Часть 1 (статья одной страницей)
Вначале заметим, что за последний год наша Энциклопедия процессорных терминов заметно обновилась и дополнилась (что будет регулярно происходить и далее), поэтому некоторые термины (например, «диспетчер» и «планировщик») имеют несколько иные значения. Также, по многочисленным просьбам отдельных товарищей, в конце статьи указаны ссылки на основные источники (помимо собственных изысканий автора и его коллег).
Что это?
Проще всего ответить так: ЦП серий Zacate, Ontario и Desna с ядрами Bobcat это то же, что и Intel Atom, но от AMD и на 3 года позже. Как и Atom, ядро Bobcat разработано с нуля специально для массовых мобильных устройств, где экономия энергии и дешевизна намного важнее скорости. Впрочем, Intel уже который год отчаянно и безуспешно старается протолкнуть Atom ещё и для смартфонов, где безраздельно властвует архитектура ARM. AMD же c этим рынком связываться не собирается. Кроме того, в отличие от «Атомов», получивших встроенные ИКП, видеодекодер и графический процессор (ГП) со 2-го поколения, «Бобкэт» имеет это с самого начала, а потому по новой терминологии AMD считается не просто ЦП, а APU. Конечно, мы дополнили наш словарь этим сокращением, но называть микросхему по-прежнему будем центральным процессором ;)

Существование этого проекта открылось в 2007 г. когда после покупки ATI AMD объявила, что ещё за год до этого начала разработку энергоэффективной микроархитектуры для диапазона потребления 1–10 Вт (на 45-нанометровом техпроцессе), которая должна выйти в 1-й половине 2009 г. На деле же первые ЦП с ядрами Bobcat вышли в январе 2011 г. с TDP 9 и 18 Вт (на 40 нм), но на вопрос «почему так долго» разработчики из Остина вполне могут ответить в стиле «сам дурак» — Intel тоже долго мурыжила Atom. Очевидно, при такой конкуренции (уже занятый рынок и 3-летняя фора) надо выставить что-то передовое — помимо вечного «наше дешевле». Кроме изначально интергированного северного моста и видеочасти, AMD предлагает и более высокую производительность, причём и в x86-ядрах, и в ГП.
Перед тем как перейти к деталям, по традиции упомянем этимологию — Bobcat можно перевести нарицательно (обитающая в Северной Америке рыжая рысь) и как имя собственное (марка небольших тракторчиков и погрузчиков для мелких работ одноимённой фирмы). В свете выхода архитектуры Bulldozer (не нуждающейся в переводе и разъяснении) второй вариант выглядит более разумным, хотя и ссылается на чужую торговую марку. В любом случае — перед нами нечто маленькое, прыткое и с амбициями. Кодовое имя архитектуры — K14.
Фронт
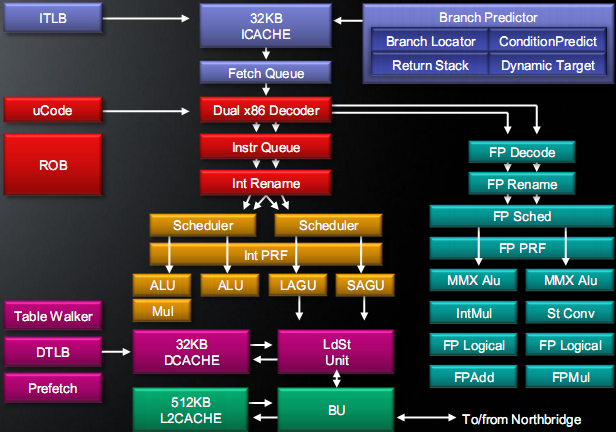
Конвейер у Bobcat 2-путный — как и у Atom. Для академического интереса также можно вспомнить и процессоры VIA Nano с архитектурой Isaiah для той же целевой ниши, но с 3-путным конвейером — правда, там и мобильными ваттами не очень пахнет… Фронт ожидаемый: предсказатель переходов, кэш L1I, предекодер и декодер. Но в каждом пункте есть изюминка.
Предсказатель переходов
Как обычно, этот блок диктует, каков будет адрес следующей порции кода. Есть 4 источника адреса: следующий по порядку, предсказанный для срабатывающего перехода, исправленный при фальш-предсказании и возврат из подпрограммы (считывается из стека возврата на 12 адресов). Как и в большинстве современных архитектур, предсказываемая порция равна 32 байтам, причём она совпадает и со считываемой (у Intel последняя вдвое меньше). Выбор очевиден, учитывая средний размер команды (4 байта) и расстояние между переходами (≈10 команд).
Впрочем, встречаются случаи и частых переходов. Для этого предусмотрено два буфера BTB — один («редкий») хранит первые 2 перехода для каждой 64-байтовой строки кэша и (официально) до 8 ссылок на ячейки второго («плотного») буфера, хранящего остальные переходы (в тех строках, где они есть) по 2 перехода на каждые 8 байт. При этом фраза «первые 2 перехода» относится к обнаруженным и срабатывающим командам: т. к. строка не обязательно выполняется с начала и до конца, есть вероятность, что позже в ней будут найдены новые переходы, либо до сих пор не срабатывавшие вдруг сработают. Как при этом дополняются записи в обоих BTB — неизвестно.
Если первые два перехода предсказываются как несрабатывающие, но и непоследние в этой порции, то начинается последовательная обработка переходов из плотного BTB в ячейках, на которые ссылается запись из редкого. Очевидна сомнительность одновременного считывания и, следовательно, хранения в ячейке редкого BTB до 8 ссылок на ячейки плотного. Объяснения два: либо ссылка только одна, и каждая ячейка из плотной BTB указывает на следующую, если переходы в строке ещё остались — потому они и обрабатываются последовательно. Либо ссылка всё равно одна, но 8 соответствующих записей в плотном BTB идут подряд, и конкретная выбирается в зависимости от смещения адреса в строке кэша. Последний вариант проще и быстрее, но куда менее оптимален по расходу плотного BTB: достаточно в одной из восьмушек строки иметь более двух переходов — и ей выделят 8 записей даже при отсутствии переходов в других частях строки. Поэтому примем первую версию.
Редкий BTB хранит 512 ячеек (по числу строк в кэше L1I), т. е. 1024 перехода, а плотный — вдвое больше. Это очень достойно не только в сравнении с крошечной таблицей в Atom на 128 адресов, но и с настольными ЦП. Механизм индексации плотного BTB и вытеснения из него неизвестен. Очевидно, речь не может идти о 512-путной структуре, а т. к. в кэше могут оказаться 512 строк с парой переходов в каждой 8-байтовой восьмушке (и им не хватит плотного BTB) — может проявиться наложение адресов и вытеснение не столь уж старых переходов.
По идее, при такой организации можно точно предсказать до 18 переходов на строку, из которых 16 будут содержаться в 8 ячейках плотного BTB. Но в тестах было получено до 16 или 17 безошибочных предсказаний в зависимости от их положений в строке. Значит, механизм разметки положений работает сложнее, чем описано. А что делать с ещё более частыми переходами, учитывая, что они могут встречаться каждые 2 байта, а возвраты — даже каждый байт? Переходы начиная с 3-го в 8-байтовом куске вытесняют первую пару, а потому имеют шанс 50% быть угаданными по поведению и ≈0% — по адресу. До сих пор у предсказателей AMD при переполнении хранящих структур «лишние» переходы динамически не предсказывались и считались всегда несрабатывающими, эффект от чего примерно тот же, что и у Bobcat.
Каждая запись в BTB, предположительно, хранит тип перехода (3 бита), адрес его последнего байта (6 бит — только смещение в строке), младшие 12 бит целевого адреса (т. е. смещение в текущей виртуальной странице) и бит, указывающий на переход за пределы страницы. Судя по описанию, базовые адреса страниц для таких «дальних» переходов хранятся в отдельной таблице, индексируемой, видимо, смещением в целевой странице. Это странное решение, ибо куда логичней хранить в дополнительной таблице полный адрес (база + смещение), а в поле смещения основной — индекс ячейки с адресом. Размер дополнительного BTB для «дальних» переходов достоверно неизвестен, но мы его сможем вычислить чуть позже.
Тип перехода определяет алгоритм предсказания поведения. Разумеется, для экономии энергии на время предсказания тактируются только реализующие этот алгоритм блоки, а остальные спят. Для относительных переходов проверяется предсказанный адрес и, в случае его несовпадения, производится коррекция (в т. ч. в таблицах), занимающая меньшее время, чем обычное фальш-предсказание. Кстати, про последнее: официально оно штрафуется 13 тактами. В тестах же эта цифра оказалась средней, а полный диапазон — 8–17 тактов, что зависело от последующих команд после точки перехода. Причём их вычислительная сущность (например, целые или вещественные) роли не играла — видимо, есть некая зависимость от числа команд и/или переходов в целевой строке.
Алгоритм предсказания лишь один (предсказателя для циклов нет): 2-уровневый, адаптивный, с 26-битным регистром глобальной истории (GBHR) и таблицей историй переходов (BHT) неизвестного размера, но уж точно меньше, чем 226 — т. е. (как обычно для 2-уровневых BPU) используется хэш-функция, сворачивающая 26 бит GBHT и часть адреса перехода в N бит индекса для BHT размером 2N. В BHT попадают только условные переходы, причём лишь те, что записаны в BTB (т. е. хотя бы раз сработавшие) — для удаления шумового эффекта малозначимых ветвлений. Помимо рекордно длинного GBHR (у Atom он на 12 бит) — ничего особенного.
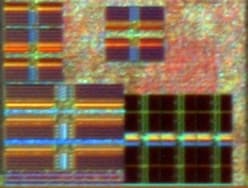 Половина фронта ядра Bobcat. Чёрные массивы и логика выше них — микросеквенсер декодера. Всё остальное — детали предсказателя. |
А теперь досрочно посмотрим на вырезку фото кристалла (детально он будет описан далее) в области BPU. Как мы позже покажем, 3 длинных массива в углу ядра (разделены посредине селекторной логикой) имеют размер по 4 КБ. Выше них — группа из двух блоков по 2 КБ (ближе к центру) и ещё одна из трёх таких блоков (слева вверху). Т. к. BHT должен иметь двоичный размер, предположим, что это первая группа: суммарный размер её массивов — 4 КБ, чего хватит на 16 384 2-битных счётчика и потребует от хэш-функции 14-битный индекс. 16 «килосчётчиков» это столько же, как и у K8/10/12 (хотя у них L1I на 64 КБ), и вчетверо больше, чем у Атома, где те же 32 КБ в L1I.
Теперь вернёмся к BTB. Редкий имеет размер вдвое меньше плотного, а три оставшихся массива по 2 КБ — вдвое меньше трёх по 4. Мы предположили, что адрес в BTB занимает 22 бита, а в каждой ячейке — 2 адреса и одна 10-битная ссылка на первую или следующую в цепочке ячейку из плотного BTB. В сумме получается 54 бита, что почти столько же, как в записи TLB (там, помимо 24-битного физического базового адреса страницы, есть ещё её атрибуты). Проверяется это тем, что TLB L2D (на вырезке не показан) также использует массив на 4 КБ, который тоже делится на 512 записей, как и у каждого BTB. Скорее всего, 3 длинных массива это оба BTB (1 для редкого и 2 для плотного), и тогда на 3 коротких остаётся вышеупомянутый дальний BTB с «хвостами» адресов.
Адресация в BTB виртуальная, поэтому хвост это 48 бит т. н. канонического (для x86-64) адреса минус 12 бит, хранимых как смещение в основных таблицах. 36 бит — число неудобное, но (снова забегая вперёд) все массивы, в т. ч. для TLB, имеют биты чётности, и если их, как обычно, 1 на байт, то физический размер записи окажется 72 бита, как раз на два хвоста. Однако для BTB чётность не обязательна, т. к. при крайне редкой аппаратной ошибке считывания самое страшное — лишнее фальш-предсказание. Таким образом, на пару ячеек BTB приходится в среднем один адресный хвост, и пара таких хвостов хранится в ячейке дальнего BTB, обслуживая две (видимо, парные) ячейки остальных BTB. К сожалению, мы не проверили — что будет, если на каждые хранимые четыре адреса более двух окажутся дальними. Зато можно точно сказать, что индексация дальнего BTB простейшая — делим индекс запрашивающего BTB на 2.
|
Весь миниконвейер предсказателя состоит из 6 тактов, но работают они не параллельно, как обычный конвейер, а последовательно, т. е. разделение на такты условно и сделано лишь для синхронизации с основным конвейером. За первый такт проверяется первая пара переходов; если оба не срабатывают, то все следующие проверяются далее по одному за такт; при срабатывании любого перехода вставляется задержка в 1 такт, поэтому самый короткий цикл будет 2-тактовым. Косвенные переходы проверяются на третьем такте — при их обнаружении задержка составит 6 тактов. Итого, по численным параметрам предсказателя Bobcat не только впереди всех в своём классе, но и местами догоняет настольных собратьев, что уже поднимает вопрос об избыточности — а ведь надо экономить драгоценные миллиметры…
Предекодер и декодер
16- или 32-байтовые порции по предсказанному адресу считываются из L1I и помещаются в буфер (у Atom — 8 байт/такт). Буфер предекодера имеет 12 16-байтовых ячеек, за такт принимает 16 или 32 байта и столько же отправляет. 16 байт записываются, если целевой адрес оказался во 2-й половине порции, либо в 1-й половине есть переход, предсказанный как срабатывающий. В остальных случаях записывается пара ячеек.
На выходе из буфера находится 2-путный и 2-стадийный предекодер-длиномер с пиковой производительностью 22 байта/такт. Таким образом, Bobcat является первой архитектурой AMD со времён древнющего Am486, не использующей спаренный с L1I кэш предекодера и выполняющей замеры длин команд «на лету». Длиномер считывает текущую ячейку буфера до конца и ещё до 6 байт из следующей. Впрочем, учитывая, что в большинстве тактов он начинает обработку не с 0-го байта порции, средняя скорость длиномера оказывается 16 байт/такт, что всё равно более чем достаточно для 2-путного ЦП (Intel довольствуется этими же 16 байтами/такт и для 4-путных ЦП). Никаких пагубных влияний разнообразных префиксов, так отравляющих жизнь декодерам x86-ЦП вообще и ЦП Intel в частности, тут нет. Видимо, поэтому решили обойтись без буфера перед самим декодером.
Декодер преследует ту же цель, что и у Atom — преобразовать команды в минимальное число мопов, используя микрослияние, т. к. остальная часть конвейера также 2-путная. Макрослияние не поддерживается. По терминологии AMD мопы у Bobcat называются COP (complex microoperations, составные микрооперации), т. е. они сложнее обычных для «больших» ЦП слитых мопов. Почти все самые частые скалярные команды генерируют 1 моп, включая и команды с модификандом в памяти, для которых требуется 4 действия — вычисление адреса, чтение из памяти, операция с данными и запись в память.
Команды для работы со стеком 1-моповые, хотя им надо совмещать обмен с памятью и арифметику с регистром-указателем E(R)SP — это намекает на наличие стекового движка, аналога «stack pointer tracker» в ЦП Intel (подробней о нём см. в описании Sandy Bridge). Однако в отличие от последнего, исполнение команд, вызывающих E(R)SP напрямую, не требует вставки синхронизирующих мопов и не вызывает задержку. Да и вызовы подпрограмм (но не возвраты) требуют 2 мопа.
Декодер, как и ожидается для 2-путного конвейера, состоит из двух простых трансляторов (выдают по 1 мопу/такт), сложного транслятора (2 мопа/такт) и микросеквенсера (последовательности из 3 и более мопов по 2 за такт). По статистике AMD, 89% команд декодируются в 1 моп, 10% — в 2, и 1% — в 3 и более. Однако для поднаборов SSE эта статистика не подходит — ниже станет ясно, почему. Поддерживаются 64-битные расширения, команды виртуализации, векторные поднаборы MMX, SSE, SSE2, SSE3, SSSE3 и SSE4A, а также отдельные команды LZCNT и POPCNT для подсчёта битов. Не хватает не таких уж новых SSE4.1 и 4.2, а также родного для AMD 3DNow!, который компания признала окончательно устаревшим. Впрочем, одна команда для программной предзагрузки оттуда всё же поддерживается, для чего ей выделили отдельный бит в «паспорте» для CPUID.
|
Официальное описание этой части фронта, приведённое в таблице, изобилует загадками. Например, упоминается очередь команд, которая по всем канонам должна располагаться после декодера и перед тылом, но тут она находится уже на первой стадии декодера. К тому же, ни в каких других местах она не упоминается, что создаёт впечатление отсутствия всякой очереди «около» декодера.
Ещё одна странность в том, что собственно декодирование растянуто аж на 3 стадии (6–8), причём это касается лишь простых команд общего назначения. Микрокодовые команды на 8-й стадии читают свои мопы из ПЗУ, а на следующей — распаковываются, что намекает на паузу в 1 такт, когда после простой команды попадается сложная. Более того, аж целый такт тратится на передачу x87- и SSE-команд в расположенный впритык к обычному «вещественный декодер», который занимает целый 10-й такт — но что там может происходить после работы основных трансляторов? На ум приходит лишь одно: почти все команды поднаборов SSE, работающие со 128-битными векторами, в этом такте каждый свой моп преобразуют в пару мопов-близнецов, т. к. векторно-вещественный исполнительный тракт (традиционно для AMD неточно называемый FPU) — лишь 64-битный, и все его стадии работают с физическими регистрами половинной ширины. А значит, нужно дублировать и использующие их мопы. Детали этого безобразия опишем позже.
Тыл
Диспетчер и планировщики
В этом месте проявляется одно из основных отличий Bobcat от Atom — процессор имеет внеочередное исполнение (чем хвастает и VIA Nano). Мопы из декодера без всяких промежуточных буферов (по крайней мере, согласно нашим тестам…) попадают в диспетчер, который переименовывает регистры и размещает мопы после их разделения на вычислительные и адресные компоненты. Мопы попадают в две (!) очереди ROB (общего назначения и для FPU) и в нужный планировщик, причём обменным мопам выделяются и записи в блоке LSU. Одновременно диспетчер принимает до 4 или 6 мопов/такт после исполнения и производит отставку до 2 команд/такт.
Общая ROB умещает 56 мопов, а векторно-вещественная — 40 (причём эта почему-то называется «retire queue», т. е. очередь отставки, хотя вроде бы это синонимы). Суммарные 96 мопов это в 2–3 раза меньше «больших» 4-путных ЦП, но больше, чем у 3-путного Nano. Главный вопрос вот в чём: до сих пор ни один ЦП не имел диспетчер с двумя ROB; почему же AMD решила использовать эту схему, если синхронизация запусков, приёмов и отставок мопов с двумя очередями сложнее, чем с одной суммарной длины?
Наш постоянный Внимательный Читатель вспомнит, что у современных настольных ЦП Intel общая очередь ROB делится поровну между двумя потоками, когда они исполняются в одном ядре, но мопы двух потоков можно уводить в отставку независимо. К тому же архитектура Bobcat всё равно 1-поточная. В случае с AMD всё может объясняться просто — в описывающем документе просто сделали ошибку (не в первый и не в последний раз…). Однако загадочная фраза, где появляется цифра 40, написана очень уверенно: . Дополнительный аргумент к тому, что FPU имеет отдельную ROB/RQ, даёт приведённое ниже распределение тактов тыла в двух трактах: все действия диспетчера для команд FPU оказываются на 2 такта позже. К сожалению, представители компании на всех уровнях упорно не дают нам возможности даже задать вопросы о таких деталях…
Для экономии энергии, как и во всех современных архитектурах (Sandy Bridge, Llano и Bulldozer, о котором тоже скоро будет статья) инженеры применили некопирующий вид планировщиков, работающих со ссылками на физические регистровые файлы (РФ). Оба РФ имеют по 64 64-битных регистра. Причём для экономии энергии как минимум в РФ с регистрами общего назначения (РОНами) при записи может включиться только младшая половина регистра-приёмника, если старшую обновлять не надо; этот же принцип наверняка применяется и в других частях ядра при похожих обстоятельствах. Хотя число ФУ небольшое, AMD расположила для них аж три 2-портовых планировщика (тут полумопом названа часть слитого мопа после его разделения диспетчером):
- целый — на 16 полумопов для скалярных целочисленных операций с РОНами;
- адресный — на 8 полумопов для вычисления адресов с РОНами;
- векторный (для FPU) — на 18 полумопов для векторных и/или вещественных операций с векторными регистрами.
Векторный планировщик оказывается одним из узких мест ЦП, учитывая, что в среднем на векторную команду приходится пара полумопов. Впрочем, по сравнению с векторными планировщиками для «больших» ЦП AMD, этот умеет исполнять простейшие команды за такт; точнее, ФУ их исполняют за такт, но лишь у Bobcat планировщик успевает зафиксировать это до конца такта. Кроме того, векторные планировщики архитектур K7–K12 печально знамениты своими «пузырями» — внутренними НОПами, вставляемыми в тройки мопов, если последние не соответствуют правилам распределения мопов по очередям портов. Неоптимальное распределение вызывает дополнительные такты ожидания на регистрацию мопов. У Bobcat каждый планировщик имеет общую для портов резервацию (как у всех ЦП Intel и VIA Nano), куда мопы попадают без всяких ограничивающих правил. Похожие улучшения сочетаемости уходящих в отставку мопов есть и у диспетчера.
| Стадия | Целый конвейер | Конвейер FPU |
| 8 | «Размещение меток» (?). | |
| 9 | Переименование РОНов. Разделение слитых мопов. | Передача в FPU. |
| 10 | Запись в ROB и резервацию(и). Планировка. | Переименование x87-стека. Декодирование в FPU. |
| 11 | Чтение регистров. Настройка шлюзов. | Переименование регистров xmm. Разделение слитых мопов. Запись в ROB и резервацию. |
| 12 | Работа ФУ (≥1 такта). | Планировка. |
| 13 | Обратная запись и передача по шлюзам результатов. | Чтение регистров. Настройка шлюзов. |
| 14 | Работа ФУ (≥1 такта). | |
| 15 | Обратная запись и передача по шлюзам результатов. | |
Странная штука под названием «Размещение меток» (token allocation) нигде в официальном тексте не пояснена, как и её положение до того места, где обычно происходит выделение ресурсов тыла — т. е. после переименования, а не до. Внимательный Читатель заметит, что это та самая 8-я стадия, которая накладывается на работу трансляторов декодера, хотя в оригинальной схеме она почему-то отнесена уже к планировщику. Тем не менее — что можно размещать для ещё не до конца декодированных команд? Более того, почему попадающие в команды FPU требуют дополнительного декодирования? Также интересно сравнить расположение действий по стадиям у целого и векторного трактов: вроде бы одинаковый 16-моповый планировщик в одном случае занимает весь такт на срабатывание, а в другом совмещает его с записями в свои ROB и резервацию.
Исполнительные тракты
В целом исполнительном тракте есть РФ (которому требуется 8 портов чтения и 2 записи), 2 АЛУ (сложное и простое), сдвигатели (аналогично), 2 AGU (отдельно для чтений и записей), умножитель и, предположительно, делитель (уточним позже). Очевидно, адресный планировщик подключен только к паре AGU, а целый — ко всем остальным ФУ. В векторном тракте — РФ (4 чтения + 2 записи) и два домена ФУ. В целом домене 2 АЛУ, 2 сдвигателя, 2 перестановщика и умножитель; в вещественном — 2 логических устройства, 2 перестановщика, сумматор, умножитель, преобразователь форматов (точнее, это могут быть несколько фУ, занимающих оба порта) и делитель-корнеизвлекатель (являющийся надстройкой над умножителем). В этих списках не указаны некоторые редкоиспользуемые ФУ, предназначенные лишь для нескольких команд.
Интересно дублирование некоторых ФУ для двух доменов, хотя в компактном ядре, где каждый квадратный микрон на счету, пара одинаковых ФУ в одном порту, из которых в каждый момент времени лишь один сможет работать, выглядит расточительством. Можно было бы предположить, что на самом деле есть лишь одна пара перестановщиков, а АЛУ умеет исполнять и «вещественную логику» (тем более, что она никак не отличается от целой) — если бы сама AMD не нарисовала на схеме ядра отдельные ФУ вещественной логики.
Между доменами расположена пара внутритрактовых шлюзов, вносящих задержку в 1 такт, когда результат из одного домена требуется как аргумент в другом. Хотя есть версия, что таких шлюзов вообще нет: 4 порта чтения подключены к двум наборам из 4 шин аргументов (по одному для домена); пары шин результатов тоже отдельные, и пары шлюзов — лишь внутридоменные (т. е. перепуск «своего» результата на «свой» аргумент). При запросе результата в чужом домене он сначала записывается в РФ (что и так должно произойти), а затем читается в другую четвёрку шин аргументов, на что и уходит лишний такт.
Впрочем, такая схема была бы оправданной для сверхвысокочастотного ЦП, где нагрузка на шины (в т. ч. по числу «лишних» шлюзов) не может быть большой. Для компактного ядра объяснение может быть другое: РФ разделён на 2 полунабора регистров — по одному для доменов, и каждый набор имеет свои 4+2 порта. Но и это не показывает, чем эта схема лучше простой установки пары междоменных шлюзов, которые (как и внутридоменные) могли бы срабатывать в тот же такт, что и генерация передаваемого через них результата. Наконец, есть версия о двух отдельных векторных трактов, как в настольных ЦП Intel — как и там, это объясняется банальной нехваткой места для единого тракта с учётом всего массива ФУ. Проверить это можно при детальном анализе фото ядра.
Распределение по портам и специализация ФУ почти такие же, как и у Atom, но есть и кардинальное отличие. Главный недостаток вообще всей архитектуры в том, что в векторном блоке нет ни одного 128-битного ФУ, а потому даже простейшие копирования регистров xmm и простая арифметика делаются парой АЛУ над половинами логических регистров. Это даёт пиковую вещественную скорость всего в 4 SP- и 1,5 DP-флопа/такт, хотя все конкуренты имеют бо́льшие значения: Atom выдаёт 6 и 1,5 флопа/такт (правда, 1,5 DP-флопа достижимы только скалярами), Nano — 8 и 3, а все «большие» ЦП — 8 и 4 (у кого есть поддержка AVX — и вдвое больше). (В трёх мобильных архитектурах DP-пики достигаются при соотношении сложений и умножений как 2:1, в остальных случаях — 1:1, что более адекватно потребностям кода.) Впрочем, сложение полноконвейерно и для «расширенной» точности (EP), из чего можно сделать вывод, что тракт скорее 80-битный, но дополнительные биты сумматора и умножителя редко используются по причине устаревания поднабора x87 вообще и в мобильных программах особенно. Если бы его по-тихому убрали (хотя бы для экономии места и упрощения логики), никто бы не огорчился.
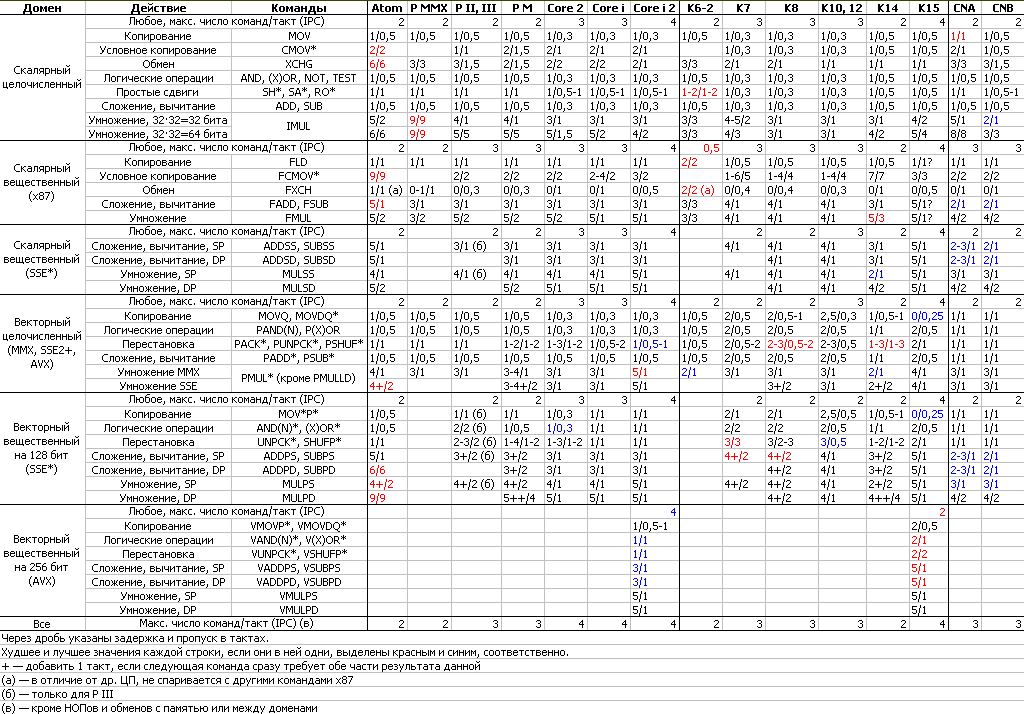
Как всегда, полные таблицы с таймингами, портами запуска и числом мопов для всех команд можно найти у Агнера Фога (стр. 175–184), а тут не менее традиционно покажем нашу таблицу с таймингами. В колонках цифр для нескольких старых архитектур и свежего K14 теперь встречаются плюсы. А внизу пояснение: каждый плюс добавляет к задержке 1 такт, если следующая команда требует в первом такте обе части результата данной.
Дело в том, что многие векторные команды исполняют свои действия над элементами независимо. Скажем 4 SP-сложения для SSE (ADDPS) могут происходить параллельно, если все части аргументов уже готовы. Т. к. вещественный сумматор лишь 64-битный, в первом такте начнётся сложение, допустим, младшей половины регистров xmm. Но он полноконвейерный, и со второго такта можно начинать складывать старшие половины этих же регистров. Когда закончится сложение младших половин, младшие суммы сразу могут быть использованы в любой команде, которой (как и сложению) достаточно иметь лишь половину элементов. Через такт она получит и старшие суммы. Т. к. вычислительные мопы планируются на запуск независимо, временной разрыв и порядок запусков обработок половин регистров могут быть какие угодно — например, старший моп может начаться за 2 такта до младшего, если его аргументы будут получены на 2 такта ранее. Наглядно это показать поможет тестовый код, циклически повторяющий такие команды:
ADDPS xmm0, xmm0;
SHUFPS xmm0, xmm0, 123;
MOVHLPS xmm0, xmm0; Посмотрим, как это работает на K8, где векторный тракт также был 64-битным. На схеме ниже указаны первые две итерации, причём длина второй является устоявшимся значением (жирные цифры), и именно для неё приведены номера тактов. Цветом показаны 3 вида мопов, запускаемых в тракт для работы над половинами регистра xmm0. 64-битное (по ширине вектора) сложение занимает 4 такта, а копирование — 2. 128-битная перестановка — 3-тактная и требует трёх мопов: два пишут по 2 элемента в половины регистра-приёмника (за 2 такта каждый), а третий нужен, скорее всего, для синхронизации физических половин архитектурного регистра. За неимением точных данных запишем его в «старшей» колонке, где он совпадёт с первым тактом первого «рабочего» мопа. Главное — что обеим половинам SHUFPS сразу нужны обе половины аргумента. Если бы за ADDPS шло ещё одно сложение, то оно могло бы начаться уже с 5-го такта, получив задержку 4 и пропуск 2 (старт нового независимого сложения возможен по нечётным тактам). Но с SHUFPS требуется ждать старшую половину, поэтому задержка увеличивается на 1 — что и обозначено плюсом в таблице таймингов.
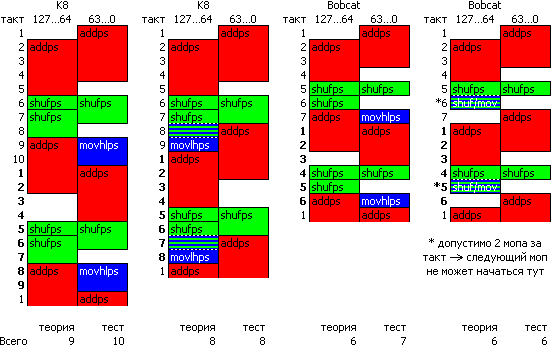
Теперь посмотрим, что будет если заменить MOVHLPS на MOVLHPS, копирующую младшую половину в старшую. Вроде бы всё симметрично, никаких изменений быть не должно. На самом деле копирование младшей половины перемешанного xmm0 начнётся уже после её готовности, что на такт раньше, т. е. на 7-м такте, пока старшая половина ещё не готова. Впрочем, она и не нужна, т. к. одновременно с младшим сложением запускается копирование этой половины в старшую. Такая тройка команд выполнится не за 9, а за 8 тактов, и эта сумма ограничена сложениями старших половин.
Рядом показана аналогичная ситуация для Bobcat, исполняющего каждую из этих команд на такт быстрее. Впрочем, если для MOVHLPS можно получить ожидаемые 6 тактов, то для MOVLHPS быстрее не получится, хотя в течение 5-го такта есть возможность запустить и перестановку старшей половины, и копирование уже перемешанной младшей, и её же сложение. Но портов всего 2, и запустятся самые «старые» мопы (последний для SHUFPS и MOVLHPS), а ADDPS стартует в следующем такте. Из этих примеров видно, что при половинной ширине вычислительного тракта компилятору и программисту на ассемблере требуется детально разбираться, что́ должно происходить в ядре, чтобы оптимизировать скорость до последнего такта даже в тривиальных (как кажется) случаях.
Однако вышеперечисленные цифры являются теоретическими; практика же внесла неприятные коррективы. После тестирования оказывается, что и K8, и K14 исполняют вариант с MOVHLPS на такт дольше, чем по модели. У K8 это можно было бы объяснить тем, что загадочный третий моп для SHUFPS исполняется не 1, а 2–4 такта, и от него зависит пропуск всей команды — но тогда задержка всей команды была бы на такт дольше. Кроме того, ещё замена ADDPS на ADDSS (скалярное сложение только младших элементов, имеет лишь младший моп) предсказуемо уменьшает сумму таймингов до 6 тактов.
Дальнейшие эксперименты показали, что теория сходится с практикой, если заменить обычное сложение на горизонтальное (HADDPS, 4+2 такта задержки и 2 такта пропуска), требующее обеих половин источников для каждой половины результата: 11 тактов для версии с MOVHLPS и 10 для MOVLHPS. А вот если вообще убрать сложение, то начальные задержки уменьшаются на 4: 6 для пары SHUFPS+MOVHLPS и 4 для SHUFPS+MOVLHPS (согласно теории должно быть 5 и 4). Попытки прояснить ситуацию в фирменном профайлере AMD Code Analyst успехом не увенчались: последние его версии не поддерживают симуляцию конвейера (pipeline simulation), а версия 2.8 (последняя с этой функцией) вылетала с ошибкой на тестовой машине на базе того же K8. Сбор статистики от счётчиков производительности ничего внятного не дал.
Ситуация осложняется тем, что официальный учебник по оптимизации (Software Optimization Guide for the AMD64 Processors), судя по всему, неверно указывает задержку команды SHUFPS для K8 (стр. 324): 4 такта с примечанием 1, гласящим, что младшая половина результата доступна тактом ранее. Но все независимые тесты показывают не 3+1 такта, а 2+1. Впрочем, с задержкой 4 вариант с MOVHLPS и в теории, и на практике даст 10 тактов, зато уже версия с MOVLHPS окажется на такт дольше рассчитанного. Интересно, что у K10 и K12 (где 128-битные векторные тракты с теми же задержками почти всех ФУ) SHUFPS ожидаемо 1-моповая, но требует трёх тактов, а не двух — т. е. как пишут в учебнике. Либо «почти все ФУ» не включают перестановщик, либо учебник прав, а все независимые тесты, включая показания AIDA64 (бывший Everest; см. строку 814) — нет.
Зачем мы так обильно ворошим «старые раны» прошлых архитектур? Ведь можно посмотреть в новый учебник, где, наверное, ошибок нет… Однако впервые в своей практике AMD для нового ЦП (более того — разработанного с нуля) такое руководство не выпустила. И это притом, что новые версии некоторых компиляторов стараниями компании уже умеют оптимизировать для Bobcat, но программистам и аналитикам эти тонкости почему-то знать не положено. Если сравнить с активно документируемой работой Intel по программной адаптации и оптимизации под Atom разных ОС и программ — получится небо и земля.
Приходится использовать имеющиеся данные для ближайшей похожей архитектуры (K8), но они, оказывается, неточны — и это после стольких лет её использования, когда все ошибки к версии 3.06 учебника можно было исправить. Не смотря на все догадки, объяснить, почему вариант теста с MOVHLPS работает на такт дольше, не получается. А теперь представьте — каково оптимизировать под Bobcat программистам, сталкивающимся с куда более сложными случаями, да ещё и с глючащими инструментами?.. Впрочем, начнём с малого: если у особо дотошных и любопытных читателей найдётся время погрызть гранит загадки лишних тактов — добро пожаловать на форум с идеями и результатами.
А пока вернёмся к самому ЦП. Если ещё раз взглянуть на нашу таблицу таймингов и сравнить их с конкурентами, то окажется, что бо́льшая часть ФУ у Bobcat лучше, чем у Atom, кроме операций перестановки и векторного сложения-вычитания SP-чисел (что не удивительно, учитывая ширину векторного тракта). Целочисленный умножитель имеет пропуск 1 для краткого 32-битного умножения, но 2, когда надо записать полные 64 бита результата в пару 32-битных регистров. Это потому, что на запись старшей половины уходит второй моп такой версии умножения, что типично для большинства ЦП, т. к. мопы имеют лишь 1 регистр-приёмник (без учёта флагов). Векторный целый умножитель работает за рекордные 2 такта для 64-битных векторов, хотя у старого K6-2 такой уже был.
Вещественный сумматор работает за 3 такта, что на 2 быстрее, чем у Atom, но на 1 меньше рекордного сумматора Nano. А вот блок FMUL — это целая история. Дело в том, что в феврале 2009 г. инженеры AMD опубликовали отдельную работу, посвящённую вещественным умножителям, одновременно энергоэффективным, компактным и не очень медленным — как раз, как надо любой мобильной архитектуре. Результаты смоделированных там таймингов точно совпали с реальными замерами вещественного умножителя в Bobcat. Для сравнения с другими ЦП они представлены в таблице рядом (в том же формате, что и выше) для скалярного (S…) и векторного (P…) умножений трёх точностей — SP, DP и EP (x87, только скаляры).
| ||||||||||||||||||||||||||||||||||||||||||||||||
Как же у AMD получились рекордно низкие тайминги для SP и нормальные для DP (в ущерб EP-умножению, которым логично пожертвовали в виде трёх тактов пропуска), хотя умножитель в 2,5 раза меньше по площади и потреблению, чем его аналог из K8, сделанный тем же техпроцессом? Для начала вспомним (или изучим ;) ), что согласно стандарту IEEE-754 о двоичном представлении вещественных чисел 32-, 64- и 80-битные точности имеют 23-, 52- и 64-битные мантиссы, которые и требуется умножать; экспоненты же обрабатываются простым блоком вроде целого сумматора. Правда, SP- и DP-числам нужно добавить отсутствующий в хранимых мантиссах бит целой части, всегда равный 1 — кроме редких денормальных чисел. (Кстати, в Bobcat штраф за обработку их, а также недополнений — 150–200 тактов.) Кроме того, внутренняя точность должна быть выше, поэтому реальная разрядность умножителя на все точности — 76 бит. И т. к. он должен быть сколько-нибудь быстрым, его делают матричной схемой. Матрица состоит из 7 многобитных сумматоров, соединённых древовидной сетью в 3 яруса.
Если требуется полноконвейерный умножитель даже для EP, то нам нужна матрица на 76×76 бит — как раз, как в K7–K12. Для мобильных ЦП это слишком масштабно, прожорливо, а главное — не нужно: бо́льшая часть вещественной нагрузки от мобильных программ — в SP-числах, которым достаточно массива в 27×27 бит. Но EP-точность всё же нужна (хоть с какой-то скоростью), да и SP-умножения бывают не только скалярные. Поэтому AMD предложила сделать массив прямоугольным — 76×27 бит. Это не ново: ЦП Cyrix (кто помнит это слово?..) когда-то имели матрицу 17×69, ещё меньшую по площади, но со слишком большим ущербом для скорости — даже SP-умножения полноконвейерными не сделаешь.
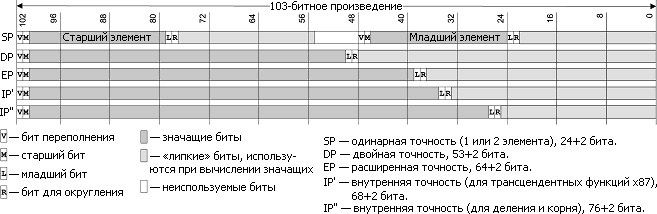
«Сырые» (неокруглённые) результаты прохода аргументов через матрицу умножетеля для разных точностей.
Внимательный Читатель задаст вопрос: а как же с DP- и EP-точностями, которым не хватит размера матрицы для полноконвейерного умножения? Для этого аргументы такой точности проходят через матрицу итеративно, получая за каждый проход очередные 27 бит результата. Для DP чисел требуется 2 прохода, а для EP — 3, что и отражено в пропуске команд. На округление тратится 1 такт для SP и 2 для DP и EP, причём округлитель может работать одновременно со следующим умножением, так что пропуск не увеличивается на время округления. Ширины матрицы хватит для двух SP-умножений за такт, что также видно в таймингах, но уже с отрицательной стороны: если бы таких прямоугольных умножителей было бы два, то их хватило бы для полноконвейерного исполнения MULPS и полуконвейерного — MULPD (как в Nano).
Зато SP-умножение впервые получилось 2-тактным, что даже быстрее сложения, а это разрушает доселе незыблемый постулат о том, что сложение быстрее умножения, т. к. проще и требует меньше аппаратных ресурсов. Причём в Bobcat это особенно странно, учитывая, что округлитель для умножителя по сложности эквивалентен сумматору и срабатывает за 1–2 такта. Конечно, такое устройство умножителя подойдёт лишь для частот до 2–2,5 ГГц; иначе на экономной версии 40-нанометрового техпроцесса сигнал не успеет пройти матрицу за 1 такт. Странно, что то же устройство не использовано в целом скалярном умножителе, не требующем округления, но работающем за 3 такта (для версии 32×32 бита). При этом все виды целого векторного умножения (в т. ч. 32×32, а также с попарным сложением произведений) исполняются за 2 такта.
Кстати, эта же группа авторов ещё ранее (аж в декабре 2007 г.) написала работу о делителях, где придуман модифицированный алгоритм Голдшмидта (GS-2), основанный на вышеописанном умножителе и делящий на 25–37% быстрее прежних. Любопытно, что в этой работе задержки собственно умножения для SD и EP оказались на такт меньше указанных в поздней работе, но «в железо» эта версия почему-то не попала. Впрочем, в реально ядер и деление оказалось на 3 такта медленнее версии GS-2, хотя всё ещё быстрый — 19 тактов для EP (8 бит/такт, 9 тактов подготовки и обработки).
Интересный момент связан с векторным вещественным делением: для DP оно равно 34 тактам, что ровно вдвое больше скалярной версии, а для DIVPS — 38, что менее чем втрое больше DIVSS (13). Т. к. деление полностью неконвейерно, у DIVPS можно было ожидать 13×4=52 такта, но 14 тактов загадочно экономятся. Возможно, ширины умножителя хватает не только для пары SP-умножений, но и для частичной параллелизации пары SP-делений. Аналогично с векторным извлечением корней.
По идее, для экономии площади делитель должен быть один и исполнять скалярное целое деление, задействуя межтрактные шлюзы для передачи аргументов и результата (как в Atom и Nano). Целое деление сравнимо по сложности (не требует нормализации, но надо получить не только частное, но и остаток), но из-за шлюзов окажется чуть медленнее вещественного. Однако в Bobcat оно аж в 2–4 раза дольше — 1 бит/такт и 17–23 такта на остальное. Это наводит на мысль об отдельном целом делителе (скорее всего, надстроенным над умножителем), что подтверждается и тем, что целое деление тоже декодируется в 1 моп, а межтрактные передачи потребовали бы ещё 2. И зачем потратили лишнее место на такого уродца, если оказывается вдвое быстрее (!) преобразовать целое в вещественное (11 тактов), поделить в FPU (17 для DP) и преобразовать обратно (ещё 11)?..
Из правила о тотальной 64-битности исполнительных ресурсов есть намёк на исключение. Две команды PS*LDQ, сдвигающие 128 бит влево или вправо, исполняются за такт на двух 64-битных сдвигателях — это получится, лишь если они умеют объединяться в общее 128-битное ФУ. Для сдвигателей это не намного сложнее, чем объединение двух одинаковых арифметических ФУ (в т. ч. АЛУ), хотя и эти команды требуют двух мопов. Но это не помогло команде PALIGNR для вырезания 16 из 32 байт, слеплённых из двух источников — она часто используется не только в обработке векторов, но и в компиляторной реализации функции memcpy Си-подобных языков для копирования блока памяти. В Bobcat она требует 20 мопов и исполняется аж 19 тактов задержки и 12 пропуска. Это может замедлить даже целочисленный скалярный код, сделанный современным компилятором.
Обмен с памятью даже 32- и 64-битных операндов команд FPU (т. е. векторных целых из набора MMX и вещественных скалярных из SSE) на 2 такта медленнее скалярных целых из-за дополнительных задержек на межтрактные пересылки. Ещё один такт добавляется, если аргументы 128-битные. Проще говоря, векторы на 2–3 такта дальше от кэша, чем РОНы, что на такт больше разницы у Atom. Куда хуже то, очевидные цифры пропуска (8 байт/такт) соблюдаются лишь для чтений; запись 4- или 8-байтового компонента вектора почему-то полуконвейерна, а пропуск всего xmm — и вовсе 3. Таким образом, максимальный темп записи из векторного тракта — 16:3=5,(3) байт/такт. У Atom же чтение или запись выровненными 16-байтовыми словами происходит каждый такт. Уже одно это может подорвать производительность любого векторного и/или вещественного кода.
Смешивание мопов с разным временем исполнения на одном порту практически не вносит никаких задержек, что намекает на возможность завершения более 2 мопов/такт. Частичный доступ к регистрам устроен просто: его вообще нет — любой 64-битный физический регистр адресуется целиком и зависит от предыдущих команд всеми частями, в т. ч. и неиспользуемыми читающей его командой. Частичный доступ к флагам также отсутствует, но это почти не замедляет 2-путное исполнение. Единственное естественное исключение — половины регистров xmm, хранимые и адресуемые отдельно по причине узости РФ и ФУ.
Почти все обнуляющие идиомы распознаются как разрывающие ложную зависимость по регистрам, однако исполнять их всё же требуется (диспетчер в Intel Sandy Bride умеет «исполнять» их на стадии переименования, не загружая планировщик и ФУ, однако это уже «высший пилотаж»). Полный их список: *XOR*, (P)SUB*, SBB (результат зависит лишь от флага переноса), *CMP* и PANDN (звёздочками указаны переменные части названий команд). А вот «вещественная логика» типа ANDNP* и единичные идиомы не распознаются, причём первый случай особенно странен, т. к. ANDNP* почти ничем не отличаются от «целой логики» PANDN.
Подсистема памяти
LSU и другая логика
Блок LSU для компактного ЦП силён качествами, но не количествами. Он, как и подключенный к нему кэш L1D, 2-портовый, но каждый порт — специализированный: 1 чтение и 1 запись. Это вполне ожидаемо, хотя один из портов вполне можно было сделать универсальным, чтобы иметь возможность совершать 2 чтения за такт. Это особенно полезно в свете главного недостатка: ширина портов — всего 8 байт. Даже при наличии единственного AGU для чтений (хотя очевидно, что никакого специального «AGU для чтений» быть не может — оба AGU одинаковы), его бы хватило для обработки одной 16-байтовой пересылки за такт (для чего, впрочем, также требуется расширить шину до FPU), но единственный 8-байтовый порт чтения выполнит её за 2 такта. Ещё одно «бессмысленное и беспощадное» (для производительности) 64-битное упорство.
Впрочем, есть чем его скрасить. Главное достоинство LSU — реализация внеочерёдного доступа к памяти, что ещё недавно было достижением лишь настольных ЦП Intel. Поочерёдный Atom, конечно, «курит в сторонке», но даже куда более сложный Nano реализует далеко не все тонкости. Bobcat умеет перетасовывать чтения и записи во всех случаях, которые не нарушают порядок записей. Очереди чтения и записи вмещают 26 и 22 команд. По утверждению AMD, есть даже предсказатель коллизий адресов чтений с пока не известным адресом записи, чем пока хвастали лишь «большие» ЦП Intel. Буфер удержания допускает до 8 промахов, в течение которых кэш L1D будет обслуживаться.
Механизм STLF работает ожидаемо: если последующее чтение умещается в уже размещённой в LSU записи (даже если данные ещё не попали в кэш), то его можно досрочно завершить — если обе операции не пересекают 16-байтовую границу. Впрочем, совокупная задержка такой пары оказывается большой: не менее 8 тактов для РОНов и 11 для векторных регистров. В случае пересечения 16 байт дополнительный штраф составит 4–11 тактов (это именно для STLF — явные невыровненные загрузки быстрее). В отличие от предыдущих ЦП AMD, Bobcat позволяет исполнять команды прямо указанного как невыровненный доступа (MOVUPD) также быстро, как и явно выровненные (например, MOVAPD) — штраф последует, только если пересылаемое слово действительно пересекает 16 байт.
Внимательный Читатель сразу заметит, что хотя LSU принимает мопы с 8 байтами, гранулярность работы STLF — 16 байт, т. е. очереди LSU имеют 16-байтовые ячейки. Это также подтверждается задержкой невыровненного доступа: он имеет 3 такта штрафа при пересечении именно 16-байтовой границы (требуется сделать ещё одно обращение к кэшу). Кстати, дополнительных задержек при пересечении строк (64 байта) и страниц (4 КБ) нет, хотя в других ЦП они присутствуют почти повсеместно.
Дополнительное доказательство, что LSU соединяется с L1D 16-байтовыми портами, заключается в скорости исполнения команд типа PUSHA (сохранение всех РОНов в стеке) и POPA (загрузка их из стека) — 8–9 тактов, в т. ч. в 64-битном режиме с 16 РОНами. Очевидно, такое возможно лишь при переносе из РФ в кэш и обратно по два 8-байтовых регистра за такт, что недоступно для отдельных команд чтения или записи. Более того, «строковые» команды, оперирующие линейными массивами, достигают максимума лишь 6,5 байт/такт (из 8) при записи в L1D и 10,1 (из 16 — в сумме на чтение + запись) при копировании. (Правда, даже это на треть быстрее, чем у Atom, но на треть медленнее, чем у Nano.) А команды MASKMOV* для выборочной записи байтов из векторного регистра напрямую в память (минуя кэш) и вовсе исполняются до 3000 (!) тактов, но это уже явная недоработка аппаратного дизайна, залатанная микрокодом (по 4 мопа на каждый байт!). Впрочем, то же число мопов и для настольных ЦП AMD, но там эти команды исполняются максимум за 26 тактов. Atom же требует 7 тактов, а Nano — 1–2…
Предзагрузчик отслеживает до 8 потоков данных единственным и очевидным алгоритмом: после 2-го промаха адреса́ команды и её промахов поступают в очередь предзагрузки, где для них вычисляется шаг. Далее для каждого потока 1–4 слова подгружаются в L1D и/или очередь загрузки (безо всяких дополнительных буферов). Просто и вполне эффективно.
Кэши и TLB
| Параметр | L1I | L1D | L2 |
| Размер | 32 КБ | 512 КБ | |
| Ассоциативность | 2 | 8 | 16 |
| Размер строки | 64 байта | ||
| Задержка | 3 такта | 20 тактов | |
| Число портов | 1 | 2 | 1 |
| Разрядность портов | 32 байта | 16 байт | 64 байт? |
| Частота | Частота ядра | ½ частоты ядра | |
| Политика работы | Почти включающая | ||
| Только чтение | Отложенная запись | ||
| Доступность | Местное ядро | ||
2-путная ассоциативность L1I может привести к вытеснению не столь уж старого кода, часто прыгающего по неблизким адресам. Странно, почему AMD не использовала 8 путей и в этом кэше, учитывая, что всё в ядре разработано с нуля, и не требуется тащить «вечные 2 пути» со времён первых Athlon, как для настольных ядер. Буфер промахов в L1I содержит лишь 2 адреса, но при 1-поточном исполнении в ядре больше и не надо.
Как и в Atom, для экономии из набора считывается только сработавший путь. Интересно, что для L1I помимо штатных тегов есть и микротеги, которые читаются до обращения в TLB. Учитывая, что для экономии обращение в TLB происходит, только если страница изменилась относительно предыдущего запроса, можно предположить, что микротег это та часть обычного тега, которая остаётся после вырезания старшей части адреса (свыше 12 бит, составляющих смещение в странице). В любом случае, даже при обращении в TLB задержка считывания составит 3 такта.
Ниже в таблице показаны описания трёх стадий конвейеров чтения (они же — стадии 1–3 и 12–14 общего конвейера для L1I и L1D), расписанных с точностью до полутактов («a» и «b»). Для L1D описан наиболее распространённый случай, когда базовый адрес сегмента равен 0. В крайне редких случаях, когда это не так, для сложения адреса из AGU с базовым используется дополнительная стадия между «1b» и «2a».
| Чтение из L1I | Стадия | Чтение из L1D | |
| ? | 1a | 12a | Генерация адреса в AGU. |
| Чтение микротега. | 1b | 12b | Запись в очередь чтения LSU. Проверка в LSU. |
| Проверка в TLB. | 2a | 13a | Проверка в TLB и тегах. Выборка набора. |
| Проверка в тегах. Выборка набора. | 2b | 13b | Сравнение адресов. |
| Сравнение адресов. Чтение строки в наборе. | 3a | 14a | Чтение строки в наборе. |
| Передача в буфер предекодера и запись. | 3b | 14b | Запись в очередь записи LSU и в исполнительный тракт. |
Как ни странно, в L1D обнаружение промаха происходит не на втором такте (после сравнения физических адресов), а на третьем. Далее идёт перенаправление запроса в L2 (на что тратится аж 3 такта), там в течение двойного такта читаются теги, потом ещё один двойной тратится на чтение выбранной строки. Она делится, скорее всего, на 4 16-байтовых слова, которые аж 6 тактов (разумеется, конвейерных) передаются обратно в 14-й такт основного конвейера. Там происходит запись в L1D, и только ещё через такт данные оказываются доступны для ФУ.
Впрочем, как показано в таблице, замеренная задержка оказалась даже не 17 тактов (из которых, как видно, бо́льшая часть просто необъяснима), а все 20. Причиной этого может оказаться излишнее стремление сэкономить ватты: перезапуск промахнувшейся в L1D команды (которая при обращении к L2 продолжает находится в очереди LSU) происходит не сразу после заполнения нужной строки в L1D, а когда команда, как пишут, «имеет высокий шанс завершиться». Очевидно, что если строка уже прочитана из L2, то команда точно завершится. Или в Bobcat ей надо выждать ещё несколько тактов «для надёжности»?..
Кэши L1 и все TLB защищены битами чётности. Выглядит логично, вспоминая совсем не серверную направленность (где требуется высокая надёжность и отказоустойчивость), низкие частоты (опять же, бо́льшая надёжность) и экономию энергии (логика коррекции ошибок требует свои милливатты, даже когда исправлять ничего не надо). Но почему тогда кэш L2 всё же корректируется через ECC? Если бы он питался пониженным напряжением — тогда вопрос был бы снят, но в таком виде это кажется излишеством. Впрочем, вспоминая, что у Atom всё также, предположение такое: для L2 используются особо экономные транзисторы, которые, в обмен на свою энергоэффективность, не очень хорошо переносят проседание питания при записи в соседние ячейки и изредка могут портить «свои» данные. О видах транзисторов мы узнаем чуть ниже…
В списке возможных запросов к L2 указаны загадочные «вытеснения атрибутов» из L1I. Что это за атрибуты, которые надо сохранять в L2? Разметка длин команд нигде не кэшируется (как в предыдущих ЦП AMD); адреса́ и, тем более, содержимое вытесняемых строк передавать в L2 тоже не надо. Возможно, в L2 сохраняется часть информации из BTB (опять же, как в предыдущих ЦП), причём для этого подойдут как раз те самые биты ECC, избыточные для неизменной информации (т. е. кода). Кстати, «почти включающая» политика работы означает, что в редких случаях (отключение редкоиспользуемых банков, совпадение адресов при обработке внешних запросов протокола когерентности) из L2 могут вытесняться данные или код с сохранением их копий в L1 — для этих строк политика оказывается исключающей.
Ещё одна странность L2 — его половинная частота (только битовые массивы; контроллер работает на полной частоте). В принципе, для экономии это допустимо, т. к. за «свой» такт L2 считывает вчетверо больше, чем требуется запрашивающему кэшу L1, хотя официальные 17 и замеренные 20 тактов задержки были бы на 2 меньше при полной частоте. Но, судя по тестам, ПС кэша L2 ограничивает шина до L1 (работающая на полной частоте) — до позорных 3–4 байт/такт (и по чтениям, и по записям). Возможно, тесты неверны, но ПС памяти ещё меньше — около четверти от теоретического пика при 1-поточном доступе и половина при 2-поточном. Более того, переход с DDR-1066 на DDR-1333 почти не даёт ускорения (по крайней мере, при работе x86-ядер), а значит фатальный затык где-то ближе к ядру. Даже Atom по этим параметрам едва достижим…
Кстати, если уж экономить на частоте, то первым кандидатом оказывается L1I: 32 байт/такт хватит и 4-поточному конвейеру (как в Bulldozer), а уж 2-поточный запросто обойдётся 16 байтами за такт или 32 за два. (Да, декодеры могут обрабатывать до 22 байт/такт, но для сглаживания перед ними есть буфер.) Более того, предсказатель переходов всё равно делает прогноз каждый второй такт. Правда, задержку тогда придётся поднять до ближайшего большего чётного числа — т. е. до 4 тактов, что на 1 увеличит штраф при фальш-предсказании (до 14 тактов).
| Параметр | TLB L1I | TLB L1D | TLB L2D | |||
| Размер страницы | 4 КБ | 2/4 МБ | 4 КБ | 2/4 МБ | 4 КБ | 2/4 МБ |
| Число страниц | 512 | 8 | 40 | 8 | 512 | 64 |
| Ассоциативность | (2, 4, 8)? | 40 | 8 | 4 | ||
| Задержка | 1 такт, учтена в задержке к кэшу | ≈7 тактов | ||||
| Число портов | 1 | 2 | 1 | |||
| Политика работы | Скорее всего, включающая | |||||
Транслятор виртуальных адресов (тут он зовётся TWE — table walk engine, движок проходки таблиц) ожидаемо имеет кэш верхних ярусов трансляции («директории страниц») неизвестного, но, как всегда, небольшого (32?) размера. Он также поддерживает «быстрое индексирование для виртуализации» (более известное как «вложенные таблицы страниц»), ускоряющее переключения между виртуальными ОС. Кроме того, поддерживаются и никому тут не нужные «сверхбольшие» гигабайтовые страницы, но лишь номинально — в TLB они вносятся разбитыми на страницы по 2 МБ (разумеется, не на все 512, а лишь по запрошенным адресам). Такое упрощение очевидно, учитывая, что физическая адресация ЦП — 36 бит, т. е. рассчитана «всего» на 64 ГБ, которых, по мнению AMD, «хватит всем». :) Зато это, как сказано выше, это позволяет хранить в TLB (помимо атрибутов) лишь 36−12=24 бита базового физического адреса страницы.
Внеядро
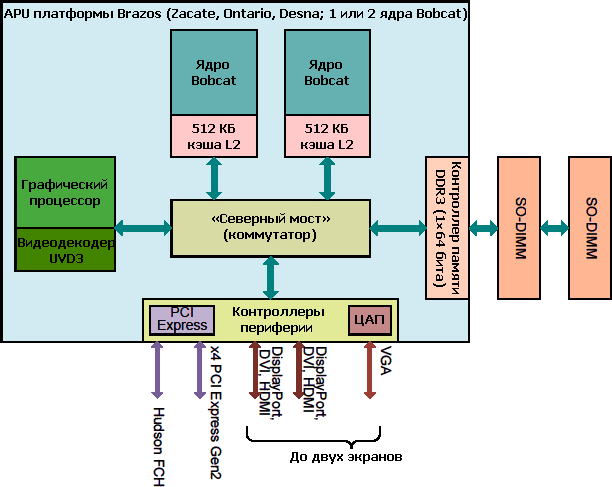
1-канальный ИКП рассчитан на использование до двух модулей памяти DDR3(L) на частотах до 1066 или 1333 МГц. Как и в Llano, ГП соединён 512-битной полнодуплексной шиной до собственного КП (на схеме выше он иерархически находится в пределах общего ИКП), не проверяющего когерентность для адресов, выделенных видеопамяти (до 512 МБ из ОЗУ). Для обращения к памяти без пробуждения или отвлечения x86-ядер ГП умеет сам посылать DMA-запросы к ИКП. В предыдущих компактных решениях ИКП был встроен в ЦП, а ГП — в северный мост, соединённый с процессором шиной HyperTransport. По мнению AMD, размещение ИКП и ГП на одном чипе уменьшает суммарное потребление системы на 1 Вт, задержку доступа к графической памяти — на 40%, а ПСП увеличивается на 17%.
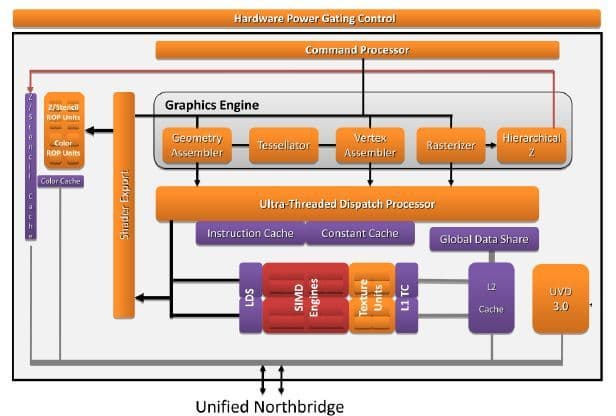
Описание архитектуры ГП Evergreen показывает, что для Bobcat взята самая слабая его версия, названная (в зависимости от базовых частот) HD 6250 (276 МГц), HD 6290 (276–400 МГц), HD 6310 (488–500 МГц) или HD 6320 (508–600 МГц). Первая пара нагружена на ИКП с частотой 1066 МГц, а вторая — 1333. Во всех версиях — по 80 графических ФУ, 8 блоков TMU и 4 растеризатора. Производительность определяется пословицей «мал, да удал»: при 492 МГц (до недавнего времени это была максимальная частота ГП среди моделей этого ЦП) 3D-движок выдаёт в секунду 78,7 SP-гигафлопа (x86-ядра на 1,6 ГГц выжимают лишь по 6,4), 123 мегатреугольника, 3,9 гигатекселя и 2 гигапикселя. Что значат все эти загадочные цифры и насколько они круты — смотрите и спрашивайте в видеоразделе нашего сайта. :)
В отличие от настольных серий HD 6000, встроенный ГП обновил свой аппаратный видеодекодер UVD до версии 3 (как и в ЦП Llano) и теперь поддерживает H.264, VC-1, MPEG-2 и -4, DivX и Xvid. Имеются 2 цифровых выхода (поддерживающих протоколы HDMI, DVI и DisplayPort), 1 LVDS (для встроенного в прибор ЖК-экрана) и 1 VGA. (Общее число работающих экранов — не более двух.) Поддерживаются стандарты DirectX 11, OpenGL 4.1 и OpenCL 1.1 (этот как раз и позволяет добавлять графические гигафлопы к «обычным» — но с трудом и не всегда), а также технология Dual Graphics (бывшая Hybrid CrossfireX) для «слияния» работы встроенного ГП с внешним, подключенным через PCIe.
Контроллер PCIe 2.0 имеет 2 4-полосных порта, к одному из которых подключается обычный разъём для периферии (в т. ч. для внешней видеокарты), а ко второму — южный мост. Все ядра, ИКП и контроллеры соединены шиной CCI (common core interface, общий интерфейс ядер), являющейся несколько переделанной версией PCIe. AMD называет её очень эффективной, однако судя по ПСП, звучит сомнительно… Тем не менее, «с высоты» мы видим компактную версию Llano, сокращённую не качественно, а лишь количественно.



{kind=link}