
СОДЕРЖАНИЕ
- Официальные спецификации
- Архитектура
- Особенности видеокарт
- Конфигурации стендов, список тестовых инструментов, качество в 2D, качество Temporal AA
- Синтетические тесты в D3D RightMark
- Качество трилинейной фильтрации и анизотропии
- Качество АА
- Качество в целом на основе FarCry
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003
- Результаты тестов: Unreal II: The Awakening
- Результаты тестов: RightMark 3D
- Результаты тестов: TRAOD
- Результаты тестов: FarCry
- Результаты тестов: Call Of Duty
- Результаты тестов: HALO: Combat Evolved
- Результаты тестов: Half-Life2(beta)
- Результаты тестов: Splinter Cell
- Выводы
Итак, настал месяц май, позади поездка в Канаду (Торонто), где мы впервые познакомились с новинкой от ATI (тогда еще под кодовым названием R420). Для желающих узнать об ATI Technology Days более подробно, даем ссылки на первый и второй дни работы форума.
А сегодня мы уже сбросим завесу таинственности с новых продуктов и рассмотрим более детально. Почему во множественном числе? — Просто на базе R420 выпускается в свет не одна карта, а несколько. На сегодня их две: RADEON X800 XT и X800 PRO. Более подробно — далее.
Недавно выходил наш материал по NVIDIA GeForce 6800 Ultra, и в анонсе этого материала высказывалось предположение: надолго ли NV40 стал королем в 3D? Не сместит ли его R420 в самой мощной своей ипостаси?
Давайте сегодня познакомимся с новинкой от ATI и заодно попытаемся ответить на этот вопрос.

Официальные спецификации Radeon X800
- Кодовое имя чипа R420
- Технология 130нм (TMSC, low-k, медные соединения)
- 180 миллионов транзисторов
- FС корпус (перевернутый чип, без металлической крышки)
- 256 бит интерфейс памяти
- До 512 мегабайт DDR/GDDR-2/GDDR-3 памяти
- AGP 3.0 8x шинный интерфейс (также будет выпущенная PCI-Express версия чипа R423)
- 16 Пиксельных процессоров, по одному текстурному блоку на каждом (X800 PRO — 12 конвейеров).
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Вычисление и запись до 32 значений глубины и буфера шаблонов за такт.
- Поддержка «двустороннего» буфера шаблонов;
- MSAA 2x/4x/6х, с гибко программируемыми паттернами отсчетов. Сжатие буфера кадра и буфера глубины в MSAA режимах. Возможность менять MSAA паттерны от кадра к кадру (Temporal AA);
- Анизотропная фильтрация степени до 16х включительно
- 6 Вершинных процессоров
- Все необходимое для поддержки пиксельных и вершинных шейдеров версии 2.0
- Дополнительные возможности пиксельных шейдеров на основе расширенной версии 2.0 — т.н. 2.0.b
- Дополнительные возможности вершинных шейдеров, сверх базовых 2.0
- Новая техника сжатия текстур, оптимизированная для сжатия двухкомпонентных карт нормалей (т.н. 3Dc, степень сжатия 4:1).
- Поддерживается рендеринг в буфера плавающего формата, с точностью FP16 и FP32 на компоненту.
- Поддерживаются трехмерные и FP (плавающие) форматы текстур
- MRT
- 2 RAMDAC 400 МГц
- 2 DVI интерфейса
- TV-Out и TV-In интерфейс (требуются интерфейсные чипы)
- Возможность программируемой обработки видео — пиксельные процессоры задействуются для обработки видео потока (задачи компрессии, декомпрессии и постобработки)
- 2D ускоритель с поддержкой всех функций GDI+
Спецификации карт, ныне выпущенных на базе R420:
- RADEON X800 XT: 525/575 (1150) MHz, 256MB GDDR3, AGP 8x/4x, 16 пиксельных конвейеров ($499) — конкурент NVIDIA GeForce 6800 Ultra.
- RADEON X800 PRO: 475/450 (900) MHz, 256MB GDDR3, AGP 8x/4x, 12 пиксельных конвейеров ($399) — конкурент NVIDIA GeForce 6800 (?).
Общая схема чипа
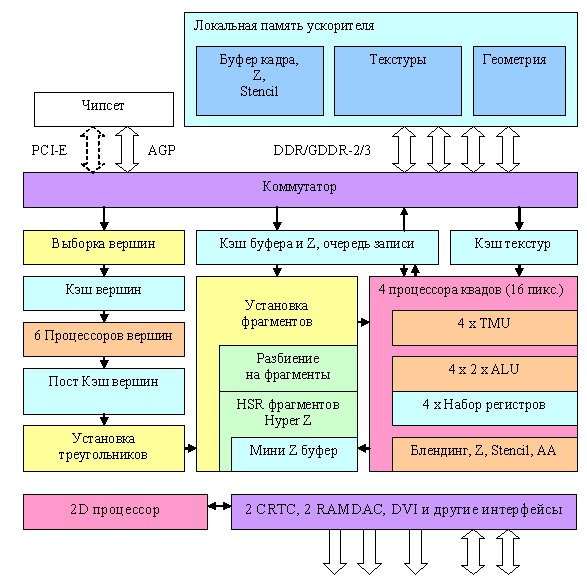
Пытливый читатель сразу отметит, что схема практически совпадает с NV40. Ничего удивительного — обе фирмы, стараются создать оптимальное решение, и уже несколько поколений исповедуют проверенную и эффективную организацию общей структуры графического конвейера. Существенные отличия кроются внутри блоков и в первую очередь в пиксельных и вершинных процессорах.
Как и у NV40, в наличии шесть вершинных процессоров, и четыре независимых пиксельных процессора, каждый из которых работает с одним квадом (фрагментом 2х2 пикселя). Скорее всего, в отличие от NV40, присутствует только один уровень кэширования данных текстур.
В наличии 4 независимых процессора квадов, каждый из которых может быть отключен — таким образом, в зависимости от потребностей рынка и наличия бракованных чипов можно отключать один, два или даже три процессора, производя, таким образом карты, обрабатывающие 4, 8, 12 или 16 пикселей за такт. Не исключено, что в будущем, энтузиасты будут так или иначе исследовать вопрос обратной «активации» отключенных при производстве (и возможно бракованных) квадов, мы же пока оставим его в стороне.
А теперь, по традиции увеличим степень детализации в самых интересных местах:
Вершинные процессоры и выборка данных
Приведем блок схему вершинного процессора R420:
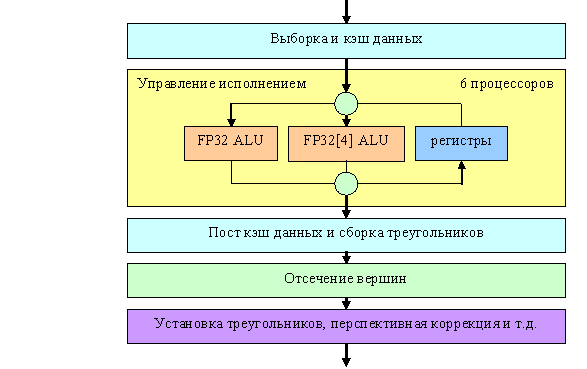
Собственно сам процессор на схеме обозначен желтым прямоугольником, остальные окружающие его блоки показаны для более полной картины. Заявлено, что R420 содержит 6 независимых процессоров (мысленно скопируем желтый блок 6 раз). Есть информация, что вершинные процессоры R420 поддерживают динамическое управление исполнением — т.е. переходы и циклы на основе принятых во время выполнения шейдера решений, однако она требует проверки. Как бы там ни было — пока эта возможность не доступна в API. Но, несомненно, если она есть, она будет использованы в OpenGL и там ничего не мешает задействовать ее полностью. В DX9, скорее всего, она так и не появятся. Вершинные блоки не соответствуют ни полной спецификации VS 3.0 (отсутствует возможность доступа к текстурам) ни расширенной спецификации 2.0 в понимании NVIDIA (т.н. 2.0.а).
Что касается арифметической производительности — то за один такт вершинный процессор R420 может выполнить одну векторную операцию (до 4-х компонент FP32) и одну скалярную FP32 операцию одновременно, так же как и вершинный процессор NV40.
Напомним, как выглядит сводная табличка параметров вершинных процессоров современных ускорителей с точки зрения вершинных шейдеров DX9
| Версия вершинных шейдеров | 2.0 (R3XX, R42X) | 2.a (NV3X) | 3.0 (NV40) |
| Число инструкций в коде шейдера | 256 | 256 | 512 и более |
| Число исполняемых инструкций | 65535 | 65535 | 65535 и более |
| Предикаты | Нет | Есть | Есть |
| Временных регистров | 12 | 13 | 32 |
| Константных регистров | 256 и более | 256 и более | 256 и более |
| Статические переходы | Да | Да | Да |
| Динамические переходы | Нет (?) | Да | Да |
| Глубина вложенности динамических переходов | Нет | 24 | 24 |
| Выбор значений текстур | Нет | Нет | Да (4) |
Еще один интересный аспект, который мы исследуем далее — производительность эмуляции FFP (T&L). Напомним, что R3XX во многом проигрывал чипам NVIDIA из-за отсутствия специальных аппаратных блоков расчета освещения, ускорявших эмуляцию T&L вот уже в трех поколениях чипов NVIDIA. Будем надеяться, что разработчики ATI проанализировали число приложений до сих пор полностью или частично использующих T&L, сделали выводы и исправили ситуацию, так или иначе.
Пиксельные процессоры и организация закраски
Рассмотрим пиксельную архитектуру R420 в порядке следования данных. Итак, после установки параметров треугольника нас ждет:
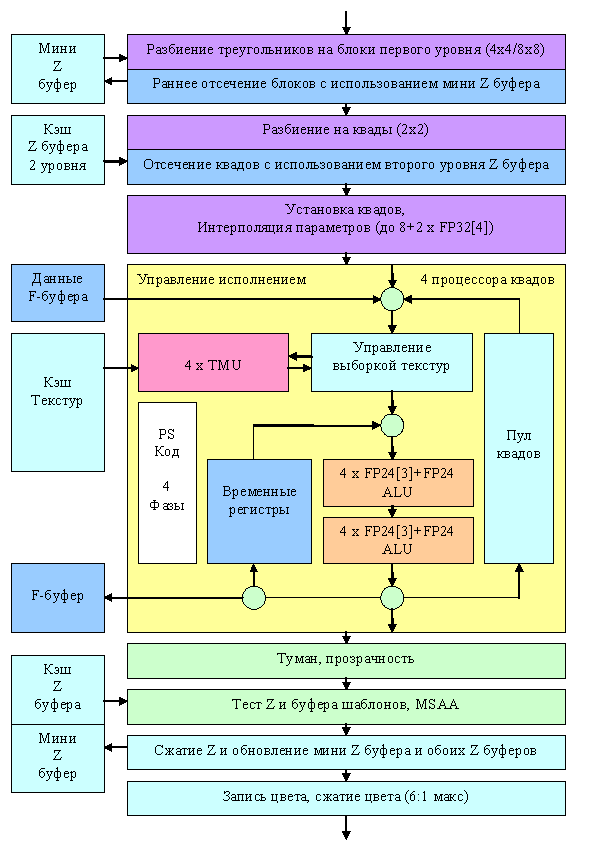
Остановимся на самых интересных фактах. Во-первых, если ранее в R3XX было максимум два процессора квадов, обрабатывающих за такт блок из четырех пикселов (2х2) то теперь таких процессоров стало четыре. Они полностью независимы и каждый из них может исключаться из работы (например, для создания облегченной версии чипа с тремя процессорами при наличии брака в одном из них).
Отметим, что во многом схема похожа на NV40, но есть и кардинальные отличия, на которых мы остановимся подробнее.
Итак, вначале треугольник разбивается на блоки первого уровня (8х8 или 4х4 в зависимости от разрешения рендеринга) и происходит первая ступень отбрасывания невидимых блоков, на основе данных полностью размещенного на чипе мини Z буфера. Его объем не афишируется, но, судя по всему, в R420 он занимает несколько менее 200 килобайт. Всего на этой стадии может быть откинуто до 4 блоков за такт, т.е. до 256 невидимых пикселей.
Затем происходит вторая ступень разбиения — на сей раз, на квады размером 2х2 и происходит раннее отсечение полностью невидимых квадов, на основе хранимого в видео памяти Z буфера второго уровня, с гранулярностью покрытия 2х2. Отметим, что в зависимости от режима MSAA один элемент этого буфера может соответствовать 4 (нет), 8(MSAA 2х), 16 (MSAA 4х) или даже 24 (6х MSAA) точкам в буфере кадра, вот почему его выделение в отдельную структуру, занимающую промежуточный уровень между мини буфером глубины полностью расположенном на чипе и окончательным буфером глубины базового уровня. Таким образом в продуктах NVIDIA мы имеем дело с двухуровневой организацией HSR и буфера глубины, а в продуктах ATI с трехуровневой. Далее, в синтетических тестах, мы обратим внимание на влияние этого фактора на производительность.
Затем происходит установка квадов, и их распределение по активным пиксельным процессорам. А далее и начинаются самые существенные отличия R420 от NV40:
Алгоритм работы пиксельного процессора NVIDIA:
Цикл по командам шейдера
Конец цикла по командам шейдера
Алгоритм работы пиксельного процессора ATI
Цикл по 4 фазам
Конец цикла по 4 фазам.
Итак, NVIDIA постепенно исполняет команды (а точнее суперскалярные пачки команд, включая команды выборки текстур), прогоняя через каждую команду все квады находящиеся в обработке. ATI же разбивает шейдер на четыре фазы (вот откуда ограничение на глубину зависимых выборок не более 4), в каждой из которых сначала осуществляется выборка всех данных текстур необходимых для этой фазы, а затем уже все вычисления над полученными данными. В том числе, и вычисление новых координат, для выборки текстур в следующей фазе.
Какой подход лучше? Сказать однозначно не возможно. Подход ATI хуже приспособлен к сложным шейдерам с управлением потоком команд или многочисленными зависимыми выборками. С другой стороны вычисления внутри каждой из четырех фаз происходят по похожей на CPU схеме — выполняются все команды, команда за командой, для одного квада, затем берется следующий квад и т.д. Таким образом, во время вычислений можно использовать полноценный пул из временных регистров, без какой либо потери производительности и пенальти за использование более 4 регистров, которое мы имеем в NV40. Кроме того, подход ATI требует менее длинных по числу стадий конвейеров. Следовательно, расходуется меньше транзисторов и потенциально достигаются более высокие тактовые частоты (или, что одно и тоже более высокий выход годных чипов на фиксированной частоте). Хорошо предсказуема производительность того или иного шейдера, легко написать код (не надо заботиться равномерной группировке текстурных и вычислительных команд или расходе временных регистров).
Из недостатков — многочисленные ограничения. Ограничение на число зависимых выборок, ограничение на число команд в одной фазе, необходимость хранить весь микрокод шейдера для 4 фаз «под рукой», т.е. прямо в пиксельном процессоре. Потенциальные задержки в случае интенсивных зависимых выборок текстур следующих друг за другом (скрадываются наличием набора одновременно обрабатываемых квадов, но их число не столь велико как у NVIDIA).
Фактически подход ATI оптимален для реализации шейдеров 2.0, без динамического контроля исполнения и достаточно ограниченной длинной. Любые попытки «привинтить» к подобной архитектуре пиксельного процессора неограниченную длину шейдеров и тем более неограниченную гибкость в текстурных выборках столкнется с проблемами.
На схеме пиксельного процессора обозначена логика F-буфера — механизма для записи и восстановления параметров временных переменных шейдера. Это ухищрение позволяет исполнять шейдеры превышающие по длине или числу зависимых (да и обычных тоже) выборок текстур ограничения пиксельного процессора, но, ценою дополнительных проходов, что само по себе не является бесплатным решением и далеко от идеала. По мере роста сложности шейдера число проходов и сохраняемых временно в видеопамяти данных будет возрастать, а вместе с ними будет возрастать и штраф по сравнению с NVIDIA подобными архитектурами, не ограниченными длинной или сложностью шейдера.
Что ж, реальные игровые приложения покажут, чей подход более оправдывает себя. А также выход годных и энергопотребление — не забываем, что гибкость шейдеров NV40 дается ценой в 220 миллионов транзисторов — это число рискует попасть за порог стабильного оправданного по себестоимости производства при технологии 0.13, и многое будет зависеть от того, как пойдет производство и борьба за выход годных.
Впрочем, вернемся к особенностям архитектуры пиксельных процессоров R420. Формат данных в процессорах при вычислениях — FP24, но в TMU, при выборке текстур, операции с текстурными координатами проводятся с больше точностью. В этом плане, все как и в случае R3XX. На каждый пиксель приходится по два ALU, причем каждое из них может выполнить две различные(!) операции по схеме 3+1 (как и в R3XX, но там ALU было одно). Подробнее об этом вопросе см. DX Current. Не поддерживается произвольное маскирование и перестановка компонент после операции, все только в рамках шейдеров 2.0 и чуть более длинных 2.0.b .
Таким образом, в зависимости от кода шейдера, может быть выполнено от одной до 4х различных FP24 операций за такт, над векторами (размерность до 3) и скалярами и осуществлен один доступ к уже (!) выбранным из текстуры в данной фазе данным. Производительность такой связки напрямую зависит от компилятора и кода, но очевидно, что мы имеем
- Минимум: один доступ к выбранным данным текстуры за такт
- Минимум: две операции за такт без доступа к текстуре
- Максимум: четыре операции за такт без доступа к текстуре
- Максимум: четыре операции за такт с доступом к текстуре
Что в пиковом варианте превышает возможности NV40. Но, не забываем, что реально это решение менее гибко (всегда схема 3+1) с точки зрения совмещения команд в суперскалярные пачки при компиляции. Реальную эффективность покажут тесты. По сравнению с R3XX вычислительная эффективность новых конвейеров выросла вдвое. Вкупе с двукратным увеличением их числа и приростом тактовой частоты, мы получаем солидный теоретический задел по сравнению с предыдущим поколением.
Все новые усовершенствования, такие как увеличенная длинна шейдеров и новые регистры будут доступны в новой версии шейдеров 2.0.b с выходом нового SDK и новой версии DirectX 9 (9.0c). А теперь — сводная таблица возможностей:
| Версия пиксельного шейдера | 2.0 (R3XX) | 2.a (NV3X) | 2.b (R420?) | 3.0 (NV40) |
| Вложенность выборок текстур до | 4 | Без ограничений | 4 | Без ограничений |
| Выборок значений текстур до | 32 | Без ограничений | Без ограничений | Без ограничений |
| Длинна кода шейдера | 32 + 64 | 512 | 512 | 512 и более |
| Исполняемых инструкций шейдера | 32 + 64 | 512 | 512 | 65535 и более |
| Интерполяторы | 2 + 8 | 2 + 8 | 2 + 8 | 10 |
| Предикаты | нет | да | нет | да |
| Временных регистров | 12 | 22 | 32 | 32 |
| Константных регистров | 32 | 32 | 32 | 224 |
| Произвольная перестановка компонент | нет | да | нет | да |
| Инструкции градиента (DDX/DDY) | нет | да | нет | да |
| Глубина вложенности динамических переходов | нет | нет | нет | 24 |
Отметим, что гибкость и возможности программирования пиксельных процессоров NV40 в DX9 пока находятся вне конкуренции.
А теперь вернемся к нашей схеме и обратим внимание на ее нижнюю часть. Там расположены блоки, отвечающие за сравнение и модификацию значений цвета, прозрачности, глубины и буфера шаблонов, а также MSAA. В отличие от NV40, поддерживающей генерацию до 4х MSAA отсчетов на основе одного пикселя, R420 генерирует до 6. Причем, производительность расчета Z и буфера шаблонов, как и у NV40 удвоена относительно базовой скорости закраски — 32 значения в такт. Соответственно, 2х MSAA дается без пенальти по скорости, а 4х и 6х занимают 2 и 3 такта. Впрочем, в случае использования пиксельных шейдеров длинной хотя бы в несколько команд, это пенальти перестает быть заметно и не играет особой роли. Более важна пропускная способность памяти. Разумеется, в MSAA режимах сжимаются как данные о цвете, так и о глубине, в оптимальном случае, коэффицент сжатия приближается к числу MSAA сэмплов, т.е. в режиме MSAA 6х достигает 6:1
В отличие от NV40, использующей RGMS (повернутую сетку отсчетов), R420, как и все чипы семейства R3XX, поддерживает псевдостохастические паттерны MSAA, на базовой сетке 8х8. В итоге, качество сглаживания краев и наклонных линий объективно выше, особенно если учесть наличие 6х режима (8х NVIDIA не сравним по производительности, т.к. он является гибридом — SSAA на основе двух блоков MSAA 4х). В новых драйверах доступен т.е. Temporal AA — временной АА. Суть его в простом изменении паттернов от кадра к кадру — таким образом, если картинка соседних кадров будет без проблем (слишком заметного мерцания) усредняться нашим глазом (или интертным ЖК монитором), мы получим некое улучшение качества сглаживания, словно мы использовали больше отчетов MSAA. Производительность при этом не падает, но и эффект может проявляться по разному, в зависимости от монитора и частоты расчета кадров в приложении.
Технологические новшества
Два основных новшества R420 по сравнению с R3XX (увеличение числа временных регистров и длинны шейдера в пиксельном процессоре мы причисляем к эволюционному развитию, а не революционным новшествам):
- Новый алгоритм F-буфера позволяющий не вычислять тот или иной проход разбитого на части пиксельного шейдера для тех пикселей, которые в этом не нуждаются. Способен заметно оптимизировать производительность пиксельных шейдеров с условиями и ветвлениями в OpenGL, исполняемых в несколько проходов с помощью F-буфера.
- Новый метод компрессии текстур 3Dc специально предназначенный для сжатия двухкомпонентных карт нормалей. Традиционные методы компрессии текстур рассчитаны на обычные текстуры — сжатие с потерями учитывает особенности нашего зрения в восприятии изображений. Однако они не подходят для сжатия карт нормалей — по сути, таблиц векторов. Что хорошо для картинки с цветами в RGB формате плохо для векторов и наоборот. Поэтому, давно назрела необходимость в специальном алгоритме сжатия карт нормалей, разумеется, поддержанном аппаратно в TMU графических ускорителей. 3Dc и займет это место. Впрочем, с точки зрения разработчиков, плохо, что пока он не поддерживается NVIDIA.

Платы
| ATI RADEON X800 XT/PRO |  |
|---|
| Карты имеют интерфейс AGP x8/x4, 256 МБ памяти GDDR3 SDRAM размещенной в 8-ми микросхемах на лицевой и оборотной сторонах PCB. | |
|---|---|
| ATI RADEON X800 XT | |
| Микросхемы памяти Samsung (GDDR3). Время выборки у микросхем памяти 1,6 ns, что соответствует частоте работы 625 (1300) МГц, память же работает на частоте 575 (1150) МГц. Частота работы GPU — 525 MHz. Шина обмена с памятью — 256 bit. |  |
| ATI RADEON X800 PRO | |
| Микросхемы памяти Samsung (GDDR3). Время выборки у микросхем памяти 2,0 ns, что соответствует частоте работы 500 (1000) МГц, память же работает на частоте 445 (890) МГц. Частота работы GPU — 475 MHz. Шина обмена с памятью — 256 bit. |  |
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| ATI RADEON X800 XT/PRO | ATI RADEON 9800 XT |
 |  |
 | NVIDIA GeForce 6800 Ultra |
 | |
 | |
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| ATI RADEON X800 XT/PRO | ATI RADEON 9800 XT |
 |  |
 | NVIDIA GeForce 6800 Ultra |
 | |
 | |
Очевидно, что дизайн R420 очень похож на своего предшественника — R360. Только из-за того, что используется GDDR3 память, несколько изменена разводка. Судя по всему, по контактам R420 полностью совместим с R360. Обратим также внимание на то, что разъем для внешнего питания по-прежнему один, да и карты «кушают» сильно меньше, чем NV40. Отметим, что у нас пока лишь опытные образцы, поэтому мы не знаем, такими же одинаковыми пойдут в серию X800 XT и PRO, или все же финальные карты будут чем-то отличаться.
А что же с системой охлаждения сделали? Как ее изменили?
ATI RADEON X800 XT/PRO | |
| А ее просто обрезали по краям! Перед нами все тот же медный кулер с вынесенным влево вентилятором, который вращается на высоких оборотам только при эксплуатации карты в тесном корпусе без продувки. Да, GDDR3 память не требует принудительного охлаждения, поэтому кулер упрощен. |  |
 | |
Итак, мы увидели, что по внешнему виду X800 практически не отличается от предшественника, унаследовав и все положительные черты, как то меньшая требовательность к мощности, однослотовая система охладения.
| ATI RADEON X800 XT/PRO | NVIDIA GeForce 6800 Ultra |
|---|---|
 |  |
Также интересно заметить, что семейство Х800 сразу же оснащено поддержкой VIVO при помощи старого доброго RAGE THEATER, когда как на 9800ХТ мы могли видеть распайку под новый Theater 200, но карт с ним так нам и не встретилось. Только лишь ASUS делал 9800ХТ с VIVO.

Давайте посмотрим теперь на сам чип. Вначале сравним размеры кристаллов у R360, R420 и NV40:

Прекрасно видно, что размеры кристалла у R420 выросли по сравнению с R360, несмотря на более тонкий техпроцесс. Все же 180 млн. транзисторов против 115 млн. — играют большую роль. И все же, самый огромный по площади кристалл — это NV40 с его 222 млн. транзисторами.
Далее сам чип вместе с корпусом:
R360

R420 XT

R420 PRO

Изготовлены кристаллы примерно в конце марта-начале апреля, то есть совсем «свежие» :-). Заметим, что никаких видимых отличий, как и по маркировке так и по расположению резисторов на подошве между чипами не видно. Поэтому снова напрашивается мысль, что урезание по конвейерам сделано программным путем через драйвера. Мы это будем еще проверять. Но если это окажется верным, то слова ведущего сотрудника ATI, сказанные им в интервью в офисе ATI о том, что больше программных урезок не будет, как-то странно сочетаются с практикой.
Теперь по разгону. Благодаря оперативности автора RivaTuner Алексея Николайчука, эта утилита уже умеет определять частоты у R420. И вот что мы видим у X800 XT:
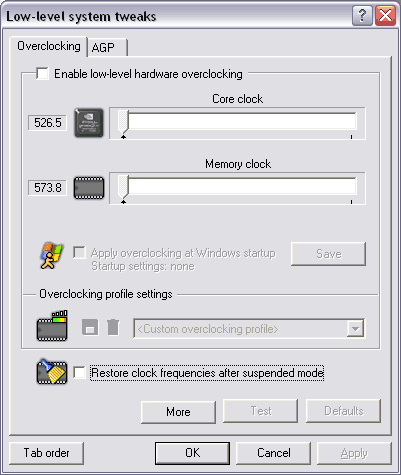
К сожалению, карта практически не разгоняется, изменение частот даже на малые интервалы приводит к их сбросу драйвером.
А вот частоты X800 PRO:
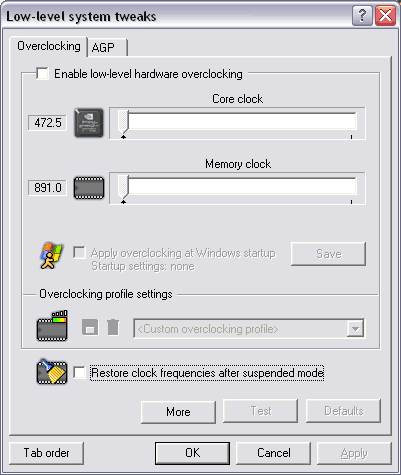
Разгон здесь возможен, и составил 540 МГц по чипу и 580 (1180) МГц по памяти. Ради проверки работы карты на частоте X800 XT мы зафиксировали частоты разгона 525/575 (1150) МГц и протестировали X800 PRO на них.


