XGI Volari Duo V8 Ultra 256MB
Очень модную везде!
Дали ему супер-норму,
Но ошиблись в КПДе…»

СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты XGI Volari Duo V8 Ultra 256MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark03
- Выводы из результатов синтетических тестов
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003
- Результаты тестов: AquaMark3
- Результаты тестов: RightMark 3D
- Результаты тестов: Tomb Raider: Angel of Darkness
- Результаты тестов: Half-Life2 (Beta)
- Результаты тестов: HALO
- Результаты тестов: Unreal II
- Выводы из результатов тестов
- Качество 3D: Анизотропная, билинейная и трилинейная фильтрации
- Качество 3D в целом
- Выводы
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителя.
-
Производительность фиксированного TCL (или производительность эмулирующего его шейдера):

Пока все не так уж плохо. По мере роста сложности задания, ATI (не имеющая специальной аппаратной поддержки для быстрой эмуляции старого фиксированного T&L) начинает проигрывать Volari. Но, пиковая пропускная способность продукта XGI не соответствует сегодняшнему дню и смотрелась бы лучше в сравнении с картами предыдущих поколений. NVIDIA остается лидиром во всех тестах, фиксированный T&L традиционно является ее сильной стороной, благодаря наличию специальных аппаратных блоков (можно сказать — специальной дополнительной инструкции для вершинного шейдера), обеспечивающей быстрый комплексный рассчет источника освещения. Итак, поздравляем: перед нами первый синтетический тест, резултаты Volari в котором можно рассматривать без слез!
С другой стороны, лимит в ~60 миллионов треугольников и столь слабая зависимость от сложности задачи могут навести на мысль об программной или программно-аппаратной эмуляции T&L. Тогда, столь странная зависимость, могла бы быть объяснена сдерживающим фактором AGP шины, а результат в 60 миллионов треугольников вполне по плечу современным SSE2 процессорам.
-
Теперь обратимся к вершинным шейдерам 1.1:
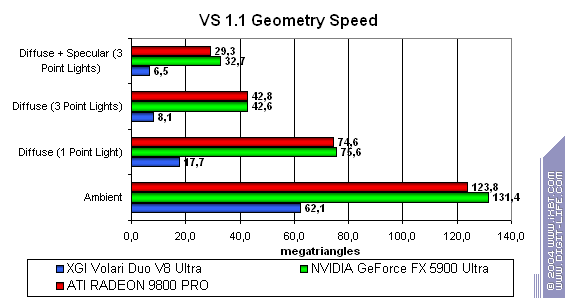
Volari вновь вне конкуренции. В печальном смысле этого слова.
-
А теперь самое интересное — шейдеры 2.0 с циклами:

Известное слабое место NVIDIA (косвенная индексация регистров выполняется не очень быстро и в итоге приводит к низкой скорости исполнения циклов, в которых она встречается практически во всех распространенных алгоритмах) ставит ее в неудобное положение, приближая результаты к Volari. Впрочем, даже в случае этого известного недостатка конкурента, XGI все равно умудрились оказаться в заметном проигрыше. Приграв NVIDIA вдвое(!) а ATI еще больше.
Hidden Surface Removal
Проверим максимальную эффективность HSR в процентах в зависимости от сложности сцены (производительность HSR), и усредненное отличие обработки
хаотичной и оптимально сортированной сцены (добротность алгоритма HSR) на сцене без
текстур. Мы не будем приводить результаты с выборкой текстур, ввиду очень неэффективной работы Volari с текстурами:
только без них мы сможем измерить реальную эффективность именно HSR подсистемы этого чипа:
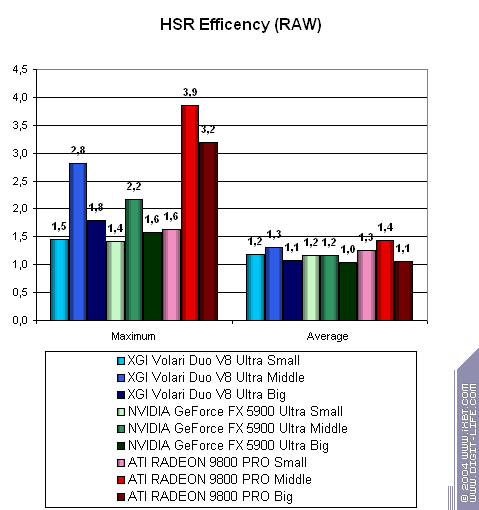
Итак, максимальная теоретическая эффективность выше у ATI — сказывается иерархический буфер глубины, кроме того, у Volari также наблюдается некий всплеск в этом случае для сцены средней степени сложности. NVIDIA на последнем месте, но как мы видим в других тестах, узкие места Volari сводят на нет этот потенциальный источник преимущества. Возможно HSR на Volari также имеет не один уровень отсечения. В эффективности алгоритма чипы показывают себя приблизительно равными. Большинство из них сбалансированны для сцен средней сложности.
Pixel Shading
В данном тесте мы измерим производительность аппаратного исполнения пиксельных шейдеров версии 2.0:
-
Сам тест, шейдеры 2.0, производительность арифметических операций:

Грустная история, особенно в случае простого шейдера. Volari проигрывает всем. NVIDIA проигрывает ATI, причем разница в 16 и 32 бит уже не столь заметна на последних драйверах. ATI в плане пиксельных вычислений (не путать с выборкой текстур) впереди планеты всей.
-
Давайте посмотрим, изменятся ли результаты при использовании альтернативных алгоритмов для тех же самых задач, когда предпочтение отдается
не вычислениям с помошью арифметических комманд а выборке данных из заранее рассчитанных таблиц (LUT — Look Up Tables), размещенных
в текстурах. Такой подход может несколько изменить расстановку сил — не забываем что продукты ATI лучше сбалансированы в области
вычислений а NVIDIA — в области выборки данных. Посмотрим в какой лагерь попадет Volari:
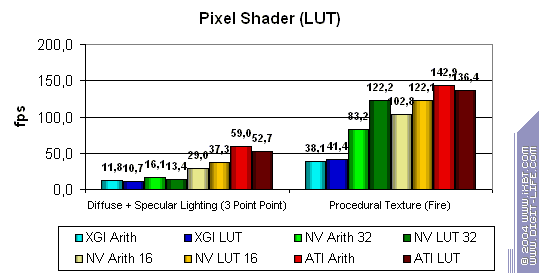
Кардинально расклад не поменялся, но NVIDIA получила небольшое преимущество. Volari выборку данных не жалует — в этом плане его поведение ближе к ATI. Впрочем по абсолютным цифрам результаты Volari не сравнимы с ATI — налицо многократный проигрыш.
Point Sprites
Итак, на последок — спрайты. В зависимости от размеров:
Опять позор. ATI и NVIDIA прекрасно знают свое дело а в Volari эта возможность реализована сугубо минимальна. И опять всему виною низкая
эффективность работы с буфером кадров.
[ Предыдущая часть (2) ]
[ Следующая часть (4) ]
| 11 февраля 2004 г. |
|
|