XGI Volari Duo V8 Ultra 256MB
Очень модную везде!
Дали ему супер-норму,
Но ошиблись в КПДе…»

СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты XGI Volari Duo V8 Ultra 256MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark03
- Выводы из результатов синтетических тестов
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003
- Результаты тестов: AquaMark3
- Результаты тестов: RightMark 3D
- Результаты тестов: Tomb Raider: Angel of Darkness
- Результаты тестов: Half-Life2 (Beta)
- Результаты тестов: HALO
- Результаты тестов: Unreal II
- Выводы из результатов тестов
- Качество 3D: Анизотропная, билинейная и трилинейная фильтрации
- Качество 3D в целом
- Выводы
Установка и драйверы
Рассмотрим конфигурацию тестового стенда, на котором проводились испытания карт:
- Компьютер на базе Pentium 4 3200 MHz:
- процессор Intel Pentium 4 3200 МГц;
- системная плата DFI LANParty Pro875 (i875P);
- оперативная память 1024 MB DDR400 SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1; DirectX 9.0b;
- мониторы ViewSonic P810 (21") и ViewSonic P817 (21").
- драйверы XGI версии 1.50.01. VSync отключен.
На стенде использовались мониторы
Для сравнительного анализа приведены результаты уже знакомых читателям видеокарт:
- ASUS V9950 Ultra (GeForce FX 5900 Ultra, 450/425 (850) МГц, 256 МБ, driver 53.03);
- HIS Excalibur RADEON 9800 PRO IceQ (380/340 (680) МГц, 128 МБ, driver 6.414);
- Inno3D Tornado GeForce FX 5700 Ultra (475/450 (900) МГц, 128 МБ, driver 53.03);
- Sapphire Atlantis RADEON 9600 XT (500/300 (600) МГц, 128 МБ, driver 6.414);
Настройки драйверов

Как я уже ранее говорил, настройки драйверов даже внешне имеют тот же облик, что было у Xabre. Полагаю, что все говорят скриншоты, пояснять чего-либо нет нужды.
Результаты тестов
2D-графика
Традиционно начнем с 2D. Отметим, что вплоть до 1600х1200 при 75Гц включительно нареканий на качество нет.
Если кандидаты в президенты России будут вам вещать, что оценка 2D-качества есть вещь объективная, то не верьте им, и не голосуйте за них,ибо «правильный» кандидат считает, что оценить объективно сие невозможно, и он прав! Поэтому напомню, что качество зависит от конкретного экземпляра, да и связка карта-монитор может по-прежнему играть огромную роль. Прежде всего, надо обращать внимание на качество монитора и кабеля. Я напомню, что тестирование 2D у нас происходит на мониторе ViewSonic P817-E совместно с BNC-кабелем Barсo.
Синтетические тесты D3D RightMark (DirectX 9)
В этой статье мы представим вам подробные описания и результаты тестирования, полученные с помощью разрабатываемого нами набора гибко-конфигурируемых синтетических тестов для API DX9.
Набор синтетических тестов из разрабатываемого нами тестового пакета RightMark 3D включает в себя (на данный момент) следующие тесты:
- Тест на закраску и фильтрацию текстур (Pixel Filling Test);
- Тест на производительность обработки геометрии (Geometry Processing Speed Test);
- Тест на производительность работы с отсечением невидимых точек и примитивов (Hidden Surface Removal Test);
- Тест на производительность сложных пиксельных шейдеров (Pixel Shader Test);
- Тест на производительность отрисовки, освещения и анимации спрайтов (Point Sprites Test).
Полагаем, что нет смысл повторять здесь освещение идеологических вопросов тестирования, поэтому еще раз просим желающих узнать по-подробнее об идеологии синтетических тестов прочитать внимательно материал по NV30. Там же можно найти и их описание.
Для тех, кто горит желанием экспериментировать с синтетическими тестами RightMark 3D, или измерить производительность собственных ускорителей, мы предлагаем скачать и опробовать последний вариант нашего теста, доступный на его сайте D3D RightMark Beta 3. Тесты снабжены удобной общей оболочкой и гибким экспортом результатов. Кроме того, вы можете скачать все использованные в данном обзоре настройки тестов.
Мы будем благодарны любым откликам, как в плане пожеланий и идей, так и информации об ошибках или странном поведении тестов.
Пишите по адресу: unclesam@ixbt.com.
Pixel Filling
-
Для начала измерим максимальный пиксельный fillrate для различного числа текстур. Это позволит нам определить реальное (эффективное) число
и конфигурацию пиксельных конвейеров. Для исключения влияния прочих факторов, в этом тесте мы используем текстуры минимального размера
и отключим какую либо фильтрацию. Итак:
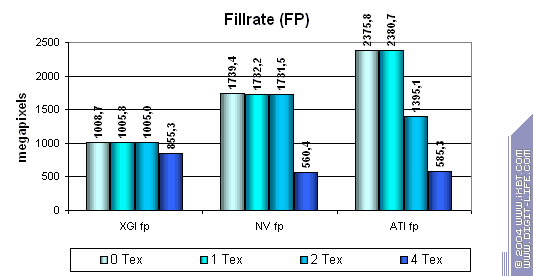
В случае 0 и 1 текстуры мы получаем практически одинаковые результаты. Это значит что тест идет хорошо, и выборка текстур не влияет на процесс — мы измеряем только скорость закраски и заполнения буфера кадров. Хорошо заметно, что NVIDIA имеет конфигурацию с 2 текстурными блоками на один пиксельный конвейер, а ATI — с одним, но большее число конвейеров. Но с Volari происходит что-то странное. Некий фактор (предположительно скорость записи в память?) существенно ограничивает его эффективную скорость закраски. Фактически, пока число текстур не достигает 4 на один пиксель, fillrate не начинает падать. Это возможно в двух случаях — реальная конфигурация чипа V8 не 8х1 а 4х2, или (а может быть и И), эффективная полоса пропускания памяти каждого из чипов при работе с буфером кадров не достаточна для записи информации всех конвейеров без снижения скорости. И тот и другой сценарий печальны, т.к. можно легко представить себе реальные приложения, на производительности которых эти факты скажутся отрицательно. Например закраска неба в симуляторах или предварительная отрисовка данных (глубины) для построения теней в Doom III.
Возможно, что реально чип представляет собою некий суперконвейер с 8 текстурными блоками и неким набором параллельных ALU, которые обрабатывают разное число пикселов за такт в зависимости от сложности алгоритма обработки (отсюда меньшее число конвейеров, указанное в спецификации для пиксельных шейдеров). Впрочем это теоретический аспект, а главное, что даже с этой, простейшей, задачей чип справился столь неэффективно, если не считать случая с 4 текстурами, где Volari cумел обогнать конкурентов за счет наличия в сумме 16 текстурных блоков. Вывод: работа с буфером кадра реализована не столь эффективно как хотелось бы, заявленная конфигурация 16х1 в большинстве случаев проигрывает 8х1 и 4х2 в исполнении конкурентов. До 5600 миллионов пикселей теоретического предела двух V8 далеко как до небес, и вину за это следует возлагать на неэффективную архитектуру чипа и подсистемы памяти.
Ранее мы производили закраску с использование фиксированных функций (доступных еще со времен DirectX 7). Посмотрим как изменится картина для различных версий шейдеров:
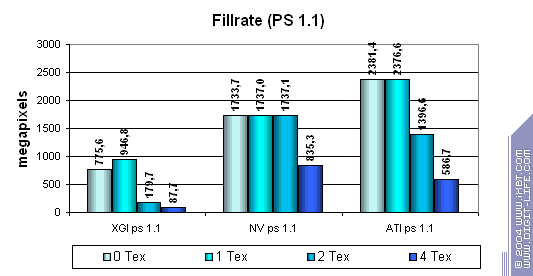

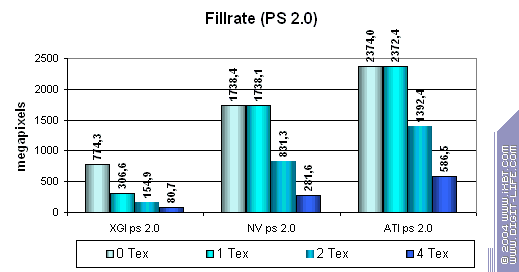
Разгром просто ужасающий! Если конкуренты исполняют простые шейдеры без потери производительности (небольшое исключение — 2.0 на NVIDIA в случае 2х текстур, скорее полезная для реальных приложений аномалия оптимизирующего компилятора, чем недостаток архитектуры), то XGI стремительно проигрывает, делая эту функцию чипа строчкой в спецификации, а не реально функционирующей возмножностью. Позор.
Заметьте, что падение скорости закраски происходит теперь при задействовании каждой дополнительной текстуры. Видимо, вычислительные ресурсы текстурных блоков и шейдерных конвейеров используются совместно (т.е. один и тот же массив ALU служит как для интерполяции координат, так и для шейдерных вычислений). Вот вам и экономия транзисторов.
-
Тест на скорость выборки текстур, в зависимости от их числа и размера позволит нам определить эффективность. Приведены результаты в
миллионах текселов в секунду, для 1, 2 и 4 текстур накладываемых на один пиксель и для разных разрешений текстур:

Если в случае маленьких размеров текстур результаты Volari порой выглядят вполне конкурентноспособными, то по мере роста размеров текстур, видимо, сказывается низкая эффективность их кэширования и работы с памятью — результаты вновь становятся настолько низкими, что никакой речи о конкуренции с продуктами ATI или NVIDIA быть не может. Причем, это заметно уже на текстурах размером 128х128, не говоря уже о 256х256 — а ведь эти размеры наиболее популярны в реальных приложениях! Работать с памятью надо уметь. Число конвейеров остается только цифрой, если вы не способны своевременно накормить все эти конвейеры данными.
-
Теперь, для полноты картины, проведем тест на скорость выборки текстур, в зависимости от их формата и размера. Приведены результаты в миллионах
текселов в секунду, для различных форматов текстур двух размеров — 256х256 и 2048х2048:
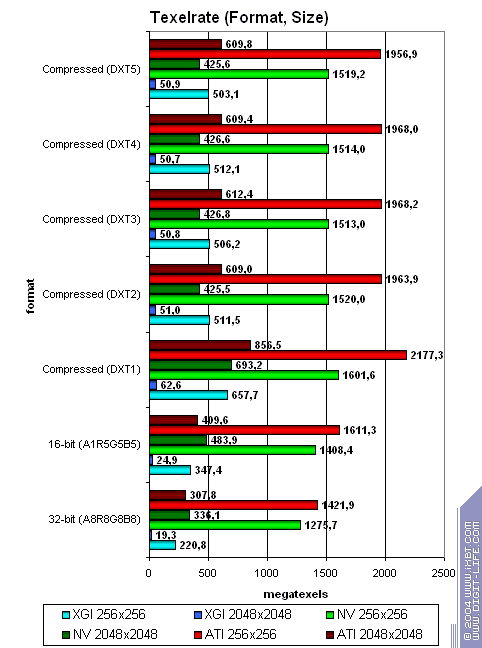
Что еще можно сказать? Там где Volari co скрипом справляется с текстурой размером 256х256, NVIDIA и ATI спокойно могут позволить себе прекрасное качество и детализацию 2048х2048(!) на равной скорости. И это при более низкой физической пропускной полосе памяти. Знания — сила, а кое-какерам — позор.
-
Посмотрим, как меняется скорость выборки текстур в зависимости от типа фильтрации. Для этого возмем распространенный размер текстуры 128х128 и
проверим результаты для 1,2 и 4 текстур на пиксель:
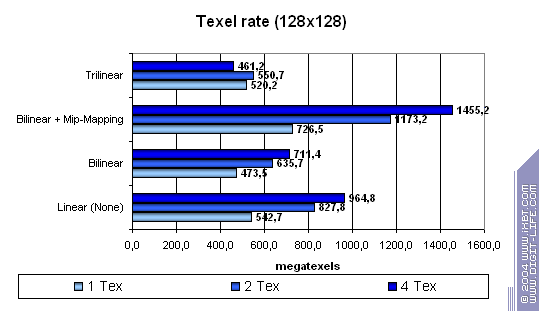
Билинейная фильтрация не стоит для Volari практически ничего (как и должно быть у любого современного чипа), использование mip-уровней заметно повышает эффективность кэширования и как следствие особенно хорошо сказывается на большом числе текстур, а вот трилинейная фильтрация дается не бесплатно, очевидно, что текстурные блоки объединяются парами — на 4 текстурах скорость упала сильнее всего, а ранее, отличия нивелировала низкая эффективность работы с буфером кадров, которую мы наблюдали в первых тестах.
-
Напоследок, посмотрим, насколько эффективно по сравнению с конкурентами выполняется трилинейная фильтрация, как известно, еще более
требовательная к кэшированию и доступу к памяти, чем билинейная:
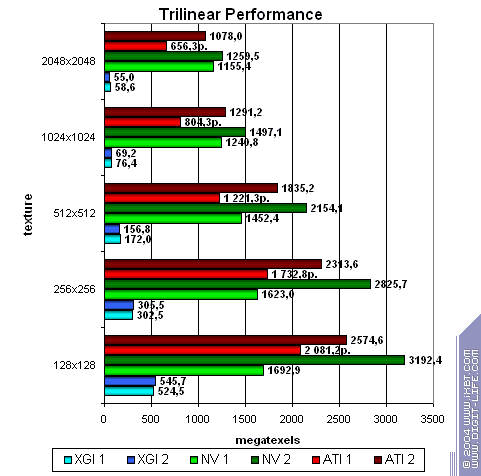
Ужас.
[ Предыдущая часть (1) ]
[ Следующая часть (3) ]
| 11 февраля 2004 г. |
|
|