NVIDIA GeForce FX 5800 Ultra 128MB
(А.Пугачева)

Как обычно, предваряя большой базовый материал анализа работы нового акселератора, мы настоятельно рекомендуем прочитать аналитическую статью, посвященную архитектуре и спецификациям NVIDIA GeForce FX (NV30)
СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты NVIDIA GeForce FX 5800 Ultra 128MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Синтетические тесты RightMark3D: идеология и описание тестов
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark2001 SE
- Дополнительная теоретическая информация и выводы из результатов синтетических тестов
- Информация по анизотропной фильтрации и по анти-алиасингу
- Архитектурные особенности и перспективы
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game1
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game2
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game3
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game4
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003 DEMO
- Результаты тестов: AquaMark
- Результаты тестов: RightMark 3D
- Результаты тестов: DOOM III Alpha version
- Качество 3D: Анизотропная фильтрация
- Качество 3D: Анти-алиасинг
- Качество 3D в целом
- Выводы
3D-графика, 3DMark2001 SE — синтетические тесты
Подчеркну, что все замеры по всем 3D-тестам проводились в 32-битной глубине цвета.
Скорость закраски
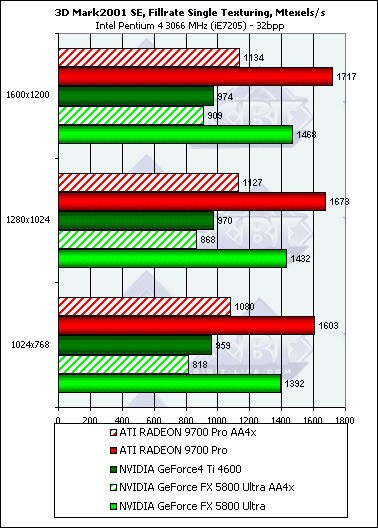
Наблюдается уже хорошо знакомая нам по результатам работы Pixel Filling теста из RightMark 3D зависимость, однако она не столь ярко выражена — добротность теста немного ниже и цифры дальше от предельных значений.
В случае мультитекстурирования:
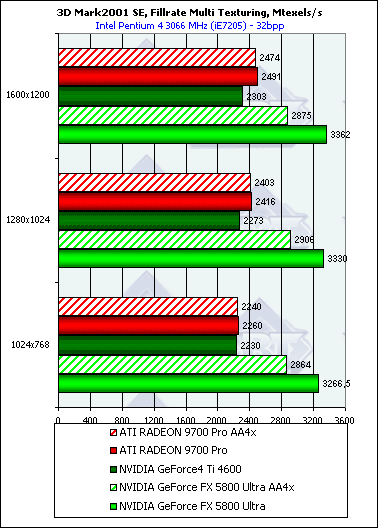
Результаты так же хорошо соотносятся с полученными нами ранее в тестах RightMark 3D. Интересно, что режим AA бьет по NV30 куда как более существенно, нежели по R300 — несмотря на сжатие буфера кадра в режиме MSAA, имеющее место как у R300, так и у NV30, сказывается более узкая ПСП 128 битной шины последней.
Сцена с большим количеством полигонов

…для одного источника света, и для восьми:

NV30 лидирует, причем отрыв возрастает с увеличением числа источников света, что вполне логично и хорошо согласуется с полученными в Geometry Speed тесте пакета RightMark 3D данными.
Пиксельный шейдер
Простой вариант:

Интересно, что NV30 лидирует в этом тесте. Причина проста — фактически этот тест достаточно интенсивно выбирает текстуры, но при этом производит минимум вычислений, кроме того, все вычисления происходят в целочисленном формате (шейдеры 1.1), NV30 же выполняет целочисленные команды вдвое быстрее, чем плавающие.
Посмотрим, измениться ли картина при условии более вычислительно интенсивных пиксельных шейдеров:

Да, теперь R300 лидирует, лишний раз подтверждая сделанные нами ранее выводы о более слабой вычислительной и более высокой текстурной производительности NV30.
Вершинные шейдеры

Тест вершинных шейдеров демонстрирует весьма странные с нашей точки зрения результаты. Все наши многочисленные тесты ранее о примерно обратном раскладе. Возможно, роль сыграл слишком короткий шейдер или большая зависимость от скорости закраски (посмотрите как падают результаты с ростом разрешения, причем у NV30 быстрее). Как бы там ни было мы склонны больше доверять предыдущим результатам, полученым на синтетических тестах RightMark 3D, которые не проявляют столь заметной зависимости от разрешения.
Спрайты
Ничего нового.
Рельефное текстурирование
Посмотрим на результаты синтетической EMBM сцены:
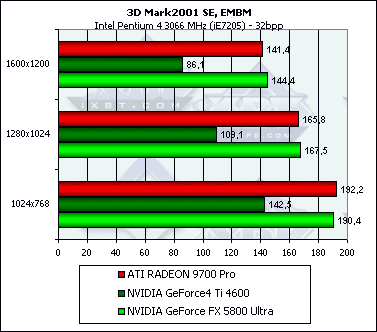
А теперь DP3-рельеф:

Здесь чипы идут нос к носу с небольшим перевесом NV30.
Итак, за исключением отдельных моментов результаты 3D Mark 2001 хорошо согласуются с полученными ранее результатами RightMark 3D, хотя и несут изначально меньше информации ввиду отсутствия каких либо настроек параметров синтетических тестов.
Дополнительная теоретическая информация и выводы из результатов синтетических тестов
Анизотропная фильтрация
Исследуем реализацию анизотропии NV30 в сравнении с R300. Для этого используем специальную
программу Xmas, предназначенную для наглядного изучения качества фильтрации:

Программа выводит цилиндрический туннель с регулируемым числом граней, что позволяет наблюдать
за всевозможными углами поворота относительно нормали к экрану. Остановившись на разумном
числе в 15 граней мы получим достаточно четкий набор плоскостей с 5 значениями углов в
диапазоне от 0 до 90 град. Итак, для максимального уровня анизотропии, слева R300, справа NV30:
| RADEON 9700 PRO | GeForce FX 5800 Ultra |
|---|---|

|

|
Хорошо видно, что алгоритм анизотропии NV30 совершенно униформичен по отношению к углу поворота плоскости, при любом угле поворота он дает одинаковую картинку, которая зависит только от наклона плоскости. А вот R300 успешно справляется с углами 0 и 90 градусов, а также, с углами близкими к 45. Все промежуточные углы (20, 30, 60, 70 и т.д.) выглядят гораздо хуже — на них алгоритм ATI работает плохо. Далее мы объясним, почему это происходит. В свою очередь, вспомним, что R200, результаты которого мы здесь не приводим, успешно справлялся только с 0 и 90 градусами.
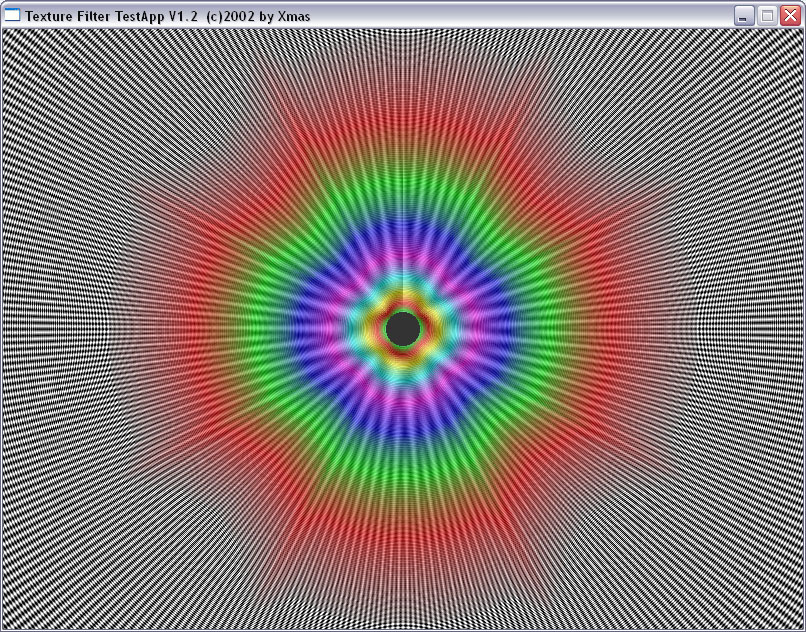
Теперь давайте посмотрим, как происходит выбор MIP уровней в зависимости от степени
анизотропии. Слева R300 справа вновь NV30:
| ANISOTROPIC | RADEON 9700 PRO | GeForce FX 5800 Ultra |
|---|---|---|
| No |

|

|
| ANISO 2 |
|

|
| ANISO 4 |
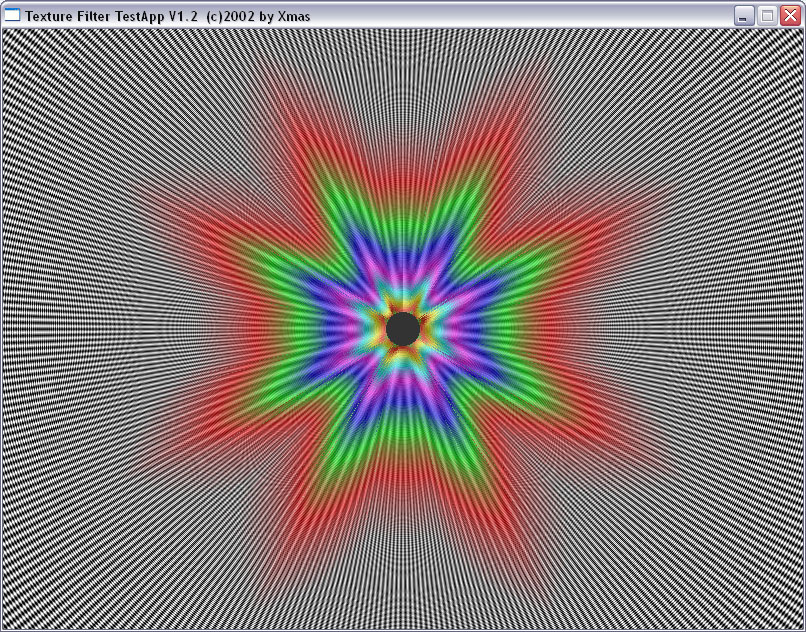
|
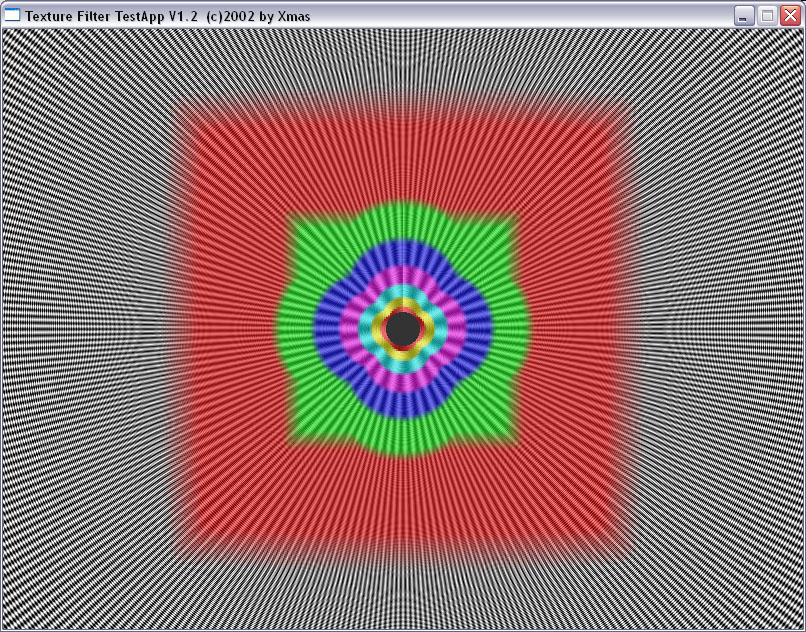
|
| ANISO 8 |

|

|
| ANISO 16 |
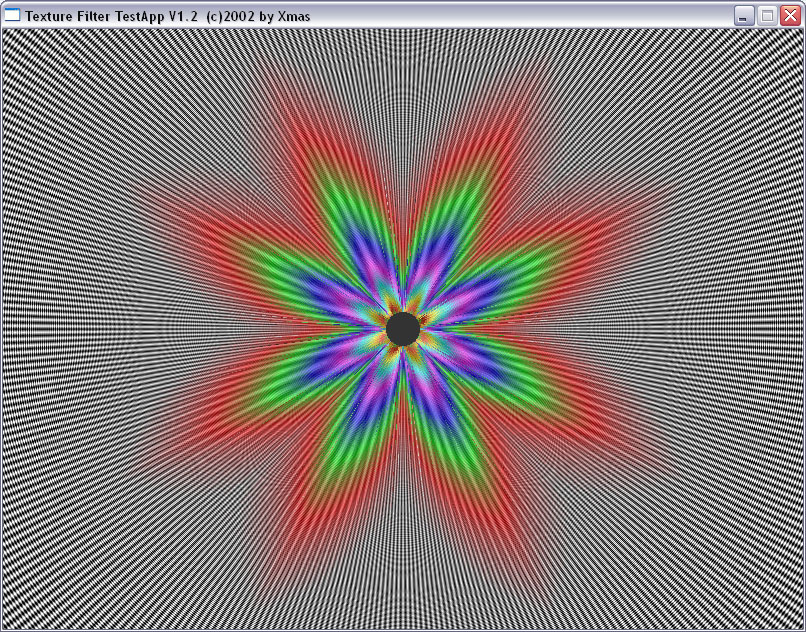
|
- |
И здесь на лицо существенные отличия. Если при малом уровне анизотропии алгоритм ATI ведет себя схоже с алгоритмом NVIDIA, обеспечивая достаточно корректный, почти идеально базирующийся на реальном расстоянии выбор MIP уровней (идеальная картинка должна была представлять собою окружности), то по мере роста уровня анизотропии метод NVIDIA и метод ATI дают принципиально разную картинку. Причем, надо отметить, NV30 при больших расстояниях (удаленный конец туннеля) и высоком уровне анизотропии ведет себя более корректно.
Итак, только сегодня и только сейчас. Алгоритмы анизотропной фильтрации NVIDIA и ATI.
NV30

Перед нами плоскость текстуры. С экрана мы наблюдаем эту текстуру под углом. Черная стрелка показывает так называемое направление анизотропии — проекцию направления нашего взгляда на текстуру через плоскость экрана. Тонкие линии показывают границы экранного пикселя, который нам надо закрасить, а точнее его проекции на плоскость текстуры. Звездочки показывают отсчеты, каждый из которых выбирается с использованием билинейной фильтрации. Позиции отсчетов определяются неким псевдослучайным алгоритмом, который стремится более или менее равномерно покрыть отсчетами всю плоскость фигуры в которую проектируется экранный пиксель. Число отсчетов зависит от угла наклона текстуры, чем больше угол, под которым мы на нее смотрим, тем длиннее проекция пикселя и тем больше отсчетов надо выбрать, чтобы получить качественные результаты фильтрации. Также это число зависит от степени анизотропии — чем выше степень, тем больше отсчетов будет выбираться при одинаковом угле наклона. От угла поворота плоскости этот алгоритм не зависит, что мы и наблюдали ранее. Слабое место этого алгоритма — честно выбираемые билинейные отсчеты. MIP уровень текстуры из которого выбираются отсчеты определяется однажды для всего пикселя.
R300

Итак, во первых хочу развеять устоявшийся миф о использовании ATI разновидности RIP-маппинга и дополнительных, сжатых по осям вариантов текстур. Ничего подобного никогда не имело и не имеет места — анизотропная фильтрация работает с такими же исходными текстурами как и в случае продуктов NVIDIA, и никакого дополнительного пространства или предварительного просчета не задействовано. Просто, в корне отлична суть самого алгоритма фильтрации. Во-первых отсчеты выбираются одиночно (по одному значению), а не с предварительной билинейной фильтрацией. Фильтрация осуществляется косвенным путем — алгоритм выбирает из какого MIP уровня следует выбрать каждый отсчет, на данной схеме маленькие квадратики — отсчеты задействованные из более детального MIP уровня а большие — из менее детального. Таким образом, можно выбрать гораздо больше отсчетов, используя те же вычислительные и пропускные ресурсы, но изначально эти отсчеты не будут фильтрованными, что может привести к потере качества. Впрочем, разница не так заметна на глаз, а правильный выбор MIP уровня для каждого отсчета ее еще больше нивелирует (здесь возможно применить некий стохастический алгоритм, чередующий разные уровни для получения более качественной анизотропии и плавных переходов между MIP уровнями, т.е. попутного выполнения трилинейной фильтрации).
Во вторых, на схеме появилась вторая красная стрелка. Она демонстрирует направление, в котором реально выбираются отсчеты. Разрешены только три направления — вертикальное, горизонтальное (пунктиром) и под углом 45 градусов, задействованное в данном случае. Именно поэтому, на промежуточных углах этот метод дает не очень качественные результаты (вспомните программу Xmas). Зато на перечисленных углах поворота он выполняется очень быстро, и с меньшими затратами пропускной полосы памяти или кэша, при схожем уровне визуального качества.
Итак, NVIDIA и ATI избрали различные пути реализации анизотропии. Анизотропия NVIDIA более униформична и академична, если так можно выразится, анизотропия ATI более практична и позволяет при схожих ограничениях выбрать больше отсчетов. До сих пор анизотропия NVIDIA существенно проигрывала ATI по скорости, но в новом чипе NV30 и его драйверах были введены существенные оптимизации, направленные на увеличение производительности без особой потери визуального качества. Увеличение производительности мы уже заметили (см. тест RightMark 3D), справедливости ради отметим что дело не только в оптимизированном выборе числа выбираемых отсчетов и их позиций, но и более высокой тактовой частоте ядра чипа. А насколько эти оптимизации отразятся на качестве, мы увидим далее, на примере скриншотов реальных приложений.
Полноэкранное сглаживание
Как мы уже упоминали в аналитическом обзоре NV30, в наличии все тот же базовый MSAA 4х мультисэмплинг и различные гибридные режимы на его основе (6xS и 8x).
Самая интересная для сегодняшних применений особенность GeForce FX — сжатие буфера кадров. Сжимаются не только значения глубины, но и значения цвета. По заявлениям NVIDIA алгоритм сжатия работает без потерь. Он основан на том факте, что в MSAA режимах большинство блоков сглаживания в буфере кадра не находится на границах треугольников и поэтому содержать одинаковые значения цвета.
Само по себе сжатие буфера кадра несет множество плюсов:
- Возможность быстрой очистки буфера кадра, так же как это было возможно ранее для буфера глубины.
- Существенная экономия пропускной полосы памяти, особенно вкупе с использованием сжатых текстур.
- В высоких разрешениях и особенно при использовании тройной буферизации кадра будет крайне ощутима экономия свободного места в локальной памяти, в которое смогут поместится дополнительные текстуры и геометрические данные, существенно разгрузив таким образом AGP шину и следовательно скачкообразно увеличив производительность.
- И, наконец, практически вдвое увеличит эффективность использования доступной полосы локальной памяти, став, таким образом, основным аргументом за использование 128 бит шины памяти без риска разгромного проигрыша конкурирующим 256 бит решениям.
Кстати, мы уже убедились, то R300 также поддерживает технику сжатия цветовой информации в буфере кадра.
Вспомним, как выполняется уже привычный нам MSAA. Никаких дополнительных вычислений не надо — все отсчеты в пределах блока сглаживания формируются из одного вычисленного пиксельным шейдером результата. Единственная причина падения производительности — необходимость пересылать увеличенный в разы (согласно установке сглаживания — при 4х буфер кадра будет вчетверо больше при 2х — вдвое) буфер кадра туда и обратно. Но, при этом в том же режиме 4х в подавляющем большинстве блоков сглаживания присутствуют два или чаще одно (!) уникальное значение цвета. Блоки, в которых три или четыре значения уникальны надо еще поискать. Грех не воспользоваться подвернувшейся возможностью и не закодировать информацию такого MSAA буфера эффективно — записав только реально присутствующие отличные цвета.
Таким образом, мы практически полностью (останутся считанные проценты дополнительных данных) компенсируем увеличение буфера при включении MSAA. Будет ли так на практике? Посмотрим ниже.
GeForce FX включает новый гибридный режим MSAA названный 8хS и новый гибридный MSAA режим 6xS. Впрочем, эти режимы являются комбинацией SS и MS сглаживания — за основу по прежнему, как и в NV25 берутся два типа базовых 2х2 блоков MSAA — 2х с диагональным расположением семлов и 4х, отсчеты из которых затем усредняются по с использованием того или иного паттерна, так же как и в предыдущем поколении. Т.е. чип как и NV25 может записывать до 4 MSAA семплов из одного вычисленного пиксельным шейдером значения. Отсюда и приводимый коэффицент сжатия 4:1. Как вы уже догадались для режимов FSAA имеющих в своей основе MSAA 2х блоки этот коэффицент будет 1:2.
Итак, главная надежда создателей GeForce FX
возложена на сжатие буферов глубины и кадра, особенно в FSAA режимах.
Факт принятия на вооружение 128 битной шины может служить косвенным
показателям того, что ставка на сжатие весьма сильна. Но оправдана ли?
Предварительные результаты синтетических тестов уже заставили нас
засомневаться в оправданности 128 битной шины.
| 14 февраля 2003 г. |
|
|