(А.Пугачева)

Как обычно, предваряя большой базовый материал анализа работы нового акселератора, мы настоятельно рекомендуем прочитать аналитическую статью, посвященную архитектуре и спецификациям NVIDIA GeForce FX (NV30)
СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты NVIDIA GeForce FX 5800 Ultra 128MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Синтетические тесты RightMark3D: идеология и описание тестов
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark2001 SE
- Дополнительная теоретическая информация и выводы из результатов синтетических тестов
- Информация по анизотропной фильтрации и по анти-алиасингу
- Архитектурные особенности и перспективы
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game1
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game2
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game3
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game4
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003 DEMO
- Результаты тестов: AquaMark
- Результаты тестов: RightMark 3D
- Результаты тестов: DOOM III Alpha version
- Качество 3D: Анизотропная фильтрация
- Качество 3D: Анти-алиасинг
- Качество 3D в целом
- Выводы
Результаты практического тестирования
А теперь самое интересное. Приведем и прокомментируем данные, полученные нами на ускорителях двух "основных" в данный момент семейств — ATI RADEON 9700 PRO и NVIDIA GeForce FX 5800 Ultra. В качестве опорной, в тестировании также принимает участие карта предыдущего поколения — GeForce 4 Ti 4600.
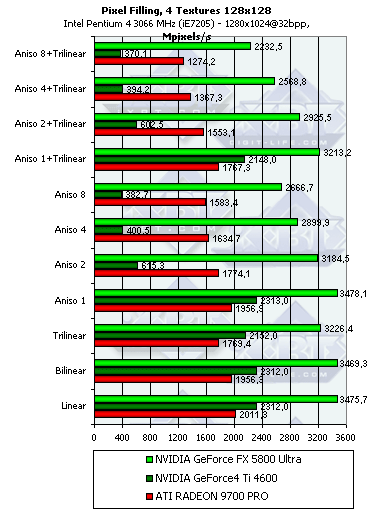
Pixel Filling
- Тест на скорость закраски буфера кадров (Pixel Fillrate). Закраска константным цветом — выборка текстур не производится. Приведены результаты в миллионах пикселов в секунду для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
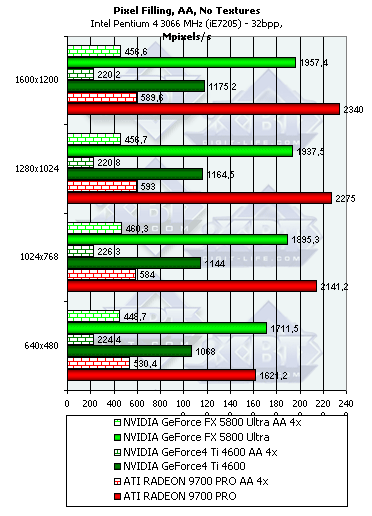
Несмотря на более высоковую тактовую частоту GFFX, мизерное преимущество FX наблюдается только в самом низком разрешении, а далее 9700 PRO уверено берет лидерство. Причина кроется в превосходящей ПСП памяти и наличии 8 пиксельных конвейеров способных записывать 8 значений цвета и глубины за такт. FX может записать только 4 полных пиксела (цвет + глубина + когда надо буфер шаблонов aka Stencil), однако 4 пиксельных процессора этого чипа имеют одну интересную оптимизацию — если мы рассчитываем шейдер или просто закрашиваем треугольник не используя значения цвета а изменяя только значения глубины или буфера шаблонов, каждый пиксельный процессор может за один такт выдать два результата. Таким образом, в сумме записав 8 значений глубины или буфера шаблонов за такт. Подобная оптимизация очень пригодится в играх с стенсильными тенями, подобных DOOM III, там она может ускорить прорисовку сцены в почти полтора раза. Однако в нашем тесте закрашиваются и значения цвета. Именно поэтому результат свидетельствует лишь о 4 пикселах выводимых за один так.
Во всех разрешениях, кроме минимального, разница хорошо соответствует разнице в пиковой ПСП, что говорит о разумном балансе чипа GF FX — 8 конвейеров даже теоретически не смогли бы записать 8 значений за такт, в таком простом (без каких либо вычислений а только с закраской) тесте. С точки зрения пиксельной скорости закраски несложных приложений 4 конвейера оправданы. Но будут ли они также оправданы в случае вычислительно интенсивных шейдеров? Далее мы проясним этот вопрос.
- Тест на скорость закраски буфера кадров с одновременным текстурированием. Добавляется выборка одной простой билинейной текстуры — проверим, насколько наличие конкурентного потока чтения из памяти понизит эффективность закраски. Приведены результаты в миллионах пикселов в секунду, для разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
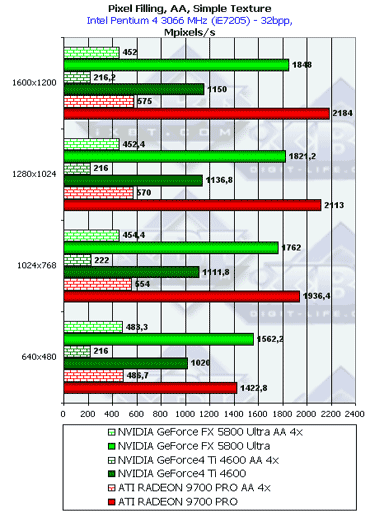
В общем и целом, картина практически та же, но пиковые значения несколько упали. Давайте посмотрим, насколько хорошо измеренная действительность соотносится с теоретическими пределами, основанными на частоте ядра и числе конвейеров:
Продукт Теоретический максимум Измеренный максимум(без текстуры) Измеренный максимум(с одной текстурой) GeForce4 Ti 4600 1200 1175 1150 RADEON 9700 PRO 2600 2340 2184 GeForce FX 5800 Ultra 2000 1957 1848 Итак, GeForce FX хорошо реализует свой теоретический потенциал. Все упирается в наличии 4 пиксельных процессоров и недостаточную пропускную полосу памяти. Фактически, можно выпустить аналогичную версию чипа но с 256-битной шиной памяти и 8 конвейерами, увеличив производительность реальных приложений почти в два раза.
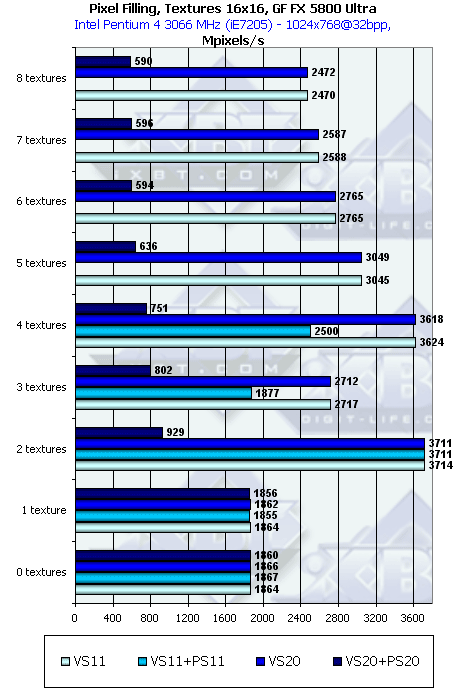
- Посмотрим на зависимость Texturing Rate (числа выбираемых и фильтруемых из текстур пикселей в секунду) от числа накладываемых за один проход текстур:
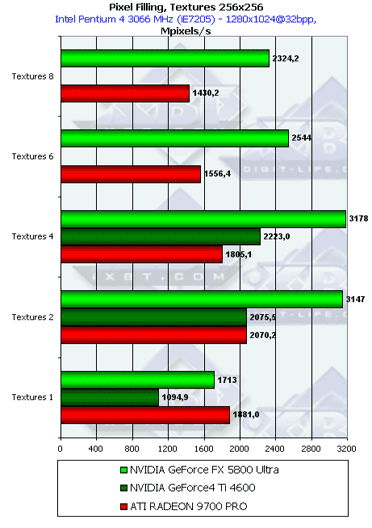
А вот и сюрприз — начиная с двух текстур на пиксель (это тот минимум, который мы наблюдаем у всех современных игр) эффективность работы NV30 резко возрастает! Оптимальное значение достигается на 4 текстурах, в отличие от R300, для которого более выгодны 2 текстуры. В принципе, подобное поведение вполне объяснимо. Если учесть что реально в NV30 присутствует по два текстурных блока на каждом из четырех пиксельных процессоров. По мере увеличения числа текстур все большую роль играет производительность их выборки и фильтрации, которая в первую очередь определяется тактовой частотой ядра чипа. Если в случае одной текстуры мы упирались в число пиксельных процессоров и скорость записи буфера кадра (и то и то ниже R300), то в случае двух и более мы начинаем чувствовать влияние тактовой частоты ядра. Кроме того, еще в теоретической статье по NV30 я упоминал о достаточно оригинальной конвейерной конструкции текстурных блоков творения NVIDIA, обеспечивающей потактовую выдачу результатов без задержек. Итак, конвейерные текстурные модули удались на славу — в вопросах выборки текстур NV30 лидер.
Отметим, что подобное преимущество NV30 должно сказываться в первую очередь в играх со сложным, многослойным текстурированием, не обремененным многочисленными пиксельными вычислениями, таких, как например DOOM III.Однако далее мы посмотрим, насколько же эта малина будет подпорчена недостаточной ПСП в работе с реальными приложениями, и не пересилит ли ее нехватка столько ощутимое преимущество. Факт спареных текстурных блоков по идее не должен досаждать GF FX особенно в случае трилинейной или анизотропной фильтрации. В случае же билинейной, не будем забывать что большинство современных игр производительность в которых критична, накладывает две и более текстуры на большую часть полигонов сцены. Впрочем могут быть и исключения — например небо в современных авиационных симуляторах может делаться одной текстурой (пример — игра Штурмовик Ил-2). В таких приложениях R300 получит дополнительное преимущество.
Продукт Теоретический максимум Достигнутый максимум Измеренный максимум(макс. текстур) GeForce4 Ti 4600 2400 2223 (4 текст.) 2223 (4 текст.) RADEON 9700 PRO 2600 2070 (2 текст.) 1430 (8 текст.) GeForce FX 5800 Ultra 4000 3178 (4 текст.) 2324 (8 текст.) - Исследуем зависимость от формата текстуры:
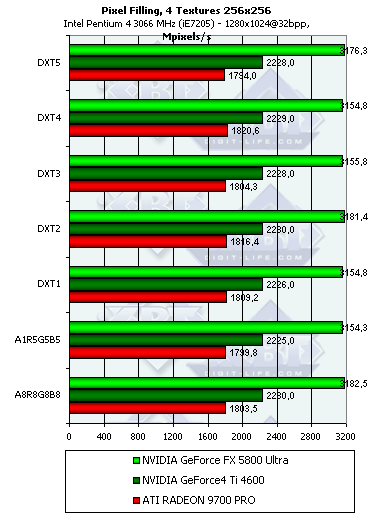
Результаты практически не меняются — все чипы давным-давно оптимизированы для 32-битных текстур и выполняют распаковку сжатых текстур без каких-либо задержек.
- Исследуем зависимость от типа фильтрации:
На более или менее существенных установках анизотропии NV25 начинает катастрофически терять производительность. Этот факт подробно исследован в наших материалах ранее и не требует дополнительных комментариев. Зато NV30 теряет производительность лишь немного более активно, чем R300 — практически в той же степени. В абсолютном значении его результаты превосходят R300 на величину даже большую, чем разница в тактовой частоте ядра — сказывается большая эффективная конвейеризация работы текстурных модулей.
По скорости падения при активации анизотропии адекватно, извечные соперники наконец сравнялись в этом вопросе, но адекватно ли качество? Далее мы исследуем этот вопрос. Вариант с 4 текстурами был выбран как некое среднее, типичное для вышедших в этом году игр — мало кто уже ограничивается двумя текстурами за проход, но и 8 текстур встречаются не так часто и лишь на отдельных объектах сцены. Далее мы увидим, как обстоят дела с анизотропией у GeForce FX в реальных приложениях, в том числе, в самом интересном режиме — в сочетании с FSAA.
- Дополнение: после выхода нашего материала в Сети стали раздаваться слухи о том, что архитектура конвейеров рендеринга вовсе не 8x1, а 4х2, поэтому мы провели еще одно исследование:
Как вы можно видеть на диаграмме зависимости скорости заполнения от количества текстур и других бенчмарках, GeForce FX ведет себя очень похоже на GPU, со схемой пиксельных конвейеров 4x2, то есть 4 пиксельных конвейера с 2 TMU на каждом. Однако как мы уже отмечали, при операциях с буфером глубины и буфером шаблона (depth & stencil) NV30 обрабатывает 8 пикселов за такт (при условии, что параллельно не ведутся какие либо операции с цветом). В остальных случаях обрабатываются 4 пикселя. Но, каждый из четырех пиксельных процессоров содержит два целочисленных ALU (две стадии) соединенных последовательно (так же как в NV25, видимо текстурные блоки и целочисленные стадии были разработаны с оглядкой на предыдущее поколение). Таким образом можно говорить о том, что за один такт выполняется сразу две команды шейдера, если его версия не превышает 1.3 или сразу две операции комбинационных стадий для старых, нешейдерных приложений (DX7). Причем, т.к. эти операции выполняются фактически над разными пикселами, они всегда могут происходить параллельно и таким образом целочисленная производительность NV30 при равной тактовой частоте эквивалентна 8 конвейерному чипу, но с одним ALU на каждом конвейере. Однако это касается только конфигураций стадий и шейдеров длинной как минимум две операции.
Таким образом, одновременно могут выполняться до 8 выборок текстур И 8 целочисленных математических операций за такт. Я умышленно выделил "И", показывая, что данные операции выполняются одновременно.
В случае шейдеров 1.4 и тем более 2.0, выполняющихся на NV30 с плавающей точкой, каждый пиксельный конвейер может выполнить лишь одну операцию за такт — таким образом всего чип выполняет по одной комманде для 4 пикселов за такт, что вдвое ниже производительности с целочисленными шейдерами. Но это еще не все — плавающие комманды не могут выполнятся одновременно с выборкой текстур! Т.е. за один такт мы можем либо выбрать 8 значений текстур, либо выполнить 4 плавающих операции шейдеров. Таким образом, NV30 вдвое (и даже более, если учесть выборку текстур) производительнее в не использующих плавающую арифметику применениях.
Итак, за один такт:
- 8 выборок текстур и 8 целочисленных операций над 4 пикселами.
- или 4 плавающих операции над 4 пикселами.
- или вычисление и запись 8 значений глубины и буфера шаблонов.
Почему была выбрана такая схема? Специалисты NVIDIA подчеркивают, что GeForce FX имеет архитектуру, оптимизированную под современные игры и сбалансированную с ПСП ее шины памяти. Многие современные игры уже сейчас используют stencil буфер для визуализации теней, и количество таких игр будет расти, достаточно вспомнить грядущий Doom III. GeForce FX прекрасно оптимизирован для данной технологии. Мультитекстурирование также уже стало стандартным для большинства современных игр, и "быстрые" TMU GeForce FX обеспечат высокую производительность в данных играх. Для 128 битной шины подобное чило конвейеров и подобный подход выглядят вполне логичными — наличие 8 конвейеров и возможности записать 8 значений цвета за такт не было бы полностью реализовано из за ограниченной ПСП но при этом добавило бы изрядную часть транзистров. Не лучше ли пустить их на более реентабельные применения, такие как кеширование или ускоренные операции с буфером шаблонов? Видимо, инженеры NVIDIA так и рассудили.
Ну а для разработчиков GeForce FX предоставляет огромные возможности, поддерживая шейдеры, намного превосходящие стандартные для DX9 ( версия 2.0) хотя и медленее чем старые 1.1…1.3 версии. Когда игры, интенсивно использующие подобные шейдеры и плавающие вычисления появятся в магазинах, там же будут находиться продукты компании NVIDIA следующего поколения, более агрессивно оптимизированные под плавающие операции…
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителей.
- Производительность фиксированного TCL (для NV30 и R300 — производительность эмулирующего его шейдера):
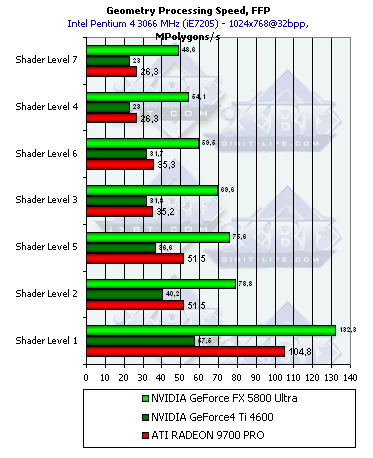
Результаты сортированы по степени сложности используемой модели освещения. Самый нижняя группа — простейший вариант, соответствующий пиковой пропускной способности ускорителя по вершинам. Результат вполне прогнозируем — здесь все зависит от частоты ядра и числа вершинных процессоров. С одной стороны, у NV30 их только три, в отличие от четырех в R300, с другой стороны, частота ее ядра существенно выше и разница частот превышает три четверти, в итоге — вполне логично увидеть преимущество NV30.
Впрочем, и на более сложных моделях освещения она впереди, эмуляция TCL в исполнении NVIDIA всегда была на высоте. Чего стоят столь близкие к R300 результаты куда как более скромной в вопросах обработки вершин NV25. Судя по всему, NVIDIA до сих пор закладывает в чип некоторые аппаратные блоки, обеспечивающие эффективное ускорение эмуляции TCL. R300 же эмулирует TCL, просто выполняя некий стандартный шейдер-эмулятор, не задействующий никаких дополнительных возможностей и компилируемый стандартным путем.
- Теперь обратимся к вершинным шейдерам 1.1:
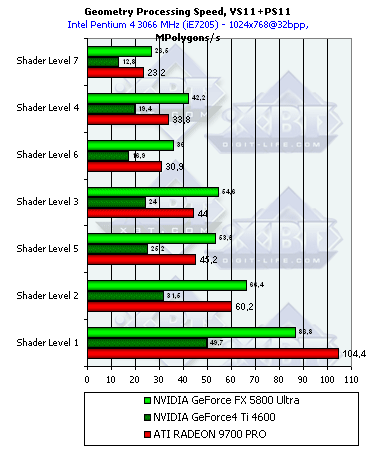
Здесь также лидирует NV30 кроме самого простого, пикового случая. Преимущество уже не столь значительно, но все равно заметно, более высокая частота берет верх над отсутствием одного конвейера. Единственный случай, где наличие четырех конвейеров R300 позволяет этому чипу выиграть — простейший шейдер. Т.к. вклад накладных расходов на запуск обработки вершины становится достаточно заметным на фоне очень короткого и простого шейдера, R300, запускающий четыре вершины параллельно, получает видимое преимущество.
- А теперь самое интересное — шейдеры 2.0 с циклами:
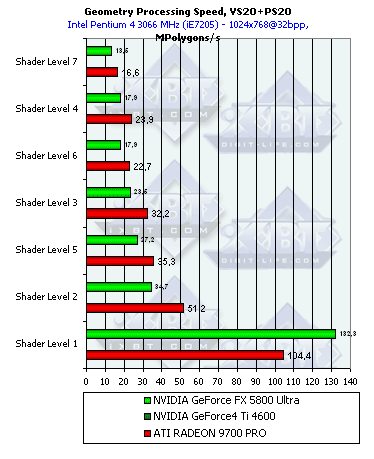
Помните, мы отмечали высокие накладные расходы R300 на выполнение циклов? Сотрудники ATI говорят, что интенсивно работают над внутренним оптимизатором шейдеров, заложенным в драйверы, и в ближайшее время эти расходы должны снизиться. Так вот, в случае NV30 накладные расходы на циклы еще более значительны! И это не удивительно, динамическое управление потоком команд может и должно вызывать большие задержки на выполнение циклов. Что мы здесь и наблюдаем. За гибкость приходится расплачиваться скоростью — при наличии цикла, преимущество NV30 в тактовой частоте растворилось окончательно. Интересно только одно исключение — простейший шейдер выполняется будучи скомпилирован как 2.0 заметно быстрее.
Аппаратная эмуляция T&L в исполнении ATI менее эффективна, чем у NV и сравнима по эффективности с вершинным шейдером 2.0. Самое сильное место NV30 — эмуляция TCL. Самое слабое — циклы. В этом плане у ATI больше простор для оптимизации в драйверах — статическое исполнение переходов и циклов позволяет применять куда как более агрессивную оптимизацию. Итак, для всех чипов обзора вторая версия далась не бесплатно — использованные циклы стоят заметного падения производительности. Причем большего, чем мы могли ожидать от одной команды цикла, на несколько десятков обычных команд.
- 4. Проверим перекрестную зависимость от степени детализации геометрии и сложности шейдера:
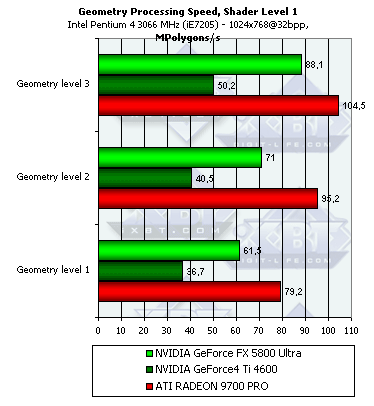
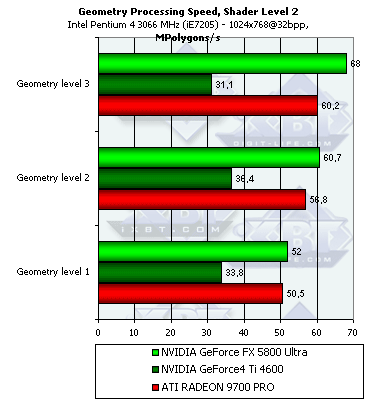
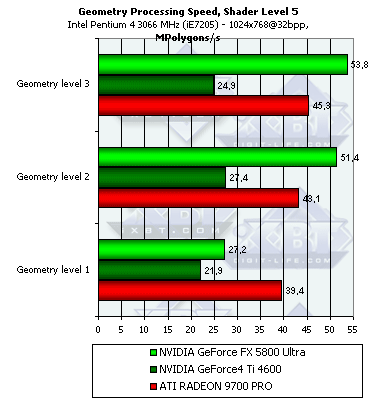
Чем выше сложность шейдера и чем выше детализация сцены, тем большее преимущество получает NV30 (сказываются кэши вершин и прочие аспекты балансировки). Эта архитектура сделана с заметным прицелом на будущее. Чем больше полигонов в модели — тем выше результаты, но зависимость крайне слаба и начиная со второго уровня детализации, и второго по сложности шейдера ее можно положить достаточной.
Hidden Surface Removal
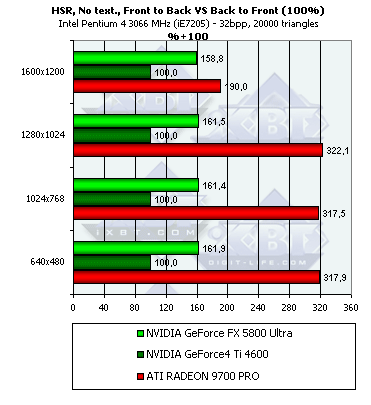
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа треугольников, на сцене без текстур (не учитывается ранняя проверка Z):
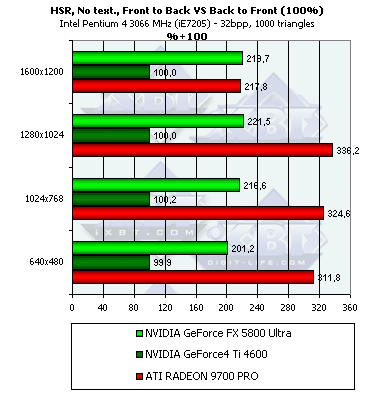
Итак, на NV25 блочный HSR по-прежнему деактивирован, результат синтетического теста с высокой точностью демонстрирует этот факт. (впрочем, как мы уже потом выяснили, возможность включения HSR вновь появилась в последних версиях драйверов, разумеется, только через твикеры, например, RivaTuner, однако по умолчанию HSR выключен). Зато на NV30 его наличие налицо. Но эффективность оного ниже, чем у R300 - дело в том что R300 использует иерархическую структуру, и зачастую отсечение происходит на более высоком уровне, а следовательно, и более эффективно, в то время как у NV30 присутствует только один уровень принятия решения, совмещенный с тайлами, на основе которых сжимается информация о глубине. В максимальном разрешении 1600х1200 происходит резкое падение эффективности HSR на R300 — видимо, по каким-то соображениям, например, соображениям экономии памяти, иерархический буфер глубины уже не используется, и решение об отсечении блоков принимается так же, как и в случае NV30, только на самом нижнем базовом уровне, совмещенном с сжимаемыми блоками в буфере глубины.
Теперь давайте посмотрим на то, как эффективность HSR зависит от сложности сцены:
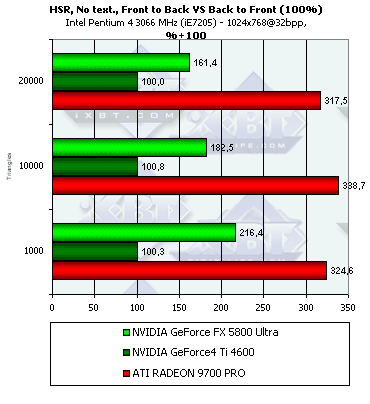
Как мы видим, для NV30, обладающей только одним уровнем тайлов, эффективность работы HSR тем выше, чем меньше полигонов на сцене, а вот R300 придерживается в этом вопросе золотой середины. Его HSR только расправляет крылья на сценах средней сложности.
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа треугольников, на сцене с текстурами (с учетом ранней проверки Z):
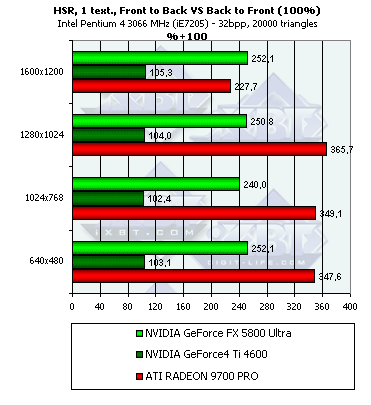
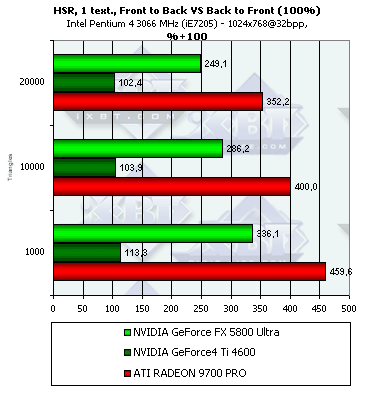
Итак, здесь и NV30, и R300 демонстрируют дополнительный рост эффективности. Для NV25 прирост эффективности минимален — всего 5%, а вот для более новых чипов он более заметен, в них ранняя проверка Z реализована видимо более эффективно. С учетом наличия текстуры, оба чипа начинают предпочитать сцены с низким числом полигонов.
- Посмотрим, как изменится эффективность в случае сравнения хаотической и сортированной сцены, как с текстурой, так и без:
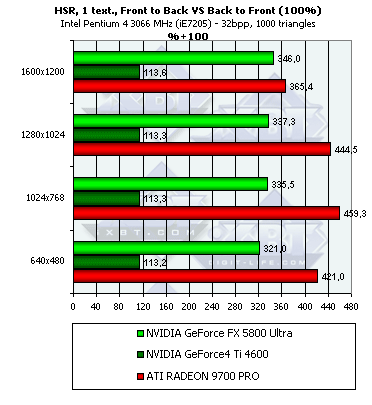
Принципиально ничего нового, однако в некоторых тестах преимущество R300 еще более велико. На не столь пиковом, но зато более-менее правдоподобном сравнении эффективности вывода сортированной и хаотической сцен, в условии наличия текстур, NV30 чувствует себя еще хуже. Зато NV25 наоборот демонстрирует 13% преимущество на сцене с текстурами.
Итак, даже в случае исходно хаотической сцены прирост велик. Наиболее заметен он в случае небольшого или среднего числа полигонов. Вывод — если хотите воспользоваться благами HSR (к несчастью, у многих чипов, как было выяснено нами в прошлом обзоре на тему DX9, отключенного) — сортируйте сцену перед выводом. Тогда и только тогда вы получите значительное, в несколько раз, преимущество. В случае же вывода несортированной сцены HSR сказывается, но не столь сильно — от единиц до десятка процентов. Впрочем, портальные приложения, так или иначе, сортируют сцену при выводе, а к ним относится подавляющее большинство современных FPS движков. Поэтому, игра с HSR стоит свеч, в первую очередь именно для этого класса игр.


