(А.Пугачева)

Как обычно, предваряя большой базовый материал анализа работы нового акселератора, мы настоятельно рекомендуем прочитать аналитическую статью, посвященную архитектуре и спецификациям NVIDIA GeForce FX (NV30)
СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты NVIDIA GeForce FX 5800 Ultra 128MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Синтетические тесты RightMark3D: идеология и описание тестов
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark2001 SE
- Дополнительная теоретическая информация и выводы из результатов синтетических тестов
- Информация по анизотропной фильтрации и по анти-алиасингу
- Архитектурные особенности и перспективы
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game1
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game2
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game3
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game4
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003 DEMO
- Результаты тестов: AquaMark
- Результаты тестов: RightMark 3D
- Результаты тестов: DOOM III Alpha version
- Качество 3D: Анизотропная фильтрация
- Качество 3D: Анти-алиасинг
- Качество 3D в целом
- Выводы
Общие сведения
Мы стоим в предверии весны 2003 года. Практически ровно год назад вышел в свет NVIDIA NV25, ставший впоследствии родоначальником целой линейки GeForce4 Ti. Давайте вспомним последние 2 года. Зимой 2001 года выходит NV20 (GeForce3), родоначальник многих уже ставших привычными технологий. Казалось бы, пройдут обещанные NVIDIA полгода, и осенью 2001 должен выйти новый продукт — NV25. Однако вмешалась жизнь (ATI Technologies со своим R200), и осенью появляются лишь братья Ti 200/500 из семейства Titanium, как стали называть линейку GeForce3. То есть, не продукты на основе нового чипа, а лишь обновленные версии карт на базе того же NV20, выход которых продиктован чисто маркетинговыми интересами. Вследствие чего случился первый сбой полугодового цикла у NVIDIA, и NV25 вышел лишь год назад. GeForce4 Ti - это своего рода доводка до ума NV20: усиление мощности 3D-ускорителя засчет более высоких частот, установка уже 128-ми мегабайт памяти (и попытка ввести этот объем в разряд стандартов) и многие другие вещи. Казалось бы, еще полгода — и появится таинственный NV30, о котором вообще ничего не было слышно, что только подогревало интерес. Даже если абстрагироваться от предыдущей задержки с выходом NV25 (потому как в противном случае NV30 обязан выйти весной 2002 года), самые оптимистичные прогнозы указывали на сроки не ранее августа 2002 года.

Казалось, что мы стоим на пороге нового витка борьбы ATI и NVIDIA. Предыдущее сражение канадская компания полностью проиграла, ибо RADEON 8500 получился весьма дорогим и мог составить конкуренцию разве что GeForce3, но никак не GeForce4 Ti. Впрочем, как выяснилось позже, у NV25 очень "хромала" по производительности анизотропная фильтрация, поэтому при активизации этой функции продукт от ATI мог с ней соперничать, правда, в свою очередь, имея при этом кучу нареканий на качество анизотропии.
Итак, летом 2002 года под звуки фанфар появляется флагман 3D-ускорителей от ATI — RADEON 9700 PRO. Разумеется, все предыдущие решения просто меркнут перед ним, и ATI завоевывает трон лидера в 3D игрового класса. Где же NV30? Все летние, а затем и осенние месяцы у NVIDIA ушли на сражения с непокорным 0.13 мкм техпроцессом, ибо руководство компании хотело хотело выпустить чип с 125 млн. транзисторов сразу по новому техпроцессу. Очень вероятно, что продукт много раз переделывался, урезался, дабы получить приемлемый процент выхода годных кристаллов. В ноябре прозвучал наконец-то анонс, мы даже смогли воочию пощупать новые карты, однако они были еще весьма сырыми. Я говорю не только про сами платы или чипы, но и про драйверы.
Таким образом, NVIDIA практически пропустила еще один полугодовой цикл. Повторный выпуск NV25 с поддержкой AGP 8x в виде NV28 — не в счет, это просто маркетинговый шаг, да и поддержка AGP8x для NV28 практически ничего не дает: 128-ми мегабайт локальной памяти пока хватает с лихвой для всех современных игр. И мы видим, что с момента выхода NV20 до появления NV25 прошел год, и от NV25 до фактического выхода в свет NV30 — тоже год. Что касается ATI, то компания придерживается 9-месячного цикла, и поэтому весной (вот-вот) должны выйти в свет ее новые продукты R350 и RV350.
Кто будет конкурировать с ними? NV30? По всем раскладам — именно она. Ведь в сумме NV30 стал самым мощным на сегодня ускорителем (подробности смотрите ниже), но! В продаже этих карт почти не будет. Из-за сильного отставания от графика и желания как можно быстрее сосредоточить внимание своих партнеров на улучшенном варианте NV30, NV35, NVIDIA сильно ограничила выпуск кристаллов NV30. Их было выпущено всего около 100 000 штук. Учитывая высочайшую себестоимость NV30, а также стратегию NVIDIA, состоящую в том, что вначале выпускается чип для профессиональной графики (NV??GL), а затем уже на его базе создается игровой (NV??), логичным стало решение NVIDIA чуть ли не более половины всех чипов NV30 пустить на выпуск Quadro FX. Благо, цены на профускорители традиционно высоки, и есть возможность частично оправдать колоссальные затраты на выпуск NV30. Как известно, часть новых карт всегда поступает к ОЕМ-сборщикам, поэтому на Retail-рынок попадет очень и очень мало карт GeForce FX 5800 Ultra (даже есть слухи, что таких карт в открытой продаже вообще не будет, а только по ранее размещенным заказам). Скорее всего, оставшаяся часть GPU пойдет на выпуск плат GeForce FX 5800. Кстати, надо напомнить, что на базе чипа NV30 строится целая линейка карт:
- GeForce FX 5800 Ultra — 500 МГц чип, 128 Мбайт 500 МГц (DDR II 1000) 128 бит локальной памяти;
- GeForce FX 5800 — 400 МГц чип, 128 Мбайт 400 МГц (DDR II 800) 128 бит локальной памяти.

Конечно, впереди еще выход в свет более дешевых (ну и менее скоростных, разумеется) вариаций, NV31 и NV34. По обещаниям компании, это будут просто урезанные решения на базе NV30, а следовательно, затраты на разработку NV3X-технологий в целом, должны покрыться и продажами таких карт. Но мы к этому вопросу вернемся позже, в свое время. А сейчас обратимся непосредственно к NV30.
Напомним характеристики:
- Технологическая норма 0.13 микрон, медные соединения
- 125 миллионов транзисторов
- 3 геометрических процессора (превышают спецификации DX9 VS 2.0)
- 4 пиксельных процессора (значительно превышают спецификации DX9 PS 2.0), каждый снабжен двумя конвейеризированными фильтрующими текстуры блоки, двумя целочисленными и одним плавающим ALU.
- системный интерфейс AGP 3.0 (8х)
- 128-битный (!) интерфейс локальной памяти DDR2
- Эффективный четырехканальный контроллер памяти с коммутатором
- Развитые техники экономии пропускной полосы локальной памяти: полное сжатие буфера кадра, включая информацию о цвете (впервые, коэффициент сжатия до 4:1, только в режимах MSAA), и глубине (сжатие Z буфера)
- Тайловые оптимизации: кэширования, сжатия и раннего отсечения невидимых поверхностей (Early HSR, Early z Cull)
- Поддержка точных целочисленных форматов (10/16 бит на компоненту) и точных плавающих форматов (16 и 32 бита на компоненту) для буфера кадра и текстур.
- Сквозная точность всех операций 32-бит плавающей арифметики (поддержка т.н. 128 бит глубины цвета)
- Новый алгоритм оптимизированной анизотропной фильтрации, будучи активирован пользователем, снижает падение производительности (читай величины fps) без особенного падения качества
- Качество анизотропии вплоть до 8х от обычной билинейной фильтрации, т.е. до 32 дискретных отсчетов на одну выборку из текстуры
- Новые гибридные режимы АА 8х и 6xS
- Сжатие буфера кадра позволяет существенно снизить падение производительности при активации FSАА
- Два встроенных RAMDAC 400 МГц
- Встроенный интерфейс для внешнего TV-Out чипа
- Встроенные в чип три TMDS-канала для внешних интерфейсных DVI-чипов
- Потребляемый чипом GeForce FX, сделанным по технологии 0.13 мкм, ток сравним с требованиями, заложенными в спецификацию AGP 3.0. Таким образом, потенциально возможно создание карт на базе GeForce FX без использования внешнего питания.


А теперь приведем блок-схему GeForce FX:
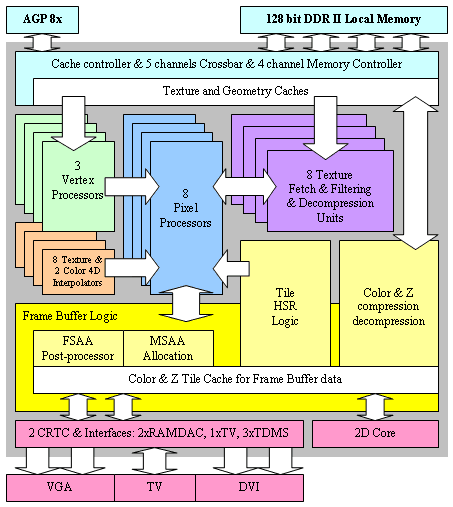
И поясним назначение блоков:
- Cache controller, Memory controller, Crossbar блок, отвечающий за обмен и кэширование данных, поступающих из локальной памяти GPU и системной шины AGP.
- Vertex Processors геометрические (вершинные) процессоры, исполняют вершинные шейдеры и эмулируют фиксированный T&L. Осуществляют геометрические преобразования и подготовку параметров для закраски и пиксельных процессоров.
- Pixel Processors пиксельные процессоры, исполняют пиксельные шейдеры и эмулируют пиксельные стадии. Осуществляют закраску пикселей и формируют запросы к блокам выборки текстур.
- Texture Fetch & Filtering & Decompression Units блоки выборки, распаковки и фильтрации текстур. Осуществляют выборку конкретных значений конкретных текстур по запросам из пиксельных процессоров.
- Texture & Color Interpolators интерполяторы текстурных координат и значений цвета, рассчитываемых, как выходные параметры в вершинном процессоре. Эти блоки вычисляют для каждого пиксельного процессора его уникальные значения входных параметров исходя из положения закрашиваемой им точки.
- Frame Buffer Logic блок, отвечающий за работу с буфером кадра, включая сжатие буфера кадра (Frame Buffer Compression & Decompression), кэширование, раннее отсечение невидимых блоков и точек (Tile HSR Logic так называемый Early Cull HSR), а также размещение сэмплов при полноэкранном сглаживании (MSAA Allocation) и их постобработку итоговую фильтрацию в FSAA-режимах (FSAA post-processor)
- Ядро двухмерной графики (2D Core)
- Два контроллера дисплея, два RAMDAC и богатый набор интерфейсов включая три встроенных DVI и один встроенный TV-Out
Полагаем, что более подробно с особенностями чипа NV30 читатель сможет ознакомиться в нашем аналитическом материале.

В заключение раздела приведем список доступных на данный момент OpenGL расширений и версию OpenGL ICD:
- Vendor: NVIDIA Corporation
- Renderer: GeForce FX 5800 Ultra/AGP/SSE2
- Version: 1.4.0
- Extensions:
- GL_ARB_depth_texture
- GL_ARB_fragment_program
- GL_ARB_imaging
- GL_ARB_multisample
- GL_ARB_multitexture
- GL_ARB_point_parameters
- GL_ARB_shadow
- GL_ARB_texture_border_clamp
- GL_ARB_texture_compression
- GL_ARB_texture_cube_map
- GL_ARB_texture_env_add
- GL_ARB_texture_env_combine
- GL_ARB_texture_env_dot3
- GL_ARB_texture_mirrored_repeat
- GL_ARB_transpose_matrix
- GL_ARB_vertex_program
- GL_ARB_window_pos
- GL_S3_s3tc
- GL_EXT_abgr
- GL_EXT_bgra
- GL_EXT_blend_color
- GL_EXT_blend_func_separate
- GL_EXT_blend_minmax
- GL_EXT_blend_subtract
- GL_EXT_compiled_vertex_array
- GL_EXT_draw_range_elements
- GL_EXT_fog_coord
- GL_EXT_multi_draw_arrays
- GL_EXT_packed_pixels
- GL_EXT_point_parameters
- GL_EXT_rescale_normal
- GL_EXT_secondary_color
- GL_EXT_separate_specular_color
- GL_EXT_shadow_funcs
- GL_EXT_stencil_two_side
- GL_EXT_stencil_wrap
- GL_EXT_texture3D
- GL_EXT_texture_compression_s3tc
- GL_EXT_texture_cube_map
- GL_EXT_texture_edge_clamp
- GL_EXT_texture_env_add
- GL_EXT_texture_env_combine
- GL_EXT_texture_env_dot3
- GL_EXT_texture_filter_anisotropic
- GL_EXT_texture_lod
- GL_EXT_texture_lod_bias
- GL_EXT_texture_object
- GL_EXT_vertex_array
- GL_HP_occlusion_test
- GL_IBM_texture_mirrored_repeat
- GL_KTX_buffer_region
- GL_NV_blend_square
- GL_NV_copy_depth_to_color
- GL_NV_depth_clamp
- GL_NV_fence
- GL_NV_float_buffer
- GL_NV_fog_distance
- GL_NV_fragment_program
- GL_NV_half_float
- GL_NV_light_max_exponent
- GL_NV_multisample_filter_hint
- GL_NV_occlusion_query
- GL_NV_packed_depth_stencil
- GL_NV_pixel_data_range
- GL_NV_point_sprite
- GL_NV_primitive_restart
- GL_NV_register_combiners
- GL_NV_register_combiners2
- GL_NV_texgen_reflection
- GL_NV_texture_compression_vtc
- GL_NV_texture_env_combine4
- GL_NV_texture_expand_normal
- GL_NV_texture_rectangle
- GL_NV_texture_shader
- GL_NV_texture_shader2
- GL_NV_texture_shader3
- GL_NV_vertex_array_range
- GL_NV_vertex_array_range2
- GL_NV_vertex_program
- GL_NV_vertex_program1_1
- GL_NV_vertex_program2
- GL_NVX_ycrcb
- GL_SGIS_generate_mipmap
- GL_SGIS_texture_lod
- GL_SGIX_depth_texture
- GL_SGIX_shadow
- GL_WIN_swap_hint
- WGL_EXT_swap_control
Плата
Карта снабжена интерфейсом
| На карте установлены микросхемы памяти Samsung марки K4N26323AE-GC1K, форм-фактора BGA. Максимальная частота работы — 550 (1100) МГц, поэтому можно сделать вывод, что время выборки 1.8 нс. По умолчанию память работает в 3D на частоте 500 (1000) МГц, в 2D — 300 (600) МГц. |  |
Как мы видим, используется практически самая быстрая на сегодня память, что есть в массовом (или предмассовом) производстве.
| NVIDIA GeForce FX 5800 Ultra 128MB | |
|---|---|
 |  |
 |  |
Перед нами уникальный продукт в части конструкции. Разумеется, прежде всего бросается в глаза охлаждающее устройство громадного размера. Мы о нем поговорим чуть позже, а сейчас я замечу, что в силу крайне сложной системы крепления, а также жесткого приклеивания радиатора к поверхности чипа, я не стал снимать с карты такой кулер, а без радиатора на снимке выше представлена карта, имевшаяся в нашей лаборатории ранее. Хотя между ними и есть различия в некоторых элементах PCB, в целом их можно считать одинаковыми.
Приведу пример, когда снятие кулера привело к отрыванию крышки чипа (снимок любезно предоставил Yinchu Chan AKA Cho:

Кстати, можно оценить и размер кристалла. И раз уж мы заговорили о чипе, то скажем, что, в отличие от ATI R300, кристалл покрыт цельнометаллической крышкой, защищающей его от сколов и играющей роль дополнительного радиатора. А упаковка кристалла такая же — FCPGA.

Как и следовало ожидать, перед нами NV30GL. Почему следовало? Выше мы уже говорили о новой стратегии NVIDIA, когда вначале выпускаются чипы со всеми возможностями как для нужд профессиональной, так и для игровой графики. А затем уже идет разделение продуктов с возможными блокировками ряда профессиональных возможностей для игровых решений.
Сама PCB очень сложна. Несмотря на поддержку только 128-битной шигы обмена с памятью, плата выполняется по 12-слойному дизайну, из которых 2 слоя — это экранирование PCB:

Это сделано для защиты суперскоростной памяти от наводок. Вообще, по некоторым сведениям, GDDR-II память весьма капризна в этом плане. Кстати, обратите внимание на то, с какой тщательностью выполнено охлаждение именно памяти. Мало того, что используется радиатор из медного сплава, там еще есть особая термопрокладка, обеспечивающая 100-процентную теплопередачу.

А раз уж мы заговорили об охлаждении, то рассмотрим эту внушительную штуковину — кулер FlowFX.
| Как мы видим, сооружение состоит из медной площадки и посаженного на нее турбинного кулера, вентилятор которого гонит воздух через трубчатый радиатор. К этому радиатору от медной площадки идут припаянные трубки с легкокипящей жидкостью внутри, через которую, собственно, и происходит теплопередача. Как мы видим, массивность охлаждающего устройства потребовала увеличения размеров видеокарты вширь, поэтому первый PCI-слот после AGP не может использоваться. На первом "этаже" карты размещены разъемы d-Sub, DVI и S-Video, на втором — отверстия для захвата холодного и выхлопа горячего воздуха. Кулер жестко посажен на многочисленные крепления: два основных на болтах и 4 клипсы по краям медной пластины около микросхем памяти. Для основного крепежа на обороте имеется пружинящая скоба. Там же и медная пластина для охлаждения микросхем памяти на обороте карты. Должен сказать, что подобное охлаждение установлено не без оснований, поскольку чипсет и микросхемы памяти обладают очень высоким тепловыделением. Впрочем, такая турбина вовсе не обязательна, опыт работы с картой, где установлен почти обычный кулер, имеется. И нареканий на стабильность нет. Разве что память обязательно нуждается в охлаждении, хотя бы пассивном. Разумеется, вся эта система очень сильно шумит (как и любое турбинное устройство). Видимо в целях уменьшения рева кулера разработчики придумали понижать частоты работы вентилятора, а заодно и частоты функционирования карты при работе в 2D. Ниже мы расскажем об этом, когда будем рассматривать работу драйверов. Регулировка работы вентилятора осуществляется, по-видимому, изменением напряжения, поскольку, как показано на снимках, у него нет тахометра. Возможно, что под радиатором есть некий логический элемент, следящий за работой чипа, либо в сам чип вмонтирована такая возможность. Последнее более вероятно, поскольку NV30 обладает аппаратным мониторингом в части слежения за температурой. Как тестер, проведший не одни сутки за работой с этой картой, скажу, что шум FlowFX весьма и весьма достает. Именно постоянными повышением и снижением шума при переходе из 2D в 3D и обратно. Когда тест, например, запускается в пакетном режиме, то очень неприятно слушать, как постоянно меняются обороты охлаждающей системы. |  |
 | |
 | |
 | |
 | |
 | |
 | |
 | |
 |


В конце рассмотрения особенностей видеокарты стоит заметить, что она имеет почти такую же длину, как и GeForce4 Ti 4600. Ну и, конечно, нельзя не увидеть, что плата требует внешнее питание, для чего справа вверху на PCB есть специальное гнездо (такое же, какое мы могли ранее видеть у 3dfx Voodoo5 5500, кстати, опять же любопытная аналогия: "FX" — в честь 3dfx, разъем внешнего питания такой же, как у Voodoo5, карта длинная (немного не хватает до длины Voodoo5 5500), ну и номер 5800 — недалеко от 5500 ушел :-) ).
Мы еще раз хотим напомнить, что, возможно, такие карты не появятся в розничной продаже, может быть, и система охлаждения фирмами-производителями будет изменена.
И последнее: в силу огромного объема данного материала мы не будем сейчас рассматривать работу TV-out у данной видеокарты. В ближайшем обзоре подобного продукта (вероятно, серийной карты на базе GeForce FX 5800) мы вернемся к этому вопросу. Замечу лишь, что у нашего экземпляра нет кодека TV-out, хотя имеется посадочное место под него. Драйвера сообщают о том, что TV-кодек интегрирован в чип. Проверим.
Разгон
К сожалению, с разгоном есть большие сложности. А может быть, и не к сожалению, ведь такую дорогую карту можно спалить неосторожным поднятием частот. Встроенный мониторинг сам регулирует частоты, и поэтому при поднятии частот мы наблюдаем либо торможение работы карты (аналогичное термальной защите современных процессоров Intel), либо сбрасывание частот драйвером карты на прежние значения, видимо, на основании информации с термальных дачтиков. Мы еще будем исследовать вопрос возможности разгона.
Установка и драйверы
Рассмотрим конфигурацию тестового стенда, на котором проводились испытания карт:
- Компьютер на базе Pentium 4 (Socket 478):
- процессор Intel Pentium 4 3066 (HT=ON);
- системная плата ASUS P4G8X (iE7205);
- оперативная память 1024 MB DDR SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1.
На стенде использовались мониторы
При тестировании применялись драйверы от NVIDIA версии 42.68, VSync отключен, компрессия текстур отключена в приложениях. Установлен DirectX 9.0.
Для сравнительного анализа приведены результаты уже знакомых читателям видеокарт:
- Gainward Powerpack Ultra/750 (GeForce Ti 4600, 300/325 (650) МГц, 128 МБ);
- Hercules 3D Prophet 9700 PRO (RADEON 9700 PRO, 325/310 (620) МГц, 128 МБ, driver 6.292).
Настройки драйверов
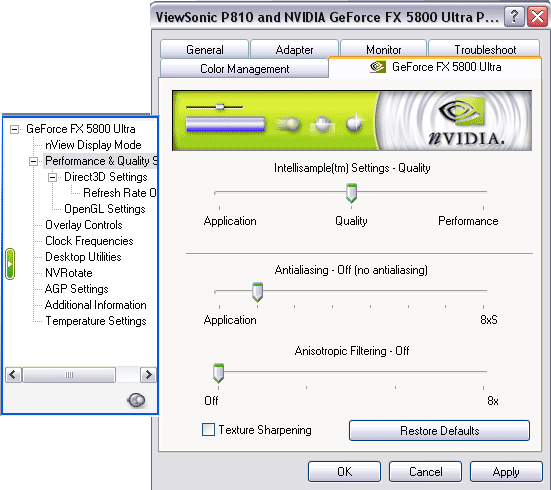
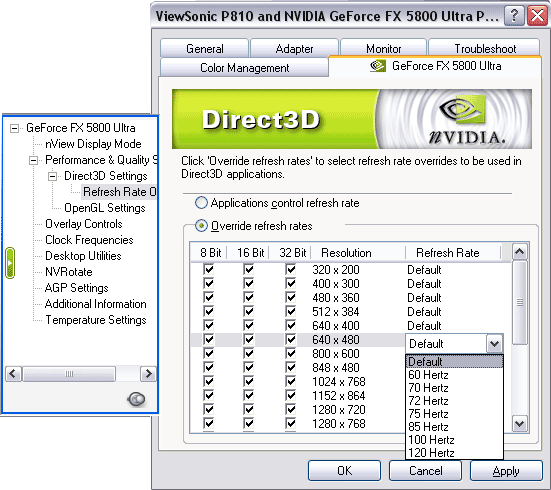
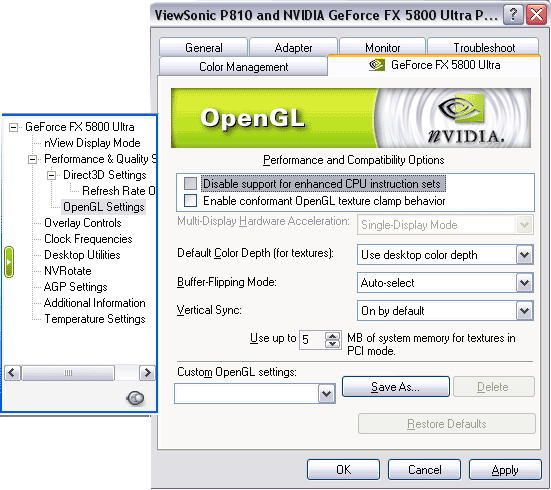
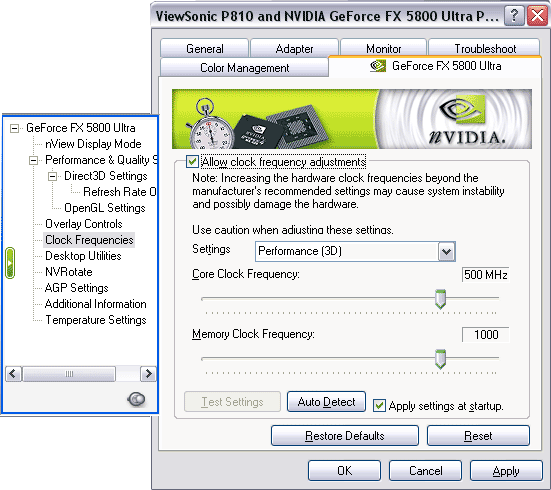
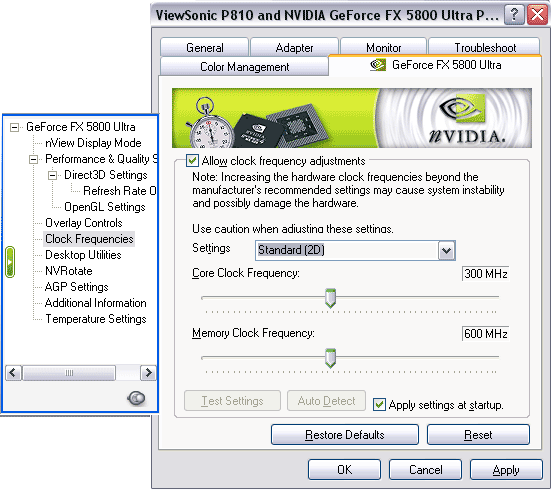
Настройки работы АА и анизотропии вынесены на одну закладку и работают одновременно и в OpenGL, и в Direct3D. Среди новшеств видим режимы АА — 6xS и 8xS. Позже мы рассмотрим их более подробно.
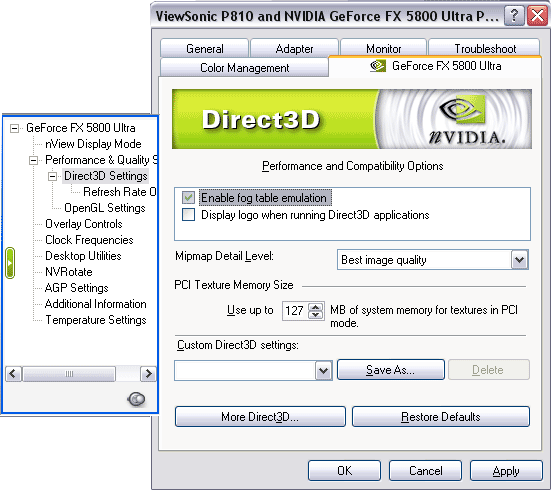
Настройки Direct3D и OpenGL стандартны и уже привычны многим пользователям видеокарт на базе процессоров от NVIDIA. Обратим внимание на то, что в разделе D3D есть возможность принудительно форсировать частоту смены кадров в том или ином разрешении.
Теперь самый интересный раздел — тактовые частоты. Получить доступ к этой закладке (а также к некоторым другим) можно, запустив патч к registry Windows XP. Так вот, мы видим, что частоты работы карты разделены на 2D и 3D. По умолчанию в 2D плата работает на частотах 300/300 (600) МГц, а в 3D, как и ожидалось, 500/500 (1000) МГц. Интересно отметить, что принудительный подъем частоты работы в 2D до 500/500 (1000) не вызывает увеличения оборотов кулера. Впрочем, после перезагрузки режим работы в 2D (300/300 (600)) восстанавливается, невзирая на установленную галочку использования заданных частот при перезагрузке Windows.
Далее идет выбор режима работы AGP и последняя интересная закладка — это аппаратный мониторинг температурного режима работы карты. Интересно, что в некоторых версиях драйверов можно увидеть не только температуру самого чипа, но и температуру карты. Вероятно, программисты еще работают над окончательным видом этой страницы.
На этом рассмотрение особенностей драйверов мы заканчиваем.
Результаты тестов
- Основой для оценки карт у нас являются РЕАЛЬНЫЕ приложения, т.е. игры. Мы постоянно их используем и корректируем список в соответствии с реалиями времени, добиваясь большей репрезентативности API и жанров;
- Мы интенсивно используем синтетические тесты (RightMark3D Synthetic и части 3DMark2001) но следует четко понимать, что делается это не для общей оценки карты, а для глубокого анализа функционирования GPU и его отдельных блоков, для своеобразной "разведки" особенностей его поведения, а также для корректного комментирования результатов, полученных на реальных играх и приложениях.
- Мы используем бенчмарки типа 3DMark, назовем их one-number-bench, дающие в результате некое финальное кол-во "попугаев" НЕ для оценки карт, а для того, чтобы удовлетворить потребности наших читателей, многие из которых хотят для удобства видеть и простое, наглядное число "попугаев", полученых той или иной картой.
2D-графика
Традиционно начнем с 2D. Удивительно, но факт: качество отменное! в 1600х1200 при 85Гц комфорт и уют. В 1280х1024 при 120Гц просто все великолепно!
Еще в письмах к декабристам император Николай I говорил, что оценка 2D-качества есть вещь субъективная (но декабристы считали, видимо, иначе. Тогда за несогласие — Петропавловская крепость, теперь — возмущения в форуме насчет "почему же нет ОБЪЕКТИВНЫХ тестов 2D"). Поэтому напомню, что качество зависит от конкретного экземпляра, да и связка карта-монитор может по-прежнему играть огромную роль. Прежде всего, надо обращать внимание на качество монитора и кабеля. Я напомню, что тестирование 2D у нас происходит на мониторе ViewSonic P817-E совместно с BNC-кабелем Bargo.
Синтетические тесты RightMark 3D (DirectX 9)
В этой статье мы представим вам подробные описания и первые результаты тестирования, полученные с помощью разрабатываемого нами набора конфигурируемых синтетических тестов для API DX9.
Набор синтетических тестов из разрабатываемого нами тестового пакета RightMark 3D включает в себя (на данный момент) следующие тесты:
- Тест на закраску и фильтрацию текстур (Pixel Filling Test);
- Тест на производительность обработки геометрии (Geometry Processing Speed Test);
- Тест на производительность работы с отсечением невидимых точек и примитивов (Hidden Surface Removal Test);
- Тест на производительность сложных пиксельных шейдеров (Pixel Shader Test);
- Тест на производительность отрисовки, освещения и анимации спрайтов (Point Sprites Test).
В этой статье мы представим всесторонне исследуем полученные с их помощью на ускорителях ATI и NVIDIA данные. Мы собираемся широко использовать эти тесты в дальнейшем для тестирования различных DX9-ускорителей, а также планируем сделать доступными для свободного скачивания нашими читателями и всеми энтузиастами компьютерной графики. Но для начала, небольшое отступление, связанное с идеологическими вопросами тестирования:
Идеология синтетических тестов
Основная идея, стоящая за всеми нашими тестами острая фокусировка на производительности той или иной конкретной подсистемы чипа. В отличие от реальных приложений, измеряющих эффективность работы ускорителя в том или ином практическом применении что называется «в комплексе», синтетические тесты пытаются вычленить отдельные аспекты производительности. Зачем, спросите вы? Дело в том, что между выходом новых ускорителей и приложений, эффективно и всесторонне использующих их возможности, зачастую проходит год или даже более. При этом, многие энтузиасты, желающие находиться на переднем краю технологий, вынуждены принимать решение о покупке того или иного ускорителя практически вслепую основываясь на результатах тестирования заведомо устаревшего программного обеспечения. Никто не может гарантировать им, что в будущем, в момент выхода столь ожидаемых ими игр, ситуация не поменяется кардинально. Кроме энтузиастов, которые добровольно идут на риск весьма дорогой лотереи по покупке только что появившихся продуктов, в непростую ситуацию попадает еще несколько категорий людей:
- Первая категория покупающие себе компьютер, что называется «по максимуму» на длительное время и не желающие связываться с постоянными обновлениями железа. Для этих людей важно сделать правильный выбор, максимально увеличив срок пригодности их компьютера для приложений и применений, которые еще только будут появляться в будущем.
- Вторая категория разработчики программного обеспечения, с первой минуты появления новых ускорителей вынужденные обращать пристальное внимание на их возможности и балансировку, дабы на основе этих данных грамотно спроектировать и сбалансировать не только движок (код), но и контент (уровни, модели) с учетом эффективного использования техники, которая получит распространение к моменту появления создаваемых ими приложений в продаже. Синтетические тесты помогут им сделать выводы, выбрав те или иные пути для реализации своих замыслов и, что ничуть не менее важно, разумно ограничив простор своей фантазии :-).
- И последняя категория людей IT-аналитики (например, из крупных оптовых фирм) и профессиональные авторы обзоров компьютерного железа люди, которые по долгу их рода занятий зачастую вынуждены делать выводы о потенциале тех или иных изделий еще до их официального анонса.
Итак, синтетические тесты позволяют исследовать производительность и возможности отдельных подсистем ускорителей, тем самым позволяя заранее строить прогнозы о поведении ускорителя в тех или иных приложениях. Причем, как в уже существующих (обобщенная оценка пригодности и перспективности для целого класса применений) так и в еще разрабатываемых, разумеется, при условии наличия определенных характерных особенностей использования ускорителя под управлением этих приложений.
Описания синтетических тестов набора RightMark 3D
Pixel Filling
Данный тест выполняет целый ряд задач. В том числе:
- Измерение производительности закраски буфера кадров
- Измерение производительности различных режимов фильтрации текстур
- Измерение эффективности работы (кэширования) с текстурами различного объема
- Измерение эффективности работы (кэширования и компрессии) с текстурами различных форматов
- Измерение эффективности мультитекстурирования
- Наглядное сравнение качества реализации тех или иных режимов фильтрации текстур
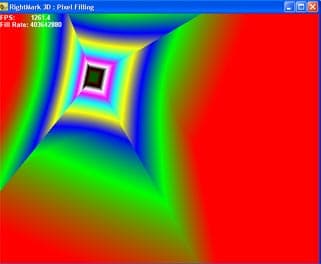
Во время тестирования выводится пирамида, основание которой лежит точно в плоскости экрана, а вершина максимально удалена от наблюдателя:

Четыре стороны пирамиды состоят каждая из двух треугольников. Малое число треугольников позволяет устранить зависимость от геометрической производительности, не имеющей никакого отношения к исследуемым данным тестом вопросам. На каждую точку во время закраски накладывается от 1 до 8 текстур. При желании можно полностью отключить текстурирование (0 текстур) и измерять только скорость закраски с использованием константного значения цвета.
Во время тестирования вершина пирамиды равномерно перемещается по кругу, а само основание при этом вращается вокруг оси Z:
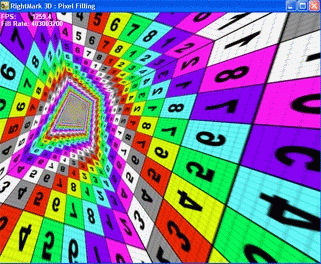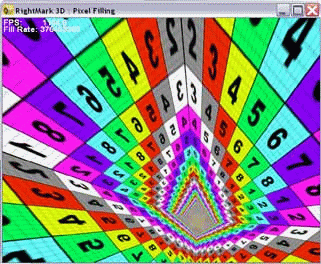
Таким образом, плоскости пирамиды поочередно принимают все возможные углы наклона в обеих плоскостях, а само число закрашиваемых точек не меняется они один раз покрывают весь экран, при этом в наличии любые расстояния до точек, начиная от минимального и заканчивая максимально удаленными. От наклона закрашиваемой плоскости плоскости и расстояний до закрашиваемых точек зависят многие алгоритмы фильтрации, в том числе анизотропная фильтрация и различные современные реализации трилинейной фильтрации. Вращая пирамиду, мы ставим ускоритель во все условия, которые только могут встретиться в реальных применениях. Это позволяет нам не только визуально проверить качество фильтрации во всевозможных случаях, но и получить взвешенные результаты производительности.
Полезна возможность выбора режима работы теста одни и те же действия могут быть выполнены шейдерами разных версий и фиксированными конвейерами, доставшимися в наследство от предыдущих поколений DX. Т.е. можно исследовать разницу в производительности в зависимости от используемой версии шейдеров.
Специальная текстура с различными цветами и цифрами облегчает исследование качественных аспектов фильтрации, а также ее взаимодействия с полноэкранным сглаживанием. При желании, также можно выделить различным цветом mip-уровни:
И сделать выводы об алгоритме их смешения и выбора.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Выделять ли цветом mip-уровни
- Режим работы (и максимальное число накладываемых на один пиксель текстур):
- Vertex Shaders 1.1 и Fixed Function Blend Stages (до 8 текстур)
- Vertex Shaders 2.0 и Fixed Function Blend Stages (до 8 текстур)
- Vertex Shaders 1.1 и Pixel Shaders 1.1 (до 4 текстур)
- Vertex Shaders 1.1 и Pixel Shaders 1.4 (до 6 текстур)
- Vertex Shaders 2.0 и Pixel Shaders 2.0 (до 8 текстур)
- Число текстур, накладываемых на точку:
- 0 (только закраска)
- от 1 до 8
- Размер текстур:
- 128х128
- 256x256
- 512x512
- Формат текстур:
- A8R8G8B8
- X8R8G8B8
- A1R5G5B5
- X1R5G5B5
- DXT1
- DXT2
- DXT3
- DXT4
- DXT5
- Тип фильтрации:
- отсутствует
- билинейная
- трилинейная
- анизотропная
- анизотропная + трилинейная
Результат работы теста выдается в двух единицах число кадров в секунду (FPS) и, что более удобно, число закрашенных в секунду пикселей (FillRate). Последнее число играет двойную роль. В режиме без текстур мы измеряем непосредственно скорость записи в буфер кадра. Таким образом, этот параметр означает число закрашенных в секунду точек экрана (Pixel FillRate). В режиме с использованием какого-либо числа текстур число выбранных и отфильтрованных значений текстур в секунду (Texturing Rate, Texture Fill Rate).
Приведем пример пиксельного шейдера, используемого для закраски в ходе самого интенсивного варианта этого теста (PS/VS 2.0, 8 текстур):
ps_2_0
dcl t0
dcl t1
dcl t2
dcl t3
dcl t4
dcl t5
dcl t6
dcl t7
dcl_2d s0
dcl_2d s1
dcl_2d s2
dcl_2d s3
dcl_2d s4
dcl_2d s5
dcl_2d s6
dcl_2d s7
texld r0, t0, s0
texld r1, t1, s1
texld r2, t2, s2
texld r3, t3, s3
texld r4, t4, s4
texld r5, t5, s5
texld r6, t6, s6
texld r7, t7, s7
mov r11, r0
lrp r11, c0, r11, r1
lrp r11, c0, r11, r2
lrp r11, c0, r11, r3
lrp r11, c0, r11, r4
lrp r11, c0, r11, r5
lrp r11, c0, r11, r6
lrp r11, c0, r11, r7
mov oC0, r11Geometry Processing Speed
Этот тест призван измерять скорость обработки геометрии в различных режимах. При его создании мы всячески стремились минимизировать влияние закраски и прочих подсистем ускорителя, и, в то же время, сделать саму геометрическую информацию, и ее обработку максимально приближенной к реальным моделям. Основная задача теста измерение пиковой геометрической производительности на различных задачах трансформации и освещения. В данный момент, тест позволяет выбирать следующие моделей освещения (вычисляемые на уровне вершин):
- Ambient Lighting простейшее константное освещение
- 1 Diffuse Light один диффузный источник света
- 2 Diffuse Lights два диффузных источника света
- 3 Diffuse Lights три диффузных источника света
- 1 Diffuse + Specular Light один диффузно-спекулярный источник
- 2 Diffuse + Specular Lights два диффузно-спекулярных источника
- 3 Diffuse + Specular Lights три диффузно-спекулярных источника
В ходе теста выводится несколько экземпляров одной и той же модели с большим числом полигонов. Каждый экземпляр модели имеет свои параметры геометрической трансформации и относительного расположения источников света. Размер модели выбран крайне малым (большинство полигонов сравнимы или меньше экранного пикселя):

и таким образом разрешение и закраска не оказывает влияния на результаты теста:
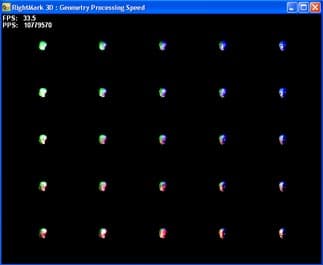
Источники света всячески перемещаются во время теста, дабы обеспечить равномерное разнообразие исходных расчетных параметров.
Допустимо выбрать три степени детализации сцены они влияют на общее число полигонов, трансформируемых в одном кадре. Подобная возможность необходима для всесторонней проверки отсутствия зависимости результатов теста от сцены и числа кадров в секунду.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров и TCL
- Режим работы:
- Fixed Function TCL и Fixed Function Blend Stages
- Vertex Shaders 1.1 и Fixed Function Blend Stages
- Vertex Shaders 2.0 и Fixed Function Blend Stages
- Vertex Shaders 1.1 и Pixel Shaders 1.1
- Vertex Shaders 1.1 и Pixel Shaders 1.4
- Vertex Shaders 2.0 и Pixel Shaders 2.0
- Детализация геометрии:
- 1 (низкая)
- 2 (средняя)
- 3 (высокая)
- Модель освещения (определяет сложность расчетов):
- Ambient Lighting простейшее константное освещение
- 1 Diffuse Light один диффузный источник света
- 2 Diffuse Lights два диффузных источника света
- 3 Diffuse Lights три диффузных источника света
- 1 (Diffuse + Specular) Light один диффузно-спекулярный источник
- 2 (Diffuse + Specular) Lights два диффузно-спекулярных источника
- 3 (Diffuse + Specular) Lights три диффузно-спекулярных источника
Результат работы теста выдается в двух единицах число кадров в секунду (FPS) и, что более удобно число трансформированных и освещенных за секунду треугольников (PPS Polygons Per Second).
Приведем пример вершинного шейдера (VS 2.0), используемого для трансформации и расчета освещения от задаваемого извне числа диффузно-спекулярных источников в этом тесте:
vs_2_0
dcl_position v0
dcl_normal v3
//
// Position Setup
//
m4x4 oPos, v0, c16
//
// Lighting Setup
//
m4x4 r10, v0, c8 // transform position to world space
m3x3 r0.xyz, v3.xyz, c8 // transform normal to world space
nrm r7, r0 // normalize normal
add r0, -r10, c2 // get a vector toward the camera position
nrm r6, r0 // normalize eye vector
mov r4, c0 // set diffuse to 0,0,0,0
mov r2, c0 // setup diffuse,specular factors to 0,0
mov r2.w, c94.w // setup specular power
//
// Lighting
//
loop aL, i0
add r1, c[40+aL], -r10 // vertex to light direction
dp3 r0.w, r1, r1
rsq r1.w, r0.w
dst r9, r0.wwww, r1.wwww // (1, d, d*d, 1/d)
dp3 r0.w, r9, c[70+aL] // (a0 + a1*d + a2*d2)
rcp r8.w, r0.w // 1 / (a0 + a1*d + a2*d)
mul r1, r1, r1.w // normalize the vertex to the light vector
add r0, r6, r1 // calculate half-vector (light vector + eye vector)
nrm r11, r0 // normalize half-vector
dp3 r2.x, r7, r1 // N*L
dp3 r2.yz, r7, r11 // N*H
sge r3.x, c[80+aL].y, r9.y // (range > d) ? 1:0
mul r2.x, r2.x, r3.x
mul r2.y, r2.y, r3.x
lit r5, r2 // calculate the diffuse & specular factors
mul r5, r5, r8.w // scale by attenuation
mul r0, r5.y, c[30+aL] // calculate diffuse color
mad r4, r0, c90, r4 // add (diffuse color * material diffuse)
mul r0, r5.z, c[60+aL] // calculate specular color
mad r4, r0, c91, r4 // add (specular color * material specular)
endloop
mov oD0, r4 // final colorHidden Surface Removal
Этот тест позволяет оценить наличие и эффективность техник, нацеленных на удаление невидимых точек и примитивов. Т.е эффективность работы с традиционным буфером глубины, а также эффективность и наличие раннего отсечения невидимых точек в том или ином виде. Тест генерирует псевдослучайную сцену из заданного числа треугольников:
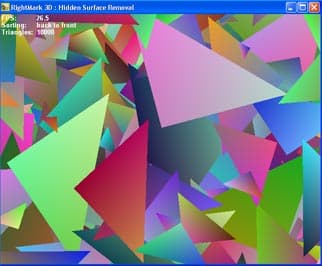
…которая будет затем выводиться в одном из трех выбранных режимов:
- Сортированные по удалению, от ближних к дальним (sorted, front to back order)
- Сортированные по удалению, от дальних к ближним (sorted, back to front order)
- Хаотически, без сортировки (unsorted)
Разумеется, что в случае 2 будут прорисованы последовательно все пиксели, в том числе и закрытые. Разумеется, если ускоритель основан на традиционной или гибридной архитектуре (в случае полностью тайлового ускорителя оптимизация возможна и тут, но не будем забывать что сортировка в итоге все равно будет присутствовать, пусть уже на уровне железа или драйвера).
В случае 1 в идеале может быть прорисовано только небольшое число видимых пикселей, остальные могут быть откинуты еще до закраски. В случае 3 мы имеем некую середину, похожую на то, с чем может встретиться механизм HSR чипа в реальной работе в не оптимизирующих последовательность вывода сцены на экран приложениях. Для того, чтобы получить представление о пиковой эффективности алгоритма HSR, необходимо соотнести результаты первого и второго режима (самого оптимального первого с самым неудобным вторым). Сравнение же оптимального режима с хаотическим (т.е. первого и третьего) даст нам приблизительную степень эффективности в реальных применениях.
Для того, чтобы максимально сгладить потенциальные особенности различных, как правило, основанных на разбиении буфера кадра на зоны, алгоритмов раннего HSR, сцена во время теста поворачивается вокруг оси Z. В итоге, треугольники и их границы принимают всевозможные положения.
Для проверки наличия и эффективности ранней проверки Z — так называемые Early Z reject (ATI) и Early Z cull (NVIDIA) технологии позволяющие не производить фактическое текстурирование и выполнение шейдера над пикселями не прошедшими Z тест, добавлена опция форсирующая текстурирование всех треугольников сцены:
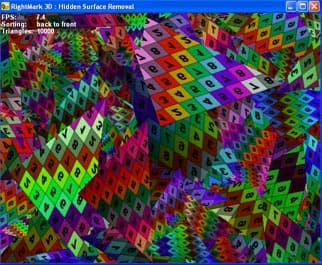
Для проверки зависимости этого теста от прочих подсистем чипа и драйверов была добавлена возможность регулировать число выводимых треугольников. Разумеется, мы можем ожидать приближения результатов к идеальным по мере роста числа треугольников, но, с другой стороны, рост оправдан только до какого-то разумного предела, после чего степень влияния на тест сторонних подсистем снова может увеличиться. Поэтому и был введен этот параметр, необходимый для проверки добротности теста в плане зависимости от числа треугольников.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров и TCL
- Режим работы:
- Fixed Function TCL и Fixed Function Blend Stages
- Vertex Shaders 1.1 и Fixed Function Blend Stages
- Vertex Shaders 2.0 и Fixed Function Blend Stages
- Число треугольников:
- От 1000 до 20000
- Режим сортировки выводимой сцены:
- Отсутствует;
- От дальних полигонов к ближним;
- От ближних полигонов к дальним
Pixel Shading
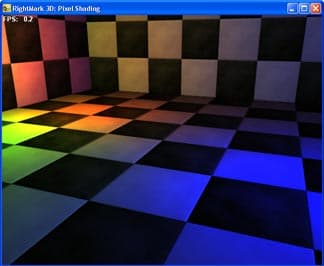
Данный тест призван исследовать производительность выполнения различных пиксельных шейдеров второй версии. Если в случае первой версии скорость выполнения шейдеров, транслировавшихся реально в настройки стадий, определялась по достаточно простым правилам, и для ее проверки было достаточно теста, схожего с Pixel Filling в режиме большого числа текстур, то в случае второй версии вершинных шейдеров все может существенно усложниться. Покомандное исполнение и новые форматы данных (плавающие числа) способны создать существенную разницу в производительности не только в случае разных архитектур ускорителей, но и даже на уровне сочетания отдельных команд и форматов данных внутри одного чипа. Мы решили применить к тестированию производительности пиксельных процессоров современных ускорителей подход, схожий с тестированием CPU. А именно, измерять производительность следующего набора пиксельных шейдеров, имеющих вполне распространенные реальные прототипы и применения:
- Расчет попиксельного освещения 1 точечный источник (per-pixel diffuse lighting with per-pixel attenuation)
- Расчет попиксельного освещения 2 точечных источника (per-pixel diffuse lighting with per-pixel attenuation)
- Расчет попиксельного освещения 3 точечных источника (per-pixel diffuse lighting with per-pixel attenuation):
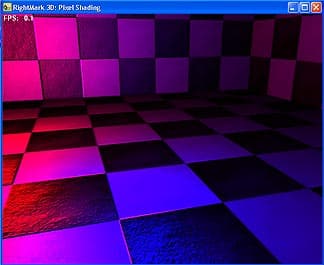
- Расчет попиксельного освещения 1 точечный источник с бликом (per-pixel diffuse lighting + specular lighting with per-pixel attenuation)
- Расчет попиксельного освещения 2 точечных источника с бликом (per-pixel diffuse lighting + specular lighting with per-pixel attenuation):
- Анимированная процедурная текстура мрамора (marble animated procedure texturing)
- Анимированная процедурная текстура огня (fire animated procedure texturing):

Два последних теста реализуют процедурные текстуры значения цвета точек вычисляются в них по некой формуле являющиеся приближенной математической моделью материала. Такие текстуры занимают очень мало памяти (хранятся только сравнительно небольшие таблицы для ускорения расчетов различных коэффициентов) и имеют при этом практически неограниченную детализацию! Кроме того, они легко анимируются простым изменением базовых параметров. Возможно, что, по мере роста вычислительных возможностей ускорителей, в будущих приложениях будут задействованы такие методы текстурирования.
Геометрически тестовая сцена максимально упрощена, и, таким образом, зависимость от геометрической производительности чипа практически нивелируется. Также отсутствует удаление невидимых поверхностей все поверхности сцены видимы в любой момент времени. Нагрузка ложится только на плечи пиксельных конвейеров.
Для проверки эффективности использования плавающего формата с половинной точностью представления FP16 введена опция, позволяющая выбирать одну из трех разновидностей пиксельных шейдеров — базовые 2.0, в которых нельзя указать точный формат операции, и две разновидности 2.X — с форсированием 16-битной точности вычислений и форсирование 32-битной точности вычислений соответственно.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров
- Используемая версия пиксельного шейдера:
- Версия 2.0
- Версия 2.X — форсирован формат FP16 (половинная точность)
- Версия 2.X — форсирован формат FP32 (полная точность)
- Пиксельный шейдер:
- 1 point light ( per-pixel diffuse with per-pixel attenuation )
- 2 point lights ( per-pixel diffuse with per-pixel attenuation )
- 3 point lights ( per-pixel diffuse with per-pixel attenuation )
- 1 point light ( per-pixel diffuse + secular with per-pixel attenuation )
- 2 point lights ( per-pixel diffuse + secular with per-pixel attenuation )
- Procedure texturing (Marble)
- Procedure texturing (Fire)
Приведем коды некоторых шейдеров. Попиксельный расчет двух источников света с бликами:
ps_2_0
//
// Texture Coords
//
dcl t0 // Diffuse Map
dcl t1 // Normal Map
dcl t2 // Specular Map
dcl t3.xyzw // Position (World Space)
dcl t4.xyzw // Tangent
dcl t5.xyzw // Binormal
dcl t6.xyzw // Normal
//
// Samplers
//
dcl_2d s0 // Sampler for Base Texture
dcl_2d s1 // Sampler for Normal Map
dcl_2d s2 // Sampler for Specular Map
//
// Normal Map
//
texld r1, t1, s1
mad r1, r1, c29.x, c29.y
//
// Light 0
//
// Attenuation
add r3, -c0, t3 // LightPosition-PixelPosition
dp3 r4.x, r3, r3 // Distance^2
rsq r5, r4.x // 1 / Distance
mul r6.x, r5.x, c20.x // Attenuation / Distance
// Light Direction to Tangent Space
mul r3, r3, r5.x // Normalize light direction
dp3 r8.x, t4, -r3 // Transform light direction to tangent space
dp3 r8.y, t5, -r3
dp3 r8.z, t6, -r3
mov r8.w, c28.w
// Half Angle to Tangent Space
add r0, -t3, c25 // Get a vector toward the camera
nrm r11, r0
add r0, r11, -r3 // Get half angle
nrm r11, r0
dp3 r7.x, t4, r11 // Transform half angle to tangent space
dp3 r7.y, t5, r11
dp3 r7.z, t6, r11
mov r7.w, c28.w
// Diffuse
dp3 r2.x, r1, r8 // N * L
mul r9.x, r2.x, r6.x // * Attenuation / Distance
mul r9, c10, r9.x // * Light Color
// Specular
dp3 r2.x, r1, r7 // N * H
pow r2.x, r2.x, c26.x // ^ Specular Power
mul r10.x, r2.x, r6.x // * Attenuation / Distance
mul r10, c12, r10.x // * Light Color
//
// Light 2
//
// Attenuation
add r3, -c1, t3 // LightPosition-PixelPosition
dp3 r4.x, r3, r3 // Distance^2
rsq r5, r4.x // 1 / Distance
mul r6.x, r5.x, c21.x // Attenuation / Distance
// Light Direction to Tangent Space
mul r3, r3, r5.x // Normalize light direction
dp3 r8.x, t4, -r3 // Transform light direction to tangent space
dp3 r8.y, t5, -r3
dp3 r8.z, t6, -r3
mov r8.w, c28.w
// Half Angle to Tangent Space
add r0, -t3, c25 // Get a vector toward the camera
nrm r11, r0
add r0, r11, -r3 // Get half angle
nrm r11, r0
dp3 r7.x, t4, r11 // Transform half angle to tangent space
dp3 r7.y, t5, r11
dp3 r7.z, t6, r11
mov r7.w, c28.w
// Diffuse
dp3 r2.x, r1, r8 // N * L
mul r2.x, r2.x, r6.x // * Attenuation / Distance
mad r9, c11, r2.x, r9 // * Light Color
// Specular
dp3 r2.x, r1, r7 // N * H
pow r2.x, r2.x, c26.x // ^ Specular Power
mul r2.x, r2.x, r6.x // * Attenuation / Distance
mad r10, c13, r2.x, r10 // * Light Color
//
// Diffuse + Specular Maps
//
texld r0, t0, s0
texld r1, t2, s2
mul r9, r9, r0 // Diffuse Map
mad r9, r10, r1, r9 // Specular Map
// Finalize
mov oC0, r9Процедурная текстура огня:
ps_2_0
def c3, -0.5, 0, 0, 1
def c4, 0.159155, 6.28319, -3.14159, 0.25
def c5, -2.52399e-007, -0.00138884, 0.0416666, 2.47609e-005
dcl v0
dcl t0.xyz
dcl t1.xyz
dcl t2.xyz
dcl t3.xyz
dcl_volume s0
dcl_2d s1
texld r0, t0, s0
mul r7.w, c0.x, r0.x
texld r2, t1, s0
mad r4.w, c0.y, r2.x, r7.w
texld r11, t2, s0
mad r1.w, c0.z, r11.x, r4.w
texld r8, t3, s0
mad r10.w, c0.w, r8.x, r1.w
mul r5.w, c2.x, r10.w
mad r7.w, c1.x, t0.x, r5.w
mad r9.w, r7.w, c4.x, c4.w
frc r4.w, r9.w
mad r6.w, r4.w, c4.y, c4.z
mul r1.w, r6.w, r6.w
mad r3.w, r1.w, c5.x, c5.w
mad r5.w, r1.w, r3.w, c5.y
mad r7.w, r1.w, r5.w, c5.z
mad r9.w, r1.w, r7.w, c3.x
mad r11.w, r1.w, r9.w, c3.w
mov r3.xy, r11.w
texld r6, r3, s1
mov oC0, r6Point Sprites
Этот тест служит для выявления производительности одной единственной функции: вывода точечных спрайтов, предназначенных для создания систем частиц. В ходе теста выводится анимированная система частиц, в которой легко угадать горящую фигуру человека:
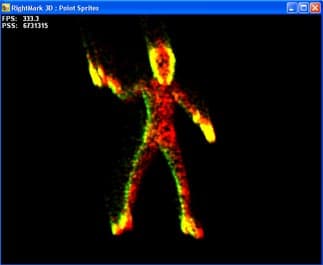
Мы можем регулировать размер частиц (который несомненно скажется на скорости их закраски), включать и выключать обработку освещения и анимацию. В случае систем частиц большую роль играет и обработка геометрической информации, именно поэтому мы не стали пытаться разделить два этих аспекта закраска и геометрические вычисления (анимация и освещение), а предоставили возможность менять степень нагрузки на ту или иную часть теста за счет регулировки размера спрайтов и включения / выключения их анимации и освещения.
Перечислим настраиваемые параметры теста:
- Разрешение
- Оконный или полноэкранный режим
- Время тестирования (накопления статистики) в секундах
- Режим программной эмуляции вершинных шейдеров
- Режим работы:
- Vertex Shaders 1.1 и Fixed Function Blend Stages
- Vertex Shaders 2.0 и Fixed Function Blend Stages
- Режим анимации:
- Отсутствует
- Проводится
- Режим освещения:
- Отсутствует
- Проводится
Оставайтесь с нами
В ближайшее время мы планируем завершить отладку и привести первые публичные результаты 6-го теста - теста, измеряющего в первую очередь "добротность" драйверов и то, насколько эффективно построена передача данных и параметров ускорителю.
Кроме того, в скором времени во всех синтетических тестах появится возможность использовать не только ассемблерные версии шейдеров, но и компилируемые с языка высокого уровня, причем как родным компилятором Microsoft (HLSL) так и комплектом от NVIDIA CG+CGFX.
Самым приятным ожидаемым событием, несомненно, является планируемый в ближайшее время релиз первой тестовой (бета) версии пакета RightMark 3D. Пока (в первой бета-версии) для свободного использования будут доступны только синтетические тесты и оболочка для пакетного запуска и просмотра результатов. Впоследствии появятся четыре различных игровых теста.
Для тех, кто уже сейчас горит желанием экспериментировать с синтетическими тестами RightMark 3D, мы предлагаем скачать и опробовать "командностроковые" варианты тестов, формирующие результирующий файл XLS в формате XML, принятом в Microsoft Office XP:
Внутри каждого архива вы найдете описание параметров каждого теста и пример .bat файла, используемого нами для тестирования ускорителей. Мы будем благодарны любым откликам, как в плане пожеланий и идей, так и информации об ошибках или странном поведении тестов.
Пишите по адресу: unclesam@ixbt.com.
Результаты практического тестирования
А теперь самое интересное. Приведем и прокомментируем данные, полученные нами на ускорителях двух "основных" в данный момент семейств — ATI RADEON 9700 PRO и NVIDIA GeForce FX 5800 Ultra. В качестве опорной, в тестировании также принимает участие карта предыдущего поколения — GeForce 4 Ti 4600.
Pixel Filling
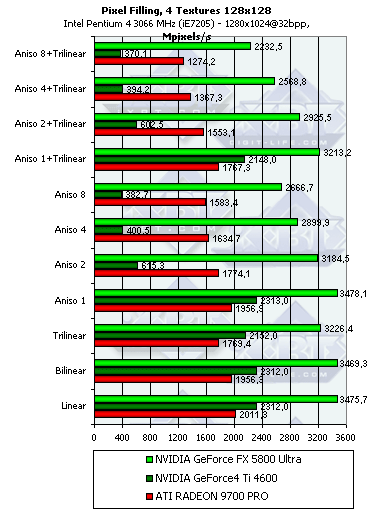
- Тест на скорость закраски буфера кадров (Pixel Fillrate). Закраска константным цветом выборка текстур не производится. Приведены результаты в миллионах пикселов в секунду для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
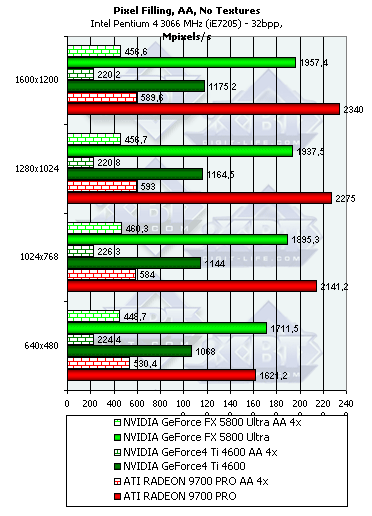
Несмотря на более высоковую тактовую частоту GFFX, мизерное преимущество FX наблюдается только в самом низком разрешении, а далее 9700 PRO уверено берет лидерство. Причина кроется в превосходящей ПСП памяти и наличии 8 пиксельных конвейеров способных записывать 8 значений цвета и глубины за такт. FX может записать только 4 полных пиксела (цвет + глубина + когда надо буфер шаблонов aka Stencil), однако 4 пиксельных процессора этого чипа имеют одну интересную оптимизацию — если мы рассчитываем шейдер или просто закрашиваем треугольник не используя значения цвета а изменяя только значения глубины или буфера шаблонов, каждый пиксельный процессор может за один такт выдать два результата. Таким образом, в сумме записав 8 значений глубины или буфера шаблонов за такт. Подобная оптимизация очень пригодится в играх с стенсильными тенями, подобных DOOM III, там она может ускорить прорисовку сцены в почти полтора раза. Однако в нашем тесте закрашиваются и значения цвета. Именно поэтому результат свидетельствует лишь о 4 пикселах выводимых за один так.
Во всех разрешениях, кроме минимального, разница хорошо соответствует разнице в пиковой ПСП, что говорит о разумном балансе чипа GF FX — 8 конвейеров даже теоретически не смогли бы записать 8 значений за такт, в таком простом (без каких либо вычислений а только с закраской) тесте. С точки зрения пиксельной скорости закраски несложных приложений 4 конвейера оправданы. Но будут ли они также оправданы в случае вычислительно интенсивных шейдеров? Далее мы проясним этот вопрос.
- Тест на скорость закраски буфера кадров с одновременным текстурированием. Добавляется выборка одной простой билинейной текстуры проверим, насколько наличие конкурентного потока чтения из памяти понизит эффективность закраски. Приведены результаты в миллионах пикселов в секунду, для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
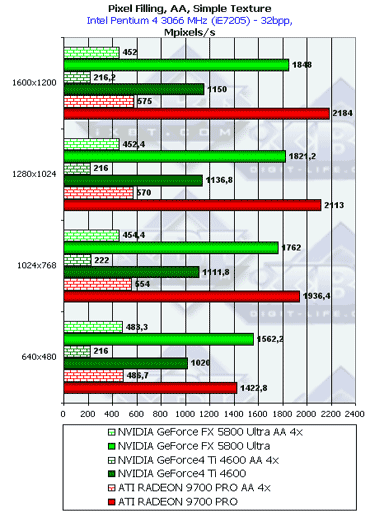
В общем и целом, картина практически та же, но пиковые значения несколько упали. Давайте посмотрим, насколько хорошо измеренная действительность соотносится с теоретическими пределами, основанными на частоте ядра и числе конвейеров:
Продукт Теоретический максимум Измеренный максимум(без текстуры) Измеренный максимум(с одной текстурой) GeForce4 Ti 4600 1200 1175 1150 RADEON 9700 PRO 2600 2340 2184 GeForce FX 5800 Ultra 2000 1957 1848 Итак, GeForce FX хорошо реализует свой теоретический потенциал. Все упирается в наличии 4 пиксельных процессоров и недостаточную пропускную полосу памяти. Фактически, можно выпустить аналогичную версию чипа но с 256-битной шиной памяти и 8 конвейерами, увеличив производительность реальных приложений почти в два раза.
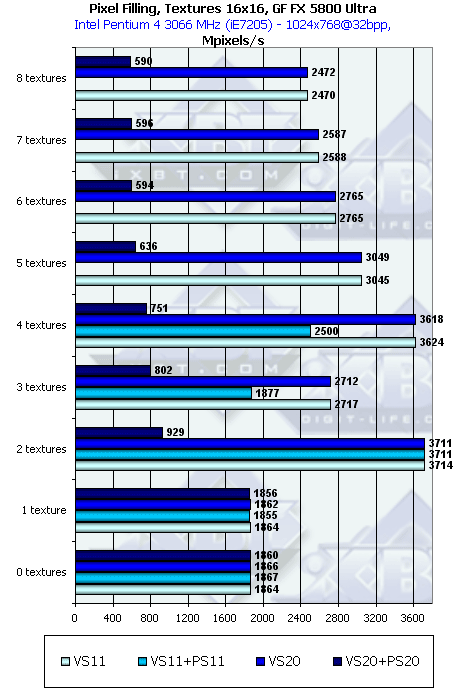
- Посмотрим на зависимость Texturing Rate (числа выбираемых и фильтруемых из текстур пикселей в секунду) от числа накладываемых за один проход текстур:
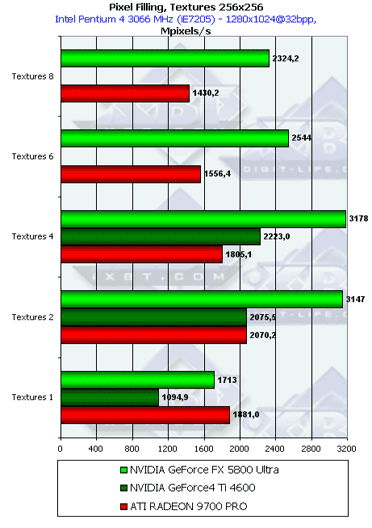
А вот и сюрприз — начиная с двух текстур на пиксель (это тот минимум, который мы наблюдаем у всех современных игр) эффективность работы NV30 резко возрастает! Оптимальное значение достигается на 4 текстурах, в отличие от R300, для которого более выгодны 2 текстуры. В принципе, подобное поведение вполне объяснимо. Если учесть что реально в NV30 присутствует по два текстурных блока на каждом из четырех пиксельных процессоров. По мере увеличения числа текстур все большую роль играет производительность их выборки и фильтрации, которая в первую очередь определяется тактовой частотой ядра чипа. Если в случае одной текстуры мы упирались в число пиксельных процессоров и скорость записи буфера кадра (и то и то ниже R300), то в случае двух и более мы начинаем чувствовать влияние тактовой частоты ядра. Кроме того, еще в теоретической статье по NV30 я упоминал о достаточно оригинальной конвейерной конструкции текстурных блоков творения NVIDIA, обеспечивающей потактовую выдачу результатов без задержек. Итак, конвейерные текстурные модули удались на славу — в вопросах выборки текстур NV30 лидер.
Отметим, что подобное преимущество NV30 должно сказываться в первую очередь в играх со сложным, многослойным текстурированием, не обремененным многочисленными пиксельными вычислениями, таких, как например DOOM III.Однако далее мы посмотрим, насколько же эта малина будет подпорчена недостаточной ПСП в работе с реальными приложениями, и не пересилит ли ее нехватка столько ощутимое преимущество. Факт спареных текстурных блоков по идее не должен досаждать GF FX особенно в случае трилинейной или анизотропной фильтрации. В случае же билинейной, не будем забывать что большинство современных игр производительность в которых критична, накладывает две и более текстуры на большую часть полигонов сцены. Впрочем могут быть и исключения — например небо в современных авиационных симуляторах может делаться одной текстурой (пример — игра Штурмовик Ил-2). В таких приложениях R300 получит дополнительное преимущество.
Продукт Теоретический максимум Достигнутый максимум Измеренный максимум(макс. текстур) GeForce4 Ti 4600 2400 2223 (4 текст.) 2223 (4 текст.) RADEON 9700 PRO 2600 2070 (2 текст.) 1430 (8 текст.) GeForce FX 5800 Ultra 4000 3178 (4 текст.) 2324 (8 текст.) - Исследуем зависимость от формата текстуры:
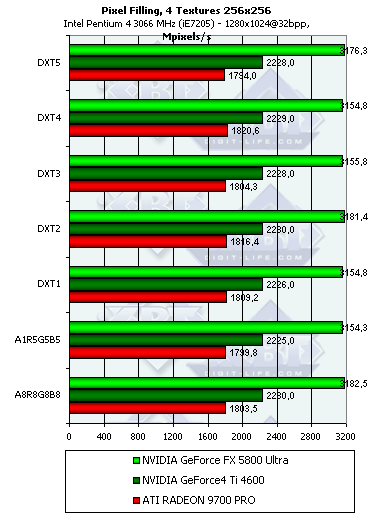
Результаты практически не меняются — все чипы давным-давно оптимизированы для 32-битных текстур и выполняют распаковку сжатых текстур без каких-либо задержек.
- Исследуем зависимость от типа фильтрации:
На более или менее существенных установках анизотропии NV25 начинает катастрофически терять производительность. Этот факт подробно исследован в наших материалах ранее и не требует дополнительных комментариев. Зато NV30 теряет производительность лишь немного более активно, чем R300 — практически в той же степени. В абсолютном значении его результаты превосходят R300 на величину даже большую, чем разница в тактовой частоте ядра — сказывается большая эффективная конвейеризация работы текстурных модулей.
По скорости падения при активации анизотропии адекватно, извечные соперники наконец сравнялись в этом вопросе, но адекватно ли качество? Далее мы исследуем этот вопрос. Вариант с 4 текстурами был выбран как некое среднее, типичное для вышедших в этом году игр — мало кто уже ограничивается двумя текстурами за проход, но и 8 текстур встречаются не так часто и лишь на отдельных объектах сцены. Далее мы увидим, как обстоят дела с анизотропией у GeForce FX в реальных приложениях, в том числе, в самом интересном режиме — в сочетании с FSAA.
- Дополнение: после выхода нашего материала в Сети стали раздаваться слухи о том, что архитектура конвейеров рендеринга вовсе не 8x1, а 4х2, поэтому мы провели еще одно исследование:
Как вы можно видеть на диаграмме зависимости скорости заполнения от количества текстур и других бенчмарках, GeForce FX ведет себя очень похоже на GPU, со схемой пиксельных конвейеров 4x2, то есть 4 пиксельных конвейера с 2 TMU на каждом. Однако как мы уже отмечали, при операциях с буфером глубины и буфером шаблона (depth & stencil) NV30 обрабатывает 8 пикселов за такт (при условии, что параллельно не ведутся какие либо операции с цветом). В остальных случаях обрабатываются 4 пикселя. Но, каждый из четырех пиксельных процессоров содержит два целочисленных ALU (две стадии) соединенных последовательно (так же как в NV25, видимо текстурные блоки и целочисленные стадии были разработаны с оглядкой на предыдущее поколение). Таким образом можно говорить о том, что за один такт выполняется сразу две команды шейдера, если его версия не превышает 1.3 или сразу две операции комбинационных стадий для старых, нешейдерных приложений (DX7). Причем, т.к. эти операции выполняются фактически над разными пикселами, они всегда могут происходить параллельно и таким образом целочисленная производительность NV30 при равной тактовой частоте эквивалентна 8 конвейерному чипу, но с одним ALU на каждом конвейере. Однако это касается только конфигураций стадий и шейдеров длинной как минимум две операции.
Таким образом, одновременно могут выполняться до 8 выборок текстур И 8 целочисленных математических операций за такт. Я умышленно выделил "И", показывая, что данные операции выполняются одновременно.
В случае шейдеров 1.4 и тем более 2.0, выполняющихся на NV30 с плавающей точкой, каждый пиксельный конвейер может выполнить лишь одну операцию за такт — таким образом всего чип выполняет по одной комманде для 4 пикселов за такт, что вдвое ниже производительности с целочисленными шейдерами. Но это еще не все — плавающие комманды не могут выполнятся одновременно с выборкой текстур! Т.е. за один такт мы можем либо выбрать 8 значений текстур, либо выполнить 4 плавающих операции шейдеров. Таким образом, NV30 вдвое (и даже более, если учесть выборку текстур) производительнее в не использующих плавающую арифметику применениях.
Итак, за один такт:
- 8 выборок текстур и 8 целочисленных операций над 4 пикселами.
- или 4 плавающих операции над 4 пикселами.
- или вычисление и запись 8 значений глубины и буфера шаблонов.
Почему была выбрана такая схема? Специалисты NVIDIA подчеркивают, что GeForce FX имеет архитектуру, оптимизированную под современные игры и сбалансированную с ПСП ее шины памяти. Многие современные игры уже сейчас используют stencil буфер для визуализации теней, и количество таких игр будет расти, достаточно вспомнить грядущий Doom III. GeForce FX прекрасно оптимизирован для данной технологии. Мультитекстурирование также уже стало стандартным для большинства современных игр, и "быстрые" TMU GeForce FX обеспечат высокую производительность в данных играх. Для 128 битной шины подобное чило конвейеров и подобный подход выглядят вполне логичными — наличие 8 конвейеров и возможности записать 8 значений цвета за такт не было бы полностью реализовано из за ограниченной ПСП но при этом добавило бы изрядную часть транзистров. Не лучше ли пустить их на более реентабельные применения, такие как кеширование или ускоренные операции с буфером шаблонов? Видимо, инженеры NVIDIA так и рассудили.
Ну а для разработчиков GeForce FX предоставляет огромные возможности, поддерживая шейдеры, намного превосходящие стандартные для DX9 ( версия 2.0) хотя и медленее чем старые 1.1..1.3 веросии. Когда игры, интенсивно использующие подобные шейдеры и плавающие вычисления появятся в магазинах, там же будут находиться продукты компании NVIDIA следующего поколения, более агрессивно оптимизированные под плавающие операции…

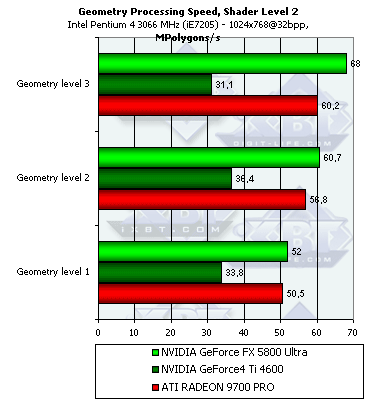
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителей.
- Производительность фиксированного TCL (для NV30 и R300 — производительность эмулирующего его шейдера):
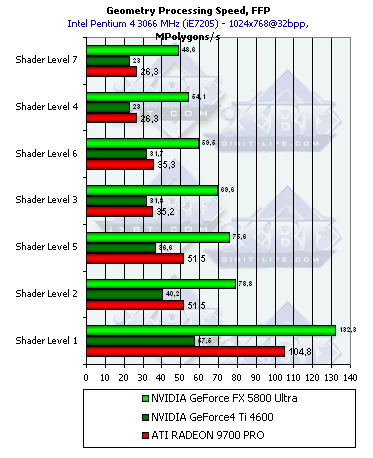
Результаты сортированы по степени сложности используемой модели освещения. Самый нижняя группа - простейший вариант, соответствующий пиковой пропускной способности ускорителя по вершинам. Результат вполне прогнозируем — здесь все зависит от частоты ядра и числа вершинных процессоров. С одной стороны, у NV30 их только три, в отличие от четырех в R300, с другой стороны, частота ее ядра существенно выше и разница частот превышает три четверти, в итоге — вполне логично увидеть преимущество NV30.
Впрочем, и на более сложных моделях освещения она впереди, эмуляция TCL в исполнении NVIDIA всегда была на высоте. Чего стоят столь близкие к R300 результаты куда как более скромной в вопросах обработки вершин NV25. Судя по всему, NVIDIA до сих пор закладывает в чип некоторые аппаратные блоки, обеспечивающие эффективное ускорение эмуляции TCL. R300 же эмулирует TCL, просто выполняя некий стандартный шейдер-эмулятор, не задействующий никаких дополнительных возможностей и компилируемый стандартным путем.
- Теперь обратимся к вершинным шейдерам 1.1:
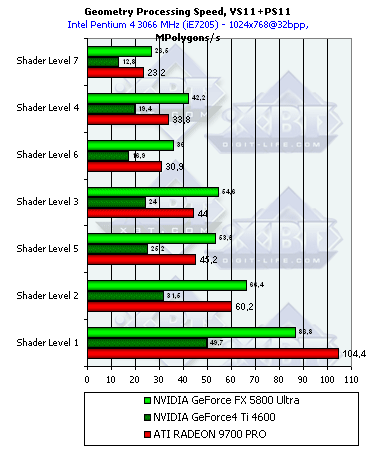
Здесь также лидирует NV30 кроме самого простого, пикового случая. Преимущество уже не столь значительно, но все равно заметно, более высокая частота берет верх над отсутствием одного конвейера. Единственный случай, где наличие четырех конвейеров R300 позволяет этому чипу выиграть - простейший шейдер. Т.к. вклад накладных расходов на запуск обработки вершины становится достаточно заметным на фоне очень короткого и простого шейдера, R300, запускающий четыре вершины параллельно, получает видимое преимущество.
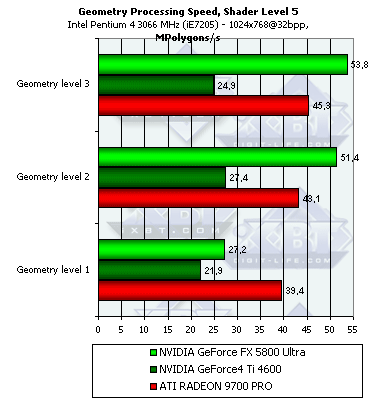
- А теперь самое интересное — шейдеры 2.0 с циклами:
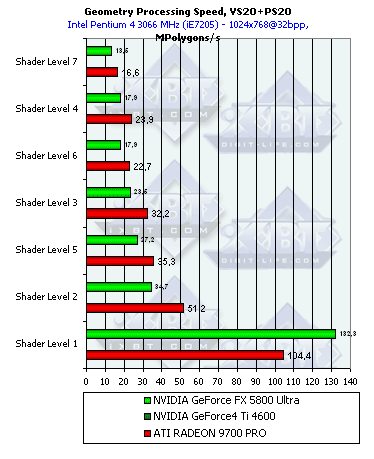
Помните, мы отмечали высокие накладные расходы R300 на выполнение циклов? Сотрудники ATI говорят, что интенсивно работают над внутренним оптимизатором шейдеров, заложенным в драйверы, и в ближайшее время эти расходы должны снизиться. Так вот, в случае NV30 накладные расходы на циклы еще более значительны! И это не удивительно, динамическое управление потоком команд может и должно вызывать большие задержки на выполнение циклов. Что мы здесь и наблюдаем. За гибкость приходится расплачиваться скоростью — при наличии цикла, преимущество NV30 в тактовой частоте растворилось окончательно. Интересно только одно исключение — простейший шейдер выполняется будучи скомпилирован как 2.0 заметно быстрее.
Аппаратная эмуляция T&L в исполнении ATI менее эффективна, чем у NV и сравнима по эффективности с вершинным шейдером 2.0. Самое сильное место NV30 — эмуляция TCL. Самое слабое — циклы. В этом плане у ATI больше простор для оптимизации в драйверах — статическое исполнение переходов и циклов позволяет применять куда как более агрессивную оптимизацию. Итак, для всех чипов обзора вторая версия далась не бесплатно — использованные циклы стоят заметного падения производительности. Причем большего, чем мы могли ожидать от одной команды цикла, на несколько десятков обычных команд.
- 4. Проверим перекрестную зависимость от степени детализации геометрии и сложности шейдера:
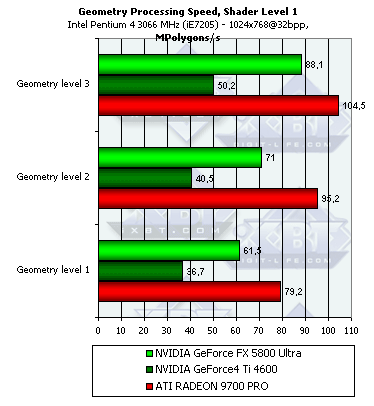
Чем выше сложность шейдера и чем выше детализация сцены, тем большее преимущество получает NV30 (сказываются кэши вершин и прочие аспекты балансировки). Эта архитектура сделана с заметным прицелом на будущее. Чем больше полигонов в модели — тем выше результаты, но зависимость крайне слаба и начиная со второго уровня детализации, и второго по сложности шейдера ее можно положить достаточной.
Hidden Surface Removal
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа треугольников, на сцене без текстур (не учитывается ранняя проверка Z):
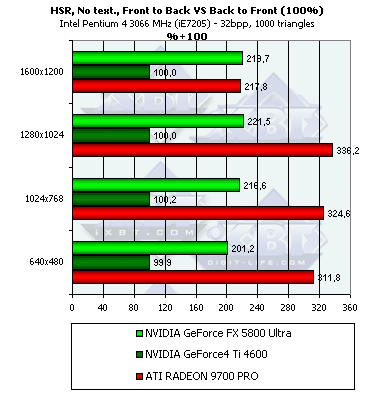
Итак, на NV25 блочный HSR по-прежнему деактивирован, результат синтетического теста с высокой точностью демонстрирует этот факт (впрочем, как мы уже потом выяснили, возможность включения HSR вновь появилась в последних версиях драйверов, разумеется, только через твикеры, например, RivaTuner, однако по умолчанию HSR выключен). Зато на NV30 его наличие налицо. Но эффективность оного ниже, чем у R300 - дело в том что R300 использует иерархическую структуру, и зачастую отсечение происходит на более высоком уровне, а следовательно, и более эффективно, в то время как у NV30 присутствует только один уровень принятия решения, совмещенный с тайлами, на основе которых сжимается информация о глубине. В максимальном разрешении 1600х1200 происходит резкое падение эффективности HSR на R300 — видимо, по каким-то соображениям, например, соображениям экономии памяти, иерархический буфер глубины уже не используется, и решение об отсечении блоков принимается так же, как и в случае NV30, только на самом нижнем базовом уровне, совмещенном с сжимаемыми блоками в буфере глубины.
Теперь давайте посмотрим на то, как эффективность HSR зависит от сложности сцены:
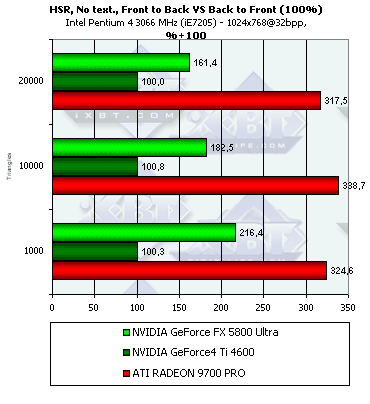
Как мы видим, для NV30, обладающей только одним уровнем тайлов, эффективность работы HSR тем выше, чем меньше полигонов на сцене, а вот R300 придерживается в этом вопросе золотой середины. Его HSR только расправляет крылья на сценах средней сложности.
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа треугольников, на сцене с текстурами (с учетом ранней проверки Z):
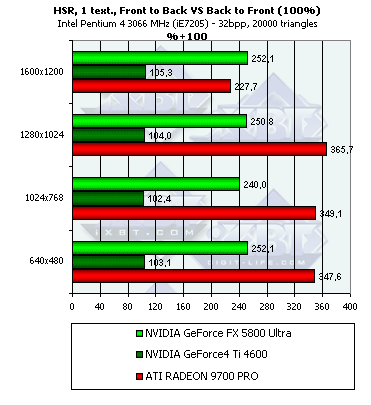
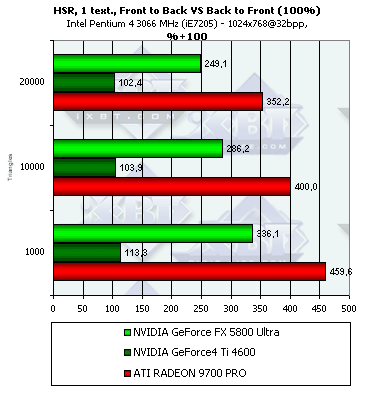
Итак, здесь и NV30, и R300 демонстрируют дополнительный рост эффективности. Для NV25 прирост эффективности минимален — всего 5%, а вот для более новых чипов он более заметен, в них ранняя проверка Z реализована видимо более эффективно. С учетом наличия текстуры, оба чипа начинают предпочитать сцены с низким числом полигонов.
- Посмотрим, как изменится эффективность в случае сравнения хаотической и сортированной сцены, как с текстурой, так и без:
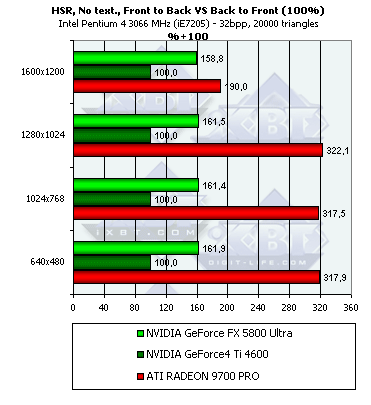
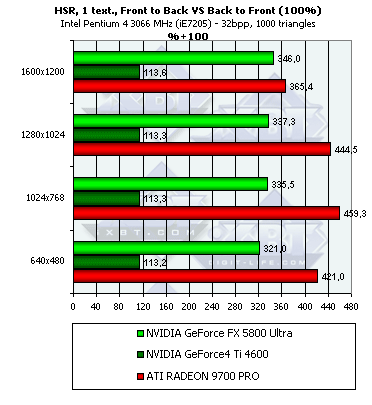
Принципиально ничего нового, однако в некоторых тестах преимущество R300 еще более велико. На не столь пиковом, но зато более-менее правдоподобном сравнении эффективности вывода сортированной и хаотической сцен, в условии наличия текстур, NV30 чувствует себя еще хуже. Зато NV25 наоборот демонстрирует 13% преимущество на сцене с текстурами.
Итак, даже в случае исходно хаотической сцены прирост велик. Наиболее заметен он в случае небольшого или среднего числа полигонов. Вывод — если хотите воспользоваться благами HSR (к несчастью, у многих чипов, как было выяснено нами в прошлом обзоре на тему DX9, отключенного) — сортируйте сцену перед выводом. Тогда и только тогда вы получите значительное, в несколько раз, преимущество. В случае же вывода несортированной сцены HSR сказывается, но не столь сильно — от единиц до десятка процентов. Впрочем, портальные приложения, так или иначе, сортируют сцену при выводе, а к ним относится подавляющее большинство современных FPS движков. Поэтому, игра с HSR стоит свеч, в первую очередь именно для этого класса игр.
Pixel Shading
В данном тесте участвуют только R300 и NV30 — т.к. аппаратное исполнение версии 2.0 пиксельных шейдеров является минимальным требованием для этого теста. Судите сами: на старой доброй GeForce4 Ti 4600 вкупе с 2 ГГц Pentium 4 программная эмуляция второй версии пиксельных шейдеров выдает порядка одного кадра в две секунды. И это — в маленьком окне.
- Сам тест, шейдеры 2.0:
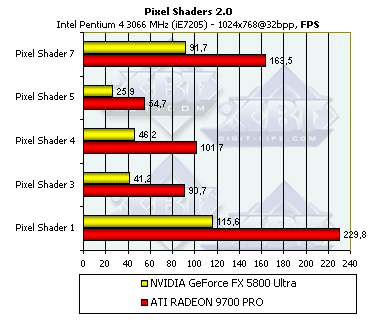
Вот это сюрприз! Если в вопросе сложной, массированной выборки текстур, NV30 была на высоте, демонстрируя порою, чуть ли не двукратное преимущество надо R300, то в вопросе пиксельных вычислений в рамках шейдеров 2.0 она вдвое проигрывает R300! Это прямое следствие того факта, что операции с плавающей точкой выполняются NV30 вдвое медленнее операций с целыми числами. А судя по результатам теста, и вдвое медленнее R300. Что ж, опять таки мы наблюдаем расплату за гибкость. Пиксельный конвейер NV30 гораздо более гибок, он не ограничен требованиями PS 2.0, и допускает использование большого числа команд и констант, в том числе команд с логическими предикатами. Все это очень хорошо, но стоило ли платить такую цену с точки зрения производительности за эти возможности? Ответ: стоило только в том случае, если разработчики будут широко использовать эти дополнительные возможности специфичные для архитектуры NV30. Но будут ли они это делать? Опыт показывает, что разработчики ограничатся наибольшим общим кратным между ATI и NVIDIA, т.е., в данной ситуации, базовой версией PS 2.0, возможно с дополнительными модификаторами из PS 2.X которые поддерживают и R300 и NV30. Но, дополнительные команды и константы, скорее всего, задействованы не будут.
Одна из глубинных причин такого проигрыша NV30 — хранение констант в виде дополнительных команд в коде шейдера. Видимо, эти отводимые под константы команды требуют не только места, но и тактов на исполнение.
- Давайте посмотрим, изменятся ли результаты при форсировании плавающих вычислений с 16 битной (половинной) точностью, возможном в пиксельных шейдерах 2.X:
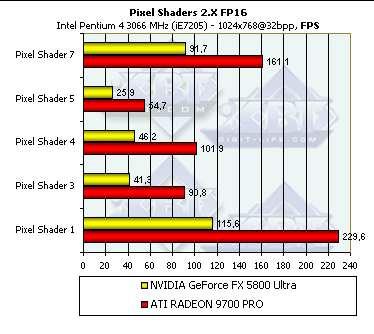
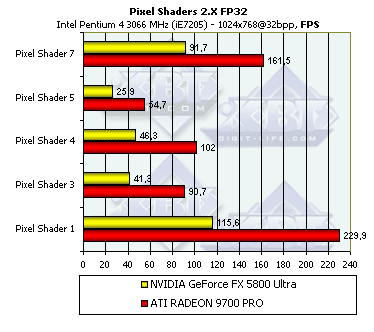
Как видно, никакой разницы — если форсирование половинной точности и происходит реально (в чем есть сомнения), оно не влияет на скорость вычислений. Итак, несомненно, пиксельные шейдеры еще будут совершенствоваться с точки зрения их оптимизации при компиляции в драйверах, но маловероятно, что столь заметное вычислительное преимущество R300 будет преодолено. Ждем R400 и NV40 которые обещают быть не только гибкими, но и чертовски быстрыми в вопросах вычислений пиксельных и вершинных шейдеров.
- На последок проверим зависимость от разрешения для обоих чипов:
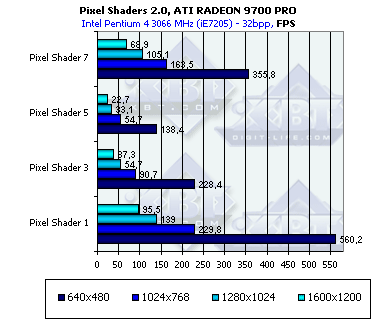
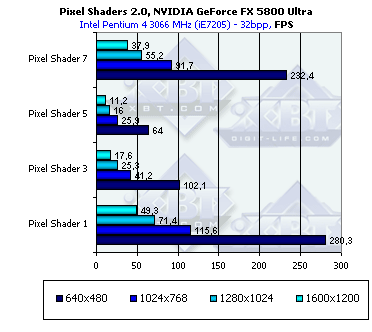
Зависимости совпадают — все зависит только от числа закрашенных пикселей, никаких аномалий не наблюдается.
Point Sprites
Итак, спрайты.
- С освещением и без, в зависимости от размеров:
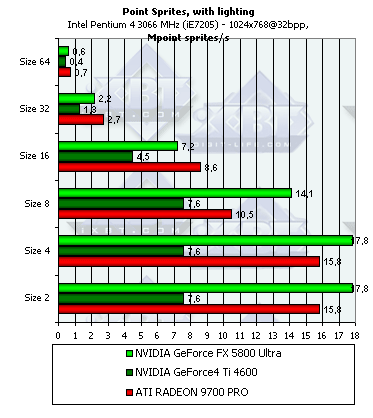
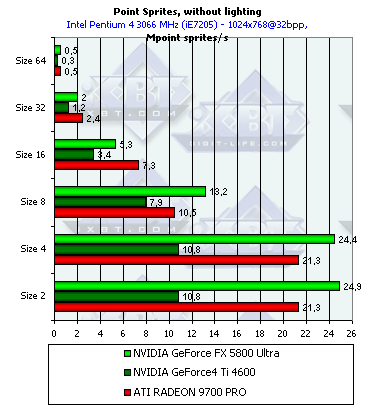
Как и ожидалось наличие или отсутствие освещения сказывается только на маленьких спрайтах, по мере роста размера все упирается в закраску. Происходит это при размере 8 и более. Итак, для вывода систем, состоящих из большого числа частиц, следует признать оптимальными размеры менее 8. До размера 8 включительно NVIDIA показывает себя гораздо лучше ATI — падение не столь заметно, монотонно и не велико. ATI же теряет бодрость духа уже между 4 и 8 и делает это весьма резко. Зато на больших размерах спрайтов проигрывает NV30 — здесь сказывается недостаток ПСП.
Пиковые значения достигаются, разумеется, без освещения, и составляют соответственно чуть более 21 миллионов спрайтов в секунду для RADEON 9700 PRO и чуть более 24 для GeForce FX 5800 Ultra.
Опять-таки отметим уже ранее озвученный вывод, что никакой особой панацеи точечные спрайты нам не приносят — цифры не сильно далеки от тех, что можно получить при помощи обычных полигонов. Впрочем, зачастую само использование точечных спрайтов с точки зрения программирования более удобно, и в первую очередь для всевозможных систем частиц.
- Посмотрим, какую роль сыграет наличие или отсутствие анимации а также версия шейдеров:
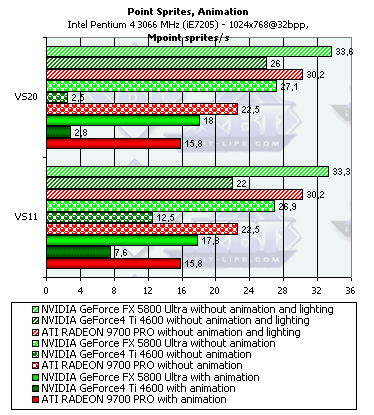
Итак, вклад анимации не столь велик, но заметен, причем вне зависимости от версии вершинных шейдеров.
На этом мы заканчиваем материал, посвященный первому широкому тестированию карт с использованием синтетических тестов для API DX9 из набора RightMark 3D.
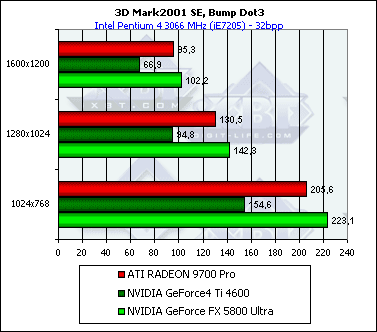
3D-графика, 3DMark2001 SE — синтетические тесты
Подчеркну, что все замеры по всем 3D-тестам проводились в 32-битной глубине цвета.
Скорость закраски
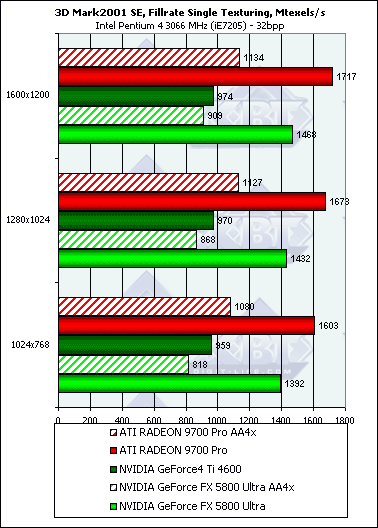
Наблюдается уже хорошо знакомая нам по результатам работы Pixel Filling теста из RightMark 3D зависимость, однако она не столь ярко выражена — добротность теста немного ниже и цифры дальше от предельных значений.
В случае мультитекстурирования:
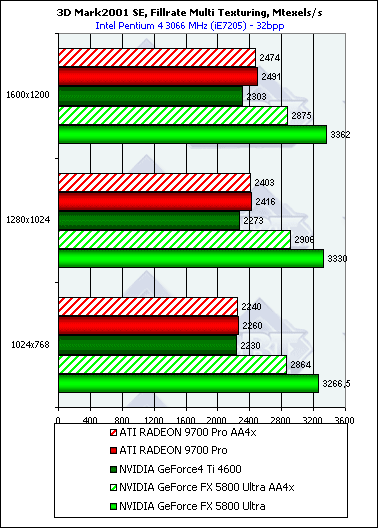
Результаты так же хорошо соотносятся с полученными нами ранее в тестах RightMark 3D. Интересно, что режим AA бьет по NV30 куда как более существенно, нежели по R300 — несмотря на сжатие буфера кадра в режиме MSAA, имеющее место как у R300, так и у NV30, сказывается более узкая ПСП 128 битной шины последней.
Сцена с большим количеством полигонов
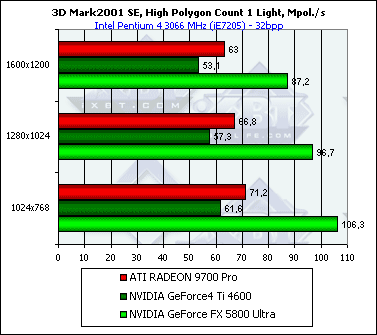
…для одного источника света, и для восьми:
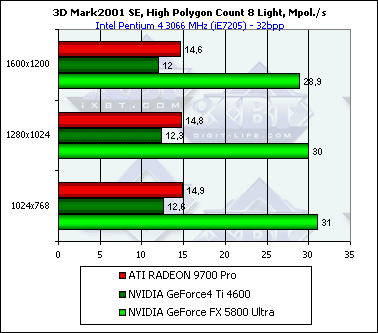
NV30 лидирует, причем отрыв возрастает с увеличением числа источников света, что вполне логично и хорошо согласуется с полученными в Geometry Speed тесте пакета RightMark 3D данными.
Пиксельный шейдер
Простой вариант:
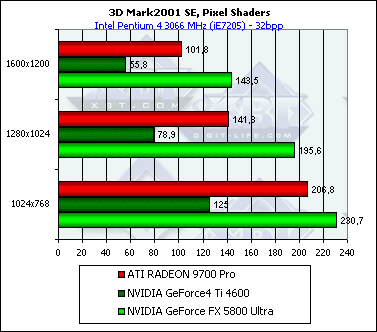
Интересно, что NV30 лидирует в этом тесте. Причина проста — фактически этот тест достаточно интенсивно выбирает текстуры, но при этом производит минимум вычислений, кроме того, все вычисления происходят в целочисленном формате (шейдеры 1.1), NV30 же выполняет целочисленные команды вдвое быстрее, чем плавающие.
Посмотрим, измениться ли картина при условии более вычислительно интенсивных пиксельных шейдеров:
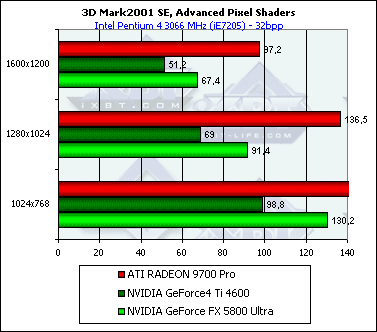
Да, теперь R300 лидирует, лишний раз подтверждая сделанные нами ранее выводы о более слабой вычислительной и более высокой текстурной производительности NV30.
Вершинные шейдеры
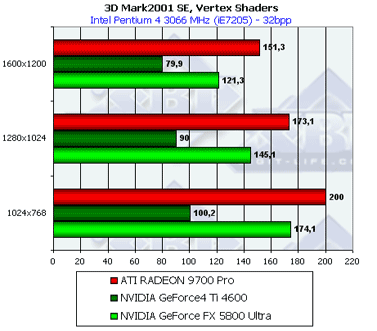
Тест вершинных шейдеров демонстрирует весьма странные с нашей точки зрения результаты. Все наши многочисленные тесты ранее о примерно обратном раскладе. Возможно, роль сыграл слишком короткий шейдер или большая зависимость от скорости закраски (посмотрите как падают результаты с ростом разрешения, причем у NV30 быстрее). Как бы там ни было мы склонны больше доверять предыдущим результатам, полученым на синтетических тестах RightMark 3D, которые не проявляют столь заметной зависимости от разрешения.
Спрайты
Ничего нового.
Рельефное текстурирование
Посмотрим на результаты синтетической EMBM сцены:
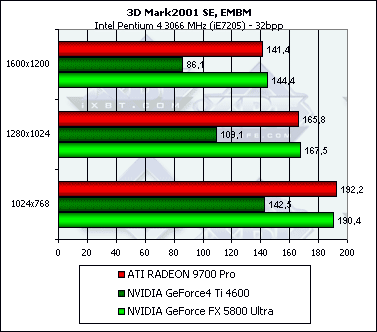
А теперь DP3-рельеф:
Здесь чипы идут нос к носу с небольшим перевесом NV30.
Итак, за исключением отдельных моментов результаты 3D Mark 2001 хорошо согласуются с полученными ранее результатами RightMark 3D, хотя и несут изначально меньше информации ввиду отсутствия каких либо настроек параметров синтетических тестов.
Дополнительная теоретическая информация и выводы из результатов синтетических тестов
Анизотропная фильтрация
Исследуем реализацию анизотропии NV30 в сравнении с R300. Для этого используем специальную программу Xmas, предназначенную для наглядного изучения качества фильтрации:
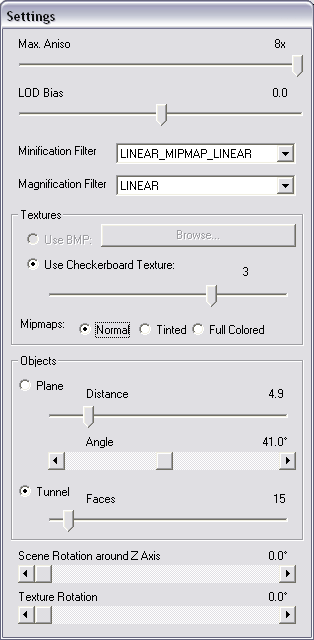
Программа выводит цилиндрический туннель с регулируемым числом граней, что позволяет наблюдать за всевозможными углами поворота относительно нормали к экрану. Остановившись на разумном числе в 15 граней мы получим достаточно четкий набор плоскостей с 5 значениями углов в диапазоне от 0 до 90 град. Итак, для максимального уровня анизотропии, слева R300, справа NV30:
| RADEON 9700 PRO | GeForce FX 5800 Ultra |
|---|---|
 |  |
Хорошо видно, что алгоритм анизотропии NV30 совершенно униформичен по отношению к углу поворота плоскости, при любом угле поворота он дает одинаковую картинку, которая зависит только от наклона плоскости. А вот R300 успешно справляется с углами 0 и 90 градусов, а также, с углами близкими к 45. Все промежуточные углы (20, 30, 60, 70 и т.д.) выглядят гораздо хуже — на них алгоритм ATI работает плохо. Далее мы объясним, почему это происходит. В свою очередь, вспомним, что R200, результаты которого мы здесь не приводим, успешно справлялся только с 0 и 90 градусами.
Теперь давайте посмотрим, как происходит выбор MIP уровней в зависимости от степени анизотропии. Слева R300 справа вновь NV30:
| ANISOTROPIC | RADEON 9700 PRO | GeForce FX 5800 Ultra |
|---|---|---|
| No |  | 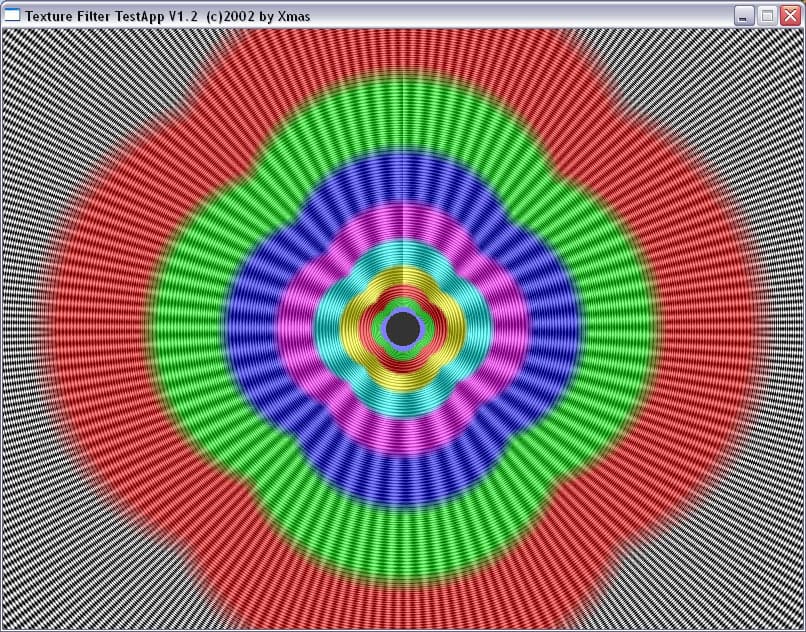 |
| ANISO 2 | 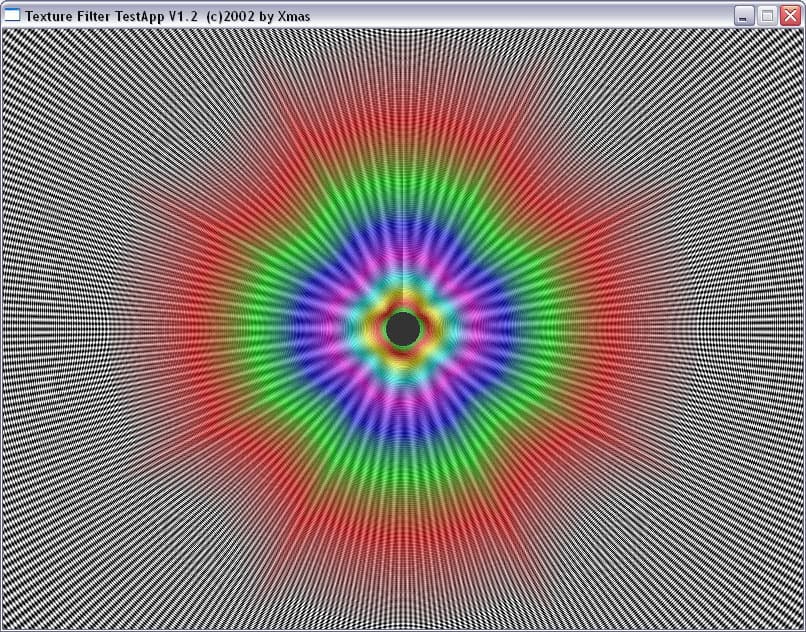 | 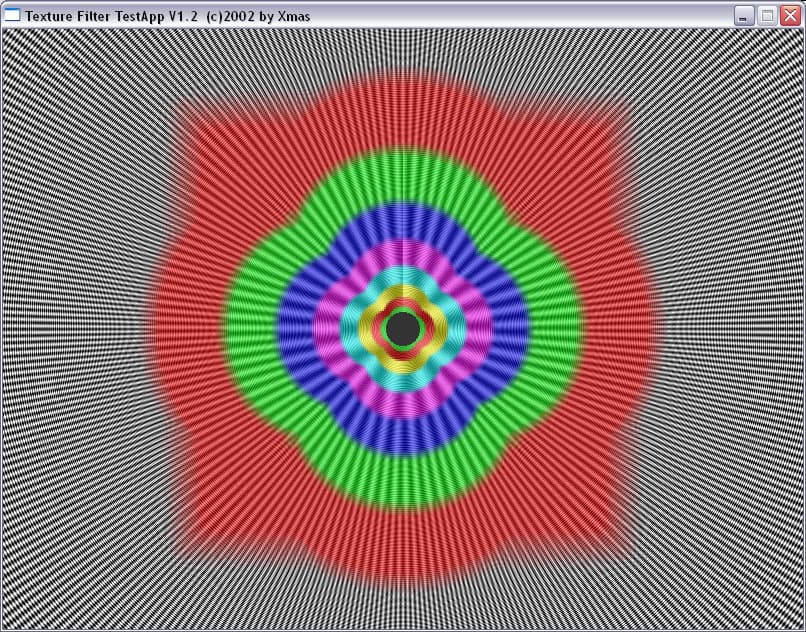 |
| ANISO 4 | 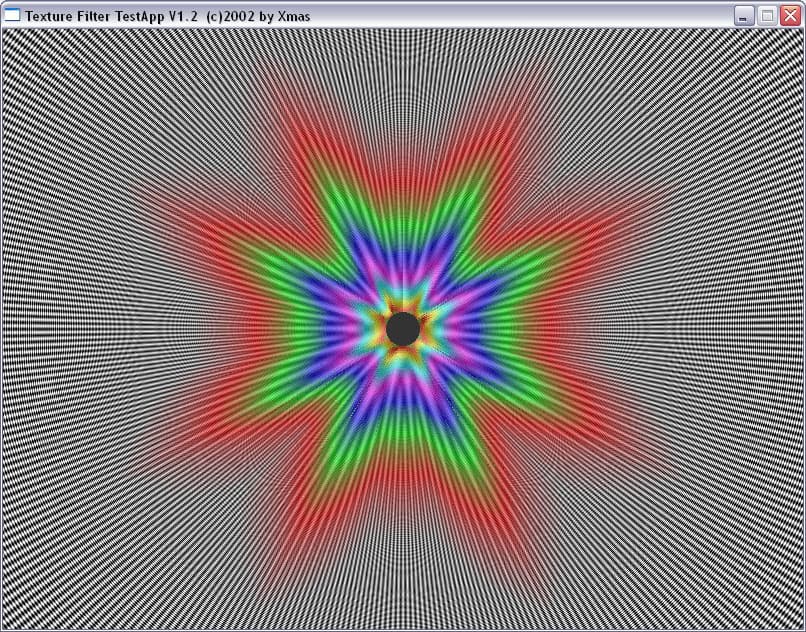 | 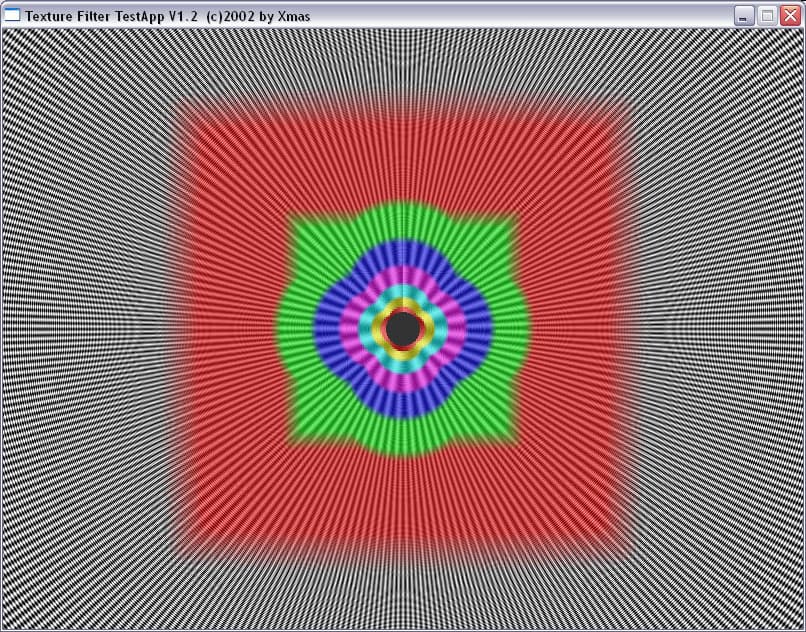 |
| ANISO 8 | 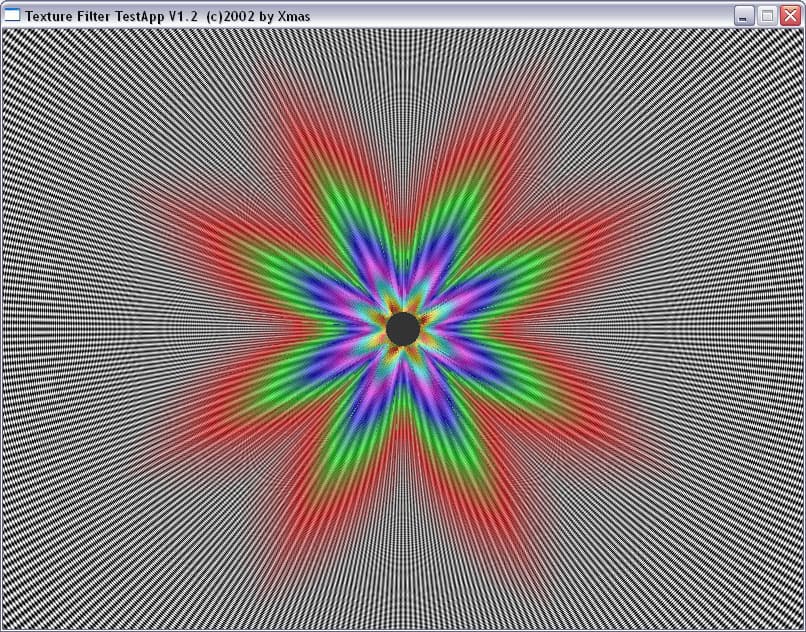 | 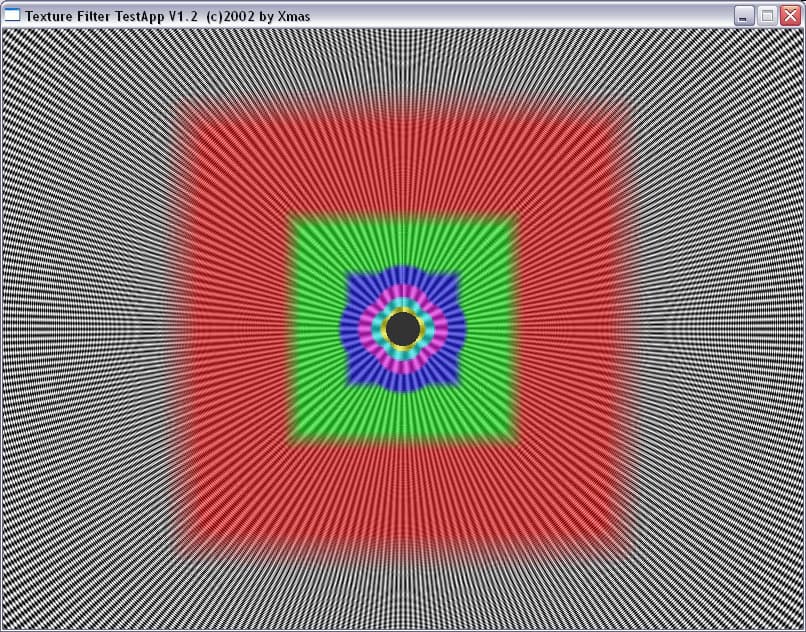 |
| ANISO 16 | 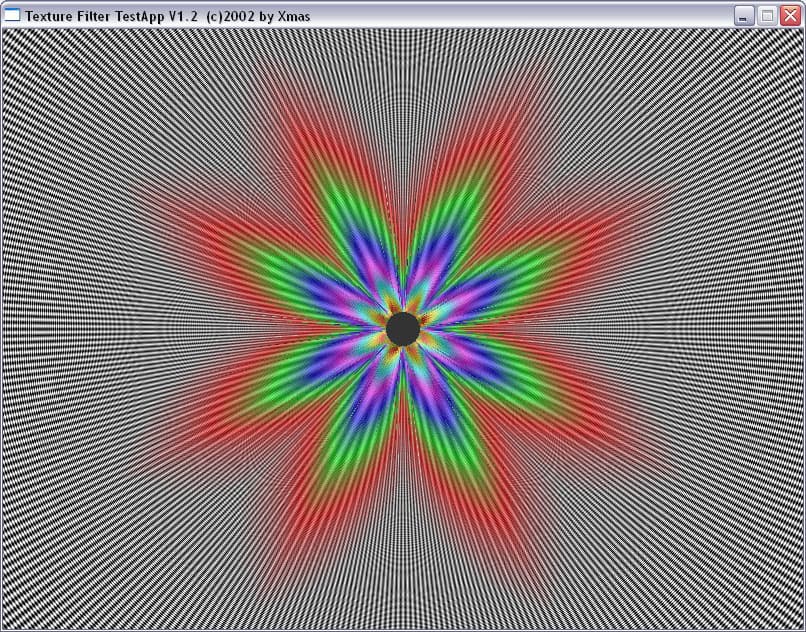 | - |
И здесь на лицо существенные отличия. Если при малом уровне анизотропии алгоритм ATI ведет себя схоже с алгоритмом NVIDIA, обеспечивая достаточно корректный, почти идеально базирующийся на реальном расстоянии выбор MIP уровней (идеальная картинка должна была представлять собою окружности), то по мере роста уровня анизотропии метод NVIDIA и метод ATI дают принципиально разную картинку. Причем, надо отметить, NV30 при больших расстояниях (удаленный конец туннеля) и высоком уровне анизотропии ведет себя более корректно.
Итак, только сегодня и только сейчас. Алгоритмы анизотропной фильтрации NVIDIA и ATI.
NV30
Перед нами плоскость текстуры. С экрана мы наблюдаем эту текстуру под углом. Черная стрелка показывает так называемое направление анизотропии — проекцию направления нашего взгляда на текстуру через плоскость экрана. Тонкие линии показывают границы экранного пикселя, который нам надо закрасить, а точнее его проекции на плоскость текстуры. Звездочки показывают отсчеты, каждый из которых выбирается с использованием билинейной фильтрации. Позиции отсчетов определяются неким псевдослучайным алгоритмом, который стремится более или менее равномерно покрыть отсчетами всю плоскость фигуры в которую проектируется экранный пиксель. Число отсчетов зависит от угла наклона текстуры, чем больше угол, под которым мы на нее смотрим, тем длиннее проекция пикселя и тем больше отсчетов надо выбрать, чтобы получить качественные результаты фильтрации. Также это число зависит от степени анизотропии — чем выше степень, тем больше отсчетов будет выбираться при одинаковом угле наклона. От угла поворота плоскости этот алгоритм не зависит, что мы и наблюдали ранее. Слабое место этого алгоритма — честно выбираемые билинейные отсчеты. MIP уровень текстуры из которого выбираются отсчеты определяется однажды для всего пикселя.
R300
Итак, во первых хочу развеять устоявшийся миф о использовании ATI разновидности RIP-маппинга и дополнительных, сжатых по осям вариантов текстур. Ничего подобного никогда не имело и не имеет места — анизотропная фильтрация работает с такими же исходными текстурами как и в случае продуктов NVIDIA, и никакого дополнительного пространства или предварительного просчета не задействовано. Просто, в корне отлична суть самого алгоритма фильтрации. Во-первых отсчеты выбираются одиночно (по одному значению), а не с предварительной билинейной фильтрацией. Фильтрация осуществляется косвенным путем — алгоритм выбирает из какого MIP уровня следует выбрать каждый отсчет, на данной схеме маленькие квадратики — отсчеты задействованные из более детального MIP уровня а большие — из менее детального. Таким образом, можно выбрать гораздо больше отсчетов, используя те же вычислительные и пропускные ресурсы, но изначально эти отсчеты не будут фильтрованными, что может привести к потере качества. Впрочем, разница не так заметна на глаз, а правильный выбор MIP уровня для каждого отсчета ее еще больше нивелирует (здесь возможно применить некий стохастический алгоритм, чередующий разные уровни для получения более качественной анизотропии и плавных переходов между MIP уровнями, т.е. попутного выполнения трилинейной фильтрации).
Во вторых, на схеме появилась вторая красная стрелка. Она демонстрирует направление, в котором реально выбираются отсчеты. Разрешены только три направления — вертикальное, горизонтальное (пунктиром) и под углом 45 градусов, задействованное в данном случае. Именно поэтому, на промежуточных углах этот метод дает не очень качественные результаты (вспомните программу Xmas). Зато на перечисленных углах поворота он выполняется очень быстро, и с меньшими затратами пропускной полосы памяти или кэша, при схожем уровне визуального качества.
Итак, NVIDIA и ATI избрали различные пути реализации анизотропии. Анизотропия NVIDIA более униформична и академична, если так можно выразится, анизотропия ATI более практична и позволяет при схожих ограничениях выбрать больше отсчетов. До сих пор анизотропия NVIDIA существенно проигрывала ATI по скорости, но в новом чипе NV30 и его драйверах были введены существенные оптимизации, направленные на увеличение производительности без особой потери визуального качества. Увеличение производительности мы уже заметили (см. тест RightMark 3D), справедливости ради отметим что дело не только в оптимизированном выборе числа выбираемых отсчетов и их позиций, но и более высокой тактовой частоте ядра чипа. А насколько эти оптимизации отразятся на качестве, мы увидим далее, на примере скриншотов реальных приложений.
Полноэкранное сглаживание
Как мы уже упоминали в аналитическом обзоре NV30, в наличии все тот же базовый MSAA 4х мультисэмплинг и различные гибридные режимы на его основе (6xS и 8x).
Самая интересная для сегодняшних применений особенность GeForce FX сжатие буфера кадров. Сжимаются не только значения глубины, но и значения цвета. По заявлениям NVIDIA алгоритм сжатия работает без потерь. Он основан на том факте, что в MSAA режимах большинство блоков сглаживания в буфере кадра не находится на границах треугольников и поэтому содержать одинаковые значения цвета.
Само по себе сжатие буфера кадра несет множество плюсов:
- Возможность быстрой очистки буфера кадра, так же как это было возможно ранее для буфера глубины.
- Существенная экономия пропускной полосы памяти, особенно вкупе с использованием сжатых текстур.
- В высоких разрешениях и особенно при использовании тройной буферизации кадра будет крайне ощутима экономия свободного места в локальной памяти, в которое смогут поместится дополнительные текстуры и геометрические данные, существенно разгрузив таким образом AGP шину и следовательно скачкообразно увеличив производительность.
- И, наконец, практически вдвое увеличит эффективность использования доступной полосы локальной памяти, став, таким образом, основным аргументом за использование 128 бит шины памяти без риска разгромного проигрыша конкурирующим 256 бит решениям.
Кстати, мы уже убедились, то R300 также поддерживает технику сжатия цветовой информации в буфере кадра.
Вспомним, как выполняется уже привычный нам MSAA. Никаких дополнительных вычислений не надо все отсчеты в пределах блока сглаживания формируются из одного вычисленного пиксельным шейдером результата. Единственная причина падения производительности необходимость пересылать увеличенный в разы (согласно установке сглаживания при 4х буфер кадра будет вчетверо больше при 2х — вдвое) буфер кадра туда и обратно. Но, при этом в том же режиме 4х в подавляющем большинстве блоков сглаживания присутствуют два или чаще одно (!) уникальное значение цвета. Блоки, в которых три или четыре значения уникальны надо еще поискать. Грех не воспользоваться подвернувшейся возможностью и не закодировать информацию такого MSAA буфера эффективно записав только реально присутствующие отличные цвета.
Таким образом, мы практически полностью (останутся считанные проценты дополнительных данных) компенсируем увеличение буфера при включении MSAA. Будет ли так на практике? Посмотрим ниже.
GeForce FX включает новый гибридный режим MSAA названный 8хS и новый гибридный MSAA режим 6xS. Впрочем, эти режимы являются комбинацией SS и MS сглаживания — за основу по прежнему, как и в NV25 берутся два типа базовых 2х2 блоков MSAA — 2х с диагональным расположением семлов и 4х, отсчеты из которых затем усредняются по с использованием того или иного паттерна, так же как и в предыдущем поколении. Т.е. чип как и NV25 может записывать до 4 MSAA семплов из одного вычисленного пиксельным шейдером значения. Отсюда и приводимый коэффицент сжатия 4:1. Как вы уже догадались для режимов FSAA имеющих в своей основе MSAA 2х блоки этот коэффицент будет 1:2.
Итак, главная надежда создателей GeForce FX возложена на сжатие буферов глубины и кадра, особенно в FSAA режимах. Факт принятия на вооружение 128 битной шины может служить косвенным показателям того, что ставка на сжатие весьма сильна. Но оправдана ли? Предварительные результаты синтетических тестов уже заставили нас засомневаться в оправданности 128 битной шины.
Архитектурные особенности и перспективы
Итак, подведем краткий итог по детальному исследованию различных блоков NV30 с помощью синтетических тестов, а также немного заглянем в будущее.
| Слабые стороны | Сильные стороны |
|---|---|
| Узкая шина памяти (сказывается на FSAA) | Высокая скорость вершинных вычислений, там где это не касается циклов и условий |
| Низкая скорость пиксельных вычислений, а также схема 4x2 в большинстве игр | Высокая скорость выборки и фильтрации текстур |
| Расплата за гибкость — снижение скорости вершинных вычислений на циклах и переходах | Значительно ускоренная анизотропная фильтрация |
В первую очередь NVIDIA следует устранить самое узкое место — пропускную полосу 128 битной шины. Очень вероятно, что следующий топовый продукт — NV35 будет снабжен 256 битной DDR2 шиной, и один этот факт способен поднять его производительность в реальных приложениях в режимах с FSAA в полтора раза (!). Кроме того, необходимо довести число пиксельных процессоров до 8 либо снабдить каждый из них двумя плоавающими ALU для выполнения операций шейдеров 1.4 и 2.0. По полной программе, для плавающих пиксельных вычислений будет оптимизирован видимо только NV40, но и NV31/35 могут получить какие либо оптимизации на этот счет, например второе плавающее ALU или истинные 8х1/4х1 конфигурации.
Можно похвалить NVIDIA за две вещи — чрезвычайно эффективные текстурные блоки, особенно хорошо справляющиеся с задачей интенсивной выборки множества текстур, и существенно возросшую эффективность анизотропной фильтрации. Еще один приятный пункт — наконец то в наличии реально действующий HSR.
Ну, и наконец, следует посетовать на то, что ничего в этом мире не дается бесплатно. Дополнительная функциональная гибкость заложенная в вершинные (дианмические переходы и циклы) и пиксельные (длинные шейдеры и большое число констант, а также предикаты) процессоры, заставила расплатиться производительностью. И если в случае вершинных это не так заметно, то в случае пиксельных — может послужить слабым местом архитектуры в будущих приложениях. С другой стороны, только такая гибкость пиксельных процессоров может открыть этому чипу дорогу в Голливуд (реалистические эффекты и рендеринг "почти в реальном времени"). Что ж, будем надеяться, что выход новых драйверов способен улучшить ситуацию с пиксельными шейдерами. Также, как и с вершинными 2.0. Это будет важно не только для NV30, но и для всех чипов архитектуры NV3х, мейнстрим представители которых (NV31/34) получат широкое распространение и обречены на долгую жизнь.
3D-графика, 3DMark2001 — игровые тесты
3DMark2001, 3DMARKS
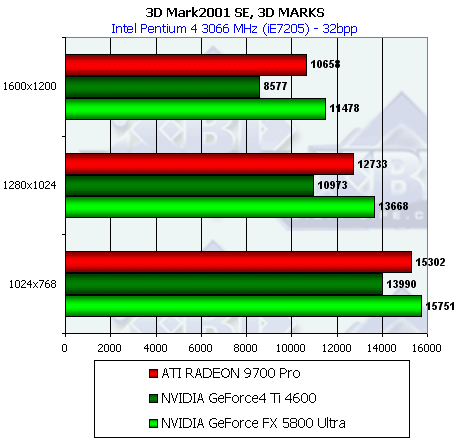
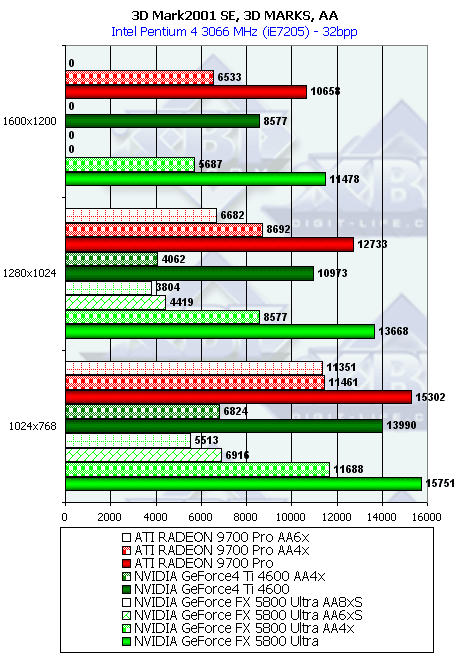
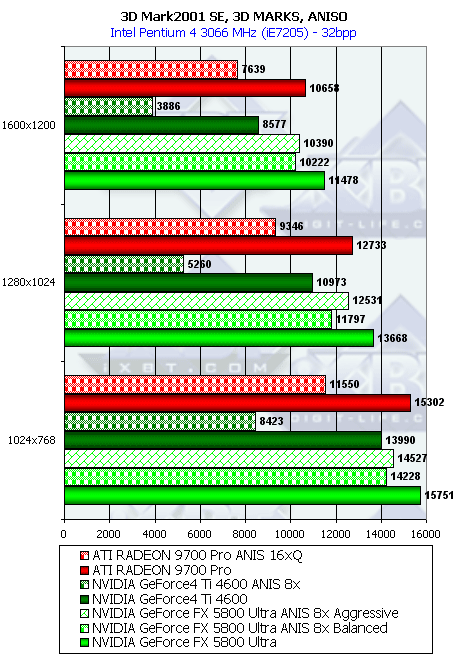
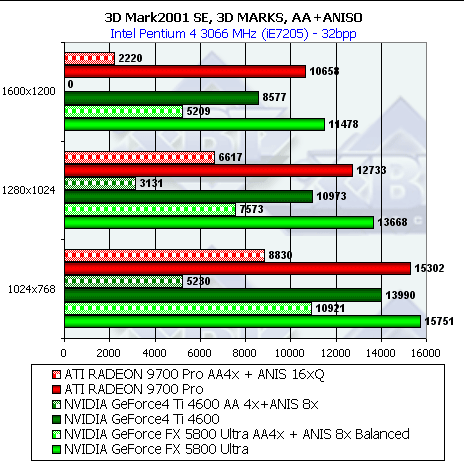
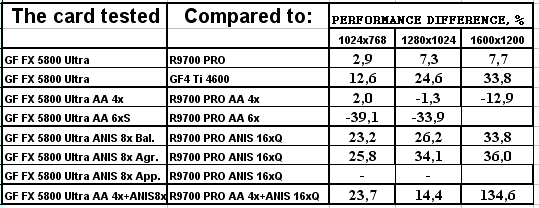
Как и следовало ожидать, мы видим у GF FX подчас прогрыш в тяжелых режимах АА, но в целом перевес на стороне детища NVIDIA, особенно в самом тяжелом режиме: АА плюс анизотропия. Да, более быстрая анизотропка очень помогает.
Если кто хочет проценты перевести в "разы", то надо к процентам прибавить 100 и все разделить на 100.
3DMark2001, Game1 Low details
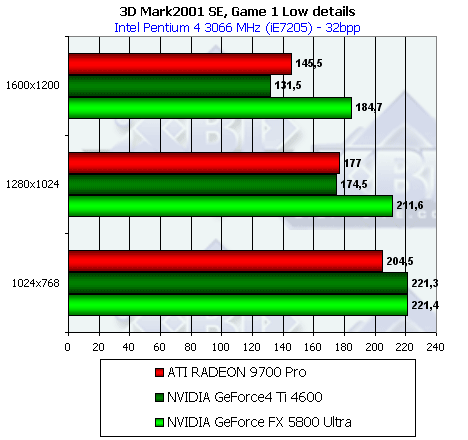
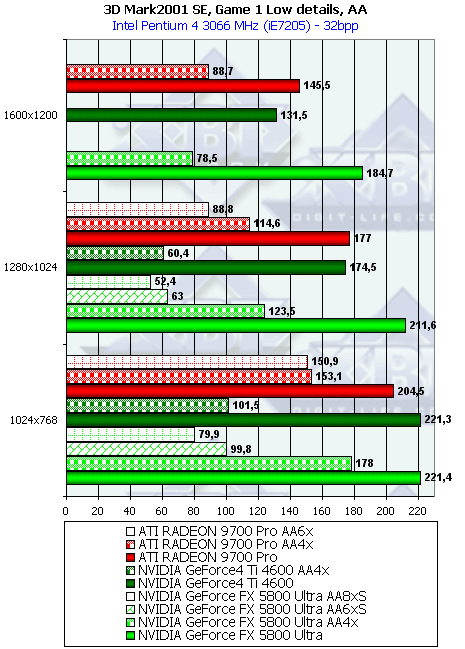
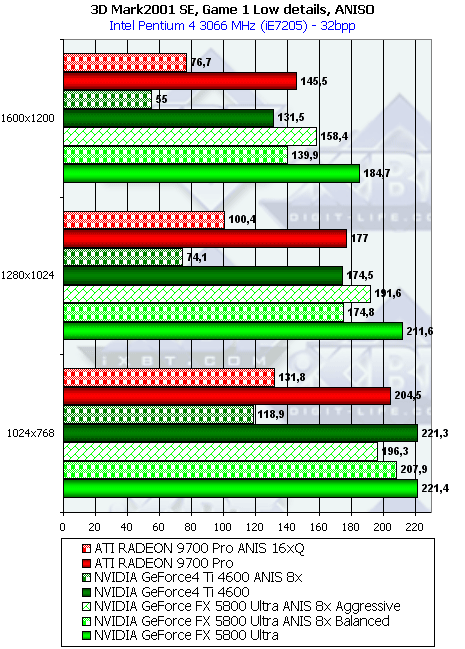
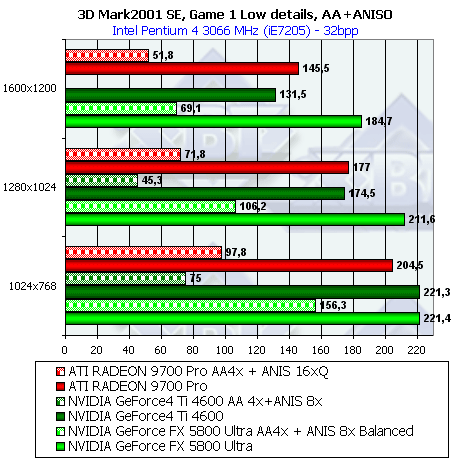
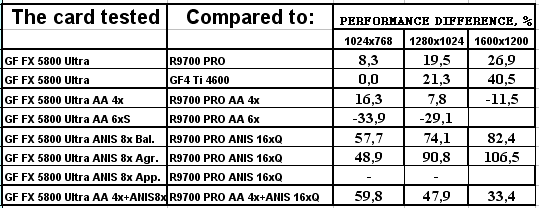
Мы видим очень хороший результат при работе с анизотропией, небольшой перевес без нагрузок и прекрасную победу над R9700Pro в самом тяжелом режиме АА с анизотропкой. Разумеется, АА 6xS показал хилость ПСП у NV30, вследствие чего провал.
3DMark2001, Game2 Low details
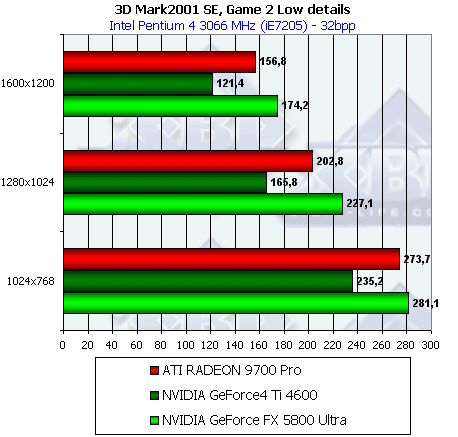
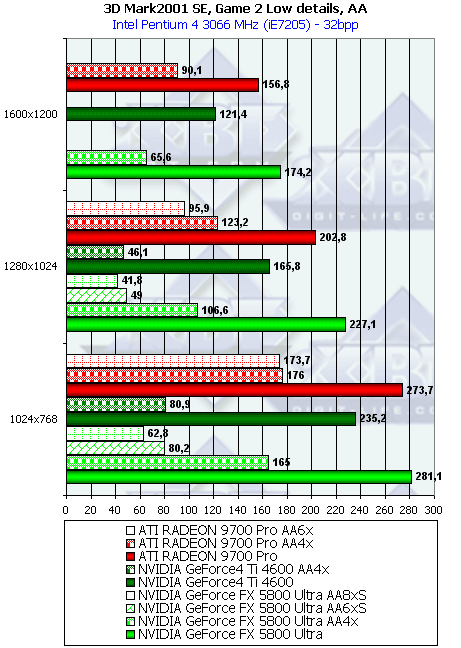
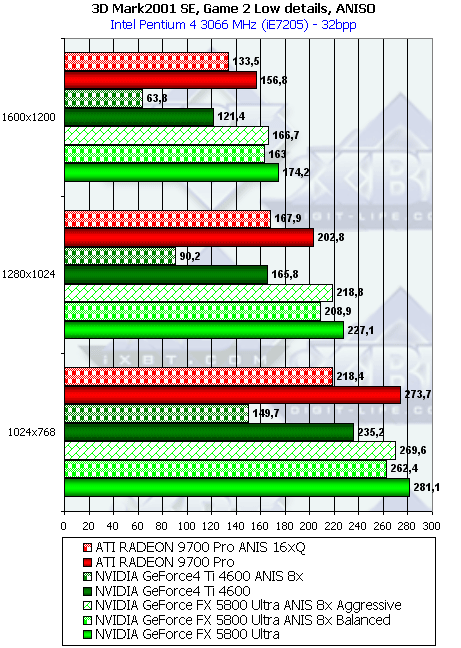
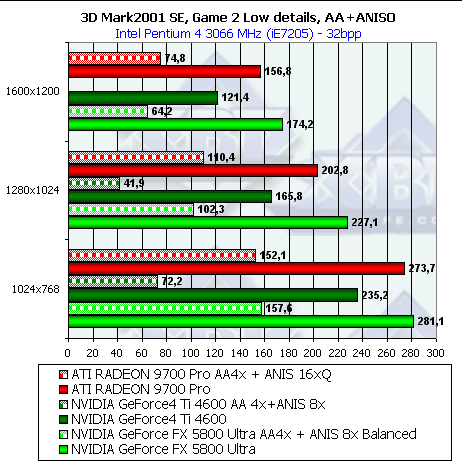
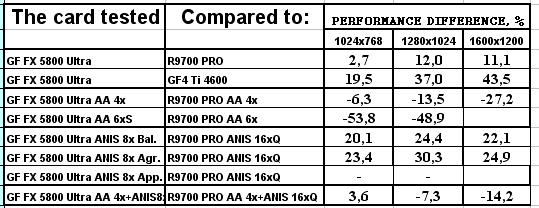
Несмотря на успех при работе с анизотропной фильтрацией, в целом перевес очень мал, а в высоких разрешениях и вовсе поражение в тяжелых режимах (очевидно, что вниз тянет проигрыш с АА).
3DMark2001, Game3 Low details
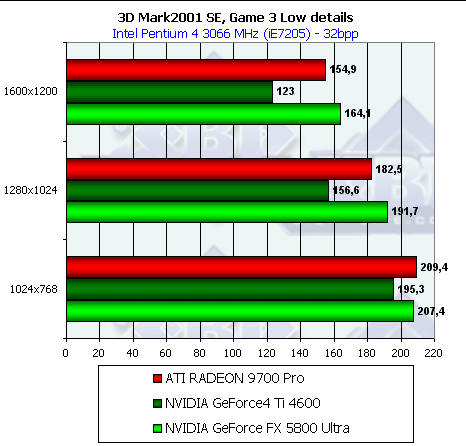
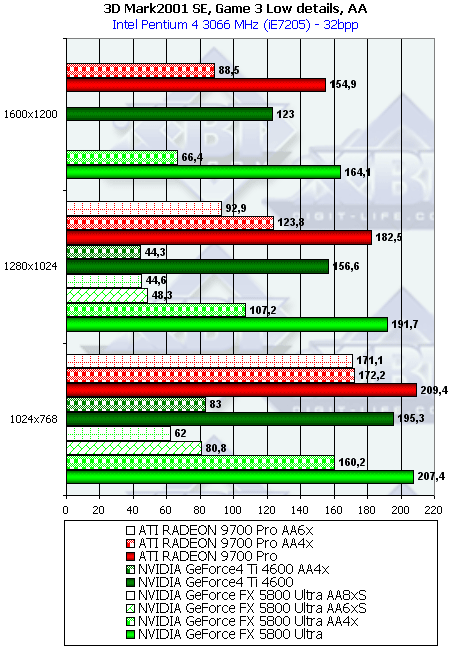
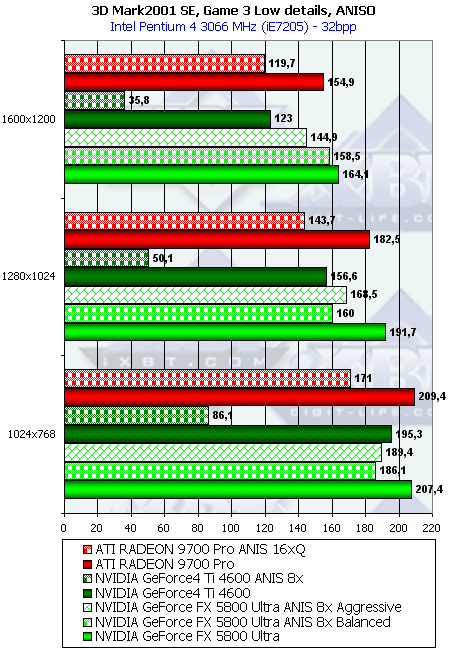
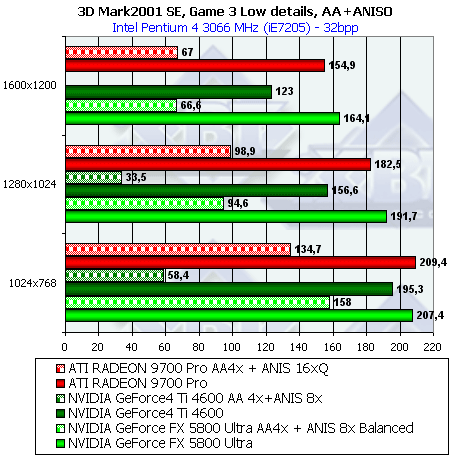
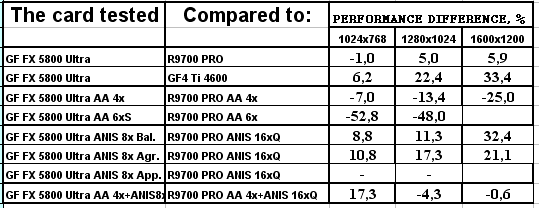
Картина аналогичная.
3DMark2001, Game4
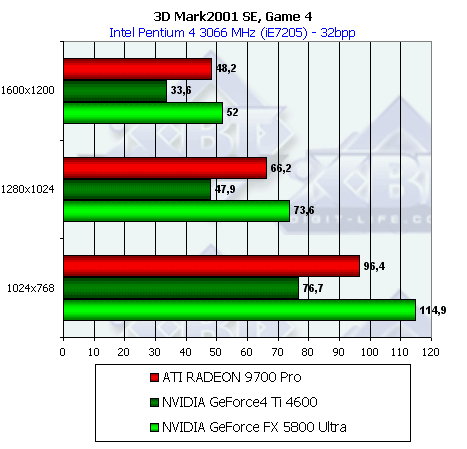
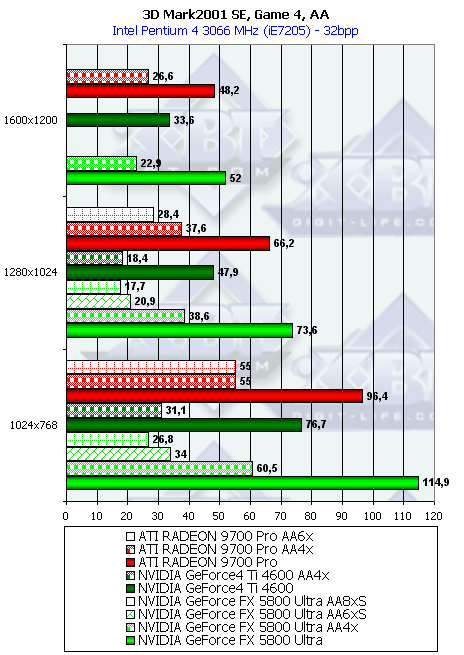
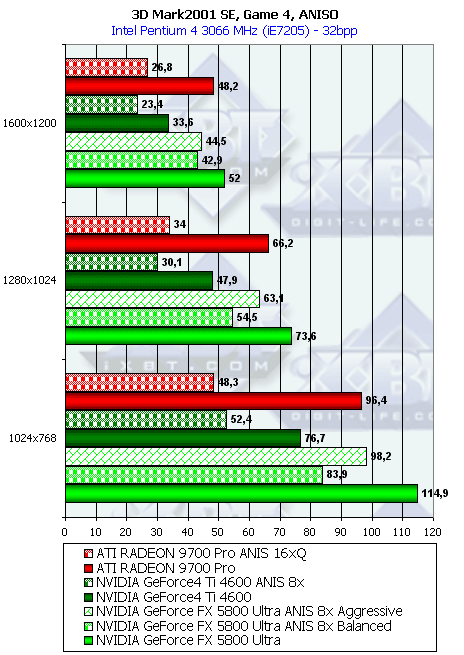
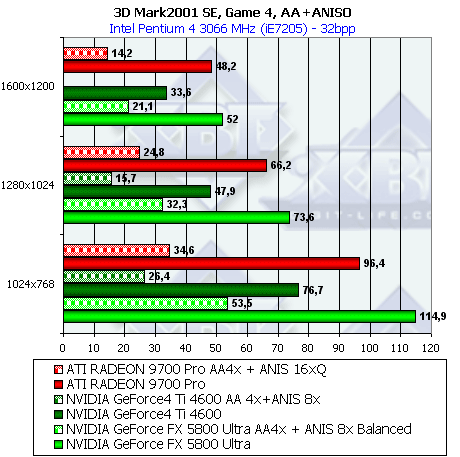
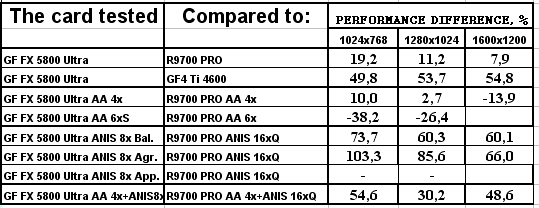
А вот здесь для NV30 все весьма радужно (кроме плачевной ситуации с тем же AA 6xS — разумеется, виновато смешение более быстрого MSAA и крайне тормозного SSAA).
Подводя итоги тестированию в 3DMark2001SE, можно сказать, что в целом NV30 показал неплохие результаты. Разумеется, мы все ожидали большего, учитывая разницу в тактовых частотах, однако то бремя "бутылочного горла", которое снова одела на свой продукт NVIDIA, сказывается и весьма фатально. Где же обещанное сжатие буфера кадра при АА, и супер-скорости? Пока, увы, оно видно разве лишь в режиме 4х. Впрочем, на сегодня и такого режима вполне достаточно. А на качество мы посмотрим ниже.
3D-графика, 3DMark03 — игровые тесты
Совсем недавно вышел долгожданный сиквел пакета 3DMark — 3DMark03.




Думаю, что нет нужды расписывать переживания по его ожиданию и чувства, образовавшиеся после его запуска. Мы этот пакет еще рассмотрим более детально в одной из наших будущих статей. Ныне посмотрим на итоговый результат:
3DMark03, 3DMARKS
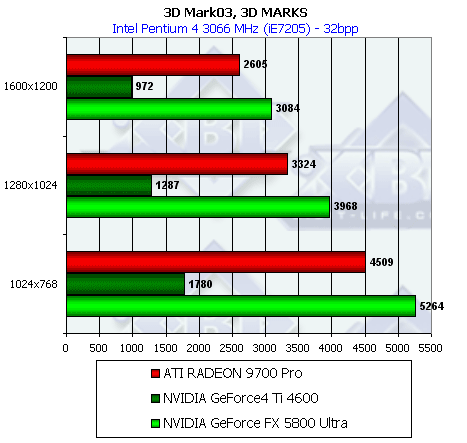

В целом NV30 держится молодцом. Но засчет чего? Давайте не будем спешить, пройдем по четырем игровым тестам, входящими в него. А в конце подведем итоги, а также поразмышляем о том, во что ныне превратился 3DMark.
3DMark03, Game1
Характеристики теста Wings of Fury:


- DirectX 7.0 тест; примерно 32000 полигонов в сцене, под текстуры используется 16 мегабайт видеопамяти, 6 мегабайт для буферов под вершины и 1 мегабайт для индексов.
- Все геометрические операции базируются на использовании вершинных шейдеров 1.1, которые могут эмулироваться через CPU (если "железо" не поддерживает аппаратно).
- Все самолеты выполнены с помощью 4-х текстурных слоев, поэтому акселераторы, умеющие обрабатывать 4 текстуры за проход, будут в выигрыше.
- Эффекты дыма и шлейфов выполнены с помощью техник точечных спрайтов и др.
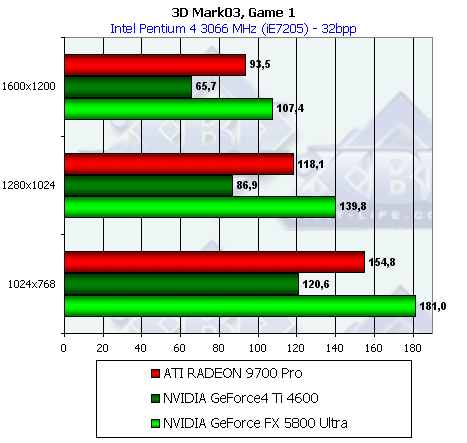

Думаю, что даже нечего рассуждать, ибо тест для таких карт весьма прост.
3DMark03, Game2
Характеристики теста Battle of Proxycon:


- DirectX 8.1 тест; примерно 250 000 полигонов в сцене при использовании пиксельных шейдеров 1.1 (и 150 000 полигонов — если используются шейдеры 1.4), под текстуры используется 80 мегабайт видеопамяти, 6 мегабайт для буферов под вершины и 1 мегабайт для индексов.
- Все геометрические операции базируются на использовании вершинных шейдеров 1.1, которые могут эмулироваться через CPU (если "железо" не поддерживает аппаратно).
- Все персонажи "одеты" также с помощью вершинных шейдеров.
- Некоторые источники света производят динамические тени, получаемые при помощи стенсил-буфера.
- Все пиксельные операции производятся с помощью шейдеров 1.1, или, если это возможно, 1.4.
- Вычисление попиксельного освещения для эффектов дымок, и других компонентов.
- Акселераторы, поддерживающие пиксельные шейдеры 1.1, используют один проход для определения Z-буфера, затем по три прохода на каждый источник света. Если акселератор поддерживает шейдеры 1.4, то ему требуется всего по одному проходу на каждый источник света.
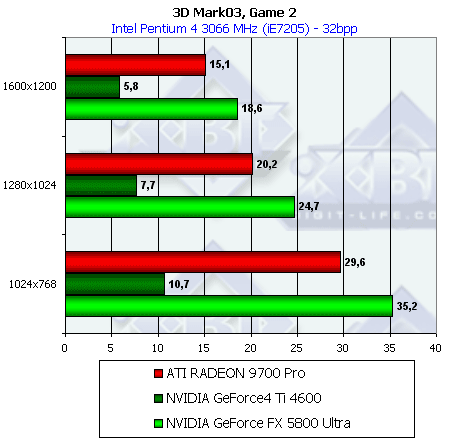

Картина аналогичная по соотношению сил. И разумеется, фатальная для GeForce4 Ti (причины все на ладони, если почитать спецификации этого теста).
3DMark03, Game3
Характеристики теста Trolls' Lair:


- DirectX 8.1 тест; примерно 560 000 полигонов в сцене при использовании пиксельных шейдеров 1.1 (и 280 000 полигонов — если используются шейдеры 1.4), под текстуры используется 64 мегабайт видеопамяти, 19 мегабайт для буферов под вершины и 2 мегабайта для индексов.
- Все геометрические операции базируются на использовании вершинных шейдеров 1.1, которые могут эмулироваться через CPU (если "железо" не поддерживает аппаратно).
- Все персонажи "одеты" также с помощью вершинных шейдеров.
- Некоторые источники света производят динамические тени, получаемые при помощи стенсил-буфера.
- Все пиксельные операции производятся с помощью шейдеров 1.1, или, если это возможно, 1.4.
- Вычисление попиксельного освещения для эффектов дымок, и других компонентов.
- Для реалистичного отображения волос героини используются физические модели, а также анизотропное освещение.
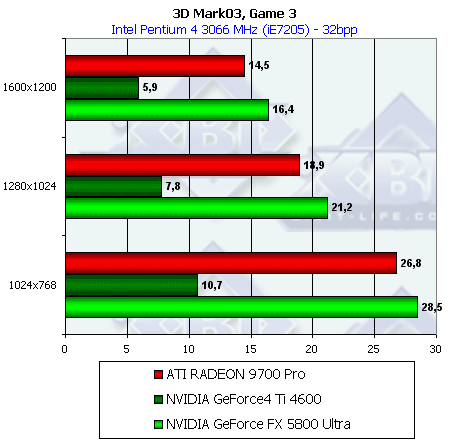

Данный тест уже посложнее, и NV30 едва-едва удерживает первенство.
3DMark03, Game4
Характеристики теста Mother Nature:





- DirectX 9.0 тест; примерно 780 000 полигонов в сцене, под текстуры используется 50 мегабайт видеопамяти, 54 мегабайт для буферов под вершины и 9 мегабайт для индексов.
- Каждый лист на деревьях отдельно анимирован при помощи вершинных шейдеров 2.0. Трава анимирована с помощью вершинных шейдеров 1.1.
- Поверхность озера образована при помощи пиксельных шейдеров 2.0.
- Небо также получено при помощи пиксельных шейдеров 2.0, для солнечных бликов используется реализованная в DX9 повышенная точность расчетов.
- Поверхность земли получена с помощью шейдеров 1.4.
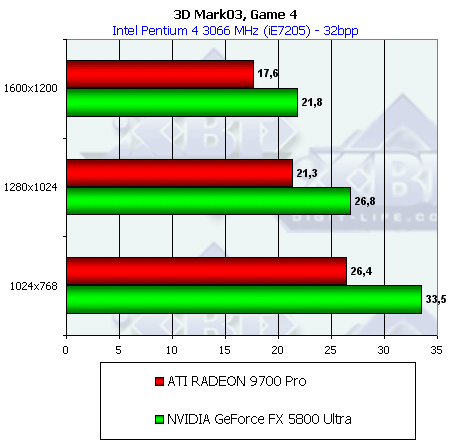

Что мы видим? Противоречивую картину. Пиксельные шейдеры 2.0 у NV30 весьма небыстры, однако в этом тесте преимущество у детища NVIDIA весьма хорошее. Засчет чего? Вот тут мы переходим к анализу в целом по 3DMark03.
Как мы видим, 3DMark03, вопреки ожиданиям, не стал полноценным DirectX 9.0 или хотя бы DirectX 8.1 пакетом, поскольку есть в его составе тесты как под DirectX 7.0, так и неполноценные DX9 тесты (Game 4 — не везде шейдеры 2.0 применяются). Да, безусловно, пакет очень тяжел для нынешних акселераторов, особенно для прошлых поколений. Авторы, как обычно, делают тест "на вырост". Но будет ли этот самый вырост? Ведь стоит подумать о том — а отражает ли, или будет в ближайшем времени отражать 3DMark03 реалии игрового мира? Будут ли выходить игры, движки которых хоть чем-то станут походить на техники из этого пакета? — Сомневаемся. Если уж 3DMark2001 был достаточно оторван от реалий, но все же худо-бедно отражал какие-то технологии, применяемые разработчиками игр (игра Max Payne выполнена на движке, который использовался как основа для 3DMark2001), то 3DMark03 — это вообще нечто отдельное: вещь в себе. Да, разумеется, мы, как и иные многие тестеры, будем использовать этот пакет для тестирования видеокарт: с целью определения соотносительных оценок. Однако все же, как нам кажется, стоит еще и еще раз издавать "глас вопиющего в пустыне", направленный к издателям современных игр: делайте же вы бенчмарки в играх! Все разработчики пользуются давно инструментами бенчмарков для внутренних целей. Только лишь издатели стоят на пути: не хотят, чтобы программисты тратили время на отладку и вынос на публику демок и бенчмарков на их основе.
Есть и другой момент. Вот вы сейчас посмотрели на результаты NV30 в этом пакете. Порадовались за карту. А еще дня три назад не было драйверов 42.68, а были только 42.63, на которых NV30 полностью провалила все тесты, отдав лидерство RADEON 9700 PRO. Программисты из NVIDIA доказали, что заточить драйвер под конкретный тест — им пара пустяков: драйвер 42.68 дал сильный прирост скорости в 3DMark03 (общие баллы подскочили с 3500 до 5264), при этом в играх скорость практически не изменилась, как и в 3DMark2001. Да, завтра программисты из ATI решат сделать то же самое, и скорость RADEON 9700 может вырасти в тех же пределах. Потом снова NVIDIA, и так далее. Поэтому мы рекомендуем читателям хорошо подумать — что же на самом деле отражает 3DMark?
Мы не хотим заниматься саморекламой, но все же напомним, что у нас есть тест — RightMark 3D, который базируется исключительно на референс-технологиях из DirectX. Мало того, мы предлагаем вместе с самим тестом и исходные коды программ, чтобы знатоки программирования могли оценить вышесказанное. К сожалению, пока это только синтетические тесты, но не за горами и выход игровых тестов в рамках этого пакета.
3D-графика, игровые тесты
Приступаем к оценке производительности видеокарты в 3D-играх. В качестве инструментария мы использовали:
- Return to Castle Wolfenstein (MultiPlayer) (id Software/Activision) — OpenGL, мультитекстурирование, Checkpoint-demo, настройки тестирования — все на максимально возможном уровне, S3TC OFF, конфигурации можно скачать тут
- Serious Sam: The Second Encounter v.1.05 (Croteam/GodGames) — OpenGL, мультитекстурирование, Grand Cathedral demo, настройки тестирования: quality, S3TC OFF
- Quake3 Arena v.1.17 (id Software/Activision) — OpenGL, мультитекстурирование, Quaver, настройки тестирования все на максимальном уровне: уровень
детализации High, уровень детализациитекстур №4, S3TC OFF, плавность кривых поверхностей резко увеличена при помощи переменныхr_subdivisions "1" иr_lodCurveError "30000" (подчеркну, что по умолчанию r_lodCurveError "250" !), конфигурации можно скачать тут - Unreal Tournament 2003 Demo (Digital Extreme/Epic Games) — Direct3D, Vertex Shaders, Hardware T&L, Dot3, cube texturing, качество по умолчанию
- Code Creatures Benchmark Pro (CodeCult) игровой тест, демонстрирующий работу платы в DirectX 8.1, Shaders, HW T&L.
- AquaMark (Massive Development) игровой тест, демонстрирующий работу платы в DirectX 8.1, Shaders, HW T&L.
- RightMark 3D v.0.4 (одна из игровых сцен) — DirectX 8.1, Dot3, cube texturing, shadow buffers, vertex and pixel shaders (1.1, 1.4).
Quake3 Arena, Quaver
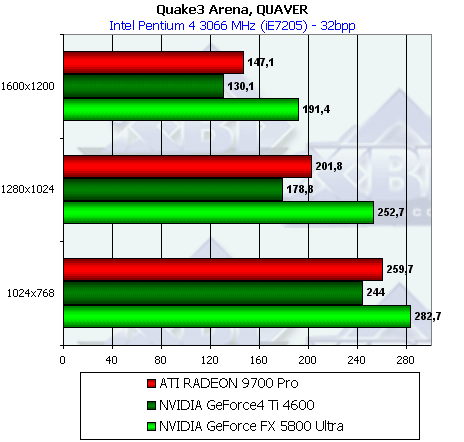
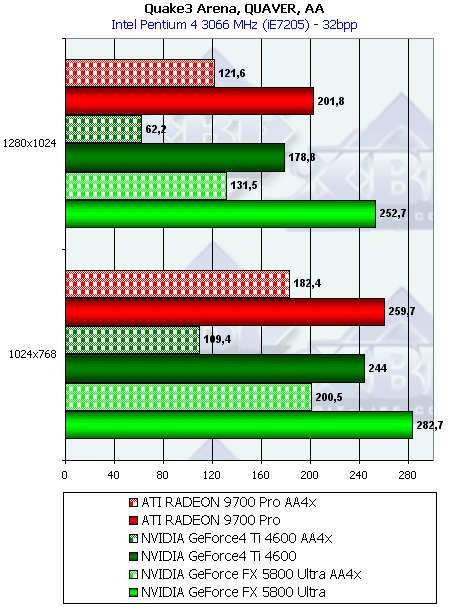
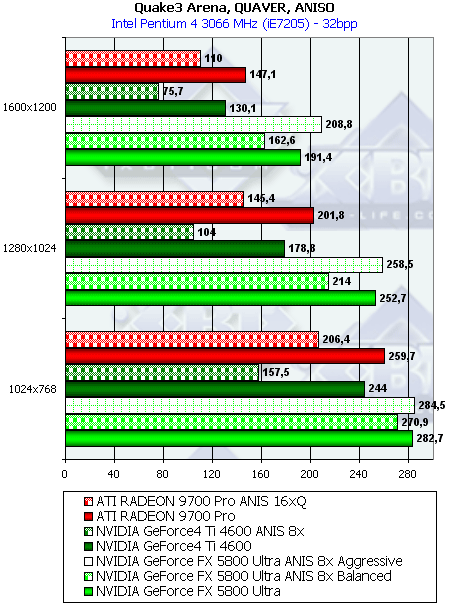
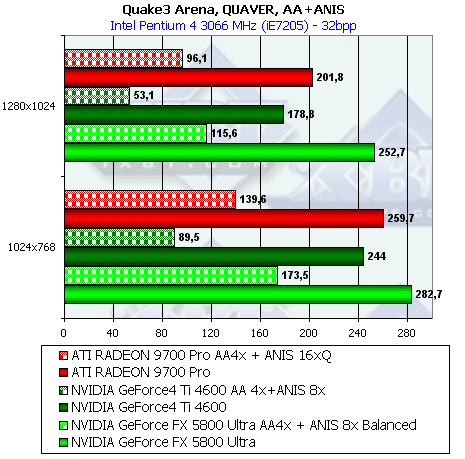
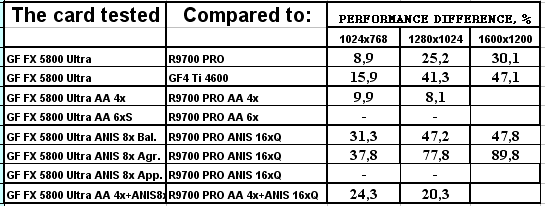
Как и следовало ожидать, заточка OpenGL-драйвера под эту игру у NVIDIA великолепная. Хотя у ATI тоже все не так плохо, перевес на стороне NV30
Serious Sam: The Second Encounter, Grand Cathedral
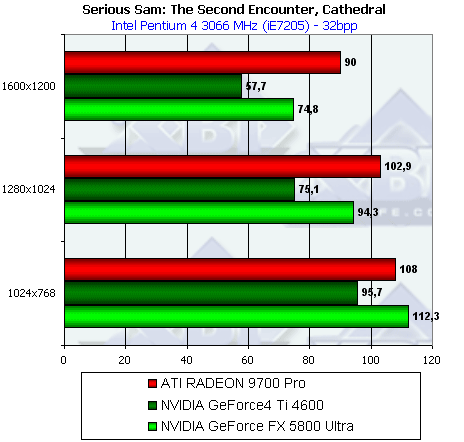
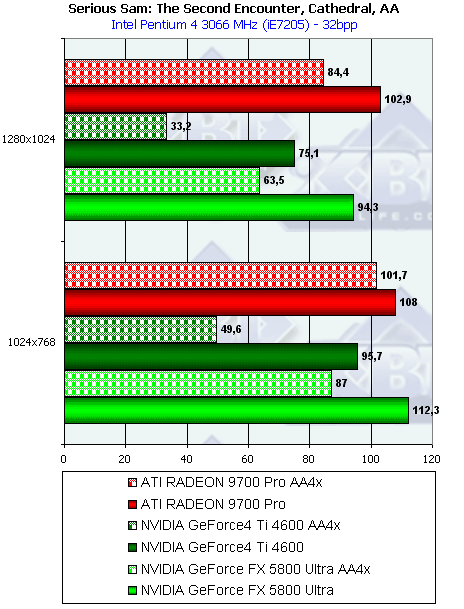
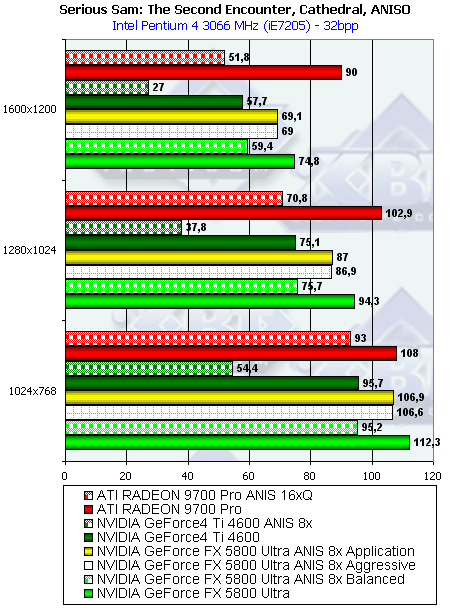

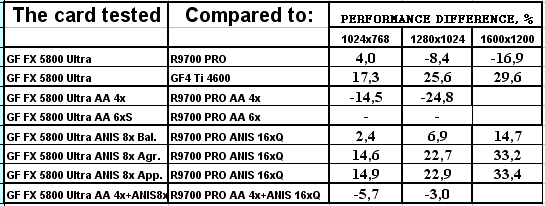
А здесь картина обратная. Если без нагрузки худо-бедно NV30 выиграл сражение, то потери в АА привели карту к полному поражению в тяжелых режимах.
Return to Castle Wolfenstein (Multiplayer), Checkpoint
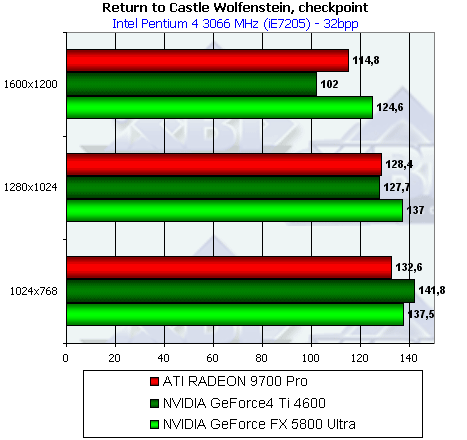
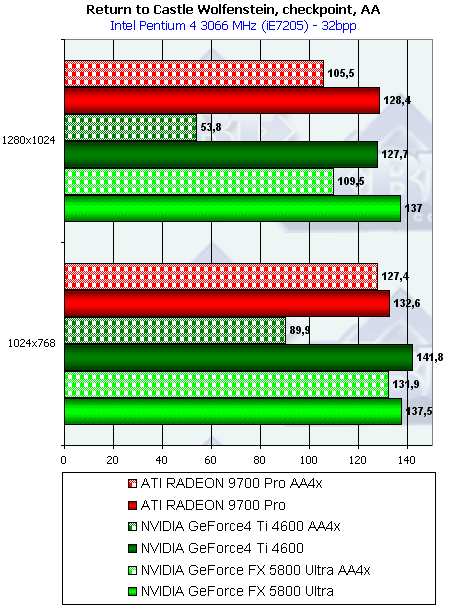
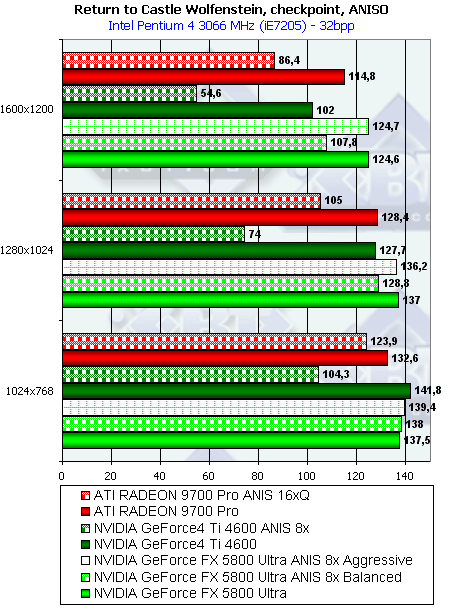

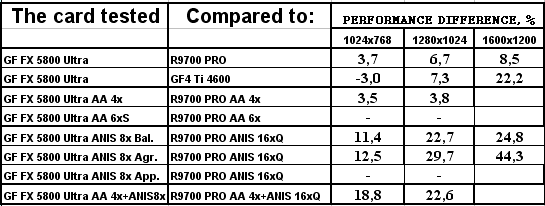
Игра достаточно процессорозависимая, поэтому пик преимуществ мы видим только в 1600х1200. В целом неплохо.
Code Creatures
Этот тест создан на базе движка от CodeCult, на котором в производстве находится несколько игр.
 |  |
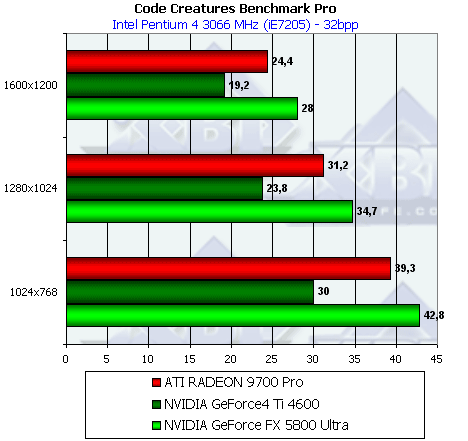

Хотелось бы большего… И весь комментарий.
Unreal Tournament 2003 DEMO
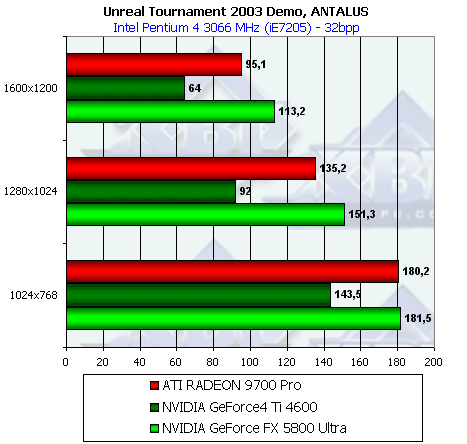
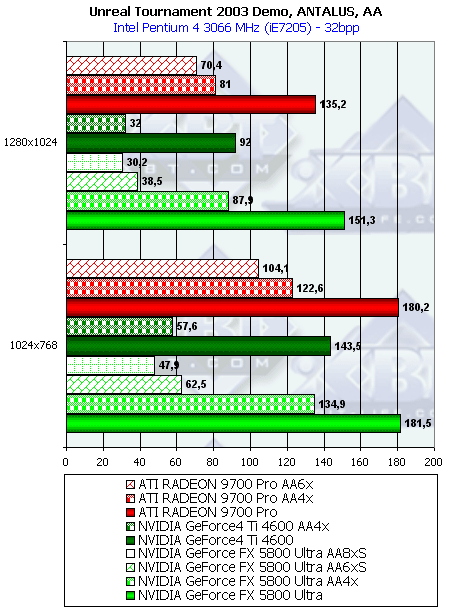
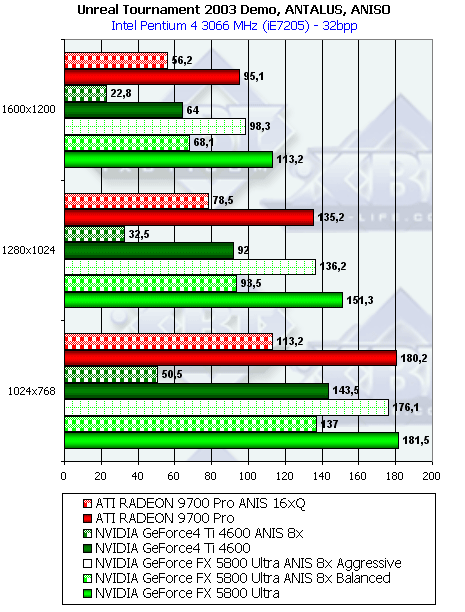
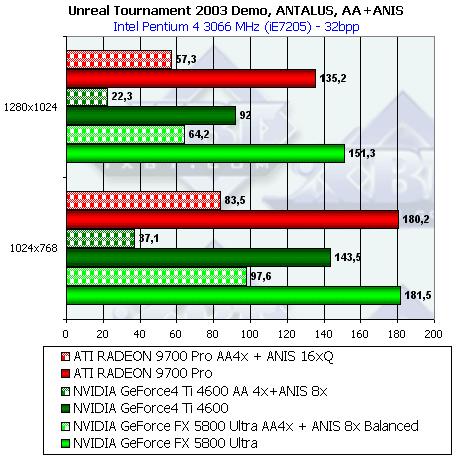
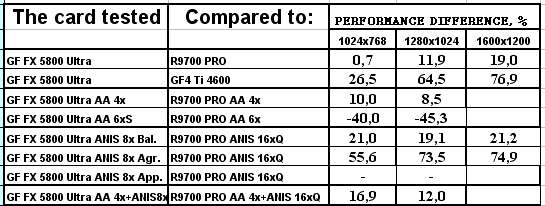
Провал с АА компенсировала быстрая анизотропия, поэтому в целом все благополучно для NV30. Хотя без нагрузки преимущества крайне малы.
AquaMark
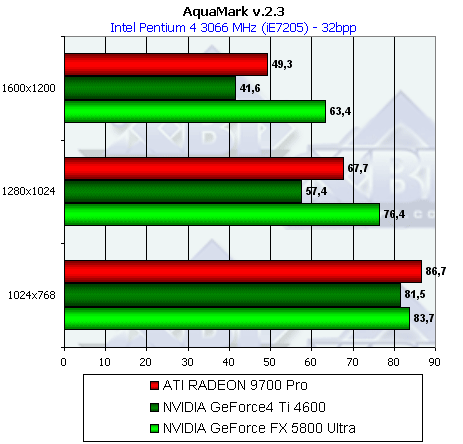
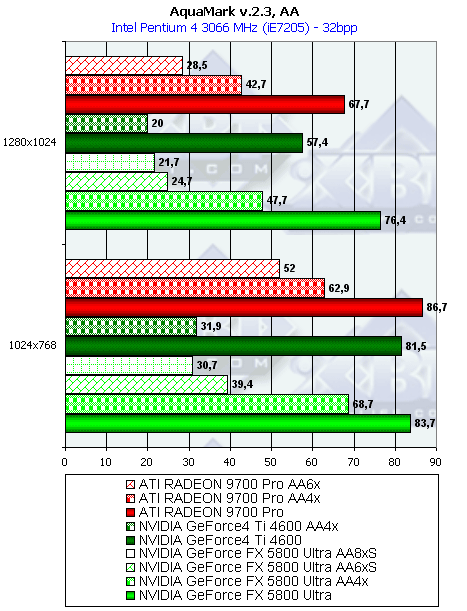
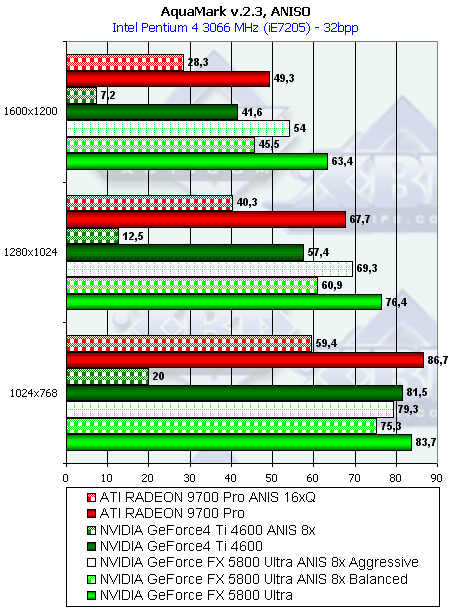
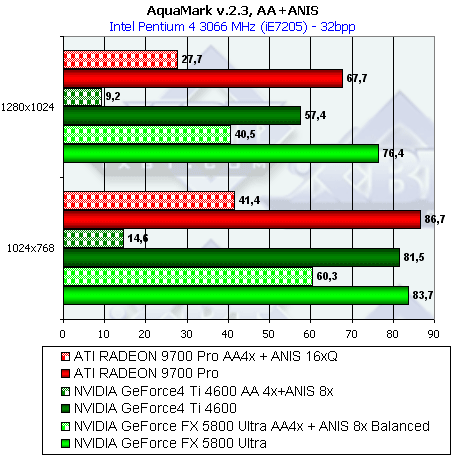
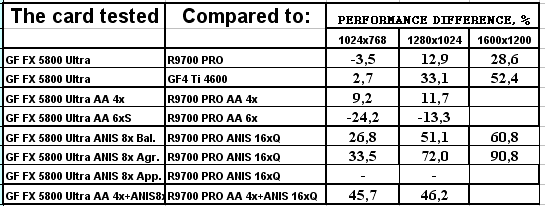
NV30 солидно выглядит и имеет прекрасные превосходства только под нагрузкой анизотропии и АА.
RightMark 3D
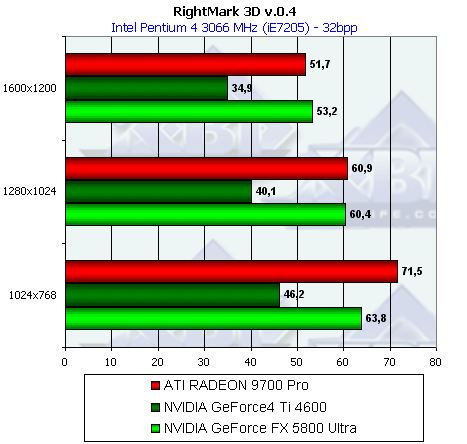
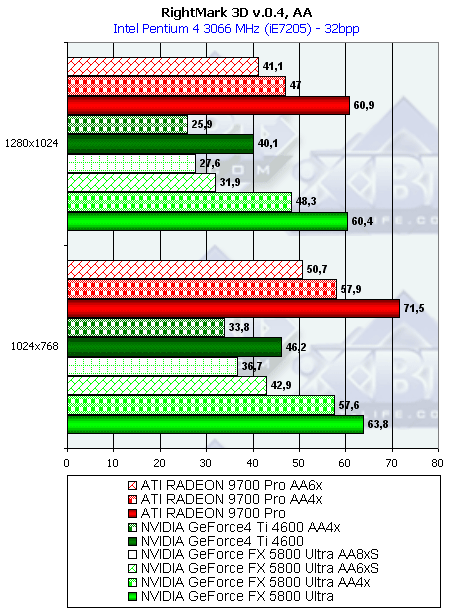
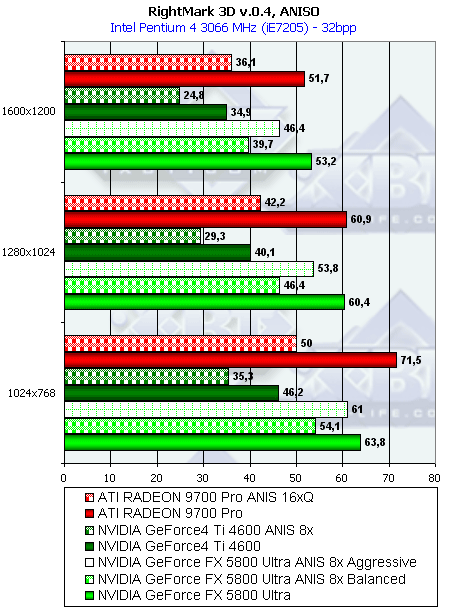

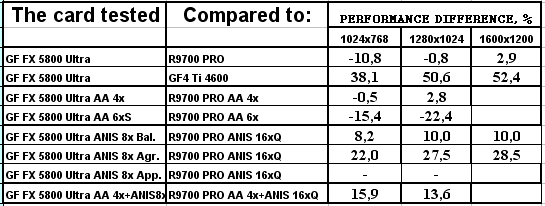
Печальная картина.. Вот оно! Снова мы видим, что столкнув шейдеры от ATI и от NVIDIA, мы сразу получаем подтверждение результатов наших синтетических тестов.
DOOM III Alpha
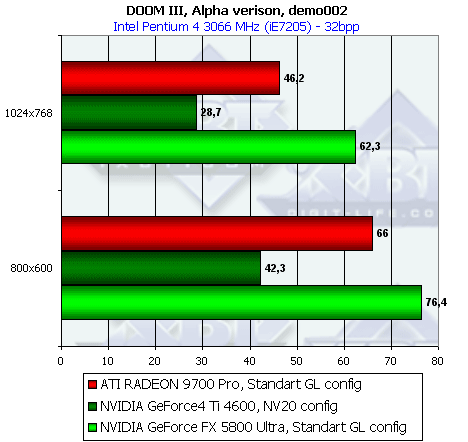
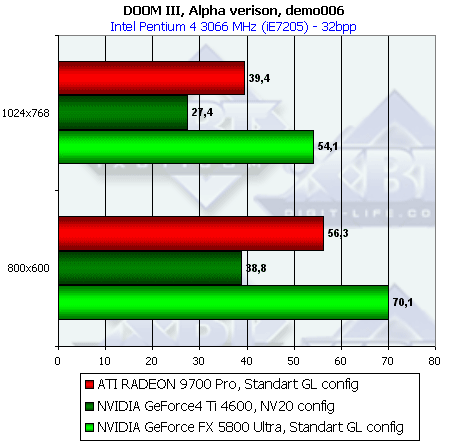
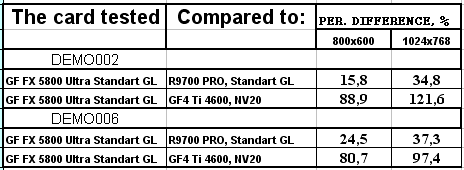
Практически первая игра, где наконец-то показали себя в полной мере достоинства NV30, о чем, собственно, мы ранее и говорили.
Качество 3D-графики
АНИЗОТРОПНАЯ ФИЛЬТРАЦИЯ
Ранее в этой статье мы затронули аспекты теории, посмотрели как работает анизотропия у RADEON 9700 и GeForce FX 5800. Хотелось бы продолжить эту тему уже на примере нашего теста RightMark 3D.
Если посмотреть на скриншоты драйверов, которые мы привели в этом материале, то можно заметить, что у NV30 есть по сути три разновидности анизотропной фильтрации: отданная на откуп приложению, сбалансированная между производительностью и качеством и агрессивная в плане предпочтения производительности качеству. По умолчанию используется сбалансированная разновидность. Мы тестировали скорость как этого подвида, так и "агрессивного".
Давайте рассмотрим теперь отличия между этими подвидами. Благо мы можем в RightMark 3D включить свои настройки анизотропки (получим подвид — Приложение), а также в качестве фильтрации использовать трилинейку, включив в драйверах форсирование анизотропии (подвиды — Сбалансированное и Агрессивное).
| ANISOTROPIC и угол наклона | RADEON 9700 PRO | GeForce4 Ti | GeForce FX 5800 Ultra | ||
|---|---|---|---|---|---|
| Приложение | Сбалансированное | Агрессивное | |||
| ANISO 8/16, 0 градусов |  |  |  |  |  |
| ANISO 8/16, 30 градусов |  |  |  |  |  |
| ANISO 8/16, 45 градусов |  |  |  |  |  |
| ANISO 8/16, 60 градусов |  |  |  |  |  |
| ANISO 8/16, 90 градусов | 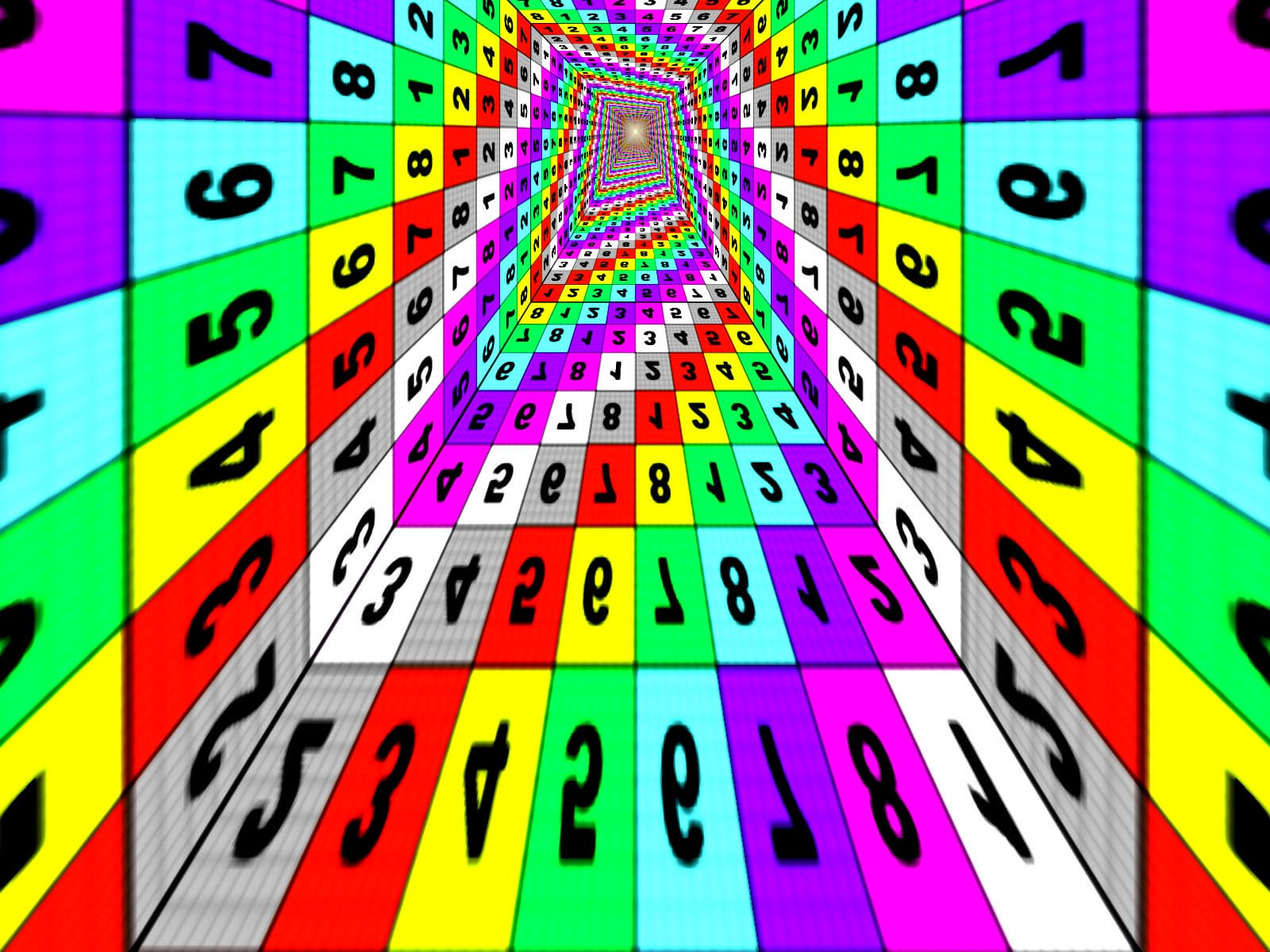 | 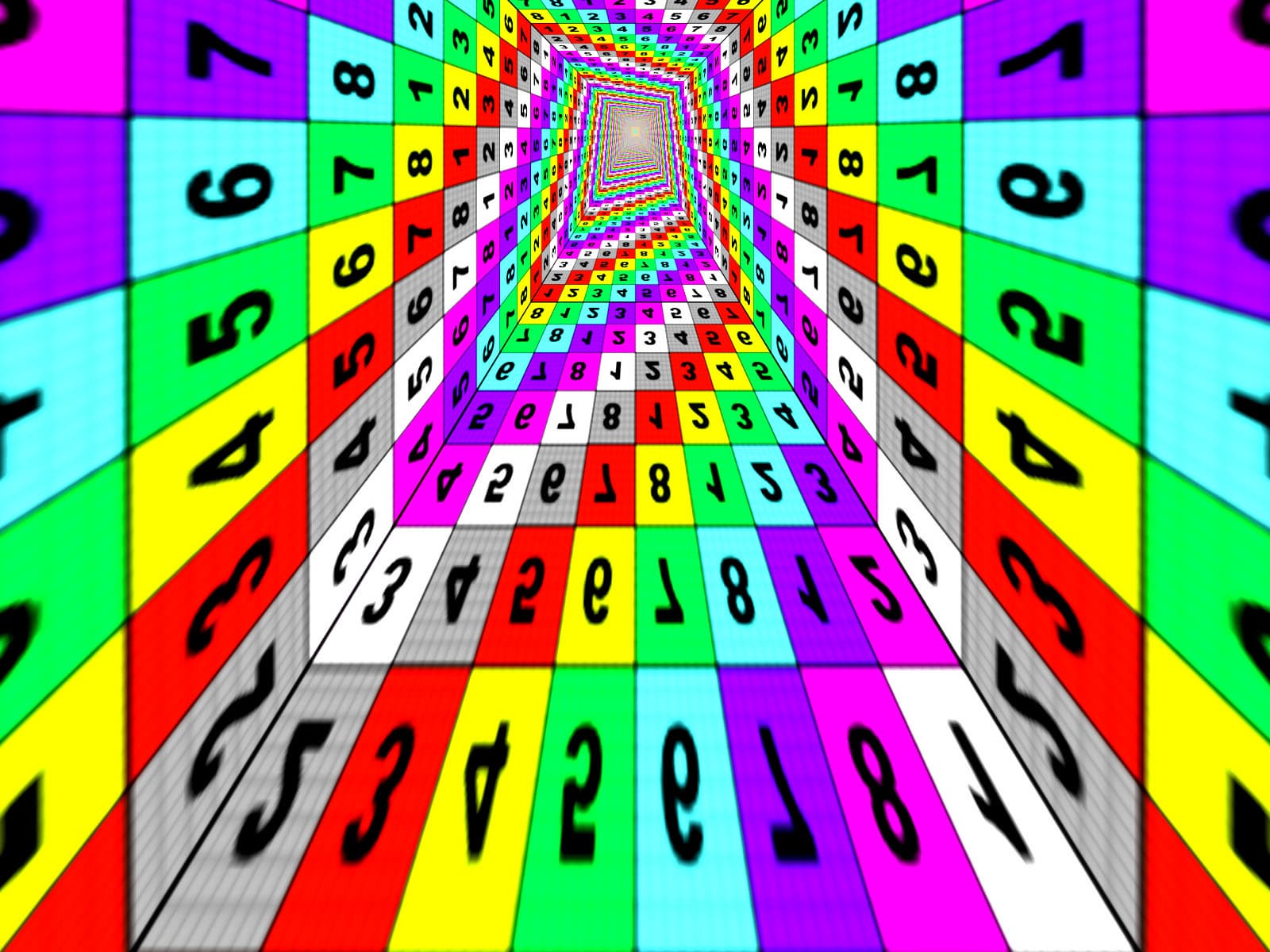 |  |  |  |
Мы прекрасно видим, что качество анизотропии у RADEON 9700 на плоскостях 0, 45 и 90 градусов просто отменное, и выше, чем у GeForce FX 5800, но зато оно падает и сильно, если плоскости параллельны углам 30 и 60 градусов. Качество же анизотропии у NV30 практически везде одинаковое. Но это в Direct3D. А что в OpenGL?
| Serious Sam: TSE. Анизотропия зависит от приложения | |||
|---|---|---|---|
| ANISOTROPIC | RADEON 9700 PRO | GeForce4 Ti | GeForce FX 5800 Ultra |
| Пример 1 | |||
| Trilinear | - | - |  |
| ANISO 2 |  |  |  |
| ANISO 4 |  |  |  |
| ANISO 8 |  |  |  |
| ANISO 16 |  | - | - |
| Пример 2 | |||
| Bilinear | - | - |  |
| Trilinear | - | - |  |
| ANISO 2 |  |  |  |
| ANISO 4 |  |  |  |
| ANISO 8 |  |  |  |
| ANISO 16 |  | - | - |
Как можно увидеть, у NV30 на дальнем расстоянии анизотропия практически резко обрывается (хотя это похоже на отсутствие трилинейной фильтрации, тем не менее она есть, можно посмотреть похожее на скринах с программы XMAS выше). Полагаю, что либо издержки драйверов, либо в OpenGL разработчики таким путем упростили анизотропию. Еще обратите внимание на качество неба на предложенных скриншотах в Serious Sam: TSE. Если присмотреться, то при анизотропии мы видим небольшой бандинг. Поэтому есть подозрение, что наряду с некоторыми операциями упрощения трилинейной фильтрации на дальних текстурах операции идут в 16-битном цвете (либо принудительно используется S3TC).
Мы не стали приводить скриншоты под разными углами, ибо проблем с этим нет (подозревающим, что NVIDIA взяла на вооружение анизотропию от RADEON 8500, беспокоиться не о чем — такого нет и вряд ли будет).
АНТИ-АЛИАСИНГ (АА)
В начале материала мы уже рассмотрели аспекты работы АА, производительность оценили в предыдущем разделе, а здесь давайте посмотрим на качество.
| AA | RADEON 9700 PRO | GeForce4 Ti | GeForce FX 5800 Ultra |
|---|---|---|---|
| Serious Sam: TSE | |||
| No AA | - | - |  |
| AA 4x |  |  |  |
| AA 6x |  | - | - |
| Unreal II | |||
| No AA | - | - |  |
| AA 4x |  |  |  |
| AA 4xS | - |  |  |
| AA 6x/6xS |  | - |  |
| AA 8xS | - | - |  |
Что мы видим?
- Практическое отсутствие разницы в качестве режимов 4х и 6хS/8xS. А, как говорится, зачем платить больше, если результат один?
- Качество АА4х у R300 выше, чем у NV30/NV25.
Качество 3D в целом
В целом нареканий нет. Можем предложить просто для справки скриншоты из NFS:HP2, полученные на NV30:


Есть только замечание на работу режима АА 8xS: во многих случаях проявляются артефакты вот такого рода:

Думаем, что также виновато несовершенство драйверов.
Выводы
Наконец-то мы смогли протестировать долгострой от NVIDIA, который в то же время несомненно является самым быстрым и гибким акселератором на сегодня! Но, условно. Почему условно? Да потому что до сих пор карт нет в продаже, и есть угроза того, что GeForce FX 5800 Ultra так и не появится на рынке (быть может только GeForce FX 5800, работающая на пониженных частотах и уж, конечно, проигрывающая RADEON 9700 PRO по скорости).
Однако мы уже сейчас можем сделать вывод, что NV30 — это реальный шаг к чрезвычайно гибко программируемому графическому процессору. Да, у GeForce FX есть свои недостатки, мы о них писали выше. Но они на поверхности, поэтому можем предположить, что в следующих выпусках чипов семейства NV3X (NV35 в первую очередь) огрехи NV30 будут учтены и устранены. Это событие не за горами. По некоторой информации уже в мае может появиться старший последователь — NV35. К тому же мы ждем и младших доступных по цене братьев NV30 — NV31/34, которые также будут включать в себя все шейдерные возможности архитектуры NV3X.
- Впервые мы рассматриваем карту, которая может не появиться в свободной продаже, но являет собой некую архитектурную базу, на которой будет затем основано целое семейство продуктов. Уже обкатанные и реализованные по медной .13 технологии исполнительные блоки позволят быстро создать и запустить в серию целое семейство новых чипов для различных ниш рынка.
- Главный минус GeForce FX 5800 — это 128 битная шина обмена с памятью, ибо даже такая быстрая память, работающая на 500 (1000) МГц, не способна обеспечить 500-мегагерцовому 8-конвейерному чипу требуемую ПСП. Этот минус самым трагичным образом сказался на АА, несмотря на наличие сжатия буфера кадра в MSAA режимах. Наличие подобного сжатия является для современных чипов стандартом дефакто, и даже при условии активации оного, ПСП 128 битной памяти никак не достаточно для записи 4000 закрашеных пикселей в секунду (при условии использования современных игр и в приложениях будущих выпусков) и NVIDIA пришлось ограничится 4 пиксельными процессорами и 2000 пикселями. В итоге, со скоростью в АА режиме дела у NV30 обстоят заметно хуже, чем у R300 (снабженного не только сжатием но и более широкой 256 бит шиной памяти). К тому же, качество алгоритма MSАА у R300 заметно выше. Всетаки, в большинстве нынешних игр NV30 работает как 4х2.
- Мы не можем оценить — насколько оправдывает GeForce FX 5800 Ultra затраты на него со стороны потенциальных покупателей, ибо совершенно неизвестны розничные цены на этот продукт (на середину февраля).
- Еще один минус — шумный кулер, который, кроме того, способен пугать пользователя своими внезапными запусками или остановками (понижением частоты вращения). Из-за такой конструкции пользователь вынужден жертвовать первым PCI-слотом. Однако, этот минус устраним, уже анонсированы карты с оригинальными системами охлаждения свободными от недостатков свойственных референс карте.
- Итак, несмотря на перечисленные минусы, перед нами самый быстрый 3D-ускоритель на начало 2003 года. В наших 3DGiТогах мы еще проанализируем работу NV30 на разных версиях драйверов, а также посмотрим на качество и стабильность работы в играх. Тогда можно будет сделать окончательные выводы.
- В рамках этого материала мы не рассмотрели работу карты с TV, а также вопросы воспроизведения DVD. В ближайшем статье по серийной карте на базе NV30 мы восполним этот пробел.


