Обзор S3 Delta Chrome S8

СОДЕРЖАНИЕ
- Введение
- Архитектура
- Особенности видеокарты
- Конфигурации стендов, список тестовых инструментов, качество в 2D
- Синтетические тесты в D3D RightMark
- Качество трилинейной фильтрации и анизотропии
- Качество в целом в играх
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003
- Результаты тестов: Unreal II: The Awakening
- Результаты тестов: RightMark 3D
- Результаты тестов: TRAOD
- Результаты тестов: FarCry
- Результаты тестов: Call Of Duty
- Результаты тестов: HALO: Combat Evolved
- Результаты тестов: Half-Life2(beta)
- Результаты тестов: Splinter Cell
- Выводы
Синтетические тесты D3D RightMark
Тест Pixel Filling
Пиковая производительность выборки текстур (texelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
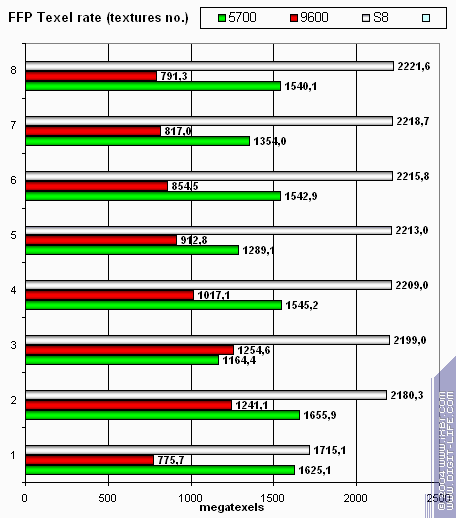
Пиковая эффективность работы TMU высока — их действительно 8 штук, и цифра хорошо согласуется с теоретическим пределом (напомним, что он равен 2.4 Гигатекселям). Интересно что организация работы TMU практически не зависит от числа текстур — начиная с двух текстур на точку в этом синтетическом тесте чип работает одинаково эффективно. Посмотрим, как он поведет себя в реальных приложениях.
А сейчас — скорость закраски буфера кадра (fillrate, pixelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
В самых простых случаях эффективность сравнима (и превышает) NVIDIA — признанный эталон в вопросах работы с буфером кадра, а по мере роста числа текстур сказывается вдвое большее число TMU, и S8 вообще становится четким лидером теста. Похвально.
Посмотрим, как скорость закраски зависит от версии шейдеров:
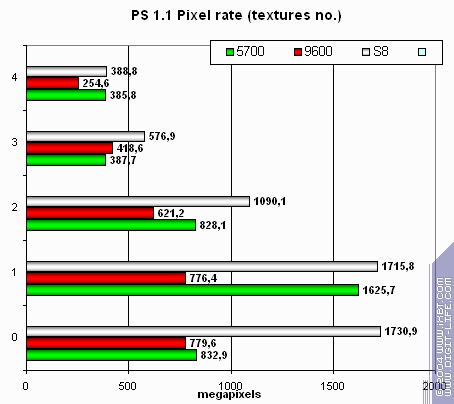
Производительность S8 несколько упала — пиксельные процессоры явно не рассчитаны на интенсивные шейдерные задачи.
Расстановка сил становится еще более равновесной,
И наконец преимущество S8 практически нивелируется в случае шейдеров 2.0. Дают себя знать несложные пиксельные процессоры (малое число ALU). Далее мы посмотрим, насколько эта тенденция проявит себя в реальных приложениях.
А теперь посмотрим, как текстурные модули справляются с кэшированием и билинейной фильтрацией реальных текстур различных размеров:
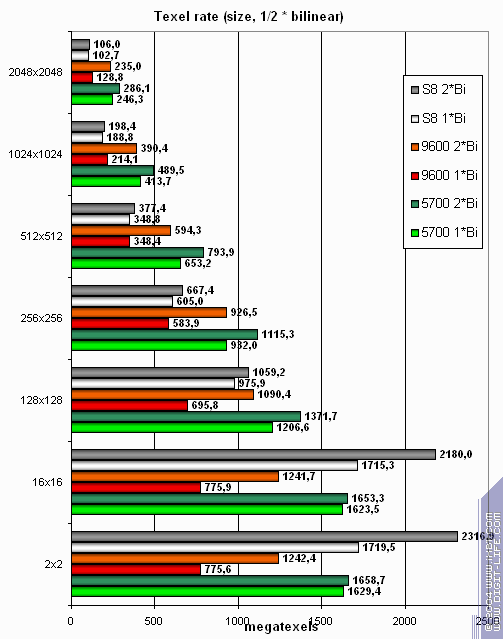
Приведены данные для разных размеров текстур, одна и две текстуры на пиксель. Очевидно, что кэширование текстур у S8 выполняется не столь эффективно как у конкурентов — с ростом их размера он проигрывает, несмотря на наличие 8 TMU.
Посмотрим, как изменится картина в случае трилинейной фильтрации:
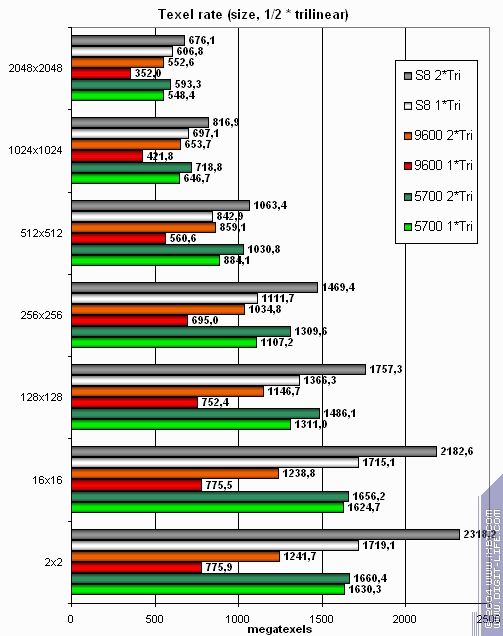
Ага, тенденция с ростом размера текстур прежняя, но общая позиция S8 стала выигрышной. Сказываются два факта — фирменный алгоритм трилинейной фильтрации S3 (декларируется что она происходит без потери такта, со скоростью равной билинейной) и наличие вдвое большего числа TMU по сравнению с конкурентами. Оба этих фактора вместе перекрывают неэффективное кэширование и работу с памятью.
Напоследок предельный случай восьми трилинейно фильтруемых текстур:
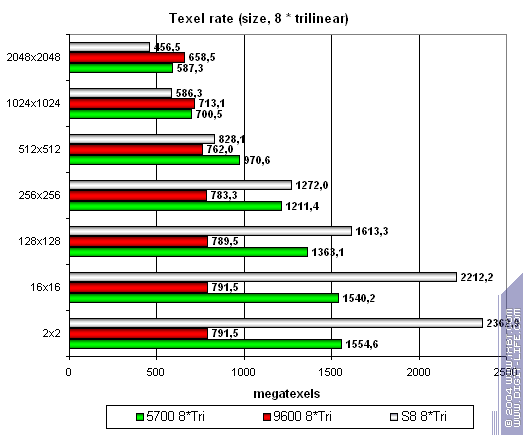
S8 лидер, но по мере роста размера текстур начинает проигрывать. Мы окончательно убедились что кэширование и работа с памятью слабые места этого чипа. А чего ждать — 80 миллионов транзисторов ушли на пиксельные процессоры и TMU.
А теперь посмотрим на зависимость производительности текстурных модулей от формата текстур:
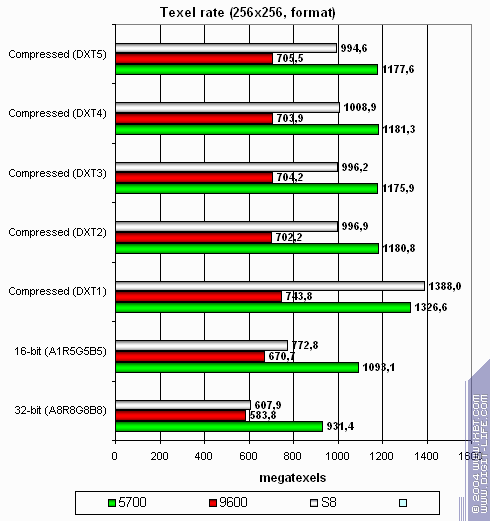
Больше размер:
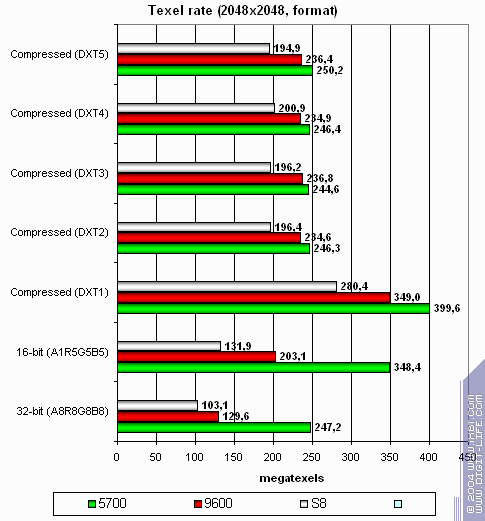
S8 идет наравне или проигрывает. Никакого лидерства мы не наблюдаем — реальные размеры текстур (256х256 и больше) не самая желанная задача для этого чипа. Судя по характеру зависимости, в кэше текстуры хранятся уже несжатыми (как и у NVIDIA).
Итак, в общем и целом, можно констатировать два факта:
- В наличии 8 пиксельных процессоров и эффективная трилинейная фильтрация.
- Но, к сожалению, высока вероятность того, что на реальных задачах они будут нивелированы низкой эффективностью кэширования и выборки текстур из памяти.
Тест Geometry Processing Speed
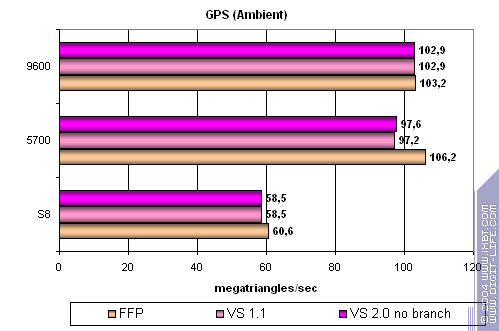
Самый простой шейдер — предельная пропускная способность по треугольникам:
Более сложный шейдер — один простой точечный источник света:
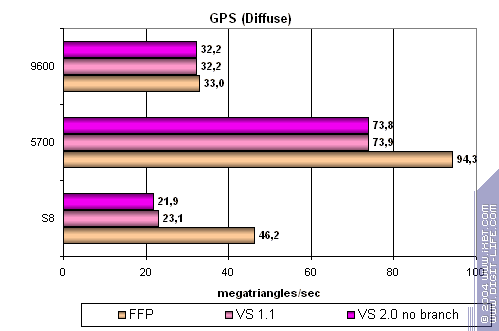
Усложняем задачу далее:
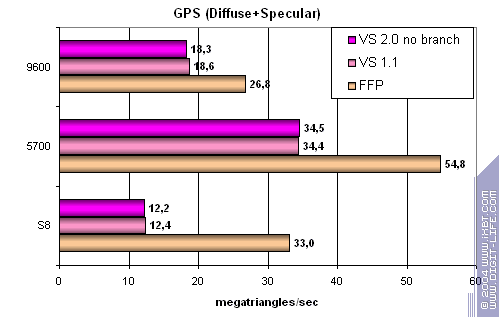
А теперь самая сложная задача, три источника света, причем, для сравнения в вариантах без переходов и со статическим управлением исполнением (динамическое пока не поддерживатеся драйверами и/или железом):
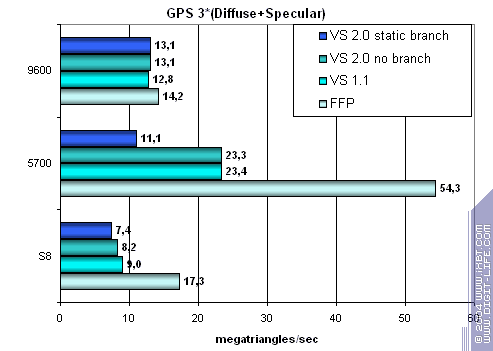
Итак :
- FFP практически вдвое производительнее — чип ориентирован на старые приложения.
- Вершинные шейдеры слабо зависят от версии — 1.1 и 2.0 (с переходами и без) исполняются практически эквивалентно.
- Чип заметно (практически вдвое) проигрывает конкурентам на шейдерных задачах и сравним с RADEON в FFP (но, проигрывает NVIDIA).
Итак, обработка геометрии не является сильной стороной S8.
Тест Pixel Shaders
Первая группа шейдеров — достаточно простых для исполнения в реальном времени, 1.1, 1.4 и 2.0:
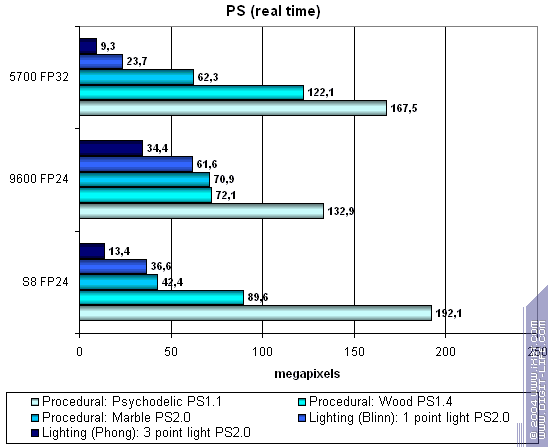
Чип сравним с конкурентами. На самой простой задаче (PS 1.1) он лидирует, на некоторых более сложных проигрывает, но немного. Однако, по большому счету, не забываем, что 8 пиксельных процессоров S8 конкурируют здесь с 2 NVIDIA и 4 ATI. Итак, гордиться особенно нечем, но в области пиксельных шейдеров адекватное соответствие конкурентам налицо. А это (учитывая опыт и мощь NVIDIA и ATI) сильно.
Посмотрим, сможет ли спасти положение S3 использование 16 битной точности плавающих чисел:
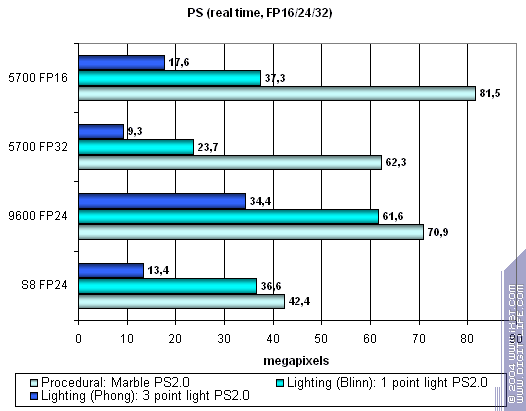
Да, S3 действительно подтягивается в тех задачах, где он выглядел не очень выгодно по сравнению с конкурентами.
Напоследок, исследуем зависимость скорости от использования арифметических или табличных методов вычисления sin, pow и нормализации векторов:
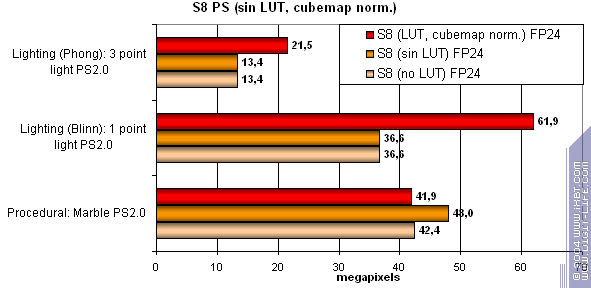
S8 не любит сложные вычисления и предпочитает им выборки табличных значений из текстур. Логично — в наличии 8 простых конвейеров с относительно невысокой вычислительной мощностью и 8 весьма эффективных TMU.
Итого, по пиксельным шейдерам :
- Сравнимая с конкурентами производительность
- Отсутствие явно выраженных слабых мест
Но не забываем, что для этого s3 понадобилось 8 пиксельных процессоров. Т.е. их штучная эффективность вдвое ниже ATI и вчетверо NVIDIA.
Тест HSR
Для начала пиковая эффективность (без текстур и с текстурами) в зависимости от сложности геометрии: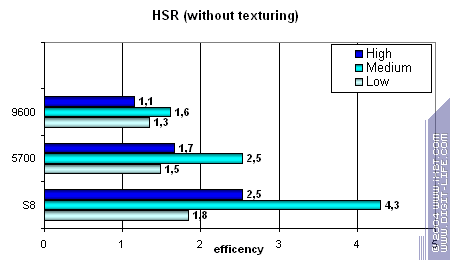
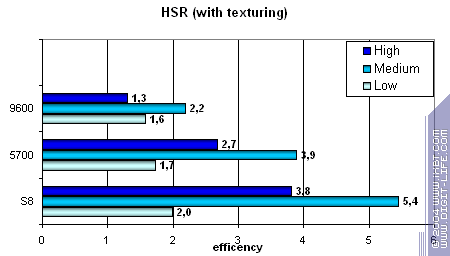
Система HSR s8 даже более эффективна чем у ATI. Это похвально. Но, спасет ли это низкую эффективность работы с памятью?
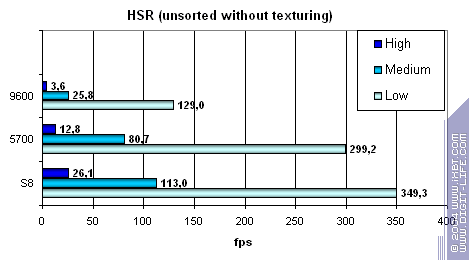
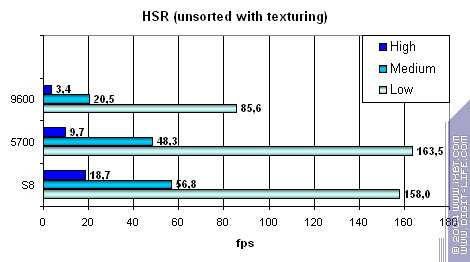
В абсолютных значениях s8 также действует похвально, хотя NVIDIA начинает наступать ему на пятки благодаря эффективной работе с буфером кадра.
Вывод :
- HSR подсистема S8 достойна всяческих похвал.
Тест Point Sprites.
S8 сравним с ATI и проигрывает NVIDIA, более эффективно работающей с буфером кадра.
Выводы по синтетическим тестам
- Высокая эффективность фильтрации текстур
- Сравнимая (с учетом большего числа) производительность пиксельных процессоров
- Сравнимая производительность фиксированного TCL
- Заметно более низкая производительность на задачах с вершинными шейдерами
- Низкая эффективность работы с памятью и кэширования текстур
Картина складывается противоречивая. чип нельзя назвать хорошо сбалансированным — видимо узкие места не дадут раскрыться его
полному потенциалу в реальных приложениях. Впрочем, скоро мы посмотрим на результаты в играх.
[ Предыдущая часть (1) ]
[ Следующая часть (3) ]
| 15 июня 2004 г. |
|
|