Долгожданный ответ AMD/ATIв виде целого семейства DirectX 10 ускорителей
в том числе и RADEON HD 2900 XT (R600)
Часть 2: Особенности видеокарт, синтетические тесты

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность) и выводы
- Качество в 3D-графике
ATI RADEON HD 2900 XT (R600): Часть 1: Теоретические сведения
ATI RADEON HD 2900 XT (R600): Часть 2: Особенности видеокарты и синтетические тесты
Итак, все подробности об особенностях архитектуры новинок уже освещены в первой части материала.
Мы знаем, что новая линейка R600 на сегодня представлена всего одной картой:
- ATI RADEON HD 2900 XT (R600) 512MB GDDR3, 675/1450/2000 MHz, 320 unified processors/16 TMUs/16 ROPs — $369-399;
В нашей лаборатории побывали три видеокарты: reference card, от MSI и HIS. Забегая вперед, скажу, что все они практически идентичны (reference card).
Сразу скажем, что автор RivaTuner Алексей Николайчук сумел ввести поддержку R600 в свою утилиту (хотя это ему стоило многодневных трудов и поисков решений):

На втором скриншоте мы видим возможность регулировки оборотов вращения кулера.. Сразу скажу, что при включении 100%… я лично подумал, что системный блок включил реактивный двигатель и сейчас улетит… Это просто немыслимые обороты и поток воздуха! Шум от самого вентилятора не очень сильно действует на нервы, но шум от воздушного потока очень и очень сильный.
Напомню, что это при включении кулера на 100%. Реально он работает в среднем на 37% в 3D-режиме (в 2D кулер не слышно — он работает на 25%). Но об этом ниже.
Платы
| MSI RADEON HD 2900 XT (R600) 512MB PCI-E | |
|---|---|
|
GPU: RADEON HD 2900 XT (R600)
Интерфейс: PCI-Express x16 Частоты работы GPU (ROPs/Shaders):: 742/742 (номинал — 750/750 МГц) Частоты работы памяти(физическая (эффективная)):: 830 (1660) MHz (номинал — 830 (1660) МГц) Ширина шины обмена с памятью: 512bit Число вершинных процессоров: - Число пиксельных процессоров: - Число универсальных процессоров: 320 Число текстурных процессоров: 16 Число ROPs: 16 Размеры: 220x100x31 мм (последняя величина — максимальная толщина видеокарты). Цвет текстолита: красный. RAMDACs/TMDS: интегрированы в GPU. Выходные гнезда: 2хDVI, TV-выход. VIVO: есть (RAGE Theater 200) TV-out: интегрирован в GPU. Поддержка многопроцессорной работы: CrossFire (интегрировано в GPU). |

|
| HIS RADEON HD 2900 XT 512MB PCI-E | |
|
GPU: RADEON HD 2900 XT (R600)
Интерфейс: PCI-Express x16 Частоты работы GPU (ROPs/Shaders):: 742/742 (номинал — 750/750 МГц) Частоты работы памяти(физическая (эффективная)):: 830 (1660) MHz (номинал — 830 (1660) МГц) Ширина шины обмена с памятью: 512bit Число вершинных процессоров: - Число пиксельных процессоров: - Число универсальных процессоров: 320 Число текстурных процессоров: 16 Число ROPs: 16 Размеры: 220x100x31 мм (последняя величина — максимальная толщина видеокарты). Цвет текстолита: красный. RAMDACs/TMDS: интегрированы в GPU. Выходные гнезда: 2хDVI, TV-выход. VIVO: есть (RAGE Theater 200) TV-out: интегрирован в GPU. Поддержка многопроцессорной работы: CrossFire (интегрировано в GPU). |

|
| ATI RADEON HD 2900 XT 512MB PCI-E | |
|
GPU: RADEON HD 2900 XT (R600)
Интерфейс: PCI-Express x16 Частоты работы GPU (ROPs/Shaders):: 742/742 (номинал — 750/750 МГц) Частоты работы памяти(физическая (эффективная)):: 830 (1660) MHz (номинал — 830 (1660) МГц) Ширина шины обмена с памятью: 512bit Число вершинных процессоров: - Число пиксельных процессоров: - Число универсальных процессоров: 320 Число текстурных процессоров: 16 Число ROPs: 16 Размеры: 220x100x31 мм (последняя величина — максимальная толщина видеокарты). Цвет текстолита: красный. RAMDACs/TMDS: интегрированы в GPU. Выходные гнезда: 2хDVI, TV-выход. VIVO: есть (RAGE Theater 200) TV-out: интегрирован в GPU. Поддержка многопроцессорной работы: CrossFire (интегрировано в GPU). |

|
|
MSI RADEON HD 2900 XT (R600) 512MB PCI-E HIS RADEON HD 2900 XT 512MB PCI-E ATI RADEON HD 2900 XT 512MB PCI-E |
|
|---|---|
|
Каждая карта имеет 512 МБ памяти GDDR3 SDRAM,
размещенной в 16-ти микросхемах на лицевой и оборотной сторонах PCB.
Микросхемы памяти Hynix 1.0ns (GDDR3). Это соответствует частоте работы 1000 (2000) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| ATI RADEON HD 2900 XT 512MB PCI-E | Reference card ATI RADEON X1950 XTX 512MB PCI-E |

|

|

|
|
| HIS RADEON HD 2900 XT 512MB PCI-E | |

|
|
| MSI RADEON HD 2900 XT (R600) 512MB PCI-E | |

|
|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| ATI RADEON HD 2900 XT 512MB PCI-E | Reference card ATI RADEON X1950 XTX 512MB PCI-E |

|

|

|
|
| HIS RADEON HD 2900 XT 512MB PCI-E | |

|
|
| MSI RADEON HD 2900 XT (R600) 512MB PCI-E | |

|
|
Очевидно, что дизайн PCB у R600 сильно усложнился по сравнению с R580 (X1950 XTX) ввиду удвоенной шины обмена с памятью. Тем не менее, производитель очень постарался соблюсти длину карты в рамках прежних решений, и обеспечить ее надлежащим кулером (также с нормальными и привычными габаритами). Для ОЕМ-поставок сборщикам имеются подобные HD 2900 XT, но оснащенные более громоздкой системой охлаждения с вынесенным за пределы PCB вентилятором, поэтому длина таких карт будет достигать 300 мм и выше. Но это только для сборщиков. В розницу такие карты не попадут.
Следует заметить, что из-за очень высокого энергопотребления (свыше 200Вт) карта имеет два разъема внешнего питания. При этом из них не привычный нам 6-пиновый, а 8-пиновый (PCI-E 2.0). Пока нет переходников для запитывания такого гнезда, впрочем и не надо, поскольку обычный 6-пиновый хвост от БП вставляется в это гнездо, а оставшиеся не задействованными два пина отвечают лишь за разблокировку разгона (драйвер определяет — есть ли питание там, и если нет — то блокирует любое повышение частоты, сделанное через него).
У карт имеется гнездо TV-выхода, которое уникально по разъему, и для вывода изображения на ТВ как через S-Video, так и по RCA, требуется
специальный адаптер-переходник, (обычно поставляемый вместе с картой). По ТВ-выходу можно почитать — здесь. Также можно заметить, что
уже традиционно все топовые модели от ATI снабжены VIVO (в т.ч. Video In — возможностью оцифровки аналогового видеопотока). Эта функция в данном случае реализована уже с помощью
RAGE Theater 200, а не традиционного Theater:

Разумеется, следует отметить полноценную поддержку HDMI, поэтому ускоритель снабжен свои собственным аудио-кодеком, сигналы которого подаются на DVI и через специальный переходник DVI-to-HDMI , поставляемый с картами, полноценное видео-аудио информационное поле передается приемнику HDMI.
Продолжая изучать карты, мы видим, что они снабжены парой гнезд DVI. Причем, Dual link DVI, что позволяет по цифровому каналу получать разрешения выше 1600х1200. Подключение к аналоговым мониторам с d-Sub (VGA) интерфейсам производится через специальные адаптеры-переходники DVI-to-d-Sub. Максимальные разрешения и частоты:
- 240 Hz Max Refresh Rate
- 2048 × 1536 × 32bit @ 85Hz Max — по аналоговому интерфейсу
- 2560 × 1600 @ 60Hz Max — по цифровому интерфейсу
Теперь о системе охлаждения. Поскольку она одинаковая у всех трех продуктов, то изучим на примере референс-продукта:
| ATI RADEON HD 2900 XT 512MB PCI-E | |
|---|---|
|
В целом стандартная конструкция. Большой радиатор (в данном случае из медного сплава, а площадка, контактирующая с GPU, отполирована до блеска), покрывающий собой не только GPU, но и микросхемы памяти, а также ряд элементов, отвечающих за питание. На радиатор одет пластиковый кожух для направления движения воздуха, в конце которого находится цилиндрический вентилятор. Последняя гонит воздух вдоль радиатора и выводит нагретый поток за пределы системного блока. Примерно такие же конструкции мы видели на всех топовых продуктах ATI/Nvidia за последние годы. Однако не зря для ОЕМ-поставок был выбран кулер огромных размеров. 100% уверен, что главным условием сборщиков было отсутствие шума от кулера, и потому его сделали монстровидным, но все же тихим. А для розницы пришлось пожертвовать чем-то, чтобы размеры системы охлаждения были в привычных рамках. В результате мы получили несколько шумную систему охлаждения. Правда шум только в 3D-режиме! в 2D — кулер тихий.
|

|

|
|

|
|

|
|
Помните, в начале этой части мы говорили про 37% от потенциала турбины, на которых обычно кулер работает? Так вот, даже при этом шум от кулера весьма ощутим.
При этом температура ядра не превышает 80 градусов:
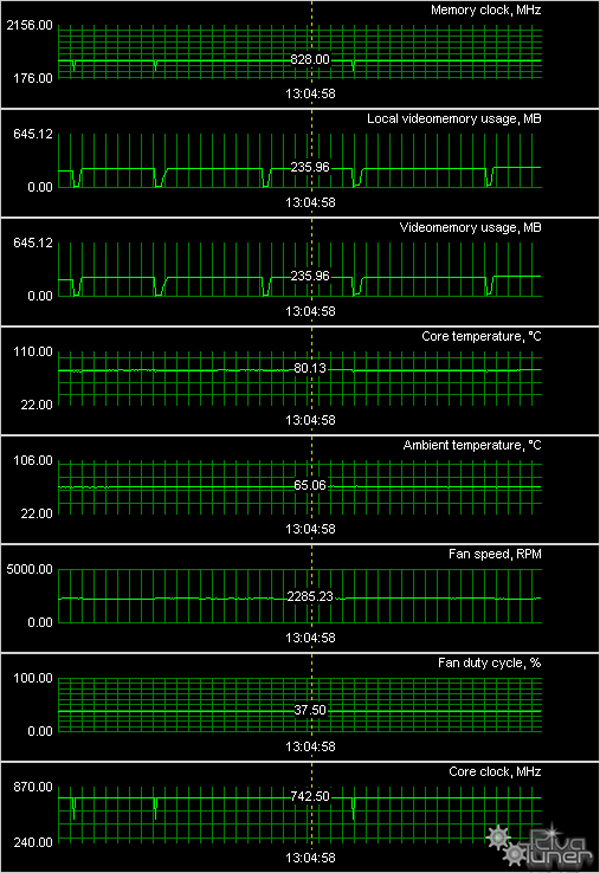
Мы попытались понизить обороты до уровня в 31% (когда шум кулера уже практически не мешает).

И прекрасно видно, что в данном случае температура ядра дошла до 100 градусов, и принудительно включился кулер на 100% (раздался просто рев!) на короткое время, а затем работа турбины снова установилась на 37%.
Дискретность установки процентов работы турбины весьма велика, и вы сможете выставить только или 31% или 37% (выше мы уже отмечали, что новая версия RT позволяет это сделать). Отсюда вывод, что 37% — это необходимый минимум работы кулера, при котором нет перегрева ядра. Ниже — уже нельзя. То есть разработчики в данном случае не перестраховывались, они реально выставили по умолчанию работу кулера в 3D на минимально уровне, при котором нет перегревов. И этот уровень нельзя назвать тихим. Это большой минус у нового ускорителя. В качестве небольшого утешения: шум идет от потока воздуха, а не от турбины, поэтому его частота не так сильно раздражают слух.
Теперь посмотрим на сам процессор.
HD 2900 XT — R600 изготовлен на 4-й неделе 2007 года, это в январе, то есть, чипу 3.5 месяца от роду

Необходимость разводки корпуса под 512-бит шину с огромным количеством контактов на подошве заставила разработчиков развернуть сам кристал на 45 градусов внутри корпуса. И мы видим не совсем привычный ракурс :)
Сравнивать чипы по размерам не будем (поскольку и так ясно, что оно будет много больше чем R580, а сравнить с G80 не получится, поскольку последний закрыт крышкой), просто скажем, что ядро очень большое и сильно нагревающееся (опыт показаал, что именно оно является источником 90% тепла от карты, поскольку микросхемы памяти работают на частотах, ниже номинальных, и их нагрев невелик).
Поскольку все представленные сегодня карты являются образцами, то об упаковках и комплектаци речь не идет. Скажем лишь, что в комплект поставки обязательно будет входить набор переходников DVI-to-VGA, DVI-to-HDMI, VIVO, кабели TV.
Установка и драйверы
Конфигурация тестового стенда:
- Компьютер на базе Intel Core2 Duo (775 Socket)
- процессор Intel Core2 Duo Extreme X6800 (2930 MHz) (L2=4096K);
- системная плата EVGA nForce 680i SLI на чипсете Nvidia nForce 680i;
- оперативная память 2 GB DDR2 SDRAM Corsair 1142MHz (CAS (tCL)=5; RAS to CAS delay (tRCD)=5; Row Precharge (tRP)=5; tRAS=15);
- жесткий диск WD Caviar SE WD1600JD 160GB SATA.
- операционная система Windows XP SP2 DirectX 9.0c; Windows Vista DirectX 10;
- монитор
Dell 3007WFP (30"). - драйверы ATI версии 8.37; Nvidia версии 158.18/158.19.
VSync отключен.
Синтетические тесты
Используемая нами версия пакета синтетических тестов D3D RightMark Beta 4 (1050) и ее описание доступны на сайте 3d.rightmark.org
В данном материале мы использовали и более сложные тесты пиксельных шейдеров версий 2.0 и 3.0 — D3D RightMark Pixel Shading 2 и D3D RightMark Pixel Shading 3, соответственно. Некоторые из задач, появившихся в этих тестах, уже применяются в реальных приложениях, а остальные обязательно появятся там в скором времени. Данные тестовые наборы доступны для скачивания здесь.
Начиная с этого материала, мы планировали использовать новую версию пакета — RightMark3D 2.0, предназначенную Direct3D 10 совместимых ускорителей в операционной системе MS Windows Vista. Некоторые уже известные тесты в его составе были переписаны под DX10, добавились новые виды синтетических тестов: модифицированные тесты пиксельных шейдеров, скомпилированные под SM 4.0, тесты геометрических шейдеров, тесты выборки текстур из вершинных шейдеров. Но уже после проведения тестов и анализа их результатов выяснилось, что тесты имеют ряд неточностей и ошибок, которые необходимо исправить для справедливого сравнения. Это требует дополнительного времени, поэтому включить результаты анализа новых тестов в данном материале не представляется возможным. Но, как только всё будет исправлено, мы выпустим отдельную статью по RightMark3D 2.0, с большим набором протестированных карт. Приносим свои искренние извинения!
Синтетические тесты проводились на видеокартах:
- RADEON HD 2900 XT со стандартными параметрами (далее R600)
- RADEON X1950 XTX со стандартными параметрами (далее R580+)
- Nvidia Geforce 8800 GTS со стандартными параметрами (далее G80)
Для сравнения с R600 был взят именно GTS вариант видеокарты на базе G80, так как именно против этой модели на рынке позиционируется HD 2900 XT. Когда у AMD выйдет топовое решение — будем сравнивать его с топовым от Nvidia (пока что таковым является Geforce 8800 Ultra).
Тест Pixel Filling
В этом тесте определяется пиковая производительность выборки текстур (texel rate) в режиме FFP для разного числа текстур, накладываемых на один пиксель:
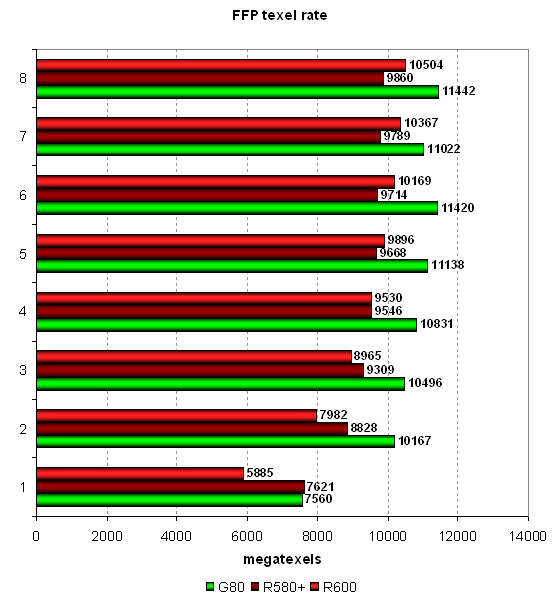
Наличие 24 текстурных блоков у Geforce 8800 GTS и достаточная пропускная способность памяти, не ограничивающая производительность, дают в результате значения, близкие к теоретическому максимуму — 12000, особенно в режимах с большим количеством текстур. У R580+ эффективность также достаточно высока, реальная скорость выборки близка к теоретической. Ну а у главного героя обзора теоретическая цифра под 12000 мегатекселей/с, а достигнутая в синтетических тестах — 10500, то есть его КПД по текстурированию чуть ниже, чем у остальных протестированных.
Судя по полученным нами результатам, чип действительно способен выбирать 16 текселей за такт для 32-битных текстур и билинейно фильтровать их, этот вид фильтрации для 32-битных текстур не вызывает падения производительности. Интересно, что в случае с небольшим количеством текстур на пиксель, R600 немного отстает от R580+, а в более тяжелых условиях вырывается вперед, то есть, новый чип более эффективен именно в тяжелых условиях.

Второй синтетический тест RightMark измеряет скорость заполнения, в нём мы видим примерно ту же самую ситуацию, но уже с учетом количества записанных в буфер кадра пикселей. В случаях с 0 и 1 накладываемых текстур он должен был получить преимущество за счет значительно более высокой пропускной способности памяти, но видимо из-за низкой эффективности работы текстурников или блоков ROP в таких условиях, показанные новым чипом результаты не впечатляют и он отстает от обоих конкурентов.
Только начиная с четырех текстур на пиксель, R600 догоняет своего предшественника, что несколько странно, учитывая равное количество блоков TMU, ROP и большую тактовую частоту. Видимо, баланс новой архитектуры смещен в сторону большего количества текстурных выборок, с большим числом текстур он выходит вперед R580+, но всё же проигрывает не самому быстрому чипу Nvidia по скорости заполнения.
Как обычно, скорее для собственного успокоения проверяем ту же самую задачу в исполнении пиксельного шейдера версии 2.0:

В этот раз никаких изменений нет, FFP и шейдеры версии 2.0 работают примерно одинаково (вероятно, FFP эмулируется эффективным шейдером), все карты показывают близкие с предыдущими результаты. В будущих обзорах мы уже не будем приводить этот график, если не увидим значительной разницы между FFP и PS 2.0.
Тест Geometry Processing Speed
Тесты исполнительных блоков начнем с уже традиционного предупреждения: к синтетике на унифицированной архитектуре нужно относиться особенно осторожно, она обычно нагружает определенные части чипа, а реальные приложения пользуются всеми его ресурсами одновременно. И если чип со старой архитектурой при хорошем балансе 3D приложения может выдавать близкие к пиковым значения, то унифицированный в таких ситуациях может ухудшить результаты, по сравнению с полученными в синтетических тестах.
Итак, рассмотрим предельные геометрические тесты. Первым будет самый простой вершинный шейдер, показывающий предельную пропускную способность по треугольникам:

Понятно, почему унифицированные чипы G80 и R600 выигрывают у R580+, почти все универсальные исполнительные блоки в этом тесте заняты геометрической работой, чего нельзя ожидать от чипа предыдущего поколения. Но всё же результаты явно упираются в возможности API и платформы, а не в пиковую производительность унифицированных блоков, слишком уж лёгкая задача у них. Эффективность выполнения задачи в разных режимах у чипов примерно равна, пиковая производительность в FFP, VS 1.1 и VS 2.0 мало отличается. Разве что у G80 видно значительное отличие в FFP режиме, почти неважное с точки зрения реальных приложений. Посмотрим, что изменится в усложненном тесте с одним diffuse источником освещения:
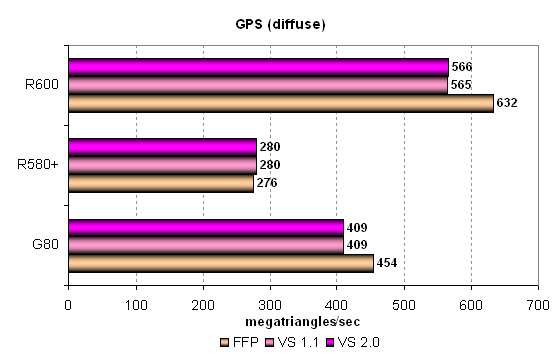
В этом тесте расстановка сил ближе к реальной, хотя потенциал унифицированных архитектур явно не раскрыт полностью. Оба чипа современных архитектур, от AMD и Nvidia, опережают старый с традиционной архитектурой, что логично. В этот раз режим FFP был быстрее и на R600 и на G80, видимо, для эмуляции FFP все же используются какие-то специализированные блоки или просто накладных расходов меньше. Но в любом случае, во всех режимах R600 более чем на треть опережает GTS вариант чипа G80.
Смотрим, что получится в еще более тяжелых условиях. Третья диаграмма GPS предлагает ещё более сложный расчет освещения с одним источником света и расчетом бликовой составляющей:

Отрыв унифицированных архитектур стал еще более явным. Лидером по геометрической производительности является R600, а G80 отстает от него чуть больше, чем в прошлый раз — примерно на 40%. Унифицированная архитектура раскрыла свои возможности, видно, что большое число универсальных процессоров значительно сильнее выделенных на геометрические задачи восьми векторных процессоров у R580+. Интересно, что на смешанном источнике света наличие оптимизированной эмуляции FFP проявляется уже у всех чипов.
Рассмотрим самую сложную геометрическую задачу с тремя источниками света, включающую статические и динамические переходы:
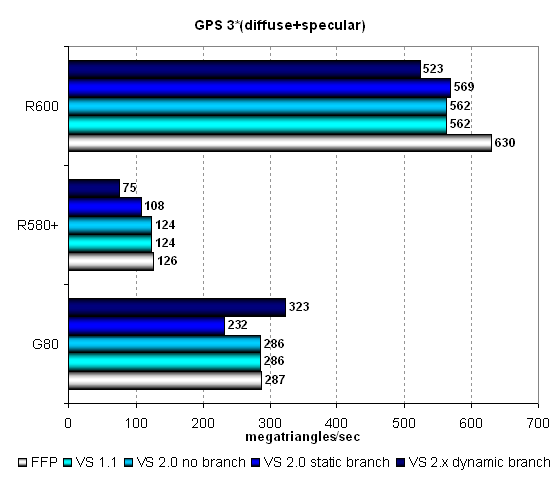
Получилось, по сути, то же самое, что и в предыдущем случае, но R600 вырвался вперед еще сильнее. Унифицированная архитектура R6xx действительно очень хороша в геометрических расчетах, и чем сложнее задача — тем лучше её результат относительно традиционных чипов и даже унифицированного G80! Результаты R600 почти в два раза выше, чем у G80. Кстати, в очередной раз отметим противоположные слабые места вершинных блоков архитектур AMD и Nvidia — динамические переходы вызывают большее падение производительности у чипов первой, а статические — у чипов второй.
Итоги по геометрическим тестам: R600 показал очень сильные результаты в синтетических геометрических тестах. Из-за своей унифицированной архитектуры и специальных модификаций (увеличенный объем вершинного кэша и др.) чип хорошо проявляет себя в таких тестах, он способен использовать все свои универсальные потоковые процессоры для решения геометрических задач. Новая унифицированная архитектура AMD особенно явно демонстрирует свои способности при работе со сложными вершинными шейдерами, остается посмотреть, что получится в реальных игровых приложениях, так как в них большую часть работы ALU будет составлять выполнение пиксельных шейдеров, а не вершинных.
Тест Pixel Shaders
Так как в сравнении не участвовали чипы старых архитектур Nvidia, которые получают преимущество при снижении числа временных регистров и их точности, мы не стали включать в сравнение результаты FP16, все тестируемые сегодня решения выполняют пиксельные шейдеры с пониженной точностью вычислений точно с той же производительностью, что и полноценные FP32.
Первая группа пиксельных шейдеров, которую мы традиционно рассматриваем, слишком проста для современных видеочипов, она включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0.

Конечно, эти тесты слишком просты для G8x и R6xx и не могут показать, на что способны унифицированные архитектуры по сравнению с R5xx. Новые чипы не получают в таких простых тестах заметного преимущества перед одним из самых мощных чипов традиционной, который имеет большое количество блоков, исполняющих пиксельные шейдеры. В самых простых тестах производительность ограничена текстурными выборками и филлрейтом, в них побеждает G80, а вот в чуть более сложных PS 2.0 тестах вперед выходит уже R600. И опять — чем сложнее задача, тем больше его отрыв от конкурентов.
Посмотрим на результаты более сложных пиксельных программ промежуточных между 2.0 и 3.0 версий:
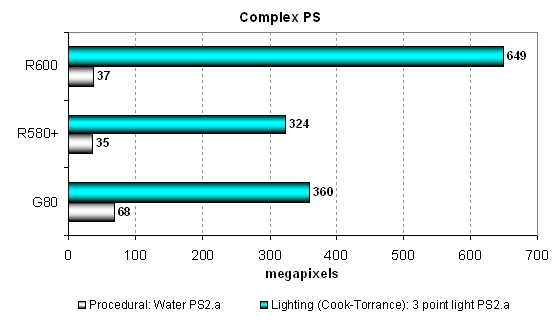
В более зависимом от скорости текстурирования тесте с процедурной визуализацией воды («Water») используется зависимая выборка из текстур больших уровней вложенности, и там у G80 нет равных ни среди старых чипов AMD, ни среди новых. Примерно равные результаты R580+ и R600 подтверждают большую зависимость от скорости TMU. Зато в более интенсивном с точки зрения вычислений втором тесте R580+ почти догоняет младший вариант G80, а R600 вообще ушёл далеко вперёд. Сказывается большее число унифицированных вычислительных блоков у R600, видимо, эта задача очень хорошо подходит для его суперскалярной архитектуры.
Тесты пиксельных шейдеров New Pixel Shaders
Эти тесты были введены не так давно, они сложнее протестированных выше. Вообще, от ранних синтетических тестов с шейдерами устаревших версий (менее 2.0) планируется отказаться в пользу 2.x, 3.0 и 4.0 шейдеров, написанных на HLSL. Ведь производительность старых версий шейдеров можно проверять в играх, где они давно используются, а синтетические тесты должны соответствовать требованиям будущего.
Данные тесты делятся на две категории, и начнем мы с более простых шейдеров версии 2.0. Доступны два новых теста, реализующие уже использующиеся в современных 3D приложениях эффекты:
- Parallax Mapping — знакомый нам по нескольким современным играм (Splinter Cell: Chaos Theory, F.E.A.R., TES4: Oblivion, Prey и др.) метод наложения текстур, подробно описанный в статье Современная терминология 3D графики
- Frozen Glass — сложная процедурная текстура замороженного стекла с управляемыми параметрами, подобные эффекты в играх также уже не в новинку, пусть и менее сложные
Оба шейдера мы тестируем в двух вариантах: с ориентацией на математические вычисления, и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:

Ситуация чем-то похожа на предыдущий блок тестов, но есть и отличия. В тесте «Frozen Glass» первое место с полуторакратным преимуществом занимает G80, а оба решения AMD идут ровненько, что опять же позволяет сделать предположение об ограничении производительности скоростью текстурных выборок, которые неизбежны в любых тестах и тем более в реальных 3D приложениях. В тесте «Parallax Mapping» получилась зеркальная ситуация — G80 и R580+ идут примерно наравне, а R600 в полтора раза быстрее обоих. Вот что значит разные тесты, с разной нагрузкой на блоки TMU и ALU, в одном тесте преимущество у одной архитектуры, во втором — у другой.
Рассмотрим те же тесты, но в модификации с предпочтением выборок из текстур математическим вычислениям:
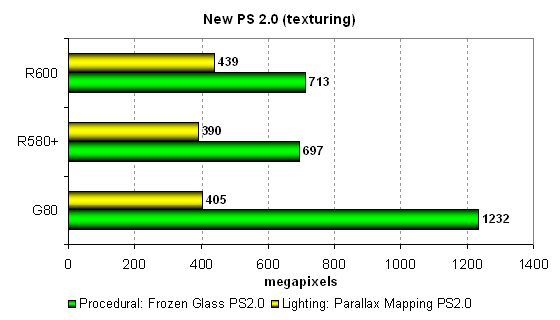
В таком варианте картина меняется, производительность в тестах больше упирается в скорость текстурных блоков, поэтому решения AMD в тесте «Parallax Mapping» приблизились к G80, а в первом тесте чип Nvidia стал еще быстрее относительно своих соперников.
По этим диаграммам видно, что на всех чипах быстрее работает вариант шейдера с большим количеством математических вычислений, для современных архитектур видеочипов смысла в варианте с упором на текстурирование нет никакого. Унифицированный чип G80 хоть и быстр в текстурных выборках, но и он «любит» вычисления больше, чем текстурирование, что уж говорить о решениях AMD(ATI), которые традиционно отдают предпочтение математическим расчетам. В реальных приложениях всё будет зависеть от предпочтений и решений программистов, чтобы раскрыть потенциал новых архитектур, им нужно выбирать вычислительно ориентированные варианты алгоритмов.
Далее мы рассмотрим результаты еще двух тестов пиксельных шейдеров — версии 3.0, самых сложных из наших синтетических тестов пиксельных шейдеров для Direct3D 9. Эти тесты также отличаются тем, что сильно нагружают не только ALU, но и текстурные модули, обе шейдерные программы сравнительно сложные, длинные и с большим количеством ветвлений:
- Steep Parallax Mapping — значительно более «тяжелая» разновидность техники parallax mapping, пока что не применяющаяся в играх, также описанная в статье Современная терминология 3D графики
- Fur — процедурный шейдер, визуализирующий мех
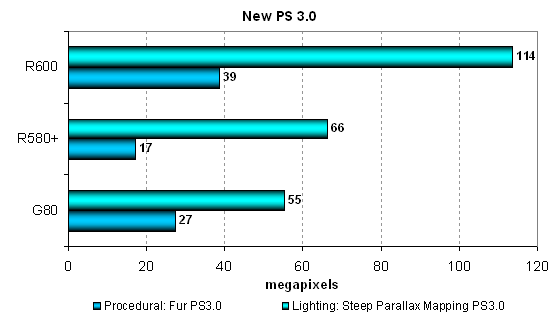
Нагрузка в этих тестах велика даже для таких современных чипов, как G80 и R600. Но и R580+ не теряется на их фоне, показывая результаты примерно на уровне Geforce 8800 GTS, в одном тесте отставая от этого решения, в другом — опережая его. Очевидно, что все архитектуры хорошо работают с динамическими переходами в пиксельных шейдерах и отлично приспособлены к подобным задачам, но не менее хорошо видно, что именно R600 обеспечивает наиболее эффективное исполнение наших сложных пиксельных шейдеров версии 3.0 с большим количеством ветвлений, его преимущество над G80 тут составляет от полутора до двух раз.
Выводы по тестам пиксельных шейдеров: R600 основан на эффективной вычислительной архитектуре, отлично приспособленной для выполнения сложных пиксельных шейдеров. И чем больше в задаче сложных математических вычислений и переходов, тем более эффективна новая архитектура AMD по сравнению с другими. К сожалению, для абсолютного лидерства R600 не хватает чуть большего количества текстурных блоков, которые важны даже в синтетических тестах пиксельных шейдеров, не говоря уже о реальных играх, в которых скорость текстурирования сказывается обычно еще сильнее. Посмотрим на результаты тестов RADEON HD 2900 XT в современных играх, которые ждут вас в следующей части статьи, и проверим, подтвердятся ли наши предположения.
Тест Point Sprites
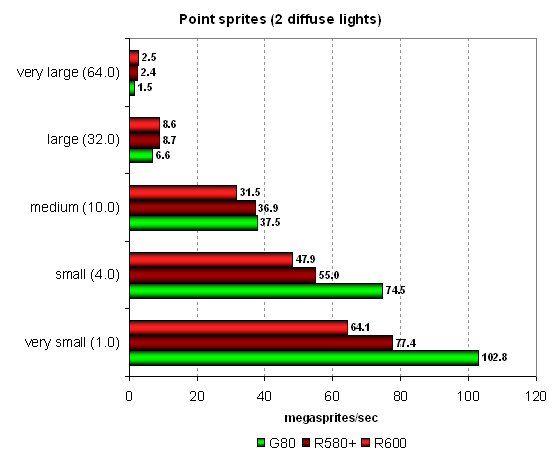
Рассмотрим работу point sprites, которые используются в небольшом количестве реальных приложений, в разных условиях. Еще раз подтверждаются результаты всех наших предыдущих исследований — чипы Nvidia опережают решения AMD на спрайтах небольшого размера, благодаря более эффективной работе с буфером кадра, но по мере роста размера частиц и сложности освещения, начинают выигрывать уже последние. R600 в этом тесте ведет себя так же, как и предыдущие решения компании, ничего интересного мы тут не видим. Вообще, этот тест на небольших размерах спрайтов упирается только в скорость закраски и не показывает любопытных результатов, так что в будущих обзорах мы планируем отказаться и от него в пользу новых Direct3D 10 тестов.
Выводы по синтетическим тестам
- R600 отличается очень высокой вычислительной производительностью, этот чип, а вместе с ним и архитектура, явно нацелены на современные и будущие 3D приложения с большим количеством сложных шейдеров всех трёх типов. Большое число и высокая эффективность универсальных процессоров позволяют R600 показывать отличные результаты почти по всех синтетических тестах, особенно в геометрических и в тестах сложных пиксельных шейдеров с ветвлениями. Преимущество нового чипа AMD перед конкурирующими в таких тестах еще и растет по мере увеличения нагрузки.
- У новых чипов AMD (в частности — R600) есть и слабые места — недостаточное, на наш взгляд, количество блоков текстурирования (TMU) и блоков ROP. Количества TMU может быть недостаточно для современных игр, даже в некоторых из наших синтетических тестов видно, что R600 проигрывает именно из-за невысокой производительности текстурных выборок. И число ROP одновременно с расширением шины памяти и увеличением её пропускной способности могли бы и увеличить. Ведь зачем видеочипам нужна высокая ПСП? Как раз для записи большого количества пикселей. Сравните R580 и R600 — количество блоков ROP у обоих чипов одинаково, но ПСП у нового решения при одинаковых микросхемах памяти будет в два раза выше! Зачем? Будет ли достаточно 16 блоков ROP, чтобы воспользоваться этим преимуществом? Посмотрим в следующем разделе материала.
Итак, унифицированная архитектура для ПК у AMD получилась очень мощной и явно нацеленной на сложные вычисления. Кроме того, она должна неплохо масштабироваться, и решения для других ценовых диапазонов, которые появятся чуть позже, должны получиться довольно неплохими. Тем более, что они будут производиться по более совершенному техпроцессу, за счет чего получат дополнительные преимущества. Вопросы вызывает лишь не очень большое количество блоков ROP и особенно TMU во всех решениях линейки. Не станет ли эта потенциальная слабость причиной не очень внятных результатов в нынешних игровых тестах, которые сильно зависят как от скорости текстурирования, так и от скорости заполнения (филлрейта)? Конечно, впереди нас ждут DirectX 10 тесты и игры, в которых будут видны настоящие возможности новых решений, именно они должны раскрыть потенциал новых архитектур как AMD, так и Nvidia, но ведь и про современные игры забывать не стоит…
В следующей части статьи мы протестируем новое решение AMD в современных игровых тестах и проверим справедливость выводов, полученных нами при анализе результатов синтетических тестов. По сути, игровая часть является самой главной, именно на основе реальных игровых тестов и следует делать выбор покупателям.
ATI RADEON HD 2900 XT (R600) — Часть 3: Игровые тесты (производительность)
Монитор Dell 3007WFP для тестовых стендов предоставлен компанией Nvidia
| 14 мая 2007 г. |
|
|