Обзор ATI RADEON X800 XT и X800 PRO (R420)

СОДЕРЖАНИЕ
- Официальные спецификации
- Архитектура
- Особенности видеокарт
- Конфигурации стендов, список тестовых инструментов, качество в 2D, качество Temporal AA
- Синтетические тесты в D3D RightMark
- Качество трилинейной фильтрации и анизотропии
- Качество АА
- Качество в целом на основе FarCry
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003
- Результаты тестов: Unreal II: The Awakening
- Результаты тестов: RightMark 3D
- Результаты тестов: TRAOD
- Результаты тестов: FarCry
- Результаты тестов: Call Of Duty
- Результаты тестов: HALO: Combat Evolved
- Результаты тестов: Half-Life2(beta)
- Результаты тестов: Splinter Cell
- Выводы
Установка и драйверы
Конфигурации тестовых стендов:
- Компьютер на базе Pentium 4 3200 MHz: — использовался для тестирования в синтетике
- процессор Intel Pentium 4 3200 МГц;
- системная плата ASUS P4C800 Delux на чипсете i875P;
- оперативная память 1024 MB DDR SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- Компьютер на базе Athlon 64 3200+: — использовался для тестирования в играх
- процессор AMD Athlon 64 3200+ (L2=1024K);
- системная плата ASUS K8V SE Deluxe на чипсете VIA K8T800;
- оперативная память 1 GB DDR SDRAM PC3200;
- жесткий диск Seagate Barracuda 7200.7 80GB SATA.
- операционная система Windows XP SP1; DirectX 9.0b;
- мониторы
ViewSonic P810 (21") иMitsubishi Diamond Pro 2070sb (21"). - драйверы ATI версии 6.444 (CATALYST BETA); NVIDIA версии 60.72 (версия 61.11 вышла, когда обзор готов).
VSync отключен, технология S3TC ОТКЛЮЧЕНА в приложениях.

Рассматривать бету-версию драйверов для этих карт нет смысла, ибо в ней все настройки те же самые, что и в обычном CATALYST 4.4.
А вот способ включения так называемого Temporal AA имеется, пока только лишь через registry:

Обратите внимание на переменную TemporalAAMultipler! Именно она и отвечает на включение такого АА. Значения 0 и 1 — это Temporal AA выключен, 2 и 3 — включен. Последние значения между собой отличаются лишь частотой смены паттернов (3 — самая высокая).
Переменная TemporalAAFrameThreshold выставляет минимальный FPS, при котором начинает работать Temporal AA, при значении 0 — он работает всегда. Например, если задать этой переменной значение 60, то при скорости в игре ниже 60 fps Temporal AA работать не будет.
Поскольку сам принцип работы этой функции основан на восприятии глазом и особенности работы люминофора (или LCD матрицы), то заснять на скриншотах работу Temporal AA невозможно. Могу лишь сказать, что при сильном отклонении FPS от частоты развертки по краям близко расположенных объектов мы можем наблюдать небольшое подрагивание (мерцание). Я попробовал фотокамерой нечто подобное запечатлеть, вот что вышло (7 MB) (смотрите на край толстой балки, АА работает именно там, а на решетке его нет, поскольку она выполнена на полупрозрачной текстуре, с которыми, как известно, MSAA не работает).
Результаты тестов
Перед тем, как кратко дать оценку качеству в 2D, я еще раз дам пояснение, что на настоящий момент НЕТ полноценной методики объективной оценки этого параметра по следующим причинам:
- Практически у всех современных 3D-акселераторов качество 2D может сильно зависеть от конкретного экземпляра, а отследить все карты невозможно физически;
- Качество 2D зависит не только от видеокарты, но и от монитора, соединительного кабеля;
- В последнее время огромное влияние на этот параметр стали оказывать связки: монитор-карта, то есть, встречаются мониторы, "не дружащие" с теми или иными видеокартами.
Что касается протестированных экземпляров, то совместно с Mitsubishi Diamond Pro 2070sb платы продемонстрировали отменное качество в следующих разрешениях и частотах:
| ATI RADEON X800 XT | 1600x1200x85Hz, 1280x1024x120Hz, 1024x768x160Hz |
|---|---|
| ATI RADEON X800 PRO | 1600x1200x85Hz, 1280x1024x120Hz, 1024x768x160Hz |
Синтетические тесты D3D RightMark
Использованная нами версия пакета синтетических тестов D3D RightMark Beta 4 (1050) и ее описание доступна на сайте 3d.rightmark.org.
Еще раз отмечу, что все тесты в RightMark снимались на компьютере на базе Pentium4.
Параметры D3D вы можете посмотреть здесь:
D3D RightMark: NV40, NV38, R360, R420
Внимание! Замете, что в текущей версии DirectX в паре с текущими драйверами возможности пиксельных 2.0.b пока не доступны. Этот вопрос разрешится с выходом DirectX 9.0c и новой версии SDK, которая также скоро будет доступна.
Все тесты включают в себя результаты из обзора NV40, поэтому мы прокомментируем только отличия и характер поведения R420 (Radeon X800 XT) и R420 с12 конвейерами (Radeon X800 PRO) . Итак:
Тест Pixel Filling
Пиковая производительность выборки текстур (texelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:

Теоретический максимум R420 в этом тесте 8,4 гигатекселов в секунду. В действительности мы достигли 7.5 гигатекселов, что однозначно свидетельствует о наличии 16 текстурных модулей. В случае одной текстуры лидирует NVIDIA — выборка одной текстуры происходит у нее более эффективно из-за особенностей архитектуры пикслельного процессора — в случае R420 это не оптимальный вариант из-за накладных расходов или иных вопросов связанных с наличием только одной очень короткой фазы в этом тесте. На 2х и трех текстурах R420 он расправляет крылья и уделывает NV40. Более высокая тактовая частота ядра (шутка ли 125 МГц разницы умножить на 16 конвейеров) дает себя знать. Скачков между четными и нечетными числами (свойственных конфигурациям с двумя TMU на пиксель нет ни у одного участника теста
А сейчас — скорость закраски буфера кадра (fillrate, pixelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
Итак, NV40 побеждает R420 на одной текстуре или константной закраске и проигрывает во всех остальных режимах. Пиковая скорость работы с буфером кадра (0 текстур -закраска цветом и одна текстура) выше у NVIDIA. Выборка текстур, по мере увеличения их числа — лучше у ATI. Помогает более высокая тактовая частота ядра.
Посмотрим, как скорость закраски зависит от версии шейдеров:
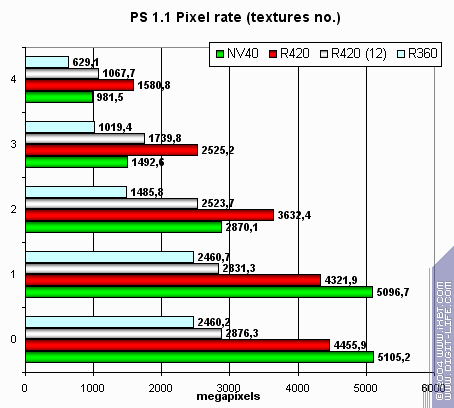
та же картина что и в случае FFP,
Опять та же расстановка сил,
Итак, в пиковом случае отсутствия текстурирования или одной текстуры NV40 смотрится лучше, несмотря на более низкую тактовую частоту. Это говорит о хорошей работе с буфером кадра. Но, реальные задачи уже давно не ограничиваются одной текстурой.
Отметим, что теперь использование разных версий шейдеров практически не влияет на скорость — странности NV3X канули в лету и теперь результаты вполне предсказуемы и линейны.
Итак, вырисовывается следующая картина предпочтений:
Версия |
1.1 |
1.4 |
2.0 |
NV40 |
Оптимально |
Оптимально |
Оптимально |
NV38 |
Оптимально |
Оптимально |
Не оптимально |
R360 |
Оптимально |
Не оптимально |
Оптимально |
R420 |
Оптимально |
Оптимально |
Оптимально |
А теперь посмотрим, как текстурные модули справляются с кэшированием и билинейной фильтрацией реальных текстур различных размеров:
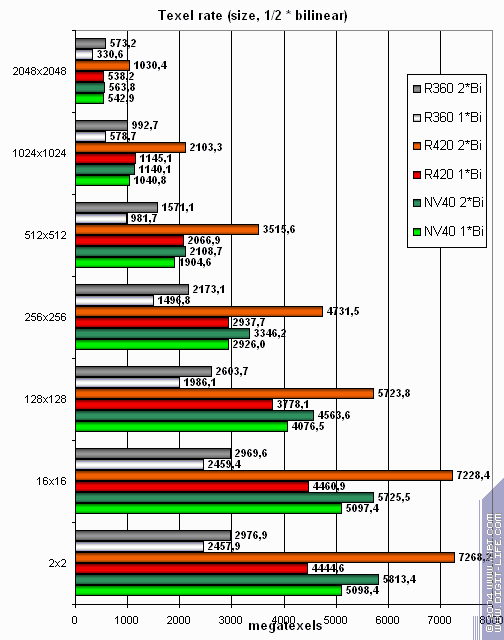
Приведены данные для разных размеров текстур, одна и две текстуры на пиксель. Интересно, что ATI хронически не любит случай с одной текстурой. Даже если ее размер вполне значителен! Очень странное поведение. Видимо сказывается некая накладная задержка при переключении фаз и окончании исполнения шейдера? Или так проявляется латентность конвейера в текстурном модуле? Как бы там ни было, в случае двух текстур все встает на свои места. В этом тесте NVIDIA выглядит неплохо, особенно по мере роста размера текстуры. Даже более высокая тактовая частота ATI не дает R420 доминировать во всех случаях — выборка текстур всегда была сильной стороной NVIDIA. Однако и NV40 никоим образом не выигрывает у R420. Лучше >= чем <= :-) — таким образом, R420 победитель.
Посмотрим, как изменится картина в случае трилинейной фильтрации:
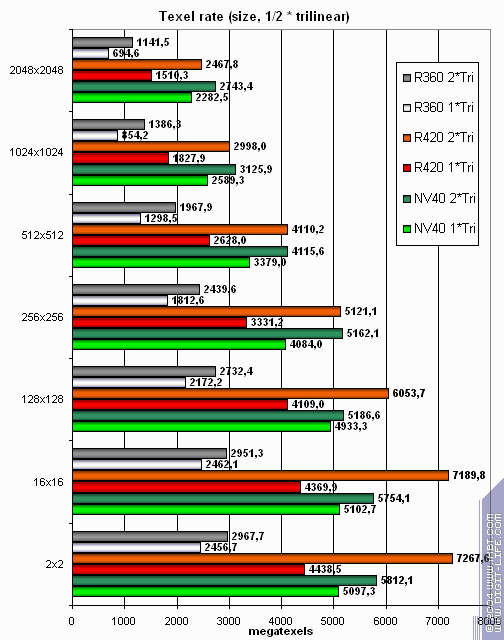
Вот это да! Здесь NV40 еще ближе подбирается к R420. Наличие мип уровней позволяет эффективно кэшировать данные текстур. И здесь двухуровневый кэш NV40 не прошел даром. В итоге, назвать результаты R420 выигрышными или проигрышными нельзя — на лицо паритет с шатким равновесием — с одной стороны лучше чувствует себя NVIDIA с другой ATI.
Напоследок предельный случай восьми трилинейно фильтруемых текстур:
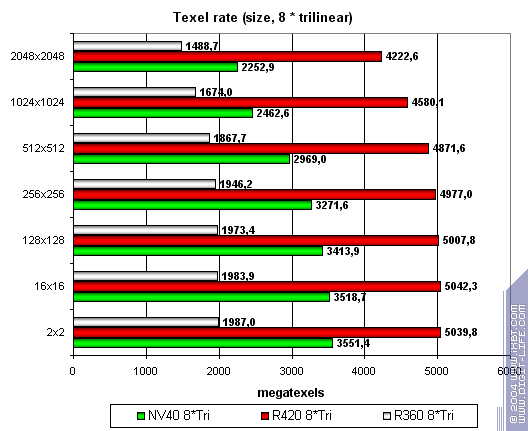
Здесь все в соответствии с частотой и числом конвейеров. Лидер — ATI.
А теперь посмотрим на зависимость производительности текстурных модулей от формата текстур:
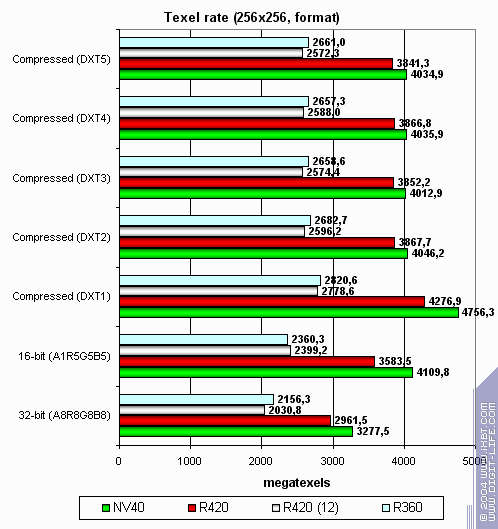
Больше размер:
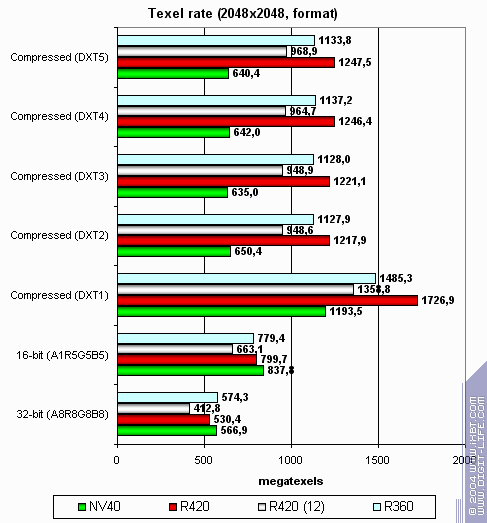
Интересная картина. NV40 более эффективно кэширует текстуры. Двухуровневый кэш рулит. R420 сравнимо эффективно работает с большими текстурами (все уперлось в память, а ПСП примерно равна), существенно лучше справляется с сжатыми текстурами. Почему ATI так выигрывает, даже у NV40, в случае больших размеров сжатых текстур? Ответ прост — в текстурном кэше NVIDIA хранятся уже распакованные текстуры, приведенные к формату 32 бита. В текстурном кэше ATI — все еще сжатые. С одной стороны эффективность выборки текстур NVIDIA будет выше — меньше простоев во время распаковки, меньше задержка, с другой стороны при большом размере текстур фактор занимаемого ими места может вывести ATI в лидеры — NV40 упрется в пропускную полосу памяти и даже 16 TMU его не спасут. Что собственно и происходит на втором графике. В реальных приложениях баланс может склониться как в ту, так и в иную сторону, в зависимости от шейдеров, числа и размера текстур и прочих параметров сцены.
Итак, в общем и целом, можно констатировать два факта:
- R420 чемпион по закраске, особенно на 2х и более текстурах. Впрочем, легендарная эффективность работы TMU и буфера кадра от NVIDIA по-прежнему в силе, в тех случаях, когда им таки удается успешно конкурировать с более высокой тактовой частотой R420. Судя по всему, в реальных приложениях, R420 еще более усилит свои позиции — эти тесты показывают нам пиковые ситуации, а в случае смеси, неожиданные положительные скачки NVIDIA в некоторых режимах будут сглажены.
- Какие либо досадные неравномерности поведения на пиксельных шейдерах любой версии отсутствуют как класс — можно свободно выбирать удобную для решения ваших задач версию.
Тест Geometry Processing Speed
Самый простой шейдер – предельная пропускная способность по треугольникам:
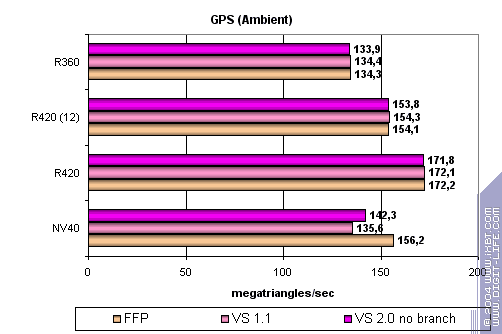
Итак, R420 лидер и его пиковая скорость прекрасно масштабируется вместе с частотой ядра. Почему результаты NV40 почти не превышают предыдущего поколения? Вопрос сложный. Судя по всему вершинные процессоры чипа просто не разворачиваются в полную силу на столь примитивной задаче. Проверим наше предположение далее, на более сложных задачах. А пока отметим, что характер зависимости скорости R420 от версии шейдера очень точно повторяет R3XX. А именно — зависимость отсутствует как класс :-)
Более сложный шейдер – один простой точечный источник света:
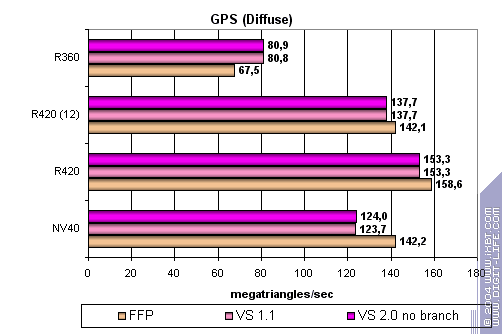
Ага! Свершилось, наконец-то ATI озаботилась эффективной эмуляцией T&L и реализовала ее. Теперь скорость не ниже, она выше, пусть и на немного. Те же 6 вершинных блоков на более низкой частоте у NV40 приводят к проигрышу, пусть и не очень значительному, но обидному.
Усложняем задачу далее:
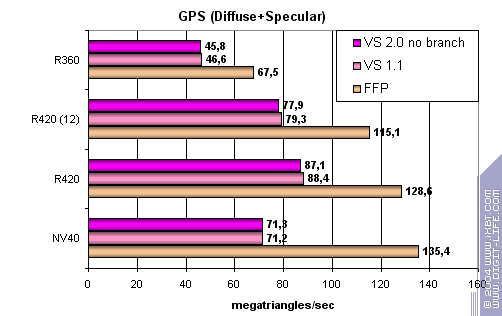
Здесь NV40 FFP лидер, несмотря на частотное преимущество ATI. FFP отрывается от шейдеров и в случае R420 — мы вновь находим подтверждение нашей гипотезе о дополнительных аппаратных блоках, теперь и у ATI. Впрочем, у NVIDIA они эффективнее. Но общая картина складывается скорее в пользу ATI.
А теперь самая сложная задача, три источника света, причем, для сравнения в вариантах без переходов, со статическим и динамическим управлением исполнением:
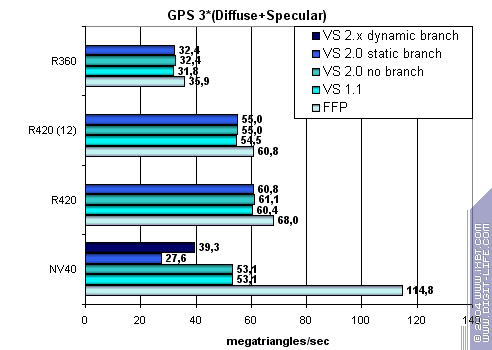
FFP силен, а статические переходы заметно ударяют по чипам NVIDIA. Парадокс в том, что динамические переходы на чипах от NVIDIA выгоднее статических. В случае ATI все достаточно ровно, FFP практически равен шейдерам, и общая картина вновь в пользу R420..
Итак :
- Наконец то FFP R420 стал заметно быстрее, чем у R3XX. Слабое место устранено, так или иначе.
- Статические переходы на ускорителях NVIDIA исполняются не оптимально.
- R420 позволяет получать ровные результаты на всех типах шейдеров. Никаких досадных аномалий, как в случае R3XX (FFP) или NV40 (статические переходы) не наблюдается. Статические переходы на ускорителях NVIDIA исполняются не оптимально.
- Напомним, что динамические переходы не поддерживаются R420.
Тест Pixel Shaders
Первая группа шейдеров — достаточно простых для исполнения в реальном времени, 1.1, 1.4 и 2.0:
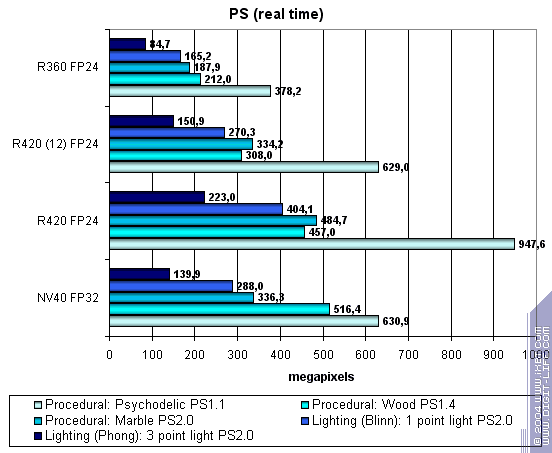
В общем и целом R420 лидер. Хотя, порой, NV40 наступает ему на пятки. И даже чуть обгоняет в случае шейдеров 1.4 — вот парадокс, детище ATI ноне уютнее всего чувствует себя на продуктах NVIDIA. Старые добрые пиксельные конвейеры R3XX качественно разогнаны и оптимизированы. А производительность шейдеров 1.1 просто потрясает — описанная выше организация пиксельного конвейера с фазами очень близка к исходным архитектурам шейдеров 1.1.
Посмотрим, сможет ли спасти положение NV40 использование 16 битной точности плавающих чисел:
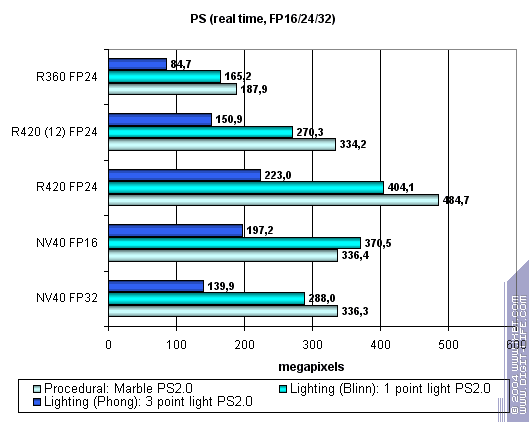
Преимущество 16 битной точности для NV40 есть, в некоторых шейдерах больше, в некоторых меньше. Но оно не позволяет отыграть пальму первенства у R420. Частота и еще раз частота.
А теперь посмотрим на действительно сложный, «кинематографичный» шейдер 2.a в силу небольшого числа зависимых выборок уложившийся в ограничения пиксельных конвейеров R420:
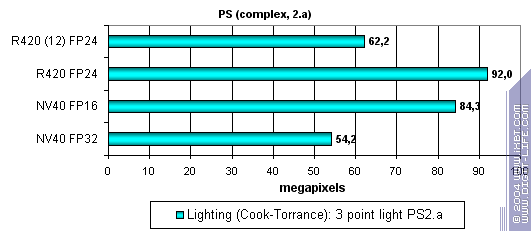
Здесь NV40 чувствует себя увереннее — ее архитектура очень хорошо приспособлена к длинным и сложным шейдерам, но, все равно не выигрывает у R420, даже в случае использования 16 битной точности. А ведь есть где развернуться — много выборок текстур, множество временных переменных, сложный код. Вот почем разница 16 и 32 бит столь заметна.
На последок, исследуем зависимость скорости от использования арифметических или табличных методов вычисления sin, pow и нормализации векторов, отдельно для всех чипов:
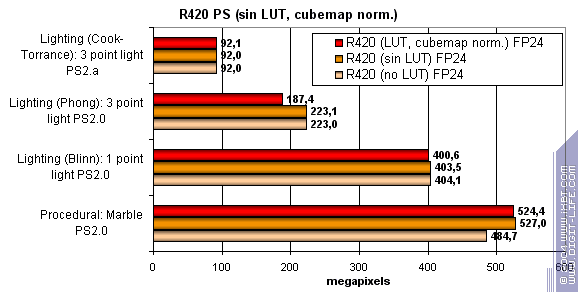
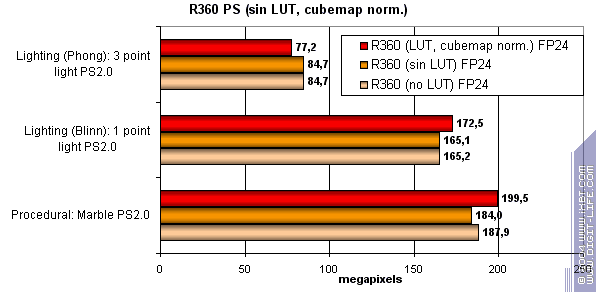
Итак, R420 зависит от разных методов, еще меньше чем R3XX. Гордость ATI — предсказуемая и ровная архитектура для оптимального исполнения любых 2.0 шейдеров. Вычисления или таблицы — ATI показывает себя ровно и предсказуемо. Лидерство без лишних проблем и аномалий.
Итого, по пиксельным шейдерам :
- Производительность вне конкуренции.
- Вредных аномалий нет.
- Динамического управления вычислениями нет
- Шейдеры 1.1 феноменально быстры.
- Остальные шейдеры просто очень быстры, и, надо отметить, быстрее NV40.
Тест HSR
Для начала пиковая эффективность (без текстур и с текстурами) в зависимости от сложности геометрии: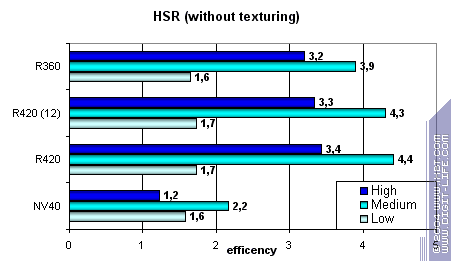
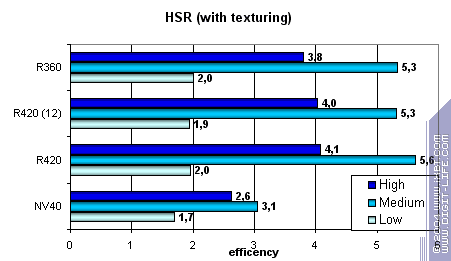
Заметно, что ATI лучше переносит средние и сложные сцены — сказывается наличие двух уровней уменьшенных Z буферов (кроме базового). У NVIDIA традиционно один дополнительный уровень, поэтому эффективность HSR в случае оптимального баланса сцены (средняя сложность) несколько ниже. Видно, что сам алгоритм HSR не поменялся — эффективность R350 и R420 практически эквивалентна — а значит и соотношение отбрасываемых за такт и закрашиваемых пикселей не изменилось. Зато абсолютные цифры существенно возросли:
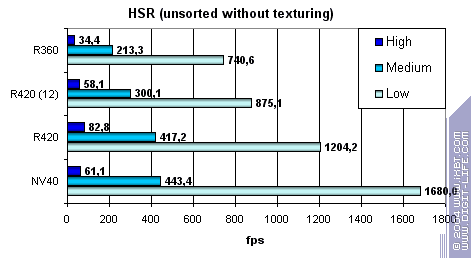
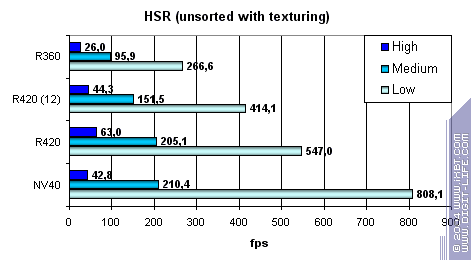
Но не до уровня NV40 на сценах с низкой и средней детализацией! Зато на большой детализации и высоком факторе перекрытия ATI отыгрывается. Простая без затей закраска, вкупе с HSR, на чипах NVIDIA очень эффективна. И это несмотря на наличие только одного дополнительного уровня иерархии.
Вывод :
- Алгоритм HSR не претерпел серьезных изменений
- Но его общая производительность увеличилась, что нормально, учитывая большее число отправляемых на отрисовку (или отбрасываемых) за такт квадов.
Тест Point Sprites.
Спрайты давно перестали быть популярным новшеством и зачастую проигрывают треугольникам по скорости вывода. ATI лучше справляется с этой задачей, NV40 упирается в какую то странную планку, а R420 наоборот, прекрасно масштабируется и четкий лидер.
Тест MSAA
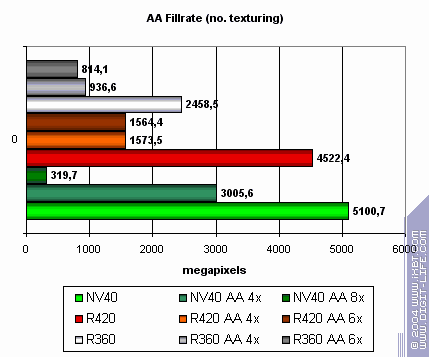
В пиковом случае MSAA NVIDIA эффективнее. Падение на 4х ниже. Но, надо это признать, сглаживание NVIDIA несколько ниже качеством. Хорошо заметно, что 8х у NV40 является гибридной установкой с использованием SSAA — скорость падает ниже допустимого уровня. Зато 6х практически не отличается у R420 от 4х и это можно только приветствовать.
Выводы по синтетическим тестам
- Работа над ошибками, которых почти не было, состоялась.
- Задел на будущее ощутим, если не считать вопросов гибкости. Гибкость проигрывает NV40
- Производительность вне конкуренции.
- R420 видится нам более успешным для игровых приложений, NV40 возможно найдет свое применение в DCC и иных профессиональных нишах требующих исполнять длинные и сложные шейдеры.
- Меньшая сложность и потребление сыграли свою положительную роль. Тактовая частота выше, и производительность вне конкуренции. Возможно, в скором времени они сыграют роль и в снижении стоимости. Прекрасное решение на сегодня.
[ Предыдущая часть (1) ]
[ Следующая часть (3) ]
| 4 мая 2004 г. |
|
|