
СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты NVIDIA GeForce FX 5900 Ultra 256MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Синтетические тесты RightMark3D: идеология и описание тестов
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark2001 SE и 3DMark03
- Выводы из результатов синтетических тестов
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game1
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game2
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game3
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game4
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
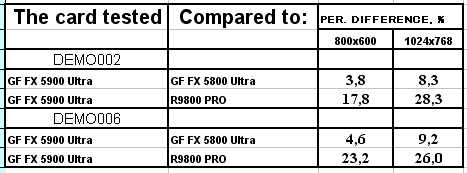
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003 DEMO
- Результаты тестов: AquaMark
- Результаты тестов: RightMark 3D
- Результаты тестов: DOOM III Alpha version
- Качество 3D
- Выводы
Общие сведения
Не хочется банальных фраз вроде "Пришла весна, началось обострение…", гм, что-то не то. "Пришла весна, и начался вылет на свет Божий новых ускорителей." Право же, и так понятно, что каждая новинка будет сопровождаться тоннами красивых слов, высокими материями из 3D-функциональности, и скриншотами из прекрасно выглядящих игр из… будущего.

А нам, по совести, очень жалко тех, кто уже потратил кровные свои деньги на супер-ускоритель GeForce FX 5800 Ultra, а ведь это подчас выше $500 (когда я посмотрел на цены на такие продукты от Gainward в ряде фирм в Москве, то мне стало нехорошо). Да-да, снова NVIDIA их обманула. Или не обманула? Разговоры о скором выходе NV35 давно ведутся, но ведь это разговоры. Официально компания не обещала и не расписывалась в том, что не стоит покупать NV30, когда вскоре будут улучшенные версии.
И вот, как только в продаже начали появляться обещанные еще перед Новым Годом, видеокарты на базе GeForce FX 5800/Ultra, бац, и анонс. Да еще выступление президента NVIDIA, где он, неделю назад, обещал выход NV35 и назвал NV30 ошибкой и неудачным продуктом. А как быть тем, кто уже купил этот "неудачный" продукт? Бесплатно на NV35 его никто не обменяет. Поэтому мы можем лишь посочувствовать тем, кто уже купился на красивые слова и манящие жесты "эльфийки".
Хотя, по сути, NV35 — это не одна карта, а опять линейка. Ходят разговоры, что будет три карты, однако пока есть достоверные сведения только о двух:
- GeForce FX 5900 Ultra — 450 МГц чип, 256 Мбайт 425 МГц (DDR 850) 256 бит шина локальной памяти ($499);
- GeForce FX 5900 — 450 МГц чип, 128 Мбайт 425 МГц (DDR 850) 256 бит шина локальной памяти ($399);
- GeForce FX 5??? — 425? МГц чип, 128? Мбайт 400? МГц (DDR 800?) 256 бит шина локальной памяти ($299);

Вообще-то, спецификации GF FX 5900 также еще могут меняться. Пока мы имеем на сегодня самый быстрый ускоритель от NVIDIA — GeForce FX 5900 Ultra, ранее имевший кодовое название NV35.
Столь малое изменение в номере от названия карты наводит на мысли, что изменений у 5900 по сравнению с 5800 не так уже и много. Однако, судя по частотам, разгона не было, более того, частоты даже снижены относительно NV30. Только добавлена 256-битная шина? В общем, будем разбираться.

Одно понятно: NV35 — это не выпуск просто новой линейки, которая (как ранее было) смещает с трона предыдушие продукты, переводя их на ступень ниже, а ЗАМЕЩЕНИЕ предыдущего продукта NV30! И в этом коренное отличие от ранее вышедших тандемов: NV10-NV15 (GeForce256-GeForce2), NV20-NV25 (GeForce3-GeForce4Ti). Да, разумеется, целью NVIDIA и тогда была замена продуктов GeForce256 и GeForce3, однако она шла постепенно и в штатном режиме продаж. А тут все иначе: мы еще не сталкивались с таким, что предыдущий продукт появляется в продаже, и буквально через месяц анонсируется новый. Разумеется, фирмы-производители обо всем знали заранее, и потому на выпуск NV30 клюнули немногие, а кто и решился, тот выпустил мизерное количество таких карт. Это объясняется еще и высочайшей себестоимостью GF FX 5800/Ultra. Но мы про все это уже писали, вот список наших статей, посвященных новому семейству GeForce FX:
- Аналитический материал по особенностям архитектуры NVIDIA NV30 (GeForce FX)
- Базовый обзор NVIDIA GeForce FX 5800 Ultra (NV30) — одностраничный
- Базовый обзор NVIDIA GeForce FX 5800 Ultra (NV30) — многостраничный
- Базовый обзор NVIDIA GeForce FX 5600 Ultra (NV31) и GeForce FX 5200 Ultra (NV34) — одностраничный
- Базовый обзор NVIDIA GeForce FX 5600 Ultra (NV31) и GeForce FX 5200 Ultra (NV34) — многостраничный
- Обзор ASUS V9900 Ultra на базе NVIDIA GeForce FX 5800 Ultra — продолжение рассмотрения качества АА и анизотропии
- Обзор Gainward FX Powerpack Ultra/1000 Golden Sample и Gainward FX Powerpack Pro/660 TV/DVI на базе NVIDIA GeForce FX 5800 Ultra и 5200 — масштабирование (зависимость производительности от частоты работы CPU) GeForce FX 5800 Ultra, а также изучение производительности GeForce FX 5200
- Обзор Leadtek WinFast A300 Ultra MyVIVO на базе NVIDIA GeForce FX 5800 Ultra — продолжение изучения зависимости производительности GeForce FX 5800 Ultra от частоты работы CPU в тяжелых режимах при АА и анизотропии
- Обзор MSI FX5800 Ultra-TD8X на базе NVIDIA GeForce FX 5800 Ultra
- Обзор видеокарт на базе NVIDIA GeForce FX 5200 производства Albatron, Chaintech, Gainward, InnoVision, Leadtek, Palit и Prolink
Технические характеристики
- Технологическая норма 0,13 микрон, медные соединения
- 135 миллионов транзисторов
- 3 геометрических процессора (превышают спецификации DX9 VS 2.0)
- 4 усовершенствованных конвейеризированных пиксельных процессора. Функциональность пиксельных процессоров значительно превышает спецификации DirectX9 PS 2.0, в два раза превосходят по мощности шейдеры в NV30 и операции, использующие плавающую точку, выполняются с истинной 128 битной точностью.
- системный интерфейс AGP 3.0 (8х)
- 256-битный интерфейс локальной памяти DDR1(!)
- Intellisample HCT (High Compression Technology) является развитием Intellisample представленной в NV30 — техники экономии пропускной полосы локальной памяти.
- Тайловые оптимизации: кэширования, сжатия и раннего отсечения невидимых поверхностей (Early HSR, Early z Cull)
- Технология UltraShadow — увеличивает скорость прорисовки стенсильных теней (называемых так из-за широкого использования стенсил (stencil) буфера при их генерации) за счет ограничения обрабатываемых объектов по глубине сцены.
- Поддержка точных целочисленных форматов (10/16 бит на компоненту) и точных плавающих форматов (16 и 32 бита на компоненту) для буфера кадра и текстур.
- Сквозная точность всех операций — 32-бит плавающей арифметики (поддержка т.н. 128-битной глубины цвета)
- Новый алгоритм оптимизированной анизотропной фильтрации, будучи активирован пользователем, снижает падение производительности (читай величины fps) без особенного падения качества
- Качество анизотропии вплоть до 8х от обычной билинейной фильтрации, т.е. до 32 дискретных отсчетов на одну выборку из текстуры
- Гибридные режимы АА — 8х и 6xS
- Сжатие буфера кадра позволяет существенно снизить падение производительности при активации FSАА
- Два встроенных RAMDAC 400 МГц
- Встроенный интерфейс для внешнего TV-Out чипа
- Встроенные в чип три TMDS-канала для внешних интерфейсных DVI-чипов
Рассмотрим этот список более детально.

- Чип из 135 миллионов транзисторов: Как мы видим, количество транзисторов в чипе увеличилось ненамного — это косвенно говорит о том, что изменения в чипе, базирующемся на архитектуре NV30, скорее косметические.
- 256-битный интерфейс локальной памяти: Пожалуй, самое ожидаемое нововведение в NV35. С момента выпуска NV30 энтузиасты трехмерной графики на ПК, предсказывая характеристики NV35, даже не представляли себе этот чип без 256-битного интерфейса обмена с локальной памятью.
- 4 усовершенствованных конвейеризированных пиксельных процессора: Здесь же вместо также ожидаемого увеличения числа пиксельных процессоров до 8 NVIDIA оставила все те же 4 процессора. Каждый из пиксельных процессоров снабжен: двумя блоками, фильтрующими текстуры, двумя смешанными целочисленными и работающими с плавающей точкой операциями ALU и одним ALU, выполняющим операции только. с плавающей точкой. То есть, всего три операции с плавающей точкой. Такая конфигурация позволяет выполнять до 12 пиксельных операций за такт. Однако, пока в силу некоторых обстоятельств, эта мощь работает только в OpenGL, в D3D все по-прежнему — только одна операция с плавающей точкой, однако обещают и это выправить. Разумеется, декларируется, что по мощности пиксельных процессоров при выполнении пиксельных шейдеров DirectX9 PS 2.0 со 128 битной точностью вычислений новый чип превосходит NV30 в два раза.
- Технология Intellisample HCT: техника экономии пропускной полосы локальной памяти: сжатие без потерь буфера кадра, включая как информацию о цвете, так и из буфера глубины (Z буфера). Возможный коэффициент сжатия — до 4:1. По сравнению с NV30 технология Intellisample была усовершенствованна — как и ранее в чипе на основании нескольких факторов определяется, будет ли эффект от сжатия передаваемых блоков данных, но теперь, в результате оптимизации, вероятность сжатия данных увеличена. Также под общим названием Intellisample HCT включены следующие техники, увеличивающие эффективность работы с локальной памятью: контроллер локальной памяти с коммутатором, текстурные кэши, раннее отсечение невидимых пикселей (z-culling), быстрая очистка буфера глубины (fast z-clear). Все эти оптимизации позволяют существенно снизить падение производительности при активации FSАА.
- Технология UltraShadow: Данная технология позволяет увеличить скорость визуализации теней при использовании техники стенсил-буфера (stencil buffer shadows), как раз той техники, которая используется в Doom III. Как часть технологии UltraShadow декларируется возможность чипов NV30/NV35 удваивать fillrate, выдавая до 8 пикселей за такт, если закрашивается только буфер глубины и/или стенсил буфер, по сравнению с 4 пикселями при обычном рендеринге. Вторая, наиболее интересная часть заключается в возможности задавать диапазон глубины в кадре, в котором объект может отбрасывать тень. Для демонстрации взглянем на рисунок:
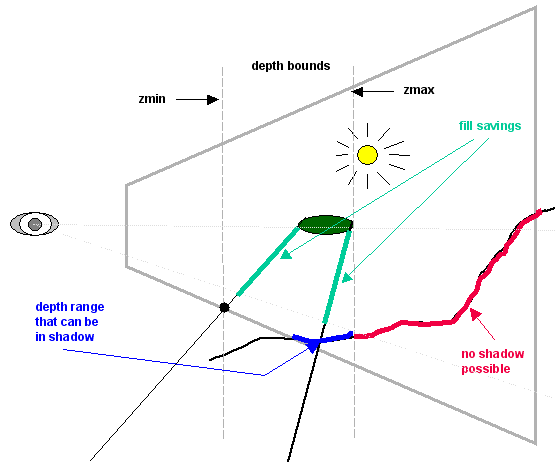
Если при прорисовке теней значение глубины пикселя, хранящееся в буфере глубины, не попадает в заданный диапазон, то стенсил-буфер для пикселя не обновляется. Таким образом, становится возможной экономия достаточно большого процента от скорости закраски (fillrate). По всей видимости, для реализации этой функции в чипе усовершенствован блок, отвечающий за раннее отбрасывание невидимых поверхностей (early z-cull), который теперь сверяет значение, хранящееся в буфере глубины, не только с текущим значением, интерполированным исходя из координат треугольника, но и с двумя дополнительными значениями. В итоге выигрыш по сравнению с другими чипами с одинаковым количеством конвейеров будет двукратный в худшем случае (8 значений буфера глубины по сравнению с 4 значениями цвета) и четырехкратный (с учетом, что early z-cull может отбрасывать до 16 пикселей за такт), даже без учета уменьшения объема данных, записываемых обратно в локальную память.
Ниже можно видеть, насколько большую площадь занимают визуализированные буферы теней.






Выше мы перечислили плюсы технологии, но у нее есть и свои ограничения.
- технология UltraShadow будет доступна только в OpenGL при помощи расширения
"NV_depth_bounds_test" - NVIDIA ожидает получения патента на технологию UltraShadow
- Технология не включается парой строчек кода (как в свое время говорили про N-Patch aka Truform) — программисты должны анализировать отображаемую сцену и эффективно задавать диапазон, в котором возможна прорисовка теней.
- Пока технология анонсирована только для NV35, расширение в текущих драйверах доступно также только на NV35. Неизвестно, будет ли в дальнейшем это расширение доступно для остальных карт на базе NV3x, хотя есть положительный сигнал, т.к. расширение
"NV_depth_bounds_test"доступно в режиме эмуляции NV30 в "Buzz/emulated" в OpenGL драйвере, выпущенном еще в августе 2002 года.
Плата
Карта снабжена интерфейсом
 |  |
| На карте установлены микросхемы DDR памяти Hynix марки HY5DU283222-AF22, форм-фактора BGA. Максимальная частота работы — 450 (900) МГц, время выборки — 2.2 нс. По умолчанию память работает на частоте 425 (850) МГц, чип — 450 МГц. |  |
Мы видим, что для набора объема памяти в 256 мегабайт используется в 2 раза большее, чем мы привыкли видеть, количество микросхем. Заметим, что суммарно они составляют 512бит, то есть при наличии аппаратной 512-битной шины обмена с памятью у чипа и PCB, карта смогла бы иметь столь огромную ПСП. Но, как выше было сказано, шина — 256 битная, поэтому мы снова сталкиваемся с таким явлением, как двухстрочная организация подсистемы памяти. Память при этом работает по двубанковой схеме, что дает некоторый прирост в скорости обмена с нею. Поэтому можно почти смело говорить о том, что если 128-мегабайтные карты GeForce FX 5900 будут иметь немного меньшую производительность, нежели 256-мегабайтные, как это было в случае RADEON 8500 64 и 128 мегабайт.
| NVIDIA GeForce FX 5900 Ultra 256MB | |
|---|---|
 |  |
| NVIDIA GeForce FX 5800 Ultra 128MB | |
 |  |


Как мы видим, карта очень большая по длине, и примерно равна PCB карты Voodoo5 5500. Расположение микросхем напоминает Matrox Parhelia:

PCB достаточно сложна по разводке, однако слоев используется меньше — всего 8 плюс экранирование (в отличие от 12-слойной PCB у NV30):

| Что касается системы охлаждения, то она состоит из двух кулеров: для процессора и для памяти, что является очень верным решением (мы уже неоднократно отмечали, что единый кулер для GPU и памяти может сыграть злую роль для менее нагревающихся элементов, неся к ним тепло от более сильногреющихся компонентов). Центральный кулер представляет собой копию того, что мы могли видеть ранее на Quadro FX или GeForce FX 5800 (не-Ultra), только с обрезанной крышкой на радиаторе, что способствует уменьшению шума. Вентилятор работает в режиме, как у GeForce FX 5800-не-Ultra: постоянно крутится на малых оборотах, при надобности включаясь на полные обороты (при повышении температуры выше определенных критических значений). Система охлаждения памяти состоит из двух массивных алюминиевых радиаторов, покрашенных в черный цвет. Тепло передается через специальные термоэлементы, приклеенные к радиаторам, они же гарантируют плотный прижим к поверхности микросхем памяти. Сам крепеж системы охлаждения тщательно продуман, нет больше никаких пластмассовых клипс (фитюлек), все на болтах с пружинами. |  |
 | |
 |
Отметим, что нагрев в целом НАМНОГО меньше, чем у NV30. Если до карты GeForce FX 5800 Ultra после часа работы в 3D просто невозможно дотронуться (даже до самой PCB!), то здесь нагрев радиаторов всего лишь чуть выше болевого порога человека (или на его уровне).
Завершая рассмотрение карты, заметим, что весь "хвост" у нее отдан системе питания, где имеется и разъем для подключения внешнего питания от БП.

Что касается TV-out, то на карте установлен кодек Philips 7108, который потенциально поддерживает VIVO.

Более подробно о работе ТВ-выхода с помощью такого кодека можно прочитать в материале Алексея Самсонова и Дмитрия Дорофеева.
Разгон
К сожалению, разгон заблокирован драйверами: частоты видны, их можно "менять", но после тестирования новых установок частоты сбрасываются на начальные. Уже после окончания тестирования было выяснено, что через Auto Detect есть возможность разгона, поэтому в следующем материале мы это проверим.
Установка и драйверы
Рассмотрим конфигурацию тестового стенда, на котором проводились испытания карт:
- Компьютер на базе Pentium 4:
- процессор Intel Pentium 4 3066 (HT=ON);
- системная плата ASUS P4G8X (iE7205);
- оперативная память 1024 MB DDR SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1;
- мониторы
ViewSonic P810 (21") иViewSonic P817 (21").
При тестировании применялись драйверы от NVIDIA 44.03, VSync отключен, компрессия текстур отключена в приложениях. Установлен DirectX 9.0a.
Для сравнительного анализа приведены результаты уже знакомых читателям видеокарт:
- Reference card NVIDIA GeForce FX 5800 Ultra (500/500 (1000) МГц, 128 МБ);
- ATI RADEON 9800 PRO (380/340 (680) МГц, 128 МБ, driver 6.307).
Настройки драйверов
Представим читателям настройки драйверов:
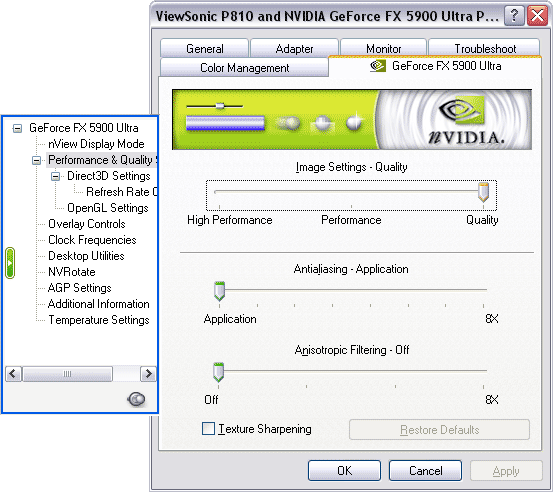
Мы видим, что предустановки режимов IntelliSample снова изменились: теперь это Quality (прежде это ApplicATIon), Performance (бывший режим Balanced), High Performance (ранее Aggressive или просто Performance). Добавился режим АА 8х (не 8xS только для D3D, а работающий и в D3D, и в OGL).
Все остальные параметры — такие же, какими мы видели их уже ранее.
Результаты тестов
2D-графика
Когда к Товарищу Сталину принесли первый серийно выпущенный телевизор, он внимательно посмотрел новости, переданные специально ради такого случая из студии на Шаболовке, оценил сам аппарат и задал вопрос находящимся с ним вместе высоким чинам в своем стиле: "А вы уверены, что качество картинки на других экземплярах будет таким же высоким? А может быть вы специально для меня сделали особый аппарат, а для трудящегося населения выдадите мутные экраны?" Высокие чины задрожали, кое-кто наделал в штаны (памперсов тогда еще не было), но заверили вождя в том, что все телевизоры имеют одинаково высокое качество 2D-картинки.
Да, и в это можно еще как-то поверить (хотя Сталин не поверил и сослал высоких чинов убирать снег в Сибири), учитывая маленькие размеры экранов в то время, а также то, что это все же телевизоры, где невелико разрешение, а как раз зернистость весьма велика. А вот если бы Товарищ Сталин спросил ныне у президентов компаний-производителей видеокарт, а также глав фирм-производителей мониторов: "Гарантируете ли вы, что все видеокарты и все мониторы будут показывать качественную картинку?", то после радостных "Да-да, конечно" компьютерная индустрия осталась бы сильно обезглавленной, но зато в Сибири снег наконец-то убрали бы.
Да, это все к тому, что несмотря на радостные восклицания по поводу 400 МГц RAMDAC и т.п., качество 2D — это явление, зависящее от вращения Луны вокруг Земли, от угла наклона астероида к оси Земли, от настроения проснувшегося утром Джорджа Буша, но никак не от заявленных характеристик. Более того, оно может меняться от экземпляра карты к экземпляру, даже если те вышли с одного завода. И еще ложка дегтя: мониторы также обладают строптивостью и не с каждой видеокартой "дружат". Поэтому наша оценка 2D является сугубо субъективной и в обзоре стоит просто для галочки.
Тестирование 2D у нас происходит на мониторе ViewSonic P817-E совместно с BNC-кабелем Bargo. И мы можем констатировать, что качество 2D у протестированной карты превосходное! В 1600х1200 при 85Гц, а также 1280х1024 при 120Гц просто все отлично.
Синтетические тесты RightMark 3D (DirectX 9)
Набор синтетических тестов из разрабатываемого нами тестового пакета RightMark 3D включает в себя (на данный момент) следующие тесты:
- Тест на закраску и фильтрацию текстур (Pixel Filling Test);
- Тест на производительность обработки геометрии (Geometry Processing Speed Test);
- Тест на производительность работы с отсечением невидимых точек и примитивов (Hidden Surface Removal Test);
- Тест на производительность сложных пиксельных шейдеров (Pixel Shader Test);
- Тест на производительность отрисовки, освещения и анимации спрайтов (Point Sprites Test).
Полагаем, что нет смысла повторять здесь освещение идеологических вопросов тестирования, поэтому еще раз просим желающих узнать поподробнее об идеологии синтетических тестов прочитать внимательно материал по NV30. Там же можно найти и их описание.
Для тех, кто уже сейчас горит желанием экспериментировать с синтетическими тестами RightMark 3D, мы предлагаем скачать и опробовать "командностроковые" варианты тестов, формирующие результирующий файл XLS в формате XML, принятом в Microsoft Office XP:
Внутри каждого архива вы найдете описание параметров каждого теста и пример .bat файла, используемого нами для тестирования ускорителей. Мы будем благодарны любым откликам, как в плане пожеланий и идей, так и информации об ошибках или странном поведении тестов.
В настоящее время доступна первая тестовая (бета) КОМПЛЕКСНАЯ версия пакета указанных выше синтетических тестов RightMark 3D . Этот сайт целиком посвящен пакету RightMark 3D. Также на этой странице в настоящее время доступна бета версия пакета RightMark Video Analyzer v0.4 (14.8Mb), которая уже некоторое время используется в обзорах видеокарт iXBT в разделе игровых тестов.
Свои замечания и предложения пишите по адресу: unclesam@ixbt.com.
Результаты практического тестирования
Что же перейдем к самому интересному. Приведем и прокомментируем данные, полученные нами на ускорителях, нацеленных, как говорят сами производители, на энтузиастов: героя сегодняшнего материала — NVIDIA GeForce FX 5900 Ultra, а также NVIDIA GeForce FX 5800 Ultra и ATI RADEON 9800 PRO. В качестве опорной для анализа видеокарты в данном тестировании выступает NVIDIA GeForce FX 5800 Ultra, как наиболее близкая по архитектуре для GeForce FX 5900 Ultra. Результаты и их анализ для ATI RADEON 9800 PRO приводятся для выяснения, смогла ли NVIDIA превзойти по производительности флагман своего конкурента — ATI.
Pixel Filling
- Тест на скорость закраски буфера кадров (Pixel Fillrate). Закраска константным цветом — выборка текстур не производится. Приведены результаты в миллионах пикселей в секунду для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
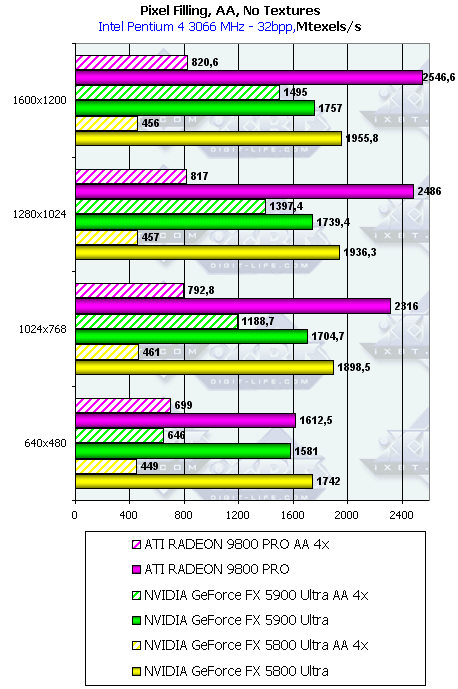
Скорость закраски в режиме без антиалиасинга в точности соответствует разнице частот между GeForce FX 5900 Ultra и NVIDIA GeForce FX 5800 Ultra (450 vs 500). Несмотря на более высокую тактовую частоту чипов GFFX — GeForce FX 5900 Ultra проигрывает конкуренту ATI во всех случаях. Из этого можно сделать вывод, что для чипов GFFX в случае простой закраски пропускная способность шины не является ограничивающим фактором. Radeon 9800 Pro берет лидерство в этом режиме за счет наличия 8 пиксельных конвейеров, способных записывать 8 значений цвета и глубины за такт и максимальные значения, показанные платой от ATI, ограничиваются именно пропускной способностью шины. FX может записать только 4 полных пикселя (цвет + глубина + когда надо буфер шаблонов aka Stencil). Однако 4 пиксельных процессора FX имеют одну интересную оптимизацию — если мы, в результате выполнения шейдера или просто закрашивая треугольник, не сохраняя значения цвета пикселя, а изменяем только значения глубины или буфера шаблонов, то каждый пиксельный процессор может за один такт выдать два результата. Таким образом, в сумме записав 8 значений глубины или буфера шаблонов за такт. Сейчас, при анонсе GeForce FX 5900 Ultra NVIDIA открыто сообщает об этой особенности GFFX, выставляя ее как преимущество и описав как часть технологии UltraShadow. Подобная оптимизация очень пригодится в играх с стенсильными тенями, подобных DOOM III, там она может ускорить прорисовку сцены почти в полтора раза. Однако в нашем тесте закрашиваются и значения цвета. Именно поэтому результат свидетельствует лишь о 4 пикселях, выводимых за такт.
Теперь рассмотрим скорость закраски при использовании антиалиасинга. Картина кардинально меняется. По сравнению с GeForce FX 5800 Ultra карта серии 5900 резко вырывается вперед, причем конкурент от ATI может что-то противопоставить новому продукту NVIDIA только в низких разрешениях. При повышении разрешения GeForce FX 5900 Ultra является безусловным лидером, и это несмотря на вдвое меньшее количество пиксельных конвейеров (помним про 256-битную шину).
- Тест на скорость закраски буфера кадров с одновременным текстурированием. Добавляется выборка одной простой билинейной текстуры — проверим, насколько наличие конкурентного потока чтения из памяти понизит эффективность закраски. Приведены результаты в миллионах пикселей в секунду, для разных разрешений, причем как в обычном режиме, так и для 4х MSAA. Ввиду того, что все последние драйвера ATI Catalyst (3.1 и выше) вкупе с нашим синтетическим тестом выдают на некоторых продуктах ATI странные, очевидно заниженные результаты, видимо, из за неудачной попытки оптимизировать работу этого теста на режимах с выборкой значений текстур, мы не приводим результатов Pixel Filling с текстурами для RADEON.
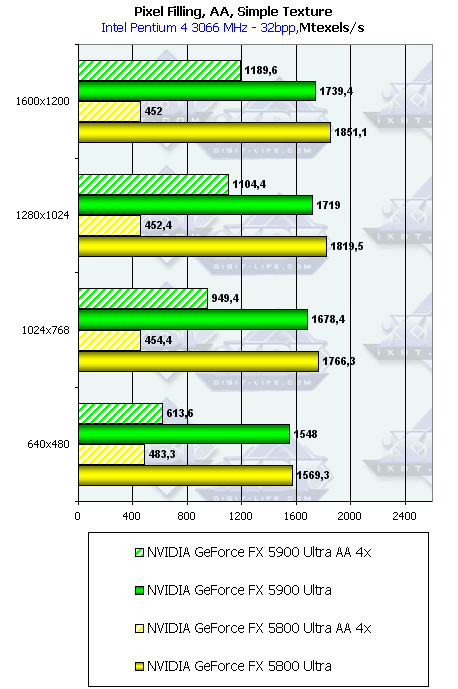
В общем и целом, картина практически та же, но пиковые значения упали. Давайте посмотрим, насколько хорошо измеренная действительность соотносится с теоретическими пределами, основанными на частоте ядра и числе конвейеров:
Продукт Теоретический максимум, млн.текселей в сек. Полученный максимум, млн.текселей в сек (без текстур). Полученный максимум, млн.текселей в сек (с одной текстурой). RADEON 9800 PRO 3000 2486 - GeForce FX 5900 Ultra 1800 1757 1739 GeForce FX 5800 Ultra 2000 1957 1848
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителей. Результаты в диаграммах сортированы по степени сложности используемой модели освещения. Самый нижняя группа — простейший вариант, соответствующий пиковой пропускной способности ускорителя по вершинам.
- Производительность фиксированного TCL (для NV3x и R3x0 — производительность эмулирующего его шейдера):
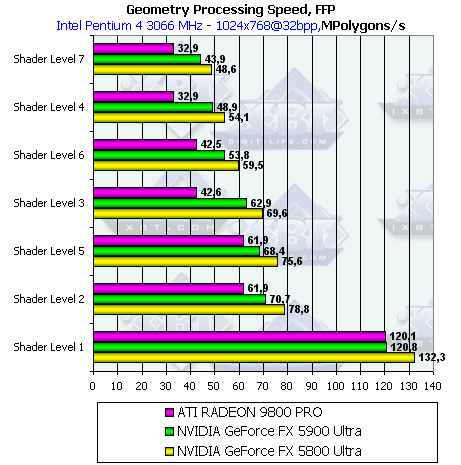
Результаты в точности соответствуют разнице частот — производительность GeForce FX 5900 Ultra ровно на 10% меньше GeForce FX 5800 Ultra (450 vs 500 Мгц)
- Теперь обратимся к вершинным шейдерам 1.1:
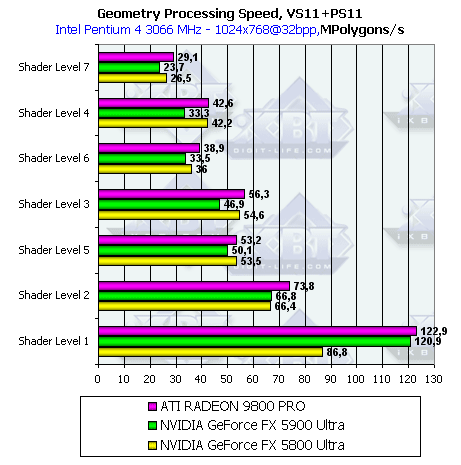
Здесь мы видим несколько странное поведение GeForce FX 5800 Ultra в сравнении с GeForce FX 5900 Ultra. В самом простом случае (Shader Level 1) карта показывает значительно меньшие результаты, чем при использовании функционально аналогичных настроек фиксированного TCL. А GeForce FX 5900 Ultra показывает сравнимые результаты между фиксированным TCL и вершинными шейдерами VS 1.1, причем это при использовании одинаковой версии драйверов, что исключает возможность оптимизации микрокода. При увеличении сложности шейдера мы опять видим ту же разницу в 10%.
- Еще один интересный тест — шейдеры 2.0 с циклами:
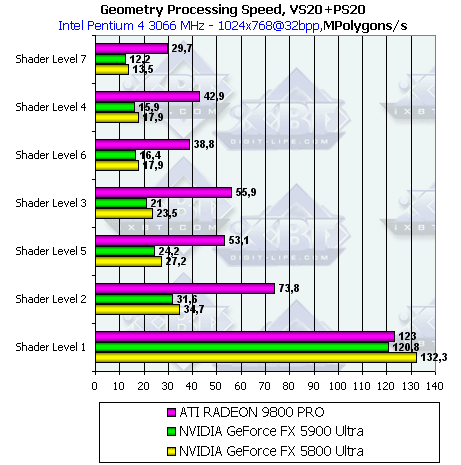
Как и на предыдущих тестах, мы видим, что разница между NV30 и NV35 в точности соответствует разнице частот. Заметим, что в случае компиляции самого простого шейдера (Shader Level 1) под вершинные шейдеры второй версии NV30 снова показывает "правильные", а не заниженные как в случае с вершинными шейдерами VS 1.1 результаты.
Очень интересный результат показывает ATI RADEON 9800 PRO: производительность исполнения вершинных шейдеров второй версии с циклами с точностью до погрешности эквивалентна производительности шейдеров первой версии, хотя ранее Radeon 9700 Pro показывал существенно меньшую производительность. Весьма велика вероятность того, что драйвер при компиляции шейдера в микрокод на новых драйверах "разворачивает" циклы в одну большую шейдерную программу.
Чипы серии NV3x видимо вынуждены эмулировать циклы со статическими переходами при помощи микрокода, рассчитанного на динамическое (зависимое от данных текущей вершины) исполнение. Поэтому в случае NV3x накладные расходы на циклы очень значительны! И это не удивительно, динамическое управление потоком команд может и должно вызывать большие задержки при выполнение циклов. Что мы здесь и наблюдаем -за гибкость приходится расплачиваться скоростью.
Но если наша догадка о "разворачивании" шейдеров в ATI RADEON 9800 PRO верна, то такая оптимизация может иметь и обратную сторону для ATI. Микрокод такого шейдера будет занимать значительно больше места по сравнению с версией с циклами — соответственно, драйвер сможет хранить меньшее количество шейдеров в кэше чипа, а время, потраченное на загрузку кода нового шейдера в чип, может свести на нет все оптимизации, полученные "разворачиванием" кода. При изменении константы задающей количество циклов драйвер также будет вынужден заново генерировать и загружать микрокод шейдера.
- Проверим перекрестную зависимость от степени детализации геометрии и сложности шейдера:
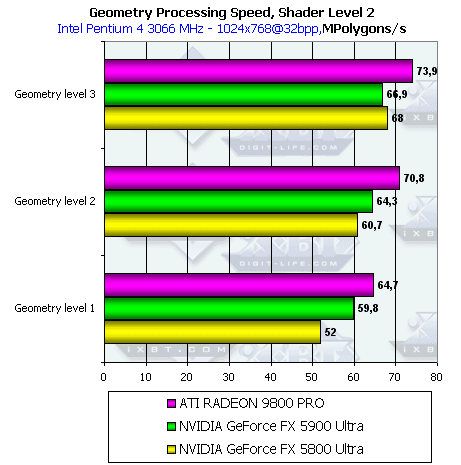
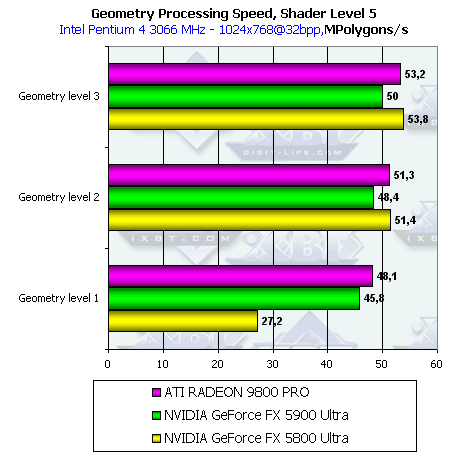
Здесь мы видим характерную картину: при малой детализации сцены (соответственно при малой загруженности геометрического блока чипа по сравнению с пиксельными конвейерами) GeForce FX 5900 Ultra выигрывает у 5800 Ultra возможно за счет намного большей пропускной способности шины и оптимизированного кэша кадрового буфера. А при увеличении нагрузки на геометрический блок вперед вырывается 5800 Ultra.
Hidden Surface Removal
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа треугольников, на сцене без текстур (не учитывается ранняя проверка Z):
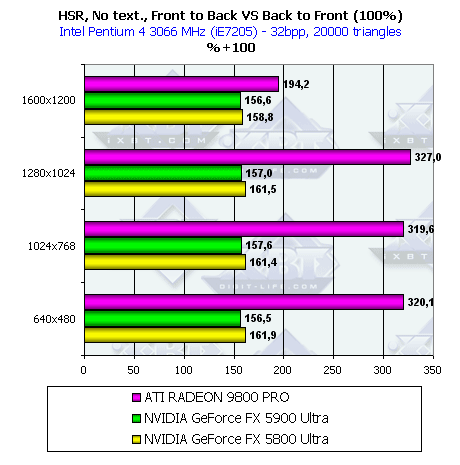
Как мы видим, из-за увеличившейся пропускной способности шины эффект от алгоритма HSR на NV35 даже несколько уменьшился по сравнению с NV30, т.к. даже в худшем случае (back to front sorting) шина памяти способна прокачать увеличившийся объем данных. Но эффективность HSR у обоих чипов все равно ниже, чем у R300 — дело в том, что R300 использует иерархическую структуру, и зачастую отсечение происходит на более высоком уровне, а следовательно, и более эффективно, в то время как у NV30 присутствует только один уровень принятия решения, совмещенный с тайлами, на основе которых сжимается информация о глубине. В максимальном разрешении 1600х1200 происходит резкое падение эффективности HSR на R300 — видимо, по каким-то причинам, например из-за ограниченности размера кэша, выделенного под иерархический буфер, он уже не используется, и решение об отсечении блоков принимается так же, как и в случае NV3x, только на самом нижнем базовом уровне, совмещенном с сжимаемыми блоками в буфере глубины.
Теперь давайте посмотрим на то, как эффективность HSR зависит от сложности сцены
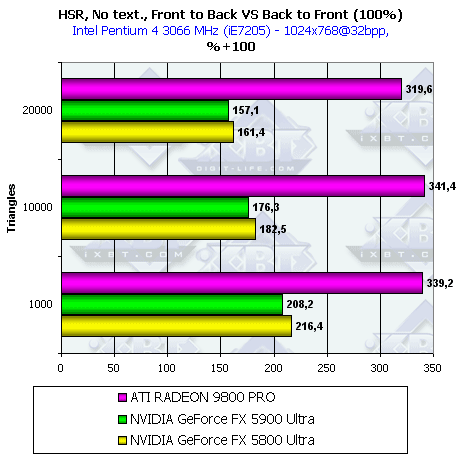
Как мы видим, для NV3x, обладающей только одним уровнем тайлов, эффективность работы HSR тем выше, чем меньше полигонов на сцене. R300 придерживается в этом вопросе золотой середины. Его HSR только расправляет крылья на сценах средней сложности.
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа треугольников, на сцене с текстурами (с учетом ранней проверки Z):
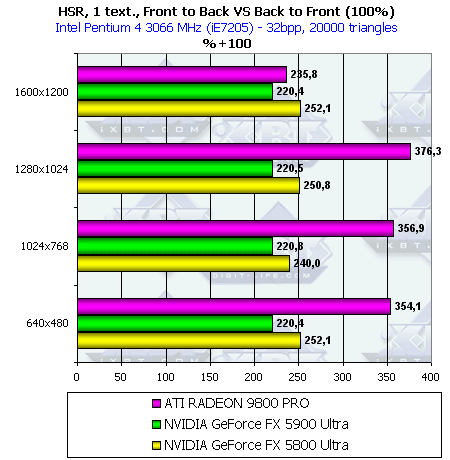
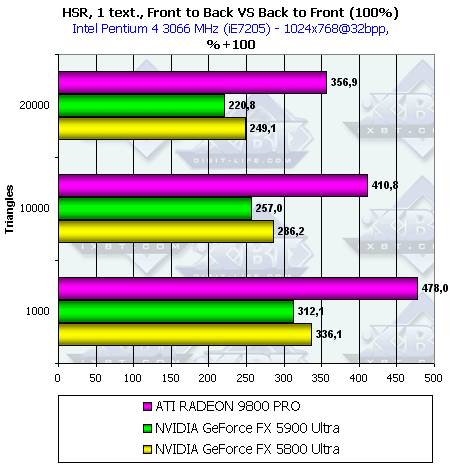
Итак, здесь все чипы демонстрирую рост эффективности от ранней проверки Z. С учетом наличия текстуры, все чипы начинают предпочитать сцены с низким числом полигонов. В остальном поведение аналогично предыдущему тесту.
- Посмотрим, как изменится эффективность в случае сравнения хаотической и сортированной сцены, как с текстурой, так и без:
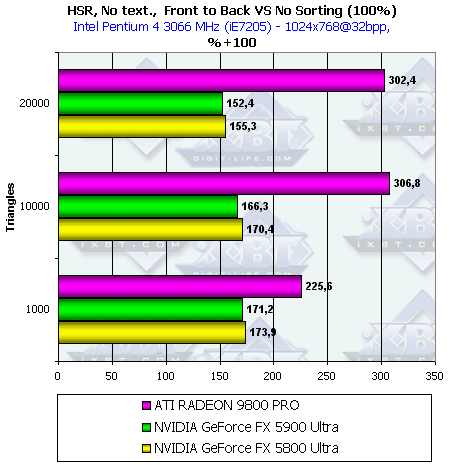
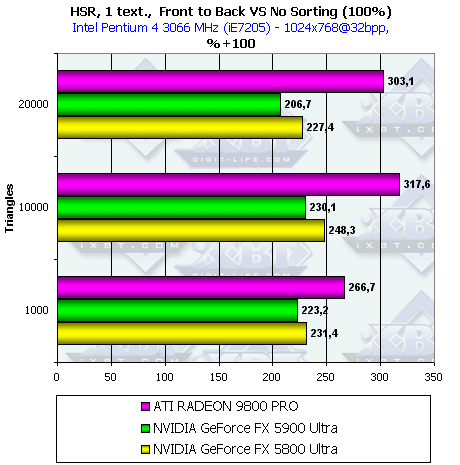
Принципиально ничего нового, соотношение эффективности HSR у разных чипов осталось прежним, прирост от техник HSR уменьшился. Но все равно при использовании текстур все чипы продемонстрировали прирост более чем в 2 раза.
Итак, даже в случае исходно хаотической сцены прирост велик. Вывод — если хотите воспользоваться благами HSR — сортируйте сцену перед выводом. Тогда и только тогда вы получите значительное, в несколько раз, преимущество!
Pixel Shading
- Посмотрим, как изменилась производительность пиксельных процессоров NV35 по сравнению с NV30.
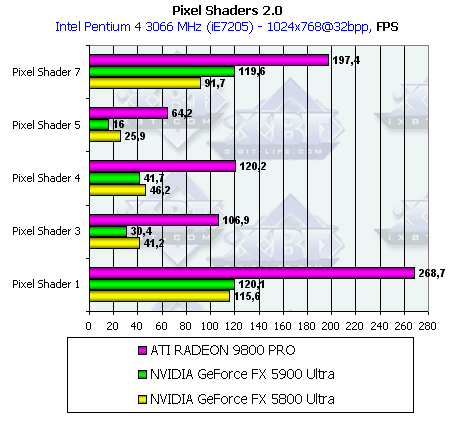
Тест с использованием пиксельных шейдеров 2.0 показывает очень интересные результаты для чипов NVIDIA, особенно учитывая заявленное повышение мощности пиксельных шейдеров DirectX9 в NV35 в два раза. Учитывая, что тактовая частота GeForce FX 5900 Ultra на десять процентов ниже, получаем следующую разницу в производительности чипов на одинаковой частоте в разных тестах:
Тест 1 3 4 5 7 GeForce FX 5900 Ultra / 5800 Ultra +15% -19% 0% -32% +46% Чтобы понять, почему на разных тестах мы видим различную разницу в производительности чипов, нужно заглянуть в код шейдеров. Вот оно, замечательное преимущество синтетических тестов RightMark 3D! Выводы, которые можно сделать из кода шейдеров, заключаются в том, что шейдеры 1 и 7 (кстати, 6-ой тоже) используют значительно большее количество текстурных выборок (а 6 и 7 тесты к тому же выбирают данные из 3D текстур) относительно арифметических команд шейдера по сравнению с остальными тестами. Отсюда можно сделать вывод, что опять повышение производительности связано с возросшей пропускной способностью шины и улучшенными алгоритмами кэширования.
Но постойте! А как же падение производительности в других тестах при заявленном росте в 2 раза! Дело в том, что GeForce FX 5900 Ultra выполняет операции с плавающей точкой в пиксельных шейдерах 2.0 с истинной 32 битной точностью (128 бит на регистр), в отличие от GeForce FX 5800 Ultra, у которой драйвер ограничивает точность операций 16 битами (64 бит на регистр). В дальшейших исследованиях GeForce FX 5900 Ultra мы несомненно исследуем поведение чипа в пиксельных шейдерах 2.0 более детально.
Что касается Radeon 9800 Pro, то он так и остался безусловным лидером.
Point Sprites
- С освещением и без, в зависимости от размеров:
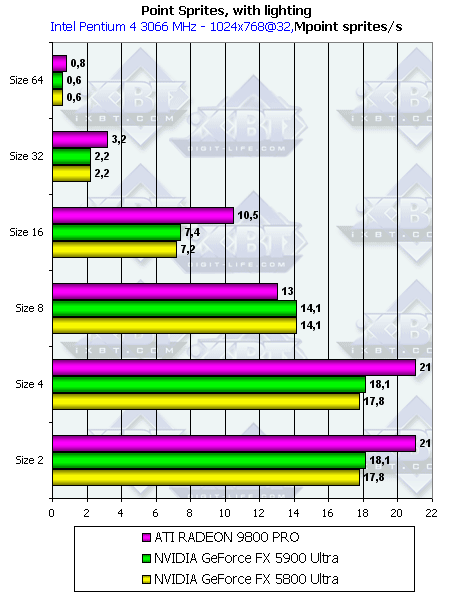
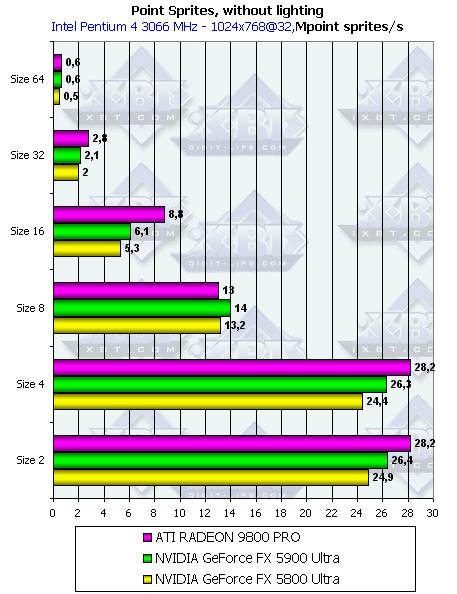
Как и ожидалось наличие или отсутствие освещения сказывается только на маленьких спрайтах, по мере роста размера все упирается в закраску. Происходит это при размере 8 и более. Итак, для вывода систем, состоящих из большого числа частиц, следует признать оптимальными размеры менее 8. Кстати, размер 8 является своеобразным оптимумом для чипов NVIDIA, при этом размере они смогл,и хотя и несущественно, но обойти Radeon 9800 Pro, возможно, это связано с размером кешируемых тайлов у NVIDIA. Также заметно увеличившаяся эффективность работы с буфером кадра у GeForce FX 5900 Ultra по сравнению с предшественником: если при использовании освещения (т.е. повышенной нагрузке на геометрический блок чипа) более 500 Ultra идет вровень, то когда основная нагрузка ложится на блок работы с буфером кадра новичок вырывается вперед.
Radeon 9800 Pro в большинстве режимов все также лидирует, сказывается наличие 8 пиксельных конвейеров, выдающих по пикселю за такт при наложении одной текстуры.
3D-графика, 3DMark2001 SE, 3DMark03 — синтетические тесты
Подчеркну, что все замеры по всем 3D-тестам проводились в 32-битной глубине цвета.
Скорость закраски 3DMark2001 SE
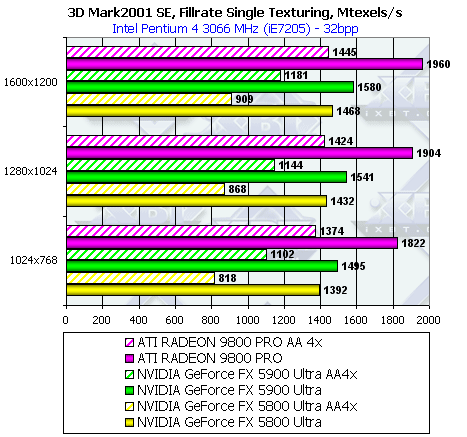
Рост производительности GeForce FX 5900 Ultra при использовании AA очевиден, хотя Radeon 9800 Pro, несмотря на меньшую пропускную способность шины, лидирует и при использовании АА. Заметим, что в отличие от RightMark 3D в 3Dmark 2001 GeForce FX 5900 Ultra опережает 5800 Ultra и без использования АА, причиной несомненно является большие требования теста в 3DMark 2001 к пропускной способности шины.
В случае мультитекстурирования:
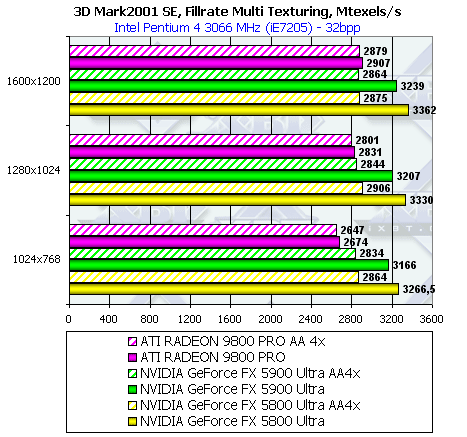
Сравнивая с предыдущим тестом, мы видим, что скорость чипов NVIDIA при мультитекстурировании выше, чем у Radeon 9800 Pro. Такое поведение вполне объяснимо. По мере увеличения числа текстур все большую роль играет производительность их выборки и фильтрации, которая в первую очередь определяется тактовой частотой ядра чипа, а не количеством пиксельных конвейеров и пропускной способностью шины. В данном случае у всех чипов количество текстурных блоков одинаково и равно 8, соответственно, главную роль начинает играть тактовая частота чипа. В порядке оной ои и выстроились: сначала 500Мгц NV30, далее 450Мгц NV35 и наконец 380Мгц R350.
Также интересно заметить, что при включенном режиме AA производительность чипов NV3x падает более существенно, нежели R300 — несмотря на сжатие буфера кадра в режиме MSAA, имеющее место у всех чипов, и даже большую ПСП у NV35.
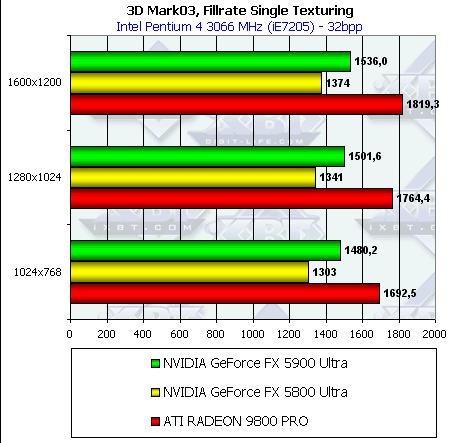
Скорость закраски 3DMark2003
В случае мультитекстурирования:
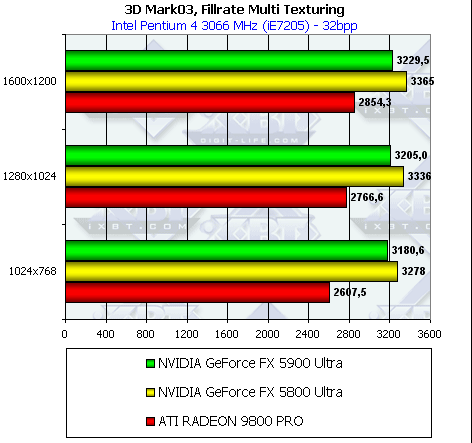
Пиксельный шейдер 2.0
Продолжая строить аналогии с тестами Shader Level 6 и 7 из RightMark 3D видим, что в RightMark 3D Radeon 9800 Pro сильно опережает оба чипа NVIDIA, а в 3DMark03 такого преимущества не наблюдается. Видимо, не зря программисты NVIDIA едят свой хлеб: оптимизация под этот тест налицо, особенно если взглянуть на результаты GeForce FX 5800 Ultra на драйвере версии 43.45.
Вершинные шейдеры 1.1
В тесте анимируются 30 тролей, каждый из которых состоит приблизительно из 5500 треугольников. Персонажи прорисовываются в четыре прохода (во время каждого прохода фигура троля заново анимируется в шейдере), используя вершинные шейдеры 1.1. Итого получаем примерно 30*5500*4 = 660,000 треугольников рисуемых в каждом кадре. Результат приводится в кадрах в секунду.
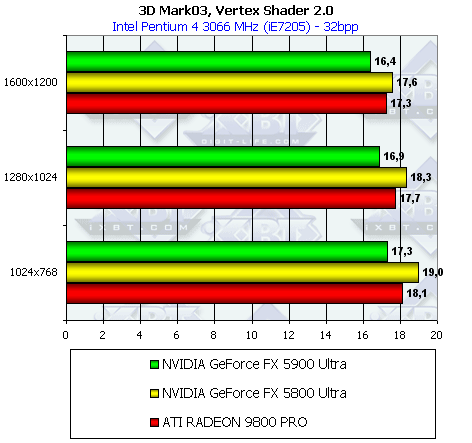
Анизотропная фильтрация
Реализация алгоритмов анизотропной фильтрации в чипе не изменилась. Все также присутствуют три режима работы, о которых мы говорили ранее (см. настройки драйверов). Ниже в разделе по качеству 3D вы сможете увидеть и скриншоты.
- Quality — максимальное качество изображения — полностью соответствует параметрам, заданным пользователем или приложением. Алгоритмы аналогичны используемым со времен GeForce 3
- Performance — в идеале драйвер пытается определить оптимальные по качеству алгоритмы фильтрации. Пример подобных оптимизаций можно посмотреть в статье Алексея Николайчука aka Unwinder. В GeForce FX в дополнение к сказанному с статье используется анизотропная фильтация, требующая меньшего количества текстурных выборок для большинства пикселей. Также изменен алгоритм трилинейной фильтрации — чипы NV3x позволяют использовать режим, в котором выборка и фильтрация одновременно из двух MIP-уровней производится только для части поверхности, находящейся наиболее "близко" к переходу между MIP-уровными. Для остальной поверхности выполняется выборка и фильтрация только одного из MIP-уровней, это приводит к двукратному росту скорости фильтрации текстур в этом месте.
- High Performance — дальнейшее упрощение фильтрации. Степень анизотропной фильтрации, применяемой в этом режиме, еще меньше, чем в режиме Performance, а трилинейная фильтрация также упрощена.
Выводы из результатов синтетических тестов
Итак, подведем краткий итог по детальному исследованию различных блоков NV35 с помощью синтетических тестов.
- Основным вкладом в изменение производительности NV35 безусловно является увеличение пропускной способности памяти, и связанная с этим переработка и оптимизация контроллера памяти и работающих непосредственно с ним блоков чипа, отвечающих за сжатие буфера кадра, а также, возможно, блока раннего отсечения по z (early z-cull) в связи с добавлением технологии UltraShadow. Возросшая пропускная способность памяти незамедлительно сказалась на тестах, использующих антиалиасинг. В тестах на скорость закраски (Fillrate) при больших разрешениях получаемый прирост измеряется не в процентах, а в десятках процентов и чуть ли не в разах.
- Каких-либо существенных архитектурных отличий в блоке, отвечающем за геометрическую обработку, не обнаружено.
- Также оптимизированы пиксельные процессоры, теперь пиксельные шейдеры, использующие операции с числами с плавающей точкой с 32-битной точностью (128 бит на регистр) выполняются со скоростью, сравнимой с операциями 16 битной точности в NV30. Хотя, к сожалению, скорость выполнения пиксельных шейдеров второй версии у Radeon 9800 Pro так и осталась недостигнутой.
3D-графика, 3DMark2001 — игровые тесты
Сразу отмечу, почему мы использовали в наших тестах настройки анизотропии 16х у карт от ATI и 8х у карт от NVIDIA. Никакой дискриминации в отношении карт от ATI нет! Алгоритмы работы этой функции у ATI и NVIDIA очень различаются (об этом мы говорили подробно в нашем материале по NV30), поэтому сопоставлять только цифры "8" неразумно. Критерий один: максимально возможное качество. У NVIDIA по ее "счетчику" — это 8х, а у ATI — 16х. Скриншоты мы уже приводили, и не один раз. К тому же, интересно будет узнать, как сопоставляются разные режимы работы анизотропии от NVIDIA с максимально качественным режимом от ATI, тем более, что опять же, скриншоты мы уже приводили, и читатель может оценить соотношение скорости и качества (милости просим в обзор NV30 за скриншотами оценки качества анизотропной фильтрации).
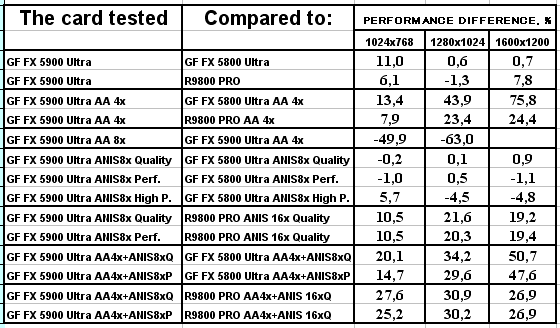
Думаю, что в таблицах соотношений все данные имеются, поэтому отдельно комментировать нет смысла.
3DMark2001, 3DMARKS
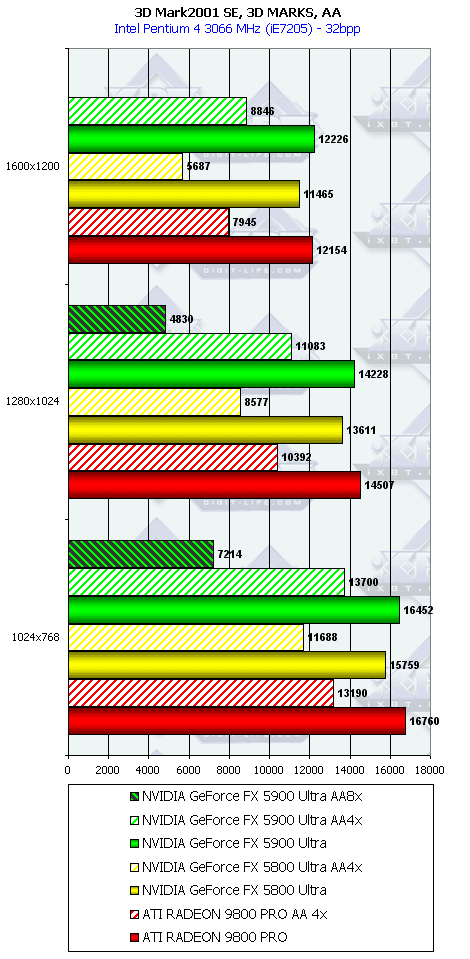
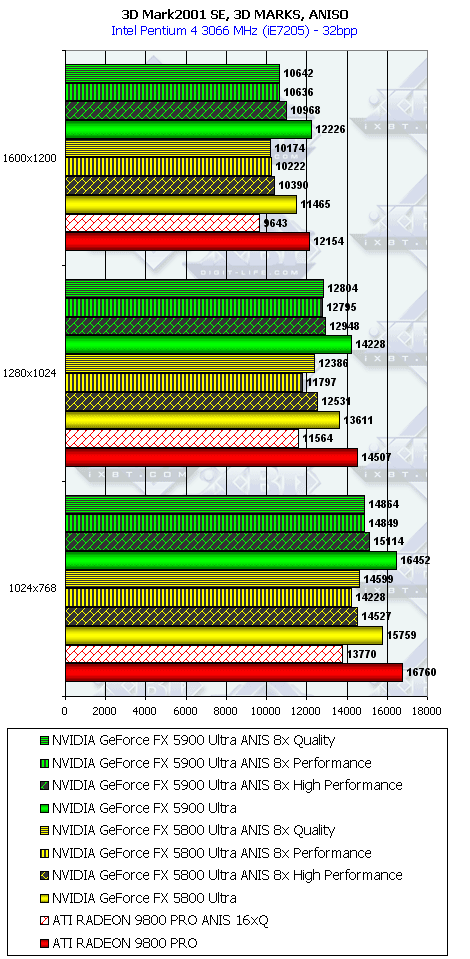
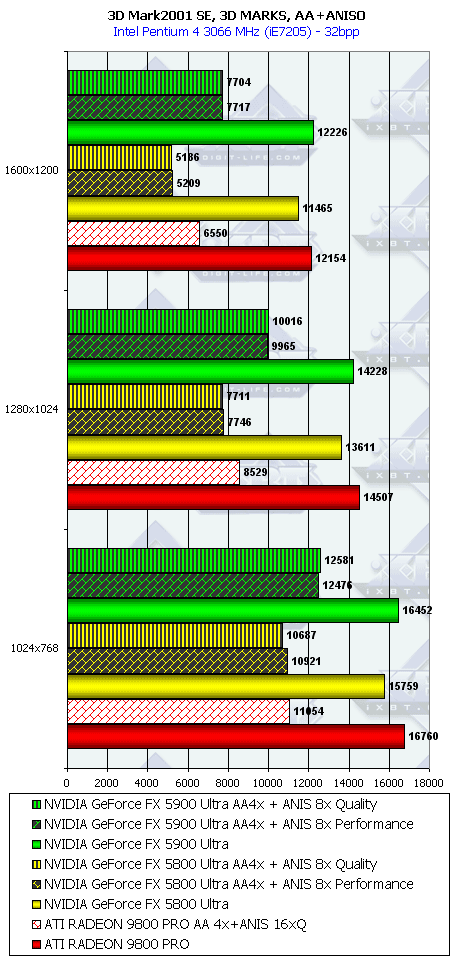
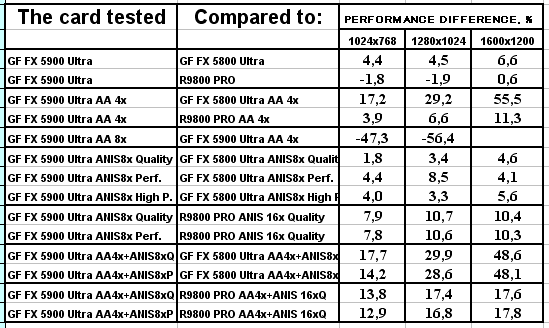
Если кто хочет проценты перевести в "разы", то надо к процентам прибавить 100 и все разделить на 100.
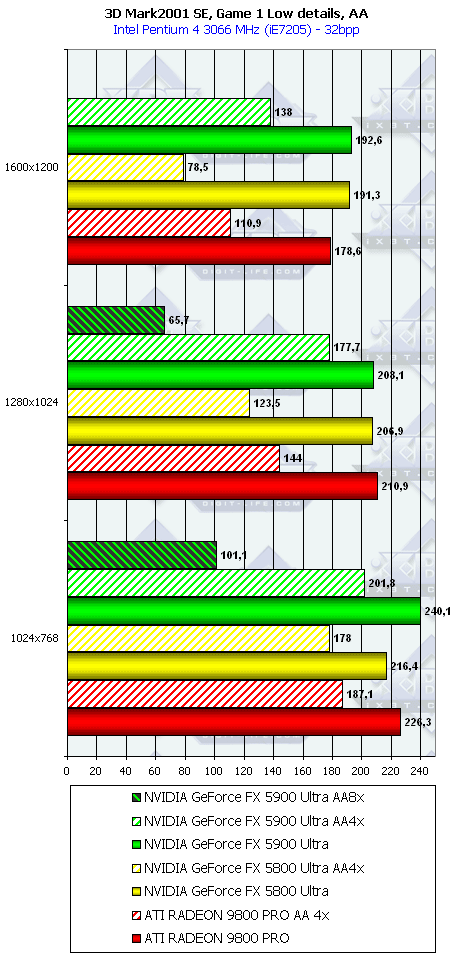
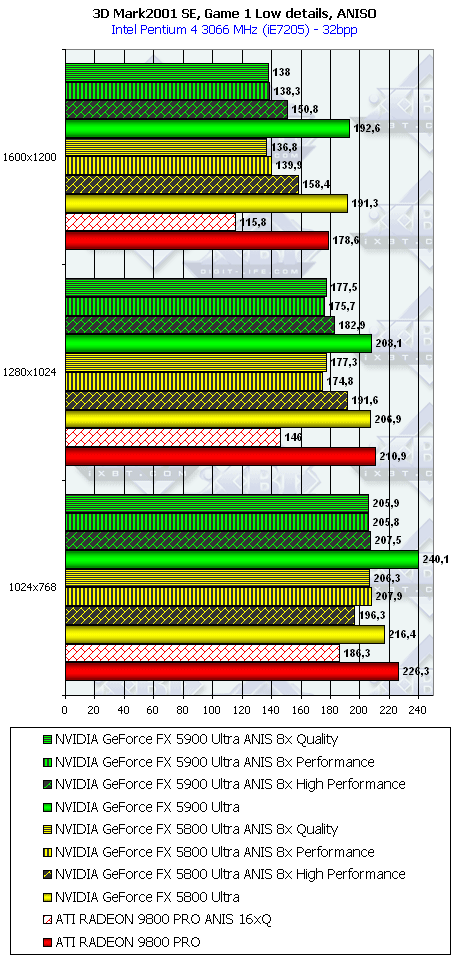
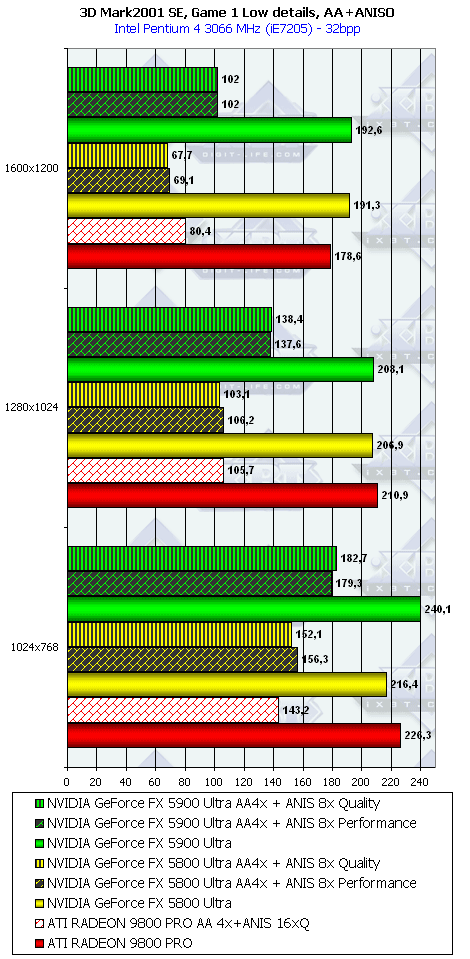
3DMark2001, Game1 Low details
3DMark2001, Game2 Low details
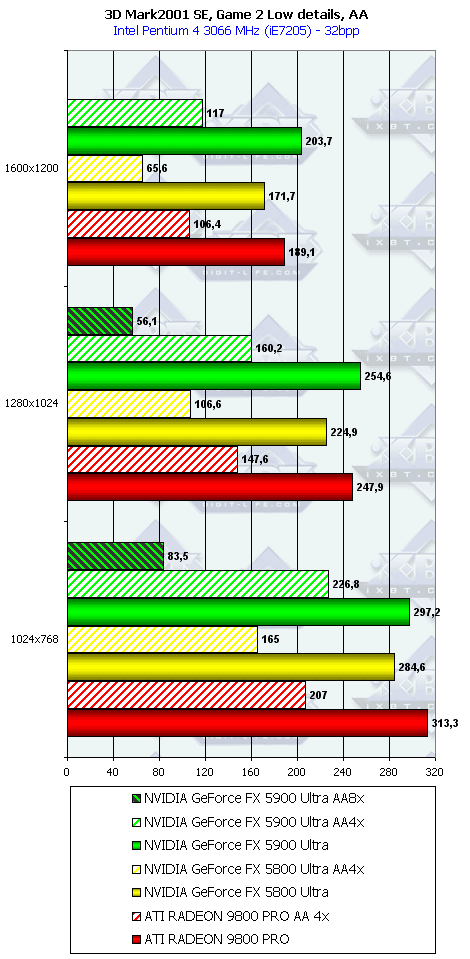
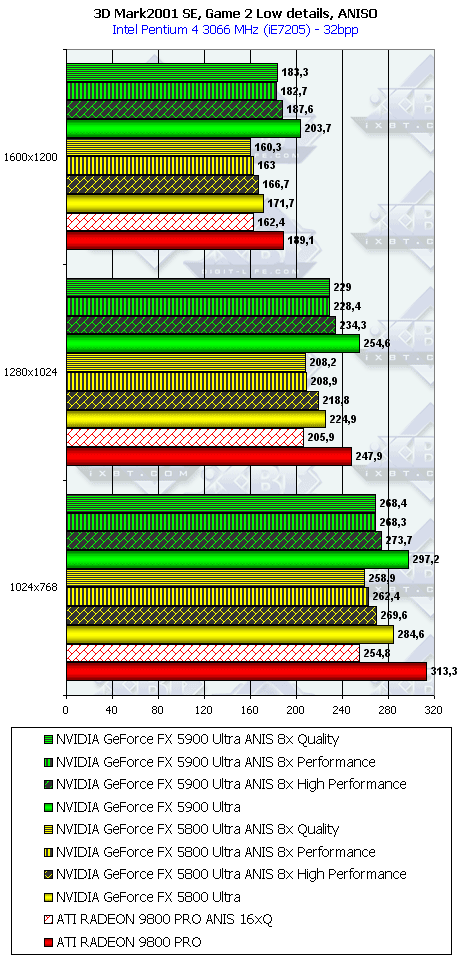
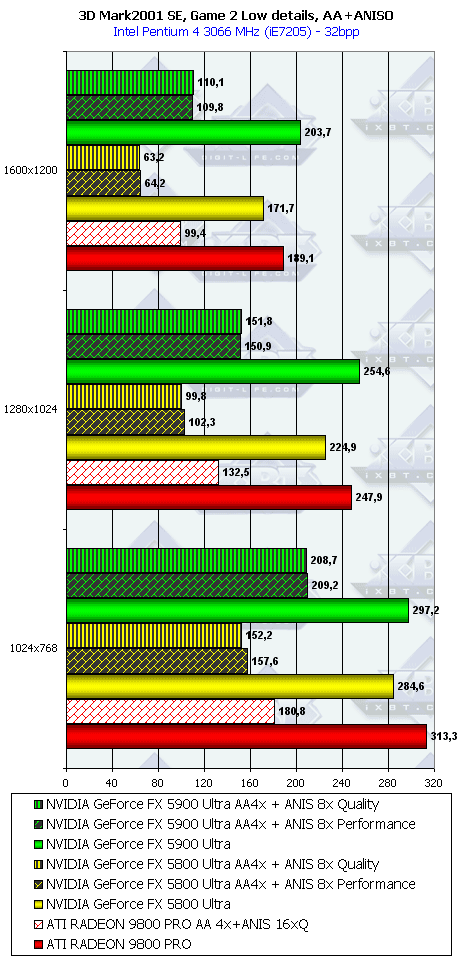
3DMark2001, Game3 Low details
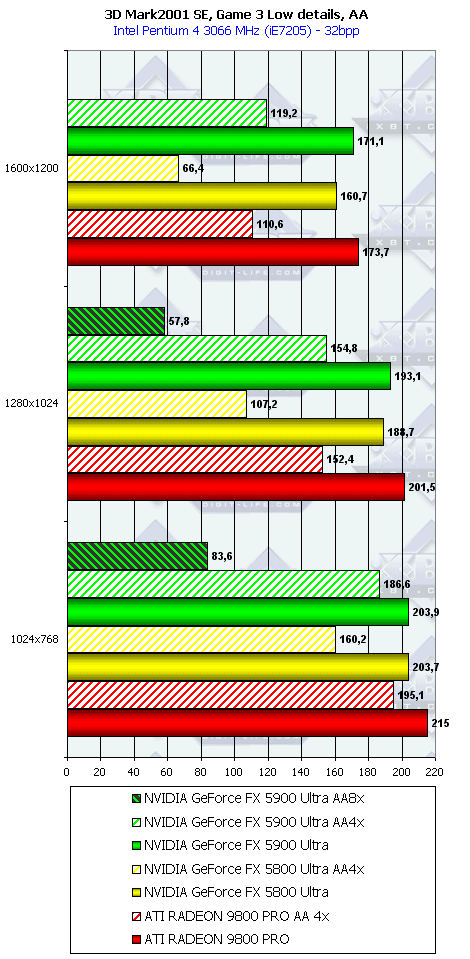
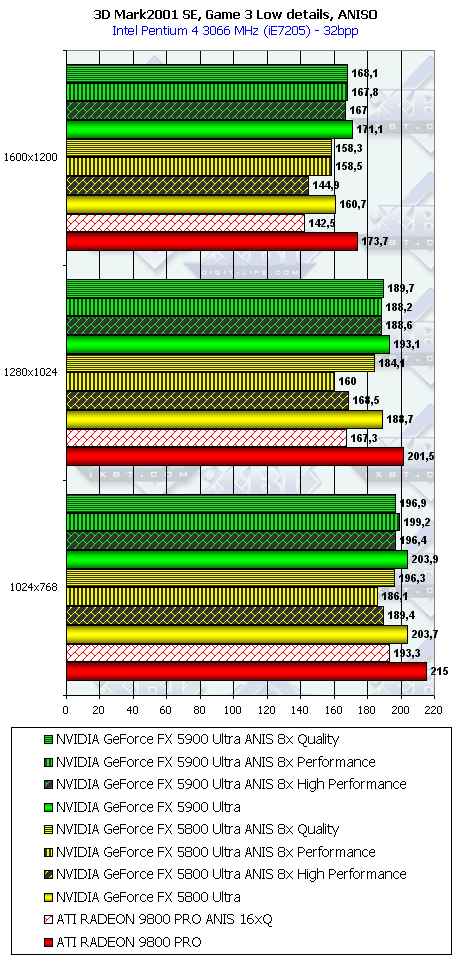
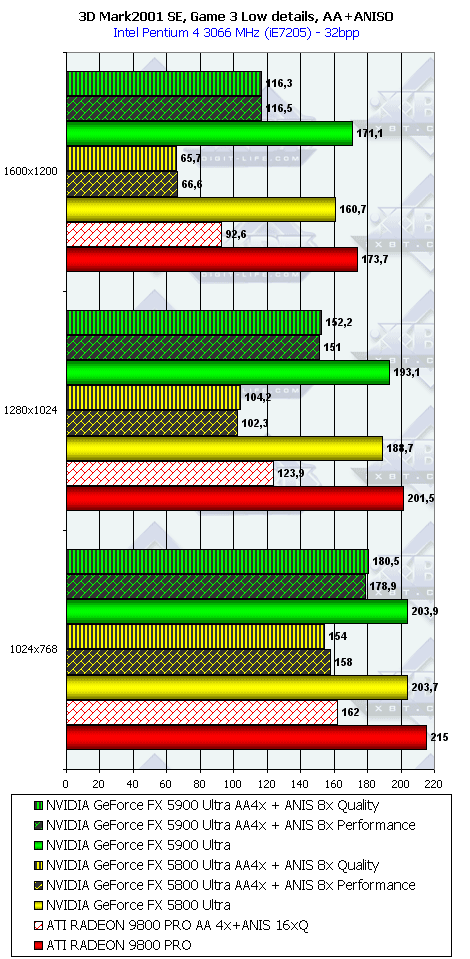
3DMark2001, Game4
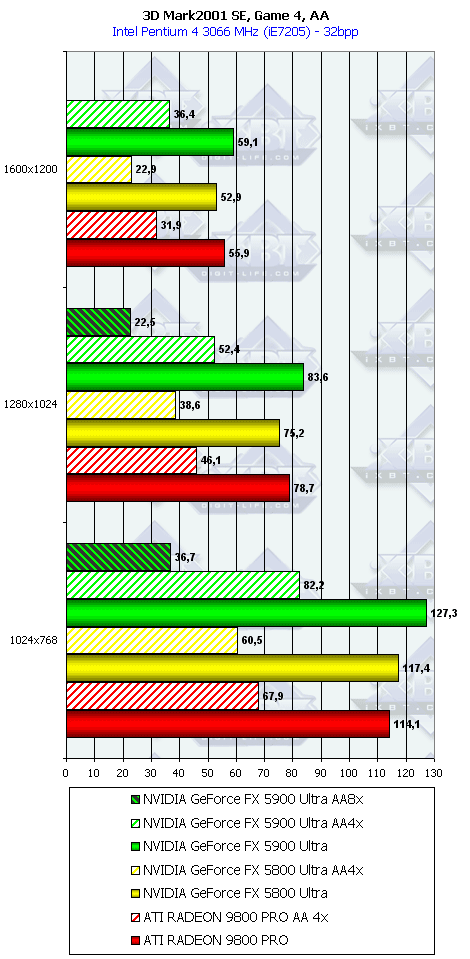
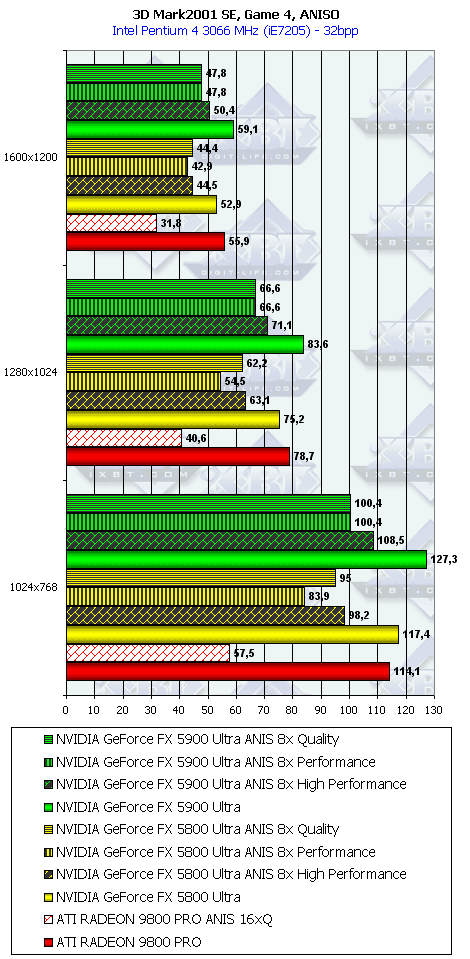
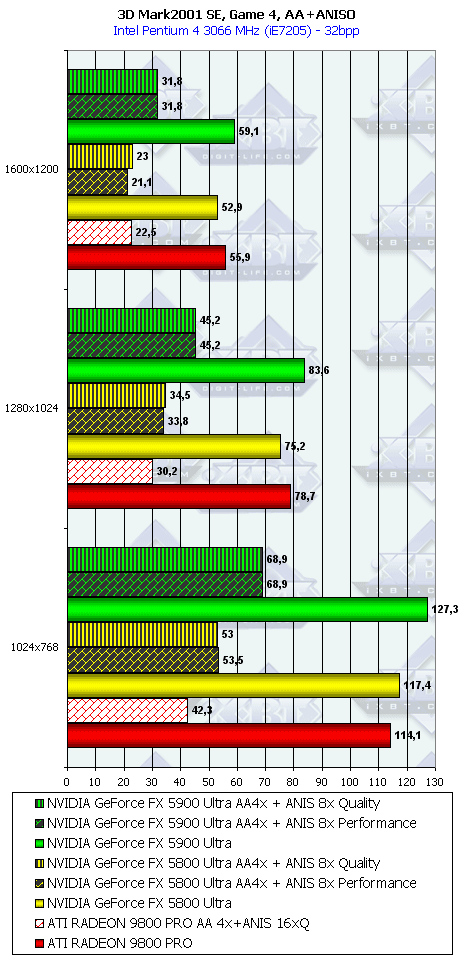
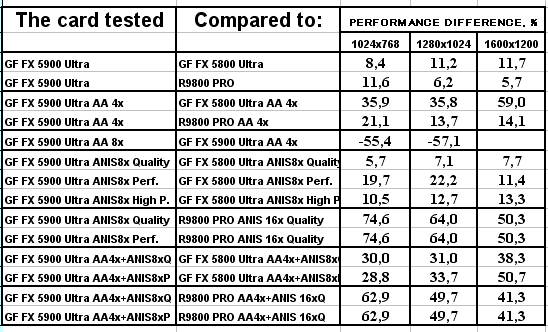
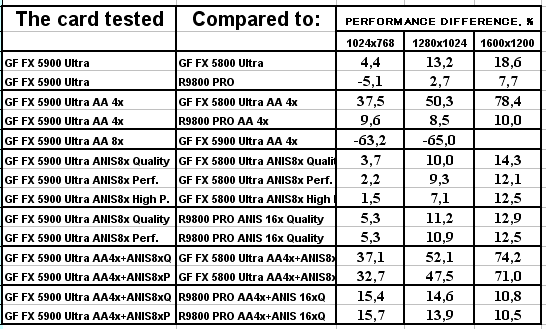
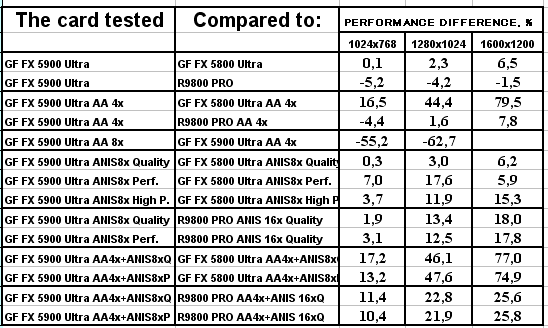
Подводя итоги тестирования в 3DMark2001SE, мы можем сказать следующее:
- Как и ожидалось, наличие 256-битной шины обмена с памятью сильно помогло NV35 в режимах с АА. Не забываем, что ПСП увеличилась в
(256 / 8 * 850) / (128 / 8 * 1000) = 27200 / 16000 = 1.7 раза. Это же сильно помогло карте выиграть и в комплексных тяжелых режимах с АА и анизотропией. И это все, несмотря на уменьшившиеся частоты работы как самого процессора (450 против 500 МГц), так и памяти (425 против 500 МГц). - Алгоритм анизотропии не претерпел изменений, однако, как мы видим, программисты NVIDIA усиленно работают над оптимизациями этой функции (более подробно о подобном в OpenGL можно прочитать в статье Алексея Николайчука AKA Unwinder). Причем, работа идет в целом по семейству GeForce FX, а не только по NV35, поэтому мы видим, что на последней версии 44.03 скорости анизотропии у NV30 и NV35 иногда почти равны. Интересно отметить, что специфика анизотропии от NVIDIA такова, что почти вся нагрузка ложится на чип, и поэтому логично было бы ждать более низких результатов у NV35 из-за более низкой частоты работы GPU, однако все же процессор оптимизировали и с точки зрения скорости выполнения этой функции.
- АА 8х, представляющий собой гибрид между MSAA и SSAA, как и ожидалось, скушал львиную долю производительности, а о его качестве мы поговорим позже.
3D-графика, 3DMark03 — игровые тесты
3DMark03, 3DMARKS
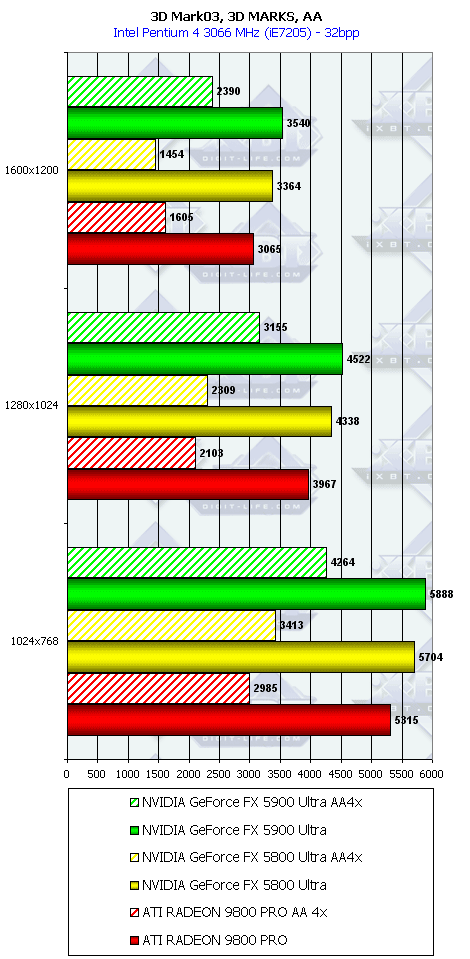
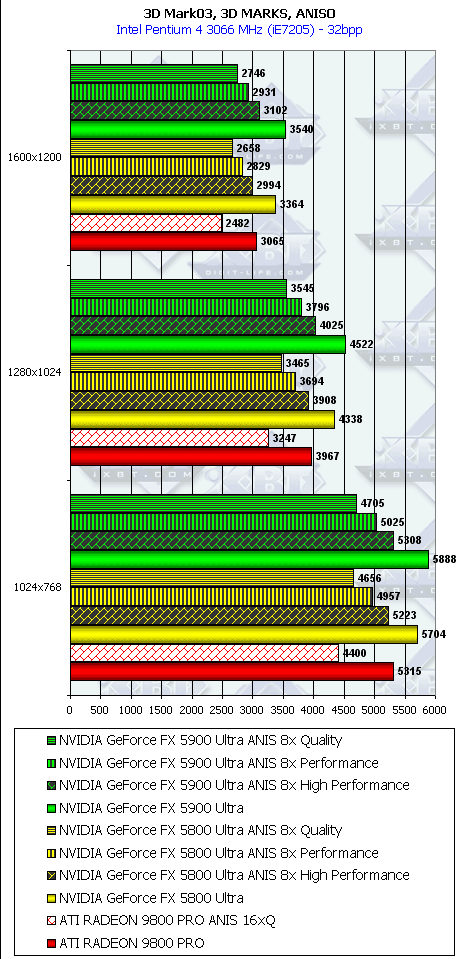
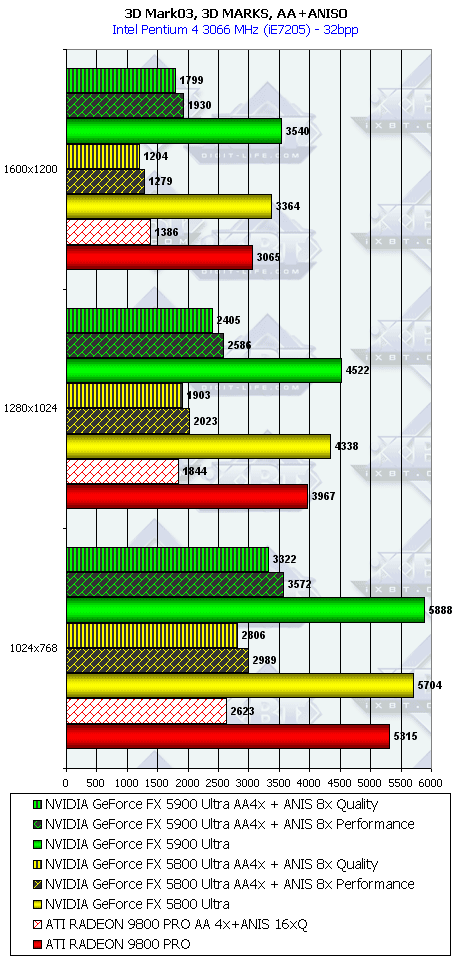
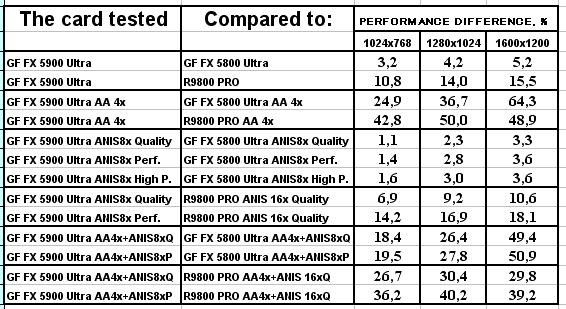
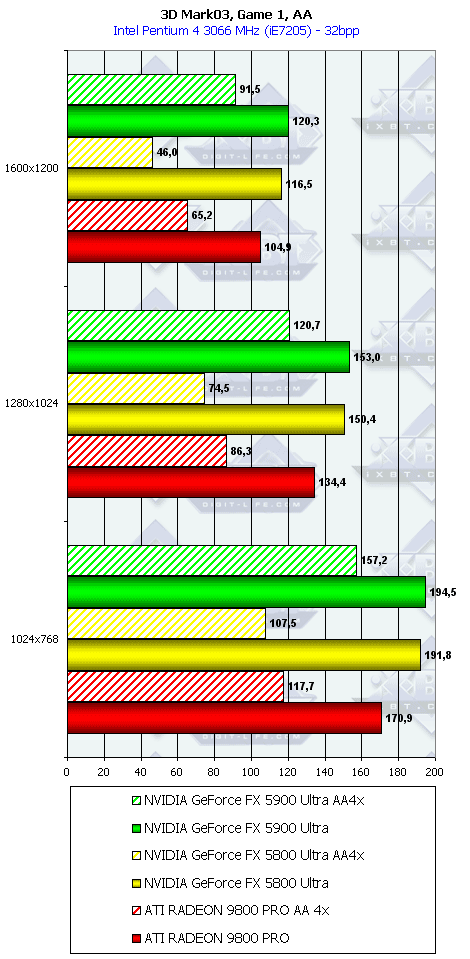
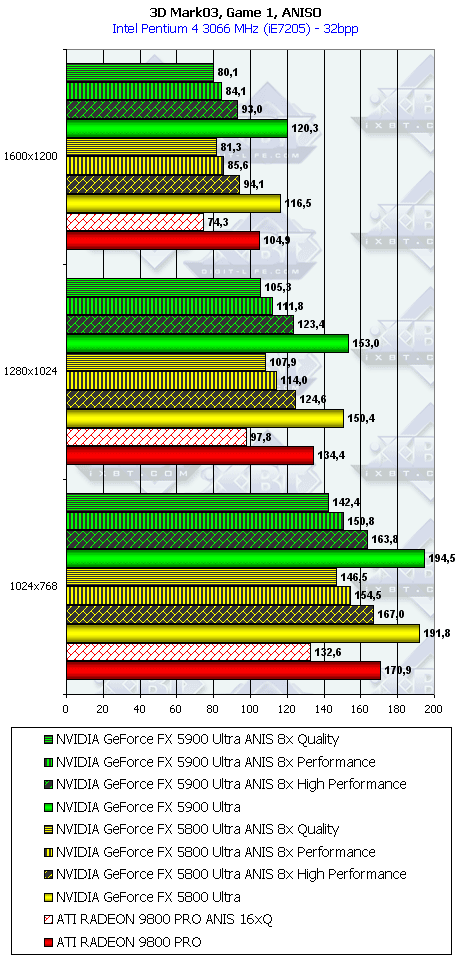
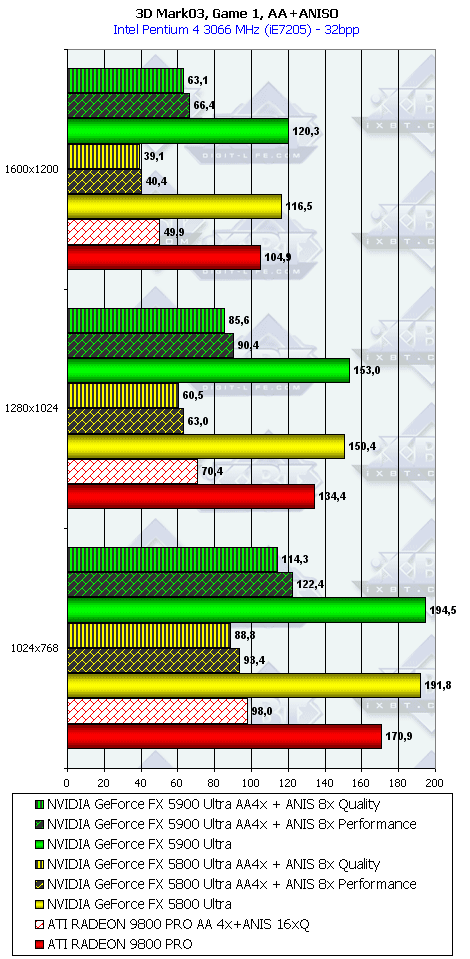
3DMark03, Game1
Характеристики теста Wings of Fury:
- DirectX 7.0 тест; примерно 32000 полигонов в сцене, под текстуры используется 16 мегабайт видеопамяти, 6 мегабайт для буферов под вершины и 1 мегабайт для индексов.
- Все геометрические операции базируются на использовании вершинных шейдеров 1.1, которые могут эмулироваться через CPU (если "железо" не поддерживает аппаратно).
- Все самолеты выполнены с помощью 4-х текстурных слоев, поэтому акселераторы, умеющие обрабатывать 4 текстуры за проход, будут в выигрыше.
- Эффекты дыма и шлейфов выполнены с помощью техник точечных спрайтов и др.
3DMark03, Game2
Характеристики теста Battle of Proxycon:
- DirectX 8.1 тест; примерно 250 000 полигонов в сцене при использовании пиксельных шейдеров 1.1 (и 150 000 полигонов — если используются шейдеры 1.4), под текстуры используется 80 мегабайт видеопамяти, 6 мегабайт для буферов под вершины и 1 мегабайт для индексов.
- Все геометрические операции базируются на использовании вершинных шейдеров 1.1, которые могут эмулироваться через CPU (если "железо" не поддерживает аппаратно).
- Все персонажи "одеты" также с помощью вершинных шейдеров.
- Некоторые источники света производят динамические тени, получаемые при помощи стенсил-буфера.
- Все пиксельные операции производятся с помощью шейдеров 1.1, или, если это возможно, 1.4.
- Вычисление попиксельного освещения для эффектов дымок, и других компонентов.
- Акселераторы, поддерживающие пиксельные шейдеры 1.1, используют один проход для определения Z-буфера, затем по три прохода на каждый источник света. Если акселератор поддерживает шейдеры 1.4, то ему требуется всего по одному проходу на каждый источник света.
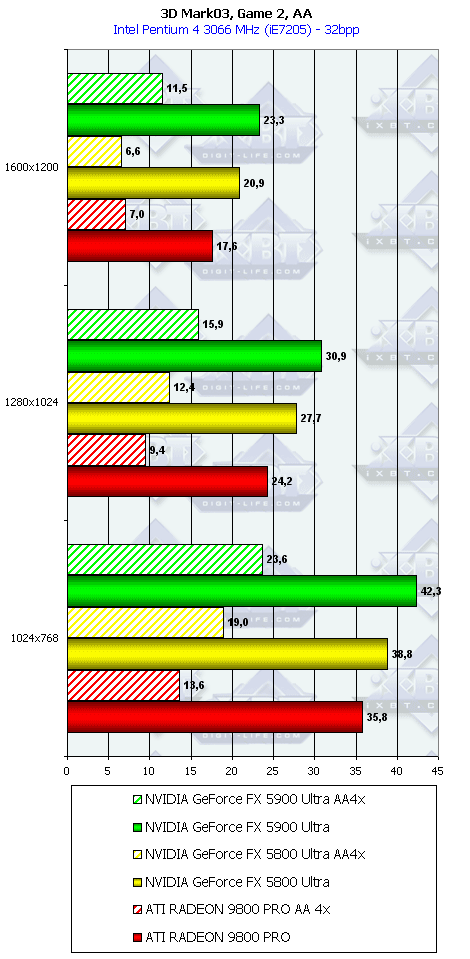
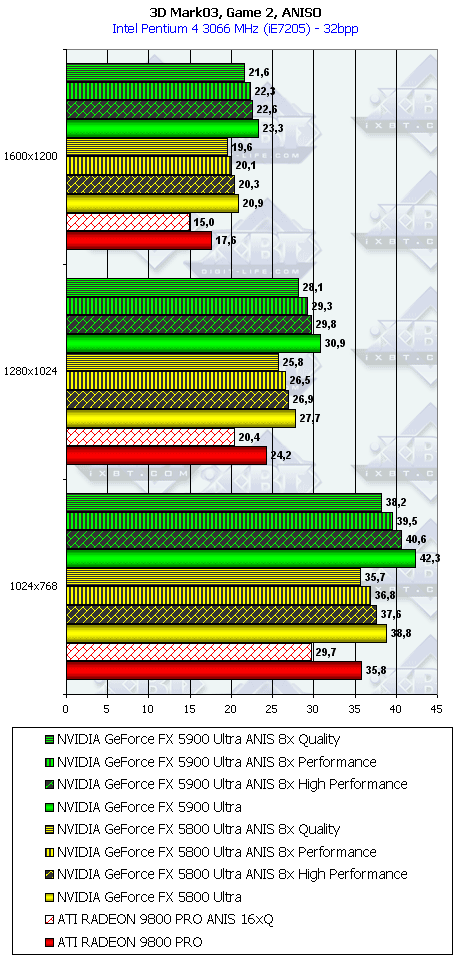
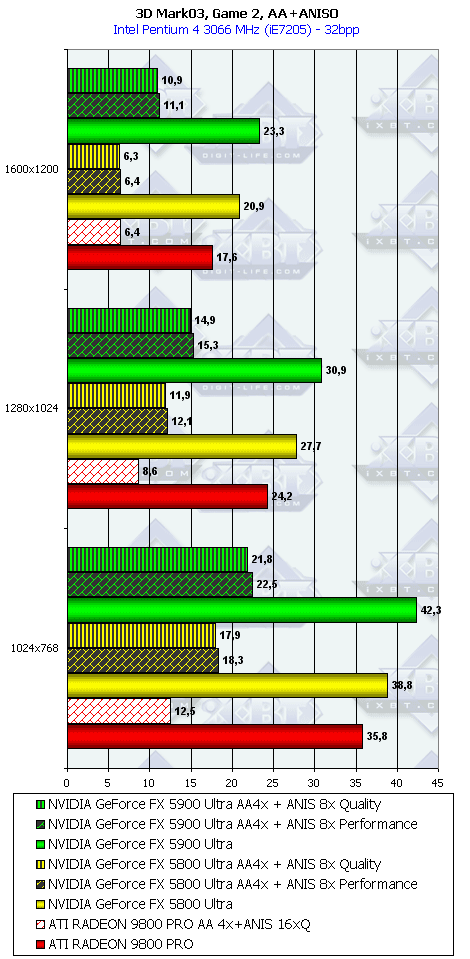
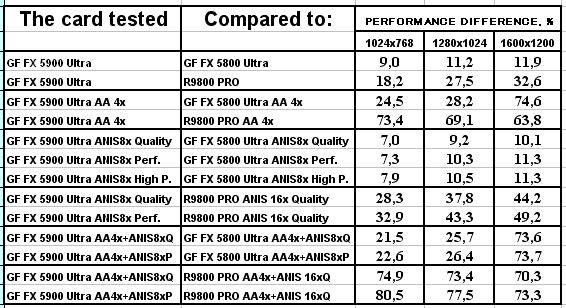
3DMark03, Game3
Характеристики теста Trolls' Lair:
- DirectX 8.1 тест; примерно 560 000 полигонов в сцене при использовании пиксельных шейдеров 1.1 (и 280 000 полигонов — если используются шейдеры 1.4), под текстуры используется 64 мегабайт видеопамяти, 19 мегабайт для буферов под вершины и 2 мегабайта для индексов.
- Все геометрические операции базируются на использовании вершинных шейдеров 1.1, которые могут эмулироваться через CPU (если "железо" не поддерживает аппаратно).
- Все персонажи "одеты" также с помощью вершинных шейдеров.
- Некоторые источники света производят динамические тени, получаемые при помощи стенсил-буфера.
- Все пиксельные операции производятся с помощью шейдеров 1.1, или, если это возможно, 1.4.
- Вычисление попиксельного освещения для эффектов дымок, и других компонентов.
- Для реалистичного отображения волос героини используются физические модели, а также анизотропное освещение.
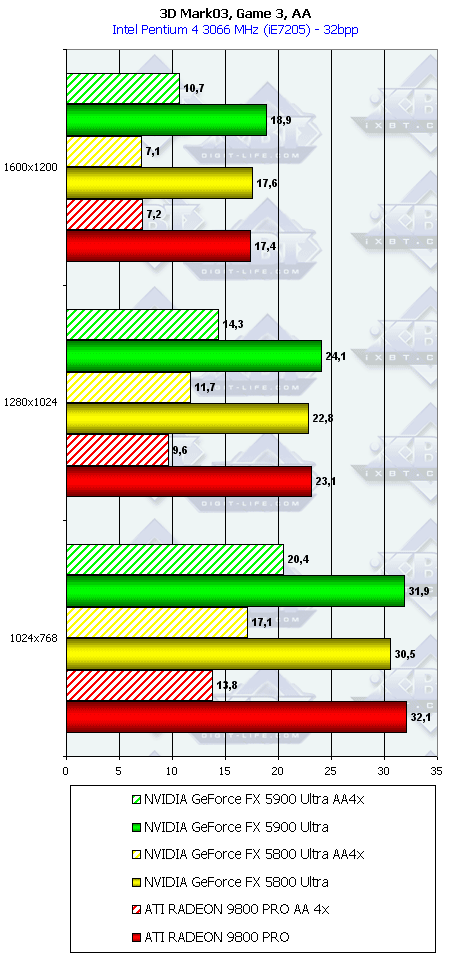
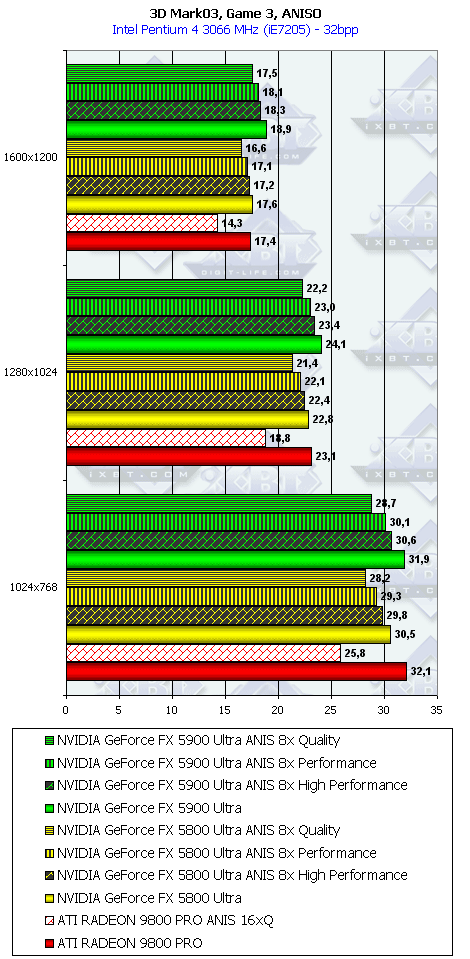
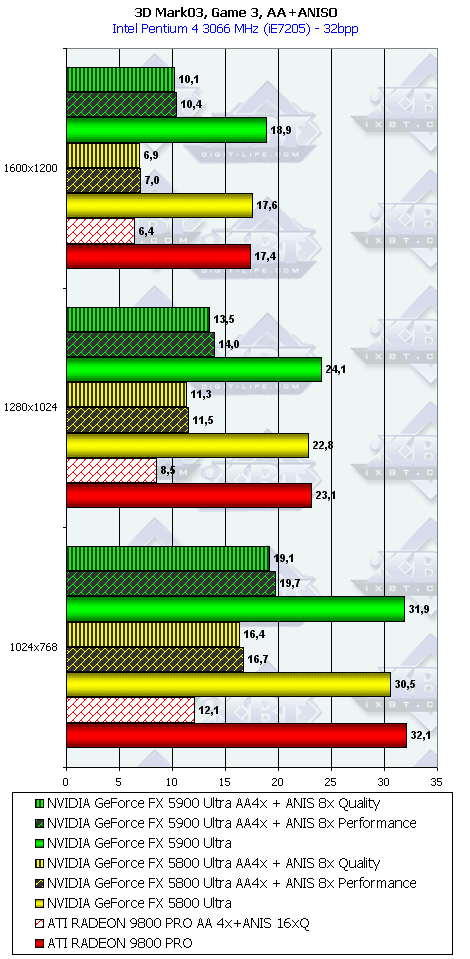
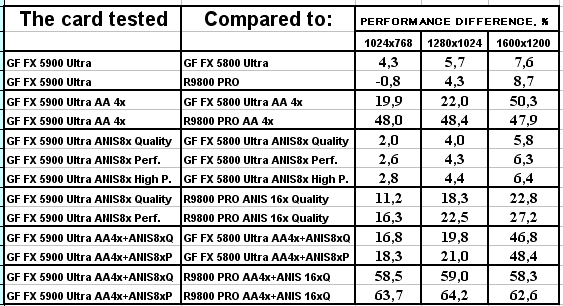
3DMark03, Game4
Характеристики теста Mother Nature:
- DirectX 9.0 тест; примерно 780 000 полигонов в сцене, под текстуры используется 50 мегабайт видеопамяти, 54 мегабайт для буферов под вершины и 9 мегабайт для индексов.
- Каждый лист на деревьях отдельно анимирован при помощи вершинных шейдеров 2.0. Трава анимирована с помощью вершинных шейдеров 1.1.
- Поверхность озера образована при помощи пиксельных шейдеров 2.0.
- Небо также получено при помощи пиксельных шейдеров 2.0, для солнечных бликов используется реализованная в DX9 повышенная точность расчетов.
- Поверхность земли получена с помощью шейдеров 1.4.
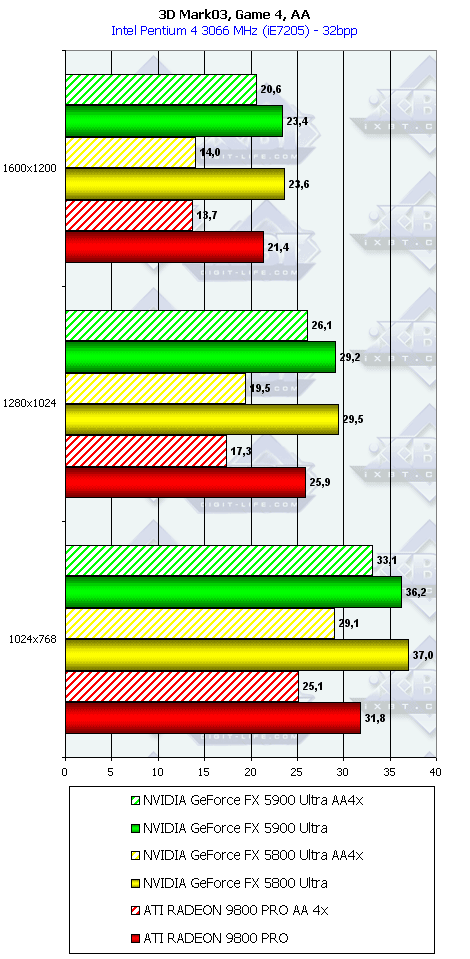
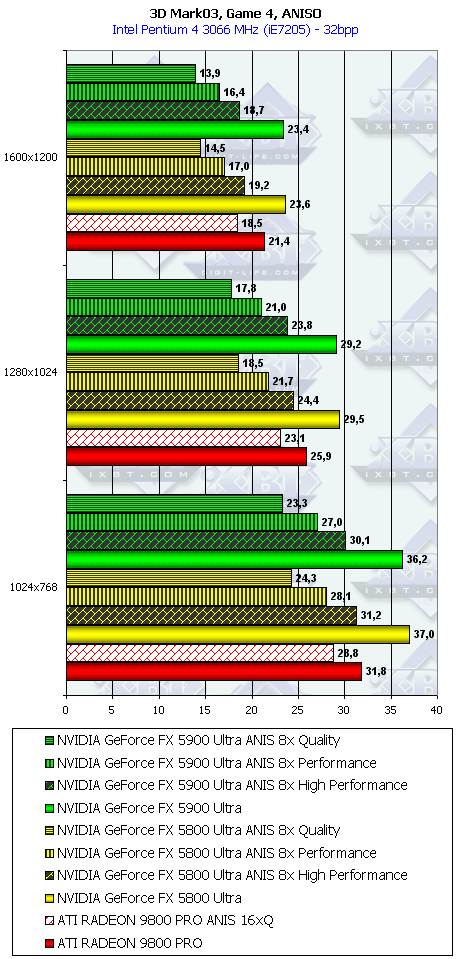
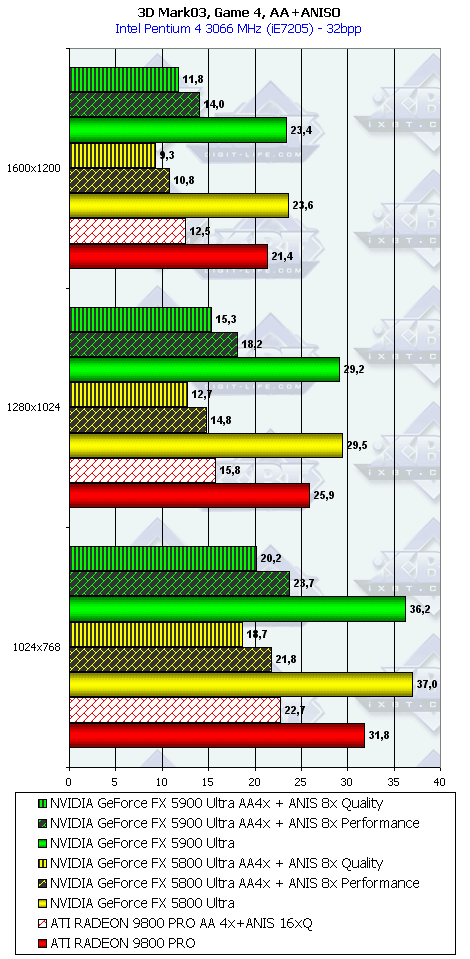
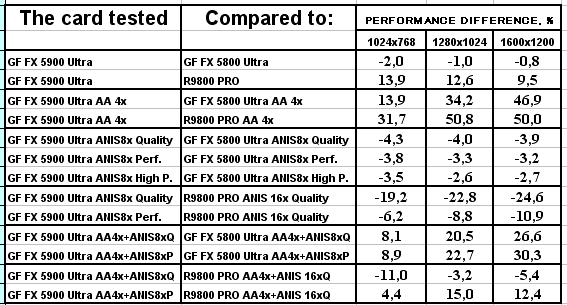
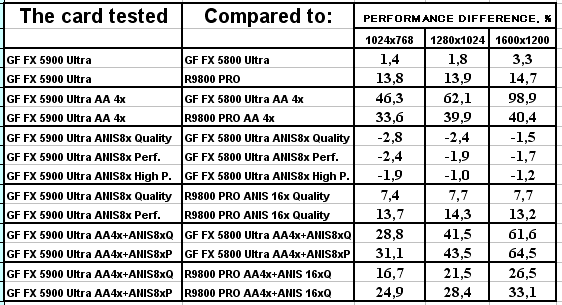
Что можно сказать по итогам 3DMark03?
- А вот в этом пакете, где тесты достаточно сложны (или, вероятно, из-за недостаточной оптимизации драйверов под этот тест), скорость анизотропии у NV35 подчас чуть ниже, чем у NV30. Тут уже играют роль более низкие частоты у первого.
- Однако наличие 256-битной шины и тут сильно помогает, и в комплексных режимах NV35 одерживает убедительную победу. И все же не будем забывать про то, что этот тест не является столь объективным, как другие, под него как NVIDIA, так и ATI могут делать оптимизации (или просто говоря, трики, заточки), мы уже видели ранее это на примере теста Pixel Shaders, когда просто драйверами NVIDIA смогла поднять скорость у NV30 в 4(!) раза, когда на деле скорость PS у NV35 особо не выросла.
3D-графика, игровые тесты
Приступаем к оценке производительности видеокарты в 3D-играх. В качестве инструментария мы использовали:
- Return to Castle Wolfenstein (MultiPlayer) (id Software/Activision) — OpenGL, мультитекстурирование, Checkpoint-demo, настройки тестирования — все на максимально возможном уровне, S3TC OFF, конфигурации можно скачать тут
- Serious Sam: The Second Encounter v.1.05 (Croteam/GodGames) — OpenGL, мультитекстурирование, Grand Cathedral demo, настройки тестирования: quality, S3TC OFF
- Quake3 Arena v.1.17 (id Software/Activision) — OpenGL, мультитекстурирование, Quaver, настройки тестирования все на максимальном уровне: уровень
детализации — High, уровень детализациитекстур — №4, S3TC OFF, плавность кривых поверхностей резко увеличена при помощи переменныхr_subdivisions «1» иr_lodCurveError «30000» (подчеркну, что по умолчанию r_lodCurveError «250» !), конфигурации можно скачать тут - Unreal Tournament 2003 Demo (Digital Extreme/Epic Games) — Direct3D, Vertex Shaders, Hardware T&L, Dot3, cube texturing, качество по умолчанию
- Code Creatures Benchmark Pro (CodeCult) — игровой тест, демонстрирующий работу платы в DirectX 8.1, Shaders, HW T&L.
- AquaMark (Massive Development) — игровой тест, демонстрирующий работу платы в DirectX 8.1, Shaders, HW T&L.
- RightMark 3D v.0.4 (одна из игровых сцен) — DirectX 8.1, Dot3, cube texturing, shadow buffers, vertex and pixel shaders (1.1, 1.4).
Quake3 Arena, Quaver
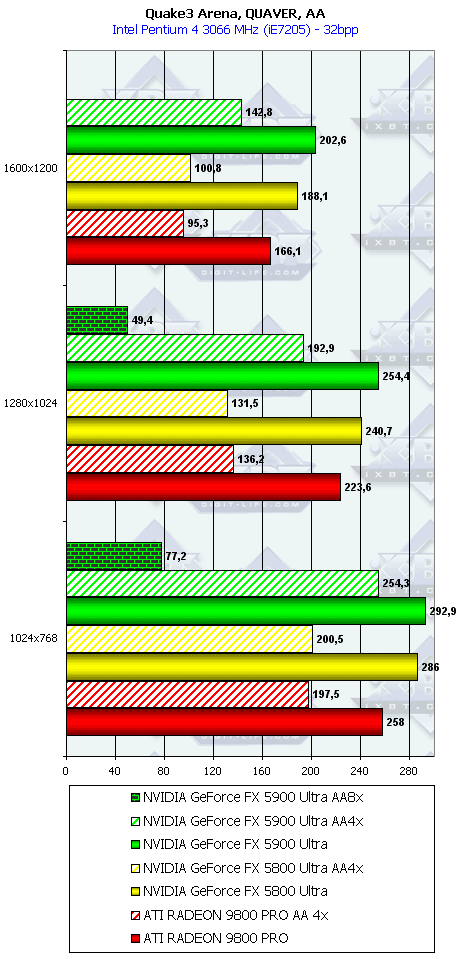
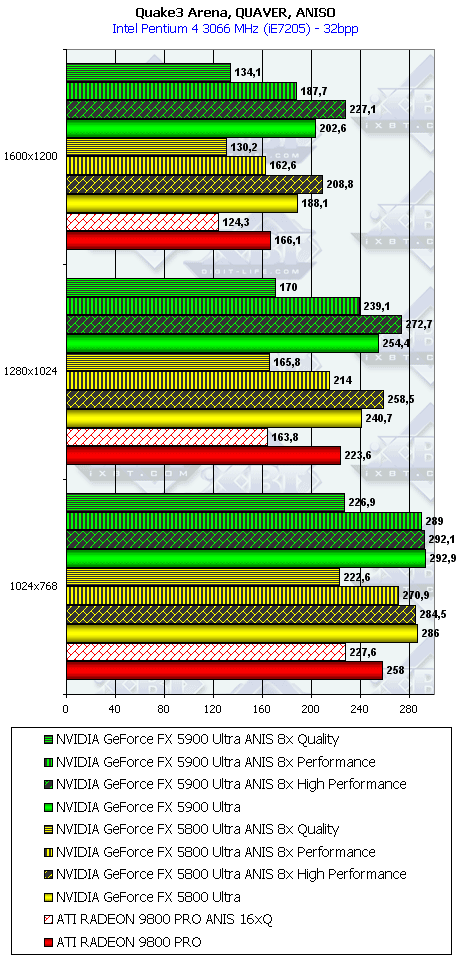
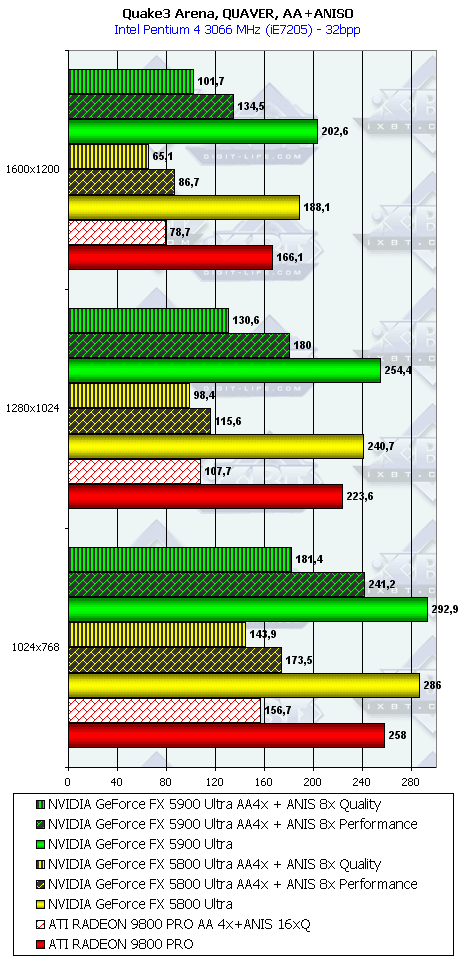
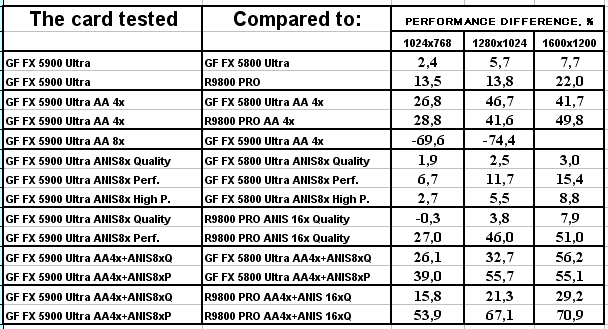
Ну что можно сказать? Почти сбываются обещания NVIDIA обогнать RADEON 9800 PRO в режимах с АА и анизотропией на 50-80%. Так оно и есть! 256-битная шина очень помогает NV35 добиться успеха в АА. Да и анизотропия весьма хороша: посмотрите, частоты ниже, а скорость выше (я про сравнение NV35 и NV30). Снова вспоминаем материал Алексея Николайчука.
Serious Sam: The Second Encounter, Grand Cathedral
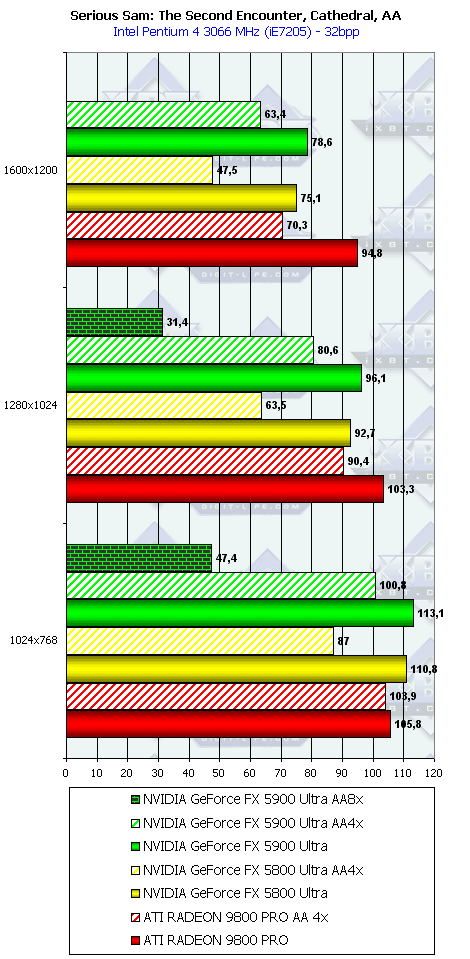
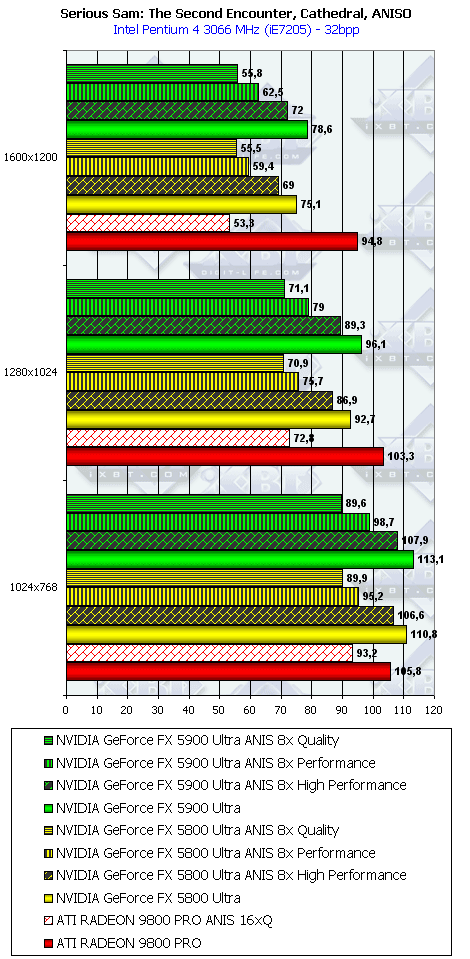
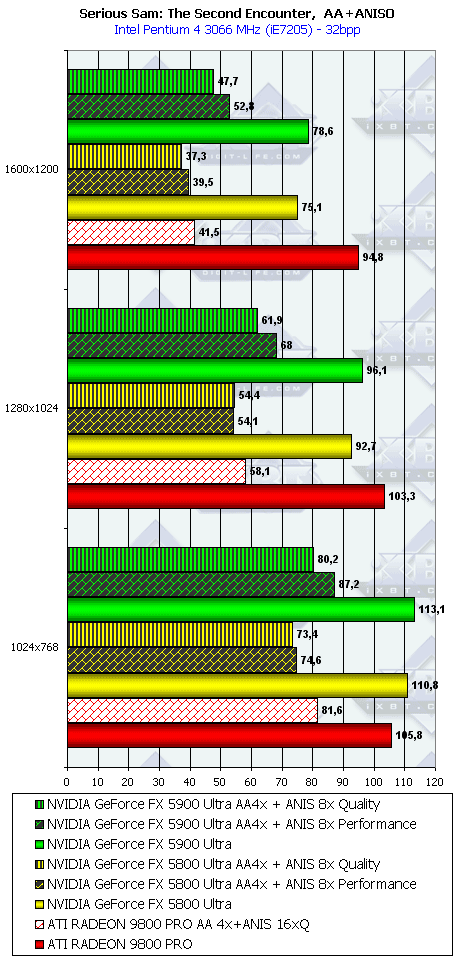
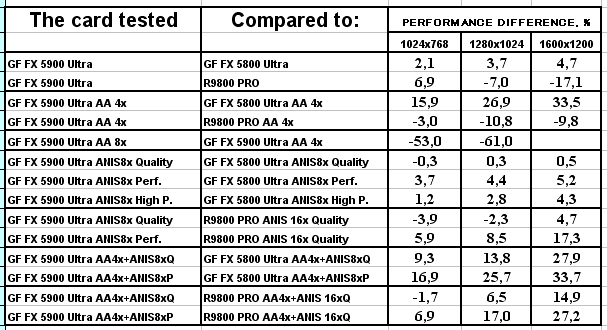
Заточенность драйверов от ATI под этот тест давно известна. Странно только, почему NVIDIA игнорирует весьма популярное детище хорватских разработчиков? Но так или иначе, а мы получаем поражение NV35 от RADEON 9800 PRO в тестах без АА и анизотропии (кроме 1024х768). Впрочем, даже АА не спасает NV35. Только более быстрая анизотропия помогает новому творению NVIDIA.
Return to Castle Wolfenstein (Multiplayer), Checkpoint
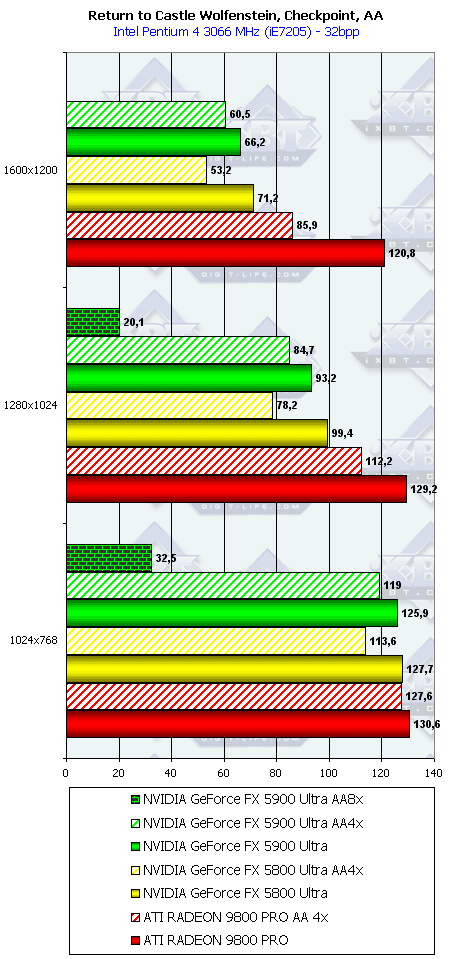

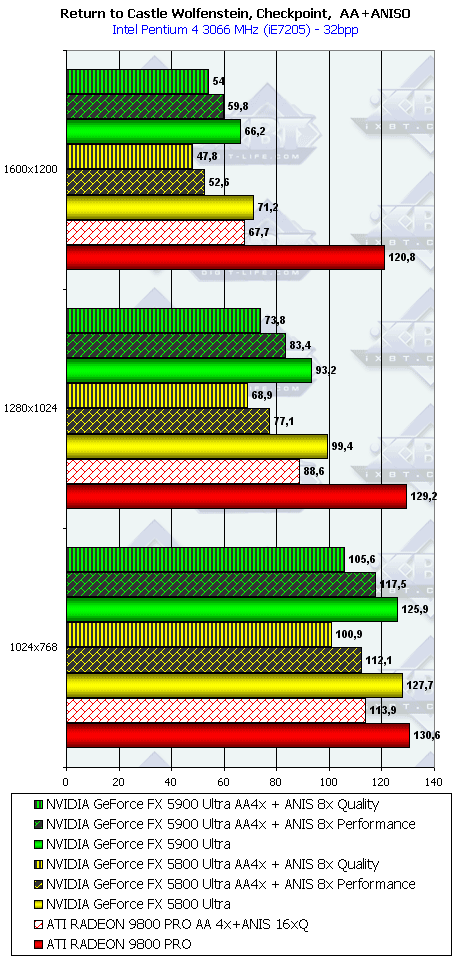
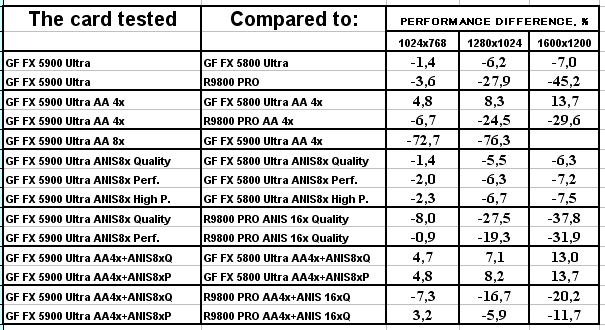
Ну а насчет этого теста вообще трудно что-либо сказать. После драйверов версии 42.82 вдруг случился резкий провал по скорости в данной игре еще у NV30. И до сих пор программисты NVIDIA не предприняли никаких мер по восстановлению справедливости! А ведь NV30 могла в 1600х1200 выдавать более 120 fps! А сейчас около 70! Это не 8-10 fps разница! Очевидно, что как NV30, так и NV35 работают неправильно в этой игре, драйвер неверно формирует архитектуру рендеринга у столь гибко настраиваемого процессора. Странно и то, что данная игра выпущена на базе движка Quake3 при участии непосредственно самой id Software, под продукты которой программисты NVIDIA давно уже оптимизируют драйверы. В общем, пока фиксируем поражение NVIDIA в этом тесте.
Code Creatures


К очень большому сожалению, в этом тесте у NV30/NV35 не работает анизотропная фильтрация, поэтому протестировать эти режимы, а также комплексные с АА и анизотропией, не получилось. Это также прокол программистов NVIDIA, как было и есть в отношении игры Elder Scrolls III: Morrowind, где точно такая же история, но в отношении АА (работает только один режим 4xS!).
Unreal Tournament 2003 DEMO
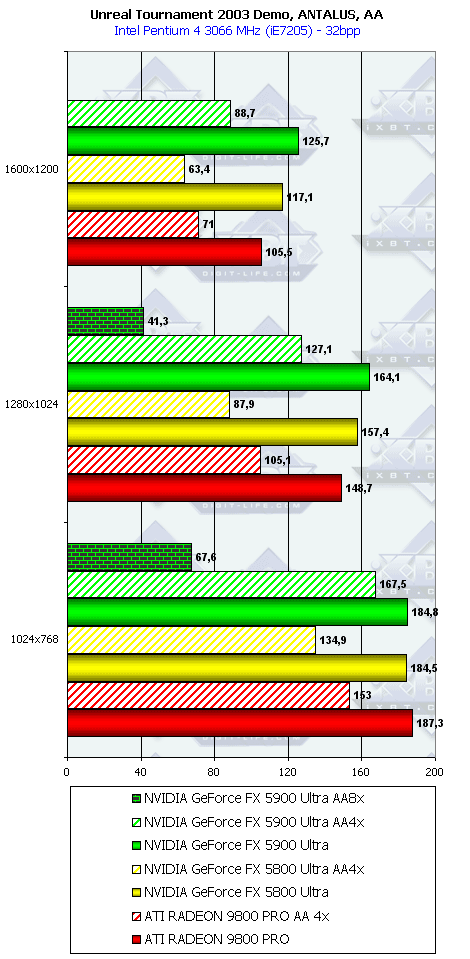

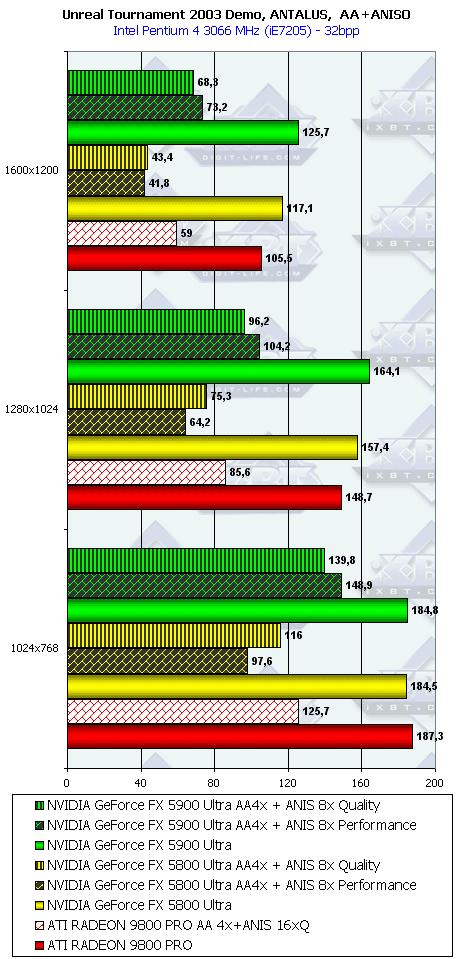
В этом тесте вроде все на своих местах, хоть проценты превосходства NV35 над соперником из стана ATI не столь велики.
AquaMark
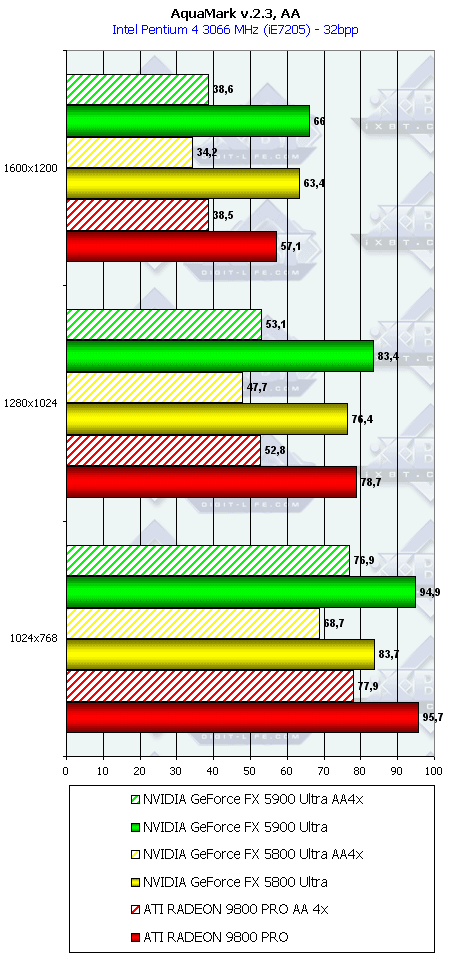
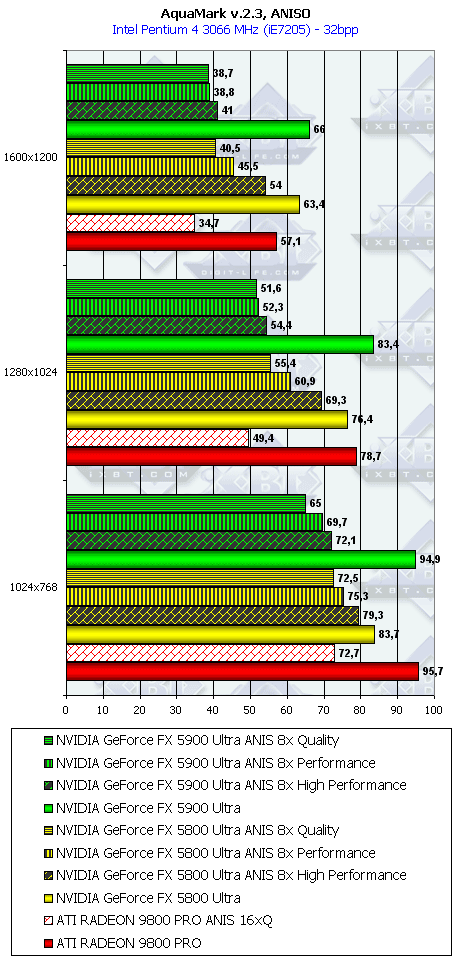
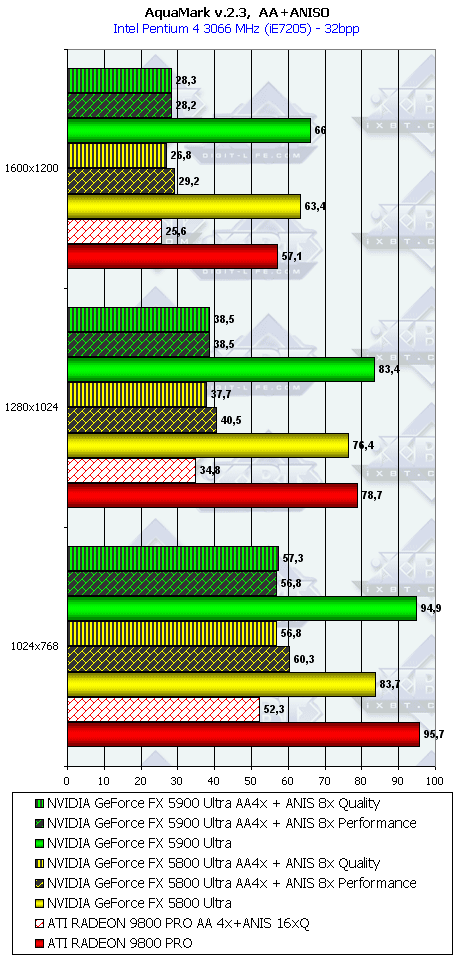
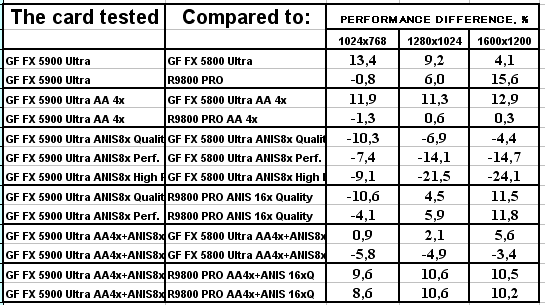
Как ни странно, но в данном тесте случился провал у NV35 с анизотропией даже относительно NV30 (по всей видимости, драйверы не были оптимизированы под данный тест), а превосходство с АА не столь велико, поэтому суммарное преимущество NV35 в комплексном тесте очень мало.
RightMark 3D
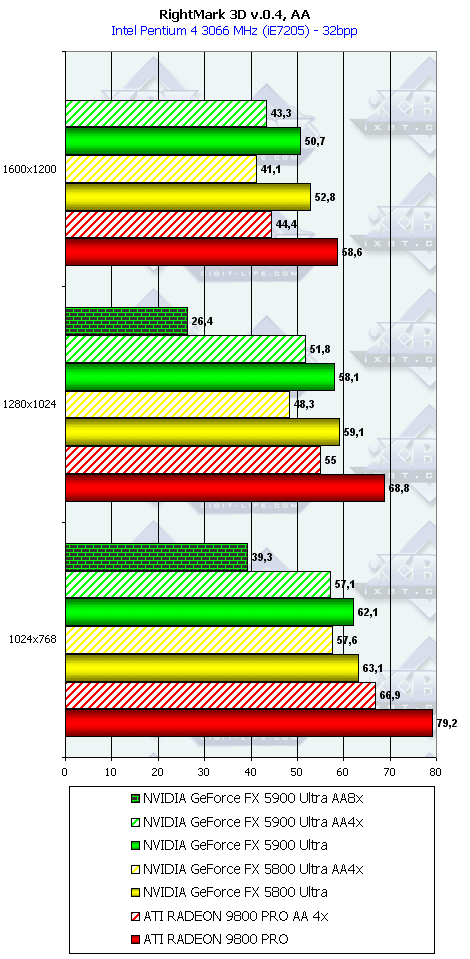
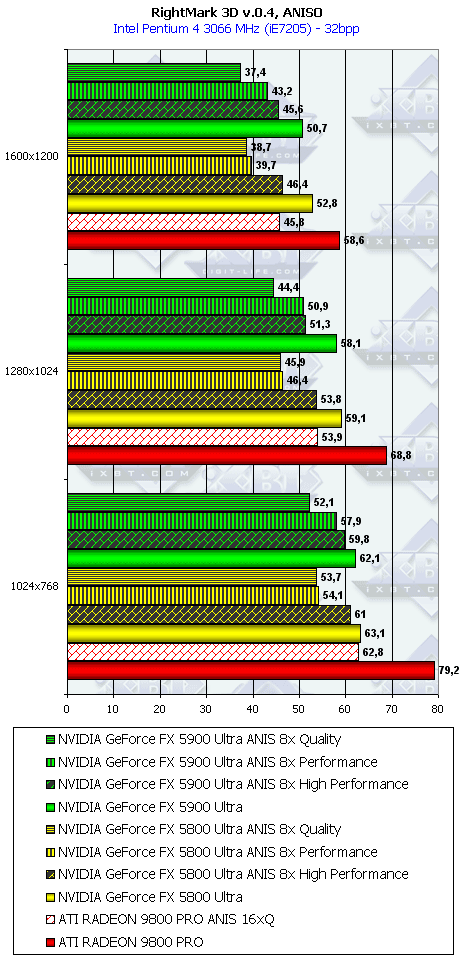
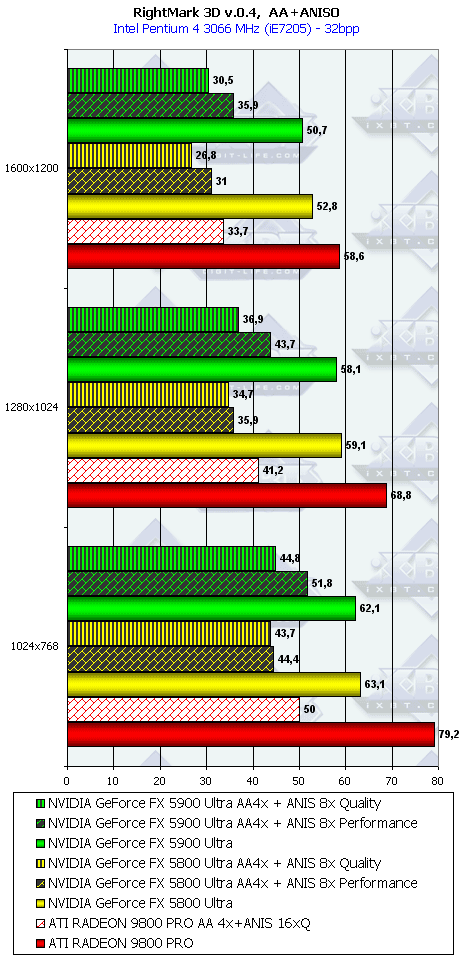
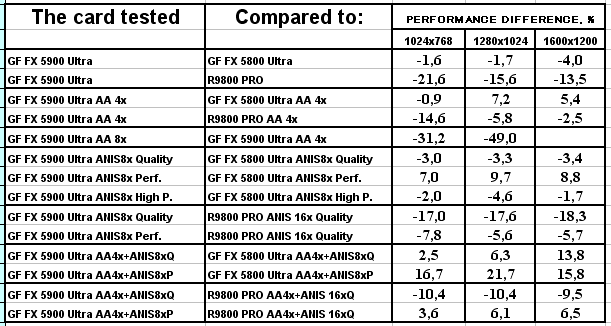
Под этот тест нет оптимизаций драйверов (поскольку самого теста не было ранее в Сети), колоссальную роль играет скорость работы пиксельных шейдеров, и, как мы видим, поражение NV35 налицо от своего же старшего собрата NV30 (частоты работы ядер снова играют главенствующую роль).
DOOM III Alpha
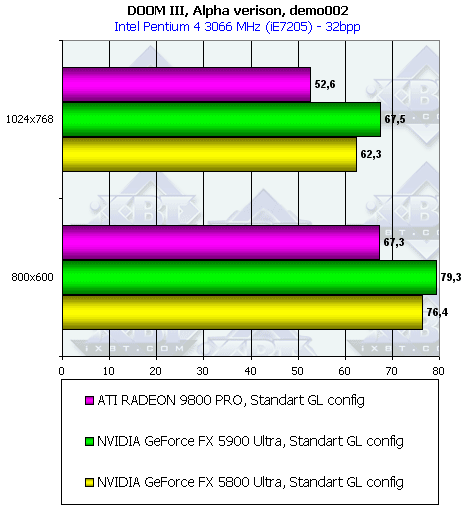
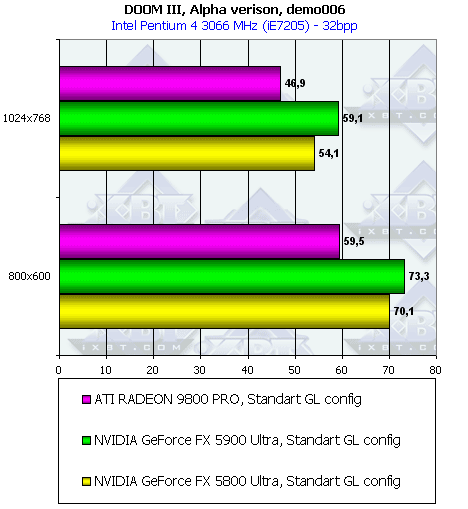
Поскольку этот тест использует все последние новации NV3x, в частности, ускоренную работу с тенями, то и результат налицо. Большой объем прокачек через память затребовал и бОльшую ПСП, поэтому и 256-битная шина прогодилась.
Качество 3D-графики
Поскольку NV35 — по сути то же ядро NV30, но с некоторыми оптимизациями, то с точки зрения поддержки игр они не различаются. Поэтому нет смысла приводить заново скриншоты, демонстрирующие качество анизотропии при том или ином режиме IntelliSample, а также разный уровень АА. В одном из предыдущих наших материалов мы очень подробно рассмотрели различия между АА и анизотропией от NVIDIA и ATI, поэтому советуем прочитать об этом в обзоре GeForce FX 5800 Ultra (теория, практика), а также в материале по GeForce FX 5600/5200 (практическое сравнение анизотропии). Разумеется, имеет смысл и обратиться к обзору RADEON 9800 PRO.
А здесь мы коснемся некоторых отличий, которые имеют место быть со времени выхода новых драйверов 44.03. Прежде всего это новые предустановки по трилинейной фильтрации. Мы помним, что режимы Quality-Performance-High Performance отличаются прежде всего упрощением реализации трилинейки:
| Предустановки | Скриншоты из Quake3 |
|---|---|
| Пример 1 | |
| Bilinear, Quality |  |
| Trilinear, Quality |  |
| Trilinear, Performance |  |
| Trilinear, High Performance |  |
| Пример 2 | |
|---|---|
| Trilinear, Quality | |
| Trilinear, Performance | |
| Trilinear, High Performance | |
| Serious Sam: TSE | |
|---|---|
| Trilinear, Quality |  |
| Trilinear, Performance |  |
| Trilinear, High Performance |  |
Отчетливо видно, что режим Quality — без изъянов, то есть трилинейная фильтрация считается как и положено ( берется по 4 сэмпла на каждом MIP-уровне, производится две операции билинейной фильтрации по каждой четверке, затем с учетом весовых коэффициентов дальности от границы между уровнями производится операция смешения между полученной парой значений), а двух других режимах только малая часть пикселей подвергается обработке трилинейкой, большинство остается лишь с результатами билинейки. Это экономит ресурсы процессора, которые вполне могут быть использованы для расчета анизотропии. Впрочем, это всего лишь предположение о высвобождении вычислительных ресурсов текстурных модулей при упрощении трилинейки, высказанное коллегой из Ф-Центра в его материале по NV30. Режим же High Performance характеризуется еще и принудительным использованием компрессии текстур, о чем можно легко догадаться по второму примеру Quake3, а также на примере Serious Sam: TSE, глядя на небо.
А что же с анизотропией? Там, по сути все тоже самое, что было и ранее у NV30 (в плане качества). Давайте просто посмотрим на скриншоты из 3DMark2001, полученные на разных предустановках IntelliSample (анизотропия везде 8х).
| Game 1 | ||
|---|---|---|
| Quality | Performance | High Performance |
 |  |  |
| Анимированный GIF | ||
 | ||
| Game 2 | ||
| Qualiy | Performance | High Performance |
 |  |  |
| Анимированный GIF | ||
| Различий между режимами нет! | ||
| Game 3 | ||
| Qualiy | Performance | High Performance |
 |  |  |
| Анимированный GIF | ||
| Различий между режимами нет! | ||
| Game 4 | ||
| Qualiy | Performance | High Performance |
 |  |  |
| Анимированный GIF | ||
 | ||
Итак, на деле мы видим, что если сцена разнородна, состоит из массы криволинейных поверхностей, присутствует много пестрых текстур, то различий между режимами IntelliSample практически нет. А если нет, то зачем платить больше, устанавливая исключительно Quality?
Что касается АА, то наряду с тем, что мы ранее видели у NV30, появился новый режим AA8x. По сути, это простое развитие 8xS на OpenGL.
Перед нами гибрид между MSAA и SSAA. Если проанализировать разницу между полученными режимами сглаживания, то скорее всего вначале производится MSAA, а затем уже вся сцена подвергается SSAA. Какой режим у MSAA, и какой режим у SSAA, — это неважно. Важен конечный результат. Обратите внимание, как положительно на четкость текстур действует наличие Super Sampling. И нельзя забывать, что прозрачные текстуры Multi Sampling не обрабатывает, поэтому в ряде сцен, где мелкие объекты формируются при помощи таких текстур, сглаживания у таких объектов при MSAA нет. Это все плюсы, а минусы — сильнейшее падение производительности, о котором мы выше уже говорили.
Выводы
Сегодня мы рассмотрели самый быстрый на сегодня игровой видеоакселератор — NVIDIA GeForce FX 5900 Ultra. Что можно сказать, подводя итоги?
- Если сложить все плюсы и минусы, то, несмотря на то, что в ряде тестов NV35 показал себя с не очень хорошей стороны, проиграв сопернику от ATI, это самая быстрая видеокарта игрового класса на сегодня. Учитывая, что в ближайшее время выйдет еще и новый драйвер Detonator FX, который способен поднять скорость еще на 15-20%, то до выхода NV40/R400 GeForce FX 5900 Ultra прочно займет место на троне короля 3D-графики. Что и ожидалось.
- Изюминкой является то, что NV35 не дополняет существующие линейки от NVIDIA, а ЗАМЕНЯЕТ СОБОЙ неудачную серию NV30. Именно так назвал NV30 даже президент NVIDIA. Поэтому по сути следует забыть о существовании NV30, и считать NV35 исправлением ошибок. Да, именно поэтому даже кодовое имя не соответствует тому, что мы видим, ведь ранее NV*5 — это плановое улучшение предыдущего поколения, несущее в себе не только работу над ошибками, но и приличные приросты по скорости, а также усовершенствования архитектуры. Тянет ли на это NV35? Трудно сказать. С одной стороны, увеличение шины памяти до 256 бит само по себе является значительным усовершенствованием, но с другой стороны, само ядро мало изменилось.
- Но так или иначе, а именно эта карта в ближайшее время станет оплотом для массового выпуска карт (если можно о таковом говорить в секторе High-End), производители, изголодавшиеся за более, чем год ожидания, ждут не дождутся отмашки со стороны NVIDIA.
- Еще раз можно посочувствовать тем, кто уже потратил огромные деньги на приобретение NV30, однако, и та карта дает прекрасную скорость, и долго послужит. Минус — сильный шум системы охлаждения у Nv30, чего нет у NV35. Кстати, этот фактор надо отдельно отметить и поблагодарить NVIDIA за сохранность нервов пользователей новых видеокарт.



