

Вначале заметим, что за последний год наша Энциклопедия процессорных терминов заметно обновилась и дополнилась (что будет регулярно происходить и далее), поэтому некоторые термины (например, «диспетчер» и «планировщик») имеют несколько иные значения. Также, по многочисленным просьбам отдельных товарищей, в конце статьи указаны ссылки на основные источники (помимо собственных изысканий автора и его коллег).Что это?
Проще всего ответить так: ЦП серий Zacate, Ontario и Desna с ядрами Bobcat это то же, что и Intel Atom, но от AMD и на 3 года позже. Как и Atom, ядро Bobcat разработано с нуля специально для массовых мобильных устройств, где экономия энергии и дешевизна намного важнее скорости. Впрочем, Intel уже который год отчаянно и безуспешно старается протолкнуть Atom ещё и для смартфонов, где безраздельно властвует архитектура ARM. AMD же c этим рынком связываться не собирается. Кроме того, в отличие от «Атомов», получивших встроенные ИКП, видеодекодер и графический процессор (ГП) со 2-го поколения, «Бобкэт» имеет это с самого начала, а потому по новой терминологии AMD считается не просто ЦП, а APU. Конечно, мы дополнили наш словарь этим сокращением, но называть микросхему по-прежнему будем центральным процессором ;)

Существование этого проекта открылось в 2007 г. когда после покупки ATI AMD объявила, что ещё за год до этого начала разработку энергоэффективной микроархитектуры для диапазона потребления 1–10 Вт (на 45-нанометровом техпроцессе), которая должна выйти в 1-й половине 2009 г. На деле же первые ЦП с ядрами Bobcat вышли в январе 2011 г. с TDP 9 и 18 Вт (на 40 нм), но на вопрос «почему так долго» разработчики из Остина вполне могут ответить в стиле «сам дурак» — Intel тоже долго мурыжила Atom. Очевидно, при такой конкуренции (уже занятый рынок и 3-летняя фора) надо выставить что-то передовое — помимо вечного «наше дешевле». Кроме изначально интегрированного северного моста и видеочасти, AMD предлагает и более высокую производительность, причём и в x86-ядрах, и в ГП.
Перед тем как перейти к деталям, по традиции упомянем этимологию — Bobcat можно перевести нарицательно (обитающая в Северной Америке рыжая рысь) и как имя собственное (марка небольших тракторчиков и погрузчиков для мелких работ одноимённой фирмы). В свете выхода архитектуры Bulldozer (не нуждающейся в переводе и разъяснении) второй вариант выглядит более разумным, хотя и ссылается на чужую торговую марку. В любом случае — перед нами нечто маленькое, прыткое и с амбициями. Кодовое имя архитектуры — K14. Фронт

Конвейер у Bobcat 2-путный — как и у Atom. Для академического интереса также можно вспомнить и процессоры VIA Nano с архитектурой Isaiah для той же целевой ниши, но с 3-путным конвейером — правда, там и мобильными ваттами не очень пахнет… Фронт ожидаемый: предсказатель переходов, кэш L1I, предекодер и декодер. Но в каждом пункте есть изюминка.
Предсказатель переходов
Как обычно, этот блок диктует, каков будет адрес следующей порции кода. Есть 4 источника адреса: следующий по порядку, предсказанный для срабатывающего перехода, исправленный при фальш-предсказании и возврат из подпрограммы (считывается из стека возврата на 12 адресов). Как и в большинстве современных архитектур, предсказываемая порция равна 32 байтам, причём она совпадает и со считываемой (у Intel последняя вдвое меньше). Выбор очевиден, учитывая средний размер команды (4 байта) и расстояние между переходами (≈10 команд).
Впрочем, встречаются случаи и частых переходов. Для этого предусмотрено два буфера BTB — один («редкий») хранит первые 2 перехода для каждой 64-байтовой строки кэша и (официально) до 8 ссылок на ячейки второго («плотного») буфера, хранящего остальные переходы (в тех строках, где они есть) по 2 перехода на каждые 8 байт. При этом фраза «первые 2 перехода» относится к обнаруженным и срабатывающим командам: т. к. строка не обязательно выполняется с начала и до конца, есть вероятность, что позже в ней будут найдены новые переходы, либо до сих пор не срабатывавшие вдруг сработают. Как при этом дополняются записи в обоих BTB — неизвестно.
Если первые два перехода предсказываются как несрабатывающие, но и не последние в этой порции, то начинается последовательная обработка переходов из плотного BTB в ячейках, на которые ссылается запись из редкого. Очевидна сомнительность одновременного считывания и, следовательно, хранения в ячейке редкого BTB до 8 ссылок на ячейки плотного. Объяснения два: либо ссылка только одна, и каждая ячейка из плотной BTB указывает на следующую, если переходы в строке ещё остались — потому они и обрабатываются последовательно. Либо ссылка всё равно одна, но 8 соответствующих записей в плотном BTB идут подряд, и конкретная выбирается в зависимости от смещения адреса в строке кэша. Последний вариант проще и быстрее, но куда менее оптимален по расходу плотного BTB: достаточно в одной из восьмушек строки иметь более двух переходов — и ей выделят 8 записей даже при отсутствии переходов в других частях строки. Поэтому примем первую версию.
Редкий BTB хранит 512 ячеек (по числу строк в кэше L1I), т. е. 1024 перехода, а плотный — вдвое больше. Это очень достойно не только в сравнении с крошечной таблицей в Atom на 128 адресов, но и с настольными ЦП. Механизм индексации плотного BTB и вытеснения из него неизвестен. Очевидно, речь не может идти о 512-путной структуре, а т. к. в кэше могут оказаться 512 строк с парой переходов в каждой 8-байтовой восьмушке (и им не хватит плотного BTB) — может проявиться наложение адресов и вытеснение не столь уж старых переходов.
По идее, при такой организации можно точно предсказать до 18 переходов на строку, из которых 16 будут содержаться в 8 ячейках плотного BTB. Но в тестах было получено до 16 или 17 безошибочных предсказаний в зависимости от их положений в строке. Значит, механизм разметки положений работает сложнее, чем описано. А что делать с ещё более частыми переходами, учитывая, что они могут встречаться каждые 2 байта, а возвраты — даже каждый байт? Переходы начиная с 3-го в 8-байтовом куске вытесняют первую пару, а потому имеют шанс 50% быть угаданными по поведению и ≈0% — по адресу. До сих пор у предсказателей AMD при переполнении хранящих структур «лишние» переходы динамически не предсказывались и считались всегда несрабатывающими, эффект от чего примерно тот же, что и у Bobcat.
Каждая запись в BTB, предположительно, хранит тип перехода (3 бита), адрес его последнего байта (6 бит — только смещение в строке), младшие 12 бит целевого адреса (т. е. смещение в текущей виртуальной странице) и бит, указывающий на переход за пределы страницы. Судя по описанию, базовые адреса страниц для таких «дальних» переходов хранятся в отдельной таблице, индексируемой, видимо, смещением в целевой странице. Это странное решение, ибо куда логичней хранить в дополнительной таблице полный адрес (база + смещение), а в поле смещения основной — индекс ячейки с адресом. Размер дополнительного BTB для «дальних» переходов достоверно неизвестен, но мы его сможем вычислить чуть позже.
Тип перехода определяет алгоритм предсказания поведения. Разумеется, для экономии энергии на время предсказания тактируются только реализующие этот алгоритм блоки, а остальные спят. Для относительных переходов проверяется предсказанный адрес и, в случае его несовпадения, производится коррекция (в т. ч. в таблицах), занимающая меньшее время, чем обычное фальш-предсказание. Кстати, про последнее: официально оно штрафуется 13 тактами. В тестах же эта цифра оказалась средней, а полный диапазон — 8–17 тактов, что зависело от последующих команд после точки перехода. Причём их вычислительная сущность (например, целые или вещественные) роли не играла — видимо, есть некая зависимость от числа команд и/или переходов в целевой строке.
Алгоритм предсказания лишь один (предсказателя для циклов нет): 2-уровневый, адаптивный, с 26-битным регистром глобальной истории (GBHR) и таблицей историй переходов (BHT) неизвестного размера, но уж точно меньше, чем 226 — т. е. (как обычно для 2-уровневых BPU) используется хэш-функция, сворачивающая 26 бит GBHT и часть адреса перехода в N бит индекса для BHT размером 2N. В BHT попадают только условные переходы, причём лишь те, что записаны в BTB (т. е. хотя бы раз сработавшие) — для удаления шумового эффекта малозначимых ветвлений. Помимо рекордно длинного GBHR (у Atom он на 12 бит) — ничего особенного.
 Половина фронта ядра Bobcat. Чёрные массивы и логика выше них — микросеквенсер декодера. Всё остальное — детали предсказателя. |
А теперь досрочно посмотрим на вырезку фото кристалла (детально он будет описан далее) в области BPU. Как мы позже покажем, 3 длинных массива в углу ядра (разделены посредине селекторной логикой) имеют размер по 4 КБ. Выше них — группа из двух блоков по 2 КБ (ближе к центру) и ещё одна из трёх таких блоков (слева вверху). Т. к. BHT должен иметь двоичный размер, предположим, что это первая группа: суммарный размер её массивов — 4 КБ, чего хватит на 16 384 2-битных счётчика и потребует от хэш-функции 14-битный индекс. 16 «килосчётчиков» это столько же, как и у K8/10/12 (хотя у них L1I на 64 КБ), и вчетверо больше, чем у Атома, где те же 32 КБ в L1I.
Теперь вернёмся к BTB. Редкий имеет размер вдвое меньше плотного, а три оставшихся массива по 2 КБ — вдвое меньше трёх по 4. Мы предположили, что адрес в BTB занимает 22 бита, а в каждой ячейке — 2 адреса и одна 10-битная ссылка на первую или следующую в цепочке ячейку из плотного BTB. В сумме получается 54 бита, что почти столько же, как в записи TLB (там, помимо 24-битного физического базового адреса страницы, есть ещё её атрибуты). Проверяется это тем, что TLB L2D (на вырезке не показан) также использует массив на 4 КБ, который тоже делится на 512 записей, как и у каждого BTB. Скорее всего, 3 длинных массива это оба BTB (1 для редкого и 2 для плотного), и тогда на 3 коротких остаётся вышеупомянутый дальний BTB с «хвостами» адресов.
Адресация в BTB виртуальная, поэтому хвост это 48 бит т. н. канонического (для x86-64) адреса минус 12 бит, хранимых как смещение в основных таблицах. 36 бит — число неудобное, но (снова забегая вперёд) все массивы, в т. ч. для TLB, имеют биты чётности, и если их, как обычно, 1 на байт, то физический размер записи окажется 72 бита, как раз на два хвоста. Однако для BTB чётность не обязательна, т. к. при крайне редкой аппаратной ошибке считывания самое страшное — лишнее фальш-предсказание. Таким образом, на пару ячеек BTB приходится в среднем один адресный хвост, и пара таких хвостов хранится в ячейке дальнего BTB, обслуживая две (видимо, парные) ячейки остальных BTB. К сожалению, мы не проверили — что будет, если на каждые хранимые четыре адреса более двух окажутся дальними. Зато можно точно сказать, что индексация дальнего BTB простейшая — делим индекс запрашивающего BTB на 2.
|
Весь миниконвейер предсказателя состоит из 6 тактов, но работают они не параллельно, как обычный конвейер, а последовательно, т. е. разделение на такты условно и сделано лишь для синхронизации с основным конвейером. За первый такт проверяется первая пара переходов; если оба не срабатывают, то все следующие проверяются далее по одному за такт; при срабатывании любого перехода вставляется задержка в 1 такт, поэтому самый короткий цикл будет 2-тактовым. Косвенные переходы проверяются на третьем такте — при их обнаружении задержка составит 6 тактов. Итого, по численным параметрам предсказателя Bobcat не только впереди всех в своём классе, но и местами догоняет настольных собратьев, что уже поднимает вопрос об избыточности — а ведь надо экономить драгоценные миллиметры…
Предекодер и декодер
16- или 32-байтовые порции по предсказанному адресу считываются из L1I и помещаются в буфер (у Atom — 8 байт/такт). Буфер предекодера имеет 12 16-байтовых ячеек, за такт принимает 16 или 32 байта и столько же отправляет. 16 байт записываются, если целевой адрес оказался во 2-й половине порции, либо в 1-й половине есть переход, предсказанный как срабатывающий. В остальных случаях записывается пара ячеек.
На выходе из буфера находится 2-путный и 2-стадийный предекодер-длиномер с пиковой производительностью 22 байта/такт. Таким образом, Bobcat является первой архитектурой AMD со времён древнющего Am486, не использующей спаренный с L1I кэш предекодера и выполняющей замеры длин команд «на лету». Длиномер считывает текущую ячейку буфера до конца и ещё до 6 байт из следующей. Впрочем, учитывая, что в большинстве тактов он начинает обработку не с 0-го байта порции, средняя скорость длиномера оказывается 16 байт/такт, что всё равно более чем достаточно для 2-путного ЦП (Intel довольствуется этими же 16 байтами/такт и для 4-путных ЦП). Никаких пагубных влияний разнообразных префиксов, так отравляющих жизнь декодерам x86-ЦП вообще и ЦП Intel в частности, тут нет. Видимо, поэтому решили обойтись без буфера перед самим декодером.
Декодер преследует ту же цель, что и у Atom — преобразовать команды в минимальное число мопов, используя микрослияние, т. к. остальная часть конвейера также 2-путная. Макрослияние не поддерживается. По терминологии AMD мопы у Bobcat называются COP (complex microoperations, составные микрооперации), т. е. они сложнее обычных для «больших» ЦП слитых мопов. Почти все самые частые скалярные команды генерируют 1 моп, включая и команды с модификандом в памяти, для которых требуется 4 действия — вычисление адреса, чтение из памяти, операция с данными и запись в память.
Команды для работы со стеком 1-моповые, хотя им надо совмещать обмен с памятью и арифметику с регистром-указателем E(R)SP — это намекает на наличие стекового движка, аналога «stack pointer tracker» в ЦП Intel (подробней о нём см. в описании Sandy Bridge). Однако в отличие от последнего, исполнение команд, вызывающих E(R)SP напрямую, не требует вставки синхронизирующих мопов и не вызывает задержку. Да и вызовы подпрограмм (но не возвраты) требуют 2 мопа.
Декодер, как и ожидается для 2-путного конвейера, состоит из двух простых трансляторов (выдают по 1 мопу/такт), сложного транслятора (2 мопа/такт) и микросеквенсера (последовательности из 3 и более мопов по 2 за такт). По статистике AMD, 89% команд декодируются в 1 моп, 10% — в 2, и 1% — в 3 и более. Однако для поднаборов SSE эта статистика не подходит — ниже станет ясно, почему. Поддерживаются 64-битные расширения, команды виртуализации, векторные поднаборы MMX, SSE, SSE2, SSE3, SSSE3 и SSE4A, а также отдельные команды LZCNT и POPCNT для подсчёта битов. Не хватает не таких уж новых SSE4.1 и 4.2, а также родного для AMD 3DNow!, который компания признала окончательно устаревшим. Впрочем, одна команда для программной предзагрузки оттуда всё же поддерживается, для чего ей выделили отдельный бит в «паспорте» для CPUID.
|
Официальное описание этой части фронта, приведённое в таблице, изобилует загадками. Например, упоминается очередь команд, которая по всем канонам должна располагаться после декодера и перед тылом, но тут она находится уже на первой стадии декодера. К тому же, ни в каких других местах она не упоминается, что создаёт впечатление отсутствия всякой очереди «около» декодера.
Ещё одна странность в том, что собственно декодирование растянуто аж на 3 стадии (6–8), причём это касается лишь простых команд общего назначения. Микрокодовые команды на 8-й стадии читают свои мопы из ПЗУ, а на следующей — распаковываются, что намекает на паузу в 1 такт, когда после простой команды попадается сложная. Более того, аж целый такт тратится на передачу x87- и SSE-команд в расположенный впритык к обычному «вещественный декодер», который занимает целый 10-й такт — но что там может происходить после работы основных трансляторов? На ум приходит лишь одно: почти все команды поднаборов SSE, работающие со 128-битными векторами, в этом такте каждый свой моп преобразуют в пару мопов-близнецов, т. к. векторно-вещественный исполнительный тракт (традиционно для AMD неточно называемый FPU) — лишь 64-битный, и все его стадии работают с физическими регистрами половинной ширины. А значит, нужно дублировать и использующие их мопы. Детали этого безобразия опишем позже. Тыл
Диспетчер и планировщики
В этом месте проявляется одно из основных отличий Bobcat от Atom — процессор имеет внеочередное исполнение (чем хвастает и VIA Nano). Мопы из декодера без всяких промежуточных буферов (по крайней мере, согласно нашим тестам…) попадают в диспетчер, который переименовывает регистры и размещает мопы после их разделения на вычислительные и адресные компоненты. Мопы попадают в две (!) очереди ROB (общего назначения и для FPU) и в нужный планировщик, причём обменным мопам выделяются и записи в блоке LSU. Одновременно диспетчер принимает до 4 или 6 мопов/такт после исполнения и производит отставку до 2 команд/такт.
Общая ROB умещает 56 мопов, а векторно-вещественная — 40 (причём эта почему-то называется «retire queue», т. е. очередь отставки, хотя вроде бы это синонимы). Суммарные 96 мопов это в 2–3 раза меньше «больших» 4-путных ЦП, но больше, чем у 3-путного Nano. Главный вопрос вот в чём: до сих пор ни один ЦП не имел диспетчер с двумя ROB; почему же AMD решила использовать эту схему, если синхронизация запусков, приёмов и отставок мопов с двумя очередями сложнее, чем с одной суммарной длины?
Наш постоянный Внимательный Читатель вспомнит, что у современных настольных ЦП Intel общая очередь ROB делится поровну между двумя потоками, когда они исполняются в одном ядре, но мопы двух потоков можно уводить в отставку независимо. К тому же архитектура Bobcat всё равно 1-поточная. В случае с AMD всё может объясняться просто — в описывающем документе просто сделали ошибку (не в первый и не в последний раз…). Однако загадочная фраза, где появляется цифра 40, написана очень уверенно: . Дополнительный аргумент к тому, что FPU имеет отдельную ROB/RQ, даёт приведённое ниже распределение тактов тыла в двух трактах: все действия диспетчера для команд FPU оказываются на 2 такта позже. К сожалению, представители компании на всех уровнях упорно не дают нам возможности даже задать вопросы о таких деталях…
Для экономии энергии, как и во всех современных архитектурах (Sandy Bridge, Llano и Bulldozer, о котором тоже скоро будет статья) инженеры применили некопирующий вид планировщиков, работающих со ссылками на физические регистровые файлы (РФ). Оба РФ имеют по 64 64-битных регистра. Причём для экономии энергии как минимум в РФ с регистрами общего назначения (РОНами) при записи может включиться только младшая половина регистра-приёмника, если старшую обновлять не надо; этот же принцип наверняка применяется и в других частях ядра при похожих обстоятельствах. Хотя число ФУ небольшое, AMD расположила для них аж три 2-портовых планировщика (тут полумопом названа часть слитого мопа после его разделения диспетчером):
- целый — на 16 полумопов для скалярных целочисленных операций с РОНами;
- адресный — на 8 полумопов для вычисления адресов с РОНами;
- векторный (для FPU) — на 18 полумопов для векторных и/или вещественных операций с векторными регистрами.
Векторный планировщик оказывается одним из узких мест ЦП, учитывая, что в среднем на векторную команду приходится пара полумопов. Впрочем, по сравнению с векторными планировщиками для «больших» ЦП AMD, этот умеет исполнять простейшие команды за такт; точнее, ФУ их исполняют за такт, но лишь у Bobcat планировщик успевает зафиксировать это до конца такта. Кроме того, векторные планировщики архитектур K7–K12 печально знамениты своими «пузырями» — внутренними НОПами, вставляемыми в тройки мопов, если последние не соответствуют правилам распределения мопов по очередям портов. Неоптимальное распределение вызывает дополнительные такты ожидания на регистрацию мопов. У Bobcat каждый планировщик имеет общую для портов резервацию (как у всех ЦП Intel и VIA Nano), куда мопы попадают без всяких ограничивающих правил. Похожие улучшения сочетаемости уходящих в отставку мопов есть и у диспетчера.
| Стадия | Целый конвейер | Конвейер FPU |
| 8 | «Размещение меток» (?). | |
| 9 | Переименование РОНов. Разделение слитых мопов. | Передача в FPU. |
| 10 | Запись в ROB и резервацию(и). Планировка. | Переименование x87-стека. Декодирование в FPU. |
| 11 | Чтение регистров. Настройка шлюзов. | Переименование регистров xmm. Разделение слитых мопов. Запись в ROB и резервацию. |
| 12 | Работа ФУ (≥1 такта). | Планировка. |
| 13 | Обратная запись и передача по шлюзам результатов. | Чтение регистров. Настройка шлюзов. |
| 14 | Работа ФУ (≥1 такта). | |
| 15 | Обратная запись и передача по шлюзам результатов. | |
Странная штука под названием «Размещение меток» (token allocation) нигде в официальном тексте не пояснена, как и её положение до того места, где обычно происходит выделение ресурсов тыла — т. е. после переименования, а не до. Внимательный Читатель заметит, что это та самая 8-я стадия, которая накладывается на работу трансляторов декодера, хотя в оригинальной схеме она почему-то отнесена уже к планировщику. Тем не менее — что можно размещать для ещё не до конца декодированных команд? Более того, почему попадающие в команды FPU требуют дополнительного декодирования? Также интересно сравнить расположение действий по стадиям у целого и векторного трактов: вроде бы одинаковый 16-моповый планировщик в одном случае занимает весь такт на срабатывание, а в другом совмещает его с записями в свои ROB и резервацию.
Исполнительные тракты
В целом исполнительном тракте есть РФ (которому требуется 8 портов чтения и 2 записи), 2 АЛУ (сложное и простое), сдвигатели (аналогично), 2 AGU (отдельно для чтений и записей), умножитель и, предположительно, делитель (уточним позже). Очевидно, адресный планировщик подключен только к паре AGU, а целый — ко всем остальным ФУ. В векторном тракте — РФ (4 чтения + 2 записи) и два домена ФУ. В целом домене 2 АЛУ, 2 сдвигателя, 2 перестановщика и умножитель; в вещественном — 2 логических устройства, 2 перестановщика, сумматор, умножитель, преобразователь форматов (точнее, это могут быть несколько фУ, занимающих оба порта) и делитель-корнеизвлекатель (являющийся надстройкой над умножителем). В этих списках не указаны некоторые редкоиспользуемые ФУ, предназначенные лишь для нескольких команд.
Интересно дублирование некоторых ФУ для двух доменов, хотя в компактном ядре, где каждый квадратный микрон на счету, пара одинаковых ФУ в одном порту, из которых в каждый момент времени лишь один сможет работать, выглядит расточительством. Можно было бы предположить, что на самом деле есть лишь одна пара перестановщиков, а АЛУ умеет исполнять и «вещественную логику» (тем более, что она никак не отличается от целой) — если бы сама AMD не нарисовала на схеме ядра отдельные ФУ вещественной логики.
Между доменами расположена пара внутритрактовых шлюзов, вносящих задержку в 1 такт, когда результат из одного домена требуется как аргумент в другом. Хотя есть версия, что таких шлюзов вообще нет: 4 порта чтения подключены к двум наборам из 4 шин аргументов (по одному для домена); пары шин результатов тоже отдельные, и пары шлюзов — лишь внутридоменные (т. е. перепуск «своего» результата на «свой» аргумент). При запросе результата в чужом домене он сначала записывается в РФ (что и так должно произойти), а затем читается в другую четвёрку шин аргументов, на что и уходит лишний такт.
Впрочем, такая схема была бы оправданной для сверхвысокочастотного ЦП, где нагрузка на шины (в т. ч. по числу «лишних» шлюзов) не может быть большой. Для компактного ядра объяснение может быть другое: РФ разделён на 2 полунабора регистров — по одному для доменов, и каждый набор имеет свои 4+2 порта. Но и это не показывает, чем эта схема лучше простой установки пары междоменных шлюзов, которые (как и внутридоменные) могли бы срабатывать в тот же такт, что и генерация передаваемого через них результата. Наконец, есть версия о двух отдельных векторных трактов, как в настольных ЦП Intel — как и там, это объясняется банальной нехваткой места для единого тракта с учётом всего массива ФУ. Проверить это можно при детальном анализе фото ядра.
Распределение по портам и специализация ФУ почти такие же, как и у Atom, но есть и кардинальное отличие. Главный недостаток вообще всей архитектуры в том, что в векторном блоке нет ни одного 128-битного ФУ, а потому даже простейшие копирования регистров xmm и простая арифметика делаются парой АЛУ над половинами логических регистров. Это даёт пиковую вещественную скорость всего в 4 SP- и 1,5 DP-флопа/такт, хотя все конкуренты имеют бо́льшие значения: Atom выдаёт 6 и 1,5 флопа/такт (правда, 1,5 DP-флопа достижимы только скалярами), Nano — 8 и 3, а все «большие» ЦП — 8 и 4 (у кого есть поддержка AVX — и вдвое больше). (В трёх мобильных архитектурах DP-пики достигаются при соотношении сложений и умножений как 2:1, в остальных случаях — 1:1, что более адекватно потребностям кода.) Впрочем, сложение полноконвейерно и для «расширенной» точности (EP), из чего можно сделать вывод, что тракт скорее 80-битный, но дополнительные биты сумматора и умножителя редко используются по причине устаревания поднабора x87 вообще и в мобильных программах особенно. Если бы его по-тихому убрали (хотя бы для экономии места и упрощения логики), никто бы не огорчился.
Как всегда, полные таблицы с таймингами, портами запуска и числом мопов для всех команд можно найти у Агнера Фога (стр. 175–184), а тут не менее традиционно покажем нашу таблицу с таймингами. В колонках цифр для нескольких старых архитектур и свежего K14 теперь встречаются плюсы. А внизу пояснение: каждый плюс добавляет к задержке 1 такт, если следующая команда требует в первом такте обе части результата данной.
{kind=link}
Дело в том, что многие векторные команды исполняют свои действия над элементами независимо. Скажем 4 SP-сложения для SSE (ADDPS) могут происходить параллельно, если все части аргументов уже готовы. Т. к. вещественный сумматор лишь 64-битный, в первом такте начнётся сложение, допустим, младшей половины регистров xmm. Но он полноконвейерный, и со второго такта можно начинать складывать старшие половины этих же регистров. Когда закончится сложение младших половин, младшие суммы сразу могут быть использованы в любой команде, которой (как и сложению) достаточно иметь лишь половину элементов. Через такт она получит и старшие суммы. Т. к. вычислительные мопы планируются на запуск независимо, временной разрыв и порядок запусков обработок половин регистров могут быть какие угодно — например, старший моп может начаться за 2 такта до младшего, если его аргументы будут получены на 2 такта ранее. Наглядно это показать поможет тестовый код, циклически повторяющий такие команды:
ADDPS xmm0, xmm0;
SHUFPS xmm0, xmm0, 123;
MOVHLPS xmm0, xmm0;
Посмотрим, как это работает на K8, где векторный тракт также был 64-битным. На схеме ниже указаны первые две итерации, причём длина второй является устоявшимся значением (жирные цифры), и именно для неё приведены номера тактов. Цветом показаны 3 вида мопов, запускаемых в тракт для работы над половинами регистра xmm0. 64-битное (по ширине вектора) сложение занимает 4 такта, а копирование — 2. 128-битная перестановка — 3-тактная и требует трёх мопов: два пишут по 2 элемента в половины регистра-приёмника (за 2 такта каждый), а третий нужен, скорее всего, для синхронизации физических половин архитектурного регистра. За неимением точных данных запишем его в «старшей» колонке, где он совпадёт с первым тактом первого «рабочего» мопа. Главное — что обеим половинам SHUFPS сразу нужны обе половины аргумента. Если бы за ADDPS шло ещё одно сложение, то оно могло бы начаться уже с 5-го такта, получив задержку 4 и пропуск 2 (старт нового независимого сложения возможен по нечётным тактам). Но с SHUFPS требуется ждать старшую половину, поэтому задержка увеличивается на 1 — что и обозначено плюсом в таблице таймингов.

Теперь посмотрим, что будет если заменить MOVHLPS на MOVLHPS, копирующую младшую половину в старшую. Вроде бы всё симметрично, никаких изменений быть не должно. На самом деле копирование младшей половины перемешанного xmm0 начнётся уже после её готовности, что на такт раньше, т. е. на 7-м такте, пока старшая половина ещё не готова. Впрочем, она и не нужна, т. к. одновременно с младшим сложением запускается копирование этой половины в старшую. Такая тройка команд выполнится не за 9, а за 8 тактов, и эта сумма ограничена сложениями старших половин.
Рядом показана аналогичная ситуация для Bobcat, исполняющего каждую из этих команд на такт быстрее. Впрочем, если для MOVHLPS можно получить ожидаемые 6 тактов, то для MOVLHPS быстрее не получится, хотя в течение 5-го такта есть возможность запустить и перестановку старшей половины, и копирование уже перемешанной младшей, и её же сложение. Но портов всего 2, и запустятся самые «старые» мопы (последний для SHUFPS и MOVLHPS), а ADDPS стартует в следующем такте. Из этих примеров видно, что при половинной ширине вычислительного тракта компилятору и программисту на ассемблере требуется детально разбираться, что́ должно происходить в ядре, чтобы оптимизировать скорость до последнего такта даже в тривиальных (как кажется) случаях.
Однако вышеперечисленные цифры являются теоретическими; практика же внесла неприятные коррективы. После тестирования оказывается, что и K8, и K14 исполняют вариант с MOVHLPS на такт дольше, чем по модели. У K8 это можно было бы объяснить тем, что загадочный третий моп для SHUFPS исполняется не 1, а 2–4 такта, и от него зависит пропуск всей команды — но тогда задержка всей команды была бы на такт дольше. Кроме того, ещё замена ADDPS на ADDSS (скалярное сложение только младших элементов, имеет лишь младший моп) предсказуемо уменьшает сумму таймингов до 6 тактов.
Дальнейшие эксперименты показали, что теория сходится с практикой, если заменить обычное сложение на горизонтальное (HADDPS, 4+2 такта задержки и 2 такта пропуска), требующее обеих половин источников для каждой половины результата: 11 тактов для версии с MOVHLPS и 10 для MOVLHPS. А вот если вообще убрать сложение, то начальные задержки уменьшаются на 4: 6 для пары SHUFPS+MOVHLPS и 4 для SHUFPS+MOVLHPS (согласно теории должно быть 5 и 4). Попытки прояснить ситуацию в фирменном профайлере AMD Code Analyst успехом не увенчались: последние его версии не поддерживают симуляцию конвейера (pipeline simulation), а версия 2.8 (последняя с этой функцией) вылетала с ошибкой на тестовой машине на базе того же K8. Сбор статистики от счётчиков производительности ничего внятного не дал.
Ситуация осложняется тем, что официальный учебник по оптимизации (Software Optimization Guide for the AMD64 Processors), судя по всему, неверно указывает задержку команды SHUFPS для K8 (стр. 324): 4 такта с примечанием 1, гласящим, что младшая половина результата доступна тактом ранее. Но все независимые тесты показывают не 3+1 такта, а 2+1. Впрочем, с задержкой 4 вариант с MOVHLPS и в теории, и на практике даст 10 тактов, зато уже версия с MOVLHPS окажется на такт дольше рассчитанного. Интересно, что у K10 и K12 (где 128-битные векторные тракты с теми же задержками почти всех ФУ) SHUFPS ожидаемо 1-моповая, но требует трёх тактов, а не двух — т. е. как пишут в учебнике. Либо «почти все ФУ» не включают перестановщик, либо учебник прав, а все независимые тесты, включая показания AIDA64 (бывший Everest; см. строку 814) — нет.
Зачем мы так обильно ворошим «старые раны» прошлых архитектур? Ведь можно посмотреть в новый учебник, где, наверное, ошибок нет… Однако впервые в своей практике AMD для нового ЦП (более того — разработанного с нуля) такое руководство не выпустила. И это притом, что новые версии некоторых компиляторов стараниями компании уже умеют оптимизировать для Bobcat, но программистам и аналитикам эти тонкости почему-то знать не положено. Если сравнить с активно документируемой работой Intel по программной адаптации и оптимизации под Atom разных ОС и программ — получится небо и земля.
Приходится использовать имеющиеся данные для ближайшей похожей архитектуры (K8), но они, оказывается, неточны — и это после стольких лет её использования, когда все ошибки к версии 3.06 учебника можно было исправить. Не смотря на все догадки, объяснить, почему вариант теста с MOVHLPS работает на такт дольше, не получается. А теперь представьте — каково оптимизировать под Bobcat программистам, сталкивающимся с куда более сложными случаями, да ещё и с глючащими инструментами?.. Впрочем, начнём с малого: если у особо дотошных и любопытных читателей найдётся время погрызть гранит загадки лишних тактов — добро пожаловать на форум с идеями и результатами.
А пока вернёмся к самому ЦП. Если ещё раз взглянуть на нашу таблицу таймингов и сравнить их с конкурентами, то окажется, что бо́льшая часть ФУ у Bobcat лучше, чем у Atom, кроме операций перестановки и векторного сложения-вычитания SP-чисел (что не удивительно, учитывая ширину векторного тракта). Целочисленный умножитель имеет пропуск 1 для краткого 32-битного умножения, но 2, когда надо записать полные 64 бита результата в пару 32-битных регистров. Это потому, что на запись старшей половины уходит второй моп такой версии умножения, что типично для большинства ЦП, т. к. мопы имеют лишь 1 регистр-приёмник (без учёта флагов). Векторный целый умножитель работает за рекордные 2 такта для 64-битных векторов, хотя у старого K6-2 такой уже был.
Вещественный сумматор работает за 3 такта, что на 2 быстрее, чем у Atom, но на 1 меньше рекордного сумматора Nano. А вот блок FMUL — это целая история. Дело в том, что в феврале 2009 г. инженеры AMD опубликовали отдельную работу, посвящённую вещественным умножителям, одновременно энергоэффективным, компактным и не очень медленным — как раз, как надо любой мобильной архитектуре. Результаты смоделированных там таймингов точно совпали с реальными замерами вещественного умножителя в Bobcat. Для сравнения с другими ЦП они представлены в таблице рядом (в том же формате, что и выше) для скалярного (S…) и векторного (P…) умножений трёх точностей — SP, DP и EP (x87, только скаляры).
| ||||||||||||||||||||||||||||||||||||||||||||||||
Как же у AMD получились рекордно низкие тайминги для SP и нормальные для DP (в ущерб EP-умножению, которым логично пожертвовали в виде трёх тактов пропуска), хотя умножитель в 2,5 раза меньше по площади и потреблению, чем его аналог из K8, сделанный тем же техпроцессом? Для начала вспомним (или изучим ;) ), что согласно стандарту IEEE-754 о двоичном представлении вещественных чисел 32-, 64- и 80-битные точности имеют 23-, 52- и 64-битные мантиссы, которые и требуется умножать; экспоненты же обрабатываются простым блоком вроде целого сумматора. Правда, SP- и DP-числам нужно добавить отсутствующий в хранимых мантиссах бит целой части, всегда равный 1 — кроме редких денормальных чисел. (Кстати, в Bobcat штраф за обработку их, а также недополнений — 150–200 тактов.) Кроме того, внутренняя точность должна быть выше, поэтому реальная разрядность умножителя на все точности — 76 бит. И т. к. он должен быть сколько-нибудь быстрым, его делают матричной схемой. Матрица состоит из 7 многобитных сумматоров, соединённых древовидной сетью в 3 яруса.
Если требуется полноконвейерный умножитель даже для EP, то нам нужна матрица на 76×76 бит — как раз, как в K7–K12. Для мобильных ЦП это слишком масштабно, прожорливо, а главное — не нужно: бо́льшая часть вещественной нагрузки от мобильных программ — в SP-числах, которым достаточно массива в 27×27 бит. Но EP-точность всё же нужна (хоть с какой-то скоростью), да и SP-умножения бывают не только скалярные. Поэтому AMD предложила сделать массив прямоугольным — 76×27 бит. Это не ново: ЦП Cyrix (кто помнит это слово?..) когда-то имели матрицу 17×69, ещё меньшую по площади, но со слишком большим ущербом для скорости — даже SP-умножения полноконвейерными не сделаешь.

«Сырые» (неокруглённые) результаты прохода аргументов через матрицу умножетеля для разных точностей.
Внимательный Читатель задаст вопрос: а как же с DP- и EP-точностями, которым не хватит размера матрицы для полноконвейерного умножения? Для этого аргументы такой точности проходят через матрицу итеративно, получая за каждый проход очередные 27 бит результата. Для DP чисел требуется 2 прохода, а для EP — 3, что и отражено в пропуске команд. На округление тратится 1 такт для SP и 2 для DP и EP, причём округлитель может работать одновременно со следующим умножением, так что пропуск не увеличивается на время округления. Ширины матрицы хватит для двух SP-умножений за такт, что также видно в таймингах, но уже с отрицательной стороны: если бы таких прямоугольных умножителей было бы два, то их хватило бы для полноконвейерного исполнения MULPS и полуконвейерного — MULPD (как в Nano).
Зато SP-умножение впервые получилось 2-тактным, что даже быстрее сложения, а это разрушает доселе незыблемый постулат о том, что сложение быстрее умножения, т. к. проще и требует меньше аппаратных ресурсов. Причём в Bobcat это особенно странно, учитывая, что округлитель для умножителя по сложности эквивалентен сумматору и срабатывает за 1–2 такта. Конечно, такое устройство умножителя подойдёт лишь для частот до 2–2,5 ГГц; иначе на экономной версии 40-нанометрового техпроцесса сигнал не успеет пройти матрицу за 1 такт. Странно, что то же устройство не использовано в целом скалярном умножителе, не требующем округления, но работающем за 3 такта (для версии 32×32 бита). При этом все виды целого векторного умножения (в т. ч. 32×32, а также с попарным сложением произведений) исполняются за 2 такта.
Кстати, эта же группа авторов ещё ранее (аж в декабре 2007 г.) написала работу о делителях, где придуман модифицированный алгоритм Голдшмидта (GS-2), основанный на вышеописанном умножителе и делящий на 25–37% быстрее прежних. Любопытно, что в этой работе задержки собственно умножения для SD и EP оказались на такт меньше указанных в поздней работе, но «в железо» эта версия почему-то не попала. Впрочем, в реально ядер и деление оказалось на 3 такта медленнее версии GS-2, хотя всё ещё быстрый — 19 тактов для EP (8 бит/такт, 9 тактов подготовки и обработки).
Интересный момент связан с векторным вещественным делением: для DP оно равно 34 тактам, что ровно вдвое больше скалярной версии, а для DIVPS — 38, что менее чем втрое больше DIVSS (13). Т. к. деление полностью неконвейерно, у DIVPS можно было ожидать 13×4=52 такта, но 14 тактов загадочно экономятся. Возможно, ширины умножителя хватает не только для пары SP-умножений, но и для частичной параллелизации пары SP-делений. Аналогично с векторным извлечением корней.
По идее, для экономии площади делитель должен быть один и исполнять скалярное целое деление, задействуя межтрактные шлюзы для передачи аргументов и результата (как в Atom и Nano). Целое деление сравнимо по сложности (не требует нормализации, но надо получить не только частное, но и остаток), но из-за шлюзов окажется чуть медленнее вещественного. Однако в Bobcat оно аж в 2–4 раза дольше — 1 бит/такт и 17–23 такта на остальное. Это наводит на мысль об отдельном целом делителе (скорее всего, надстроенным над умножителем), что подтверждается и тем, что целое деление тоже декодируется в 1 моп, а межтрактные передачи потребовали бы ещё 2. И зачем потратили лишнее место на такого уродца, если оказывается вдвое быстрее (!) преобразовать целое в вещественное (11 тактов), поделить в FPU (17 для DP) и преобразовать обратно (ещё 11)?..
Из правила о тотальной 64-битности исполнительных ресурсов есть намёк на исключение. Две команды PS*LDQ, сдвигающие 128 бит влево или вправо, исполняются за такт на двух 64-битных сдвигателях — это получится, лишь если они умеют объединяться в общее 128-битное ФУ. Для сдвигателей это не намного сложнее, чем объединение двух одинаковых арифметических ФУ (в т. ч. АЛУ), хотя и эти команды требуют двух мопов. Но это не помогло команде PALIGNR для вырезания 16 из 32 байт, слеплённых из двух источников — она часто используется не только в обработке векторов, но и в компиляторной реализации функции memcpy Си-подобных языков для копирования блока памяти. В Bobcat она требует 20 мопов и исполняется аж 19 тактов задержки и 12 пропуска. Это может замедлить даже целочисленный скалярный код, сделанный современным компилятором.
Обмен с памятью даже 32- и 64-битных операндов команд FPU (т. е. векторных целых из набора MMX и вещественных скалярных из SSE) на 2 такта медленнее скалярных целых из-за дополнительных задержек на межтрактные пересылки. Ещё один такт добавляется, если аргументы 128-битные. Проще говоря, векторы на 2–3 такта дальше от кэша, чем РОНы, что на такт больше разницы у Atom. Куда хуже то, очевидные цифры пропуска (8 байт/такт) соблюдаются лишь для чтений; запись 4- или 8-байтового компонента вектора почему-то полуконвейерна, а пропуск всего xmm — и вовсе 3. Таким образом, максимальный темп записи из векторного тракта — 16:3=5,(3) байт/такт. У Atom же чтение или запись выровненными 16-байтовыми словами происходит каждый такт. Уже одно это может подорвать производительность любого векторного и/или вещественного кода.
Смешивание мопов с разным временем исполнения на одном порту практически не вносит никаких задержек, что намекает на возможность завершения более 2 мопов/такт. Частичный доступ к регистрам устроен просто: его вообще нет — любой 64-битный физический регистр адресуется целиком и зависит от предыдущих команд всеми частями, в т. ч. и неиспользуемыми читающей его командой. Частичный доступ к флагам также отсутствует, но это почти не замедляет 2-путное исполнение. Единственное естественное исключение — половины регистров xmm, хранимые и адресуемые отдельно по причине узости РФ и ФУ.
Почти все обнуляющие идиомы распознаются как разрывающие ложную зависимость по регистрам, однако исполнять их всё же требуется (диспетчер в Intel Sandy Bride умеет «исполнять» их на стадии переименования, не загружая планировщик и ФУ, однако это уже «высший пилотаж»). Полный их список: *XOR*, (P)SUB*, SBB (результат зависит лишь от флага переноса), *CMP* и PANDN (звёздочками указаны переменные части названий команд). А вот «вещественная логика» типа ANDNP* и единичные идиомы не распознаются, причём первый случай особенно странен, т. к. ANDNP* почти ничем не отличаются от «целой логики» PANDN. Подсистема памяти
LSU и другая логика
Блок LSU для компактного ЦП силён качествами, но не количествами. Он, как и подключенный к нему кэш L1D, 2-портовый, но каждый порт — специализированный: 1 чтение и 1 запись. Это вполне ожидаемо, хотя один из портов вполне можно было сделать универсальным, чтобы иметь возможность совершать 2 чтения за такт. Это особенно полезно в свете главного недостатка: ширина портов — всего 8 байт. Даже при наличии единственного AGU для чтений (хотя очевидно, что никакого специального «AGU для чтений» быть не может — оба AGU одинаковы), его бы хватило для обработки одной 16-байтовой пересылки за такт (для чего, впрочем, также требуется расширить шину до FPU), но единственный 8-байтовый порт чтения выполнит её за 2 такта. Ещё одно «бессмысленное и беспощадное» (для производительности) 64-битное упорство.
Впрочем, есть чем его скрасить. Главное достоинство LSU — реализация внеочерёдного доступа к памяти, что ещё недавно было достижением лишь настольных ЦП Intel. Поочерёдный Atom, конечно, «курит в сторонке», но даже куда более сложный Nano реализует далеко не все тонкости. Bobcat умеет перетасовывать чтения и записи во всех случаях, которые не нарушают порядок записей. Очереди чтения и записи вмещают 26 и 22 команд. По утверждению AMD, есть даже предсказатель коллизий адресов чтений с пока не известным адресом записи, чем пока хвастали лишь «большие» ЦП Intel. Буфер удержания допускает до 8 промахов, в течение которых кэш L1D будет обслуживаться.
Механизм STLF работает ожидаемо: если последующее чтение умещается в уже размещённой в LSU записи (даже если данные ещё не попали в кэш), то его можно досрочно завершить — если обе операции не пересекают 16-байтовую границу. Впрочем, совокупная задержка такой пары оказывается большой: не менее 8 тактов для РОНов и 11 для векторных регистров. В случае пересечения 16 байт дополнительный штраф составит 4–11 тактов (это именно для STLF — явные невыровненные загрузки быстрее). В отличие от предыдущих ЦП AMD, Bobcat позволяет исполнять команды прямо указанного как невыровненный доступа (MOVUPD) также быстро, как и явно выровненные (например, MOVAPD) — штраф последует, только если пересылаемое слово действительно пересекает 16 байт.
Внимательный Читатель сразу заметит, что хотя LSU принимает мопы с 8 байтами, гранулярность работы STLF — 16 байт, т. е. очереди LSU имеют 16-байтовые ячейки. Это также подтверждается задержкой невыровненного доступа: он имеет 3 такта штрафа при пересечении именно 16-байтовой границы (требуется сделать ещё одно обращение к кэшу). Кстати, дополнительных задержек при пересечении строк (64 байта) и страниц (4 КБ) нет, хотя в других ЦП они присутствуют почти повсеместно.
Дополнительное доказательство, что LSU соединяется с L1D 16-байтовыми портами, заключается в скорости исполнения команд типа PUSHA (сохранение всех РОНов в стеке) и POPA (загрузка их из стека) — 8–9 тактов, в т. ч. в 64-битном режиме с 16 РОНами. Очевидно, такое возможно лишь при переносе из РФ в кэш и обратно по два 8-байтовых регистра за такт, что недоступно для отдельных команд чтения или записи. Более того, «строковые» команды, оперирующие линейными массивами, достигают максимума лишь 6,5 байт/такт (из 8) при записи в L1D и 10,1 (из 16 — в сумме на чтение + запись) при копировании. (Правда, даже это на треть быстрее, чем у Atom, но на треть медленнее, чем у Nano.) А команды MASKMOV* для выборочной записи байтов из векторного регистра напрямую в память (минуя кэш) и вовсе исполняются до 3000 (!) тактов, но это уже явная недоработка аппаратного дизайна, залатанная микрокодом (по 4 мопа на каждый байт!). Впрочем, то же число мопов и для настольных ЦП AMD, но там эти команды исполняются максимум за 26 тактов. Atom же требует 7 тактов, а Nano — 1–2…
Предзагрузчик отслеживает до 8 потоков данных единственным и очевидным алгоритмом: после 2-го промаха адреса́ команды и её промахов поступают в очередь предзагрузки, где для них вычисляется шаг. Далее для каждого потока 1–4 слова подгружаются в L1D и/или очередь загрузки (безо всяких дополнительных буферов). Просто и вполне эффективно.
Кэши и TLB
| Параметр | L1I | L1D | L2 |
| Размер | 32 КБ | 512 КБ | |
| Ассоциативность | 2 | 8 | 16 |
| Размер строки | 64 байта | ||
| Задержка | 3 такта | 20 тактов | |
| Число портов | 1 | 2 | 1 |
| Разрядность портов | 32 байта | 16 байт | 64 байт? |
| Частота | Частота ядра | ½ частоты ядра | |
| Политика работы | Почти включающая | ||
| Только чтение | Отложенная запись | ||
| Доступность | Местное ядро | ||
2-путная ассоциативность L1I может привести к вытеснению не столь уж старого кода, часто прыгающего по неблизким адресам. Странно, почему AMD не использовала 8 путей и в этом кэше, учитывая, что всё в ядре разработано с нуля, и не требуется тащить «вечные 2 пути» со времён первых Athlon, как для настольных ядер. Буфер промахов в L1I содержит лишь 2 адреса, но при 1-поточном исполнении в ядре больше и не надо.
Как и в Atom, для экономии из набора считывается только сработавший путь. Интересно, что для L1I помимо штатных тегов есть и микротеги, которые читаются до обращения в TLB. Учитывая, что для экономии обращение в TLB происходит, только если страница изменилась относительно предыдущего запроса, можно предположить, что микротег это та часть обычного тега, которая остаётся после вырезания старшей части адреса (свыше 12 бит, составляющих смещение в странице). В любом случае, даже при обращении в TLB задержка считывания составит 3 такта.
Ниже в таблице показаны описания трёх стадий конвейеров чтения (они же — стадии 1–3 и 12–14 общего конвейера для L1I и L1D), расписанных с точностью до полутактов («a» и «b»). Для L1D описан наиболее распространённый случай, когда базовый адрес сегмента равен 0. В крайне редких случаях, когда это не так, для сложения адреса из AGU с базовым используется дополнительная стадия между «1b» и «2a».
| Чтение из L1I | Стадия | Чтение из L1D | |
| ? | 1a | 12a | Генерация адреса в AGU. |
| Чтение микротега. | 1b | 12b | Запись в очередь чтения LSU. Проверка в LSU. |
| Проверка в TLB. | 2a | 13a | Проверка в TLB и тегах. Выборка набора. |
| Проверка в тегах. Выборка набора. | 2b | 13b | Сравнение адресов. |
| Сравнение адресов. Чтение строки в наборе. | 3a | 14a | Чтение строки в наборе. |
| Передача в буфер предекодера и запись. | 3b | 14b | Запись в очередь записи LSU и в исполнительный тракт. |
Как ни странно, в L1D обнаружение промаха происходит не на втором такте (после сравнения физических адресов), а на третьем. Далее идёт перенаправление запроса в L2 (на что тратится аж 3 такта), там в течение двойного такта читаются теги, потом ещё один двойной тратится на чтение выбранной строки. Она делится, скорее всего, на 4 16-байтовых слова, которые аж 6 тактов (разумеется, конвейерных) передаются обратно в 14-й такт основного конвейера. Там происходит запись в L1D, и только ещё через такт данные оказываются доступны для ФУ.
Впрочем, как показано в таблице, замеренная задержка оказалась даже не 17 тактов (из которых, как видно, бо́льшая часть просто необъяснима), а все 20. Причиной этого может оказаться излишнее стремление сэкономить ватты: перезапуск промахнувшейся в L1D команды (которая при обращении к L2 продолжает находится в очереди LSU) происходит не сразу после заполнения нужной строки в L1D, а когда команда, как пишут, «имеет высокий шанс завершиться». Очевидно, что если строка уже прочитана из L2, то команда точно завершится. Или в Bobcat ей надо выждать ещё несколько тактов «для надёжности»?..
Кэши L1 и все TLB защищены битами чётности. Выглядит логично, вспоминая совсем не серверную направленность (где требуется высокая надёжность и отказоустойчивость), низкие частоты (опять же, бо́льшая надёжность) и экономию энергии (логика коррекции ошибок требует свои милливатты, даже когда исправлять ничего не надо). Но почему тогда кэш L2 всё же корректируется через ECC? Если бы он питался пониженным напряжением — тогда вопрос был бы снят, но в таком виде это кажется излишеством. Впрочем, вспоминая, что у Atom всё также, предположение такое: для L2 используются особо экономные транзисторы, которые, в обмен на свою энергоэффективность, не очень хорошо переносят проседание питания при записи в соседние ячейки и изредка могут портить «свои» данные. О видах транзисторов мы узнаем чуть ниже…
В списке возможных запросов к L2 указаны загадочные «вытеснения атрибутов» из L1I. Что это за атрибуты, которые надо сохранять в L2? Разметка длин команд нигде не кэшируется (как в предыдущих ЦП AMD); адреса́ и, тем более, содержимое вытесняемых строк передавать в L2 тоже не надо. Возможно, в L2 сохраняется часть информации из BTB (опять же, как в предыдущих ЦП), причём для этого подойдут как раз те самые биты ECC, избыточные для неизменной информации (т. е. кода). Кстати, «почти включающая» политика работы означает, что в редких случаях (отключение редкоиспользуемых банков, совпадение адресов при обработке внешних запросов протокола когерентности) из L2 могут вытесняться данные или код с сохранением их копий в L1 — для этих строк политика оказывается исключающей.
Ещё одна странность L2 — его половинная частота (только битовые массивы; контроллер работает на полной частоте). В принципе, для экономии это допустимо, т. к. за «свой» такт L2 считывает вчетверо больше, чем требуется запрашивающему кэшу L1, хотя официальные 17 и замеренные 20 тактов задержки были бы на 2 меньше при полной частоте. Но, судя по тестам, ПС кэша L2 ограничивает шина до L1 (работающая на полной частоте) — до позорных 3–4 байт/такт (и по чтениям, и по записям). Возможно, тесты неверны, но ПС памяти ещё меньше — около четверти от теоретического пика при 1-поточном доступе и половина при 2-поточном. Более того, переход с DDR-1066 на DDR-1333 почти не даёт ускорения (по крайней мере, при работе x86-ядер), а значит фатальный затык где-то ближе к ядру. Даже Atom по этим параметрам едва достижим…
Кстати, если уж экономить на частоте, то первым кандидатом оказывается L1I: 32 байт/такт хватит и 4-поточному конвейеру (как в Bulldozer), а уж 2-поточный запросто обойдётся 16 байтами за такт или 32 за два. (Да, декодеры могут обрабатывать до 22 байт/такт, но для сглаживания перед ними есть буфер.) Более того, предсказатель переходов всё равно делает прогноз каждый второй такт. Правда, задержку тогда придётся поднять до ближайшего большего чётного числа — т. е. до 4 тактов, что на 1 увеличит штраф при фальш-предсказании (до 14 тактов).
| Параметр | TLB L1I | TLB L1D | TLB L2D | |||
| Размер страницы | 4 КБ | 2/4 МБ | 4 КБ | 2/4 МБ | 4 КБ | 2/4 МБ |
| Число страниц | 512 | 8 | 40 | 8 | 512 | 64 |
| Ассоциативность | (2, 4, 8)? | 40 | 8 | 4 | ||
| Задержка | 1 такт, учтена в задержке к кэшу | ≈7 тактов | ||||
| Число портов | 1 | 2 | 1 | |||
| Политика работы | Скорее всего, включающая | |||||
Транслятор виртуальных адресов (тут он зовётся TWE — table walk engine, движок проходки таблиц) ожидаемо имеет кэш верхних ярусов трансляции («директории страниц») неизвестного, но, как всегда, небольшого (32?) размера. Он также поддерживает «быстрое индексирование для виртуализации» (более известное как «вложенные таблицы страниц»), ускоряющее переключения между виртуальными ОС. Кроме того, поддерживаются и никому тут не нужные «сверхбольшие» гигабайтовые страницы, но лишь номинально — в TLB они вносятся разбитыми на страницы по 2 МБ (разумеется, не на все 512, а лишь по запрошенным адресам). Такое упрощение очевидно, учитывая, что физическая адресация ЦП — 36 бит, т. е. рассчитана «всего» на 64 ГБ, которых, по мнению AMD, «хватит всем». :) Зато это, как сказано выше, это позволяет хранить в TLB (помимо атрибутов) лишь 36−12=24 бита базового физического адреса страницы. Внеядро

1-канальный ИКП рассчитан на использование до двух модулей памяти DDR3(L) на частотах до 1066 или 1333 МГц. Как и в Llano, ГП соединён 512-битной полнодуплексной шиной до собственного КП (на схеме выше он иерархически находится в пределах общего ИКП), не проверяющего когерентность для адресов, выделенных видеопамяти (до 512 МБ из ОЗУ). Для обращения к памяти без пробуждения или отвлечения x86-ядер ГП умеет сам посылать DMA-запросы к ИКП. В предыдущих компактных решениях ИКП был встроен в ЦП, а ГП — в северный мост, соединённый с процессором шиной HyperTransport. По мнению AMD, размещение ИКП и ГП на одном чипе уменьшает суммарное потребление системы на 1 Вт, задержку доступа к графической памяти — на 40%, а ПСП увеличивается на 17%.
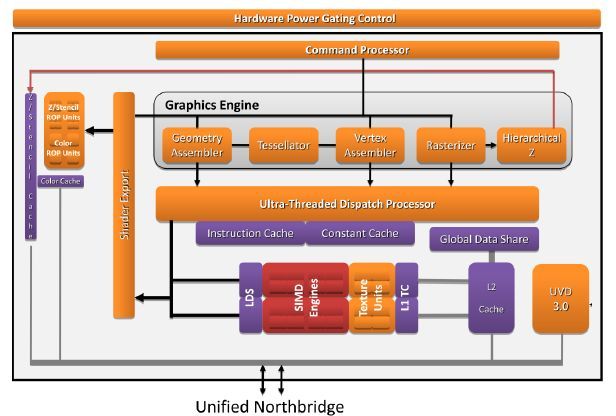
Описание архитектуры ГП Evergreen показывает, что для Bobcat взята самая слабая его версия, названная (в зависимости от базовых частот) HD 6250 (276 МГц), HD 6290 (276–400 МГц), HD 6310 (488–500 МГц) или HD 6320 (508–600 МГц). Первая пара нагружена на ИКП с частотой 1066 МГц, а вторая — 1333. Во всех версиях — по 80 графических ФУ, 8 блоков TMU и 4 растеризатора. Производительность определяется пословицей «мал, да удал»: при 492 МГц (до недавнего времени это была максимальная частота ГП среди моделей этого ЦП) 3D-движок выдаёт в секунду 78,7 SP-гигафлопа (x86-ядра на 1,6 ГГц выжимают лишь по 6,4), 123 мегатреугольника, 3,9 гигатекселя и 2 гигапикселя. Что значат все эти загадочные цифры и насколько они круты — смотрите и спрашивайте в видеоразделе нашего сайта. :)
В отличие от настольных серий HD 6000, встроенный ГП обновил свой аппаратный видеодекодер UVD до версии 3 (как и в ЦП Llano) и теперь поддерживает H.264, VC-1, MPEG-2 и -4, DivX и Xvid. Имеются 2 цифровых выхода (поддерживающих протоколы HDMI, DVI и DisplayPort), 1 LVDS (для встроенного в прибор ЖК-экрана) и 1 VGA. (Общее число работающих экранов — не более двух.) Поддерживаются стандарты DirectX 11, OpenGL 4.1 и OpenCL 1.1 (этот как раз и позволяет добавлять графические гигафлопы к «обычным» — но с трудом и не всегда), а также технология Dual Graphics (бывшая Hybrid CrossfireX) для «слияния» работы встроенного ГП с внешним, подключенным через PCIe.
Контроллер PCIe 2.0 имеет 2 4-полосных порта, к одному из которых подключается обычный разъём для периферии (в т. ч. для внешней видеокарты), а ко второму — южный мост. Все ядра, ИКП и контроллеры соединены шиной CCI (common core interface, общий интерфейс ядер), являющейся несколько переделанной версией PCIe. AMD называет её очень эффективной, однако судя по ПСП, звучит сомнительно… Тем не менее, «с высоты» мы видим компактную версию Llano, сокращённую не качественно, а лишь количественно. Экономия и авторазгон
 Модель зависимости частоты ГП (МГц) от питающего напряжения (В). |
Чип имеет две регулируемые силовые шины — VDD для x86-ядер и VDDNB для встроенного северного моста и ГП. Ядра Bobcat оптимизированы под напряжение 0,8–1,2 В, хотя как минимум среди первой ревизии были чипы с питанием 1,3 В, и даже в простое это напряжение не опускалось ниже 1,09 В. ГП, судя по предоставленному графику, может запитываться 0,65–1,3 вольтами, а на самом деле — 0,8–1 В с шагом 0,1. Хотя, если судить по официальным частотам, выше 0,9 В ни в одной модели эта шина подниматься не должна — если, конечно, график точен… Также есть две фиксированные линии для питания драйверов интерфейсных шин.
 |
Как обычно для современных чипов, применяется концепция силовых островов — областей, подключенных к какой-либо силовой шине напрямую или через силовые ключи. Они применяются для x86-ядер, UVD, ГП и графического КП. Тут можно спросить — а зачем отключать и последний? Ведь даже при просмотре статичной картинки требуется выводить изображение на экран, читая его из видеобуфера в ОЗУ. Верно, но по меркам ЦП это происходит так редко (если группировать запросы), что в паузах между чтениями (а это 94% времени) и память, и её контроллер можно глубоко усыпить. Для x86-ядер процедура перехода в энергосостояние C6 («всё выключено») и пробуждения из него такая же, как у Llano, т. к. состояние ядра сохраняется в ОЗУ, а не специальной накристальной памяти (как у Atom).
Интересно, что для лучшей энергоэффективности при усыплении обоих x86-ядер шина их питания может быть снижена до 0, чтобы сэкономить даже на остаточных утечках, неизбежных и с выключенными силовыми ключами. Если и ГП спит, то это состояние называется Package C6 (т. е. C6 для всей микросхемы). Однако поднятие напряжения на целый вольт требует много времени, и если переходы в состояние «2-ядерного сна» слишком часты, то медленные пробуждения заметно замедляют реакцию ЦП. В этом случае силовой контроллер указывает регулятору напряжения снижать шину питания лишь до 0,45 В.
Интересно, что силовые ключи (основанные на p-канальных транзисторах) отключают именно шину напряжения, а не земли (как у Llano и Bulldozer), причины чего не объяснены. Силовая нагрузка подаётся через пару слоёв, где отдельно расположены горизонтальные и вертикальные дорожки (в проекции «сверху»). Для x86-ядер это 9-й и 10-й слои (т. е. самые верхние и толстые, пригодные для наибольшей плотности тока), а северный мост и ГП запитывается через 7-й и 8-й. Шины идут тройками — земля («ноль» или минус), подводная и коммутируемая (к ней подключена нагрузка). На некоторых из пересечений таких троек находятся транзисторы-ключи, соединяющие подводную и коммутируемую шины. Для x86-ядер ключей ≈30 000, а общая длина их затворов — около метра (бурные, продолжительные аплодисменты…). Правда, так устроено лишь над логикой, которую можно раздвинуть для помещения силовых ключей в наиболее удобном, шахматном порядке. У куда более высокоплотных массивов это не получится, поэтому там ключи расположены вдоль двух сторон одинарными или двойными рядами (в зависимости от длины массива).
Во избежание ошибок из-за помех по питанию, вызванных резкими перепадами напряжения при включении или отключении блоков, ключи организованы как «двойная гирлянда». Для каждого острова параллельно соединённые ключи делятся на два ряда — слаботочные (для инициации контакта со «средним» сопротивлением) и сильноточные (для устойчивого контакта с низким сопротивлением). В каждом ряду ключи срабатывают последовательно, чтобы плавно нарастить или снизить потребление. При включении сначала проходит активация слаботочных ключей, а после задаваемой паузы — сильноточных. При отключении — наоборот. Пауза программируется при заводской юстировке, исходя из возможностей конкретного экземпляра ЦП. Результат на примере подключения ГП таков: проседание напряжения — не более 2%, а совокупное сопротивление всех ключей — 600 мкОм. Пиковая плотность потребления тока на единицу площади питаемого участка — до 0,5 А/мм², чего хватит даже для жарких серверных ЦП. AMD указывает, что эта полезная схема применяется для шины VDDNB, промолчав про ключи для x86-ядер…

Ребята из AMD в очередной раз напакостили, перевернув кадр №4 — пришлось исправлять.
Выше приведено загадочное «меридианное фотонное излучение» (упоминание которого найдено лишь в документах по Llano и Bobcat) для четырёх состояний кристалла: всё включено (№1), одно ядро выключено (№2 и №3) и всё-что-можно выключено, т. е. «package C6» (№4). Тактирование полностью убрано, выдержка — 30 с, напряжение VDD — 1225 мВ для первых трёх случаев (снова попались на превышении заявленного диапазона 0,8–1,2 В) и 875 для №4, а VDDNB везде равно 875 мВ. На кадре №4 видны постоянно подключенные блоки: собственно северный мост, некоторые контроллеры внешних шин со своими драйверами, все внутричиповые шины и их порты для x86-ядер (где происходит преобразование частот и уровней напряжений для данных). Причём эти порты ярко светятся (т. е. много потребляют) даже у простаивающего ядра, если хоть одно активно (кадры №2 и №3).
Об экономии в L2 и прочих массивах сказано не было, но известно, что Intel со времён Pentium M применяет такой нехитрый приём: кэш L2 (тогда он был на 2 МБ) делится на 32 банка, каждый из которых имеет счётчик тактов, сбрасываемый при каждом обращении в этот банк. Если за определённый период в банк не было обращения, то счётчик переполняется, банк смывается в память, и питание от него отключается. (Правда, тут уместно спросить — если всё так, то чего же Intel молчит о том, что силовые ключи у неё давно есть, пусть лишь для одного кэша?..) Скорее всего, чтобы не пробуждать зря банк при редких доступах, при обращении (и промахе) в спящий банк сначала запускается счётчик, и если до его переполнения сюда обратятся ещё раз, то банк получит питание и начнёт накапливать данные от промахов. Возможно, в Bobcat применяется что-то похожее.
Ещё одно место приложения энергоэффективных технологий — буферы-защёлки, в т. ч. межстадийные. Внимательный Читатель вспомнит эту диаграмму из статьи о микроархитектуре ЦП VIA Nano, иллюстрирующую, что . Сегодня уже для любых процессоров надо оптимизировать число и потребление буферов, чтобы уложиться в температурный бюджет. Что AMD предлагает изменить? А ничего! Видимо, разработанный TSMC энергоэффективный техпроцесс настолько хорош, что для частот до 2 ГГц потребление невелико. Правда, 2 ГГц на этих транзисторах достичь не удаётся, поэтому некоторые изменения в буферах всё же произошли, и экономии они совсем не касаются — об этом чуть позже.
{kind=link}
Все тонкости управления питанием доступны для ОС через драйвер, что даёт возможность настраивать баланс скорости и потребления в разных ситуациях (работа от сети, от свежих батарей или от севших…), а также оптимизировать настройки программным обновлением. Т. е. если ваш нетбук на платформе AMD маловато работает на одном заряде — обновление драйверов ЦП (теоретически) может отсрочить покупку более ёмкого аккумулятора. Впрочем, и сейчас есть чем похвастаться: при простое ЦП потребляет 3 Вт (причём разгон с «ленивых» 800 МГц до штатной частоты происходит только после исполнения миллионов команд), в состоянии «лёгкого сна» (C1 или C3) — 0,8 Вт, а полностью выключенный — 0,2 Вт. Но это всё равно больше, чем у Atom, даже если брать лишь его 2-е поколение: уже интегрированное, но ещё на 45 нм. Кристалл
Параметры и блоки
Впервые в своей практике AMD стала производить ЦП не на своих заводах (пусть и бывших — с учётом выделения производственных мощностей в самостоятельную компанию GlobalFoundries), а на совсем чужих — компании TSMC, которая является крупнейшим в мире контрактным производителем микросхем (GF — третья). Возможно, инженеры подумали, что с затягиванием перехода на 32 нм в GF затягивать выход самого ЦП не обязательно — не зря же AMD теперь является бесфабричной компанией. Кроме того, TSMC известна своими оптимизациями техпроцессов под малое энергопотребление, что как раз кстати на фоне скромных результатов по этому пункту бывших фабрик AMD.
В общем, решено использовать «полушаг» на 40 нм. Ранее полушаги (расположенные между двумя стандартными технормами — в данном случае 45 и 32 нм) применялись в основном для памяти и прочих регулярных схем. Теперь же их всё чаще применяют для чипсетов и ГП. Кроме того, конкретно у ATI были давние связи с TSMC, выпускавшей все её ГП, так что не грех воспользоваться контактами и после слияния с AMD. Более того, т. к. большая часть чипа занята ГП, который к моменту окончания разработки уже выпускался на 40 нм в дискретном виде, логично и остальные части кристалла сделать на этом же процессе. Если точнее, TSMC для 40 нм предоставляет 10 слоёв медных проводников, обычный поликремниевый затвор (никаких новомодных HKMG) и обычную кремниевую пластину (а не SOI, как во всех ЦП AMD ранее). Интересно, что, как и в других мобильных ЦП AMD, тут отсутствует теплораспределительная крышка — радиатор непосредственно контактирует с тыльной стороной кристалла.

Вид кристалла с шариками припоя для монтажа на подложку. Наложены обозначения основных блоков. По ссылке — большая версия без обозначений. Виден верхний слой дорожек, перераспределяющих напряжение (большая часть выводов — силовые; сигнальные расположены над контроллерами интерфейсов). Диагональные дорожки от центра — верхний ярус тактораспределительного дерева. Ниже дан более привычный вид (повёрнут на 90°) — без шариков и нескольких верхних слоёв дорожек.


Раскладка блоков чипа делится на два уровня. Слева указан верхний: 2 ядра Bobcat с L2, их умножители (CK), графическая часть (gnb), северный мост (CNB) и набор интерфейсов. Внизу: CRTDAC — аналоговый для VGA, LVTMDP и TMDPA — два цифровых, DPLL — 2 тактовых генератора к последним. PA — видимо, силовой контроллер. Второй уровень — ядра x86 и ГП (показан справа). Расшифровку этих сокращений понять куда труднее, помимо очевидных: UVD, MC (графический ИКП), DC (контроллеры экранов) и SP (2 блока по 40 графических ФУ). CP — возможно, «коммуникационный процессор» (часть северного моста).
 Ещё одна версия раскладки, в которой чуть ясней указаны периферийные блоки, и выделен белым центральный канал длиной 4,41 мм, разделяющий ГП пополам. Вдоль него проложены 1400 линий между северным мостом и x86-ядрами, лежащие на уровнях 2, 4 и 8 по горизонтали и 3 по вертикали. Поперёк проходит 21 000 дорожек ГП на уровнях 5 и 7 по вертикали и 8 по горизонтали. Нетрудно заметить, что слои металла чередуются по направлению дорожек. |
Кристалл единственного вида упакован в корпус BGA-413 размером 19×19 мм. Размер собственно кристалла — 9,1×8,1 мм, площадь — 75 мм², TDP — до 18 Вт (в ранних документах сказано, что корпус выдерживает до 20 Вт). По мнению AMD, предыдущая мобильная платформа для той же производительности должна иметь ЦП класса Athlon II X2 (117 мм², до 25 Вт), северный мост (66 мм², 13 Вт) и отдельный ГП младшего класса (59 мм², 8 Вт). Выгода интеграции очевидна, хотя ядро Bobcat, конечно, не дотягивает по скорости не только до равночастотного K10, но и до K8.
Зато выиграть можно в т. ч. и по цене, частично определяемой площадью кристалла: на 75 мм² уместилось два x86-ядра по 4,9 мм² (плюс 3,1 для L2), 35 мм² занимают графика, контроллеры и генераторы частот, а 24 — драйверы шин. Для сравнения: площадь 2-ядерного Atom 2-го поколения (Pineview, 45-нанометровый техпроцесс) — 87 мм², одного его ядра — 9,7, а кэша L2 того же объёма — 4,4. Уменьшение до 40 нм в идеале дало бы сокращение этих величин лишь на 21%, а тут ядро и кэш в 1,5–2 раза меньше, и при большей скорости. AMD хвастается, что ядро Bobcat втрое меньше K8, даже если последнее уменьшить с родных 65 нм до 40 — притом, что производительность у Bobcat меньше всего на 10–20%.

ЦП платформы Brazos (слева), дискретный ГП (в центре) и 2-ядерный «Атлон» (справа). А ведь ещё нужен северный мост…
Кстати, на секунду представим себе, что будет в сравнении с K10. При очень приблизительном подсчёте оказывается, что пара ядер Bobcat с кэшами L2 и по площади (16 мм²), и по числу транзисторов (116 Мтр.) примерно равна ядру К10 с L2 на 1 МБ, изготовленному на общем техпроцессе. При этом пара «Бобкэтов» обгонит равночастотный K10 по скалярной производительности, сравняется по векторной в SP и вполовину отстанет по DP (которые в K10 также полноконвейерны). Впрочем, главный недостаток версии «K10 на 40 нм для планшетов» в том, что при избытке вычислительных мощностей внутри ядра нечего отключать от питания, а из двух ядер одно можно усыпить. Т. е. два маленьких, но по 3 рубля ватта, лучше одного большого, но по 8–10.
Транзисторы
| Число экземпляров | Виды транзисторов | ||
| Макросы | 225 | HVT, 40 нм | 24,76% |
| Память | 866 | HVT, 42 нм | 30,85% |
| Цепочки | 2 473 912 | SVT, 40 нм | 21,94% |
| Логика | 8 080 771 | SVT, 42 нм | 20,86% |
| Буферы-усилители | 3 089 581 | LVT, 40 нм | 1,51% |
| Всего | 13 645 355 | LVT, 42 нм | 0,01% |
| Битов памяти | Число транзисторов | ||
| В ГП | 10 559 376 | Память | 144 200 024 |
| В x86-ядрах и L2 | 12 230 872 | Логика | 305 330 039 |
| Всего | 27 790 248 | Ввод-вывод | 1 828 283 |
| Всего | 451 358 346 | ||
Применены 3 вида транзисторов, отличающихся пороговым напряжением срабатывания: HVT, SVT и LVT — высокий, стандартный и низкий. При предельной температуре 105 °C утечка тока в LVT-транзисторах в ≈4 раза больше, чем в SVT, а у этих — в ≈3,5 раза больше, чем в HVT. Каждый вид дополнительно делится на два типа по длине канала: стандартная (около 40 нм) и увеличенная на 2 нм (этот тип позволяет чуть уменьшить утечку за счёт увеличения размера). Все функциональные блоки делятся на простые схемы («экземпляры»), в пределах которых применяются транзисторы лишь одного вида. Но ничто не бывает бесплатно: HVT — самые медленные (применяемые и для силовых ключей), SVT — среднескоростные (для ГП), а LVT — самые быстрые, используемые лишь в критических местах x86-ядер, где иначе не выжать даже скромные 2 ГГц. В частности, избежание использования LVT для экономии на утечках и привело к решению сделать массивы кэша L2 получастотными.
 |
Большое внимание уделено тактированию. В чипе есть 16 рабочих частот, 10 сканирующих (применяемых при проверке монтажа ЦП на плату через интерфейс JTAG) и 11 отладочных (для фабричных тестов). Цифровой синтезатор частоты (DFS, ранее уже применялся в AMD Turion, то бишь в мобильных «Атлонах») генерирует 9 рабочих частот из 4-фазного опорного сигнала от системного умножителя частоты (PLL), причём при смене множителя не требуется задержка на аналоговую адаптацию (как у обычного PLL) — достаточно сменить схему цифрового коммутирования фаз. Этот умножитель получает внешнюю синхронизацию — базовый сигнал на 100 МГц или некий альтернативный тактовый генератор «DFT mode clock». Есть ещё 4 умножителя, 2 из которых, используемые для видеовыходов, также требуют дополнительное внешнее видеотактирование. Генерируемые частоты попадают в сети тактораспределения пяти разных видов — в основном это разные виды деревьев, но x86-ядра используют сеть с 6–8 «этажами» усилителей. Для точной синхронизации разных частот имеются программируемые линии задержки, срабатывающие с точностью в полтакта быстрейшей частоты.
 Жёлтые дорожки (крестом в центре) — верхний ярус тактораспределительного дерева для ГП. Голубым и красным обозначен средний ярус. Для x86-ядер используется разряжённая сеть — зелёные и фиолетовые дорожки. |
Обычный буферный (D-)триггер имеет 2-ступенчатый тип «мастер-помощник» (политкорректный советский перевод деспотичного оригинала master-slave), т. е. состоит из двух триггеров, срабатывающих в 1-й и 2-й полутакты. Схема компактна, в меру прожорлива, но не очень быстра, если её делать на энергоэффективных транзисторах (как в Bobcat). Поэтому был придуман куда более громоздкий (и даже более прожорливый!), но скоростной тип буферов — 3-стадийный (с задержкой в 3 FO4-вентиля), ассиметричный (переключения 0→1 и 1→0 занимают разное время), с коммутатором и предзарядом выходной линии. Достаточно было заменить на него 12,6% обычных буферов ядра (естественно, находящихся лишь на критических для распространения сигнала местах), чтобы получить подъём частотного потолка на 7% ценой увеличения площади на 2,06%. Неподготовленным читателям схему этого монстрика лучше рассматривать при поддержке нижней челюсти. :) Ну а вы, смельчаки, кто захотел ещё и понять, как он работает, — спрашивайте на форуме.
{kind=link}
Ядро

Полюбовавшись кристаллом, приблизим x86-ядро (для наглядности обработанное поканальной нормализацией яркости). «Гвоздь программы» тут не количественный, а качественный: Bobcat — первое ядро AMD, сделанное с применением почти исключительно автоматизированных САПРов (HLS: high-level synthesis, высокоуровневый синтез схемы) и почти без ручной оптимизации логики (custom logic). Аналогию с программированием можно привести такую: HLS это использование библиотек и компиляторов, а ручная сборка блоков из транзисторов — кодирование на ассемблере. С железом — как и с программами: САПРы намного ускоряют работу, требуют меньше знаний всяких тонкостей, но часто выдают неоптимальный результат; ручная работа — долгий и дорогой эксклюзив. (Кстати, английская микроэлектронная терминология тоже использует термин SAPR, но с другой расшифровкой: synthesis auto place-and-route — синтез схемы с авторазмещением вентилей и авторазводкой их соединений.)
Эти две противоположности в чистом виде, разумеется, давно не применяются, а сосуществуют в виде смеси, но в случае Bobcat доля ручной работы почти нулевая. Борьба «САПРы против рук» ведётся давно, копий сломано много, а конкретно в AMD даже произошёл небольшой скандал. Причиной стало тесное интегрирование старой команды AMD и новой от только что купленной ATI, которое должно было позволить им использовать наработки друг друга — но это оказалось возможным только в рамках САПРов и крупных блоков. Дизайнер Cliff Maier, ранее работавший ещё над DEC Alpha (детальней об этом предшественнике «Атлонов» читайте в обзоре Llano в главе «Кристалл со странностями»), несколько лет назад (когда начались работы над Bobcat) покинул компанию, будучи несогласным с решением руководства положиться только на САПРы и не использовать ручную доводку даже критических частей ЦП.
По мнению инженера «старой школы» Клиффа Мэера, отказ от низкоуровневой оптимизации выдаёт на выходе чип, который на 20% больше и на 20% медленней. Насчёт частоты, возможно, и так (хотя ровно по такой же методике разрабатывался и вполне высокочастотный Bulldozer), но вот насчёт потерь в площади позволим не согласиться с уважаемым дизайнером. Кстати, аналогичное несогласие Мэеру высказал другой инженер на том же форуме сайта Mac Rumors. А дизайнеры самой AMD в докладе для конференции IEEE даже похвастались, что применение SAPR позволило обойтись меньшим числом инженеров и даже обогнать поставленные руководством сроки. Самое время вспомнить, что по времени Bobcat всё равно отстал от Atom на 3 года…
Раскладка ядра Bobcat на блоки. Жёлтые полосы — цепочки силовых ключей и, возможно, усилителей тактовых сигналов. Чёрные области в углах не использованы. (Ниже L2 также есть неиспользованная полоска, которую почему-то не видно тут.) Большое оранжевое пятно в центре и бордовое выше него, возможно, относятся к планировщику и логике управления FPU, хотя, судя по размерам тощего диспетчера (а в нём должен быть ROB!), сюда бы точнее подошёл именно он… Блоки справа вверху также не обозначены, но на увеличенной версии есть внутренние сокращения, намекающие на разные части контроллера L2.
Но вернёмся к чипу — в отличие от «квадратно-гнездового» метода стыковки блоков, привычного по всем остальным ЦП, в ядре Bobcat границы между логическими блоками едва видны и чётко прочерчены лишь на официальной карте. (Матрицы, разумеется, видны отлично.) Амёбообразные очертания являются характерным признаком автоматической оптимизации в масштабах всего ядра, чего ранее не делалось просто по причине исключительно больших вычислительных затрат (детальней об этом читайте в 3-й части обзора Atom). Сегодня же, благодаря более мощным серверам, обновившимся библиотекам IP-блоков и продвинутым алгоритмам САПРов можно получить результат, близкий к профессиональной ручной работе, только выглядящий совершенно по-другому. Примерно так же выглядят границы блоков у процессоров архитектуры ARM — потому что эта компания поставляет конечным производителям описания ядер, из которых они потом синтезируются под конкретный техпроцесс.
Например, то, что для человека должно быть регулярной структурой (скажем, матричный умножитель), для алгоритма оптимизации — просто набор логических вентилей, которые не обязательно располагать какой-либо матрицей. В результате привычные блоки могут оказаться хитрозакрученными и даже разделёнными на части (как целочисленный тракт). Состоят они из «логических экземпляров», которых всего в ядре набирается 1,1 млн. Не считая L2 и его тегов (это отдельная от ядра «плитка»), РФ и мелких буферов (тут это тоже «логика»), также есть 35 массивов семи видов. С ними связано не меньше любопытного, и это не только уже проведённый нами анализ размеров структур предсказателя.
Аккуратный подсчёт даёт 8 видов массивов, а не 7 (яркие полоски вдоль краёв — входящие в блок обслуживающие схемы, в т. ч. логика). Сумма 35 получается так: L1D разбит на 4 блока по 8 КБ, для кэша L1I, «редкого» BTB и TLB L2D использовано 10 массивов по 4 КБ (6+3+1), а остальные блоки имеют массивы на 2 КБ (кроме крошечного TLB L1D для 8 больших страниц). TLB L2D, как видно, расположен впритык к LSU, а потому его задержка в ≈7 тактов странна — такие массивы используются и в кэше L1I, который сам по себе срабатывает всего за 2 такта.
Кстати, о нём: L1I почему-то создан из массивов аж трёх видов — 6 по 4 КБ (на фото вытянуты горизонтально и разбиты посредине на два полумассива), 2 по 2 КБ (аналогичное разбиение) и ещё 2 очень похожих блока, но с другой «сервисной полоской» (зеркально отражены от предыдущей пары). Зачем было так выделять эту четверть кэша вместо ещё пары массивов по 4 КБ? Если бы L1I был 4-путным, то можно было предположить, что один из путей особо выделен, но для 2-путного кэша разбиение может быть только по номерам наборов, т. е. по кускам физических адресов кода. Это бессмысленно для экономии энергии и площади; может быть, чуть уменьшается время распространения сигнала из этого угла кэша до логики?..
Сравнение двух трактов показывает, что векторный физически вдвое шире целого — как во всех «больших» ЦП Intel, где векторный тракт ограничен длиной, а не шириной. Там это объясняется тем, целочисленная и вещественная части со своими РФ и ФУ совершенно отдельны (не считая Sandy Bridge, где всё несколько сложнее), хотя архитектурно относятся к регистрам xmm и ФУ для команд SSE. Если тут объяснение то же, то оказывается, что вместо 128-битного тракта присутствует 2 64-битных с разными ФУ. Доказательство чему наличие задержки в 1 такт на срабатывание междоменного шлюза — выходит, что домен тут это не просто группа ФУ на общем тракте, а отдельный тракт. Кроме того, один из них чуть длиннее другого — видимо, вещественный, т. к. в нём куда более «толстые» ФУ. Антураж
Модели
Итак, что мы видим из таблиц по Bobcat-содержащим APU в Википедии? Что за прошедший с анонса год число моделей оказалось весьма мало (изначально их было лишь 4), что даже хорошо — вроде бы не запутаешься. Читатели прошлого Фелидариума уже коварно потирают руки, однако имена моделей, в отличие от большинства других процессорных номенклатур, вполне удобны хотя бы отсутствием исключений. Но сначала надо познакомиться со словарём кодовых названий платформ: и AMD, и Intel обожают использовать кодовые слова почти для всего, над чем они работают, так что ликбез не помешает.
Итак, Fusion (парадигма «слияния» x86- и графических ядер на кристалле) содержит в себе настольные платформы Lynx и Sabine, отданные ЦП Llano, и ультрамобильную платформу Brazos, где применяются ядра Bobcat. Причём под «ультрамобильными» понимаются в т. ч. неттопы, но не смартфоны. У Brazos имеются 4 применения и 4 ряда ЦП: Zacate (ряд E для неттопов), Ontario (C для нетбуков), Desna (Z для планшетов) и встроенный Brazos-T (T или G-T — причём этих ЦП имеется 10 моделей, а остальных трёх в сумме — 9). Их общие параметры приведены в таблице.
| Ряд | Число x86-ядер | Часто́ты, МГц | Память DDR3 | TDP, Вт | |
| x86 | ГП | ||||
| E | 1, 2 | 1300–1650 | 488–508 | 1066 или 1333 | 18 |
| C | 1000–1200 | 276 | 1066 | 9 | |
| Z | 2 | 1000 | 4,5–5,9 | ||
| T…E | 280 | 6,4 | |||
| T…L | 1, 2 | 800–1400 | нет ГП | 1066 или 1333 | 5–18 |
| T…R | 1 | 1000–1500 | 280–500 | 5,5–18 | |
| T…N | 2 | 1000–1650 | 280–520 | 9–18 | |
Ожидаемая технология Turbo Core присутствует всего в четырёх моделях, включая две «потребительские»: E-450 умеет разгонять ГП с 508 МГц до 600, а C-60 — с 276 до 400. Последний также ускоряет и x86-ядра — с 1000 до… И вот тут поджидает очередной сюрприз: по показаниям утилит вроде CPU-Z частота 1333,(3) МГц получена умножениям базовых 100 МГц на коэффициент 13,(3). Но умножители частоты имеют целые или полуцелые коэффициенты (последний тут применяется лишь в модели E-450, где он равен 16,5), но никак не кратные трети. Умножение на 13,(3) можно получить по формуле 100:3·40, но коэффициент 40 сложно достижим, учитывая напряжение питания и потребление PLL. Остаётся предположить, что новый цифровой синтезатор частоты умеет так манипулировать 4-фазным опорным сигналом, что на выходе может получиться и частота, кратная 1/3 входной. Кстати, заметно, что часто́ты ГП имеют квант всего 4 МГц — вот с каким малым шагом синтезатор умеет устанавливать этот параметр.
Поддержка DDR-1333 взамен DDR-1066 в свежевыпущенных моделях серии E особой роли для x86-производительности не играет, а вот ГП, куда более жадному до ПСП, весьма поможет. 3 модели T…L не имеют ГП: надо же куда-то девать те кристаллы, где фатальные дефекты при тестировании обнаружены именно в нём — и это будут встроенные компьютеры, которым графика ни к чему. Кроме того, для особой экономии некоторые встроенные модели поддерживают память типа LV-DDR3 вместо обычной, но только для 1066 МГц (изначально и для этого типа заявляли о 1333 МГц). Странно, что это же не сказано хотя бы об особо экономном ряде Z. Не исключено, что на деле поддержка есть в нём, но AMD не всегда аккуратно публикует описания…
Дело, впрочем, не только в описаниях — и вот тут снова начинается странный бардак. Как видно по таблице в Википедии, встроенные модели вскоре после объявления были перевыпущены под теми же именами, но с заметно лучшими характеристиками. Может быть, потому что первые версии почти не покупались?.. Например «новая» модель T24L получила на 200 МГц больше частоты x86, T40N — авторазгон для ГП (есть подозрения, что и для x86), T48N — +20 МГц для ГП, T52N — более скоростную память, а T56N — +50 МГц для x86, память и авторазгон. Такая вот подковёрная раздача «встроенных слонов».
Соперники
Все модели ЦП с Bobcat можно разделить по TDP на три группы: 18, 9 и <7 Вт. 18 это горячо в сравнении с самыми крутыми «Атомами» — например, 2-ядерный «нетбуковый» N570 на 1,67 ГГц потребляет скромные 8,5 Вт, «неттоповый» D525 на 1,83 — 13 Вт, а недавно выпущенный 32-нанометровый D2700 (2133 МГц для x86-ядер 640 для обновлённой графики) — 10. Причём линейка Cedarview благодаря своим частотам уже может поспорить с Zacate по производительности и даже местами выиграть. Правда, графика даже после обновления железа в подмётке не годится даже миниатюрным Radeon (о видеодрайверах Intel умолчим с прискорбным выражением лица). Тем более, что при реальных замерах на чисто процессорных задачах 2 ядра Bobcat (на частоте 1,6 ГГц) и ИКП потребляли как раз те же 10 Вт.
Изначально AMD сравнивала модель E-350 с Turion Neo X2 L625 (65-нанометровый техпроцесс, 2 ядра K8 с 512 КБ L2 в каждом, 1,6 ГГц и 18 Вт TDP), указывая, что равночастотный E-350 всего на 11% медленнее, получая за те же ватты и меньшие деньги северный мост с новым ГП в придачу. А как выглядит расклад сил, если сравнить с соперниками, вышедшими в 2011 г.?
| Месяц 2011 г. | ЦП | Частота ядер, ГГц | Наиболь- ший кэш | ГП: тип и частота, МГц | TDP, Вт | Технорма, нм |
| Январь | Turion II Neo K685 | 1,8 | 2×1 МБ L2 | Нет | 15 | 45 |
| Athlon II Neo K345¹ | 1,4 | 12 | ||||
| Февраль | Core i7-2637M | 1,7+1,1 | 4 МБ L3 | HD3000, 350–1000 | 17 | 32 |
| Июнь | Core i7-2677M | 1,8+1,1 | HD3000, 350–1200 | |||
| Ноябрь | Atom D2700 | 2,13 | 2×0,5 МБ L2 | GMA 3650, ?–640 | 10 | |
| Декабрь | Celeron 807UE (1 ядро) | 1 | 1 МБ L3 | HD, 350–800 | ||
| 4-й квартал | VIA Nano X2 (E) U4025 | 1,2+0,266? | 2×1 МБ L2 | Нет | 18 (13?)² | 40 |
¹ — 64-битный FPU.
² — в скобках указан предположительный параметр для встроенной (E) версии ЦП. Северный мост чипсета VX900 потребляет 4,5 Вт, а южный — 1,5 Вт.
Core i7 можно убрать сразу — они в разы выше по скорости, но и по цене (оба — 317 долларов). Лучшие модели серии i5 тоже дороги — 250 долларов. D2700 уже обсудили выше, но и VIA Nano (кстати, производимые той же TSMC и на том же техпроцессе) после обновления кое-где оказываются соперниками. Требуя 3, а не 2 микросхемы для построения полной системы, за 19–24 Вт (смотря каким цифрам верить) VIA предлагает среднюю скорость в x86 (по меркам компактных систем) и графику Chrome9 HD уровня 2-го (но не 3-го) поколения Atom. У Zacate всё новее и быстрее, но часть рынка встроенных систем (где VIA ныне только и сильна) новые Nano всё же отожмут. В эту же нишу метит Celeron 807UE, но его одному ядру (пусть и архитектуры Sandy Bridge, но без AVX и Hyper-Threading), одному гигагерцу, одному мегабайту L3 и одному каналу ИКП не управиться с E-350 (а то и C-60). Про графику тоже ясно.
Главные вопросы — о внутренней конкуренции. Во-первых, выделяется разница между вышеупомянутыми Turion II Neo и Athlon II Neo: +400 МГц и полноценный FPU ценой лишних 3 Вт. Учитывая разницу в производительности до двух раз (в векторном коде, не налегающем на кэш), Athlon II Neo кажется либо слишком медленным, либо слишком прожорливым. И вот что интересно — сколько бы потерял Bobcat при той же частоте, если бы вместо 64-битного FPU был бы 128-битный? Кажется, что всего 1–2 ватта. Ну, частоту бы немного снизили взамен — зачем же было так экономить?..
Тем не менее, даже Athlon II Neo оказывается конкурентом, ведь 128-битный FPU это хоть и главное, но не единственное отличие K10 от K8: при частоте на 200 МГц ниже, чем у E-350, его скорость может быть выше, ведь у него вдвое больший L2. Даже с 12 ваттами, плюс сколько-то (кто-нибудь знает цифру?..) для северного моста 880M получится (вероятно) примерно те же 18 Вт. Да, E-350 компактней и дешевле пары микросхем, да и графика получше, но осадок остаётся — скорость и потребление всё же важней размеров и цены, и по первым параметрам даже урезанный K10 на своих 45 нм вполне ещё «тянет». Кстати, о ценах: полгода назад отдельно взятый C-50 оценивался в 55–60 долларов, а плата с E-350 — в ≈100 долларов.
С нижней границей диапазона TDP тоже не всё гладко. Новые Atom N2600 на 3,5 Вт выдают 1,6 ГГц для x86 и 400 МГц для ГП, а N2600 на 6,5 Вт — 1,87 ГГц и 640 МГц. Цены Intel установила также очень конкурентные. Против них выступает модель Z-01, недавно обновлённая до Z-03 (в ней отключены ненужные там контроллеры VGA и PCIe): 1 ГГц и 276 МГц при 5,9 ваттах (Z-03 — 4,5). Встроенные версии T имеют минимальный TDP в 5 Вт для 1-ядерной модели T24L (без ГП) и 6,5 Вт для T40E — обе на 1 ГГц. Как видно, AMD уж было переплюнула извечного соперника в энергоэффективности и скорости одновременно (в рамках ультрамобильных ЦП), как тот выкатил новые версии «Атомов» и снова оказался на коне.
Даже ARM подтягивается — недавно анонсированное ядро Cortex A15 сильно выделяется на фоне доселе немощных собратьев по архитектуре: 3-путный конвейер (ранее — 2-путный), внеочерёдное исполнение, поддержка половинной точности (HP) для вещественных чисел (видимо, аналог CVT16 для x86), ECC для кэшей данных (даже L1), до 1 МБ L2 на ядро (вдвое больше, чем было), 40-битная физическая адресация (ранее — 32-битная), виртуализация и до 4-х ЦП в системе. Первые 4-ядерные SoC с A15 выйдут в ближайший год, конкурируя со всеми игроками стана x86.
Чипсеты
Как и с почти всеми современными чипсетами, в данном случае речь идёт о южном мосте под названием Fusion Controller Hub (FCH) серии Hudson. Все, кроме одного, имеют корпус FCBGA-605 размером 23×23 мм и изготовлены по 65-нанометровой технологии. Из 10 выпускаемых или анонсированных видов Hudson 5 предназначены для Brazos. Примечания к таблице в Википедии вот какие:
- все виды имеют встроенный тактовый генератор (для базовой частоты) и поддержку UEFI-биоса;
- D1 (он же A45) предназначен не только для платформы Lynx (точнее, Value Lynx), но и для Zacate; его потребление — 5 Вт;
- M1 (он же A50M, подробней описан в нашей статье) сделан для Ontario; его TDP — 2,7–4,7 Вт (зависит от числа и типа подключенных устройств);
- M2T (он же A55T) — не только для Brazos-T, но и Desna; помимо указанных отличий от A45, у него лишь 2 канала звука, зато добавлены контроллер SD-карт, порт контроллера WiFi и поддержка AOAC (Always on, always connected — возможность пробуждения из глубокого сна для постоянно подключенных к сети устройств); этот чип подключен к ЦП лишь по двум полосам шины UMI (из 4) и на половинной частоте, имеет размеры 19×19 мм и потребляет 1 Вт;
- M3L (он же A68M) выпущен на замену M1;
- E1 (он же A55E) также применим для Brazos-T.
Сначала укажем, что AMD хочет улучшить и внедрить во всех APU вообще:
- новые x86-ядра Jaguar (вместе с Bobcat они теперь почти официально называются «семейство кошачьих» — Cat family);
- меньший техпроцесс;
- более тесное управление питанием и более точный авторазгон с учётом потребностей и x86-, и графической частей; сейчас Turbo Core для x86 работает лишь при простое одного ядра и вне зависимости от загрузки ГП, поднимая частоту на фиксированный шаг — простейшая схема, пройденная Intel 4 года назад;
- новое поколение ГП с лучшей поддержкой GPGPU (вычислений общего вида с использованием шейдерных ФУ);
- общее адресное пространство для x86 и ГП — когерентность, виртуальная память и переключение контекста задач будут доступны и ГП; включает в себя когерентность для PCIe и подключенной к нему видеокарты.
Обломы
Громадье планов споткнулось о реальность. Изначально на 2012 г. AMD планировала заменить платформу Brazos на Deccan, а линейки Zacate и Ontario — на Krishna и Wichita. Этим ЦП полагалось иметь до 4 ядер и встроенный южный мост типа Hudson D2 (причём не вторым кристаллом в корпусе, а именно вместе с ЦП). Но осенью 2011 г. объявили, что быстрое развёртывание 28-нанометрового техпроцесса на GF не получается; срочно переносить чип обратно на TSMC (где на этом процессе сейчас выпускаются новые дискретные ГП той же AMD; точнее, вроде бы выпускаются — см. ниже) почему-то не стали и просто отменили планы. Вместо Deccan во втором квартале 2012 г. предлагается Brazos 2.0, причём до конца года старшие модели, возможно, частично подменят устаревшие Llano серий E2 и даже A4.
Названия этих моделей будут начинаться с E1 или E2 и содержать 4 цифры. 40 нм по прежнему не позволят разместить более двух ядер, но ГП всё равно обновится до HD 7000 (это не новая архитектура GCN, а предыдущая VLIW4). Часто́ты и x86-ядер, и ГП чуть повысятся. Блок ULV получит поддержку MVC (Multiview Video Coding — декодирование стереопары) и SAMU (аппаратная дешифровка) для проигрывания 3D Bluray. ИКП станет понимать DDR3-1600, а также (на меньшей частоте) особо экономную ULV DDR3. TDP останется на том же уровне, хотя есть слухи о появлении 7-ваттовых 2-ядерных версий. Чипсеты Hudson D2 и D3L также останутся внешними (теперь — в корпусе BGA-656), но некоторые модели ЦП, возможно, перейдут на корпус FT2 для монтажа припоем, хотя планшетная Z-серия будет использовать нынешний FT1. Также предполагается, что у новых ЦП Z-серии (бывшие Hondo, теперь — Brazos-T) TDP опустится ниже 4,5 Вт (после перехода на 28 нм эта цифра может быть и 2 Вт).
В 2013 г. нас ждут Kabini и Temash: это уже полноценные SoC — APU (с новыми ядрами Jaguar и графикой GCN) и FCH на 28-нанометровом кристалле. Более того, AMD недавно сообщила, что в некоторые модели могут быть встроены IP-блоки других компаний. Intel давно опробовала эту тактику, используя купленные у Imagination Technologies ГП серии PowerVR SGX (их же покупает и Apple). А в прошлом году была выпущена целая линейка Intel Atom с кодовым именем Stellarton (серия E6x5C), включающая рядом с кристаллом ЦП программируемую вентильную матрицу (FPGA) производства Altera, применяемую (в виде отдельных микросхем) в узкоспециализированных устройствах, а также в исследованиях и разработке новой техники.
Фраза «вроде бы выпускаются» насчёт 28-нанометровых чипов объясняется недавними слухами о том, что в середине февраля TSMC полностью остановила производство всех 28-нанометровых чипов на 4–5 недель, чтобы сделать срочные поправки к техпроцессу, видимо связанные с низким выходом годных. Вообще, остановка столь массового производства это чрезвычайный аврал, который за всю историю отдельно взятого завода не должен произойти ни разу. В итоге получается, что AMD теперь не на кого положиться в деле надёжного выпуска 28-нанометровых чипов (и ЦП, и ГП), что совсем не поможет в конкурентной борьбе с Intel, только что выпустившей ЦП Ivy Bridge по 22-нанометровой технологии. Дополнение: только что стало известно, что AMD почти наверняка решила выпускать все свои 28 нм чипы на GF — не в последнюю очередь из-за вышеописанного затыка у TSMC.
Впрочем, проблемы с реализацией всего вышеперечисленного могут оказаться не только технические, временны́е и финансовые. В течение 2011 г. из AMD ушли несколько высокопоставленных сотрудников, включая CEO Дёрка Мэера, а в ноябре даже стало известно о целом проекте «Project WIN»: аудит и «оптимизация расходов» для «уменьшения влияния бюрократии на инновации». В результате 10–12% рядовых сотрудников уже тогда потеряли работу, и прежде всего это были разработчики ЦП. Из-за этого, как тогда стало известно, пришлось замораживать некий готовившийся к анонсу ЦП, т. к. делавшая его команда целиком перекочевала в другую компанию. Возможно, эта «оптимизация инноваций» и была главной причиной отмены Deccan.
Кстати, Внимательный Читатель несколькими страницами выше дёргал нас за рукав, рассматривая левую часть рисунка с сетью тактирования, где должны располагаться ядра Bobcat. И что мы там видим? Да их 4! Выходит, что к началу 2012 г. (когда подготовили доклад с этой иллюстрацией) 4-ядерный Deccan уже детально просчитывался (хотя в других местах чипа изменений не видно). И всё это улетело в мусор.
В общем, если такие кадровые потери в AMD будут продолжаться, то будущие чипы просто некому будет делать. Кроме того, возможно, что между выходами Brazos 2.0 и «Brazos 3.0» (кодовое имя этой платформы пока неизвестно) пройдёт меньше года. Вероятно, крупные OEM-фирмы не будут ничего выпускать на такой короткоживущей платформе (слишком мало времени для возврата вложений), решив дождаться сразу версии 3.0. И тогда даже хороший процессор будет лежать на складах.
Что делать, и кто виноват нам поможет?
Предчувствуя нехорошее, представитель AMD в январе 2011 г. сделал малозамеченное заявление о том, что теперь компания изжила привычную парадигму «AMD против Intel» и приспосабливается к новому времени. Какому? За последние годы на рынке массовых процессоров стало больше игроков, и все новички производят ЦП архитектуры ARM. Причём, в отличие от гигантов x86-архитектур, эти фирмы (тоже, кстати, далеко не малые) не очень кичатся многоядерностью и гигагерцами. Тем не менее, платформа ARM всё больше завоёвывает место под солнцем.
Одновременно поднимается голова у гетерогенных вычислений, где ядра разного вида (например x86 и ГП) могут работать над одной задачей — именно к этому AMD стремится на всех парах. Но не только AMD производит ГП (в т. ч. для мобильных SoC) — таких компаний множество, что усиливает конкуренцию. Продажи настольных ПК почти не растут, бум ноутбуков тоже прошёл, зато на подъёме популярность смартфонов и планшетов, но там x86 не ждут. Большинство ОС (и даже, впервые, Windows 8) будут совместимы в т. ч. с ARM, которая в мобильном сегменте — как дома. Более того, большинству покупателей этой техники плевать, что там внутри — только ради надписи «Intel Inside» или «AMD Fusion» ничего покупать не будут.
Вывод AMD: надо больше обращать внимание не на шаги конкурентов, готовя противодействия, а на требования пользователей — а они чётко показывают, какая архитектура больше всего им нравится в самом аппетитном сегодня компьютерном сегменте. Но вместо боданий с ARM AMD решила объединить с ней усилия (интересно, против кого?..), о чём было заявлено летом 2011 г. Точнее, планируется создание «виртуальной ISA» — платформо-независимой архитектуры FSA (Fusion System Architecture), которая могла бы исполнять программу на любом доступном виде вычислительных ядер с максимальным параллелизмом и «разделением труда».
Промежуточный код перед выполнением переведётся на машинные языки физических ядер (на манер исполнения байт-кода Java) с поправками и перестановками доступов к памяти и прочими требованиями целевых архитектур. Для упрощения жизни программистам в исходный язык (а им может быть обычный C++) будут добавлены конструкции для параллелизма, многозадачности, обработки исключений, виртуальных функций и памяти, вызовов ОС, отладки и пр. — и всё это должно исполняться на железе любого типа. Разумеется, на аппаратном уровне (например, в ИКП и шинах) также будут сделаны изменения для универсализации.
Что мешало сделать это до сих пор? Исключительная сложность современных компьютеров. Надо помнить и понимать устройство ядер с внеочерёдным исполнением, многопоточностью и кучей других «ускорялок», оптимизацию под многоядерность (с учётом конфликтов доступа к разделяемым ресурсам), а теперь — и программирование ГП для GPGPU. При этом ГП не менее сложны, чем x86-часть, но хуже описаны и имеют менее развитые программные инструменты. В результате оптимизация под гетерогенные многоядерные системы превращается для разработчиков в поток споров, проб и ошибок. В конце концов программисты либо получают не то, что хотели, либо бросают дело на полдороге — и в обоих случаях винят производителей железа.
AMD пытается упростить ситуацию, создав стандарт абстракции эффективного программирования чего-угодно на чём-угодно. Для этого впервые раскрываются (заплатившим лицензию партнёрам) интерфейсы не только до и для ЦП, но и внутри него — между крупными IP-блоками. Разумеется, спецификации и детали будут контролироваться AMD как интегратором — тем более, что у неё уже сейчас есть многое из нужного (ядра, шины, ISA и протоколы), но для x86. Чтобы получить бо́льшую долю в мобильном рынке, AMD намекает на сближение ISA x86, ARM и разных ГП для упрощения задачи программистам, получая, как минимум, совместное проживание этих ядер на чипе с общими ресурсами и исполняемым кодом. И такое сближение, собственно, и составляет суть объявленной, но незамеченной революции.
И тут как раз пригождается то, что ядра Bobcat синтезированы SAPR-инструментами: не имея ручных оптимизаций под конкретный техпроцесс, их описания на стандартных языках (Verilog и VHDL) можно передать любому партнёру, чтобы наладить совместный чип на любом фабе — как это сейчас происходит с ядрами ARM. Например, возможно появление ЦП с ядрами Cortex A15 и ГП Radeon. Выходит, что AMD давно вынашивала вышеозначенные планы, и ядро Bobcat является лишь их началом. Хорошо бы теперь не растерять запал по дороге…
Масла в огонь подливает недавний слух о том, что AMD может купить компанию MIPS Technologies, владеющую правами на одноимённую (и давно известную) архитектуру. MIPS хорошо развита, давно (в отличие от ARM) имеет 64-битные, векторные и многопоточные расширения, и её часто изучают в ВУЗах по всему миру. Сегодня реализации MIPS используются прежде всего в микроконтроллерах, сетевом оборудовании и в игровых консолях Sony PlayStation 2 и PlayStation Portable. Есть даже ЦП российского производства: серия КОМДИВ-32/64/128 для военно-космических применений (в т. ч. радиационно-стойкие), а также гетерогенно многоядерные МУЛЬТИКОР с DSP-ядрами (тоже явно не гражданские). В 1990-х гг. MIPS широко использовалась многими компаниями в т. ч. для ПК и суперкомпьютеров. Во второй половине 1990-х гг. каждым третьим производимым ЦП был MIPS-процессор.
Интересная для AMD часть этой истории начинается с того, что у компании уже были два продукта с архитектурой MIPS. Это используемая в телевизорах и приставок к ним SoC ATI Xilleon (позже — AMD Xilleon), которую (вследствие реструктуризации из-за нехватки денег) в 2008 г. AMD продала в Broadcom. А также SoC Alchemy, изначально разработанные одноимённой компанией и купленные в 2002 г. AMD. Но через 4 года продали и их. Сейчас они применяются в спутниковых навигаторах и мультимедийных плеерах. Если слух верен, то AMD придётся отбиваться от очевидных вопросов типа «а чем вы раньше думали?» и как-то совместить покупку MIPS, сотрудничество с ARM и собственные мобильные x86-изделия. Выводы и пожелания
Итак, AMD впервые за многие годы сделала продукт, соревнующийся наравне с конкурентами в общей рыночной нише. Ну или почти — если учесть вышедшие одновременно или чуть позже процессоры конкурентов и некоторые свои же. Т. е. теперь конкуренция местами возможна уже по техническим характеристикам (скорости и потреблению), а не только в цене. Доказывают это цифры продаж: 30 млн. ЦП за 15 месяцев — рекорд для чипов AMD всех видов. Не удивительно, что планы настрогали такие, что фабы не справляются. Но могло ли получиться лучше? Учитывая всё вышесказанное, представим, что желательно дополнить и улучшить в грядущем через год Jaguar по сравнению с Bobcat.
Главное — обязательно удвоить ширину FPU до 128 бит. Это не только удвоит производительность, но и уполовинит нагрузку на планировщик и сократит размер микрокода. Представитель команды разработчиков пояснил, что половинный FPU является разменом скорости на экономию площади и энергии. Но если посмотреть на конкурентов, то окажется, что они все имеют что-то 128-битное: у Atom — АЛУ и вещественный сумматор, у Nano — всё, кроме делителя. У вышеупомянутого Cortex A15 DP-числа обрабатываются (в FMAC) всё ещё скалярно, а вот SP — 128-битными векторами.
Очевидно, что затрачиваемая энергия при обработке 128-битного вектора в 64-битном тракте окажется больше за счёт накладных расходов двух команд вместо одной (генерация второго мопа, переименование, размещение, планировка и отставка). Что касается площади, то внимательный взгляд на фото ядра показывает массу свободного места рядом с L1I — если бы последний расположили «вдоль стеночки» (т. е. как L1D, но в противоположном углу), то рядом оказалось бы свободное место для расширения FPU. По другую сторону место можно освободить переносом контроллера шины в пространство между половинами кэша L2 (как в банке L3 у Sandy Bridge).
Учитывая необходимость компактности, достаточно удвоить ширину обоих АЛУ и вещественного сумматора. Умножитель также нужен на 128 бит, но ставить второй такой же блок будет слишком расточительно по площади. Учитывая потребность прежде всего в SP-умножениях (именно для мобильных применений), можно было бы дополнить имеющийся EP-умножитель двумя SP-блоками, которые займут меньше места, но обеспечат скорость в 4 SP-умножения за такт, как и в A15. Однако мы не зря детально описали умножитель — матрица шириной 54 бита вместо двух на 27 позволила бы вычислять и DP-умножения, пусть и с пропуском в 2 такта. Выходит, что тогда уже выгодней к имеющемуся EP-умножителю добавить ещё один на 1 DP- или 2 SP-элемента.
Для большей экономии места можно сократить EP-умножитель до DP, пожертвовав поднабором x87, применение которого сегодня (при кросс-платформенности не только программ, но и ОС) окончательно потеряло смысл: на ARM и MIPS никакие 80 бит не ночевали, а поддерживать сохранение вещественного стека только для x86 никто не будет. Но т. к. x87 всё же изредка встречается в настольных программах (а неттопы — одна из целевых платформ), то достаточно будет иметь их программную эмуляцию драйвером ЦП. Это намного медленнее, но для крайне редких программ сойдёт и так, зато в FPU можно будет убрать лишние 20% транзисторов и дорожек тракта (упростив и его логику выкидыванием поддержки 3-го вида точности). Там же удаляем таблицы констант для трансцендентных функций (их со времён SSE2 считают программно — векторами через суммы рядов), а в декодере — массу микрокода для сложных вещественных команд.
Теперь добавим остальные пожелания:
- Ускорить проблемные команды: PALIGNR, MASKMOV* и целое деление.
- Расширить шину FPU–LSU до полнодуплексной на 16+16 байт, что должно дать возможность читать и писать по одному xmm-вектору за такт.
- Удвоить ширину портов LSU до 16 байт и обеспечить 2-портовость большинстве случаев. Ещё лучше — обеспечить возможность 2 чтений за такт через многобанковость L1D, что также потребует реверсивности одной из полушин между LSU и трактами (2 чтения или чтение + запись). Также рекомендуется улучшить STLF и уменьшить штрафы при невыровненном доступе.
- Уменьшить TLB L1I до тех же 40 страниц, что и TLB L1D, а TLB L2 сделать общим для обоих TLB L1. Так можно сэкономить место во фронте почти без потерь в скорости.
- Подтянуть ПС L2 и ИКП ближе к пикам, в т. ч. для 1-поточной нагрузки — и по чтениям, и по записям.
- Сделать L2, транслятор страниц и контроллер шины общими для пары ядер, запитав их отдельным набором силовых ключей. Это также позволит отключить часть кэша при фатальных дефектах в нём, не жертвуя одним из ядер. Такая же схема питания, тактирования и отбраковки принята для общего L3 у Sandy Bridge. Или вот SoC NVidia Tegra 2, весьма похожая на Zacate/Ontario (в т. ч. по целям экономии — ватты и миллиметры в ущерб скорости): 2 ядра ARM Cortex A9, те же частоты и размеры кэшей L1, но общий L2 на 1 МБ.
- Внедрить самый современный авторазгон, как в «больших» ЦП Intel.
Думается, этих изменений хватит на то, чтобы новое ядро при чуть большей площади и потреблении стало куда быстрее, а именно такая комбинация и даёт возможность экономить ватты: быстрее закончим считать — быстрее перейдём в простой. Прочие возможности (добавление 3-го пути конвейера или гиперпоточности) слишком сложны и потребуют полной переделки ядра. Вместо этого при нехватке скорости можно просто удвоить их число, что и планируется. Ну а как выйдет на самом деле — узнаем через год.
Правда, если AMD снова не выпустит учебник по оптимизации (что куда проще разработки новой архитектуры), или выпустит, но опять с ошибками в цифрах, то любые полезные добавки снова будут недоиспользованы. И тогда, как уже бывало, снова окажется, что инженеры AMD разработали неплохой продукт, а маркетологи и менеджеры на ровном месте прострелили себе и коллегам коленки и упали, едва не догнав конкурента. Может, надо «оптимизировать» не инженеров, а руководство?.. Источники
По многочисленным просьбам некоторых лодырей с форума широких народных масс трудящихся и жаждущих истины, приводим список основных использованных источников — не считая тех, ссылки на которые уже даны выше. Остальные, коих десятки, поставляли лишь отдельные утверждения, причём часто противоречивые. После внимательного прочтения данной статьи этот список больше подойдёт не для реального использования, а просто ради демонстрации своей ненужности:
- «Bobcat». AMD’s New Low Power x86 Core Architecture. Brad Burgess. (Конференция Hot Chips 2010)
- Bobcat: AMD’s low-power x86 processor. Brad Burgess, Brad Cohen, Marvin Denman, Jim Dundas, David Kaplan, Jeff Rupley. (IEEE, Vol. #31, Issue #2, Mar-Apr 2011)
- A Low-Power Integrated x86-64 and Graphics Processor for Mobile Computing Devices. Denis Foley, Pankaj Bansal, Don Cherepacha, Robert Wasmuth, Aswin Gunasekar, Srinivasa Gutta, Ajay Naini. (IEEE/ISSCC, Vol. #47, Issue #1, Jan 2012)
- Revision Guide for AMD Family 14h Models 00h-0Fh Processors. (Публикация #47534. Revision: 3.08)
- Instruction tables. Lists of instruction latencies, throughputs and microoperation breakdowns for Intel, AMD and VIA CPUs. Agner Fog, 2012-02-29.
- The microarchitecture of Intel, AMD and VIA CPUs. Agner Fog, 2012-02-29.