550 Мгц, но имел потребляемую мощность в 3-6 раз меньше.
Виртуализация
Выделилось и ещё одно направление применения бинарной трансляции — виртуализация (приложение), но виртуальные машины, как правило, эмулируют только привилегированные инструкции, создавая впечатление для нескольких гостевых ОС единовластного обладания микропроцессором.
Внутриплатформенная динамическая оптимизация
Во второй половине 90-х ряд систем был ориентирован на чисто динамическую трансляцию. Они проводили оптимизацию уже скомпилированного кода, подстраивая его под текущее поведение программы, т.е. используя информацию времени выполнения, недоступную на стадии статической компиляции программы, написанной на языке высокого уровня. Оптимизации могли проводиться на глобальном уровне, охватывая несколько модулей (исполняемый модуль и DLL-библиотеки). Неоптимизированные участки кода напрямую исполнялись на машине (ведь в данном случае, в отличие от предыдущих, исходная и целевая архитектуры просто совпадали). Наибольшего успеха достиг проект Dynamo/Dynamo RIO [1], [5], но выигрыш от оптимизаций не превосходил накладных расходов, вызванных проведением этих оптимизаций. Похоже, что это направление бесперспективно без использования специальной аппаратной поддержки, которая отсутствует в существующих на данный момент микропроцессорах.
Инструментирование кода
На протяжении последних 15 лет были созданы чрезвычайно мощные по своим возможностям средства для инструментирования (приложение) программ такие, как Pin [10], [16], Atom [2], EEL [6], Etch [7], Morph и т.д. Инструментирование — добавление некоторого кода, в двоичную программу для получения сведений о её поведении во время выполнения. Это достигается за счёт динамической бинарной трансляции. Эти средства анализа, прежде всего, полезны для разработчиков ПО, но абсолютно бессмысленны для конечных пользователей. Оптимизации внутри средств инструментирования понимаются как минимизация издержек, обусловленных самим процессом инструментирования, и имеют мало общего с оптимизациями кода исследуемой программы.
Содействие проникновению на рынок новых архитектур
Многие исследователи в области ДТ полагают, что у ДТ есть великое будущее в области сотрудничества с инженерами, разрабатывающими новые типы архитектур, не совместимые с IA. Сейчас почти невозможно представить коммерческий успех какого-либо процессора, который не поддерживает x86-архитектуру, потому что Intel де-факто является монополистом на рынке микропроцессоров, и все разработчики ПО ориентируются на процессоры, выпускаемые компанией Intel, так что никто не станет перекомпилировать уже написанный исходный код для новых процессоров.
IA-32 EL [17] нельзя рассматривать как пример такой системы, поскольку большинство пользователей процессоров Itanium используют код, специально скомпилированный для него, а не транслируют x86-код. Transmeta и Elbrus впервые в мире создали подобные системы, но Elbrus является закрытым проектом, поэтому ни о каком коммерческом применении говорить нельзя, а Crusoe не оправдал всех надежд и по ряду причин не смог выжить на рынке. По крайней мере, эти два продукта доказали возможность реализации подобных систем.
Главное условие успешности — это создание такой архитектуры, преимущества которой могли бы значительно перекрыть издержки ДТ.
Взаимодействие ДТ с другими областями Computer Science
Не стоит рассматривать ДТ как совершенно независимую ветвь информатики (Computer Science), она активно взаимодействует с другими технологиями такими, как ОС, агрессивные оптимизации, профилирование, оптимизации на основе профилирования, параллельные вычисления, базы данных и т.д. В этом разделе я рассмотрю ключевые области Computer Science, с которыми приходится активно «сотрудничать» при создании систем ДТ.
- Операционые системы
- ABTS-системы вынуждены чётко отделять приложение от работы ОС; для обработки системных вызовов, используемых приложением, ABTS должна взаимодействовать с используемой ОС. FBTS-системы не сталкиваются с такой проблемой, потому что они полностью транслируют и ОС, и приложения, но FBTS поддерживает многие элементы, встроенные в ОС, такие, как: управление памятью, управление временем, которое тратит ЦПУ на обработку каждого потока, поддержка механизма исключений и т.д.
- Гарантия качества
- Системы ДТ должны обеспечивать высокий уровень надёжности, особенно FBTS, т.к. если происходит ошибка внутри ABTS, то это не приведёт к чему-нибудь серьёзному, кроме невозможности исполнения какого-либо приложения, но если что-то случится внутри FBTS, то придётся перезагружать компьютер, что, естественно, недопустимо.
- Профилирование и оптимизации на его основе
- Такой подход является обычным для современных оптимизирующих компиляторов, но он наталкивается на ряд ограничений, прежде всего из-за отсутствия необходимой аппаратной поддержки. Оптимизации на основе собранного профиля гораздо чаще применяются в системах ДТ, но и здесь желательна аппаратная поддержка.
- Многопоточность
- Поскольку современные ДТ могут выполнять несколько действий одновременно, например, транслировать несколько приложений одновременно, проводить сбор профиля других программ, выполнять фоновую трансляцию и т.д., поэтому приходится использовать преимущества многопоточности и тщательно организовывать взаимодействие и синхронизацию между отдельными потоками.
- Работа с базами данных
- Системы ДТ сохраняют уже оттранслированный код во внешней памяти для дальнейшего использования. Это позволяет устранить дополнительные накладные расходы, связанные с повторной трансляцией, но требуется тащтельно продуманный механизм управления и контроля такой памяти.
Ключевые концепции двоичной трансляции
- Многоуровневая система оптимизаций
- Этот метод предусматривает многоуровневую систему баланса между затратами на оптимизации и выигрышем, получаемым от них. Часть системы ДТ, которая занимается оптимизациями внутри транслированных частей кода, следит одновременно за «температурой» кода (как часто исполняется та или иная часть кода). Очевидно, что чем агрессивнее оптимизации, тем больше времени на них тратится. Естественно, не стоит сильно оптимизировать тот код, который исполняется редко. Различные системы ДТ применяют статические или динамическаие (адаптивные) пороги, т.е. если «температура» превосходит пороговое значение, то этот кусок кода надо перетранслировать, применив более высокий уровень оптимизации. Пороги могут динамически меняться в зависимости от поведения программы, например, как в Elbrus.
- Агрессивная оптимизация, основанная на «оптимистических» предположениях
- Такого рода оптимизации открывают новые возможности для ДТ, будучи недоступны статическим компиляторам. Сложность x86-системы команд требует от компилятора построения такого кода, который учитывал бы даже крайне маловероятные случаи, в результате происходит замедление во времени выполнения программы. ДТ способен выкинуть ряд проверок из кода на основе предположений, что такие ситуации крайне маловероятны, например, можно считать, что адрес возврата из процедуры не меняется внутри неё самой и т.д. Безусловно, такие предположения должны проверяться во время выполнения, в случае их нарушений код должен быть перетранслирован.
- Сочетание online и offline трансляции
- Довольно перспективен подход, сочетающий трансляцию во время выполнения и фоновую трансляцию. Фоновая трансляция несостоятельна сама по себе, ей требуется профиль выполнения программы, собранный на основе одного или нескольких предыдущих запусков. В то же время фоновая трансляция не накладывает никаких ограничений на издержки, связанные с агрессивностью оптимизаций и областью анализа. Она обладает рядом недостатков, например, не всегда может обрабатывать динамически генерируемый код. Такой подход был применён в FX!32 [4]. Более подробно этот пункт будет рассмотрен в рамках главы статическая двоичная трансляция.
- Адаптивный метод выбора единиц трансляции
- Статический компилятор работает в рамках отдельной процедуры, оптимизирующие компиляторы применяют межпроцедурные оптимизации, разрушая тем самым границы процедуры, но всё равно работа статического компилятора неразрывно связана с понятием процедуры. ДТ может выбирать в качестве единицы трансляции абсолютно произвольный кусок кода, не обращая внимание на границы процедур, если они мешают выполнению оптимизаций. Кроме этого, ДТ позволяет очень эффективно отслеживать зависимости между отдельными единицами трансляции для того, чтобы в случае локальных изменений кода не пришлось бы перетранслировать всю программу, а статический компилятор не может сохранять подобную информацию.
- Сочетание агрессивных оптимизаций с возможностью получить точный контекст
- В системах ДТ существует ещё одна проблема — получение точно контекста (приложение) после инструкции, вызвавшей прерывание, но, поскольку эта инструкция находится внутри кода, подвергнутого агрессивным оптимизациям, то просто так получить точный контекст не удастся, потому что он не будет соответствовать тому, который был бы получен в исходном приложении. Существуют чисто программные, чисто аппаратные решения а также их комбинация. Система Transmeta's Code Morphing [14], [15] использовала аппаратуру, Dynamo [1], [5] использовала программные методы, которые будут более подробно рассмотрены в разделе динамическая трансляция.
- Получение состояния только в случае необходимости
- Ещё один подход, применяемый в системах ДТ, заключается в устранении избыточности x86-кода путём выполнения ряда инструкций только в том случае, если их результат действительно необходим. Например, если результат инструкции важен только в том случае, если произойдёт исключение, то её можно выполнить после того, как произойдёт исключение.
- Необходимость совместного проектирования ДТ и аппаратуры
- Это крайне важно для FBTS систем, поскольку они нуждаются в большем сотрудничестве с аппаратурой, чем ABTS. Отимальное распределение решаемой задачи между аппаратным обеспечением и программным позволяет реализовать отдельные части наиболее оптимально и добиться впечатляющей производительности. Аппратура может содействовать в обработки самомодифицирующегося кода, обработке исключений и т.д. Например, в проекте Elbrus было более 20 особенностей в аппаратуре, специально предназначенных для нужд ДТ.
- Уменьшение специфичных для ДТ накладных расходов
- Издержки, связаные с ДТ, не могут быть полностью устранены, но их можно значительно уменьшить. Например, самая широко известная проблема — динамическая трансляция адресов. Косвенные переходы в x86-коде могут замедлить работу ДТ до трех раз по сравнению с трансляцией x86-кода с отсутствием косвенных переходов. Для этого применяются различные методы (о програмных реализациях этих методов в Dynamo будет рассказано в главе динамическая трансляция), в том числе и аппаратные методы. В итоге, в рамках проекта Elbrus было доказано, что этот тип издержек можно снизить до 1% всех накладных расходов.
- Самомодифицирующийся код
- Самомодифицирующийся код — камень преткновения систем ДТ, но современные системы отлично справляются с такими случаями. Они используют чисто программные решения (ABTS) или их сочетание с аппаратными (FBTS). Стоит отметить, что ABTS-системы вносят существенное замедление при обработке таких кусков кода, хотя FBTS-системы, используя аппаратуру, транслируют такой код без каких-либо специфических накладных расходов.
Анализ осуществлённых проектов
История ДТ насчитывает более 20 лет, но всего лишь известно несколько проектов, которые хоть и не добились широкого распространения, но достигли поставленных целей. Среди ABTS стоит отметить IA-32 EL [17] и Rosetta [19], Pin (средство для инструментирования) [10]; FBTS: Эльбрус [18] и Transmeta [14], [15]. Разработка системы ДТ эквивалентна созданию современной ОС и оптимизирующего компилятора вместе взятых, поэтому и неудивительно, что за столько лет было создано считаное число ДТ. Учитывая доминирование на рынке микропроцессоров x86-архитектуры, никому не приходит в голову разрабатывать ДТ, потому что во многих случаях легче перекомпилировать старое ПО. Но ДТ следует рассматривать как нечто, что может позволит создать новую архитектуру, не стоит ждать, пока она появится, а после разрабатывать ДТ — система ДТ должна быть её составной частью.
Неудача компании Transmeta свидетельствует о том, что прорваться на рынок небольшой компании и с архитектурой, не превосходящей x86, почти невозможно, точнее, удержаться на рынке невозможно. Но эта неудача не ставит под сомнение саму идею ДТ. Как упомяналось выше, архитектура должна быть значительно лучше x86, чтобы скомпенсировать издержки двоичной трансляции. Не стоит считать, что x86-архитектура настолько сложна, что просто невозможно создать полностью совместимый с ней транслятор. Transmeta и Эльбрус смогли и были пионерами в этой области, значит, можно продолжать исследования и разрабатывать более сложные многопроцессорные системы.
На аналогичную проблему наткнулись системы динамической оптимизации такие, как Dynamo RIO [5] и Microsoft Mojo. Невозможно значительно улучшить существующий код при трансляции x86—>x86, потому что слишком мало информации есть у ДТ о структуре кода, являются ли обращения к памяти действительно volatile или нет и т.д.
Существует подход, использующий аннотации, добавляемые статическим компилятором, но на практике это не применяется и вряд ли будет применять в течение следующего десятилетия, поскольку требуется разработка некоторого стандарта основными производителями компиляторов на эти анотации. К тому же, задача динамической оптимизации не является первостепенной. В рамках совместного проекта Intel-Elbrus была произведена оценка преимущества использования аннотаций. Оно составило примерно 10%, но это не та цифра, которую ждут конечные пользователи. Едва ли кто-нибудь согласиться использовавть средства динамической оптимизации, значительно повышающие риск сбоя в системе, ради выигрыша в производительности размером в 10-15%. Следовательно, в ближайшем будущем это направление следует считать бесперспективным.
Системы ДТ влекут за собой некоторое увеличение энергопотребления компьютером, поскольку микропроцессору приходится выполнять дополнительную работу, связанную с транслированием и оптимизацией кода. Механизм многоуровневой трансляции позволяет сделать оптимальными и эти издержки тоже. В целом это неактуально для современных технологий трансляции.
Переходя от общих концепций к деталям их практической реализации, нельзя не упомянуть о двух направлениях двоичной трансляции. Затем я их рассмотрю на примере конкретных систем.
Динамическая и статическая бинарная трансляция
Можно выделить два взаимно дополняющих направления бинарной трансляции: статическая и динамическая трансляция.
Статический подход не позволяет полностью проанализировать уже скомпилированный модуль, потому что данные и код могут быть расположены внутри модуля в произвольном порядке, т.е. данные и код могут чердоваться, и при статическом подходе просто не хватает информации о том, как интерпретировать некоторую последовательность байт, как данные или как код. Кроме того, неизвестны адреса косвенных переходов и функций, вызываемых динамически: также отсутствует информация о загружаемых во время исполнения динамических библиотеках и динамически генерируемом коде.
Я предлагаю рассмотреть эти два подхода на примере наиболее значимых систем в истории двоичной трансляции, реализовавших их в своё время, поскольку они воплотили в жизнь ключевые идеи бинарной трансляции и в значительной степени определили последующее развитие подобных систем. Итак, FX!32 [4] можно считать примером системы, использовавшей статическую двоичную трансляция, хотя в ней, безусловно, присутствует элемент динамического анализа, а именно — получение профиля программы. DynamoRIO [5] — полностью динамическая модель бинарной трансляции.
Динамический подход
В последнее время наметилась тенденция по уменьшению качества кода, генерируемого native-компиляторами (приложение), которое измеряется в терминах скорости выполнения программы вследствие того, что значительная часть информации о поведении программы становится доступной только во время её исполнения. Оптимизации native-компилятора, во-первых, ограничены границами анализируемого кода (ведь динамически загружаемые модули просто ему не доступны для анализа), а, во-вторых, использованием разработчиками ПО опций компилятора, не предусматривающих агрессивные оптимизации, так как они затрудняют отладку программы. Вследствие этого представляется разумным применение дополнительных оптимизаций на стадии выполнения. Сбор профиля и фоновая трансляция, как сделано в FX!32, не всегда может привести к повышению производительности в системе двоичной трансляции, в которой исходная и целевая архитектуры совпадают, т.к. поведение программы может меняться в зависимости от входных данных и может зависеть от пользователя в случае, если программа интерактивная.
Главное преимущество динамической трансляции — возможность произвести адаптивную, архитектурно-зависимую и межмодульную оптимизации.
Адаптивная оптимизация выполняется на основе сведений, непрерывно поступающих от программы, о том, какой код является горячим. Рабочее множество (working set), как правило, непрерывно меняется. В рамках проекта Dynamo [5] (это система ДТ, призванная оптимизировать код во время выполнения программы) было обнаружено, что если частота этих изменений не настолько велика, что Dynamo тратит на поиск «горячих» трасс (приложение) больше времени, чем выигрыш от оптимизаций, то применение Dynamo и других подобных систем является оправданным. Кстати, именно этот критерий используется Dynamo, чтобы установить, нужно ли вообще транслировать программу или выгоднее её выполнять напрямую на процессоре.
Межмодульная оптимизация принципиально не может быть выполнена статическим native-компилятором, т.к. динамически загружаемые библиотеки доступны для анализа только во время выполнения. Именно эта оптимизация позволяет «стереть» границы между отдельными частями программы, в рамках которых и работал native-компилятор.
Динамические оптимизации обладают также и существенными недостатками. Во-первых, время их выполнение должно быть меньше выигрыша во времени, получаемого вследствие этих оптимизаций. Это ограничивает размер области кода, которая принимается во внимание при их выполнении. Во-вторых, динамическая система должна обеспечивать «прозрачность» оптимизируемой программы, т.е. её состояние (контекст, стек, память) не должно зависеть от присутствия самой динамической системы в том же адресном пространстве. Работа динамической системы в том же адресном пространстве, а не в виде отдельного процесса, связана с желанием устранить издержки, обусловленные обменом информацией между процессами через разделяемую память или файл.
Типичные оптимизации
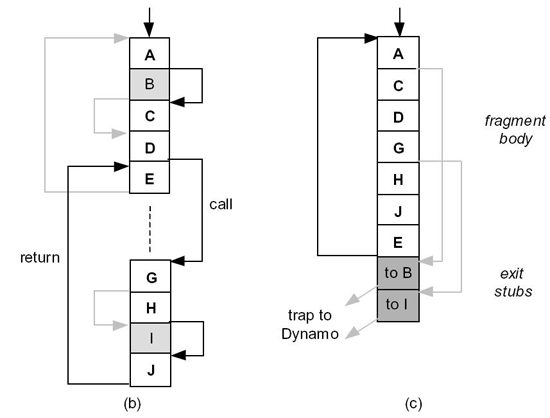
Рис. 1
Система динамической трансляции может работать с различными единицами кода, подлежащего оптимизации. В зависимости от решаемых задач это могут быть как отдельные инструкции, базовые блоки, процедуры, трассы, так и регионы (приложение). Например, трасса в Dynamo может содержать вызовы функций и команды перехода.
Работа с регионами как с единицами трансляции позволяет проводить оптимизации за счёт удаления переходов, вызова процедур и возврата из них. Косвенные переходы выполняются следующим образом: адрес перехода определяется во время выполнения, как правило, такие инструкции чаще всего переходят на один и тот же адрес, поэтому возможно осуществить связывание отдельных регионов и добавить контроль для проверки во время выполнения, корректно ли выполнен переход.
Благодаря достигнутой линейности потока управления внутри трассы становятся возможными оптимизации по удалению избыточности (избыточных инструкций load, избыточных присвоений) и типичные для native-компилятора оптимизации такие, как распространение копий и констант, «раскрутка» циклов и т.д. Также можно удалить инструкции ret (если адрес возврата не меняется) и присвоение регистру перед выходом из фрагмента, если он в другом фрагменте перезаписывается перед использованием.
Ещё одна «оптимизация» осуществляется на стадии соединения фрагментов (т.е. транслированных «горячих» регионов) (рис. 1), она состоит в связывании переходов, являющихся выходами из отдельных фрагментов, с адресами начала фрагментов, если такие имеются в кэше. На рис. 1.b показан исходный набор фрагментов и переходы между ними, а на рис. 1.c те же самые фрагменты, но уже в связанном виде. Последнее действие значительно уменьшает время выполнения программы и является одним из базовых во всех бинарных трансляторах, т.к. устраняются накладные расходы, связанные с передачей управления среде окружения.
Управление кэшем фрагментов
Оттранслированные фрагменты хранятся в кэше фрагментов, потому что было бы нелогично каждый раз заново транслировать некоторый фрагмент, если ему снова передаётся управление. Кэш фрагментов позволяет значительно снизить издержки, связанные с повторной трансляцией. В динамических системах кэш фрагментов устроен так, что сами фрагменты внутри него неперемещаемы, иначе пришлось бы менять ссылки во всех фрагментах, так как переходы могут происходить из одного фрагмента в другой, но это влечёт за собой огромную потерю производительности. В процессе работы программы, как уже не раз упоминалось, рабочее множество может меняться, это вызывает генерацию новых фрагментов, разрастание кэша фрагментов, возможное уменьшение локальности расположения фрагментов (одно из преимуществ, извлекаемых от использования кэша). Реализация алгоритмов для отслеживания кода в кэше, который становится «холодным» (приложение), чтобы его потом удалить, также требует больших накладных расходов, как и алгоритмы размещения вновь создаваемых фрагментов на месте только что удалённых.
Один из перспективных подходов — полная очистка кэша и всех связанных с ним структур, хранящих информацию об отдельных фрагментах. Полное опустошение кэша следует проводить лишь в том случае, когда потребность генерирования новых фрагментов превосходит некоторый порог. Это всего лишь,свидетельствует об изменении рабочего множества, следовательно, прежние фрагменты с большой долей вероятности не понадобятся. Если это не так, то они будут сгенерированы заново. Этот метод позволяет избежать всех рассмотренных выше недостатков.
Обработка прерываний
Обработка прерываний — отдельная проблема двоичной трансляции, т.к. во время исполнения некоторой ранее оптимизированной бинарным транслятором единицы кода невозможно восстановить контекст приложения, который необходимо передать обработчику прерывания (оптимизатор меняет порядок инструкций и удаляет избыточные инструкции). Существует несколько подходов для решения этой задачи.
Один из них предусматривает создавать контрольную точку, сохраняющую точный контекст приложения, перед исполнением очередного TU (translation unit). Если прерывание возникнет во время выполнения TU, то следует вернуться к контрольной точке, восстановить контекст, запустить интерпретатор, выполняющий native-инструкции без оптимизаций. На этом проходе того же самого блока кода будет доступен контекст в момент возникновения прерывания.
В проекте Dynamo асинхронные прерывания помещались в очередь, т.к. сама система Dynamo отслеживала вызов обработчиков прерываний. Во время прихода прерывания производилась остановка выполнения фрагмента, но перед возобновлением исполнения корректировались все переходы из этого фрагмента в другие и переходы в циклах так, чтобы Dynamo получило управление сразу же после выхода из данного фрагмента без перехода в другой фрагмент (если это было возможно в отсутствие прерывания). Такая корректировка переходов, которая начинается сразу же после завершения исполнения текущего фрагмента, уменьшает задержки перед обработкой асинхронных прерываний. Контекст, передаваемый системному обработчику, естественно не имеет ничего общего с тем контекстом, когда произошло прерывание. Главная идея состоит в том, что асинхронные прерывания можно «немного» задержать перед обработкой и передать им новый контекст, доступный при выходе из фрагмента.
С синхронными прерываниями нельзя так поступать, т.к. их нельзя задерживать, поэтому было введено понятие консервативных (conservative) и агрессивных (agressive) оптимизаций. Первые позволяют восстановить контекст исходного приложения с помощью выполнения некоторых действий. К консервативным оптимизациям относятся constant propogation, constant folding, strength reduction, copy propogation, redundant branch removal и т.д. Агрессивные оптимизации добавляют к списку консервативных следующие: dead code removal, code sinking loop invariant code motion. Сначала к выбранному региону применяются агрессивные оптимизации, пока не встретится команда, которая может привести к возникновению синхронного прерывания. В этом случае трансляции данной трассы начинается заново с применением консервативных оптимизаций.
Разработчики Dynamo предложили и ещё один метод: запись log-файлов, которые должны добавляться оптимизатором к каждому фрагменту и содержать компенсирующие действия для того, чтобы из имеющегося контекста получить оригинальный контекст. Log-файлы должны содержать информацию о том, какие именно инструкции были удалены.
Поиск горячих регионов
Применяются различные методы для выделения «горячих» регионов. Размер такого региона тоже может определяться его степенью «нагретости». Динамический подход, реализованный в Dynamo, позволил значительно сократить время, необходимое для отслеживания «горячих» трасс. Несмотря на то, что выделение «горячих» трасс объединяет абсолютно разные по своей сути системы: Dynamo и FX!32, методы их поиска существенно различаются. В Dynamo вместо профилирования использовался механизм MRET(most recently executed tail) [4], основанный на элементарном предположении, что команда, следующая за «горячей» инструкцией, является тоже «горячей». Процесс выбора инструкций прекращался при выполнении условия «конец трассы». Кроме очевидного выигрыша во времени, было достигнуто сокращение используемой памяти по сравнению с профилированием.
Dynamo
Рассмотрим теперь в общих чертах сам проект Dynamo (рис. 2), потому что все остальные системы динамической бинарной трансляции используют очень похожую концептуальную модель.
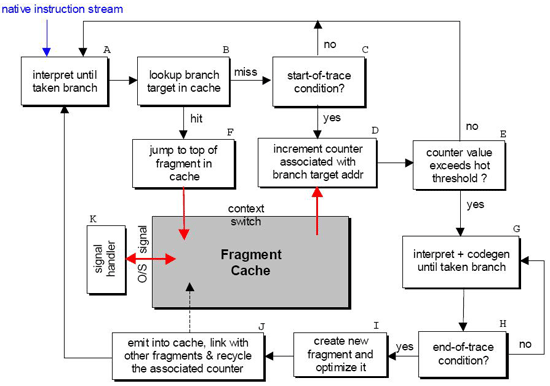
Рис. 2
Dynamo сначала начинает интерпретировать source-код до тех пор, пока не встретит команду перехода (А). Если адрес перехода находится в кэше фрагментов, то управление передаётся этому фрагменту(B), в противном случае если адрес перехода удовлетворяет условию «начало трассы», то инкрементируется счётчик, связанный с этим адресом(D). В случае превышения этим счётчиком некоторого порогового значения(Е), интерпретатор переходит в режим кодогенерации(G) пока не выполнится условие «конец трассы»(H). В этот момент запускается оптимизатор, который создаёт из полученной трассы фрагмент с одним входом и несколькими выходами (I). Далее этот фрагмент передаётся компоновщику, помещающему его в кэш и связывающему адреса переходов, встречающихся внутри фрагмента, с адресами других фрагментов в кэше, если они там присутствуют.
Статический подход
Статическая трансляция имеет некоторые преимущества перед динамической, такие, как: отсутствие медленного старта (динамическому транслятору нужно выявить рабочее множество и оттранслировать его одновременно с началом исполнения программы), более агрессивные оптимизации, меньшие накладные расходы при выполнении коротких программ, отсутствие временных ограничений.
Для выполнения статической трансляции необходимо иметь некоторую динамическую информацию, потому что адреса функций, вызываемых динамически, динамических функций и косвенных переходов неизвестны во время статического анализа кода.
Обычно во время первого исполнения программа эмулируется (в схемах со статической трансляцией), и записывается её профиль, содержащий следующую информацию (на основе технической документации по FX!32):
- адреса, являющиеся аргументами инструкций call
- исходные адреса косвенных переходов и их целевые адреса
- адреса инструкций, выполняющих «невыровненные» (unaligned) обращения к памяти
Интерпретатор размещает эту информацию в хэш-таблице. Например, когда встречается очередная команда call, он записывает в хэш-таблицу адрес вызываемой функции. Когда образ выгружается из памяти, все данные в хэш-таблице, относящиеся к нему, записываются в соответствующий файл. В этот момент может быть запущен транслятор в фоновом режиме для только что выгруженного модуля. Транслятор в FX!32 разбивает исходный код на процедуры, и они являются единицами трансляции.
Рассмотрим типичные фазы статического транслятора на примере одного коммерческого проекта, который нахожится в стадии разработки:
- Выделение базовых блоков
На этом уровне анализируется подаваемый на вход исполняемый файл для х86-архитектуры, выделяются инструкции; декодирование осложнено тем, что инструкции и данные расположены вместе, и заранее неизвестно, как интерпретировать рассматриваемую последовательность байт — как код или как данные. Применяется следующий подход к декодированию: сначала транслятор пытается декодировать код с некоторой позиции в файле, потом — с другой точки, отстоящей от предыдущей на один байт. Если начальная точка выбрана неправильно, т.е. она не соответствует началу некоторого фрагмента кода в файле, то, проанализировав декодированную последовательность команд, станет ясно, что данная начальная точка выбрана неверно.
- Выделение процедур
На основе представления программы как совокупности базовых блоков происходит выделение отдельных процедур.
- Преобразвание совокупности процедур в промежуточное представление
Строится промежуточное представление в терминах x86 кода
- Преобразование промежуточного представления
Построенное промежуточное представление в терминах x86 кода преобразуется в промежуточное представление для новой архитектуры
- Оптимизации
Выполняется 2 типа оптимизаций кода: первый тип — шаблонные оптимизации, которые работают на основе поиска характерных последовательностей команд в коде и заменяют их наиболее оптимальными последовательностями; второй тип — оптимизации на основе анализа графа потока управления (преобразование циклов, раскрутка циклов и т.д.)
- Выделение регистров
Происходит выделение регистров и других ресурсов
- Преобразование промежуточного представления в asm-код
Преобразуется промежуточное представление в ассемблерный код целевой архитектуры
- asm—>код
Преобразуется полученный на предыдущей фазе ассемблерный код в машинный код целевой архитектуры
В FX!32 процесс трансляции запускается вновь, если наблюдается значительный рост размера профиля, генерируемого эмулятором. Это значит, что рабочее множество изменилось, и кэш фрагментов содержит много уже устаревших кусков транслированного кода. Поскольку транслятор работает в фоновом режиме, становится неважным, как много времени он тратит на анализ и оптимизацию, т.е. доступны большие области для оптимизации данных и более агрессивные методы оптимизации, чем в случае с динамическим транслятором.
В Alpha (целевая архитектура для FX!32) придаётся большое значение тому, выровнены ли данные в памяти или нет, какие команды используются для доступа к данным (как выровненным данным или нет), поэтому отдельно контролируется «выровненность» данных в x86-образе.
В рамках проекта Strata [11] были выявлены основные источники замедления систем двоичной трансляции и получены численные оценки вносимых ими накладных расходов. Было обнаружено, что даже при наличии в кэше фрагментов того фрагмента, которому будет передано управление в результате косвенного перехода, необходима смена контекста, т.е. передача управления самой системе трансляции, которая найдёт нужный оттранслированный фрагмент. Вообще, смена контекста является одной из главных причин уменьшения производительности системы по сравнению с выполнением программы в рамках native-системы. Хорошо известно, что в установившемся рабочем множестве косвенный переход, скорее всего, будет происходить на один и тот же адрес или на один из небольшого количества адресов, которые, как правило, уже встречались до этого при работе программы. Следовательно, был предложен подход использовать динамическую бинарную трансляцию для предсказания адреса перехода и заодно повышения локальности фрагментов в памяти.
В фоновом режиме на основе профиля в проекте Strata строились трассы, состоящие из транслированных ранее базовых блоков (т.е. отдельная трасса состояла из нескольких фрагментов, каждый из которых являлся транслированным базовым блоком). Объединение фрагментов в трассу происходило на основании того критерия, чтобы уменьшить число косвенных переходов, приводящих к передаче управления среде выполнения. Большинство косвенных переходов встречавшихся, внутри объединяемых фрагментов, прогнозировалось так, что они будут совершены на некоторый фрагмент, принадлежащий этой трассе, но, насколько это предсказание соответствует действительности, становится известным только во время выполнения, поэтому добавлялся дополнительный код, гарантировавший, что в случае неправильного предсказания управление будет передано Strata. Этот метод использовался в сочетании с динамической трансляцией. Благодаря данному нововведению производительность была увеличена вплоть до 39%. Среднее улучшение производительности составило 20%.
Список литературы
- An Infrastructure for Adaptive Dynamic Optimization
Derek Bruening, Timothy Garnett, and Saman Amarasinghe, Laboratory for Computer Science Massachusetts Institute of Technology, Cambridge, MA 02139 - ATOM A System for Building Customized Program Analysis Tools
Amitabh Srivastava Microsoft Research, One Microsoft Way, Redmond, WA
Alan Eustace, Google, 2400 Bayshore Parkway, Mountain View, CA - Advances and Future Challenges in Binary Translation and Optimization
ERIK R. ALTMAN, KEMAL EBCIOG? LU, MICHAEL GSCHWIND, SENIOR MEMBER, IEEE, AND SUMEDH SATHAYE - DIGITAL FX!32 Running 32-Bit x86 Applications on Alpha NT
Anton Chernoff, Ray Hookway, Digital Equipment Corporation - Dynamo: A Transparent Dynamic Optimization System
Vasanth Bala, Evelyn Duesterwald, Sanjeev Banerjia, Hewlett-Packard Labs 1 Main Street, Cambridge, MA 02142 - EEL: Machine-Independent Executable Editing
James R. I.arus and Eric Schnarr, Computer Sciences Department, University of Wisconsin–Madison - Instrumentation and Optimization of Win32/Intel
Executables Using Etch
Ted Romer, Geoff Voelker, Dennis Lee, Alec Wolman, Wayne Wong, Hank Levy, and Brian Bershad, University of Washington, Brad Chen, Harvard University - Compile-Time Planning for Overhead Reduction in Software Dynamic Translators
Naveen Kumar, Bruce R. Childers, Daniel Williams, JackW. Davidson, and Mary Lou Soffa - On Static Binary Translation and Optimization for ARM based Applications
Jiunn-Yeu Chen, Wuu Yang, CS Department, National Chiao Tung University, Taiwan; Tzu-Han Hung, CS Department, Princeton University; Charlie Su, Andes Technology, Taiwan; Wei Chung Hsu, CSE Department, University of Minnesota - Pin: Building Customized Program Analysis Tools with Dynamic Instrumentation
Chi-Keung Luk Robert Cohn Robert Muth Harish Patil Artur Klauser Geoff Lowney, StevenWallace Vijay Janapa Reddi, Kim Hazelwood - Overhead Reduction Techniques for Software Dynamic Translation
K. Scott, N. Kumar, B. R. Childers, J. W. Davidson, and M. L. Soffa - Binary translation: static, dynamic, retargetable?
Cristina Cifuentes, Vishv Malhotra - System Support for Automatic Profiling and Optimization
Xiaolan Zhang, Zheng Wang, Nicholas Gloy, J. Bradley Chen, and Michael D. Smith - Rob Hughes, Transmeta's Crusoe Microprocessor, 2000,
www.geek.com/procspec/features/transmeta/crusoe.htm - Jon Hannibal Stokes, Crusoe explored, 2000,
arstechnica.com/articles/paedia/cpu/crusoe.ars/4 - rogue.colorado.edu/Wikipin/index.php/Publications
- IA-32 Execution Layer: a two-phase dynamic translator designed to support IA-32 applications on Itanium-based systems, 2003
Leonid Baraz, Tevi Devor, Orna Etzion, Shalom Goldenberg, Alex Skaletsky, Yun Wang, Yigal Zemach - Elbrus SOW materials.
Приложение
- Проблема точного прерывания
- Это проблема состоит в том, что в момент возникновения прерывания ОС должна получить значения регистров процессора (т.е. контекст), являющиеся актуальными после выполнения предыдущей команды. Поскольку, как правило, двоичная трансляция осуществляется на основе областей больших, чем одна инструкция, то если внутри набора команд целевой машины, который получается транслированием блока команд исходной архитектуры, происходит прерывание, то не всегда можно восстановить контекст исходной машины.
- Профилирование
- Cбор характеристик работы программы. Инструмент, используемый для анализа работы, называют профилировщиком. Характеристики могут быть аппаратными (время) или вызванные программным обеспечением (функциональный запрос). Инструментальные средства анализа программы чрезвычайно важны для того, чтобы понять поведение программы. Проектировщики ПО нуждаются в таких инструментальных средствах, чтобы оценить, как хорошо выполнена работа. Программисты нуждаются в инструментальных средствах, чтобы проанализировать их программы и идентифицировать критические участки программы. Это часто используется, чтобы определить, как долго выполняются определенные части программы, как часто они выполняются, или генерировать граф вызовов (Call Graph). Обычно эта информация используется, чтобы идентифицировать те участки программы, которые работают больше всего. Эти трудоёмкие участки могут быть оптимизированы, чтобы выполняться быстрее. Это — также общая методика для отладки.
- Виртуализация
- Набор средств и технологий, позволяющих распределять совокупность ресурсов вычислительной системы между несколькими средами выполнения приложений, например, в случае виртуализации серверов для «гостевой» ОС создаётся впечатление, что она непосредственно работает с аппаратным обеспечением, хотя на самом деле между аппаратным обеспечением и ОС существует прослойка программного обеспечения, которая занимается тем, чтобы предоставить ОС требуемые ресурсы.
- Инструментирование
- Получение сведений времени выполнения о поведении приложения.
- Native-компилятор
- В данном тексте под понятием native-компилятор подразумевается компилятор, транслирующими программы, написанные на языке высокого уровня, в машинные инструкции.
- Трасса в Динамо
- Единицей трансляции в проекте Dynamo являлась трасса, это фрагмент кода с одним входом и несколькими выходами.
- Регион
- Единица трансляции с несколькими входами и несколькими выходами.
- «Горячий» и «холодный» код
- Программный код называется «горячим», если он исполняется часто в процессе работы приложения, в противном случае он считается «холодным». Как правило, в системах ДТ существует несколько классификаций «горячего» кода, границы между которыми определяются частотой исполнения кода.
- SAVE/RESTORE
- Операции сохранения в памяти некоторого регистра и последующего восстановления из памяти
- Стек вызова процедур
- Стек, хранящий структуры, содержащие информацию о процедурах, которые были вызваны, но возврат из них ещё не произошёл.
- Самотрассировка
- Запись последовательности выполняемых инструкций самим приложением, в данном случае, система ДТ инструментирует приложение и записывает выполняемые инструкции.


