Продолжая почивать на лаврах лидера после выпуска архитектуры Sandy Bridge (SB) в 2011 г., Intel продолжает следовать своей стратегии «тик-так», приготовив очередной «тик»: переход на новый, 22-нанометровый техпроцесс с 3-сторонними затворами у транзисторов (описанный в третьей части нашего микроэлектронного обзора) совмещён с небольшими изменениями в архитектуре. Причём большая часть изменений касается помощневшего графического (со)процессора (ГП): версия HD2000 обновилась до HD2500 (оставив те же 6 графических трактов), а HD3000 (12 трактов) доросла до HD4000 (16 трактов). QuickSync (аппаратный перекодировщик видео) обновлён до версии 2.0, которой рекламируют удвоенную скорость. Заявлена поддержка библиотек DX11, OpenGL 3.1, OpenCL 1.1 (на этот раз — настоящая, т. е. аппаратная, а не эмуляция на x86-ядрах) и MFX (Multi-Format Codec), а также разрешений до 4096×4096 и до трёх экранов. Детали производительности ГП описаны в этих двух тестированиях, а сила x86-ядер изучена как в абсолюте, так и в равных условиях. Нам же осталось посмотреть, какие мелочи решила добавить Intel к и так передовому «песчаному мосту», превратив его в «плющевый».
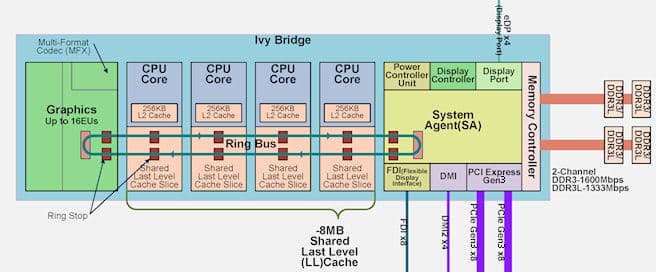
Устройство процессоров Core 3-го поколения с x86-ядрами архитектуры Ivy Bridge. Иллюстрация PC watch (с исправленной ошибкой).
Ядро
С точки программно доступных изменений, Ivy Bridge (для краткости будем называть его IB) получил несколько мелочей:
- поддержка мини-поднабора CVT16 (ранее доступного лишь последним ЦП AMD), причём сразу в полноконвейерном режиме (преобразование вектора имеет задержку 6–10 тактов);
- быстрый доступ к сегментным регистрам FS и GS (только эти из 6 сегментных регистров разрешены к использованию после внедрения x86-64) с помощью 4 новых команд — пригодится для ускоренного управления переключением контекста задач со стороны программы;
- DRNG (digital random number generator) — цифровой генератор случайных чисел (ГСЧ) и команда для их чтения (строго говоря, сам ГСЧ расположен во внеядре, но командно доступен всем ядрам);
- SMEP (supervisory mode execution protection) — защита исполнения в режиме супервизора.
О ГСЧ и SMEP, наличие которых удостоено дополнительными битами в паспорте ЦП (читаемому командой CPUID), детально напишем ниже.
Что касается чисто аппаратных улучшений, то начнём с блока, ускорение которого в тестах едва чувствуется: один из двух видов предзагрузчиков для кэша L1D теперь может переходить через 4-килобайтовые границы виртуальных страниц. В момент пересечения он инициирует (как при явном обращении в L1D) чтение(я) из TLB (и L1, и L2), а если там будет два промаха — то даже и трансляцию адреса в PMH. Причём если PMH наткнётся на ошибку доступа или нерезидентную страницу (перемещённую из ОЗУ в файл подкачки), то вместо фиксирования исключительной ситуации и вызова её обработчика PMH просто остановится. Ведь предзагрузка это упреждающее действие, поэтому ЦП не может быть уверен, что данные по этому адресу точно потребуются, так что преждевременное прерывание делать неверно. В подсистеме кэшей есть также некие улучшения при чтении невыровненных 32-байтовых слов из L2, о чём в официальных документах ничего не сообщается — видимо, из-за крайне малого влияния на что-либо.
Ну а остальные улучшения измерены куда детальней и приносят бо́льшую пользу. Во-первых, ускоренный вещественный делитель-корнеизвлекатель: деление для точностей SP, DP и EP теперь исполняется за 7, 14 и 18 тактов (было — 14, 22 и 24); почти так же ускорено и извлечение квадратного корня. Тем не менее, это ФУ осталось единственным крупным 128-битным в векторном тракте — все остальные имеют полную ширину в 256 бит. Также сюда можно добавить несколько команд (таких как некоторые простые битовые сдвиги и вращения), ускоренных на 1 такт или исполняющихся парами, а не по одной, что из всех алгоритмов пока заметно ускоряет лишь вычисление хэшей типа SHA1 и SHA256.
Пара (по одному на поток) буферов мопов (IDQ), находящихся между декодером и кэшем мопов со стороны фронта и диспетчером со стороны тыла конвейера, теперь для 1-поточной нагрузки умеет притворяться единым буфером на 56 мопов — SB в таком случае просто отключал второй буфер. В идеале, конечно, было бы ещё лучше, если бы это физически был единый буфер, который при 2-поточной загрузке делился бы не поровну, а динамически, как большинство остальных структур ядра. На производительность это почти не влияет (ибо кэш мопов и так гарантирует, что тыл почти всегда сможет получать по 4 мопа/такт), однако становится ясно, почему Intel оставила эту структуру — при блокировке цикла в буфере (за счёт функции LSD) можно отключить даже кэш мопов, экономя таким образом ещё немного энергии. И если для 1-поточной нагрузки буфер оказывается вдвое больше, то шансов на то, что очередной цикл там поместится, куда больше. За подробностями о правилах работы IDQ и о 4 видах разделения ресурсов между потоками отправляем к соответствующим описаниям в обзоре SB по данным тут ссылкам.
Также появились «бесплатные» копирования из одного регистра в другой, «исполняющиеся» уже на стадии переименования регистров и не занимающие ресурсы планировщика и ФУ:
- скалярные MOV для 32- и 64-битных РОНов (8- и 16-битные копирования — обычные);
- скалярные MOVZX (беззнаковое расширение РОНов с заполнением старших битов нулями) типа 8→32 и 8→64, кроме случаев, когда 8-битный источник это регистр AH/BH/CH/DH (т. е. старшие байты младшего слова первых 4 РОНов) — такие варианты исполняются штатно, как и все виды MOVSX (знаковое расширение с заполнением старших битов копией бита знака аргумента);
- векторные MOV*** (6 видов) для xmm и ymm и обоих типов элементов (целые или вещественные).
Таким образом, к обнуляющим идиомам в SB, которые также «бесплатны» и могут исполняться до 4 за такт, в IB добавили и самые частые копирования, что в некоторых программах может чуть поднять среднюю величину IPC и сэкономить несколько миллиджоулей. Физическая реализация очевидна: т. к. планировщик (как и у SB) оперирует не содержимым регистров, а ссылками на физический РФ, то копирование регистра можно заменить копированием 8-битной ссылки, и реализовать это можно было ещё в SB.
Сложнее с частичным доступом в эти регистры (детали этого непростого действия описаны в конце этой главы). Согласно требованиям x86-64, запись в 32-битную младшую половину РОНа обнуляет его старшую часть (а обнуление, как мы помним, также бесплатно), а вот запись в 16- или 8-битные порции сохраняет остальные биты. Однако команда MOVZX всё же их обнуляет, и потому она в «бесплатном» варианте допустима с 8-битным источником. Могла бы сработать и с 16-битным, но по историческим причинам (восходящим к далеко не идеальному способу, которым Intel в 1985 г. свою изначально 16-битную архитектуру IA-16 доработала до 32-битной IA-32, ныне называемой x86) почти все 16-битные команды в современных x86-ЦП давно попали в разряд вредных и медленных.
Данное выше описание считалось верным до тех пор, пока независимое тестирование не показало странности работы этой «копировальной машинки». Запустив простой цикл, тело которого состоит из 2–4 команд MOV в разных вариантах, а эпилог — в виде макросливаемой пары команд (генерирующей только 1 моп), обнаружено, что обещанный в документах темп в 4 копирования за такт не получается нигде. Для РОНов 1-тактное исполнение итерации цикла выходит с одной-двумя командами MOV, а с тремя — уже за 2 такта (хотя такой цикл займёт 4 мопа, передающиеся из фронта в тыл за такт). Добавление 4-го MOV увеличивает темп до 2,33 тактов на итерацию.
При копировании векторных регистров все задержки увеличиваются ещё на 1 такт, причём уже проявляется зависимость от операндов (далее цифрами обозначены номера регистров xmm): перемещение 0→1→2 + 0→1→2 — 3 такта, 0→1→2→3→0 — 3,33, 0→1→2→3→4 — 3,5, а 0→1 + 2→3 + 4→5 + 6→7 — 3,67. Т. е. 4 копирования в цикле будут исполняться за 2,33–3,67 такта, хотя в идеале должно быть 1,25 (5 мопов). Есть, конечно, остаточная надежда, что тесты оказались неточными (как это уже бывало), но пока результаты по этому пункту крайне странные…
Ещё одно видимое улучшение (тоже отдельно отмеченное в паспорте ЦП битом ERMSB) — скоростные операции со строками. Речь идёт не об обработке текста, а об особом виде данных из терминологии x86. Для программиста «строки» это располагаемые в памяти линейные массивы произвольной длины с целочисленными элементами размером 1, 2, 4 или 8 байт. Для их обработки ещё со времён самого первого ЦП «нашей эры» — i8086 — существует 7 команд, обрабатывающих 1 элемент строки (и неявно использующих почти все нужные им регистры), REP-префиксы для их повторения (в т. ч. с досрочным выходом из цикла) и специальный бит управления в регистре флагов. Команды позволяют копировать строку (MOVS), сравнивать строки до первого (не)совпадения (CMPS), заполнять строку константой (STOS), загружать очередной элемент строки в регистр (LODS), сравнивать строку с константой (SCAS) и выводить или вводить строку в/из порт(а) ввода-вывода (OUTS и INS, добавленные уже в 286).
Из этого разнообразия сегодня наиболее употребительными остались лишь комбинации REP MOVS и REP STOS, используемыми библиотечными функциями языка Си memcpy(), memset() и memmove(), которые в том или ином виде встречаются почти везде, выполняя, например, копирование объектов. Поэтому за последние лет 5 процессоры научились ускорять эти команды (особенно, когда копируются или заполняются десятки элементов, расположенные как минимум в нескольких строках кэша) за счёт переноса данных только в пределах самого кэша. В IB такой аппаратный ускоритель оптимизирован, причём только для байтовых элементов (т. е. наиболее общего случая). При обработке ≥256 байт экономия составит аж 30–50 тактов. Однако Intel предупреждает, что не смотря на скорость режима ERMSB и компактность спецкоманд, обработка строк векторными командами всё равно оказывается чуть быстрее, если операнды выровнены, а их размер нацело делится на длину вектора.
Режим SMEP
SMEP является защитой от атак типа «повышение привилегий», когда вредоносный код с уровнем привилегий 3 (пользовательский и самый низкий), не имея возможности запуститься на высоком уровне, разными способами передаёт ссылку на себя в ОС, чтобы исполниться с более высокой привилегией (обычно уровни 2 и 1 занимают компоненты ОС, а 0 — её ядро). При включении режима SMEP (через бит в одном из управляющих регистров) ядро не сможет исполнять команды из линейного адресного пространства, в дескрипторе виртуальной страницы которого выставлен бит её принадлежности к пользовательскому коду. Проще говоря, если ядро ОС поддерживает включение SMEP, то система с имеющим этот режим процессором станет чуть более защищённой. По крайней мере, так обещали в прошлый раз, когда внедряли похожую защитную функцию — бит NX, который разные вирусы и трояны весьма быстро научились обходить. На этот раз взлом произошёл ещё быстрее.
IB был официально объявлен в продаже 29 апреля 2012 г., а уже в сентябре Артём Шишкин, эксперт компании Positive Research, специализирующейся на инфобезопасности и защите, опубликовал подробный отчёт о частичном обходе SMEP на Windows 8 (пока ни для какой другой ОС поддержка SMEP не заявлена). Более того, автор указывает, что могут существовать и другие способы обхода — с помощью сторонних драйверов. «Тем не менее, в том виде, в каком реализована поддержка SMEP на x64-версиях Windows 8, она может считаться достаточно надёжной и способной предотвратить различные атаки.» В общем, бой меча и щита никогда не закончится, как и ожидалось.
Цифровой ГСЧ и Большой Брат
Сначала сделаем небольшое, но важное отступление. Внимательный Читатель, пересматривая предыдущие обзоры процессорных микроархитектур и технологий, наверняка заметит, что мы как-то обошли такую популярную тему как мировые заговоры. Непорядок-с :) Ну, многие помнят, как в 1999 г. при выпуске Pentium III мировая конспирологическая общественность обратила внимание на уникальный серийный номер (PSN), которым Intel собиралась помечать каждый ЦП, и так громко завопила «Ага, попались!», что в уже ноябре Оценочная комиссия по наукам и технологиям (STOA) при Европарламенте всерьёз стала обсуждать запрет на импорт новых «Пней» в Европу, опасаясь цифровой слежки. Так что Intel пришлось через 2 года убрать PSN в чипах Tualatin. Точнее, так нам сказали ;)
Но главные компьютерные заговоры, разумеется, лежат в логовах штаб-квартирах коварных спецслужб (например, американского Агентства Национальной Безопасности, АНБ) и охмуряемых ими фирм-гигантов (например, ненавистной многим Microsoft). Причиной охмурения стало то, что «с появлением быстрых компьютеров, с бесконтрольным распространением сильных криптографических алгоритмов […] у всех желающих появились возможности для надёжного засекречивания не только текстовых, но и речевых коммуникаций». Поэтому ещё со времён Windows NT, как утверждают аналитики, АНБ пыталось внедрить чёрный вход в самую популярную серию ОС. Если бы это удалось, то «граждане, фирмы, организации и государственные ведомства в случае засекречивания своих коммуникаций должны использовать лишь такие криптосредства, которые без проблем могут быть расшифрованы правоохранительными органами».
Естественно, АНБ в этом не одинока — в 2006 г. обнаружилось, что «Британские власти ведут переговоры с представителями Microsoft по поводу умышленного создания уязвимостей в системе защиты новой операционной системы Windows Vista, чтобы сотрудники спецслужб могли проникать в компьютеры злоумышленников […] — это “поможет предотвратить террористические акты”» (ну разумеется, куда же мы без борьбы с мировым тараканизмом…). MS быстро заверила, что «в Windows Vista не будет “чёрных ходов” для спецслужб», но через год появилось продолжение — «В работе над Vista принимало участие АНБ, …[чтобы] убедиться в том, что новая ОС Microsoft соответствует всем необходимым требованиям Пентагона… Правозащитники полагают, что при участии АНБ в состав ОС могли быть включены средства […] доступа к конфиденциальным данным.»
В общем, Мировая Закулиса не дремлет. Ну, кто бы сомневался, но причём же тут случайные числа? А вот тут и начинается самое интересное. Дело в том, что крипто в Windows и др. ОС может быть взломано «плохим» ГСЧ (реализованным в ОС программно) или случайной ошибкой в процессоре. (Да простят читатели автора за столь обильное цитирование, но в выжимке ниже сказана вся суть.)
«Примером тому может служить случайное открытие в середине 1990-х глубоко спрятавшегося “бага деления” в процессорах Pentium… Если какая-нибудь спецслужба […] обнаружит (или тайно встроит) хотя бы лишь пару таких целых чисел, произведение которых микропроцессор вычисляет некорректно, то […] любой ключ в любой криптопрограмме на основе RSA, работающей на любом из миллионов компьютеров с этим процессором, может быть взломан… Если взломан ГСЧ, то в большинстве случаев можно считать взломанной и всю систему безопасности…
В новый спецвыпуск Национального института стандартов США, […] описывающий 4 одобренных к использованию схемы RNG, включен генератор Dual_EC_DRBG, разработанный в недрах американского АНБ… Выяснилось, что …[константы шифрования] связаны со вторым, секретным набором чисел… Если вы знаете эти секретные числа, то всего по 32 байтам выхода можно предсказывать всю генерируемую “случайным генератором” последовательность… [Dual_EC_DRBG] используется во всех приложениях [Windows 2000]… Функция запускается в режиме пользователя, […] что делает очень лёгким доступ к состояниям генератора… Никто толком не знает, как устроен ГСЧ в XP, но есть веские основания полагать, что он не слишком отличается от Windows 2000.»
Наконец, «Dual_EC_DRBG вошёл как опция в пакет обновления Service Pack 1 ОС Windows Vista».
Таким образом, начиная с 1995 г., история шифрования в Windows и пакета Office показывает систематически кочующие из версии в версию уязвимости, объяснить которые можно только намеренным ухудшением защиты по приказу Большого Брата. А чтобы пингвинофилам не стало обидно за обделение вниманием — в прошлом году всплыла история о том, «как ФБР и АНБ США встраивали закладки-бэкдоры в криптографию операционной системы с открытыми исходными кодами»:
«В 2003 г. программисты-разработчики, занимавшиеся созданием […] ядра ОС Linux, […] обнаружили и ликвидировали в открытых исходных кодах системы тайный бэкдор. Причём реализован этот бэкдор был настолько хитро и искусно, что […] разговоры о неуловимых троянах в открытом ПО перестали звучать как бред… Человек, знавший […] экзотическое сочетание управляющих флагов плюс место, где их следует применить, получал бы благодаря этим двум строчкам полный, с максимальными привилегиями Root, контроль… В сообществе OpenBSD начались аудиторские проверки криптоподсистем этой ОС. Первые же дни пристрастных перепроверок позволили выявить в кодах пару существенных и прежде незамеченных багов.»
Итак, мы уже трепещем: Большой Брат достал своими щупальцами до каждого ПК (кто-нибудь сомневается, что и продукция Apple не обойдена стороной?). Более того, по требованию АНБ и производители невычислительных устройств могут укоротить фактически используемую длину ключа, заполняя часть битов константой. Так это сделано в телефонах стандарта GSM и противоугонных автомобильных системах: в применявшихся до этого года чипах радиочастотной идентификации (RFID) фирмы Texas Instruments фактическая длина ключа составляла лишь 40 бит из 64, а в системах на основе KeeLoq фирмы Microchip — 28 из 64. Впрочем, взлом телефонов и угон авто — это совсем не наша тема, а вот как насчёт компьютеров?
И тут все в белом выходят маркетологи Intel и как-бы говорят: Аллилуйя! Свершилось! Повальная интеграция всего и вся в процессор достигла и случайных чисел! Тем более, что ускорение шифрования, где они так нужны, тоже давно добавлено в виде AES-NI и некоторых отдельных команд. Что говорите? Аппаратный ГСЧ ещё с 2003 г. как есть в процессорах VIA (в составе PadLock), начиная с C3 и заканчивая последними Nano? Да кто эти Нано видел-то? Вот то-то же, а вот мы — великая Intel! Поэтому с нашими Ivy Bridge ваши, граждане, случайные числа будут на 146% случайней обычных. Аминь! Ура, товарищи!
Технология аппаратного ГСЧ получила кодовое имя Bull Mountain («Бычья гора») в честь селения в штате Орегон рядом с городом Хиллсборо, где расположился исследовательский центр Intel’s Circuit Research Lab, в недрах которого технология и родилась. Перед тем как описать её суть, следует сделать теоретический экскурс, поясняющий суть задачи. Ещё Клод Шеннон показал, что лучший способ сделать так, чтобы никто, кроме целевого получателя, не мог восстановить дискретную информацию — максимально исказить её шифрованием. Более того, существует абсолютно стойкий шифр, принципиально невскрываемый аналитически — даже при наличии бесконечных петафлопсов и времени. Для этого надо всего лишь для каждого шифрования генерировать идеально случайный ключ длиной с весь шифруемый текст, причём использоваться он должен только раз.
Шеннон позаимствовал для своей теории понятие энтропии — математической меры хаотичности термодинамической системы. Энтропия по Шеннону стала мерой хаоса сигнала. И до сих пор наиболее качественными источниками хаоса являются физические явления, а не алгоритмы ГСЧ. Но т. к. программный генератор есть вещь нематериальная, то именно такой вид и применяется чаще всего, ибо он наиболее прост. И т. к. числа в нём на самом деле не очень-то случайные, то вернее его называть генератором псевдослучайных чисел (ГПСЧ, PRNG). Помимо простоты «конструкции» ещё одно важное преимущество перед аппаратными генераторами истинно случайных чисел (ГИСЧ, TRNG) — программная сущность позволяет им куда быстрее работать, что очень важно, когда шифровать надо много (для сетевых служб и устройств это особенно востребовано). Однако результат ГПСЧ должен быть криптографически стойким на случай атак и взломов, суть которых проста: следует наблюдать выходные числа или менять стартовое состояние ГСЧ, чтобы предсказывать следующие его значения, либо как-то ещё вмешиваться в его работу. И чаще всего это получается.
Дело в том, что обычные ГПСЧ, как и любая другая программа для машины с конечным числом состояний (а таков любой цифровой компьютер), основаны на детерминированном алгоритме, потому их числа лишь притворяются случайными. Для начала генерации им требуется посевное число или затравка (seed), из которого конкретный ГПСЧ всегда выдаст одну и ту же последовательность чисел, которые к тому же ещё и неизбежно начнут повторяться (хоть и с очень большим периодом — для 32-битного ГПСЧ Mersenne Twister MT19937 период равен 219937−1). Такие псевдослучайные числа подойдут для управления ИИ-соперниками в играх или в приближённых моделях в прикладной науке. Но для криптографии ГПСЧ неприменимы. Поэтому появился подвид «криптографически безопасных» ГПСЧ (КБ-ГПСЧ, CSPRNG). Он значительно лучше удовлетворяет основным требованиям к случайным числам для шифрования:
- последовательность должна быть статистически неотличима от случайной;
- восстановление прошлых или будущих состояний алгоритма по текущему должно быть максимально затруднено, а в идеале — невозможно. (Для вышеупомянутого MT19937 достаточно протестировать всего 624 числа для точного предсказания всех следующих.)
Лучший способ превратить обычный ГПСЧ в криптографически безопасный — обеспечить ему периодическую «рандомизацию», подмешивая настоящие случайные числа, полученные извне, т. е. от ГИСЧ. Таким образом можно получить много чисел, которые будут куда случайнее, чем от ГПСЧ, но при этом на единицу времени их будет куда больше, чем от медленного ГИСЧ. Но почему же медленного? А потому, что эти генераторы ничего сами не считают, а выделяют энтропию из некоего физического источника и оцифровывают её. Таким источником могут быть тепловые шумы в усилителе или специальном шумовом диоде, случайные распады радиоактивного вещества (с поправкой на темп полураспада согласно известному периоду), колебания атмосферы, хаотичное поведение микро- или макрообъектов в жидкости, и пр. Датчики, преобразующие это в последовательность нулей и единиц, работают не очень быстро.
Более того, не смотря на «природность» источника энтропии, и его статистические свойства бывают неидеальны. Например, тепловые шумы, очевидно, зависят от температуры, а броуновское движение — ещё и от внешних толчков и колебаний (даже малейших). Поэтому самые крутые ГСЧ имеют составную или «каскадную конструкцию» (КГСЧ, CCRNG): числа от встроенного ГИСЧ попадают в буфер, названный «бассейном (пулом) энтропии». Оттуда они периодически читаются в качестве недетерминированных «затравок» для КБ-ГПСЧ. Таким образом получаются и качественный хаос на выходе, и высокий темп его генерации.
Так что же нового сделала Intel? Она попыталась уместить на кристалле (причём дешёвом и массовом) все компоненты КГСЧ, чтобы любой пользователь мог иметь настоящие случайные числа, не покупая за большие деньги приставку к ПК, считающую колебания луча лазера от пролетающего за окном комара. Если не вспоминать про других производителей (тем более, что об их решениях не так уж и много известно), то конкретно Intel впервые сделала такую интеграцию ещё в 1999 г., встроив в микросхему БИОСа ГИСЧ, фиксирующий тепловой шум в виде разности сопротивлений близко расположенных резисторов. Шум усиливался и подключался к кольцевому генератору, постоянно меняя его период. Выход генератора оцифровывался через равные промежутки, фильтровался от псевдослучайных влияний (внешние электромагнитные наводки, температура и колебания шины питания) и подавался в буфер, откуда его можно было читать спецкомандой.
Часть этой схемы является аналоговой и потребляла довольно много энергии, особенно на стадии усиления — причём постоянно, пока подано питание. 13 лет назад на лишние милливатты никто внимание не обращал, но сегодня это катастрофично. Другой минус аналоговых схем — крайне трудное моделирование, которое требуется проводить не только при проектировании первого образца, но и каждый раз при переводе чипа с этой схемой на новый техпроцесс. Разумеется, цифровые схемы также моделируются, но для них это проще благодаря детерминированности. Аналоговые же компоненты всякий раз требуют ещё и коррекции для обеспечения нужного качества сигнала, причём начиная с 45 нм это оказывается крайне трудно. Так что помимо ваттов хорошо бы сэкономить и человеко-часы инженеров. Да и 75 Кбит/с на выходе этого ГСЧ сегодня кажутся смешными — профессиональные ГИСЧ выдают 10–20 Мбит/с.
Поэтому в 2008 г. конструкторы Intel занялись созданием полностью цифрового ГИСЧ, отвечающего американским государственным стандартам на такие приборы (NIST SP800-90, FIPS-140-2 и ANSI X9.82). Спустя 4 года именно его мы и получили в IB в составе встроенного каскадного ГСЧ. Этот генератор формально нарушает одну из аксиом построения цифровой схемы: она должна находиться в точно определённом и предсказуемом состоянии. Очевидно, новый ГИСЧ должен делать прямо противоположное, но теми же транзисторами, что и обычные вентили. Для этого генератор стал метастабильным, что для обычной логики является дефектом.
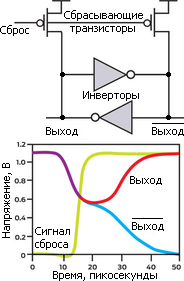 Упрощённая схема кольцевого инвертора и график одного из двух вариантов его срабатывания (второй — очевидно, инвертированное состояние первого). |
Состоит он из обычного кольцевого инвертора, который применяется в любой ячейке СОЗУ для хранения бита. Сигналом сброса оба вывода (прямой и инверсный) на очень короткое время подключаются к шине питания (т. е. логической «1»), образуя короткое замыкание. Чтобы не закоротить весь чип до снятия сброса, к питанию подключаются изолированные диодами буферные конденсаторы, которые и запитывают выводы генератора до снятия сброса. После этого каждый инвертор генерируют на выходе «0», которая смешивается с «1» и попадает на вход другого инвертора. Срединное значение на входах приводит к неустойчивому равновесию, когда малейшее отклонение из-за теплового шума сдвигает баланс к случайному из крайних состояний. Достаточно одному из инверторов хоть немного перетянуть вольтаж от центра, как его выход «убедит» напарника сдвигать своё значение в противоположном направлении — в результате через короткое время с любого инвертора можно читать бит. Момент фиксации также генерирует импульс для местного тактирования, нужный для схемы сброса и 1-й стадии обрабатывающей случайные биты логики.
|
Расположенный во внеядре ГСЧ Bull Mountain оформлен как частично асинхронный 4-стадийный конвейер (см. схему-таблицу). Стадия №2 срабатывает только после заполнения буфера перед ней. А стадии №3 и №4 имеют внешнее тактирование; причём, являясь по сути одной схемой, они не могут работать одновременно. 1-я стадия — метастабильный кольцевой инвертор, генерирующий хаос с энтропией >80%. Далее каждый бит потока смешивается с предыдущим, а результат подаётся в 512-битный регистр сдвига. Формируемые на выходе порции подаются на статистический тестер (стадия №2), который проверяет фактическую случайность порции — побитным сравнением с результатом математической модели кольцевого генератора и плавающим окном на 64 Кбит. Если энтропия недостаточна, то такую порцию отбрасывают. Т. о. после тестера темп потока качественных порций непредсказуем.
Проверенные порции подаются в очиститель (стадия №3), где делятся на половинки, которые проходят через сложные взаимные преобразования, чтобы сделать 256-битное слово-результат ещё случайней. Причина такой обработки — те самые псевдослучайные влияния, от которых пришлось защищаться ещё в 1999 г. К вышеописанному списку сегодня добавляется ещё как минимум разброс параметров транзисторов, который сильно мешает жить и дизайнерам обычных цифровых схем. На выходе очистителя стоит КБ-ГПСЧ (стадия №4), представляющий чуть изменённый аппаратный шифратор по алгоритму AES. 256-битные слова-затравки подмешиваются в поток генерируемых им 128-битных векторов псевдослучайных чисел, которые буферизуются и становятся доступными командой RDRAND. Также присутствуют схемы стартовой самопроверки и отладочные блоки. Когда все буферы заполнены, вся логика, включая кольцевой генератор, отключается от питания для сохранения энергии.
Производительность самосинхронизированного генератора энтропии — 2,5–3 Гбит/с, что зависит от параметров конкретной пары инверторов. Поэтому он сильно подвержен джиттеру (уходу частоты), с которым обычно нещадно борются. Тестер имеет собственный источник тактирования, который, как нетрудно подсчитать, считывает 512-битные порции с частотой не более 5–6 МГц. А вот очиститель и ГПСЧ тактируются твёрдыми 800 МГц (непонятно только, с какого умножителя частоты их подают — неужели с отдельного?). Очиститель, судя по всему, срабатывает за такт, а вот ГПСЧ требует 11 тактов для каждого 128-битного вектора, генерируя 0,8/11×128≈9,3 Гбит/с. Впрочем, на одной из иллюстраций указано, что верная цифра — ≈6 Гбит/с… Как только новая порция готова и протестирована, из неё тут же вычислят очередную затравку, которая сначала попадает в буфер, а в ГПСЧ будет использована через некий определяемый им самим интервал. Согласно теории (делим 800 МГц на пиковую частоту подачи порций), затравки в среднем хватит на 12–15 векторов, но документ Intel говорит, что максимум из неё можно сделать аж 511 векторов, из чего можно сделать вывод, что тестер, видимо, пропускает в среднем примерно каждую 20-ю порцию.
Аргумент RDRAND — 16-, 32- или 64-битный РОН, причём если в момент обращения буфер пуст, то вместо числа будет выставлен флаг переноса. Происходит это, когда ядра слишком часто читают буфер, быстро его опустошая. С ядрами ГСЧ связан через ту же кольцевую шину, что и остальные компоненты чипа, а потому её частота (равная частоте ядер) теоретически тоже может оказаться ограничивающим фактором. Например, если от внеядра к любому запросившему ядру передаётся только 2/4/8 байт(а)/такт (а не 32, на что способна шина), то именно эта скорость — 8 байт/такт на все ядра — и является пиковой в этом месте. Но буфер всё равно можно опустошить, т. к. темп его заполнения ещё меньше — например, для частоты ядер в 3,5 ГГц это ≈24 такта на 8-байтовое число (или даже ≈37, если цифра ≈6 Гбит/с верна). Более того, в реальных тестах время задержки при непрерывном чтении оказалось и вовсе 104 такта, что всего вдвое меньше чтения из ОЗУ. Почему — неясно.
В официальном учебнике по оптимизации для x86-ЦП Intel написано: «the total bandwidth to deliver random numbers via RDRAND by the uncore is about 500 MBytes/sec». При этом даже 2-ядерный ЦП с частотой 3 ГГц при задержке ГСЧ в 100 тактов будет читать 480 МБ/с. А если он 4-ядерный?… Другие, не менее официальные источники пишут о 800 МБ/с (т. е. 4 Гбит/с) или «70 million RDRAND invocations per second» (т. е. 560 МБ/с, если читать 8-байтовые числа), и даже «RDRAND Response Time and Reseeding Frequency — ≈150 clocks per invocation» (т. е. аж 150 тактов задержки). Все эти цитаты с детальным анализом цифр каждой из них собраны в этом обсуждении, вывод из которого простой: какая бы цифра ни была верной, темп генерации всё равно оказывается недостаточным для удовлетворения вала запросов от всех ядер, а потому уже придумана схема возможной атаки — повесить на два ядра потоки-паразиты, постоянно запрашивающие случайные числа, чтобы из вечно пустого буфера остальным программам ничего не досталось…
Тем не менее, несмотря на некоторые странности, можно заключить, что благодаря стараниям инженеров Intel мир впервые получил массовый, дешёвый и качественный источник случайных чисел. Вроде бы всё хорошо, если бы не ложка дёгтя: некоторые из прошлых криптоидей Intel также описывались как абсолютно надёжные, например — система CSS для защиты DVD. Сегодня программы копирования дисков так легко её «ломают», что большинство их пользователей и не подозревают о само́м факте взлома шифра, некогда отрекламированного как очень сильный. Почему так получилось — официально никто не объяснял. Однако в сетевых дебрях гуляют анонимные признания сотрудников, согласно которым Intel, наряду с Microsoft и другими фирмами, попала в список «охмуряемых» — некто «попросил» её реализовать слабую защиту, понадеясь на сохранение решения в тайне.
Ныне же всё может измениться. Благодаря компьютерам с процессорами IB кто угодно, включая террористов, хакеров и педофилов (любимый контингент жупелов в доводах государства за ослабление шифров…), получает возможность быстро и дёшево создавать шифры, абсолютно невзламываемые даже для самого АНБ! Неужели нам следует поверить, что на этот раз в таинственной спецслужбе внезапно перестали пробивать внедрение очередной лазейки? Или же мы всё-таки чего-то не знаем? Пока…
Внеядро и ГП
Помимо добавления ГСЧ, остальные блоки внеядра («системного агента») изменились немного. ИКП для памяти DDR3 поддерживает штатные частоты до 1600 МГц, а разогнанные — до 2800 (SB — до 2133). Причём теперь их можно задавать не только с шагом 266,(6) МГц, но и 200 — в частности, 2800 это не 266,(6)×10,5 (в отличие от большинства остальных, этот множитель не может быть полуцелым), а 200×14. Мобильные ЦП смогут поддерживать экономную LP-DDR3 (с неизвестной пока частотой — тем более, что ни один ноутбук или планшет с такой памятью пока не вышел), причём у модуля памяти теперь может быть своё значение TDP для защиты от перегрева. Контроллер PCIe дорос до версии 3.0. (У Xeon на базе SB такой уже есть, но серверный чипсет X79 почему-то позволяет ЦП включать только режим 2.0…) 16 полос PCIe могут использоваться как 16, 8+8 и 8+4+4 — но не всем моделям доступны все комбинации. Шина DMI (по сути — та же PCIe на 4 полосы) осталась версии 2.0 и обеспечивает пропуск в 20 Гбит/с.
Энергоэффективность и авторазгон
По этим пунктам нового немного: снижение напряжения и потребления ЦП в энергосостоянии S3 (сон всей системы), внедрение силовых ключей в контроллеры ввода-вывода (отдельно для памяти и остальных), и технология PAIR (power aware interrupt routing — подача ядрам сигналов о прерываниях с учётом экономии энергии), которая при частичной нагрузке выбирает одно из включенных ядер для обработки всех прерываний, чтобы остальные ядра продолжали спать. Также внедрена приоритезация прерываний — обработка малозначимых и не требующих немедленной реакции событий может откладываться, пока какое-то из ядер не проснётся…
Эта глава получилась бы очень куцей, однако в прошлом году на конференции Hot Chips 2011 был опубликован весьма подробный доклад на эту тему, касающийся Sandy Bridge. Многие указанные там подробности были упущены даже в нашем наиподробнейшем обзоре. Поэтому далее следует по сути дополнение к сказанному там — тем более, что всё это наверняка присутствует и в IB.
Во-первых, оказывается, в каждом банке кэша L3 есть два силовых домена, в которых находятся две половины ячеек, несущих собственно данные и биты ECC. Центральная (осевая) часть банка, где находятся контроллер и местный агент кольцевой шины, от питания не отключается. Куда в этой схеме попадают массивы с тегами — неясно. Оба домена включаются и отключаются одновременно. До сих пор было известно, что после засыпания всех ядер в состояние C6 мобильные модели могут отключить и весь L3. Теперь же оказывается, что банки могут отключаться по-отдельности — к сожалению, остаётся лишь гадать, по какому алгоритму. Возможно, он похож на тот, что появился ещё в Pentium-M для L2, и который мы описали в обзоре архитектуры Bobcat. Общее правило одно: чем большая порция кэша оказывается выключена — тем больше данных будет недоступно при обращении к L3, а значит — тем больше надо будет их подкачивать из ОЗУ, тратя на это больше времени и драгоценных микроджоулей, чем при попадании в кэш.
| Напряжение | Число ядер | Базовая (Turbo) частота ядер, ГГц | TDP всего | TDP при 800 МГц |
| Повышенное (XE) | 4 | 2,5 (3,5) | 55 | 36 |
| Нормальное | 2,2 (3,4) | 45 | 33 | |
| 2 | 2,5 (3,4) | 35 | 26 | |
| Низкое (LV) | 2,1 (3,2) | 25 | 12 | |
| Оч. низкое (ULV) | 1,4 (2,7) | 17 | 10 |
Далее, у силового контроллера, управляющего в т. ч. и авторазгоном по технологии Turbo Boost 2.0, помимо обычного показателя TDP есть ещё один — для случая, когда как минимум одно ядро находится в низкочастотном (LFM) режиме простоя (при частоте 800 МГц для мобильных ЦП и 1600 для остальных), а остальные ядра спят. Указанные этой цифрой ватты почти монопольно достанутся встроенному ГП. Из таблицы, где приведены параметры линеек мобильных SB, можно узнать ещё много интересного. Например, при стандартном напряжении разница между 2-ядерным и 4-ядерным ЦП составляет аж 33−26=7 Вт для 800 МГц, но почему-то всего 10 Вт для базовой частоты. Параметры для IB, очевидно, другие (хотя часто́ты простоя те же), но отношение должно быть похожим: ГП получит в лучшем случае ¾ номинального TDP, т. к. всё тепловыделение кристалла не может быть сосредоточено на одном пятачке сбоку.
Впрочем, после продолжительных периодов простоя, когда чип успел охладиться, Turbo Boost 2.0, как мы уже знаем, может превысить показатель TDP на время до 64 с (этот максимум программируется), пока температура не достигла предела. А теперь известно, и насколько можно превысить — на 20–30%. Причём мгновенное потребление энергии может быть ещё выше и ограничивается аппаратным максимумом подачи тока для данного корпуса ЦП. На него также должен быть рассчитан расположенный на системной плате модуль VRM, подающий регулируемые напряжения потребителям (прежде всего — ЦП). А у IB вдобавок обнаруживается возможность программировать несколько уровней TDP. Например, у ноутбука можно отключить кулеры для полностью бесшумной работы, и ЦП должен быть «официально» оповещён (через ОС и драйверы) о сильно сниженной теплоотводной способности. Зато включив режим турбопылесоса, можно добавить несколько ватт в резерв авторазгона.
Более того, реально потребляемые ватты, как ни парадоксально, можно экономить и при хорошем охлаждении, учитывая общее свойство любой КМОП-схемы — при нагреве растут утечки, причём пропорционально аж 4-й степени температуры. Например, при 100 °C (373 кельвина) они вдвое больше, чем при 40 °C (313 K) — теперь ясно, зачем оверклокерам жидкий азот. А утечка в современных ЦП — это ≈20% всей мощности, что для экономного IB означает 10–15 Вт. Половину которых, стало быть, вполне можно сэкономить, если активней охлаждать процессор. Только вот на само́м таком охлаждении можно потерять столько же, да и шумом турбопылесос быстро достанет…
Также стало известно, что силовой контроллер для оптимального баланса между скоростью и экономией вычисляет метрику «масштабируемости». Это не самое удачное название, исходя из сути. Суть же заключается в том, что метрика является прогнозом производительности при понижении частоты ниже текущей. Если вычисляется, что в данный момент метрику можно поднять при незначительном замедлении фактической работы — то частота будет сброшена на одну или несколько ступенек умножителя. Самый верный для этого момент — когда ядра особенно часто стопорятся из-за кэш-промахов в L3, и тогда их частота оказывается не так важна на фоне темпа работы ОЗУ. Если её понизить, скажем, на 10% (разумеется, вместе с напряжением) — это поможет сохранить 25% потребления ценой потери 5% темпа фактически выполняемых вычислений. А вот если метрика приближается к 1, то производительность меняется почти линейно от частоты, и последнюю лучше не снижать. Смысл всех этих замеров и регулировок — чтобы «масштабируемость» в любой момент была поближе к 1 (100%). По утверждению Intel, у SB этот параметр редко опускается ниже 90%, держась в среднем на уровне 95% и часто поднимаясь до 99%.
Любопытно взаимодействие потоков с их индивидуальными оповещениями о загрузке (программа может указать процессору через ОС, что её можно усыпить). Один из потоков в ядре не может перевести его в состояние сна, если второй активен. Но вот если таких ядер два, то два спящих потока можно спарить в одном ядре, которое и уснёт, а два активных — в другом. Разумеется, это наверняка снизит их суммарную производительность, и тут важную роль играет выставленный в ОС режим работы (скоростной, «оптимальный» или экономный), правильно написанные драйверы и отдельно обновляемая прошивка силового контроллера самого ЦП. У ядер есть 4 C-состояния: C0, C1, C3 и C6. Если все ядра (хотя неясно насчёт ГП…) находятся в C3, то весь ЦП переходит в PC3, а если в C6 — то в PC6. Буква P тут означает package — упаковка, т. е. корпус. Из PC6 можно уснуть в самую глубокую «кому» — PC7, когда отключено почти всё. Отдельный набор из трёх экономных состояний есть у ИКП: обычный простой, отключение предзаряда битовых шин и их терминаторов (оконечной нагрузки), а также (дополнительно) отключение местного умножителя. Перевод модуля в режим авторегенерации также управляется силовым контроллером.
Наконец, доблестный процессор защищает не только себя, но и систему. При перегреве модуля памяти силовой контроллер ЦП использует дросселирование (пропуск тактов) шины и уполовинивает период регенерации. Последнее нужно, т. к. при высокой температуре чипа ОЗУ происходит ускоренное рассасывание заряда, что приводит к повышенной вероятности неверного прочтения данных. А температуру контроллер берёт либо из встроенного в модуль термодатчика (который пока редкость), либо из VTS — «виртуального термосенсора».
VTS предсказывает температуру, имея, во-первых, данные из чипа SPD (который давно имеется во всех видах DIMM и подключен к ЦП по последовательной шине) о примерном нагреве модуля при различных операциях с памятью (предполагая, что эти цифры там присутствуют и верны, что не факт…), а во-вторых — собранную в ИКП статистику фактических операций с этим модулем. Однако этих данных недостаточно для точного предсказания (в частности, обдув модуля берётся как среднеожидаемый «по больнице», т. е. по разным корпусам), и VTS часто показывает якобы перегрев до 80–100°C, что ведёт к дросселированию шины памяти. Поэтому если в модуле нет термодатчика, то такую «защиту» рекомендуется отключать, для чего есть, например, утилита «Memory Throttle».
Модуль VRM тоже имеет свой сенсор, показания которого, по идее, также должны спасать VRM от перегрева — видимо, уменьшением нагрузки. Кстати, модулей VRM может быть несколько, но начиная с SB (а также последних ЦП AMD) они все управляются общей 3-проводной шиной стандарта SVID — причём речь идёт не только о регулировке напряжений, но и числа активных фаз (опять же, для экономии). По этой же шине VRM сообщает о своих возможностях и ограничениях, а также текущей температуре и сопротивлении силовых шин.
SB, как и предыдущие ЦП (начиная ещё с Core 2 Duo) поддерживает ещё одну цифровую шину управления силовыми параметрами — PECI (Platform Environment Control Interface), который в 2011 г. Intel почему-то назвала новой. Через этот интерфейс встроенный силовой контроллер подключается к внешнему, расположенному на плате, и сообщает ему всё нужное, в т. ч. для регулировки оборотов кулера. Внешний чип же может управлять пределом потребления ЦП (и пиковым, и средним) и другими настройками, диктуемыми требованиями платформы.
Модели
Как обычно, прокомментируем список моделей в Википедии. Процессоры с ядрами архитектуры IB официально называются Core 3-го поколения, но т. к. первым поколением считается Nehalem и его родственники (хотя до этого слово Core как торговая марка уже давно использовалась Intel), то точнее будет сказать, что это 3-е поколение Core i. Если не считать серверных Xeon E3-12xx(L)V2, то наименование всех видов Core отличается от прошлых ЦП первой цифрой 4-значного номера (3 вместо 2), а всё остальное весьма похоже. У настольных моделей имеются такие линейки (троеточие указывает на отличия от пункта выше):
- Core i7 38xx и 39xx: предположительно, с такими номерами выйдут «экстремальные» модели без ГП, только вот незадача — у SB-экстремалов номера тоже начинаются с тройки. Но почему? И их как не перепутать? Ответ см. ниже…
- Core i7 37xx (пока доступны только модели с цифрой 70, зато их аж 5): 4-ядерные ЦП со включенными Hyper-Threading (HT) и авторазгоном всего (ГП — до 1150 МГц), имеют 8 МБ кэша L3 и старший ГП HD4000, официально поддерживают память до DDR3-1600;
- Core i5 35xx: …минус HT и 2 МБ L3; HD4000 доступен пока лишь у 3570K, а у почти всех остальных моделей тут и далее — HD2500;
- Core i5 34xx: …Turbo-частота ГП — 1100 МГц, а модель 3470T совсем выбивается из общего ряда — она даже не 4-ядерная; 3475S — единственная с HD4000;
- Core i5 33xx (в списке пока не указана планируемая модель 3335S): … Turbo-частота ГП — 1050 МГц, а у 3350P графика полностью отключена;
- Core i3 32xx: 2 ядра, HT, 3 МБ L3, PCIe только версии 2.0 (хотя вы почти ничего не потеряете), и без авторазгона x86-ядер;
- Pentium G21xx: …минус AVX, HT и спецфункции ГП (Quick Sync Video, InTru 3D, Clear Video HD, Wireless Display и Insider), в результате чего последний тут зовётся просто HD Graphics — точно также, как и в предыдущих двух поколениях «Пентиумов». Снова те же вопросы: почему номера этих моделей начинаются с двойки, и как не перепутать их HD Graphics с аналогами в предыдущих ЦП? А по кочану и никак — это работает фирменная технология Intel Bardack 3.0 :)
- Pentium G20xx: …память — только до DDR3-1333;
- Celeron G16xx: …минус 1 МБ L3 (останется 2).
Что касается буквы после номера, то её расшифровка неизменна:
- нет буквы — большой TDP;
- K — большой TDP и разблокированный множитель (который, кстати, теперь достигает 63 и может вручную меняться без перезагрузки);
- S — средний TDP;
- T — малый TDP;
- P — процессор с выключенным ГП и «особым» TDP;
- X — предполагаемые «экстремалы» наверняка снова будут заканчиваться этой буквой.
TDP настольных моделей (если не считать P-версии и грядущих «экстремалов») принимает значения 77, 65, 55, 45 и 35 Вт. Причём значения букв K, S и T в этом ряду не обязательно соседние. (Поначалу тут ещё была цифра 95, но Intel быстро стала указывать и для этих ЦП 77 Вт, заявив, что «95» было нужно разработчикам материнских плат и кулеров для совместимости и с SB, и с IB, а вот тепловыделение самих IB на 18 Вт меньше.) «5» в конце номера означает HD4000 вместо HD2500, но только не для 37xx и K-моделей (где старший ГП и так есть), да и к будущим «Селеронам» и «Пентиумам» это также вряд ли будет относится. Уже запутались? Подбираете изощрённую пытку для маркетологов Intel? Погодите, ведь ещё есть мобильные модели! Они опознаются по отдельному набору букв (слава Муру, что и тут расшифровка одинакова для Core, Pentium и Celeron):
- XM — «экстремально» 4-ядерный;
- QM — просто 4-ядерный;
- M — просто 2-ядерный;
- U — особо экономный 2-ядерный (и базовая частота ГП тут не 650 МГц, как у предыдущих, а 350);
- Y — самый экономный 2-ядерный;
- E — для встроенных применений;
- C — у новых версий SB, вышедших в этом году (ЦП Gladden для платформы Crystal Forest), эта буква означет особо экономные встроенные версии, работающие на очень низких частотах (например, Xeon E3-1105C — 4 ядра, 1 ГГц и 25 Вт), лишённые ГП и авторазгона, но (даже у 1-ядерных версий) сохраняющие в наличие все остальные свойства полноценного чипа: AVX, HT, ECC-память и т. п. Не лишним будет предположить, что и среди IB появятся аналогичные модели с той же буквой C.
А вот из номеров понятно чуть более чем ничего — у Core вторая цифра модели бывает от 1 до 9, и по ней нельзя точно определить даже число ядер: 1–5 это 2-ядерные ЦП, 7–9 — 4-ядерные, а 6 — как придётся. Хорошо, что у всех мобильных Core i включен HT, а у Pentium и Celeron его нет — но не факт, что очередная новая модель не станет исключением. Цифра в конце номера означает:
- 2 — пониженный TDP;
- 5 — +100 МГц к Turbo-частоте у ГП;
- 7 — низкий TDP (но тогда зачем буква U?);
- 9 — самый низкий TDP (дублёр буквы Y).
Мобильные Pentium 2020M и 2117U, в отличие от настольных тёзок, получат лишь по 2 МБ L3 — также, как и у встроенных Celeron 1020E и 1047UE. Наконец, есть ещё Celeron 927UE — 1 ядро, 1 поток и 1 МБ L3. И наверняка это не последняя 1-ядерный IB. Причём, судя по эволюции моделей на ядрах SB, некоторые из будущих 1-ядерных Селеронов могут даже получить HT.
Мобильный ряд TDP таков: 55 (только для -XM), 45, 35, 17, 13 и 10 Вт. Как и обещано, некоторым из этих моделей разрешено регулировать TDP «на лету»: 7←10←13, 14←17→25 (младшим 25 Вт недоступны) и 45←55→65. Да-да, 65 Вт в ноутбуке, а ведь там ещё и видеокарты бывают! Оплатив $1096 за один только процессор, вы, помимо прочего, сможете пожарить под ноутбуком яичницу, но вот таскать батарейки в чемоданах лучше только в «Ералаше»… На противоположном конце диапазона — модели с буквой Y, которые могут сокращать TDP аж до 7 Вт (называется это сценарным потреблением), но ценой ещё большего снижения скорости и максимальной выдерживаемой температуры (со 105 до 80°C).
Для работы с IB подойдут и некоторые старые чипсеты 60-й серии (Z68, P67 и H67), и новые — 70-е, работающие только с SB. Их настольные версии подробно описаны в нашем материале, а полные данные на все 12 видов (включая 6 мобильных) даны тут. Главная цифра оттуда: TDP мобильных версий — 3–4,1 Вт. В сумме с наиэкономнейшими из ЦП получается всего 20 Вт.
Кристаллы и то, что сверху
| Код | Число ядер | Объём кэша L3, МБ | Версия ГП | Размеры и площадь кристалла, мм(²) |
| HE-4 | 4 | 8 | HD4000 | 19,631×8,141=159,8 |
| HM-4 | 6 | HD2500 | 17,349×7,656=132,8 | |
| H-2 | 2 | 4 | HD4000 | 14,505×8,141=118,1 |
| M-2 | 3 | HD2500 | 12,223×7,656=93,6 |
Пока известно о 4 видах кристаллов, но по аналогии с SB можно предположить, что сюда ещё должны войти как минимум две серверные версии (E и EP) без ГП, с 4-канальным ИКП и 40-полосным контроллером PCIe: 4 ядра + 10 МБ L3 и 8/10 ядер + 20/25 МБ. Более того, судя по последним сообщениям, 22-нанометровый техпроцесс позволит выпустить даже 12-ядерные версии с 30 МБ L3. Имеющиеся сегодня кристаллы упаковываются в корпуса LGA-1155 (для одноимённого настольного разъёма), rPGA-988B (для мобильного Socket G2), BGA-1023 и BGA-1224 (эти два — для непосредственной пайки к плате) — все они знакомы по SB, так что с тыльной стороны корпуса выглядят как обычно.
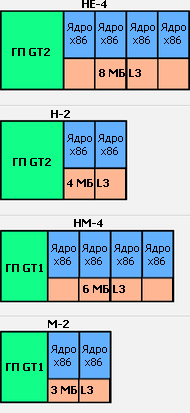 Относительные размеры переменной части кристаллов. Ниже находится ИКП, а правее — остальные блоки внеядра. |
Интересно, что показанные в таблице цифры для кристалла HE-4 соответствуют степпингу E1, который выпущен на продажу. А вот ранее показанные публике чипы имеют предыдущую версию (видимо, E0). Эта же версия попала исследователям из фирмы UBM TechInsights, которые оценили площадь в 170 мм² и установили, что дополнительные 1,5–2 мм длины угадываются в районе трактов ГП. Такого удлинения как раз хватило бы, чтобы увеличить их число с 16 до 24. Может быть, до последнего времени у Intel были такие проблемы с надёжностью работы этой части, что она решила заложить в ГП 50%-ный резерв? Или это тестировалась новая, 24-трактовая версия?
К сожалению, число транзисторов, с которым мы так любим забавляться, известно только для самой крупной версии HE-4 — 1420 МТр. Для похожей по параметрам старшей версии настольных SB ранее указывали 995 МТр, но потом показания изменились на 1160, аргументируя тем, что, дескать, в прошлый раз не посчитали некие сервисные структуры, необходимые для реализации логической схемы в кремнии. На этот раз, видимо, в 1420 МТр таковые вошли, потому хоть одно арифметическое действие мы сможем сделать: 1420−1160=260 МТр, из которых, допустим, половина добавлены новому ГП (в старом HD3000 было 114 МТр), что вполне линейно бы соответствовало полученному ускорению в его работе. Бо́льшая часть остального — добавки и доработки внеядра. А ядрам (в каждом из которых у SB было по 55 МТр) наверняка достались всякие мелочи.
Глядя на первые фотографии этой версии кристалла (а других мы пока не имеем), видно, что относительные размеры основных структур ядра не изменились, что не удивительно. Масштабирование матриц L3 тоже почти такое же, как и у логики — если, конечно, её специально не разрядили, ибо раскладка чипа на крупные блоки такова, что делать ядро у́же банка L3 смысла нет.

Всё привычно и знакомо по SB: в центре — 4 x86-ядра и их банки L3, внизу слева — пустое место, справа — ИКП, левый край занят ГП, правый — внеядром. В ГП хорошо видны 16 векторных трактов и 2 одинаковых блока управляющей логики (вверху и внизу) для каждой половины трактов, а по центру ещё один общий блок. Нижние четверти банков L3 имеют пустоты между левыми и правыми матрицами — в версии HM-4, где у банков эта четверть отсутствует, сюда вдвигается ИКП. В старшем 2-ядерном кристалле H-2 ИКП левой частью подлезает под ГП. А вот как H-2 обрезается до M-2, пока неясно — в ГП надо что-то дополнительно удалять, чтобы уместить по ширине ИКП.

Тот же чип, но не на уровне транзисторов и (может быть) первого слоя металла, как мы привыкли видеть, а почти со всеми слоями — кроме самого верхнего, на которой «накатываются» шарики-контакты, и, возможно, ещё нескольких.
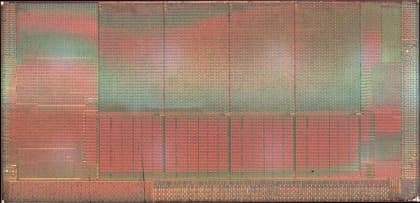

А вот готовые кристаллы SB и IB (под одинаковым увеличением), полностью покрытые выводами, под которыми почти ничего не видно даже на крупных снимках. (С сайта EE Times) Кстати, нижний снимок как раз и демонстрирует удлинённый степпинг HE-4.

Однако даже на уровне транзисторов без правильной методики съёмки мало что видно. Фото (с сайта ElectroIQ) сделано компанией Chipworks в процессе «разборки» кристалла после растворения всех медных дорожек и межслойных изоляторов.

Сравнение размеров полноценных 4-ядерных кристаллов SB и IB в одинаковом масштабе. За счёт сильного усложнения ГП его площадь даже увеличилась, причём вместе с пустым местом левее ИКП (что неизбежно при такой раскладке).

А вот это изображение показали первым — ещё на форуме IDF’2011. При сравнении с поздними ясно, что никаких новых технических тонкостей отсюда не выловишь, ибо в Intel сидят такие же мастаки Фотошопа, что и в AMD. Мало того, что низ чипа заменён зеркальным отражением, так ещё и с ГП намухлевали.
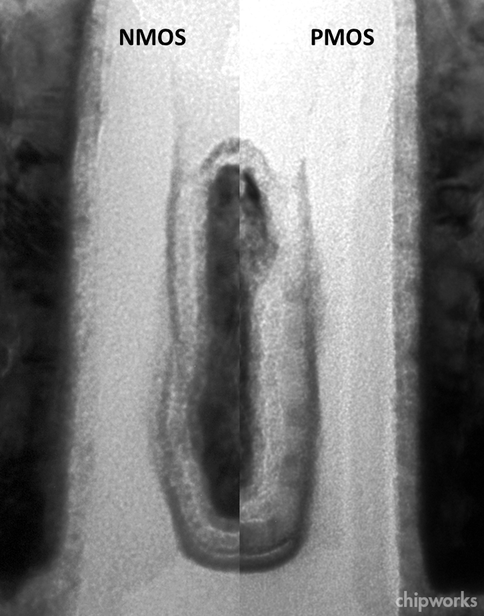
Вскоре после выхода ЦП на свет оверклокеры выяснили, что разгоняемость новых ЦП, не смотря на многообещающую экономию нового техпроцесса, оказалась меньше, чем у SB. На это есть две причины: во-первых, меньшая площадь кристалла позволяет рассеивать пропорционально меньшее количество энергии, ибо удельная теплопроводность кремния на единицу сечения неизменна. Во-вторых (и это влияет куда больше площади), если учесть не только кристалл, то удельная теплопроводность в данном случае всё же изменилась, причём также в меньшую сторону, т. к. отвод тепла ограничивается не столько площадью кристалла, сколько качеством контакта со встроенным теплораспределителем (IHS, integrated heat spreader) — металлической крышкой, покрывающей кристаллы большинства современных ЦП. Её роль в том, чтобы верхняя её часть, которой касается радиатор, выделяла тепло максимально равномерно. Без неё оказалось бы, что с кристалла надо уводить ≈50 Вт/см², зато оставшаяся вокруг площадь не отводит почти ничего.
Чтобы распределитель работал эффективней, его контакт с кристаллом должен иметь максимальную теплопроводность, чтобы тепло как можно быстрее уводилось сквозь него. До сих пор Intel использовала безфлюсовую пайку металла с тыльной частью кристалла. (Флюс это добавка к металлу для удаления поверхностных окислов, мешающих пайке. Но он имеет худшие тепловые и электрические параметры, чем принимающий металл, поэтому требуется создать условия, либо не вызывающие поверхностное окисление металла даже при нагреве, либо удаляющие окислы до спекания — и тогда можно обойтись без флюса.)
Однако в IB пайка заменена термопастой, которую обыватели привыкли видеть между процессором и радиатором, но её теплопроводность хуже. В результате максимальная выдерживаемая кристаллом температура опустилась с 94 до 85 °C (если судить по показаниям термодатчика ЦП), выше которой начинается троттлинг (дросселирование) частоты. А при разгоне разница с SB достигает уже 20 °C при прочих равных. Более того, теплопроводность конкретно этой пасты хуже других её видов, так что перед разгоном теперь рекомендуется снять крышку, очистить от высохшей старой пасты (не повредив кристалл и не поцарапав крышку, что весьма непросто), нанести новую (качественную) и установить крышку на место.


SB (вверху) и IB со снятыми IHS. Вверху на крышке видны следы пайки, а внизу — термопаста. (Нижнее фото — с Overclockers.com)
Ранее такой же прокол случался с линейками Core 2 с E4xxx по E6xxx. Как и тогда, предполагаемая причина — экономия денег. Какая экономия получилась на самом деле, учитывая, что блогеры и обозреватели успели раздуть скандальчик, — вопрос спорный. Intel лишь подтвердила, что при разгоне температуры будут выше ожидаемых, но заверила, что при штатных частотах надёжность не пострадала.
Детали о транзисторах
Независимый анализ кристалла компанией ChipWorks показал, что в чипе по-прежнему 9 уровней межсоединений, а длина затвора равна 22 нм (для техпроцесса с такой же численно технормой длина должна быть 11 нм, но памятливые читатели наверняка вспомнят 3-ю часть нашего микроэлектронного обзора, где наглядно показывалось, что́ происходит с нанометрами на самом деле), а минимальное расстояние между затворами (например, в СОЗУ) — 90 нм. Для предыдущего, 32-нанометрового техпроцесса Intel эти параметры были 30 и 113 нм соответственно. Как видите, никакого линейного уменьшения нет, но мы это и раньше выяснили… Кстати, для ясного понимания нижеследующих изображений периодически сравнивайте их с нашим теоретическим описанием 22-нанометрового техпроцесса (по ссылке выше).

Кристалл в разрезе. Огромная «байда» в центре — последний, 9-й уровень металла, на который насажены шарики припоя для контакта с подложкой. Остальная площадь кристалла, не занятая шариками, покрыта защитным изолятором, который тут виден поверх металла. Огромная площадь сечения 9-го слоя относительно других обусловлена тем, что он используется как силовой и тепловой распределитель. А в самом низу виден слой транзисторов. (Тут и далее в этой главе — фото ChipWorks)
Это сечение параллельно затворам ряда транзисторов. Серыми стрелками обозначены затворы, а белыми — истоки и стоки. Выше виден первый уровень дорожек.
Тут видны первые 5 уровней дорожек и инвертор в виде пары многозатворных транзисторов типа FinFET (с каналами-плавниками): nМОП слева и pМОП справа. Стрелкой обозначен контакт к их затворам, а под ним — двойной ряд затворов. Над каждым транзистором виден общий для плавников контакт истока или стока (они одинаковы и зависят лишь от направления тока), а под ними — обычная пластина (а не дорогая типа SOI, как у AMD).
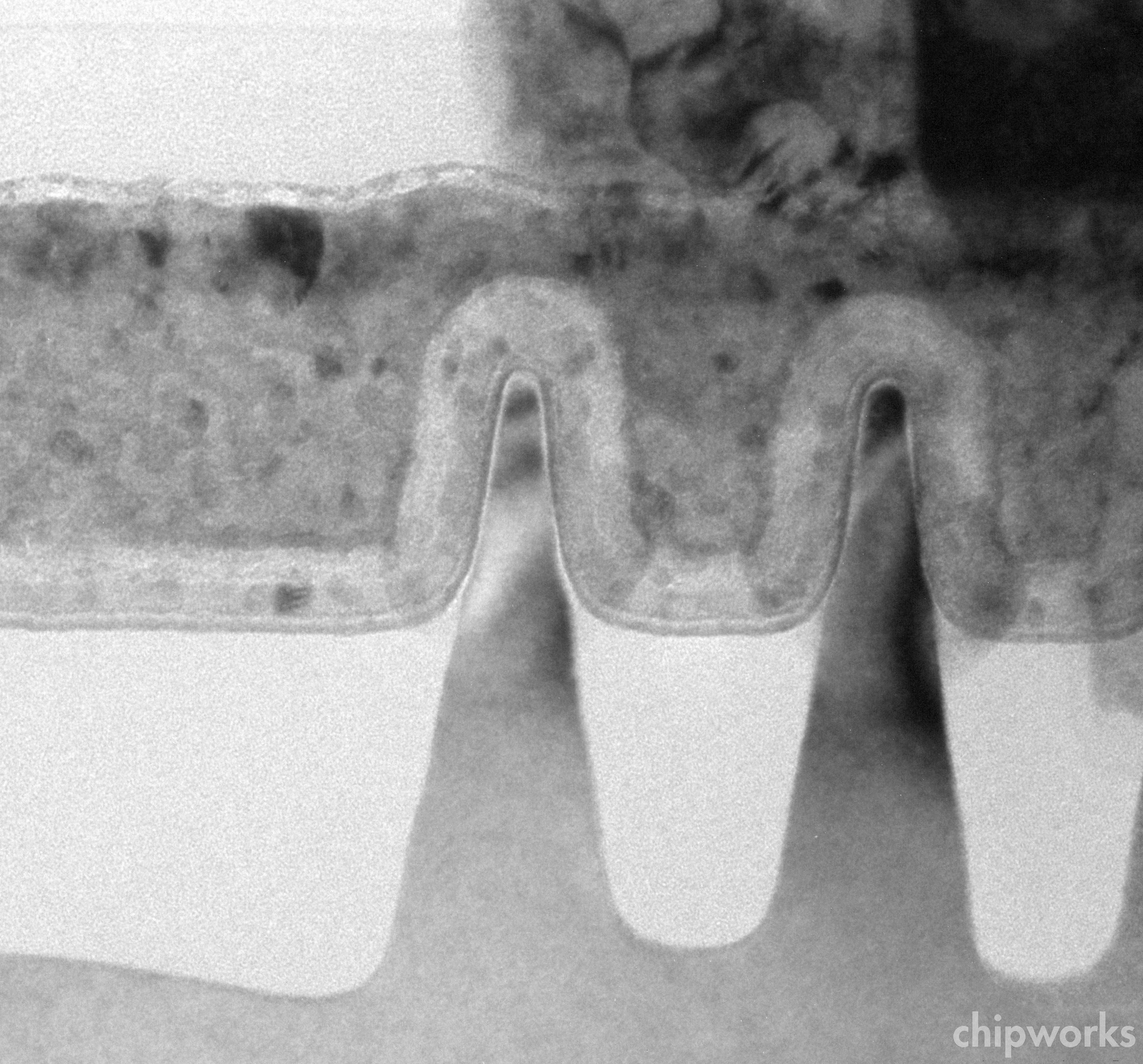
Затвор nМОП-транзистора огибает каналы, имеющие в сечении форму высокого треугольника с закруглённой вершиной (pМОП-каналы со стороны напоминают шахматного слона). Тонкая тёмная линия вдоль нижнего края затвора — высокопроницаемый (high-k) подзатворный изолятор. Сам затвор выстлан нитридом титана (TiN, толстый светлый слой), являющимся «рабочим металлом» для nМОП, как и в 32- и 45-нанометровом техпроцессах Intel. В pМОП эту функцию исполняет TiAlN. (Если читатель захочет вспомнить, зачем нужна и чем важна вся эта химия — всё описано тут.)
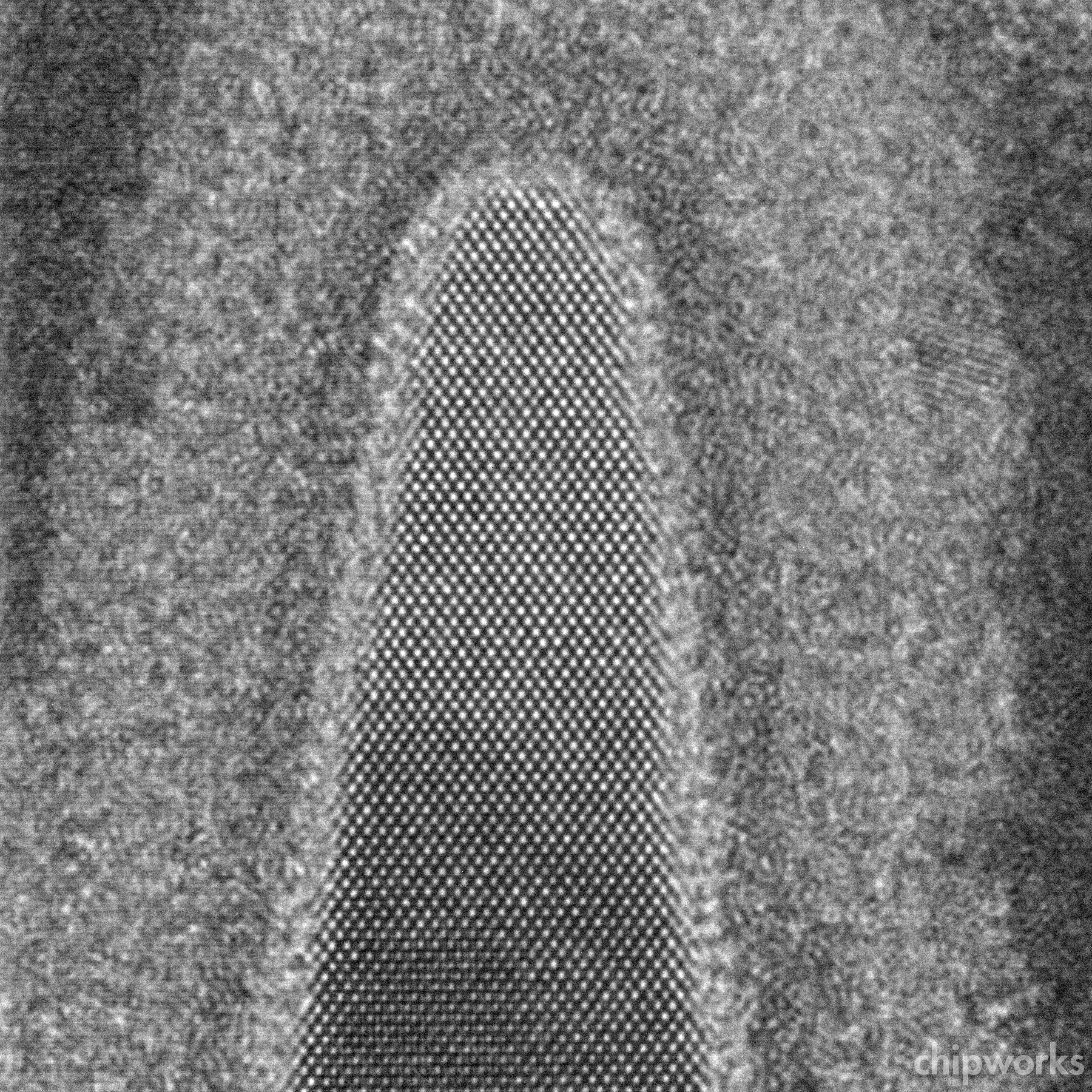
Раз уж нам так нравится считать транзисторы в чипах — почему бы не посчитать и атомы в них? :) Вот вершина канала nМОП-транзистора под максимальным увеличением. Точки — это ряды атомов кремния. Тут наглядно видно, что каналы в транзисторах (не только этого типа, а везде и давно) ориентированы в направлении <110> — т. е. вдоль одного из трёх направлений кубической решётки кремния, чтобы проходящие по каналу электроны пореже сталкивались с атомами (в чём суть электрического сопротивления).
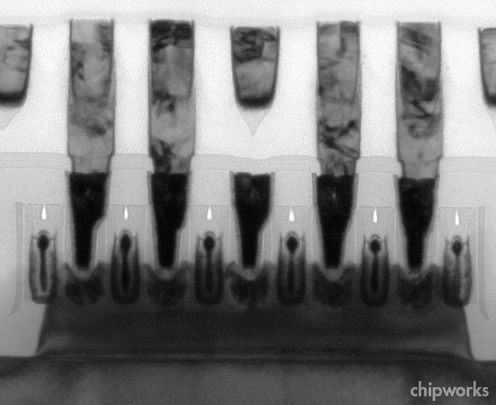
Этот сечение массива pМОП-транзисторов с общим каналом (т. е. перпендикулярно видам на фотографиях выше). Тут есть 4 рабочих затвора и 2 ложных, работающих лишь как законцовки плавника. У этих 4 транзисторов наверняка есть и другие каналы, параллельные данному — ближе и/или дальше плоскости этого сечения. Интересно, что вершины затворов вытравлены и заполнены изолятором, а контакты к истокам и стокам — самосовмещённые, как у микросхем памяти.
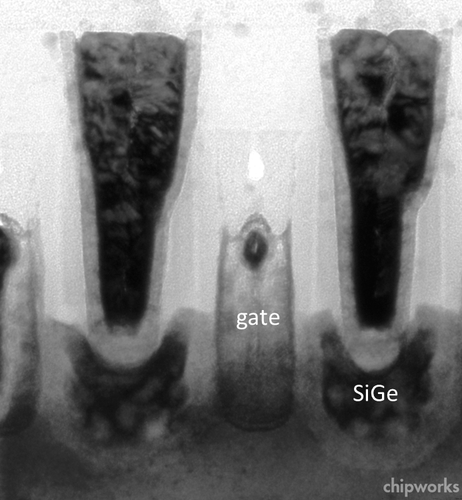
Крупным планом показан один из транзисторов. Контакты (в которых хорошо виден выстилающий нитрид) опускаются до истоков и стоков, сформированных из кремния, легированного впрыснутым в него германием, чтобы растянуть шаг решётки в этой области. Это создаёт механическое сжатие вдоль канала, что полезно для мобильности дырок. У nМОП-транзисторов канал, наоборот, растягивается, увеличивая мобильность электронов. Таким образом, в плавниковых транзисторах тоже формируется напряжённый кремний, как и в предыдущих техпроцессах.
Сравнение затворов двух видов транзисторов. Металл-заполнитель был сменён со сплава титана и алюминия на вольфрам (тёмное «ядро» по центру). Его оказывается больше в nМОП-затворах, т. к. в pМОП ради экономии на числе операций с пластиной присутствуют оба рабочих металла, а вот из nМОП нитрид титана (в pМОП он — краевой слой с плавными переходами между оттенками серого) после покрытия вытравливается, а потом сверху во все транзисторы осаждается TiAlN (более светлый и зернистый).
Наглядный ракурс на транзисторы под углом. Вертикальные светлые полосы — затворы, в т. ч. общие для комплементарной пары транзисторов. Затворы пересекают (или утыкаются — если они ложные) тоненькие стеночки-каналы, у которых видны небольшие бугорки или колонки — это вспучивания SiGe в местах истоков и стоков. Причём нечто похожее наблюдается и у nМОП-транзисторов, но это остатки металла контактов. Вобщем, всё не совсем так, как на цветных диаграммах…
Итог
Каждый раз для последней главы первое, что приходит в голову автору — текст, напоминающий новогоднее обращение российского президента к народу: этот год был непростым, но успешным, а следующий будет ещё труднее, но и ещё успешней, а также про такие-то проценты роста надоев в Закрома Родины и ВВП на душу населения… Говоря о новых процессорах, получается примерно так: прошлая архитектура была сложной и во многом новаторской, а нынешняя стала ещё сложнее и ещё передовее, получив такие-то проценты роста производительности и экономности (которые большинство читателей и так выяснили из ранее вышедших тестов)… Вместо банальностей лучше напишем о том, чего не надо делать, когда вы только что выпустили отличный процессор: про него не надо врать. А Intel тут почему-то прокололась.
9 января 2012 г. на выставке CES один из высоких руководителей в Intel Мули Идэн представлял Ivy Bridge и системы на их основе. По ходу презентации он показал то, что в его речи представлялось гоночной игрой Formula 1 с графикой DX 11, гоняемой на новом «ультрабуке». Но все местные Внимательные Зрители заметили интерфейс программы VLC, которая просто проигрывала ролик вместо реальной игры (точнее, пыталась, ибо даже воспроизведение клипа получилось рваным). Фото и ссылки на видео есть тут, где предлагается и очевидное объяснение: качество графики (и, особенно, драйверов) у ГП Intel всё ещё такое паршивое, что доверить им современную игру в реальном времени на презентации всё ещё нельзя — не смотря на все заявления о возможности такой игры.
В 2006 г. появился первый чипсет Intel со встроенным 3D-движком — G965. Драйверы не работали уже тогда, и каждый раз перед выходом нового поколения ГП компания обещала, что вот теперь-то всё заработает. Шли годы… Драйверы для графики SB до кондиции так и не довели — обещанные ещё в 2010 г. возможности аппаратного ускорения DX11 так и не выполнены, а OpenCL по-прежнему исполняется лишь x86-ядрами. (Кстати, упоминание поддержки DX 10.1 было удалено из поздних версий рекламных материалов для платформы Cedar Trail для новых ЦП Atom, когда публика обнаружила, что даже ей там не пахнет…) И вот теперь недоиспользованным возможностям HD3000 пришли на смену недопоказанные возможности HD4000.
Что обычно происходит, когда заявленное и обещанное не выполняется? «Скажем, что это лишь предпродажные образцы, тут возможны небольшие глюки»… «Перелопатим миллион чипов и отберём те два, которые полностью заработают — их и покажем»… «Вручную оптимизируем код “демок”, чтобы вытянуть всё что можно из этих ЦП, даже если в реальных программах такой оптимизации почти не будет»… Это и тому подобное вполне часто используется на презентациях. А вот чего обычно не делают, так это не подменяют живую картинку роликом и уж тем более не обманывают об источнике этой картинки даже после разоблачения. Мули, разумеется, сразу понял, что для зрителей уже «всё пропало», но отшутился, заявив, что игра «запущена из-за кулис», что тоже неправда.
Мораль тут проста — если что-то не совсем получается, то про эту часть лучше вообще не говорить, чем бросать пыль в глаза. Тем более, коли есть масса деталей, которые полностью готовы и отлично работают. Иначе получится, что кому-то из Внимательных Читателей или Зрителей придёт в голову крамольная идея о том, что не только игра «запущена из-за кулис», но и всякие прочие заявленные возможности являются не более чем блестящими фантиками. Даже если, как в случае с Ivy Bridge, это совсем не так.


