NVIDIA GeForce FX 5600 Ultra (NV31) и GeForce FX 5200 Ultra (NV34)

Уже по традиции, предваряя большой материал анализа работы нового акселератора, мы настоятельно рекомендуем прочитать аналитическую статью, посвященную архитектуре и спецификациям NVIDIA GeForce FX (NV30), а также практический обзор NVIDIA GeForce FX 5800 Ultra, поскольку рассматриваемые сегодня ускорители базируются на технологиях NV30
СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарт NVIDIA GeForce FX 5600 Ultra и 5200 Ultra
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Синтетические тесты RightMark3D: идеология и описание тестов
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark2001 SE
- Выводы из результатов синтетических тестов
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game1
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game2
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game3
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game4
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003 DEMO
- Результаты тестов: AquaMark
- Результаты тестов: RightMark 3D
- Результаты тестов: DOOM III Alpha version
- Качество 3D: Анизотропная фильтрация
- Качество 3D в целом
- Выводы
Результаты практического тестирования
Приведем и прокомментируем данные, полученные нами на бюджетных и мэйнстрим ускорителях двух "основных" в данный момент семейств (ATI и NVIDIA).
- ATI:
- RADEON 9000 PRO 128 Mb
- RADEON 9500 64 Mb
- RADEON 9500 PRO 128 Mb
- NVIDIA:
- GeForce 4 MX 440-8x
- GeForce 4 Ti 4200-8x
- GeForce 4 Ti 4600
- GeForce FX 5200 Ultra
- GeForce FX 5600 Ultra
Число пиксельных конвейеров и их конфигурация
Для начала нам не терпится определиться с самым интригующим и спорным вопросом — реальным числом конвейеров и текстурных блоков новых членов семейства GeForce FX.
Вначале NV34:

Итак, налицо все признаки конфигурации 2х2 — два пиксельных конвейера с двумя текстурными блоками
на каждом. Цифры очень близки к теоретическим значениям именно такой конфигурации. Теперь посмотрим,
что происходит в случае использования пиксельных шейдеров 1.1 и 2.0:
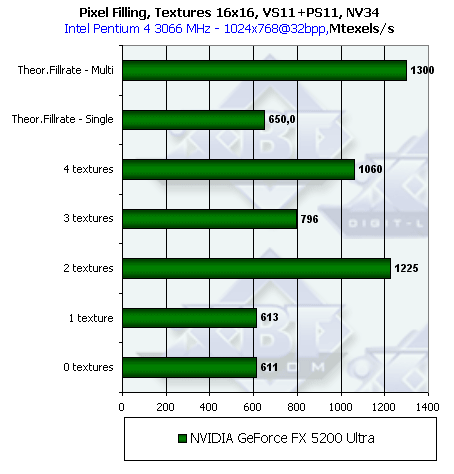
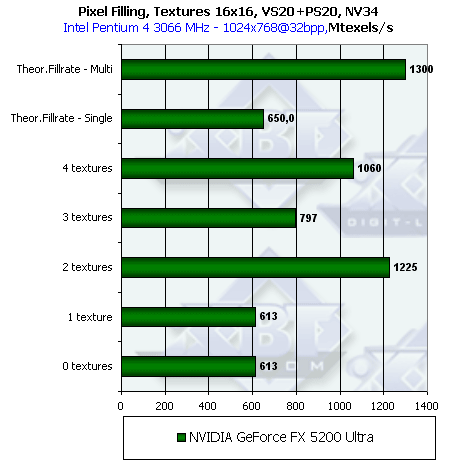
Удивительно, но результаты совершенно аналогичные! Итак, либо теперь все операции выполняются единым ALU (и не факт что плавающим — возможно это ALU с фиксированной запятой и это еще предстоит выяснить) либо драйверы выполняют агрессивную оптимизацию, сводя шейдеры до минимальной функционально необходимой версии. Т.е. те задачи, которые могут быть уложены в знакомые еще по DX7 картам рамки бленд стадий (register combiners) и укладываются в оные драйверами. Несколько далее, мы проверим это предположение на основе результатов производительность сложных шейдеров версии 2.0.
Теперь NV31:


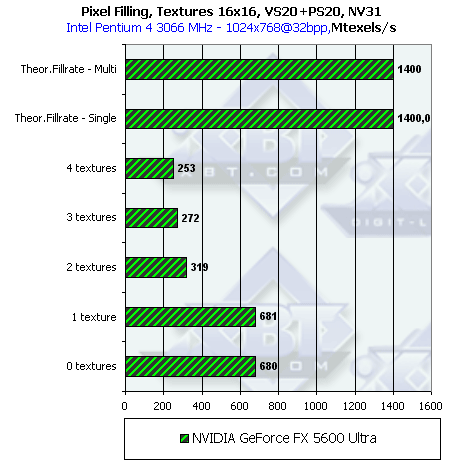
А здесь все еще интереснее! Для программ, не использующих шейдеры, в случае одной текстуры чип работает как 4х1, но для 3 текстур, судя по всему, как 2х2 (!) из чего можно сделать вывод, что и для 2 и 4 текстур тоже используется схема 2х2. В случае использования шейдеров первой версии мы совершенно четкую картину 2х2. В случае использования шейдеров второй версии, мы сталкиваемся с чем-то аналогичным NV30 — 2х2, но гораздо медленнее из-за того, что выборка текстур не может выполняться параллельно с вычислительными командами шейдера. Т.е. NV31 можно назвать 2х2 чипом с 4х1 оптимизацией для частного случая, не использующих пиксельные шейдеры приложений. Видимо, так или иначе пиксельный блок чипа состоит из массива гибко конфигурируемых ALU (стадий) которые могут объединяться в различное число конвейеров в зависимости от текущей ситуации (настройки стадий или шейдера).
Итак, подведем итоги:
- NV31 — 4х1 чип на приложениях без пиксельных шейдеров и 2х2 на приложениях с пиксельными шейдерами.
- NV34 — 2х2 чип в любой ситуации, причем на данном тесте производительность от версии пиксельного шейдера не зависела (!).
Pixel Filling
- Тест на скорость закраски буфера кадров (Pixel Fillrate). Закраска константным цветом -
выборка текстур не производится. Приведены результаты в миллионах пикселов в секунду для разных
разрешений, причем как в обычном режиме, так и для 4х MSAA:
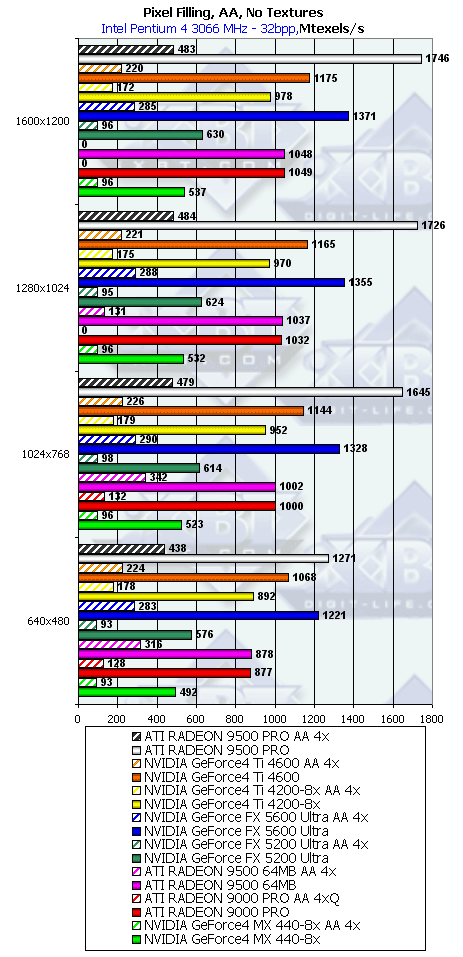
RADEON 9500 PRO лидер, сказывается наличие 8 пиксельных конвейеров (закраска без текстур зависит от числа пиксельных конвейеров, частоты ядра, пропускной полосы памяти и эффективного ее использования). На втором месте NV31 в лице GeForce FX 5600 Ultra, конвейеров в этом тесте у нее 4, но отставание куда как меньше двукратного — RADEON 9500 PRO в этом тесте упирается в пропускную полосу памяти, а 5600 Ultra нет — что говорит о разумном балансе последнего. Сохранится ли этот баланс в случае вычислительно интенсивных шейдеров? Далее мы проясним этот вопрос.
По результатам хорошо видно, что 5600 Ultra является DX9 заменой для 4600. Впрочем, не забываем, что прогресс не стоит на месте и эта замена выходит в свет по существенно более низкой цене. С точки зрения MSAA чипы показывают удивительно схожую эффективность, точнее, удивительно схожее, значительное падение.
NV34 показывает куда как более скромные абсолютные результаты — сказывается наличие только двух пиксельных конвейеров. Этот чип будет отличной DX9 заменой для ниши GeForce 4 MX 440. Впрочем, далее мы посмотрим, не поможет ли более совершенная архитектура нового чипа более заметно вырваться вперед относительно своего старого собрата в реальных приложениях.
- Тест на скорость закраски буфера кадров с одновременным текстурированием. Добавляется выборка
одной простой билинейной текстуры — проверим, насколько наличие конкурентного потока чтения из
памяти понизит эффективность закраски. Приведены результаты в миллионах пикселов в секунду, для
разных разрешений, причем как в обычном режиме, так и для 4х MSAA:
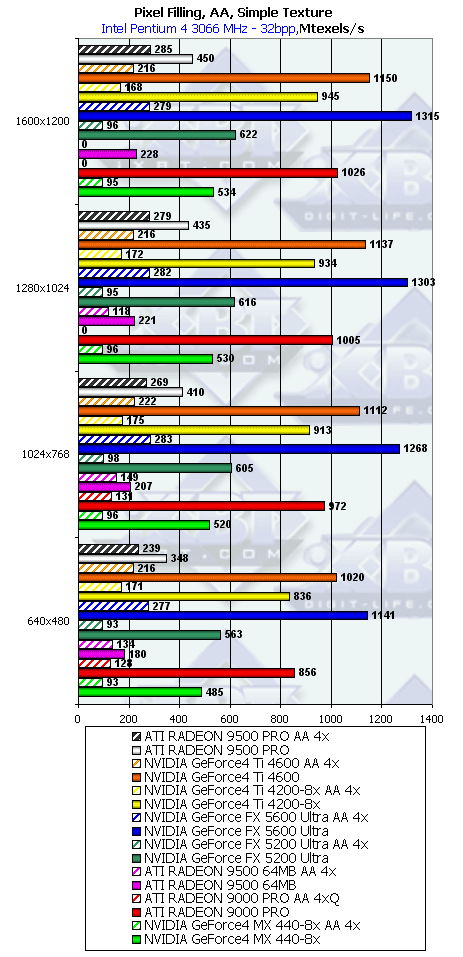
В общем и целом, картина практически та же, но у некоторых карт пиковые значения несколько упали. А вот с RADEON 9500 PRO творится что то странное. Цифры явно не соответствуют возможностям чипа - видимо происходит какой то лаг вызванный взаимодействием теста и драйверов. В данный момент мы пытаемся разрешить эту проблему со специалистами ATI. Интересно отметить, что в случае RADEON 9700 и 9700 PRO (см. обзор RADEON 9700 PRO DX9 часть 2) ранее, таких аномалий не наблюдалось!
Давайте посмотрим, насколько хорошо измеренная действительность соотносится с теоретическими пределами, основанными на частоте ядра и числе конвейеров:
Продукт Теоретический максимум Измеренный максимум(без текстуры) Измеренный максимум(с одной текстурой) RADEON 9000 PRO 1100 1049 1026 RADEON 9500 1100 1049 228 ??? RADEON 9500 PRO 2200 1746 450 ??? GeForce4 MX 440-8x 550 537 534 GeForce4 Ti 4200-8x 1000 978 945 GeForce4 Ti 4600 1200 1175 1150 GeForce FX 5600 Ultra 1400 1371 1315 GeForce FX 5200 Ultra 650 630 622 Итак, все карты кроме RADEON 9500 PRO хорошо реализуют свой теоретический потенциал. Но в режиме с одной текстурой с семейством RADEON 9500, как мы уже отмечали, происходит что-то странное.
- Посмотрим на зависимость Texturing Rate (числа выбираемых и фильтруемых из текстур пикселей
в секунду) от числа накладываемых за один проход текстур более менее реального размера 256х256:
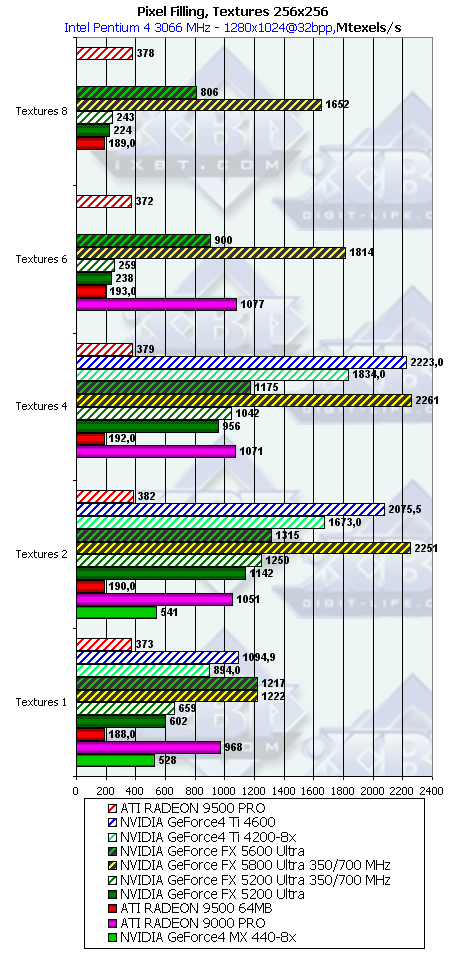
А вот и сюрприз — мы совсем забыли о том, что 4х2 конфигурация GeForce 4 4200 обеспечит ему заметное преимущество в режимах с мультитекстурированием (от 2 до 4 текстур). Преимущество на лицо - однако, посмотрим, скажется ли оно на реальных приложениях.
Для сравнения мы привели результаты NV34 разогнанной до частоты NV31 как по шине памяти так и по ядру и результаты NV30 опять таки на частоте NV31. Хорошо видно что на закраске с одной текстурой, когда можно не использовать бленд стадии вообще, эти чипы сравнялись по производительности, а в остальных случаях NV30 вдвое производительнее NV31.
Продукт Теоретический максимум Достигнутый максимум GeForce FX 5200 Ultra 1300 1142 (2 текст.) GeForce FX 5600 Ultra 1400 1315 (2 текст.) - Исследуем зависимость от типа фильтрации:

На более или менее существенных установках анизотропии обе карты на базе NV25 (4200 и 4600) начинают катастрофически терять производительность. Этот факт подробно исследован в наших материалах ранее и не требует дополнительных комментариев. Зато NV31 и NV34 теряет производительность лишь немного более активно, чем произведения ATI. И снова мы наблюдаем аномальное поведение RADEON 9500.
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителей.
- Производительность фиксированного TCL (для NV30 и R300 — производительность эмулирующего его шейдера):
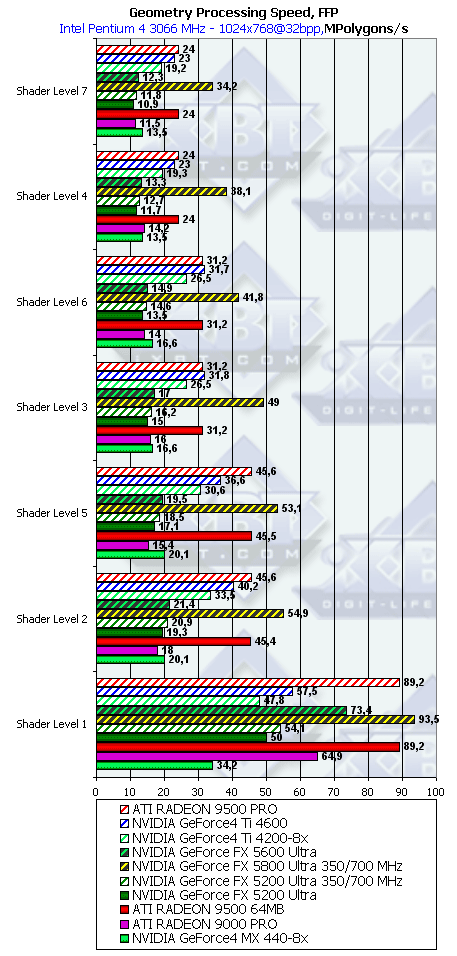
Результаты сортированы по степени сложности используемой модели освещения. Самый нижняя группа — простейший вариант, соответствующий пиковой пропускной способности ускорителя по вершинам. Интересно, что геометрическая производительность NV31 и NV34 на большинстве задач практически эквивалентна, заметное отличие есть только на самом простом варианте и связано оно с объемами вершинных кэшей а не скоростью обработки геометрии. В остальных заданиях NV31 и NV34 все время в 2.5 раза медленнее NV30 на равной частоте — видимо число вершинных ALU урезано именно во столько крат. Сразу отметим, что полученные результаты свидетельствуют о наличии аппаратной обработки геометрии в обоих чипах. На этой задаче NV31 и NV34 проигрывают RADEON 9500 PRO в среднем в полтора раза. Но не будем забывать, что RADEON 9600 PRO будет иметь вдвое более низкую геометрическую производительность!
- Теперь обратимся к вершинным шейдерам 1.1:
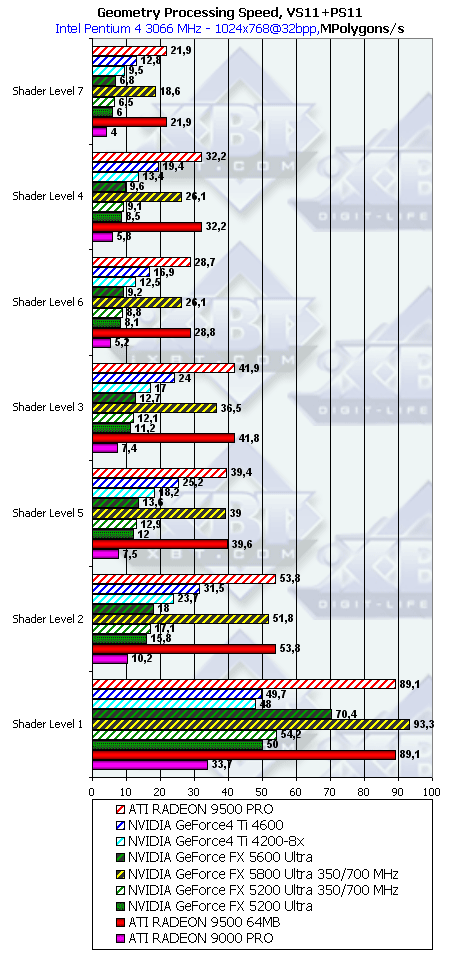
Та же самая картина — взаимная расстановка NV30, NV31 и 34 не поменялась — чипы используют схожие по организации геометрические блоки. RADEON 9500 опять на высоте — его геометрическая мощь не урезана и равна RADEON 9700 — что существенно превышает возможности NV31 и NV34.
- А теперь самое интересное — шейдеры 2.0 с циклами:
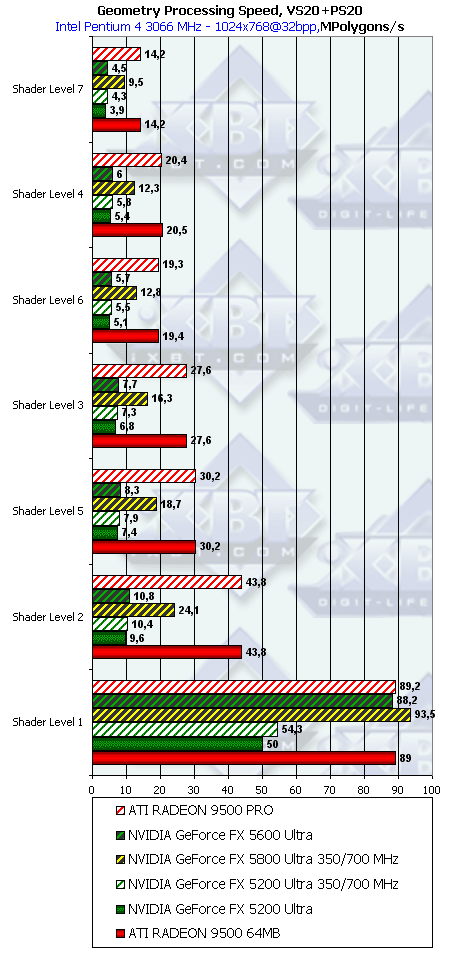
Картина повторяет оную для вершинных шейдеров 1.1, разве что преимущество ATI чуть увеличилось.
Итак, аппаратная эмуляция T&L в исполнении ATI менее эффективна, чем у NV и сравнима по эффективности с вершинным шейдером 2.0. Самое сильное место NV3x — эмуляция TCL. Самое слабое — циклы. В этом плане у ATI больше простор для оптимизации в драйверах — статическое исполнение переходов и циклов позволяет применять куда как более агрессивную оптимизацию.
Производительность NV31 и NV34 в вершинных задачах эквивалентна и приблизительно в 2.5 раза ниже производительности NV30 на равной частоте.
- Проверим перекрестную зависимость от степени детализации геометрии и сложности шейдера:
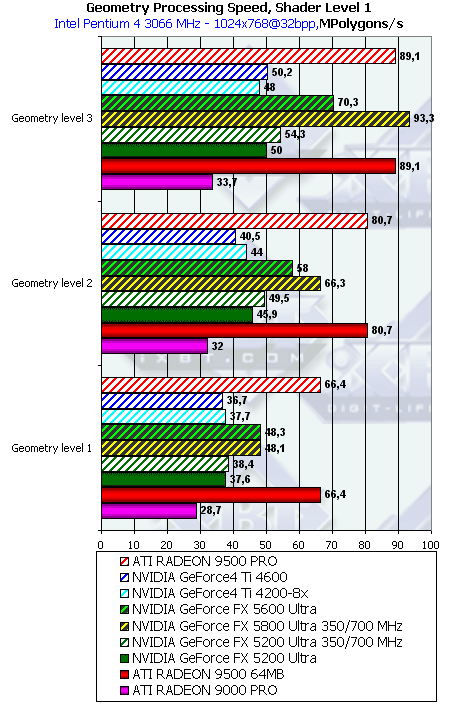
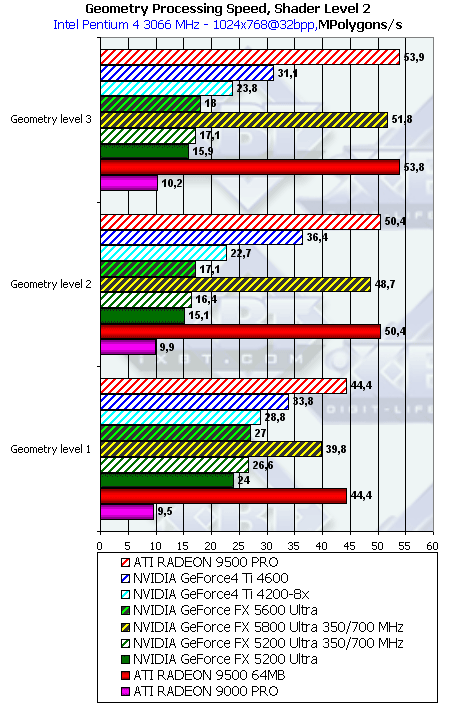
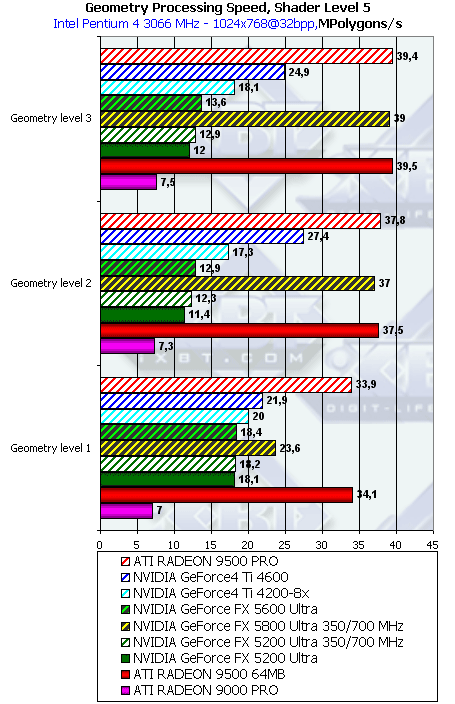
Чем выше сложность шейдера и чем выше детализация сцены, тем большее преимущество получает NV30 (сказываются кэши вершин и прочие аспекты балансировки). А вот для NV31 и NV34 картина обратная — они оптимизированы для не умерено детализированных сцен.
Hidden Surface Removal
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от числа
треугольников, на сцене без текстур (не учитывается ранняя проверка Z):
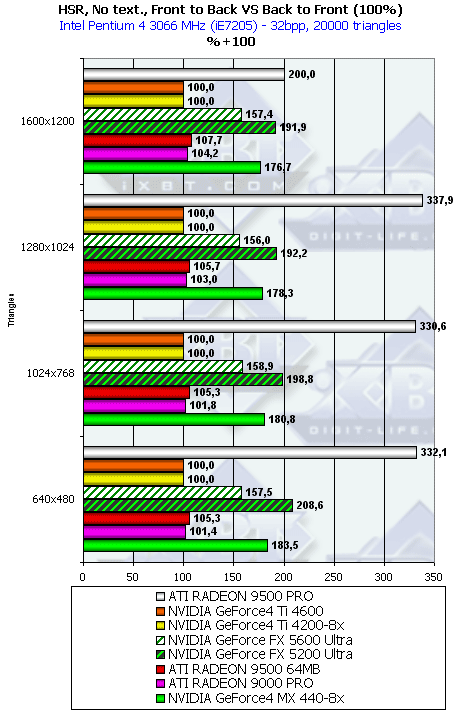
Итак, NV31 и NV34 снабжены эффективным HSR, причем эффективность оного в NV34 несколько выше. Кроме того, GeForce 4 MX также может похвастаться работой этого блока! В RADEON 900 PRO, 9500 и семействе GeForce 4 Ti HSR деактивирован. В RADEON 9500 PRO этот блок работает в полную силу, так же как и в RADEON 9700 PRO.
R300 использует иерархическую структуру, и зачастую отсечение происходит на более высоком уровне, а следовательно, и более эффективно, в то время как у NV30 присутствует только один уровень принятия решения, совмещенный с тайлами, на основе которых сжимается информация о глубине. В максимальном разрешении 1600х1200 происходит резкое падение эффективности HSR на R300 — видимо, по каким-то соображениям, например, соображениям экономии памяти, иерархический буфер глубины уже не используется, и решение об отсечении блоков принимается так же, как и в случае NV30, только на самом нижнем базовом уровне, совмещенном с сжимаемыми блоками в буфере глубины.
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и
от числа треугольников, на сцене с текстурами (с учетом ранней проверки Z):
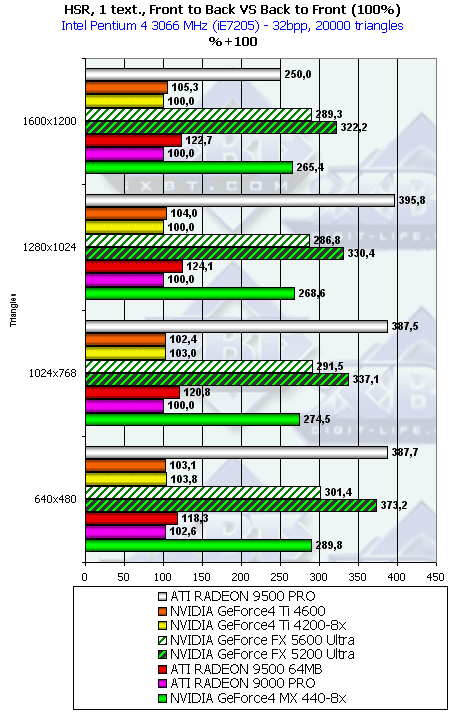
Итак, здесь и NV31/NV34, и R300 демонстрируют дополнительный рост эффективности. Причем, у NVIDIA он заметно больше — NV31 и NV34 почти достигли рекордных показателей RADEON 9500 PRO а в максимальном разрешении даже превысили их!
Pixel Shading
В данном тесте участвуют только R300 и NV3x — т.к. аппаратное исполнение версии 2.0 пиксельных шейдеров является минимальным требованием для этого теста. Судите сами: на старой доброй GeForce4 Ti 4600 вкупе с 2 ГГц Pentium 4 программная эмуляция второй версии пиксельных шейдеров выдает порядка одного кадра в две секунды. И это — в маленьком окне.
- Сам тест, шейдеры 2.0:
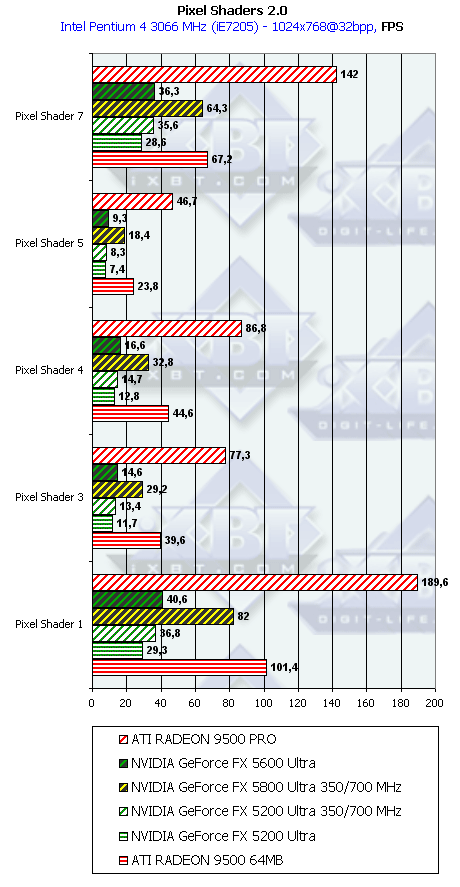
На равной частоте NV31 и NV34 выполняют пиксельные шейдеры 2.0 с одинаковой скоростью, вдвое медленнее NV30. Ничего удивительного. R300 в различных ипостасях лидирует, разумеется, благодаря 4 (8) пиксельным шейдерным конвейерам против 2 в случае NV31 и NV34.
- Проверим зависимость от разрешения:
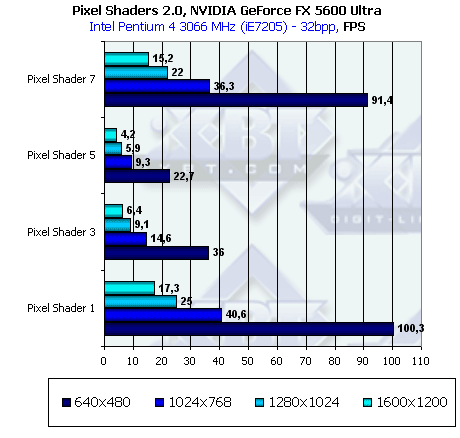
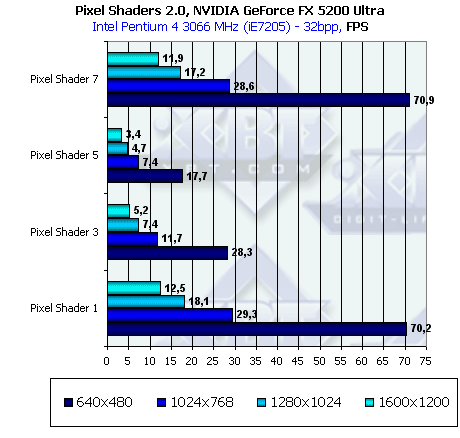
Все нормально. Зависимости совпадают — все зависит только от числа закрашенных пикселей, никаких аномалий не наблюдается.
Отметим, что в случае форсированной установки 16 или 32 битной точности в DirectX никаких отличий в производительности не наблюдается, видимо драйверы всегда сами принимают решение о точности операций игнорируя соответствующие модификаторы команд в шейдерах.
Point Sprites
Итак, спрайты.
- С освещением и без, в зависимости от размеров:
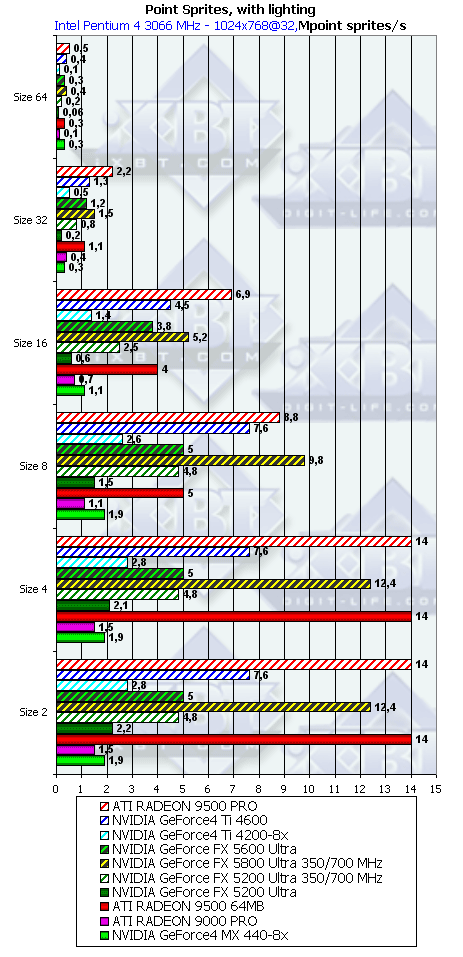
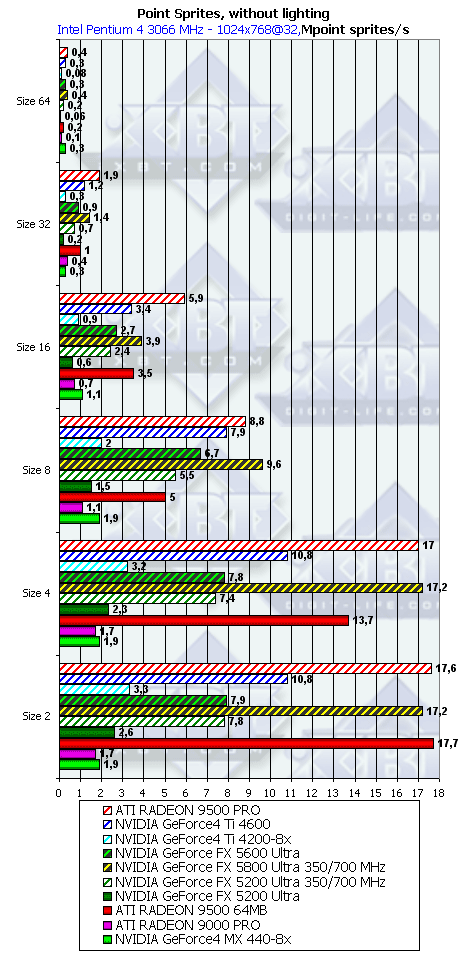
Как и ожидалось наличие или отсутствие освещения сказывается только на маленьких спрайтах, по мере роста размера все упирается в закраску. Происходит это при размере 8 и более. Итак, для вывода систем, состоящих из большого числа частиц, следует признать оптимальными размеры менее 8.
NV31 и NV34 отстоят от NV30 на равной частоте на уже хорошо нам знакомые по тесту геометрической производительности величины. В случае большего размера спрайтов различие нивилируется за счет (здесь искусственно полученной торможением NV30) ПСП. Т.е. — как и ожидалось, ПСП начинает играть все более и более заметную роль.
Пиковые значения достигаются, разумеется, без освещения, и составляют соответственно около 8 миллионов спрайтов в секунду для NV31/34 и около 17 миллионов для заторможенной до частот GeForce 5600 Ultra NV30 и RADEON 9500 (PRO).
Опять-таки отметим уже ранее озвученный вывод, что никакой особой панацеи точечные спрайты нам не приносят — цифры не сильно далеки от тех, что можно получить при помощи обычных полигонов. Впрочем, зачастую само использование точечных спрайтов с точки зрения программирования более удобно, и в первую очередь для всевозможных систем частиц.
| 12 марта 2003 г. |

|
| Дополнительно |
|





